
Abstract
Retrieving mathematical expressions from scientific documents is a challenging task as mathematical expressions or formulae are quite different from the traditional text. Mathematical expressions are highly symbolic and complex. Moreover, the structure of a mathematical formula conveys a semantic meaning which cannot be overlooked. This paper proposes a scientific document retrieval system based on mathematical formula query. The paper explores the concept of Structure Encoded String (SES), which has been employed for mathematical expressions to capture the relations among the formula structures. A pattern based trie indexing scheme has been proposed for faster retrieval. The Jaro-Winkler Similarity has been adopted for matching and ranking. Experiments are conducted, results are reported using standard evaluation measures and compared with similar existing systems.
Introduction
Mathematical formulae and expressions are predominantly used in disciplines such as STEM (Science, Technology, Engineering, and Mathematics) research and education. A distinctive feature of the text retrieval system and mathematical information retrieval (MIR) system lies in the very nature of the data that these systems handle. To be precise, a text retrieval system enables information need of the user (usually documents) based on terms and keywords [1,2]. MIR system, on the other hand, deals with mathematical entities, symbols, expressions, formulae and complex structures. Consequently, for efficiently searching mathematical expressions, traditional text retrieval systems fail because these systems are not appropriate to handle text with complex structures [3,4].
Scientific documents which inherently contain math contents present the following challenges related to its layout and semantics in context to information retrieval [5–9]:
Non-linear Structure: Mathematical expressions and formulae are not linear in nature. These non-linear structures actually represent an inherent semantic meaning of the expressions [5]. For instance,
Notational Ambiguity: To formally define and convey the meaning of a particular concept or scientific/natural phenomena, mathematical notation and symbol set are used. There may exist several different manners of writing the same fundamental meaning. This happens due to the lack of notational inconsistency and limited symbol set [6,8,9]. For example,
Normalization: An implicitly equivalent mathematical expression could be written in various ways using a different set of variables and symbols or constants. The process of normalization enables to reduce mismatch among the semantically similar expressions in nature. For example, the formulae a
2 + b
2 and 𝛼2 + 𝛽2 are semantically equivalent as they retain the same structure while using different variables or symbols [5–7].
Encoding Schemes: The encoding schemes used by textual statements and mathematical expressions differ significantly. There are several encoding schemes available for mathematical expressions like MathML [10], LATEX [11], and Open-Math [12] to name a few. Predominantly, LATEX is the de-facto standard for encoding mathematics in a scientific document among academic communities, whereas MathML a W3C standard, is gaining widespread popularity although not all browsers still support complete features of MathML.
In the case of mathematical retrieval systems apart from the aforementioned challenges, indexing of mathematical content and similarity measures of mathematical formulae also remain open challenges. Indexing mathematical content to achieve efficient outcomes involves the process of variable ordering, term unification, and normalization which can also be utilized for query processing and query refinement [13,14]. As compared to text retrieval systems, mathematical information retrieval (MIR) system has been explored only for the last two decades. Unlike text, the structure of Mathematical Expression (ME)/formula is complex in nature and poses a vital challenge for indexing. The majority of math-aware search engines handle this aspect by using either of the two approaches of indexing namely text-based or tree/substitution tree based [5,15–17].
In text-based approach, a mathematical formula markup is converted into a plain text string. Then the traditional text retrieval schemes are implemented using existing information retrieval tools like Lucene framework or its counterparts. This conversion itself presents another set of challenges like retaining structure information of MEs into the string, resolving notational ambiguity and normalization of the string [8,18].
In Egomath2 (designed by Jozef Misutka as an extended version of Egothor by Leo Galambos, MFF UK Prague) mathematical formulae are stored using reverse polish notation. In turn, it employs an augmentation algorithm to the input by applying both transformation and generalization rules along with an ordering algorithm [8,18,19]. For instance, x
2 will be represented in simple text consisting of three terms
In the tree-based approach, mostly symbol layout tree (SLT) or operator tree (OPT) was employed to index formulae. Attributes of tree structures like sub-expression or path were extracted as index terms. Indexing all sub-structures of a formula can lead to high recall but suffers from index size growth. To address the issue of indexing the sub-structures of semantic formula, a substitution tree indexing technique was proposed by Kohlhase et al. [23] and later modified by Sojka et al. [15]. Originally substitution tree indexing was proposed by Graf [13] for theorem provers. Similarly, it was also used by Schellenberg et al. [14] for indexing layout presentation of formulae. Also, WikiMirs [8,18] is based on the notion of explicit or implicit operands of LATEX markup. The input was extracted from the Wikipedia dataset and represented as Presentation Tree after pre-processing. The process of term normalization was employed to generate generalized terms. Moreover, it used a modified similarity score based on term frequency-inverse document frequency (tf-idf) scheme and utilized an inverted index. The modified similarity score was used to evaluate the distance of the matched terms on different levels of the presentation tree.
Albeit existing MIR systems have addressed most of the challenges, but the results from the standard evaluation measures are still not convincing. To be applied to document retrieval systems, these techniques still need to be re-examined or amalgamated with other methods to improve the overall quality of the system [5,16].
To this end, this paper aims to construct a text-based MIR system: The representation of mathematical content (and query) of a document in linear form using Structure Encoded String (SES) to achieve term generalization. Using a pattern mapping table to realize normalization among equivalent mathematical expressions. A pattern-based trie (PB-Trie) indexing for faster retrieval and improved precision. Two popular MIR systems namely Math Indexer and Searcher (MIaS) and WikiMirs were chosen for the purpose of performance comparison with the proposed system AlongMath.
The remainder of this paper is organized as follows. In Section 2, the proposed system: AlongMath, and its modules are discussed. Section 3 elaborates on the pattern-based indexing scheme. Subsequently, the experimental environment, evaluation measures & comparison, along with data and results are discussed in Section 4. Section 5 concludes the paper.
Overview
The complete workflow of the proposed system AlongMath is depicted in Fig. 1. The system consists of 5 modules: MathExtract Parser, Structure Encoded String (SES) Generator, Pattern Generator, Indexer, and Ranker. The system retrieves relevant documents from the index database depending on the mathematical query issued by the user. To achieve effectiveness, the framework is divided into two segments: the offline phase used for indexing and the online phase for retrieving purposes as depicted in Fig. 1.
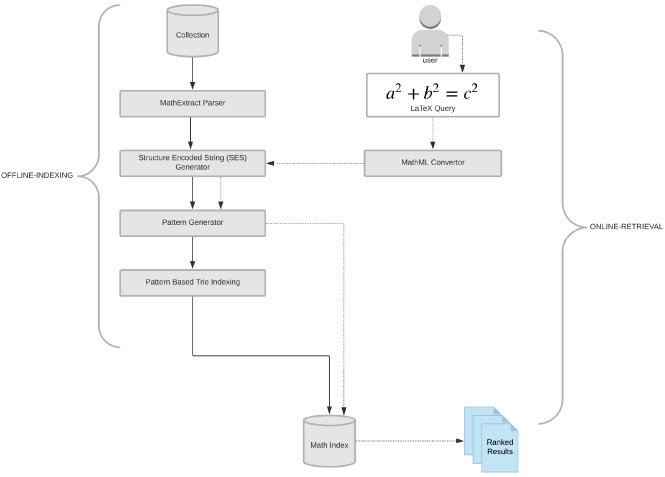
Workflow of the proposed system: AlongMath.
Presentation MathML (P-MML) is the primarily supported format of AlongMath. Wikipedia corpus serves the basis of AlongMath, which is publicly available at NTCIR (NII Testbeds and Community for Information access Research) Project -12 MathIR Task [24]. In the offline phase, mathematical formulae, expressions, and entities are extracted defined inside <math>... <∖math> markups by MathExtract parser. Next, Structure Encoded String (SES) is generated for the reference symbols of the mathematical formulae through the SES Generator module. By taking into account the class of operators, operands, and special mathematical symbols, string patterns are generated using a mapping table. The generated string patterns maintain the order of original expressions and are indexed using pattern based trie (PB-Trie). In online retrieval, when a user searches a formula (in TEX), the query is transformed into an internal MathML format using which the SES is generated. Thereafter, a pattern is generated and searched in the proposed pattern based trie (PB-Trie) to check the existence of the pattern. Finally, the ranker module calculates the similarity scores of the relevant formulae and presents the list of documents sorted according to the similarity score of the user query.

A mathematical formula a 2 + b 2 = c 2 and its corresponding P-MML markup.
MathML [10], a form of XML, focused towards encoding syntax and semantics of mathematical expressions, has got two major forms: presentation and content. Presentation MathML (P-MML) markup as illustrated in Fig. 2 comprises 30 elements accepting around 50 attributes. Most of these elements are related to the syntax or layout of the representation and can be categorized into the following four broad categories:
Token elements: <mi>, <mo>, <mn> etc.
Layout elements: <mrow>, <mfrac>, <mfenced> etc.
Script elements: <msub>, <msup>, <munder> etc.
Tables and matrices: <mtable>, <mtr>, <mtd> etc.
During pre-processing stage following elements were ignored and removed: The elements <mtext>, <mspace> and <ms>. The elements focusing on appearance, binding actions and styling like <mstyle>, <merror>, <mpadded>, <mphantom>, <mmultiscripts>, <mlabeledtr> and <menclose>.
The aforementioned elements were eliminated as because they do not contribute to the meaning or semantic aspects of mathematical contents. These elements are more inclined towards the alignment, justification and appearance of symbols/mathematical expressions/formulae.
In this module, the Structure Encoded String (SES) has been discussed which is a linear representation of a Mathematical Expression (ME). In the context of mathematical contents, the term Structure Encoded String (SES) was proposed by Kumar et al. [25]. The authors designed an automated performance evaluation of Mathematical Expression (ME) recognition. The authors identified six surrounding positions viz. top-left (TL), above (A), top-right (TR), bottom-left (BL), below (B) and bottom-right (BR) which can be spatially associated with an ME symbol. The base of the expression is denoted by the symbol M which occupies the central position. The symbols TL, A, TR form the top region which is considered as a single sun-expression and is called northern region (N). Similarly, the symbols BL, B, BR form the bottom region which is called southern region (S). This concept is shown in Fig. 3.
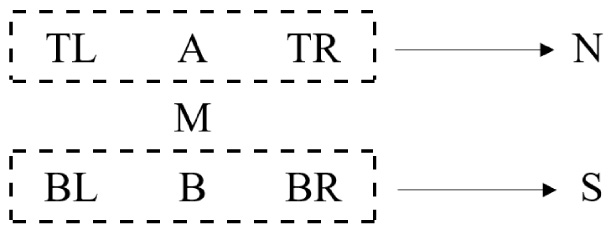
Possible spatial regions around mathematical symbol M. Other symbols are TL (top-left), A (above), TR (top-right) for northern region represented as N and BL (bottom-left), B (below), BR (bottom-right) for southern region represented as S.
The work presented in [25] is based on LATEX input. In this paper, the similar notion has been adopted and extended to work in the context of presentation MathML (P-MML) documents and thus the SES has been generated. The module is significant as it enables to achieve term generalisation to reduce the mismatch among the mathematical fragments.
To generate SES, firstly a scanning of the Presentation MathML (P-MML) markup has been performed from left to right i.e. from <math> to <∕math>. Moreover, the structural information of ME is preserved by the use of two special sets of structure symbols i.e. Ns and Ne (Ss and Se). Here, Ns and Ne represent North start and North end respectively. Similarly, Ss and Se are designated for southern region subexpressions.
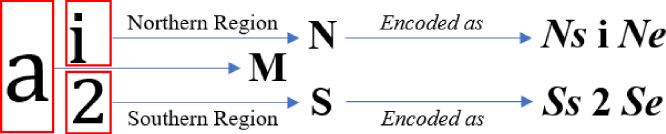
SES encoding of northern region with Ns and Ne and southern region with Ss and Se.
Considering Fig. 4, the Structure Encoded String (SES) for
Similarly, the SES for a 2 + b 2 = c 2 will be <a, Ns, 2, Ne, +, b, Ns, 2, Ne, =, c, Ns, 2, Ne>. Therefore, this approach aids in converting the non-linear mathematical expression into Structure Encoded String, thereby making expression linear while preserving the structural information.
After encoding a mathematical expression into a sequence of SES, the patterns for operands and operators are generated.
Mapping table
Mapping table
Considering the two MEs i.e. x 2 + y 2 = 1 and a 2 + b 2 = 1, it can be observed that they are semantically equivalent but they disagree in the context of variables used. If x, y, a and b can be transformed to an equivalent group/common term, then both the MEs can be considered as equivalent match. Retrieval depends on match type and the match type is based on the user requirements. This module is closely related to unification and normalization process. Matching can be of any type like exact, instantiation or generalisation [16,25,26].
Pattern generation
In this module, a mapping table consisting of 12 kinds of groups of operators created by The Pennsylvania State University 1 has been employed. A common mapping term is generated for a particular group of operators, and the complete mapping table is shown Table 1. Based on Table 1, patterns have been generated for MEs. Examples of pattern generation for some MEs are shown in Table 2.
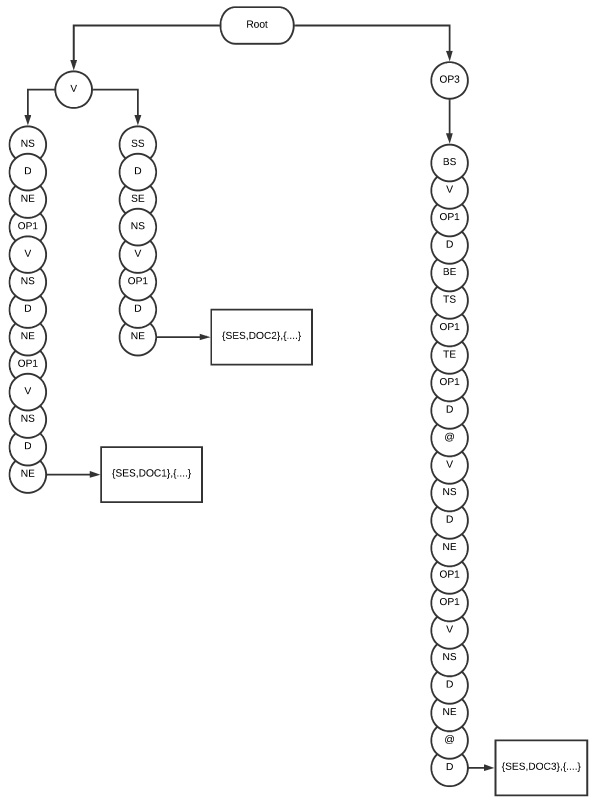
A pattern based trie indexing scheme along with posting list associated with the leaf node.
One of the predominant data structures for indexing text is Trie, additionally called a Digital Tree or Prefix Tree. A trie facilitates a convenient way for storing strings as it provides one node for every common prefix and the whole string is stored in additional leaf nodes. The Trie data structure eradicates the need of storing overlapping prefixes which are stored only once thereby making it a compact structure [27].
Formally, let Σ be some fixed alphabet.
A trie is a tree where each node stores
A bit indicating end of a string An array of |Σ| pointers, one for each character Each node x corresponds to some string given by the path traced from the root to that node. In vector space model, bag of words representation is used where order of terms is ignored [18,25,28]. But for the formula retrieval, the order of operators is a crucial feature. So, for effective formula retrieval, a pattern based trie (PB-Trie) indexing structure is constructed to preserve the order. (Trie).
In a pattern based trie (PB-Trie), which is a prefix tree of patterns, a node is defined as a triplet < P, C, E > where P contains the pattern information, C denotes a pointer to the child node of the current node and E flags end of the information.
The leaf node marks the end of the pattern setting E to true and pointing to its posting list that contains the records (M, Loc), where M contains SES information and Loc contains the canonical path of the actual document.
Considering the ME, a
2 + b
2 = c
2, the generated SES is

Online retrieval
The goal in this phase is to efficiently retrieve relevant mathematical expressions (MEs) based on a given ME query, both in terms of speed and accuracy. The constructed PB-Trie is thus used, with the online retrieval algorithm to achieve the purpose.
Query processing and pattern generation
The proposed approach takes LATEX string as ME query and transforms it into its corresponding Presentation MathML (P-MML) using SnuggleTeX 2 which is an open-source Java library developed at the University of Edinburgh. This transformed P-MML serves as input to the SES Generator module from which SES of the query is obtained. The SES is then again converted to its corresponding pattern through Pattern Generation module.
Matching and retrieval
Let Σ∗ be the set of all possible strings over Σ. The Jaro measure d j : Σ∗×Σ→∗→ [0,1] is a string similarity measure approach which was developed originally for name comparison in the U.S. Census. It is a string similarity measure which accounts for insertions, deletions and transpositions. The algorithm computes the total number of common characters c between two strings and the number of transpositions of c considering the greatest integer of half the length of the longer string [29,30].
Consider a character s
i
of string S and a character t
j
of another string T to be the common characters of S and T if
The Jaro similarity measure for the two strings is then given by
The Winkler modification improves the Jaro similarity measure that puts more emphasis on matching prefixes (up to four) if Jaro similarity exceeds a certain “boost threshold” b
t
, originally set to 0.7. It is calculated as
A given ME query is first searched in the PB-Trie and consequently in its posting list as well if a match is found. Thereafter, scores of all the MEs are calculated existent in the current posting list by using Jaro-Winkler similarity algorithm recursively. The scores so generated, are sorted in a descending order. First come first serve approach is used if more than one mathematical expressions acquire the same score. Top k results are then shown to the user.
For a given LATEX query x 2 + y 2 = z 2, the pre-processed pattern of the query string is shown in Table 3.
Query pattern generation
Query pattern generation
Assume that a leaf node of the proposed trie matches with the example query which contains the following three sets of <SES, DocID> pairs:
As shown in Table 4, the similarity scores obtained for each of these documents yield the following
ranking: Doc3 > Doc1 > Doc2.
Similarity scores for the query x 2 + y 2 = z 2
The performance of the proposed system
Corpus characteristics
The corpus contains 31,839 MathTag articles and 287,850 Text articles which contribute approximately 10% and 90% of the collection respectively. The corpus contains a total of 592,443 formulae out of which 580,068 marked formulae are distributed amongst the MathTag articles and 12,375 marked formulae in the Text articles. The size of the corpus is 5.15 GB in uncompressed format [33]. Also, the query set is taken from the same source which contains 100 queries written in LATEX format.
Evaluation measures
To evaluate the system performance, Precision and Discounted Cumulative Gain (DCG) are calculated respectively, for 100 queries.
“It measures the exactness of the retrieval process. If the actual set of relevant documents is denoted by I and the retrieved set of documents is denoted by O, then the precision is given by: (Precision).
“DCG measures the usefulness, or gain, of a document based on its position in the result list. DCG of the top-k retrieved results can be calculated using: Like precision at k, it is evaluated over some number k of top search results" [34,35].
To measure the relevance of the top-k retrieved formulae for each test query, each result has been evaluated and labelled manually depending on the subject. On an average about 676ms is incurred in searching math formulae for each query.
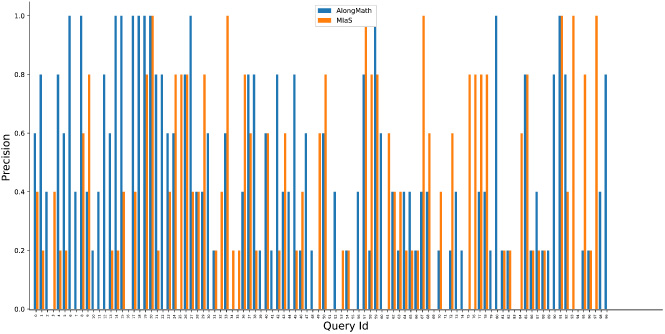
P@5 comparison of AlongMath with MIaS.
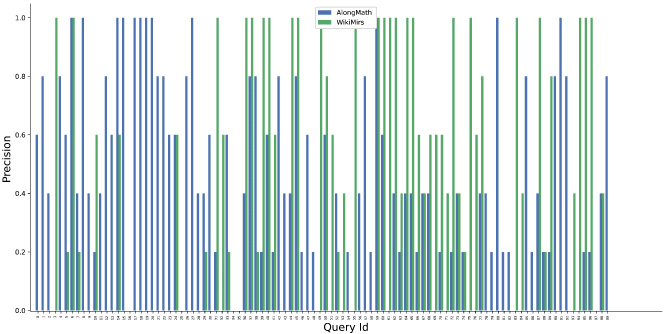
P@5 comparison of AlongMath with WikiMirs.
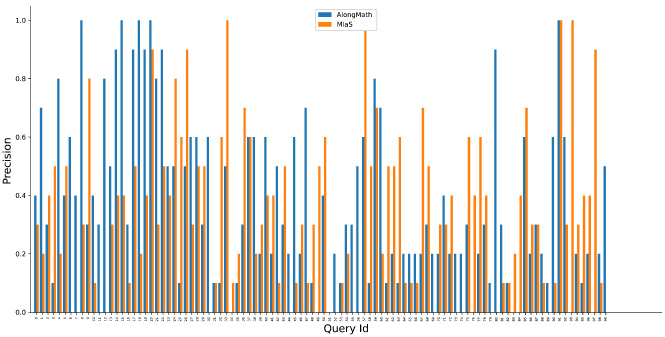
P@10 comparison of AlongMath with MIaS.
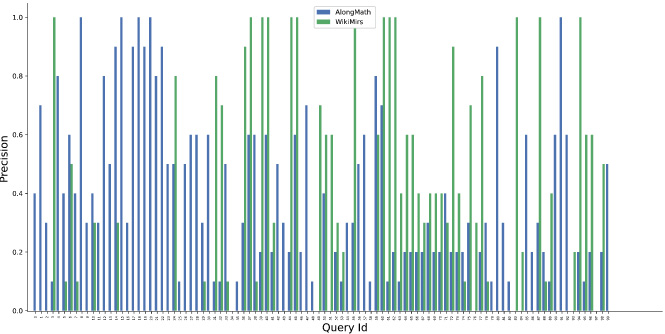
P@10 comparison of AlongMath with WikiMirs.
It can be observed from Figs 6, 7, 8 and 9 that the proposed system AlongMath performs better than MIaS and WikiMirs in terms of P@5 and P@10. In case of queries having isolated symbols or wildcards the MIaS system achieves better results than AlongMath since MIaS also incorporates a tf-idf scheme using Lucene framework for indexing the content. In some cases, WikiMirs precision is much higher than AlongMath because of its two-level indexing and incorporation of a structural weighting scheme. It can also be observed that, in many cases a single relevant result could not be fetched by WikiMirs in terms of P@5 and P@10. Also, in the Table 5 and Table 6, a comparison of mean average precision and mean reciprocal rank of AlongMath, WikiMirs and MIaS is shown respectively which highlights the proficiency of AlongMath over others.
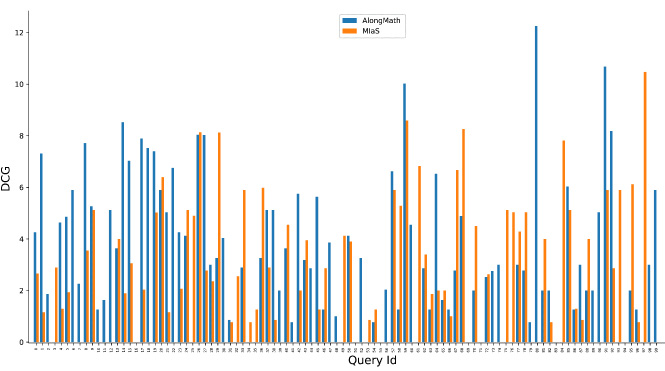
DCG@5 comparison of AlongMath with MIaS.
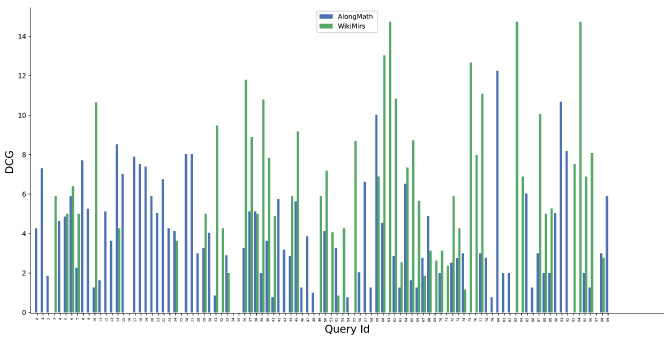
DCG@5 comparison of AlongMath with WikiMirs.
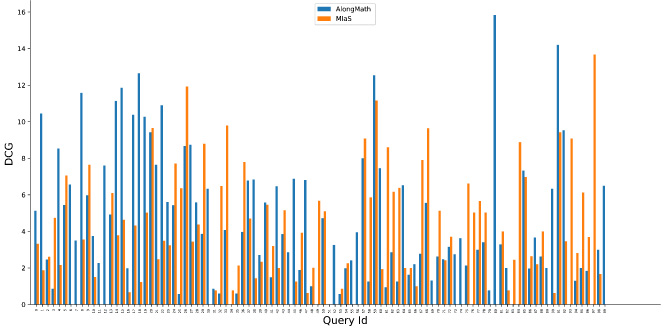
DCG@10 comparison of AlongMath with MIaS.
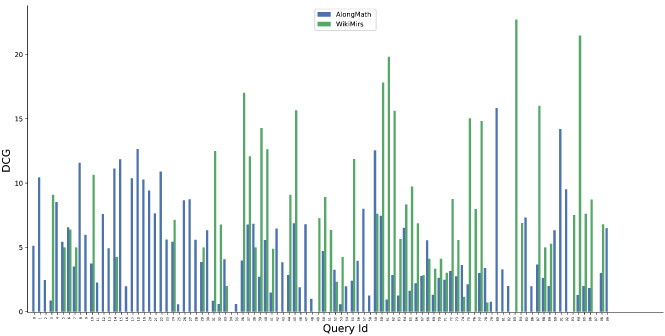
DCG@10 comparison of AlongMath with WikiMirs.
Similarly, Figs 10, 11, 12 and 13 indicate the performance comparison of AlongMath with MIaS and WikiMirs in the context of DCG@5 and DCG@10 respectively. In some of the cases of both MIaS and WikiMirs, DCG values are closer to zero due to non-retrieval of relevant results higher in the ranking. Experiments on accuracy also have been carried out in context of several different evaluation measures. Overall, AlongMath obtains more accurate results and ranks formulae better than MIaS and WikiMirs.
Mean average precision (MAP) comparison
Mean reciprocal rank (MRR) comparison
To this end, following critical observations of the proposed system AlongMath are presented below:
AlongMath primarily aims at retrieving scientific documents based on mathematical queries. However, it does not support textual content and wildcards. Indexing with trie also has its consequence in terms of index size. This is because each pattern is an extension of an existing SES and these extensions made the trie very sparse. For this reason, Patricia trie [36] could be used, as this optimization may reduce the size to approximately one third of its uncompressed version.
Conclusion
In this paper, a scientific document retrieval system AlongMath is presented that facilitates scientific document retrieval using math queries. The system employed the concept of structure encoded string to convert the mathematical expression into a string that enabled to achieve term generalization. AlongMath utilized pattern-based trie for normalization and indexing. The system achieves a MAP score of 0.595 and MRR score of 0.678 outperforming the other systems in consideration. As part of the future work, the system aims the following:
Equipping the system to handle co-occurrence of formula and keywords. Introducing multi-level indexing for text and formulae. Considering Content MathML for achieving better performance. To explore weighting schemes and other similarity measures. To use machine learning algorithms for ranking and re-ranking like RankSVM.