
Abstract
This research explores the potential of Long Short-Term Memory (LSTM) and Natural Language Processing (NLP) for automated essay generation. The goal of the study is to create a model that can produce high-quality essays that are not only grammatically correct but also semantically meaningful and contextually relevant. The rise of NLP and Deep Learning has made it possible to generate text that is coherent and semantically sound. In this research, there is an advantage by leveraging the ability of LSTMs to capture long-term dependencies and context within the text, and combining it with NLP techniques, such as word embeddings, to process and encode textual data. The results of experiments show that the proposed model can effectively generate essays that are coherent, contextually relevant, and semantically meaningful. This is a significant advancement in the field of text generation and has potential applications in areas such as education, content creation, and language translation. In education, for example, the model could be used to generate essays for language proficiency tests or as a writing aid for students. In content creation, it could be used to generate articles, blog posts, and other written content. In language translation, the model could be used to generate essays in the target language that are semantically and contextually equivalent to the source language essay. The findings of this study contribute to the advancement of NLP and deep learning techniques in the area of text generation and open up new avenues for future research. Short after the proposed model was deployed, it was discovered that it outscored Multi-Topic Aware LSTM (MTA-LSTM), Topic-Attention LSTM (TAT-LSTM), and Topic-Averaged LSTM (TAV-LSTM) in human evaluation by 6.84 percent, 25.40 percent, and 34.94 percent, respectively. Furthermore, it enhanced automatic BLEU score evaluation scores by 11.68 percent, 26.23 percent, and 54.11 percent in MTA-LSTM, TAT-LSTM, and TAV- LSTM, respectively.
Keywords
Introduction
Natural Natural Language Generation (NLG) [1], a subset of Artificial Intelligence [2], is a method for converting data into plain language. The technology may be used to write semantic sentences and paragraphs to tell stories, very much like an analyst. For a long time, communication occurred through data ideas. Computers can extract concepts from data on a vast scale with great precision and eloquence. Productivity increases when computers automate analytical and communication tasks, allowing employees to dedicate more time to higher-value activities. Natural language can be prescribed for many applications to link with visuals. Natural language has been proposed as a means of communicating with visual interfaces in a range of applications. Dashboards may be physically appealing, but when it comes to information density, they are less so when it comes to language. A prosperous and sophisticated storyline can be told in a single paragraph as well as a few bullet points.
However, the work of essay generation is currently beset by a slew of issues. To begin with, when regarded as a whole, the sentences in the essay generated by the algorithm are unrelated to the theme terms employed. For example, if the topic words are ‘A day in the park,’ one line of the essay might describe a day when the sun is shining but there are a few issues. To begin with, the sentences in the essay generated by the algorithm are unconnected to the theme phrases used when taken as a whole. For example, if the topic words are ‘A day in a park,’ one line of the essay might describe a day, such as the sun shining, while another might define what a park is. This problem is referred to as topic relevance. Also, if one statement is like “We had a lovely day,” the next sentence is frequently unconnected to the previous sentence, such as “Our Ford Car Choked.” Output essays must be fluid to achieve human-level performance. There is also a lack of cohesiveness among the components. Coherence in writing refers to the reader’s ability to understand what the writer is trying to say. Making everything flow smoothly is what coherence is all about. Everything is semantically structured and related, and the reader can see that the overall relevance to the theme terms is maintained. The essay’s integrity has also improved significantly. The degree of vocabulary and phrases utilised to communicate sentiment in the essays is what is meant by integrity.
The proposed method addresses the issue of coherence, topic integrity, and relevance by using three distinct mechanisms: the Pool hike method, the Topic integrity mechanism, and the Coherence mechanism. Pretrained GLOVE [3] and trained word2vec embeddings, as well as the use of context vectors in attention processes, target one or more of the above concerns, allowing the model to be controlled to produce better essays. To be precise, incorporated a pool hike mechanism to the model to address the problem of text production repetition, while the inclusion of pretrained Glove and trained word2vec [4, 5, 6] embeddings ensures the essay’s subject relevance and integrity. The use of context vectors in attention [7, 8, 9] mechanisms solves the problem of repetition and maintains text coherence.
TAV-LSTM extracted topic word embeddings, averaged them, and ran them through recurrent neural networks, whereas TAT-LSTM extracts embeddings of every subject word and then applies attention to them. MTA-LSTM now includes a subject coverage vector to help track the attention mechanism.
The following are the contributions of this research work:
Comprehensive review of prior research in the essay generation domain, highlighting shortcomings, Topic-Attention LSTM (TAT-LSTM), and Topic-Averaged LSTM (TAV-LSTM) are compared, and it was found that TAT-LSTM is better than TAV-LSTM as it enhances integrity and uses Context-Vector in the attention [7, 8, 9] mechanism. To integrate the Pool hike mechanism, the Topic integrity mechanism, and the coherence mechanism into a model that focuses on the a fore mentioned aspects of coherence, topic integrity, and relevance. The use of context vectors in attention processes, trained word2vec [4, 5, 6] embeddings, and trained GLOVE address one or more of the a fore mentioned issues, allowing the model to be manipulated to create better essays. To develop a comprehensive model for automated essay generation that combines Long Short-Term Memory (LSTM) and Natural Language Processing (NLP) techniques to produce grammatically correct, contextually relevant, and semantically meaningful essays. Significance placed on enhancing coherence, integrity, relevance, fluency, and diversity in essay generation.
In Section 2, prior efforts in the domain of Essay Generation are examined, which were then updated by improved adaptations of models in the same domain. The next section delves into job definition, data collection, and general construction, as well as the concept. Then, in Section 4, the methodology used in the suggested model for writing the essay is discussed, which takes into account all of the aspects that go into writing a good essay. The experimental conditions and assessment criteria that were utilised to evaluate the generated essay are discussed in the following subsections. The experimental results are reviewed in Section 7, and the conclusion and future work are explored in part 8.
In 2016, Kiddon et al. [10] attempted to address problems by employing a planned item list, and two attention processes were introduced into the model based on the idea of this list text: monitoring used agenda items and monitoring unused agenda items.
In 2019 [11], Welleck et al. combined likelihood/probability and unlikelihood training. Likelihood gives an output probability for the next token based on the frequency with which the token appears, whereas unlikelihood generates an output probability for the token not being the following word.
The authors Feng et al. [12] used attention and word embeddings in 2018, which improved topic relevance and integrity. TAV-LSTM, TAT-LSTM, and MTA-LSTM were the three architectures described in the study. The topic word embeddings was discovered in TAV-LSTM, then average them before feeding it through the Recurrent Neural Network (RNN) [13, 14, 15]. Because the last average vector can be identical for different word sequences and has a low complexity, the outcome may be the least accurate in the list. TAT-LSTM is the process of finding each topic word’s embeddings, paying attention to them, and then forwarding them to the RNN network.
TAT-LSTM surpasses TAV-LSTM because topic words are given more attention and weight based on where they appear in the essay. As a result, the integrity of the essay has been enhanced. In MTA-LSTM, the author used TAT-LSTM and included it in the subject coverage vector, which records time. The procedures adopted address relevance, coherence, and integrity issues to some amount, but they do not significantly promote diversity.
The strategy promoted diversity by expanding the pool of words utilised to generate text (common sense words
Lin et al. [18] solved the issue in 2020 by using GLOVE and BERT [19, 20] portrayals in self attention guidance creation, as well as a target-side contextual history method. Repetition and low attention retention issues can be resolved as a result of this. As contextual embeddings, GLOVE Word vectors and BERT embeddings are used [21]. In addition, each is linked via a dynamic weighted total to help with linguistics information inequality. There are two sections to the architecture. To begin, an encoder that uses contextual embeddings to reduce information disparity and contains a pre-trained language model BERT. GLOVE Word vectors and BERT embeddings are used as contextual embeddings, which are subsequently coupled and delivered to the encoder. By combining the covered states of BERT across encoded levels, the semantics of the subject words are enhanced/enriched, as well as exchange between multiple themes. Furthermore, a shifting weighted total is employed, resulting in more advanced semantic difference ease/semantic gap closure work. Second, a target-side contextual history mechanism in a self-attention network guides the generation. The quality of the generated text is improved by using the context aware generator. This is done to account for duplicated difficulties as well as poor attention retention.
The author presented COMMONGEN in [22], which is a novel constrained job of text creation for generative commonsense reasoning that utilises a big dataset. The author examined the task’s few obstacles, including compositional generalisation [23] and relational thinking [24]. The authors analysed the in-depth experiments for contemporary models on language production on the task in a consistent manner. Then they realised that the performance isn’t up to par with that of humans, with grammatically correct but actually ludicrous utterances being generated.
Authors, particularly ODETG, predicted a new task for 2020 [25]. (Open Domain Event Text Generation). In schemes where traditional generation tasks are ineffective, the proposed task can be applied. The WikiEvent dataset was developed by the authors and was used to pick the models that will answer the ODETG problem. The model contains “34,000” pairs (entity chain, text) consisting of an entity and its description text. Furthermore, an encoder, a retriever, and a decoder were presented as three pieces of a framework. The entity chain is encoded into hidden depiction by the encoder. To improve the generation procedure, the retriever retrieves related data. The decoder then displays an entity chain with extra accurate data and an uneven drop component in a sequence. The proposed model outperforms a few baselines in terms of delivering better event text on the WikiEvent dataset.
In 2020, the author [26] developed a Plug and Play for Controlled Language Model (PPLM), which flexibly associates an extensive, pre-trained Language Model (LM) with a Bag of Words (BoW) [27] or a small discriminator that is easy to train. They talked about how disciplined LMs should act ethically. With the use of a gradient-based sampling technique, PPLM achieves a fine-grained command of attributes. In addition, PPLM can manage generation while controlling fluency and hold affirmation for enabling the next generation of language models.
In [28], the author suggested a challenge called Generalized Few-Shot Detection, which aims to distinguish between a previously preoccupied joint label space, rich annotation, and a preoccupied novel with only a few cases. The goal (Generalized Few-Shot Detection) was intended to be replaced by CG-BERT (Conditional Text Generation with BERT), a model that creates new claims based on a preoccupied book. In addition, the suggested approach outperforms the competition on two real-world preoccupied word detection datasets.
The authors of [29] introduced BLEURT, a reference-based statistic for text production in English. The metric can accurately mimic human judgement because it is taught point-by-point.
A few problems in current essay creation approaches were found after completing a thorough examination of the literature. There are few designs that explicitly address all of the issues associated with essay generating. The generated essays’ integrity and coherence are not at all comparable to human performance. Integrity, Relevance, Fluency, and Diversity are all concerns that the proposed model tries to address. Coherence.accuracy. Furthermore, pre-training boosts the measures. Specifically, both the domain and the quality drift are booming.
From the literature review, it was concluded that essay generation technologies continue to have problems.
Only a few systems are specifically focused on all aspects of essay generating. In comparison to human performance, the coherence and integrity of the created essays are far from satisfactory. Relevance, Integrity, Fluency, Coherence, and Diversity are all concerns that the proposed approach tries to address.
Methodology
Task definition
The goal of essay creation is to generate an article (a paragraph) within the theme of these topics using a set
Data collection and preprocessing
A concatenated corpus of highly perceptive writings by Paul Graham [30], which includes a variety of essays on various topics, was used. The dataset contains 452944 words and has a vocabulary of 30064 terms. It was predetermined that 5 words would be used to produce the next word, 4 words would be used to forecast the next word, and so on because this corpus is in the form of continuous text. All punctuation, except full stops and commas, is removed from the text, which turns all letters to lowercase and removes all noise from the dataset (urls, font size, references, etc.).
Diagram representing pool hike mechanism.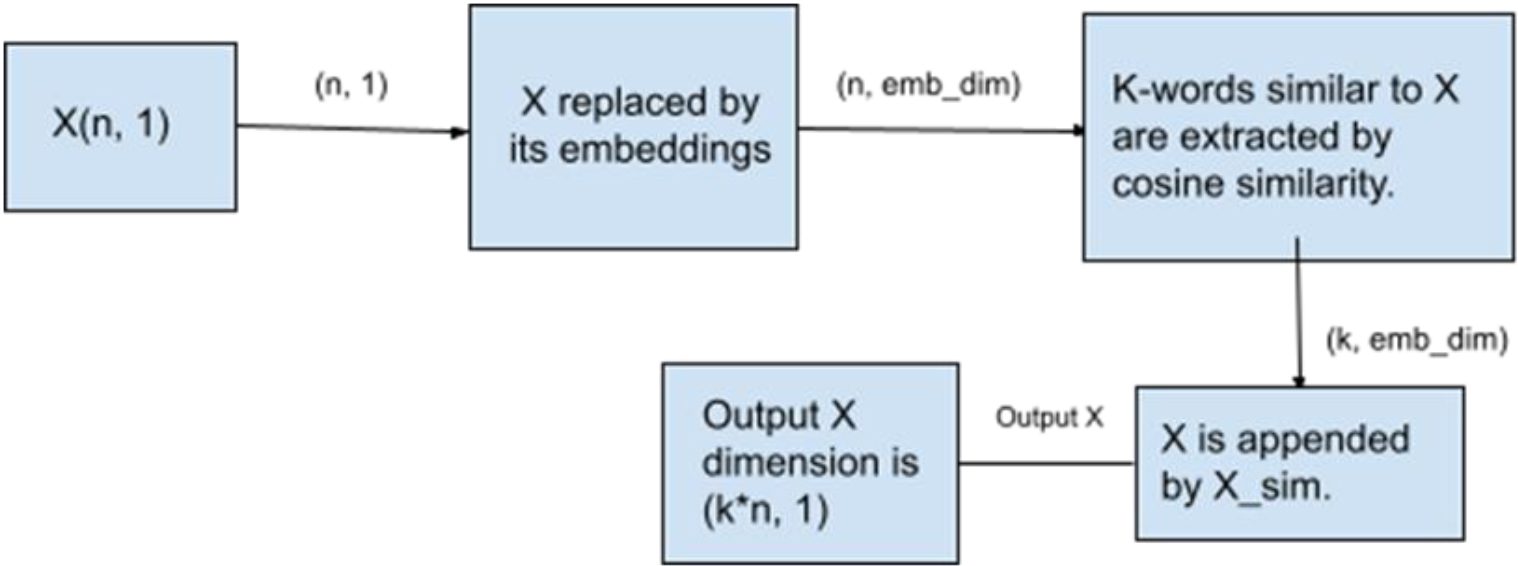
This technique, as shown in Fig. 1, was used to address the issue of duplication and ensure the diversity of the output articles. The process increases the input size by a scalar multiple; hence, the model proposed has more words to draw from when producing output essays, leading to the production of more varied essays. Assuming an input with
Where
Here,
Euclidean distance:
With this method, the input size is increased by
Figure representing the use of pretrained Glove and trained word2vec embeddings.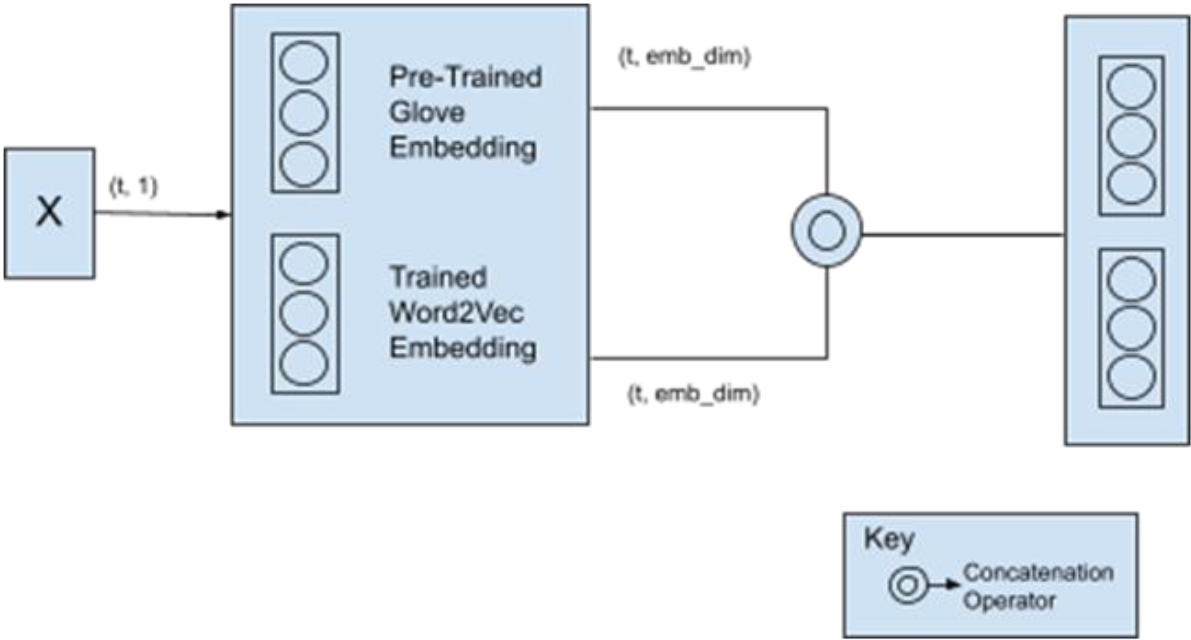
Word embeddings are vector representations of input words as shown in Fig. 2, with reduced cosine distance between comparable words having similar vectors. These embeddings are employed in this suggested model because they provide finer semantics than tokenization alone, which just converts words to numbers, can. Word2vec embeddings and pretrained glove embeddings are the two types of word embeddings employed in the suggested model. Glove embeddings are known to occupy finer semantics of words (in many cases faster as well as finer as compared to humans) because they are pre-trained over a vast amount of knowledge. The model’s semantic understanding is then considerably improved by including these and the word2vec embeddings. For instance, depending on the dataset, if the word “good” is provided as an input, trained embeddings may learn other words like “day” or “car,” but by linking them with the reliable pretrained Glove embeddings, the enormous understanding gap between the suggested model and that of humans is narrowed. Therefore, even if it wasn’t learned from the dataset that, this model will also be aware that “human,” “grief,” and “good” can all coexist.
First, construct Word2vec embeddings and then extract pretrained embeddings of the
Diagram representing context vector mechanism.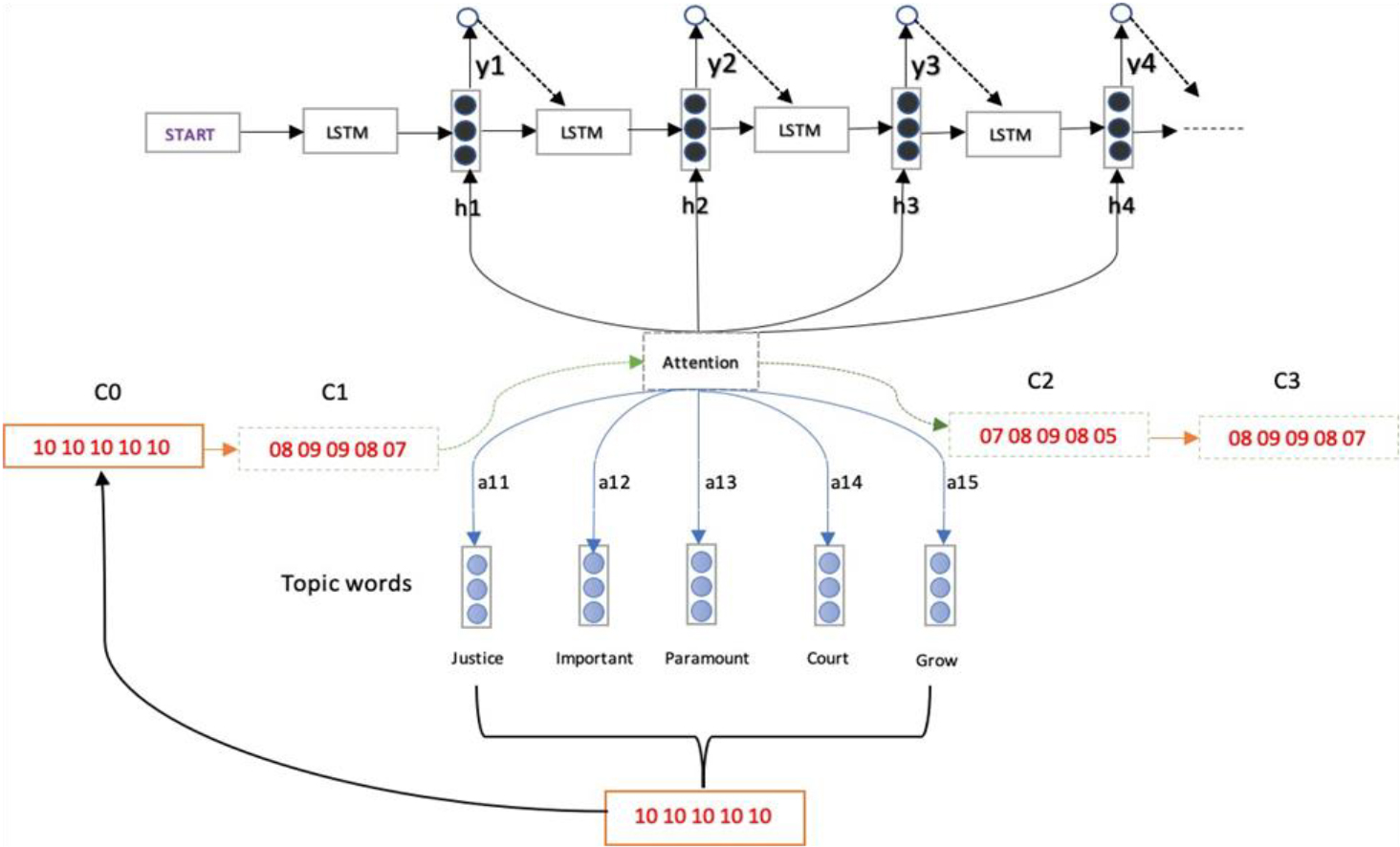
When performing prediction tasks, the neural network may train in relevant input components as well as a good deal of irrelevant components thanks to the attention mechanism.
Targeting attention is crucial for understanding the processes humans engage in. For instance, when manually translating a lengthy sentence, individuals often focus more intently on a specific word or phrase in the translation process, without necessarily considering its location within the input sentence. For neural networks, attention recreates this mechanism.
In sequence-to-sequence models, the attention mechanism is frequently employed. Without an attention mechanism, the model would have to summarize the entirety of the input sentence or sequence in one hidden state (depicted by S in the diagram below), which is not an ideal solution to try and apply. This drawback becomes more pronounced the longer the input sentence or sequence is.
This paradigm is strengthened by the Attention mechanism, which permits us to “glance back” at the input sentence at each stage of the decoding process. Currently, each decoder output is dependent on a weighted average of all the input states rather than just the most recent decoder state.
But there are also disadvantages. The essay concentrates on a small number of words since it skips past prior attention-grabbing information, which causes select theme words to appear more obviously than others. To keep track of the frequency with which each topic term was used, context vector is created. In order to control the attention strategy and enable the model to evaluate more unbalanced topic words, this is done by maintaining a topic coverage context vector c, which denotes the degree to which a subject word should be conveyed in subsequent generation. This is also safeguarded by a parameter
where
As a result, the probability of the next word
The only method for converting a discrete feature into a vector format is through embeddings. Every machine learning algorithm utilises a vector as input and produces predictions as output. Therefore, when dealing with a categorical feature, the only viable approach for incorporating it into a machine learning model is by embedding it into a vector.
The most basic form of embedding is one-hot encoding:
1
Categorical feature can be replaced with three possible values with the vectors as above without losing any information.
These vectors have as many elements as the number of values of the categorical feature. When the categorical feature has a lot of possible values, it is often better to replace it with embeddings with lower dimensionality.
Lower dimensionality gives two advantages:
It is more computationally efficient, because smaller embeddings require less memory. It regularizes the model, because the smaller number of parameters the model has, the better it is regularized.
Embeddings are often used to map words to vectors in NLP systems; words represented as vectors can be used as an input for recurrent neural networks.
The suggested paradigm is succinctly defined in Fig. 4. A “Pool hike mechanism” uses an array of input words to expand the pool size of the word array by
The workings of this model are depicted in above diagram.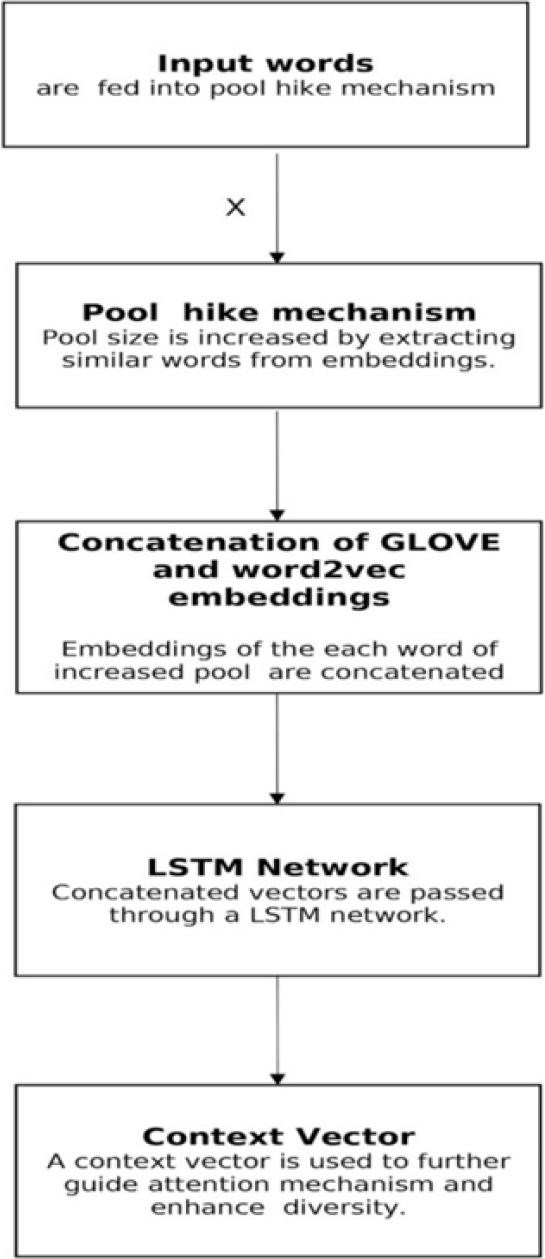
Suppose the input sentence is ‘go house park’ and
[‘go’:[ e1,e2,e3],‘open’:[e10,e11,e12], ‘beginning’:[e13,e14,e15], ‘House’:[e4,e5,e6],‘family:[e17,e18,19],‘palace’:[e20,e21,e22] ‘Park’:[e7,e8,e9],‘grass’:[e23,e24,25],‘swings’:[e26,e27,e28] ]
Then
[[e1, e2,e3],[e4, e5,e6], [e7, e8,e9]]
[[e1, e2, e3],[e10,e11,e12], [e13,e14,e15] ,[e17,e18,19],[e20,e21,e22] ,[e23,e24,25],[e26,e27,e28]] Its Dimension Is Now [
Input received in this mechanism is the output from pool hike mechanism. Therefore
[[e1,e2,e3], [e10,e11,e12], [e13,e14,e15] ,[e17,e18,19],[e20,e21,e22] ,[e23,e24,25],[e26,e27,e28]]
In this step, another embedding matrix is created. In this embedding matrix, mappings are learnt from the respective corpus only. Suppose this looks like:
[‘go’:[ pe1,pe2,pe3],‘open’:[pe10,pe11,pe12],‘beginning’:[pe13,pe14,pe15], ‘House’:[pe4,pe5,pe6],‘family:[pe17,pe18,pe19],‘palace’:[pe20p,e21,pe22] ‘Park’:[pe7,pe8,pe9],‘grass’:[pe23,pe24,pe25],‘swings’:[pe26,pe27,pe28]]
These are concatenated with the previous embeddings present in
[[ e1, e2, e3,pe1, pe2, pe3], [e10,e11,e12,pe10,pe11,pe12], [e13,e14,e15, pe13,pe14,pe15], [e4, e5, e6, pe4,pe5, pe6], [e17,e18,19, pe17,pe18,pe19], [e20,e21,e22,pe20p,e21,pe22] [e7,e8, e9,pe7, pe8,pe9], [e23,e24,25,pe23,pe24,pe25], [e26,e27,e28,pe26,pe27,pe28]]
This is then passed into the next mechanism which outputs a probability for each word present in vocabulary. Output dimension is [word_vocab, 1].
Human evaluation
Twenty participants with an understanding of the English language were given 25 distinct essays from each model. The essays were graded on “Topic-Integrity,” “Topical-Relevance,” “Fluency,” and “Coherence” by these individuals. Each component of the essay is given as cores ranging from 1 to 5, with 5 being the highest. Finally, all the scores were added up and averaged to get a final score.. Despite the fact that scores were not always stable, it was discovered that they followed a consistent pattern.
BLEU score
As a metric for automatic evaluation, Bilingual Evaluation Understudy (BLEU) [34, 35] was employed. This measure is commonly used in machine translation systems for automatic evaluation. For automatic evaluation, original essays were used to construct and find a BLEU-2 score.
BLEU measures the discrepancies between an automatic translation and one or more reference translations of the same source sentence that were written by humans.
The BLEU algorithm calculates the number of matches in a weighted manner by comparing the consecutive phrases of the automatic translation with the consecutive phrases it discovers in the reference translation. These competitions don’t consider position. A higher score and greater similarity to the reference translation are indicated by a higher match degree. Grammar and intelligence are not taken into consideration.
The advantage of BLEU is that it correlates well with human judgement by averaging out individual sentence judgement errors throughout a test corpus rather than attempting to simulate every single phrase’s identical human judgement.
The amount of data that has to be trained with and the consistency of the test data with the training & tuning data set all have a significant impact on the BLEU outcomes. One can anticipate a high BLEU score if models were trained on a certain domain and the training and test sets of data matched.
BLEU looks at words, phrases, word-break (related to test sets), and order of the words to generate its probability score. The more the machine translation is in line with all three metrics of the human translation, the higher the score.
Experimental settings
In this study, Paul Graham essay dataset has been used, which contains a collection of Paul Graham’s works. It is made up of several writings on diverse topics. The top 50,000 words are chosen for training and testing. This suggested model employs word2vec and glove embeddings, each with a dimensionality of 300. The first five words of each batch in the dataset are utilised for training to predict the next word. The suggested model was developed utilising the Keras API, TensorFlow, as well as other libraries like Genism, Numpy, and String. Each of the three LSTM layers in this suggested model has 300 hidden units. The value of “
Experimental result and discussion
Table representing human evaluation scores of this model with different values of ‘
’ in the pool hike mechanism
Table representing human evaluation scores of this model with different values of ‘
Experimentation was conducted with several
The following is an explanation for this behaviour:
Word embeddings are employed to locate words that are similar to those in the input. Now, diversity grows at first because the model has a larger pool of vectors to utilize in prediction, but as
Table comparing various similarity measures
In Table 2, it is discernible that Cosine similarity yields the most favourable outcomes among the three similarity metrics considered (Euclidean, Jaccard, Cosine). Given the superior average score achieved by Cosine Similarity, the selection was made to adopt Cosine Similarity as the chosen similarity measure. The table presented above, designated as Table 2, has been cited from a prior paper [36].
Table representing human evaluation scores of various models
Table representing BLEU scores of various models
Table 3 shows the findings of the human examination, from which similar conclusions can be drawn. With a 12.5 percent improvement in integrity and a 7.8 percent improvement in topic relevance, it is clear that the model surpasses baselines by a large margin. Fluency improved by 4%, coherence improved by 11%, and diversity increased by 22%. All of this can be attributed to the several methodologies merged in this model, each focused on one or more metrics. The table above, Table 3, has been referenced from another paper [36].
Table 4 shows the findings of the BLEU score evaluation. As it can be seen, the model outperforms the comparison model in practically every metric by a large margin. This indicates how effective the approach is and how much the quality of the essays created improves as a result of it.
This comprehensive study has delved into a wide array of techniques to advance text generation, addressing vital aspects like coherence, topic integrity, and relevance. Through the integration of methods such as the Pool hike mechanism, trained word2vec embeddings, and context vectors within attention processes, remarkable results have been achieved. The model, when compared to three prominent models – TAV-LSTM, TAT-LSTM, and MTA-LSTM – demonstrates superiority across nearly all evaluated criteria. Particularly, it excels in categories such as coherence, topic relevance, and integrity, marking a significant leap in text generation. In terms of future work, envisioning the incorporation of BERT embeddings, renowned for their reliability and potential to enhance results. Additionally, a shift towards an iterative process of finding relevant words throughout generation, as opposed to at the outset, could introduce more diversity into the generated content.
Moreover, the integration of adversarial training shows substantial promise for further enhancing the model’s performance. Through systematic implementation of these improvements, the aim is to push the boundaries of text generation, making substantial contributions to the domains of Natural Language Processing and Deep Learning. While this study represents a significant milestone, it merely marks the inception of a journey towards more advanced and versatile text generation systems.