
Abstract
To address the problems of underutilization of samples and unstable training for intelligent vehicle training in the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm, a TD3 algorithm based on the Composite Prioritized Experience Replay (CPR-TD3) mechanism is proposed. It considers experience immediate reward value and Temporal Difference error (TD-error) based and respectively to construct priorities to rank the samples. Subsequently composite average ranking of the samples to recalculate the priorities for sampling, uses the collected samples to train the target network. Then introduces the minimum lane change distance and the variable headway time distance to improve the reward function. Finally, the improved algorithm is proved to be effective by comparing it with the traditional TD3 on the highway scenario, and the CPR-TD3 algorithm improves the training efficiency of intelligent vehicles.
Keywords
Introduction
In recent years, with the rapid development of artificial intelligence, big data and other technologies, automatic driving has become an important part of the future intelligent transport system. The automatic driving system is generally composed of four modules: perception, decision-making, planning and control. The decision-making module is to generate reasonable driving behaviors based on the the information of the surrounding environment and the state of the self-vehicle, and to incorporate the generated driving behaviors into the motion control system, so as to realize the efficient driving of the intelligent vehicle. As the core of intelligent vehicle, how to efficiently make instructions according to the environment is an important prerequisite for the automatic driving [1]. Currently, the algorithms of decision-making module are mainly classified into rule-based algorithms and learning-based algorithms.
Rule-based algorithms
The rule-based decision-making approach relies on a database of rules constructed which is based on a large number of traffic regulations, driving experience, and driving knowledge [3], and then determines strategies based on different states of the vehicle this category represents methods for Finite State Machine (FSM) [28, 29]. In [2], the authors classify the vehicle’s behavior into four states, such as lane keeping, and use the FSM method to build the relationships between individual driving behaviors and the transitions between states. In [32], the authors use a hierarchical state machine approach for decision making in lane changing for intelligent vehicles, where the decision is made by dividing the lane change into a forced lane change scenario and a free traveling lane change scenario. In [33], the authors consider the difficulty of extracting lane-changing rules in complex environments, and use the rule extraction method of CART decision tree to extract the lane-changing rules, which proves that the extracted rules are effective. The main advantage of the rule-based decision-making algorithm is good interpretability. In the case of abnormal system behaviors, the expert can quickly identify the module that has a malfunction. However, its design still requires a lot of driving experience and repeated adjustments, and the whole system becomes difficult to maintain. Such algorithms are difficult to establish high-quality driving rules and cannot enumerate all possible events when dealing with complex and dynamic road scenarios.
Learning-based algorithms
Compared with the rule-based algorithm, the decision algorithm based on learning are mainly represented by deep reinforcement learning algorithms, obtains the optimal strategy by continuous trial and error through the continuous interaction between the agent and the environment and gets rid of the limitations of rules [4]. In [5], the authors use a Deep Q Network (DQN) approach for intelligent vehicle highway scenario lane-changing behavior decision-making, and simulation experiments show that the decision-making performance of this approach is better than that of the traditional rule-based approach. In [6] the authors study the lateral lane changing problem by adding rule constraints. In [30], the authors propose an end-to-end reinforcement learning strategy for lane keeping, which is simulated on a racing simulator using a deep Q-network algorithm with good lane keeping results. Intelligent vehicle decision learning based on deep Q-network algorithms avoids the process of discretization of the state space. However, the traditional reinforcement learning method represented by DQN adopts discrete action space during the training of intelligent vehicles, which leads to frequent lane changing of intelligent vehicles on highways. With the development of reinforcement learning, the algorithms based on continuous action space such as DDPG and TD3 have achieved better control results in the field of autonomous driving, where intelligent vehicles interact with the environment to output continuous actions, and complete decision-making tasks such as lane keeping [7] and lane changing [8] by controlling throttle opening and steering wheel angle. In [9], the authors use a stochastic strategy and experience replay to improve the lane keeping ability of an autonomous driving strategy under new road conditions. In [10], the authors construct a decision-making framework to achieve vehicle safety for handling emergency situations based on the DDPG algorithm. In [26], the authors fuse the DDPG algorithm with a mixture of sensor information features to improve vehicle control in terms of speed and lateral displacement. While the DDPG algorithm can lead to the problem of overestimation of the value during training because of the instability of the value function, the TD3 algorithm limits this problem by using a dual estimation Q network and achieves better results In [11], the authors use the TD3 algorithm for training the lane keeping ability of intelligent vehicles. In [12], the authors propose a dynamic delayed policy update to speed up the convergence of the algorithm based on the TD3 algorithm. Deep reinforcement learning obtains the optimal strategy by interacting with the environment with self-adjustment and self-learning ability, which provides a new idea for driving decision-making of intelligent vehicles in complex traffic environment, but the driving decision-making based on deep reinforcement learning still exists poor data utilization ability and low learning efficiency.
Experience replay
Intelligent vehicles need to interact with the environment a lot during training process, and the experience tuples obtained from the interaction once are stored into the experience pool, which the reply buffer is one of the most important parts of deep reinforcement learning. Initially, the experience pool sampling only learns based on the previous state, which can cause that there will be a deep correlation between neighboring states. In [13], the authors use the experience replay method to uniformly and randomly sample from the experience cache pool, which reduces the correlation between neighboring samples. The TD3 algorithm adopts the experience replay mechanism to reduce the correlation between samples, and updates the network parameters by random sampling. However, at the beginning of training the intelligent vehicle generates a large number of lower quality samples in the exploration phase, which will interfere with the training effect of the intelligent vehicle and increase the training time. To further improve the efficiency of experience replay in reinforcement learning, in [14], the authors proposed Priority Experience Reply (PER) which takes TD-error as a benchmark for the importance of experience, and prioritizes the selection of experiences with larger errors for training. In [15], the authors combine the DDPG algorithm with the PER method to accelerate the convergence speed of the model. In [16], the authors store the experience samples in episodes, calculated the cumulative returns of the episodes separately, and sampled the samples with larger returns to improve the training quality. In [27], the authors propose a TD error-based resampling preference mechanism for updating neural networks to improve algorithm performance by lowering the priority of high-priority experiences. Although the PER mechanism improves the utilization of data, as the experience pool continues to expand, when updating the network Q parameters, only a lesser number of samples are updated in priority, and most of the experiences can no longer satisfy the sampling requirements, which can lead to an increase in the priority difference between the stored and actual samples [17, 18], and ranking experiences by TD-error ignores the effect of immediate returns on the convergence of neural networks, while PER based on immediate returns is more robust but less capable of utilizing good samples [19].
In order to better solve the problems of high randomness of action selection and low training efficiency in the training process of intelligent vehicles under reinforcement learning algorithms, we establish a TD3 intelligent vehicle driving decision model based on composite priority experience replay in highway scenario. Firstly, the priority of immediate return and the priority based on time error are calculated and sorted respectively, and the experience is sorted by composite average. The sampling probability is calculated according to the composite priority for sampling the experience pool and updating the network parameters, and this kind of method ensures the diversity of samples. Secondly, the action space selection of intelligent vehicles is considered, and the reward function is designed by combining the theory of minimum lane change safety and variable headway to guide the intelligent vehicles to learn from high-value strategies and improve driving safety.
Modelling framework
Reinforcement learning model
Reinforcement learning models obtain rewards to feed back to the intelligences by the intelligences interacting with the environment. Through continuous learning, maximizes the reward value to obtain the optimal strategy. The learning process can usually be expressed as Markov Decision Process (MDP), which is defined as a quintuple, denoted as (S, A, R, P,
Reinforcement learning model.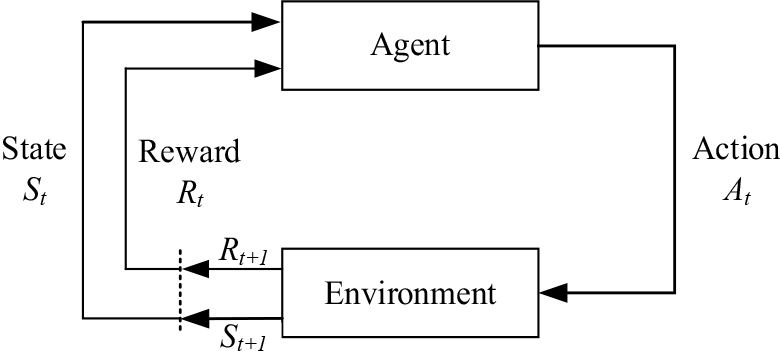
The TD3 algorithm is a reinforcement learning algorithm based on the Actor-Critic framework. The actor network takes the state of the intelligent vehicle as input and is responsible for action generation according to the network parameters. The critic network is responsible for the estimation of the state-action Q value, judging the performance of the actor network in executing the action, and guiding the actor network to be updated [20]. The DDPG algorithm is unstable in training and may fall into local optimum due to the problem of over-estimation of the value function. The TD3 algorithm optimizes the actor network and critic network on this basis, including:
It adopts a double-Q network for updating, establishes two independent critic network computations, and selects two computational errors with smaller objective values to limit the overestimation problem of the DDPG algorithm as shown [21]:
where To avoid the problem of overfitting, the TD3 algorithm also adds noise
where A delayed strategy is used to update, as opposed to the critic value network parameters which are updated every round, the actor policy network is updated less frequently, typically every 2 rounds to reduce the error in the approximated action value function. The actor network parameters
Subsequently, each target network is updated using soft updates as shown in Eq. (4).
where
Twin delayed deep deterministic policy gradient.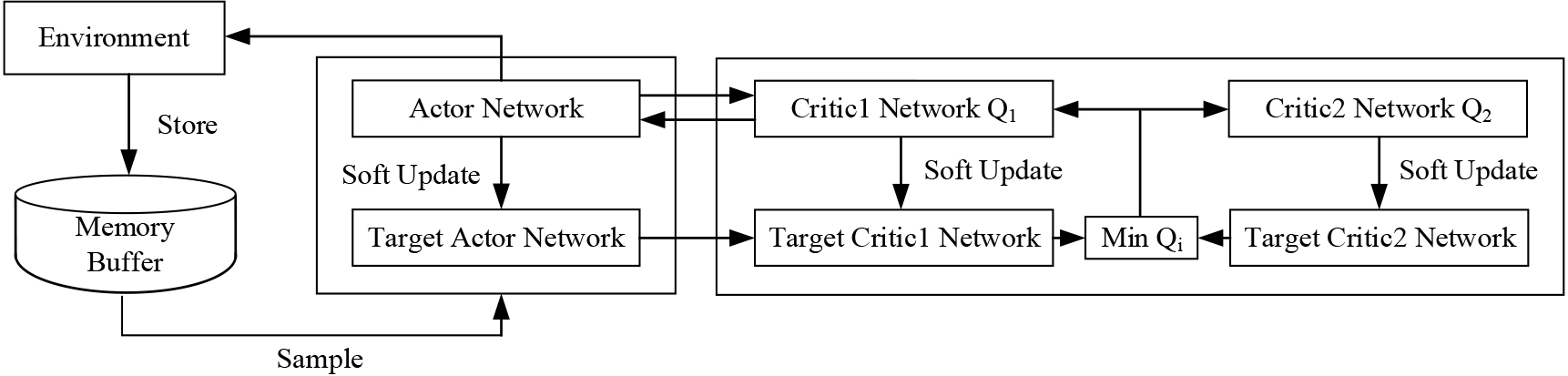
In traditional deep reinforcement learning algorithms, samples from the experience pool are randomly drawn with equal probability, however, such sampling does not take into account the fact that different experience samples have different importance, and randomly drawn samples are under-utilized for samples that play a large role in updating the network model parameters. The principle of priority experience replay is to make the probability of each experience sample being sampled and the absolute value of the respective TD-error monotonically related to each experience sample, in order to improve the probability of poorly performing samples being sampled and the learning efficiency of the model. The larger the value of TD-error, the more valuable the sample is.
In the priority experience replay, TD-error is defined as:
where
Non-uniform sampling of samples in the priority experience replay, its priority has two forms of expression: the first is directly with the absolute value of TD-error
The sampling probability of the sample is:
where
Priority experience replay increases the sampling probability of samples with larger weights by introducing TD-error to speed up the convergence of the training model. However, in the TD3 algorithm network, the parameters of the neural network will be updated with each step of the agent, when a certain set of samples with a larger absolute value of TD-error enters into the experience pool, the sample will be given a larger weight, and at the same time the probability of this sample being sampled is higher But with the continuous updating of the network parameters, the absolute value of the TD-error of this sample is reduced, and the probability of this sample data being sampled remains high due to the previous weight assignment, resulting in the probability of the sample data being sampled is still high, which will lead to the emergence of some lower quality samples, interfering with the learning efficiency of the model [22]. Therefore, this paper combines the TD-error mechanism and the immediate return mechanism, which are able to ensure the sample priority while also considering other important sample information [23].
Define the priority
where Arranging the experiences in order of
Calculate the priority of the composite:
where the variable Define the probability of sampling experience as:
where
In order to reduce the meaningless collisions in the training process of intelligent vehicles and accelerate the training convergence efficiency, the experience replay pool and reward function in the TD3 algorithm are improved, and the highway scenario is used as the training environment for simulation verification.
Overall framework
In order to improve the stability of intelligent vehicles in the training process and increase the utilization of priority samples, this paper introduces a composite priority experience replay mechanism and the design of the reward function. The decision-making framework based on CPR-TD3 is shown in Fig. 3.
The framework for TD3 algorithm based on composite priority experience replay.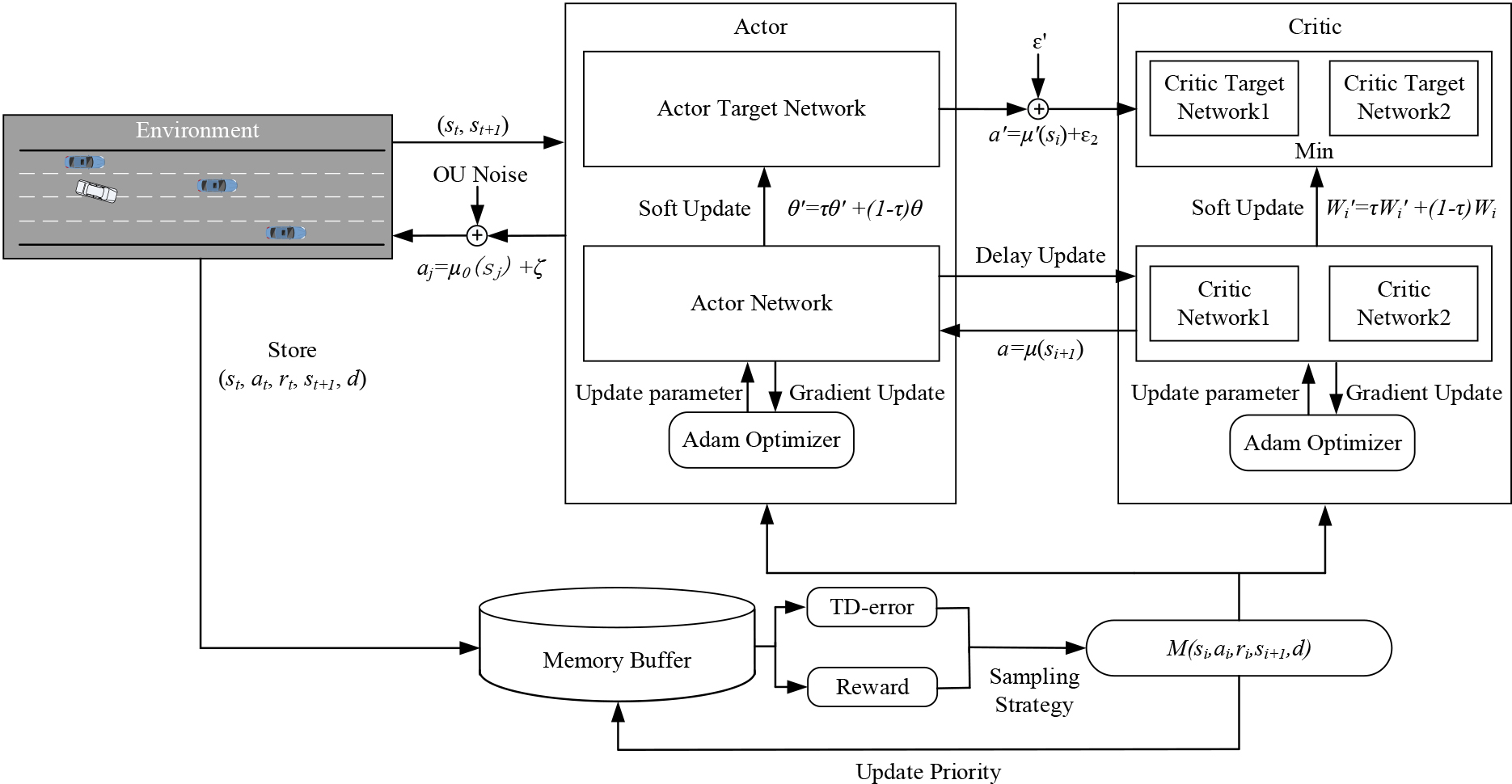
During the driving process, the intelligent vehicle driving on the highway scenario generates
The state space is the state information of the vehicle during driving, containing whether the vehicle is observed or not and the normalized lateral and longitudinal relative speeds and relative positions. The action space is the action commands executed by the auto-vehicle. In this paper, we use the continuous action space, which is set to [throttle, steering], to control the vehicle travelling by adjusting the throttle and steering wheel turning angle. The steering wheel angle is set to [
Minimum lane change distance
The lane change minimum safe distance scenario is shown in Fig. 4, where L
Minimum safe distance scenario for lane change.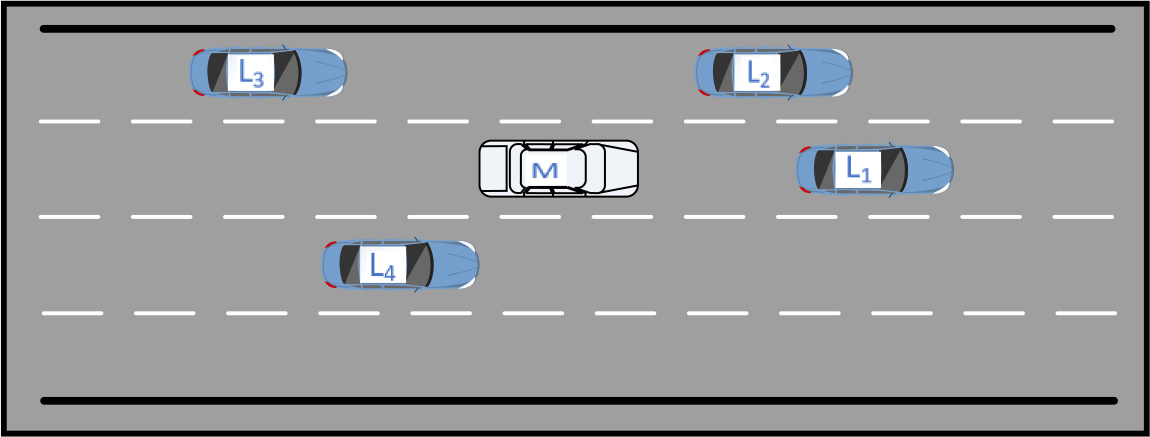
The minimum safe distance for changing lanes is [25]:
where
The distance to safety at variable headways is:
where
where
The reward function plays an important role in guiding whether the intelligent vehicle can obtain the optimal strategy. The original reward function in this paper’s scenario only considers speed reward and collision penalty, which is easy to fall into the dilemma of only pursuing high speed and leading to collision or driving at the lowest speed until the end of the round, and it is not conducive to the training of intelligent vehicles. Aiming at the shortcomings of the original reward function Eqs (15) (16), this paper considers factors such as relative speed and relative distance to improve the importance of distance maintenance by intelligent vehicles.
Speed reward function
where Collision reward function
where Distance reward function
where
where Lane changing reward function
Lane keeping reward function
In summary, the modified composite reward function is:
where
Simulation parameters and environment settings
In this study, the highway scene is selected to build a simulation environment, and the TD3 algorithm based on composite priority experience replay and improvement of the reward function (CPR-TD3) is applied to intelligent vehicle driving behavior decision-making To verify the validity of the algorithm in the highway scene and the convergence speed, and to compare with the traditional TD3.
The simulation environment is as follows: the CPU is Inter Core i7-12700, the memory is 16 GB, and the deep reinforcement learning compilation framework is Pytorch. According to the applicable scenarios and needs of vehicle decision-making, the highway scene is set as a one-way 4 lanes, and the number of other vehicles in the scenario is 50. The other vehicles are caused by the minimization of total braking caused by the lane change and the intelligent driver model for horizontal and vertical control, the specific training parameters are shown in Table 1, and each parameter of the Highway-env environment is shown in Table 2.
Experimental training parameters of CPR-TD3 algorithm
Experimental training parameters of CPR-TD3 algorithm
Environmental parameters of highway
Experimental data of TD3 algorithm
Comparison of different algorithms for improving the experience replay mechanism
In this experiment, the TD3 algorithm is used as the basis for comparison experiments, and the TD3 with the addition of priority experience replay (P-TD3) and the TD3 with the addition of composite priority experience replay (CP-TD3) are implemented to compare their training respectively. In the simulation analysis, the number of training rounds is uniformly set to 2000 rounds due to the time cost. In order to avoid the volatility of the training results from interfering with the reading, and at the same time, to make the results display more intuitive, the average reward, speed, and maximum distance travelled of the output of the three algorithms were smoothed using python’s built-in SavitzkyGolay filter.
Comparison of average reward function.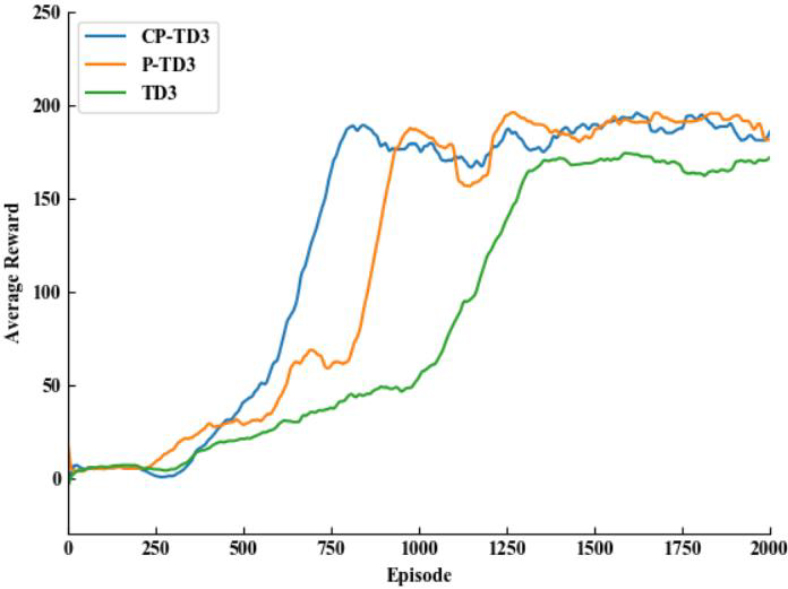
Comparison of maximum distance travelled.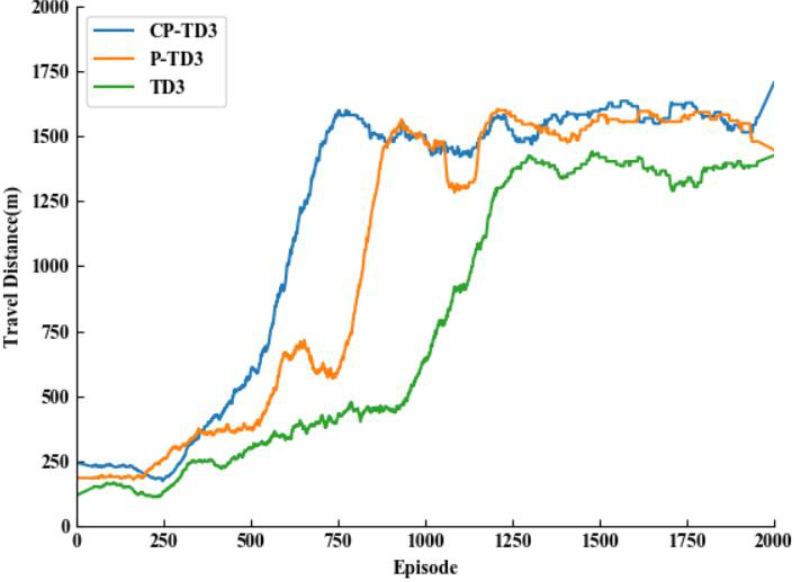
Comparison of average vehicle speeds.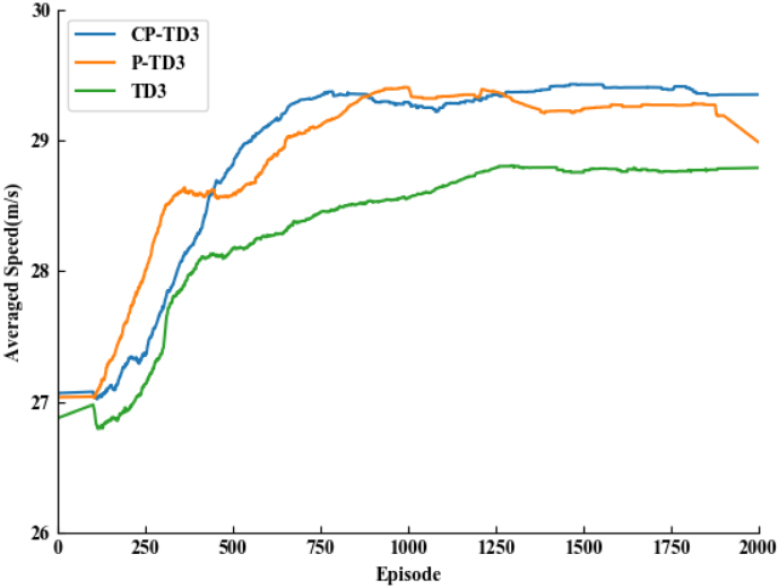
Figures 5–7 show the comparison of the average reward value, distance travelled, and average speed for the three TD3 algorithms with the original reward function, respectively. The three methods converge at approximately 1420, 1200, and 854 rounds, respectively. From Table 4, it can be seen that the traditional TD3 algorithm converges more slowly, with a success rate of only 42%. By adding the preferred experience replay mechanism, thanks to the improvement of sampling experience, P-TD3 accelerates the convergence speed by about 16% compared with the traditional TD3 algorithm, and obtains higher reward values and driving distances. The CP-TD3 algorithm, by composite sorting of the TD-error and the immediate reward, has a higher experience sample utilization is higher, the convergence speed is accelerated by 42% compared to the traditional TD3 algorithm, and the obtained reward value and driving distance are also significantly improved.
According to the original reward function’s, the modified reward function was trained several times, and after several validations, the weights took the values of 1,
Comparison of two algorithms for improving the reward function
Comparison of two algorithms for improving the reward function
Comparison of maximum travelling distance.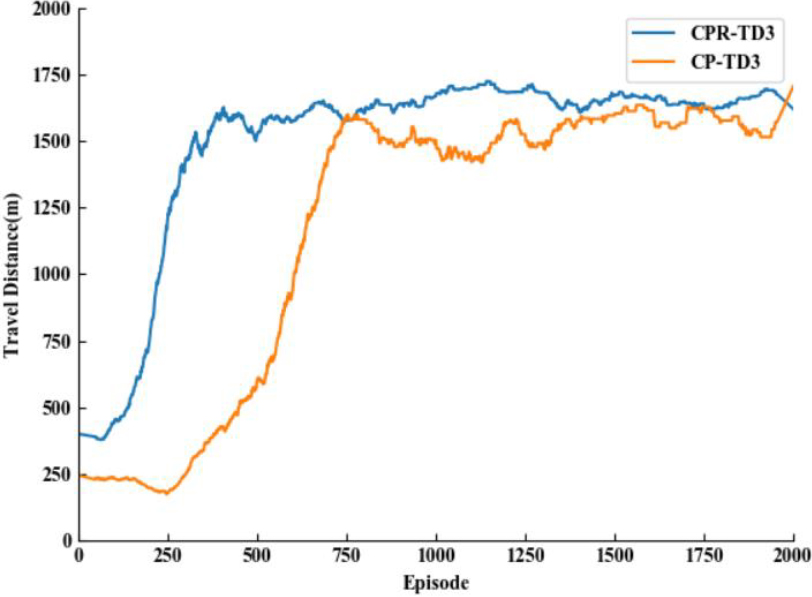
Comparison of average vehicle speeds.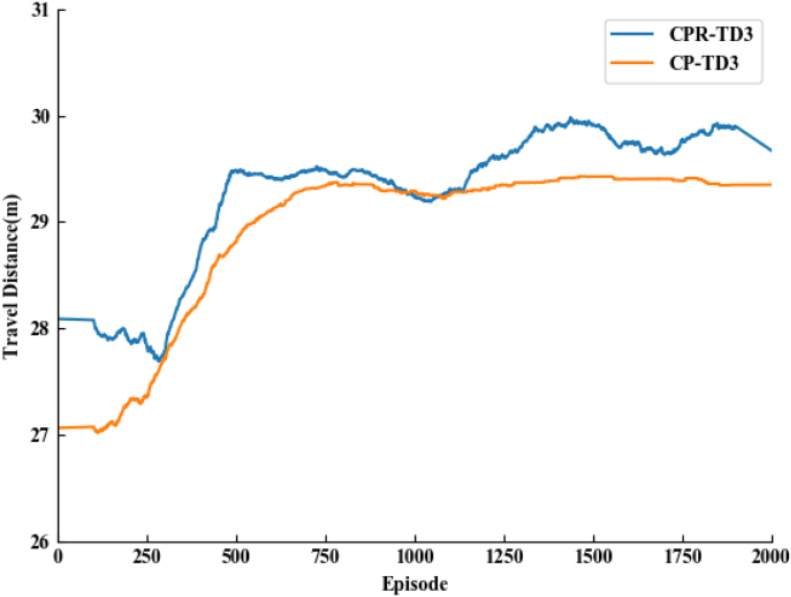
Taking the TD3 algorithm which introduces the composite priority experience replay mechanism as the base algorithm, combined with Figs 8, 9 and Table 4, by comparing the original reward function and the improved reward function, the average distance travelled and the success rate are significantly improved, the fully improved TD3 algorithm converges at about 410 rounds, and the success rate is improved by 36% compared with the traditional TD3 algorithm, maintaining a safe distance from the vehicle in front of the vehicle has become the key to the success of the intelligent vehicle, which demonstrates that the composite priority experience replay mechanism and the reward function designed according to the minimum distance have further improved the performance of the intelligent vehicle.
Aiming at the problems of low training efficiency and insufficient sample utilization of intelligent vehicles under reinforcement learning algorithm, this paper improves the sampling process of TD3 algorithm and the main work is summarized as follows:
Introducing a composite priority experience replay mechanism, sorting the experience separately by TD-error priority and immediate return priority, and then calculating the experience sampling probability by composite sorting, which improves the utilization efficiency of the experience, increases the robustness, and speeds up the training speed of the network model. Designing a combined reward function based on the minimum safe distance and variable headway spacing to improve the success rate of intelligent vehicles during lane changing.
Meanwhile, the study also has the following shortcomings:
The reward function designed in this paper does not consider the steering wheel steering angle and other factors and the reward function designed in this paper has room for supplementation. The experimental environment of this paper is relatively simple, and the difference between the real application scene is large, the follow-up should be considered in the real car scene for experimentation.