
Abstract
Background noise often distorts the speech signals obtained in a real-world environment. This deterioration occurs in certain applications, like speech recognition, hearing aids. The aim of Speech enhancement (SE) is to suppress the unnecessary background noise in the obtained speech signal. The existing approaches for speech enhancement (SE) face more challenges like low Source-distortion ratio and memory requirements. In this manuscript, Recalling-Enhanced Recurrent Neural Network (R-ERNN) optimized with Chimp Optimization Algorithm based speech enhancement is proposed for hearing aids (R-ERNN-COA-SE-HA). Initially, the clean speech and noisy speech are amassed from MS-SNSD dataset. The input speech signals are encoded using vocoder analysis, and then the Sample RNN decode the bit stream into samples. The input speech signals are extracted using Ternary pattern and discrete wavelet transforms (TP-DWT) in the training phase. In the enhancement stage, R-ERNN forecasts the associated clean speech spectra from noisy speech spectra, then reconstructs a clean speech waveform. Chimp Optimization Algorithm (COA) is considered for optimizing the R-ERNN which enhances speech. The proposed method is implemented in MATLAB, and its efficiency is evaluated under some metrics. The R-ERNN-COA-SE-HA method provides 23.74%, 24.81%, and 19.33% higher PESQ compared with existing methods, such as RGRNN-SE-HA, PACDNN-SE-HA, ARN-SE-HA respectively.
Keywords
Introduction
Hearing aids is a minor electronic gadgets plan towards better hearing on people have damaged hearing, utilizing sophisticated audio signal processing approaches and methods [1, 2, 3]. SE approaches for hearing aids separate ecological sound, increase speech though giving reflection to hearing attributes as well as ecological environments [4, 5, 6, 7, 8].
SA algorithm was suggested to increase speech grade of hearing aid environment via solicit sound depletion with deep neural network (DNN) learning on the basis of sound categorization [9, 10]. To assess speech improvement in real hearing aid environs, ten types of noise for using convolutional neural networks (CNN) [11, 12, 13]. Sound depletion with speech improvement was used through DNN construct at sound organization [14, 15]. The speech enhancements removed utilizing the DNN and connected ecological sound displays the enhancement of the conventional hearing aid approaches [16, 17, 18]. The speech qualities are calculated with perceptional assessment on speech quality score; short-time impartial intelligibility score, log likelihood correspondence score and the total quality combine scale [19, 20].
Speech enhancement (SE) is an important and difficult task in most of the applications. Some approaches for SE have been developed so far. The existing approaches can deal background noise perfectly, but they are limited in non-stationary noise as well as complicated. They are not appropriate for real-time applications due to their poor Source-distortion ratio, lengthy training time, and memory requirements. They also do not utilise information found in the phase spectrum. To overcome these issues, R-ERNN optimized with Chimp Optimization Algorithm based SE for hearing aid is proposed. The novelty of the proposed approach is the lessening of training time and improves noise suppression using R-ERNN. The proposed technique introduces to address the limitations of existing methods for speech enhancement, including the high speech distortion and low Source-distortion ratio.
The major contributions of this manuscript are summarized below:
In this manuscript, R-ERNN optimized with Chimp Optimization Algorithm based Speech Enhancement for Hearing Aid is proposed. R-ERNN is introduced to reduce the training period of deep network and improve speech enhancement by separating clean speech spectra via noisy speech spectra. COA is employed to improve the non-stationary sound without any pre-training of sound methods. The performance metrics is examined to find the robustness of the proposed speech enhancement system. This paper attempts to directly incorporate the short-time objective intelligibility measure (STOI) in an R-ERNN speech enhancement approach to optimize for speech intelligibility.
Remaining manuscript is organized as follows: the literature survey is depicted in Section 2, the proposed approach is illustrated in Section 3, Section 4 demonstrates the result, conclusion is given in Section 5.
Many study works were suggested in the works related to Speech Enhancement for Hearing Aids; a few recent works are reviewed here.
Saleem et al. [21], have presented a residual gated RNN-augmented kalman filtering for SE with identification. The clean speech along noise signals was modeled as autoregressive procedure then the parameters were consists of linear prediction coefficients and driving noise variances. RNN was train to assess the line spectrum frequencies, while optimization issue was overwhelmed to reach noise variations to lessen the difference among the modeled and estimated noise contaminated speech autoregressive spectrums. It provides higher SSR and lower PESQ metrics.
Hasannezhad et al. [22], have presented a phase-aware composite deep neural network for SE to handle higher computational complexity and memory requirements defies. To be more precise, two important sub tasks of the novel network to improve the phase and magnitude spectra were phase reconstruction with phase derivative and magnitude processing with spectral mask. It provides higher SSR and lower PESQ metrics.
Pandey and Wang [23], have presented self-attending RNN for speech enhancement to enhance cross-corpus generalization. To promote cross-corpus generalization, a self-attending recurrent neural network, also called an attentive recurrent network (ARN) was presented for time domain speech augmentation. ARN contains recurrent neural networks enhanced with feed forward and self-attention blocks. Then assess ARN in low SNR scenarios using several corpora containing non-stationary noise. The outcomes of the experiments show that ARN performs significantly better at time domain speech augmentation than competing methods. It provides higher PESQ than SSR metrics.
Lei et al. [24], have suggested a Low-Latency Hybrid Multiple Channel SE scheme for Hearing Aids. Three modules make up the system: post-processing, multi-channel augmentation, and rule-based dereverberation. The system may achieve average hearing aid speech perception index score 0.696 together with hearing aid speech quality index score 0.320 without the use of head rotation information along enrollment speech. It provides higher SSR than PESQ metrics
Cantu and Hohmann [25], have suggested Spectro-Temporal Post-Filtering under Short-Time Target Cancellation (STTC) for Directional SE in a Dual-Microphone Hearing AID. STTC processing takes advantage of the computational power of the Short-Time Fourier Transform (STFT) for the post-filtering, while the hearing aid technique was employed for the adaptive beamforming. STTC processing was effective, and simple STFT-based processing to attain real-time lower latency (
Wang et al. [26], have suggested the FNeural SE with Less Algorithmic Latency and Complexity utilizing Integrated full-and sub-band Modeling. To increase speech in the short-time Fourier transform (STFT) domain for both single and multi-channel applications, FSB-LSTM based architecture was used. Through many FSB-LSTM modules, the method sustains information highway to flow over-complete input depiction. An FSB-LSTM module has full-band block that simulates spectro-temporal patterns on every frequency as well as sub-band block that simulates patterns on every sub-band. It provides higher SSR and lower CSII.
Proposed methodology
Proposed R-ERNN-COA-SE-HA methodology.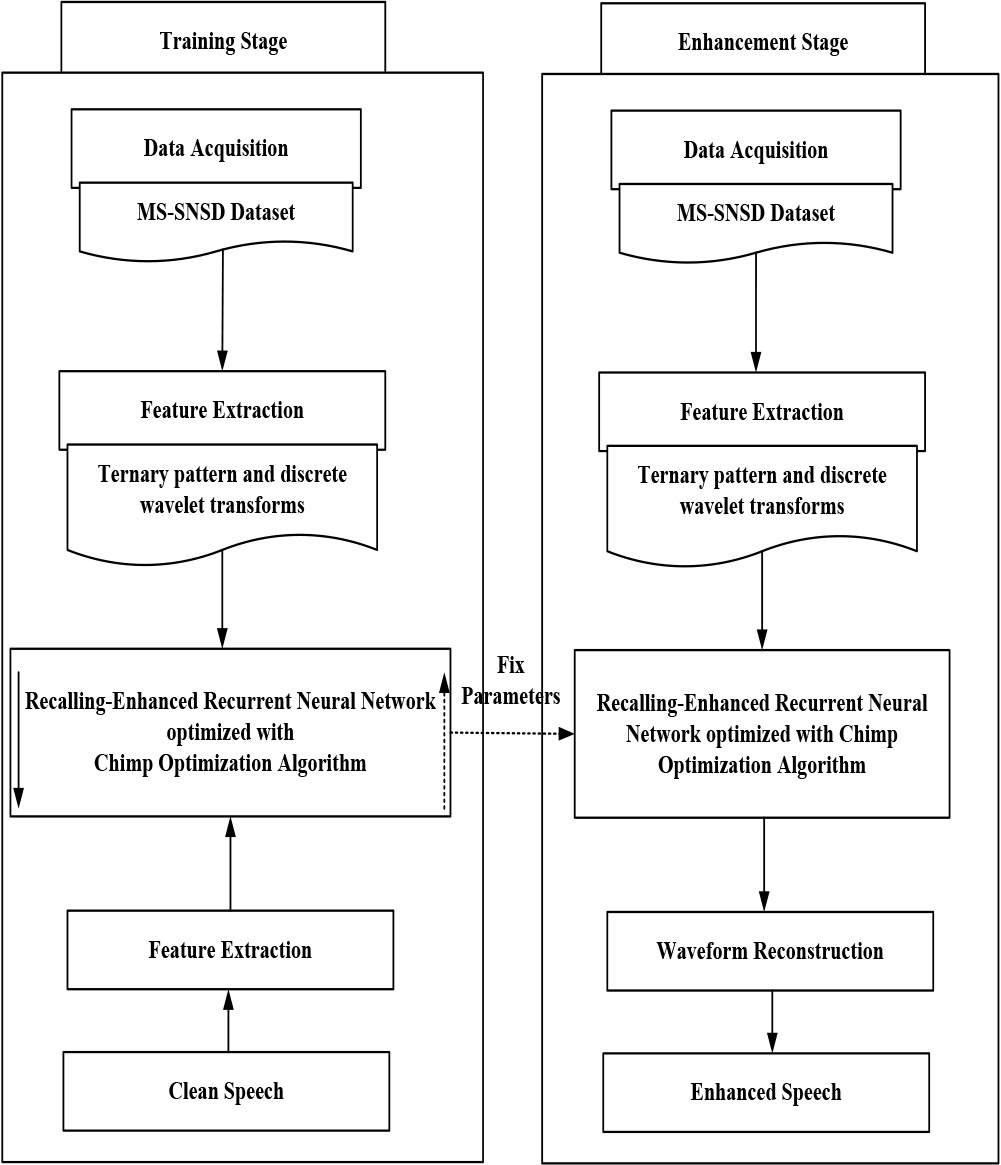
In this manuscript, R-ERNN by COA based SE-HA is discussed in this section. Figure 1 displays the proposed R-ERNN-COA-SE-HA methodology. The detail discussion regarding proposed R-ERNN optimized by Chimp Optimization Algorithm based speech enhancement for hearing aids is discussed as follows.
Initially the input of clean speech and noisy speech data are taken from Microsoft Scalable Noisy Speech Dataset (MS-SNSD) [27]. Then the input speech signals are fed for the encoded process.
Input signal encoded using vocoder analysis
Here, the input speech signals are first encoded using vocoder analysis, which compress input speech signals into the compact bitstream (encoder) and then the Sample RNN decode the bitstream into samples [28]. The extensive-band variant of the linear prediction coding (LPC) vocoder serves as the foundation of the encoder scheme. The following parameters are generated as a consequence of per-frame input signal analysis: A
Pitches are quantized utilizing a vocoder analysis of prophetic with memory less coding. Although uniform quantization is used, it is carried out in a pitch-distorted domain. Where input speech signal is encoded using Eq. (1) as follows,
where,
where
where
While teaching stage, the types of speech signals are removed using TP-DWT [29]. The proposed TP-DWT approach provides the acoustic signal and features. The features extracted from acoustic signals for identifying types of SE. In this, TP-DWT is utilized to extract spectral features of speech signals. In this, the TP-DWT base feature extraction extracts the local features with 3
where
The set of coefficients used in features is called MFDPCC, and it is built using the vocal track information’s frequencies. It offers information based on the spectrum’s structure of the speech signal. Twenty factors in total were used.
The global energy of speech signal are determined in its root mean square energy, which are computed using the Eq. (5),
where
where
While improvement stage, the noisy speech features deals with Recalling-Enhanced Recurrent Neural Network (R-ERNN) based method to calculate the clean speech features, with valued log power spectra features of attained clean speech waveform.
Recalling-Enhanced Recurrent Neural Network (R-ERNN)
Nowadays, RNN based networks can attain speech enrichment, however its computation load remains big and takes more training time. Recalling-Enhanced Recurrent Neural Network (R-ERNN) [30] a condensed version of recurrent architecture is used in this study to address these issues. In this part, we go over the R-ERNN network-based speech enhancement procedure. The first step is to use the spectral characteristics of voice like input network and output network. R-ERNN architecture then parallel concept is explained. Full model structure, containing the general learning framework as well as R-ERNN network training process is finally provided in detail.
The selected features are given to R-ERNN to classify speech enhancement problems in means of neural network depends upon optimal features. The RERNN has 7 layers: input, output, state, memory, sum, hidden, and delay. Let
Then the
Form Eq. (8),
where
where
where
where
Concealed layer contains
From Eq. (13),
Finally, Output layer contains
where
In this manuscript, COA can be exploited to expand the R-ERNN for discovering the optimum parameters. COA is used for tuning the hyper parameters of R-ERNN Network. Especially, some techniques are used for restriction creation; for example, the explorations of grid, manual and random. However, these sharing its unfamiliar feebleness concerning reiteration period and not has subterfuge-assembled acquainted enquiry. Therefore, intimidated the problems, COA are used. COA is a meta-heuristic algorithm. It gathers a prospect method to predict the speech signal and clear waveform utilizing random exploration of the purpose of minimum error rate. COA approach is selected, because it have own improvement; it acquires less iteration time than other tuning methods to determine optimal hyper parameters value.
Chimp Optimization Algorithm (COA) [31] is proposed for exploiting R-ERNN method presentation with speech enhancement. Therefore, the proposed R-ERNN method provides appropriate speech waveform and also decreases the possibility of error to minimum. The COA is founded on the intelligence displayed by chimps during group hunting. Even though no two chimps in a group are exactly alike in terms of intellect or behaviour, they all work well together to complete tasks. Similar to humans, chimps seek out meat in an erratic manner in order to gain communal benefits like grooming and sex. These two qualities play a crucial role in the creation of the COA. Fast convergence of the COA results in an efficient optimal answer. The step by step procedure of COA are expressed as follows,
Step 1: Initialization
Initially, Chimp population are initially dispersed at random throughout the search area and are represented in Eq. (15)
where
Step 2: Random Generation
Afterward the initialization, the input parameters of COA is created at random to obtain the best solution.
Step 3: Fitness function estimation
It achieves the objective function to optimize
Step 4: Chasing and driving the prey for optimizing
For the period of the exploration with exploitation phases, the prey is hunted. Equation (17) expresses the drive and chase of the prey in an excessively mathematical way,
where the number of current iteration is represented as
Step 5: Attacking method for optimizing the
Attacker chimpanzee leads the hunting procedure. Chimpanzees who act as driver, chaser and barrier occasionally engage in hunting behaviour. However, there is currently no knowledge about the ideal position during an abstract search area. The very first attacker, barrier, driver and chaser are considered to have superior knowledge of the locations of feasible prey to numerically emulate the behaviour of chimpanzees. The remaining chimps are compelled to modify their positions in accordance with the positions of the 4 best solutions so far found, which are saved. The Eq. (18) shows the relationship between the attacker, barrier, driver and chaser,
Step 6: Termination
Finally, the proposed R-ERNN with COA calculate the consistent clean speech spectra in the noisy speech spectra, optimum solution is achieved, after iteration are stopped, if not, steps 1, 2 and 3 is repeated till the halting measures,
This section describes about R-ERNN optimized with COA based speech enhancement with hearing aids. The suggested method is executed in MATLAB. The method was implemented on PC along Intel-core i5, 2.50 GH central processing unit and 8 GB of Random Access Memory. The performance metrics, like PESQ, STOI, CSII, SD SDR is analyzed. The efficacy of the proposed technique is analyzed to the existing models, such as residual gated RNN-augmented Kalman filtering for SE with identification (RGRNN-SE-HA), a phase-aware composite deep neural network for speech enhancement (PACDNN-SE-HA), Self-attending recurrent neural network for SE to enhance cross-corpus generalization (ARN-SE-HA) respectively.
Perceptual estimation of speech quality
Perceptual estimation of speech quality
Flowchart of COA.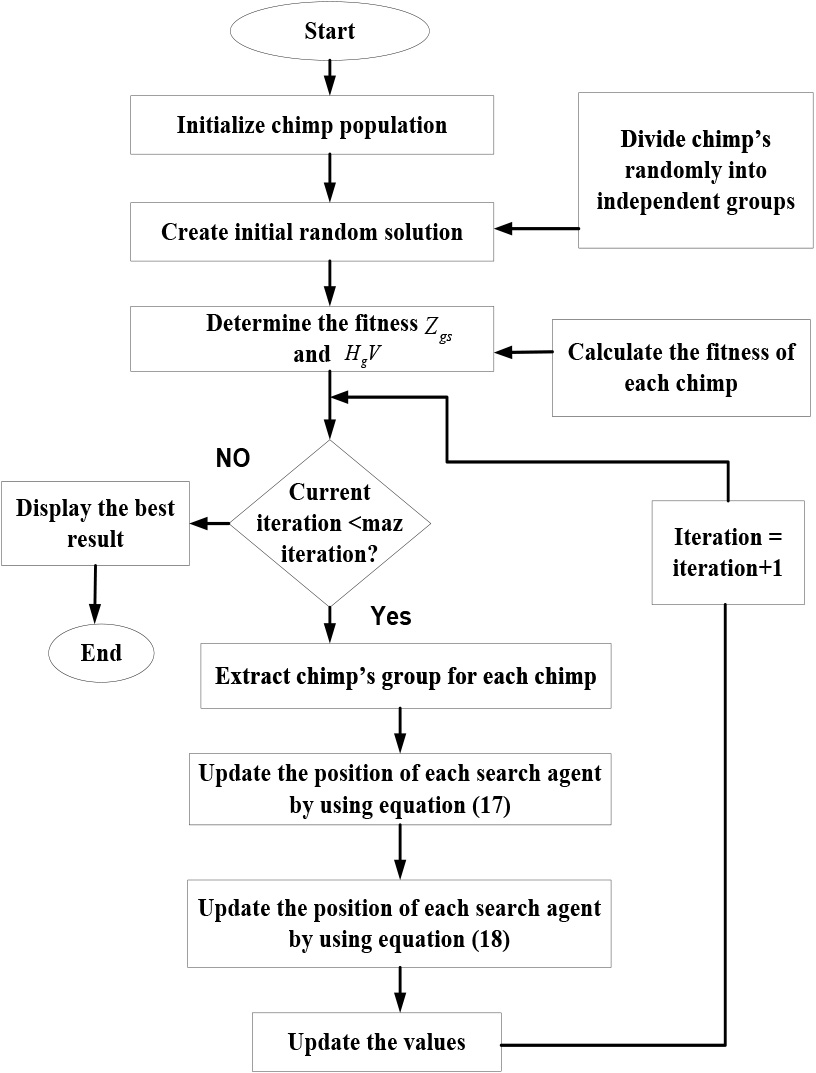
The proficiency of the proposed technique is assessed under the metrics like PESQ, STOI , CSII, SD as well as source-to-distortion ratio SDR are employed.
Table 1 demonstrates PESQ analysis. Here, the proposed R-ERNN-COA-SE-HA method attains 23.74%, 24.81%, and 19.33% higher PESQ for SNR rate 2; 32.16%, 26.19%, and 34.80% higher PESQ for SNR rate 4; 38.71%, 20.90% and 27.38% higher PESQ for SNR rate 6; 32.48%, 25.87% and 36.10% higher PESQ for SNR rate 8; 20.27%, 28.04% and 40.77% higher PESQ for SNR rate 10 compared with existing RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively.
Short-time objective intelligibility
Short-time objective intelligibility
Table 2 demonstrates Short-time objective intelligibility analysis. Here, the proposed R-ERNN-COA-SE-HA method attains 34.19%, 24.38% and 32.38% higher STOI for SNR rate 0.6; 19.78%, 30.33% and 27.18% higher STOI for SNR rate 1; 28.37%, 34.92% and 26.15% higher STOI for SNR rate 1.4; 36.21%, 24.78% and 20.24% higher STOI for SNR rate 1.8; compared with existing RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively.
Coherence speech intelligibility index
Table 3 demonstrates Coherence Speech Intelligibility Index (CSII) analysis. Here, the proposed R-ERNN-COA-SE-HA method attains 32.41%, 19.65% and 28.26% higher CSII for SNR rate 0.5; 16.15%, 40.32% and 51.21% higher CSII for SNR rate 1; 17.95%, 18.34% and 31.74% higher CSII for SNR rate 1.5; 30.04%, 24.76% and 27.84% higher CSII for SNR rate 2.5; compared with existing RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively.
Speech distortion
Table 4 demonstrates Speech Distortion (SD) analysis. Here, the proposed R-ERNN-COA-SE-HA method attains 28.78%, 26.79% and 31.38% lower SD for SNR rate 0.5; 18.54%, 26.61% and 17.78% lower SD for SNR rate 1; 26.84%, 21.28% and 34.32% lower SD for SNR rate 1.5; 24.95%, 24.17% and 26.71% lower SD for SNR rate 2.5; compared with existing RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively.
Source-distortion ratio
Table 5 demonstrates Source-distortion ratio analysis. Here, proposed R-ERNN-COA-SE-HA method attains 24.85%, 21.34% and 35.30% higher SDR for SNR rate 0.5; 27.45%, 26.74% and 26.96% higher SDR for SNR rate 1; 17.75%, 19.40% and 26.84 higher SDR for SNR rate 1.5; 26.21%, 28.20% and 19.81% higher SDR for SNR rate 2.5; compared with existing RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively.
Training and validation label distribution.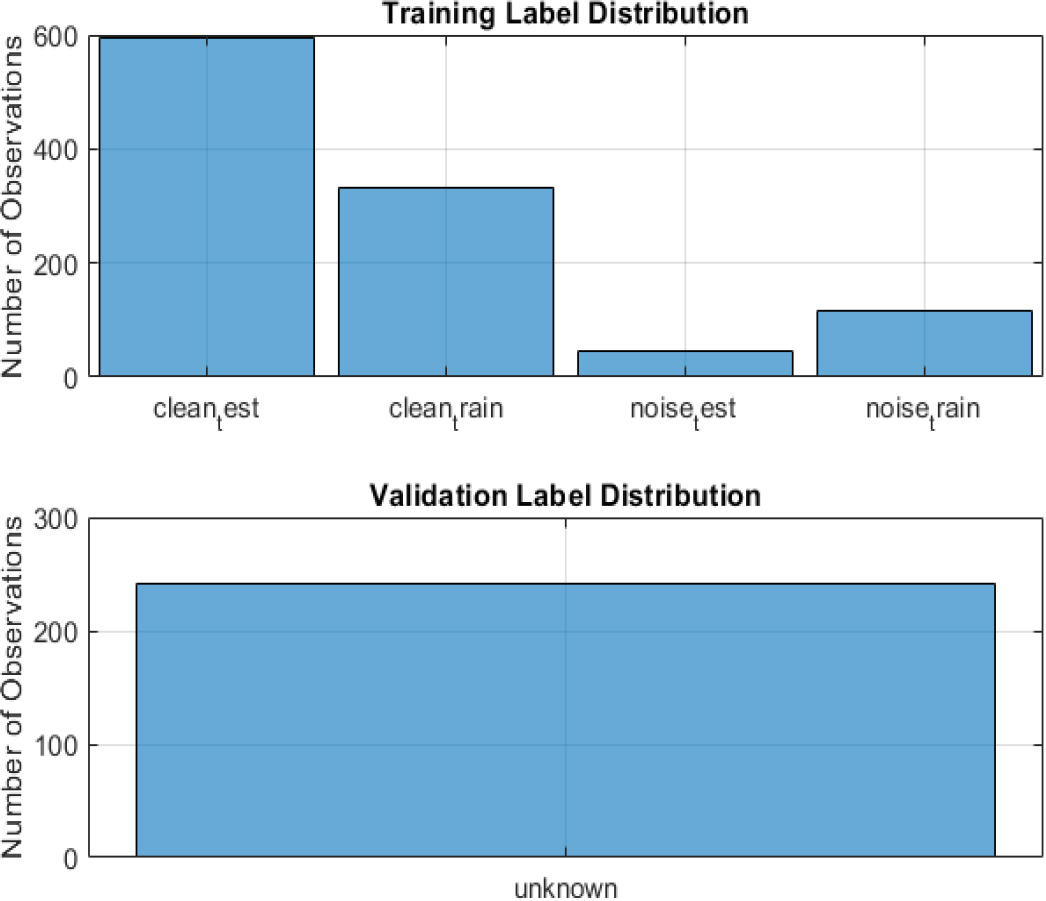
The training and validation label distribution of proposed method is shown in Fig. 3.
In this manuscript, R-ERNN optimized with COA based speech enhancement for hearing aids is successfully implemented. The proposed R-ERNN-COA-SE-HA is activated in MATLAB and the efficiency is evaluated by using several performance metrics, such as PESQ, STOI, CSII, SD and SDR. Here, the proposed R-ERNN-COA-SE-HA method attains 34.19%, 24.38% and 32.38% higher STOI and 28.78%, 26.79% and 31.38% lower SD compared with existing methods like RGRNN-SE-HA, PACDNN-SE-HA and ARN-SE-HA models respectively. Various adaptive beamforming techniques are introduced which can improve speech enhancement of hearing aids in the future. The proper functioning of speech recognition systems for challenging and complex issues may work. In the future, the new task of speech recognition system will be to use all available incentives to project the ideals of society and business into human-machine conversations.