
Abstract
Advancements in modern technology have led to an endless reliance on the Internet. This has created a great demand for the fast and accurate development of web applications. Web development has benefitted from programming approaches such as Model-Driven Web Engineering (MDWE). MDWE allows developers to choose pre-defined models and utilize them for their requirements. This kind of structural blueprinting, called wireframing, enables efficiency in software development. However, these techniques are seldom understood by people without a technological background. Hence, much of the coding central to a project remains the responsibility of a few tech-educated people. This work proposes an approach that offloads some of the typing to a machine-based code generator. This has been achieved by pairing MDWE methods with Deep Learning capabilities. This ensures a less coding-intensive web development methodology that can be utilized even by non-web developers. This work makes several contributions to improving overall MDWE methods.
Introduction
Collaboration and teamwork are central components of any web development procedure. Diverse members of a team must work together on a single project or task. These team members will possess different skills and share varied expertise. The right tools and services can aid such collaboration working between individuals with different responsibilities. A good tool allows the users to work quickly and clearly. Miscommunication can be avoided with a cohesive understanding of design, goals, and technicalities. Often, team members may only be remotely available. In such a scenario, full responsibility for inter-team dialogue rests upon the collaborative tool chosen. Inbuilt support for reviewing and feedback for code segments can reduce the chances of overlooking issues. A version control system can also be integrated into the tool. In the case of teams with heavy workloads, work can be distributed rapidly and resourcefully among the team members.
The foundation for web development collaboration lies in the architecture of the web portal. The design of a website gives us many insights into its programming [1]. Firstly, it describes how the User Interface (UI) should look. Front-end developers get to overview the CSS or other styling for the project. The design also gives back-end developers an estimate of data points. They are tasked with developing the Application Programming Interfaces (APIs) for the site. A single page on a web portal may have multiple APIs. During a normal sprint in an Agile web development setting, those working on APIs will need to have them ready first. Then, the front end can work to provide, present, and interface these APIs. In the next sprint, back-end programmers can develop APIs for the next few pages, while the website’s front end follows from behind. Another approach is to develop stub APIs or use boilerplate codes. This method is used when we quickly need some structure to a component and do not have time to start from scratch.
Programming in real time leaves us with some coding restrictions. Real-time constraints can be segregated as soft or hard real-time constraints. Soft real-time environments include those that can handle a certain degree of delay. For example, suppose a programmer shares his coding environment with his teammates via a video conferencing app. Other team members get to view code in progress and simultaneously offer suggestions. Here, some deadlines can be tolerated. If a comment is delayed, the programmer who is coding will still be able to make the required changes and continue the project. On the other hand, hard real-time environments cannot tolerate any delays or missing deadlines. Here, systems or team members need to react in time. Failing to do so might fail the entire project. An example of these is emergency server-side issues that need to be examined immediately. These critical tasks take priority over lower-priority jobs. Another constraint faced by real-time programming is resource constraints, including limited memory and communication limits.
Model-Based Web Engineering (MDWE) gives web programmers simulations and models before development [2]. Model Driven Development (MDD) proposes to use such representation as a basis for coding. These models have been worked on and developed by researchers. Codes from the models can be generated with automatic code generators. Using Artificial Intelligence, these generators can create boilerplate and template codes. Human programmers then only need to work on refining this generated code. Properties and components are changed based on the requirements of their system. In the agile programming scheme, this adds the advantage of not having to start coding from scratch. Models and architectures for the web portal can be represented by different techniques and methodologies. These diagrams can be understood even by the inexperienced programmer. Thus, web modeling along with code generators offers a convincing enhancement to web development procedures.
Related works
In this section, we discuss prior research that is related to our work. We begin by describing MDWE, followed by an analysis of code generation in literature. We conclude this section with related work on the integration of MDWE and modern software engineering techniques. This attests to the importance of this work involving collaborative web development.
Model-driven web engineering
In the 1990s, Web Engineering was established as an independent and prominent domain within Software Development [3]. Techniques that allowed accurate and fast web development became a necessity. Model-based web designs were introduced in 2004 to speed up the implementation of web applications [4]. Model-Driven Web Development (MDWE) continues to serve important functions in different use cases. Abrahão et al. used MDWE to facilitate tool integration to improve user experience [5]. Security and privacy in the work of Ghelani et al. were ensured using a model-driven technique [6]. Luna et al. used a model-based approach to overcome scalability problems using run-time transformations [7]. Accessibility and functionality of application features were achieved using MDWE in the work of Todorova et al. [8]. In these examples, MDWE acts as a foundation on which functionality is built. These functionalities are fine-tuned to suit the application’s objective.
To permit such customization to take place, there is a need for a modifiable modeling interface [9]. The extent to which we can change a model is dependent on what the model is based on. Most web development architectures are based on visual representation [7], and presentation [10]. Model diagrams are usually generated from modeling languages such as Unified Modeling Language (UML), Systems Modeling Language (SysML), and Domain Specific Languages (DSLs) [11]. Allowing us access to change certain features of a model increases the similarity between the model and code. It also encourages web developers to utilize model-based approaches for their tasks. In this regard, Pando et al. took a reverse approach [12]. The authors forced programmers to make alterations to the model diagram whenever coding changes were made. Other improvements to model-driven development include attention to non-functional requirements [13] and the creation of interface-based platforms [14]. Thus, modeling and web development are two closely related subjects.
Code generation
Automation of code is one way of speeding up the web development process. Machine-based code generation can assist developers in some of their coding tasks. This is another useful feature of using pre-defined model architectures. Definite styles and arrangements can be mapped to specific code outlines. This can be used to build model-to-code generators. Several researchers have used code generation software to semi-automate portions of development. Huynh et al. used model diagram images exported from MagicDraw software to build a typical web application using a code generator called CODEGER-UWE [14]. The ANDROMDA code generator was used by Deepa et al. to transform a website model into a web application solution [15]. Falzone et al. proposed ‘intelligent’ code generation that facilitated changes in file structure with built-in conflict resolution [16]. The high abstraction coding in the work of Ida et al. allowed the development of a web-based IoT software development platform [17].
Cabot et. al. proposed cognifying Model-Driven Software Engineering via modeling bots that perform code autocompleting, model reviewing via feedback, and collaborative modeling [18]. Tools that instinctively convert web models to code using code-model mapping were presented by Nunez et al. [19]. A builder HTML script and image processing techniques were employed for the conversion of web design images to HTML code in the work of Asıroglu et al. [20]. Khandekar et al. utilized a deep learning-based system for non-web developers to write HTML code by inputting images [21]. Thus, code generation for web development continues to attract the attention of researchers. Machine learning and deep learning techniques are behind many of these generators. They exploit artificial intelligence in order to produce code from sources. In other words, these models act as artificial team members who have been taught to code. Thus, code generators based on models behave as facilitators of efficient web engineering.
Modern web development
For industry standards, MDWE and automatic code generation need to be integrated with existing software development methodologies. MDWE involves writing and implementing software quickly and efficiently, and hence perfectly fits into the Agile Development Cycle [22]. It can even be used to update legacy software [23]. Several researchers have proposed various ways of modifying Agile software approaches to include these model-driven features. Rivero et al. proposed integrating Agile development with MDWE using an iterative approach called Mockup-Driven Development (MockupDD) [24]. Mockups can be useful in guiding the MDWE process to simplify the development cycle [25]. Agile MERODE was proposed by Snoeck et al. to formalize a structure for agility in Model-Driven Development [26]. MDWE can also be integrated with Agile development to support continuous change in web development methodologies [27]. Integrated models and generators can help facilitate teamwork between experienced and inexperienced developers. Team members can employ a generator or model or sections where they would be unable to complete otherwise. Researchers have found the requirement for a platform that allows such collaboration [9, 28]. A transient plane is used to avoid congestion in software defined networks. An automation process of it can be utilized for web development [40, 41].
Proposed system
The proposed system, named ‘Screen2Web’, comprises three main components. These are a UML-to-code generator, a collaborative code editing tool, and a deep learning-based website image-to-code generator. We will describe these three components in the forthcoming paragraphs of this section. The architectural overview of the work presented in this paper is depicted in Fig. 1.
The architecture of the proposed system.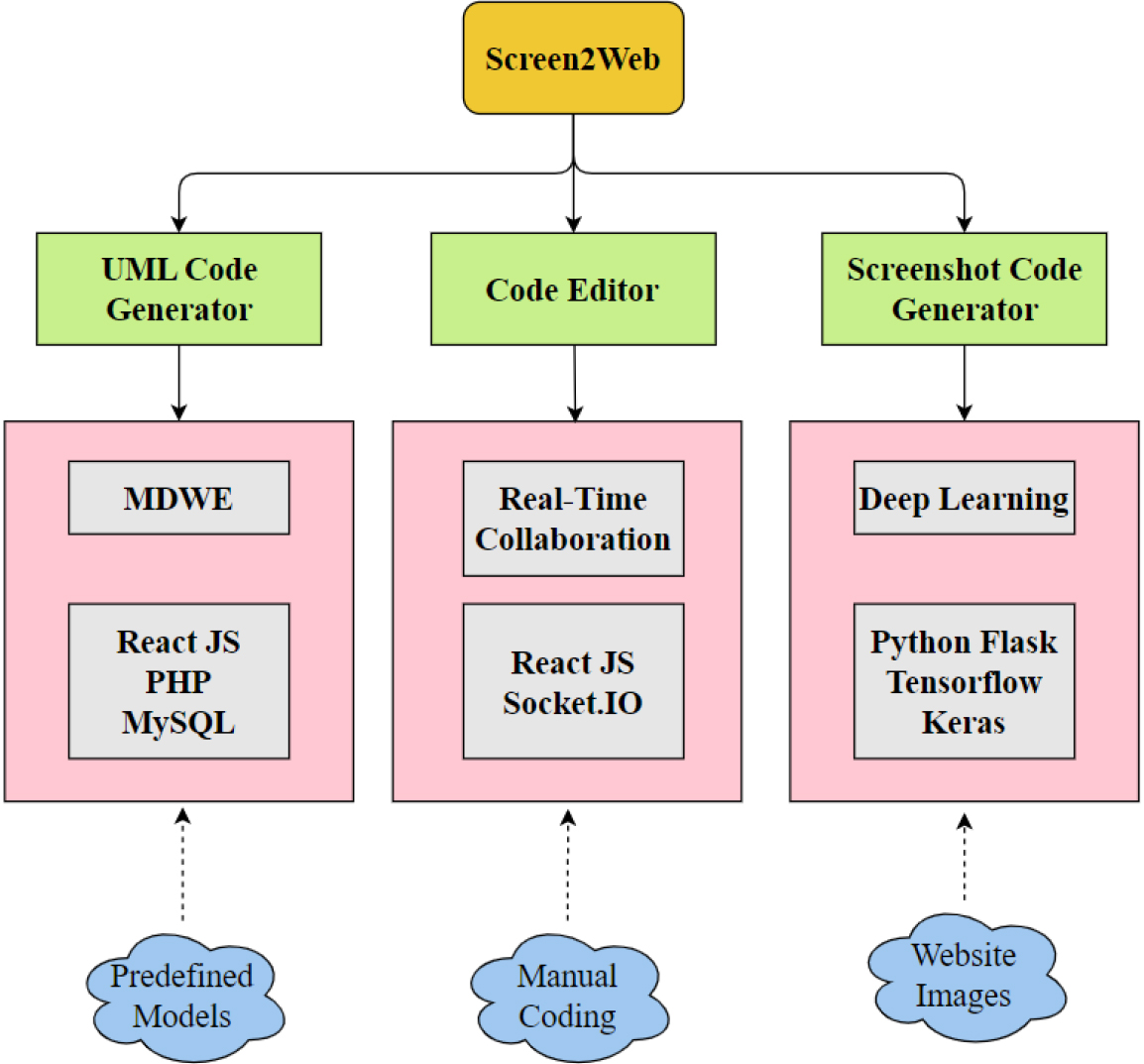
Unified Modeling Language (UML) is a popular and efficient way in which a systems architecture or model can be described. Complex software drawings can be visualized and implemented with a UML diagram. UML offers a quick and easy way for software developers to track the relationships and interlinkages between different components of their program. Software documentation is a vital part of the Software Development Life Cycle. UML diagrams offer quick visual documentation, helping engineers better understand intricate coding structures. This simplifies their coding effort. From the very beginning, UML was created with the aim to standardize the designs of software and open the way to model-driven web development [29]. Hence, this language is of crucial importance to this work. Today, UML has achieved the position of an official standard approved by the International Organization for Standardization (ISO) [30]. Many practitioners at different levels of expertise in software development include elements of UML in the design plans, even if they use traditional hand-drawn diagrams. Thus, UML is an important modeling language in developing web applications. This proves its importance in the Model-Driven Web Engineering (MDWE) domain.
UML is not a coding language, but rather forms a visual semantic. It helps visualize designs and models for a software developer. Software and tools are available to easily generate UML diagrams. Some of these involve coding, such as in C++ or other languages. On the other hand, there are online tools that generate UML diagrams using simple drag-and-drop methods. This methodology is much easier for us to generate visually appealing models. The UML-to-code component is built on the idea of giving a user constant access to the UML diagram while he is coding. And similar to the drag-and-drop techniques that are available to develop UML diagrams, the user will be presented with a drag-and-drop option to build websites. This uses Document Object Model (DOM) offered in JavaScript to generate code. For example, for a use case diagram, the user will need to create users and classes on their website. On our platform, the user has the option to drag-and-drop new users and functionalities. Based on the user input, users and classes can be generated using the JavaScript function. The developer can continue to build a boilerplate code by dragging and dropping different uses and cases and generating the respective HTML code. Using DOM, we can generate a tree of nodes. As the page progresses, the tree height increases. The minimum height of the tree at any point of the function can be given as in Eq. (1).
where ‘
In the Screen2Web platform, the user is first given the option to upload a UML diagram to the software. The portal will take him to a canvas where he will be able to work on his website. The canvas is a single web page where the window is divided into sides. One side holds the UML diagram for the user to see and the other holds the website preview of the website that the person is building. The person has the option to add users and add cases. When the programmer selects add user a new user profile will be added to the navigation bars. Then the next cases that correspond to that particular user can be generated. Let us take the example of a Library Management System (LMS). In an LMS system, a librarian must have access to all the book records and the log of transactions of all the users of the library. Regular students who are using the library do not need access to every book’s transaction history. Therefore, the programmer should adjust their use cases accordingly. When the programmer is satisfied, they can proceed to generate code. The extract code option will present the HTML code for the website visible on the canvas. This code can be used as a foundation for the programmer to continue implementing the backend on it. More specific changes can also be made.
The next major component is the collaborative code editor. Collaboration features are the most prominent feature of internet-based word developers, such as Google Docs and Word Online. These tools have inbuilt cloud-based synchronizing features. When any changes are made to a document on Google Docs, the cloud stores a copy of the modified document. When the document is accessed again, all the changes are retrieved from the cloud. Thus, all secondary users are able to work on an updated document. Such automatic services negate the need to physically share the document each time a change is made. The entire synchronization process is done automatically without any human intervention. This allows the human programmers to focus on what they are collaborating on. This is a useful trait for team collaboration. Different members of a web development team will need to view live changes in a program that is being worked on. However, Google Docs or other word editing software is rarely used to conduct code collaboration. Tools built for programming are used instead, such as Visual Studio Code Live Sharing. This feature allows different team members to work together on a single file. Any user can see changes made to that file in real time. This is called real-time collaboration.
Synchronization is brought about when continuous changes in one place are equivalently made in another. Mathematically, this can be thought of using phase models. If an event occurs periodically in time, such as a change in a document, a phase can be introduced such that its derivative is equal to this change. This relation between change that permits synchronization is depicted in Eq. (2).
where ‘
We can think of the document as the phase. We need to equate the rate of change in the document to the frequency of updates. This can be better understood using a server-client network. Let the programmers’ computers (clients) be connected to a server. The updates made on a document by the clients are read by the server. The server makes changes to its version of the document as well. When the next user accesses the document, it will utilize the server’s document version. Two entities work in parallel, the server pushing updates to all clients connected to it and clients continuously updating their copy. In a remote system, a remote connection is made between the client and the server. On a single computer, different programs or processes can be connected to the same server if they are connected to an identical port number. For example, if Port 4005 is open on a computer, then all processes accessing that port number will be connected to the same server. This assumes that a port allows connections from multiple processes.
The Code Editor component presented in this work was inspired by the functioning of Google Docs. The React JS framework was used to develop the front end of the portal where the users can type code. The backend server uses Socket.IO to sync the code between two processes. The client-side service runs as a standard React application. In our prototype, the React App is started from the terminal. When the server starts, the application opens a socket for the clients to connect to. A third-party library is also used to make updates to the server’s version of the program. This is done such that if a person types a single new letter, that letter alone is relayed back to the server. This is in contrast to sending the file’s entire contents. This letter fetching API denies the need for a cloud version of the document or code. Every time code is updated, i.e., a letter is received, this letter is transmitted to the other connected programs via the socket. Thus, the letter will appear on the other process as well and the code is synchronized between the users.
The final component of our proposed model is the deep-learning-based code generator. Deep learning is a new and emerging technology in the domain of computer science. It is a method to achieve machine learning based on artificial neural networks. Deep learning technologies have been applied in numerous domains including computer vision, speech, language recognition, and medical image analysis. It has a wide range of applications in different domains. Deep learning can improve the way devices operate by enabling us to automate manual methods. Neural networks that are utilized in deep learning mimic the working of the human brain in order to function effectively. This brain-like feature gives it the ability to learn new things such as image features, language features, etc. A deep learning model may consist of one or more deep layers in its neural network. By adding or hiding deep learning layers, we can refine and improve the accuracy of the model’s prediction. Unlike machine learning, deep learning procedures can work with unstructured data and can automatically execute feature learning. In fact, deep learning procedures themselves identify what features are most important to distinguish between different classes of input data of images or text. Further, deep learning can be classified as structured or unstructured based on whether the input data that is fed into the deep learning model has labels present for the data or not.
One of the domains where deep learning can be used is the domain of web development. This is what has been exploited in this work. Deep learning architectures can learn how websites are compiled from code. For example, a deep learning model can analyze a website screenshot and the code that gets executed to build that website. It can then execute algorithms to identify important features within the code to generate the website. For HTML codes, tags are the most important features. A webpage is created based on the order and structure of these tags. A deep learning model that learns the sequence of opening and closing tags will be able to predict how a webpage will look based on the code that it is given. More importantly, the deep learning models will be able to predict the HTML code from the image of a webpage. It will be able to determine which tags were used to generate that image. Deep learning models achieve this by mapping the features that it observes from the website images to certain tags that are present in the HTML code. Thus, with this prediction, we can build an HTML code generator.
The Screenshot-to-code component plays a crucial role in the system proposed in this work. The dataset that was provided for this model was custom-built. This was done by selecting a set of basic tags from the popular web development learning website, W3Schools [31]. We have chosen this set of tags because it resembles how actual web development can be learned. Hence, treating our model as a human developer, the intention was to ‘teach’ it the set of basic HTML tags. The dataset that was generated utilized the same set of words and images in different portions of a webpage. Some are in the form of headings, and some as paragraphs. The images also appear in different portions of the website, such as at the top, under a heading, or with a caption. We have used the same image since the focus here is on the tags, not the sources of images. In future work, we could run a reverse internet search to find the image and load a link to tag it. The words that are used in the dataset websites are also repeated. Had this been a text-determining or an Optical Character Recognition (OCR) model, the text could have been changed and the model could be allowed to learn to ‘read’ the text as well.
Each of the three components was separately developed utilizing a suitable technology stack. We will discuss each of these components and their environmental setup in the forthcoming paragraphs.
The front end of the UML-to-code component was created using HTML and CSS. A webpage to allow a user to upload a UML diagram to the portal was developed. The canvas page, which presented the UML diagram and the website preview beside each other, was also created using this tech stack. To upload the image of the UML diagram of the page into the directory, PHP scripting language was used. PHP was used to ensure database connectivity. This allowed the image to be obtained from the user’s device and stored in a server directory. The portal provides a choice between uploading class diagrams and use case diagrams. The canvas used JavaScript to create the Web pages according to the user’s requests. Document Object Model (DOM) was used for this purpose.
The DOM model allows us to create elements based on nodes and their connections. Nodes and their child nodes form a network that can be displayed by a website. JavaScript is useful for enabling this kind of dynamicity in websites. We have used this feature to build the website preview system as well. The DOM will generate the website within the preview sector, showing the user what the website would look like. To operate the PHP and the HTML, Apache Web Server along with MySQL server was utilized. To run both these servers for our prototype, the researchers have run the ‘XAMPP’ software [32]. The application worked seamlessly on the given version of the software.
The collaboration model was implemented using React JS and Socket.IO frameworks in JavaScript. Socket.IO is a web application library that is used for creating real-time web applications [33]. It allows communication to take place between web servers and clients. The Socket.IO framework is used to develop connections between different nodes in an application. These nodes may be visualized as a graph. Each node can connect to the nodes that are connected to it. The most well-connected node will hold the port numbers. We can identify the most well-connected node using the degree centrality formula as given in Eq. (3).
where ‘
These apps were run on separate port numbers to ensure concurrent execution. Two Microsoft Edge browser tabs were kept open to make two connections to the port number. Here we could verify whether or not updates were being saved to the server. If an update made in one tab was correctly updated in the server, it would relay those changes to the second tab. Thus, if one user was coding on one tab, and the other on another tab, they would be in sync. This synchronization between tabs enables collaboration to take place. The base text editor shares the same interface as Quill. Quill is a free and open-source text editor which has a very simple interface. The researchers have chosen this text editor since its simple layout and implementation can allow the addition of a collaboration feature. The client-side program was built on the boilerplate code that was generated from the Create React App service in ReactJS. This provided a basic executable application. For the server side of the collaboration service, the Socket.IO library was used. This library uses the WebSocket protocol to implement its interface. It provides many other features as well, including broadcasting to different sockets and storing information. Hence, it is called an event-driven library and is considered by researchers to be suitable for this work.
The deep learning model was implemented in Python 3.7 using Jupyter Notebook. The notebook was run on the freely available Graphical Processing Unit (GPU) available on the Google Colab platform. The platform offers Tesla K80 GPU to use till a certain limit. The limit was well beyond requirements; hence this was selected as the right platform to execute our notebook. Once the notebook was executed, the trained model was saved. This model could then be used to predict the HTML tags based on the image of the website. To develop the model, the Tensorflow Keras library was imported. Tensorflow is an open-source library of deep learning, machine learning, and artificial intelligence function. It is particularly useful for the development and training of deep neural networks. This library was chosen for its flexibility in the application, which is required for this image-to-HTML converter. Keras is a high-level API of the Tensorflow library. It gives access to many built-in functions and methods, thus simplifying the development of a deep learning model. The python library NumPy was also imported to deal with labels and arrays. NumPy is a Python programming library that offers support for mathematical operations, as well as arrays and matrices of high dimensions. It was required to enable the program to handle the image features and the features from the text containing the HTML code.
The first step was to convert all the screenshots of the images of the websites into NumPy arrays using a built-in function. These arrays were then passed into the pre-defined preprocess_input function. For developing the image feature extraction module, we employed the InceptionResNetV2 model [34]. The Inception models represent a series of hybrid models inspired by the original ResNet. ResNet is a residual neural network used to achieve deep learning and classification. The first version of InceptionNet, Inception V1 was also known as GoogLeNet. This network was improved in the Inception V2, which included batch normalization to optimize the learning and feature extraction. The computation of batch normalization can be understood from Eq. (4).
Where ‘
In this work, the initial features were extracted by running all the images through the built-in prediction function that is available in InceptionResNetV2. These features have been extracted without the use of a classification layer. For storing the HTML tags, referred to as ‘tokens’, we use the Tokenizer function. This will act as a register of possible tokens that the model can extract from the texts. The list of all the tokens forms the model vocabulary. It is from this vocabulary that the deep learning model will generate the code during the test phase. The vocabulary forms one of the inputs to the neural network.
The neural network is built with an encoder, a language model, and a decoder. The encoder consists of a dense layer that uses Rectified Linear Unit (ReLU) as an activation function. The language model includes two Long Short-Term Memory (LSTM) layers and a Dense Layer. The activation function chosen in this layer is also ReLU. Finally, the decoder consists of an LSTM layer and a Dense layer. A Softmax activation function is used in this final let. The mathematical equations for ReLU and SoftMax activation are given in Eqs (5) and (6).
where ‘
These layers are compiled using Categorical Cross Entropy and with Root Mean Squared Propagation (RMSprop) as the optimizing function. The formula that is used to calculate the weights in RMS Prop is given in Eq. (7).
where ‘
The batch size selected for the model training was 64. The model was trained for 500 epochs in the Google Colab Environment. After training, we take one image that the model has not seen for testing purposes. This image is converted to an array and run through the preprocessing function. The features are extracted from this function using the InceptionResNetV2 ‘predict’ built-in function. We define a separate function to generate the sequence of code from the features that are extracted. We achieve this using a probability function that computes the probability of a portion of the image to be attributed to a particular token. Once the token is determined, it is printed. This process is repeated to generate the entire HTML code. The generator function first prints a ‘START’ token and stops once the ‘END’ token is reached.
Performance analysis
The accuracy of the model was determined by comparing the test code with the newly generated code. Comparing these two texts showed good accuracy. A text similarity tool called CopyLeaks [35] was used to determine the similarity percentage between the two HTML files. In our analysis, the code from the generator achieved an accuracy of 86.8%. This is higher than the accuracy of other code generators including NL2SQL [36] and BERT
Comparison of code generators
Comparison of code generators
Coding typing speed manually and with Screen2Web.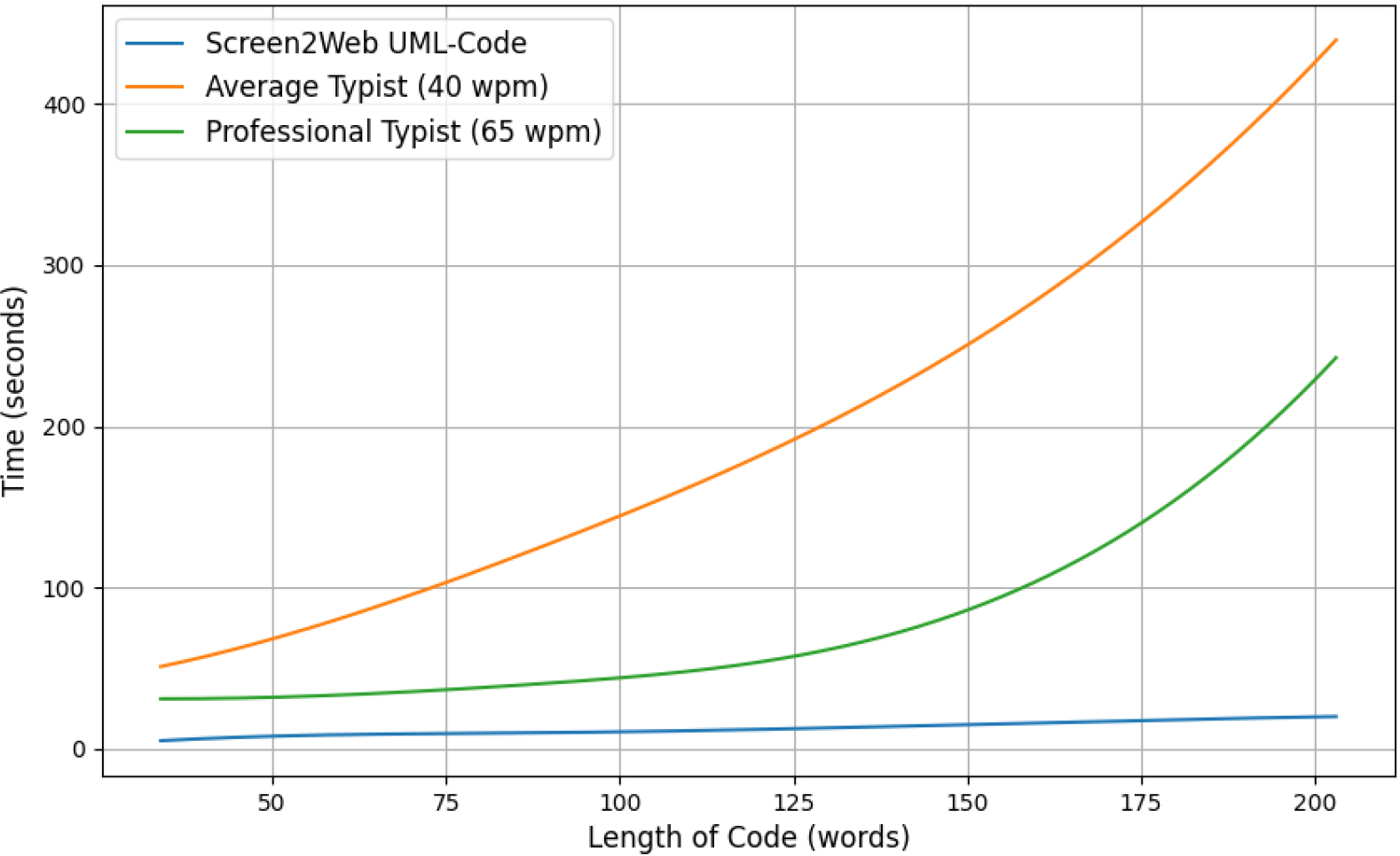
Following this, the speed of the HTML code generation from UML was examined. The time taken to by the Scren2Web component includes obtaining the required manual input and receiving the UML diagram. Five test cases were selected using HTML code length corresponding to different levels of functionality of the prototype. The comparison between the typing speeds and the Screen2Web UML-code generator is visible in Fig. 2.
The UML to code generator component was able to generate the code at a very fast rate. For reference, the speed of the programmer using the generator can be compared to the speed of a typist. We can observe the time taken by Screen2Web remains almost constant relative to manual typing. A marginal increase is observed around the 100-word mark. This can be attributed to the increasing complexity and dependency within the HTML tags.
Time comparison between human and machine-generated code.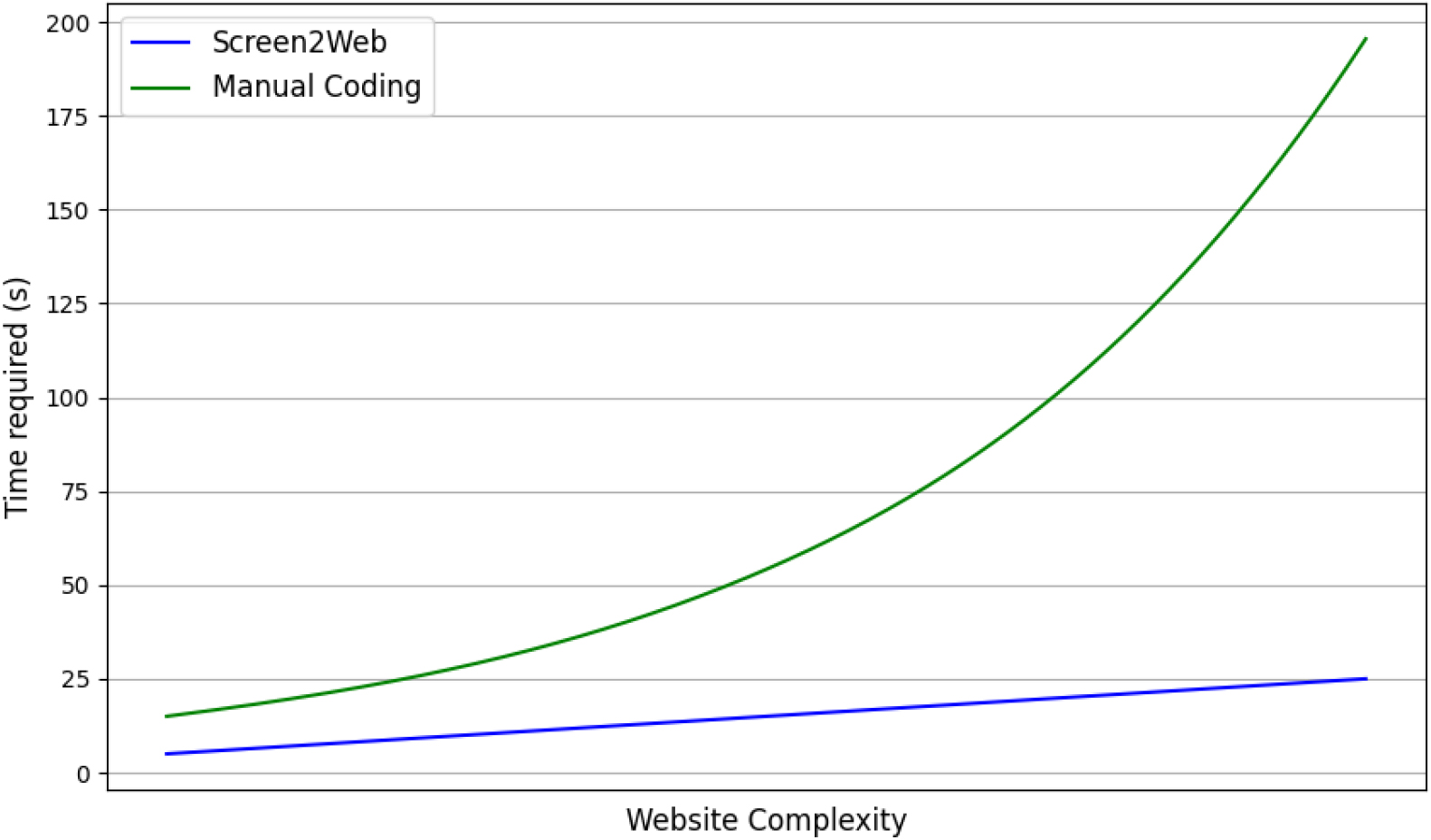
To gain further insight, the researchers have examined the relationship between HTML code complexity and ease of coding. A comparative study was conducted for the effort it takes to build boilerplate code of various complexity. A comparison of the time taken by the generator versus that taken by a human developer is presented in Fig. 3.
For small and basic websites, the difference between the time taken by a human and that of the deep learning algorithm to predict and generate the code is minimal. On increasing the size and complexity of the website, there is an exponential increase in the amount of work required by the manual coder. There is also an increase in the time taken by the deep learning model since it generates code based on the image features. However, this time does not increase exponentially. Rather, the difference between human time and machine time increases with greater complexity. As a result, the code generator is more useful and suitable in cases where the website is large and complex. However, training a model on a larger and more complex website may be challenging. This is due to the increasingly complex inputs to the model. A large website will require a larger image to be processed by the model.
The backend performance of the code editor used for the model was also scrutinized. As the code is manually typed, we count the number of messages that are relayed to the React server. This was conducted to observe the effectiveness of integrating the Quill framework. A comparison between the server messages from a normal editor and the editor used in this work is presented in Fig. 4.
For a clearer demonstration, the graph displays the count of server messages to a character length of seven. Initially, the Screen2Web editor has a greater number of server messages that are relayed. This is due to protocol-defined headers required by the Quill editor. At around a character length of four, it can be observed that the normal editor overtakes the Screen2Web editor in messages. This is because although the Quill editor requires headers, every subsequent character demands only a single message. This results in a linear increase in the number of server messages. On the other hand, normal editors relay the entire text each time an edit is pushed to the server. This causes exponential growth in communication.
Finally, the contribution of this work to web engineering was examined. The percentage of time that someone would spend on wireframing was measured by running 10 trial cases. The average amount of time a user would spend on modeling the website using the UML and editing components were measured. This was then compared with the percentage of wireframing time in other works, as presented in Table 2.
Wireframing in web development
Comparison of server updates from different editors.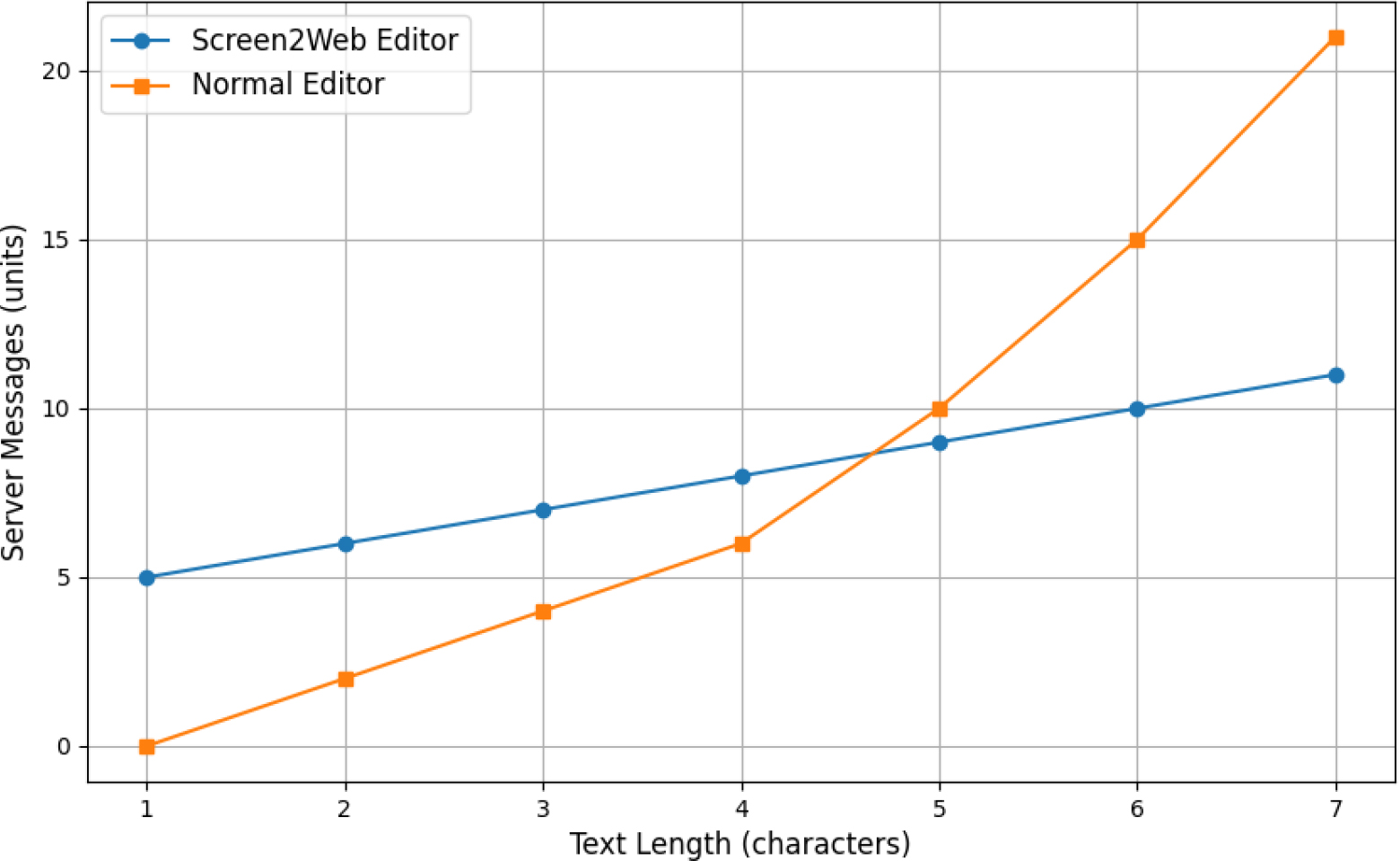
It can be observed that Screen2Web reduces the amount that is required for wireframing. This is due to the UML and Screenshot compatibility that the platform possesses. Using a predefined UML diagram of a model architecture, web programmers can directly work with the HTML code. There is no requirement for a separate code structure in this case. The programming phase is also simplified since developers only need to modify the generated code.
In this section, a comprehensive comparison between the Screen2Web model and traditional Large Language Models (LLMs) of text generation is offered. Presenting this comparison is significant as it highlights the distinct attributes and advantages of Screen2Web for web application development.
CPU and memory usage by model.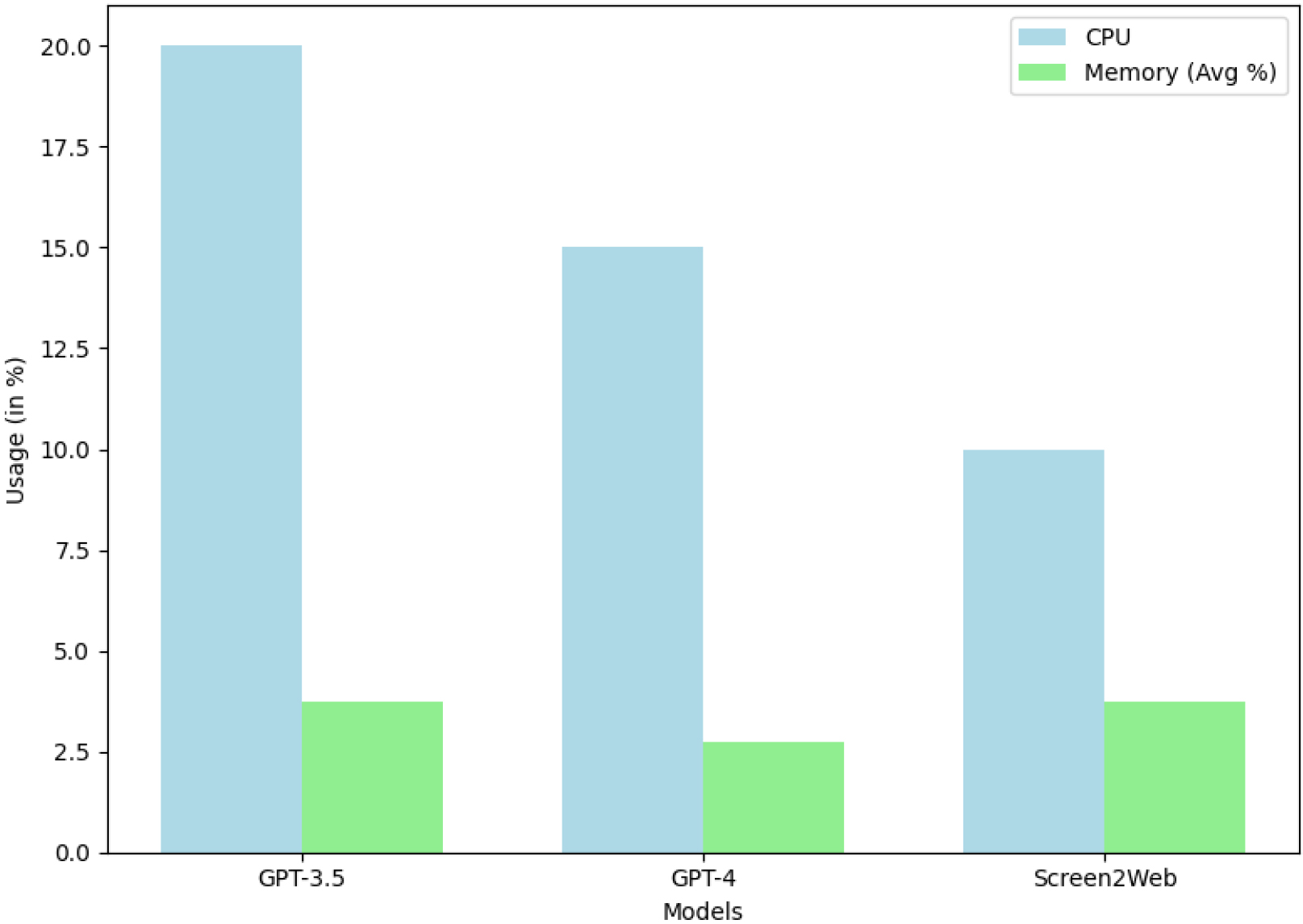
One of the most conspicuous distinctions between Screen2Web and LLMs lies in their parameter sizes. Screen2Web possesses a significantly lean architecture, with a modest 1.7 million parameters. In sharp contrast, conventional LLMs carry parameter counts that extend into the billions. This disparity arises from the specific purpose of Screen2Web, which is tailored for the precise task of web page wireframing, as opposed to the broader text generation objectives of LLMs. To facilitate a meaningful comparison, six light-weight models were selected: Bloom Lite, Turing NLG Lite, Elmo, GPT, Transformer-Elmo, and GPT-2. For a vivid visualization of Screen2Web’s compactness and relative simplicity, a logarithmic plot of model parameters is presented in Fig. 5.
Trend in model parameters.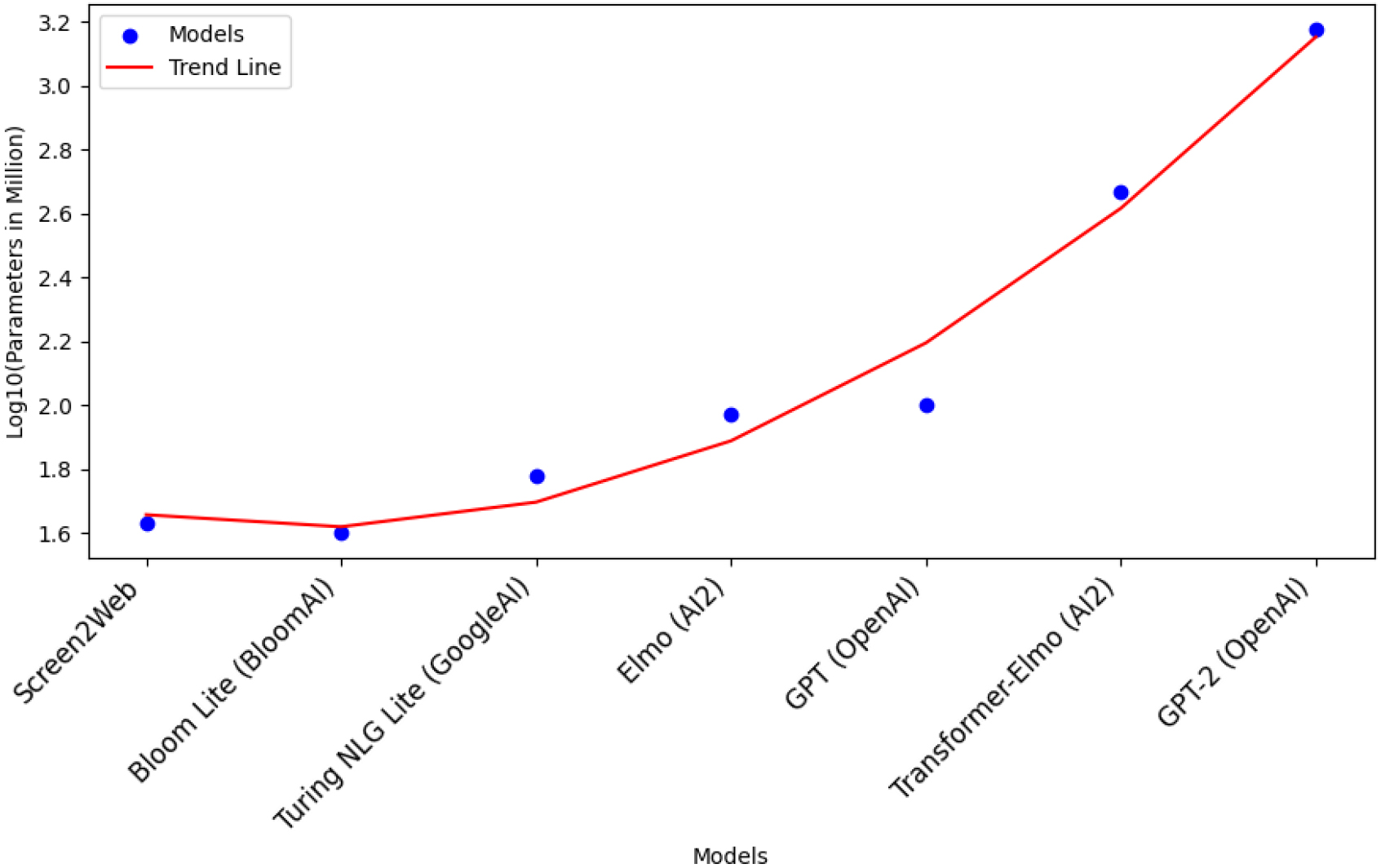
The logarithmic plot demonstrates sizable differences in model complexity. As models grow in sophistication, parameter volume surges exponentially. Notably, this parameter drop yields a useful benefit – reduced computational resource requirements. This results in diminished demand for memory and processing power, providing Screen2Web the edge in efficiency, scalability, and resource conservation.
Comprehensive performance testing involving Screen2Web, GPT-3.5, and GPT-4 was conducted. These tests entailed measurement of CPU utilization and memory usage under measured conditions. GPT-3.5 was executed within the Google Chrome browser using OpenAI’s ChatGPT web portal, while GPT-4 was assessed through Microsoft’s Bing Chat running within Microsoft Edge. Screen2Web’s evaluation was evaluated in a Python environment, utilizing Microsoft Visual Studio Code. Memory usage was quantified as a percentage of 4000 megabytes. Each model was tasked with generating websites based on UML diagram descriptions. The results are presented in Fig. 6.
Screen2Web demonstrated superior computational resource efficiency, noticeably reducing CPU computational demands compared to GPT-3.5 and GPT-4. Moreover, Screen2Web matches the memory usage statistics of the other two models. This can be attributed to its architectural simplicity and reduced parameter count, highlighting its efficiency at resource utilization. Importantly, this translates into reduced hardware demands for Screen2Web.
Model comparison across categories.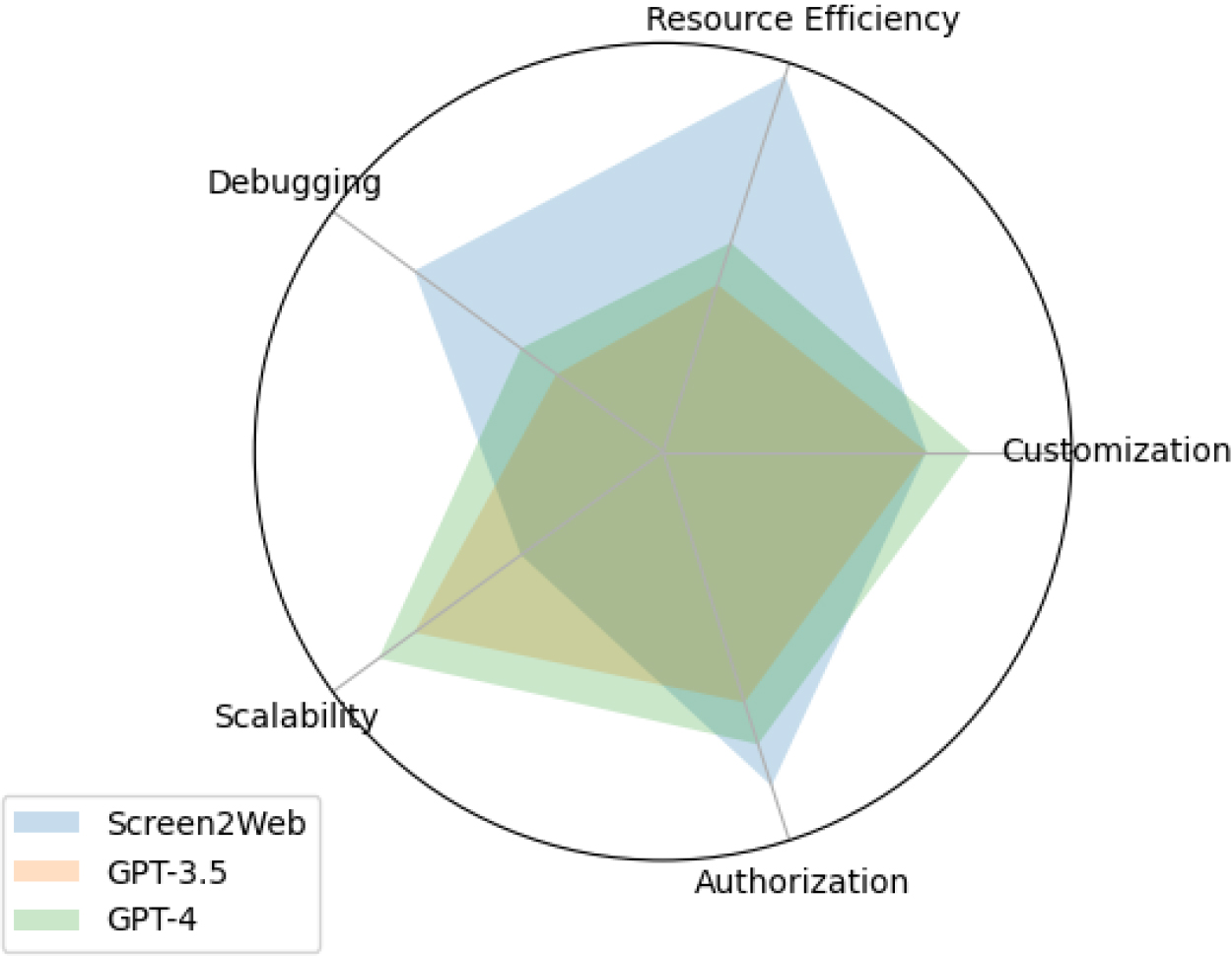
An additional facet highlighting Screen2Web’s usefulness pertains to user control and customization. Unlike LLMs, Screen2Web empowers users to fine-tune the model for distinctive web designs. Such a capability is valuable in specialized domains, such as healthcare and governance. Furthermore, access to input data speeds up debugging. This offers a unique advantage over LLMs that may generate misbehaving code. Security enhancements can be swiftly implemented to restrict access to authorized users, ensuring data confidentiality. Nevertheless, it is essential to acknowledge that Screen2Web may exhibit limitations in scalability compared to LLMs like GPT-3.5 and GPT-4, where the latter excel. A summary of practical utility in industrial contexts is presented in Fig. 7.
Nevertheless, incorporating LLMs such as ChatGPT into model-driven web development is promising [42]. ChatGPT, with its conversational nature, facilitates code scaffolding and UI/UX mockup creation based on high-level requirements. GitHub Copilot, an AI-powered code completion tool, can enhance code-writing efficiency by providing context-aware code suggestions, ranging from code snippets to entire functions. However, extended reliance on such tools has its limitations. Generated code may require human review and refinement to align with specific project requisites. Rigorous testing and validation are essential to ensure the accuracy of generated outputs. To maximize the utility of LLM-powered code generators in model-driven web development, it is advisable to establish guidelines that address challenges related to resource utilization, project-specific customization, and code integrity.
In this work, a technique for the collaborative development of web applications, named Screen2Web, is introduced. It incorporates a deep learning model to enhance a Model-Driven Web Development methodology. The necessity for such a platform in relation to previous research work in this domain has been described. The platform is built using two code generators and a code editor. The editor facilitates live manual editing and real-time collaboration. The code generators convert UML diagrams and website screenshots into HTML Code. The dataset required to train the deep learning model has been defined suitably to achieve optimal performance. This study includes the development and examination of a prototype platform. The execution of the prototype and its measurements from it proves the efficiency of this method. The results show that the scheme illustrated in this work has the potential to enhance Web Application Engineering.
In future work, the collaborative model can be scaled to tackle larger projects. Industry-size ventures often have sub-architectures that fit within an overall model. Support for this kind of development will enable a wider acceptance of the approach proposed in this work. Another possible research direction is an AI-based recommendation system for web modeling. This could assist developers to make appropriate changes to a model architecture.