
Abstract
Temporal link prediction based on graph neural networks has become a hot spot in the field of complex networks. To solve the problems of the existing temporal link prediction methods based on graph neural networks do not consider the future time-domain features and spatial-domain features are limited used, this paper proposes a novel temporal link prediction method based on two streams adaptive graph neural networks. Firstly, the network topology features are extracted from the micro, meso, and middle perspectives. Combined with the adaptive mechanism of convolution and self-attention, the preprocessing of the feature extraction is more effective; Secondly, an extended bi-directional long short-term memory network is proposed, which uses graph convolution to process topological features, and recursively learns the state vectors of the target snapshot by using the future time-domain information and the past historical information; Thirdly, the location coding is replaced by the time-coding for the transformer mechanism, so that past information and future information can be learned from each other, and the time-domain information of the network can be further mined; Finally, a novel two-stream network framework is proposed, which combines the processing results of point features and edge features. The experimental results on 9 data sets show that the proposed method has a better prediction effect and better robustness than the classical graph neural network methods.
Keywords
Introduction
The networks in the real world are changing dynamically with time. The topology of the dynamic network is evolving and updating [1], where a new edge appears and the old disappears. Real-world networks and various graph signals could be regarded as dynamic networks. Graph signal processing often uses spectral estimation, probability reasoning, statistical learning, etc. [2] Link prediction based on a graph neural network model is an essential branch of graph signal analysis used to predict the future or reconstruct the network topology.
Many existing temporal link prediction methods based on the traditional static link prediction indices, regarded static snapshots as an unweighted training graph or a weighted cumulative graph for similarity training [3]; Many scholars have studied the methods which combine static similarity indices with time series analysis models. After calculating the static indices of each snapshot, combined with moving average, regression, and exponential smoothing, the results can express the prediction of network topology [4]; Drawing on the strong ability of representation learning for feature information extraction, the researchers have proposed DeepWalk [5], node2vec [6], LINE (Large scale Information Network Embedding) [7] based on node random walk and shallow neural network, which can also effectively realize temporal link prediction.
With the graph neural network to mine more effective spatial and temporal features, this paper proposes a novel temporal link prediction method based on two streams adaptive graph neural network, which can effectively learn the spatial and time information of the dynamic network. The model designs adaptive preprocessing of multi-dimensional topological features and proposes an encoding layer based on the extended bidirectional LSTM model and the optimized transformer model, as well as the two stream processing architecture for node feature data stream and edge feature data stream. The highlights are listed as follows:
For the precoding process, combined with convolution and self-attention mechanism, an adaptive feature processing method is proposed to extract network structure features from the micro, meso, and middle perspectives. A novel multi-layer GCN and GAT is proposed to mine more information on the network. For the training and learning process, a novel BiLSTM model is proposed, which uses GCN to process spatial-domain information. It also combines the future and past time-domain data to predict the network. And a novel time coding mechanism is proposed to replace the position-coding for the transformer encoder. For the decoding process, a novel two-stream network model is proposed. The results of node and edge features are fused to form the final representation vector. And the multi-layer perception is used to achieve temporal link prediction. The experimental results on 9 data sets show that compared with several classical methods based on the GNN model, the proposed method achieves better prediction performance.
To mine effectively the evolution information of dynamic networks, dynamic graph neural network (DGNN) models are increasingly used in the field of complex networks. When dynamic networks are processed by discrete snapshots, they can be modeled in three ways: stacking DGNN, integrated DGNN, and dynamic graph automatic encoder [8].
Stacked DGNN-based models use static graph models to process each snapshot, which can get the node feature representations through end-to-end learning. GNN can capture the nonlinear relationship between nodes, and combine recurrent neural network (RNN) models to process the time-domain information of network evolution [9], which can more effectively aggregate node embedded representations at different moments, and significantly improve the accuracy of temporal link prediction. Liu et al. proposed a new graph convolution network (GCN) model, which uses GCN to process node features and k-core method decomposition features, and then uses a recurrent neural network to process the representation vector at each time [10]. Manessi et al. proposed WD-GCN (Waterfall Dynamic GCN) and CD-GCN (Concatenated Dynamic GCN). These two models also use GCN to process each snapshot and use LSTM models for each node [11]. Many other scholars have used the graph attention networks model to replace the standardized operations in GCN [12]. GAT can use the self-attention layer to learn the different effects of the neighbor node on the central node and give them different weights to focus on the key features. Zhang et al. proposed the Gated Graph Attention Network, the performance was further improved by combining gating and attention mechanisms [13]. Sankar et al. proposed the DySAT model by combining GAT with the temporal self-attention mechanism. This model first uses GAT to process the spatial structure features of each snapshot, and it uses the self-attention mechanism to extract the time-domain features contained in the network snapshots to obtain the representation vector of historical information [14].
The model based on integrated DGNN integrates GNNs with RNNs, instead of separately processing according to spatial-domain and time-domain. GConvLSTM model uses both temporal and spatial information to change the connection weight in LSTM to convolution operation [15]. EvolveGCN also integrated GNN and RNN, and the model updated the GNN coefficient matrix using the RNN method [16]. Wang et al. proposed the ST-LSTM model, which processes spatial and temporal information in a memory processing unit and transfers memory messages in horizontal and vertical directions. Input parameters are not only the hidden state but also cell state with the previous time step from the two directions[17]. GC-LSTM model regards LSTM as a hidden layer and uses GCN to process the input and output of the hidden layer. It takes the adjacency matrix as the input parameter to LSTM, and proposes a new graph convolution model in the hidden layer [18]. Similarly, the LRGCN model integrates the improved R-GCN [19] with LSTM in the hidden layer, which can realize the state embedding analysis in the dynamic network [20]. ReNet model integrates stacked R-GCNs into a dynamic knowledge map for complex network analysis [21]. Bonner et al. designed a two-layer Temporary Neighbourhood Aggregation (TNA) model uses hierarchical convolution with different depths and adjustable variational sampling [22].
The model based on GAE (Graph Auto Encoder) regards DGNN as an encoder. Reference [23] proposed the DyLink2Vec model, which uses an optimization coding mechanism to improve representation learning. DyLink2Vec consists of two steps: compression and reconstruction. The goal is to minimize reconstruction error and use the gradient descent method to optimize the training process. DynGEM model optimizes the self-encoder by using the weight of the snapshot at the previous time based on static graph self-coding [24]. The E-LSTM-D model has designed the encoding layer, stacked LSTM blocks, and decoding layer. At the encoding layer, LSTM is used to handle the representation vector of nodes. The encoder realizes the learning of complex network structures. The stacked LSTM blocks learn the time evolution features. The decoder converts the extracted features to the original space for prediction [25]. The GraphSAGE model proposed by Hamilton et al. optimizes the encoder. First, it uses uniform sampling to fix neighborhood nodes and uses different aggregation functions to handle neighborhood information aggregation [26]. Hajiramezanali et al. introduced the variational mechanism and proposed two kinds of variational self-encoders for dynamic networks, including the Variational Graph Recurrent Neural Network (VGRNN) and Semi implicit VGRNN (SI-VGRNN). These two models both integrate GCN into RNN as an encoder, which could get more optimized node representation vectors [27]. LI et al. proposed the TSAM model, which uses the graph attention network to process the structural features, and uses the gated loop unit to extract the temporal evolution features from the network snapshots. And the model also uses the self-attention mechanism to focus on the more important network snapshots [28].
Summarize the above three kinds of models based on the graph neural network. On the one hand, GNN-based models include GCN, GAT, GAE, and RNN-based models include LSTM, GRU, etc. The optimization efforts of these models do not focus on further research on the design of input and output. On the other hand, when using RNN to process the time evolution information, the prediction function often uses past historical information to predict the network topology but does not use future information.
Preliminary
Problem definition
It is common to divide the dynamic network into a series of snapshots with the same interval. Then we can research various complex network tasks based on the discrete graphs. The discrete DGNN method can not only use the time series analysis models to handle the evolution information but also easily use the graph neural network model for learning structure information. Given a discrete dynamic network, it can be divided into some snapshots at a fixed time interval, and the general model for graph neural network training is shown in Eq. (1):
where
where
The temporal link prediction problem based on a neural network model can be summarized into the following three steps:
Aiming at the spatial features of the dynamic network structure information, the GNN optimization models are studied; Aiming at the time features of the dynamic network evolution information, the RNN optimization models are studied; According to the final output representation vectors, the prediction and evaluation of the network topology can be realized.
The evaluation Metrics commonly used to measure the performance of link prediction methods, mainly including AUC (Area Under Curve), Brier Score, MAP (Mean Average Precision), MAE (Mean Absolute Error), RMSE (Root Mean Square Error), etc. [29].
The AUC metric is widely used to measure the accuracy of prediction methods. The measurement of this index is in the range of [0,1]. For
The Brier metric can be considered as a measure of the calibration of a set of probability predictions. The corresponding cases of this set of probabilities must be mutually exclusive, and the sum of probabilities must be 1. The lower the Brier score for a set of predicted values, the better the prediction calibration. The Brier Score can be expressed as:
The MAP metric is the mean average precision value, representing the geometric average value of the accuracy of all categories. The link prediction problem is essentially a binary classification problem. Precision reflects the proportion of the samples predicted to be Class
The MAE index is the mean absolute error value, which represents the average of the absolute value of the error between the predicted and the real value, which can better reflect the actual performance of the methods. The RMSE index is the root mean square error value, which can measure the deviation between the two values and be sensitive to abnormal data. As shown in Eq. (3.2),
The existing graph neural network methods do not consider the diverse scenarios of input feature parameters, and they mine the future time-domain features and spatial-domain features limited. A novel temporal link prediction method based on two streams adaptive graph neural network (TSAGNN) is proposed, which can fully learn the spatial and temporal information of the dynamic network. As shown in Fig. 1, the TSAGNN consists of the AGBLTE model and decoder model, including the adaptive graph convolution attention layer (AGA), the extended long short-term memory network layer (exBiLSTM), the transformer encoder layer and the decoder layer.
Overall logic architecture of TSAGNN.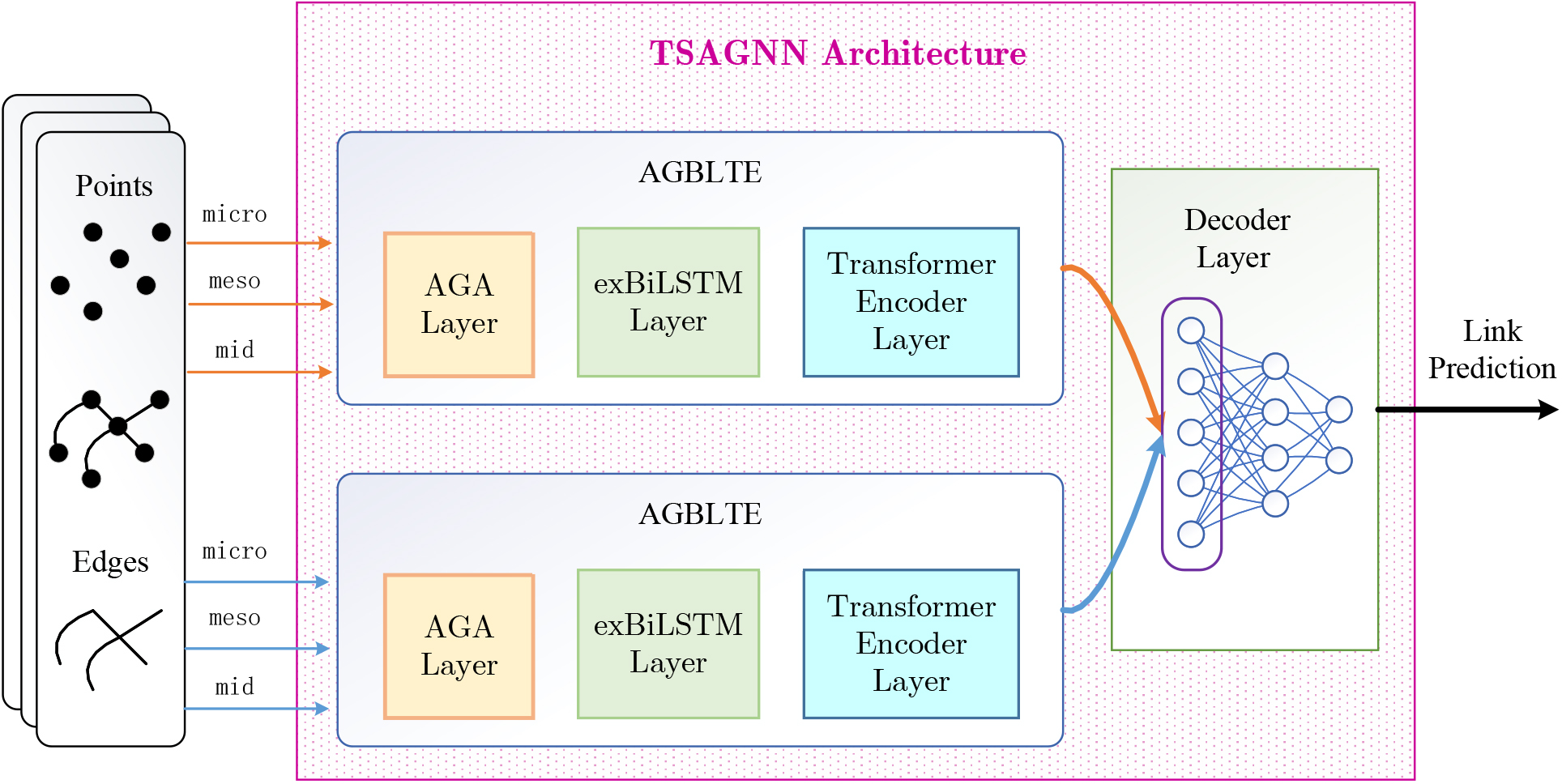
First, the AGA layer proposes a novel adaptive mechanism, which combines some GNN and GAT layers for the spatiotemporal features from different scales of network structures. After convolution and self-attention processing for the input, the features of different scales are transformed into the same dimension and adaptively perform depth coupling on each other according to the feature weight. Secondly, the exBiLSTM layer further mines spatial features by using GCN to process topology information between LSTM cells, while the exBiLSTM layer makes full use of the time-domain characteristics of the network at the same time. Based on the LSTM network, it supports the simultaneous learning of the past and future network data. After processing the past and future information respectively, it fuses the past and future results as the state information of the target time. Thirdly, the Transformer Encoder layer further optimizes the output vector results and proposes a new time-encoding to replace the position-encoding for the encoder, while using the Transformer’s mechanism to realize mutual learning between past and future information. Finally, the decoder layer is proposed based on the two-stream network architecture, which consists of multi-layer perception (MLP). The processing results of node features and edge features are handled respectively. The full connection network is used to process the feature vector of two stream outputs, which makes sense to the temporal link prediction method based on TSAGNN.
The input parameters of GNN models such as GCN or GAT include adjacency matrix and eigenvectors of all nodes. The eigenvectors of nodes can be label attributes, similarity indices, walking representation vectors, etc. The general GNN model uses the label attribute or one hot vector to represent the feature of the node. A novel adaptive convolution processing layer is designed, as shown in Fig. 2. Specific details of the AGA layer are as follows: a set of mapping functions is defined to extract the features of the input adjacency matrix, and the topological similarity of different perspectives is considered. After multiple convolutions and self-attention operations, we set adjustment parameters to make features fusion adaptively according to the different weights.
Schematic diagram of adaptive convolution processing layer.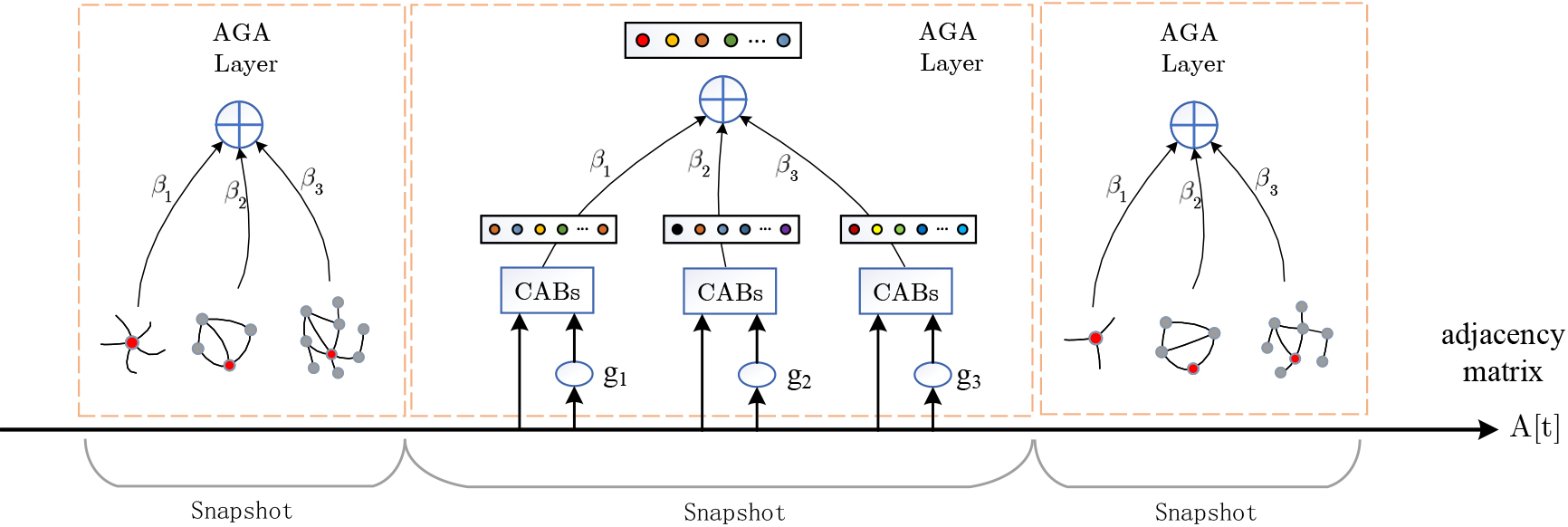
The structure of complex networks can be classified from different perspectives, such as the microscopic, mesoscopic, and midscopic. The stability, density, and concentration of nodes can represent the micro features of nodes. The characteristics of motifs can represent the mesoscopic features of the local network structure. The random walking vector and community centrality within subgraphs can represent the midscopic features of networks. At last, an adaptive adjustment mechanism is used in the final feature fusion according to the score proportion of these different features.
From a microscopic perspective, based on the sociological influence, the more neighbors a user has, the greater its influence is. The micro similarity of nodes can be characterized by the first-order and second-order degrees of nodes [30], as shown in Eq. (7),
From a mesoscopic perspective, the number of the most basic triangular motifs of the network also can be used to represent the influence of a node. The larger the number of motifs, the greater its influence is. The mesoscopic similarity can be characterized by the first-order and second-order number of triangular motifs, as shown in Eq. (8),
From a midscopic perspective, the centrality of the subgraph eigenvector can be used to represent the influence of nodes. First, the network is divided into some communities. Then, the first-order and second-order centrality indices of nodes within the community are used to represent the midscopic similarity, as shown in Eq. (9),
The feature mapping functions are not limited to the above three types. From the micro perspective, the reciprocal of degree, the label attributes of nodes, or other local structure similarity indices can also be used to characterize nodes; From the mesoscopic perspective, except using triangular motifs, the common features of quaternion motifs can also be taken into account; From the midscopic perspective, the similarity can also use the path feature, as well as other centrality indices such as betweenness centrality and closeness centrality, etc.
The feature dimensions after mapping and processing from different perspectives are different. The graph neural network is used to further mine the network’s spatial information, and multiple convolution attention blocks (CABs) are designed to process the input features. After two convolution layers and two self-attention layers, the feature dimensions of all outputs are the same dimensions. Then, we put the node features and adjacent matrix into CABs to realize convolution and attention processing, as shown in Fig. 3.
Schematic diagram of feature fusion processing module.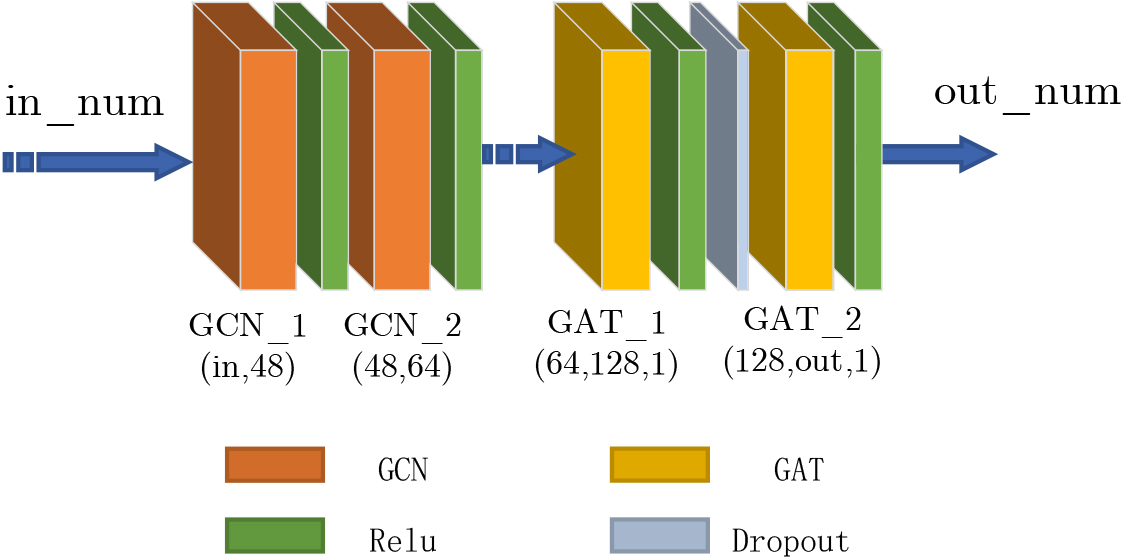
By capturing the adjacent information propagation process in the graph topology, the specific implementation of the GCN processing unit can be expressed as Eq. (10).
where
where X is the input node feature matrix, A is the adjacent matrix, and
After the two-layer convolution operation, combined with the influence of the neighbor information, the attention mechanism is used to optimize the output state vector.
where
The attention coefficient
Then, the attention coefficient of the neighbor node set is weighted and summed to obtain the final output parameters, as shown in Eq. (14).
Finally, the features of nodes are quantized from multiple perspectives, and the results processed by CABs are adaptively fused. The output results are normalized, and the fusion factor is defined to represent the weight proportion of each feature. The calculation is shown in Eq. (15). The vector inner product method is used to fuse multiple output state vectors, such as Eq. (16), where
RNN is generally used to process time series data or semantic data, but the output of each layer of RNN can only affect adjacent moments and does not support long-term impact. GRU and LSTM both can solve this problem. Based on LSTM, this paper designs an extended bidirectional LSTM mechanism and reconstructs the present network topology by combining the past and future time domain information.
Most prediction tasks are based on past historical information to achieve the prediction. The output at the current time is not only related to the historical state of the time series data but also related to the future topology state. For example, to predict the missing words in a sentence, you need to not only handle the preceding text but also consider the content behind it so that you can judge based on the context.
Schematic diagram of extended bidirectional long short-term memory network.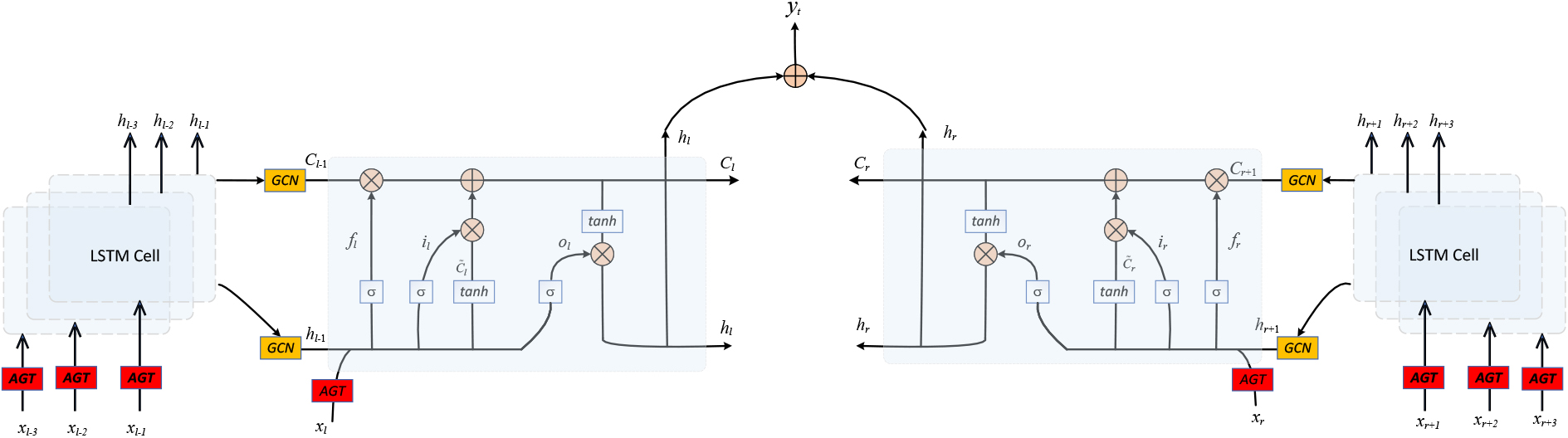
Three gate structures are designed in LSTM, which are the forgetting gate, input gate, and output gate. They are used to realize information forgetting, long-term memory, and short-term memory. Usually, bidirectional LSTM performs forward and reverse two-loop processing on time series data, and concatenates the final results. In this paper, an extended bidirectional long short-term memory network is proposed. As shown in Fig. 4, the past time snapshots are represented by variable
Firstly, according to the step size
Secondly, the data at each moment is input into the LSTM cell for training. The GCN is used to process the short-term state
Thirdly, calculate and output the long-term state and short-term state of the LSTM cell, as shown in Eqs (20)–(22).
Finally, the left series and right series are trained respectively, and the final hidden state vector
The ExBiLSTM layer uses the Adam optimizer to optimize the model. The loss function of the training process is defined in Eq. (24), which represents the error between the prediction expectation and the true labels.
Based on the attention mechanism, Google also proposed Transformer [31] model by using the stacked Encoder Decoder structure. It completely uses the attention method to replace the RNN serialization function. Through the training of different weight matrices, it can achieve better results by the attention mechanism. Because the model discards the time attribute of the sequence, it designs a position-coding mechanism, which endows each node with corresponding position information.
Functional Diagram of Transformer Coding Layer. (a) Transformer Encoder. (b) Multiple attention mechanism.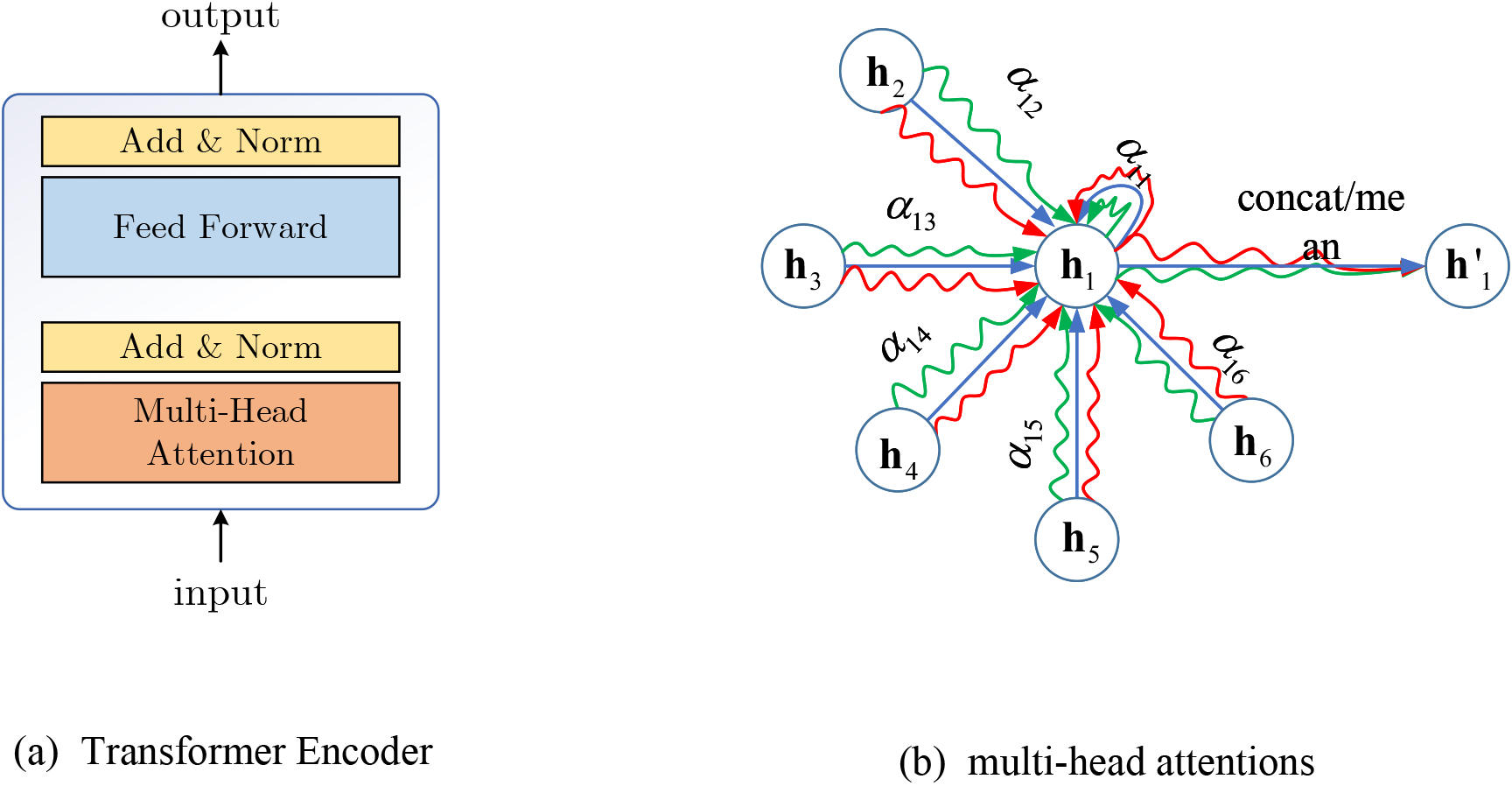
Although the exBiLSTM model uses the history and future data for training, the time evolution information of their sequences is learned respectively. However, future information has an impact on the current time and the past time. Similarly, historical information has an impact on the future. For further utilization of the network time-domain information, two sequences can learn from each other. Based on the mechanism of the Transformer coding layer to handle the node state vector information, we can further mine the context information of the network data by replacing the position-coding with the timing coding. As shown in Fig. 5(a), the Transformer coding layer includes the multi-head attention mechanism, the Add&Norm layer, and the Feed Forward layer. As shown in Fig. 5(b), the multi-attention mechanism is used to get more semantic information and concatenate or average the results to get the final value. After the weighted sum of attention is updated by the activation functions, the feature vector of the node can be expressed as Eq. (25). When considering that the sum of the weights of all neighbors is 1, use multiple heads of attention for processing, and the calculation can be shown in Eqs (26)–(27).
where
The Add&Norm layer will sum and normalize the results of the multi-head attention output so that the neighbors with larger weights can gain stronger expression ability, and the neighbors with smaller weights can weaken their influence. Then the Feed Forward layer can perform another Add&Norm layer to process the final vector, it can map the representation vector of high-dimensional space to the low-dimensional space, which can better learn the interaction relationship with the context.
Schematic diagram of state vector processing based on Transformer Encoder.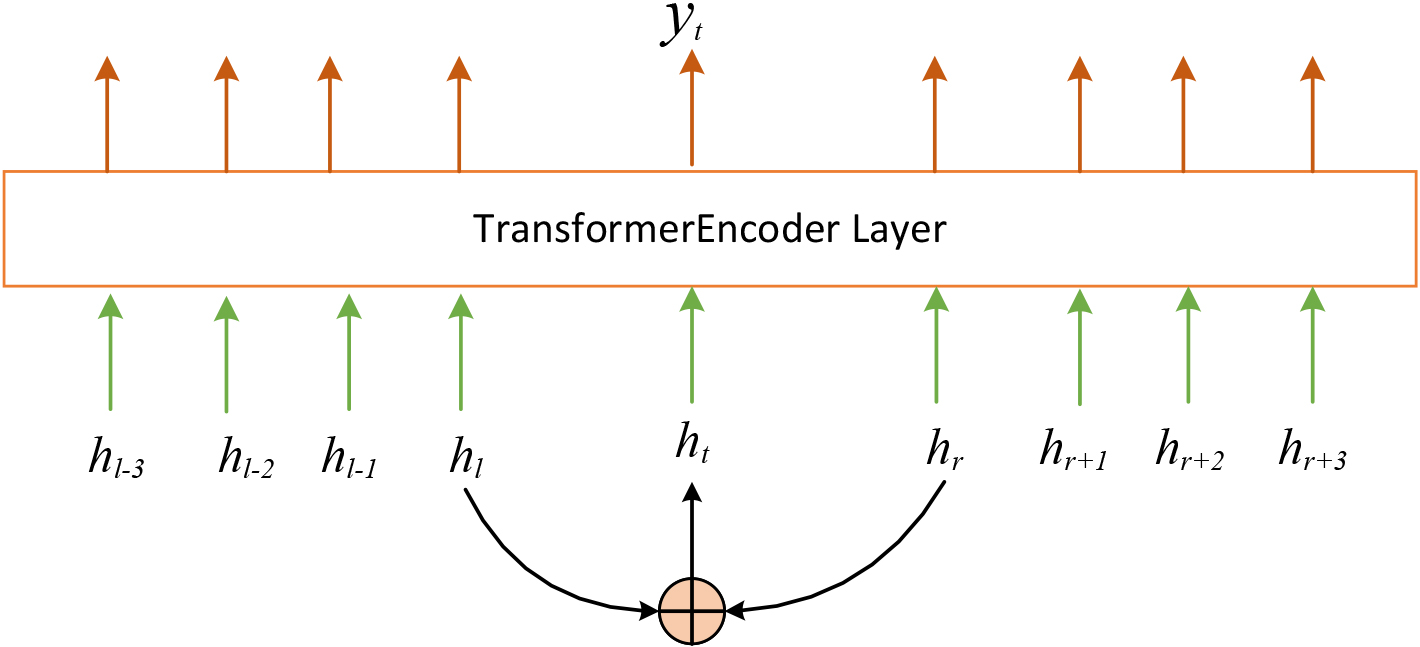
This paper only uses Transformer Encoder to process features, without considering the decoding function of the transformer. As shown in Fig. 6, after the six-layer coding process of the Transformer, the feature information in the past and the future can learn from each other and finally output the represented feature vector.
For translation tasks, the transformer uses location coding to identify the word location. In this paper, the number of nodes in each snapshot is unvarying, and the location of the nodes does not change, so it is meaningless to code the location. Motivated by this reference [32], it proposed the timing code replace the position code according to the length of the time sequence snapshot. Based on the Bochner theorem, the kernel function is obtained by using the Euler formula and Monte Carlo integration, as shown in Eq. (28).
where d is the feature dimension and w is the weight parameter of the feature vector. For this paper, as shown in Eq. (29),
Motivated by reference [33], which proposed a novel two-stream framework to predict human behavior, the attributes of human joints are regarded as the characteristics of points, and the attributes of bones are regarded as the characteristics of edges. This paper proposes the second AGBLTE model to process the edge features. When the output edge results are obtained, we concatenate the point results and edge results, then the full connect network is used to implement the binary classification.
Input Multi-perspective edge features
Similar to the way of processing node features, the edge features are also quantified from the micro, meso, and middle perspectives to obtain multiple features of the edge data. After the AGA layer processing, the results are transferred to exBiLSTM as input parameters for further processing.
From the micro perspective, the similarity indices of static link prediction can be used to represent the features of the edge, such as the common neighbor (CN) index, preferential attachment index, Resource allocation index, etc. This paper uses the CN index to characterize the edge feature from a micro perspective. As shown in Eq. (30), we use first-order and second-order common neighbors both express the attribute of the edge, and
From the meso perspective, the number of triangular motifs is used to characterize the edge feature. As shown in Eq. (31), the number of triangular motifs passing through the edge is a first-order attribute, the number of triangular motifs between the endpoints on both sides of the edge and the common neighbors is a second-order attribute, and
From the middle perspective, the influence of nodes is characterized by the centrality of the edge within the subgraph. First, the network is divided into communities, then the betweenness of the edges within the community is used to characterize the edge feature from the middle perspective. As shown in Eq. (32). The numerator represents the number of edges from node
Any graph network can be described by nodes and edges. As shown in Fig. 7, the two stream networks based on the AGBLTE model for node data and edge data respectively, and the node stream results are coupled with the features of the AGA layer to ensure the stability of the final features. Based on the cosine similarity method, as shown in Eq. (33), the edge similarity is represented by the two endpoint vectors.
where dot represents the inner product of two vectors, and nom represents the normalization of the vector.
Schematic diagram of processing flow based on two stream network.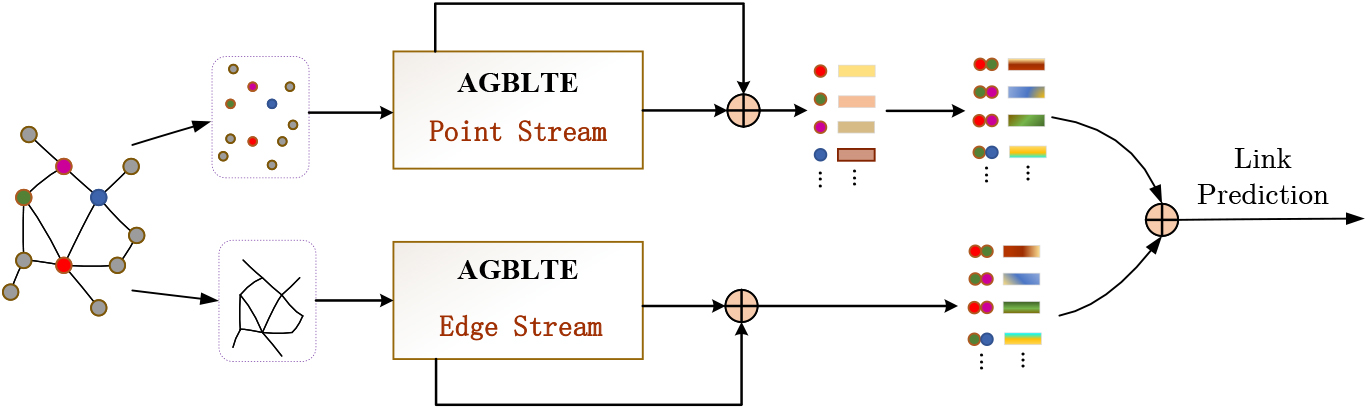
The AGBLTE processing of the edge stream is as same as that of the node stream. The output edge features are also coupled with the features of the AGA layer. Then they are further fused with the features of the node stream. As shown in Eq. (34),
Datasets
This paper uses 8 real social network data sets and 1 randomly generated dynamic network data set to evaluate the performance. Email data set [34] is the email data of a large research institution in Europe. The WIKI dataset [34] contains the time series data of the user’s message operation on other users’ pages in Wikipedia. SXC2Q data set [34] is an interactive log on Math Overflow, an interactive mathematics website, which includes users’ questions, answers, comments, and other data. DNC data set [35] is the mail communication data collected in the mail leak incident of the Democratic National Committee of the United States; MAN dataset [35] is an e-mail record among employees in a manufacturing factory; LEM data set [36] The interactive event records collected by the US Kansas Event Data System, which contains the interactive information between Egypt, Israel, Jordan, Lebanon, Palestine, Syria, the US, and Russia. The IAEE dataset [37] consists of email data sent between Enron employees. SWE data set [38] is the network data selected by Wikipedia for voting and evaluation of administrators, reflecting the user’s approval or opposition to administrators. SBM dataset [16] is the dynamic network data generated by simulation using a random block model commonly used for community evolution simulation.
Basic characteristic parameters of dataset
Basic characteristic parameters of dataset
GC-LSTM model [18]: This model embeds graph convolution network GCN into long short-term memory networks to achieve end-to-end dynamic link prediction. GCN can provide structure learning of network topology for each snapshot, while LSTM is responsible for time domain feature learning of each snapshot. STGCN model [39]: This model combines the GCN and CNN into a function block for processing Spatial-temporal data. It can extract the most useful spatial features and continuously capture the most basic temporal features. It uses a bottleneck strategy to achieve scale compression and feature compression and uses a normalization function after each layer to prevent overfitting. A3T-GCN model [40]: This model is also composed of multi-layer GCN and GRU, which can capture the global time dynamics information and spatial correlation information at the same time. GRU learns the short-term trend of time series, and GCN learning is based on the spatial dependence of network topology. The model also proposes the attention mechanism to adjust the importance of different sequence positions and integrates the global time information to improve prediction accuracy. GConvLSTM model [15]: This model combines the Chebyshev convolutional network GCN based on the spectral domain with the LSTM is used to realize the temporal link prediction function of the dynamic network. EvolveGCNO model [16]: This model uses GCN to process the information of the snapshots and uses the LSTM model to adjust the weight parameters of GCN, which could capture the dynamic features of the network. LRGCN model [20]: This model is mainly used to deal with data’s temporal and spatial correlation. The model uses a two-layer GCN and attention mechanism to achieve the classification function of dynamic network data. DynGEM model [24]: Based on static graph self-coding, this model minimizes the two objective functions corresponding to first-order approximation and second-order approximation and maps the input data to a highly nonlinear space to capture the evolution trend of the network. DyGrEncoder model [41]: This model designs an unsupervised encoder-decoder framework, which projects the dynamic graph into multi-dimensional space at each time step, and simultaneously considers the topological structure features and evolution features of the network. TREND model [42]: This model uses Hawkes process-based GNN to integrate with event and node dynamic features. It uses GNNs to materialize the temporal representations by receiving and aggregating messages of the node itself and the historical neighbors. It also integrates the event and node losses to jointly optimize event and node dynamics. MLjFE model [43]: This model proposes a special case of a multi-label learning framework for temporal link prediction. It is developed for temporal link prediction by joint multi-label learning and feature extraction, where features can capture the information in a parameter matrix for temporal link prediction.
The experimental running environment is 64-core Intel (R) Xeon (R) Gold 5218 CPU @ 2.30 GHz, NVIDIA Geforce RTX 3090 GPU, 256 GB memory. The Python version is 3.8.12, and the PyTorch version is 1.9.0. The learning rate parameter LR of the optimizer is 0.01, and the training parameter epoch of the model is 20. Since the large node number of some data sets such as WIKI, SXC2Q and SWE, we sample 3000 nodes from each dataset, which ensures that the sampled nodes and edges are partially occurrent at every moment. Set
Comparison and analysis of prediction performance
GC-LSTM, STGCN, and A3T-GCN belong to the stacked GNN model. GConvLSTM, EvolveGCNO, and LRGCN belong to the integrated GNN model. DynGEM, DyGrEncoder, and TREND belong to the dynamic coding model. MLjFE belongs to the Matrix decomposition model. The input parameters of these models adopt a one-hot feature or degree matrix feature, we select the results with better effect for comparison. Set the train window size
AUC performance result table
AUC performance result table
Because the stacked GNN model has separately extracted the spatial features of the network topology at each moment, the effect of GCLSTM, STGCN, and A3TGCN in most datasets is better than that of the integrated model and dynamic coding model. The proposed TSAGNN model also uses the stacking method to process the features of each snapshot, and the input spatial information is more than the stacked GNN models. From Table 2, we can see that the effect of AUC has been significantly improved. Compared with the baseline methods with better prediction results, the performance of the method in nine datasets has been improved by 2%
The integrated GNN model processes spatial and temporal information at the same time. The TSAGNN model also uses the way of the integrated method. While processing temporal information between each LSTM cell, GCN is also used to further process spatial information. The effect of the integrated model in the SWE dataset is better than that of the stacked model and the dynamic coding model. Similarly, the TSAGNN model has also achieved the best AUC effect, which makes an average improvement of more than 14%.
Moreover, the effect of the TSAGNN model is also significantly improved compared with DynGEM, DyGr, TREND, and MLjFE models, and the average improvement effect is between 4% and 30%.
Brier performance result table
The average Brier accuracy of the TSAGNN model has also been greatly improved in most datasets except SBM. As shown in Table 3, TSAGNN performs a little better in SWE, about 4% higher than the GC-LSTM model. For the other seven datasets, the average performance is improved by more than 30%.
MAP performance result table
The average MAP accuracy of the TSAGNN model has also been greatly improved. As shown in Table 4, TSAGNN performs a little better in SXC2Q and IAEE, about 4% higher than the baseline models. For the other seven datasets, the average performance of TSAGNN has been greatly improved, which is about 2%
Schematic diagram of RMSE and MAE experimental results.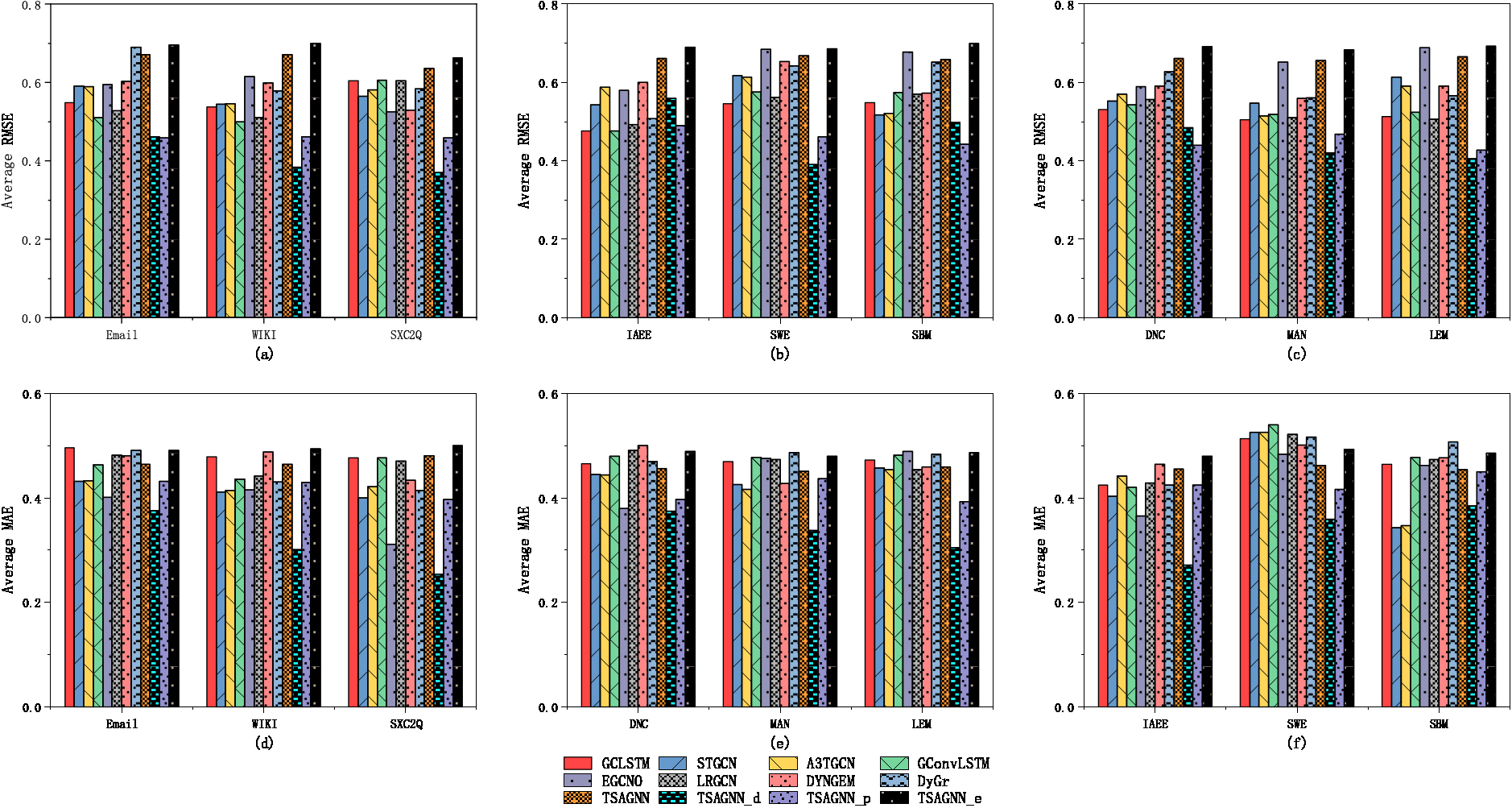
As shown in Fig. 8(a) (b) (c), the result is the test comparison of the RMSE effect in nine data sets. The error of the TSAGNN and TSAGNN_e are relatively bigger in the experiment. Except that the RMSE of GCLSTM and GConvLSTM in the IAEE dataset is the minimum value, TSAGNN_p and TSAGNN_d have achieved better results in other cases. The average RMSE of the TSAGNN_d is reduced by more than 10%. When the same features are inputted, the better results of the TSAGNN_d show that the design of the two-stream graph neural network processing layers and the transformer encoder has better RMSE performance.
Similarly, as shown in Fig. 8(d) (e) (f), it is the experimental comparison results of the MAE effect in nine data sets. TSAGNN_d in other data sets except the SBM data set is relatively better, and the average of MAE is reduced by more than 15%. The MAE performance of the TSAGNN_p is better than TSAGNN_e and TSAGNN, which indicates the processing of edge features may make a bigger error result.
Schematic diagram of input characteristic sensitivity test. (a) Comparison of ablation model results with different input characteristics. (b) Comparison of graph network results with different layers.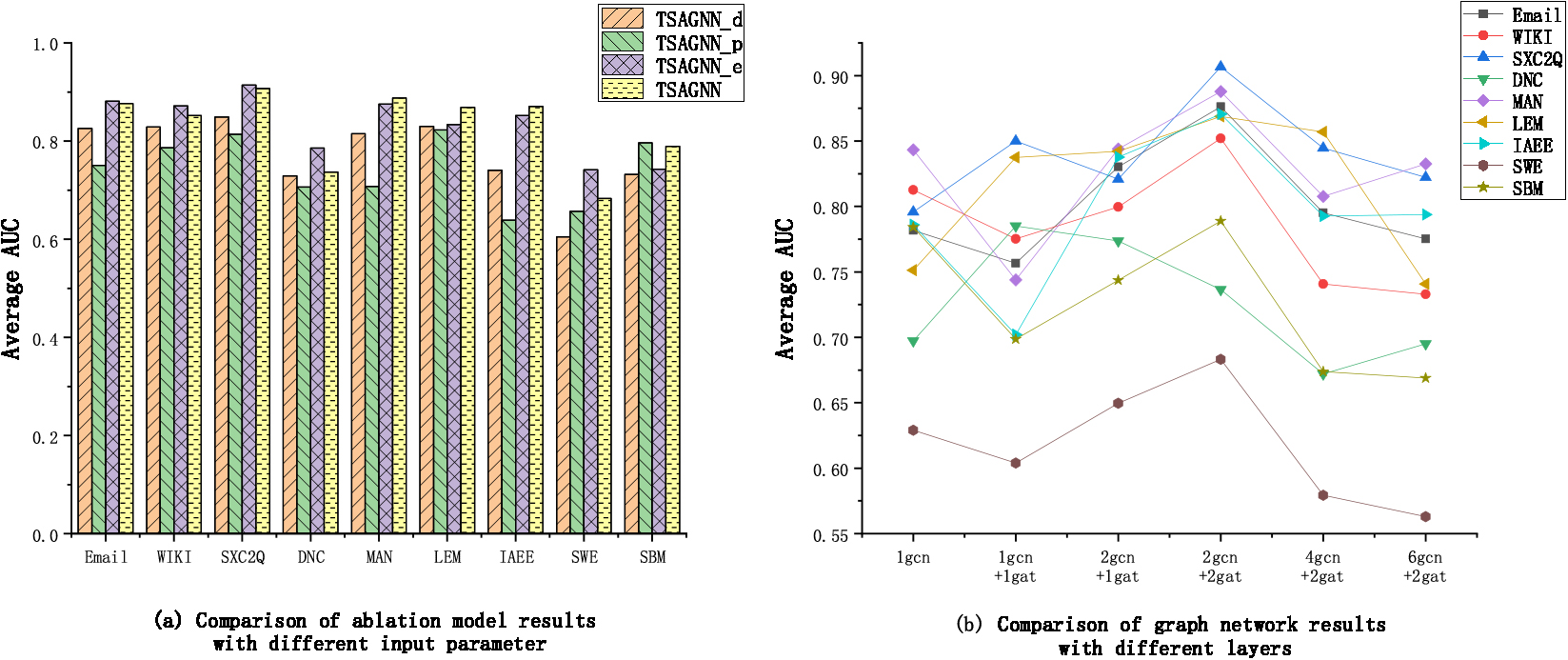
First, we test the performance of different input features and compare TSAGNN_d, TSAGNN_p, TSAGNN_e, and TSAGNN. As shown in Fig. 9(a), the AUC effect of TSAGNN is better than the TSAGNN_d in all nine data sets, which indicates the more features that can be input, the better performance can be gotten. The average improvement effect is about 7%. And in the SBM dataset, TSAGNN_p based on point features could get better results, and the results of TSAGNN_e based on edge features in other datasets are better, which indicates the fusion of node features and edge features can better improve the prediction performance in different network environments.
Moreover, the CABs of the AGA layer are used to process the input information using multi-layer neural networks, and the influence of different neural network structures on the AUC performance is tested. We test the 1-layer GCN network, the 1-layer GCN and 1-layer GAT network, the 1-layer GCN and 2-layer GAT network, the 2-layer GCN and 2-layer GAT network, the 4-layer GCN and 2-layer GAT network, the 6-layer GCN and 2-layer GAT network respectively. The average AUC results are shown in Fig. 9(b). while the optimal situation occurs in the 1-layer GCN+1gat mode in the DNC data, the best case in other data sets is 2gcn+2gat. The AUC effect of the 4gcn+2gat and 6gcn+2gat drop sharply, which indicates the more layers of the neural networks, the effect of the performance may be worse. According to the experimental results, it is suggested that the number of layers for setting CABs should not exceed 4 and that 2-layer GCN and 2-layer GAT networks can achieve the best processing results in most situations.
Temporal robustness
According to the total size of the snapshots of different datasets, we choose 20–30 consecutive target snapshots for testing to observe the prediction effect of different methods. As shown in Fig. 10, the TSAGNN method has improved the prediction effect at most times in nine data sets, and the AUC curve has higher performance and stability at different moments. In contrast, the prediction accuracy of other baseline methods decreases greatly at some time, the AUC curve of them fluctuates greatly, and the average AUC is significantly lower than TSAGNN. The above results verify that TSAGNN has better temporal robustness in dynamic network link prediction tasks.
Schematic diagram of AUC performance with different methods changing in time sequence.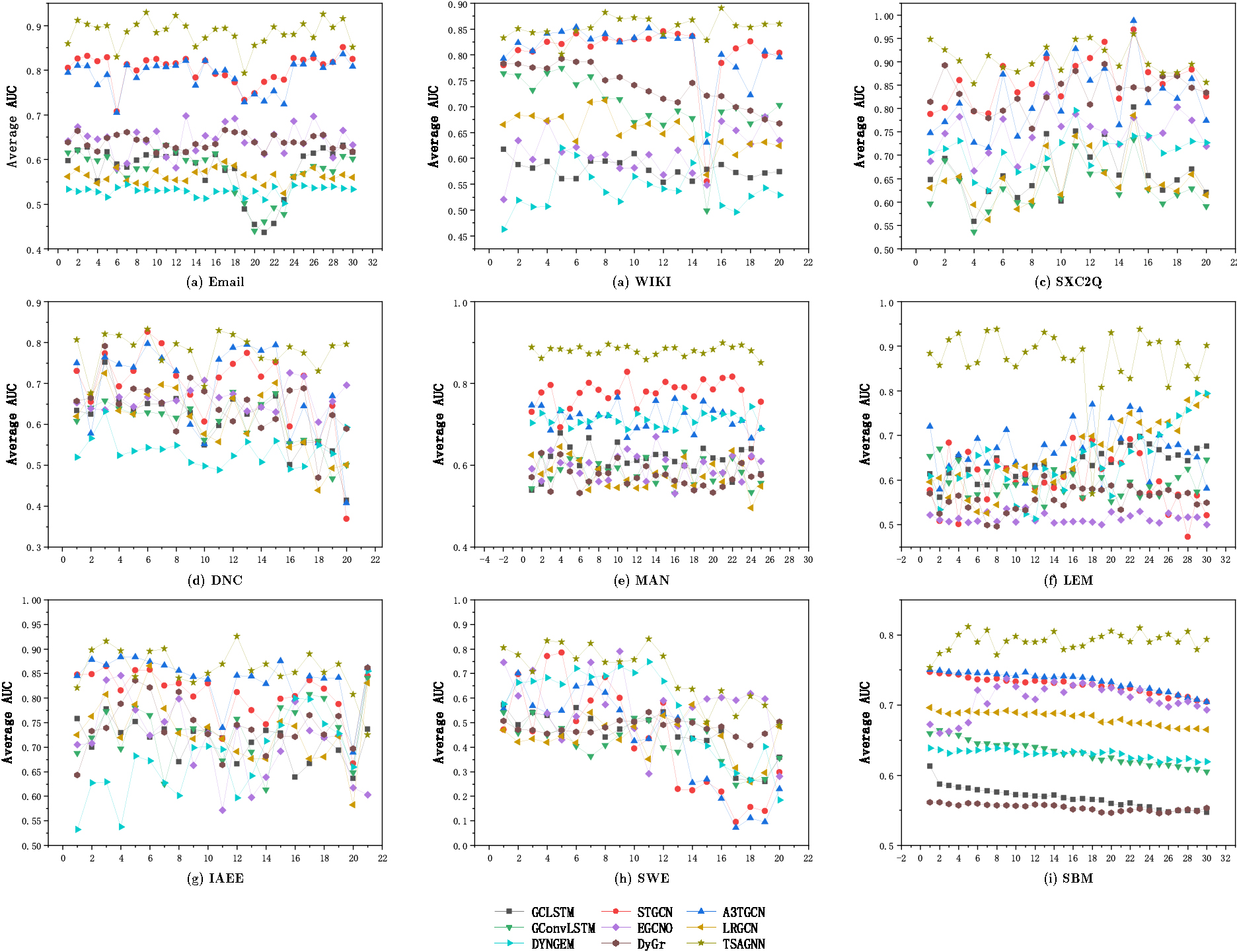
In this paper, we research the temporal link prediction problem of dynamic networks based on graph neural networks. At present, many graph neural networks often use one-hot feature or label features as the original input, they do not consider the diverse scenarios of input feature parameters, and the utilization of time-domain features and spatial-domain features is limited. To solve these problems, a novel temporal link prediction method based on two streams of adaptive graph neural networks is proposed, which can fully mine the spatial and temporal information of the dynamic network. Firstly, we propose an adaptive mechanism that combines convolutional neural networks and self-attention networks for the spatial features of different scale network structures. Secondly, an extended bi-directional long short-term memory network is proposed, which uses graph convolution to process topological features, and recursively trains the time-domain memory information. Thirdly, the location coding is replaced by the time-coding for the transformer encoder, so that the past information and the future information can be learned from each other, and the time-domain information of the network can be further mined. Furthermore, a two-stream network framework is proposed, which combines the processing results of point features and edge features, and the fully connected network for decoding to realize the temporal link prediction. Finally, the experimental results on 9 network datasets show that the proposed method has a better prediction effect and better robustness than the classical graph neural network methods under the AUC, Brier, MAP, RMSE, and MAE metrics. The follow-up research problem in the future is how to predict and reconstruct multi-layer networks, self-organizing networks, weighted networks, and continuous networks with various dynamic spatial-temporal information.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (No.61803384).