
Abstract
Crowd-Sourced software development (CSSD) is getting a good deal of attention from the software and research community in recent times. One of the key challenges faced by CSSD platforms is the task selection mechanism which in practice, contains no intelligent scheme. Rather, rule-of-thumb or intuition strategies are employed, leading to biasness and subjectivity. Effort considerations on crowdsourced tasks can offer good foundation for task selection criteria but are not much investigated. Software development effort estimation (SDEE) is quite prevalent domain in software engineering but only investigated for in-house development. For open-sourced or crowdsourced platforms, it is rarely explored. Moreover, Machine learning (ML) techniques are overpowering SDEE with a claim to provide more accurate estimation results. This work aims to conjoin ML-based SDEE to analyze development effort measures on CSSD platform. The purpose is to discover development-oriented features for crowdsourced tasks and analyze performance of ML techniques to find best estimation model on CSSD dataset. TopCoder is selected as target CSSD platform for the study. TopCoder’s development tasks data with development-centric features are extracted, leading to statistical, regression and correlation analysis to justify features’ significance. For effort estimation, 10 ML families with 2 respective techniques are applied to get broader aspect of estimation. Five performance metrices (MSE, RMSE, MMRE, MdMRE, Pred (25) and Welch’s statistical test are incorporated to judge the worth of effort estimation model’s performance. Data analysis results show that selected features of TopCoder pertain reasonable model significance, regression, and correlation measures. Findings of ML effort estimation depicted that best results for TopCoder dataset can be acquired by linear, non-linear regression and SVM family models. To conclude, the study identified the most relevant development features for CSSD platform, confirmed by in-depth data analysis. This reflects careful selection of effort estimation features to offer good basis of accurate ML estimate.
Keywords
Introduction
S Software development effort estimation (SDEE) is considered one of the most crucial software project management activities by researchers and practitioners [12, 17, 46]. SDEE is inevitable since underestimation can lead to insufficient resources allocation and poor-quality projects, consequently, results in incomplete project requirements [28, 36]. On the other hand, overestimation induces unnecessarily high budget and resources in project. As a result, a rise in project costs and bidding disadvantages may be encountered. Thus, accurate effort assessment at early stages of software lifecycle is essential. Development effort can be calculated based on task completion [78], measured in person-month (PM) or person-hour (PH) [13]. Various SDEE techniques have been proposed over the past four decades. Jorgensen and Shepperd [38] conducted a systematic literature review (SLR) based on 304 studies. Reported from SLR, estimation is done majorly using expert judgment [37], statistical analysis of historical project data [8] or machine learning (ML) techniques [4, 19, 23, 52]. There has been an increasing trend of incorporating ML methods for SDEE as they work better in modeling complex relationship between effort and software features [56]. Especially when dependent and independent features follow non-linear relationship and don’t seem to have any predetermined form. ML techniques are also known for overcoming biasness [25]. Decision tree (DT), neural network, support vector regression (SVR) and ensemble methods are majorly explored in SDEE domain by recent researchers.
Crowdsourcing is an evolutionary problem-solving platform, which works in distributed environment and combines human-intensive work with machine computation [6]. Software crowdsourcing (SWCS) or Crowdsourcing software development (CSSD) is an evolving domain of crowdsourcing, integrates traditional software engineering task in competition-based crowdsourced environment. Usually, CSSD enables software development through an open call format. Recent implementations of CSSD platforms are first devised by Jeff Howe in 2006 [32] and contain similarity with earlier idealistic development models, established by Free Software Movement.
For any CSSD project, “task” is characterized as the starting point, which is basically one work unit made available on CSSD platform. CSSD task represents need or problem in hand (i.e., software development, design, or quality assurance). General architecture of CSSD involves three types of actors or stakeholders: Client, also known as task requesters (TR), Developer, also known as crowd worker (CW), and CSSD platform collaborating TR and CW. In competitive CSSD platform, a TR requests a task and offers award for task completion, while CW (software developer/designer/tester), participates in given software task. Crowdsourcing platform provides an online marketplace within which TR and CW can collaborate (also reflected in Fig. 1).
An overview of proposed work.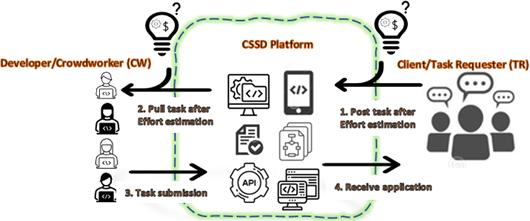
Multiple CSSD platforms including Amazon Mechanical Turk, TopCoder, TaskCity, eLance, vWorker, Guru, oDesk and Taskcn are providing crowdsourced services to larger software community. TopCoder among all CSSD platforms, contains the largest software developer community, and known to produce projects for well-recognized organizations such as Google, Facebook, Microsoft and AOL [68]. TopCoder platform is geared towards highly skilled CWs, who undertake time-consuming, complex, and quality software development tasks. The size of requested projects on TopCoder bear complex inferences and larger magnitudes compared to microtask platforms (i.e., Amazon Mechanical Turk). Thus, the necessity of coming up with a justified price with respect to amount of work required for the task is an imperative decision problem for the stakeholders involved [72].
[43] identified key challenges faced in CSSD platform, such as ineffective decision making on task selection, task completion uncertainty, costing issues and task quality assurance [35]. From CW’s perspective, adapting a task while not considering effort, may lead to low capital consumption efficiency or task starvation [26]. Since award money is established at the time of task posting by TR, which should be sufficiently attractive to the crowd. From TR’s perspective, inappropriate price can often lead to loss of potential crowd as well, hence price must be in accordance with effort demanded by the task in-hand. Valid pricing is well-known motivational factor behind CW’s task selection [43, 59], one of the top five key challenges for crowdsourced software development [42]. Further, task completion uncertainty prevails if unconscious attempt in task selection is made, i.e., not considering effort to be consumed on task. Effort based pricing strategy is crucial since mere intuition of TR about the price does not provide justified costing mechanism for CSSD task. Moreover, estimation needs to be supported by a good set of features to formulate an accurate effort estimation model. Since crowdsourced task requires in-time decision by CW whether to opt for the task or not, so features included in estimation must be those which are already available with the task, rather to rely on previous data. Considering the need of effort estimation in the field of CSSD with highly relevant, development-centric features, this study aims to incorporate ML based effort estimation for CSSD tasks. TopCoder is selected as CSSD platform for the study, due to its increasing utilization by recent researchers [1, 48, 80]. Basic working of the study is shown in Fig. 1 and main contributions of the study are as follows:
Defining a dataset for software development tasks posted on TopCoder platform, with features readily available and not having any dependability on previous phases data (i.e., software requirement, specifications, or design). A detailed statistical, regression and correlation analysis is performed on selected TopCoder features along with model significance and normality considerations to justify relevance of dataset features. Performing ML-based effort estimation with an empirical analysis using 20 ML techniques to identify the best performing estimation algorithm for TopCoder dataset.
The rest of the paper is organized as follows: Section 2 presents related work of past studies covering SDEE and CSSD literature and Section 3 listed the problem formulation. Section 4 contains methodology used for this study and complete framework description in underlying sections. Section 4.3 listed effort estimation algorithms used for the study, Section 5 includes experimental setup having performance metrices. Results are discussion are elaborated in Sections 6 and 7 while Section 8 define threats to the study’s validity. Section 9 describes future for the study.
SDEE is a well-recognized field in traditional and agile software project management and worked-upon a lot in past. CSSD on the other hand, is comparatively newer field but due to its underlying potential, researchers are widely using it for past 15 years [68]. This section further describes previous work done in the field of SDEE and CSSD.
Related work on SDEE techniques
As mentioned earlier researchers are contributing to SDEE and proposed many techniques in last four decades. Overall, these techniques are grouped into three main categories [20]: expert judgment, which takes effort opinion of one or more experts to determine the effort required by project [33]; parametric techniques, utilizing statistical and/or numerical analysis of historical project data [10] and machine learning (ML) techniques, based on a set of AI algorithms, including as artificial neural networks (ANN), genetic algorithms (GA), analogy-based or case based reasoning (CBR), decision trees, and genetic programming [34, 78].
Use of Random Forest (RF) is added to effort estimation by [53] and performance is compared with regression tree model. Experiments are performed on a benchmark dataset named ISBSG R8, Tukutuku, and COCOMO. The study concluded that RF provides good estimation compared to simple regression tree in terms of Pred (0.25), MMRE and MdMRE regression metrices. Another contribution in traditional SDEE is made using Support vector regression (SVR) by [18]. The study discussed that SVR provides good estimation when it comes to the problem related to higher dimensionality and outliers. Another SDEE work done by Zare et al. [81] used three level Bayesian network. This work also utilized optimization algorithms (GA and PSO) extracting optimal coefficients of effort on COCOMO NASA benchmark dataset.
Work of [47] in SDEE domain was to analyze the estimation power of different neural network variants. A comparative study is conducted on Multilayer Perceptron (MLP) and radial basis function (RBF) against multiple linear regression model (MLR) and concluded that neural network-based regression models perform statistically better than linear regression models. Effort metrices used for the work are MAR with MdAR with appropriate consideration of normalization and cross-validation on ISBSG benchmark dataset. An emperical study conducted by [69] analyzed various algorithms included Support Vector Machine (SVM), Multi-Layer Perceptron Neural Network (MLPNN), Linear Regression (LR) and K-Nearest Neighbor (KNN). Performance of SDEE model is estimated in terms of “Coefficient of determination (
Related work on CSSD
CSSD is a relatively newer domain yet gained a great deal in recent software practices. Research work contributing in CSSD domain are listed below.
Summary of previous CSSD work
Summary of previous CSSD work
Work done by Mao et al. [49] was the first study to address the pricing issue for TopCoder CSSD platform using machine learning models. The studyconstructed structural and non-structural pricing models on 490 TopCoder projects having 16 price drivers. Four categories of price drivers (input features) are formed including (1) Development Type (DEV), (2) Quality of Input (QLY), (3) Input Complexity (CPX), and (4) Previous Phase Decision (PRE). Pricing models are evaluated using three traditional methods (COCOMO’81, the random guessing, the Naïve model) and estimation is performed using: regression models (Multiple Linear Regression, Logistic regression), analogy-based schemes (KNN-1, KNN-k), and ML models (C4.5, CART, QUEST, Neural Network (NNet, SVM). The study concluded that price can be relatively predictable for this new paradigm. Also, C4.5 gives good prediction with more than 80% (84.3%) of estimates with an error lower than 30%. The study provides the grounds that high predictive quality is possible to achieve, which can outperform existing pricing models, facilitating TR to adopt actionable insight. Another CSSD cost estimation work is done by [1] named as Context-Centric Pricing (CCP) method using 6 cost drivers extracted from task description of TopCoder. 7 cost models are created using ML techniques including Linear Discriminant Analysis (LDA), Linear Regression (LR), kNN, CART, Naive Bayes, SVM and NNet. Compared to [49] cost models, CCP method can work with limited information available on task description, reducing the dependability on previous task data. However,it is not providing improved results with ML models. Moreover, cost drivers related to CW’s working ability and competitor’s status are not included which limits the decision support ability for constructing costing model.
Another cost estimation study is conducted by [48]. Pricing models using LR, logR and kNN are established on TopCoder dataset and models are empirically evaluated. Initially, 13 features are considered, out of which 9 are dropped due to their least relationship with pricing. Results concluded that logistic regression outperformed with 90% accuracy while kNN (
CWs’ dependability in tasks selection for CSSD is examined by [2]. Study investigated crowd worker’s behaviors with empirical analysis and behavioral aspects included are: (a) workers’ behavior at time of registration and task announcement; (b) worker’s performance and award money relationship; (c) groupwise effect of development type; and (4) evolution in workers’ behavior due to skill development. Study findings conclude that task response by most reliable CW’s group is within 10% of registration time and finished the task within 5% of allotted time.
Research presented in [79] worked on analyzing CW’s behavior and proposed dynamic decision systems for CWs. The study aims to make recommendations on CW’s best matching tasks with high winning rate. Influencing factors of CW’s behaviors are investigated in a competitive CSSD environment using RF and predicted that who will be most likely to complete/quit or win the task. Study results confirmed that a particular CW can be categorized as a “potential winner” with average 78% and 88% precision and recall respectively when all decisive features are incorporated. Further, models created have shown high performance recall for “submitter” class.
Another work by [45] identified factors influencing defects which can occur in resulting software. The work represented “project rating” to characterizes the “in-process quality of a project”, “amount of work in the process” to indicate “project effort”, and “amount of work required in the maintenance process” to indicate “quality assurance effort”. Features included for estimation are project size, total prize investment, and number of contests, with proposed Multiple Linear Model (MLM).
An empirical study is conducted by [77] to determine extend of task pricing strategies implemented in CSSD platform. Study worked on the data from TopCoder, while an algorithm is devised to analyze impact of CW’s behavior on pricing strategies. Tasks are labeled as over-price, under-price and Nominal. To represent “Nominal” price for each task, ML algorithms such as LR, kNN and SVM are used. The work is done from TR’s perspective and conclusion is made that overpriced tasks gained attention of more workers. They tend to register and submit for those kinds of tasks and show higher task completion velocity. Similarly, underpriced tasks gained comparatively less registrants and submitters along with lower task completion velocity. However, when it comes to delivering actual task outcome, i.e., task score, there might be chances that worker may exert less effort due to higher competition in overpriced task. The study further concluded that overpricing will not guarantee the quality of final deliverable by merely attracting more submitters. Another work in CSSD domain by [80] evaluated strategies on overcoming onboarding barriers or challenges faced by CWs. Barriers include task finding based on CW’s ability, environment setup for performing the task, and managing one’s personal time. Six strategies are proposed and evaluated through web-based questionnaire from CSSD experts. Results concluded that CSSD should incorporate task matching system with CW’s profile, virtual environment, and stable communication channel for requirement clarification.
Table 1 shows a summarized version of previous CSSD work, including what outcome each study has produced, actor who is mainly facilitated by the work and whether they used any ML scheme to facilitate the estimation. Table 1 also established the fact that TopCoder is a majorly utilized platform CSSD research. This brings motivation for this work to consider TopCoder as exploratory CSSD platform. However, from the past SDEE and CSSD work analyzed above, limitations arise are:
Most of SDEE work gathers around using benchmarks datasets of PROMISE and ISBSG repositories, which majorly contain in-house or traditional software projects, while crowdsourced software projects are not considered to perform any effort estimation work. In CSSD literature, cost estimation and pricing model for CSSD was the major focus of past literature as almost 50% work is about pricing estimation techniques. For CSSD actors (TR and CW), it is crucial to have an estimation about total effort needed for task completion, which is not much discovered in past. Work of [45] considered effort prediction but used as one of the factors to estimate task’s quality. That is, the focus was mainly on task quality assessment, not effort requirement. Also, estimation is done using three project features for building ML model, which is relatively fewer feature count for achieving better performing ML model [66, 73]. [49] has considered features of previous software development phase i.e., software design for cost estimation. Often, it is challenging to get previous record of the task in CSSD platform, and a task may require just in-time development with no record previous phases. ML techniques are rarely explored for CSSD estimation domains and where used, very few techniques are considered. Mostly parametric and linear regression is followed [1, 45, 49] while other families of ML techniques are not examined to verify whether estimation is giving stable results in all contexts.
This work attempts to address following issues, from the limitations identified in literature (Sections 2.1 and 2.2):
No joint framework is present in CSSD platform for facilitating both task requester (TR) and crowd worker (CW)/developer to conduct a decisional process about task commencement. For TR, it’s necessary to know about effort involved in task before posting it, so winner’s cost can be adjusted accordingly. For CW, again getting intuition on whether to accept a task based on effort required is necessary. In this study, a framework for predicting effort is defined, facilitating both (TR and CW) to estimate effort based on task features.
Cost analysis on TopCoder tasks is mainly focused on the past studies [1, 49]. However, core focus on effort for CSSD task is still unaccounted. Consequently, no proper criteria of cost justification are present. Effort consideration holds impact as TR desires to get idea whether cost of winner(s) is justified according to effort required by task. For CW’s perspective (developer), task completion can also be ensured if CW can assess the effort of posted task beforehand. In this work, core effort estimation for TopCoder development tasks are taken into account, facilitating TR and CW to estimate effort for task in-hand, and make criteria of cost justification.
Extraction of appropriate features and data collection play a vital part in crowdsourced environment analysis [22]. TopCoder dataset features used by earlier research are limited in number as well as dependent on previous software development phase. Dependency on previous-phase features becomes problematic for estimation since it is difficult for developers to get access of any previous tasks data. To mitigate this issue, all features available on the time of task-publishing are incorporated in the study to estimate effort. Extracted features encompass multiple categories like characteristics of application being developed, developer’s working abilities, task outcomes and size.
Descriptive statistics of all features and dataset normality are another important parameters, especially when ML based estimation systems are developed. The reason is estimation result may vary according to normal and non-normal distribution of dataset. Data normality measures are missing in most of the studies incorporated ML algorithms in their working. This will leave the ML model difficult to comprehend in terms of statistical distribution of values. Also, what distribution dataset follows and what impact it brings to model’s performance is not reported in any CSSD study. In this work, a detailed descriptive statistical analysis of input features as well as output variable is examined alongside normality distribution assumptions. Investigation is made to analyze if model is still significant enough after transforming the dataset into normal distribution.
Analyzing the impact of individual independent (input) variable on dependent (output) variable and examining the worth of keeping certain feature in dataset is necessary for building estimation model. For that reason, model significance and detailed multiple regression analysis is performed for justifying the importance of each extracted feature and scrutinizing which feature needs to be controlled to minimize effort. Along with this, multicollinearity among input features, as well as correlation between input and output is determined to justify that model is highly suitable to perform ML analysis for forthcoming effort predictions.
For verifying estimation stability and to avoid biases associated with individual approach, ML techniques with all major families are explored. ML families included for the study are linear/non-linear regression family, decision tree family, SVM family, neural network family, heterogenous and homogenous ensemble family. Two techniques from each family are taken to establish effort prediction model.
This section presents the methodology used to build TopCoder Effort Estimation Model for predicting effort consumed on a CSSD task. Figure 2 shows the proposed framework, which consists of three main stages:
Basic structure of proposed framework.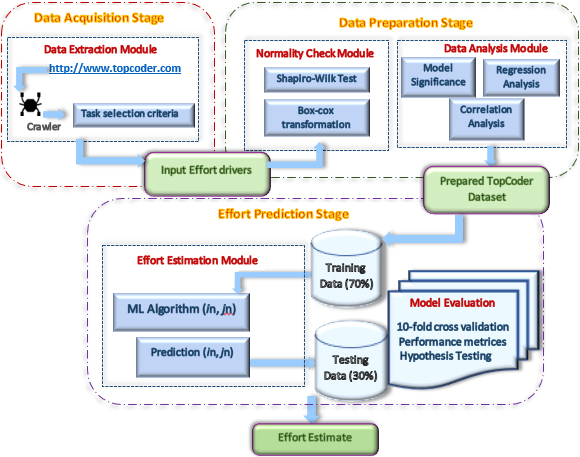
Data Acquisition Stage (Section 4.1); describes the details of extracted data. Features which are part of dataset and their relevance with effort is elaborated.
Data Preparation Stage (Section 4.2); contains detailed analysis performed on dataset to shape it in a form suitable for feeding to ML algorithm. Data is investigated in terms of statistical analysis (Section 4.2.1), normality checking (Section 4.2.2) regression analysis (Section 4.2.4) and correlation analysis (Section 4.2.5).
Effort Prediction Stage (Section 4.3); presents effort estimation modeling with ML techniques, to identify best performing ML algorithm for TopCoder dataset.
Data of 1500 TopCoder development tasks are extracted using Octaparse crawler.1
Data The following criteria is applied for task selection: dataset contains TopCoder development tasks completed between past year, i.e., 2020 to 2021 are taken. All tasks are accomplished, with 60 above submission score. For the sake of simplicity, only those tasks are selected with one winner (i.e., award money is given to the first winning submission). Tasks with source code information (repository or Gitpatch) are selected. After applying selection criteria, 1200 tasks remain to be part of dataset.2
Dataset contains a total of 15 input features (also referred as “Effort drivers”) and 1 output feature, i.e., Effort. Input features are grouped into 5 categories, depending upon the data they represent. Each feature contains numerical or ordinal values. Ordinal levels assigned to the features are “very high”, “high”, “nominal”, “low” and “very low” and each level is given a numerical value from 1 (very low) to 5 (very high) to establish ML estimation models later in the study. Table 2 listed all input features along with their names, category, abbreviation, and data types described further as follows:
Development characteristics (DVCH) category shows what type of development a task requires.
The first feature of this category, APPT shows type of application under-development. Application types found for most tasks in extracted dataset are desktop, mobile, web applications, API, frontend (UI/Ux/Cx) and frontend-backend integration patch. Higher ordinal levels are assigned to more complex application, i.e., desktop and mobile application (dashboards, management information systems) since these applications involve large backend integration requirement [58]. Nominal to low ordinal levels are assigned to small scale websites, APIs and frontend applications (UI/UX/Cx) since they require less lines of code and mostly involve the designing part of software application [16, 54]. Next feature, DEVT, defines whether the task implies developing entirely new application or adjustment/updation in a previous task. Higher ordinal values are assigned for “from-the-scratch” application development, while updation tasks are given lower ordinal values.
Personnel Metrics (PERS) category illustrates aspects of developer’s skill, reflecting his/her development ability.
First feature of this category, win percentage, WINP determines developer’s winning tendency, i.e., trend of developer winning a submitted task. Higher WINP reflects good analytical capability of developer, which in turn affects the required effort i.e., less effort required by developer with higher WINP. Descriptive statistics of TopCoder dataset effort drivers
SBRT shows the tendency of developer to submit a task for which he/she has registered. Numerical values of both WINP and SBRT are directly extracted from the developer’s profile. Higher SBRT shows developer’s continuity in completing tasks and enhanced development capabilities.
EXPR defines developer’s experience in performing tasks of TopCoder development category. Numerical values are assigned as duration (in years) between first submitted task and latest submitted task by developer in development category.
RATN shows quality of work produced by developer in previous tasks. Developer’s rating (RATN) is directly extracted from profile.
TSCR is technology/language/tool score of developer. Developers’ skills (listed in developer’s profile, verified by TopCoder platform) are extracted, matched with skills required for task and score is assigned. For instance, if a task needs implementation of 3 languages/tools/technologies and developer previously has worked with 2 of them in past tasks, then TSCR will be 2/3 (0.67).
NSUB is determined as total number of submissions made by developer which reflects developer’s analysis ability of current task and thoroughness of implemented code.
Task complexity (TCPX) shows complexity level infused by programming language, tools, and technology on the task.
NoLN, is the number of languages required to develop a particular task.
PRLN is assessed by type/complexity of programming languages required for development. Complexity is based on language generation, built-in libraries and automated function calls offered by language. Newer generation languages generally enable the provision of off-the-shelf libraries which in turn improves the development efficiency and subsequently decrease effort.
TOOL represents tool/technology needed for task development. Like PRLN, modern tools provide built-in functionalities with service invocation via interface, and are less code-oriented, hence reduce development effort. Values of both features are assigned based on complexity and ease of development they offer, i.e., recent generation programming languages (PRLN) and tool/technology (TOOL) are given higher ordinal level.
CNST referred to several constraints imposed on development or deployment process, such as design, platform and environment constraints. Extensive measures are needed if code is built with constrained environment, hence results in increased effort.
Artifact complexity (ACPX) defines; what kind of provided and required artifacts involved in task and what is their complexity level.
ASST feature of this category, reflects facilitation level provided by documents/artifacts posted with the task. From TopCoder data, commonly found assets are: design files, prototype links, branch codes, micro frames, repos (containing code for the updation or bug-fixing tasks), which client (TR) provides with the task. Higher ordinal levels are assigned if artifact has increased helping level.
DLVB evaluates the overhead created due to the deliverables required to submit at the end of task. In addition to source code, more deliverables need extra effort for a task. From extracted data, deliverables found are: git patches, bug report, verifications videos/documents and database schema. Higher values are assigned if a higher number of deliverables must be produced by the developer.
Size category determines task size. Software lines of code (LOC) are taken as size measures of effort calculation, for which numerical values of task size are obtained. Higher size reflects greater task effort.
Effort is a dependent feature of the dataset and measured based on size and completion time of development task. Since challenge/task posted on crowdsourced platform opens for 24-hours till the deadline, so keeping in mind time differences of country a developer belongs, unit selected for Effort is person-hour (PH) in this study.
After data is extracted, statistical and multiple regression analysis is performed next, to shape the data suitable for effort estimation model. Details are presented further in this section.
Statistical analysis of TopCoder dataset
This stage starts with descriptive and statistical analysis of input effort drivers. Table 3 presents the statistical measures for all independent attributes (effort drivers) in dataset. For ordinal features, statistical values are considered to get the idea which data values against these ordinal features are most prevalent in dataset. For instance, we can conclude from Table 3 average tasks in dataset belong to “nominal” level of application type (APPT), i.e., most tasks require to develop WebApp (Backend) or Application programming interface (API). For DEVT feature, most tasks belong to “nominal” level as represented by their means since most published tasks required updation of any a previous project. Coming to Personnel Metrics (PERS) category, average developers in dataset have 39% winning percentage (WINP), while highest WINP is 100 which shows, some developers have won all tasks they have registered for. Same for SBRT, maximum 100% submission rate is found which again reflects, at maximum, developers submitted all tasks they have registered for, while 50% submission rate is found on average. For RATN feature, maximum rating achieved by developer is 1972, while on average developers belong the rating of 1467. Developers are present with an average EXPR of almost 2 years and the highest experienced developers contain 9 years of experience. Maximum technology expertise (TSCR) of developer is 1, depicting developer have worked with all skill in past as required by task. For TCPX measures, average tasks need development of using only 1 language, but at max, some tasks may require 4 languages to work on. Programming languages used (PRLN) in task are mostly on “nominal” complexity level, indicates that most tasks require 3G languages.3
Descriptive statistics of TopCoder output variable (effort)
After statistically analyzing input effort drivers, statistical details of output variable i.e., Effort are reported in Table 3. Effort is considered in person-hours (PH) measure. The level of effort recorded was between 8.2 and 5333.7 PH (with an average of 801.5 PH). Skewness and Kurtosis measures (Table 3) verified that collected data is positively (right) skewed (i.e., Skewness
Effort distribution in TopCoder dataset
Effort distribution for TopCoder dataset.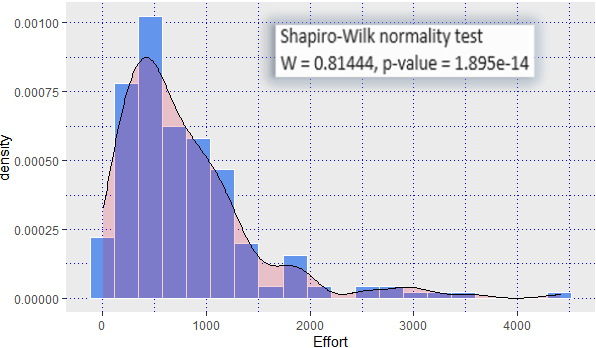
Normality measures in effort values are verified using Shapiro-Wilk test [50] at significance level (
Effort distribution after transformation.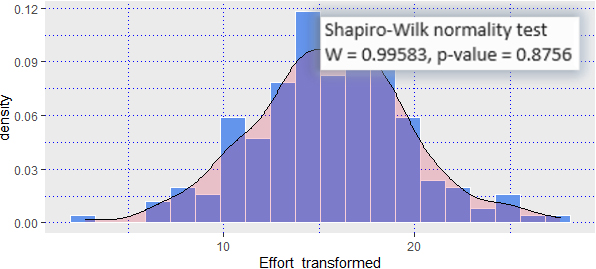
Statistical inference of collected TopCoder dataset started with the
Null hypothesis (H0): no predictive relationship between the effort drivers and “Effort” in the population i.e., the model with no independent variables fits the data as well as the model.
Alternative Hypothesis (H1): at least one effort driver fits the data better than the intercept-only model.
In our model,
Model significance analysis
Diagnostic plot of residuals with transformed effort.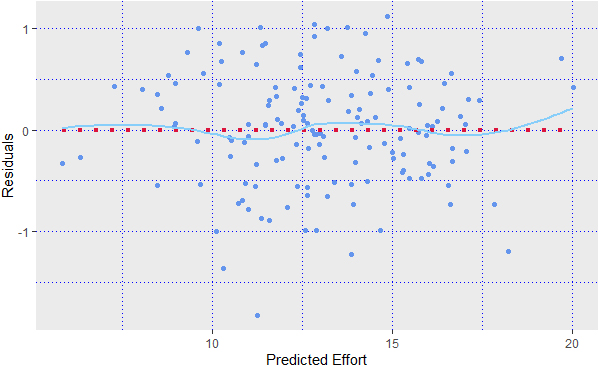
This section explains regression details between dependent and independent variable. After confirming over all statistical significance of model, we proceeded with statistical inference using
Regression analysis details between effort and effort drivers
Table 6 presents complete regression details of all input features where Standard error (with 95% CI) is showing the coefficient variation under repeated sampling. Next,
Null hypothesis (H0): effort driver (with regression coefficient
Alternative Hypothesis (H1): effort driver (with regression coefficient
As it is clear from Table 6, for all effort drivers,
In DVCH category, regression coefficient for DEVT feature (129.02) is higher than other feature of same category, APPT (70.61) indicates that, development type has more impact on increasing the effort. Further, all else equal, a task with developing new application puts an additional 129 PH (on average), compared to task that required just updating of previous application (as shown by DEVT feature). Compared with APPT, tasks that arrive with Android/iOS development, for instance, adds up average 71 PH compared to a task requiring front end development (or any relatively simpler application type). For PERS category, the most impacting regression coefficient is for WINP (
In addition to reporting descriptive, statistical and regression analysis of dataset, this stage of proposed framework applied Pearson’s correlation [55], referred as linear correlation. Multicollinearity problems arise when input features are too similar with each other and hold degree of relationship. This will raise the challenge of having similar effect of all explanatory variables (input features). The model, in turn, will not identify the impact of individual input variable in estimating dependent variable. A correlation coefficient close to zero implies no relationship between two features while values closer to 1 or
Pearson coefficient multicollinearity on TopCoder features.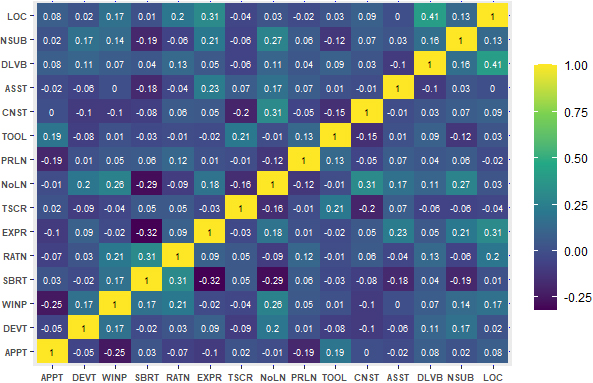
The extent of the multicollinearity is examined in Fig. 6 representing Pearson correlation coefficient among all input features. A small to moderate amounts of multicollinearity is seen in the TopCoder dataset features, which is usually not a problem [71]. Negative Pearson correlation values in analysis range from [
Positive Pearson correlation in TopCoder feature.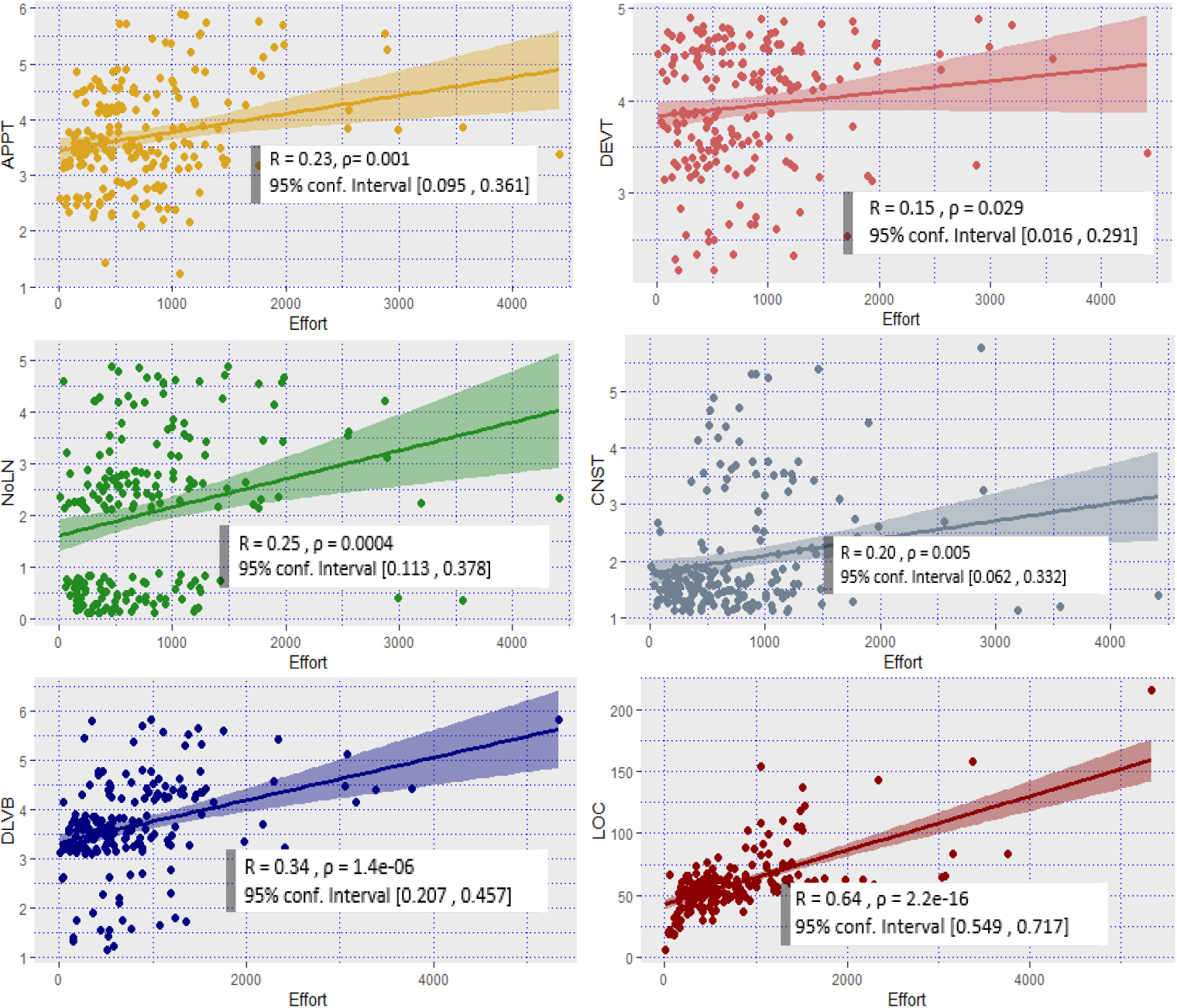
Negative Pearson correlation in TopCoder features.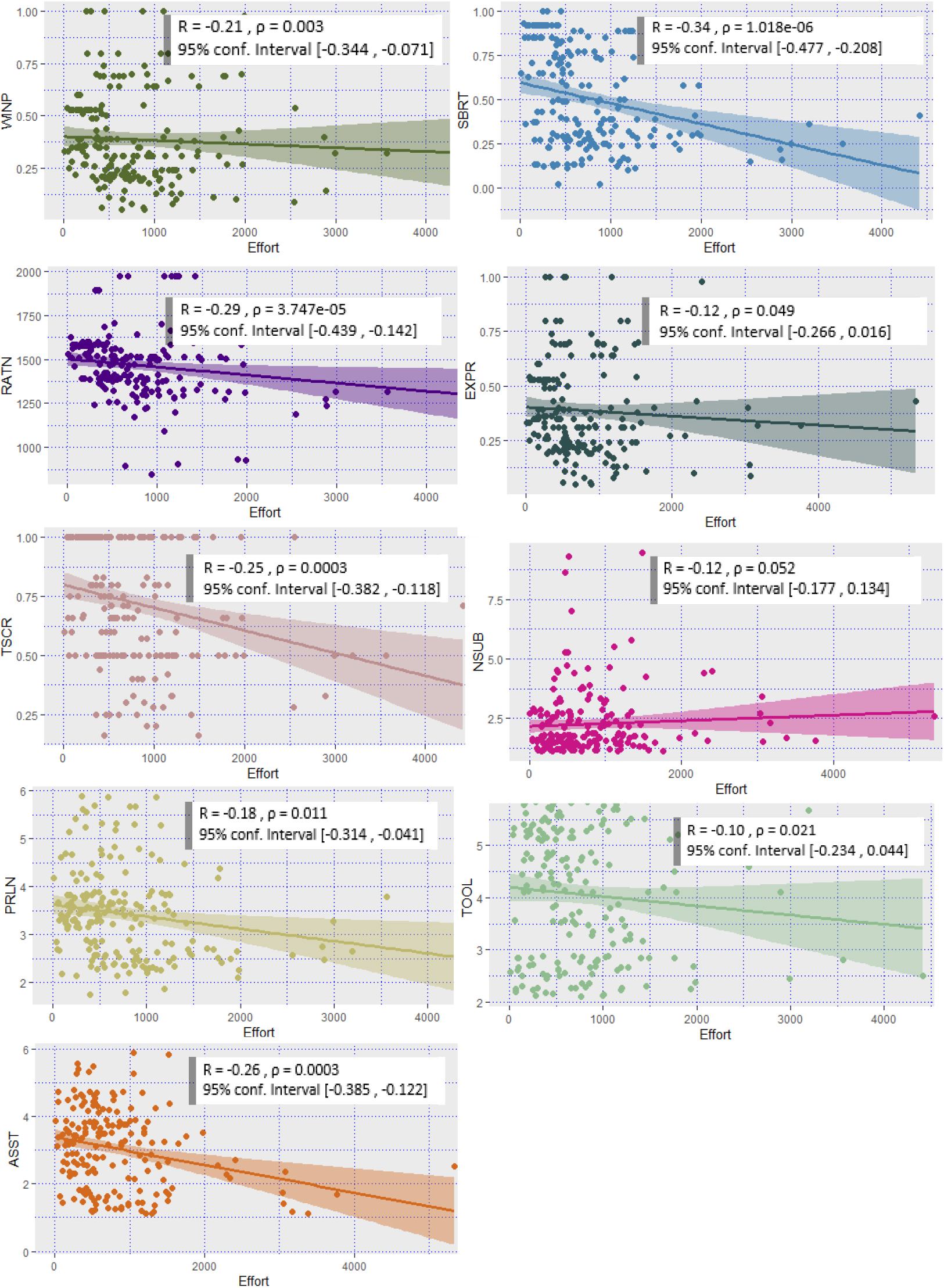
Correlation between dependent and independent features is analyzed next, again using Pearson correlation at significance
Effort estimation techniques used in study
After analyzing and preparing the TopCoder dataset, model training to estimate development effort comes next. For effort prediction, 10 ML families are considered, and two algorithms per family are part of experimentation. Table 7 shows each ML family, their respective two algorithms and parameter setting used to train each model in this study. Parameters of selected models are tuned using Grid search (GS) [51]. The selected ML algorithms are also used in SDEE literature to generate considerable results. Moreover, previous CSSD work also incorporated some of ML algorithms for estimation (Table 1). ML techniques mentioned in bold text (Table 7 Column 3) are used by previous CSSD work while non highlighted techniques are incorporated in tradition SDEE literature. For HT ensemble, the best performing algorithm from each family is selected and combined in form of ensemble. The idea behind choosing these algorithms is to incorporate estimation techniques from the different flavors of the ML domain and to broaden the spectrum of experimental evaluation. Moreover, it is established in previous literature (Section 2.1) [3, 78] NNet, SVM, Decision tree (RF and CART) and Linear Regression are frequently used for SDEE. NNet and SVM also outperformed in most of the studies. Among NNet family, MLPNN and RBFNN are widely utilized versions of neural network. Ensemble models, on the other hands, are also proved to generate better estimation accuracy by avoiding bias created by individual model [66, 74]. Besides this, we also incorporated comparatively less renowned ML models (ZeroR, OneR Naive Bayes) to give better judgement about working of ML techniques on our dataset.
Experimental setup
In order to assess the effectiveness of each estimation model, we applied 10-fold cross validation (10-fold-CV) by randomly dividing dataset into 70-30 ratio. All experiments and statistical evaluation are performed in RStudio using R programming language. Performance evaluation metrices (Section 5) are applied on each model. All experiments are executed for 500 repetitions to get unbiased results from each algorithm and mean and Standard Deviation (SD) of the error is calculated. Besides, we performed statistical tests, i.e., Welch’s
Where
Although with evaluation metrices, we have populated performance results of each ML model. To ensure if models results are statistically significant [21], we used Welch’s
Null hypothesis (H
Alternative hypothesis (H
This section discussed the experimental results after applying ML algorithms mentioned in Section 4.3 using TopCoder collected data.
Results of performance metrices evaluation
For all experiments, mean and standard deviation (SD) of each evaluation metrics (Section 5) are calculated, with 500 iterations of each experiment Table 8 shows the resulting means (
Results of ML algorithms applied to TopCoder dataset
Results of ML algorithms applied to TopCoder dataset
RMSE boxplot of ML models.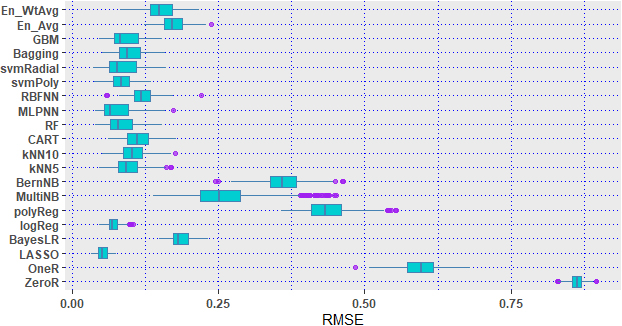
Welch 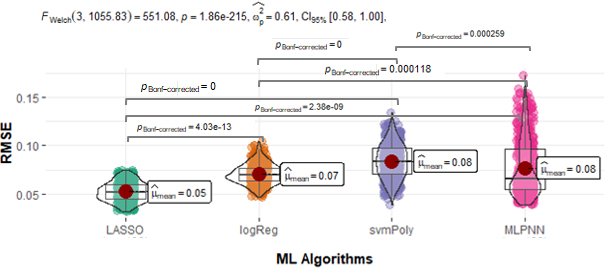
Analyzing the results obtained in Table 8, it is possible to conclude that estimation obtained from regression family (both linear and non-linear), NNet family and SVM family gained smallest number of errors in most of metrices. Figure 9 shows the boxplot graph with RMSE of each model, which represents those models like LASSO, BayesLR, SVM, HT, DT families and En_wtAvg are not showing outliers. It is possible to observe that Rule based models have overestimated the model while LASSO, logReg, kNN5, MLP and SVM family have shown relatively better performance. Besides, boxplot of LASSO and logReg are less distorted than those of the other models while MultiNB has shown larger amount of estimation outliers, influencing RMSE mean to higher end.
For As mentioned earlier, Welch’s
Models are significantly different if they show difference between their error means less than 0.05. The plot clearly depicts that LASSO and logReg are giving significantly good performance compared to MLPNN since
Results of Welch’s
-test for model significance
Results of Welch’s
Besides four best performing models, Welch’s
This study focuses on the fact that effort consumed on crowdsourced task is comparatively appropriate criteria for task selection rather than mere intuition. Work established vast range of TopCoder dataset feature covering major crowdsourced development aspect to estimate effort. Mostly dataset extracted in CSSD work have not performed any analysis to ensure whether the selection for attributes is justified in terms of statistical, regression and correlation measures. Section 4.2 clearly depicts that selected attributes for dataset possess model significance, regression, and correlation relationship with the output feature i.e., “Effort” making dataset more reliable for ML experimentation. Performing regression and correlation analysis further revealed which feature to focus on, for manipulating the effort. In our analysis, development type, assets available for the task and developer’s enhanced skill set are those domains which are influencing task effort the most.
The features identified for this study are independent from previous phases i.e., features related to software requirement specification and design (as included in previous studies [49]), for example, winner’s submission score attained in design phase, number of registrants and submissions in design phase, number of pages in requirement/component specification. Rather focus is made on just in-hand features, relevant to task characteristics, developer’s skill set and task artifacts.
Catering to the matter of accuracy in estimation, intelligent methods are known for their accurate and unbiased results. Furthermore, taking the opinion of multiple ML models is another way to achieve effort estimation accuracy. There is trend of utilizing ML for estimation in CSSD work (Table 1), but number of models used for estimation are not sufficient. This work incorporated 10 ML families with 2 algorithms each, hence total 20 models are trained on TopCoder extracted dataset (as mentioned in Table 7 Further, most of the past ML-based CSSD studies relied on only linear, tree based or neural network-based models. This wok shows, some algorithms which are not part of any estimation in previous CSSD work are also providing considerable performance, such as Bayesian Linear Regression, Polynomial Regression, Bernouli Naïve Bayes, Bagging, Gradient boosting machine, with RMSE values 0.186, 0.436, 0.360, 0.099 and 0.091 respectively.
Comparing our work with the initial study made on CSSD cost estimation by Mao et al. [49], ML models employed and their achieved performance in MMRE is as follows: SVMR (0.46), CART (0.216), Linear regression (0.279), Logistic regression (0.350), NNet (0.324) and kNN (0.397). Relevant models in our study achieved MMRE values as: svmRadial (0.045), svmPoly (0.050), CART (0.074), logReg (0.048), MLPNN (0.052), RBFNN (0.085, kNN5 (0.060), kNN10 (0.063). It is evident from the results; all models of this study have achieved 60% improved MMRE. This clearly shows careful and relevant features selection in dataset.
Threats to validity
This section presents threats to validity of the proposed study. For internal validity, several aspects need to be discussed, e.g., ML techniques to construct estimation model, choice of data transformation technique and parameter setting methods can be common threats to internal validity of ML based effort estimation.
For this study, a large variety of ML estimation techniques are applied to identify a relatively unbiased technique working for TopCoder CSSD platform. ML techniques in previous effort estimation work (Table 7) are also part of this study. However, there is a margin of testing other ML learners to verify if performance tends to improve. Further, ML learners are implemented under grid search-based parameter settings rather than assigning default values, providing more context-oriented results. However, grid search involves larger computation compared to other automated parameter tuning techniques i.e., swarm intelligence or evolutionary methods. Hence computation-effective solutions can be incorporated. Another internal validity threats can be found when effort drivers are indirectly related to the software efforts. In this work, input features included to construct dataset possess enough correlation with dependent feature (effort) in terms of Pearson correlation, hence suitability of dataset for applying supervised ML learning to predict effort is ensured.
External validity is determined by the extent to which the study’s conclusion can be generalized. ML algorithms and ensembles used in the study are implemented with parameter values coming from grid search tuning. For other datasets, additional parameter setting may be required for obtained optimum prediction model. Optimized parameter settings can be used to drive similar conclusions. In our work, effort estimation scheme is primarily designed for crowdsourced tasks, structured on the format followed by TopCoder platform. The dataset obtained for proposed scheme implementation is dependent on CSSD platform, i.e., features selected for each crowdsourced tasks can be found in tasks published on TopCoder. Execution of proposed scheme can be generalized for any other CSSD platform, using similar task posting mechanism like TopCoder. Moreover, this study mainly focuses on tasks from “TopCoder development category”. So, features selected for estimating effort are related to development/coding perspectives. For other TopCoder task categories (design, testing), different features set is needed.
Conclusion validity is achieved by measuring the degree to which the study’s conclusions are reasonable. We used the 10-fold CV method to confirm the ability of a ML models to predict new data. Furthermore, all experiments are executed with 500 repetitions for having enough iterations to conclude results. This procedure is adequate to prevent biasing the results and minimizes training sample dependences. Similarly, these redundant tests are carried out for performance metrices, ensuring no evaluation metric can bias the conclusion results.
Conclusion and future work
Effort estimation measures are crucial in crowdsourced task for a well-established CSSD platform like TopCoder, having thousands of clients and developers. Effort estimation can serve the basis of award money decision associated with each task. In this work an effort estimation framework is proposed for TopCoder CSSD platform facilitating both client and developer by analyzing the task in terms of effort.
The proposed framework includes three stages. Data from TopCoder development tasks is extracted including highly development-oriented features (Data acquisition stage). Data is prepared in terms of normality and
As future work, we aim to analyze other task categories on TopCoder platform i.e., software design and QA, to identify appropriate features relevant to software design and testing aspects. Furthermore, CSSD platforms apart from TopCoder will be explored for dataset preparation and establishing effort estimation model to verify generality of proposed scheme.