
Abstract
The quest for transparency in black-box models has gained significant momentum in recent years. In particular, discovering the underlying machine learning technique type (or model family) from the performance of a black-box model is a real important problem both for better understanding its behaviour and for developing strategies to attack it by exploiting the weaknesses intrinsic to the learning technique. In this paper, we tackle the challenging task of identifying which kind of machine learning model is behind the predictions when we interact with a black-box model. Our innovative method involves systematically querying a black-box model (oracle) to label an artificially generated dataset, which is then used to train different surrogate models using machine learning techniques from different families (each one trying to partially approximate the oracle’s behaviour). We present two approaches based on similarity measures, one selecting the most similar family and the other using a conveniently constructed meta-model. In both cases, we use both crisp and soft classifiers and their corresponding similarity metrics. By experimentally comparing all these methods, we gain valuable insights into the explanatory and predictive capabilities of our model family concept. This provides a deeper understanding of the black-box models and increases their transparency and interpretability, paving the way for more effective decision making.
Introduction
The increasing ubiquity of machine learning (ML) models in devices, applications, and assistants, which replace or complement human decision making, is prompting users and other interested parties to model what these ML models are able to do, where they fail, and whether they are vulnerable [1]. However, many ML models are proprietary or black-box, with their inner workings inaccessible to users for confidentiality and security reasons. This is the case of FICO or credit score models, health, car, or life insurance application models, IoT Systems Security, medical diagnoses, facial recognition systems, etc. While publicly available query interfaces provide access to these models, they can also be exploited by attackers who can use ML techniques to learn about the behaviour of the model by querying it with selected inputs. This raises the issue of adversarial machine learning [2, 3] where the model’s intrinsic flaws and vulnerabilities are exploited to evade detection or game the system. In such scenarios, the attacker can gain an advantage by knowing the ML family and the true data distribution used to generate the attacked model.
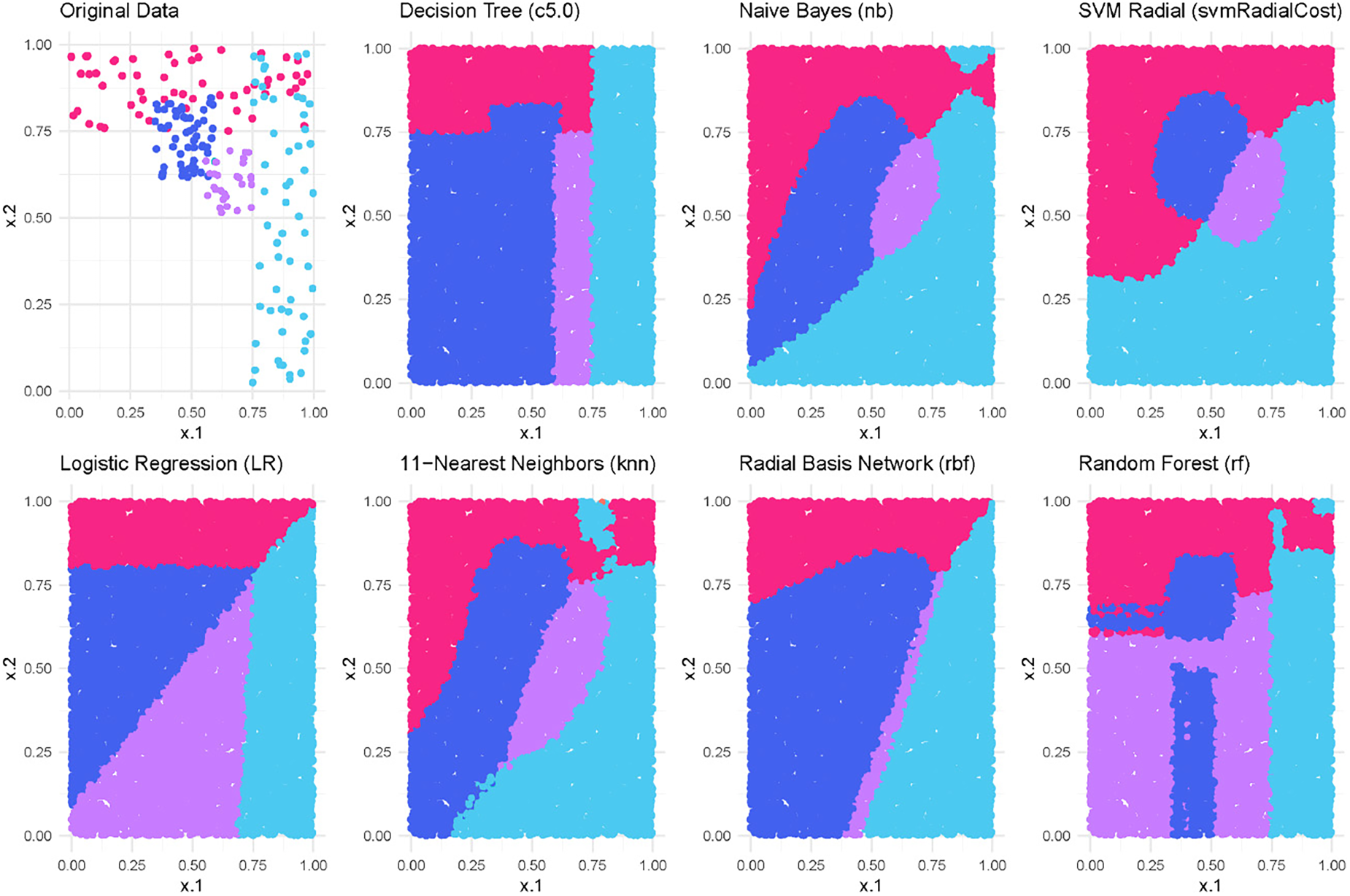
Behaviour of different models trained over the same four-class classification dataset (shown on the top-left plot). The pictures show the different prediction for particular class regions (known as decision boundaries) in dense and sparse areas.
One of the main reasons for not having general techniques for exploiting black-box models may be due to the intrinsic differences between ML techniques. Different models generated by specific machine learning techniques may differ not only in their decision boundaries, which are hypersurfaces that divide the input space into distinct classification regions, but also in their method of extrapolation in regions with few or no training examples. This is illustrated in Figure 1, where the top left plot shows the original training data of a bivariate dataset used to train several machine learning models using different techniques. The observation here is that all models show similar behaviour, i.e. they produce comparable partitions of the input space in densely populated zones where the training examples are located. However, their behaviour in areas with sparse or no training examples tends to be unpredictable and highly dependent on the specific ML technique employed. Recognising the distinctive decision-making characteristics of different ML families is fundamental to the aims of this paper [4, 5]. In particular, these less densely populated zones are more prone to error. Given the different ways in which different model families extrapolate within these sparse regions, specific strategies have been developed to attack, extract and steal machine learning models belonging to particular families, such as Support Vector Machines [6], (Deep) Neural Networks [7], Naive Bayes [8], and even various online prediction APIs [9]. Knowing the model’s family can thus help predict its vulnerabilities and promote more comprehensive defence strategies against adversarial attacks [10, 11].
ML family identification also holds importance across various domains that benefit from understanding model behaviour, especially in areas with sparse or no training data. This is particularly relevant for Open Set Recognition [12] and Novelty Detection [13], where the goal is to detect unseen classes or categories that were not present during the model’s training phase. Similarly, in outlier and anomaly detection [14, 15], identifying sparse classes within the training data is a major challenge. In addition, understanding the ML family is critical to meeting the legal and ethical requirements of AI deployment [16]. Knowledge of the ML family serves as a key measure of transparency, potentially satisfying regulatory requirements and preemptively addressing ethical concerns.
In this paper, we address the problem of experimentally determining the machine learning technique family that was used for training a model that is presented as a black-box model. Unveiling the family of a model, if possible, could be seen as the initial step for an adversarial learning procedure. Once we have some knowledge of the ML family used in the model, we can apply specific adversarial techniques tailored to that family, such as those mentioned above. Our aim is to address this issue in a realistic context where our ability to make queries is not unlimited, and we assume that we lack any information about the model, including the learning algorithm used for training, as well as the original data distribution. Our goal is not to duplicate the machine learning model or to identify the full hypersurface that divides the feature space. Instead, we seek to identify the specific machine learning technique by using queried input-output pairs. This technique should exhibit behaviour that closely mirrors the behaviour manifested by the black box model across the data space.
Our approach considers the black-box model as an oracle for labelling a synthetic dataset generated by following a specific query strategy. This approach is particularly useful when we have no information about the black-box model or its training data distribution, as is often the case in real-world applications. This artificial dataset serves as the basis for training different models, each of which uses different machine learning techniques from different learning families to approximate the behaviour of the oracle. These models are called surrogate models. We propose two methods to identify the ML family of the oracle based on the (dis)agreement between the decisions made by the oracle and each surrogate model. The first is the crisp scenario, where the oracle only provides the class label for each example. That is, it returns a qualitative value indicating the predicted class among the possible categories, without any additional information. This scenario includes all cases where the output of the oracle is strictly limited to these class labels. The second one is called the soft scenario, characterised by the fact that the oracle provides class probability estimates along with the class labels. These are essentially confidence scores for each class, adding a layer of quantitative judgement to the prediction. The soft scenario plays a key role in applications where it is essential to have predictions in the form of scores or probabilities rather than just class labels. Examples of such applications include weather forecasting [17, 18], where predictions may be accompanied by a percentage chance of occurrence; betting-based forecasting [19, 20], which relies on probability estimates to make decisions; or sentiment analysis tools [21, 22], which quantify the sentiment expressed in text data. These scenarios require a more nuanced understanding of predictions, making the soft scenario particularly relevant.
The structure of our paper is as follows. Section 2 provides a brief overview of related work. In Section 3, we present our approach for predicting the ML family of a black-box model. The experimental evaluation is discussed in Section 4. Lastly, we conclude our paper in Section 5, where we summarize our findings and outline directions for future research.
In this section, we review the literature related to the learning from queries labelled by an oracle (human or ML model) and approaches to interpretable machine learning that rely on learning a substitute model for explaining the decisions of any model.
There is extensive literature on the topic of learning from queries labelled by an oracle or an expert. Examples can be found in the fields of learning theory [23, 24], concept learning [25, 26, 27], learning of regular sets [25], and active learning [28, 29]. In all these cases, it is assumed that the information about the data distribution is given in order to generate the queries about the concept to be learned.
The area of adversarial machine learning [30, 31, 32, 33]has addressed the task of learning from queries labelled by a model (the oracle) but with the aim of attacking it [34]. Thus, the queries are used to capture information about the decision layouts of the model to be attacked trying to discover its vulnerabilities. To this aim, several specific query strategies exist depending on the type of model to be attacked, for instance, support vector machines [6], or deep neural networks [7, 35, 36, 37, 38].
Different query-based methods have been introduced to explain and replicate the behaviour of an incomprehensible model. A simple way to capture the semantics of a black-box ML model consists of mimicking it to obtain an equivalent one. This can be done by considering the model as an oracle and querying it with new synthetic input examples (queries) that are then labelled by the oracle and used for learning a new declarative model (the mimic model) that imitates the behaviour of the original one. Domingos et al. [39] addressed this problem by creating a comprehensible mimetic model (decision trees) from an ensemble method. Blanco-Vega et al. analysed the effect of the size of the artificial dataset in the quality of the replica and the effect of pruning the mimetic model (a decision tree) on its comprehensibility [40], developing also an MML-based strategy [41] to minimise the number of queries. Papernot et al. [10] also applied a mimicking strategy but for adversarial purposes. The idea is to create a replica of the original black-box model aiming at crafting examples on the basis that the examples that affect one model also affect any other model trained for the same task. More recently, Yang et al. [42] presented a query black-box based attack method that adapts the surrogate model by constructing a high-gradient computation graph, in order to approximate the surrogate model to the oracle model, in both forward and backward pass.
Another related area is ‘interpretable machine learning’ [4] (or the broader ‘explainable AI’, XAI [43]) which aims at making machine learning models and their decisions more interpretable. In this field, black-box models are described by considering aspects like feature importance, accumulated local effects, or addressing the justification of individual predictions. A popular work is LIME [44], a technique that explains a prediction of any classifier by learning an interpretable linear model locally around the prediction. Similarly, LORE [45] explains specific predictions of a classifier by learning an interpretable model locally to the instance, providing a rule and a set of counterfactual rules. Recently, Maaroof et al. [46] extended the LORE method to explain the decisions of multi-class fuzzy-based classifers.
Our proposal differs from the previous approaches in that we do not aim to replicate the black-box model, nor to determine the full decision boundary that partitions the feature space. Instead, our focus is on identifying important features of the model, such as its ML family, which can serve as a crucial first step before applying more specific adversarial techniques. To achieve this goal, we treat the black-box model as an oracle and generate a set of synthetic input examples to be labelled by the oracle. Our approach also differs from the traditional mimetic method in that we use the labelled artificially-generated input examples (by assuming no prior knowledge of the original model or training data) to train multiple surrogate models using different ML techniques with the aim of approximating the behaviour of the black-box model. By comparing the decisions made by the oracle and each surrogate model, we can identify the ML family of the black box model. This approach is particularly useful in scenarios where the original model is proprietary or confidential, and there is no access to information about the learning algorithm or the original data distribution. Another approach also based on the idea of using examples labelled by a black-box model to discover some of its proprietary properties has been explored in [47], but with the goal of finding out some properties of neural networks such as the type of activation, the optimisation process and the training data.
Model family identification
As we discussed in Section 1, the behaviour of a model depends on, among other factors, the ML technique applied to learn the model. Hence, one way of determining the ML family of a black-box model could be to mimic it trying to approximate the nature of the decision boundaries. One way of doing this is to create different surrogate models using techniques from different learning families and input-output pairs generated by the original black-box model as an oracle. We can then compare the decisions made by each surrogate model with those made by the original oracle, using an appropriate measure of agreement/discrepancy or disagreement.
Generating surrogate models
A black-box model can act as an oracle, denoted
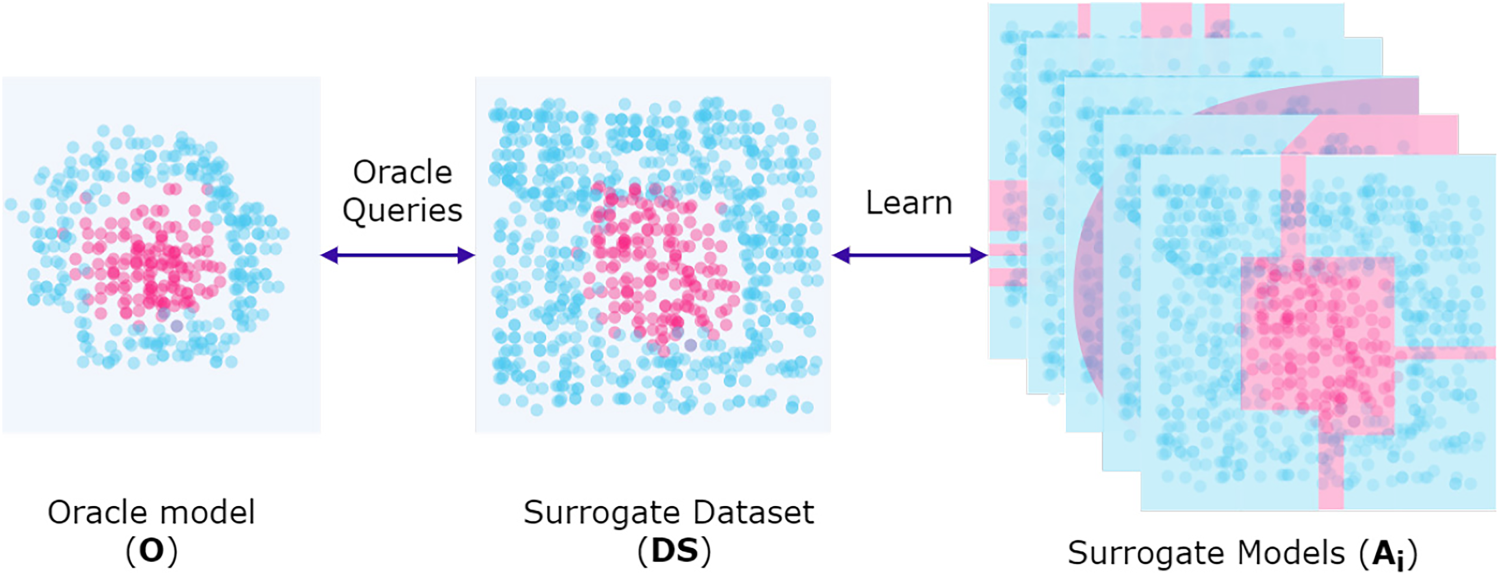
A black-box model (oracle) trained on an unknown original dataset acts as a source of labels for synthetic surrogate datasets. These synthetic datasets are generated by following specific query strategies designed to capture the decision-making process of the black-box model. The surrogate dataset (SD) is then used to train multiple surrogate models, each using a different machine learning technique. The goal is to approximate the behaviour of the black-box model without having access to its original data distribution or the specific learning algorithm used to train it.
The generation of synthetic examples to interrogate the black box model
The artificial inputs, paired with the class labels predicted by
To identify the family of the oracle, it is necessary to use evaluation measures that estimate the similarity between the surrogate models and the oracle with respect to a given dataset. In the case of the crisp scenario, where the classifiers predict class labels, Cohen’s kappa coefficient (
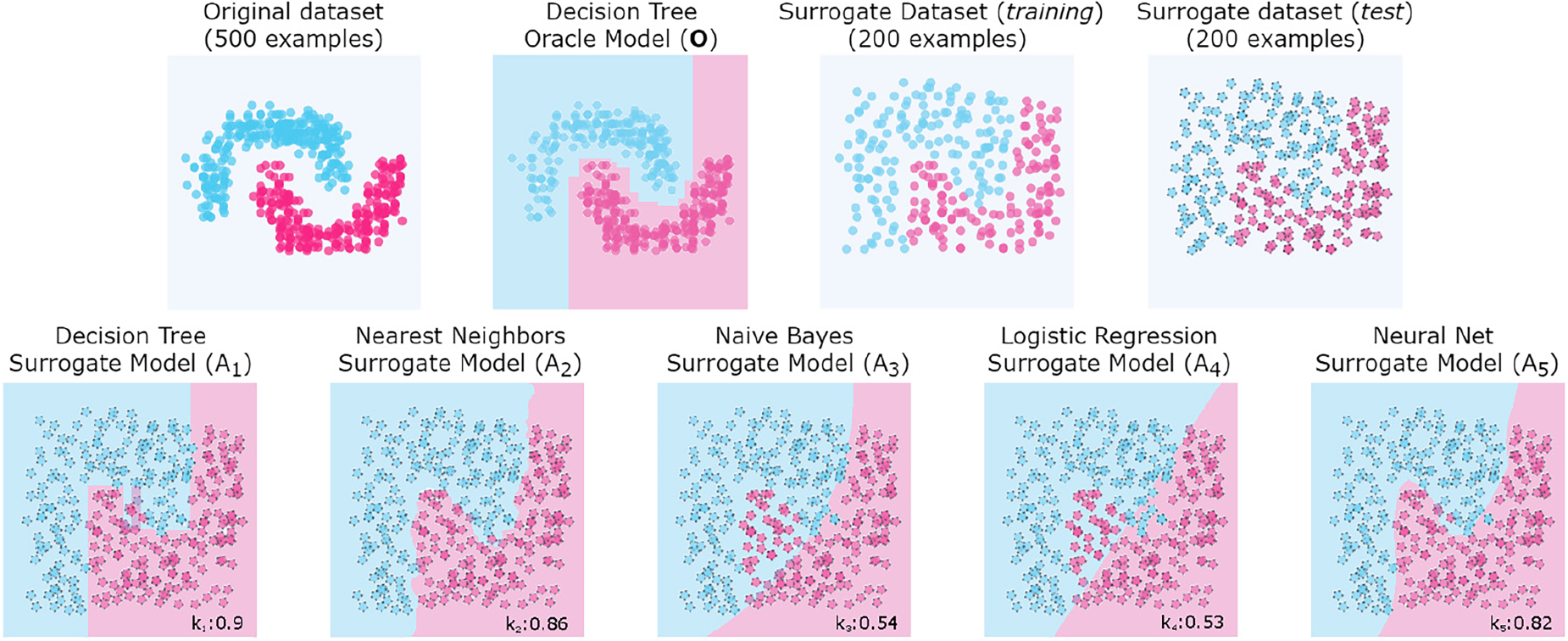
Synthetic example to show the
At the top of the Figure 3 we see (from left to right) the original dataset, the oracle model
As mentioned above, the way different families of models extrapolate decision boundaries can vary significantly depending on several factors, such as overfitting, underfitting or generalisation. In addition, such factors depend on the characteristics of the original dataset, such as noise, sparsity, or separability. For example, logistic regression and Naïve Bayes models can produce similar decision bounds for a linearly separable dataset. However, if the dataset is not linearly separable (as shown in Figure 3), other learning techniques can produce similar boundaries, such as decision trees, nearest neighbours, and even neural networks. However, we have no prior knowledge of the original dataset used to train the oracle. We do not know the sparsity, separability, or any other property that might be relevant to accurately identify the family of models. Hence, it is convenient to compare the behaviour of the oracle with a variety of surrogate models from different learning families to increase the likelihood of correctly identifying the original model family.
In the example in Figure 3, we observed that the family of the oracle model
Crisp classifiers
In the scenario where both the oracle and the surrogate models are crisp classifiers, identifying the ML family of the oracle is relatively straightforward. We first evaluate the surrogate dataset SD with the different surrogate models

In the scenario where the oracle and surrogate models are soft classifiers, we cannot use Cohen’s kappa metric because it is only applicable to crisp classifiers. Instead, we need to measure the difference between the class probability vectors estimated by
To quantify the similarity in behaviour between
Therefore, we adopt the maximum similarity approach, which consists of calculating the negative value of the mean L1-norm of each surrogate model on the dataset SD, denoted as

It is important to note that the difference between the crisp and soft scenarios lies in the similarity measure:
A more sophisticated approach is to use a meta-model to predict the family of a black-box model. In the meta-similarity approach, the goal is to extract internal information about the family of a black-box model from the surrogate models. To achieve this, a meta-model is learned to predict the ML family of an oracle using a set of meta-features that abstractly describe the oracle based on the
To train the meta-model, we consider that from an original labelled dataset
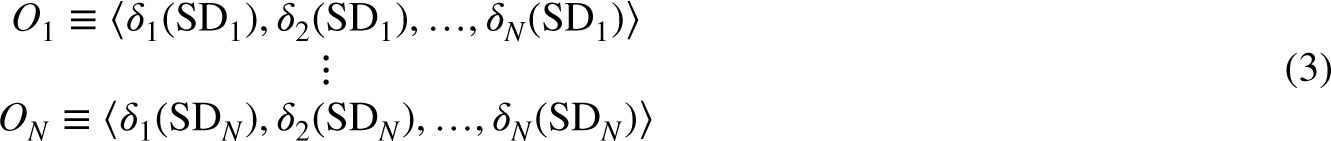
By applying this procedure to a set of
This section describes the experiments carried out to evaluate the proposed family identification methods (For the sake of reproducibility and replicability, all the experiments, code, data and plots can be found at
List of ML families, their representative algorithm, the hyperparameters used and the R package and method used. The ML families are: Discriminant Analysis (DA), Ensembles (EN), Decision Trees (DT), Support Vector Machines (SVM), Neural Networks (NNET), Naïve Bayes (NB), Nearest Neighbours (NN), Generalized Linear Models (GLM), Partial Least Squares and Regression (PLSR), Logistic and Multinomial Regression (LMR), and Multivariate Adaptive Regression Splines (MARS).
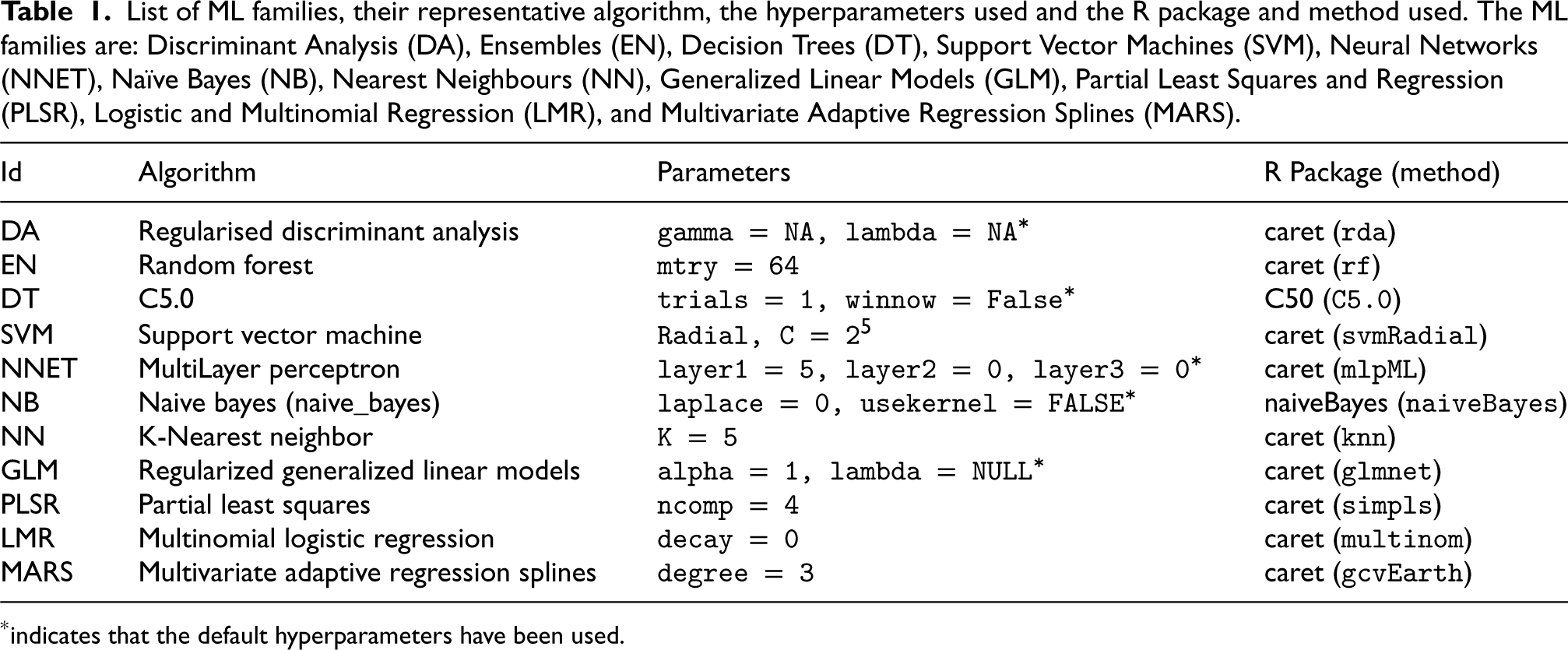
List of ML families, their representative algorithm, the hyperparameters used and the R package and method used. The ML families are: Discriminant Analysis (DA), Ensembles (EN), Decision Trees (DT), Support Vector Machines (SVM), Neural Networks (NNET), Naïve Bayes (NB), Nearest Neighbours (NN), Generalized Linear Models (GLM), Partial Least Squares and Regression (PLSR), Logistic and Multinomial Regression (LMR), and Multivariate Adaptive Regression Splines (MARS).
*indicates that the default hyperparameters have been used.
Characteristics of the 25 datasets from the
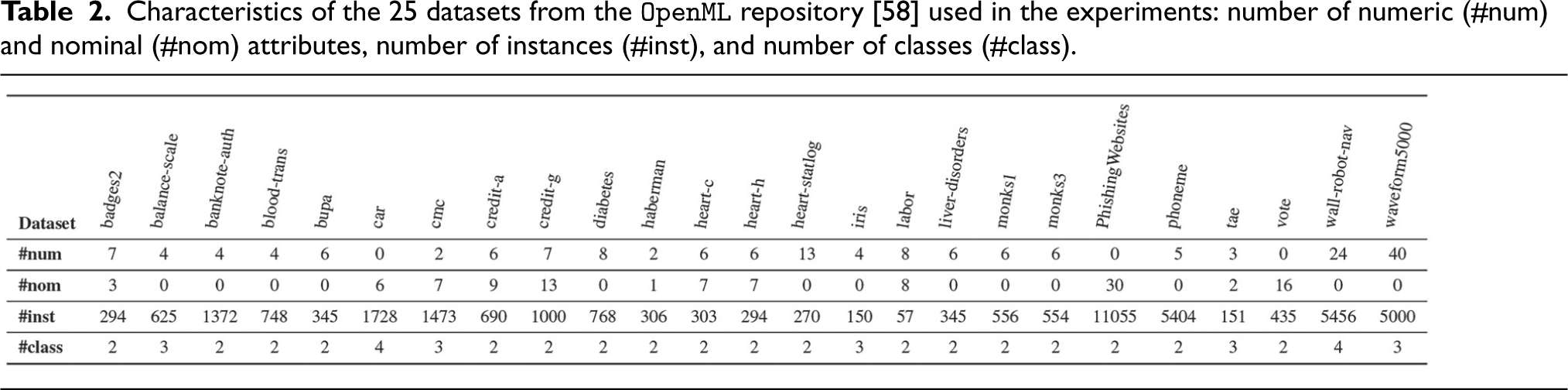
For the experiments, we have selected a set of machine learning techniques that are commonly used in practice and are typically grouped into families based on their formulation and learning strategy, as documented in [54, 55, 56, 57]. Specifically, we considered
For each dataset, we trained
To evaluate each surrogate model
Confusion matrices (actual class in rows vs. predicted class in columns) showing the results for the Maximum Similarity approach evaluated for two different scenarios. The matrix on the top corresponds to the crisp scenario, where the
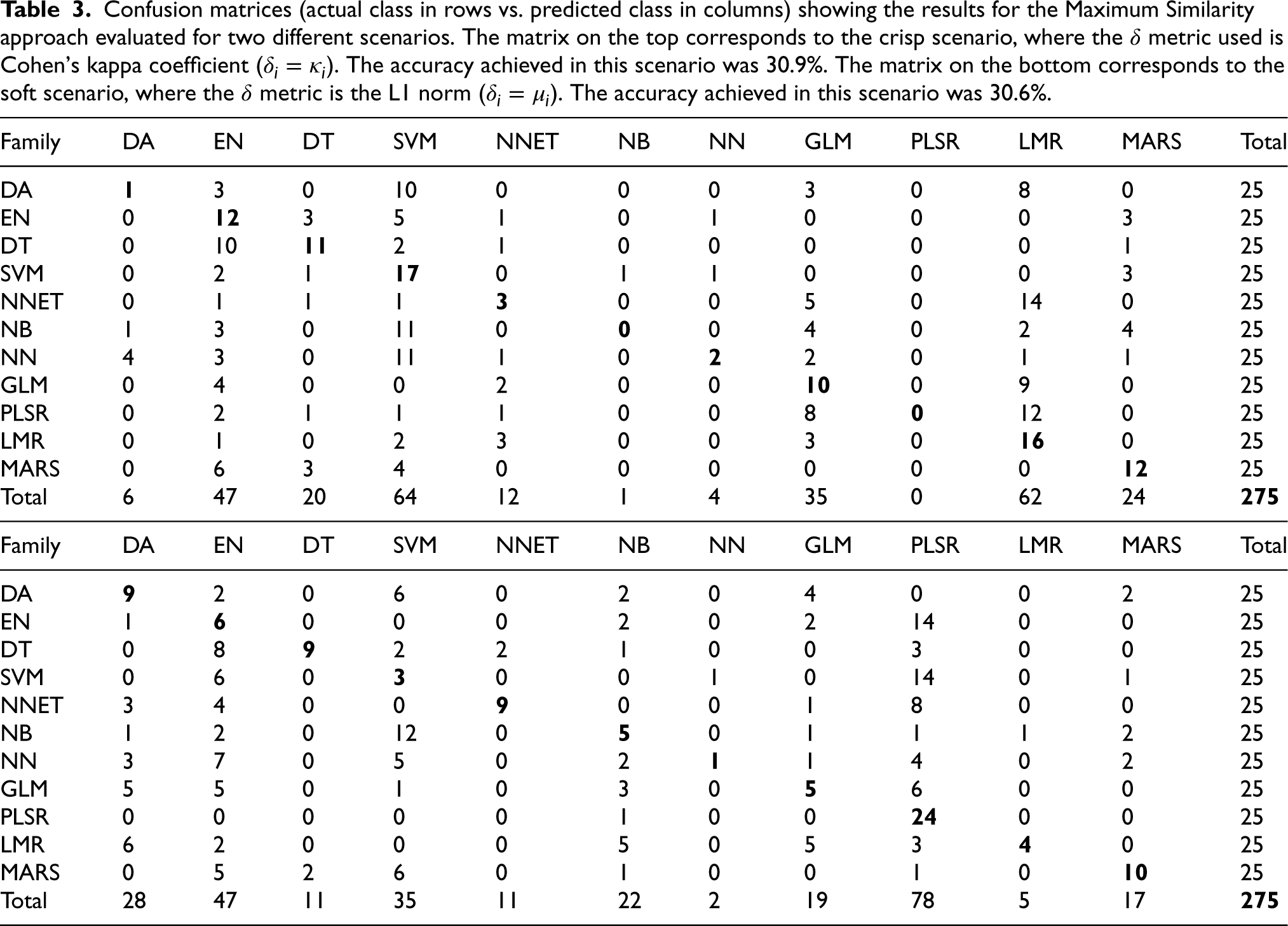
Table 3 shows the confusion matrices for the experiments using the Maximum Similarity approach. In the crisp scenario (as shown in the top matrix of Table 3), we observed that the SVM and LMR families had the highest number of positive identifications, with 17 (68%) and 16 (64%) correct identifications, respectively. The MARS and EN families followed closely with 12 correct identifications each (48% success rate). However, there were some families for which the maximum similarity approach performed very poorly, such as PLSR and NB, for which none of the models predicted correctly. In addition, the DA, NN and NNET families had only 1, 2 and 3 correct identifications, respectively. Most of these families were highly confused with SVM and LMR, and sometimes with GLM (mainly PLSR, NB, and NNET). We also noticed that GLM was often confused with LMR, with 9 incorrect identifications, and DT was confused with EN 10 times. Looking at the predicted family column, we observed that the models with the highest positive identifications (SVM, LMR, MARS, and EN) tended to be over-predicted, i.e. many of the other families were strongly confused with them. Conversely, the poorest performing families (PLSR, NB and NN) tended to be under-predicted, i.e. almost no correct or incorrect identifications were made for these families. In summary, the maximum similarity approach achieved an overall accuracy of 30.6% in the crisp scenario.
In the soft scenario (bottom matrix in Table 3), the PLSR family achieves the best results with 24 correct identifications (96%), followed by MARS with 10 correct identifications (40%). Other families such as NNET, DT and DA achieve similar results with 9 correct identifications each. However, PLSR tends to be over-predicted as many other families are often confused with it. The families with the fewest correct identifications are NN with only 1 correct identification, followed by SVM with 3 correct identifications, and LMR, NB and GLM with 4, 5 and 5 correct identifications respectively. NN is most often confused with EN with 7 incorrect identifications, but also with SVM with 5 incorrect identifications. The EN and SVM families are strongly confused with PLSR with 14 incorrect identifications. Similarly, the NNET family is often confused with PLSR with 8 false identifications. The LMR family tends to be confused with DA, NB and GLM. The GLM family is mainly confused with PLSR, DA and EN. In this scenario, the overall accuracy of the maximum similarity approach was 30.9%, almost identical to that obtained in the crisp scenario.
The results of our experiments suggest that the decision boundaries between machine learning families may not be clearly defined. Despite its limitations, our maximum similarity method significantly outperforms the results of a random baseline, which would predict an accuracy of around 9%. This superior performance highlights the effectiveness of the dissimilarity measures we use, allowing us to effectively extract and use relevant information from the model’s responses, thus providing an informed approach to model family identification. Interestingly, we obtained a very similar overall accuracy for both the crisp and soft scenarios, with values of 30.6% and 30.9% respectively. However, the families that were correctly identified in both scenarios were quite different, as can be seen from Table 3 (top and bottom). This suggests that, depending on the type of predictions provided (class labels vs. class conditional probabilities), some ML families may be easier to identify than others. Overall, our results suggest that the problem of identifying the model family of a black-box model is not trivial, but our maximum similarity approach is a promising starting point.
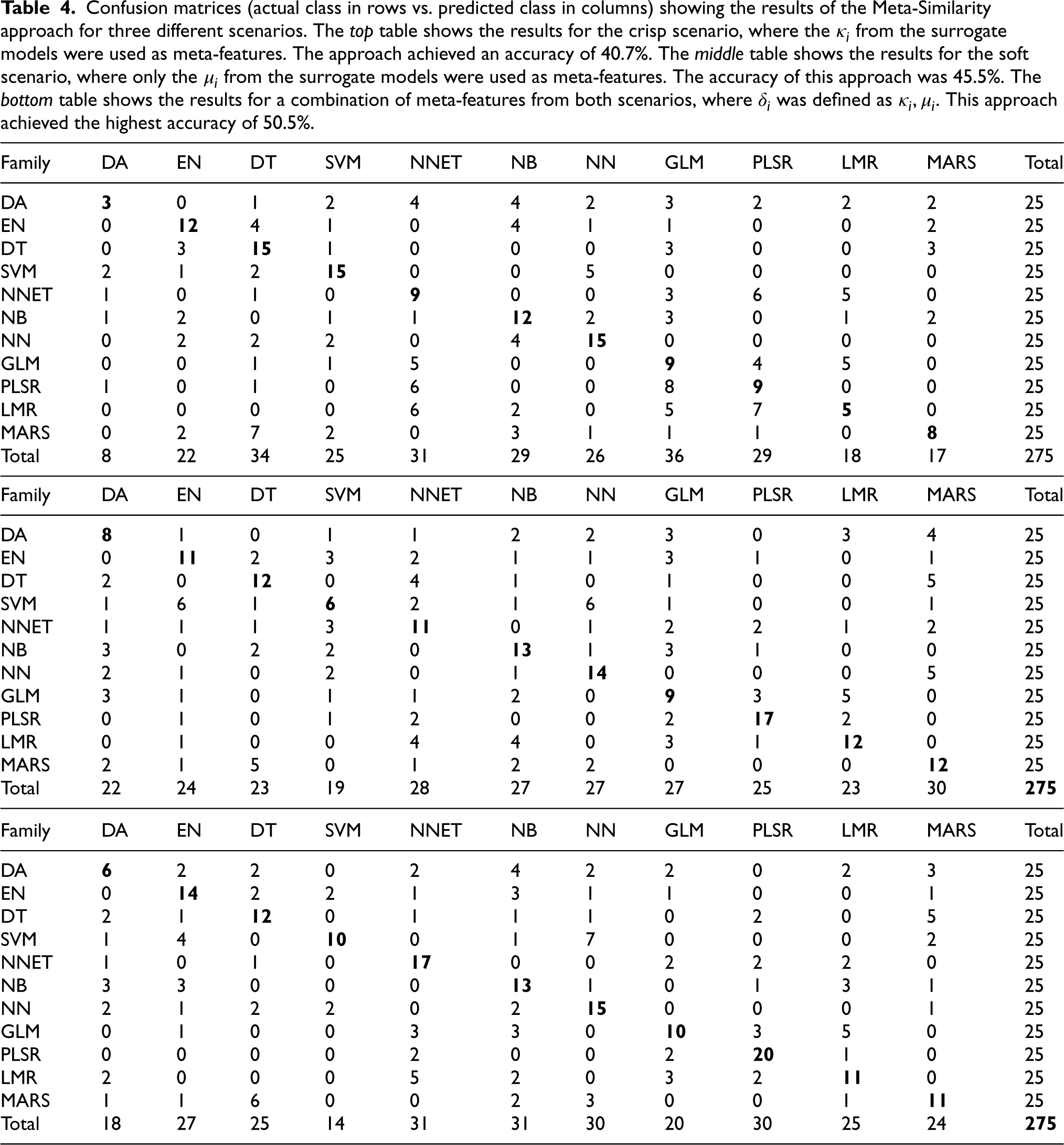
Confusion matrices (actual class in rows vs. predicted class in columns) showing the results of the Meta-Similarity approach for three different scenarios. The top table shows the results for the crisp scenario, where the
from the surrogate models were used as meta-features. The approach achieved an accuracy of 40.7%. The middle table shows the results for the soft scenario, where only the
from the surrogate models were used as meta-features. The accuracy of this approach was 45.5%. The bottom table shows the results for a combination of meta-features from both scenarios, where
was defined as
. This approach achieved the highest accuracy of 50.5%.
Confusion matrices (actual class in rows vs. predicted class in columns) showing the results of the Meta-Similarity approach for three different scenarios. The top table shows the results for the crisp scenario, where the
The confusion matrix for the meta-similarity approach in the crisp scenario is shown in Table 4 on the top. The results show an improvement over the maximum similarity approach, with an overall accuracy of 40.7% (compared to 30.6% obtained by the maximum similarity approach in the crisp scenario). We can see that SVM, DT and NN are now the easiest family to identify, with 15 correct identifications (60%), followed by EN and NB with 12 correct identifications (48%). On the other hand, DA and LMR families were the most difficult to identify, with 3 and 5 correct identifications, respectively. In terms of confusion patterns, SVM is confused mainly with NN and sometimes with DA, DT and EN. DT is confused with EN, GLM and MARS. The NN family is confused with NB principally, but also with EN, DT and SVM. DA is frequently misclassified as NNET and NB, but also with other models. The LMR model is mainly confused with PLSR, NNET and GLM, while GLM is often confused with LMR, NNET and PLSR. PLSR is mainly confused with GLM, and NNET. In addition, MARS is confused with DT. Overall, we can see that some families have significantly improved results compared to the maximum similarity approach, such as NN, NB, PLSR and NNET. However, the LMR and MARS families present worse results in the meta-similarity approach. SVM and GLM families have slightly worse results in the meta-similarity approach.
The Table 4 on the middle shows the results of the meta-similarity approach for the soft scenario. Using the meta-features based on the
In line with the results obtained using the maximum similarity approach, the meta-similarity approach shows that the effectiveness of ML family identification is largely influenced by the metric used for evaluation. This suggests that a hybrid approach that integrates the information from both similarity measures,
As expected, we observed that the overall accuracy of the hybrid approach is the best of all the proposed approaches, achieving an accuracy of 50.5%. This approach also shows similar or improved identification results for most of the families compared to the previous meta-similarity approaches. For example, the EN, NNET, NB, NN and GLM families show 14, 17, 13, 15 and 10 correct identifications respectively, which is an improvement compared to the results obtained by the previous approaches. The SVM and LMR families obtain better results in the crisp scenario with the maximum-similarity approach (17 and 16, respectively). The identification of other families remains unchanged or slightly lower than the best result, such as DT, PLSR and MARS. However, DA emerges as the most difficult family to identify, with only 6 correct identifications. In addition, all the approaches provide poorer results in regard to the identification of this family.
The overall results of our experiments suggest that identifying the ML families of black-box models is a challenging but promising approach. The use of dissimilarity measures based on predicted class labels or class conditional probabilities has proven to be effective in identifying ML families with a reasonable degree of accuracy. It is important to note that the complexity of the family identification problem is due to the fact that many ML families share similar characteristics and decision boundaries. Therefore, it is difficult to find clear differences between them that allow for straightforward identification. This complexity is also reflected in the fact that the best performing approach varies depending on the evaluation metric used (i.e.
Conclusions and future work
This work addresses the problem of identifying the model family of a black-box learning model. For this purpose, we propose two approaches based on dissimilarity measures
The experiments conducted in this study show that the first proposed approach for identifying ML families, based on
To enhance the performance of our meta-model-based approach for identifying the family of black-box learning models, we plan to investigate the use of additional measures of model divergence and diversity as meta-features. For example, measures such as Bhattacharyya distance [60], Jaccard similarity coefficient [61] and Tanimoto distance [62] have been proposed in the literature to compare probability density functions [63] and could be explored to capture different aspects of model dissimilarity. In addition to our focus on operational efficiency and effectiveness, we are also interested in exploring alternative query strategies for generating surrogate datasets. For example, Latin Hypercube [64], Centroidal Voronoi Tessellation [65] and Sobol [66] sampling approaches are promising alternatives that could improve the representativeness of surrogate datasets and increase the accuracy of the model identification process.
Footnotes
Acknowledgments
This work has been partially supported by the grant CIPROM/2022/6 funded by Generalitat Valenciana, the MIT-Spain – INDITEX Sustainability Seed Fund under project COST-OMIZE, the grant PID2021-122830OB-C42 funded by MCIN/AEI/10.13039/501100011033 and ERDF A way of making Europe, EU’s Horizon 2020 research and innovation programme under grant agreement No. 952215 (TAILOR).
Appendix A. Study of the impact of the surrogate dataset size
Generating the surrogate dataset SD is a crucial step in identifying the model family, and our approach for generating SD follows a simple strategy of employing a uniform distribution for each feature. This is because we treat the oracle as a black-box model, meaning that we have no knowledge of the training data it used. Therefore, we cannot use any information from the training data, such as data sparsity, separability, or attribute correlations, to guide the generation of the surrogate dataset.
The size of the surrogate dataset is thus a decisive aspect of our methodology, as it is the basis for learning and evaluating the surrogate models. In this sense, we conducted an illustrative experimental study to observe how the size of the dataset affects the accuracy of the family identification task. The method we followed is similar to that described in Section 3.1, where we generate oracles and their corresponding surrogate models, but we varied the size of the surrogate dataset. Specifically, we computed the size of the surrogate dataset as
To evaluate the impact of the size factor (
It might seem that a larger SD would provide more information, leading to better accuracy in model family identification. However, in our simple experiment we observed that the maximum accuracy for family identification was achieved when using a
Appendix B. Exploration of the Meta-model hyperparameters
Our meta-model, a Random Forest algorithm [59], gives us the opportunity to tune its hyper-parameters. This allows us to delve deeper into the task of identifying model families and the different representations for each scenario. By performing a grid search and cross-validation to find the best hyperparameters, first, we adjusted the number of trees in the meta-model (NT), ranging from 1 to 1024. This variation helped us to assess the complexity inherent in the datasets of meta-features created using
The variations in these two parameters highlight interesting aspects of the identification of model families using a meta-similarity approach. In the crisp scenario, optimal performance was achieved with 64 trees, indicating that additional trees up to 1024 do not significantly improve the accuracy of the meta-model. This implies that the meta-features in the crisp scenario provide a simple representation, achieving an accuracy of 40.7% with these features alone. For the soft scenario, at least 128 trees were required to achieve maximum accuracy, suggesting a more complex set of features. Combining both meta-features required 256 trees for maximum accuracy.
Looking at the ’number of features’ parameter, it is clear that not all available features were used to achieve maximum accuracy in all scenarios; 7 out of 11 features for the crisp scenario, 10 out of 11 for the soft scenario, and 18 out of 22 for the hybrid scenario. This suggests the presence of redundant meta-features, probably generated by closely related model families. This is shown in more detail in Appendix Figure B1: the most relevant features used in the hybrid approach are also the most used within their individual methods. Interestingly, both the hybrid and crisp methods exclude the same meta-features related to kappa values for classifiers such as DA, MLP, NB and PLSR. The soft method, on the other hand, only excludes SVM. Decision trees (DT) and generalised linear models (GLM) emerge as significant in all three methods. While NB, PLSR and DA are considered less significant in the crisp method, it is noteworthy that they are in the top five in both the soft and hybrid approaches. However, neural networks (NNET) and SVM consistently show low relevance, either not being selected at all or being selected last, indicating their limited utility in family identification tasks.
Overall, the meta-features of the crisp scenario, which require fewer trees for optimal performance, show simpler patterns. In contrast, the meta-features of the hybrid approach, which require more trees for peak accuracy, offer a more complex representation. Simpler representations require fewer features for higher accuracy.