Abstract
Crises such as natural disasters and public health emergencies generate vast amounts of text data, making it challenging to classify the information into relevant categories. Acquiring expert-labeled data for such scenarios can be difficult, leading to limited training datasets for text classification by fine-tuning BERT-like models. Unfortunately, traditional data augmentation techniques only slightly improve F1-scores. How can data augmentation be used to obtain better results in this applied domain? In this paper, using neural network explicability methods, we aim to highlight that fine-tuned BERT-like models on crisis corpora give too much importance to spatial information to make their predictions. This overfitting of spatial information limits their ability to generalize especially when the event which occurs in a place has evolved and changed since the training dataset has been built. To reduce this bias, we propose GeoNLPlify,1 a novel data augmentation technique that leverages spatial information to generate new labeled data for text classification related to crises. Our approach aims to address overfitting without necessitating modifications to the underlying model architecture, distinguishing it from other prevalent methods employed to combat overfitting. Our results show that GeoNLPlify significantly improves F1-scores, demonstrating the potential of the spatial information for data augmentation for crisis-related text classification tasks. In order to evaluate the contribution of our method, GeoNLPlify is applied to three public datasets (PADI-web, CrisisNLP and SST2) and compared with classical natural language processing data augmentations.
Introduction
Environmental degradation and the increasing effects of climate change are causing an augmentation of the number of disasters and their impacts [1]. The combination of disasters aggravates crisis situations. Monitoring the evolution of crises is therefore a major challenge to help those affected. Social and press media can fulfill this role since they can provide information that can assist with disaster response efforts. Indeed, they offer the potential to retrieve valuable information for reporting local crisis situations, such as identifying individuals who are still in danger or volunteers who offer help and shelter [2, 3]. In order to enable better management of these situations, it is necessary to use efficient data analysis methods using natural language processing (NLP). The problem we face is the limited labeled data available. In particular, for health crises, the rarity and nonsimilarity of events are important [4]. Even by applying adaptation methods to the crisis domain [5], no satisfactory solution exists.
At the same time, as NLP has been revolutionized by the rise of language models (LMs), this study aims to enhance the performance of these methods for crisis-related situations. These models, based on attention mechanisms [6], have given pride to very large datasets. Even if LMs are intended to be used in transfer learning downstream tasks using a smaller corpus, they still need a sizeable dataset [7]. How can these major advancements be beneficial when working on a small corpus? Borrowed from the computer vision field, different data augmentation techniques have been developed in NLP [8]. The objective is to improve the performance of a text classification model by artificially generating new labeled data to increase the training corpus size. These methods work at multiple textual levels: sentence level, word level, and character level. At the sentence level, methods such as back-translation, text paraphrasing, and sentence shuffling are employed to generate diverse instances by manipulating the order and structure of sentences. Word-level augmentations involve word substitution, where synonyms or semantically similar words replace existing words in the text. Additionally, contextual word replacement techniques utilize surrounding context with language models to generate alternative words. At the character level, noise injection methods introduce random perturbations by adding, removing, or modifying characters in the text. However, several approaches are ineffective when using LM because they are invariant to various transformations [9], such as replacing letters in words or predicting self-masked words in documents. As manually annotated data by humans are too expensive, the goal is to find new data augmentation methods that have a positive impact on LM classifiers for crisis monitoring.
In this paper, we present an analysis of the outcomes obtained from employing a deep learning explanation method [10] on a fine-tuned language model. Our investigation reveals that fine-tuned BERT-like models exhibit a propensity for overfitting on spatial information when trained on crisis corpora. Since the majority of documents in crisis corpora mention a location (such as a country, a city or a place name where an event takes place), models tend to associate certain locations with labels. Indeed, for example, if its training dataset a model learned that Pakistan is associated with flood, it may misclassify other events occurring in Pakistan.
Our hypothesis [11] is that BERT-like fine-tuned models overfit on spatial information in this context. Among all the methods to reduce overfitting, only data augmentation does not change the model architecture. Indeed, different regularization methods exist such as dropout (randomly deactivates some neurons) or L2 (reduces the weights of neurons when these are too high compared to the others). The model we use in this paper, RoBERTA, already includes these regularization mechanisms, leading us to focus on data augmentation. To do this, we aim to create variations of the original documents by replacing the locations mentioned in texts. This helps to expand the model’s exposure to different variations of geographical entity names, reducing the overfitting on pairs of places and labels encountered in the training dataset and increasing the model’s generalizability to new examples. By employing this approach, the model is guided to redirect its attention towards the non-spatial words present in the document, thereby enhancing their significance in the overall attention mechanism. This approach can lead to an effective data augmentation with a strong quality of the artificially labeled data and reduce this geographical overfitting. Thus, we introduce GeoNLPlify, a new approach that integrates three data augmentation techniques based on the spatial information contained in texts. GeoNLPlify has a positive impact on the performance of LM classifiers.
GeoNLPlify detects location mentions with Spacy and then geocodes them using OpenStreetMap data. Finally, GeoNLPlify proposes to replace these places with others (either at the same spatial level or by zooming in or out) in order to create artificially labeled documents.
To evaluate the GeoNLPlify impact on the spatial overfitting reduction, we apply it to three datasets. The first two are directly related to crises since the first, PADI-web [12],2 deals with epidemiological crises in animal health and the second, crisisNLP [13],3 with natural disasters. The last one, SST2 [14],4 does not focus on disasters at all but on sentiment analysis in film reviews. It, therefore, allows us to evaluate the contribution of GeoNLPlify when spatial overfitting is not observed. For all these datasets, we compare GeoNLPlify with two state-of-the-art NLP data augmentation provided by nlpaug [15] by substituting words with (i) WordNet (nlpaug_synonym) [16] and (ii) contextual embedding (nlpaug_contextual_embedding) [17].
To sum up, this article proposes two main contributions: (i) We demonstrate that BERT-like models overfit on spatial information in the context of crises and (ii) Our method, GeoNPLlify, is effective to reduce this bias.
In the following of this paper, we will provide an overview of related work in the field of data augmentation in Section 2. Our proposed methods, detailed in Section 3, will demonstrate that BERT-like models overfit on spatial information and the using of GeoNLPlify reduces this bias. Section 4 will describe, in details, the experimental framework and provide the results of the benchmark comparison of several data augmentations on three public datasets. In the Discussion Section 5, we will interpret the results to better understand why GeoNLPlify performs so well on crisis-related corpora, but also to identify if there are new potential sources of bias when using our method. Finally, the Conclusion Section 6 will summarize our findings and recommendations for future work.
Related work
The natural language processing (NLP) domain has been significantly improved by the emergence of language models (LMs). Several models have been trained and made available, such as BERT [18] and RoBERTa [19]. The strength of these approaches, in addition to the quality of their deep learning architecture, relies on pre-training, which requires very large datasets. These models are nonspecific and can be specialized or fine-tuned to a particular domain, such as crisis management [2], which is of interest to us in this study. Unfortunately, this field struggles with a lack of data [20], also called a low data regime (
To overcome this issue, manually labeled datasets must be enlarged. The first way is to ask experts to manually label new data. However, these processes are unfortunately not always possible due to the cost, nonavailability of experts and time needed [21]. The other way is to artificially create new labeled data. Different semisupervised training can be applied [22] to unlabeled data. They can be based on heuristics (for example, in sentiment classification, if an unlabeled document contains words, such as “cry” or “sadness”, the pseudo label can be artificially set as negative) [22], but these kinds of rules are not easily findable. Another way is to train a second model that will generate, by inferring from unlabeled data, reliable pseudo labels [23]. The text classifier model is then trained on the labeled and pseudo-labeled data. Other methods propose using a single model that will be interrupted in its training to infer (with the current weights of the model) unlabeled data [24, 23]. Two limitations can be opposed to these approaches. The first is to overrepresent the data for which the classification is simple, and the other is to take the risk of generating incorrect pseudo-labels.
In contrast to these previous methods, data augmentation (DA) does not operate on unlabeled data to artificially generated pseudo labels. The objective is to make some variations of labeled data to generate new labeled data while guaranteeing the quality of the annotations. Although DA is very popular in computer vision, it is difficult to apply it in NLP due to the data complexity [21]. However, several DA strategies have been provided by the community. Easy data augmentation [25] aims to create a variation of labeled data content by replacing, subsisting or adding characters or words by synonyms or random mechanisms. LM can also be used to replace words with another word enriched by their context [17, 26]; the model will self-mask a word and will infer a replacement thanks to the contextual information. Unfortunately, due to their nature, LM classifiers are invariant to this kind of variation [9]. DA is also applied to evaluate NLP models, which is called adversarial training, by introducing some variations in data until the models infer a wrong label [27, 28, 29, 30]. Data interpolation between two labeled data points can be performed using their LM embedding representation [27], but the quality of the artificially labeled data is not guaranteed. Other NLP tasks, such as translation or summarizing, can benefit from back translation (translating a sentence to another language and returning to the original one) [31].
In this paper, we propose an original spatial data augmentation strategy that has a positive impact on text classifiers. To justify the choice to work on spatial information, we propose to analyze which kind of words the fine-tuned classifier relies on its predictions using saliency maps, such as LIME [10] or SHAP [32]. As it will describe and evaluate in Sections 3 & 4, the analysis of these explainable techniques shows that LMs overfit the spatial information when working on a small corpus related to crises.
Method
The crisis management field struggles with a lack of data [4, 5], so our main objective is to increase the training dataset since it is not enough to let BERT-like models generalize on new data. To highlight this issue, we introduce our training pipeline as illustrated by Fig. 1. The data used for fine-tuning RoBERTa [19] is PADI-web [12], a corpus of expert annotated documents related to animal health surveillance. Labels corresponding to a crisis stage are assigned to press media articles. For example, the article called “Bird flu cases confirmed at Nottingham’s Colwick Country Park as public warned” (published by Nottingham Post)5 has been annotated as an outbreak declaration, whereas “The decline in the supply of chicks penalizes the poultry sector” (published by El Watan)6 received the label Consequences.
Prediction workflow.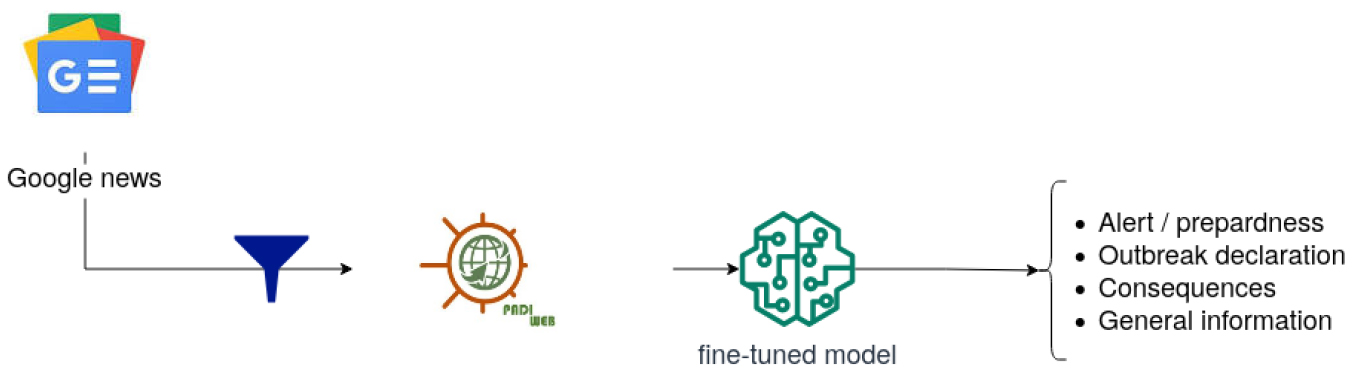
Using this pipeline, we aim to find out which kind of token the models overfit on to lead our DA strategy. We then propose GeoNLPlify, a set of new data augmentation approaches based on spatial information contained in words. As stated by Longpre et al. [9], LMs are invariant to common data augmentation. Thus, before introducing GeoNLPlify, we propose an interpretation of explanation techniques for LMs that highlight the salience of spatial information for text classification on a tiny crisis-related corpus for which BERT-like models overfit. GeoNLPlify takes advantage of this finding by focusing its variations on geographic information.
To understand what types of words our fine-tuned RoBERTa relies on its predictions, we use LIME [10] as the interpretation method. LIME trains local explanatory models by monitoring the impact of input token variations on the prediction (output) of the model to be explained. Thereby LIME detects which token contributes the most to the predicted class. In the example of Fig. 2, the title of the article “Human case of avian influenza A (H5N1) in Nepal” has been classified with the label Outbreak and the tokens that contribute the most were Case, H5N1, Nepal, Influenza, whereas Human decreased the confidence of the model. This is called local explanation. The token “case” has the highest contribution score, i.e. when the model encounters this word in this sentence, it relies on it to assign the label “outbreak declaration”. Indeed, outbreak declarations often report several cases. On the other hand, how does the geographical information “Nepal” (3rd contributor) help the model to classify the document as an “outbreak declaration”? Why does its prediction also rely on this word? Our hypothesis is because our fine-tuned RoBERTa encounters, in its training dataset, several documents containing “Nepal” and manually labeled by experts as “outbreak declaration”. However, we are aware that explicability or interpretability methods in LM are controversial [33], so we do not use it as a full explanation of our classifier, but we consider the LIME result to be a powerful tool to gain intuition about our fine-tuned model.
LIME results for text: “Human case of avian influenza A (H5N1) in Nepal”.
Distribution of the most salient tokens in NER categories by crisis phase.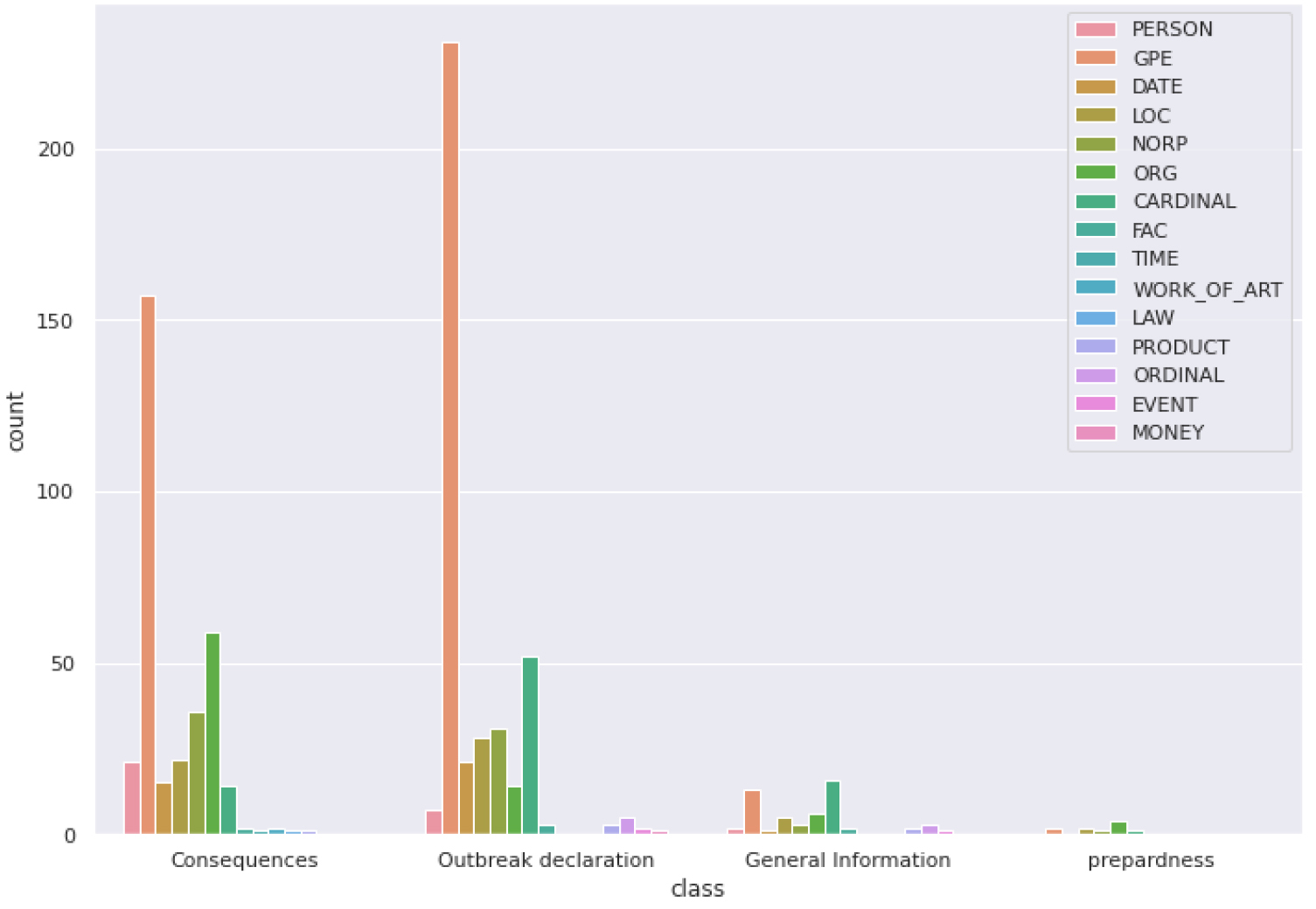
For each data point in the annotated corpus, we extract the three most salient words of each inference. Let
For each salient token, we apply name entity recognition (NER), a NLP task that classifies tokens into well-known predefined categories, such as a person names, organizations, locations or GeoPolitical entities (GPE), which are cities, states or countries. We use spaCy,7 which provides an easy-to-use LM implementation and is often used as a baseline for studies that aim to improve the NER task [34].
As illustrated by Fig. 3, the GPE tokens contribute the most to the RoBERTa fine-tuned classifiers local predictions (explained in details in the experiments in Section 4.2.1). These results confirm our hypothesis that the classifiers rely on spatial information to make their predictions. However, the importance given by models to spatial information can lead to misclassification. Indeed, when situations evolve over time, the type of information reported in the newspapers or social networks also evolves, leading to a change of document label related to a place over time. However, if the model learned to associate a type of information with a place, it will have difficulty generalizing future situations that will occur in this place. For this reason, in the next section, we attempt to take advantage of the spatial information saliency to propose several data augmentation strategies and to reduce this spatial overfitting.
Number of spatial levels of geocoded GPE entities by crisis phase.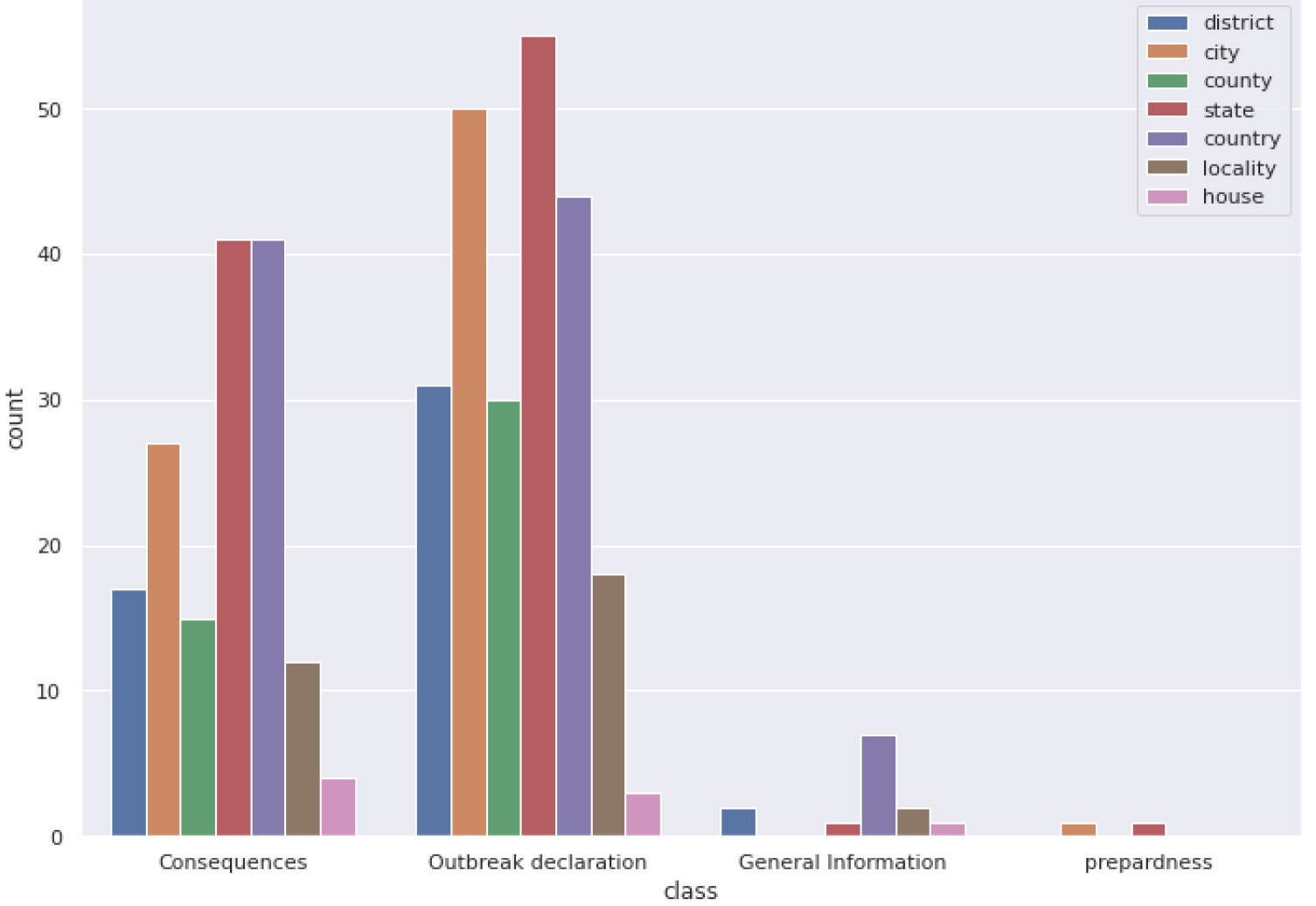
GeoNLPlify: The 3 Spatial enhancements.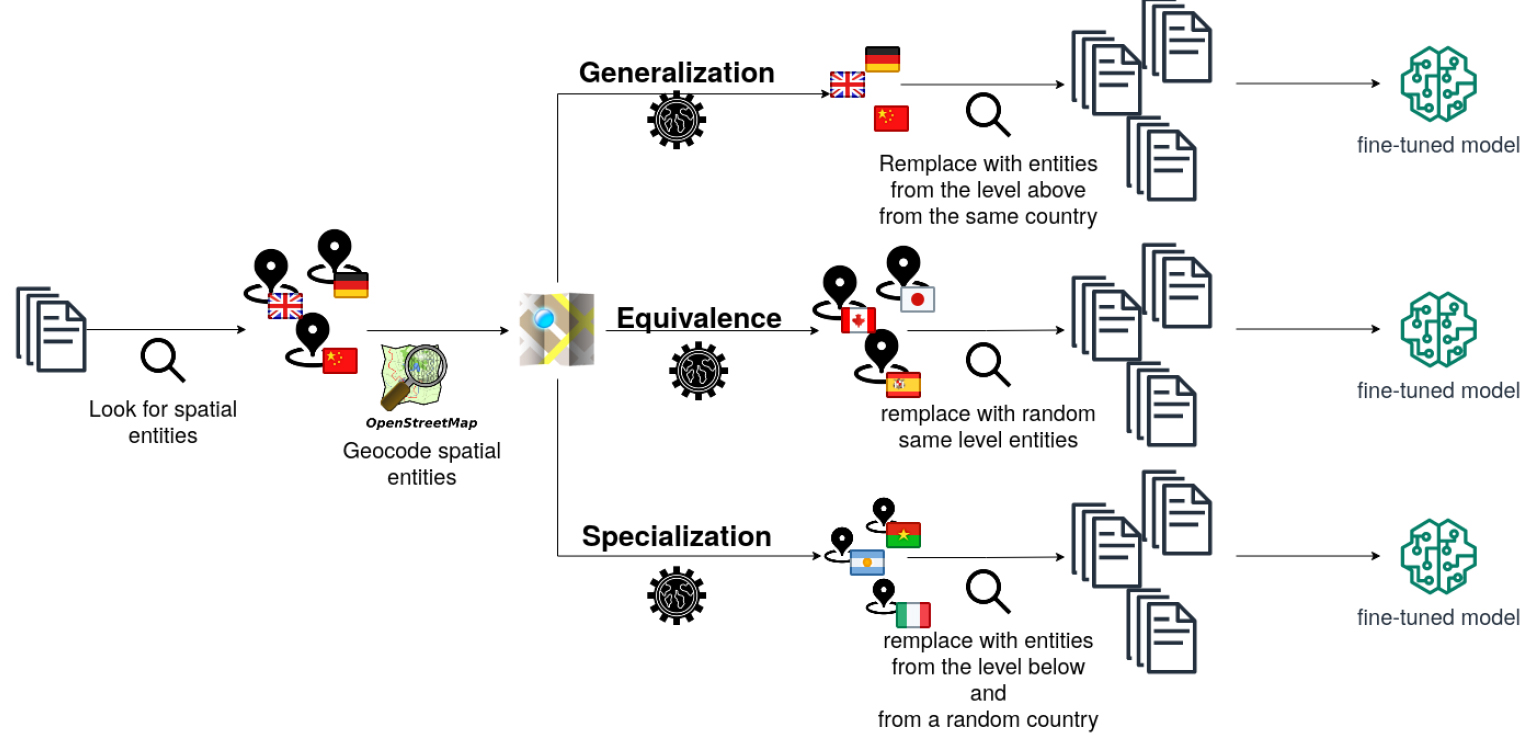
GeoNLPlify is a set of three data augmentation methods that make variations of original annotated data using spatial information to increase the training corpus size. Indeed, as highlighted in the previous section, fine-tuned BERT-like models tend to overfit on tokens carrying spatial information when working with crisis-related datasets. By artificially creating new documents by making variations on geographical entities, GeoNLPlify aims to expose the model to a lot of new different locations, which makes it better able to generalize when it encounters, in inference mode, new places or when spatial information is missing. Its attention to spatial entities decreases in favor of the other words in the document. At the same time, our empirical intuition is that the spatial level has an influence on the classification (by spatial level, we mean city, state or country level); people provide a better report of the local situation during a crisis by being at the right spatial level [35, 36]. For example, an outbreak declaration will focus on the city or state level where the case occurs, although the consequences will be reported at a country level, as illustrated by Fig. 4. This figure shows the spatial level distribution in the training dataset, by label, of GPE tokens that contribute the most to model predictions. To evaluate this assumption, we define three strategies.
The three GeoNLPlify DA methods are illustrated in Fig. 5. The first one,
In this study, we aimed to highlight the spatial overfitting of BERT-like models on crisis-related corpora and to propose a new data augmentation to reduce this bias. To achieve this, we conducted a series of experiments using two crisis-related datasets and a third not dealing with this subject.
The experiments process involves saliency maps and different RoBERTa fine-tuning on several data augmentation methods in order to compare them on these datasets.
The results of our experiments show GeoNLPlify is successful in reducing spatial overfitting and allows fine-tuned models with the best F1-score.
Dataset description
We present the three datasets used in our study: PADI-web, CrisisNLP and SST2.
PADI-web
PADI-web class distribution.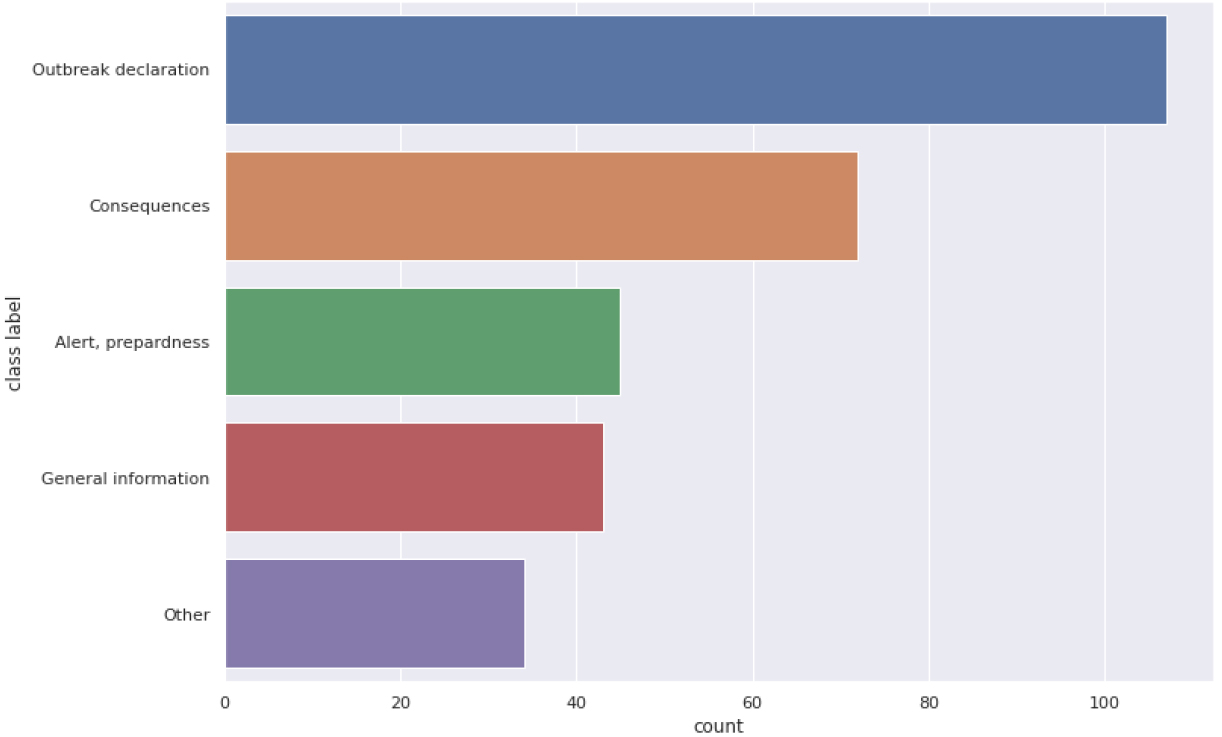
PADI-web is a manually annotated corpus of new articles. The dataset of 300 fully annotated articles addresses outbreak diseases in an animal health context. For each document, the annotation provides a category corresponding to a crisis stage (preparedness, outbreak detection, consequences and general information). The distribution of documents between these categories is illustrated in Fig. 6.
CrisisNLP class distribution.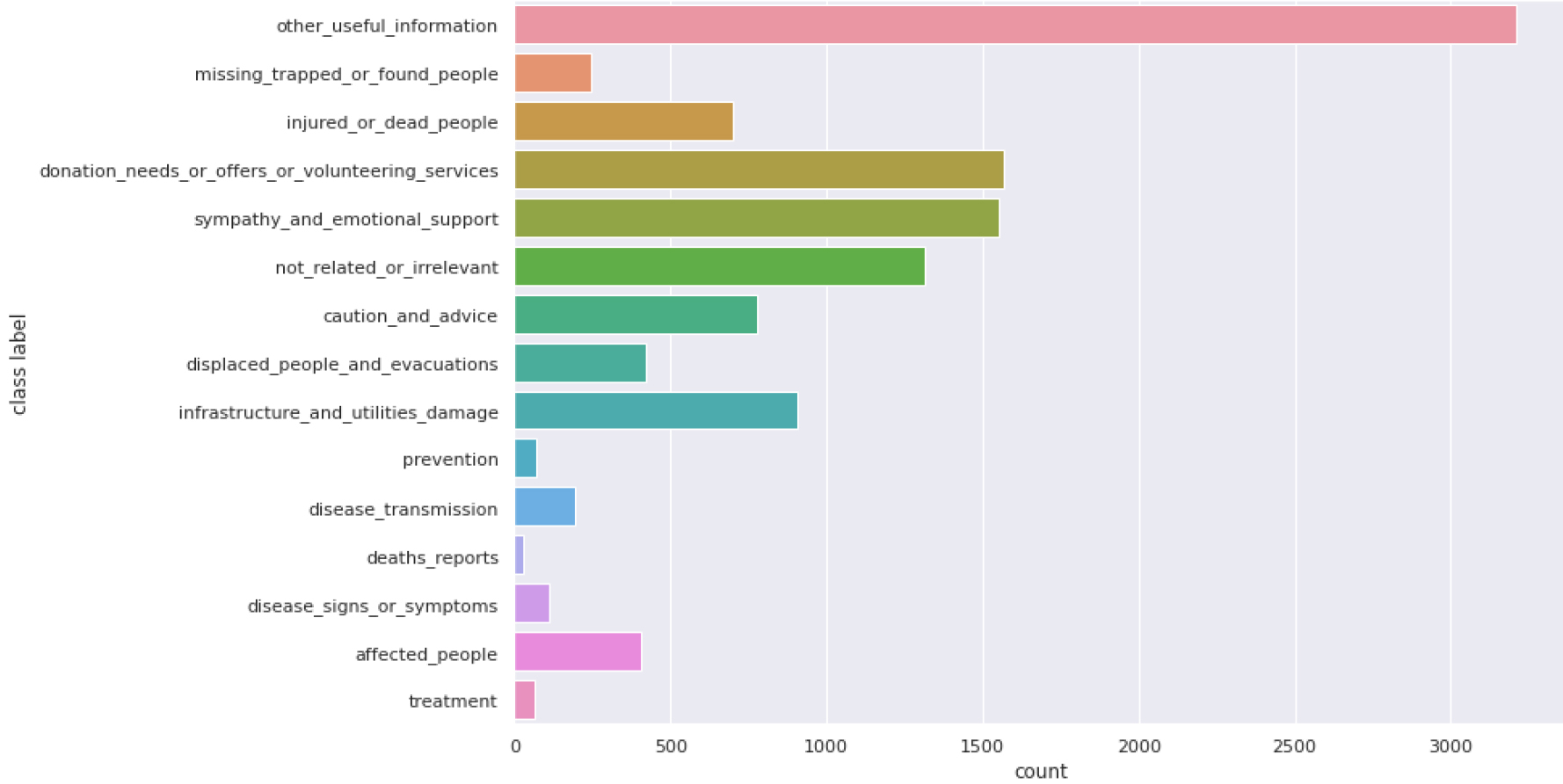
CrisisNLP is a human-annotated Twitter corpora of crisis-related messages [13] collected during 19 different crises between 2013 and 2015. Two kinds of annotation were performed: one by volunteers and the second by paid workers. For this benchmarking, we use both to obtain 11570 tweets with a label among 14 categories (Affected people, caution and advice, deaths reports, disease signs or symptoms, disease transmission, displaced people and evacuations, donation needs, offers or volunteering services, infrastructure and utilities damage, injured or dead people, missing trapped people of found people, not related or irrelevant, other useful information, prevention and sympathy and emotional support). The distribution is, once again, very unbalanced, as illustrated by Fig. 7. What interests us in using CrisisNLP is that it is a reference dataset in crisis management. Another aspect is although CrisisNLP is a dataset with acceptable dimensions for fine-tuning a model (i.e.,
The Stanford Sentiment Treebank (SST) consists of sentences from movie reviews and human annotations of their sentiment (positive/negative). SST-2 is part of the general language understanding evaluation benchmark [14], which is a collection of resources for training, evaluating and analyzing natural language understanding systems.9 The training dataset contains more than 67K sentences. As this study focuses on tiny corpora, we artificially reduced the number of documents by random selection to 300 and 11000 to be closer to the PADI-web and CrisisNLP corpus sizes. In using SST, the objective is to analyze how GeoNLPlify performs on a dataset when the spatiality does not matter to better evaluate the generality of our method.
Experimental process description
Two experiments have been conducted. The first one, the saliency map, aims at showing the overestimation of the role of spatial information granted by fine-tuned models on a non-augmented corpus related to crises. To set up this experimentation, a pre-trained RoBERTa has been fine-tuned on PADI-web data and LIME has been applied to each prediction of our model for the whole dataset. The second experiment aims to compare GeoNLPlify against classical NLP data augmentation on three public datasets. The technical aspects of both experiments are described in the two following sections.
Saliency map
To gain insight into which type of tokens a pre-trained model (such as RoBERTa) relies on to classify documents, saliency maps are computed by the Python library LimeTextExplainer,10 which implements LIME [10]. The three most salient tokens are extracted for each document and categorized using name entity recognition (NER) with spaCy, as shown in Fig. 3. As described in Section 3, fine-tuned model on non-augmented corpus relies on its prediction on GeoPolitical Entities (GPE) tokens. This means that the model considers certain locations as class markers. For example, if in the training dataset, an outbreak event occurs in Indonesia, then the model may classify new documents with Indonesia as a new outbreak. However, the article may well report on the end of a crisis or general information. We interpret this as overfitting that we aim to reduce using GeoNLPlify as a data augmentation method.
GeoNLPlify evaluation process
The evaluation framework is divided into three steps. The first one is applying the multiple DAs (three GeoNLPlify and two nlpaug). The second one deals with the training strategy. Finally, the last step is the evaluation protocol.
Applying data augmentation
From the original datasets, five augmented datasets are processed. The three first come from GeoNLPLify and the two last from nlpaug.
GeoNLPlify data augmentation relies on a three-step pipeline: NER, geocoding and spatial variation. First introduced in 1996 [37], NER aims to provide a category to tokens, such as organization, person or location. Since then, multiple methodologies have been used [38]. To simplify the implementation, our pipeline uses a spaCy algorithm.11 The second step focuses on tokens identified by NER as geographical entities (GPEs). Using OpenStreetMap (OSM)12 data through the photon geocoder,13 the pipeline retrieves a token’s spatial information, such as its spatial level (i.e., city/county/state/country). To reduce the number of queries for the geocoder, the results are stored in a cache.14
Depending on the spatial data augmentation methods, the third step uses spatial-level information to create variation. The generalization approach replaces the GPE cities by their country, while the specialization retrieves a randomly selected city for each GPE country, and finally, the spatial equivalence replaces the GPE cities. The two last methods use the Simple Maps database.15
We provide a Python library to easily re-use GeoNLPlify. The repository is available at
To compare the GeoNLPlify data augmentation to classical NLP data augmentation approaches, the nlpaug python library [15] is used. This library provides several augmentations at different levels (i.e., character, word and sentence) through multiple approaches (contextual embedding, synonym, back translation, random variation, etc.). Two augmentations have been used for the comparison, both at the world level (such as GeoNLPlify): (i) nlpaug_synonym: based on synonyms (using WordNet [16]) and (ii) nlpaug_contextual_embedding based on contextual word embedding (using the BERT model [18]). Multiple studies used DA at the word level [25, 17, 26]. It first randomly selects tokens from the document and then replaces the drawn tokens with one of its variant candidates proposed by WordNet or BERT (also randomly selected). The default parameters are used, i.e., up to 30% of words are changed in documents.
As shown in Fig. 8, the different classes of the three datasets are not equally augmented. Indeed, while nlpaug can generate variation in any sentence, GeoNLPlify only amplifies documents that contain spatial information. For example for the PADI-web, the classes “General Information” and “Other” appear to be disadvantaged. As spatial information is scarce in SST2, the GeoNLPlify variations are made on a small group of documents. For example, the sentence it seems a disappointingly thin slice of lower-class
Data augmented distribution.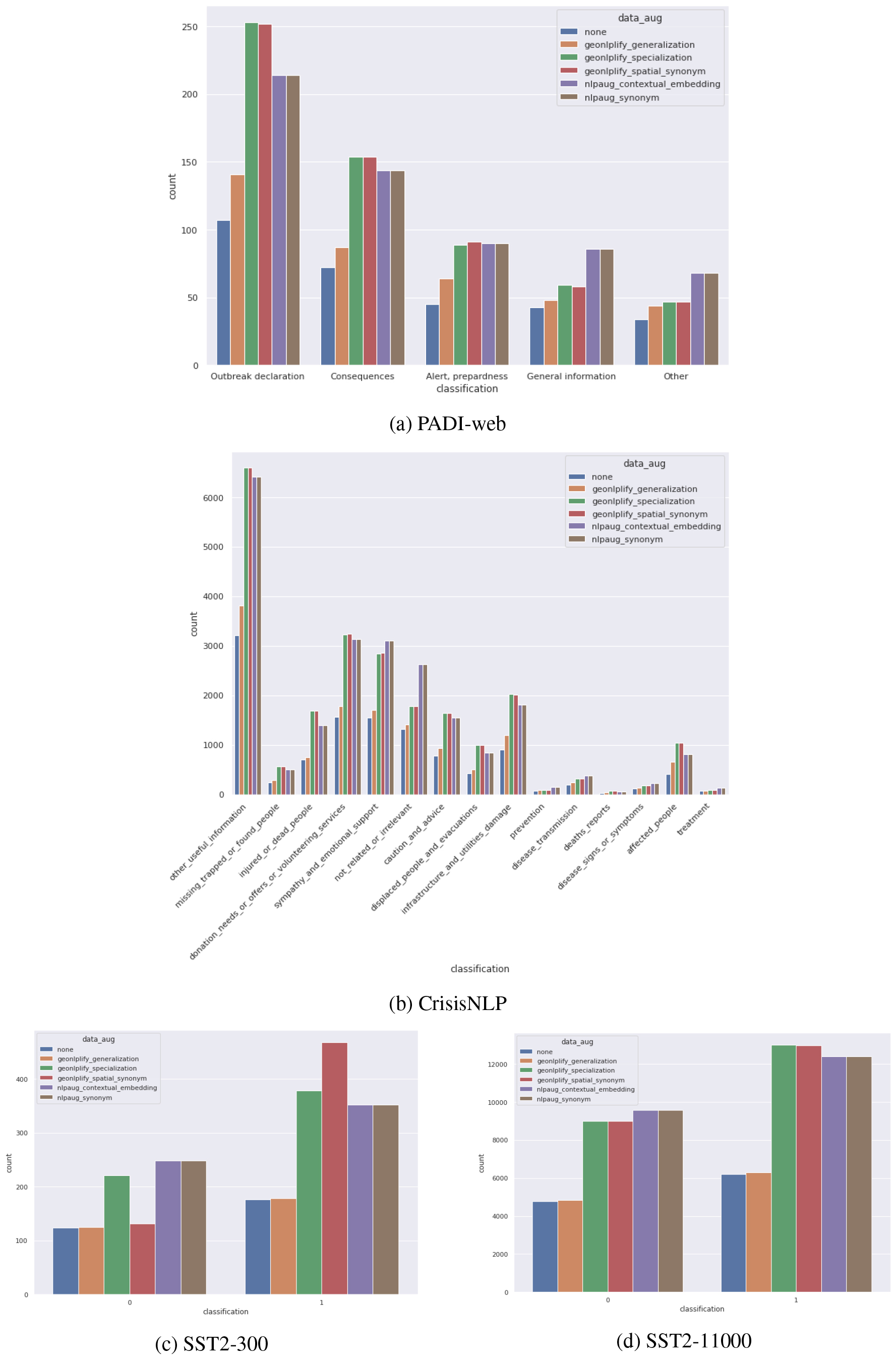
Training strategy
Both GeoNLPlify & nlpaug augmentations and the original datasets use the same training pipeline. A cross-validation process is used with ten folds. The folds preserve the class imbalance. RoBERTa is then fine-tuned with 3 epochs on a server with a V100 NVIDIA and 315 GB RAM using the HuggingFace python library.16 To make the results reproducible, all random seeds (shuffling data and the last fine-tuning layers initiating weights) are fixed [39].
Evaluation protocol
The evaluation metrics are computed on the 10-fold evaluation datasets without any augmentation (they are all removed to keep only original documents). The means of the evaluation metrics (F1-score, recall and precision) on k-folds are calculated (with their standard deviation) for each data augmentation method to be compared in the next section.
We propose to compare the three GeoNPLify data augmentations with two other NLP data augmentation methods: nlpaug_synonym (by replacing words with Wordnet [25]) and nlpaug_contextual_embedding (by self-masking words and replacing them by inferring using an LM [17]).
In addition, we add 4 combinations of the previous methods to further improve the scores. Among all the possible combinations, we propose the following: (i) combined_nlpaug: which applies nlpaug_synonym and nlpaug_contextual_embedding, (ii) combined_geonlplify_s_eq: for GeoNLPlify_specialization, (iii) combined_geonlplify_all: for all the three GeoNLPlify methods and GeoNLPlify_equivalence (which obtained the best results) and finally (iv) combined_geonlplify_nlpaug: for GeoNLPlify_specialization & GeoNLPlify_equivalence and nlpaug_synonym & nlpaug_contextual_embedding.
The benchmarking is performed on three different datasets. The first two are related to crises (PADI-web [12] and CrisisNLP [13]). The third one is dedicated to sentiment analysis applied to movie critics (SST2), and it is part of the general language understanding evaluation (GLUE) [14]. SST2 was created to evaluate the text classification models. Since SST2 has very little spatial information, it is interesting to observe how GeoNLPify behaves with corpora for which spatiality matters very little.
PADI-web
The five data augmentation methods alone and the four combinations are applied to the PADI-web dataset. The F1-score of each class is shown in Table 1. Concerning the benchmark of the DAs alone, the first observation is that all augmentation techniques achieve better results than without augmentation (called “None” in the figure). Second, two GeoNPLlify methods, “spatial equivalence” and “Specialization” obtain better results comparing the nlpaug “Synonym” except for the class “General Information”. The fact that this class has little geographic information does not completely explain the poorer results that GeoNLPlify receives since we do not observe a decrease in results for the “Other” class.
The best combination is “combined_geonlplify_nlpaug” which obtains also the best results for all the classes.
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
10
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
The same five data augmentation methods and the four combinations are applied on CrisisNLP. As
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
10 on CrisisNLP
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
illustrated by Table 2, GeoNLPlify, especially in terms of spatial equivalence and specialization, has better performance. For only one class, “not related or irrelevant”, the NLP classical synonym (Wordnet) competes with GeoNLPlify.
Once again, the best combination is “combined_geonlplify_nlpaug” which outperforms all methods except for two classes (“affected people” & “treatment”) where GeoNLPlify_specialization is better.
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
10 on SST2 - 300 reviews
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
Comparing the average F1-score for each class using the data augmentation strategy on a k-fold
The results are shown in Tables 3 and 4. The first observation is that no augmentation method truly stands out from the original dataset (e.g., without augmentation). The second observation is that the size of the dataset (300 reviews or 11000 reviews) greatly influences the results and their stability. Indeed, for the dataset truncated at 300 reviews, “nlpaug_synonym” is the best, while “geonlplify_specialization” comes first on the 11000 reviews dataset. The third observation is that GeoNLPlify still performs better than it would without augmentation for all the sizes, whereas nlpaug performance is completely degraded on the 11000 documents corpus (especially for the negative class). This may be because some reviews are very small. Often, these reviews do not contain spatial information, so GeoNLPlify is unable to create variations from them. The nlpaug, however, offers variations that completely degrade the meaning of the review. For example, the review “deep deceptions” gives the nlpaug_contextual_embedding variation “political deceptions” and the nlpaug_synonym “deep illusion”, which are far from the original meaning and cannot be easily inferred by the text classifiers for this particular task: does the review say that the film is good?
The results of our study suggest that GeoNLPlify is an effective method for data augmentation in text classification tasks, but does not provide information explaining why it achieves good results compared to baselines and if it induces new bias when a class is correlated to geopolitical entities. That is why, in this discussion, we explore both the interpretation of GeoNLPlify’s effectiveness, potential sources of bias and avenues for future research.
Interpretation of GeoNLPlify effectiveness
As shown in the experiments Section 4, GeoNLPlify substantially improves a fine-tuned LM on text classification even on datasets for which the spatial information matters less, such as sentiment analysis on movie reviews (SST-2). However, GeoNLPlify is similar to other data augmentation approaches, i.e., duplicating documents by making changes at the word level. How then, can we explain the better results achieved by GeoNLPlify compared to the classical techniques? Longpre et al. [9], by an empirical study, stated that DA techniques help only when they provide linguistic patterns that are not seen during pretraining. Linguistic patterns are a set of grammar, syntax rules and semantics. According to [40], the BERT-like models store their syntax knowledge in their token representations (embedding) and not on their attention heads. Indeed, even if attention layers capture some basic syntax links between tokens (such as subject and verb), most of the syntax and semantic information are contained in the token embedding [40].
To better understand what GeoNLPlify brings to the model in terms of syntax and semantic representation, we propose to analyze documents embedded representations for each DA corpus. Thus, for each document, its embeddings are retrieved in the form of a 768-dimensional vector. To visualize the document representations in a scatter plot vectors dimensions are reduced to two dimensions (using T-SNE). Figure 9 shows the distribution of DA documents for each class in this space for PADI-web data (for more details see Appendix A). In this figure, the proximity of the dots indicates the degree of similarity between the corresponding documents as measured by the model. The closer the dots are, the more similar the documents are. We can observe that the GeoNLPlify and nlpaug_synonym have documents with representations that are the most distant. Since it can be difficult to visually analyze the extent brought by each DA in the figure, we propose to compute and compare the area of the smallest polygon containing all the 2D points for each DA. The sizes of these polygons enable to estimate and compare the semantic extent in order to quantify the linguistic patterns brought by each DA. Table 5 shows these results and we can see that the GeoNLPlify methods increase the semantic extent of the training dataset significantly. GeoNPLify artificially creates labeled data very similar to the original data for a human but not for an LM. For example, the cosine similarity (which is the common measure of the distance between two vectors) between the embedding of two countries, such as New Zealand and France is only 17% (for Germany and France it is 60%). France and New Zealand seem to have very different representations, yet semantically, they are close; they both indicate a country. Therefore, if “France” is replaced by “New Zealand” in a document, the meaning of the sentence does not change, especially for a text classification task, but it will introduce new linguistic patterns to the model.
Extent of minimum bounding polygon for data augmentation sentence embeddings on PADI-web data. The first row shows the semantic extent for each original dataset augmented by a DA. The second row indicates the increase in the surface area provided by the data augmentations
Extent of minimum bounding polygon for data augmentation sentence embeddings on PADI-web data. The first row shows the semantic extent for each original dataset augmented by a DA. The second row indicates the increase in the surface area provided by the data augmentations
The contribution of these new linguistic patterns is not sufficient to explain the significant GeoNLPlify results observed on the corpora related to crises. Indeed, it is also important to note that the variation of words carrying geographical information leads to a decrease in overfitting. To highlight this, let us observe the evaluation loss during the multiple DA training on PADI-web data. The mean and standard deviation (STD) of evaluation loss during the training (over the 10-folds training), shown in Table 6, reveals fine-tuned models without DA overfits more than with DA. GeoNLPlify specialization and spatial_equivalence obtain the smallest evaluation loss. By exposing the models to new and multiple combinations of label and location during the training, GeoNLPlify helps models to better generalize when they encounter new combinations during the evaluation. Indeed, the overfitting reduced by GeoNLPlify seems to come from a too strong association between a place and the types of events that happened there in the training.
Mean and STD of eval loss during training over the 10-folds on PADI-web data. The smaller the average evaluation loss, the less the learning process has led to overfitting. The standard deviation indicates whether the evaluation loss was consistent across folds (when its STD is low)
Sentence embedding representation of DA techniques on PADI-web data for all classes.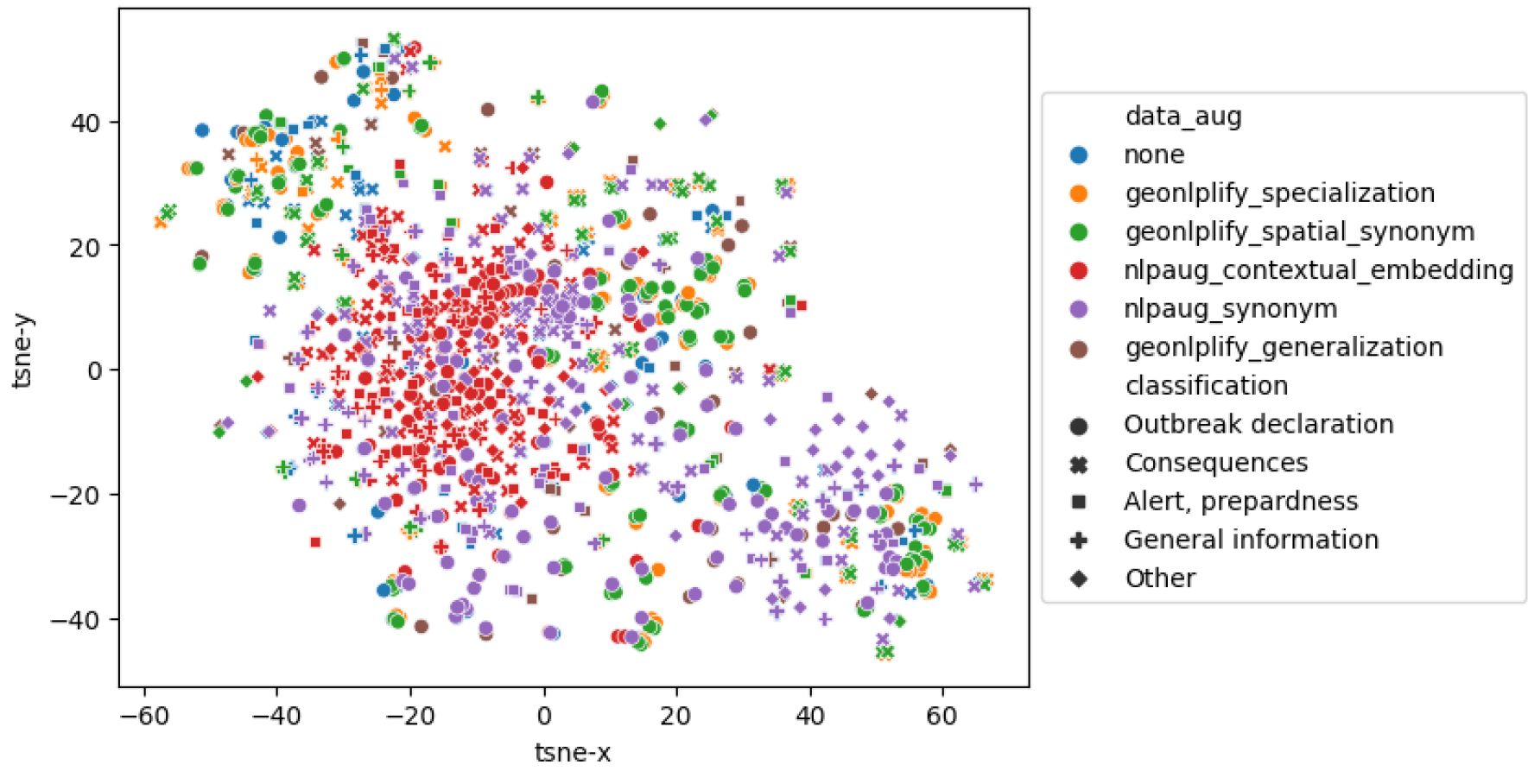
Finally, and contrary to our empirical intuition, the level of the spatial hierarchy does not matter. Indeed, in Section 3, we had shown that spatial levels were associated with certain labels as illustrated by Fig. 4 in the training non-augmented dataset. For example, newspapers reporting on a flood will use city-level locations, while those talking about the consequences of a crisis will report at the country level. Indeed, GeoNLPlify specialization obtains sometimes better results than spatial equivalence. This indicates that changing the spatial hierarchy level (from country to a random city) also reduces the spatial overfitting bias as shown in Table 6. This leads us to believe that BERT-like models make little or no use of the level of the spatial hierarchy. The spatial variations with the greatest impact are therefore not to conserve the spatial scale (replace a city with another city for example), but the change by a very distant location. Thus, the semantics carried by this new location (and thus its vector representation) brings new linguistic patterns.
One of the potential risks of using data augmentation is the introduction of new biases into the data. This is particularly true for textual data, where the use of natural language can introduce subtle biases that are difficult to detect. The risk that we identify when using GeoNLPlify is that real links between labels and geographical entities may be unlearned by the models.
To estimate this, we propose to analyze the texts for which the models trained with GeoNPlify make a classification error while the models trained without augmentation do not. The Table 7 shows the results for PADI-web data of the first fold for each GeoNPLify augmentation and combination. Thus for each augmentation, we apply two models (augmentation and without augmentation) on 10% of the PADI-web dataset, i.e., approximately 30 data points. Furthermore, we add a column, GPE, indicating whether a geographical entity is contained in the text. On this fold of 30 data points, GeoNLPlify_generalization misclassified seven points, GeoNLPlify_specialization two points, and GeoNLPlify_equivalence only one. The classification errors of the combinations appear to be inherited from the simple augmentations. Out of the 16 errors, only less than half (seven) contain a geographical entity. Based on this observation, we can estimate that GeoNLPlify does not create a systematic bias and does not break the real links between labels and locations.
Future directions
The approach proposed in this paper, which led to the development of GeoNLPlify, can be further expanded in two ways. Firstly, by continuing the exploration of variations in the geographical dimension. Secondly, by investigating other dimensions of textual corpora, such as temporality or thematic aspects.
Enhance GeoNLPlify with complex geographical relationships
In addition to the inclusion, generalization, and equivalence relations used by GeoNLPlify, other geographical relationships can be explored. Specifically, variations can be created based on adjacency and varying distances of spatial entities. These relationships could complement the spatial equivalence method proposed by GeoNLPlify. Through experimentation, we could assess the significance of the distance between spatial entity variations in generating new linguistic patterns, while also avoiding the reinforcement of the bias mentioned in the previous paragraph.
Furthermore, GeoNLPlify could also consider the co-occurrence of spatial entities and their relationships. Presented in [36], spatial textual representations (STRs) are spatial representation graphs of spatial entity co-occurrences found in texts. This formalization in the form of STR enables the comparison of different documents based on their respective list of spatial entities. GeoNLPlify could leverage these findings to further enhance its capabilities by generating STR. Experimentation could be conducted by comparing models trained using data augmentations based on coherent and incoherent variations of co-occurrences via the STR approach. Coherence would involve preserving the type of spatial relationship between the co-occurrences, i.e., preserving the original relationships such as inclusion, generalization, or distance between spatial entities. This would enable evaluating whether BERT-type models take into account these types of spatial relationships.
List of texts misclassified by GeoNLPlify but correctly classified without augmentation. The columns name Label, DA_prediction, without_DA_prediction stand respectively for ground truth label, label predicted by a model trained with DA and labeled predicted by a model without DA. The column da shows the DA used and column GPE indicates if there is a GPE contained in the text. Rows in red indicate, also, the presence of GPE in the original text
List of texts misclassified by GeoNLPlify but correctly classified without augmentation. The columns name Label, DA_prediction, without_DA_prediction stand respectively for ground truth label, label predicted by a model trained with DA and labeled predicted by a model without DA. The column da shows the DA used and column GPE indicates if there is a GPE contained in the text. Rows in red indicate, also, the presence of GPE in the original text
For crisis-related corpora such as PADI-web or CrisisNLP, spatial information is ubiquitous and can lead to overfitting between class and spatial entities. It is conceivable that this type of overfitting may occur in other dimensions of information as well. For instance, the temporal dimension could also be explored. As demonstrated in this study by using model explicability methods like LIME [10] or SHAP [32], the models might unfortunately learn to classify certain documents based on the temporal entities found in the text. For example, in the context of crisis management, if the training dataset contains a large number of documents about floods that occurred in 2018, would the classification model tend to classify all new documents containing “2018” as flood events? If so, data augmentation by varying this dimension could mitigate this overfitting bias and facilitate domain transfer, such as training a model on a flood corpus to use it on a wildfire event for example.
Variations on other types of entities could be considered, provided that they lead to overfitting between a class and a type of entity. However, the risk of introducing new biases appears to be more significant than with spatial and temporal dimensions, as their variations minimally alter the semantic meaning of the text. For instance, replacing organization or personal names could potentially alter the sentence’s intended meaning.
Conclusion
In conclusion, this paper presents a significant contribution to the field of text classification by demonstrating the potential of exploiting spatial information to improve text classification performance on crisis-related data. Our study demonstrates the issue of BERT-like models overfitting on words carrying spatial information, and offers a solution, GeoNLPlify, a set of data augmentation methods that reduces significantly the bias of spatial overfitting. Our experiments show that all NLP data augmentation used in this paper reduce overfitting but GeoNLPlify goes one step further and outperforms existing data augmentation techniques on multiple datasets, indicating its effectiveness in enhancing the performance of language models on text classification tasks.
However, this study also raises important questions about the representation of spatial information by language models. Further research is needed to better understand how these models use and reason on spatial information, and how their spatial knowledge can be leveraged to enhance their performance on downstream tasks. GeoNLPlify could be used to reinforce the BERT-like model representations of spatial information (and its hierarchy) to increase their knowledge of spatiality. Our results suggest that the exploitation of spatial information has the potential to unlock new capabilities in language models and contribute to the advancement of the field.
Footnotes
wurlhttps://www.openstreetmap.org.
Acknowledgments
This study was partially funded by EU grant 874850 MOOD and is cataloged as MOOD059. The contents of this publication are the sole responsibility of the authors and do not necessarily reflect the views of the European Commission. We would like to thank Bruno Martins (INESC-ID, Portugal) and other participants of the MOOD project for their suggestions to enrich this work.
Appendix
Sentence embedding representation of data augmentations applied on PADI-web data
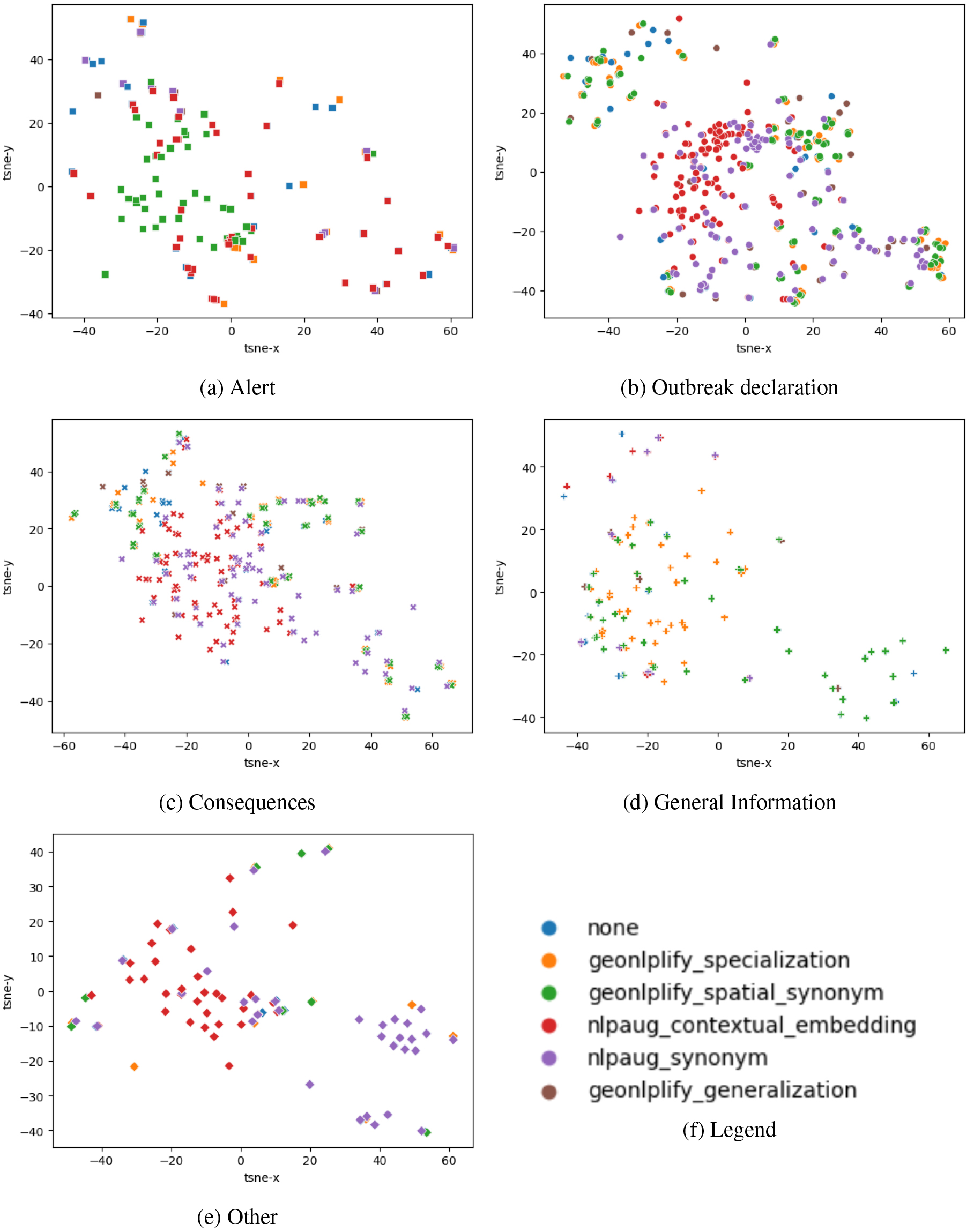
In this appendix, we present in more details Fig. 9 which is decomposed into two sets of subplots. The first one (Fig. 10) proposes a decomposition by data augmentation and the second by PADI-web classes (Fig. 11).
The subplots in Fig. 10 show the distribution of document representations for the different data augmentation methods: ‘none’, ‘nlpaug synonym’, ‘nlpaug contextual embedding’, ‘geonlplify specialization’, ‘geonlplify spatial synonym’, and ‘geonlplify Generalization’. The first observation is that nlpaug augmentations are more compact than GeoNLPlify. Furthermore, nlpaug augmentations are in the center of the original dataset representation space (“none”) whereas GeoNLPlify tends to push the boundaries by augmenting at the edge of the dataset. This, as illustrated in Table 5, shows that GeoNPLify extends the representation space further.
The subplots in Fig. 11 propose to analyze the sentence embedding representations by PADI-web classes: “Alert”, “Outbreak declaration”, “Consequences”, “General Information” and “Other”. We observe, once again, that GeoNLPlify does not augment all classes in a balanced way. The three classes the less augmented by GeoNLPlify (“Alert”, “Other”, “General Information”) did not benefit from the same quality of augmentation. As illustrated in Table 1, “Other” and “General information” are the two only classes for which nlpaug is better than Geonlplify_specialization and Geonlplify_equivalence. The scarcity of spatial information alone does not explain GeoNLPlify’s performance on data-poor classes. The original distribution and heterogeneity of document spatiality have an impact on the effectiveness of GeoNLPlify. Thanks to the embeddings in Fig. 11, we can see that the original documents (“none”) in “General Information” were already very semantically dispersed, so GeoNLPlify adds no new semantic pattern. Concerning the “Other” class, it is probably too noisy to be interpreted. Finally, as also seen in the previous Figure (Fig. 10), it appears that GeoNLPlify extends the most the semantic space of representation (except for the “Alert” class).
Sentence embedding representation of data augmentations applied on PADI-web data – by Data Augmentation.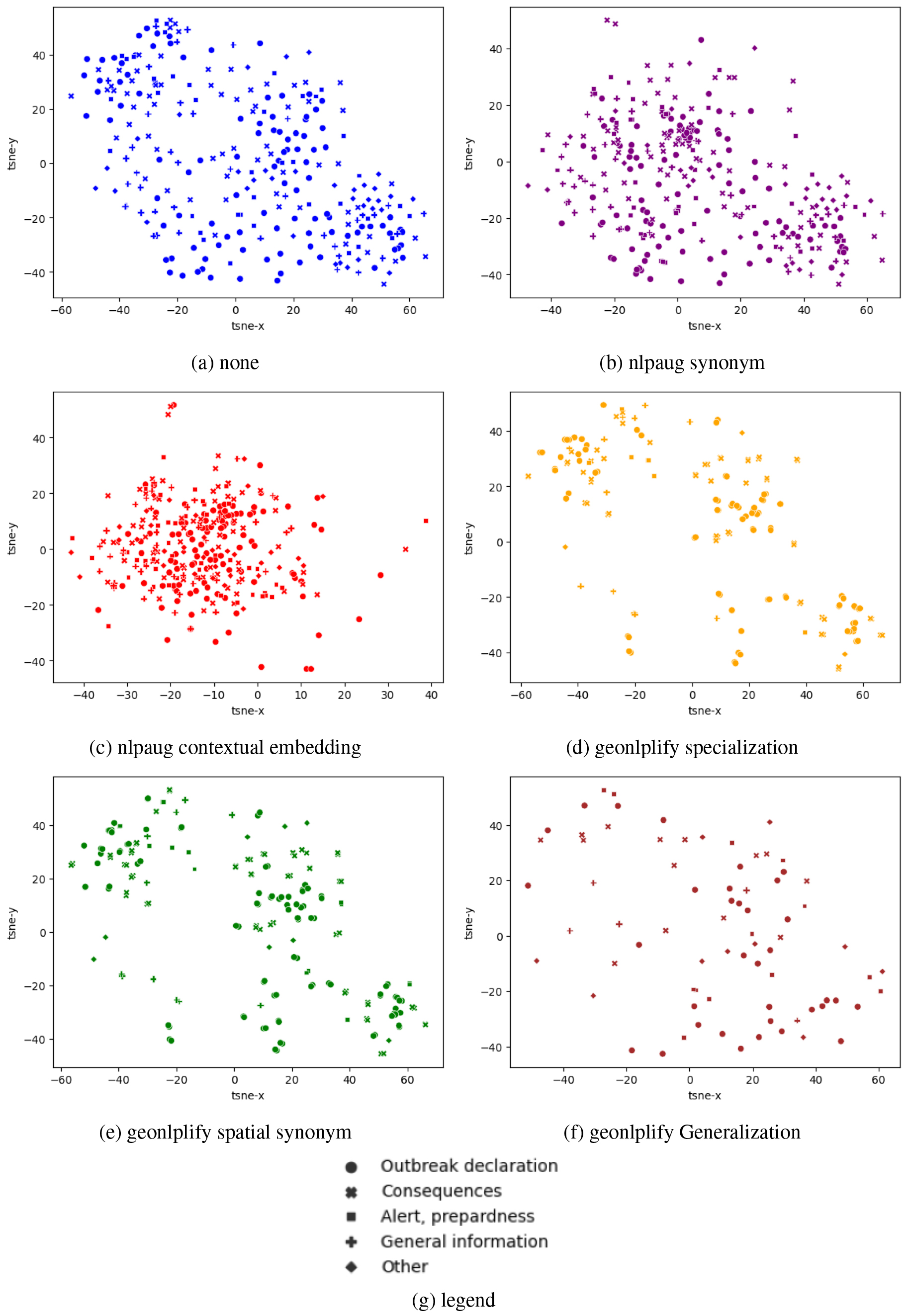
Sentence embedding representation of data augmentations applied on PADI-web data – by Class.