
Abstract
Sequential recommendation aims to predict users’ future activities based on their historical interaction sequences. Various neural network architectures, such as Recurrent Neural Networks (RNN), Graph Neural Networks (GNN), and self-attention mechanisms, have been employed in the tasks, exploring multiple aspects of user preferences, including general interests, short-term interests, long-term interests, and item co-occurrence patterns. Despite achieving good performance, there are still limitations in capturing complex user preferences. Specifically, the current structures of RNN, GNN, etc., only capture item-level transition relations while neglecting attribute-level transition relations. Additionally, the explicit item relations are studied using item co-occurrence modules, but they cannot capture the implicit item-item relations. To address these issues, we propose a knowledge-augmented Gated Recurrent Unit (GRU) to improve the short-term user interest module and adopt a collaborative item aggregation method to enhance the item co-occurrence module. Additionally, our long-term interest module utilizes a bitwise gating mechanism to select historical item features significant to users’ current preferences. We extensively evaluate our model on three real-world datasets alongside competitive methods, demonstrating its effectiveness in top
Keywords
Introduction
With the explosive growth of online information, recommender systems provide an increasingly important role in knowing users’ requirements and providing personalized suggestions. In the real scene, user interaction sequences are generated chronologically, which reflects users’ dynamic interests, and there is a strong correlation between adjacent interactions [1]. Therefore, unlike traditional recommendation tasks that model users’ preferences in a static way, sequential recommendation can capture dynamic preferences and predict the next interacting items, which is more suitable for realistic requirements.
Recurrent neural network (RNN)-based and graph neural network (GNN)-based sequential recommendation models [2, 3, 4] demonstrate the effectiveness in learning the transition relations among items and modeling short-term user preferences, but have difficulty in capturing long-range dependencies. One way to deal with the problem is adopting a self-attention mechanism, such as SASRec [5] and Bert4Rec [6]. Another way is separating modeling the short-term and long-range contextual, such as CLSR [7] and SLi-Rec [8]. In recent work, MA-GNN [9] models user general interests, short-term interests, long-term interests and item co-occurrence patterns simultaneously to fully describe user preferences and capture the joint occurrence of related items. These works do achieve good performance but still have limitations. First, they only consider the item transition relations, neglecting the attribute-level transition patterns. Second, modeling the items in an interaction can only distill the explicit item co-occurrence patterns, ignoring the implicit item-item relations.
To address the limitations of existing methods of sequential recommendation models, we propose integrating knowledge graph (KG) and collaborative signals to jointly conduct sequence modeling. As shown in Fig. 1, the middle arrow illustrates the behavior sequence
An illustration of Alice’s interaction sequence. 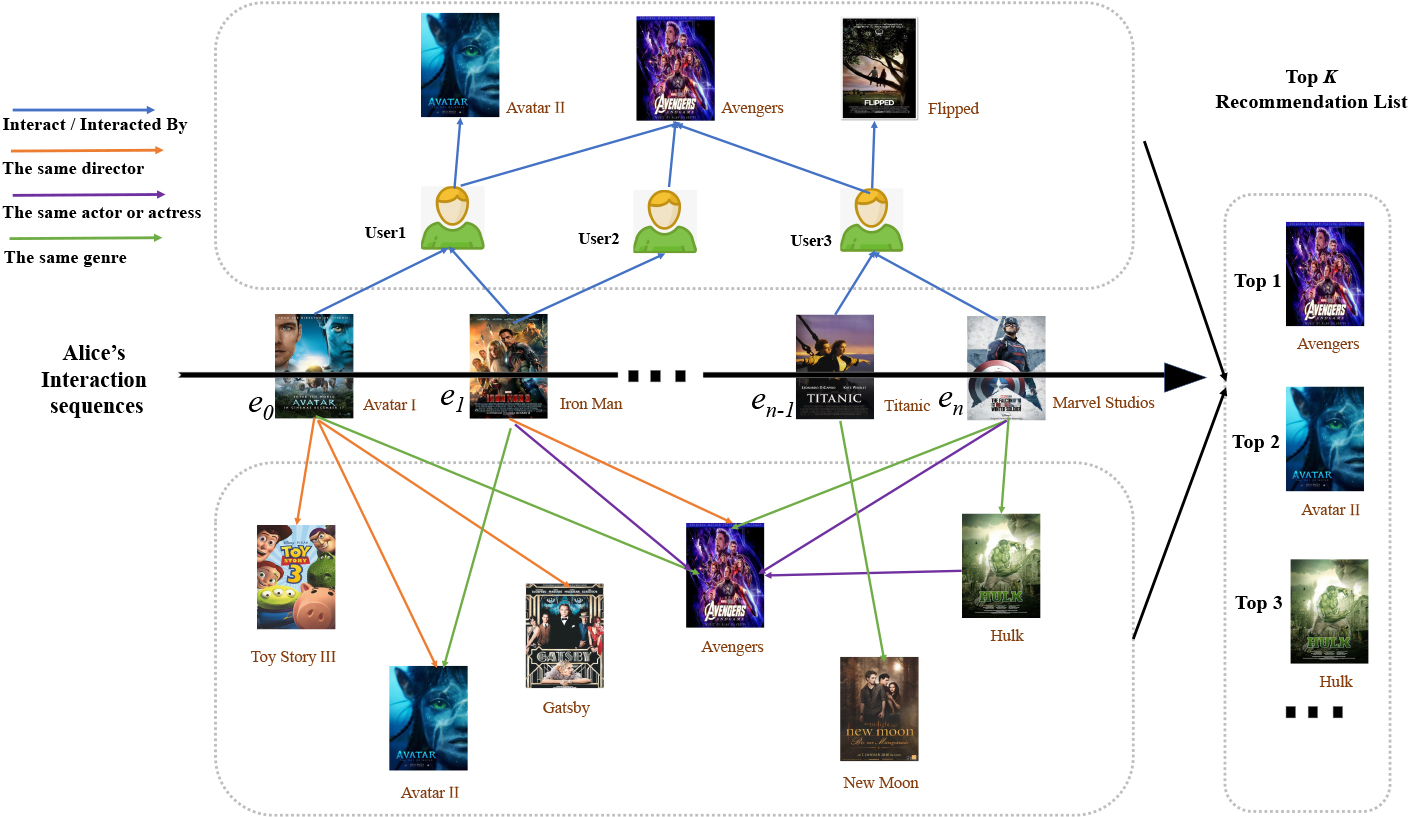
Based on the above observations, we Aggregate Knowledge and Collaborative Information for Sequential Recommendation (AKCISR), thereby improving the accuracy. It consists of a general interest module, short-term interest module, long-term interest module and item co-occurrence module. Specifically, AKCISR first incorporates external information into item embeddings based on the knowledge graph embedding (KGE) method. Then, the user preferences are modelled through the four modules. User vectors are the representations of general interests. In the short-term module, we combine the knowledge propagation and gate recurrent unit (GRU) mechanism to capture the user’s attribute-level and item-level preference transitions in an end-to-end manner. In the long-term module, a bitwise gating mechanism is used to dynamically discriminate the importance of each item feature. In the co-occurrence module, we propose a collaborative item aggregation mechanism to enrich the item representations, thereby integrating collaborative signals to enhance its ability. To summarize, the major contributions of this paper are listed as follows:
We embed items with knowledge-based (KB) information in users’ interactions to capture users’ interests. We design a KG propagation augmented recurrent neural network to learn the structure information and semantic information of the KG as well as transition relations. We aggregate collaborative information in interactions to capture the implicit item co-occurrence patterns. Experiments on three real-world datasets demonstrate the efficacy of AKCISR over several baselines.
KGs are usually introduced in traditional recommendation tasks in order to supplement external information and enrich the representations, but are rarely introduced in sequential recommendation tasks. In this section, we briefly describe the recent advances in KGs for recommendation methods, sequential recommendation methods and the combination of them that inspired our work.
Knowledge graphs for recommendation
Introducing a KG in a recommendation system helps to improve its diversity and interpretability. According to the survey [10], existing KG-based recommendation algorithms are mainly divided into three categories. The first is the embedding-based method, which usually embeds the items with external knowledge into low rank embedding to enrich the representation of the item or user. For instance, DKN [11] and KSR [12] adopt the two-stage method: pretraining the item embeddings with the involvement of KG and loading the embedding results into the recommendation model. CKE [13] and SHINE [14] train the KGE module and recommendation module jointly, providing additional regularization items for recommendation tasks. The second is the connection-based method, which introduces interpretability through the connectivity of the path. However, it is computationally intensive and time-consuming. For the propagation-based method, the enriched user and item representation can be obtained by combining the semantic representation and connectivity information of entities. Representative works, such as Ripplenet [15], KGCN [16], and KGAT [17], demonstrate significant superiority over many other baselines.
Sequential recommendation
Sequential recommendation aims to learn the changes in users’ interests and predict users’ subsequent behavior by modeling history sequences. Traditional algorithms apply Markov chains to model the relevance of behaviors. For instance, FPMC [18] constructs the transition matrix of items through history interactions, while Fossil [19] alleviates the problem of sparsity according to high-order Markov chain and similarity-based methods.
After the rise of deep learning, some basic deep neural networks based on RNN, Convolutional Neural Network (CNN), and Graph Neural Network (GNN) are demonstrated to be helpful for predicting successive items. RNN is suitable for learning the transition patterns between items. Classical RNN-based models such as GRU4Rec [2] and NARM [3] show good performances in session recommendation tasks. CNN can be used to capture the global information of the sequences, such as Caser [1], capturing point-level, union-level and skip behaviors through two horizontal and vertical filters. Wu et al. [20] propose a mapping session sequence into a graph, thereby taking complex transitions of items into account through the GNN algorithm, leading to the rise of GNN-based sequential recommendation. However, all the above studies have the problem of long-term dependencies. To address these limitations, SASRec [5] and BERT4Rec [6] leverage a self-attention structure to model long sequences, while RUM [21] utilizes a memory network structure to store historical user preferences. MA-GNN [9] combines multiple channels to improve recommendation accuracy effectively; but neglects the associated information of items, causing insufficient item embeddings. Therefore, a few sequential recommendation methods introduce KG to capture more fine-grained user preferences.
Knowledge graph for sequential recommendation
KSR [12] and ADKGN [4] incorporate KG with the KGE method, which takes semantic representation into consideration but neglects the connectivity pattern. Note that KSR [12] also proposes a memory network to integrate the external knowledge. Although it indeed improves the interpretability, the attribute transition relations are difficult to be captured. KASR [22] adopts a propagation-based method and RNN mechanism to model user preferences. However, the attention score is computed only on the basis of relation and item embeddings, lacking personalization. In addition, being segmented by a sliding window, the incomplete records are used to model user preferences, which is insufficient.
Based on the preliminaries above, our work also considers multiple factors, namely, the general interests, the short-term interests, the long-term interests and the co-occurrence probability of items. However, the difference is that we integrate KB information into the short-term interest module through a personalized way and involve CF signals into the item co-occurrence module. Therefore, AKCISR not only captures the transfer relationship and co-occurrence relationship between items, but also leverages KB and CF information to assist decision-making.
Problem formulation
We deal with the recommendation tasks under the implicit feedback circumstance. The user-item interaction sequences are generated chronologically, represented by
Based on the user-item historical interaction sequences and the KG, the problem is to choose a list of items from
Methodology
The framework of our method is illustrated in Fig. 2. We start with an embedding module using the KGE method, and then model user preferences through the four factors which are general interest module, short-term interest module, long-term interest module and item co-occurrence module. Finally, the prediction and training process is introduced.
The architecture of AKCISR. AKCISR consists of three major components: the embedding module, the user interest module and the prediction module. Specifically, 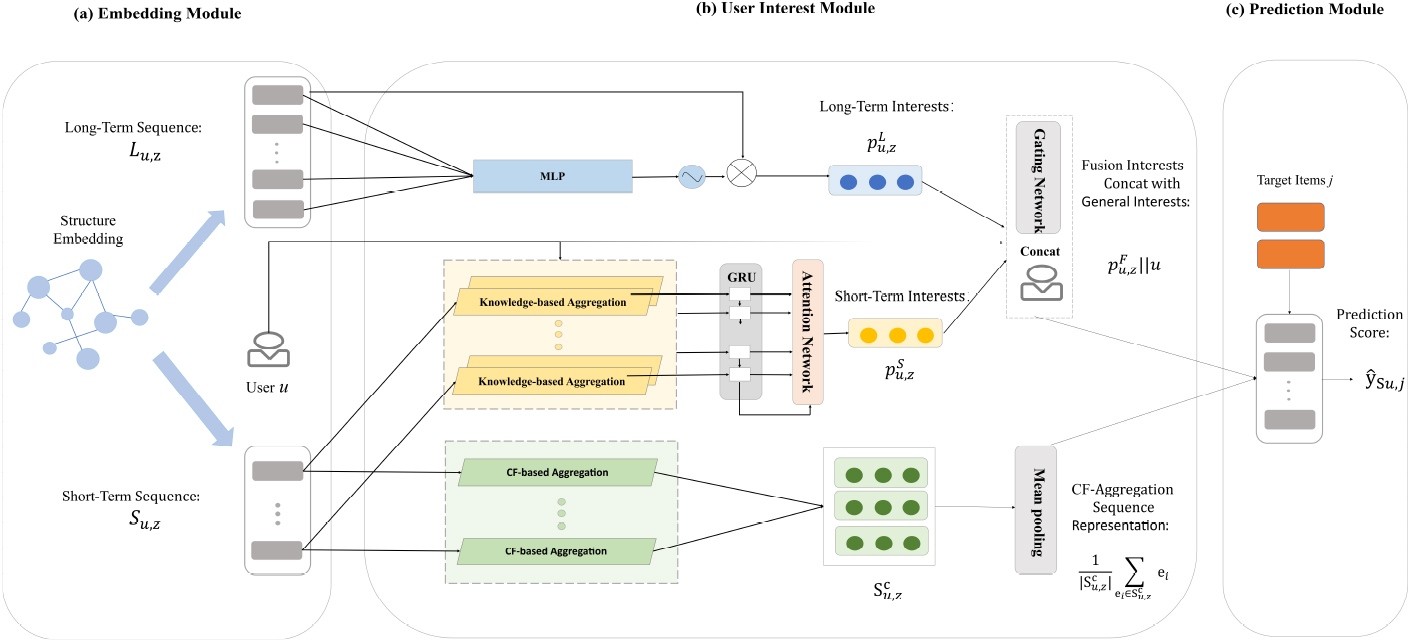
The embedding module is shown as (a) in Fig. 2. We convert the entity, and relation in KG into low-dimensional vector representations by the TransD [23] method to preserve structural information. Compared with some other previous KGE methods, TransD is a more fine-grained framework that regards relations as translations from head to tail entities. Each entity or relation is represented by two vectors. Specifically, assume the dimension of entity space and relation space is
where
The score function is correspondingly defined as:
where
According to (b) in Fig. 2, the user interest module contains four sub-modules: the general interest module, short-term interest module, long-term interest module and item co-occurrence module. The detailed information is presented in the section.
General interest module
To capture the inherent preference of user, we take the embedding of user
Short-term interest module
For each user’s interaction sequences
For each item (entity) representation
Similar to KGCN, we perform neighborhood aggregation on each item in the interaction sequences for a given user, corresponding to the yellow box in Fig. 2. The attention score
where
Given this, the neighborhood aggregation can be computed by linear combination:
We adopt a sum aggregator to combine the entity embedding
where
where the updated embedding
The sequences are fed into GRU, which is appropriate to learn the transition patterns of items. Because the side information has already been incorporated, users’ attribute-level preference transition relations can also be captured. For each input, the hidden state can be computed by:
where
We essentially take
where
: Constructing Knowledge-propagation Interaction Sequences[1]
Compared with short-term interactions, which are of great significance for capturing users’ current interest, long-term interactions are more appropriate for storing users’ historical preferences, preventing the long-term dependencies and the homogenization of recommendation lists.
As shown in the top channel of Fig. 2, AKCISR applies the position function and bitwise gating mechanism to learn the long-term sequence, rather than the GRU mechanism in the short-term sequence. One reason is that the gating mechanism is demonstrated to be effective in learning the importance of each item embedding dynamically, wakening the unimportant items and strengthening the important ones. Another reason is that modeling the short-term sequence and long-term sequence in a different way helps them decouple.
For the
where
where
Similarly, we also apply the gating mechanism to fuse long-term and short-term embedding, since it can adjust the contribution of the two channels, which has been demonstrated by a few studies [25, 9]. When the user continuously pays attention to the same type of items, the short-term interest module may give more importance to the fusion results. In contrast, the importance of the long-term interest module must be increased. Therefore, the function is defined as:
where
Different from the short-term and long-term modules that learn user preferences with external knowledge, the item co-occurrence module focuses on capturing the similarity of user behavior. This module is a key component since the items strongly correlated with those in
Given this, we propose a more direct way to utilize collaborative filtering information to enrich the item information and capture the implicit item-item relations. This module corresponds to the bottom channel of Fig. 2. To be clearer, we first determine the relevant item sets for each item to form a similar-item matrix based on the ItemCF-IUF algorithm [26]. The algorithm is used to measure the item correlations according to the ratio of common users. Formally, the correlation score between item
where
where function
The aggregation of the
The final aggregated representation is constructed by the sum aggregator, injecting collaborative signals.
where
where
: Constructing Interaction Sequences with CF Information[1]
Given a user’s interaction sequence
where
We optimize the proposed model by using gradient descent on the cross-entropy loss:
where
In this section, our proposed model is analysed to explain the following research questions (RQs).
RQ 1. What effect do the hyperparameters neighbor sampling size
Datasets
Since our model requires KB information, only the recommendation benchmark data, including the corresponding KG, are considered. We conduct experiments on MovieLens-1M,1
The KG of Amazon-Book and Last-FM datasets are available at
Detailed information of the three datasets is shown in Table 1.
Basic statistics for the three datasets
We transform the three datasets into implicit feedback. After arranging the interactions of each user in order according to the timestamp, we hold the first 70% of the actions in each user’s record as the training set, and leave the next 10% of actions as the validation set to tune the hyper-parameters. The remaining 20%, as the test set, is used for reporting the performance of the model.
We compare AKCISR5
To evaluate all the models, we adopt three widely used top
Effect of neighbor sampling size Effect of aggregation depth
Effect of collaborative item size 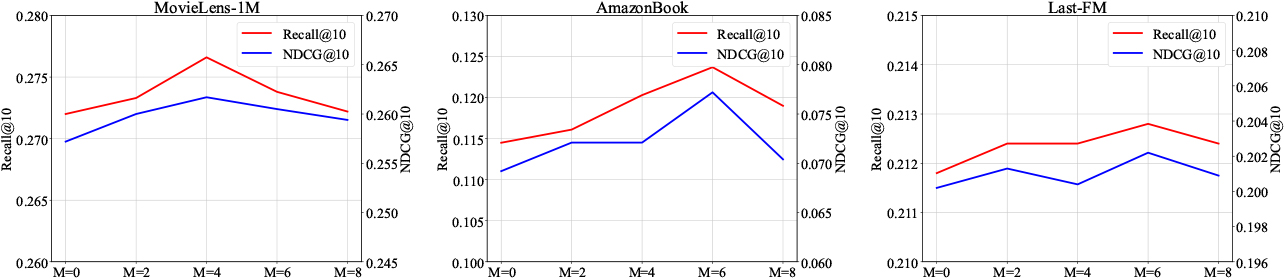
To get deep insights into how our proposed model will work well, we investigate the impact of three hyper-parameters: neighbor sampling size
(1) Effect of neighbor sampling size
in the short-term interest module
We vary the number of neighbors sampled in the KG from 2 to 8 across all the datasets. The results are illustrated in Fig. 4. Obviously, the neighbor sampling size
(2) Effect of aggregation depth
in the short-term interest module
As described in Fig. 4, the first-order aggregation achieves the best performances on the three datasets, which is similar to some previous work (e.g., KGCN and KASR). However, high-order aggregation leads to the performance degradation. The reason is that a long relation-chain may capture irrelevant information and decrease performance.
(3) Effect of collaborative item size
in the item co-occurrence module
The variation of
According to the tuning results of the hyper-parameters, we set
Performance comparison (RQ 2 and RQ 3)
We first report the overall comparison and then evaluate how our model can deal with the sparsity and cold start problem.
Overall comparison
The performance results of all the methods are illustrated in Table 2. We make the following observations.
Recommendation Performance. The best performing method is boldfaced. The underlined result represents the best baseline for each metric.
indicates the statistical significance for
compared to the best baseline method based on the paired
-test
Recommendation Performance. The best performing method is boldfaced. The underlined result represents the best baseline for each metric.
Our proposed model, AKCISR, yields the best performance on all three datasets with evaluation metrics. Compared with the best baselines for each dataset, AKCISR improves Recall@10 by 11.3%, 29.0% and 20.0%, MAP@10 by 16.9%, 32.9% and 33.0%, and NDCG@10 by 12.0%, 34.1% and 36.5%, respectively. First, AKCISR outperforms Caser which only models users’ short-term interests, while AKCISR models short-term interests, long-term interests and item co-occurrence probabilities separately. In particular, the Recall@10 of AKCISR is 42.3% higher than that of Caser on LastFM dataset. Second, compared with SASRec which leverages the self-attention mechanism to capture the item transition patterns, AKCISR combines the KG transfer module and GRU module to capture both the item transition patterns and feature transition patterns simultaneously. Third, with reference to MA-GNN who model user preferences through different channels, AKCISR also take different modules into consideration. In addition, it aggregates KG and CF information to enrich these modules. We can see that the recall@10 of our model exceeds MA-GNN by more than 15%, 29% and 36% on the three datasets. Fourth, AKCISR achieves better performance than KGCN and KGAT, since these methods only capture the user’s general interests, neglecting the sequential patterns. For the sequential recommendation models Caser, SASRec and MA-GNN, Caser achieves better performance on the MovieLens-1M datasets in terms of Recall@ For the KG-based recommendation method, their performances are relatively worse probably because they are not appropriate for the sequential recommendation tasks. In addition, we can see that KGAT consistently outperforms KGCN on all datasets. One possible reason is that KGAT models the high-order connectivities in collaborative knowledge graph, while KGCN only takes KG information into consideration. We conduct the Nemenyi test [28] and Fig. 6 shows the critical difference (CD) diagram over the average ranks of the tested recommendation models. The group of classifiers that are not significantly different is connected by a bar (with length 4.35). The Classifier with the lowest(best) rank lies on the far right. According to Fig. 6, the result is not sufficient to distinguish the performance among AKCISR, SASRec, MA-GNN, KGCN, KGAT and Caser. However, AKCISR is statistically superior to the other methods and significantly better than KGCN.
The cold start and sparsity problem usually limit the performance of the recommender system. Here we compare AKCISR with competitive sequential recommendation baselines to evaluate whether our model can alleviate these problems and whether incorporating KG and CF information is valid.
We divide users into groups according to their interaction numbers, with the total interaction numbers roughly the same in each group. Taking the MovieLens-1M dataset as an example, the interaction numbers per user are less than 95, 199, 356, and 1440, respectively. The results w.r.t NDCG@10 on our model and sequential recommendation baselines are shown in Fig. 7. Note that AKCISR-wo-kg
According to Fig. 7, we can see that the density level increases with the interaction numbers. The NDCG@10 of all the methods also shows the same tendency. AKCISR outperforms the sequential recommendation baselines in all user groups, especially on the four user groups in the Last-FM dataset. From Section 5.5, we can observe that the KG information plays a great role on this dataset. If removing the KG and CF parts in AKCISR, the performance will decrease in most cases, further supporting the importance of KG and CF information in catering to user groups with varying densities.
CD diagram over the average rank of AKCISR and the other 5 methods.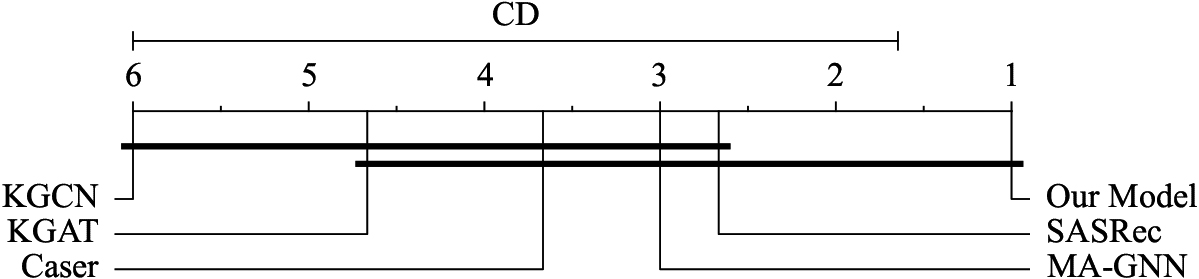
To verify the effectiveness of the proposed modules in AKCISR, we conduct ablation analysis in Table 3 to demonstrate how each module contributes to our model. In (1), we utilize user vector to model user general preferences, and leverage GRU and attention mechanism to model user short-term interests. (2) We utilize the KG transition method to enhance the short-term interest module on top of (1). (3) We fuse long-term interests and short-term interests by gating mechanism on top of (2). (4) We also apply KG transition method in long-term interests module. (5) We incorporate the item co-occurrence module by a linear function to capture item-item relations on top of (3). (6) We screen similar items based on the CF method and perform aggregation to enrich the item co-occurrence patterns. (7) We adopt transD, a KG embedding method, to pretrain the representation on top of (5) and obtain our final proposed model, AKCISR.
According to the results shown in Table 3, we make the following observations.
Leveraging the user general interest module and short-term interest module to represent user preferences could obtain reasonable results, as (1) indicated. By comparing (1) and (2), incorporating KG propagation in the short-term interest module can obviously improve the performance of the MovieLens-1M dataset and slightly improve that of
Performance comparison over the sparsity distribution of user groups on different datasets. The background histograms indicate the density of each user group; meanwhile, the lines demonstrate the performance w.r.t. NDCG@10. Recommendation Performance. The best performing method is boldfaced. The underlined result represents the best baseline for each metric.
Last-FM dataset. However, there is no significant change on the AmazonBook dataset. This may be related to the scale of the KG. By selecting neighbourhoods from too many entities, the information aggregated into the item representations may be weakly related. Therefore, the learning difficulty can be increased.
Integrating short-term and long-term interest module achieves slight improvement, as shown in (2) and (3).
Acording to (3) and (4), incorporating KG information in both the short-term module and long-term module is worse than only incorporating it in short-term module, since aggregating side information for long interactions can bring much noise.
(5) and (6) add the item co-occurrence module and CF-based co-occurrence module respectively. We observe that (6) can further improve the performance on all the datasets, compared with (5). This shows the effectiveness of aggregating items themselves with similar item information, which helps to capture implicit item-item relations.
The KGE method also plays a role in enriching the representations, especially on the Last-FM dataset, according to (7).
Overall, the improvement on MovieLens-1M dataset is mainly affected by KG propagation, corresponding to (2), with an increase of 4% at Recall@20. AmazonBook dataset is mostly improved by 3.4% at Recall@20 through collaborative item aggregation, as (6) indicated. In addition, KG embedding plays a great role on Last-FM dataset with the improvement of (7) more than 12.7%.
In this paper, we propose an AKCISR framework with four modules for sequential recommendation. The external knowledge and collaborative information are integrated in the short-term module and item co-occurrence module through neighborhood aggregation, respectively. Gating mechanisms are adopted in the long-term module to strengthen the important items that appear in the historical interactions. The comparison results demonstrate that AKCISR outperforms all other baselines across various evaluation metrics. Moreover, the experiments focusing on interaction sparsity levels unequivocally indicate that our proposed model effectively alleviates the sparsity problem. Additionally, the ablation experiments provide compelling evidence for the significant contributions made by our proposed modules within the AKCISR framework. Further research should be performed to improve the parallelism efficiency of our model. Meanwhile, we could integrate the information of semantic paths in KG to design more explainable recommendation systems.
Footnotes
Acknowledgments
This work was supported by the National Key R
Conflict of interest
The authors declare that they have no conflicts of interest.
Data availability
The MovieLens-1M dataset, AmazonBook dataset, and Last-FM dataset used to support the findings have been deposited in the GroupLens repository (![]() ] in recommendation systems.
] in recommendation systems.