
Abstract
Classifier combination through ensemble systems is one of the most effective approaches to improve the accuracy of classification systems. Ensemble systems are generally used to combine classifiers; However, selecting the best combination of individual classifiers is a challenging task. In this paper, we propose an efficient assembling method that employs both meta-learning and a genetic algorithm for the selection of the best classifiers. Our method is called MEGA, standing for using MEta-learning and a Genetic Algorithm for algorithm recommendation. MEGA has three main components: Training, Model Interpretation and Testing. The Training component extracts meta-features of each training dataset and uses a genetic algorithm to discover the best classifier combination. The Model Interpretation component interprets the relationships between meta-features and classifiers using a priori and multi-label decision tree algorithms. Finally, the Testing component uses a weighted k-nearest-neighbors algorithm to predict the best combination of classifiers for unseen datasets. We present extensive experimental results that demonstrate the performance of MEGA. MEGA achieves superior results in a comparison of three other methods and, most importantly, is able to find novel interpretable rules that can be used to select the best combination of classifiers for an unseen dataset.
Introduction
Finding a high-performing classification system for a given dataset is highly challenging [1, 2]. A common approach to tackle this challenge is the use of ensemble systems, that is, systems that combine classifiers in an effective way [3]. One of the most popular methods for combining classifiers in ensemble systems is majority voting [4]. Majority voting has two main variants: simple majority voting, and weighted majority voting. Simple majority voting assigns the class predicted by the majority of classifiers to each example, and weighted majority voting weighs the prediction of each classifier based on its previous voting performance. The selection of initial classifiers, which the set of individual classifiers to combine is selected among them, and the level of diversity among them has a direct influence on the performance of ensemble systems [5, 6].
There are three different ways to ensure diversity among possible initial classifiers [7]: first, using different initial parameters for individual classifiers; second, having different views of the same problem using feature selection methods; and third, using different types of individual classifiers. Moreover, manual selection of individual classifiers to combine among the selected set of initial classifiers in the ensemble system usually is very time-consuming [8]. It is common to apply meta-learning techniques to reduce this time complexity by predicting the best classification methods for an unseen dataset. The idea of meta-learning is learning to find the best learning algorithm for a given problem, considering its characteristics [9, 10]. Meta-learning extracts features, such as number of attributes, number of examples and etc. from problems to describe their nature and differentiate among them. These features are called meta-features and are used to find the most similar problem among a set of problems to a given problem [11]. Meta-learning records the performance of individual classifiers and meta-features of each problem into a knowledge base [12]. This knowledge base is used in conjunction with a learning method, such as k-nearest-neighbors (kNN), to predict the appropriate classification method for an unseen problem, considering problems with similar nature to it. In this paper, we propose a novel ensemble method that combines meta-learning and genetic algorithm [13, 14]. This method is called MEGA, which stands for using MEta-learning and a Genetic Algorithm to recommend a combination of classifiers for an unseen dataset using dataset’s meta-features. MEGA offers several desirable key features. In particular, it guarantees diversity in the ensemble system, it ensures a varied range of meta-features and individual classifiers, and most notably, it is able to generate novel interpretable rules for predicting the best classifier combination. This paper is organized as follows: Section 2 discusses previous work on meta-learning and ensemble systems. The methods used in MEGA are discussed in details in Section 3. In Section 4, we present the empirical results. Section 5 concludes and identifies promising future work.
Related work
This work is mainly based on three concepts, namely, ensemble systems, meta-learning and genetic algorithm. In Section 2.1, the main approaches used with ensemble systems are discussed. In Section 2.2, we discuss the predominant work that has been done on meta-learning; and in Section 2.3 we introduce genetic algorithm.
Ensemble systems
An ensemble system is a multi-classifier system that aims at combining different classifiers to achieve a higher level of efficiency than individual classifiers achieve [7, 15, 16, 17, 6].
An effective factor for the performance of an ensemble system is the diversity of the individual classifiers. As a result, using a variety of classifiers in the ensemble system can substantially improve the overall performance [3, 18, 7, 16]. The design of an ensemble system involves two important steps:
Architecture selection The most popular ensemble architectures are bagging [19, 20], boosting [21, 22, 23] and multi-boosting [16, 24]. The idea of bagging is based on data resampling. Bagging uses bootstrap replicas on training datasets to promote diversity across the used classifiers. Usually a random selection method with replacement is used to select instances of each replica. Each subset of the training dataset has the same number of instances as the original dataset [19, 20]. Similarly to bagging, boosting uses a random selection method; however, it focuses on wrongly classified instances by selecting them with a higher probability in the sample set [21, 22, 23]. Multi-boosting is a combination of bagging and boosting [25]. The base learning algorithm of multi-boosting is C4.5 and has lower error rate compared to bagging and boosting methods [26]. Component selection Ensemble components, which are selected individual classifiers among initial classifiers to combine, can contain either the same set of classifiers (homogeneous model) or various classifiers (heterogeneous model) [17, 24]. Diversity is supported by using heterogeneous ensembles [21].
Nascimento et al. [24] applied a
Meta-learning is an efficient technique for predicting the best classification method for a given problem based on its meta-features [12]. Examples of meta-features are “the number of features” [7, 20, 21, 22, 28], “the number of missing values” [27, 29, 30, 31, 32] and “class entropy” [7, 29, 33]. Meta-learning uses meta-features to describe a given problem [34]. Meta-features are mainly categorized into the following five categories: General, Statistical, Information-theoretic, Land-marking and Model-based [34, 28, 11]. Not all categories need to be used simultaneously in a given application, though they can be combined. For instance, Filchenkov et al. [29], Casteillo et al. [35] and Gama et al. [36] used only general, statistical and information-theoretic meta-features to improve the performance of the meta-learner.
Most of the previous work on meta-learning methods are based on individual classifier selection and very little work has been done on how to best combine a selected set of classifiers [37]. We can divide previous studies on meta-learning into two main groups:
In
While the resulting performances of both
There is no classifier combination applied in In order to explore more varied hypothesis spaces,the methods in Considering the main drawbacks of
Genetic algorithms [14] are a heuristic search method inspired by biological evolution. As it is shown in Fig. 1, a possible solution to a given problem is coded as a chromosome, which is a sequence of genes that have certain values. For instance, if the problem is to find the shortest route that connects n cities, a chromosome could be used that consists of n genes where each gene refers to one of the n cities. A genetic algorithm operates on a set of chromosomes (hence on a set of possible solutions), where such a set is called a population. The initial population is composed of randomly generated chromosomes. Then, in an iterative process, subsequent generations are generated through operations called mutation and crossover and through fitness-oriented selection of the best chromosomes found so far. Mutation and crossover are applied on the selected chromosomes to create new chromosomes to be contained in the next generation. Various variants of mutation and crossover have been described in the literature (e.g. see [41]).
An example of a simple population composed of three chromosomes, each consisting of six genes.
Genetic algorithm is used in varied fields. For instance, Thammasiri et al. [27] used 30 individual classifiers and encoded them to a binary chromosome (0: classifier not selected, 1: classifier selected). Finally, it used majority voting on the selected classifiers of the genetic algorithm for the final decision. Canuto et al. [17] proposed a genetic-based approach to select the best set of meta-features in the ensemble system.
MEGA has three main components: a Training component, a Model Interpretation component and a Testing component. Figure 2 gives an overview of MEGA, including its three components and the main steps they are responsible for. We discuss each of the components in details in the following subsections.
Overview of MEGA and the main steps executed by its three components. The Training component generates a model from meta-features by applying a genetic algorithm on input datasets. The Model Interpretation component interprets the generated model using a multi-label decision tree and an a priori algorithm. The Testing component recommends a combination of classifiers for an unseen dataset using kNN algorithm.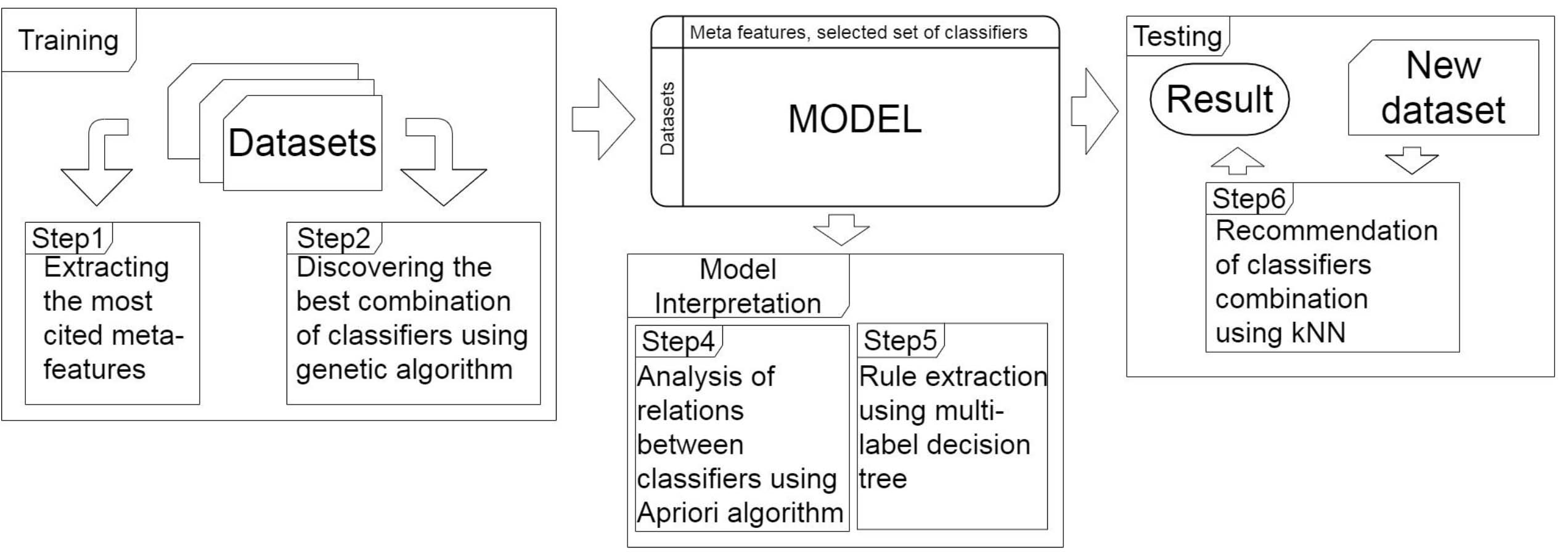
The main input of MEGA is given by different datasets. If
Set of meta-features in addition to A) list of citations and B) meta-feature group
Set of meta-features in addition to A) list of citations and B) meta-feature group
The comparison of MEGA performance with a different subset of meta-features (mf) based on their number of citations. The performance of MEGA is the best among others when meta-features with at-least two publications are used as the set of meta-features.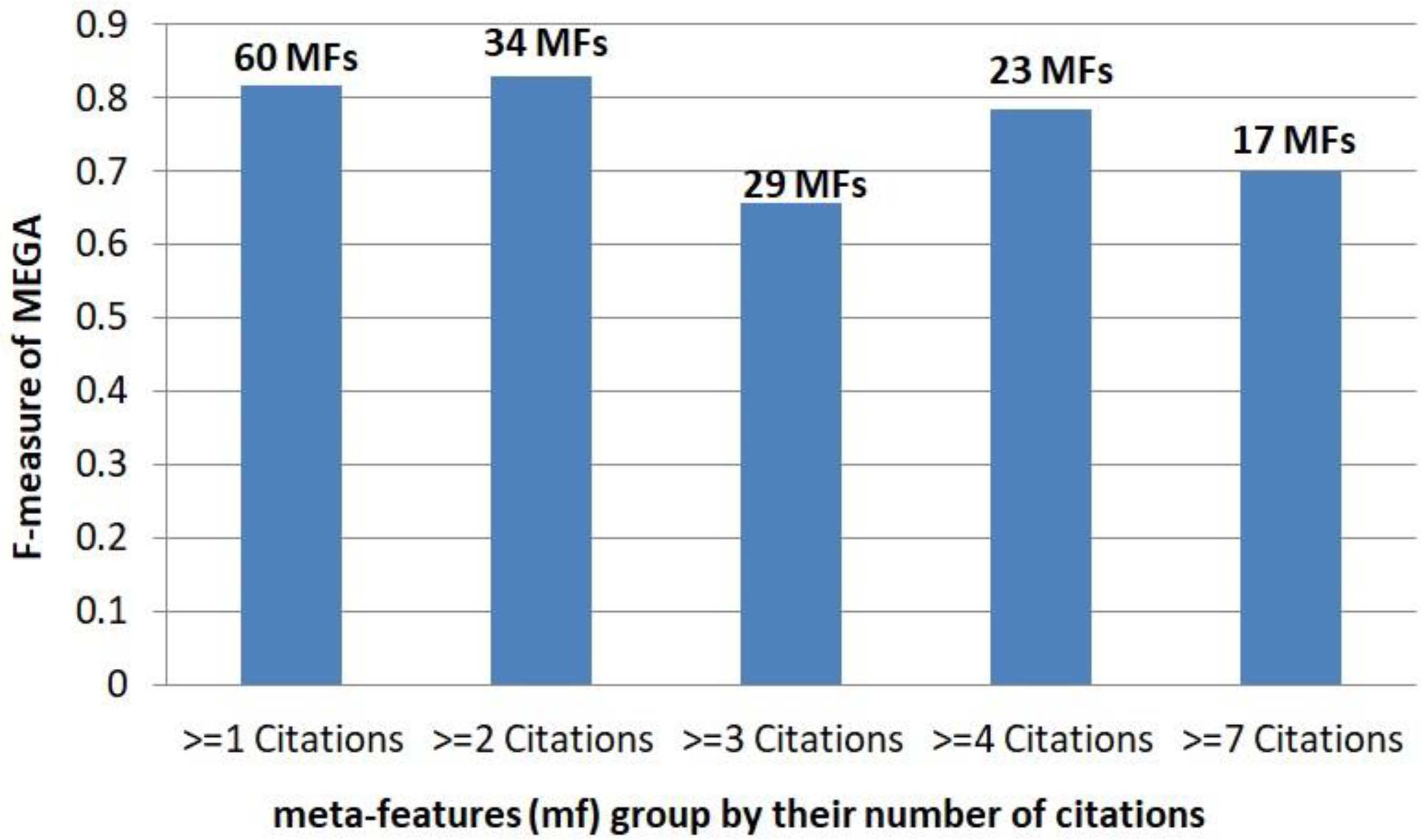
MEGA uses 14 initial classifiers: J48, Random forest, Stump, Random tree, REP, Decision table, JRIP, OneR, PART, IBk, LWL, Bayes net, Naive Bayes and MLP. Table 2 shows these 14 initial classifiers, their families (according to Weka [32] family categorization) and publications cited them in the ensemble systems and meta-learning fields. As it is shown in Table 2, Naive Bayes, MLP and JRIP are the most cited classifiers in the literature. Moreover, in order to discover the best combination of classifiers, MEGA uses a genetic algorithm, in which each gene is the binary representation of 14 individual classifiers existence in the recommended combination (1 means this individual classifier is in the combination and 0 means it is not). Figure 4 shows the chromosome and genes of the genetic algorithm, which is partitioned into the following five groups according to the five classifier families: 1) decision tree, 2) rule based, 3) lazy, 4) bayes based and 5) function based classifiers. After applying the genetic algorithm, MEGA represents the best found combination of classifiers for each dataset
The chromosome of each individual as used by the genetic algorithm. It is partitioned into five classifier families, including Decision tree, Rule based, Lazy, Bayes based and Function based. Each gene expresses whether or not the respective individual classifier is part of the classifier combination.
The Training component concatenates two one-dimensional vectors,
The matrix model MFBCC. The model establishes relationships between meta-features and classifier combinations for the training datasets 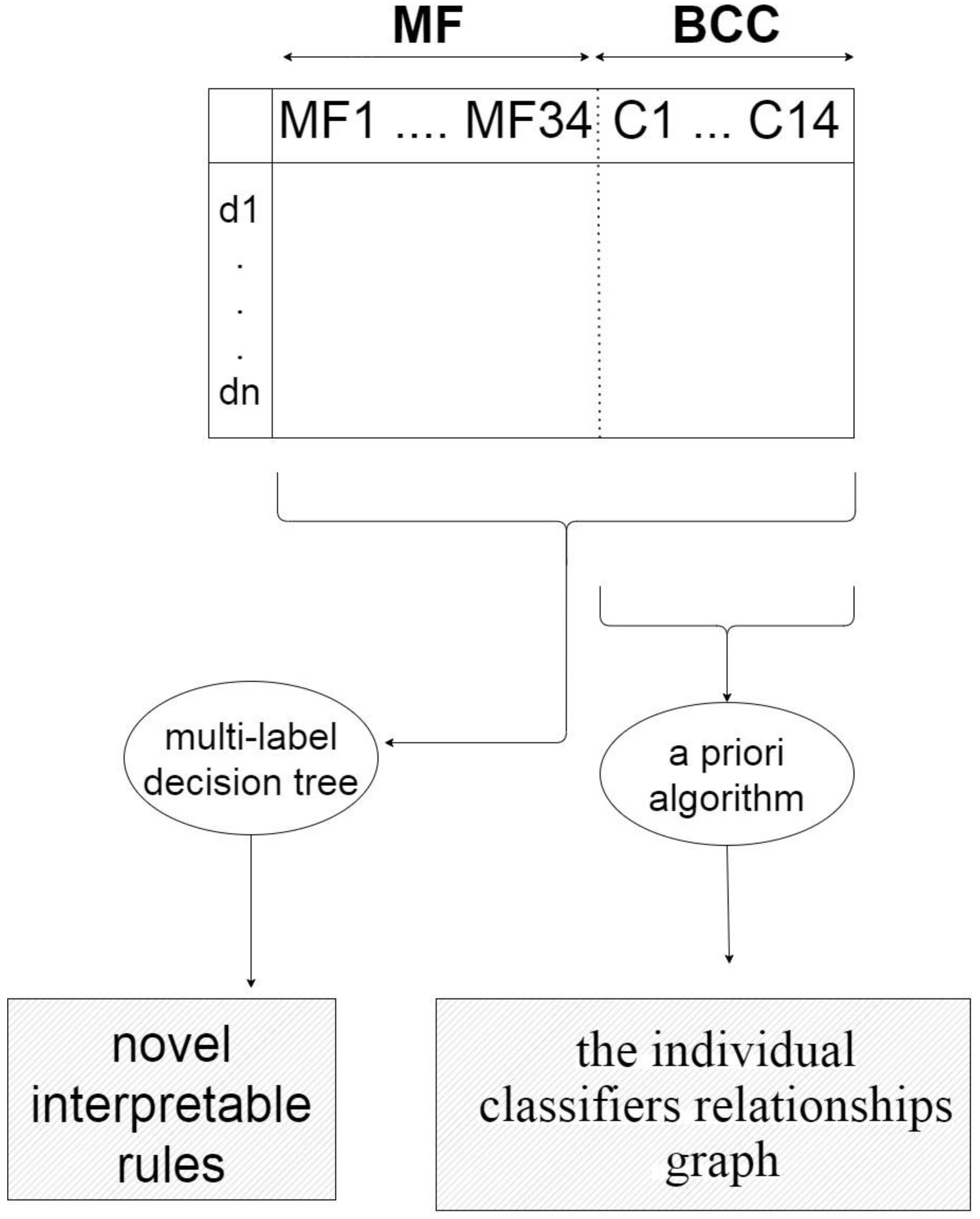
The 14 selected classifiers, the families to which they below, publications citing them, and number of citations
This component is responsible for interpreting the matrix
First, MEGA applies an a priori algorithm [61] to the BCC part of The applied a priori algorithm is a frequent item sets mining algorithm, which has two main measures, named support and confidence [61, 62, 63, 64]. The support is the probability of transactions that contain both A and B ( Next, MEGA applies multi-label learning and, specifically, uses MEKA [66] to generate a multi-label decision tree that allows to identify novel interpretable rules for recommending a useful combination of classifiers for an unseen dataset on the basis of its meta-features. Instead of just one label, the Multi-label learning approach predicts a set of labels (the existence of individual classifiers in an ensemble system) for each example (a given problem) [67, 68, 69]. For illustration, as it is indicated in Table 4 and will be discussed in details in Section 4.2.1, in dataset cases where the class entropy meta-feature is more than a threshold, then J48 classifier is recommended to be part of classifier combination in an ensemble system. In other words, class entropy and number of outliers meta-features describe the situations where J48 classifier suits best in ensemble systems.
The main task of this component is to predict the set of classifiers for a new dataset
where
In the following, we first introduce our datasets and then we discuss the results of the Training, Model Interpretation and Testing components of MEGA.
Results of the training component
In this subsection, we introduce our selected set of training datasets and describe the configuration of the genetic algorithm used for discovering the best combination of classifiers for each training dataset.
Training datasets
Table 3 shows 50 training UCI datasets [70] that are used in at least one of the previous methods discussed in Section 2 (together with their values of three fundamental meta-features “Number of classes”, “Type of features” and “Number of features”). These datasets are related to a number of subjects, including economics, medicine and politics, among others.
50 UCI datasets and their characterization in terms of the meta-features “number of features”, “type of features” and “number of classes”
50 UCI datasets and their characterization in terms of the meta-features “number of features”, “type of features” and “number of classes”
The most important rules generated by MEKA that relate the meta-features to the combination of classifiers. As can be seen from this table, these extracted rules use 21 of the 34 selected meta-features (“class entropy”, “number of outliers”, and so forth)
The
First, for each Second, tuning the hyperparameters for each classifier is interesting and still very challenging task. The optimal value for hyperparameters of each classifier may be different from one dataset to another. As a result we use the default hyperparameters of each classifier in WEKA/MEKA. Third, to discover the best combination of classifiers, the genetic algorithm (i) uses an initial population of 1000 with a generation of 100. Each chromosome of the population has the structure shown in Fig. 4, (ii) applies single-point crossover with probability 0.6, (iii) applies bit-string mutation with probability 0.05, and (iv) finally combines the selected individual classifiers by simple majority voting.
This subsection describes the interpretation of the
Using a multi-label decision tree to extract novel interpretable rules from the MFBCC model
As described above, MEGA reduces the task of predicting the best classifier combination to a multi-label classification task. For this purpose, MEKA [66], uses N binary classifiers for multi-label classification with N labels. Because of the MEKA’s [66] configurations, each extracted rule from MEKA [66] indicates the existence of only one individual classifier. After computing meta-features of each dataset, in order to discover the existence of each individual classifier in the best combination, the set of meta-features must be compared to the “if part” of each extracted rule. Table 4 shows rules generated by MEKA.
Using an a priori algorithm to discover relations among individual classifiers
The BCC part of
Each node belongs to one of the classifier families indicated in Table 2 and accordingly, the diversity of classifiers in the proposed ensemble is guaranteed. IBK classifier with the highest degree (with in-degree The cluster classifiers of MLP, Random forest and IBK, are the best set of classifier combinations in ensemble systems. They complement each other in varied perspectives, guaranty more variety in ensemble systems and explore more hypothesis spaces. Additionally, from interpretability point of view, MLP and Random forest are in complete opposite of each other. The results of MLP are more like black-box and Random forest produces easily interpretable results.
Graph of relationships among the individual classifiers. Each node represents individual classifiers and each edge is the co-occurrence of individual classifiers in the best combination of classifiers.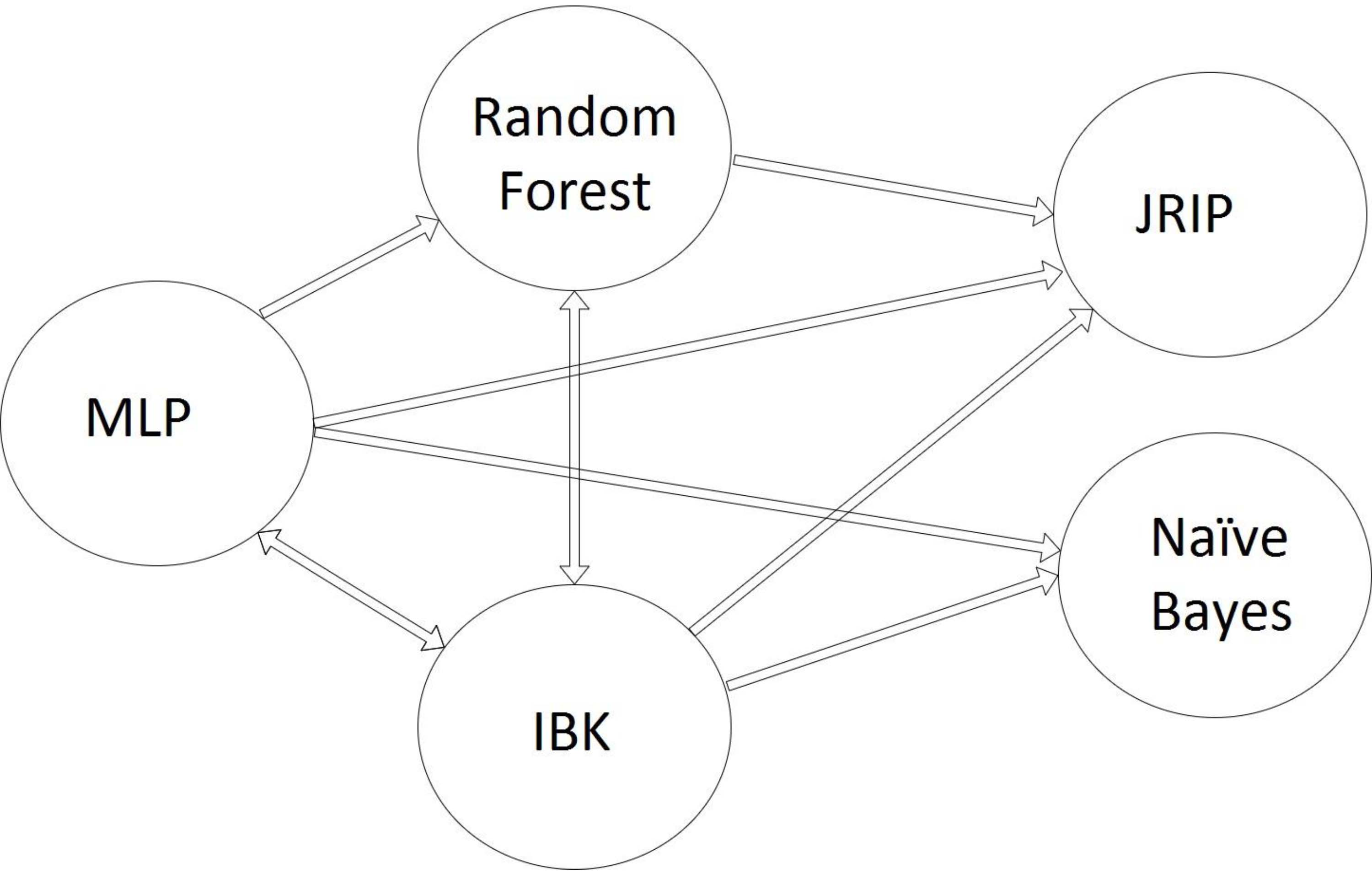
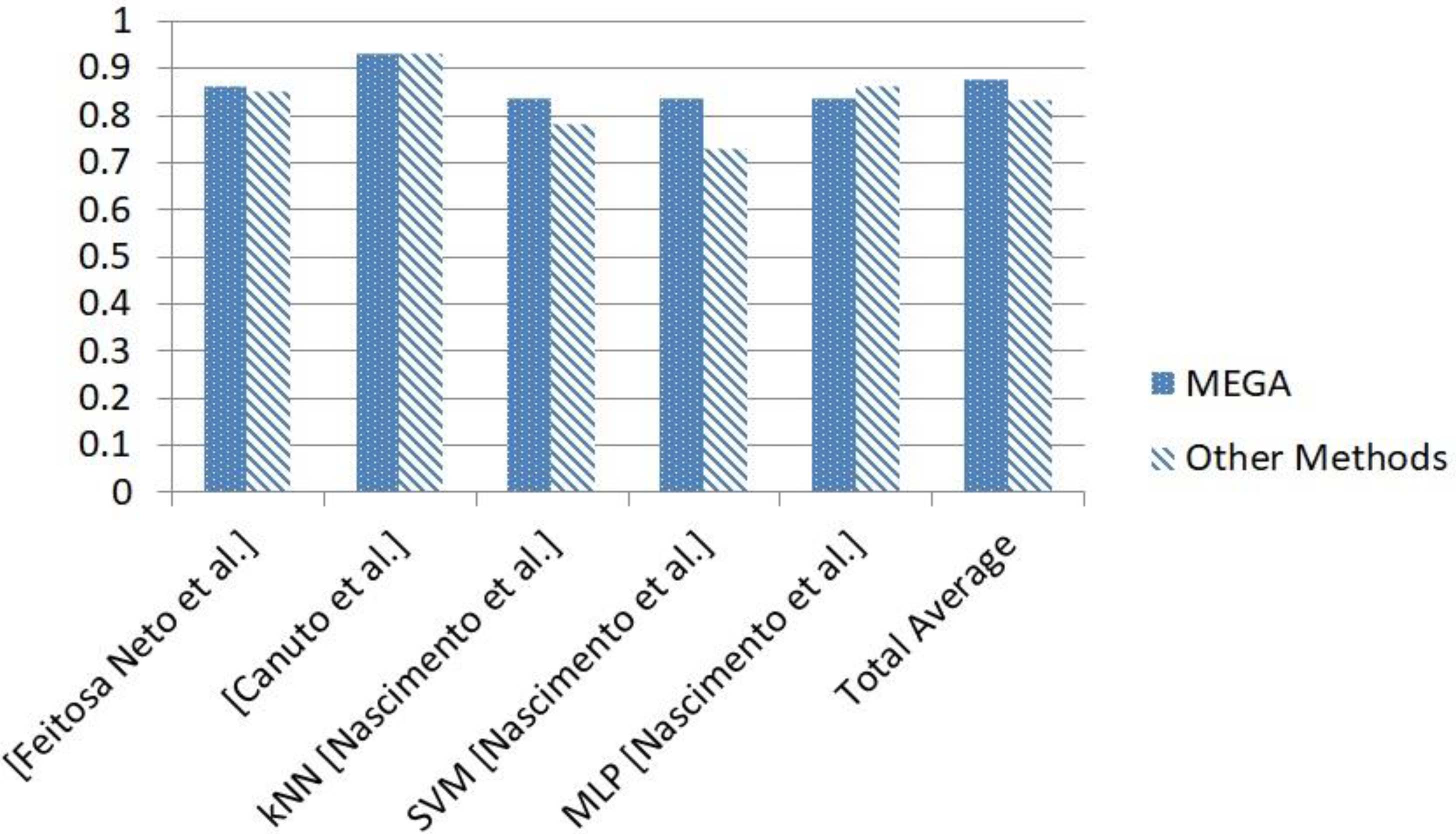
As described in Section 2.2, MEGA belongs to
Conclusions and future work
Classifier combination is one of the most effective methods for improving the performance of classifications. The most important issue for classifier selection apparently is the selection of the most suitable set of individual classifiers that should be combined. Because of the variety of individual classifiers, this selection can be extremely time-consuming. In this paper, we proposed MEGA, a novel method for classifier combination that exploits meta-learning and genetic algorithms and is composed of components for Training, Model Interpretation and Testing.
Comparing to previous work, the main contributions of MEGA are: (i) Varied range of meta-features and individual classifiers, (ii) automatic guarantee of diversity in the ensemble system and (iii) novel interpretable rules. Numerically, MEGA generates superior results comparing to three methods.
MEGA does not only achieve superior classification results compared to existing methods, but is also able to generate novel, human-interpretable classification rules. This “interpretability feature” makes MEGA particularly valuable for applications in domains (e.g., in the medical sector) that require explainable classification results, be it for legal or ethical reasons. Apart from this, MEGA is unique in that it additionally ensures diversity in the ensemble system and variability of the meta-features as well as the individual classifiers.
MEGA opens several promising avenues for future research. Among them is the exploration of other ensemble architectures such as bagging, boosting and multi-boosting, which can improve the performance of the result combination. As it is known genetic algorithm is an evolutionary algorithm, which its performance and the final result might be differ from one set of configuration to another. So, another avenue worth to investigate concerns the configuration of the genetic algorithm, possibly using different fitness functions such as accuracy and logarithmic loss, among others. A third promising avenue is using different meta-learners, such as SVM and different searching algorithm for finding the best combination of classifier in place of the genetic algorithm.