Abstract
Adverse weather conditions, such as snow-covered roads, represent a challenge for autonomous vehicle research. This is particularly challenging as it might cause misalignment between the longitudinal axis of the vehicle and the actual direction of travel. In this paper, we extend previous work in the field of autonomous vehicles on snow-covered roads and present a novel approach for side-slip angle estimation that combines perception with a hybrid artificial neural network pushing the prediction horizon beyond existing approaches. We exploited the feature extraction capabilities of convolutional neural networks and the dynamic time series relationship learning capabilities of gated recurrent units and combined them with a motion model to estimate the side-slip angle. Subsequently, we evaluated the model using the 3DCoAutoSim simulation platform, where we designed a suitable simulation environment with snowfall, friction, and car tracks in snow. The results revealed that our approach outperforms the baseline model for prediction horizons
Introduction
Novel safety systems which control vehicle dynamics monitor key sensor signals such as wheel angular velocities, steering angle, yaw rate, and vehicle side-slip angle [1]. The side-slip angle, also known as drift or attitude, represents the misalignment between the vehicle’s longitudinal axis and its travel direction, making it crucial for systems like ESC to ensure safety. Vehicle control systems including the ESC, active steering, and ATC rely on real-time vehicle state assessments, particularly the VSA [2, 3]. The vehicle’s state comprises longitudinal and lateral velocity or acceleration, steering angle, yaw rate, and more. These properties can be measured directly (like acceleration, steering angle) or inferred from sensor data. However, calculating the VSA is complex as it depends on wheel and ground friction, wheel forces, and vehicle dynamics [2, 3, 4]. Determining these factors directly is costly and complicated, requiring high-precision sensors [5, 2, 3, 4, 6, 7]. Therefore, researchers have long investigated VSA estimation methods, starting as early as 1990 [2]. This study primarily employs an empirical descriptive model to explore and confirm the relationships between vehicle and road factors and VSA. To ensure a comprehensive understanding of these relationships, we have employed statistical analyses using both Spearman and Pearson correlation methods, allowing us to analyze the data in multiple dimensions. As indicated in [5], the vehicle maneuverability strongly depends on the size of the VSA. Under dry road conditions the vehicle can achieve a VSA of up to ten degrees. However, in snowy conditions, this value is limited to a maximum of four degrees to ensure the vehicle remains maneuverable.
Top view of a vehicle during a right turn, with a fixed coordinate frame at 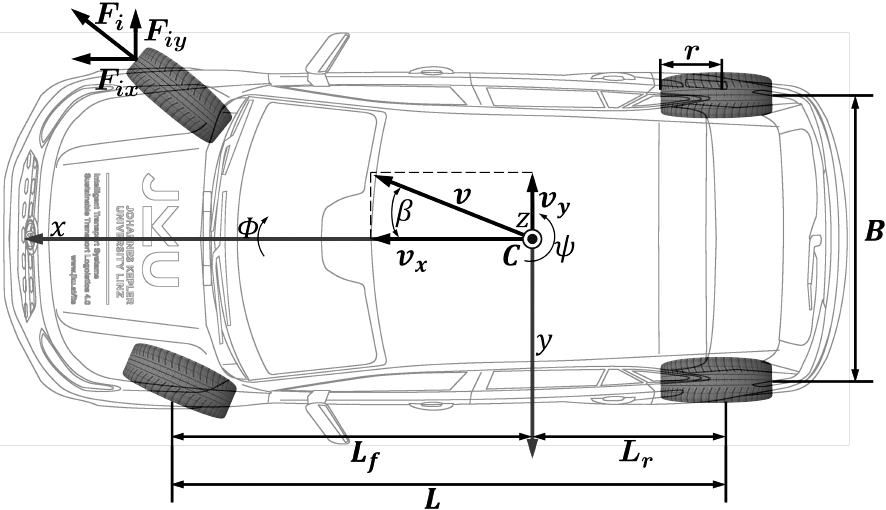
Typically, when estimating the VSA, the physical properties depicted in Fig. 1 are taken into account. These properties are either provided by (CAN) BUS data or acquired through proprioceptive sensors. In the following, we aim to provide a wide baseline for understanding the performance of various VSA estimate methodologies, particularly under diverse situations, and according to [2, 3, 8, 9], these approaches can be primarily classified as:
Observer – based: These approaches rely either on a kinematic or dynamic model of the vehicle in combination with an observer, where the most common ones are derivatives of the bayes filter, such as KF and its non-linear derivatives EKF and UKF. Neural Network – based: Most approaches rely on the same NN structure consisting of a total of three layers composed of one input layer, one fully connected hidden layer with log-sigmoid activation, and one output layer with linear activation.
The issue of estimating the VSA becomes particularly relevant under non-optimal weather conditions such as cases involving snow-covered roadways, as described in [10]. As observer-based estimators drastically rely on models of not only the vehicle but also of the tire-road interaction, the performance of these varies according to the accuracy of the model as well as the sensor systems utilized. Moreover, the non-linear characteristics of driving make it difficult to obtain a satisfactory model and estimation performance.
The findings presented in [3] elucidate several points on vehicle dynamics. Dynamic-based observer methods apply effectively only at
In [4] four different NN estimators for VSA estimation were compared: FFNN [11], RNN [12], GRU [13], and LSTM [14]. These networks were compared in terms of accuracy based on the RMSE, mean training time, and mean estimation time. They concluded that FFNN achieved the highest accuracy and lowest estimation time but also the highest training time. LSTM outperformed GRU in terms of accuracy, but took longer for each prediction and overall training.
As stated at the beginning of this section, accurate estimation of the VSA is crucial for efficient ESC, which in turn can significantly mitigate vehicle spinning – a primary contributor to nearly 25% of human-injury-related accidents [4].
Prompted by this necessity, we contribute to the state of the art in VSA estimation, by proposing an enhanced sensor configuration and a novel approach to integrate sensor data for more precise estimation over an extended prediction horizon.
We present a model for estimating VSA on snowy roads – a challenging scenario for ESC systems [5]. Building on the premise that exteroceptive sensor data, strictly speaking visual characteristics, can enhance prediction accuracy [15, 16], we introduce an approach that integrates image features extracted by a CNN [17] into a hybrid artificial neural network [8]. This method leverages the rich visual cues from CNN-processed camera feeds, thereby uncovering previously unexplored VSA-related information and improving prediction accuracy over existing techniques.
Camera-based features provide extensive information about road conditions, including wet, icy, or uneven surfaces thus enabling the system to adapt to diverse road scenarios. Additionally, they capture visual cues related to vehicle dynamics, such as relative orientation or position changes during adverse conditions like snow, which enhance the understanding of the vehicle’s state. Furthermore, this integration reduces the model’s reliance on potentially erroneous sensors and enhances the overall reliability of VSA estimation.
Our model surpasses current research [3, 4, 8] in terms of an extended prediction horizon and combines the benefits of FFNN and GRU-based VSA estimation methods with deep learning-driven perception models. We also incorporate a kinematic model as outlined in [8] to strengthen the prediction capabilities of our CNN-GRU architecture.
The verification of our approach was conducted at two levels:
We scrutinized the correlation between the image features and the VSA by employing Pearson’s correlation coefficient and Spearman’s rank correlation coefficient [18]. This evaluation utilized a simulated dataset, where both CNN features [17] and side-slip angles were collated. The collected image features underwent preprocessing through PCA [19]. The resulting relationship between the reduced image features and the side-slip angle was then further examined and analyzed. To evaluate the proposed model, we integrated the extracted image features into a pipeline based on a GRU. The model’s performance was evaluated by comparing its results with the GT values from a separate evaluation dataset and a baseline model, as described in [8].
This article is structured as follows: The following Section 2 introduces the problem of VSA and the general architecture for NN-based estimation approaches, further we provide preliminary information on the utilized NN architectures (CNN, GRU) as well as on the motion model (single-track model) utilized in this research. In Section 3 related literature on research estimating the VSA as well as approaches combining CNNs with GRU networks are reviewed, followed by our proposed approach in Section 4. The results are presented and discussed in Sections 5 and Section 6 respectively. Finally, Section 7, concludes the manuscript and presents future work.
This section lays the foundation for understanding the complexities of vehicle dynamics and the perception models used for their prediction, focusing primarily on the vehicle side-slip angle estimation problem. The challenges of accurately determining the side-slip angle with conventional methods lead to the exploration of machine learning-based alternatives. Through exploring neural networks and kinematic constructs, this section offers a concise overview of the methodologies implemented in this work.
For a technical explanation of the CNN, GRU architecture or the single-track model the authors refer the reader to [20, 21, 13, 22, 23].
Vehicle side-slip angle estimation problem
Centered on a vehicle’s mass, its motion is characterized in a horizontal celestial system. The overall velocity
with
However, accurate determinations are impracticable, which necessitates the exploration of alternative VSA estimation methods. Typically, VSA ranges from
Machine learning models, particularly CNNs and GRUs, have become increasingly popular in the realm of artificial intelligence in recent years. While CNNs have proven their proficiency in tasks such as human action recognition, object detection, and natural language processing, GRUs have found applications in time series forecasting [24], semantic analysis [25], and also natural language processing [26]. In the realm of VSA estimation, machine learning models, especially CNNs and GRUs, offer significant advantages in contrast to traditional approaches. CNNs aim to extract spatial features from images which makes them suitable for processing visual data from cameras to detect road conditions and vehicle dynamics. On the other hand, GRUs are adept at handling sequential data capturing the temporal dependencies in VSA estimations over time.
Convolutional neural networks
CNNs, a variant of deep feed-forward ANNs, are effective in applications such as image analysis [27], and natural language processing [28] due to their high-dimensional vector handling capability.
CNNs consist of feature extraction and classification parts, where alternating convolutional and pooling layers create feature maps. Information propagates from early layers, holding low-level details, to later layers with high-level details. The reduced-dimensionality output from the last feature extraction layer is input to a fully connected layer for classification.
CNNs’ core components are (i) convolutional layers, (ii) pooling layers, and (iii) fully-connected layers.
Convolutional Layer
These layers utilize kernels to perform convolution operations on input data, traditionally utilized for tasks such as blurring and information extraction, but primarily aimed at extracting features from spatial data in this context. By utilizing weighted kernels, these layers generate feature maps from input images. The process involves applying activation functions like the ReLU activation function to neurons and conducting convolution at each point between the kernel and image. This operation of convolution helps detect features like edges, consequently enhancing image sharpness for specific tasks.
Pooling Layer
This layer aggregates input data to create downsampled outputs by utilizing a summary statistic, enhancing efficiency, reducing overfitting, and retaining spatial invariance, but with lower spatial dimensions. The pooling operation can be seen as a form of image averaging (blurring) that retains the most salient features while reducing dimensionality.
Fully-Connected Layer
In this layer all inputs from the preceding layer link to every activation unit of the next layer, creating a high-level feature map. This layer integrates the extracted features, supporting tasks like object recognition or classification based on the detected patterns.
Gated recurrent unit
Single GRU cell architecture. This showcases the primary components including the input layer that receives data, the hidden state carrying information through the network, the reset gate which determines the extent to which previous information is forgotten, and the update gate that decides how much of the current state should be updated with the new proposed state.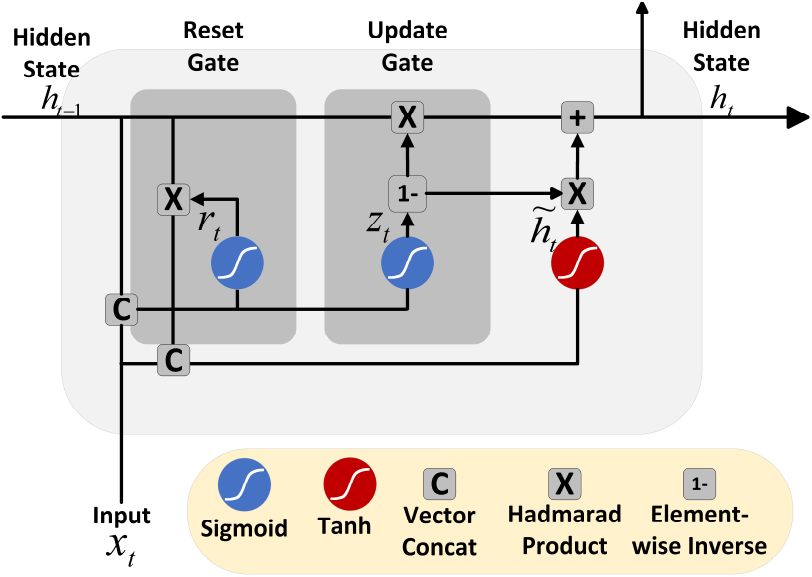
GRUs, introduced in [13], are a type of RNN [12] designed to capture long-term dependencies in sequential data while overcoming the short-term memory limitations of traditional RNNs. They have comparable accuracy to other RNN structures like LSTM [14], but offer faster training and prediction due to fewer model parameters [29, 30].
Comparison between the Ackermann steering model and single-track model.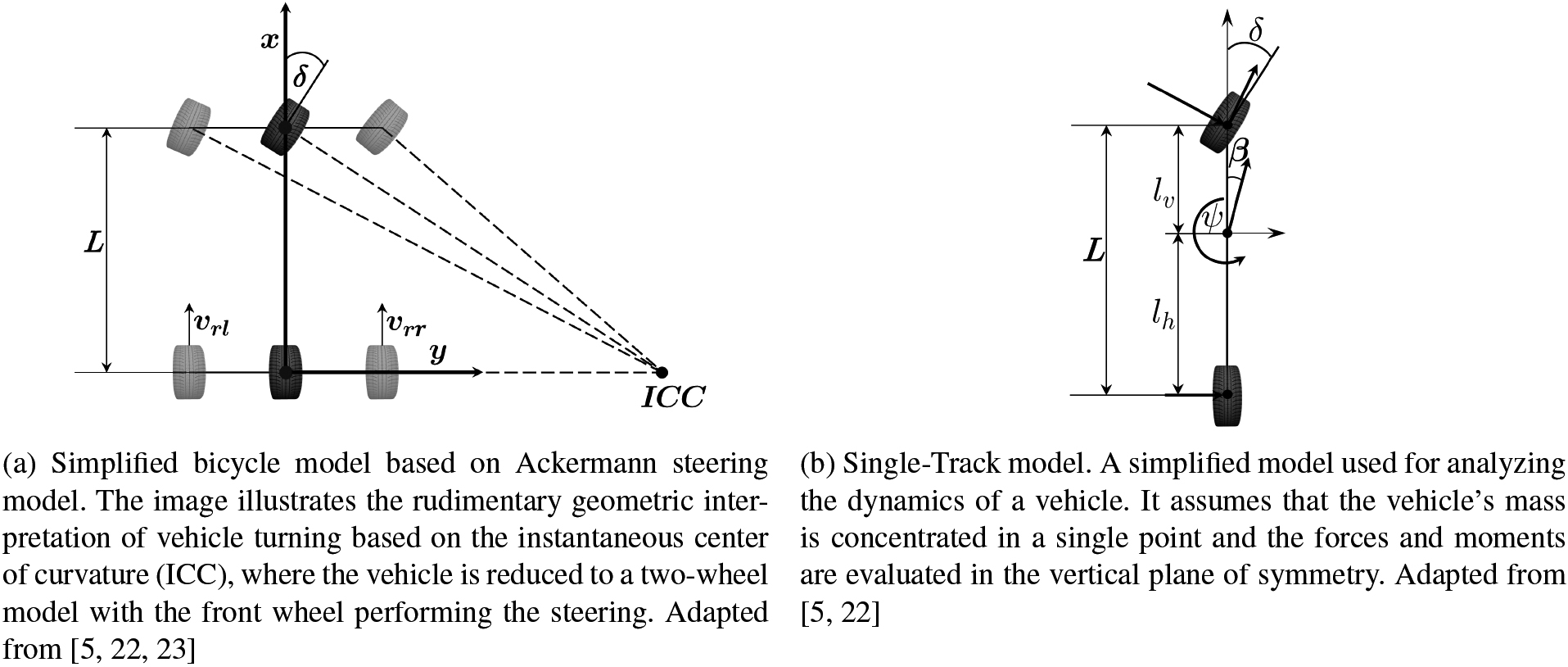
As Fig. 2 illustrates, the GRU cell is governed by:
where
Reset Gate
The reset gate (
Update Gate
The update gate (
It’s worth noting that while GRUs inherently transfer information across time steps in a sequence, this mechanism is distinct from the traditional concept of transfer learning, where pre-trained models are adapted for a different but related task [31, 30].
The single-track model, a physics-based kinematic model often used as a simplified version of the Ackermann steering model [23, 32], delivers a plausible representation of vehicle behavior without requiring extensive modeling or parameterization [22, 32]. This kinematic model was proposed for lateral accelerations below 0.5 g [32].
The bicycle model, a simplified version of the Ackermann model, as depicted in Fig. 3a, merges the front and rear wheels into single points each. This enables the model to depict lateral vehicle dynamics in a physically plausible manner as illustrated in Fig. 3b [33, 22]. The single-track model’s acceleration around the center of gravity is given by:
In the single-track model, the vehicle’s mass is assumed to be concentrated at its center of gravity, a common simplification in vehicle dynamics. While this assumption streamlines the model, it may overlook some real-world complexities. However, neural networks, especially CNNs and GRUs, can learn and account for such intricacies. Leveraging the deep learning capabilities highlighted by [34], our hybrid CNN-GRU architecture learns transformations, including those related to the center of mass, enhancing the model’s adaptability and accuracy.
In this section, we address the topic of VSA estimation as well as CNN-GRU hybrid models. As outlined in the introduction, the majority of VSA estimation methods gravitate towards either a model-based approach, employing a kinematic or dynamic model coupled with an observer, or a black-box model which utilize machine learning models. However, only a few of these approaches exploit a combination of both strategies.
In [35], three FFNN configurations were designed to estimate the VSA. Network A utilized basic vehicle dynamics, while Networks B and C integrated time-delayed signals and feedback for improved accuracy. While A faced challenges with speed variations, B showed adaptability, and C, despite its feedback mechanism, had inconsistent performance. Overall, Network B was the most reliable for estimating the sideslip angle across varying conditions.
The authors of [9] utilized an LSTM RNN in combination with a fully connected layer as output to determine the lateral vehicle velocity which is inherently necessary to calculate the VSA. They collected approx. 88 minutes of simulation data with varying road friction coefficients and applied a 90/10 train-test split. For evaluation they performed a double lane change experiment and reported that their method achieved accurate estimation of the vehicle lateral velocity during low and medium speeds of
In [8] a GRU network was combined with a kinematic model for the estimation of the VSA. The authors collected approx. 16 hours of sensor data, in a real-world vehicle, under three different road conditions and compared their VSA estimation approach with a sensor fusion of GPS and IMU. The authors set a plain GRU network against a hybrid kinematic GRU model for comparison. The former model incorporated inputs such as the steering wheel angle, longitudinal speed, longitudinal and lateral acceleration, yaw rate, and all four wheel speeds for prediction. In contrast, the latter model, aside from using the previously mentioned inputs, also took into account the change in side-slip angle
The authors of [36] proposed a hybrid state estimation approach to estimate the roll angle of a vehicle using a combination of data-based estimators represented by a GRU network and existing physical knowledge. The proposed method was evaluated using real-world driving data and showed improved precision compared to traditional methods such as EKF and UKF. The results showed that the hybrid state estimation approach provided accurate estimates of roll angle compared to traditional methods such as EKF and UKF. The RMSE of roll angle estimation using hybrid state estimation was 0.23
Utilizing the feature extraction capabilities of CNNs and using them as (additional) input for GRU networks has seen an up-rise in recent years as many researches combined the benefits of those two methods creating a CNN-GRU deep learning framework [37, 38, 39, 40, 41].
The combination of CNN and GRU was employed in [40] to learn the dynamic time-series relationship between variable working conditions and clamping point force for the prediction of the clamp force for handling deformable parts. Here a fully connected CNN was utilized for feature extraction and dimensionality reduction of high dimensional data representing the change of force state at the clamping point. The extracted features were utilized as inputs for a GRU network for prediction of the clamping point force under complex time-varying conditions and proved the effectiveness of the CNN-GRU prediction framework.
The research conducted in [37] proposed a two-step hybrid CNN-GRU network to predict short-term electricity consumption in residential buildings. The CNN consisted of two convolutional layers with ReLU activation function and a kernel size of two and a filter of 1
A spatial-temporal feature-selection algorithm was also utilized in [41] to determine relevant inputs for a CNN-GRU for short-term traffic speed prediction. The network structure consisted of the LeNet-5, for the CNN, and a bidirectional GRU, so that the predictions could also incorporate previous inputs in addition to the current input vector for greater accuracy. The findings showed that this hybrid model overcame the constraints of single models, fully utilized the space-time properties of the traffic data, and predicted traffic speeds with high accuracy.
Component comparison of state-of-the-art literature with our approach
Component comparison of state-of-the-art literature with our approach
The car model, as well as the BoxCollider and WheelColliders. The mesh of the wheels are disabled to avoid visual occlusion of the WheelColliders.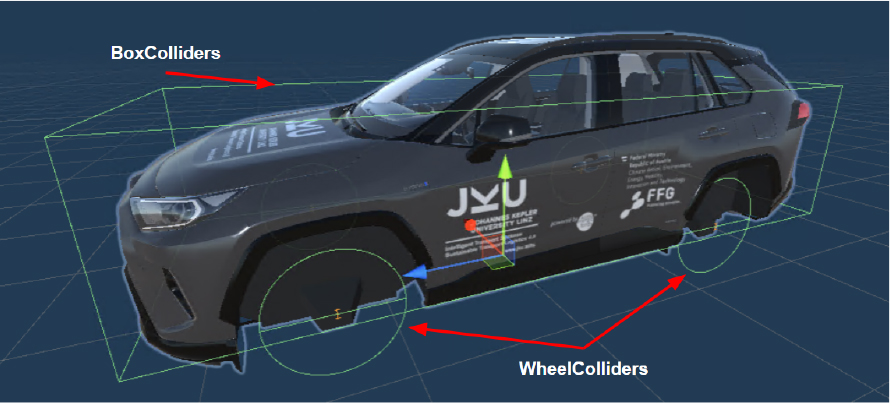
Existing research highlights the potential of hybrid GRU models for VSA estimation, but their performance is limited in challenging conditions like snowy environments [8]. The effectiveness of hybrid CNN and GRU models for VSA estimation in adverse conditions remains largely unexplored. Our study addresses this research gap and aims to enhance VSA estimation models by integrating visual cues from camera data thus reducing reliance on error-prone sensors, particularly in challenging snowy road conditions.
To provide a clearer perspective on how our approach stands in comparison to existing literature, we present Table 1 that juxtaposes the key components and features of various state-of-the-art methods with our proposed methodology. This table elucidates the comprehensive nature of our approach, highlighting its distinctiveness and advancements in the field. By examining the table, it becomes evident that our approach amalgamates a diverse set of features and methodologies, setting it apart from the current state-of-the-art literature. This comprehensive integration is pivotal in enhancing the accuracy and robustness of VSA estimation, especially under challenging conditions.
This section initially presents the simulation environment, which was used to generate the data for this study. Subsequently, we outline the methodology used to explore the relationship between the image-based features and the VSA. Furthermore, this section introduces the proposed model that integrates CNN-based features for accurate VSA estimation.
Experimental setup and simulation environment
We used the Unity3D based 3DCoAutoSim [42] platform to simulate the environment with snowfall, friction, and car tracks on the snow. The test ground setup used in this work is based on [10], which is a snow covered 4-lane dual carriageway circular test track. The friction between the road surface and the wheels is directly achieved by setting the Unity WheelColliders, which will be explained in more detail later. The setting of the test ground is mainly to extract visual data such as car tracks on the snow. For the dataset creation we performed multiple laps, in both directions of the course, and stored the sensor data in separate rosbag files.
The vehicle model in the simulator corresponded to a Toyota Rav4 Hybrid (2020) [43] and closely resembles it in terms of track-width, wheelbase, and mass which is equally distributed over the volume of the vehicle. In order to perform the collision volume of the vehicle, we used a Unity BoxCollider that covered the complete body of the vehicle, being its center of mass selected from the geometric center of the vehicle chassis, as seen in Fig. 4. The four wheels were respectively controlled by four Unity WheelColliders, and their steering occurred in conformity with the Ackermann steering model. The control scripts set of the vehicle relied on [10], which was implemented via the RealisticCarControl V3 [44].
The friction parameter settings of the WheelColliders
The friction parameter settings of the WheelColliders
The parameters of the WheelCollider controlled the friction between the wheels and ground. The default settings of the friction parameters for the experiment are shown in Table 2. We also implemented a 9 degree of freedom Inertial Measurement Unit (IMU), GPS sensor, as well as longitudinal velocity. In addition, we monitored the steering angle of the vehicle as well as the side-slip angle. All these data were either directly received from Unity or calculated from the sensor data. Finally, we used two cameras with a resolution of 640
The foundation of this study is built upon an existing relationship between the data obtained from imaging sensors and the VSA. This approach is motivated by the acknowledged limitations of black-box machine learning models [45].
To develop a reliable model, we performed a comprehensive analysis of this relationship. This involved the collection and processing of image and VSA data from the simulated environment discussed above, conducting rigorous statistical tests to investigate correlations, and scrutinizing the relationship between the variables.
In each timestep
In each timestep, we applied the GoogLeNet CNN [17] and obtained 1024 features for each image. In order to evaluate the relationship between these features and the VSA, we first standardized the features and extracted a de-correlated representation relying on the PCA [19]. We chose a variance-based method (PCA) since it offers a clear and intuitive understanding of the data’s structure. The principal components (lateral dimensions) derived from such methods are orthogonal, ensuring no redundancy, and they capture the directions of maximum variance in the data, making it more readable.
The proposed method with a batch size of 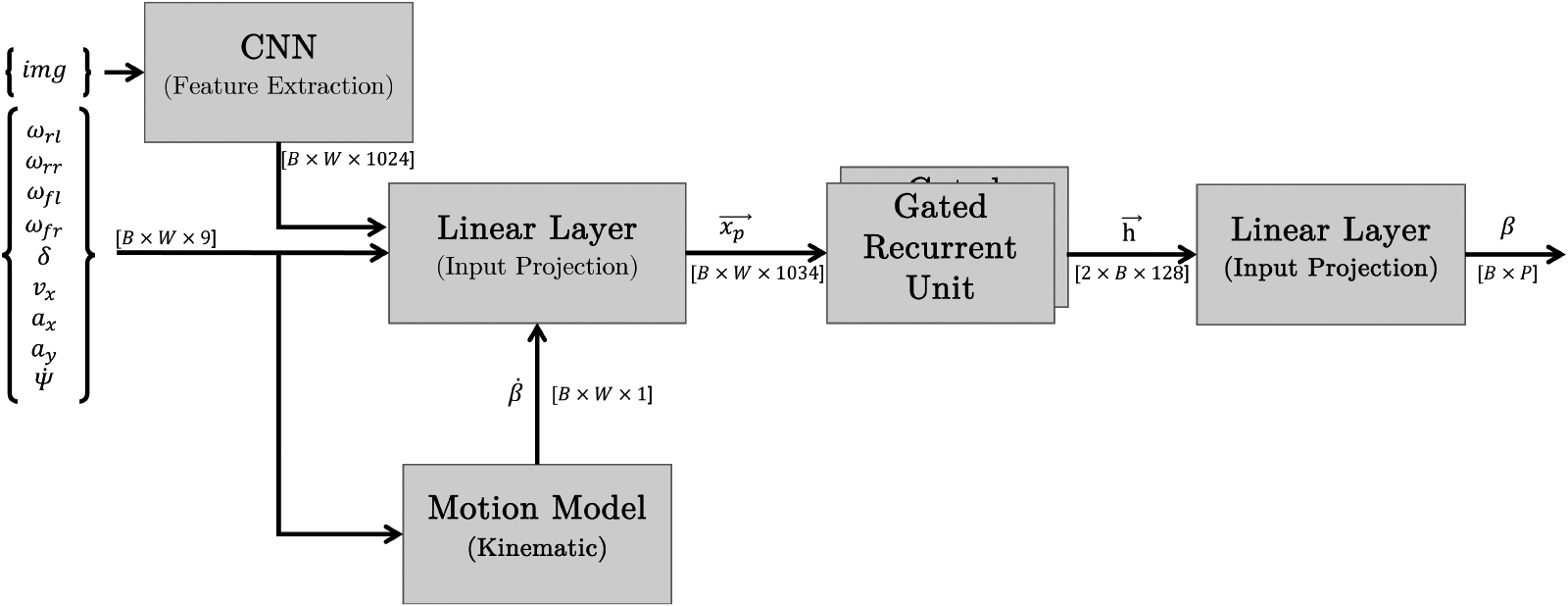
The relationship between the first five principal components and the VSA was assessed using both Pearson’s and Spearman’s rank correlation tests. Pearson’s test was chosen as it effectively measures linear relationships between continuous variables providing insights into any linear correlation between the latent features and
We formulated two null hypotheses for our analysis.
Null Hypothesis 1, denoted as Null Hypothesis 2, denoted as
Both hypotheses tested whether there was a significant relationship between the variables under consideration. If the p-value, the probability of observing the data or more extreme results under the assumption that the null hypothesis is true, was found to be less than the predefined significance level
Our implemented prediction model consisted of a CNN, specifically GoogLeNet [17], for feature extraction on images, and a GRU, for time series prediction, as visualized in Fig. 5. The choice of GoogLeNet was motivated by its efficiency in feature extraction, computational affordability, and its ability to learn multi-scale features through inception modules [17], metrics that are crucial in various applications, including digital photogrammetry of piping systems [46]. These evaluation criteria align with the comprehensive computational exploration conducted by [47], who also emphasized the importance of methodological choices and feature extraction techniques. The chosen inputs consisted of a sliding window sequence
Furthermore, our research explored both sequence-to-one (S2O) and sequence-to-sequence (S2S) predictions. Specifically, S2O prediction involves processing a sequence of input data to produce a single output, while S2S prediction takes a sequence of input data and predicts a corresponding output sequence, allowing for more dynamic and temporally structured predictions [48]. The examination of different sliding window lengths provides critical insights into the temporal influence on the prediction accuracy of the model. We utilized the last feature map of a CNN [17] to provide exteroceptive information of the environment to the prediction model. We argue that the incorporation of exteroceptive information from image streams provides long term correction data and thus will improve the sequence-to-sequence prediction capabilities. Besides the aforementioned sensor data we utilized the kinematic single-track model to compute the derivative, of the prediction target which is fed to the linear layer via the motion model. For this we transformed the formula Eq. (6) to derive
We argue that the proposed sensor suit is applicable for the use case due to the fact that (i) all new vehicles manufactured on or after May 1
Dataset metrics
3 best validation scores of 3-fold cross validation. Best result in
Dataset metrics.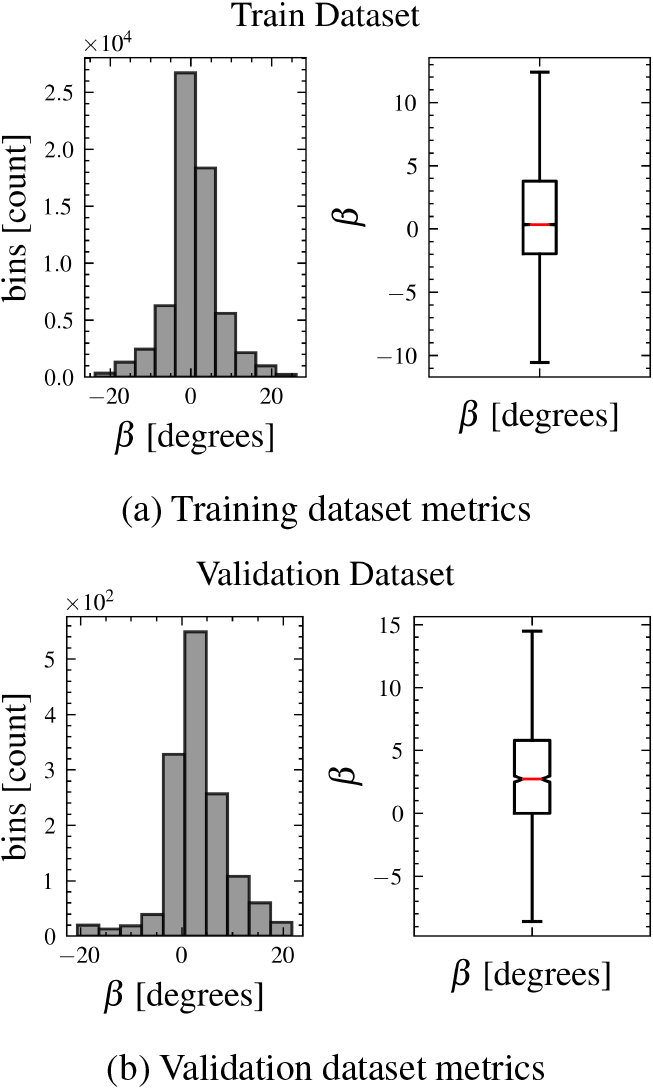
We implemented the model using PyTorch [53] and Cuda 12.1. To train and test our model we collected a total of 110 min data on snow covered asphalt in the 3DCoAutoSim simulator [54]. Table 3 depicts an overview of the dataset composition. For the initial hyperparameter estimation, we relied on 3-fold cross-validation with 20 epochs, Table 4 visualizes the results and selected parameters. Besides the initially chosen hyperparameters we utilized learning rate scheduling based on ReduceLRonPlateu1
Used to reduce learning rate when a metric has stopped improving
Besides the proposed approach shown in Fig. 5, we compared our model in S2O and S2S prediction to the approach implemented in [8]. In all cases we used a separate validation dataset to evaluate our model that was neither used during training nor testing. Since the frequency of the sensors differed, we re-sampled the collected data, in preprocessing, to a frequency of 10 Hz. We then performed outlier removal, by relying on the z-score of 3, which indicates that data points beyond 3 standard deviations from the mean were considered as outliers, and further prepared the dataset in a sliding window approach as depicted in Table 5. Furthermore, we employed a feature scaling technique to normalize the range of the independent variables in the dataset as part of the data preprocessing step. The resulting dataset consisted of 65919 sample points valid for training, testing, and evaluation. Figure 6 visualizes the distribution of the ground truth VSA over the complete dataset.
Dataset structure for sequence-to-sequence prediction using a sliding window approach. The table represents input sequences with
In light of the correlation analysis, the highly non-linear feature processing within our proposed CNN pipeline, and the distinct correlation of front and rear camera features with the VSA, we pursued two distinct experimental approaches. These approaches not only included image data but also leveraged other sensor information as previously described in this section.
Approach A utilized both front and rear image data in conjunction with the sensor data. This aimed to assess the combined impact of front and rear cameras and other sensor information on the model’s VSA prediction capabilities.
On the other hand, Approach B focused exclusively on the front image data and the sensor information, intentionally omitting the rear image data. Despite using the same dataset as Approach A, Approach B truncated the rear camera information. The rationale behind this strategy was to test the relevance and impact of the rear camera data as suggested by the correlation analysis.
Sequence-to-one prediction
To evaluate the precision of both models in the S2O prediction paradigm, we employed the sMAPE, as elaborated at the end of this Section. For the performance of our proposed hybrid CNN-GRU model on the task of S2O prediction we set during training the hyperparameter
Sequence-to-sequence prediction
Given the interdependent nature of the VSA data, which dynamically evolves based on past, present, and future states, the S2S prediction paradigm is integral to our models, designed to capture and interpret the complex temporal dependencies that exist among different states in a sequence, thereby producing accurate estimations of future vehicle side-slip angles.
To evaluate the effectiveness of our S2S models, we conducted a series of comparative analyses using different prediction horizons. We employed the sSMAPE as our performance metric, providing a robust measure of the prediction accuracy of our models across various time horizons
Ground truth VSA of the evaluation dataset.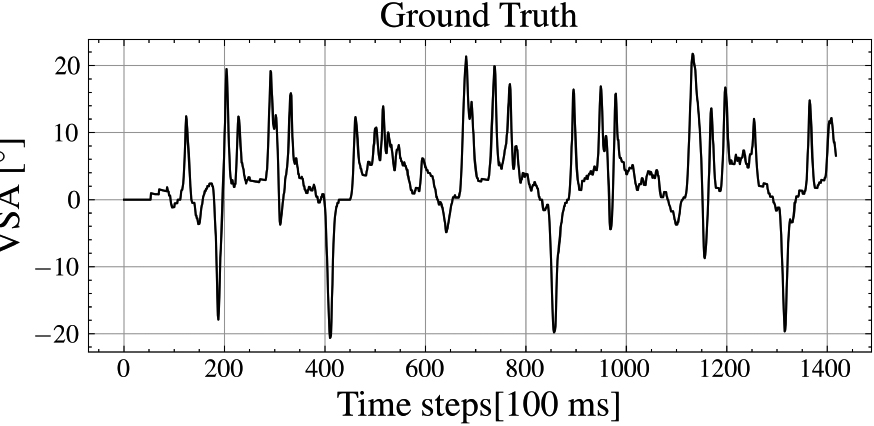
The outcomes yielded by our two experimental strategies in relation to the two distinct prediction paradigms, S2O and S2S, are delineated in Sections 5.2 and 5.3, respectively. To further fine-tune our models, we trained them using an array of hyperparameter combinations, these encompassed various sliding window input sizes
Finally, we evaluated the model performance using the sMAPE, sequence wise sMAPE (sSMAPE) as well as the averaged sSMAPE (
sMAPE
For evaluating the models’ accuracy we relied on sMAPE, the most commonly used metric to determine the accuracy of time sequence predictions [57]. Further, the sMAPE metric is especially suited for forecasting problems, as it provides a symmetric, scale-independent error measure, which is particularly useful when dealing with datasets that may contain zeros, as seen in Eq. (8) [58].
being
Statistical investigation of the relation of the PCA-based processed CNN features of the front and rear camera to
Sequence wise sMAPE
In our computation, we applied Eq. (8) to the predictions generated by our sequence-to-one/sequence model. Given that our model produced a set of sequences as its prediction output, the calculation was done on a per-sequence basis over all time steps and subsequently divided by the total number of time steps, yielding the sMAPE per sequence sSMAPE (sequence wise sMAPE) as described in Eq. (4.4):
In this equation,
Averaged sSMAPE
To provide a comprehensive overview of the performance of the models, we averaged the error metrics across all prediction sequences. This mean error, as seen in Eq. (10), represented the overall performance of the models across different prediction horizons and offered a summary measure of their accuracy.
where
This section describes the results of the relationship analysis of CNN image features and the VSA
We had to implement a minor modification on the output regression head so that the model could also be used for S2S prediction.
Table 6 reports the detailed findings of the correlation analysis described in 4.2, summarizing the estimated correlation values and their associated p-values for both Pearson’s and Spearman’s rank correlation methods. Each row represents one of the principal components from the PCA-based processed CNN features. Each column shows the estimate and p-value of the respective correlation method for both the front and rear cameras.
Comparative differential plots of S2O predictions from 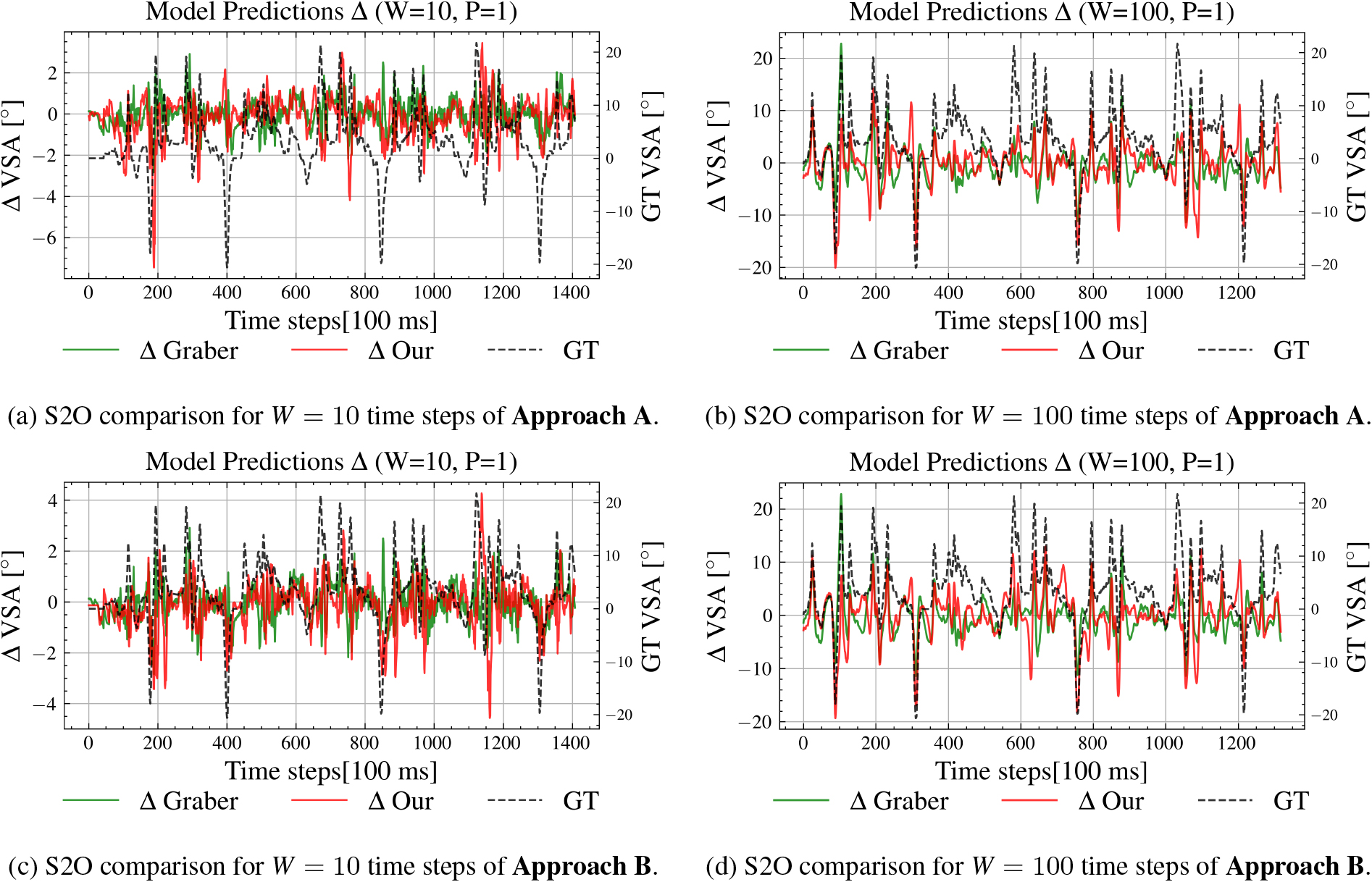
Figure 8 showcases the effectiveness of our hybrid CNN-GRU model in executing the S2O prediction task. It presents comparative differential plots for both Approach A and Approach B under different sliding window lengths of
sSMAPE compared to ground truth for
time step. Approach A uses all features, Approach B does not use rear image features, and [8] is the baseline model used for comparison. Best result in bold
sSMAPE compared to ground truth for
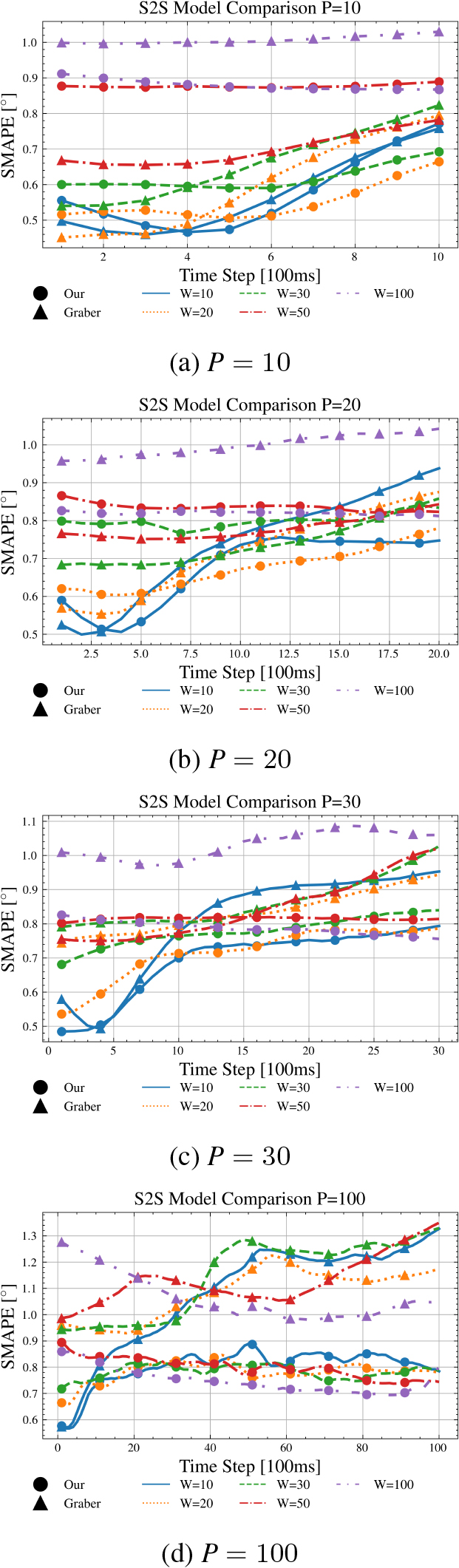
S2S sSMAPE comparison for each individual prediction horizon sequence.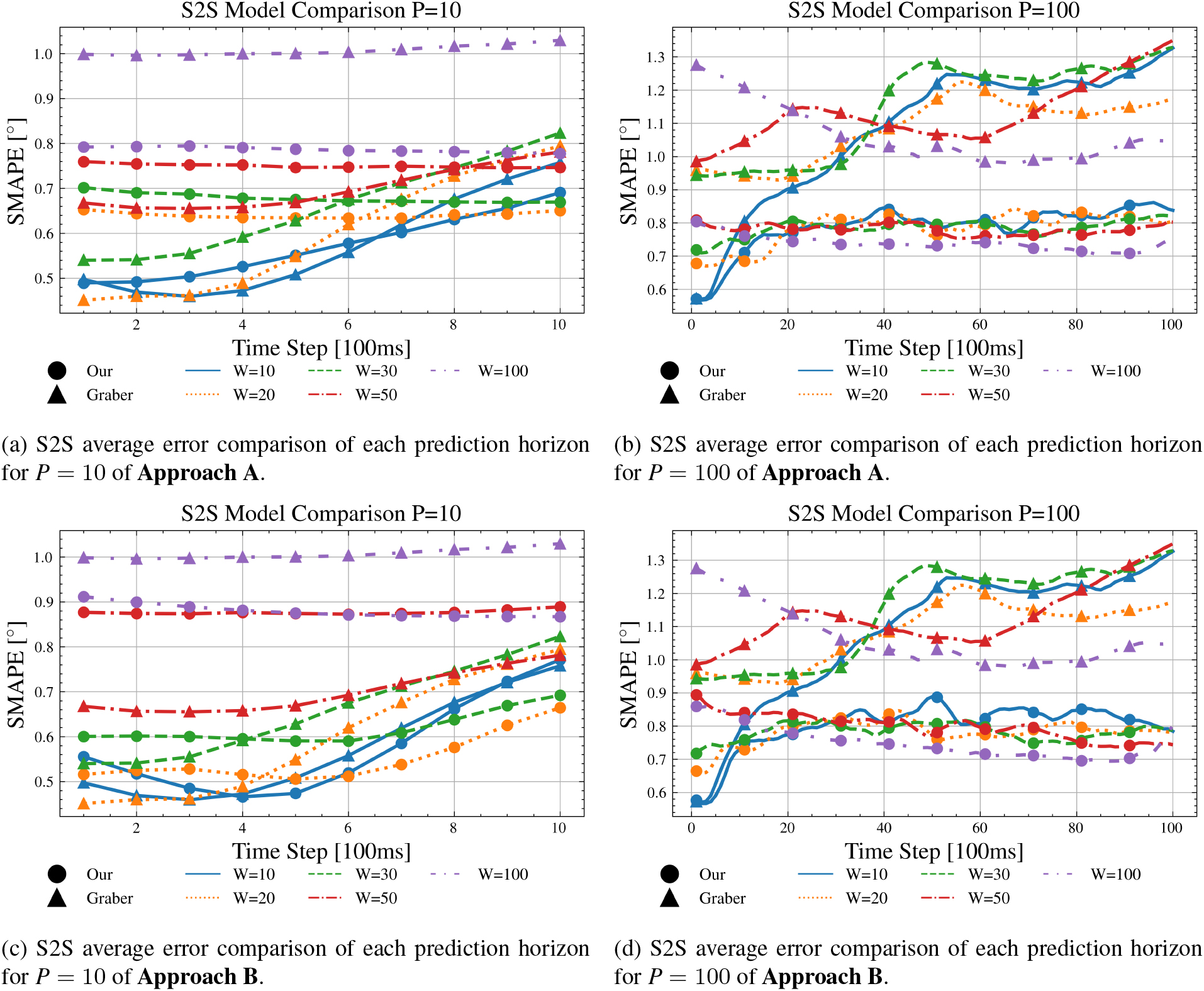
In Fig. 8a and c we can see that, compared to the ground truth and the approach of [8], our models generated similar accurate results, except for cases when the target value is close to the min/max values of the training data, e.g. as seen at
Comparison of Average Errors (
) for different sliding window sizes in Sequence-to-Sequence prediction. The table is divided into four sections based on prediction horizon (
). Each section compares the performance of Approach A, Approach B, and the benchmark model [8] for varying window sizes
. The best-performing method for each window size is highlighted in bold
Comparison of Average Errors (
Figure 9 presents the outcomes of applying the S2S prediction paradigm, illustrating the sSMAPE metric at each prediction horizon. For a more granular perspective see Table 8, as it displays the mean sSMAPE
The comparison of S2S averaged sMAPE for each individual prediction sequence for different horizons
The comparison of the S2S prediction paradigms is demonstrated through Fig. 9, which illustrates the sSMAPE for each prediction horizon. The results for
When comparing Approach A with Approach B, results for the first prediction step show Approach A surpassing Approach B only in 2 out of 5 instances when
For the last prediction step, the dynamics shift somewhat. Approach A surpasses Approach B in 4 out of 5 cases when
Another point of comparison is the fluctuation of the sSMAPE over time. As depicted in Fig. 9a and c, our models generally exhibit an initial decrease in the sSMAPE which eventually increases after reaching a minimum. In contrast, the model of [8] holds a stable sSMAPE for the early time steps, followed by an increase. This observation suggests that both our models surpass the model of [8] in long-term predictions, with the exact intersection point varying based on the window size
Finally, the models were compared based on their average sSMAPE (
Correlation analysis
The results of the correlation analysis presented in Table 6 demonstrate several key insights regarding the relationship between PCA-based processed CNN features of the front and rear camera to
High correlations are observed in the second, third, and fifth latent dimensions with
These results are echoed by the Spearman’s rank correlation, suggesting that these statistical relationships are robust. The third latent dimension, in particular, shows a negative correlation, implying an inverse relationship with the VSA in this dimension. The first and fourth latent dimensions also display correlations significant at
The correlations for the rear camera present a different narrative, being notably lower across all latent dimensions compared to the front camera. Nevertheless, most latent dimensions still display statistical significance at
Sequence-to-one prediction
Based on the results of the S2O prediction paradigm we recognize the need for a more in-depth exploration of our model’s capacity. We recognize that (i) additional data augmentation or an expanded training dataset may be necessary for superior data extrapolation. This realization emerged as we compared our approach to that of [8]. On the other hand, (ii) the divergence could also be rooted in the different methodologies for feature extraction from sensor data between our model and [8]’s. Furthermore, (iii) our model extends beyond the approach of [8] by incorporating exteroceptive sensor data, specifically image streams from vehicle cameras processed via CNN. Consequently, our CNN-GRU model captures a different spectrum of information for predicting the extremes of the VSA compared to a standalone GRU. This divergence may contribute to reduced accuracy near the extreme values of the training data. As we continue to refine our model, adjustments to the CNN and the inclusion of supplementary data sources are avenues we plan to explore for improving accuracy.
Sequence-to-sequence prediction
Approach A seems to be slightly more beneficial, especially for window sizes
It is worth noting that Approach A surpassed Approach B in 13 out of 25 cases. This indicates that notwithstanding the diminished correlation of the rear camera features with the side-slip angle, these features nonetheless deliver consequential information that augments the prediction accuracy of our model. The origin of this discrepancy may be rooted in various elements. First and foremost, the nexus between the rear camera features and the side-slip angle could be non-linear and intricate, reducing its detectability by conventional correlation measures but can still be deciphered by state-of-the-art prediction models such as deep neural networks. The sophisticated architecture of such models enables them to extract latent, non-linear patterns in data, thereby enhancing prediction performance even in the absence of an evident linear relationship. Secondly, an overlooked aspect in the correlation analysis is the potential synergistic effect among different data types. In this scenario, the interaction of rear camera features with other pieces of information, such as front camera features or steering angle, could substantially enrich the predictive capacity of the model. This collective effect is not discernible by examining individual correlation coefficients, which provide a somewhat simplistic view of the relationship between individual variables and the target. Lastly, it is plausible that the rear camera features serve as particularly vital information in specific circumstances, for instance, when the vehicle is reversing or during a sharp turn. Such contextual utility of rear camera features contributes to a comprehensive, more accurate prediction across a variety of situations. Taken together, these observations highlight the importance of including diverse types of data in complex prediction tasks, even those with seemingly low correlation to the target variable. It underlines the multifaceted nature of data utility in model performance and cautions against over-reliance on individual correlation measures when making decisions about feature inclusion. The analysis thus suggests the potential benefit of leveraging machine learning models capable of capturing both linear and non-linear relationships and interactions among features.
Compared to the baseline model of [8] both of our models outperformed it for longer prediction horizons (
Conclusion and future research
In this work we presumed that the incorporation of CNN features from the cameras of a car can besides the normally utilized kinematic and dynamic parameters improve the estimation of the side-slip angle. Our statistical analysis results revealed a significant relationship between the second, third, and fifth latent dimensions of the front camera and the side-slip angle (denoted as
Contrary to the correlation analysis results, our empirical investigation, relying on our hybrid CNN-GRU, illuminated that exploiting all available features (Approach A) often led to superior side-slip angle predictions relative to utilizing all features excluding the rear camera features (Approach B).
Our investigation concentrated on three principal areas: correlation analysis, sequence-to-one prediction, and sequence-to-sequence prediction. In Section 4.2 we explored the relationships between latent variables inherent to the front and rear image features and the VSA
The insights gained from these results contribute to a wider understanding as they do not only highlight the efficacy of our proposed models but also underscore potential limitations, particularly in utilizing the S2S prediction paradigm in VSA estimation. The real-world applicability of our model is evident in its potential to improve vehicle control in adverse conditions like snow. Its strength in longer prediction horizons makes it valuable for autonomous driving systems, where precise side-slip angle estimation is crucial for safety. The model’s ability to integrate diverse sensor data also adds contextual adaptability, useful in specific driving scenarios such as reversing or sharp turns.
Future research is needed to confirm these results and should consider integrating attention mechanisms and encoder-decoder structures into the model. Attention mechanisms could enhance feature relevance at each time step, potentially improving prediction accuracy. Moreover, encoder-decoder or autoencoder structures might enhance performance for larger input window sizes and prediction horizons, as they are adept at capturing temporal dependencies in sequence-to-sequence prediction tasks. These adjustments could offer a promising avenue for model performance improvement in side-slip angle prediction. In addition to the aforementioned avenues for future research, it may be beneficial to explore different CNN architectures to optimize VSA estimation. This could include direct estimation as well as the use of temporally contiguous gray-scale images. Ablation studies could help to isolate the effects of each architectural component and input modality and separate projection layers for each input could offer more flexibility in learning the weights and biases for each input. Moreover, investigating the use of sensors to dynamically determine the most suitable approach based on conditional probabilities and safety conditions could provide a more adaptive and robust system for VSA estimation on real systems. Finally, considering different hybrid models tailored to specific input states might optimize a first step towards real-time performance of the hybrid model. As an alternative to the current use of PCA for dimensionality reduction, future research could consider other dimensionality reduction methods such as [59] for discovering the most effective feature spaces and optimizing the number of features. This could provide a more robust and accurate approach for VSA estimation.
Footnotes
Appendix A. S2O Differential Plots
S2O differential plots of 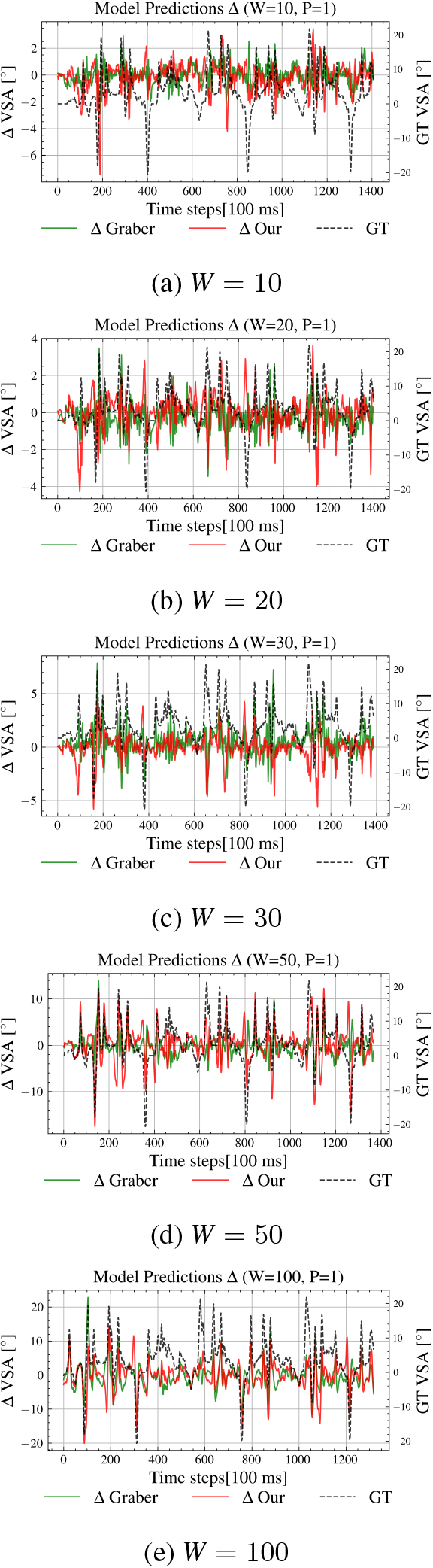
S2O differential plots of 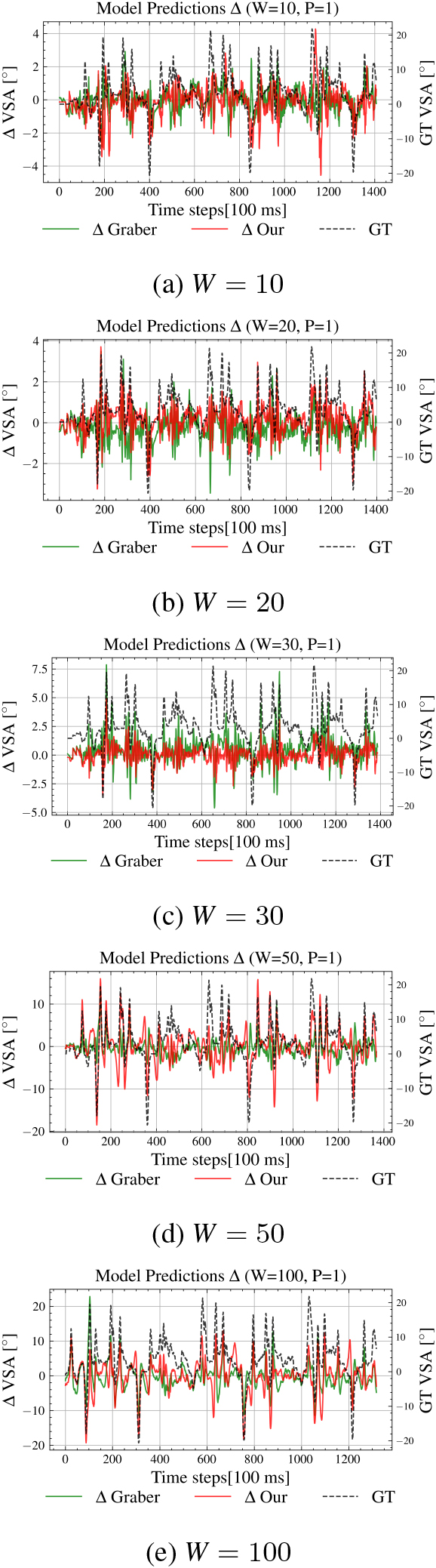
Appendix B. S2S Average Error Comparison
S2S averaged sMAPE comparison for 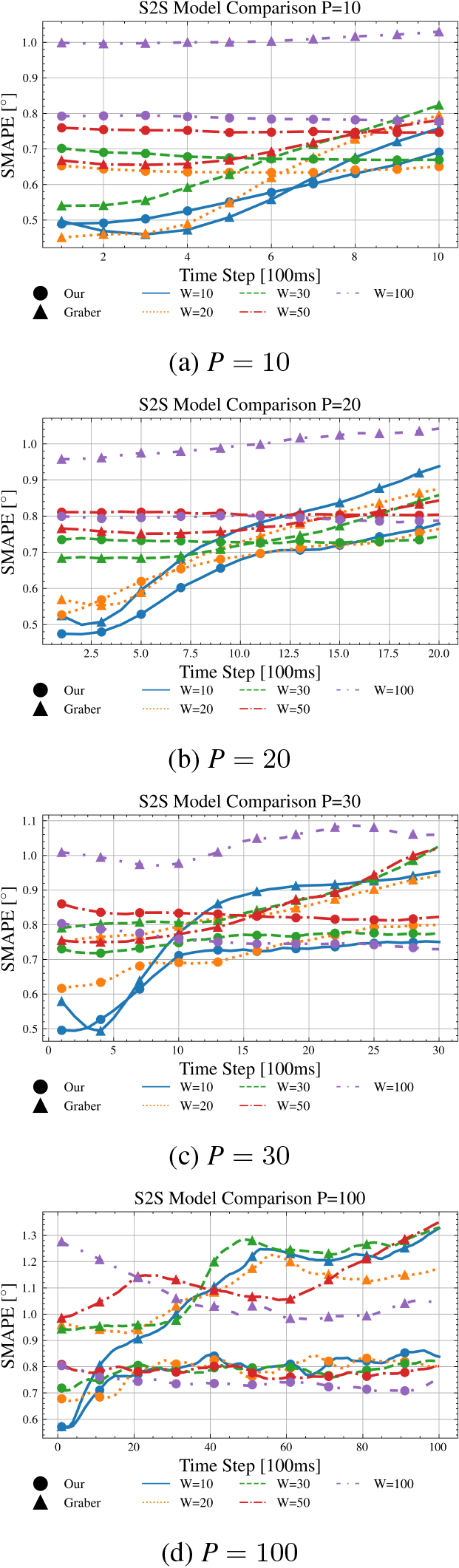
S2S averaged sMAPE comparison for