
Abstract
Private and military troll factories (facilities used to spread rumours in online social media) are currently proliferating around the world. By their very nature, they are obscure companies whose internal workings are largely unknown, apart from leaks to the press. They are even more concealed when it comes to their underlying technology. At least in a broad sense, it is believed that there are two main tasks performed by a troll factory: sowing and spreading. The first is to create and, more importantly, maintain a social network that can be used for the spreading task. It is then a wicked long-term activity, subject to all sorts of problems. As an attempt to make this perspective a little clearer, this paper uses exploratory design science research to produce artefacts that could be applied to online rumour spreading in social media. Then, as a hypothesis: it is possible to design a fully automated social media agent capable of sowing a social network on microblogging platforms. The expectation is that it will be possible to identify common opportunities and difficulties in the development of such tools, which in turn will allow an evaluation of the technology, but above all the level of automation of these facilities. The research is based on a general domain Twitter corpus with 4M
Introduction
Propaganda and counter-propaganda have long been used by governments (including the military) and private companies. However, online social media provide a special environment for propaganda [1] that is being exploited by groups of individuals who spread propaganda and conduct cyber-attacks, often referred to as troll factories. As troll factories are obscure facilities, their inner workings and especially their technology are largely unknown.
Understanding troll factories is a cornerstone of prevention and countermeasures. Most attempts in this direction are based on: a) compiling information leaks to build a coherent picture [2]; b) observing the rumour chain in online social media to infer how they work [3]; or c) examining unclassified military material [4]. This paper follows an alternative approach based on Design Science Research (DSR) [5, 6] but apply it to reverse engineering.
The idea of reverse engineering is to understand how a technology works [7]. If the artefact to be studied is available, a systematic study of it can be carried out. If it is not available, logic is used to infer the technology from images, descriptions and possibly parts of it. If almost no information is available, as is the case for this paper, a speculative design can be used to explore what the technology might be and the likely limitations it might have.
This paper has a fairly extensive introductory section, which aims to provide a broad context for the research that will be undertaken. First, a landscape of the spread of fake news is provided to show the breadth and complexity of the issue. Then, as this paper is not based on a positivist stance, a longer explanation of the methodology is recommended. With the methodology explained, it is possible to draw the working hypothesis for this paper. This leads to the description of the setup in which the experiment will be conducted. The introduction ends with an ethical disclaimer.
The following section (Section 2) presents the exploratory design experiments in which the possibility of building the artefacts discussed is estimated. Since it follows an inductive reasoning, two steps are considered; one discussing the base case (Section 2.1) and another generalising inferences from the base case (Section 2.2). Induction considers single and multiple bots interacting with single and multiple users. The following section (Section 3) discusses the results of the experiments considering the proposed hypothesis. The last section presents some concluding remarks and future work.
Note that Twitter has recently been rebranded as
Fake news spreading landscape
A troll is a person, often behind one or more inauthentic profiles, who posts or engages in inflammatory, disingenuous, and rambling actions on the Internet aimed at provoking emotional responses [8]. This is a convenient attitude for propaganda, which can be defined as
An online social media post containing fake news that reaches a wide audience is said to have gone viral. In a successful campaign, several posts containing fake news have gone viral, which is called infodemics[13] (term often related to, but not limited to, healthcare information). The virus metaphor is often deepened through the SEIR model (SEIR stands for susceptible, exposed, infectious, recovered) but applied to online social networks [14]. In this sense, the work of a troll factory is to find susceptible people, expose them to propaganda, and make them infectious. The work of counter-propaganda is to prevent this procedure from happening and to turn infectious people into recovered.
Online social media is a conducive environment for infodemics. There are two key features of online social media that are the cornerstone of this effort. One is that these platforms are capable of triggering the dopamine reward behaviour training [15], which acts as a Skinner box[16]. Another is the mediation algorithm which, in addition to reinforcing behavioural training and yielding to various cognitive biases due to segmentation [17], enables the targeting of susceptible people to be sent the malicious content [18].
In order to exploit the features as such, a large number (eventually millions or tens of millions of [19]) of inauthentic profiles is required [2]. This group includes bots, cyborgs, paid followers, etc. In the bot group there are several types such as influencing bot, echoing bot, spamming bot, etc. [20]. Twitter estimates that 5% of its accounts are bots (
A requirement to be met by the mediation algorithm is to provide an infinite timeline [22] to keep people online as long as possible [18]. Consider a mediation algorithm that uses a semantic network to relate someone’s interests. Let this person be tagged as interested in astronomy. After exhausting the recent content on astronomy, which is not expected to be much, the mediation algorithm might start showing posts on astrology, flat Earth (Earth is an “astro”), etc.; see Fig. 1.
ConceptNet [23] shortest path from astronomy to astrology.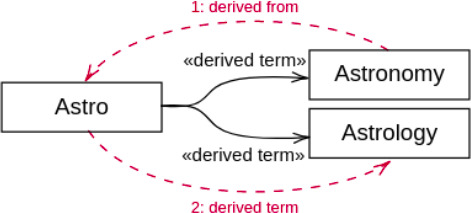
The infinite timeline would facilitate the spread of fake news (and perhaps radicalisation) [24] as long as it exists in quantity. This feature is related to the agenda setting phenomenon [25], i.e. the amplification of content by exposing it to a wide audience. The more people talk about something (whether in agreement or not), the greater the change in a susceptible person exposed to a particular speech. It also triggers the group consensus effect [26], in short, if “everyone” in a community is committed to an idea, there is a tendency for the dissonant individual to merge with the crowd.
Finally, at present, it is not possible to say that spreading rumours is an activity limited to a single online social media. For example, some malicious content on COVID-19 started on 4chan, went through Telegram and Gab, and finally reached Facebook [27]. It is not the case that Facebook is safer than the other media; it seems to be the best place to spread links [28]. Thus, each online social media is used for different purposes and probably for different audiences [29].
Microblogging (e.g. Twitter, Gab, GETTR, TruthSocial, etc.) plays an important role in this mosaic. Twitter, or rather microblogging, seems to be the preferred platform for many leaders associated with the alt-right (e.g. Donald Trump, Jair Bolsonaro, etc.). It has not been possible to find an in-depth explanation for such a preference, and it is beyond the scope of this paper to discuss it. Nevertheless, it is known that Twitter is a primary recruitment source used by terrorist groups [30]. It can therefore be suggested that microblogging, more than a broadcast channel, is perhaps a lynchpin in the recruitment of supporters.
For remarks, note that not all troll factories are professional (i.e. skilled in exploiting online social media features) or propaganda-oriented. For example, Desinfomedia is a company that publishes an online tabloid aimed at making money through Google AdSense by spreading rumour [31]. In another example, a group of trolls sent strobing images on Twitter targeting people suffering from stroboscopic epilepsy [32].
It is also worth noting the difference between propaganda and marketing. In a nutshell, the ultimate goal of propaganda is to spread an idea [33] whereas that of marketing is to sell products [34]. An overlap between the two is inevitable, but because the goal is different, so must the strategy. For example, social media propaganda is often based on [a swarm of] inauthentic accounts (e.g.bots, cyborgs and trolls) [3, 2] organised into a botnet as coordinated agents cf.[35], whereas social media marketing must rely on an authentic corporate account and advertisers. It is therefore not easy to use marketing strategies to spread propaganda.
Note also that there are slight differences between propaganda, counter-propaganda and civil propaganda; a propaganda operation is usually an attack from a foreign country (warfare) or a competing company (dirty strategy), so the source of the propaganda must be kept hidden. For counter-propaganda, a credited source backed by an echoing botnet is often a suitable setup [33]. Civilian propaganda, on the other hand, usually has a credited source, e.g. the president of a country, spreading or reinforcing a propaganda [36].
Also, not all bots are designed for propaganda. In social media marketing, chatbots are used to provide highly available customer channels [34]. There are also bots used to spread religious messages [37] and a botnet of over 350k bots randomly quoting the Star Wars novel without any other apparent behaviour [38].
In summary, the spread of fake news is a complex “ecosystem” composed of different actors distributed across different environments.
Research question. One question that arises from this understanding is on the nature of trolls. Are they humans or bots? In other words, can a troll factory be a fully automated facility? Answering this question is essential for assessing the threat level and planning countermeasures. The aim of this paper is to provide such an answer.
Comparison between three philosophical stances [39]
Comparison between three philosophical stances [39]
The steps of the Design Science method cf.[5].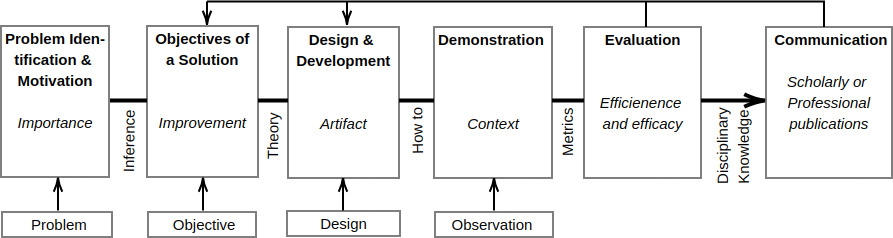
Design science, also known as the science of the artificial, is a research method proposed in [40] for dealing with technology. In short, technology research differs from science in the sense that technology is concerned with producing artefacts, whereas science is concerned with understanding phenomena. The difference between applied science and technology is that the former relies on science, whereas the latter does not [41, 42]. Simply put, historically, technology has progressed without the need for science; for example, primitive people developed bows and arrows without understanding the underlying mechanics.
It is beyond the scope of this paper to present a discussion between the various existing research paradigms. Table 1 summarises the main differences between constructivism (the underlying Design Science paradigm) and other common research paradigms. It is worth mentioning that the experiments carried out on the constructivist paradigm (see methodology in Table 1) are based on the production of artefacts (either an artefact can be built or not) and on the measurement of its impact in the world of the problem (to what extent an artefact is able to change the environment to the desired state) cf.[43]. Note that there are several levels of development that an artefact can achieve, see [44] for a reference. In short, the development level of an artefact can be summarised as proof of concept, prototype, or product; expected to run in laboratory, relevant and operational environments, respectively. The Design Science method is shown in Fig. 2.
Perhaps the most appropriate approach to the problem of this paper is reverse engineering[7]. In short, reverse engineering uses deductive reasoning to understand, or at least gain an insight into how a technology works based on the information available. It should be emphasised that it is not always possible to have access to the artefact being reversed [45], in which case the most likely solution is considered reasonable. For example, during the Second World War, some enemy technologies were reversed by inferring from field information such as descriptions and photographs.
The case for this paper is a little more difficult, because if the troll factories are fully automated, the number of managers would be so small that no leakage would be expected. On the other hand, if the trolls are humans, not all trolls are expected to be above user level, so the descriptions would be of little use. Finally, assuming the existence of a technical team, it would be expected that these professionals, with the exception of a few architects, would be so compartmentalised that they would not be able to understand the big picture; any leakage would therefore be incidental. Since there is no material for inference, the alternative is to carry out an exploration cf.[46]. Exploratory programming is an iterative and incremental middle-out design approach in which disposable artefacts are elaborated just enough to provide the understanding needed to carry out the inference.
The falsifiability principle states that the cases that are more likely to falsify the hypothesis must be pursued [47]. Applied to the context of this paper, the design hypothesis must be that it is possible to build a fully automated troll factory. Therefore, research must focus on the artefacts that are central to the design, but also less likely to be possible to build; i.e. the most wicked essential feature. A wicked feature is a feature whose properties correspond to those of wicked problems cf.[48, 49].
Roughly, a troll factory has two main activities, sowing and spreading[2], which are intertwined [50, 51]. The sowing activity aims to create and maintain a social network that can be used for the spreading activity. In short, it is the same profile that engages in social interactions with its network to opportunistically spread malicious content. As an example of the alternation between these two stages, it is not uncommon for fake profiles to be presented with a photo of a young girl in a bathing suit, which acts as “bait”, and then change to a middle-aged man in a suit for the spreading stage.
One task in the sowing activity is to produce smooth posts. A smooth post is a tweet that the reader would find worthy (e.g. interesting, funny, etc.) and that leads to engagement (e.g. to a like action). In other words, it is a post whose content is in line with the reader’s beliefs, desires, and values [17]. A smooth interaction occurs when a smooth post results in a positive response; i.e. when the actors reinforce each other’s attempts to share information [52].
Thus, it can be said that sowing is more wicked than spreading. In short, the sowing task is a long-term relationship-building activity, subject to all sorts of problems that can come either from the online social media or from the actors [53]. Considering the possible interactions that can be carried out in an online social media, producing a smooth content for a post is certainly more wicked than the other types of interactions such as like and share [54]. In terms of text, there are at least two types of content [55], news post (consisting of a link with or without a snippet of text) and opinion post (expressing a speech act, see [56]). The second is more wicked, as it requires coherence with a fact, news, or post. In this sense, a replying post is more wicked than an initial post.
The automatic production of smooth replying content for a single bot is bad enough. This is because it is not just a matter of producing content for a single reply, but, as suggested, for several posts over a long period of time, in such a way that some coherence is maintained, including the bot’s feed. For example, the exact same post should not appear more than once in the feed (except in special circumstances). However, a troll factory operates tens of thousands of bots within a botnet. So it is not just one bot’s feed, but several. For example, it would be awkward if two or more profiles participating in someone’s network posted the exact same phrase (again, except in special circumstances). So such a tool needs to work in a way that avoids the uncanny valley cf.[57].
Furthermore, if it is true that microblogging platforms are used for recruitment, it can be assumed that this is a suitable place to sowing attacks. It is therefore a suitable target environment. This is opportune because microblogging is perhaps more wicked than the other text-based social media platforms due to its reduced post length that makes it easier for followers of a profile to realize when a post is being repeated, does not make sense, etc.
Working hypothesis. Finally, the working hypothesis for this paper is that it is possible to design an artefact capable of automatically producing smooth replying post content for a botnet running on a microblogging environment.
A caution with the exploration of such hypothesis is that it must not fall into imagination. Thus, any technology that is not publicly available or cannot be built, cannot be considered for the experiment. In addition, considering average private troll factories, they are not expected to use top of the hedge or obscure NLP technology to support their activities due to the cost of implementation and maintenance. Therefore, only widespread and publicly available NLP technology is considered for the experiment. The exploration is carried out on a Fujitsu LIFEBOOK A3510 notebook running Ubuntu 22.04.1 LTS and Python 3.10. The main external modules are CMUTweetTagger, emoji, nltk, numpy, pandas, textblob, and twint; organised as Fig. 3.
Diagram showing the main data flow and connections between the main modules used.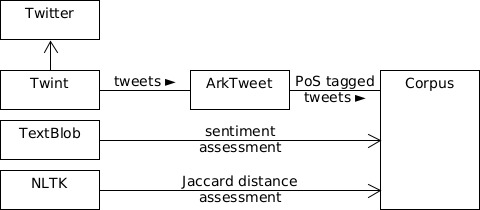
One question that arises in addressing this hypothesis is what would be the design for an artefact as such, this is answered in [58, 53]. Another question is whether it is possible to generate automatic post content regardless of whether it is smooth or not, the answer if positive is discussed in [55, 54]. This paper can then be seen as an extension of those four.
Microblogging platforms such as Twitter can be understood as a kind of structured dialogue cf.[59], as
where
The concatenation is given by equating
In this sense, it is possible to establish an attribute expression cf.[60] to keep the semantic coherence [61, 62] between posts [53] as
where
The
A structure as such is useful for building rapport by reproducing someone’s beliefs and feelings about something [3]. Establishing rapport is important for building trust between peers, so it is an essential feature of sowing. This approach is also known as mirroring. The rapport is established when one’s ideas are recognised in another, which in turn requires time and a sufficient number of tweets.
Representation of elements in a tweet.
The
Given that social media interactions affect people’s psychological states, researching them is like researching people. Therefore, the authors felt it was important to emphasise that no experiment was conducted in actual online social media. However, this did not affect the results of this paper, as due to its current maturity cf.[44], running the prototype in an operational environment was never expected. In fact, the results obtained suggest that this was not the case. All data collected was publicly available at the collection stage and de-identified cf.[66] for privacy reasons [67].
A paper like this could be accused of developing technology for use in propaganda. In response, this is an individual initiative, the scale of which cannot be compared to fully funded development teams. Furthermore, its exploratory nature precludes the production of fully developed artefacts that could be used to cause harm. However, even in the unlikely event of a breakthrough, the fact that it is in the public domain would help people to understand and counter any propaganda that could arise from it.
Design experiment and results
Since the falsifiability principle is applied, research has so far followed a hypothetical-deductive rationale, searching for the most wicked property to build.
Once identified, it is necessary to provide a constructivist proof, i.e. to build the intended artefact, or to show that it is not possible to build it (at least with current technology). An inductive procedure is then proposed as an appropriate reverse engineering approach. Note that the inductive reasoning used for the experiment is not opposed to the deductive reasoning used for hypothesising, as they are independent steps in the design research method. Induction here means exploring possible designs for a concrete scenario as a base case, and then discussing the suitability of these proposals for constructing an artefact that would fit the general case. The hypothesis is evaluated at the induction stage. Also, since sowing is an open domain situation, it is not worth considering the most wicked case, as it is likely to be a marginal case; average cases are preferred.
On addressing language-intensive applications, there are currently two paradigms to consider [68]: corpus linguistics and language models. In addition to these paradigms, the naive NLP paradigm, which is mostly based on heuristics, can be included. These three paradigms are treated as dimensions in this exploration. Note also that the design exploration follows an iterative and incremental approach, i.e. the simplest design that delivers value is considered and complexity is added incrementally.
For an organization, this section is divided into two sections, one dealing with the base case (Section 2.1) and one dealing with the induction step (Section 2.2). Thus, Sections 2.1.1, 2.1.2, and 2.1.3 discuss the base case of the Naive NLP, Corpus-based, and LLM-based approaches, respectively. In the induction part, different setups are proposed, split between Sections 2.2.1 and 2.2.5.
Base-case
A typical Twitter interaction (de-identified).
For the case study, consider the tweet in Fig. 5a. This is a random tweet with no particular property. For reference, Fig. 5b shows the reply the tweet received at the time of collection. Thus, Fig. 5 shows a typical random Twitter interaction serving as discussion basis for this exploration.
There are several NLP approaches that can be used to generate replies to tweets [69, 68]. Roughly, it consists of parsing the text to extract features of interest and building the reply based on them. This approach is called naive in the sense that it overlooks actual features present in most tweets and relies on heuristics.
Following Eq. (5), perhaps the simplest solution would be an element-wise match along a dimension. So let the dimension be sentiment valence and text subjectivity, then
sweet (i)
A similar approach would be to consider cross-element productions, aiming to get closer to the case study, it would be 















 . Thus, for an instance,
. Thus, for an instance,
(ii)
In both examples, as can be seen in Fig. 5b, the solution produced would be suitable as a smooth reply; although some of them are a little awkward, it should be noted that some awkwardness is also a feature of Twitter posts. The next iteration is straightforward and would be to combine these two approaches to create an increasingly featured response such as “sweet
”. This can be further improved by incorporating heuristics such as extending the vowel cf.[72], e.g. “sweeeet
” and randomising some properties of the parameters such as case and position in the text cf.[55]. This can be further enhanced by cognitive reinforcement cf.[54] into something like
sweeeet  #LOVE #MOVIE (iii)
#LOVE #MOVIE (iii)
The next natural step is to consider the use of
The AIML alternative is based on matching an input to a pattern and retrieving a template. The template part is straightforward in the sense that it can be programmed to be enriched with the smooth function discussed so far; the pattern part is not so straightforward. There are two strategies to consider: one is to create a very general template based on the Netflix and movie. Another would be to create a template for each movie or series in the Netflix. The first template would be necessarily general and thus likely to fall into the uncanny valley, whereas the second would be quite convincing at the cost of ongoing maintenance. Considering the second case, it could return, after reinforcement, something like
I love the way it shows the ups and downs of
the two perspectives. The actress who plays (iv)Natalie, WOW!
#LOVE #MOVIE
The Rasa alternative is based on probabilistic intent detection that retrieves a deterministic response. So if used for the training part, this tweet text would be included as an example of, say, the uncompromised interaction intent that would call the smooth function described so far to return the response. Because Rasa is based on Transformers technology, it is able to generalise to any post that is similar to the example. Despite this advantage, Rasa does require some fine-tuning and recommends special hardware to run properly. Although it would probably be best to fit the tweet into a pattern, the response would be quite the same as the one presented in quote (iv).
In terms of results, balancing the strengths and weaknesses of both approaches, it is possible to suggest that for the average case they are equivalent and would provide sufficient performance [75]. Consider also that Twitter, apart from the direct messaging feature, has a type of dialogue in which it is more difficult to enter the uncanny valley compared to a direct dialogue [59]. It is then possible to suggest that any of these approaches would provide a convincing smooth reply to the case study.
Corpus-based approach
World cloud illustrating common tweet structures. See the tags description in Table 2.
Section 2.1.1 presented four productions that could be used to reply to the base case tweet. The problem with this solution is that it does not take into account how tweets actually are. For example, consider quote (iii); although it appears to be a common tweet, it is not. For example, it is not reasonable to assume that a real person browsing Twitter would be concerned about including hashtags in a tweet as such. In fact, only about 6% of the tweets use hashtags [55]. Furthermore, in the same example, the word sweet was extracted from a list of common English words; the question is whether or not the same list applies to Twitter. For answering questions as such, a corpus-based approach is recommended.
In short, a corpus is a dataset annotated with linguistic features. A major challenge in creating a general purpose corpus is to collect a collection of text that is sufficiently diverse to be considered representative of the language as it is spoken [76]. This is particularly difficult for Twitter [77, 78], as the collection strategy must avoid using the search engine and recursive crawling to ensure the randomness of the sample. For reference, most of the Twitter corpora on Kaggle are domain specific due to such difficulty.
Broad purpose corpora can be either general or monitoring. The first type, such as the Broad Twitter Corpus (165,739 tokens [77]) and TweeBank (55,607 tokens [78]), are often too small. The second type, such as the Spritzer (2Gb daily files over ten years), is usually too large. For the purposes of this paper, a larger general Twitter corpus needs to be created. It is worth noting that, except for the monitoring corpora, each corpus is a snapshot of the language at a particular time and possibly place (e.g. before 2022 there was no King Charles III of England). Note also that it is not currently possible to perform independent scrapping in Twitter [79], so the extractions are limited and potentially biased by the Twitter API.
Ark’s PoS Tagger symbols [72]
To avoid these biases, a corpus was built using an onomatological approach, as described in Appendix Appendix A[1]. In short, this approach avoids common biases by randomly generating Twitter handles [80] and discarding the tweets from these accounts. Thus, the search is neither based on the search engine nor on crawling users’ networks, which results in higher randomness. The resulting corpus is composed of 4,412,656 tokens from 253,720 English tweets produced by 2172 different profiles that were active at the time of collection. It is therefore sufficiently representative to provide a snapshot of the language. An overview of the results can be found in Fig. 6, the glossary of tags in Table 2.
On the basis of this corpus, it is possible to continue with the exploration of smooth tweets. Repeat the experiment that generated the phrase (i), but based on the corpus, it retrieves the best matching words that are actually used in Twitter (ordered by frequency): secure, advanced, bizarre, incomparable, risk-free, non-violent, securely, wealthy, ecological. Again, perhaps with the exception of the word bizarre, each could be considered a smooth Twitter reply.
Thanks to the corpus, it is now possible to check whether or not an answer consisting of adjectives like the ones presented is a common structure on Twitter. When querying the corpus, we find that tweets consisting of a single adjective are the 53
@xpto secure. (v)
is a very common Twitter structure. Note that this is a counterintuitive result, as you would expect an answer like (iv) to be better than (i) or (ii), but it is not. This actually makes sense considering the actual use of Twitter, people do not have the time to produce elaborate texts like (iv), especially for each subject.
For reference, Table 3 shows the 10 most common syntactic patterns in the corpus that were used to automatically compose responses based on sentiment proximity and frequency. Tags that could not be associated with a sentiment, such as pronouns and determiners, for which only frequency is considered. Also, tags such as mentions, URLs and numbers are kept as placeholders. Again, any instance in Table 3 table could be used for an uncompromised answer, but not always.
Top-10 PoS patterns in the corpus
The natural next attempt would be to look for relationships between the words. However, the absence of syntactic patterns suggests the absence of n-gram structures. It may therefore be worthwhile to focus on language models.
An alternative approach to those presented here is that of large language models (LLMs) cf.[68]. In short, a language model takes a corpus as a data set and computes the relationship between the words in it. The currently most popular architecture for generating language models is Transformers [81], which uses the attention mechanism to score the importance of words in a sentence, thus improving context detection. A large language model receives as dataset different types of corpora from several sources. It is therefore useful to evaluate its ability to generate smooth tweets. It is worth noting that the computing power of Transformers of a context-free language [82].
The use of AI to automate tweet generation is not new, as it is a widely used digital marketing tool. There are several approaches, which, in addition to using a general Twitter dataset, include generating tweets based on the target user’s own content [83]; interest or topic oriented [84]; persuasion tailored [85]; etc. However, most of these approaches are designed to produce targeted initial tweets, not replies, so most of the strategies are not directly applicable. In addition, there are models fine-tuned for Twitter in the Huggingface, but none of them stand out (the most trending model was downloaded 24 times in mid-2023) or have performance worth discussing. Then, using the existing approaches on the corpus created for this purpose is also unlikely to result in a model with good performance. This is left to the general purpose LLM to be assessed.
Two LLM generations for replying Fig. 5a.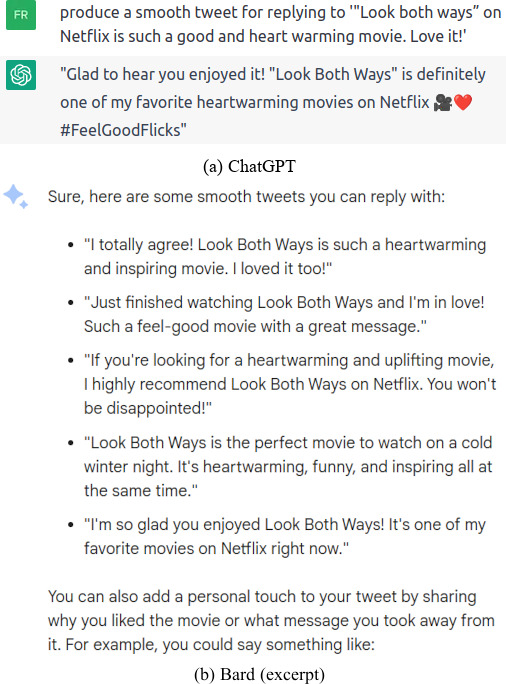
Perhaps the two best known LLMs currently available are ChatGPT and Bard. Figure 7 shows the response generated by these tools for the base case tweet in Fig. 5a. It is worth mentioning malicious LLMs such as WormGPT as it is claimed to be suitable for social engineering. As WormGPT is a paid Dark Web tool, it was not possible to evaluate it in the same way as ChatGPT and Bard. However, as suggested in [86], there is no particular concern regarding these tools as the performance is at most equivalent to any other LLM. The main difference between benign and malicious LLM is that the latter has no content moderation filters [86]. So malicious LLMs can be asked to produce malicious content (e.g. hate speech, phishing material, etc.) that is prevented on benign LLMs. For reference, unfiltered LLMs come closer to the Tay chatbot [87]. The point is that there is no reason or evidence to support the idea that malicious LLM would be able to produce replies whose quality would exceed the results of benign LLM. Finally, it is possible to suggest that LLMs with similar training size are equivalent in practice.
Considering the responses shown in Fig. 7 and the actual response in Fig. 5, it is possible to suggest that for this particular case, there is no material adequacy in the generation. Furthermore, considering Table 3, it is possible to suggest that these responses do not share a common tweet structure either. Nonetheless, each of these instances would be suitable smooth replies for the base case.
Engineered replying prompt (ChatGPT).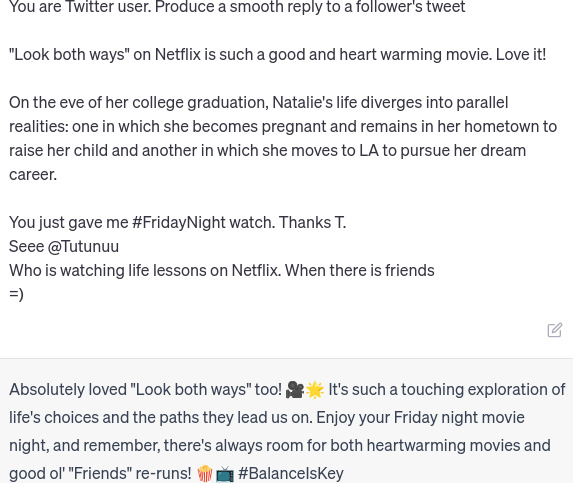
Bearing in mind that LLMs are short-term learners, it is often preferable to use prompt engineering cf.[88] than to go through a fine-tuning process [89]. A canonical prompt consists of: a) role; b) instruction; c) input data; d) context; and e) few-shot examples. Figure 8 shows the result of using this structure to generate the response. Note that the role and instruction would be the same for each tweet, the input data is the tweet to reply to, the context was retrieved from the IMDb website, and the examples are actual replies to the tweets in Fig. 10. This is a prompt that could be generated automatically.
Note, however, that the response has both strengths and weaknesses. The strengths come from the context, which has enabled the model to generate a properly contextualised response. The weaknesses come from the response examples. The authors were not able to generate a text that followed the example texts (on ChatGPT 3.5); all generations were complete, well-written texts. Note that not all replies are smooth, resulting in awkward places in the generated text. So it would be necessary to filter the replies that can be used or to create a set of smooth examples to be considered on each case.
GPTZero assessment for a ChatGPT generation. Since GPTZero requires a minimum of 250 characters, the ChatGPT was asked for rewriting the tweet for 280 characters (the maximum allowed length in Twitter).
Finally, looking at Fig. 7b, it is possible to see that, despite some variation, all generations follow a “style” of writing. This is the underlying premise of models used to judge whether or not a text is machine-generated, such as GPTZero (a tool for evaluating whether a text was written by ChatGPT), by training it on text generated by a given model, see Fig. 9. The point is that neither of these examples fits the common structures of tweets as shown in Table 3. So sooner or later it would enter the uncanny valley or be detected. An hybrid approach is a possibility to consider [90].
A sample of related tweets for illustration (de-identified).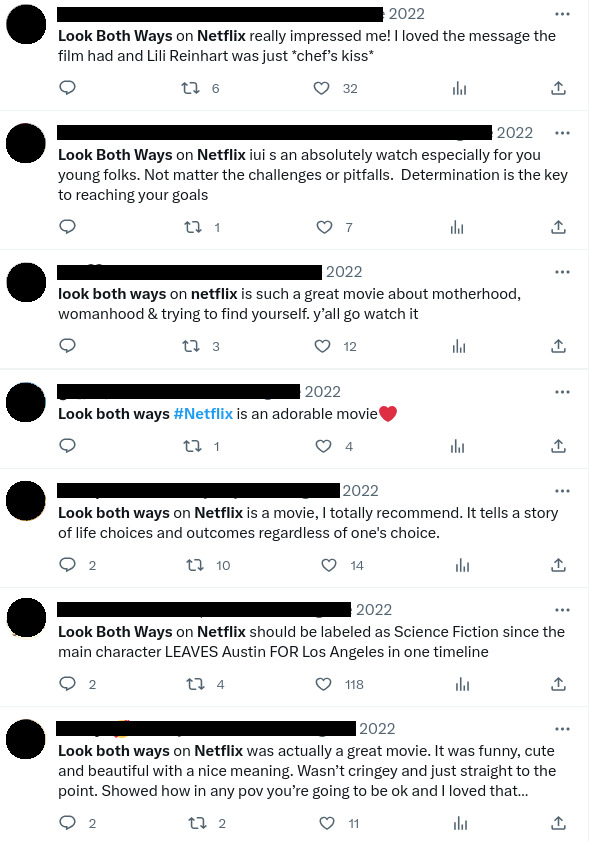
Continuing with the case study, Fig. 10 shows other random tweets on the same topic as the tweet shown in Fig. 5. Note that this is a regular induction step, since for a strong induction it would be necessary to consider every tweet. Regular induction is then the natural next step in this exploration.
The tweets shown in Fig. 10 are illustrations of the general case (not to be taken as individual cases), tweets that it would be expected to be handled by a topic specific replying tool.
Note that there are several other tweets that use the expression look both ways, for example in the context of car traffic, or even others, but are not included because they are considered off-topic for this induction.
As an estimate of the number of tweets on the subject of this case study, a search on Goggle using the query site:twitter.com “look both ways” netflix returns around 1200 results, almost all of them from mid-2022, when the film was released. A first issue appears here. Note that the number of tweets on this topic is extremely small and the time frame in which this topic arose is extremely short. It is then impractical to create rules, analyse patterns or fine-tune models for each specific topic as suggested in (iv). The actual procedure must then be a general solution or the involvement of humans. Only non-specific approaches are then considered in the following explorations.
For directing the discussion, as already mentioned, the dimensions considered are: a) a single bot handling multiple posts from multiple people; b) a single bot handling multiple posts from a single person; c) multiple bots replying to a single post; d) multiple bots handling multiple posts from multiple people; and e) multiple bots handling multiple posts from a single person.
This is the base-case, already discussed.
Single bot handling a single post from multiple people
There are two situations to consider here, one is when the people the bot has responded to are not in the same network. This situation is a variation of the base case, so there is no need to discuss it further. The other is when the people the bot has replied to are in the same network. This situation is more difficult in the sense that the bot’s reply will eventually be seen by the target’s follower feed (which is also a target). If a user then sees the same or similar response that they received, it would be embarrassing and break the rapport.
Worst of all, if the bot response is antogonic, e.g. two people in the same network mentioned Look Both Ways, one rated for positive sentiment, the other for negative. The smooth function would produce a positive and a negative response to each of these users. Assuming they are in the same network and both people saw the bot’s replies, it could result in a major loss from a social perspective. If repeated, it could lead to a blocking action from both parties. It would be even stranger if these two people were replying to each other.
Nevertheless, it is not difficult to imagine an algorithm that could manage such a situation. In fact, it can be argued that it might even work better than employing humans to do the job. In short, a bot can commit to a position, such as positive sentiment, and only reply to tweets with that valence. It can also use cues such as “I’m telling everyone” and check the phrases already used to avoid repetition. It is not unreasonable for two initially independent target profiles to start following each other, it is unlikely that they will identify similar replies from old tweets, but to be on the safe side the bot may have a policy of deleting old tweets to avoid such situations.
Another caution to consider is the balance of the reply tab (a Twitter section that shows the replies of the profile). This is unlikely to be a problem in the seed phase, but it will need to be addressed in the propagation phase in order to avoid security algorithms establishing a pattern of interaction.
Single bot handling multiple posts from a single person
The problem with all the approaches appears on multiple and continuous interactions. In the base case, given the structure of Twitter, almost any response with a similar tone, as in Eq. (5), would work. The problem arises with continuous interactions. Assuming a profile that always replies with the same structure, which could be either simple as (i) or complex as (iv), it will soon fall into the uncanny valley, especially if the profile attracts the attention of the target user. Considering that the majority of the population does not have adequate digital literacy, the Twitter user may consider this profile not as a bot, but as a clumsy person.
Ten ChatGPT’s generation for replying Fig. 5b.
When considering LLMs, note that their productions end up resembling instance (iv). As a reference, consider ten different generations shown in Fig. 11. As mentioned, these are not common structures in Twitter, especially from personal profiles. Note also that since the attention mechanism is based on words, it is inevitable that some words will be paraphrased from the source tweet (see for example the emoticons produced in (ii) compared to the tweets generated in Fig. 11). This also quickly becomes annoying. Note that according to the lexicon, emoji (appearing in
Perhaps an alternative to addressing these issues on this dimension is to use a CBR approach such as Rasa, which consists of a balanced but large set of responses following the phrase structures in the corpus. Certainly, the film Look Both Ways is not a long-lived topic, but for those that are, specific intents and responses can be considered. Then, assuming that there is a team to continually adapt the agent (assuming they are able to do so in time), that it has a measure to avoid repetition of sentences, and that the model does not mismatch intents, it is possible to suggest that it would be able to run without close supervision. However, there are too many independent variables, some of which are not mentioned here, to accept that this would work in practice.
Now imagine a situation where several bots are driven to reply to the same tweet. There are several reasons for this, one of which is to inflate a position in order to exploit a social bias. The question then is how to avoid falling out of common structures and thus avoid entering the uncanny valley. So if there is a mechanism in place to avoid repetition and to prevent bots from posting more than a certain number of replies to that post, to avoid spam behaviour, it is likely to be successful.
However, the use of a botnet raises additional concerns that have not been discussed so far. Consider, for example, a Rasa-based solution. Are all the bots expected to behave in the same way or should they be different? One property of human dialogue is vocabulary, individuals are accustomed to using certain words instead of others. This goes further, including syntactical structures, expressions, etc. Note that these variations are not paraphrases, but linguistic preferences of individuals. This goes even further to include cognitive aspects such as differences in mental characteristics and the influence of social norms, which in turn determine the interaction patterns of individuals.
The question is whether, and to what extent, these concerns are expected of a seed bot. If differences in vocabulary are to be expected, it is no longer a question of building, training and tuning a single chatbot model, but one for each type of vocabulary. Note also that each group of people has its own signs and norms that need to be respected (without considering the dog whistles). If these elements were to be taken into account, the result would be a combinatorial explosion of models. As already discussed, especially as illustrated by the GPTZero, LLMs do not seem to be an alternative to address this issue.
Botnet tweets example [91].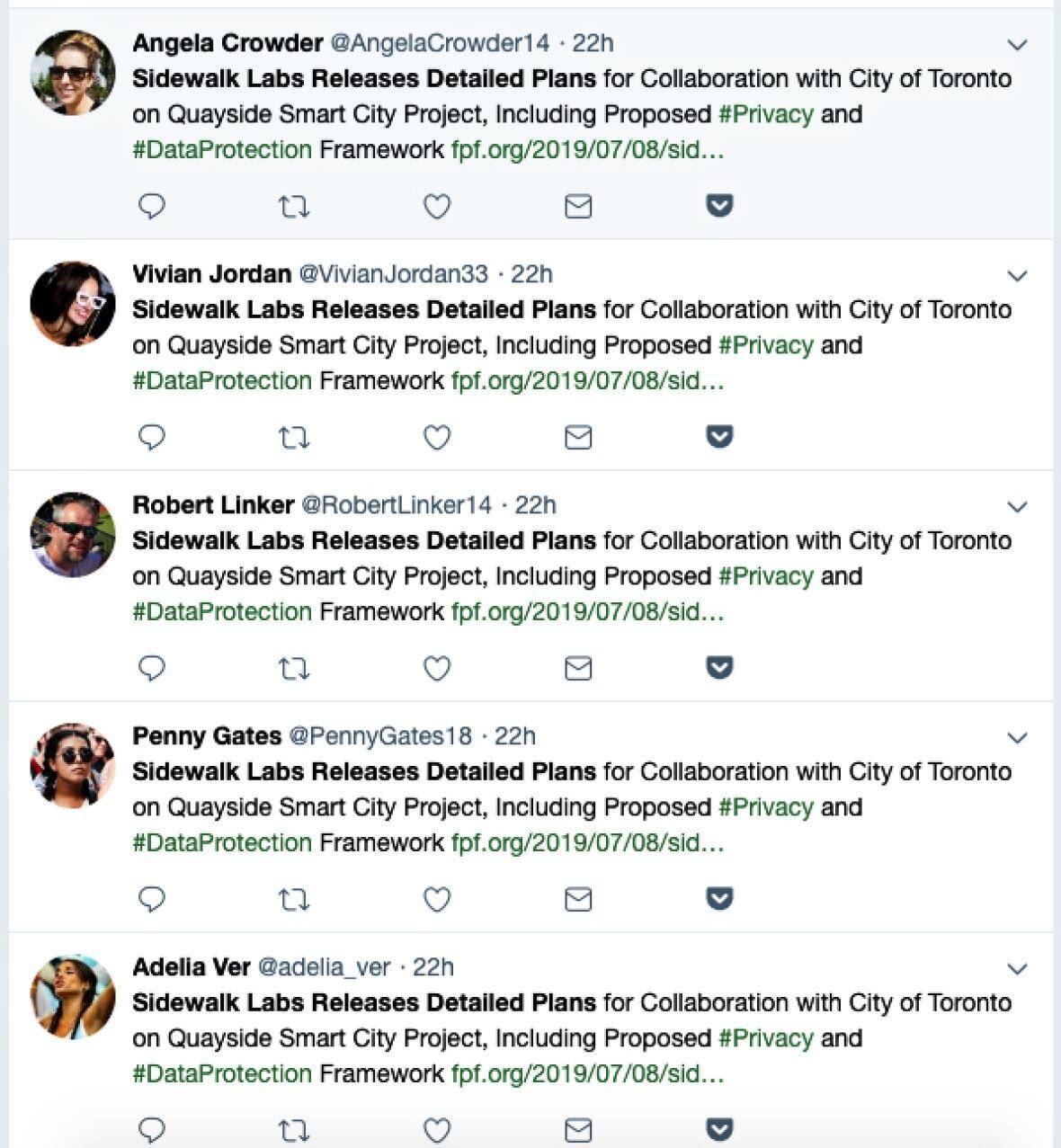
In other words, the question is whether the seed agents are expected to realise a persona or not. In the negative case, the use of a botnet composed of several bots that behave in the same way, despite some randomisation and paraphrasing, would lead to problematic situations like the one shown in Fig. 12. Given that such examples are increasingly rare, the alternative is to consider the positive case, i.e. that agents embody personas. Then the complexity of building a botnet with multiple personas must be considered.
Again, there are two situations to consider. One is to assume that each troll factory builds its own botnet from scratch. The complexity of such an endeavour would probably make most of it unfeasible. Another is to consider the possibility of existing companies selling such technology on the black market cf.[92]. This adds another dimension to the problem. However, there are some mitigating factors. The difficulties of buying, deploying and maintaining software are well known in the legal market; the black market is no different. In addition, the maintenance problems already discussed would still exist; so no silver bullet.
This issue is related to botnet coordination. A botnet is not expected to follow and interact with a single profile, but it may coordinate to increase the strength of the interactions. If individual interactions are considered cognitive attacks, then this situation would be a social attack. A common example is social bias exploiting cognitive dissociation. In this sense, a person can be induced to agree with a propaganda if a sufficient number of people support the claim [17]. Thus, given a tweet, the botnet would coordinate to create a consensus illusion on that user. Up to the critical mass point, the botnet is applicable.
Plot of the evolution of the radicalisation score over time [93]. The red line is the control group and the blue line the targeted users.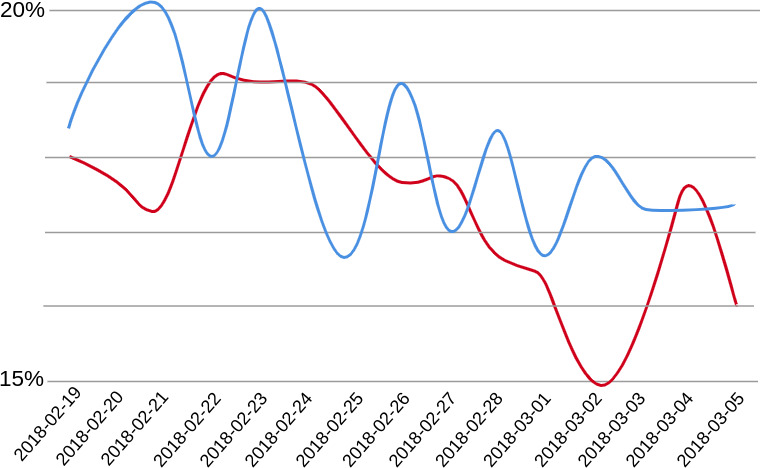
From a reply perspective, the botnet can coordinate to boost or deboost the user’s tweets. Those that meet the botnet’s goals would be praised and those that do not would be blamed. This would lead to behavioural training of the user [93] (see Fig. 13). The problem here is identifying which tweets should be boosted and which should be deboosted. It is certainly possible to train a classifier, but it would fall into the various problems already discussed, including those related to the open domain. For such a classification, the use of humans would probably be most appropriate.
Note that at this level, it is no longer a matter of a bot developing an artificial relationship with a person, but with the entire subset of a botnet, interactions that are reinforced by the botnet’s complement set. Which may have a serious impact on solitary people. Note, in addition that this same botnet can be simply set into a digital mob for cancelling cf.[94] that same person.
This issue is about managing multiple social networks. In other words, which bots are expected to follow which bots and which bots are expected to follow which profiles. Furthermore, it is not expected that the same profiles will interact all the time, it has to be a rotation policy that allows different levels of interaction. In the end, this can be reduced to a combinatorial problem, and is therefore best suited to be managed by computers.
At the surface level, it falls into the case that a single bot is replying to a single post from multiple people (refer to Section 2.2.2). Difficulties emerge from continuous interation between user a botnet and an user (refer to Sections 2.2.3 and 2.2.5). The problem at this level is how to coordinate a botnet in a way that it is able to establish different levels of proximity with different people. Assuming that each bot in the botnet is attached to a persona, it is unavoidable that the target user would prefer interactions from some bot personas than others. By tracking it, it is possible to adapt the interaction policy accordingly.
In addition to controlling the networks within the botnet, it is necessary to set up the connections between the bots, taking into account the networks of multiple users. This becomes a rather complex graph management problem. Considering human-guided search, see [95], the result can be improved with human help (such as Google maps). However, considering a massive botnet, this is not a feasible task for one person. The alternative is to consider multiple trolls working to improve local results, which are aggregated into global botnet management. Continuing this discussion would lead to considering the trolls themselves, which is beyond the scope of this paper.
Result
The induction revealed two levels of operational activity, one associated with the content of the tweets and another with the coordination of the botnet. Arguments suggest that the first is better addressed by employing humans, but the second would be best served by machines. However, in several situations it is clear that humans would benefit from computer assistance with content creation, and that botnets could perform better if guided by humans in coordinating the bots. In this sense, based on the information presented, the most likely setup of a troll factory from a design perspective, is to be composed of a hybrid approach, thus by cyborgues.
Discussion on the hypothesis
For context, the hypothesis of this research is that troll factories are fully automated. The hypothesis deduction addressed in this paper, driven by higher wickedness, is that it is possible to create a fully automated sowing agent to run on a microblogging platform. An additional deductive step led to the scope reduction that it would be speech-act sowing on Twitter. It was then shown that it is possible to automate the creation of smooth tweets, but the question is whether these facilities can work without human supervision at the operational level (then fully-automated).
Considering the presented design experiments, it is possible to say that although it is possible, it is unlikely. Consider, for example, Table 3, there are patterns that are smoother than others, none of them being the actual reply that the base-case tweet actually received (Fig. 5b). It is worth mentioning the question of the material adequacy of formal systems cf.[96]. In short, as given by the T-schema ‘
The concern for material adequacy is a cornerstone for a sowing agent, a formal system that interacts directly with the material dimension. To ensure high quality material adequacy, there is no alternative to employing humans to verify the suitability of productions. However, for limited contexts, Kripke worlds are a solution [97] (for the generative approach, this would mean fine-tuning ChatGPT to multiple domains). This is then a discussion of open vs. closed domain; extensively covered in the literature. In short, it is impossible to create enough Kripke worlds to solve all possible problems in open domain conversations. The expected behaviour of a sowing agent is to handle open domain issues, even considering a more restricted type of dialogue such as that conducted on Twitter.
So there are two options. The first is to create multiple knowledge-based contextualised speech act models and a coordination model for moving them; the second is to use human effort. Leaks to the press suggest that the second choice is at least the most common [2] (this is a pre-ChatGPT statement, but probably still valid).
As already mentioned, there are both state (including military) and private troll factories. State troll factories are more sensitive to politics, while private troll factories are more sensitive to economics. Since there is a rationale behind economic motivations, it will only be considered private troll factories. In short, there are costs associated with building, tuning and maintaining a trolling agent model. These costs include developer salaries and computer infrastructure. If these costs are higher than hiring human operators to deliver analogous quality, then humans will be hired. There is also the time constraint, tuning models for different situations takes time and requires data curation that, except for a fairly mature process (at least Capability Maturity Model integration – CMMi – 4, see [98]), it would probably lose time to market.
The likely setup then is the use of human operators assisted by computer tools (something like “computer aided propaganda”). It is cheaper and faster to develop less sophisticated models, whose shortcomings would be compensated by human knowledge, than to develop highly sophisticated ones. On the other hand, the cost of employing people at operational levels whose capacities could be improved by computer devices (also called cyborgs) is likely to be cheaper and faster than employing additional technical people and machine resources. The use of cyborgs has the advantage of being difficult to detect [99]. In this sense, troll factories would work like a call centre. It is therefore based on the work of many people “puppeting” a number of fake profiles.
To derive the number of profiles a single person can manage in a working day, consider that a typical botnet has around 10k
For large companies, it is not difficult to consider a call centre with 1000 positions, then to keep the same ratio, 700 trolls would be needed to manage 70k puppets. Divided into two shifts, this could be achieved with 350 “seats” (or workstations). Deepening the troll factory as a call centre concept would make it possible to reuse decades of research on call centres, resulting in a highly optimised operation, but this is beyond the scope of this paper.
Although this suggests that a raw sowing operation does not require computational support at the operational level, it is unlikely that these facilities can do without it. Several errors attributed to inauthentic accounts, such as repentant sentences, profile mismatch, etc., are becoming increasingly rare. Errors as such are amenable to avoidance with the assistance of computational tools, especially in a botnet context. It is reasonable to assume that without the support of tools as such, the scale and impact would probably be much smaller and the errors much more frequent. Operational level technologies are not often mentioned in the news. This is probably due to bias, perhaps considering that these tools are somewhat analogous to widely used social media marketing tools and therefore not worth mentioning.
As already mentioned, the focus has been on speech acts. However, sowing is a complex task that involves a whole social interaction, i.e. reciprocal actions between peers sharing information [103]. Information here is not limited to knowledge, but includes social cues that are as important to sowing as speech acts. Positive nonverbal cues are follow, like and retweet, whereas unfollow, block and report are negative. For example, a decision has to be made whether or not to engage with a given tweet, which is not a simple decision as it interacts with the dopamine and cortisol levels of the tweet author [104]. Therefore, although not addressed in this paper, these are also candidates for composing a computerised propaganda platform.
This is a significant finding as it suggests that the capacity of these facilities, although huge, is limited. The limitation is related to the number of workers and the number of profiles that each person can handle at the same time. It follows from this finding that counter-propaganda efforts must include both educational and social dimensions to help people avoid working for such companies. As a point of reference, workers in these establishments consider themselves, or convince themselves, to have a regular job [31]. Emphasise that this does not mean that there is less of a threat, only that automation, if it exists, is limited to a computer-aided realm and that it can be demobilised by appealing to human traits.
For the sake of simplicity, some of the exploits in this paper considered proprietary LLMs such as ChatGPT and Bard, which would not be used by troll factories, since these companies may decide or be forced to deny service to a particular user. This is an unacceptable risk to take. The WormGPT is not an alternative, as it suffers from similar problems, with the appropriate differences. Building in-house models is also out of the question for most companies due to the costs involved, so it must not be an option for most troll factories. Perhaps the best alternative is to use open source LLMs such as Meta’s llama or EleutherAI, the underlying model of WormGPT. However, since the same technology is used, the achievements and problems of these models are analogous to those discussed in this paper. For a reference, see Fig. 14.
Llama generation for replying Fig. 5a.
Considering then the proposed hypothesis, for the various reasons presented in the paper, and considering the currently available natural language processing technology, it can be said that it was falsified in the sense that trolls at the operational level are more likely to be cyborgs than fully automated accounts.
Finally, note that the aim of a sowing activity is to turn a social network into a critical mass of radicalised people [33]. Radicalisation begins with an obviously false claim that is harshly rejected by society; if this person finds a community that embraces his or her beliefs, the tendency is towards commitment and radicalisation [105]. In the critical mass situation, on the one hand, the network begins to grow by itself and, on the other, a reduced number of [semi-]automated profiles are able to carry out the dissemination when needed. For a radicalised audience, it is enough that the charismatic leader provides the propaganda for it to spread [9].
This implies the existence of an early sowing phase aimed at achieving critical mass, and a late sowing phase after critical mass has been achieved. Early sowing may last for a short to medium time frame, either for success or failure. Automated sowing tools may be a cornerstone for the early stage, but probably a secondary issue for the late stage. All these features are taken into account when evaluating the cost/benefit of developing a more or less sophisticated seeding tool.
This paper aims to provide a design perspective on the troll factory phenomenon. It then uses exploratory design research to address a reverse engineering case study to test the hypothesis that troll factories could be fully automated. The research suggests that although it is feasible, it is unlikely due to economic and time constraints, especially when considering private efforts. Even if full automation at the operational level is considered unlikely, it is also unlikely that the sowing task is carried out without any automation at the operational level. It was considered reasonable to assume that each troll could be responsible for approximately 12.5 profiles/hour, working simultaneously. Such an activity is very error-prone and therefore suitable for computer assistance. Therefore, the most likely setup, at least for private facilities, is to employ cyborgs (humans assisted by computers). This allows humans and computers to work together to avoid each other’s mistakes, especially in a botnet context.
The proposed research approach succeeded in bringing an additional perspective to the matter. It confirms known information, such as that these facilities resemble call centre operations, but with the added rationale of explaining why this is likely to be the case. It helped to identify possible biases, such as the reduced number of references to operational level tools found in the press. It also helped to dispel some likely misconceptions about the inner workings of these facilities by attempting to build them. In addition, it helped to refine the understanding of sowing activity and to place the automated tools at the operational level in a more fine-grained context.
In order to carry out the research, it was necessary to build several artefacts, which are also contributions. To mention a few, the General Twitter Corpus, which is 2.7 times larger than the Broad Twitter Corpus, and also the algorithm used to build it. It was also possible to derive a Twitter lexicon with words actually used on this platform, and a PoS dataset with the syntactic patterns of the retrieved tweets as templates. As ChatGPT is a disruptive technology, it is also a contribution to address some of its behaviour and possible impact on troll factories.
There are several lines of research that can be pursued. One is to develop the troll factory as a call centre concept by incorporating the numerous call centre related studies to see which of them make sense considering the troll factory domain. Another is to use the produced corpus for fine-tuning open source LLMs to ensure that the result would not be expressively different considering similar approaches. Also, to explore tools for dealing with non-verbal interactions and tools aimed at the tactical and strategic levels of a troll factory operation.
Perhaps the most interesting development, however, is the production of multi-layered embeddings. For example, this paper has shown that parts-of-speech produce more appropriate responses than word relations. However, although it was possible to find some papers on parts-of-speech and sentiment embeddings [106, 107], they are scarce; scarcer considering a broad cognitive spectrum that includes emotions, mental traits and social norms [108]. No embedding fusion was found for these traits.
Footnotes
Acknowledgments
This work is financed by National Funds through the Portuguese funding agency, FCT – Fundação para a Ciência e a Tecnologia within project 2022.06822. PTDC.
Onomatology-based corpus
This section describes the corpus assembly for Section 2.1.2. It follows the scheme in Fig. 3, an overview of the results is presented in Fig. 6, the glossary of tags is presented in Table 2. In short, a corpus is a dataset annotated with linguistic features [76], then this section describes these two procedures.
Nickname onomatology heuristics used in this paper [80]
Heuristic
Example
Description
Initials
ZS from Zachary Smith
The first letter of each name.
Portions
Liz from Elizabeth
A nickname may come from the front, end, or middle of a name.
Separation
Mary-Ann from Maryann
If a name is a composition of two other names then split.
Contraction
Ike from Eisenhower
Ad hoc formation, usually due to socio-historical circumstances.