
Abstract
The destructive power of a landslide can seriously affect human beings and infrastructures. The prediction of this phenomenon is of great interest; however, it is a complex task in which traditional methods have limitations. In recent years, Artificial Intelligence has emerged as a successful alternative in the geological field. Most of the related works use classical machine learning algorithms to correlate the variables of the phenomenon and its occurrence. This requires large quantitative landslide datasets, collected and labeled manually, which is costly in terms of time and effort. In this work, we create an image dataset using an official landslide inventory, which we verified and updated based on journalistic information and interpretation of satellite images of the study area. The images cover the landslide crowns and the actual triggering values of the conditioning factors at the detail level (5
Keywords
Introduction
Landslides are geological processes that involve bodies or parts of soil, rock, and debris moving over a plane or surface [1, 2]. These are frequent and dangerous natural events whose destructive capacity can generate large amounts of material and human losses. It should be taken into account that approximately 90% of these losses can be avoided if the problem is detected on time and appropriate prevention and control measures are taken [3].
Prediction of landslide risk and determination of areas susceptible to landslides have attracted increasing interest. Several authors propose conventional methodologies based on fieldwork and multi-criteria analysis [4, 5]. However, these methods have a deterministic approach with defined rules, consider a reduced number of fixed variables, and become subjective as they depend on expert criteria, especially in difficult- to-access geographical areas. In addition, they involve many time-consuming studies that complicate development and increase costs, not to mention the high dependence on the work environment and the tendency to low accuracy.
In recent years, work based on the use of Artificial Intelligence (AI) techniques has provided promising results in several areas [6]. Although there have been numerous researches undertaken on disaster susceptibility assessment and prediction models in geology [7], the application of AI algorithms has been a great advance in the analysis of natural phenomenons such as landslides, floods, and volcanic events. Among the most widely used techniques are Support Vector Machine (SVM), Random Forest (RF), and Logistic Regression (LR) [8, 9, 10]. These algorithms are part of classical machine learning (ML), where computers can solve specific tasks without the need for a human to explicitly program [11, 12, 13]. Landslide prediction is usually treated as a binary classification problem, that is, occurrence or nonoccurrence of the phenomenon. The workflow begins by delineating a geographical study area, which is divided into a grid of cells or pixels, and for each pixel, data are collected for the features or variables considered convenient. From a history or inventory of landslides, a positive response label is associated with all records in the area covered by the landslide, and negative otherwise. By using a supervised ML algorithm, it is possible to learn the relationship between the conditions given as input and the occurrence of the phenomenon as output.
This treatment involves the creation of a dataset consisting of a manual process of converting pixels into records of quantitative values. Some selected variables may include qualitative values that require specialized analysis to be transformed into quantitative values [14, 15, 16]. In addition, during the training of these traditional algorithms, the records are processed in batches and randomly without considering the spatial relationship of the pixels they represent. On the other hand, the entire area occupied by the landslide, which includes places where the phenomenon was not triggered, is considered a positive case of occurrence. Therefore, feature values that do not actually cause the phenomenon are included and adversely influence the training process and the accuracy of the predictive model.
The aforementioned drawbacks motivate the proposal of a method based on Deep Learning (DL), which allows direct leverage of the images of the geographical area of interest considering exclusively the specific location where the landslide occurs. Although a landslide can cover a large extension of land, from a geological point of view, this type of phenomenon originates in the upper part known as the crown [1]. The variables that condition the occurrence of the phenomenon should be analyzed at the starting point of the landslide. Therefore, we proceeded to identify the highest points (landslides crowns) and the nearest surrounding pixels to form small 5
For the experimentation and validation of our proposal, we present as a use case the Aloag-Santo Domingo highway, one of the most important road arteries in Ecuador, since it connects the highlands with the coast [17]. It is believed that there is some type of geological structure, regional or local, responsible for the frequent occurrence of landslides in this area. Topographic, climatic, and anthropic factors could be identified using deep learning, specifically convolutional neural networks (CNNs). These networks have the ability to recognize and classify images through specialized hidden layers with a hierarchy of extraction from simple to more complex patterns [18, 19, 20, 21].
Therefore, our purpose is to use a CNN for the prediction of landslide risk. In turn, the probability values are used to generate a susceptibility map. We begin by delimiting the study area as a grid of cells or pixels, in which we geographically locate the collected landslides, previously verified and updated. Next, we define a total of 19 variables, each represented by a map covering the study area at the same resolution. These maps are stacked to extract images of dimensions (5
The main contributions of our work are: 1) the generation of a reliable image dataset representing the most influential variables in the phenomenon, as well as the updated and verified inventory of landslides in the study area; 2) a more realistic approach, as the images correspond to the actual place where the phenomenon starts and its closest surroundings, unlike traditional studies that take into account the entire landslide area; 3) the proposal of a general methodology that can be applied to other geographical areas, thus becoming a tool to help authorities make appropriate decisions to mitigate or avoid economic and social losses related to the phenomenon, and also to facilitate further research; 4) the resources used, the products obtained, and the code developed are publicly available at Github.1
The remainder of the paper is structured as follows. Section 2 reviews related work. Section 3 describes in detail each of the steps of the methodology used. Section 4 presents the experimental part and discusses the results obtained. Section 5 explains the landslide susceptibility mapping process. Section 6 mentions the respective conclusions. Finally, the future work is in Section 7.
Related work
Landslide risk prediction is crucial to reduce the human and economic losses associated with these natural events. Traditional methods used for this task have limitations in terms of accuracy, cost and scalability. In recent years, AI has become a powerful alternative to address problems in a variety of fields. In particular, the use of machine learning techniques for landslide prediction has been the subject of increasing research. In this section, related work with these techniques is reviewed. To our knowledge, the present work becomes a pioneer in the Aloag-Santo Domingo highway. In the literature on our case, there are works that refer to mitigation, that is, after the event. With regard to prevention, only the use of the Fuzzy Logic technique is registered [17]. This technique determines the susceptibility to landslides on this highway for the zoning and identification of critical places. Seven variables were selected: proximity to rivers, roads, geological faults, vegetation cover, type of rock, precipitation, and slope. As a result, the localities of El Paraiso and Union del Toachi are in a critical zone, while Alluriquin, La Palma, San Antonio, San Ignacio, and Manuel Cornejo are in zones of high susceptibility, which are represented in landslide susceptibility maps. The dangerous morphological and climatological conditions of this geographical area, together with the lack of information on landslides, have limited the research and application of modern techniques to landslide prediction on the Aloag-Santo Domingo highway. This motivated our earlier work by applying classical machine learning classifiers (SVM, LR, and RF) to address this problem [25, 26, 27, 28]. The present research differs from the previous ones by the application of deep learning. There are no works related to landslide prediction using convolutional networks specifically for this highway, so the following is a description of the relevant works compiled worldwide. The geographical area analyzed, the variables of the phenomenon used, the models applied and the results obtained through a performance metric are included, as shown in Table 1.
Work collected and aspects considered in the review of the literature
Work collected and aspects considered in the review of the literature
The locations in Asia, mainly in China and India, are the most analyzed geographical areas for landslide risk prediction. These areas present a mountainous and irregular relief similar to that of our case study, so the same variables of the phenomenon are considered for the highway of interest. The following types of conditioning factors are identified: geomorphological (GM), geological (G), lithological (L), topographical (T), meteorological (M) and land cover (LC). The preferred and most influential variables in the phenomenon are geological and geomorphological. The machine learning (ML) models that process these variables as input include: Support Vector Machine (SVM), Random Forest (RF), Logistic Regression (LR), NaiveBayes (NB), Decision Tree (DT), K-nearest neighbor (KNN), Convolutional Neural Network (CNN), Deconvolutional Neural Network (DNN), Recurrent Neural Network (RNN), Elaboration of Persuasion Probability Model(ELM) and Deep Belief Network (DBN). The most commonly used methods are classical machine learning algorithms, while deep learning algorithms are used less frequently, but are very promising for their ability to automatically analyze and extract features from images, which can be of great help in disaster risk prediction. This allowed us to select the CNN model for application in our work.
In comparison with other works published in the literature, our proposal emphasizes on the dataset quality. In this context, the location of each landslide is verified with thematic maps using GIS and Street View in Google Earth. Furthermore, the amount of data on landslides occurring on the road that have not been mapped has been increased by integrating information extracted from social networks, news and videos. Thus, we contribute with a reliable and updated landslide dataset on the study road. A remarkable aspect is the use of images at detail level (5
Landslide risk prediction and identification of susceptible areas are difficult tasks. This phenomenon does not have well-defined rules and is conditioned by countless factors of various types. Conventional methods are based on certain influential variables, which are weighted, and by means of mathematical formulas, it is possible to obtain a potential hazard value. One of the best known is the so-called Mora-Vahrson method, which allows us to obtain zoning of the susceptibility of the terrain to landslide by combining the assessment and relative weight of various morphodynamic indicators [36]. This type of treatment is practically deterministic for a problem of a nondeterministic nature. Therefore, our work is motivated by the need for a more appropriate interpretation of the phenomenon to obtain a more accurate and reliable prediction model.
Methodology used for landslide prediction and susceptibility map generation.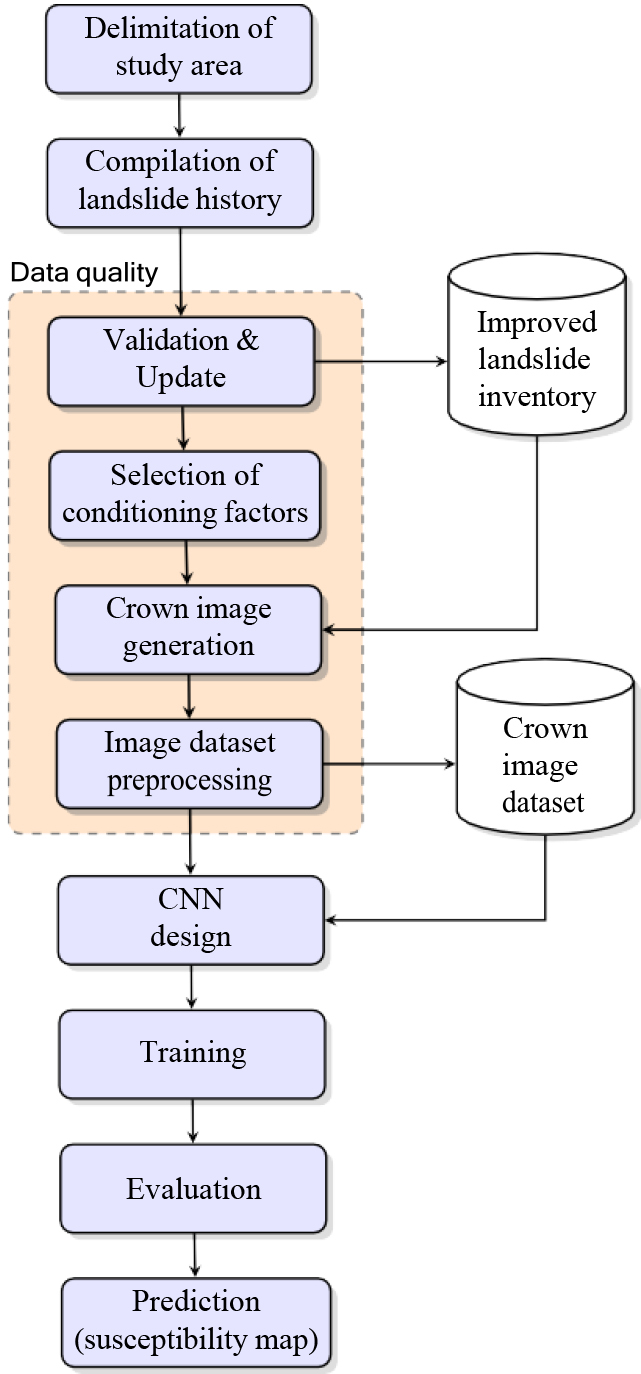
We use a methodology that takes into account the quality of the data and incorporates the landslide crown as the main novelties with respect to related work (Fig. 1). Data quality is fundamental for a good performance of a prediction model, so we carry out the exhaustive validation, correction and updating of the history of landslide events. This task is rarely addressed in other studies, but it is essential when the available information comes from external sources. Our approach considers the geographic position of the landslide crown and the nearest proximity. This new delineation allows capturing the actual conditions that triggered the landslide. Therefore, we have a representation of the phenomenon that is closer to reality and a better accuracy is expected. Typically, related work involves a set of qualitative and quantitative data, whose design, preparation and labeling is a costly task in terms of time and effort. This motivates us to create a dataset composed of images covering only the landslide crown and the surrounding pixels, together with the conditioning factors of the phenomenon. Our solution uses computer vision based on deep learning with a convolutional network, which is currently state-of- the-art tool [37, 38, 39, 40, 41], for a problem that is traditionally treated with classical machine learning.
In the following, we explain in detail these and the other activities that conform the proposed methodology, which is supported by computational tools such as Google Earth, ArcGIS, QGIS, SAGA-GIS, Python programming language and deep learning libraries.
Geographical location map of the study area.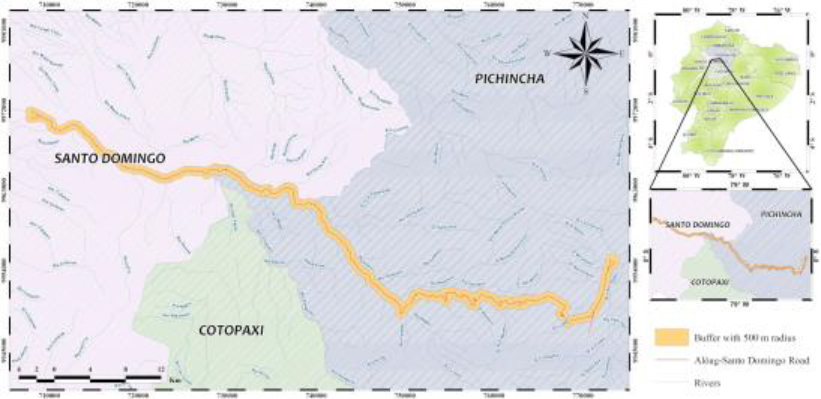
Landslides occur in large parts of our planet, especially in mountainous areas of highly variable relief and climate [42]. The prediction of these events is becoming a problem of growing interest world-wide. The methodology proposed can be applied to any place or region of the world where landslides are a recurrent phenomenon. We selected the geographical area crossed by the Aloag-Santo Domingo highway (Ecuador), which has been considered in several of our previous studies [25, 26, 27, 28]. This due to the high importance of the phenomenon for the economic and industrial development of the country and the human and material losses it frequently causes.
The highway extends approximately 100 kilometers in the northwestern region of the country, covering the provinces of Pichincha and Santo Domingo (Fig. 2). Its transition from the highlands to the coast gives it great strategic importance. Unlike other related studies [34], our analysis focuses on landslide risk only in the immediate area of influence of the highway, in the form of a corridor, rather than over a vast geographic area. This allows us to obtain a more detailed and accurate understanding of how this phenomenon specifically affects this highway. With the support of GIS, the study area was delimited using the buffer tool, setting a radius of 500 meters on each side to analyze the susceptibility to landslides that directly affect the road and surrounding population.
Map of the new landslide dataset (manual digitization).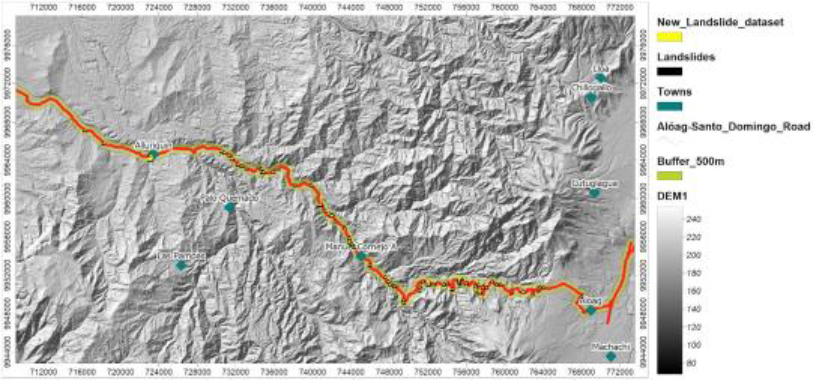
The next step is to know the landslide events that have occurred in the delimited geographical area. What happens in the past can provide clues on what may happen in the future. Compiling a history or inventory of landslide events from scratch can be a more complex process and require more time and resources than requesting government records. We use an inventory provided by the Provincial Autonomous Government (GAD) of Pichincha upon request to access it, which includes the location, date of occurrence, type of mass movement, and photographs of each landslide on the road. A total of 45 landslides were identified from June to September 2014. Although this information derives from an official source, it is necessary to validate, correct possible errors and, most importantly, update the events. One of our main contributions is the creation of a reliable and updated inventory of landslides that have occurred along the Aloag-Santo Domingo highway.
The available information is transferred to GIS to verify the coordinates of the landslide points with reference to satellite images, discarding those that did not coincide with the place of occurrence of the phenomenon. We updated this inventory with landslide events from 2014 to 2021 through a compendium of information on the date, description, type, and place (kilometer number) of occurrence of the event, mainly from news highlights and videos on social networks. As a physical technical inspection of the site was not possible, a virtual visit was carried out using the digital tool Google Street View, which allowed the extraction of geographical information such as the location in UTM coordinates and the kilometer number of the landslides. The new dataset was digitized from base maps corresponding to the GIS satellite image services.
Figure 3 shows the generated map that including the study area (buffer), the digital elevation model (DEM), existing towns and rivers, as well as the validated landslides from the initial inventory, and the manually digitized polygons of the new places of occurrence of landslides. The final dataset consists of 75 landslides that have not been documented on websites or government sites.
Landslide conditioning factors
Once the geographical area and the landslide events are known, the most influential conditions for the occurrence of the phenomenon are identified. These variables can be of various types as geological, geomorphological, climatological, vegetation cover, land use, etc. They are called conditioning factors of the phenomenon and can be many and very diverse. The selection of the most appropriate variables is a task for researchers. Numerous conditioning factors have been proposed in the literature. Previous studies corroborate the close relationship between conditioning factors and the occurrence of landslides [2, 9, 18, 43].
Maps of the conditioning factors automatically generated from the 5-meter resolution DEM.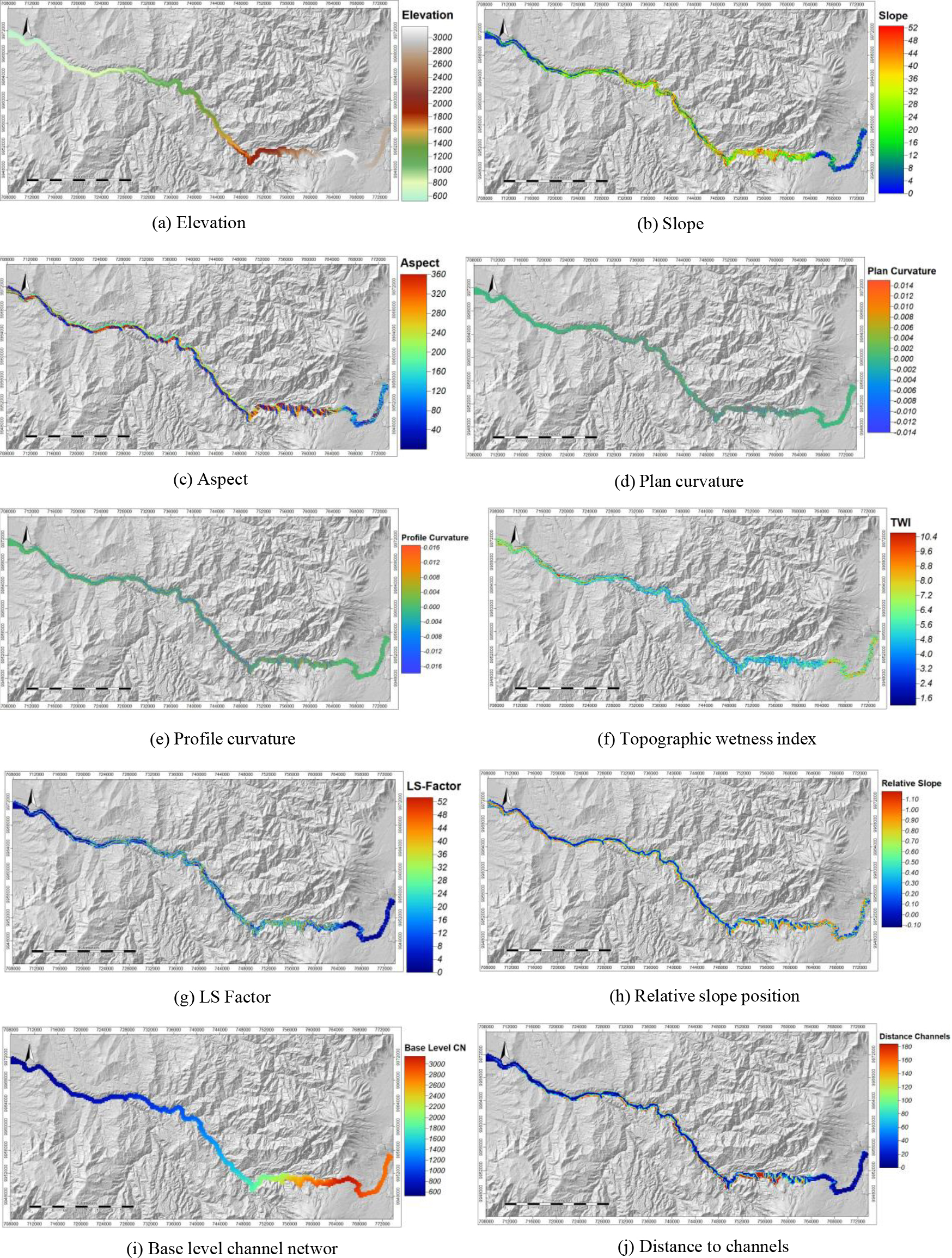
The values of each conditioning factor in the study area are represented by a map from which the CNN input images are extracted [24, 44, 45]. To generate the maps of conditioning factors, a 30-meter resolution DEM of the study area was downloaded from the OpenTopography2 platform. By extracting contour lines and interpolating every 5 meters, a new DEM was obtained with an improved pixel resolution of 5 meters for greater detail using SAGA-GIS. Therefore, all the maps of the variables must have the same pixel resolution. From the new DEM, we can automatically generate 10 maps of different variables through the Basic Terrain Analysis tool (Fig. 4). It is important to note that this DEM, from which the maps of the condi- tioning factors are generated, dates from 2011 and the landslide inventory is from 2014 to 2021, so the information is taken before the landslide event, just as the predictor should be trained.
A group of 14 conditioning factors is selected based on the frequency of appearance in related work, the degree of affectation on the road, and the spatial distribution of landslides [29, 31, 32, 33, 46]. One of the most influential variables is the slope, which is correlated with most of the other variables. It is important to point out the relationship of each conditioning factor with landslides, as well as their behavior in the study area. Elevation or altitude has a direct relationship with relief and slope; strong elevation changes imply steep slopes and instability that contribute to the occurrence of landslides. Elevation increases from 600 m in the west (coast) to 3000 m in the east (highlands) (Fig. 4a). Slope is the inclination of the terrain, so steep slopes are very prone to landslides. The slope ranges from 0
Maps of manually generated conditioning factors.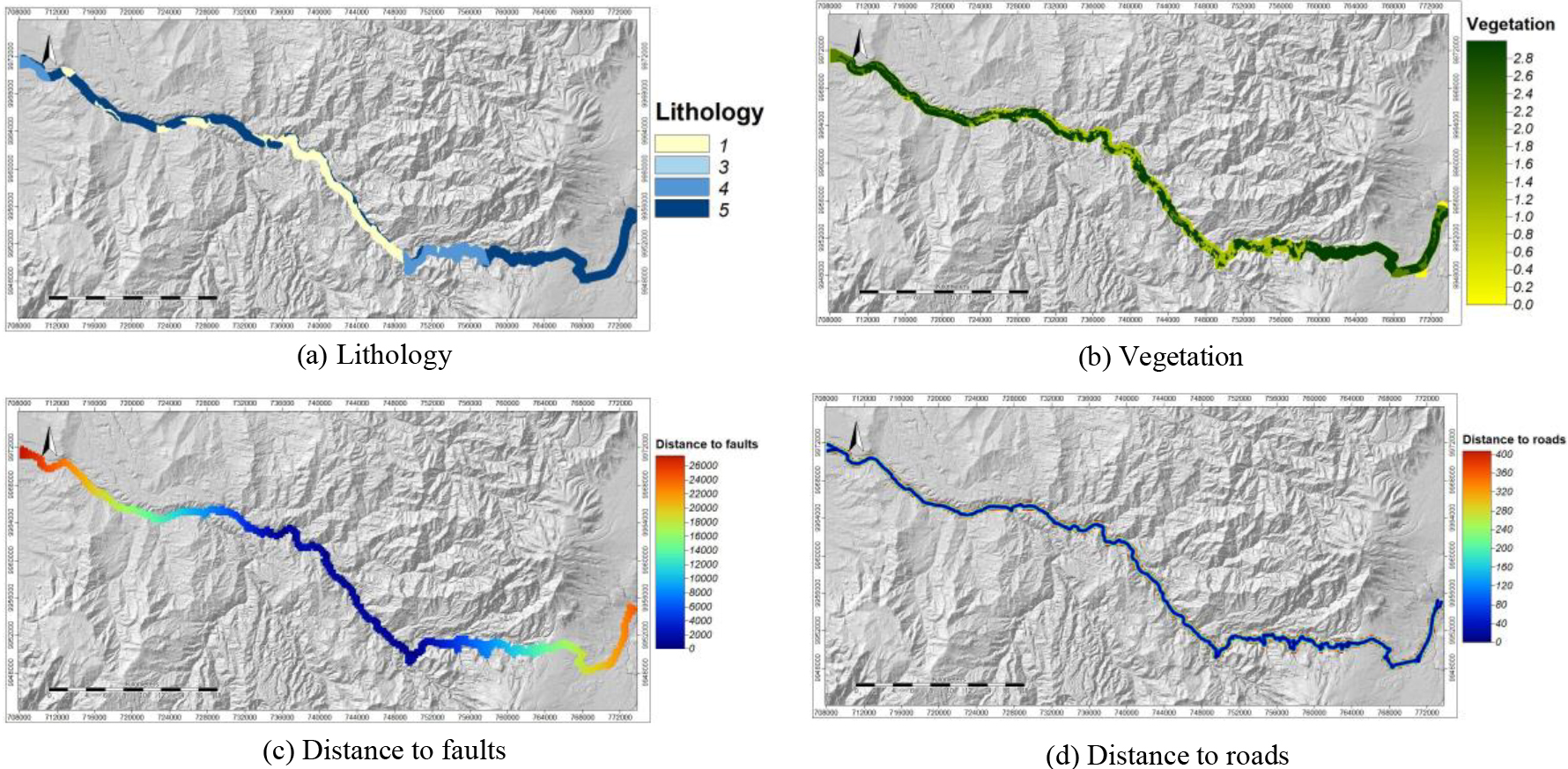
The remaining 4 maps of conditioning factors are generated manually (Fig. 5) from the geological cartography of Quito, Machachi, Las Delicias, and Santo Domingo at 1:100.000 scale, SNI,3 GAD Pichincha, and SIGTIERRAS-MAG.4 Lithology (geology) considers the physical and mechanical properties of rocks, their composition, state, nature, etc., and can determine the instability of slopes. Certain types of lithology are more prone to landslides depending on their conditions. In the study area, there are 4 classes (Fig. 5a): a) andesites, sandstones, and intrusive bodies; b) volcanoclastic sediments and volcanic conglomerates; c) volcanoclastic sediments and undifferentiated terraces; and d) alluvial and colluvial deposits. Vegetation influences the occurrence of landslides. Forests provide stability to the terrain due to the roots that prevent erosion, while anthropic areas and agricultural lands favor it and accelerate landslides. The area shows 3 classes (Fig. 5b): a) forests, b) water bodies and anthropic zone, and c) agricultural lands, shrub and herbaceous vegetation, and other lands. Qualitative values for geology and vegetation must be converted into numerical values for the processing of the prediction model. Following the coding technique known as One-hot encoding, we assign in binary form (values of 0 or 1) the 4 lithology classes and the 3 vegetation classes found in the study area. Distance to roads reflects the impact of anthropic activity and represents the vertical distance of the landslide crowns from the road infrastructure. The degree of affectation may be related to the size and extent of the landslide. There are values between 0 m and 200 m of proximity (Fig. 5d). Finally, distance to faults is the proximity to faults that influence slope breaks and affect not only surface structures but also the permeability of the terrain. The Tandapi (east) and Baba River (west) fault systems are located in the area. They exert structural control over the road, with values between 0 m and 12000 m in landslide zones near the faults and values from 14000 m to 26000 m in zones far from the faults (Fig. 5c). These last two distance variables require the generation of a grid of points with the FishNet tool of ArcGIS; the distance from each landslide crown to the road and the distance from each point to the faults are calculated using the Near tool; the vector layers resulting are joined with the Merge tool and interpolated with the Inverse Distance Weighted (IDW). The generated polygons are then rasterized with the PolygontoRaster tool, which assigned a cell size of 5 meters.
The maps of the conditioning factors or variables of the phenomenon reveal certain values that are closely related to the occurrence of landslides. Our aim is to identify the places with the highest risk and to determine the level of susceptibility along the road.
We have a set of maps of the 14 conditioning factors, of which ten are obtained automatically from a DEM of 2011, while the maps corresponding to distance to roads, distance to faults, lithology, and vegetation are produced manually. Due to the 4 qualitative values of lithology, it was necessary to replace them with 4 quantitative variables of binary type, where 1 means the presence of lithology and 0 is its absence. Thus, 4 maps related to lithology are generated. Following the same criteria, vegetation generated 3 maps due to the 3 vegetation values found in the study area. Therefore, a total of 19 maps in raster image format, each image or map is represented as a grid of pixels, where each pixel is a 5-meter square.
This pixel or cell is the mapping unit and its size is a key aspect for analysis and prediction. It corresponds to the interpolation every 5 meter of contour lines from the original DEM. This size is appropriate because the smaller the size, the greater the redundancy; the larger the size, the greater the loss of information. For instance, many cells with the same value of elevation, since in a few meters this value do not change significantly; while a larger size may imply a significant change in this variable with two or more values that cannot be included in a single cell.
Previous studies assumed that each map pixel within the area occupied by the landslide is the value that triggers the phenomenon. This situation is unrealistic, as the extension of a landslide may reach flat areas, even part of the road, where the elevation and slope values are low or null, however, they are taken as positive records of the occurrence of the phenomenon. This undoubtedly distorts the task of relating the occurrence of the landslide and its causes, and the accuracy of the model will decrease under these conditions.
Our proposal is the generation of images covering the starting zone of the landslide as the center and its closest proximity, that is, where the phenomenon originates. The process to identify the crown of the landslide and its associated image consists of the following steps: 1) we manually digitized the shape of each landslide from our updated inventory using ArgGIS and Google Earth satellite imagery as background; 2) the layer of contour lines obtained every 5 meters is superimposed on the previous one; 3) the highest contour level is identified to locate the nearest border of the landslide; 4) we mark on this border the points rep- resenting the crown or origin of the phenomenon. The dimensions of some of the landslides imply that the crowns actually correspond to small areas rather than precise points (Fig. 6); and 5) from the crown of each landslide as the central pixel, we manually generate 5
Landslide crown localization and imaging.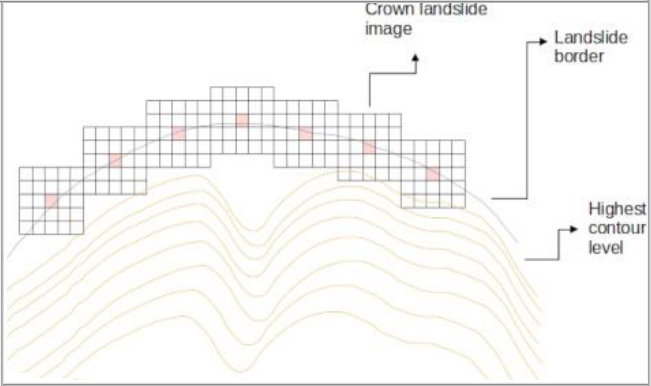
A 5
The treatment given to the other variables is different because the location of the pixels did not match. To solve this problem, the elevation variable raster is converted into points using the Raster to Point tool. For each point generated from the raster (1 point per pixel), the values corresponding to geology, vegetation, distance to faults, and distance to roads are obtained with the Extract Values to points tool. The reverse process was carried out using the Point to Raster tool rasterizing the points with a pixel size of 5 meters so that all pixels have the same spatial location. Subsequently, we use the Clip Raster by Mask Layer tool in QGIS for cropping the images to the desired size of 5
5 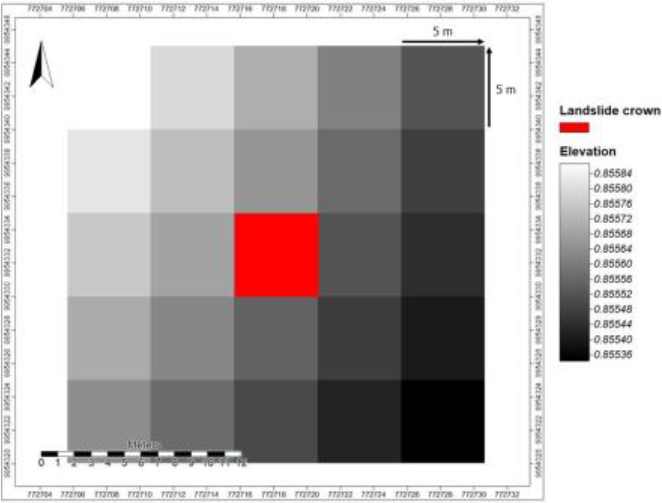
Datasets are key resources in machine learning. Our proposal is to directly use the images representing the landslide crown and variables of the phenomenon. A dataset composed of the images generated in the previous section is the input to train a CNN, which learns the conditions that trigger the phenomenon and obtains a model that predicts the landslide risk. However, it is first necessary to balance, debug, normalize, stack and split the image dataset.
In the learning process, it is recommended to have an equal number of examples of positive and negative landslide occurrences so that the prediction model is free of biases and preferences of any kind. For this reason, nonlandslide images are added to balance the dataset. We identify the areas in which the terrain conditions allow us to ensure a null or almost null probability of the occurrence of the phenomenon. We consider certain criteria such as the slope with values below 10 degrees [47]. Nonlandslide zones are assigned based on the filtering and superposition of the variables with the analysis of frequency histograms, so there is a visual relationship of approximately 1:10 between the values of each variable that favors and avoids landslides. Each nonlandslide point is located in places with very low or no susceptibility to landslide occurrence.
Dataset debugging
Each of the landslides is verified to obtain a quality dataset, with special attention to elevation and slope variables. Inconsistent values of these variables are discarded, for example, slopes less than 10
Normalization
Different scales and units of measurement of variables can be a problem training a model. The normalization of the pixels is made with Raster Calculator in QGIS, calculating the maximums and minimums of each quantitative variable. Then, the standardization values between 0 and 1 with MinMaxScaler in Python. For qualitative variables, the one-hot encoding technique is used, which creates new binary columns that indicate the presence or absence of each value within the original data. Thus, these variables are subdivided into 4 geology variables and 3 vegetation variables. Once the normalization is done through the NumPy library, the number of variables increased to 19.
5 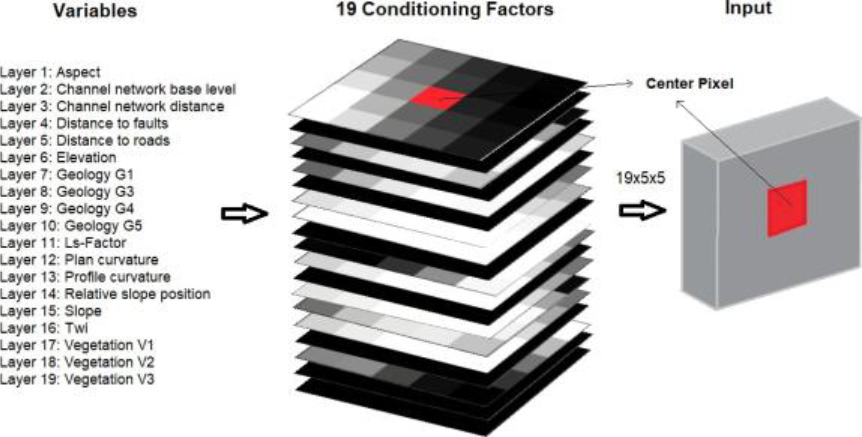
Images processed by a CNN usually contain 1 or 3 channels, corresponding to grayscale or color, respectively. In our case, the images are made up of 19 channels, each associated with a variable. The dstack method from NumPy allows stacking this number of channels in 5
Dataset split
This operation is classic in machine learning and consists of dividing the dataset into two subsets. The train subset is used to fit the model, while the test subset to evaluate the model performance. A third subset called validation is needed at training time. Based on the proportions recommended in the literature [18, 48], we used a split of 80:20 for training (209 images) and testing (53 images), respectively. For this purpose, the train_test_split function from scikitlearn automatically performs the division in a random way. Furthermore, the training part will be divided into training and validation using cross validation of the data.
2D convolutional neural network architecture.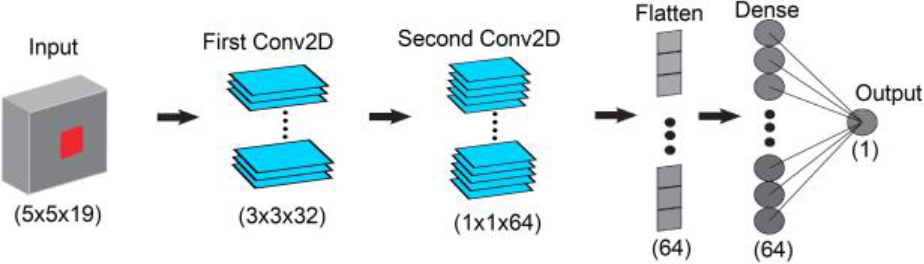
Once the dataset was properly prepared for the training process, we design the CNN architecture considering landslide prediction as a binary classification problem, i.e., occurrence or nonoccurrence of the phenomenon. A customized convolutional network that accepts the dimensions of the input image is needed instead of pretrained models, which have image size restrictions and receive conventional 1- or 3-channel color images. The structure of the convolutional network is shown in Fig. 9.
Images of dimensions
The number of parameters generated is 28225, which are adjusted during model training. It is worth noting that the model do not use a pooling layer because the aim is not to reduce the size of the image, so we work with the same input dimension of 5
Experimentation and results
This section describes the experimental part of the project. It focuses on the training of the previously defined CNN processing our image dataset. The model performance is evaluated through learning curves, confusion matrices and accuracy metrics. This allows knowing the suitability of the model for landslide risk prediction and the determination of susceptible areas. The development and execution platform is Google Colaboratory, which is free and offers GPU (Graphics Processing Unit) processing, a large amount of RAM and direct access to data stored in Google Drive or GitHub. The implementation is through programming notebooks using Python and libraries for deep learning such as Keras, Tensorflow, Sklearn and Torch. In addition, OS and Pathlib for folder and file system management, Pandas for data manipulation and analysis, NumPy for data structures and numerical representation of images in tensors, Matplotlib for graph creation and visualization and PIL for image processing.
Training
The training process starts with the reading of the dataset, which consists of landslide and nonlandslide samples in the same number for image balance. The CNN is trained with all training data (including validation data) and the obtained model is evaluated with the test data. Since our dataset is small, we implement stratified k-fold cross-validation to avoid high variance and increase confidence in the results. This method reduces bias since most of the data is used to train the CNN with different validation subsets. We define k
Previously, it is necessary to set the hyperparameters that control this process. The loss function is binary crossentropy, 0 for nonlandslide and 1 for landslide, the Adam optimizer with a learning rate of 0.001, and the accuracy metric are established. The image dataset is fed in batches (batch size
Learning curves of each training and validation of the 5-fold method. Accuracy (left) and loss (right).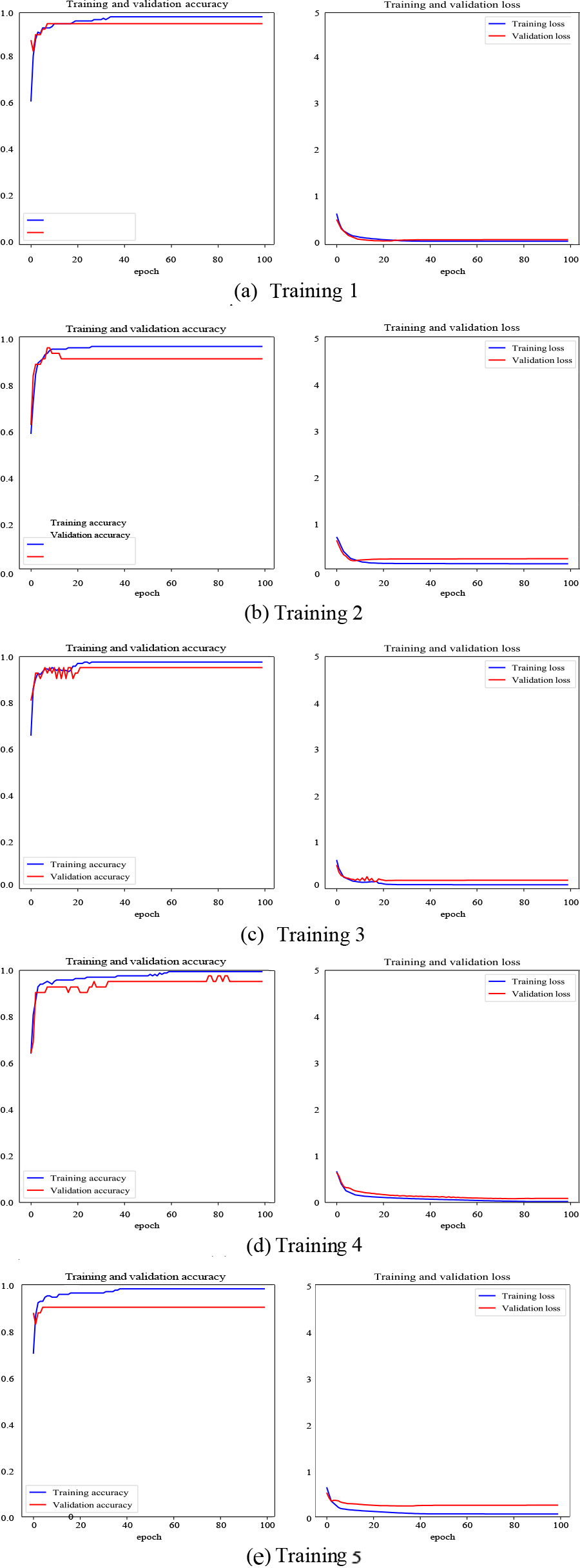
Accuracy and loss in the test subset for each model. Mean and standard deviation are included
Central region of the highway used for landslide prediction.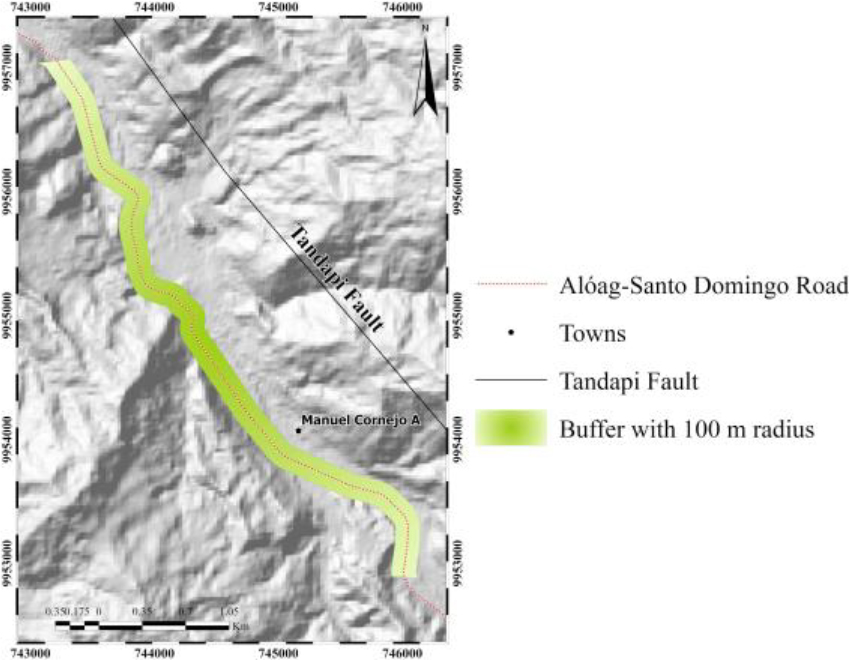
The different runs allow us to detect the variability in the performance and generalization ability of the model. To know how the model behaves during training and validation, visual tools such as learning curves are used. The Matplotlib library allows to plot the accuracy and loss values stored in the history, both in the training and validation stages. The training results of the 5 models are shown in Fig. 10.
The performance of the five models is quite satisfactory. The accuracy curves in both the training and validation phases increase as the epochs progress and remain stable at a high percentage of accuracy. Moreover, these curves is very close to each other, evidencing that there is no overfitting. For the loss or error curves, the behavior is similar, but in the opposite direction. There is a marked trend to zero for both curves.
Evaluation must be performed on the test data, which is the data not seen during the training stage. For this purpose, the accuracy metric is calculated using the same test subset in each training. The final evaluation performance of k runs is averaged as the overall model performance. In addition, we provide the mean and standard deviation of the accuracy of the k runs used for k-fold cross-validation.
Table 2 summarizes the evaluation performed on the test data. The arithmetic mean of the five runs (94.72%) is reported as the final measure of the accuracy of our model. This measure is considered more robust to the problem that different divisions of the data can lead to different results. The standard deviation (0.0279) is small, reflecting a low variability of the precision values obtained from the 5 evaluations. We also include the loss values, which are in the range between 0 and 1, suggesting acceptable behavior.
Since we use a different dataset, architecture and geographic area than other landslide-related studies, our contribution is novel and it is not possible to directly compare the current work with others. Experimental results show an average accuracy of 94.72%, which becomes the state of the art performance for the specific dataset developed and geographical area considered.
Landslide susceptibility map
We have proved five models that are acceptable, however, the best one (98.11% accuracy) is selected to predict the occurrence of landslides and generate the susceptibility map of the Aloag-Santo Domingo highway. The prediction is made for each of the pixels of the study area. We must consider that the model receives input images of 5
Workflow for generating the landslide susceptibility map.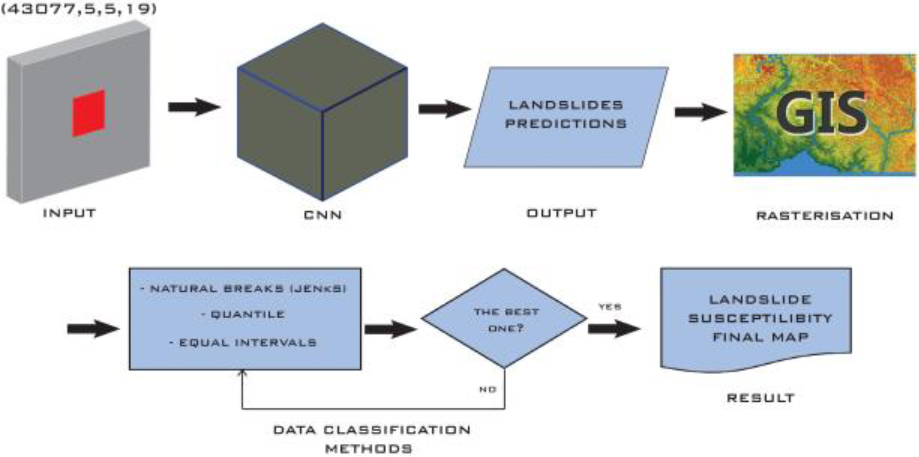
A sample of the predictions file exported to GIS.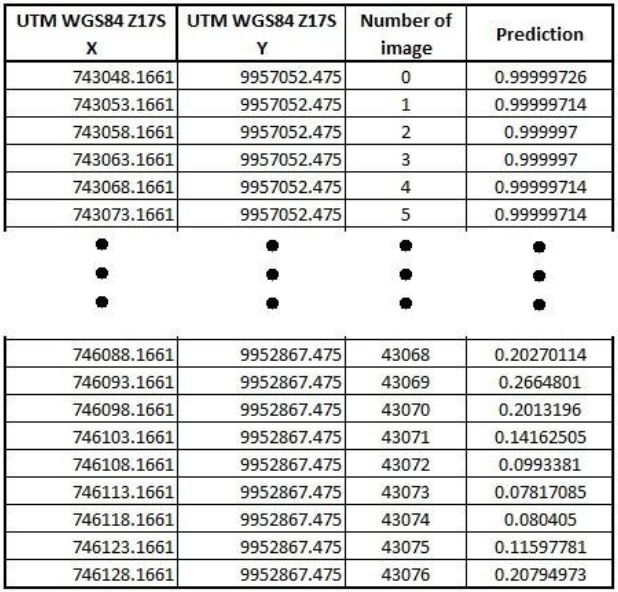
The elevation raster is converted to points using ArcGIS and resulting an equal spacing grid in which each point is located in the center of each pixel. The buffer operation is applied from each point as a center to generate circles of 12.5 m radius, which are then transformed into 25
Landslide susceptibility map.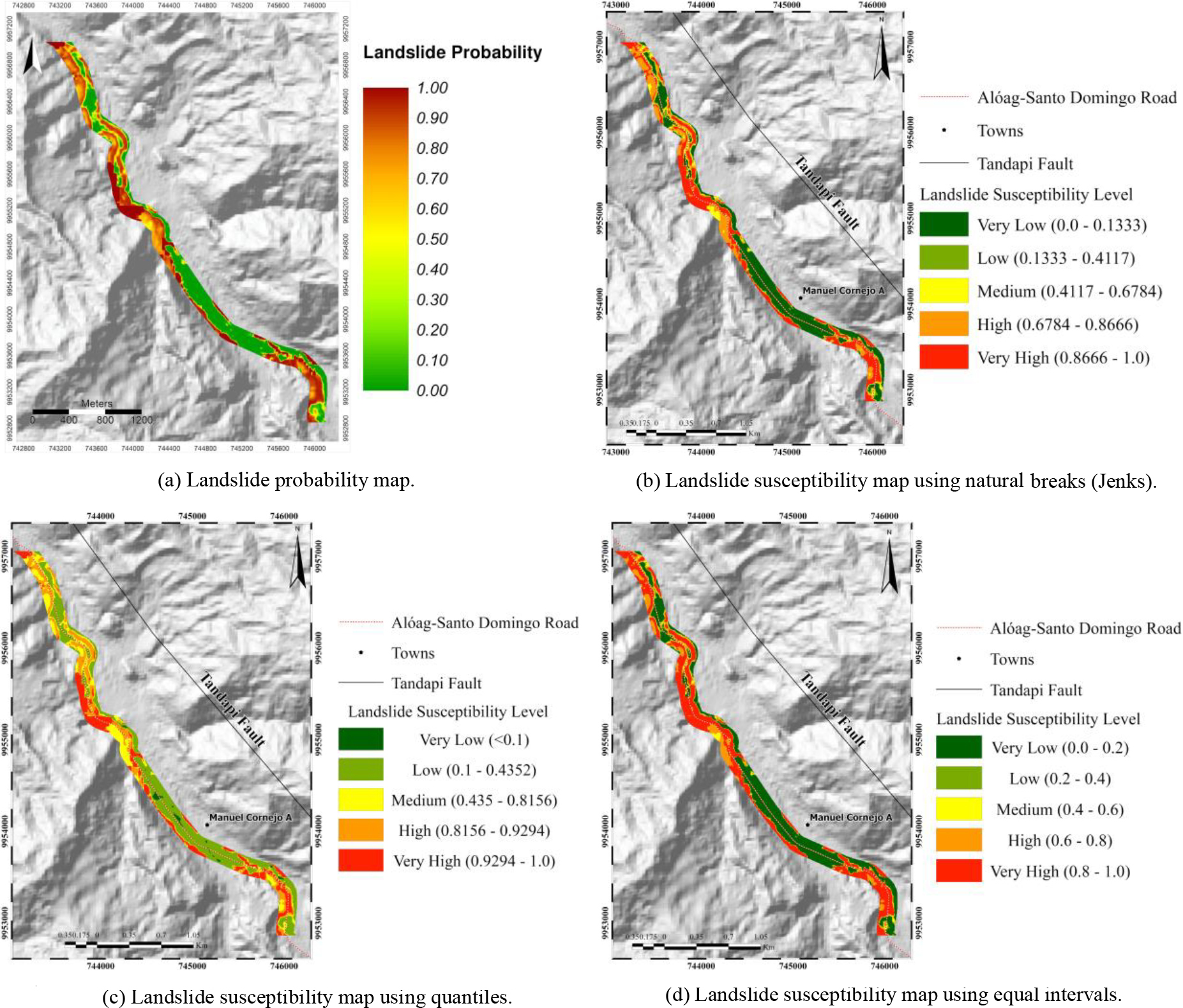
Images are organized and stored in folders, each of which corresponds to each conditioning factor. An important aspect is the nomenclature used to name the images and facilitate stacking them prior to prediction. This name is constituted by the raster of the variable followed by the position in numerical order and the file format, for example, Aspect_105.tif, Elevation_105.tif, Slope_105.tif, etc. First, they are sorted alphabetically so that all the tensors of each image contain the same conditioning factor. Then we generate empty tensors of dimensions (43077,5,5) using NumPy to store 43077 input images of 5
The landslide susceptibility map is generated following the procedure illustrated in Fig. 12.
The probability values obtained from the prediction are exported by means of a Pandas data frame to GIS together with the image number, the predicted value and the geographic location of the central pixel in UTM coordinates (WGS84-17S). Figure 13 shows an extract with the header and tail of this list of values. The determination of the coordinates of the central pixel is simple because the polygon number used for clipping (generated by the buffer) corresponds to the same as the image plus one, that is, if the image number is 50, the polygon number is 51, so that by calculating the coordinates of the centroid of the polygon, we know to which central pixel it corresponds.
The data file is imported into a GIS and converted into a colored raster with values between 0 and 1, representing the probability of landslide of the central area of the highway (Fig. 14a). However, it is necessary to distribute the probability values in classes associated with different susceptibility levels. There are several methods for the distribution of values, each with characteristics that can better reflect reality. We analyze which is the most convenient for our case among the following ones: Natural Breaks (Jenks), Quantiles, and Equal intervals.
Natural Breaks minimize the mean deviation between values of the same class and maximize the mean deviation between classes, that is, intervals are defined in places where there are relatively large jumps between one class and another [49, 50, 51]. Quantiles allow each class contains the same proportion of values, the classification is adapted to classes that have a good linear distribution; however, it is a somewhat misleading method since low values can be included within classes with high values [52]. Equal intervals divide the range of attribute values into classes of equal size, which is useful when it is desired to emphasize the amount of value of an attribute in relation to the other values [52].
It is possible to choose one of these methods in ArcGIS as well as the number of risk categories, ranging from very low, low, medium, high to very high susceptibility. Once the three maps have been generated, we make a visual comparison to select the most appropriate one. Based on the landslide inventory, all maps provide a high level of confidence because areas with a higher concentration of landslides have a higher susceptibility [53]. However, the map generated by the quantile method (Fig. 14c) is quite similar to the map of landslide probability values without classification. This is not suitable for representing well-defined zones and levels of landslide susceptibility. The Jenks and Equal Intervals maps (Fig. 14b and 14d, respectively) are very similar and show a closer representation of what may occur in reality. There are slight differences between both maps, but the Jenks method presents a better visualization where all classes are clearly visible. In particular, we are interested in higher variability of values from different classes (interclass variability) and lower variability of values from the same class (intraclass similarity). This is exactly how the natural breaks method works.
We have used CNN-based deep learning to perform landslide risk prediction and the generation of a susceptibility map of the area of interest. The visual and accuracy results indicate that this solution is a comparable alternative to classical ML methods. The performance of a learning model depends on the quality of the data, so one of our main tasks was to improve the dataset needed for landslide risk prediction. By using previous geological and fieldwork information provided by a governmental entity, we validated and updated the historical record on landslides through journalistic sources and satellite image interpretation. We provide a more reliable and up-to-date landslide inventory that is the basis for generating an image dataset that represents each conditioning factor of the phenomenon. These images 5
Future work
The landslide susceptibility map must be made for the entire study area. This requires processing a quantity of 3 million 5
Footnotes