
Abstract
This article summarizes principles and ideas from the emerging area of applying conditional computation methods to the design of neural networks. In particular, we focus on neural networks that can dynamically activate or de-activate parts of their computational graph conditionally on their input. Examples include the dynamic selection of, e.g., input tokens, layers (or sets of layers), and sub-modules inside each layer (e.g., channels in a convolutional filter). We first provide a general formalism to describe these techniques in an uniform way. Then, we introduce three notable implementations of these principles: mixture-of-experts (MoEs) networks, token selection mechanisms, and early-exit neural networks. The paper aims to provide a tutorial-like introduction to this growing field. To this end, we analyze the benefits of these modular designs in terms of efficiency, explainability, and transfer learning, with a focus on emerging applicative areas ranging from automated scientific discovery to semantic communication.
Introduction
In the last twenty years, neural networks (NNs) have undergone two opposing trends. On one hand, the number of practical applications has continued to grow, fueled by successes in, among others, language modeling [37], drug design [93], rendering, and language-vision reasoning [64]. On the other hand, their design has crystallized around a very small set of layers (e.g., multi-head attention) and principles (e.g., permutation equivariance), while the focus has shifted on scaling up their training, both in terms of data and parameters [37]. Apart from scale, maybe less than a dozen components and variations thereof are enough to categorize the vast majority of neural networks deployed nowadays.
Among these design principles, sequentiality has remained a key component. NNs, be they convolutional, recurrent, or transformers, are composed of a stack of differentiable operations, which are activated in sequence for each input to be processed. Stated in another way, their computational graph, i.e., the sequence of primitive operations executed on the underlying hardware, is fixed beforehand when instantiating them. Because NNs have continued to scale in depth and width, this has led to several issues in terms of computational performance and efficiency [22]. Standard techniques to make NNs more efficient only address this partially, by replacing the original network with other static models having fewer layers (distillation [95], pruning [42]), less precision per parameter, or by approximating each weight matrix (e.g., via low-rank factorization).
By viewing neural networks as computing systems, this behavior is counter-intuitive. Hardware components are designed based on their expected peak usage, while only executing a fraction of their resources at any given time (e.g., memory). Similarly, software libraries and operating systems are composed of millions of lines of code, only a handful of which are selected and run in a given moment, thanks to the use of branches, loops, and conditional execution. Recently, a large body of literature has flourished on embedding similar sparse modularity principles in the design of neural networks [67]. Based on the original idea of conditional computation [5], this has blossomed into a large number of practical implementations, ranging from mixture-of-experts (MoEs) [85] to dynamic mechanisms to select tokens and layers in transformers [52]. This tutorial is intended as an organized, uniform overview and entry point into this growing body of literature.
The benefits of developing networks that can dynamically adjust their computational graph go beyond memory or time efficiency. More and more, neural networks are treated in the same way as software [40], and deploying them requires the possibility of quickly debugging their predictions [11], continually fine-tuning them on new data, and transferring parts of their knowledge from one network to the other [3], similarly to standalone software libraries. As we will see, dynamically-activated neural networks provide a principled way to improve both zero-shot transfer and generalization [70] (Section 4.2) and explainability of the models (Section 4.3). This aligns with the requirements of many novel applications of NNs, from scientific discovery [93] to AI-native telecommunications [86, 99]. In particular, smart semantic communication networks [86] envisioned in the so-called beyond 6G model necessitate networks that can flexibly adapt to bandwidth and energy constraints, while ensuring transferability and communication through separate neural modules.
For the purpose of this tutorial, we consider three flavors of dynamism: (a) neural components that can restrict their computation to a smaller subset of input tokens (dynamic input sparsity); (b) layers that can selectively activate sub-components for processing a token (dynamic width sparsity); and (c) layers that can be completely skipped during their execution (dynamic depth sparsity). As we show in Section 2, a simple mathematical formalism encompasses all three cases. Section 2 also highlights how modularity can be achieved with the addition of a small set of primitives to our networks’ toolkit, namely, the possibility of sampling in a differentiable way elements from a set. We discuss in Section 2.2 the simplest technique to this end, the Gumbel-Softmax trick [35, 50], and some common extensions.
We then proceed to discuss three notable implementations of these concepts in Section 3: early-exit (EE) models, mixture-of-expert (MoE) layers, and token selection mechanisms. While these models are generally discussed in separate fashions (e.g., see [51, 82] for EEs, and [20, 105] for MoEs), viewing them as specific instances of a general framework highlights many similar trends and characteristics. In fact, we argue that designing networks with dynamically activated components is not simply a matter of enhancing performance: in all these cases, the resulting networks are more apt at adapting to variable system’s constraints (e.g., decreased energy usage), specialization, catastrophic forgetting, and multimodality. We build on these insights in Sections 4 and 5, where we list potential research directions for these models including adapting their computational cost and energy at inference and training time in an elastic way, zero-shot transfer, robustness, and explainability.
Three types of conditional computation
A general formalism for sparse modularity
Neural networks can be described as the composition of several trainable, differentiable operations of the form:
Most of our discussion focuses on transformer-like architectures, where the input is composed of a set of tokens, representing parts of the complete input [78] (e.g., subwords in a sentence or patches in an image). The input x in (1) is purposefully left vague: depending on the scenario and the layer, x can be a single token (e.g., for the fully-connected blocks inside a transformer), the entire set of tokens, a mini-batch of inputs, or other forms of data aggregation.
We are interested in augmenting (1) to allow the dependence of the different quantities to vary based on some
Suppose we have available some trainable subsampling operation, defined over the conditioning input x
c
and over some set
This small addition allows us to implement several levels of modularity inside our neural network. First, assume the input x can be decomposed into smaller components x ={ x1, …, x
n
}. In many cases, this is a natural decomposition, e.g., tokens inside a transformer, time instants for a sequence, or frames for a video input. However, they can also correspond to additional register tokens [18], to elements extracted from some external memory (e.g., AdaTape [101]), or additional views or modalities. Then, dynamic input sparsity (Fig. 1) is achieved by combining the layer with a subsampling operation on the input:
Input sparsity: A differentiable mechanism subsamples input tokens to be processed by the later parts of the network (we show original image patches in the figure, but the tokens can be equivalently be replaced by their latent representations if we consider an intermediate layer of the architecture).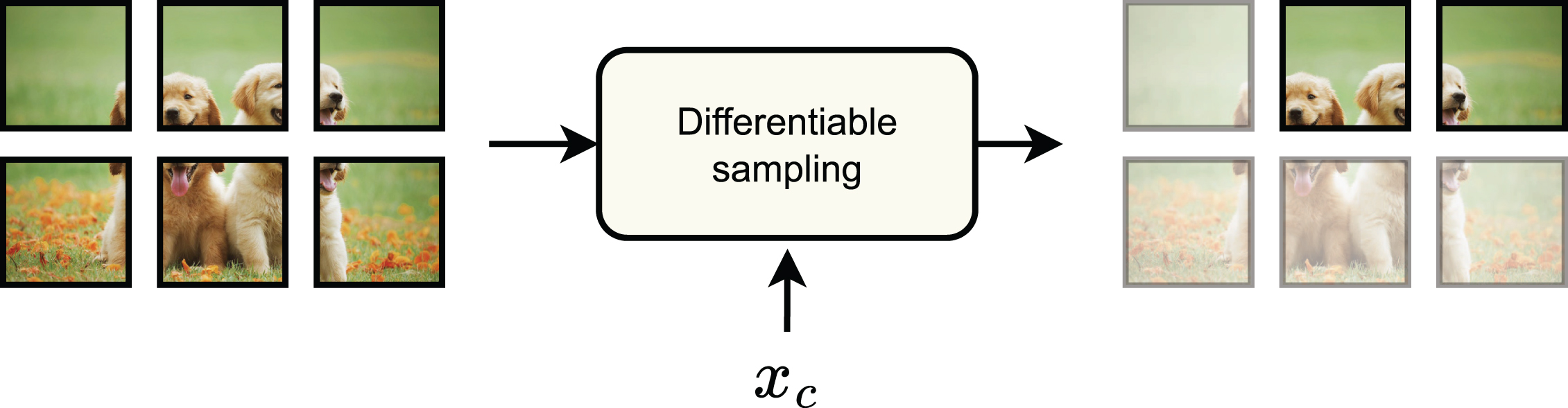
Second, assume the weights themselves can be decomposed into blocks b ={ w1, …, w
m
}, and the entire function decomposed as:
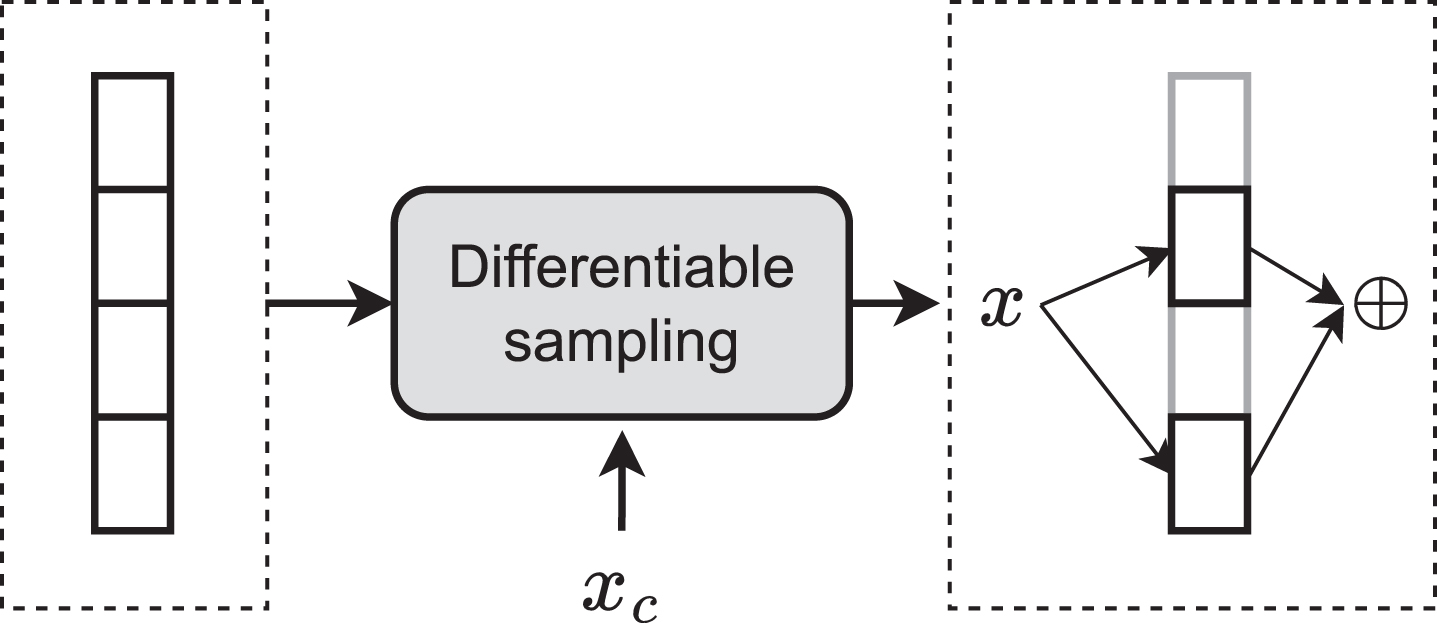
Width sparsity: Different parts of a layer (e.g., experts) can be activated based on the conditioning value.
Third, even if a weight decomposition is unavailable, dynamic computation can still be achieved by considering the entire layer as a single block and conditionally skipping its execution. This dynamic depth sparsity (Fig. 3) can be achieved easily by rewriting the layer with an additional, untrainable scalar weight σ = 1, and writing:
Depth sparsity: A subset of the layers can be deactivated by the sampling mechanism, like in early-exit networks.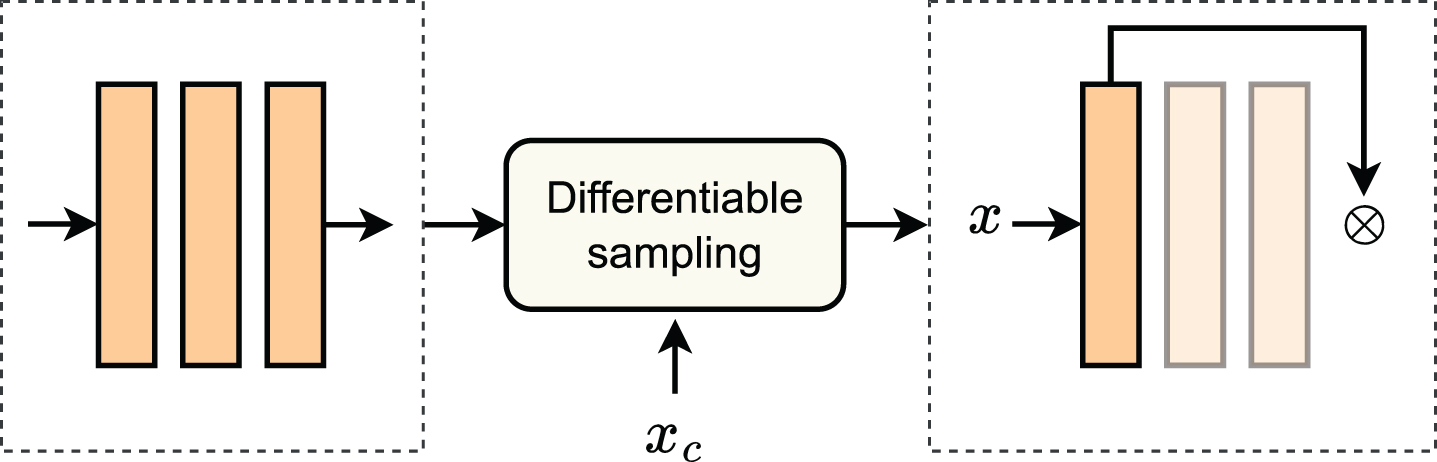
Before proceeding, we discuss briefly the implementation of the subsampling layer Γ. As a prototypical example, we restrict our analysis to subsampling a single element from the set in input. In this case, a very common implementation is the so-called Gumbel-Softmax (GS) trick [35], also known as the concrete distribution [50]. In this section, we only provide a high-level overview, and we refer to [34] for a fuller exposition.
First of all, we process the inputs with some trainable layer
The operation in (11) is not easily trainable via gradient descent (since its gradient will be zero almost everywhere), but it can be relaxed with a softmax approximation:
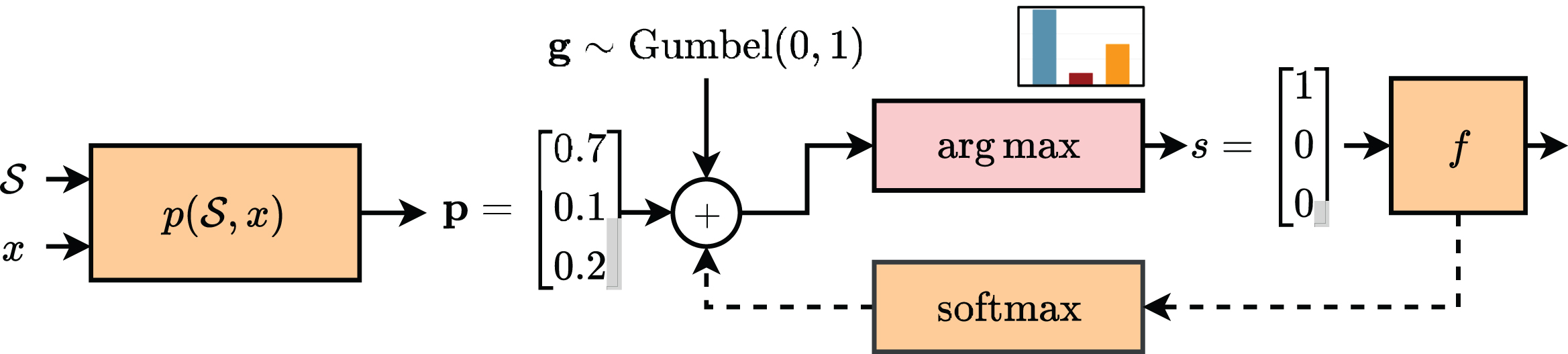
Overview of the Gumbel-Softmax trick. We show in orange differentiable operations (the argmax’s gradient being zero almost everywhere) and with a dashed arrow the relaxed backward path.
The GS trick can be easily extended to sampling more than a single value by replacing the arg max with a top-k operation [43]. Suitable generalizations, such as the entmax family [16], can also sample binary vectors with a variable number of elements. The simplicity of the GS trick makes it widespread in many applications, but several other types of sampling layers can be found in the literature, especially for more complex combinatorial spaces, for which we refer to [59]. A larger overview of possible sampling operations for MoE layers is also given in Section 3.3.
The previous section has introduced a generic framework for designing networks with dynamic computational graphs. In the literature, these ideas have coalesced around a few, notable set of implementations. In this section we overview three of the most popular ones:
Early exits
Early exit neural networks (EENNs) were introduced based on the idea that not all the inputs to a network are required to go through all the layers of the model to be correctly classified [89]. In fact, the accuracy of a network can decrease with respect to the depth on particularly easy samples, a phenomenon known as overthinking [80].
Consider a neural network (sometimes called the backbone network in this context), which can be either trained from scratch or pre-trained. In an early-exit framework, the backbone is augmented with auxiliary classifiers (early exits) which are connected at intermediate outputs of the backbone. These auxiliary blocks can be trained all at the same time or in a layer-wise fashion [82], while at inference time they are used to halt the computation when the model is confident enough about the prediction. This is an example of dynamic depth sparsity (Section 2), except that an entire subset of layers is skipped at the same time.
We introduce first the most common formulation of EENNs, in which early exits are jointly trained while the early exit logic is defined manually with additional hyper-parameters. As already stated, we can see a neural network as a composition of b sequential blocks:
These networks have found applications in many fields recently. Concerning NLP, many strategies with BERT have been proposed [98, 114], varying from patience-based EE [111] to extra classification layers [98]. For computer vision, EE applications vary based on the strategy, including multi-exiting [4, 95], and loss-weight adjustment [94]. Also, the tasks vary, spanning semantic segmentation [44], video recognition [23], adversarial training [41], and image compression [99]. Recently, EE strategies have been proposed also for vision-language models [88].
Although this formulation of EENNs (or minor variations thereof) is very common in the literature (see e.g., [8, 111]), it only fits partially our view of dynamic sparsity, since the computational graph is unchanged during training and the dynamism is only obtained via an external heuristic. To this end, [81] proposed a mechanism to optimize the early exit selection during training, called differentiable branching. Suppose we augment each early exit with an additional output that we denote as γ
i
(x). The key idea of differentiable branching is to define a new recursive output, which is given by a soft composition of the original outputs:
Mixture-of-Experts (MoEs) models were introduced more than thirty years ago as adaptive algorithms to perform dynamic ensembles of individual machine learning algorithms, denoted as experts in that context [105]. Recently, MoE layers in neural networks have gained popularity, especially for LLMs and large vision modules [78]. They allow scaling the model’s parameters while keeping the compute budget constant, and they offer the possibility of distributing the training by decomposing the computation of a layer over multiple GPUs [78]. As a side product, they offer dynamic width sparsity by selectively activating only parts of the layer for each input. At the time of writing, the largest open source language and vision models are based on a MoE formulation [17, 78].
In a MoE layer, the trainable parameters are grouped into topologically identical blocks called experts. In the forward pass, a decision block (called router in this context) selects a subset of expert blocks (typically, only a fixed number of k experts, with k selected beforehand, is chosen) that will be activated and routes the input data to the selected experts. More formally, the MoE layer can expressed as:
The unique advantage of MoEs is that only a fraction of the network parameters, depending on the chosen value for k, are used for computation. Such fraction can be tuned by changing the value of k. Additionally, one can devise routing functions such that experts focus on different areas of the input space, leading to specialized sub-networks (see Section 4.2 for a discussion on specialization and Section 3.3 for an overview of routing algorithms for MoE layers).
As stated earlier, the seminal idea of MoEs dates back to [39], where this paradigm is regarded as an ensembling technique with soft gates. The first work that adopts MoEs in a modern deep learning scenario is [84]. Here, the gate becomes sparse, i.e., a fixed top-k operation and the main goal is scaling the number of parameters. Based on these initial results, in the past few years, the deep learning community witnessed a steep growth of MoE’s success in conjunction with transformer architectures.
Unlike early exiting, where the routing function typically works at the level of input samples (e.g., images for a CNN), an MoE layer as in (18) can work at the level of individual tokens in a transformer. More specifically, in the fully-connected layers of a transformer block, each token can be assigned to one or more experts. Transformer MoEs have been proposed for NLP [21, 72], for vision [78] and even for multimodal training [58]. Additional variants can be applied to individual heads of an attention block [108] or adapters in a fine-tuning context [106].
Different routing strategies can be adopted to orchestrate the experts. These are defined in the gating function γ and usually leverage some differentiable sampling method similar to the Gumbel-Softmax trick (Section 2.2). Routing is a crucial aspect of any MoE architecture, as it must perform a matching between input data and expert network, conditioned on the input data itself. Decisions taken by the routing function govern the training. They can determine faster convergence and expert specialization or cause expert starvation, a peculiar situation where only a few experts are always activated due to their ever-increasing expertise.
The routing algorithm usually adopts a dot product for computing similarity between the embedding of each routed sample (e.g. a token in a transformer) and n trainable expert embeddings (one for each expert). Once this operation has occurred, the assignment can happen according to various methods.
In top-k token choice, each token is assigned to the k most similar experts, where k is an arbitrary value. This is the original approach from [84], and it usually requires additional regularization to avoid expert starvation and training instability. The same approach has been adopted with minor changes (e.g. balancing loss and the k factor) in [21, 74]. Top-k expert choice, proposed in [112], tries to solve the expert balancing problem by assigning each expert to the k most similar tokens, where k is an arbitrary value. Other works [15, 79] cast the expert assignment problem into a reinforcement learning framework and train over a routing policy to assign each token to a single expert. Finally, [115] achieves surprisingly good results by randomly assigning experts to routed samples. An empirical comparison of different routing functions can be found in [49], while a broader overview of MoE layers is given in [20].
Soft routing
We discuss here a variant of the MoE layer in (18), known as soft MoE, which has become popular recently to avoid training instabilities in the layer. The key idea is to use the gating function to combine the layer’s inputs [71] or weights [57] instead of the model’s outputs. These variants also provide a fixed compute budget which is decoupled from the total number of parameters, but they are generally easier to implement and train.
First, denote by x1, …, x
n
the tokens in input to the layer. The first soft MoE variant we consider can be defined as [71]:
A thorough comparison of the relative benefits of hard vs. soft routing is still lacking in the literature, but we highlight a few benefits in Section 4.
We conclude with a brief analysis of token selection mechanisms. In particular, we consider two cases of token selection, which we refer to as token dropping (removal of tokens from the model) and token merging (combination of tokens). Both are conditional computation techniques that can be employed in any transformer model. The fundamental idea behind token dropping and token merging is that the input data often contains information that is nearly useless for the final task. Since transformers operate on set-based inputs with no fixed cardinality, one can dynamically reduce the number of tokens being passed to each layer depending on the relevance of said tokens for the final task.
More formally, let Token dropping: Token merging:
Both methods aim to reduce the computational cost of the forward pass of a transformer by reducing the number of tokens. The mask
Token dropping and token merging have been largely explored in recent years; some of the most impactful works on these topics in the field of vision transformers are [52, 76] for token dropping, while [9, 62] explored token merging. These techniques have also been employed in other fields where transformers are predominant: in 3D computer vision token dropping has been applied to point cloud transformers by [103], while in NLP [32] applied token dropping in the pre-training of BERT, obtaining significant speedups.
Designing neural networks with sparse modularity principles has a number of benefits. The first and most studied is increased efficiency, both in training and in inference (Section 4.1). However, modular networks show emergent properties also in terms of specialization and transferability (Section 4.2), as long as providing a blueprint for a new type of explainability techniques (Section 4.3). We briefly overview these aspects in the following sections.
Efficiency in training and inference
Conditional computation has gained significant attention for accelerating training and inference in deep learning models [22, 67]. Often, the time saving comes with a drop in accuracy, making it important to assess the accuracy/computation trade-off. An interesting example is shown in Fig. 5. The approaches can vary based on several factors. For example, some research investigated the sparsification of CNNs [91] and of transformers [12, 36], some others focused on some specific aspects of the net, such as the gradients [19], the backpropagation, the activations [13] and the attention layers [14, 90]. For clarity, we focus here, mainly, on efficiency aspects related to the three families of models seen in Section 3, focusing on emerging trends and open challenges. To make the analysis more timely and precise, we have reported all the methods analyzed in Table 1.
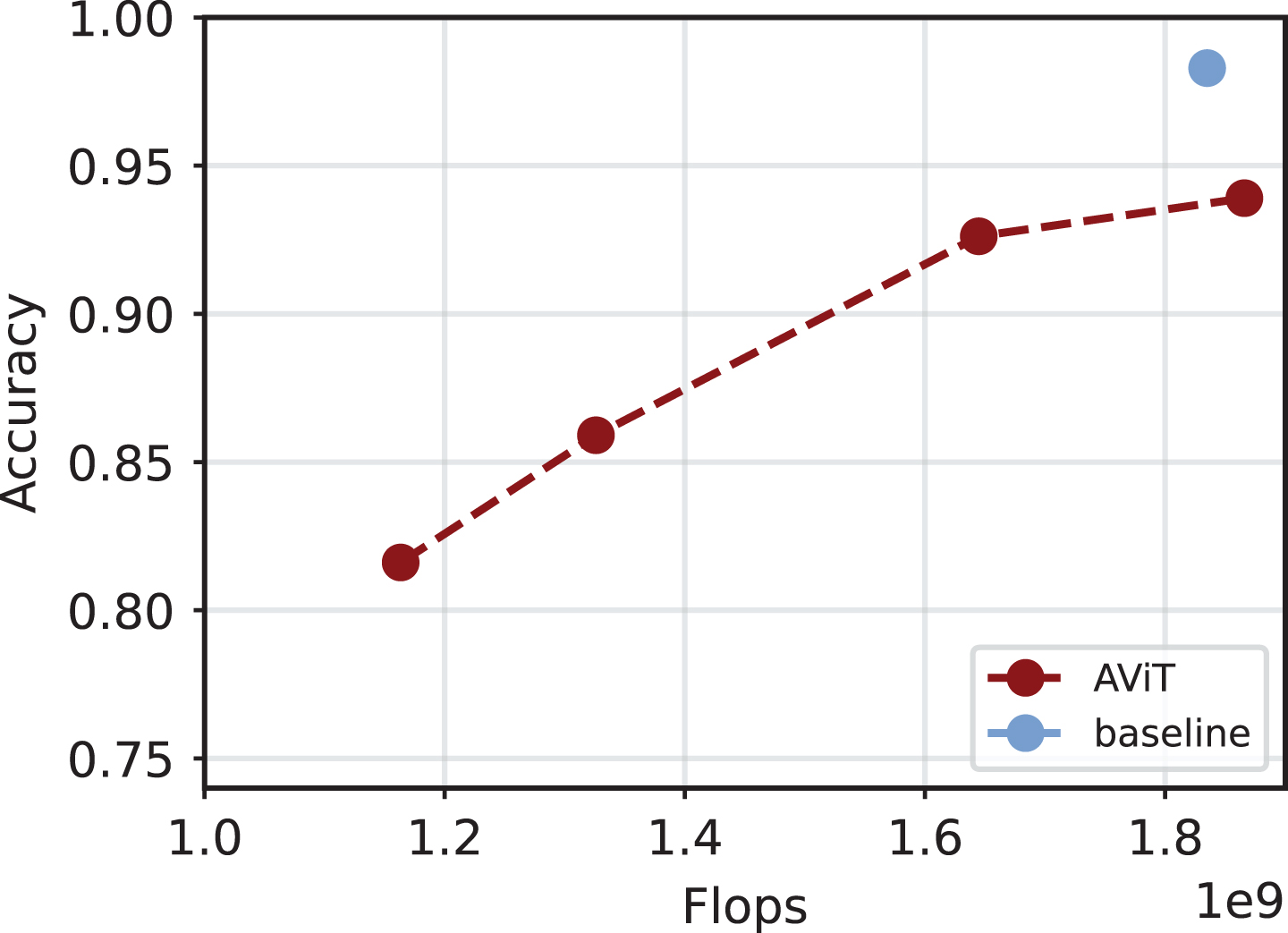
Example of accuracy-flops trade-off for inference with A-ViT [104]. Specifically, the architecture is a DeiT, trained on Imagenette.
Overview of methods to improve efficiency of the models, including baseline algorithms not discussed in the text (e.g., pruning)
When training from scratch an EENN, the joint training described in Section 3.1 cannot provide faster training since all exits must be trained simultaneously. Soft combinations of the early exits [81] combined with sampling tricks could be useful, but this aspect has been scarcely explored in the literature, possibly due to training instabilities and collapse. Still, EEs can provide indirect benefits to training by accelerating the convergence of deep neural networks [8, 89]. They can also improve the inference efficiency of large-scale pre-trained models [25, 111], making them more discriminative [89], act as a regularization technique [80], and possibly reduce training problems (e.g. vanishing gradient phenomena) [63]. In addition, they can be trained in a layerwise fashion if one starts from a pre-trained network [24]. In Table 1, we can see that most of these methods require additional parameters, leading to a latency reduction.
Compared to EEs, MoEs were investigated mostly to speed up training by distributing the experts across different GPUs [20], or to accelerate inference by activating a subset of experts for each forward pass. For the former, tiling the model across separate machines requires customized implementations [74]. In addition, to achieve an effective stable throughput, training must avoid collapses of the routing function, and care must be taken to balance the number of tokens that are sent to the different experts. This last point can be achieved with the addition of so-called balancing losses, e.g., batch prioritized routing [15, 78]. Due to these problems, open-source implementations of large MoE models have generally lagged behind proprietary models, with some preliminary steps being taken in this direction [102], as observable also in Table 1.
The benefits of applying MoEs can also vary depending on the specific component that is being replaced. In [84], MoEs replace MLP layers to scale-up transformers. A similar methodology, for vision, was presented in [78]. Other approaches proposed to replace attention layers [108], entire blocks [87] of the net, and adapters [106]. By comparison, soft MoEs (Section 3.4) can reach similar gains as standard MoE layers while being simpler to train. Finally, the majority of MoEs are trained from scratch, but recently moefication has emerged as an interesting research direction, in which a pre-trained model is converted to an MoE variant by clustering the activations [73, 109] (see Table 1 to see the approaches based on pre-training). These variants provide different accuracy-time trade-offs based on the specific routing function. Additional emerging research trends are exploring dynamic variants of routing to provide a flexible inference budget instead [68, 96].
Finally, reducing the number of tokens with token selection techniques is a straightforward strategy to improve the inference time of the network. Most methods in this sense have focused on token dropping [9, 104]: A-ViT adopts a token halting approach (shown also in Fig. 5); AdaViT [52] proposes a light-weight decision network, attached to the backbone to produce decisions on-the-fly; DynamicViT [76] proposes an attention-masking strategy to block interaction of redundant tokens; MSViT [28] proposes a conditional gating mechanism that selects the token scale for every image region; GTP-ViT [100] introduces a Graph-based Token Propagation (GTP) to propagate the information of less significant tokens. During training, token selection is generally achieved by masking the corresponding input elements (Section 3.5). Designing token selection mechanisms that can improve training time (for a fixed compute budget) is still an open challenge.
Some works have focused more on specific tasks, such as diffusion [10], long-input sequences [1], or to better understand the general pattern of token dropping [27]. For token merging, PatchMerger [77] proposes a module that reduces the number of tokens by merging them between two consecutive intermediate layers [77]. Recently, a hybrid solution, Token Fusion (ToFu) [42], proposed to put together the benefits of both token pruning and token merging. Token selection can also be combined with the other methods discussed in this paper. As an example, Adaptive Computation Module (ACM) [96] is a technique that combines token dropping with a dynamic width principle, in which each token is allocated a variable width for each layer in the network.
Modularity can also lead to specialization benefits in specific tasks [54, 110], such as language modeling [47, 53], cross-lingual transfer [3, 92], speech processing [53, 66], computer vision and multi-modality [2, 75], and task generalization [56].
Specialization can happen in two ways: implicitly if no external information is provided, or explicitly if additional information (e.g., the speaker identity) is known. The key insight is that knowledge of, e.g., the task, the domain, or the speaker provides latent information that can be used to condition the routing blocks (Γ in Section 2), thus specializing specific parts of the network or specific components to different scenarios. This can be achieved in different ways: manual routing in which different components are pre-selected for the different latent vectors [67], direct conditioning of the routing functions [113], entropy regularizers to force the distributions w.r.t. to a specific latent vector to have low entropy [58], or weight sharing across tasks [88]. Soft merging [57] also seems to offer specialization benefits.
Studies on quantifying the quality of the resulting specializations were carried out recently in the literature [102]. MoEs showed promising performance due to their nature, and, specifically, hard routing facilitates module specialization [67]. On the other hand, learned routing could lead to sub-optimal results [54, 55] w.r.t to fixed routing, except for specific cases [70]. As another example, [102] showed that many routing decisions tend to ignore context, and they can be fixed during the early stages of training. Generally speaking, understanding the interplay between routing and specialization and the extent to which this specialization correlates with human-understandable semantics and biological plausibility remain open challenges that will require novel benchmarks and metrics [73, 110]. Recent moefications works show that some form of emergent modularity may also be found in pre-trained networks with no specific modularity bias [73, 109].
A benefit of having specialized sub-structures and components is that the networks can perform better in multi-task learning [56] and multi-domain scenarios [58], and they can potentially enable zero-shot transfer and generalization of the resulting sub-structures. We list a few interesting examples from the recent literature. PHATGOOSE [56] is a MoE specialized in zero-shot generalization, thanks to a new post-hoc routing strategy. EMoE focuses on the implicit modular structures (Emergent Modularity) of large pre-trained transformers [73]. DSelect-k [29] presents a continuously differentiable and sparse gate for multitask learning. Uni-Perceiver-MoE [113] is a generalist conditional MoE that shows SOTA performance when compared to specialized MoEs. LIMoE [58] is focused on language-image pre-training. DeepSeekMoE [17] manages to ensure expert specialization for language models, still reducing computational costs. Other approaches include modular submodels to scale language models [6] and a class-aware channel pruning for queriable NNs [38].
Explainability
Finally, modularity and sparsity can provide significant gains in explainability, which is a significant issue when deploying systems [26]. In particular, analyzing and plotting the routing decisions made by the subsampling blocks Γ almost always provide valuable insights into the predictions. These include, but are not limited to, visualizing representative tokens sent to each expert [58], visualizing the early exits distribution for a given sequence in an autoregressive model [83], visualizing the tokens that were never discarded in a network having token selection [52, 76], or the number of experts that were activated token-wise [96]. These techniques can provide benefit also for specific tasks, such as object detection [13].
Also in this case, we lack principled benchmarks and frameworks to analyze the resulting plots, which is an open problem in explainability in general [26]. In addition, for networks having thousands of blocks or experts, manually analyzing each of them can be a time-consuming process. LLMs can potentially help in automating this process [7]. From a mechanistic interpretability point of view, fully understanding and being able to track the evolution of modules in these networks could be a large step forward in better understanding overfitting, generalization, and fine-tuning [33]. Finally, we note that being able to plot and visualize internal decisions of the network provides a direct way for providing feedback on, e.g., whether specific modules should be kept or ignored, and to perform interventional analyses [11].
Conclusions and future trends
In this tutorial paper we have provided an introduction to the emerging field of designing neural networks which are sparsely activated in a modular fashion, via the use of conditional computation techniques. To this end, we have provided both a general mathematical formalism to categorize these approaches, and then an overview of several concrete implementations including mixture-of-expert models and early exit neural networks. Although these models have been investigated mostly for improving training and/or inference time, we have discussed a number of additional emerging benefits from this approach, including specialization, generalization, and explainability. Many of these benefits are only starting to be investigated, opening up interesting avenues of research.
Some common challenges have also emerged from our discussion: (a) being able to control and adapt the inference and/or training time is still an open challenge, with most techniques providing a fixed accuracy-time trade-off (e.g., MoEs with top-k routing); (b) sparse routing introduces balancing and collapse challenges that must be taken care of; (c) most routing decisions are taken only locally (e.g., layer-wise), while taking them globally requires sampling from a combinatorially large search space requiring new sampling techniques [59]; (d) outside of accuracy, benchmarks and metrics for evaluating specialization and generalization of these models are still being developed [54].
There are also several research directions that we were not able to touch due to space constraints: these include scaling laws for modular models [15], biological plausibility [82, 110], and exploiting these models in specific applicative fields such as split computing [51] and semantic communication [107].
Acknowledgments
S. Scardapane is partly funded by Sapienza grants RM1221816BD028D6 (DESMOS) and RG123188B3EF6A80 (CENTS). P. Minervini is partially funded by ELIAI (The Edinburgh Laboratory for Integrated Artificial Intelligence), EPSRC (grant no. EP/W002876/1), an industry grant from Cisco, and a donation from Accenture LLP.