
Abstract
Game-Based Learning (GBL) and its subset, Board Game-Based Learning (bGBL), are dynamic pedagogical approaches leveraging the immersive power of games to enrich the learning experience. bGBL is distinguished by its tactile and social dimensions, fostering interactive exploration, collaboration, and strategic thinking; however, its adoption is limited due to lack of preparation by teachers and educators and of pedagogical and instructional frameworks in scientific literature. Artificial intelligence (AI) tools have the potential to automate or assist instructional design, but carry significant open questions, including bias, lack of context sensitivity, privacy issues, and limited evidence. This study investigates ChatGPT as a tool for selecting board games for educational purposes, testing its reliability, accuracy, and context-sensitivity through comparison with human experts evaluation. Results show high internal consistency, whereas correlation analyses reveal moderate to high agreement with expert ratings. Contextual factors are shown to influence rankings, emphasizing the need to better understand both bGBL expert decision-making processes and AI limitations. This research provides a novel approach to bGBL, provides empirical evidence of the benefits of integrating AI into instructional design, and highlights current challenges and limitations in both AI and bGBL theory, paving the way for more effective and personalized educational experiences.
Keywords
Introduction
Context of the study
This study explores the implementation of generative artificial intelligence (AI) to facilitate Game-Based Learning (GBL) and its subset, Board Game-Based Learning (bGBL), both of which harness the power of games to enhance the educational experience. The landscape of educational practice is evolving towards learner-centered methodologies to develop relevant competencies and prepare today’s students, and tomorrow citizens, to a society driven by rapid and unpredictable transformations. As these transformative approaches become more prevalent, they bring with them complex challenges: While the literature on GBL and bGBL presents a compelling case for their effectiveness [1–8], translating these findings into successful implementation in real-world educational settings has proven difficult [9–13]. Educators often struggle with the task of designing and delivering game-based lessons that align with the evidence-based principles outlined in the literature [10, 14–16]. The divide between theory and practice requires careful planning, teacher training, and ongoing support to bridge the gap effectively [17–19]. Within this context, we consider the profound impact of AI in conjunction with GBL. AI has the potential to revolutionize education by enhancing the quality of teaching and learning practices, promoting personalized learning, automating routine tasks and allowing smart management of classes and resources [20–30]. In particular, general large language models (LLM) such as GPT-4 can act as a “swiss knife” to assist a variety of educational processes. However, along with ethical and transparency issues, one significant question that educators and researchers face is the reliability and the quality of responses generated by AI systems in the context of GBL and bGBL. The issue of prompting and the potential for AI models to produce erroneous or incomplete information are valid considerations that can make or break the success of AI-enhanced education [29–31]. Thus, the effectiveness of AI-supported GBL hinges on the ability to provide accurate, relevant, and meaningful guidance to teachers and learners.
Game-Based Learning (GBL) and board Game-Based Learning (bGBL): a pedagogical and ludic perspective
Game-Based Learning (GBL) and Board Game-Based Learning (bGBL) are innovative and dynamic educational methodologies that use games as effective tools for fostering learning and knowledge acquisition [32–35]. In GBL digital, video, or tabletop games become a pedagogical medium [36, 37] that can be leveraged to sustain a variety of educational scenarios [38–40]. Games can captivate learners by transforming complex concepts and academic content into enjoyable challenges and quests [41]. As learners navigate the game system, they absorb information, strategize employing critical thinking and problem-solving skills, often without even realizing they are actively engaged in complex learning tasks [42]. This allows for differentiated instruction, accommodating diverse learning styles and abilities, and promoting inclusivity in education [43]. bGBL is a subset of GBL, focusing specifically on tabletop board games [44] as the educational catalyst. Board games offer a tactile and social dimension to the learning experience [45]. Depending on the game, gameplay is driven by interaction between player(s) and the physical components of the game, such as dice, cards, board, or tokens. bGBL promotes face-to-face interaction, collaboration, and healthy competition, fostering interpersonal skills and teamwork among learners [46–48]. Moreover, it often encourages strategic thinking, decision-making, and the application of knowledge in a real-world context [6, 50]. bGBL has specific features that distinguish it from GBL based upon digital (video)games (sometimes referred to as vGBL): First, it does not require any digital device or software, internet access, subscriptions, and/or digital competences to be implemented [51]. Second, due to the physical nature of its components, it is easier to modify or personalize games or components to better align with instructional or educational goals or to improve accessibility [52–54] or as a design challenge for students [38, 56]. Third, board games are transparent systems in that the relationship between the parts (rules and components) is explicit and visible to the player, rather than hidden “under the hood” of the calculator [57], favoring exploration, reflection, and tinkering [58]. Fourth, game rules are implemented by players and not the software; this makes board games more prone to rule misinterpretation, which might hamper the game experience by generating discussion or frustration among players. Fifth, board games have limitations in terms of the number of participants and logistics, whereas vGBL can be easily scaled to reach a wider audience through online platforms. Sixth, being primarily based on face-to-face interaction, bGBL is known to elicit a sense of “togetherness” and “social presence” [46, 48] which can enhance emotional and social engagement towards the activity, contributing to social construction of knowledge [57]. Despite the specific properties and educational potential of board games, the scientific literature on game-based learning has mostly focused on digital games, to the point of sometimes identifying GBL with vGBL. This is problematic from a pedagogic point of view since most GBL instructional models are tailored on vGBL and cannot easily be transferred to bGBL due to its specificities [59]. There are a few notable exceptions, such as Weitze’s Smiley Model [60], Sousa’s MBGTOTEACH framework [61] and Andreoletti and Tinterri’s GDBL ID model [62], that are constructed with the specific needs of bGBL in mind. However, a few critical steps in bGBL design remain loosely investigated. Those include defining the specific goals that can be attained through gameplay and aligning them with the learning goals of the activity [63, 64]; personalizing the game of choice to achieve better constructive alignment with the activity goals [52, 65–67]; evaluating the efficacy of play within bGBL [68]; and evaluating and choosing a board game for the learning activity. Researchers themselves often preselect or construct the games used in experiments [58], [69–71]. Indeed, the choice of the game is both a crucial and complex step in GBL requiring curricular knowledge, practical pedagogical or “school” knowledge, knowledge of board games, and GBL competences on the teachers’ side [19]. Thus, clear and comprehensive evaluation criteria are needed to ensure that bGBL serves as a productive and intentional methodology rather than a mere diversion [51, 72–74].
Using game choice to explore the synergy of board game-based learning and artificial intelligence
bGBL and artificial intelligence (AI) is a dynamic convergence that is reshaping the educational landscape in profound ways [75–77]. The experiential nature of games invites active participation, fueling intrinsic motivation, which is a cornerstone of effective knowledge acquisition [78]; AI, on the other side, brings to the table sophistication and personalization opportunities [79]. The use of Artificial Intelligence in the educational context (AIEd) has represented a growing interdisciplinary field since the 1970s to improve course design and expected student outcomes [80]. The sudden diffusion and large-scale popularity of new tools such as ChatGPT, Google Bard, Microsoft Copilot, and others, represented a turning point in educational practices: their user-friendly conversational interfaces significantly lowered the entry barrier to using AI, allowing non-experts, including researchers and educators, to assist a growing range of everyday tasks [27]. Their main features include large-scale language models, in-context learning, and reinforcement learning from human feedback [81]. Even though empirical evidence is still limited, most researchers agree that generative AI tools, when integrated into a pedagogical framework, could improve the effectiveness of the teaching and learning process: they enhance the teachers’ ability to discern each learner’s unique strengths, weaknesses, and pace of learning, tailoring educational content to suit individual needs [22, 82–84]. Researchers suggest that AI can be used to assist or automate instructional design [85], assuming a variety of roles according to different steps. We argue that the same logic can be applied with bGBL design and we describe potential applications of AI tools in bBGL design according to the GDBL ID model, structured upon the popular Analysis, Design, Development, Implementation, Evaluation (ADDIE) [91] framework. We defined for each step of the ADDIE the phases of GDBL and identified potential roles of AI tools for each phase (Table 1).
AI tools can assist the designer in instructional steps that are common to all teaching and learning methods as well as those that are specific to bGBL, supporting decision-making and helping to circumvent roadblocks by providing context-sensitive analysis and suggestions. However, integrating AI in bGBL design requires teachers to know and understand how AI tools function, how to use such tools in a critical and responsible manner and understand ethical implications of using AI, a set of competencies referred to as AI literacy [88, 89]. ChatGPT and similar models have known limitations and drawbacks that must be carefully considered. Those include, but are not limited, to lack of common sense, limited understanding of context, possible use of biased training data, and lack of emotional intelligence [21, 95]. Furthermore, due to their Transformer architecture, which acts by stochastically computing each next word based on the previous [81, 90], tools like ChatGPT are “black boxes” in that there is no way to access the information they were pre-trained on and, at the same time, it is not possible to know what sources are used to formulate answers. This is a key issue that conflicts with current European regulations, which highlight that AI systems must be “developed and used in a way that allows appropriate traceability and explainability, while making humans aware that they communicate or interact with an AI system, as well as duly informing deployers of the capabilities and limitations of that AI system and affected persons about their right” [90, p.25]. With those crucial issues in mind, from an instructional design perspective it is therefore important to understand whether general LLM-based AI tools can provide sufficient advantages to warrant their implementation in bGBL. To this aim, we defined three key issues that must be addressed. The first is consistency: given their stochastic nature, these tools able to provide consistent output or is it excessively variable to be relied upon? (RQ1). Moreover, the success of AI and bGBL synergy rests on the ability of AI tools to provide not only consistent but also accurate answers to the designer’s questions. We are still in an exploratory phase of understanding how accurate artificial general intelligence answers can be; this is especially true for complex, open-ended tasks, such as those are required for the design of bGBL, whereas assessing the accuracy of the AI tools often relies on expert evaluation from humans [92]. Thus, the second question is: are AI tools able to provide sufficiently accurate game suggestions compared to human experts? (RQ2). First indications suggest that the accuracy of the performance depends on the type of challenge [93–95] and the subject [25], as well as from contextual and reinforcement information provided by the user [29, 96–98]. Still, despite the emergence of good practices such as defining a persona, structuring key ideas, and using specific rather than general requests [29, 99], it is not yet clear how contextual and reinforcement input should be organized to maximize output quality and how sensitive the instrument is to user-provided contextual information. This is another key requirement for AI-assisted bGBL: given specific instructions, are AI suggestions sensible to the educational context? (RQ3). Thus, the goal of this exploratory study is to evaluate the consistency, accuracy, and context-sensitivity of ChatGPT as an assisting tool for instructional designers in Board Game-Based Learning (bGBL). To this aim, we tested ChatGPT performance on a specific phase of bGBL, the choice of a board game for the educational activity (Table 1); the rationale for this choice is threefold: a) This process is specific to GBL (Table 1) b) it is critical for successful bGBL [61]: board games are characterized by different game mechanisms [100], structures [101], genres, and themes [102] that allow different kinds of cognitive, emotional, social and motivational engagement [46, 62], favor different pedagogical approaches [103], provide different challenges for accessibility and inclusion [53], and opportunities for internal assessment of educational goals [68]. The process of choosing board games, whether for educational enrichment or sheer entertainment, necessitates a meticulous evaluation of a multitude of factors. c) Game choice is often considered by teachers as one of the most difficult steps in GBL [10, 104] as they often lack the knowledge of games and the ability to achieve constructive alignment [65] between the learning goals and the game activity. When making selections, it’s essential to weigh elements like the intended age group, the number of players, the intricacy of game mechanics, alignment with predefined learning objectives, and the desired depth of engagement. Thus, automating this process with generative AI could help overcome one of the main roadblocks that hampers successful implementation of bGBL. Therefore, the research questions for this study have been defined as such:
RQ1: The first research question concerns the consistency of the tool. Are ChatGPT game choices for a specific learning activity replicable, given the same instructions?
RQ2: The second research question concerns the accuracy of the tool. Are ChatGPT game choices comparable with those provided by human experts?
RQ3: The third research question considers the context-sensitivity of the tool. Is ChatGPT able to adapt its game choices according to different didactic backgrounds and/or disciplines?
To answer these questions, the research was conducted in four steps: definition of the instructional framework and contextual information; prompt building and execution; independent expert evaluation; analysis and data comparison (Fig. 1).
Summary of the experimental phases.
In educational design, crafting meaningful and impactful learning experiences requires a deliberate and harmonious alignment of various critical components [100]. These components include specific academic disciplines, dimensions of competence, the infusion of engaging and immersive playful scenarios, and the careful selection of pedagogical approaches. This alignment is the keystone upon which the effectiveness of educational interventions is built [101]. We initially defined three “sets” of contextual elements, each instrumental in providing an in-depth understanding of the intricate interplay between these components and how they manifest in diverse learning environments [102].
In Hangøj’s model, the teacher can adopt different pedagogical approaches that can significantly impact the learning experience in GBL:
For this study, the “Drill and Skill” and “Pragmatic” approaches are linked to the “Socialization” purpose, whereas the “Drill and Skill” and “Explorative” approaches are tied to the “Qualification” purpose. The eight Learning Units (LU) obtained by combining the three “sets” that constitute the pedagogical framework used in this case study are shown in Table 2.
Outline of the combinatorial approach for the definition of the Learning Units (LU) used in this case study. Each LU is a unique combination of the three “sets” that constitute the pedagogical framework developed for the study
Outline of the combinatorial approach for the definition of the Learning Units (LU) used in this case study. Each LU is a unique combination of the three “sets” that constitute the pedagogical framework developed for the study
The choice of competence dimensions, playful scenarios, and pedagogical approaches in educational settings is closely related and should be carefully aligned to create an effective and engaging learning experience. Here’s how they are interconnected:
In the context of the research at hand, a careful and judicious approach was taken to curate a selection of five board games based on a rigorous set of criteria. The selection process focused on games that not only enjoyed widespread recognition and acclaim but were also well-understood and endorsed by experts in the field. The researchers undertook a detailed examination of the main characteristics of chosen games [62,103, 62,103], summarized below according to the main characteristics of board games: Title, theme, structure, genre, and main mechanisms of the game (Table 3).
Characteristics of the board games examined. This table offered insights into the essential characteristics of each game, including thematic elements, activated game mechanics, genre categorization, and internal structural intricacies, as defined in [62]
To evaluate the effectiveness of games as educational tools, it becomes imperative to establish a set of evaluation criteria. In our illustrative case, we have defined five such criteria: Accessibility provided internally by the game: Measures how easy it is for students to access the resources and rules of the game. This metric not only measures the ease of entry into the educational gaming experience but also determines how readily learners can engage with its components. Setting (time needed to prepare and play the game): Measures how long it takes to start and complete a game. This factor is vital in understanding whether the game can be seamlessly integrated into the curriculum without consuming excessive time, ensuring that it aligns with educational objectives. Content (use of thematic knowledge to address the challenges of the game or mere accessory): Examines whether the thematic content of the game contributes to learning or is only a superficial aspect. Learning curve Assesses how easy it is for learners to learn to play the game and develop skills over time. It is pivotal in determining whether the game caters to a broad spectrum of learners, from novices to those seeking more advanced challenges, or if it alienates a significant portion of its intended audience. Opportunities to assess standards of success: Determines if the game provides opportunities for students to assess their success against the learning objectives and competence dimensions. This feature assesses the game’s capability to foster self-assessment and alignment with educational goals.
These criteria serve as a shared yardstick, both for experts in the field and for ChatGPT, when ranking the usefulness of games within various educational contexts. The use of a scale from 1 to 5 empowers us to quantitatively assess the efficacy of these games in the educational domain. Starting from this framework and these evaluation criteria, the experimentation on ChatGPT and with experts was then activated.
The researchers first set up a prompt to obtain game rankings from ChatGPT as follows: the first prompt set up the persona [98], provided specific information concerning the task [96] and, using a numbered list, indicated the content that would be provided in successive prompts, including the definition of playful scenarios, pedagogical approaches, the board games to be ranked, the criteria for board game evaluation, and the two educational contexts. Furthermore, we provided in successive prompts the characteristics of each LU. A summary of the prompts used to obtain answers from ChatGPT are presented in Fig. 2.
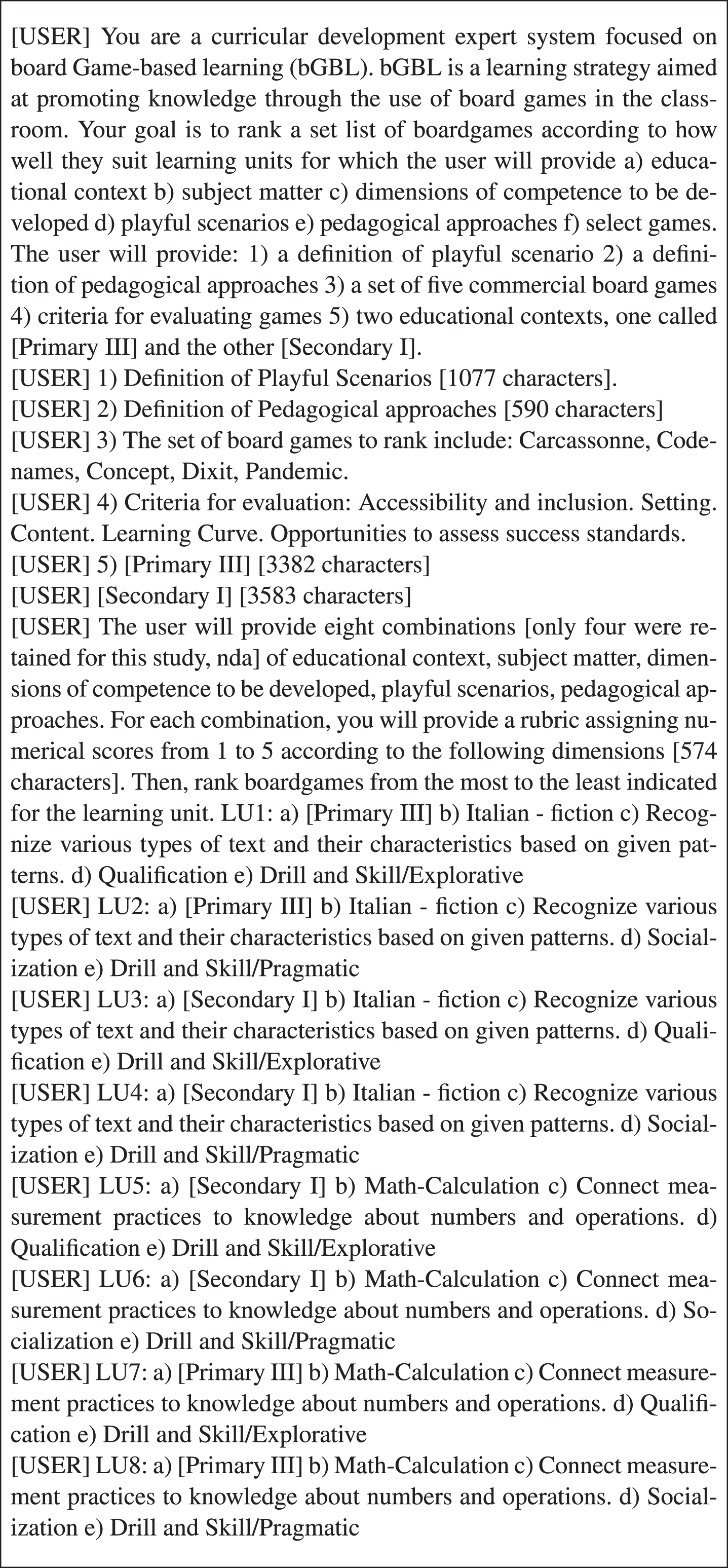
The table shows the user messages provided to ChatGPT to obtain game rankings for each LU.
The collaborative evaluation of bGBL strategies featured the integration of ChatGPT with a panel of three expert evaluators [104], each of whom possessed a wealth of domain-specific knowledge and extensive experience in the realm of instructional design and bGBL. These experts were selected to bring their unique insights and specialized understanding to the assessment process, ensuring a comprehensive and informed evaluation. The experts were provided with the same information (educational context, description of the framework and clarification of the main terms) that were inserted in ChatGPT prompts. The evaluation process entailed the use of a blind Excel file, which served as a standardized platform for assessing the bGBL strategies. Within this Excel file, experts had to rank, for each LU, the games from least to most suitable for the activity, as well as providing a short motivation for their choices based on assessment criteria. This approach allowed for a clear and systematic comparison of the strategies.
Analysis and data comparison
To measure the internal consistency of ChatGPT (RQ1), we pooled the rankings given to LUs for pairwise comparison. We first analyzed the correlation between the results obtained by three single runs on the same account. The first two runs were obtained by using the “regenerate answer” option. The third run was obtained by running a different chat, with the same prompts as the former. To measure external consistency, we ran this process on two different accounts. We averaged the results obtained by the three runs on the same account, obtaining an ensemble (a new ranking based on the averaged results); then, we compared the ensembles obtained by the two accounts. To provide a measure of consensus between ChatGPT and between the experts’ evaluation (RQ2), we first measured disagreement between individual experts (Table 6). Then, we pooled together experts ranking for each LU and compared it with the Ensemble ranking obtained from ChatGPT. Then, we pooled together experts ranking for each LU and compared it with the Ensemble ranking obtained from ChatGPT. We used Spearman’s Rank correlation and Kendall’s Tau correlation; both are commonly used rank-based coefficients used to assess monotonic relationship between ordinal data. Spearman’s method measures the pairwise disagreements between two rankings [105], whereas Kendall’s Tau focuses on the concordance between pairs of observations [106]. The test output is in both cases a value that lies on a scale from minus 1 to 1,where values of 1, minus 1, and 0 signify a perfect positive relationship, a perfect negative relationship, and no overall ordinal relationship at all, respectively [107]. Generally, values between 0.9 and 1 are considered very high, between 0.7 and 0.9 high, and values between 0.4 and 0.7 moderate positive relationships [108]. We also used Kemeny distance, a measure based on the assumption that voters have the same probability of comparing correctly two alternatives [109], to measure disagreement as the minimum number of pairwise swaps needed to transform one ranking into the other. This approach enables cross-validation of results, enhancing the reliability and validity in assessing the consistency between game rankings. To measure the context-sensitivity of ChatGPT and experts (RQ3), we matched the ensemble rankings of both ChatGPT and experts’ rankings according to the dimension investigated. We formed pairs of LUs to isolate and investigate specific dimensions (e.g. to investigate the “background” dimension, LU1 was paired with LU3, LU2 was paired with LU4, and so on; to investigate the “discipline” dimension, LU1 was paired with LU7, LU2 with LU8, and so on; etc.) and used the degree of discordance among ratings as an indicator of context-sensitivity. Statistical analysis was performed using Google Colab; ChatGPT was used to assist the generation of Python code, which was tested and verified by an independent expert.
Results
We first analyzed the internal consistency of the answers provided by ChatGPT. To this aim, for each LU we calculated the ensemble score by averaging the repeat rankings obtained within the same account, repeating the analysis for two different accounts (Ensembles 1 and 2). For each LU, we show the average ranking (with standard deviation in parentheticals) and the Kemeny distance indicating total disagreement within each account (Table 4).
The table shows the ensemble rankings for two ChatGPT accounts. Ensemble 1 is the average of runs 1-3, Ensemble 2 is the average of runs 4-6. Kemeny distance shows disagreement between pairs of runs (Run 1-Run 2; Run 1-Run 3; Run 2-Run 3 for Ensemble 1; Run 4-Run 5; Run 4-Run 6; Run 5-Run 6 for Ensemble 2) which are indicated between parentheticals
The table shows the ensemble rankings for two ChatGPT accounts. Ensemble 1 is the average of runs 1-3, Ensemble 2 is the average of runs 4-6. Kemeny distance shows disagreement between pairs of runs (Run 1-Run 2; Run 1-Run 3; Run 2-Run 3 for Ensemble 1; Run 4-Run 5; Run 4-Run 6; Run 5-Run 6 for Ensemble 2) which are indicated between parentheticals
For Ensemble 1, we observed strong agreement on game rankings when using the “Regenerate answer” (run 1-2, tau = 0.91, p < 0.001; rho = 0.95, p < 0.001, d = 8) and moderate agreement when comparing output from two different chats (run 1-3, tau = 0.57, p > 0.001; rho = 0.642, p < 0.001; d = 31; run 2-3, tau = 0.57, p = 0.001; rho = 0.64, p < 0.001; d = 31). In Ensemble 2, we observed strong agreement both within the same chat (run 4-5, tau = 0.81, p < 0.001; rho = 0.86, p < 0.001; d = 12) and different chats (run 4-6, tau = 0.83, p < 0.001, rho = 0.88, p < 0.001, d = 13; run 5-6, tau = 0.88, p < 0.001; rho = 0.93, p < 0.001; d = 9). Thus, we observed significant positive agreement in repeated runs from the same account, going from moderate to very strong, indicating good internal consistency of ChatGPT answers. For external consistency, we compared the agreement between Ensemble 1 and Ensemble 2. We found significant, moderate agreement (tau = 0.67, p < 0.001; rho = 0.77, p < 0.001; d = 26) between the two ensembles, suggesting that, when provided the same prompt, repeated ChatGPT answers are sufficiently consistent across different accounts but subject to variability. The second research question aimed to understand whether ChatGPT rankings were accurate compared to human experts. To this aim, three external evaluators, all competent with the five games provided, were provided with the same information as ChatGPT and asked to rank the games anonymously and independently according to the different combinations. There was significant, moderate agreement among evaluators’ rankings (Evaluator 1-Evaluator 2: tau = 0.48, p < 0.001; rho = 0.56, p < 0.001; d = 34; Evaluator 2-Evaluator 3: tau = 0.37, p = 0.004, rho = 0.43, p = 0.005, d = 39; Evaluator 1-Evaluator 3: tau = 0.68, p < 0.001, rho = 0.77 p < 0.001, d = 23). However, some context/scenario combinations elicited more disagreement than others: for instance, in Primary III/Italian-Fiction, all three evaluators chose a different game as first choice: Concept, Dixit and Codenames received one first-place ranking each; in general, LUs with Primary III context elicited more disagreement from evaluators than Secondary I. The mean rankings obtained for each LU (standard deviations in parentheticals), along with the Kemeny distance indicating total disagreement between evaluators, are shown in Table 5.
The table compares the mean rankings from bGBL experts for the eight LUs examined. Data are presented as mean ± standard deviation. Kemeny distance shows total disagreement between individual raters (Evaluator 1-Evaluator 2; Evaluator 1-Evaluator 3; Evaluator 2-Evaluator 3), indicated in parentheticals
From the average ranking of the evaluators, we obtained a pooled ranking for each LU and compared it with the Ensemble ranking obtained from ChatGPT. A comparison of the pooled rankings obtained by AI and evaluators is shown, together with Kemeny distance measuring total disagreement (Table 6). Overall, ChatGPT rankings have a moderate positive correlation with experts ranking (tau = 0.477, p < 0.001; rho = 0.59, p < 0.001), indicating that ensembled ChatGPT rankings are reasonably accurate with respect to expert evaluation, although accuracy varies according to the specific LU.
The table compares the pooled rankings from ChatGPT and the pooled rankings of bGBL experts for the four didactic contexts examined. Kemeny distance shows total disagreement between the pooled rankings from ChatGPT and bGBL experts for each LU
The third research question concerns the sensitivity of ChatGPT to contextual information. For the “Background” dimension, ChatGPT paired LUs show a moderate positive correlation (tau = 0.56, p = 0.002, rho = 0.64, p < 0.003, d = 14), indicating that the software slightly adjusted its ranking according to the background; for comparison, experts show a similar tendency, although with a slightly lower correlation (tau = 0.42, p = 0.022, rho = 0.518, p = 0.02, d = 20). For the “discipline” dimension, ChatGPT shows a moderate negative correlation (tau = –0.39, p < 0.03; rho = –0.54, p = 0.01; d = 44) indicating that its ranking decisions were strongly dependent on the discipline, so that games that were ranked high for Italian tended to receive a low rating for Mathematics, and vice versa. Experts ranking also show a similar tendency, although in this case the negative correlation was not statistically significant (tau = –0.32, p = 0.08; rho = 0.41, p = 0.07; d = 36). Finally, for the “educational purpose/pedagogical approaches” dimension, ChatGPT showed a strong correlation between matched LUs (tau = 0.726, p < 0.001; rho = 0.797, p < 0.001, d = 10) suggesting that its rankings were only slightly influenced by this dimension. Once again, this tendency is similar to the behaviour of human evaluators, whose ratings for LUs differing for the playful scenario/pedagogical approach show moderate to strong correlation (tau = 0.59, p < 0.001; rho = 0.705, p < 0.001; d = 14). Taken together, these results suggest that both ChatGPT and human evaluators modify their ranking according to contextual factors, that they seem to weight similarly the influence of different dimensions in their rankings, and that among the dimensions examined in this study “discipline” seem to be by far the most influential for both human evaluators and ChatGPT, although experts seem to factor in slightly more the other dimensions. These results are summarized in Fig. 3.
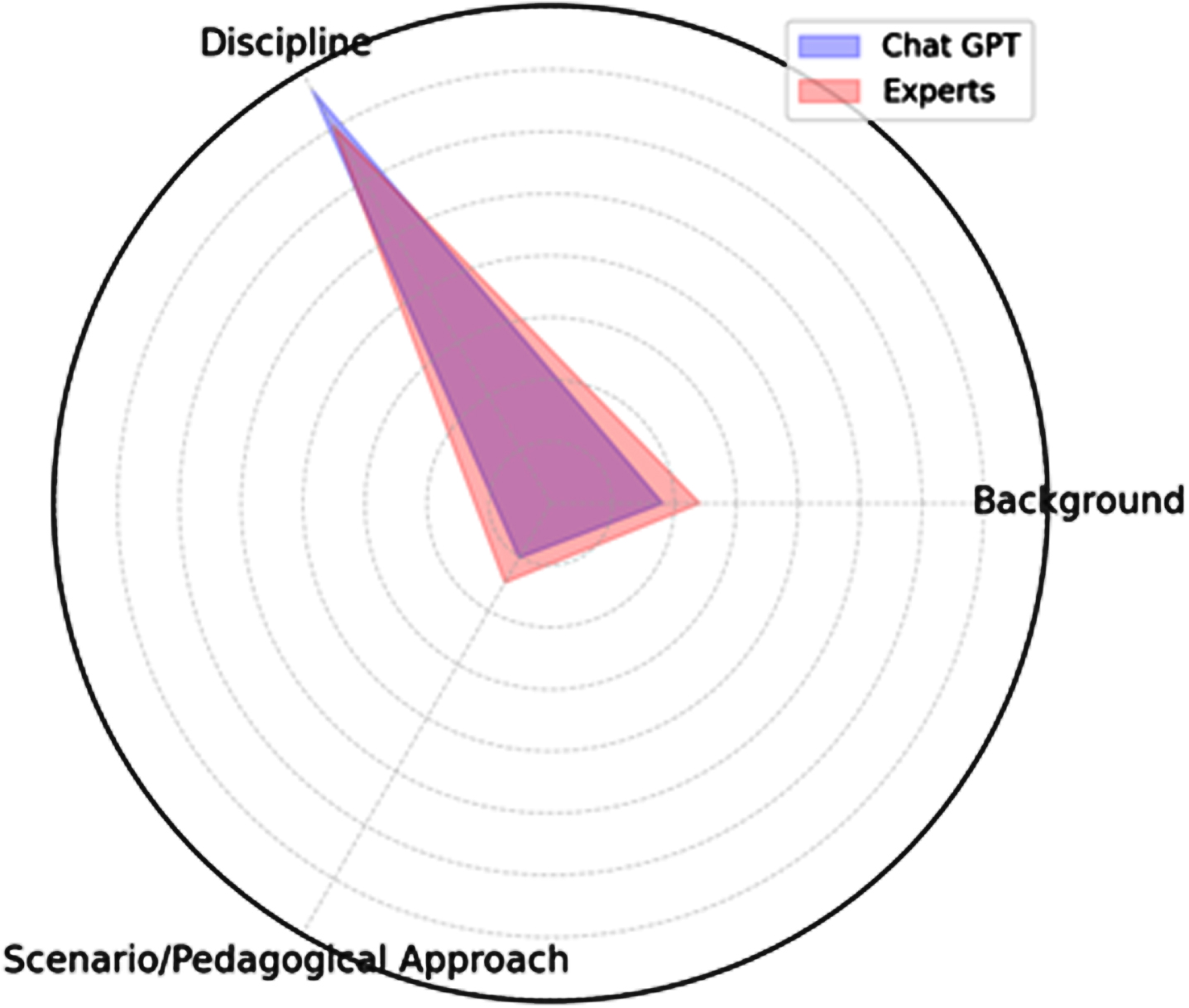
A visual indication of the influence of contextual elements in board game rankings by ChatGPT and experts. The graph represents Spearman’s rank correlations from 1 (origin) to -1 (outer circle). The higher the correlation, the lower the estimated incidence of the dimension on the ranking decision.
In this study, we analyzed crucial properties of ChatGPT for the task of automating board game-based learning (bGBL): consistency (RQ1), accuracy (RQ2), and context-sensitivity (RQ3). We found that the current version of ChatGPT is not entirely consistent. Given the same prompts, the software tends to provide overall similar answers within the same chat, across different chats and different accounts. Still, there is a certain degree of variability that cannot be explained within the confines of the current study. It is important to acknowledge the limitations and fallibility of AI tools to “address the impact of dogmatic overconfidence in possibly erroneous suggestions” generated by large language models [97]. The potential inconsistency of AI-generated answers is a significant problem for the automation of bGBL design; further research is needed to understand whether the variability observed can be addressed by reducing the complexity of open tasks, for instance by providing more accurate and analytic prompts, in addition to generate ensemble answers by repeating prompts in different conditions (regenerating answers, running separate chats, repeating the prompts on multiple accounts). Due to the design of the study, this result is subject to several limitations: for instance, we limited the analysis to only one general AI tool, Open AI’s ChatGPT with GPT-4 model. It is likely that using different models, such as GPT-3.5, Anthropic Claude, or Google Bard could have led to significantly different results. Furthermore, GPT-4 being a premium, paid-for tool, coupled with its “black-box” nature, suggest that alternative AI models more in line with European regulations on the use of AI in education [91] should be explored in the future. Second, our study indicates that, when provided with similar background information, ChatGPT can produce board game recommendations that are comparable with those of bGBL experts. The evaluation of a game for a bGBL activity is a complex, open-ended decision; as would be expected given the difference in experience, background, and individual preferences, even experts’ rankings were consistent but not overlapping, as each expert considers and values the given criteria differently. Still, when comparing the pooled answers from both experts and ChatGPT, we observed a significant correlation, suggesting that ChatGPT can be considered accurate enough to assist the choice of games for bGBL activity. To further validate this claim, we investigated how the choices of the chatbot were influenced by the instructional context and examined how it compared with human evaluators. Context was provided through a combinatorial set of didactic backgrounds, disciplinary contents, and educational purposes coupled with the relative pedagogical approaches. By matching the rankings for contexts (LUs) that differed for only one of those factors, we observed that the software can modify its choices according to the variables provided. Although we cannot exclude that the internal variability of ChatGPT accounted for part of the differences observed, the extent to which the rankings varied according to contextual factors was surprisingly similar to that of human experts (Fig. 3). Game evaluations were strongly influenced by the discipline dimension, whereas the class background and the scenario/pedagogical dimensions altered evaluators’ ranking less dramatically. However, it is important to highlight the experimental constraints that limit the generalization of these results. First, given the still-evolving literature on prompting techniques, and the exploratory nature of the study, the construction of prompts might have introduced biases in ChatGPT answers. In particular, the background information was provided via two long, descriptive prompts (Fig. 2), whereas information concerning the pedagogical scenarios and approaches was more analytic and information on the discipline was provided very synthetically. Since we currently have little knowledge on how ChatGPT incorporates contextual information produced by the user, we cannot exclude that this influenced the results obtained. A limitation of this study is that we did not compare results produced with different prompting techniques. Second, the need for competent external evaluation to assess the accuracy of AI choices influenced the experimental setup: all experts were experienced in using GBL in school, orienting the definition of background to real school cases, and limiting the choice to five games that all experts were competent with. Codenames, Concept and Dixit are all family-oriented, language-based games, whereas Carcassonne and Pandemic focus on different processes (spatial reasoning and cooperative decision-making, respectively) and share considerably less similarities than the three former games. This might have contributed to the bias towards the discipline dimension observed in game ranking. Furthermore, given that all games share a similar level of complexity (with the partial exception of Pandemic, slightly more complex than the other games), this might have limited the influence of background factors. Further studies will be needed to assess ChatGPT ability to select and evaluate games when given a wider range of educational contexts and less restrictive choices. A third issue is the lack of evidence and guidance in the literature for critical aspects of GBL, and bGBL, instructional design: current limitations include lack of: a) a clear definition of the multifaceted educational goals that can be achieved with games, b) guidance towards the achievement of constructive alignment between learning goals and game goals, c) criteria for selecting and evaluating specific games, as well as the related question of linking specific board game mechanisms with learning processes (see, for GBL, the LM-GM model by Arnab et al. [110], discussed in the context of bGBL by Abbott [52]) and d) identifying opportunities and tools for internal and external assessment. Addressing those issues is instrumental to achieve a better understanding of the factors that bGBL designers must consider for operating their choices, in turn providing better instruction to AI tools to assist on bGBL design. The criticalities that emerge from our analysis can be at least in part overcome by developing more operative instructional frameworks for bGBL. Despite those limitations, our study provides a strong indictment towards the potential of AI-assisted bGBL, supporting its unexplored potential for facilitating other difficult instructional steps in bGBL. This synergy will provide double benefits: in the first place, it will facilitate the adoption of bGBL in formal education settings, such as the school and the university, streamlining teacher training processes and instructional design tools. In turn, this will help the recognition and appreciation of games in education not just for their engagement and motivational properties, but as true learning environments for the development of significant knowledge, skills, and competencies [17, 49]. In the second place, it will facilitate the use of AI tools to assist instructional design by generating more consistent, context-sensitive, and accurate suggestions.
Conclusion
In the realm of educational technology and game-based learning (GBL), the use of generative AI tools to assist in the instructional design of board game-based learning (bGBL) and GBL on a broader scale represents a pioneering endeavor. As far as our current knowledge extends, this comprehensive analysis marks the first significant foray into exploring this synergy, specifically in the context of board games. This trailblazing work has profound implications for the future of educational design and technology integration, shedding light on uncharted territory; indeed, this study not only offers a novel perspective, but also exposes the hitherto underutilized potential of generative AI in shaping educational methodologies. It underscores that AI has the capacity to act as a transformative force in addressing the challenges that have historically hindered the effective implementation of GBL, including the creation of tailored content, scalability, and the need for personalized learning experiences. One of the study’s implications is the need for the development of a comprehensive and integrated framework for instructional design in the context of board game-based activities. This framework would not only facilitate the seamless integration of AI but also offer a roadmap for designing educational experiences that harness the intrinsic appeal of board games for effective learning. In conclusion, the study’s findings, while acknowledging its inherent limitations, showcases the tantalizing potential of AI and GBL to work in harmony, complementing each other’s strengths. This synergy can pave the way for more effective, efficient, and personalized educational experiences.
Ethic statement
The authors declare no conflict of interest. The authors also declare that all experiments have been conducted in line with current ethical guidelines.