
Abstract
In this data article, we present and describe datasets designed to address multiskilled personnel assignment problems (MPAP) under uncertain demand. The data article introduces simulated datasets and a real dataset obtained from a retail store in Chile. The real dataset provides details on the structure of the store, including the number of departments and workers, the type of labor contract, the cost parameter values, and the average demand across all store departments. The simulated datasets, consisting of 18 categorized text files, were generated through Monte Carlo simulation to encapsulate information about the stochastic demand for store departments. These text files are classified based on: (i) type of sample (in-sample or out-of-sample), (ii) type of truncation method (zero-truncated or percentile-truncated), and (iii) demand coefficient of variation (5%, 10%, 20%, 30%, 40%, 50%). This categorization allows academics and practitioners to select the scenarios that meet with their specific research or application needs, increasing the flexibility and applicability of the datasets. In addition, researchers and practitioners can use these comprehensive real and simulated datasets to benchmark the performance of diverse optimization methods under uncertain demand, thereby ensuring robust multiskilling levels for similar MPAPs. Furthermore, we offer an Excel workbook with the capability to generate up to 10,000 demand scenarios for varying coefficients of variation in demand.
Introduction
Optimizing workforce composition, task and shift assignments, and ensuring cost-effectiveness are critical aspects of personnel scheduling for companies ([22,24]). Comprehensive investigations conducted by Henao et al. [19], Henao et al. [21], and Mercado et al. [33] have identified six primary personnel scheduling problems (PSPs): staffing, shift scheduling, days-off scheduling, tour scheduling, assignment, and workforce training. Staffing involves determining the required workforce for each task type and shift, while shift scheduling involves the daily allocation of work shifts to the hired workforce. Days-off scheduling focuses on allocating weekly rest days, and the tour scheduling problem integrates the weekly assignment of work shifts and rest days. The assignment problem allocates specific task types to employees without assigning shifts or rest days. Finally, the workforce training problem aims to establish the optimal training plan for the hired employees.
The combination of the following two PSPs – the assignment problem and the workforce training problem – results in what is known in the literature as the Multiskilled Personnel Assignment Problem (MPAP). The objective of the MPAP is to cost-effectively design a workforce training plan that addresses key aspects, such as: (i) determining the number of single-skilled employees (those trained for a one task type) and multiskilled employees (those trained for two or more task types), (ii) specifying the types of tasks in which each employee should be trained, and (iii) devising a weekly work-hour distribution for each employee based on their trained skills. Therefore, as multiskilled employees can be transferred from tasks with staffing surplus to those facing a staffing shortage, solving the MPAP enables the design of a workforce that can flexibly adapt to fluctuating demand patterns (e.g., [3,4,6,31,45,46]). In turn, an optimal training plan not only improves demand coverage but also minimizes labor costs arising from mismatches between staffing levels and staff demand ([5,8,10,12,13,18,26,38]).
The MPAP solution is relevant to a wide range of industries, including both manufacturing and service sectors such as transportation, call centers, healthcare, and retail. However, the MPAP solution is particularly crucial to the retail industry. Retail is known for its need to employ large numbers of workers to meet highly seasonal and uncertain demand ([11,27,35]). This means that retail stores experience significant fluctuations in staffing requirements on a monthly, weekly, daily, and even hourly basis ([2,9,39,40]). This underscores the imperative need for an effective workforce training plan. Therefore, in the context of the retail industry and considering stochastic demand, solving the MPAP becomes paramount to effectively minimize both training costs and the costs associated with under/overstaffing.
As detailed in the following section, extensive research has been conducted on the crucial role of PSPs for retail industry managers, with a specific focus on the MPAP, addressing the challenges related to multiskilled employees. However, despite the numerous research articles and solution methods outlined in the literature for tackling these issues in the context of the retail industry and its inherent demand uncertainty, a notable gap remains evident. Essentially, there is a need for datasets that offer academics and practitioners access to the necessary data for input into their mathematical models. This is particularly valuable because optimization models rely on the assumption that the model’s parameters are accurate. Consequently, the lack of data availability or errors in data estimation can lead to biased assessments of the multiskilling requirements for the workforce. In line with the above, the accessibility of such datasets would enable both academics and practitioners to conduct benchmarking exercises for similar or identical MPAPs that are addressed through different optimization approaches amidst the backdrop of uncertain demand.
To fill the identified gap, this data article presents and describes datasets used (but not previously published) by Henao et al. [19] to solve a MPAP in the context of uncertain demand in a retail setting. The datasets contain real and simulated data taken from a Chilean retail store. The real dataset was collected from a home improvement retail store, while the simulated datasets were randomly generated using Excel formulas associated with the inverse normal probability distribution. It is important to note that, using these same datasets, Henao et al. [20], Henao et al. [23], and Henao et al. [19] solved a MPAP using the robust optimization (RO), closed-form equation (CF), and two-stage stochastic optimization (TSSO) approaches, respectively.
In conclusion, this data article contributes to the academic and practitioner community through the following key aspects:
A MPAP in a retail store with uncertain demand can be solved using the real and simulated datasets provided in this article.
Robust multiskilling levels that minimize the cost of personnel training and the cost of over/understaffing can be determined using the datasets in this article.
Academics and practitioners can find robust solutions to a similar or identical MPAP performing a benchmark of different approaches for optimizing under uncertainty using the datasets provided in this article.
For different coefficients of variation of the staff demand, an Excel workbook with a Monte Carlo simulation that generates up to 10,000 demand scenarios is provided. This feature adds an extra layer of practicality and scalability, enabling users to customize and generate demand scenarios tailored to their specific requirements.
Characteristics of datasets used to solve PSPs in different industries
Characteristics of datasets used to solve PSPs in different industries
Background on PSPs in different industries
Table 1 presents a list of research articles that have addressed PSPs in application contexts other than retail, sometimes considering multiskilled workers and sometimes not. In addition, the articles listed in Table 1 are characterized by having an associated data repository with public access, thus providing valuable datasets for researchers or practitioners to conduct experiments and/or benchmarking. The table categorizes the articles according to the following characteristics:
Personnel scheduling problem (PSP): Indicates the PSP addressed in the article, which is subject to the application context of the problem: (a) tour scheduling (TS), (b) multi-skilled resource-constrained project scheduling problem (MS-RCPSP), (c) integrated truck and workforce scheduling (ITWS), and (d) unit load devices scheduling problem (ULDSP). Multiskilling (MS): Indicates whether the PSP considered the presence of multiskilled employees. Data type used (DT): Indicates whether the datasets used in the research article contain real data (RD) and/or simulated data (SD). Available data repository (ADR): Provides the specific reference where the reader can find the data repository used by the research article to solve the PSP. Application (AP): Indicates the economic sector or industry in which the research article applied its solution methodology. This may be: (a) healthcare (H), (b) transportation (T), (c) restaurant (R), (d) software company (SC), and (e) railway construction (RC). Publication year (PY): Indicates the year in which the research article was published.
Background on PSPs involving multiskilled staff in a retail setting
To illustrate the gap addressed by this data article, Table 2 presents an exhaustive classification of research articles with applied case studies in the retail industry, focusing on PSPs considering multiskilled employees. This classification is based on the following characteristics:
Personnel scheduling problem (PSP): Indicates the PSP addressed in the article: (a) staffing (S), (b) shift scheduling (SS), (c) days-off scheduling (DOS), (d) tour scheduling (TS), (e) assignment (A), and (f) workforce training.
Solution method (SM): Indicates the solution methods used in the article to solve the PSP: (a) linear programming (LP), (b) constraint programming (CP), (c) integer programming (IP), (d) mixed integer programming (MIP), (e) two-stage stochastic optimization (TSSO), (f) robust optimization (RO), (g) column generation (CG), (h) heuristic (H), and (i) closed-form equation (CF).
Data type used (DT): Indicates whether the datasets used in the research article contain real data (RD) and/or simulated data (SD).
Availability of complete datasets (ACD): Indicates whether the research article published a data repository or has an associated data article, allowing any researcher or practitioner to access all the data used in the research article for experimentation.
Publication year (PY): Indicates the year in which the research article was published.
Characteristics of research articles addressing PSPs that involve multiskilled staff in a retail setting
Characteristics of research articles addressing PSPs that involve multiskilled staff in a retail setting
Several aspects can be highlighted from Table 2. First, it can be noted that most articles used MIP models or a combination of MIP models and heuristic approaches as their chosen solution method. Notably, articles such as Henao et al. [20], Henao et al. [23], Abello et al. [1], Fontalvo Echavez et al. [16], Mercado and Henao [32], Mercado et al. [33], and Henao et al. [19] also incorporated optimization techniques such as RO, TSSO, or CF to address the challenge of uncertain demand.
Second, among the 17 articles listed in Table 2, twelve of them addressed a workforce training problem (i.e., [1,16,19–23,32,33,41,44,54]). Therefore, in each of these articles, one of the objectives was to establish the optimal training plan for the staff. However, 8 of these 12 articles specifically addressed a MPAP (i.e., [19–21,23,32,33,44,54]), which is identified in the table by the nomenclature A + WT. Remember that a MPAP simultaneously solves an assignment problem along with a workforce training problem. We emphasize that, unlike other workforce training problems that may also involve shift scheduling, days-off scheduling, or tour scheduling, the MPAP specifically focuses on multiskilling decisions rather than on scheduling decisions (such as weekly schedules with work shifts and rest days).
Third, while Mirrazavi and Beringer [34] did not explicitly define whether they used real data, simulated data, or a combination of both, the articles by Henao et al. [22], Mac-Vicar et al. [30], and Hassani et al. [17] used real data only, while the rest of the articles used a combination of real and simulated data. It is noteworthy that a common element in those articles that used simulated data was the inclusion of staff demand for each store department within the simulated datasets, incorporating various levels of variability in these demands.
Fourth, most of the articles in Table 2 did not disclose 100% of the data used in the experimentation and validation stages of their research. This notable limitation poses a challenge for practitioners and researchers seeking to replicate the published results of such articles with the utmost precision. Continuing the discussion, only five research articles reported the complete datasets used in their investigations. These are as follows:
Three articles – Henao et al. [19], Henao et al. [20], and Henao et al. [23] – using the datasets disclosed in this data article (previously unpublished), addressed the same MPAP but used different optimization techniques under uncertainty. Thus, these datasets are valuable to practitioners and researchers because they allow fair benchmarking of different approaches. This in turn demonstrates the applicability and validity of the datasets, as they have been used in articles published in high-impact journals.
Porto et al. [41] have a related data article, Porto et al. [42], which, similar to our data article, contains real and simulated datasets from a home improvement retail store. However, despite these similarities, there is a clear difference between the two data articles. Our data article aligns with the data requirements for solving a MPAP, while the data article written by Porto et al. [42] aligns with the data requirements of a tour scheduling problem. In essence, the datasets presented in our data article can be used to solve an assignment problem, defining the MPAP as a PSP where rest days or work shifts are not assigned. This distinguishes the MPAP from other PSPs, as staff demand is aggregated on a weekly basis (typically in man-hour units). In contrast, PSPs that involve shift scheduling, days-off scheduling, or tour scheduling decisions require the disaggregation of staff demand into days and even short periods within each day (typically less than an hour) to address the strong seasonality of demand.
Porto et al. [44] have an associated data repository, Porto et al. [43], with real, processed, and simulated datasets obtained from a home improvement retailer. These datasets were used to solve an extended version of the MPAP, but with consideration for a deterministic demand. Unlike the MPAP addressed by Henao et al. [19], Henao et al. [20], and Henao et al. [23], the authors of Porto et al. [44] considered a planning horizon of 54 weeks instead of one. This choice is driven by the examination of the labor flexibility strategy known as annualization of hours, where employees’ weekly work assignments are distributed irregularly throughout the year to address the weekly seasonality of demand. Furthermore, Porto et al. [43] limited the simulated staff demand data to 10 instances per department per week due to their adoption of a deterministic approach. In contrast, our data article reports up to 10,000 demand instances per department, as optimization approaches under uncertainty require extensive data for models’ experimentation and validation.
This section provides a full description of the real and simulated datasets used in Henao et al. [19], Henao et al. [20], and Henao et al. [23].
Real data
The Chilean workforce management company SHIFT SpA [47] provided us with real data from a prominent home improvement retailer. The real dataset consists of information related to the number of store departments, number of single-skilled workers hired for each department, weekly hours that each worker has to work given his/her labor contract, average staff demand per week per department, and staff costs related to a Chilean retail store. For a better understanding of the data, consider that a retail store has a known number of departments, and these store departments usually have hired a set of workers originally single-skilled and, thus, skilled to work in one department. In addition, each department requires possessing certain basic skills and the working hours of workers depend on what is stipulated in their labor contracts.
Table 3 shows a full description of the parameters and sets associated with the real dataset. Also provided with these sets and parameters is a file named ‘real-data.txt’ written in the mathematical programming language AMPL. This file can be accessed from the Zenodo data repository archived at
Full description of the real data
Full description of the real data
Now, it is important to note that the MPAPs addressed in Henao et al. [19], Henao et al. [20], and Henao et al. [23] have two notable assumptions: (1) Unscheduled personnel absenteeism is not considered; that is, all employees are available 100% of the time for which they were hired. (2) Employees are assumed to be homogeneous; thus, all employees have maximum productivity in all departments for which they are trained. However, aiming to enrich the versatility and usefulness of this data article, we have included new real data derived from the experience of Chilean retailers. These data, which focus on unscheduled personnel absenteeism and the phenomena of learning and forgetting, are included in the file named ‘real-data.txt’. Notably, these data have already been used in two of our published research articles, Mac-Vicar et al. [30] and Henao et al. [21].
On the one hand, in Mac-Vicar et al. [30], the authors addressed a tour scheduling problem considering multiskilled employees. In order to assess the effectiveness of a set of flexible labor strategies to mitigate the negative effects of uncertain demand and unscheduled absenteeism, they conducted experiments with three probable absenteeism scenarios: 5%, 10%, and 15%. Specifically, the authors assumed that the probability of an employee missing a scheduled shift followed a Bernoulli distribution, with probabilities set at
On the other hand, in Henao et al. [21], the authors addressed a MPAP involving a multiskilled and heterogeneous workforce, which was subject to the learning/forgetting phenomena. In other words, they considered a heterogeneous workforce, where the productivity of multiskilled employees may vary depending on the number of departments to which they are assigned. Therefore, to address their MPAP, the authors modeled three parameters related to the learning and forgetting phenomena, as follows:
The first,
The second parameter,
The third parameter,
The values for
The simulated datasets consist of information related to the stochastic demand of the store departments. They consider two sample data types related to the uncertain demand: in-sample and out-of-sample. In-sample refers to the data employed to obtain the in-sample solutions of the MPAP with the TSSO approach. Conversely, out-of-sample refers to the data employed to compare the performance of the reported solutions with the three optimization approaches: TSSO, RO, and CF.
To generate the in-sample data, Monte Carlo Simulation (MCS) was used to randomly create 2,000 demand scenarios for the random parameter
Datasets with the realizations of the stochastic demand in a retail store
Datasets with the realizations of the stochastic demand in a retail store
Summarizing, this subsection provides three datasets: two in-sample and one out-of-sample. Each dataset contains 6 files (one for each CV) as listed in Table 4. Each file presents the stochastic demand realizations for six store departments, such that each row represents a department and each column represents a demand scenario (2,000 if it is in-sample and 10,000 if it is out-of-sample). The name of the files is coded by three characters i-j-k, where i = IS, OS specifies the type of sample (in-sample, out-of-sample); j = PT, ZT specifies the type of truncation method for the normal distribution (percentile-truncated, zero-truncated); and
Boxplots were created to visualize the simulated data. Figure 1 graphically compares both truncation types for the in-sample data, considering a coefficient of variation of 50% in the 6 store departments (i.e., ‘IS-PT-50.txt’ vs ‘IS-ZT-50.txt’ files). For the same coefficient of variation (50%) the percentile-truncated data range from 24 to 655 hours, whereas the zero-truncated data is broader and has atypical values, ranging from 0 to 937 hours, considering all departments.
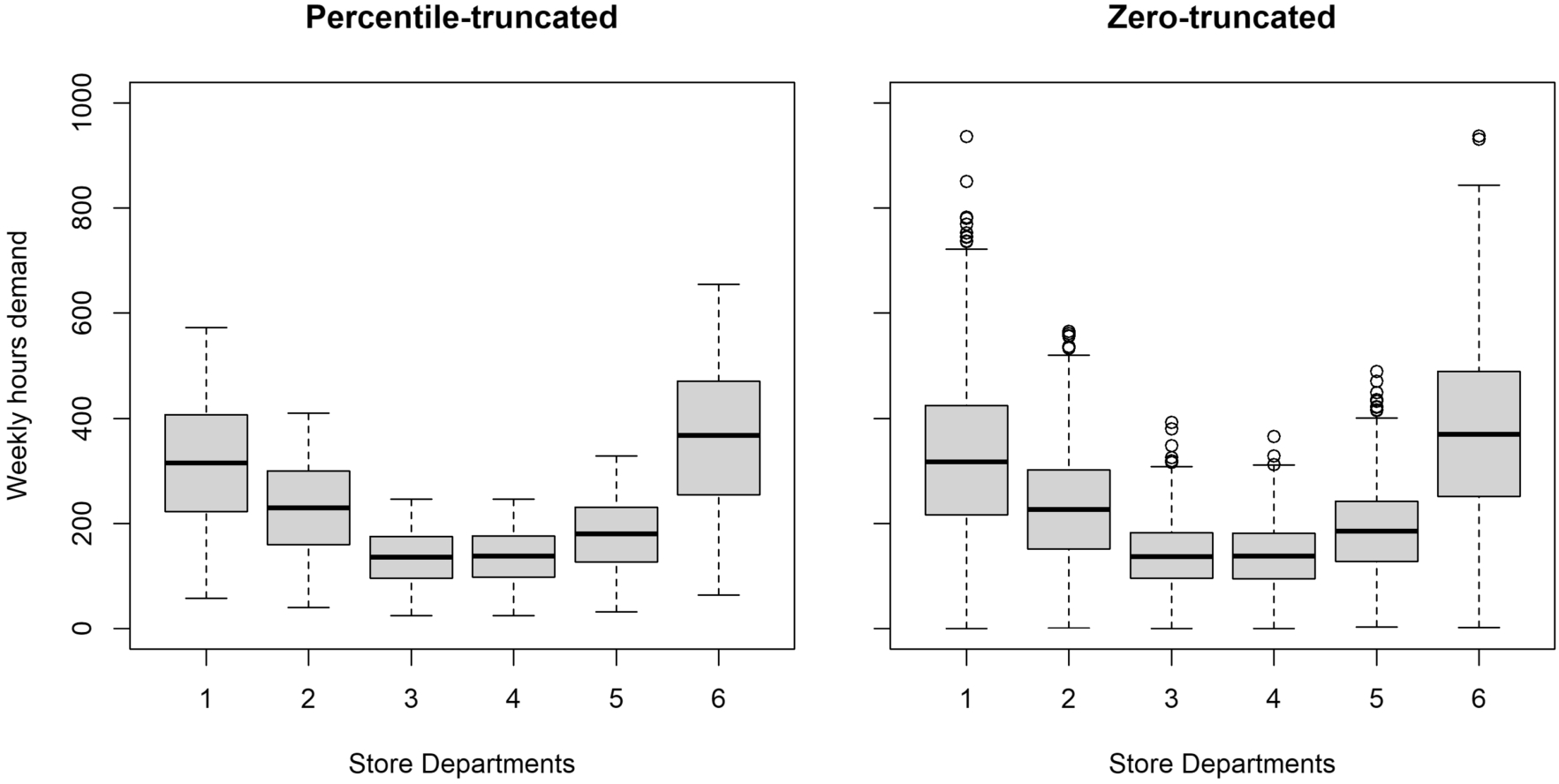
Percentile-truncated vs zero-truncated, with a coefficient of variation of 50% in the 6 store departments.
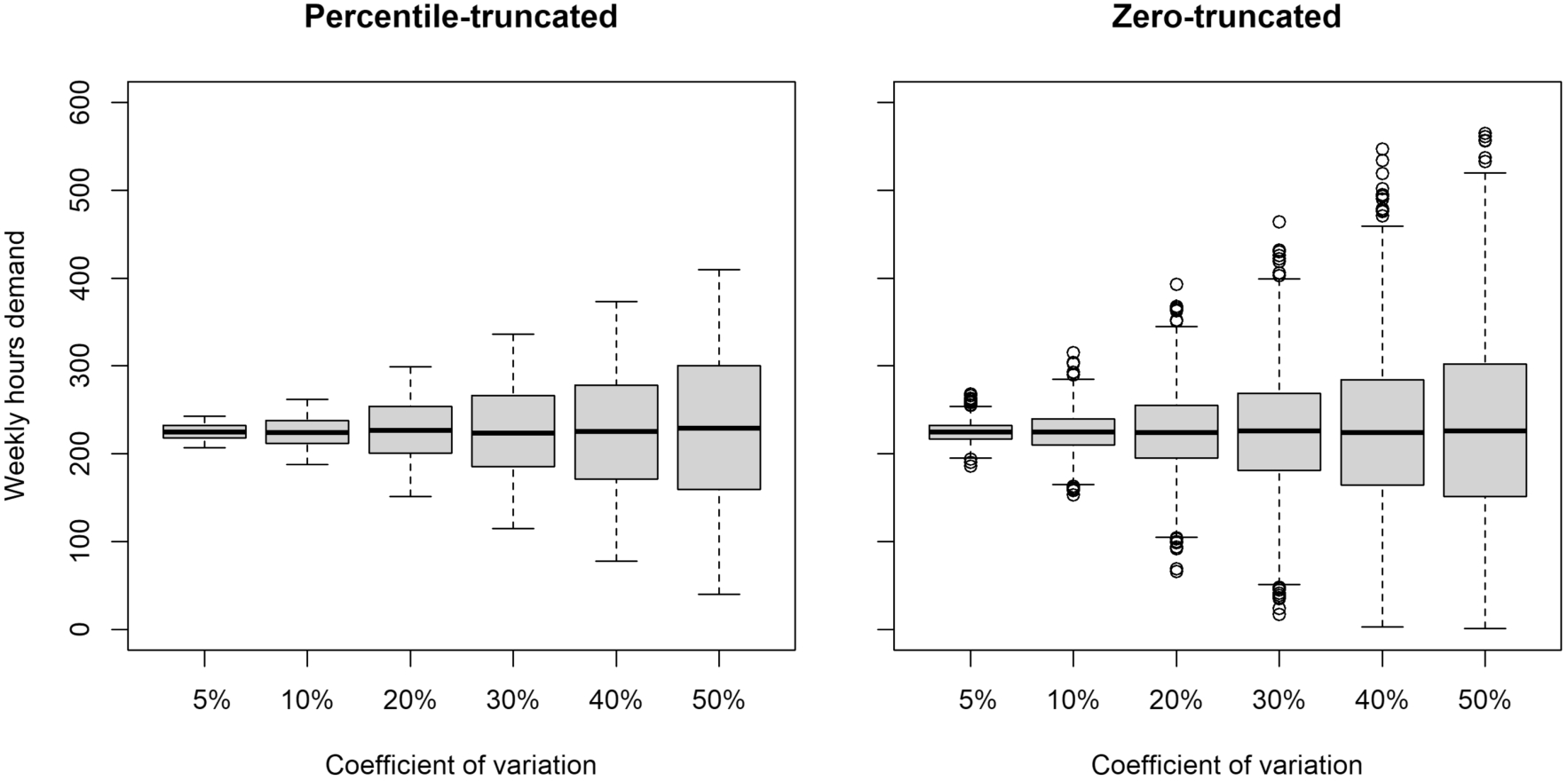
Percentile-truncated vs zero-truncated, in the second department with 6 coefficients of variation.
In addition, for the second department and each CV, Fig. 2 graphically compares both truncation types for the in-sample data. Remember that the second department has an average weekly demand of 225 hours. Here, it is evident that as the coefficient of variation increases, the range of the weekly hours demand values systematically expands. Similar to Fig. 1, the zero-truncated data is broader, ranging from 1 to 565 hours, whereas the percentile-truncated data ranges from 40 to 410 hours, considering all the coefficients of variation.
The boxplots for the out-of-sample data are not shown, but as expected, they have a similar distribution to the in-sample data. However, in this case, the number of demand scenarios for each box plot is 10,000, instead of 2,000.
This section outlines the methods utilized to estimate the mean demand in weekly hours for each department and explains the source of information related to the staff costs. Also, it is provided a detailed description of the MCS used to generate the stochastic demand realizations.
Calculating the mean weekly hours demand and staff costs
SHIFT SpA provided us with the real data for this case study. SHIFT SpA is a company that optimizes the shift schedules of thousands of employees across Latin America, which validates the quality and relevance of the real data they provided. Specifically, they used a specialized software to estimate the average weekly person-hours demand values for each department. This software works in two stages: (1) forecasting transactions and expected sales and (2) generating workforce requirements.
First, the software uses multiple linear regression to forecast the expected sales and number of transactions for each department in the store. The regression requires between 24 and 72 months of historical data to ensure greater accuracy. Second, considering typical customer service times, the software converts the forecast of transactions and expected sales into a staff demand quantified in person-hours.
Regarding the staff costs, it was assumed that each worker has a minimal cost of training (
Monte Carlo simulation
The MCS utilized to generate the stochastic demand realizations in Sect. 3.2 (simulated data), was carried out in an Excel workbook available in the Zenodo data repository archived at
The weekly hours demand follows a normal probability distribution; therefore, two parameters are needed to create the stochastic demand realizations in the 6 store departments: (i) the average weekly person-hours demand, which was shown in Table 3; and (ii) the standard deviation in weekly hours, which is calculated as the product between the average value and the coefficient of variation (CV) of the demand. Thus, the CV value can be chosen by the store manager to indicate the degree of uncertainty in the demand that best fits the store’s operations. In the Excel worksheets, both parameters are denoted in yellow cells, indicating that they can be changed.
Some statistics were also calculated in the Excel worksheets. In the ‘percentile-truncated’ worksheet, the 5th and 95th percentiles were calculated. Meanwhile, in the ‘zero-truncated’ worksheet, the standard score (z), denoting a weekly person-hours demand value equal to zero, along with its corresponding quantile in percent, were calculated. These results are presented in cells with gray text, indicating that these cells must not be modified because they are being calculated using Excel formulas.
Then, by using random values and using Excel formulas associated with the inverse normal distribution, it becomes possible to calculate the outputs. In the ‘percentile-truncated’ worksheet, the random values vary between 0.05 and 0.95 with a step size of 0.000001, following a normal distribution. Conversely, in the ‘zero-truncated’ worksheet, the random values vary between the quantile associated with the standard score (z) and 1, with the same step size, ensuring that the realizations of the stochastic demand are non-negative. In both worksheets, the stochastic demand realizations are organized into six rows representing the store departments, and up to 10,000 columns representing the demand scenarios. These results are presented in cells with blue text, indicating that these cells are the results calculated by Excel formulas and must not be modified.
Finally, we emphasize that the detailed description provided above regarding the implementation of the MCS method can be easily cross-referenced and verified by carefully examining the Excel worksheets and the set of Excel formulas used. All these details are readily available to the reader in the Excel workbook.
Conclusions
In this article, we have introduced comprehensive datasets that include real-world data from a Chilean retail store with simulated data. This dual-source proposal enriches the data article by providing a diverse and representative collection of scenarios for addressing MPAPs under uncertain demand in a retail setting. The versatility of the datasets emerges as a key strength, providing a valuable resource for fair benchmarking different optimization approaches under uncertain conditions. In addition, the categorized simulated datasets, along with an Excel workbook capable of generating up to 10,000 demand scenarios with different coefficients of variation, enhance the scalability and flexibility of the datasets. This feature allows users to test and evaluate different approaches under diverse conditions, accommodating the varied needs of researchers and practitioners, thus enabling a wide range of experiments and analyses. Finally, this resource effectively addresses a significant gap in the literature, serving as a practical tool for researchers and practitioners to explore and overcome challenges associated with designing workforce training plans in environments characterized by uncertain demand.
Limitations and future research
Despite the valuable contributions provided by this data article and its datasets, future publications could complement or address the potential limitations of the datasets. More specifically, we have identified two potential limitations and, in turn, possible directions for future research.
First, the datasets presented in this article focus on a retail store with six departments and thirty hired employees. This may limit researchers and practitioners who wish to test instances of the problem involving stores with more departments and employees. However, we believe that other researchers and practitioners can extrapolate or simulate missing data for larger instance sizes based on the information we provide, or alternatively, present new real data. Therefore, future data articles may present datasets associated with larger retail stores.
Second, the MPAP focuses specifically on multiskilling decisions rather than scheduling decisions. Thus, the datasets provided in our article facilitate solving an assignment problem in which employees are not assigned rest days or work shifts, and staff demands are aggregated on a weekly basis. However, this aggregation may limit the solution of PSPs that require more detailed scheduling decisions. PSPs that emphasize scheduling decisions require more granular estimates of staff demand to accurately reflect the seasonality across days of the week and within each day. For example, days-off scheduling needs daily disaggregation, shift scheduling requires hourly disaggregation, and tour scheduling entails further disaggregation of staff demand into days and even shorter periods within each day. Therefore, although the authors in Porto et al. [42] presented datasets associated with a standard-sized retail store that allow solving tour scheduling problems considering multiskilled employees, future work could aim to present new datasets with representations of staff demand that fit shift scheduling and days-off scheduling problems. In addition, such datasets could also provide data associated with larger retail stores.
Footnotes
Acknowledgements
Special thanks to the company SHIFT SpA for providing the real data used in the case study. The authors would also like to thank the “Fundación para la Promoción de la Investigación y la Tecnología (FPIT)” for supporting this study under Grant 4.523. Finally, the authors thank the three reviewers for their valuable comments, which significantly improved the article.