
Abstract
New, multi-channel personal data sources (like heart rate, sleep patterns, travel patterns, or social activities) are enabled by ever increased availability of miniaturised technologies embedded within smartphones and wearables. These data sources enable personal self-management of lifestyle choices (e.g., exercise, move to a bike-friendly area) and, on a large scale, scientific discoveries to improve health and quality of life. However, there are no simple and reliable ways for individuals to securely collect, explore and share these sources. Additionally, much data is also wasted, especially when the technology provider ceases to exist, leaving the users without any opportunity to retrieve own datasets from “dead” devices or systems. Our research reveals evidence of what we term human data bleeding and offers guidance on how to address current issues by reasoning upon five core aspects, namely technological, financial, legal, institutional and cultural factors. To this end, we present preliminary specifications of an open platform for personal data storage and quality of life research. The Open Health Archive (OHA) is a platform that would support individual, community and societal needs by facilitating collecting, exploring and sharing personal health and QoL data.
Keywords
Introduction
The qualitative and quantitative data collection of biological, physiological, psychological and social-environmental factors may tell the beholder unprecedented information about the data subject – his behaviours, health risks and life quality in the long term. The World Health Organization (WHO) defines health as “a state of complete physical, mental and social well-being and not merely the absence of disease or infirmity.” This definition has recently been challenged by a team of international experts to be shifted to “the ability to adapt and self-manage in the face of social, physical, and emotional challenges” [1]. Health is directly related and contributes significantly to the quality of life (QoL) [2]. QoL can be defined via a more global approach (ex. happiness vs. unhappiness), a categorical breakdown (e.g., physical or psychological aspects) and field-specific definitions (Liver QoL) [2,3]. However, across different QoL definitions, there is some agreement that QoL integrates an individual’s multidimensional evaluation of his/her life [4]. Forging meaning from multidimensional factors in order to get a better understanding and outcomes of own quality of life (QoL) is undoubtedly a good reason to gather personal data. In this paper, we elaborate on the opportunities and challenges of collecting, exploring and sharing personal data to find effective solutions across the individual-community-society spectrum that help to improve QoL. A query in Google Trends1
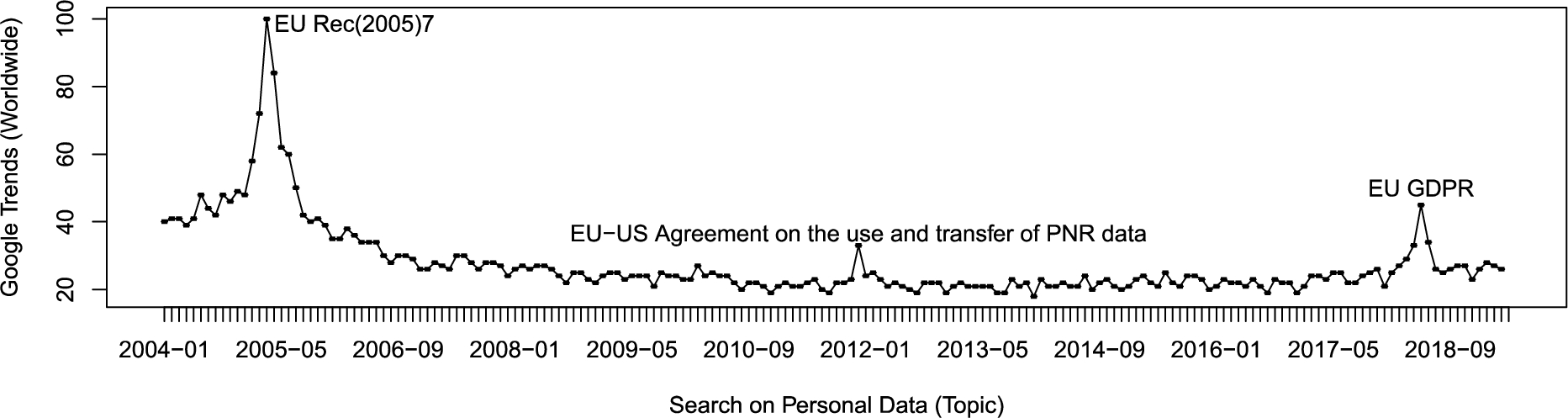
The term “Personal Data” – Google global search trends reached peaks that coincide with relevant events related to EU policy for protecting privacy.
Alongside the developments within the personal data sphere, there is a demand of “multidimensional measurement of QoL” [5] at the individual and the population level. The World Health Organization (WHO) indicates that measuring QoL can provide valuable information in medical practice, for improving the doctor-patient relationship, as well as for assessing the effectiveness and merits of treatments, in health service evaluation, in research and policy making [6].
At the same time, the use of non-medical devices to maintain or restore health [7,8], reinforces the importance of patient-driven health care models [9] and consumer health care models [10] that include mobile health (mHealth) applications to track lifestyle habits, wrist-band trackers, or other kind of Internet of Things (IoT)/wearable devices. There is a plethora of scientific peer-review pervasive computing systems for health care [11–14]. Big data and IoT open the opportunity to bring global health innovations. They come with the promise of an algorithm-supported healthcare system that will be more efficient than the current one, prone to human errors, and will save more lives. However, digital technology produces these main trade-offs: privacy vs security, control vs freedom, dependence vs independence [15].
This dilemma raises tensions and concerns that lead to the question on why data controllers and data processors are usually data holders in the first place, suggesting the need for revisions on regulations to protect the right of the data subject to choose the storage location. One pitfall of EU data protection regulation is the “passive” role for the consumer/patient or study participant. The use of the term data subject does not empower the individual, whose voice is ultimately reduced to a signed data consent policy. Meanwhile, applications that target powerless consumers by claiming to give them control over personal data are multiplying. Some solutions offer personal data markets for helping individuals to generate revenue. Such business requires transparency to avoid facing legal, economic, technical and social challenges [16].
Overall, despite the data deluge of modern life, researchers rarely gain access to significant sources of personal data that integrate the multiple aspects of life. The wearable market will continue to grow while databases are kept behind commercial, ethical and legal barriers. The market will have a compound annual growth rate of 18.4% over the next three years, i.e., 222.3 million shipments in 2021 [17]. Based on the predictions, it is reasonable to expect a growing research interest in data retrieved from wearable technologies. Furthermore, projections for the year 2020 indicated that healthcare data would require 2,314 exabytes of storage space if it continues with a growing annual rate of 48% [18]. Thus it makes sense to rethink solutions for collecting, exploring and sharing personal data and its applications for quality of life.
Towards this end, in this paper, we elaborate on strategies to manage and preserve the sheer amount of personal data from a quality of life perspective. Building on a considerable body of literature, we strive for answers that respect individual, community and societal values, encourage individuals to be more engaged in healthy behaviours without losing control over their digital traces, and empower researchers and citizen scientists with an ever-growing health data source.
This article extends our paper [19] presented at the 4th Workshop on “Data-driven self-regulating systems” as part of the Foundations and Applications of Self* Systems (FAS* 2018). The main novel contributions are: Why, a semi-systematic review of the status of data providers as evidence of the human data bleeding defined later in this paper; How, our argumentation about five main issues to promote data access and sharing in this area; and Where, the set of requirements and design considerations for the Open Health Archive (OHA) derived from the literature and properties of existent solutions.
In this section, we briefly examine two approaches that impact on the design of health information systems, namely, the disease-centric and the patient-centric approaches. Then, we consolidate the different elements that create personal health information and analyze the role of emerging technologies as health outcomes. Finally, we elaborate on the difficulties to integrate emerging technologies into traditional healthcare systems.
Health information systems
Health information systems refer to systems that deal with health data and are used by patients, doctors, and decision-makers. By contrast, we use the term personal health information (ϕ)3
We prefer the abbreviated form ϕ instead of “PHI” to avoid the confusion with the term “protected health information” used in the context of US HIPAA regulation. PHI refers to 18 identifiers, typically numbers and addresses that HIPAA distinguishes to protect individual’s privacy from re-identification.
Due to the myriad of technology innovations that provide sources for personal health information, we loosely characterize ϕ (uncountable) dimensions. We hypothesize that leveraging these dimensions can help researchers to get a holistic view of the person’s quality of life unfolding and changing over time, as well as a better understanding of health outcomes. This hypothesis is supported by numerous studies and reviews of the use of technology in health conditions, e.g., mental illness, injuries and disabilities, and cardiovascular diseases [20–25].
Decision making in healthcare systems is mostly based on health outcomes. Health outcomes are measurements of an aspect of health that provide a unique view of a health condition. Health outcomes could be generic or disease-specific [26], and both can be used in combination to gain more insight and compare alternative treatments. Disease-specific outcomes are considered ill-suited for the general population or patients with multiple chronic conditions; instead, the alternative patient-centric models that considered the perspective of the patient to measure health outcomes are promising [27].
Meanwhile, the vast bulk of patient data is collected in clinical studies through clinician-reported (ClinRO), performance-based (PerfO), self-reported (SRO) outcomes and emerging technologies (TechOs) [28]. Professionals assess activities in PerfO, while the participant is required to fill SRO. However, PerfO are momentary and expensive and SRO may be inaccurate due to perception bias.
Patient-centric approaches aim at providing a holistic approach that takes into account the multidimensional aspects of health, QoL and well-being. There is general agreement that QoL and well-being measurements have to be sought from the individual own’s perception, and wearable devices and smartphones facilitate its quantification in daily life activities. Consumers and patients with chronic conditions keep showing interest in these devices. In particular, quantified-self trackers are extreme consumers that wear multiple sensors and may develop their solution to capture data and run analytics if the market fails to satisfy their needs. In a sense, self-quantification and life-logging technologies are invaluable data sources for patient-centric research. These data collections can augment patient-supplied data in healthcare systems even for individuals who are not patients at any given moment.
The spiral shown in Fig. 2 illustrates the ever-growing ecosystem of emerging technologies that create personal health information. Its inner sections correspond to records generated by healthcare/domain experts. Its outer sections incorporate data generated by non-experts and with less discrimination extends to the rich variety of lifelog data sources, examples can be found in the reference [29]. We assume that the integration of non-expert sources contributes to reducing data acquisition costs and increases the possibilities to capture with higher fidelity the “dynamic nature of quality of life” [30]. At least for healthy patients, the innermost section generates records every couple of months or years and frequency increases as we move towards the outer sections. An exception can be found in patients treated with complex medical procedures, where the innermost section becomes a source of high-dimensional high-resolution data too.

The main sources for personal health information are electronic medical records, electronic health records, patient-generated health data, wearable devices and mHealth apps. They contribute to fill the ever-growing volume of phi dimensional data about an individual.
In patient-centric models, emerging technologies are likely to improve health outcomes. The time interval between measurements taken by experts can be long (except for patients with critical health conditions who are closely monitored in hospitals). The use of dynamic data is encouraging to understand if interventions are working or not. In other words, laying data out over time is useful to understand trends and improve analytics. Thus, measurements taken at home may unveil relevant patterns even if the measuring device was not designed for medical purposes. Furthermore, in the QoL domain, Evans and other researchers have argued that objective measurements should rely more on the actual manifested behaviour and current circumstances of the person compared with an external baseline [31]. Overall, dynamic data can provide a more comprehensive quantification than static data or self-reports used alone.
Prevalent raw and algorithm-driven data in TechO+
The spiral in Fig. 2 follows the distinction between “medical records” and “health records” given by the Office of the National Coordinator for Health Information Technology (ONC), US Department of Health and Human Services (HHS),4
and the taxonomy given in the Montreal accord on patient-reported outcomes [28]. The innermost section includes electronic medical records (EMRs), a digital version of the traditional paper patient’s history written in a 5 × 7 inch card. Electronic health records (EHRs) expand the value of EMRs. They contain information from all the clinicians involved in the patient’s care. Patient-generated health data (PGHD) expand the value of EMRs even more with health-related data created, recorded, or gathered by or from patients, family members or other caregivers. They include but are not restricted to patient-reported outcome measures (PROMs), observer-reported outcomes (ObsRO) and proxy reported outcomes (ProxRO). Examples are self-reported questionnaires, face to face interviews and telephone interviews about physical, mental, and social health. In the Montreal accord, technology-reported outcome (TechO) is vaguely mentioned as part of the clinician-reported outcomes (ClinRO) branch and directly linked with performance-reported outcomes (PerfO), which are assessments done by clinicians in close cooperation with the patient. However, health-related quality of life (HRQoL) measurements done with emerging technologies are gaining preponderance. We propose TechO+ to distinguish and take into consideration the data that is collected by apps, sensors, trackers and other IoT devices either worn by the user or available in the user’s environment, e.g., smart home or a smart car, to quantify different aspects of their life. TechO+ makes the outermost section of the spiral. It comprises raw data and algorithm-driven data that quantifies physical health, psychological health and social relationships, and the environment as described in Table 1. The main difference between Tech and TechO+ is that clinicians do not control data generated by TechO+.The introduction of emerging technologies in the healthcare sector is not new. A central argument is that PGHD and TechO+ data open the opportunity to develop new clinical decision-making metrics, where these new data sources can be leveraged for better diagnosis, assignment of treatment, prognosis and prediction of future health outcomes. The use of personal devices to create digital biomarkers can help researchers and doctors to diagnose diseases. For example, researchers are experimenting with keystroke and touch-screen tracking to early detect mental disorders [32]. ‘Bring your own device’ and similar policies can provide the means for more active patients, hence increasing the levels of patient engagement. However, the integration of emerging technologies into healthcare systems is not close to becoming a reality. The adoption level of patient engagement oriented technologies is varied, and there is space for improvements [33]. Countries like US and UK are just progressing towards nationwide electronic health systems, but migration is costly and complicated [34]. Healthcare information systems are dominated with inflexible legacy systems that do not integrate ClinRO, PerfO and SRO with external data sources. One main difficulty is the role of security and privacy in medical device software [35]. The WannaCry ransomware put in evidence that hospitals infrastructures are populated with outdated software [36]. Other challenges are the cost and legal implications in the case of devices that are prescribed by doctors. On a growing scale, questions are raised concerning data ownership, access rights and sharing of data collected with wearable medical devices due to intellectual property protections [37]. More questions are raised concerning the validity of measurements taken with consumer-grade devices, for example, the sensor placement plays a vital role [38]. Although techniques to minimize these errors are available, the position of the sensor is not always registered with the measurements. In addition, most vendors do not make their algorithms public; versions and update dates to these algorithms are not well documented. The same measurement can have different meanings across data captured with sensors from different vendors or across the same database during different periods.5
The human body and behaviour is a source of big data, especially in the context of health. For example, a single X-ray accounts for 30 MB of data, a mammogram for 120 MB, 3D MRI for 150 MB, while 3D CT scan for 1 GB. Raw sequencing data per person accounts for 4 TB [41]. Stored healthcare data will continue to grow, and it is expected to be around 2,300 EB in 2020 [42]. Medical image archives are increasing 20–40% annually [43]. Electronic tattoos (e-tattoos) used together with a portable wireless multichannel electrical potential recorder can synchronously record three-channel ECG with a sampling rate of 1 kHz [44]. The Artemis system [45] supports the acquisition and storage of raw physiological streaming and clinical data to monitor multiple premature-born babies. Data channels such as ECGs and electroencephalograms are time sampled at 0.5–1 kHz. The initial pilot test generates less than 0.2 Mb/s network traffic. A soccer players dataset, which includes field position, heading, and speed, was collected with a highly accurate tracking system taking samples at 20 Hz [46]. That means a player who participates in a full game generates approximately 108,000 records. A coronary artery bypass grafting surgery is another example of a high-dimensional, high-resolution data source. This procedure can produce more than 200,000 points with potential value for outcome prediction and research. Nonetheless, data is discarded using a reductionist process to reduce investment in proper infrastructure [47].
Based on the above observations, we examine the challenges for collecting, exploring and sharing personal health from the individual’s and researcher’s perspective.
Individual perspective
Lifelogging, as defined by Microsoft MyLifeBits research project (1998–2007) [48], is the storage of selected qualitative and quantitative facets of life, namely professional communications, personal records and family activities. Based on MyLifeBits, it has been estimated that a 10-year personal collection required approximately 100 GB. This space requirement may change from one person to another, but such collections would fit in standard consumer hard disks. However, the big data and cloud storage market promotes a different approach. Lifelogging repositories are fragmented, in the sense that personal collections are stored in remote locations and distributed across different vendors. In this scenario, individuals may give away privacy based on illusions of what the solution claim to provide. A study in the US showed that 58.23% (934/1604) mobile phone users downloaded health-related mobile apps mostly with a focus on fitness and nutrition [49]. Many of these applications are unreliable. There are multiple examples of negligence and/or abuses of individual users’ trust that can lead to vulnerabilities and/or security breaches to gain more information about a subject [50–52]. If human blood is for traditional (analogue) healthcare the equivalent to human data for digital healthcare, we can talk about human data bleeding.
Furthermore, if not bleeding, the data may become inaccessible and completely lost when companies go out of business. Namely, nowadays, the app stores, as well as consumer electronics stores, host a variety of mobile health solutions. Smartphone users can choose from tens of hundreds of applications, designed to assess the behaviors (e.g., physical activity) and states (e.g., mood) and enable to prevent or manage certain diseases, or induce behavior change to improve health and life quality in general. There are also a variety of affordable, miniaturized and fashionable wearable devices that are designed to assess various behaviors (e.g., sleep, physical activity) unobtrusively to the wearer. In addition, there are patient-focused social networks that create an ecosystem to discuss health conditions with family, friends, informal caregivers, and health professionals. However, it is also observed that these apps, devices, and social networks get discontinued due to company acquisitions, business shifting focus, companies shutdown, and when research project supporting the wearable/apps has been completed. The disappearing networks, apps and dead wearables often imply that their data collections get lost, in most cases – without offering data migration solutions to the users.
To illustrate the wasted resources we discuss the state of the “lost data” evidence via a semi-systematic review of providers, as follows. We review 438 latest available personal wearable technologies enabling self-monitoring, as previously surveyed by Wac [53]. With respect to the wearables, 265 or 438 wearables surveyed by Wac, do not exist anymore. Many of the mobile apps and wearables that disappeared do not even have a corresponding website with information to their users anymore (e.g., web link returns an error or the domain is on sale). For the devices, we estimate the amount of data being lost assuming three (3) months of use, having different data channels (e.g., accelerometer, GPS) collected via a device. For each data channel, based on our past and ongoing experience with body area networks and wearable psycho-physiological devices [54,55] we firstly assume a continuous data stream ranging from high frequency/high resolution, for example, ECG (assumed 128 leads, each 256 Hz frequency, 16 bits per sample) to low frequency, for example, button interaction (assumed 1 event/minute on average, 8 bits per sample). We assume that the psycho-physiological data stream is collected 24/7, and an audio/video stream is collected on average an hour a day. Based on that, we calculate the total data loss incurred in three months for all discontinued devices [56]. We only compile it for the wearables, because we were able to archive the wearables database entries used at that time.7
We are unable to compile that for the mobile apps because we have not archived the details about the mobile apps themselves. The estimate of the data lost due to discontinuity of the wearables (and their corresponding apps) is as follows. For 265 discontinued devices, the overall data loss is estimated to be in the range of 6 TB (out of 9.85 TB for all the devices), with an average of 22.71 GB per a discontinued device providing on average four different data channels. Data waste is substantial.Other complications appear with patient- and consumer-generated data from wearables and other sensors used for life tracking. The common practice is that devices synchronize their data to cloud-based storage systems directly or via smartphone applications. It becomes challenging to keep track all together with the data from multiple sensors all along the life span of the person. We conjecture that the lack of a reliable storage platform to keep personal health and health-related records may have a repercussion in the user engagement with mHealth technologies and health self-management.
From the perspective of researchers, there is no clear line between data ownership and data stewardship. In practice, the researcher takes the role of data owner, and study participants donate data for particular studies. Despite the tacit donation “to science”, databases are kept in silos to the detriment of large scale studies, cross-validation and data reuse. In some countries, study participants have the right to request their data, but that may require complex procedures. The archives of universities, institutions, and research labs are not meant as a backup for study participants.
Undoubtedly, access to data is essential to conduct data-driven research [57]. However, academic labs often lack resources to gather data on a large geographical scale. A remedy could be to conduct research in association with an industry partner to gain access to big data repositories. But, that introduces the risks of statistical bias since data collected by users of a single product brand, e.g. Apple Watch or Fitbit trackers, may not represent the general population. Another problem is that research projects that involve personal health data require ethical approvals. From our own experience, and that of others, the application process can be complex, time-consuming and not necessarily successful.
Clinical studies usually involved large cohorts (in the order of thousands) and some studies extend across 10–30 years. Conversely, the studies in the QoL Technologies Lab extend on average 6 months, involve small cohorts (20–30, sometimes up to 100 participants) and involve analytic systems for high-dimensional, high-resolution data (the outer layers of the ϕ spiral). Similarly, the studies based on smartwatches for health and wellness applications report promising solutions but most of them are only based on small sample sizes [58].
To sustain innovation in the QoL domain, we need data to conduct measurements covering physical health, psychological, social relationships and the environment. To the best of our knowledge, there are no such large vendor-independent data banks for data gathered with wearable devices, i.e., wearable data. Large biobanks have gather wearable data from large cohorts, but only for short periods, e.g., UK Biobank includes a repository of 1-week wearable data used by more than 100K participants. Other sources for research studies are community-based projects and crowdsourcing data. In this direction, we collaborate with the Open Humans (OH) Foundation. This non-profit organization built and support a community-based platform that collects personal data for personal exploration and research study participation [59]. OH has, as 30 of May of 2019, 6,976 members and 42% of them contribute or have contributed to a myriad of private and/or public databases. The most successful projects are related to genetic data. Through this collaboration, we could obtain data from approximately 400 activity trackers (OH’s Fitbit database). Some self-trackers have data from 2008; a pitfall is that OH’s Fitbit database only kept a single summary record per day. Crowdsourcing data is being tested in many areas, e.g., epidemiology studies, infection diseases, nutrition, and diabetes [60–63]. We hope that crowdsourcing mHealth systems may speed research and innovation with high-fidelity and reliable data.
To sum up, we identify two critical aspects for bringing data-driven research and innovation in the QoL domain: (1) increasing the user engagement to quantify and track QoL measurements; (2) facilitating data gathering and data sharing. In this paper, we provide some design guidelines for a system addressing these two key aspects.

The hierarchical value of health and health-related data.
The value of personal data goes beyond the individual. There are countless examples of the benefits of personal data to communities and the society as a whole, but lack of transparency erodes trust and the willingness of individuals to share sensitive personal data such as health data [64]. Organizations with collaborative relationships that highly invest in trust can bring considerable innovation [65]. From what has been said above, we assign a hierarchical value to health and health-related data to classify systems in a pyramid of three non-exclusive categories, as illustrated in Fig. 3 and described as follows. Individual value is attainable by products or services designed for (a) one-time use, e.g., a particular clinical study conducted with the help of a mHealth app, or (b) single-user, e.g. commercial applications that satisfy the needs of individuals. Community value is possible when data is kept in well-curated institutional repositories, biobanks or public microdata collections. Temporal, economic, geographical and other restrictions may apply; consequently, benefits are subscribed to a group of individuals. Open, and ideally raw, data generate more opportunities to create societal value. Solutions that gain space in the upper part of this pyramid can bring social innovation since QoL measurements can have a significant impact in many fields that need creative solutions to meet social goals. Some of these fields are the rising incidence of long-term conditions, behavioural problems, happiness, rising life expectancy, and more examples given in the literature [66].
Certainly, the need for more trust, collaboration and transparency is a requirement to attain community and societal value. On the contrary, as we move towards the solutions located at the bottom of the pyramid, privacy prevails. However, high trust compensates for low privacy and vice versa [67]. In that study, the authors did not find any substantial decrease on self-disclosure of personal information in environments that combined high trust with weak privacy policies, or its counterpart, low trust with strong privacy policies. Then, it seems reasonable to think that organizations that design solutions to fit in all three pyramid levels may strive to increase the levels of trust, collaboration and transparency progressively. A pitfall is that the all-or-nothing approach that prevails in privacy policies found in mainstream products/services is not adequate to design innovative solutions for managing the broad diversity of personal data sources throughout a human lifetime and give back value to each level of the pyramid.
Modernising this area – with improved data access, sharing and long-term archiving methods – requires to consider multiple aspects. We reason upon five groups of issues to promote data access and sharing regimes identified by members of an Organization for Economic Cooperation and Development (OECD) follow-up working group [57]: (a) technological, (b) financial and budgetary, (c) legal and policy, (d) institutional and managerial, and, (e) cultural and behavioural factors. The rest of this section examines these aspects and place them in context with previous work and existent community and commercial solutions to manage and archive personal health-related data.
Technological issues
A system that collects data from many sources relies on the definition of data standards to implement interoperability solutions. The caveat is that the definition of data standards is affected by competition, overlapping goals, and poor coordination at national and international levels [68]. Particular to health standards, the Health Level Seven (HL7) specifications are widely used across the globe. HL7 specifications are designed for semantic interoperability, i.e., “the ability for data shared by systems to be understood at the level of fully defined domain concepts” [69]. Fast Healthcare Interoperability Resources (FHIR) is a draft HL7 standard describing data formats and elements and an application programming interface for exchanging electronic health records.
Consumer applications can use FHIR to import patient health data directly to mobile phones. There is a large ecosystem of apps that using free, open healthcare application programming interfaces (APIs) can connect to any EHR [70]. For instance, the Health app8
Data exploration that goes beyond the default tools and features is available in the market. Knowledge sharing via community-driven and research-driven software seeks to reduce the burden of building ad hoc solutions. As examples, we can mention PACO11
The development of personalised solutions requires expertise to implement data connectors that integrate data sources in own research hub. The creation of connectors is time consuming due to the myriad of consumer devices that are ingesting human data. Some of the data management platforms that provide data connectors to facilitate development are vendor-agnostic while others only provide connectors for a particular vendor, e.g., Fitabase.12
Almost any data aggregation solution moves data to cloud-based infrastructure without giving the option to choose the storage location. The use of public cloud storage means that the provider has some control over the data. A claim to sovereignty is a claim of domain under control. Hence, embracing claims to sovereignty is crucial to assure data privacy in a trustless system. Blockchain, often in combination with off-chain data, has gained much attention to address self-sovereignty and manage healthcare data [72–74]. With the freedom to choose the storage location, individuals could opt for personal data vaults (PDV) [75], their proprietary storage media (such available space in local disk), a hybrid storage solution [76] or other communal/cooperative in-house storage systems. For example, a hybrid storage solution may combine media owned by the user and remote resources owned by peers organised in a decentralised architecture. Distribute medical data in different places would be a safer way to protect privacy and information; in fact, many countries have implemented decentralised systems that include data sharing and informed consents [77,78] many years before the boom of blockchain-based solutions. Communal/cooperative in-house storage systems require an upfront investment, but the cost could be afforded with a registration fee. On-premise solutions can keep the data where it should be, in the hands of the cooperative and, preferable, in the hands of the data subject only.
Government incentives can help to speed up the adoption of new technologies. For instance, EHR adoption among US hospitals gained eight percentage points in the five years after the implementation of the Health Information Technology for Economic and Clinical Health Act (HITECH Act) [79]. The All of Us Research Program plans to build a database of 1 million US citizen profiles that incorporate lifestyle, environment and biologic factors. The program received $130 million from the US National Health Institute to accelerate precision medicine [80].
Worldwide, independent programs are run and financed cooperatively. A health cooperative model can be self-sustainable by reinvesting earnings from data but challenges remain [81]. Pilot studies based on the cooperative model have been built in different places, Swiss13
Concerning data storage, a cost-effective model is needed, whether it is done by the individual or by a steward organization. The economics of long-term archives are different from models develop to store data that has a lifespan shorter than the life of the storage device [84]. Long-term data preservation has maintenance costs to avoid physical and logical obsolescence. Carefully chosen data types and formats can reduce migrations due to logical obsolescence. The selection of the storage medium, e.g., hard disk (HDD), solid-state device (SDD), tape, dictates physical replacement cycles. Tape storage [85] is a winner technology for archived data due to cost per Gigabyte and duration. However, tape is more susceptible to environmental damage; consequently, it may not be the best solution for individuals who wish to keep personal data at home.
For steward organizations, three main models for long-term preservation systems are: (a) rented storage in a public cloud, (b) monetised storage, and (c) endowed storage. In addition, developing markets for rented storage proliferate in P2P networks. Individuals may keep storage at home and share some resources with other individuals to build a P2P system with higher performance and reliability. Shared resources can be used to increase the performance and reliability of the system by storing redundant encrypted data. Sharing quotas can help to balance the equation costs for each user. But more research is needed to assess the cost-effectiveness of P2P-based solutions and their ability to provide long-term storage services. In a separate project, one of us is conducting experiments to further investigate P2P-based solutions. The monetised model is not a valid option neither for open data nor private data. While we do not suggest that individuals should not monetised data, this model is not compatible with our ultimate aim at designing a system that promotes open data for research and innovation. However, monetary incentives could be introduced for data generated during participatory studies as there is evidence that incentives are effective to improve the response rate in a survey [86]. In the endowment model, individuals pay endowed money that should cover the entire lifetime of data with some part used to pay the initial setup costs such as buying media and the rest is invested. Under the hypothesis that a system designed for long-term archiving of personal data will attract many users, endowed storage seems to be cost-effective in comparison with rented storage. Researchers showed that own private cloud is cost-effective with large clusters and that the cost of ownership of raw storage is almost 100× cheaper than the costs cloud storage providers service [87]. Other study highlighted that over the long term owning the infrastructure can save money [88]. Finally, researchers that studied the endowment model over a 100 years simulated archive founded that SSDs are a better choice media to keep the costs low [89].
Regulations give a tool to public officers to control what companies are doing with data. Controls are only a first step, as stated by the Open Data Institute (ODI) in its guidance [90]: “Data-related activity can be unethical but still lawful.” Besides, regulations serve to accelerate innovation by providing government incentives, e.g. the case of personalised medicine in the US [91]. Although there are multiple cases of users showing autonomy and “wilfully sharing data”, there is limited protection to open data initiatives [92].
In the US, the Health Insurance Portability and Accountability Act (HIPAA) is the legal framework to protect patient’s privacy and guarantee that patients can have their data on request. It should be noticed that companies that provide services using health data may not be healthcare providers under the provisions of HIPAA; hence, HIPAA is not mandatory to those companies. For example, the website of Lydia, the suggested replacement for the Microsoft Health Vault service,15
In Europe, individuals, so-called “data subjects”, are protected through the General Data Protection Regulation (GDPR) – (EU) 2016/679. GDPR imposes obligations to data controllers and data processors, among other protections, to defend the individual’s right to access, move and forget data.
The level of data protection legislation around the globe may differ from country to country.16
Compliance to regulations often means the obligation to obtain informed consent from users. But decades of raised concerns about the reading level of those privacy statements, which may be intelligible only to a minority or inadequate to vulnerable populations [94–96], suggest room for improvement. Individuals may give consent to gather data based on the expectations to address health concerns. In this context, tech/health giants keep exploiting business opportunities with closed data, although it may affect individuals who become exposed to privacy and security tensions in an undisclosed algorithmic decision-making world [15,97].
Data subjects are powerless with respect to data control and data process. The mere term “data subject” imposes a passive role to the individual that actually generates data. Data subjects are expected to give consent to others to act on their behalf. An active role requires participatory engagement. For that, we need systems that empower users and regulatory frameworks that act accordingly.
In the governance of health data, trust in developers and regulators is a key condition to generate innovations in digital health [98]. Trust may be only generated with secure technologies and individuals with control [99]. Solutions that gather personal data without empowering the individual to take control may leave the data subject at the mercy of technology providers, researchers, healthcare providers, doctors, wellness centers, and others. All of them may have in place their systems to manage and store data from their patients/consumers, hence multiplying silos and points of attacks and vulnerabilities. Even if systems must comply with the law, there is still room for arbitrarily decisions in privacy and security policies, and for ambiguities that can lead to different interpretations affecting data subjects. For that reason, interpretative guidance and compliance with standards could become useful aids to organizations.
Transparency is closely related to trust. It helps the data subject to know how the data is processed, supporting the principle of accountability. A transparent system, which is now a GDPR requirement, needs to provide the data subject with the means to verify that the usage policies are being followed and that the business process complies with the policies consented by the user and the applicable data protection regulations [100]. Transparency suggests a socio-technical concept of global interest. Transparency Enhancing Tools (TETs) can help to accomplish transparency, at least as a technical principle [101].
The FAIR principles were designed to ensure transparency, reproducibility and reusability of scientific data [102]. FAIR stands for findability, accessibility, interoperability, and reusability. These principles are described as guidance to support proper data management and stewardship As an example, in the Netherlands, the personal health train initiative promotes the use of FAIR principles and citizen-controlled health data lockers [103]. Trains are a metaphor for data workflows, each responding to specific research questions, built and maintained by a researcher.
Cultural and behavioural factors
The OECD working group conclude in their study [57] that reward structures for those who produce and those who manage research data are a necessary component for promoting data access and sharing practices. In the context of our study, self-tracking cultures [104] are sustained by selfhood, i.e., the motto “self-knowledge through numbers”, and communities. Online communities of practice promote the engagement of healthy individuals and patients in their health care [105]. They are vehicles for sharing their personal self-tracking experiences which other members. The Quantified Self community18
Self-tracking practices may bring into effect the values of autonomy, solidarity, and authenticity. In practice, these values are enacted differently, and consequently, researchers have begun to ask what type of practices will guarantee these values in meaningful ways to individuals and communities [107].
Long-lasting designed solutions that encompass a holistic view of human data can help to overcome the lack of persistent solutions and fragmented databases. A large number of platforms can be used to collect, explore and sharing personal data; surveying all of them is outside the scope of this work. Table 2 lists some examples to show the diversity of approaches in this field. The projects are sustained via three main models: non-profit/community, commercial projects and cooperatives. They target different audiences: end-users, as well as developers, healthcare partners and researchers. The table includes a column for a perceived value that indicates, when available, the number of members. The numbers may be imprecise due to artificially inflating the number of Twitter followers [108] or fabricated download figures to make the app seem more popular [109].
Examples of existent solutions that can be used to collect, explore and share data
Examples of existent solutions that can be used to collect, explore and share data
In 2017 Personal merged with Digi.me
K = 1000
M = 1,000,000
Raised funding information derived from
From the perspective of a researcher it is important to know how many members are active, the number of days/months/years contributed, the number of data points registered, the variables, and if the platform has multiple projects, it is essential to know which users join which project. Researchers need all this information to judge possible partnerships for their studies. PatientsLikeMe has the largest number of users and presents open statistics about the members living conditions, e.g., the number of patients with certain symptoms, or a chart with age/sex of patients with liver cancer. Open Humans is open with respect to membership information and provides resources to citizen scientist and research institutions. It has a smaller database more focused on TechO+ and genome data.
From the perspective of individuals, it is almost impossible to evaluate an app without signing consent and give away personal data. Further, user needs may change throughout life and to choose the best solution for that particular moment in time, better information is needed. Migrating data from one solution to another may not be possible, or at least easy, and concerns about data loss may make users dependent on the same product. Open Humans and Wolfram Data Drop seem to offer the most flexible solution. The platforms offer a way to aggregate data from multiple sources and then explore all together with the help of powerful and stable resources such Jupyter Notebooks and Wolfram Notebooks. Overall, it is difficult to judge the value yield across the individual-community-society spectrum by the eight solutions. Some are more focused on individual values; some include interesting features for particular communities, etc.
The solutions listed in Table 2 may disappear. Product discontinuity, interoperability issues and geographical limitations are typical. For example, Google Health launched in May 2008 and was dissolved in January 2012 based on the lack of broad impact and Microsoft Health Vault will shutdown this year. Instead, Microsoft launched early this year Microsoft Health Bot, a cloud service based on AI algorithms, to take medical data from trusted sources at the conversational level. Medical data includes conditions, symptoms, specialists, medications and procedures.
There is room for improvements in the management of personal health information to reduce human data bleeding and disappearing communities built in dead applications. We believe that the lack of stable infrastructures to systematically collect data throughout all stages of human life penalize research and innovation. This section outlines the requirements and design choices to set the foundations for the creation of a platform, called Open Health Archive (OHA), that we derived based on the analysis of past experiences and initiatives as presented above and Sections 4 and 3.
The main design principle aims at helping individuals with the preservation of health-related data generated throughout life in a user-controlled and open infrastructure that together protect private, shared and public data. We argue that in order to have control over personal data collections, individuals should participate in the system administration and, ideally, have physical access to the storage devices that hold their data repositories. A user-controlled and open infrastructure built with Free/Libre and Open Source Software (FLOSS) can provide more control and more options to customize solutions to individual specific health and life conditions. Furthermore, FLOSS enjoys transparency and other characteristics that facilitate transdisciplinary research dialog [111].
Our vision for OHA is to emphasize the creation of value in a pyramid structure that benefits the individual, communities and society. To generate sustainable benefits to communities and societies, we propose a bottom-up innovation that emerges from empowered individuals and transparent management of personal data. Little has been done to provide individuals with tools and resources that empower them with independence and self-sufficiency, in other words, to become more active with their health-related data. In this regard, a case study on the Camfield Estates-MIT project that gives thought to community and individual empowerment point out that information and a sense of control are instrumental in participatory behavior [112]. FLOSS is a key factor in individual and community empowerment since everyone can contribute and customize tools to help individuals in longitudinal self-quantifying own experiments. That may help to achieve low participation attrition in future studies conducted inside OHA. OHA will allow gradual openness to protect and respect the privacy according to individual preferences while making easier the path to share data whenever the data subject decides it, including consenting options for posthumous donations. We discuss strategies that can create value such as the creation of a knowledge base and pseudo-anonymous profiles for each of the core QoL domains.
We envision a self-regulated system that shares computer resources in a decentralised storage system, assures patient/consumer-centric data management administration, and provides for each user a monolithic view of their life-tracking log. Developers could offer services or applications running on top of OHA but, at least, the OHA system’s core should be sustained by an open-source project. In this paper, we put more emphasis on the two outermost sections of the spiral, PGHD and TechO+ data. We assume that the data subject has already some control over these data collections, for example, access to fitness data. The ultimate mission is to preserve all type of personal health information. However, accessing medical records and stored them under the data subject realm is a complex issue with resistance and concerns, which fall outside the scope of this work.
The platform should not become a vehicle to push, impose and exploit self-tracking. Most of the data collections kept in the platform may remain private. Data is stored privately by default; gradually open data will be an option. Individuals may opt to participate in research studies and donate data to communities.
Building a cooperative, self-organized health archive system is a complex and long-term endeavour. We suggest that the initiative to create OHA must be taken by a non-profit organization that acts in the best interest of its members and adopts conflict of interests policies to assure that OHA remains open and has a transparent development and administration. This section elaborates more about our vision and outlines what can be the initial OHA requirements.
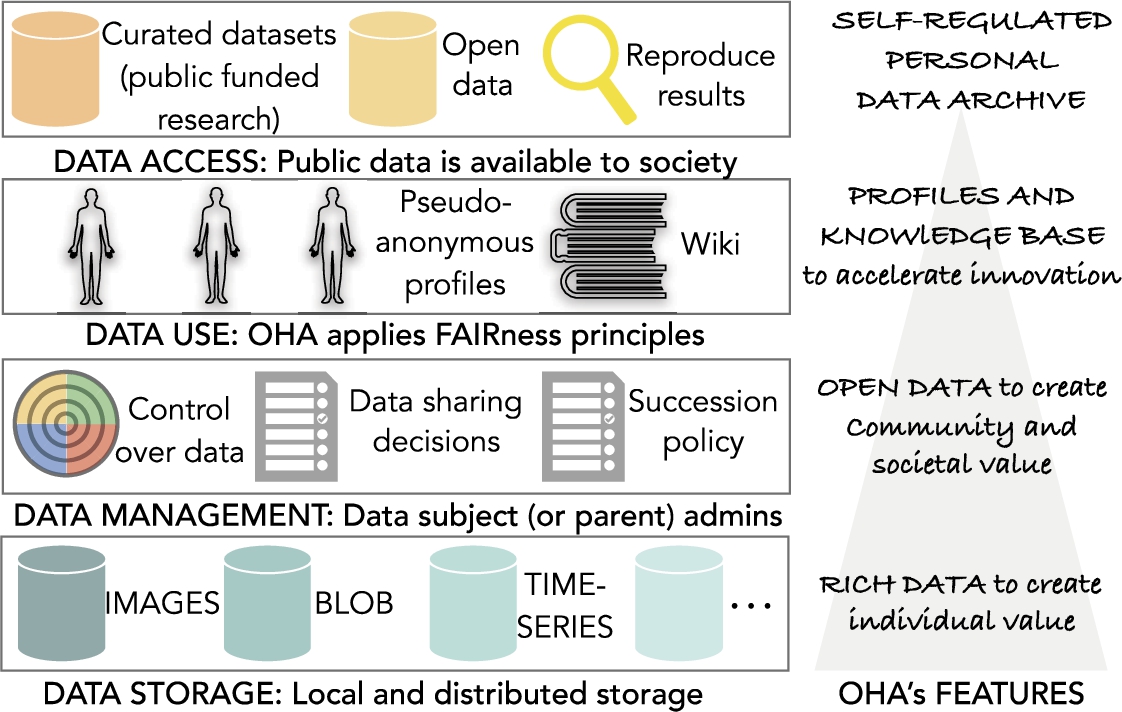
Overview of the open health archive (OHA).
At this stage of the research, our specifications are necessarily speculative since OHA is not yet implemented. However, given the crescent attention to health data governance and stewardship, this subsection presents some of the novel aspects of our design. We propose and examine the following OHA’s core features; an overview diagram is shown in Fig. 4.
Data storage
Shared and public/open datasets, namely curated datasets, will be supported economically by independent non-profit foundations, institutional repositories, and biobanks. Other datasets will reside in a community-based database supported by a decentralized infrastructure where individuals share resources such as storage and bandwidth for the benefit of the commons.
OHA moves the focus of attention from big data and features rich data. Rich data is constructed by aggregate inputs from different sources (or connectors) that create personal health information. Gathering data from different sources is possible via the integration of open standards, e.g., open mHealth standards [113]. Data sources include time-series, images, and other data formats that may require different repositories. These repositories will be kept in a hybrid infrastructure that combines local storage owned by the user and distributed storage shared or leased to the user. The sole use of traditional cloud storage service is discouraged to avoid single points of failure, expensive long-term storage costs and privacy threats often associated with central administrations.
These rich data repositories per individual give the possibility to design a monolith life-tracking log. The log will enable time travel visualizations through lifestyle patterns. Thus, the individual can monitor themselves their quality of life, and provided that they have the right instruments designed by experts in the field, visualize the correlations between different factors that may impact on their health.
Data management
OHA allows gradual openness to promote data sharing and open data. Users may opt to share partial information with formal (i.e., medical experts) and informal caregivers, specific community groups or with the whole society. Sharing can be done at any time (for example, information can be shared after the appearance of a disease), including automatically after subject death with previous consent. When records are inserted in open datasets, in the form of aggregated records, it is not technically feasible to delete them. However, those records do not contain information that can be associated with an individual. However, shared datasets should comply with state-of-the-art data protection requirements like GDPR.
OHA enables learning from patients with similar health concerns and learning from individuals with similar lifestyle patterns. It may be possible to conduct performance tests, e.g., 6-minute walk test, and compare results with previous personal measurements, community members or standard references.
To protect open data, OHA adopts a small number of possible licenses to donate content. End-users may opt among standards such Open Data Commons Public Domain Dedication and License (PDDL), Open Data Commons Attribution License (ODC-by), Public Domain Dedication (CCZero or CC0), or Community Data License Agreement (CDLA). Also, succession policies are put in place so that users state clear instructions regarding data deletion or posthumous data donation to family members and health research institutions. Decisions are modifiable at any time by the data subject. Succession process starts with a valid death certificate.
OHA collects data that (optionally) spans the whole life of a human (suggested 100-year data retention). Parents or guardians are named data administrators until the subject achieves legal adult age.
Data use
OHA is a computational stakeholder powered by algorithms developed by the community to help humans with the management and archival of personal health information. Non-experts are guided to gather more reliable and reusable data for investigations. Mechanisms to discover public data are put in place. Towards that goal, data stewardship follows good practices for scientific data management such the FAIR Guiding Principles, a recently published recommendation to “support knowledge discovery and innovation” [102]. FAIRness data means that data and metadata are findable, accessible, interoperable, and reusable. However, data is stored privately by default and sharing is not mandatory in OHA. Detailed analysis of FAIR data access in the cases of shared and open data is postponed for future work.
OHA repositories are a source to generate statistical knowledge using validated instruments such as WHOQOL-BREF 36 self-questionnaire. Users may participate in surveys to contribute to a large-scale statistical knowledge base and get feedback without fears of hidden data sharing policies. Optionally, this information is included in a pseudo-anonymous vector profile that is used by OHA’s knowledge discovery mechanisms to connect people with compatible needs, e.g. a patient with type II diabetes and a researcher studying the effects of depression on patients with diabetes type II.
Data access
Researchers who are granted total or partial access to private monolith logs will be able to conduct retrospective or prospective studies that take into consideration QoL dynamics and multidimensions. Participants may expect to receive economic incentives or other benefits from sharing data.
In addition, researchers will have access to a large-scale repository built with donated data. Then, multiple scientists can reproduce scientific findings based on the open repository. OHA will stimulate investigations based on the open repository to accelerate health innovation.
Discussion
Solutions are starting to emerge with alternatives to give people control over their personal data. Though personal data management still suffers from ambiguities or undefined policies. Who is the data owner [114]? Who is the data holder? On the contrary, answers to these two questions are evident in the domain of personal computers. Users can collect, explore, organize and share documents using the file system installed in their personal computers. They can decide whether the documents are stored locally or in the cloud. But file systems are not designed to receive input from the myriad of devices that generate TechO+ data. If personal computers empower individuals, systems or platforms designed to handle TechO+ data empower individuals too. We expect that next-generation systems will let consumers decide where TechO+ personal data should be stored. In the current status-quo, most app vendors store personal data in the cloud, usually in the US, with consequences in privacy, sovereignty and quality of service (latency) [115–117]. The same is true with IoT and smart devices, which could synchronize data directly with local computers, but instead send to cloud repositories and, only after that, the user may exercise the right to download data. The following questions remain: If users have full control of their personal data repositories, will they need to sign others consent policy terms? Instead, will users have the right to define their own consent policies when they share data? The initiative for democratizing data access via cooperatives can provide new models for informed consent policies where the individuals gain growing recognition of their rights [118].
Concluding remarks
Health and health-related data are being jeopardised by patient portals, mHealth apps and non-medical IoT devices that populate the market but with high probability disappear in a short time. Common pitfalls are lack of transparency and a shortage of simple procedures to move/share data into systems controlled by the data subject. Databases that are fragmented and hidden between walls hinder coordination among all healthcare actors and discourage individuals. The focus on big data ignores the fact that individuals are sources of rich data. Much of these rich data is lost. As a result, individuals may become less engaged in improving their health and well-being. To address these challenges, we propose to consider the individual-community-society spectrum and provide the requirements for OHA, a FLOSS platform that collects, explores and shares personal data to speed up research and innovation on quality of life.
Footnotes
Acknowledgements
We thank Bastian Greshake Tzovaras and Mad Price Ball from Open Humans Foundation for sharing valuable insights and expertise that improved this work although they may not agree with all the interpretations provided in this paper.