
Abstract
Since its introduction by Mark Weiser, ubiquitous computing has received increased interest in the dawn of technological advancement. Supported by wireless technology advancement, embedded systems, miniaturization, and the integration of various intelligent and communicative devise, context-aware ubiquitous applications actively and intelligently use rich contextual information to assist their users. However, their designs are subject to continuous changes imposed by external factors. Nowadays, software engineering, particularly in the fields of Model-Driven Engineering, displays a strong tendency towards developing applications for pervasive computing. This trend is also fueled by the rise of generative artificial intelligence, paving the way for a new generation of no-code development tools and models specifically trained on open-source code repositories to generate applications from their descriptions. The specificities of our approach lies in starting with a graphical model expressed using a domain-specific language (DSL) composed of symbols and formal notations. This allows for graphically instantiating and editing applications, guiding and assisting experts from various engineering fields in defining ubiquitous applications that are eventually transformed into peculiar models. We believe that creating intelligent models is the best way to promote software development efficiency. We have used and evaluated recurrent neural networks, leveraging the recurrence of processing the same contextual information collected within this model, and enabling iterative adaptation to future evolutions in ubiquitous systems. We propose a prototype instantiated by our meta-model which tracks the movements of individuals who were positive for COVID-19 and confirmed to be contagious. Different deep learning models and classical machine learning techniques are considered and compared for the task of detection/classification of COVID-19. Results obtained from all techniques were evaluated with confusion matrices, accuracy, precision, recall and F1-score. In summary, most of the results are very impressive. Our deep learning approach used a RNN architecture produced up to 92.1% accuracy.
With the recent development of OpenAI Codex, optimized for programming languages, we provided the same requirements to the Codex model and asked it to generate the source code for the COVID-19 application, comparing it with the application generated by our workshop.
Keywords
Introduction
The term ‘ubiquitous computing’ was first proposed in 1991 by Mark Weiser [117]. In his seminal article entitled ‘the computer for the 21st century’, Weiser’s vision describes environments filled with miniaturized and integrated computing devices embedded in everyday objects, coupled with wireless communication infrastructures. This coupling aims to enable communication and liaison between multiple mobile or fixed systems and deliver relevant services. Weiser’s vision has been proved to be exact, based on the observation; every person is surrounded by numerous computers and network devices. We have shifted from the era of central computers, which has characterized the mainframe era where many individuals shared a single computer, to the era of personal computers where individuals could have their own personal computers, and now to the stage where a large number of computers are embedded as one for a single person. Interactions transcend beyond the traditional human-to-human or human-to-machine framework to incorporate direct machine-to machine communications [66]. To support these intelligent interactions, computing devices host tools and software developed to leverage contextual information. New online networks and platforms of interactions are emerging, harnessing machine learning, such as ChatGPT, a conversational interface agent (chatbot) that is capable of engaging in conversations and generating natural language [33]. Hence, by 2023, future networks will emerge, forging connections with invisible life and nanoscopic nature [65,74] (Fig. 1).
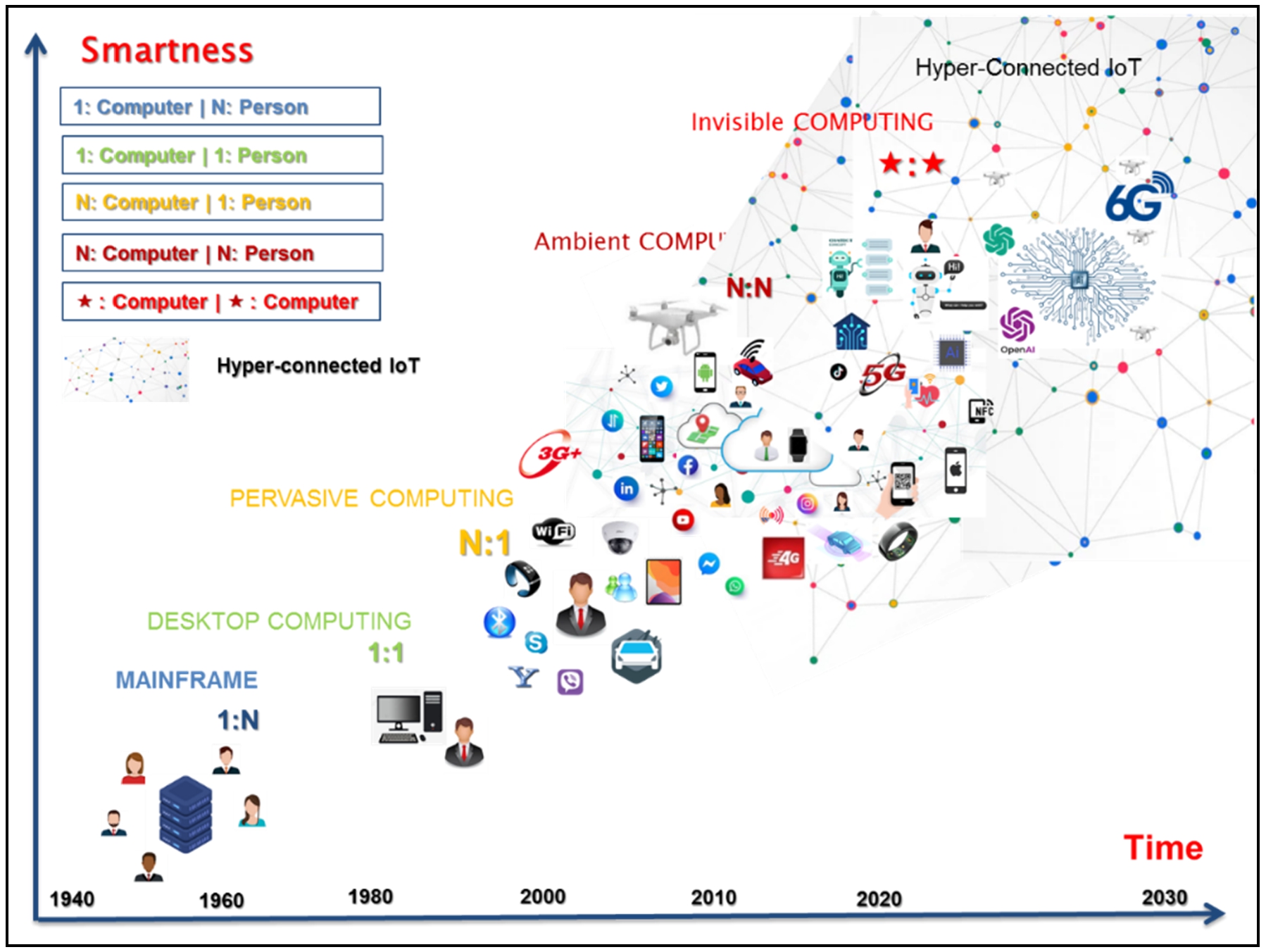
Evolution of smart ubiquitous computing (adapted from Fig. 1 in [66]).
By studying the vision of ubiquitous systems throughout various literature review works, we observed that several domains are increasingly leaning on adopting ubiquitous applications. These technology-dependent applications adopt a large number of sensors and devices to collect data about the user, their background and the environment, considering context as the target to offer personalized and relevant services [108]. The need to design ubiquitous applications has led to the emergence of context models in various disciplines. Development approaches based on generative engineering provide high-level meta-models to produce adaptive models that evolve with the supporting ubiquitous characteristics, as shown in Fig. 3. Generative artificial intelligence supports this approach. The ChatGPT project is based on the GPT-3 (Generative pre-trained transformer) language model [107]. It employs a concrete syntax that is capable of understanding and generating natural language, computer code, and UML diagrams using machine learning algorithms [37]. OpenAI has announced the launching of Open AI Codex, a descendant version of the GPT-3 meta-model, as depicted in Fig. 2. It is specifically trained on open-source code repositories to enable developers to quickly generate applications from their descriptions [33].
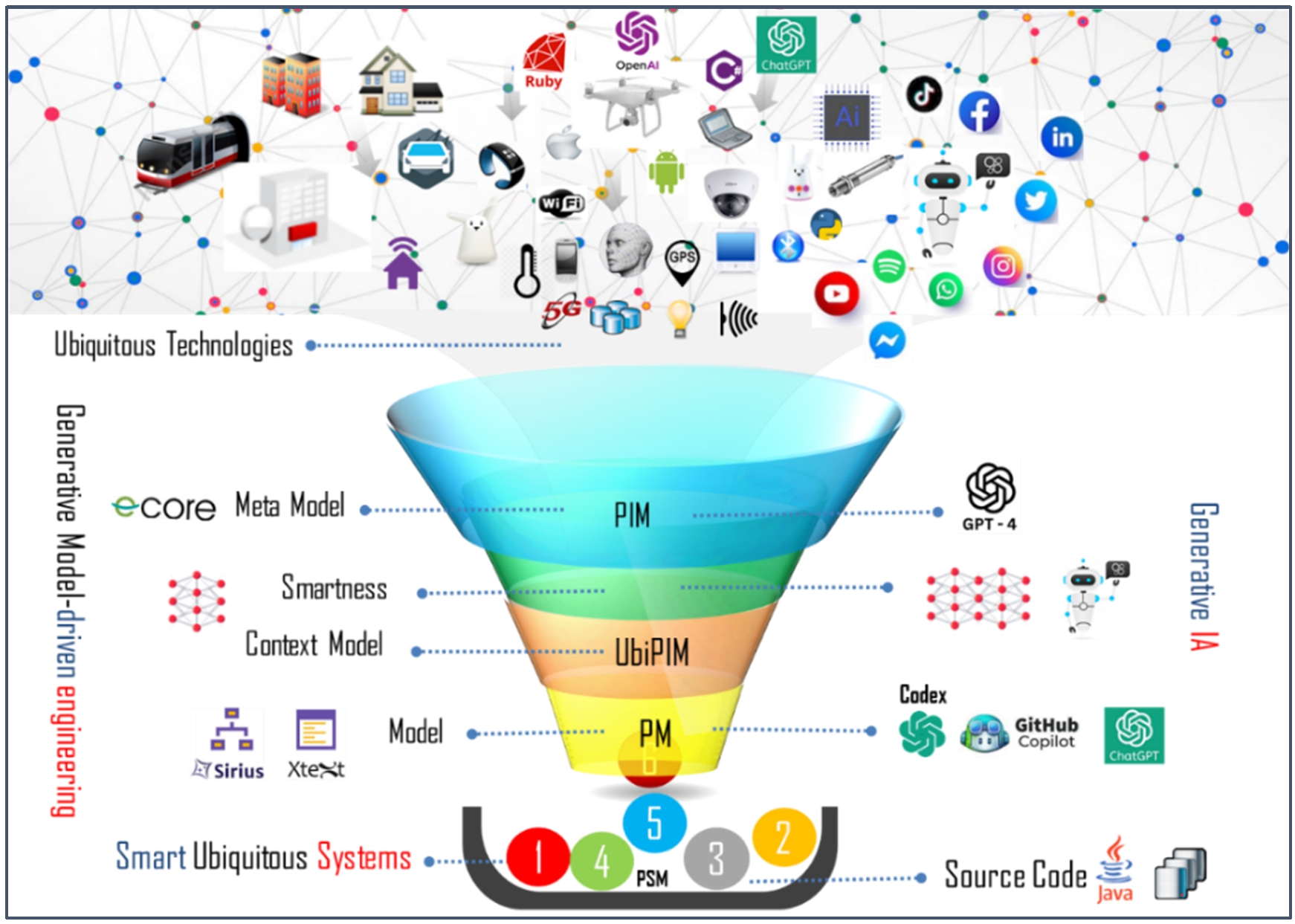
Generative model driven and generative AI for smart ubiqutous application (adapted from Fig. 2 in [109]).
The contribution of our work is revealed in how we use the MDE approach, targeting non-expert users who take the place of specialists. To achieve this end, we opted for an architectural approach that separates these concerns. Consequently, the development process is not compromised by the possible evolution of technological supports. Our approach offers a tool-supported process based on MDE that is combined with machine learning to promote development efficiency. We propose an abstract syntax and a concrete syntax expressed using a DSL that allows non-expert users to perceive the application in various forms and representations using icons. In [109], we initiated a research work that exclusively focus on artificial neural networks. Nevertheless, we targeted to explore the capabilities of a different type of neural network: recurrent neural networks. These networks seemed better quitted to effectively handle temporal sequences as they recurrently process the same collected information, taking into consideration past and future contextual information in their decisions.
We are interested in the field of the COVID-19 pandemic. First, we will leverage our graphical concrete syntax to generate an instance of the Meta-model using Acceleo. The generated code allows for the design of a mobile application (Android) that alerts people who have been in contact with an infected individual to anticipate COVID-19 risks.
Several performance evaluation indices including recall, precision, F-1 score, and accuracy were computed to evaluate and compare classification performance. As a result of the evaluations, our model, achieved 90.1% classification accuracy. The study results indicate that the proposed model CNN + SVM + Sobel filter is a fast and inexpensive method for assisting COVID-19 diagnosis, which can have potential to assist and helps the doctors and nurses to know the stage of the infection and thus shorten the time and give the appropriate dose of treatment for this stage.
Next, we use the textual graphical syntax (textual description) provided by the OpenAI Codex playground to provide it with information relevant to the requested prototype, such as contextual data and user preferences. Finally, we contrast the quality of the code generated by OpenAI Codex.
This article is organized as follows: Section 2 briefly introduces the evolution of programming languages, as well as the tools and meta-models that are used to generate code from models and Machine Learning, Deep learning for Ubiquitous Applications. Section 3 gives details about the AI generative and modeling, followed by a synthesis. Section 4 exhibits the architectural model of the suggested system and the graphical modelling workshop using the Eclipse Sirius means for the graphical representation of PIM models. Section 5 presents an instance of the proposed Meta-model that permits the anticipation of COVID-19, compared to the one generated by OpenAI Codex. We present a SWOT analysis. In Section 6, we conclude by assessing our contributions and presenting future prospects.
From programming-to-modeling-to-prompts
In recent years, we have witnessed a high rate of complexity in software environments. Computer applications are often composed of multiple tiers or require deployment in distributed, open and dynamic environments that undergo continuous and frequent contextual changes, which introduce a new dimension of impairment [112]. The increased number of users and the proliferation of devices are additional factors that contribute to make computer applications challenging to implement the traditional development cycles.
Generations of programming language are a way to classify programming languages based on their proximity to generated machine code and their ease of use by a programmer. A common trend in computer application development is to add more problem-solving capacities following a higher level of abstraction [63]. A new generation of no-code development tools is emerging. Leveraging machine learning enables the automation of applications’ creation based on its description. Simply submit the desired software description, and these tools will produce it. The Codex model derived from GPT 3.0 is part of the new generation of no-code development environments [113].
The early programming languages were closely associated with the computer’s hardware. As new programming languages have developed, some features were added within which allowed programmers to be less concerned with the computer’s expected complexity [20]. Moving from the level of abstraction to a lower one adds technical and technological details. We have classified programming languages into seven different generations based on their levels of abstraction, as depicted in Fig. 3.
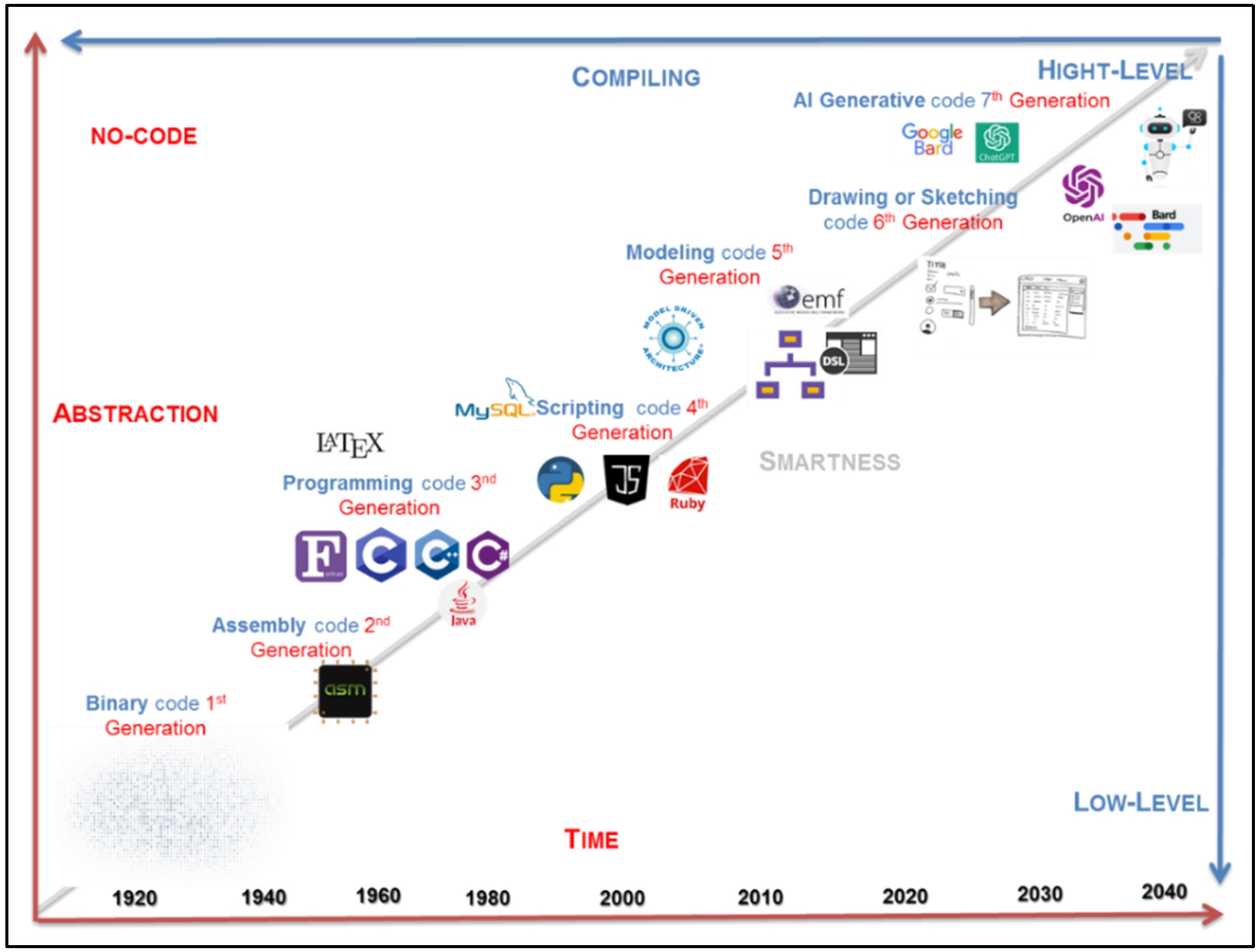
Evolution of programming languages according to their levels of abstraction and intelligence.
Modeling languages and tools
A modeling language can be graphical and textual. Graphical modeling languages use diagrams to represent concepts, while textual modelling languages typically use specific keywords to make expressions interpretable [36]. There are general-purpose modeling languages like UML, SysML [34], and domain-specific modeling languages (DSMLs) which are designed to meet the needs of a peculiar domain [78,79]. A number of modelling tools are available, as shown in Table 1.
Modeling languages and tools
Modeling languages and tools
The OMG has defined the MOF standard as a common language for meta-modeling, which is a common language to all modelling languages [79] Meta-modeling tools are developed environments for creating and modelling languages [51]. They enable the design of DSMLs and the generation of tools to instantiate these languages [96,108]. Examples include Plant UML, a visualization and modelling tool that provide a textual concrete syntax for creating UML diagrams [29]. Furthermore, the tools based on the EMF framework like Xtext and EMF Text can generate textual editors, while GEF, GMF, TOPCASED, or OBEO Designer can generate graphical editors [21,40]. The tools primarily used in the MDE community are described in Table 2 [92].
Meta-modeling languages and tools
Meta-modeling languages and tools
In the context of MDE, model transformation permits the generation of a myriad of artifacts, such as source code, from a single model. There are multiple families of languages and tools specifically designed for model transformation, which can be integrated into standard development environments [51,96]. We present some languages that are widely experimented in the MDE community. As shown in Table 3 [92]. In this category, we find the following tools [57].
Languages and tools dedicated to model transformations
Languages and tools dedicated to model transformations
The history of OpenAI in artificial intelligence
ChatGPT is a next-generation conversational agent that utilizes artificial intelligence and deep learning [82]. This tool was created by OpenAI, a pioneering company in machine learning, not only for text generation with ChatGPT but also for image generation with Dall-E [94]. OpenAI was founded in 2015 by a group of AI experts, including Elon Musk [95]. The company’s objective is to develop AI technologies and make them accessible to all. While ChatGPT is now the flagship product of OpenAI, the American company also offers a range of AI products and services to help businesses improve their productivity [53]. Among the most popular tools are [71]:
Assistance in programming with ChatGPT
Programming is just a means to solve a problem. In this sense, the programmer’s task is to solve a problem using a tool consisting of a computer (hardware) and software (compiler, AI, No Code, Excel, etc.) [109]. In recent years, there has been a strong emergence of generative Artificial Intelligence (AI) that can produce images, text, and even computer code to assist programmers. Can AI truly replace a programmer? These tools are good for assisting programmers, but as they currently stand, they cannot build an application from A to Z without human intervention. It is important to understand that AI is just one tool among many [108]. Under these circumstances, it can be assumed that the programming profession will undergo profound changes in the years to come.
Tools like ChatGPT and Codex launched in June and December 2022 respectively, can prove to be useful in the field of computer programming [113]. OpenAI has developed the Codex model, which possesses a significant understanding of natural language from GPT-3 and has been specifically trained to generate functional code [89]. Codex is now at the core of the programming assistance solution, Copilot, on GitHub. On the other hand, ChatGPT can provide detailed functional specifications for an application based on a natural language input expressing the requirements.
By combining these two technologies, one could potentially achieve a fully development-oriented conversational AI for no-code development. In this new paradigm, developers can focus on truly innovative functionalities and optimize their working time to become more efficient in their programming tasks [69].
AI generative language models and meta-modeling tooling
Several AI generative models have emerged in recent months, including ‘conversational’ models such as chatbots or virtual platforms that respond to different queries formulated by a human agent in a natural language [71]. ChatGPT is a virtual/ online platform that uses the GPT language model for conversational AI applications, pre-trained on large amounts of textual data [37].
Codex, another model developed by OpenAI, is specifically designed for developers. It has been trained on data extracted from GitHub, Microsoft’s code repository. Codex is also the AI behind GitHub Copilot, a tool created by Microsoft for developers. It offers propositions during programming and can directly translate software specifications into lines of code [111]. CodeT5 is an open-source programming language model based on Google’s T5 (Text-to-Text Transfer Transformer) framework. To train Code T5, the team extracted over 8.35 million code instances, including user comments, from publicly accessible GitHub repositories. DALL-E is a deep learning model that generates images from textual instructions that are labelled ‘prompts’ [111]. Meta, Facebook’s company, recently announced the launching of a novel AI model called LLaMA (Large Language Model Meta AI). It enables computers to understand natural language and generate text. The following AI tools are systematically summarized in Table 4 [73].
Languages models and méta-modélisation tooling
Languages models and méta-modélisation tooling
Machine Learning is a branch of artificial intelligence that concentrates on studying how machines can learn to recognize patterns from a database or sensors for intelligent decision-making [71]. The data can be labelled or unlabeled, depending on the desired learning type. Machine learning techniques and their applications continue to progress, especially with the emergence of new technologies such as ubiquitous computing and Internet of Things (IoT) network [35,61]. The dynamic nature of these constantly evolving systems has paved the way for researchers in the field to develop algorithms that can automatically detect patterns in collected data, enabling them to make decisions in new situations. There are different types of algorithms to use, depending on the task at hand, the available data (large or small), and the problem addressed (recognition, classification, and so forth.).
Supervised learning
It involves learning from a set of pre-labelled examples provided by an expert [4]. Once the model has completed the learning process, it can be tested on a set of data where predictions could be made (Fig. 4). This learning approach is used for prediction, diagnosis, or classification tasks [83]. The ChatGPT project is trained on a dataset and cannot provide answers with regard to what will happen in the future or news of similar type. Here are some algorithms implemented in this work.
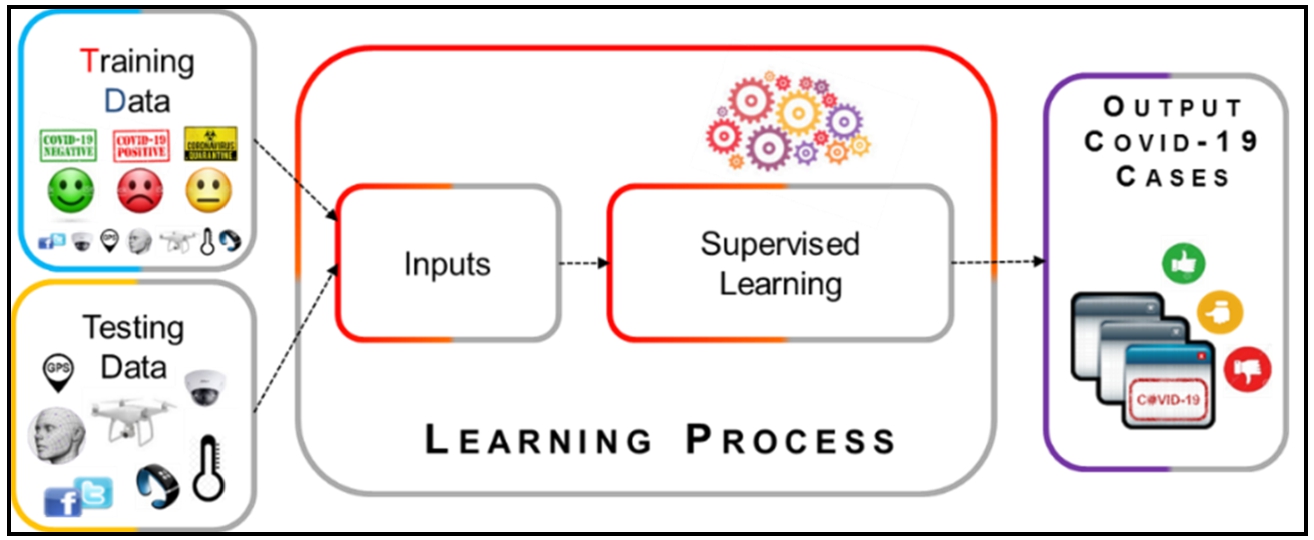
Supervised learning approach [109].
Neutral networks They consist of inter-connected nodes called neurons, capable of processing and transmitting information from one node to another. Within these networks, there are fully connected hidden layers, each associated with a set of weights corresponding to the input’s variables. Neural network learning includes adjusting the synaptic weights so that the network’s response matches the desired output. The output of a neural network is an estimation of the posterior probabilities of belonging to different classes
K-nearest neighbors This method does not induce a model from the examples. Its principle is based on the assumption that objects closest to each other are more likely to belong to the same category. To predict the class of a new case, the algorithm searches for the K nearest neighbors based on the weighted Euclidean distance
This type of learning is used when the training data is not labelled in advance [4]. It aims to identify groups of similar objects or individuals (clusters) from a set of unlabeled input datasets (Fig. 5). Here are some algorithms implemented in this work.
Unsupervised learning approach.
Clustering It classifies different elements into groups based on their similarity to each other. A cluster represents objects that shares common features. Among the commonly used methods: K-Means: it provides the minimum distance between similar data points and the maximum difference between clusters [56]. It is used to determine that suggestions can be made to a user based on the preference of other similar users.
Its aim is to learn behavior in a given environment to achieve a specific objective. Training data is directly collected from the environment. The system adjusts its parameters based on the feedback received from the environment, which then provides feedback on the decisions made (Fig. 6). In addition to pre-training, the ChatGPT project continues to self-train through interactions with users. This allows it to memorize context and remember messages from a conversation. The main method used in Reinforcement Learning.
Reinforcement learning approach.
Hidden Markov models There are dynamic Bayesian networks based on a statistical Markov model (a probabilistic model that defines future states based on the current state).
It is a type of learning that uses both labeled and unlabeled data for training [4] (Fig. 7). Labeled observations are used for learning, while unlabeled observations are used to refine class separation and find optimal boundaries that optimize data categorization [35].
Semi-supervised learning.
Deep Learning (DL) is a branch of artificial intelligence that uses artificial neural networks designed to handle large amounts of data by adding layers to the network [4]. In DL, neural networks typically consist of millions of parameters, allowing them to capture complex relationships between inputs and outputs [9] (Fig. 8). In deep learning, the algorithm does not require structured data. It can identify features on its own without the intervention of a developer [88]. DL algorithms often outperform traditional machine learning methods, especially when dealing with nonlinear and complex data. The model used is as follows:
Deep learning.
They have connections between neurons that allow information to flow via the layers of neurons multiple times. These feedback loops enable the system to build a memory to predict sequences of data in the near future [9]. This makes them suitable for processing temporal sequences such as language, videos, numerical data, and images [88]. Like most large language models (LLMs) [72], GPT-3/3.5/4 is based on transformer architecture [111]. Similar to recurrent neural networks (RNNs), transformers are artificial neural networks designed to process sequential data [77]. This model can parallelize computations during the learning phase, allowing it to handle massive volumes of training data in reduced time. The strength of recurrent neural networks lies in their ability to consider contextual information through the recurrence of processing the same information. This self-sustaining dynamic can be exploited to identify disease symptoms through voice and cough, X-ray images, SpO2 (oxygen saturation) measurements, etc.
Related works
Model Development engineering is a form of generative engineering in which all or part of a computer application is generated from models. In this section, we focused on representative examples of IDM processes that are related to various application domains. For example, several processes are dedicated to context quality [7,24,48], interactions, adaptation, and automatic generation of Human-Machine Interfaces (HMIs) [15,18,27,98], on Service-Oriented Architecture (SOA) architectures [2,85,114,118], on the development of secure applications [101], on data quality management [10,60,96], on pervasive middleware development [22,23,32,38,42,49,52,76,80,102,106,110,115], on context-aware systems [6,13,17,41,43,59,93,104], on service-based context-aware systems [26,30,41,68,81,93,97,100,104,116], on targeted domains [3,44,46,50,62,87,91,99], on Pervasive Systems [39,67], and on Self-Aware Pervasive Systems.
Recent years have seen the rise of generative Artificial Intelligence (AI) models that can produce images, text, and even computer code to assist programmers. In the context of creating software, there are AI models that generate computer code.
OpenAI Codex: It is a deep learning model which is able to translate natural language into computer code. It is a descendant of the GPT-3 model and has been trained on natural language and billions of lines of public code from GitHub. The initial version of the tool supports several programming languages such as JavaScript, PHP, Python, Ruby, Go, Perl, Swift, and TypeScript. OpenAI also offers specific Codex models for code understanding and generation [19].
GPT-3, GPT-3.5, and GPT-4: GPT-3 is a complex learning model with 175 billion parameters and criteria, making it significantly larger than its predecessor, GPT-2. GPT-3 belongs to the LLM family, a new type of AI algorithm that is trained to predict the possibilities of a given word sequence based on the context of preceding words. GPT-3.5 and GPT-4 differ from the GPT-3 version in terms of power and their ability to handle different types of data. GPT-4 may have better capabilities in handling multi-modal tasks (images + text) and uses reinforcement learning to improve performance on complex tasks. However, larger-scale models generally require more computing resources, storage space, and relatively high energy consumption.
GitHub Copilot is the result of a partnership between GitHub, the development platform, and the company OpenAI [107,111]. Copilot is powered by the artificial intelligence model: OpenAI Codex. It uses open-source code lines to train an artificial intelligence and provide code suggestions to developers for designing other applications. Copilot works with a wide range of frameworks and languages, including Python, JavaScript, TypeScript, Ruby, Java, and Go. The tool also introduces a new paradigm that is labelled Fill-In-the-Middle (FIM), which provides developers with better hints for code suggestions.
The production of ubiquitous applications is a complex task for which model-driven engineering brings essential mechanisms and tools. On the other hand, generative AI has given rise to a new generation of “no-code” developing environments. Leveraging machine learning, these environments enable the translation of natural language into computer code. To characterize and compare the works related to our proposal, we use a number of criteria [108]. Some criteria are inspired by the reviewed works, while others are identified based on the requirements of our problem, Table 5.
Synthesis of ubiquitous application development approaches
Synthesis of ubiquitous application development approaches
In order to characterize and compare the works related to our proposal, we use a set of criteria [108]. Some are inspired by the reviewed works and others were identified based on the requirements of our problem, Table 5:
[1] introduced a labeled corpus of 430K of Arabic Q&A into 20 different categories. Also, the study applied three deep learning techniques to the proposed dataset. Mainly, the study experimented with the performance of the dataset on LSTM, Bi-LSTM, and Transformers. Researchers [55] reviewed the state-of-the-art BERT and deep CNN models for sentiment analysis of COVID-19 tweets. They recommend to use BERT models. the performance of several literature studies on sentiment analysis of COVID-19 tweets using BERT or CNN-based models are presented. Researchers [8] investigated the competency of deep uncertainty quantification techniques for the task of COVID-19 detection from CXR images. A novel confusion matrix and multiple performance metrics for the evaluation of predictive uncertainty estimates are introduced. Researchers [5] proposed a semi-supervised approach for COVID-19 diagnosis using limited amount of labeled data. They utilized GAN to learn (unsupervised training) key features of CT images of COVID-19 patients [105]. They utilized the probabilistic output of the discriminator as some sort of uncertainty measure to reject classification of samples that the discriminator is uncertain about. Researchers [54] presented four classification methods (Decision Tree (DT), Random Forest (RF), standard Neural Net (NN), and Deep Neural Network (DNN)) combined with Global Feature Extractor (GFE) based on CT scan images for automatic COVID-19 diagnosis for the classification of infected and healthy patients. In [11], the aim is to predict confirmed and deaths cases recorded in Iran and Australia by. This study applied six models: LSTM, GRU, and Convolutional LSTM with their bidirectional extension. In [70], an amalgamation of convolutional neural network and auto encoders has been implemented to predict the survival chance of the infected cases. Researchers [103] combined ML, DL, and Sobel filtering for COVID-19 detection from X-ray images was proposed. They reviewed 25 existing approaches on COVID-19 detection from X-ray and CT images with DL models and proposed the scopes of their work.
Covid-19 approaches
Ubiquitous applications that are sensitive to their environments leverage the richness of contextual information to actively and intelligently assist users [84]. We demonstrate how MDE techniques, along with the definition of a meta-model and a graphical DSL, can provide users with personalized views and tools to modify or build applications. Specifically, the result of our work is a graphical editor called 3ML4UA (
The reference architectural model.
The Context Meta-Model, which involves creating a platform-independent model (PIM) that is independent of all execution platforms. This is based on an abstract grammar using the EMF tool. The proposed abstract syntax is supplemented by a concrete syntax: the development of a graphical modeling workshop using the Eclipse Sirius tool for the graphical representation of PIM models.
Defining OCL (Object Constraint Language) constraints to capture constraints on the models that cannot be captured by the meta-models.
Code generation, defining a model-to-text transformation (M2T) with Acceleo. The generated code is used for designing Android applications. The Android project can be generated within the same Eclipse instance of the modeling environment. Therefore, the designer/developer does not need to change the environment to test the generated application.
Generating Java code using natural language instructions for mobile applications using OpenAI Codex.
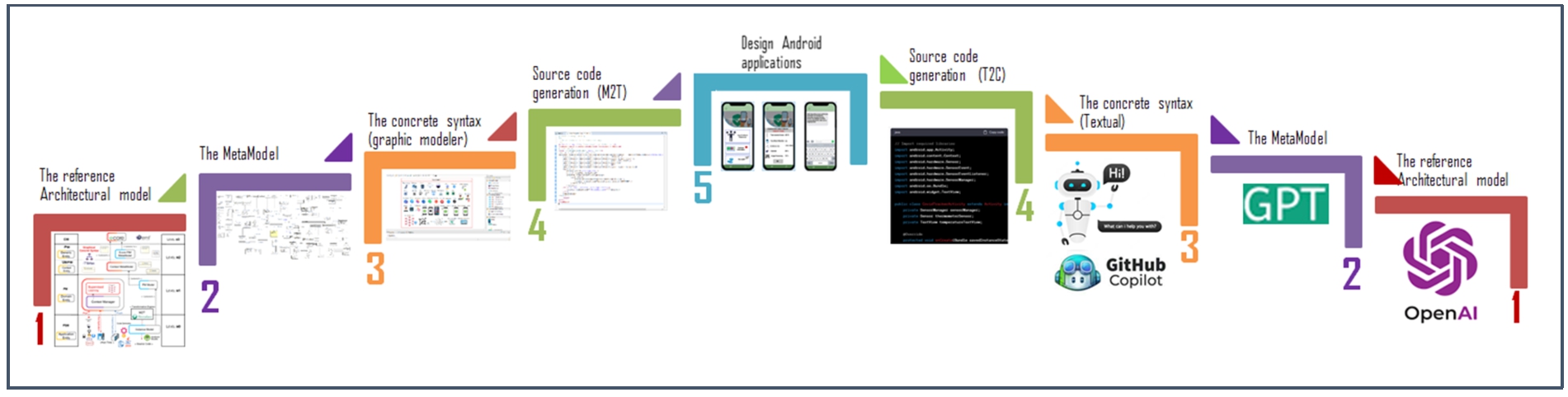
The main diagram that represent each step.
In addition to the technical separation offered by the MDA standard, our approach explicitly separates the business (functional) part from the ubiquitous (contextual) part from the conceptual modeling phase (PIM: Platform Independent Model and UbiPIM: Ubiquitous Platform Independent Model). These choices motivated the creation of a ubiquitous development level independent of technical and functional requirements. Any type of concern (business, technical, or contextual) is expressed using a specific level (respectively: PIM, UbiPIM, PM, and PSM) [108].
We wanted our framework to be based on standards in this field and a toolchain capable of describing our meta-model and automatically generating code from it. This toolchain mainly consists of tools that run in an Eclipse Integrated Development Environment (IDE): EMF, Sirius, Xtext, and Acceleo [90]. When combined, they form Fig. 10, which presents the technical architecture of our workshop and how the different tools are interconnected [36].
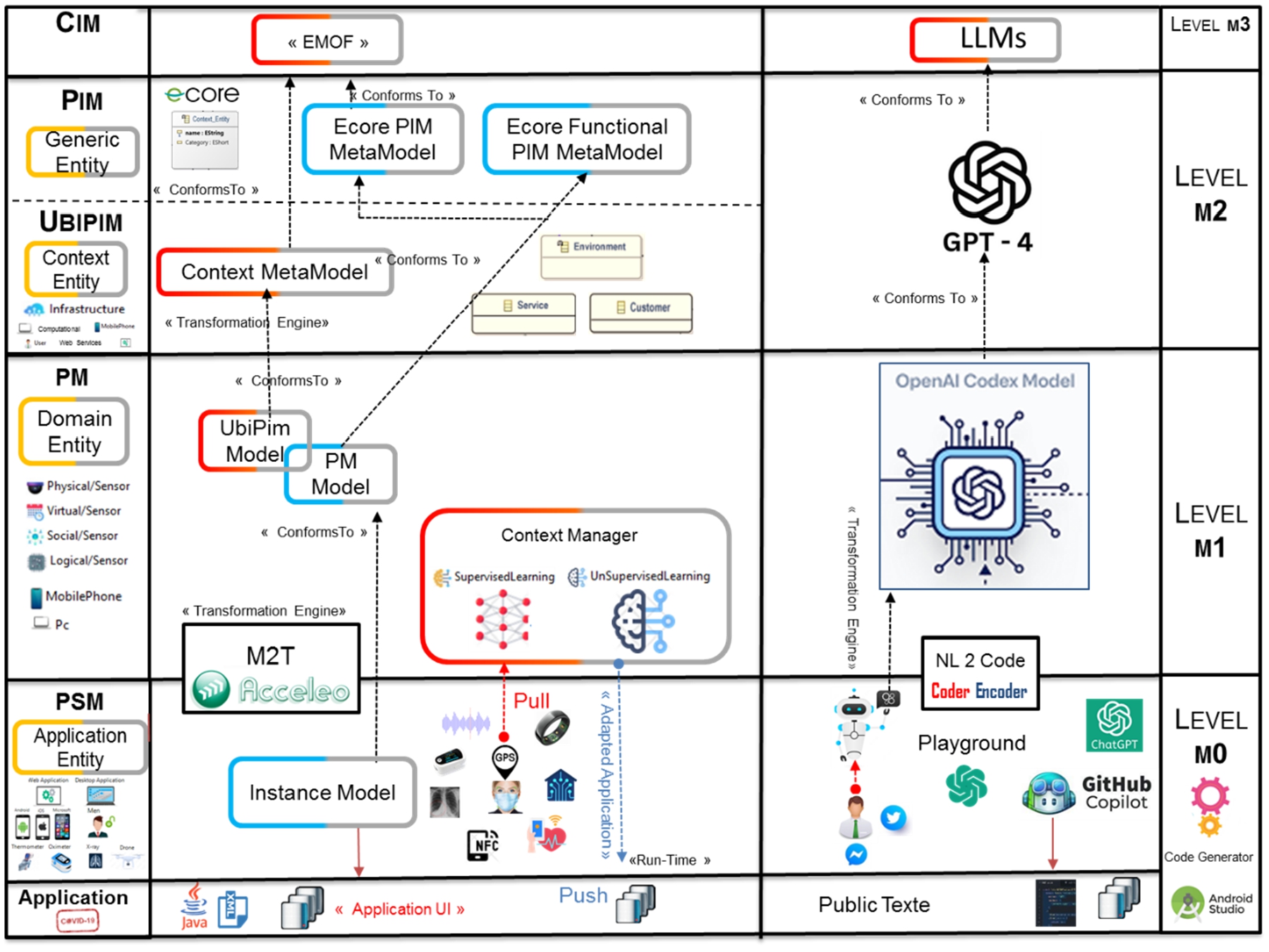
Architecture of our approach (adapted from Fig. 6 in [109]).
Building ubiquitous applications requires accurate modeling of all context information to store it in a repository for future utilization. Existing literature works either provide an abstract level of abstraction that doesn’t encompass all contextual entities or focus on specific application types (e.g., home automation, tourism).
Abstract syntax specification
The abstract syntax is typically the initial step in meta-modeling, serving as the basis for defining concrete syntax and semantics. It specifies the concepts and relationships required to model a domain [34]. For this research work, we choose to use EMF (Eclipse Modeling Framework) to define a meta-model expressed in Ecore [69]. Ecore is a high-level graphical language that is used to create meta-models compliant with the EMOF (Essential Meta-Object Facility) standard. It uses UML’s graphical syntax, which is relatively well-known and intuitive [47]. Our intention is to make these models intelligent by combining machine learning with EMF. The Meta-model is extended with machine learning concepts during the modeling phase. The proposed abstract syntax consists of several entities, and we will present the new classes added to our Meta-model defined in [108].
Management and adaptation actions primarily rely on conditional structures. To account for the uncertainty of ubiquitous environments, we decided to introduce techniques which are based on machine learning and deep learning (Fig. 11).
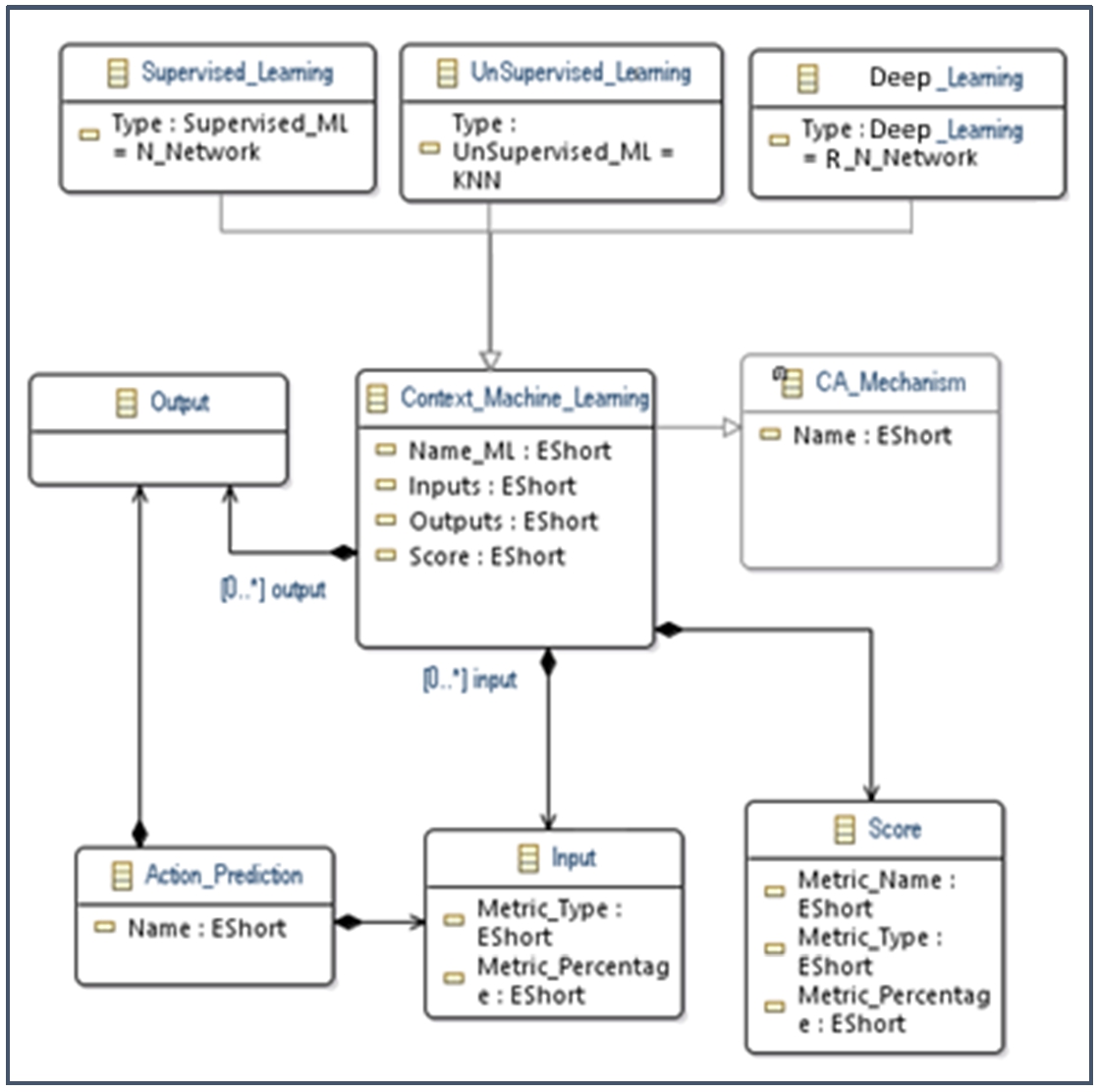
MetaModel machine learning.

The use of Java services: RNN (deep learning).
Our Meta-model can also be extended to incorporate aspects of confidentiality and privacy regarding the context source entity. Collecting contextual data about an individual (e.g., their location) should be done with the person’s agreement and in accordance with their preferences and needs.
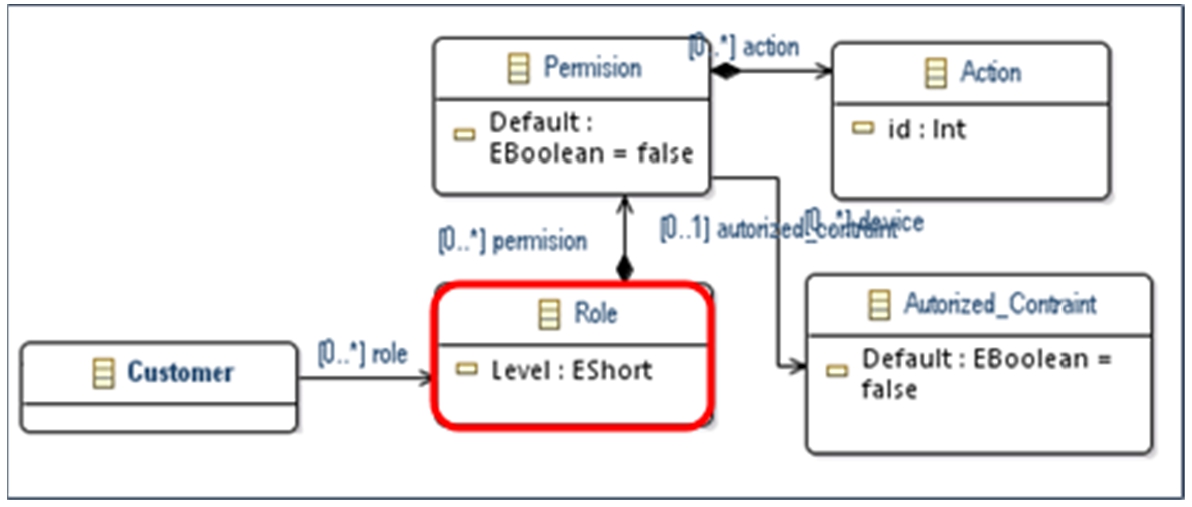
MetaModel of security.
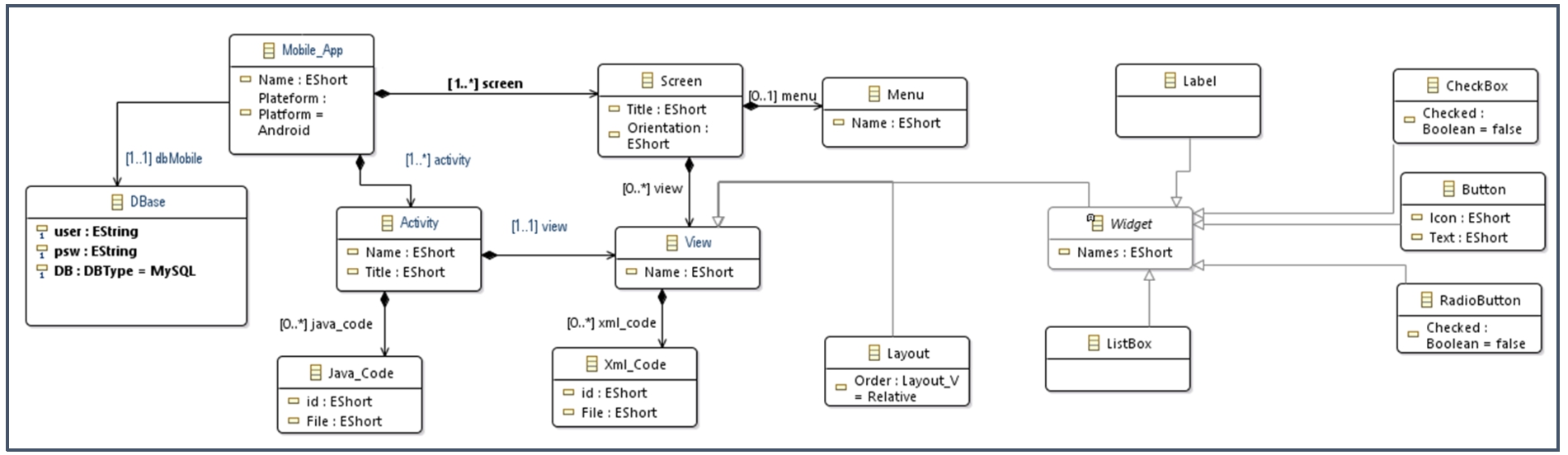
MetaModel for mobile application.
The concrete syntax (CS) of a language allows the user to formally express and manipulate the concepts of the abstract syntax. Each concept of the abstract syntax is represented by a graphical symbol that associates the elements of the abstract syntax with their graphical notations. We will define a graphical concrete syntax using the Sirius tooling, which can be adapted to ubiquitous and domain-specific needs.
Eclipse Sirius:
Sirius is an open-source tool developed by
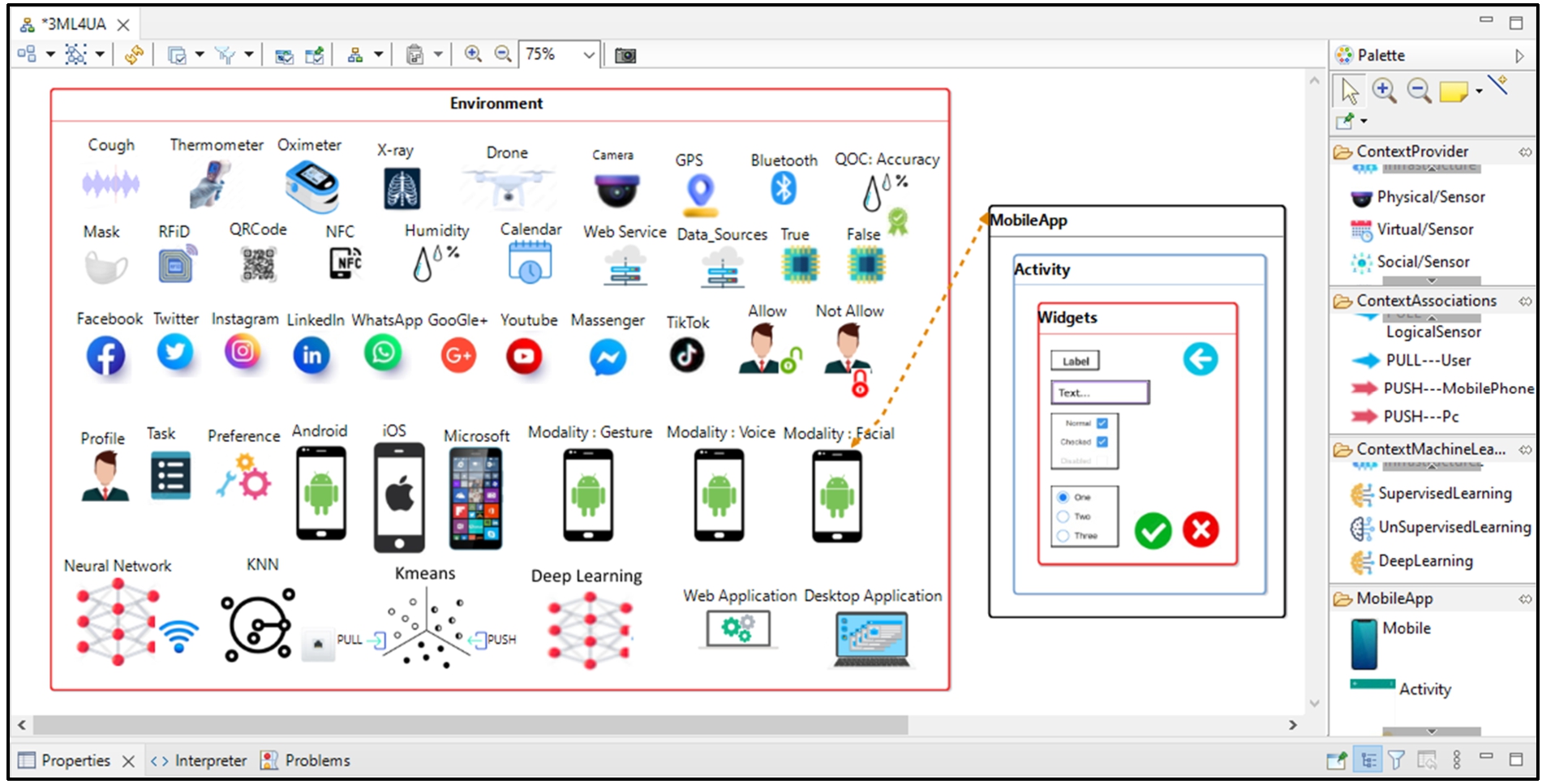
Main interface of the modeler based icon representation (adapted from Fig. 9 in [109]).
.
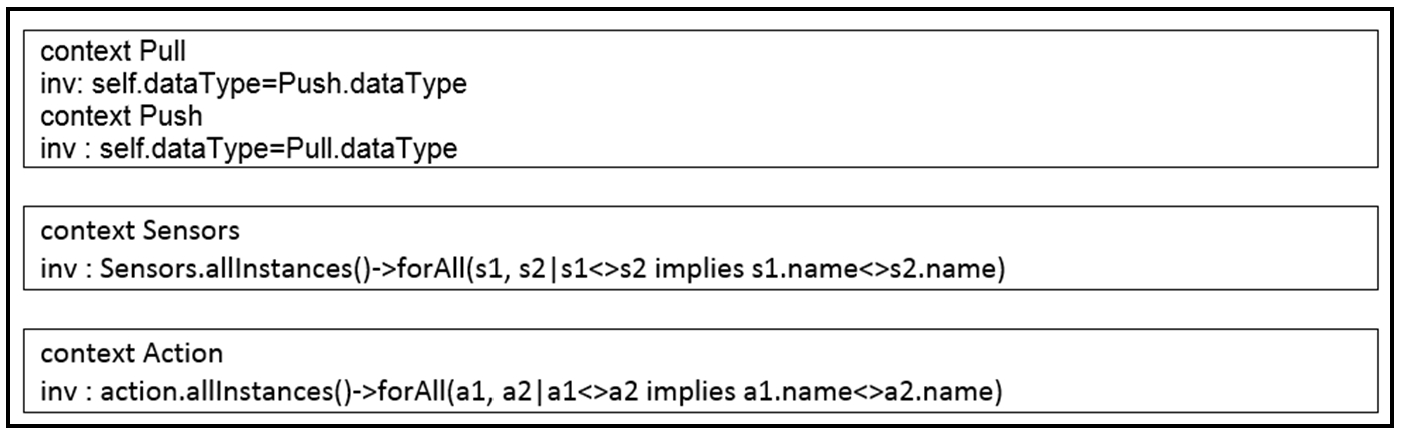
We used the Ecore meta-modeling language to define our meta-model. However, it does not allow expressing all the constraints that models must adhere to and does not avoid certain ambiguities. To address this, we used OCL (Object Constraint Language) to define dozens of validation rules to ensure the compatibility of models created with the meta-model. Among the defined OCL rules for validation, the following are mentioned [109] (Fig. 16).
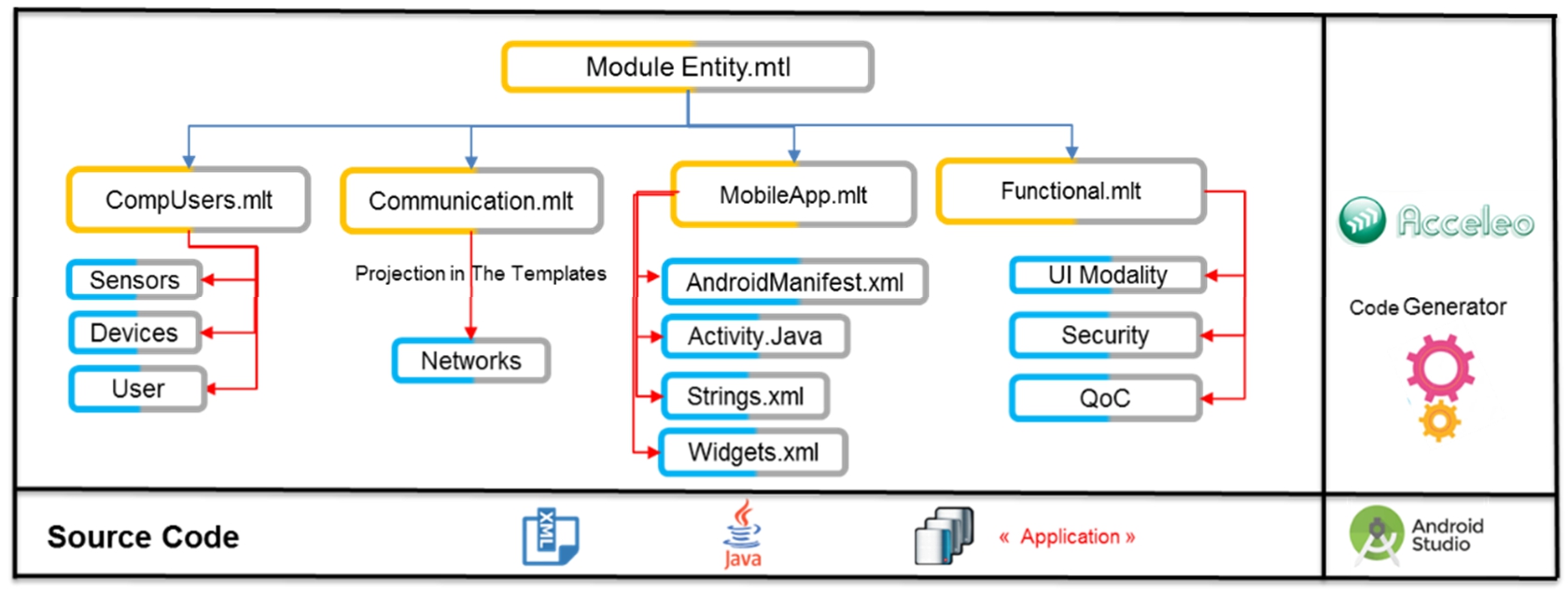
We count mainly on Acceleo to achieve automatic generation from high-level modeling. The general principle of Acceleo is to adopt a generation template based on a starting model to obtain code that can be executed on an Android device. We decided to initially develop for Android as it is the most widely used mobile operating system. The generated folder structure for Android follows the project design model in Android Studio in the form of a hierarchy. Figure 17 illustrates the main model of transformation rules that are performed based on templates residing in “.mtl” files, which are used by Acceleo to generate the application’s structure.
Different stages of generating an Android application.
After creating the Acceleo project and selecting the source meta-model (named 3ML4UA – Meta Model Machine Learning for Ubiquitous Application), we will create the main code generator module, “EntityGenerator.mtl,” for the Android application. It will invoke other modules (MobileApp, CompUser, Communication, NonFunctional) and templates to generate code in an Android Studio project imported into Eclipse and intended to be executed on an Android device. Figure 18 illustrates the main module of the code generator [109].
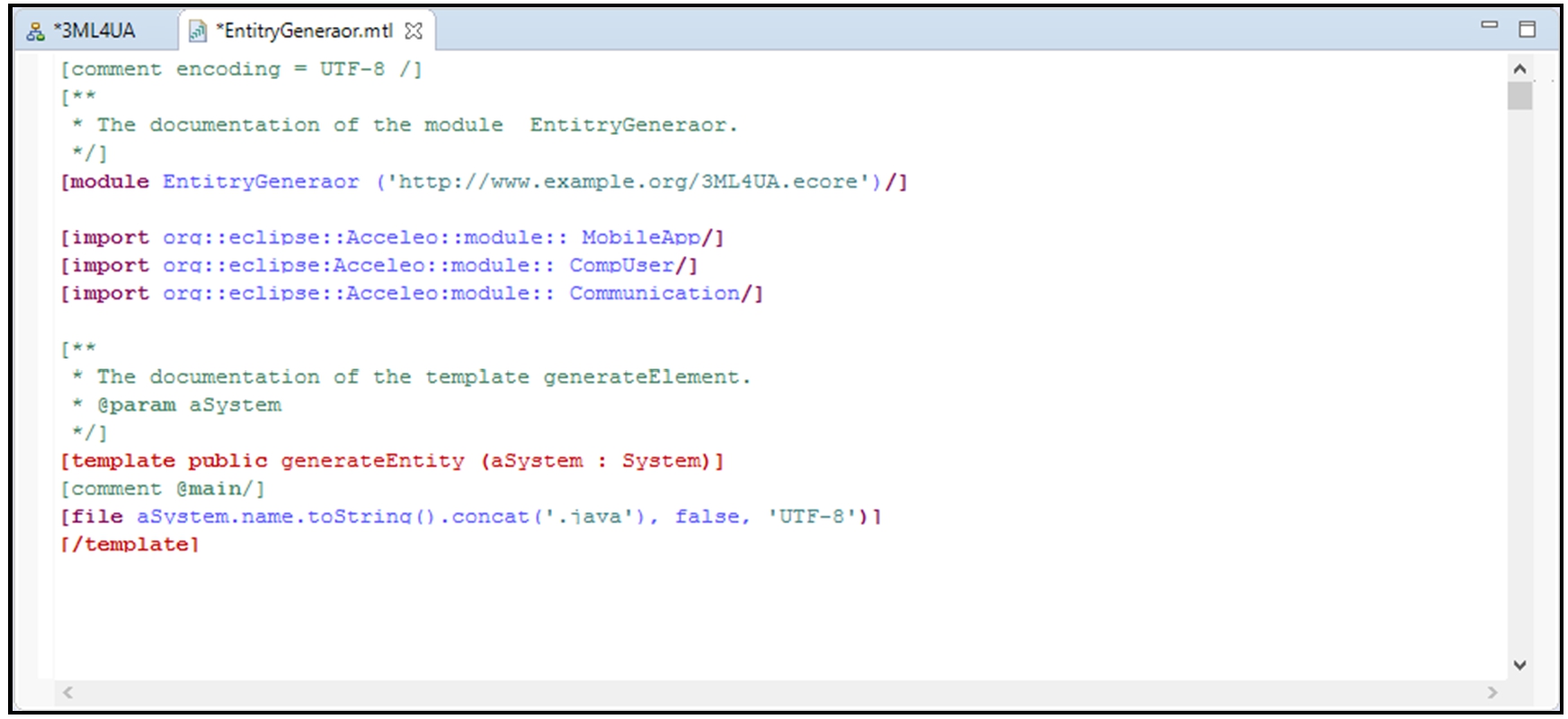
The main module of the code generator
This section describes the current capabilities of ChatGPT to perform programming tasks. Steps are described in Fig. 19.
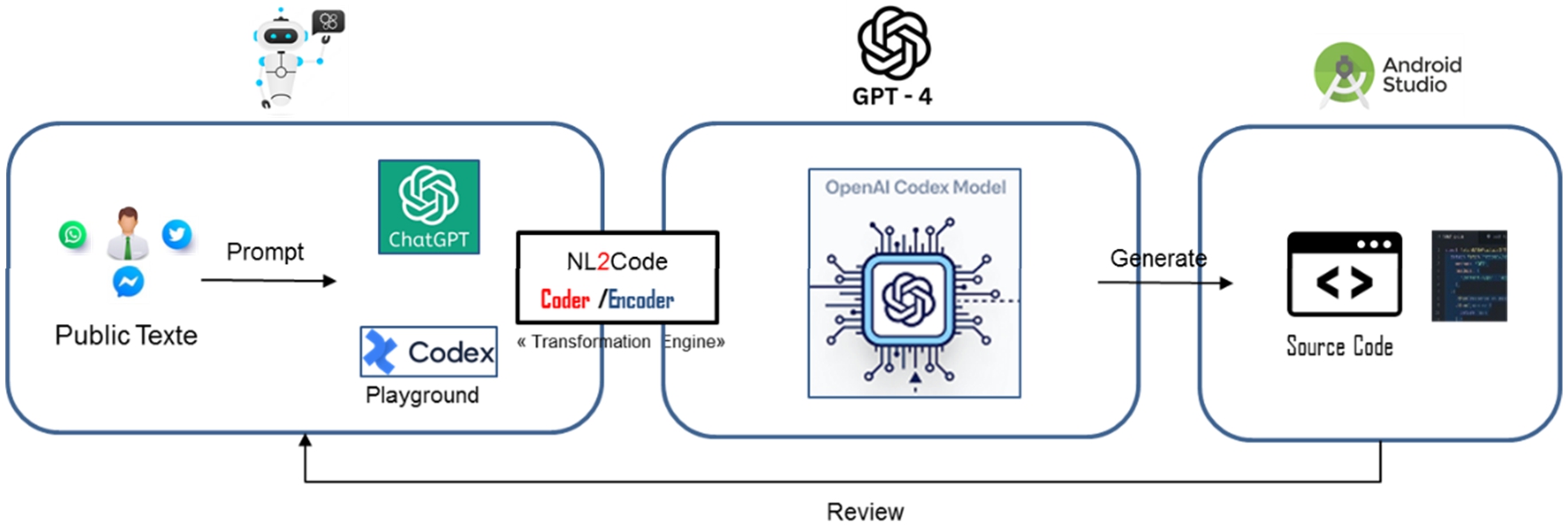
Process used for generate source code from OpenAI codex via the playground and ChatGPT-3.5.
Presentation of the case study
Our work consists of generating a simulable model based on the concepts of model-driven engineering. To illustrate our approach, we will take an example of a current application that could limit the spread of the virus by identifying transmission chains. The idea is to notify individuals who have symptoms of COVID-19 or have been in contact with a confirmed positive case, so they can test themselves and, if necessary, receive quick treatment or self-isolate. The use of data and IoT to monitor the population is not new, but the phenomenon has significantly accelerated with the health crisis (Fig. 20).
Development process.
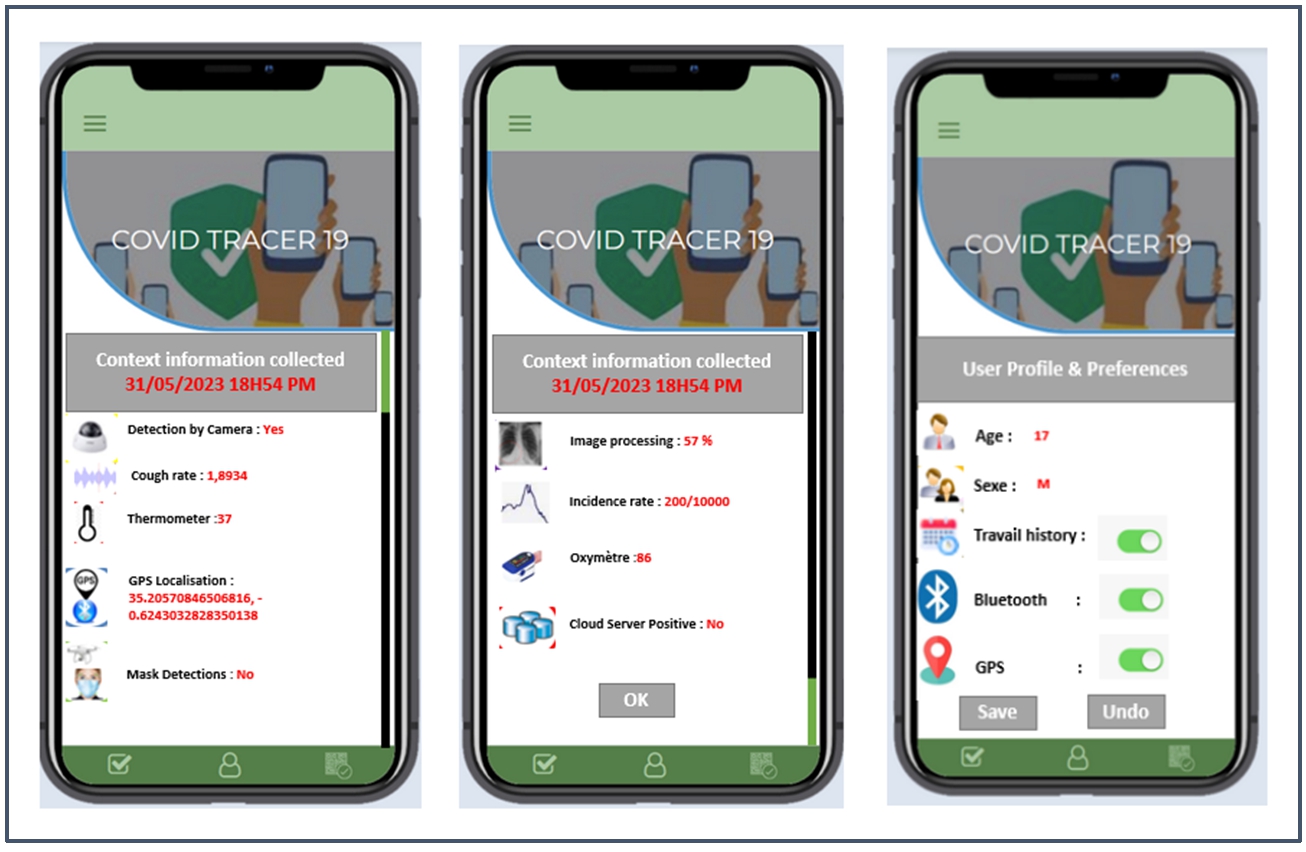
In order to curb the COVID-19 epidemic, the application will notify users whether they have been in the same location or in close contact with a person who has tested positive for COVID-19. The data can be stored either on a server or on the user’s device.
We have chosen to leverage geo-location made possible by GPS integrated into smartphones. The application will use GPS data to collect personal data and trace the history of all movements in public spaces (office buildings, shopping malls, residential complexes, subway, etc.) over a given period, and cross-reference them with the movements of users who were positive for the coronavirus infection.
To determine the health status, information is collected through various sensors such as dry cough, X-ray, oxygen saturation level, mask usage, recent movements, and comments on social networks. Thermal cameras can be used to detect abnormal body temperature. Furthermore, temperature measurement can be carried out by drones equipped with thermal cameras.
We have also taken advantage of
Via an SMS or push notification,
To stay at home and self-isolate,
To be tested, and
To track the movements of infected individuals.
To ensure compliance with confinement measures, the application locates and monitors the movements of individuals who are required to observe a 14-day quarantine period. It utilizes technologies such as geo-location and facial recognition. Users placed under quarantine are required to take a selfie at any given moment during the day while they are at home. These photos are geo-located and preserved in databases. The application could detect individuals in quarantine by analyzing the selfies taken via surveillance cameras which are in return connected to a facial recognition system.
The use of data and IoT to monitor the population is not a new concept, but it has significantly accelerated with the COVID-19 health crisis. The architecture of the application is mainly based on continuous and real-time monitoring of potentially COVID-19-infected patients. The current study utilizes a sensor network to collect user’s personal information and infection symptoms.
The proposed model employs machine learning techniques to diagnose COVID-19 by analyzing the symptoms collected by various sensors. The recorded data is separated into training and testing sets. The trained model is tested using other datasets validated by experts. The results from the predictive model are communicated to medical professionals to obtain an accurate prescription. Based on the results, the expert suggests whether the patient should be tested, hospitalized, be provided with a prescribed medication, or to be isolated. The results are also useful for individuals with negative prediction results. The expert can recommend them to follow secure measures such as practicing social distancing, wearing masks, and using hand sanitizers.
To model the Trace COVID-19 case study, the Sirius tool was used. An initial version of our modeler has been implemented, which relies on the Eclipse Modeling Framework, EcoreTools, Sirius, and Acceleo. It provides a multi-view representation of a ubiquitous application, as shown in Fig. 21.
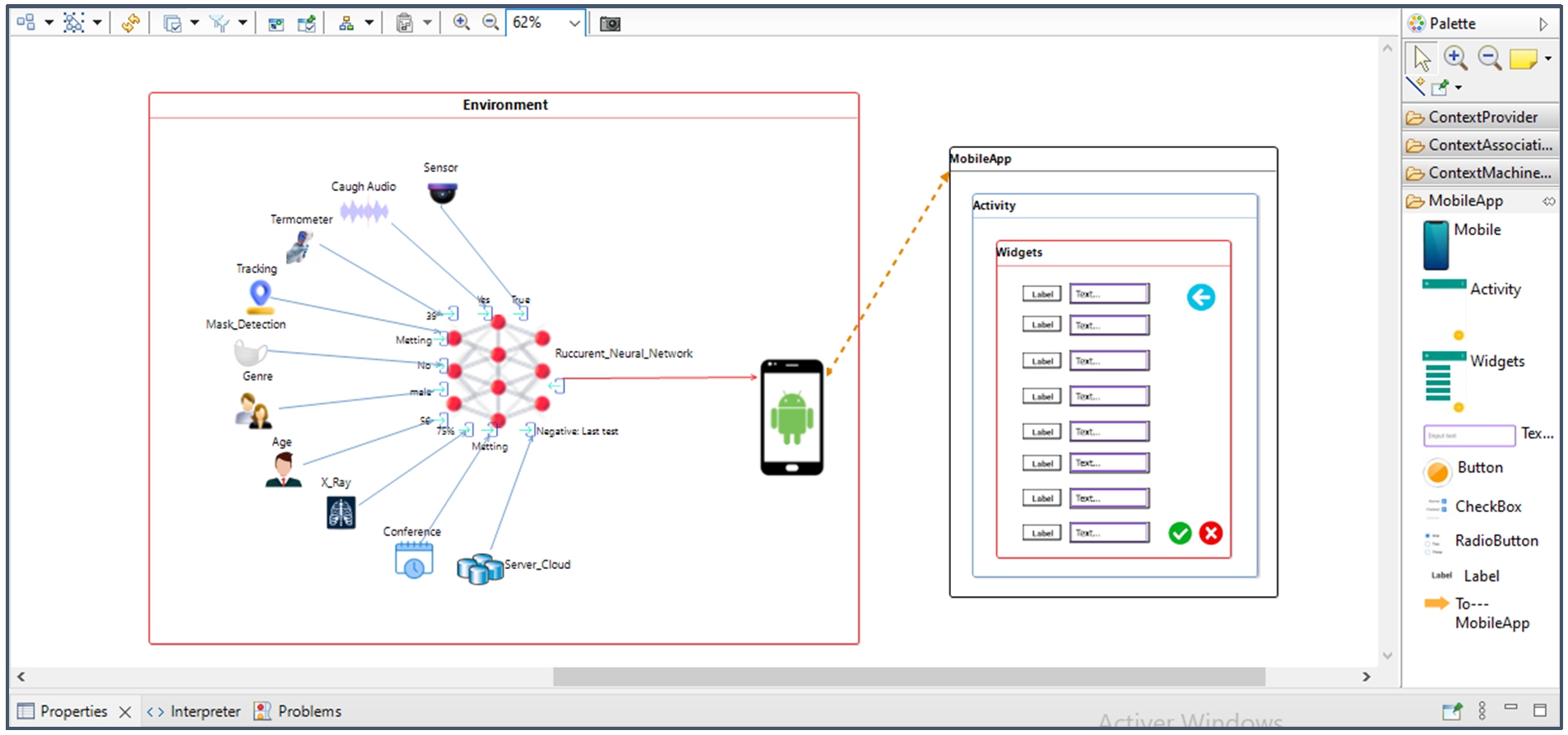
Instantiation of the Covid-19 model.
Dataset description
The dataset used in this research is publicly accessible at [45]. Our objective is to identify symptoms at an early stage in patients who are infected with COVID-19. In fact, the dataset contains a number of anonymous patient-related information. The dataset is comprised of twelve columns, as shown in Fig. 26, of which we have chosen eight (Gender, age, Fever, Cough, Travel history, SARS-CoV-2, Pneumonia, Lung infection, Isolation treatment). The other characteristics are presented in the Table 7.
Patient characteristics [45]
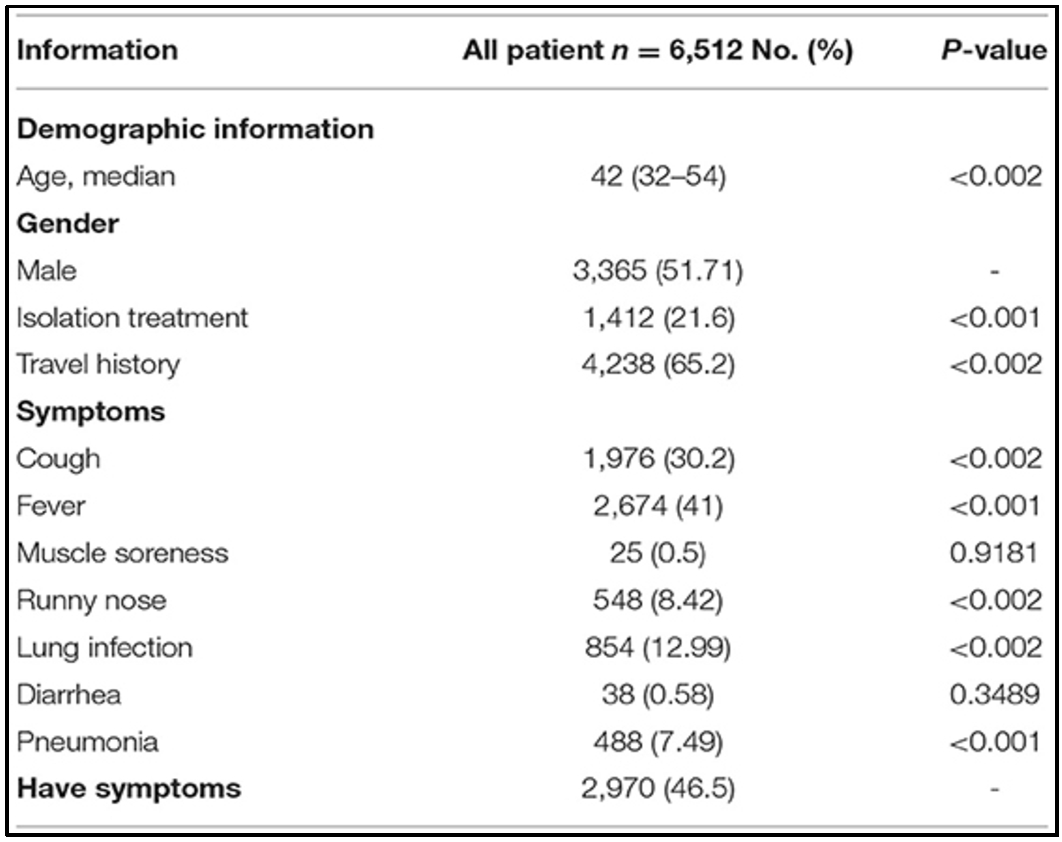
Patient characteristics [45]
The data used were collected from a study conducted by the “Beijing University’s Big Data High-accuracy Center” group at Peking University. They collected these datasets. The dataset contains 6,512 individuals. We applied the split-test approach and randomly divided the dataset into training (80%) and testing (20%) sets, respectively, to validate our models. The data include two different types of variables: static variables that remain constant, such as sex or age, and dynamic variables that are measured at different times, such as location, fever, and cough.
The information collected by connected objects will be used by a deep learning model to help in prediction. The strength of recurrent neural networks lies in their ability to consider contextual information collected through the recurrence of processing the same information, allowing systems to iteratively adapt to future developments. To train our proposed model, we defined the following parameters, as shown in Fig. 22:
An input layer composed of 8 neurons.
A hidden layer composed of three sub-hidden layers, where each sub-layer consists of five neurons.
The output layer consists of a single neuron.
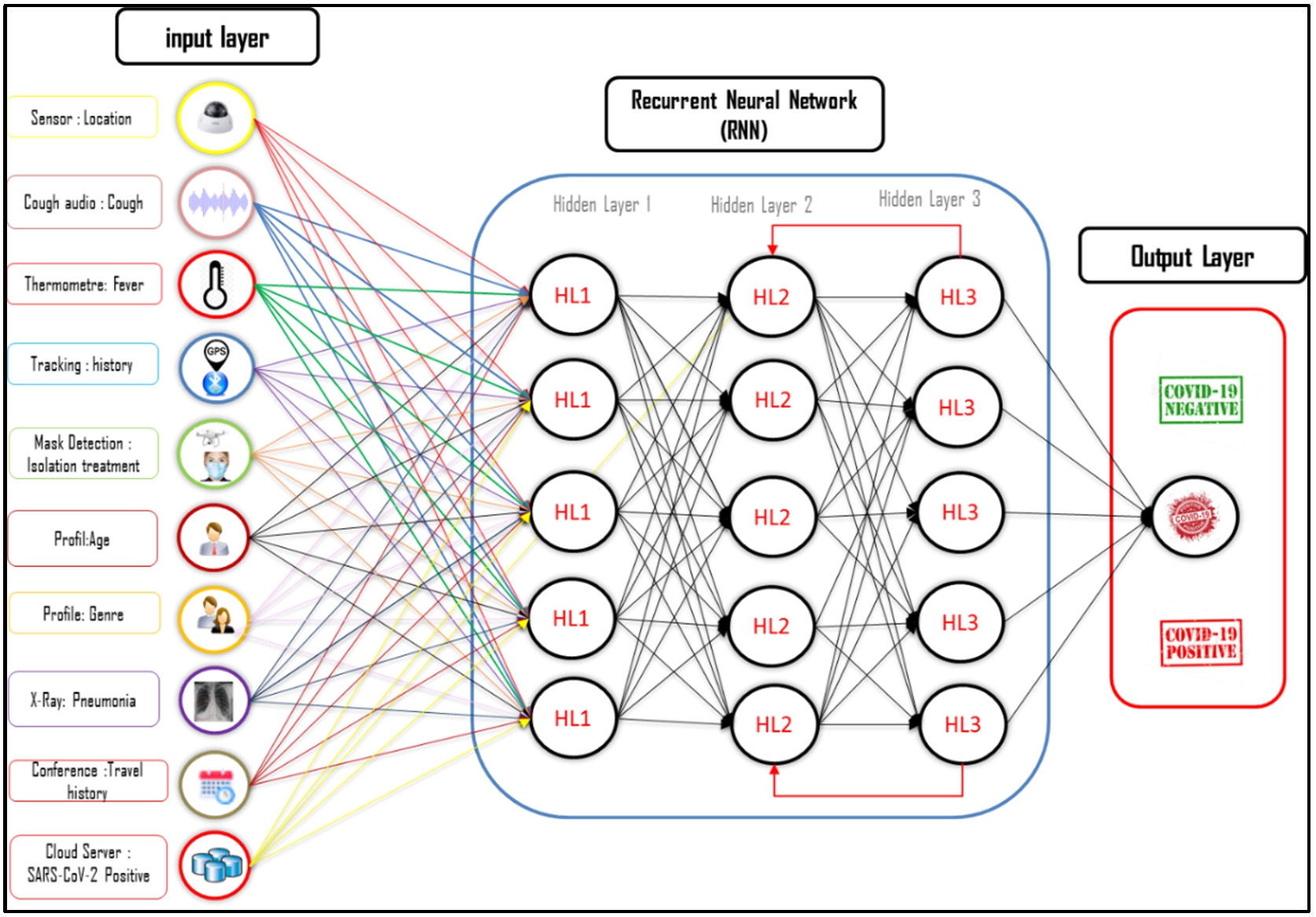
Architecture of the proposed RNN.
Generate ubiquitous application for Covid-19 by the modeler
We present an illustrative example of our approach to automatically generate the application code for the Android platform. Figure 23 illustrates the main screen containing a set of components defined during the graphical modeling phase. The editor allows generating Android code for this model, as well as for any model written with our meta-model.
PIM to PSM.
We provided OpenAI Codex with a textual description of the requirements in natural language, gradually adding additional information, refining the question, and requesting details for certain parts that have similar requirements and functional specifications as the Trace COVID-19 application generated by our tool. We asked Codex to generate the source code for the COVID-19 application to compare it with the application generated by our workshop. We chose to interact with OpenAI Codex via the Playground, and ChatGPT-3.5 [89] (Fig. 24).
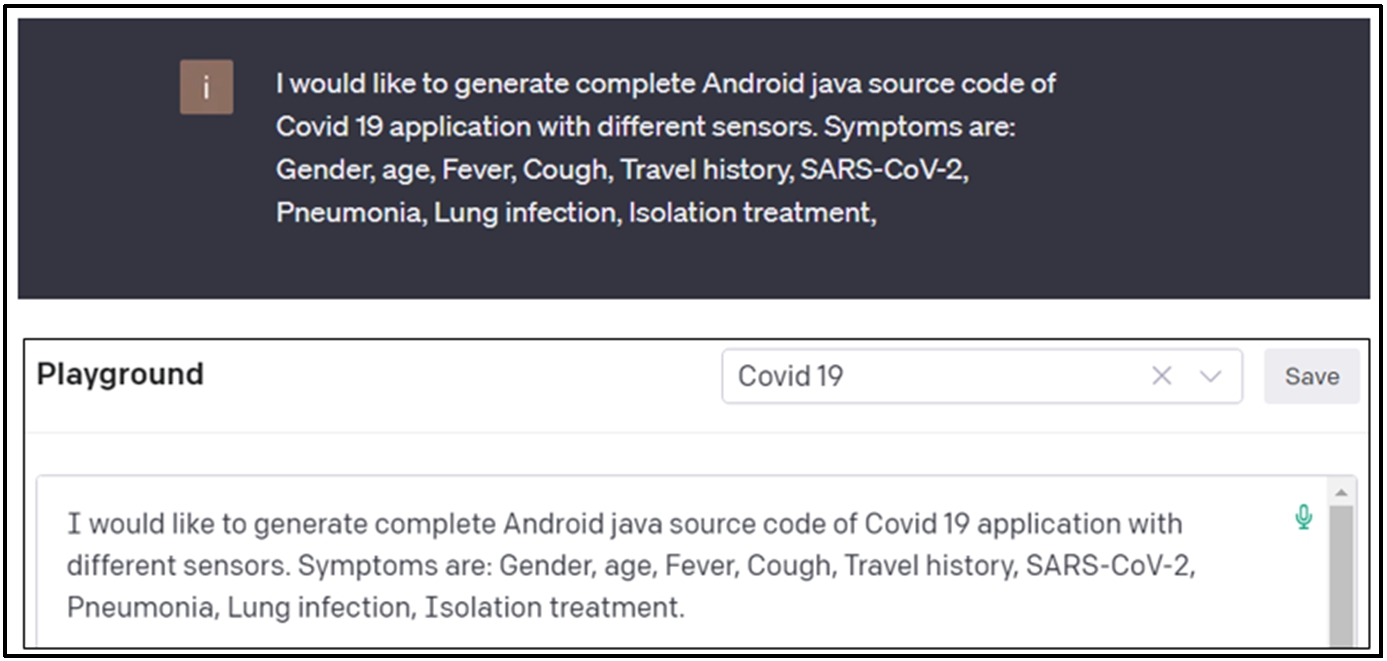
Prompt used to ask ChatGPT.
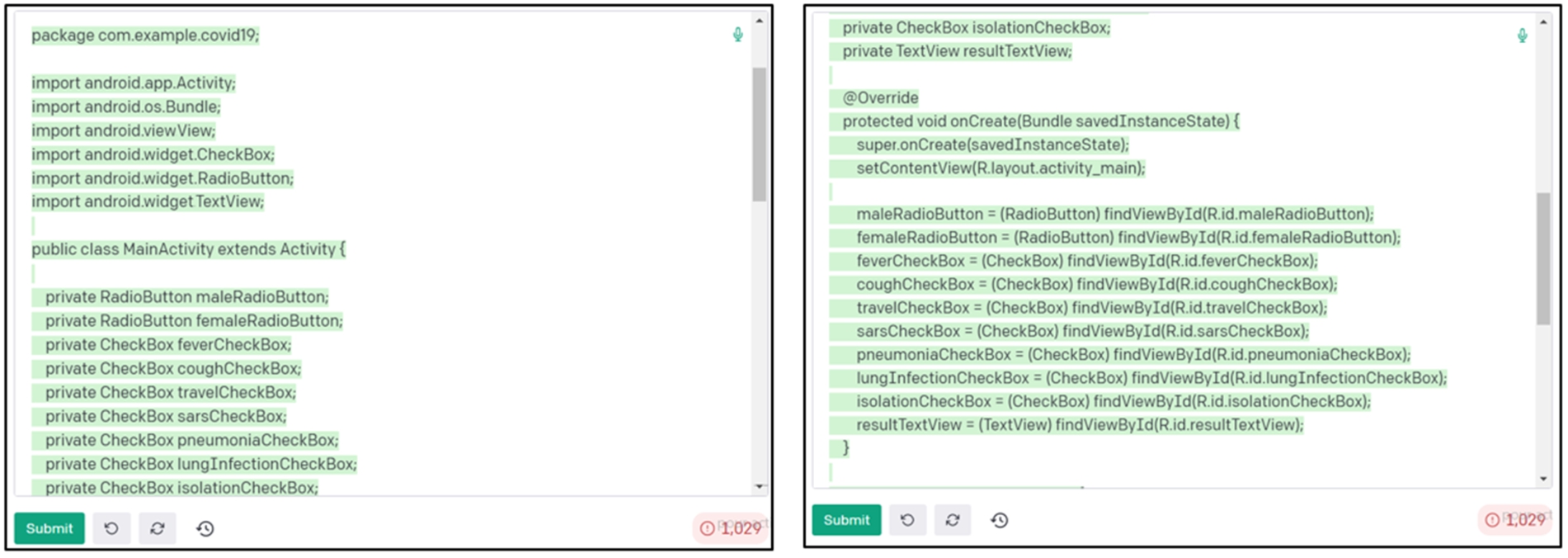
Prompt used to ask OpenAI codex to generate source code with the playground.
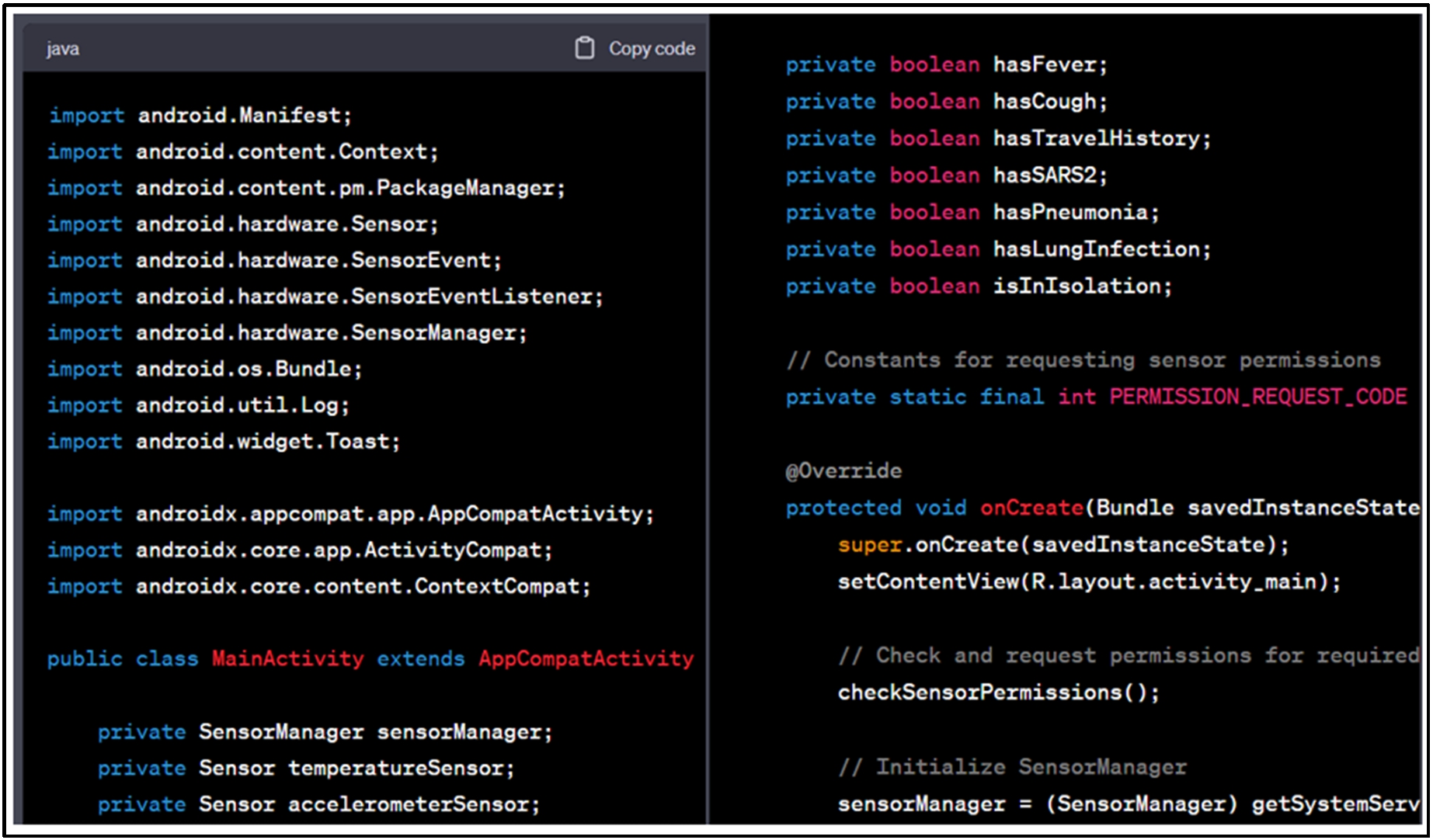
Prompt used to ask ChatGPT to generate source code with the ChatGPT conversational.
Although AI is a highly advanced technology, it is still far from replacing roles such as that of a developer. In an initial review of code generated by ChatGPT and Codex, they are good at assisting the programmer by relieving them of certain programming tasks (Figs 25 and 26). However, as it currently stands, they still have significant limitations. They cannot build an application without human intervention. In the following paragraph, we have prepared a SWOT analysis.
An initial SWOT analysis (non-exhaustive) is proposed to identify the main strengths, weaknesses, opportunities, and threats of code generation based on AI and modeling. It serves as a self-assessment tool to better understand the external and internal factors that are favorable or unfavorable in achieving different objectives. Please refer to Table 8 for more details.
Swot matrices of comparison between generative IA and generative modeling
Swot matrices of comparison between generative IA and generative modeling
Evaluation metrics
The Confusion Matrix is an N*N matrix, where one axis represents the predicted label by the model, and the other axis represents the true label. N corresponds to the number of classes, Table 9. One advantage of the confusion matrix is that it quickly shows whether a classification system is able to classify correctly. A confusion matrix allows for the visualization of parameters such as accuracy, precision, specificity, and recall.
To extract necessary information from a Confusion Matrix, including different metrics, the results are classified into 4 categories, as shown in Table 7:
Confusion matrix for diagnosis of Covid-19
Confusion matrix for diagnosis of Covid-19
Figure 27 shows the confusion matrix for determining COVID-19. Here, 5998 patients of the samples in the COVID-19 class were correctly predicted. 1665 of the patients were estimated as negative and 4333 as positive.
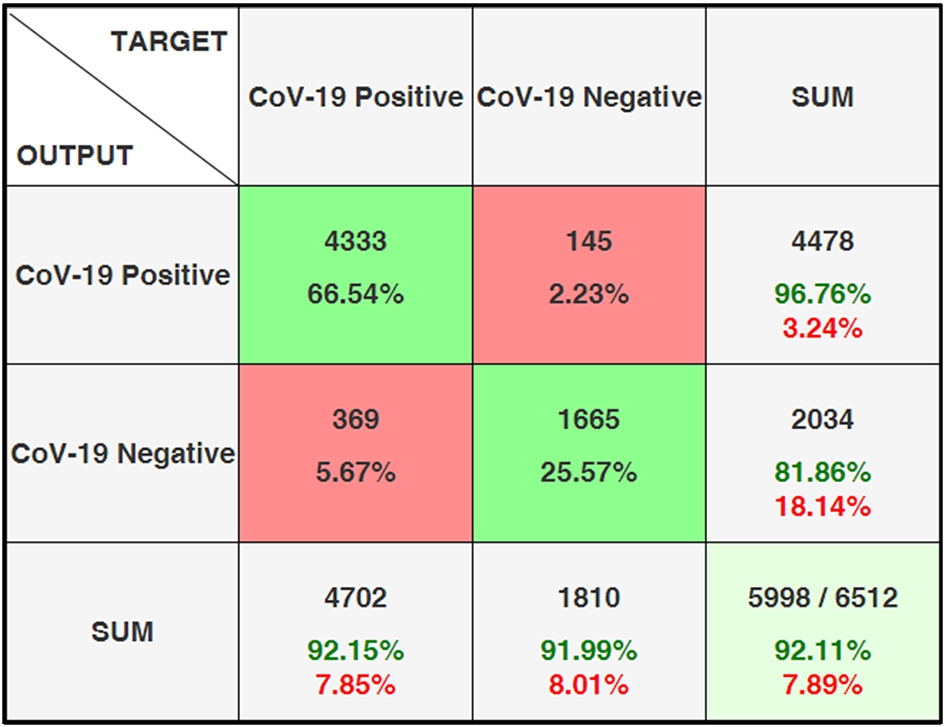
Confusion matrix for diagnosis of Covid-19.
Confusion Matrix are a tool commonly used in assessing the performance of diagnostic tests, including those used for COVID-19. Confusion Matrix allow for the measurement of a test’s performance by comparing its results to the actual outcomes. To interpret the Confusion Matrix more easily and evaluate the model’s performance, there are different metrics that can be used. The mathematical formulae for these performance measures are as follows.
Results and performance
Table 10 presents the performance evaluation measures obtained by applying different algorithms.
Comparison of the performances of the various approaches. AUC “N/A” means that the AUC were not given or computed in a way that does not reflect the secure computation
Comparison of the performances of the various approaches. AUC “N/A” means that the AUC were not given or computed in a way that does not reflect the secure computation
Figure 28 reveals that the method combining multiple models, 2D-CNN, SVM and Sobel filter (CNN-SVM + Sobel) achieved the highest classification accuracy, sensitivity and specificity of 99.02%, 100% and 95.23%, respectively in automated detection of COVID-19. The model employed by [103] has also yielded highest detection of COVID-19 patients. The 2D-CNN architecture used is consisted of three main layers, convolutional layers, max-pooling, and fully connected (FC) layers are used. The preprocessed images are fed to the convolutional layers of the 2D-CNN network to extract the features. Using Sobel, they performed edge detection on the images to improve the deep networks classification performance. the experiments have shown that Sobel was able to provide with acceptable results because it employs two separate filters to extract vertical and horizontal edges. The last part of 2D-CNN is FC, there is a Sigmoid activation function that is responsible for binary classification. SVM is a robust binary classifier which draws a decision boundary between samples of the two classes such that the gap between them is maximized. In 2D-CNNs, replacing Sigmoid with support vector machine (SVM) may lead to better results and obtain highest classification performance.
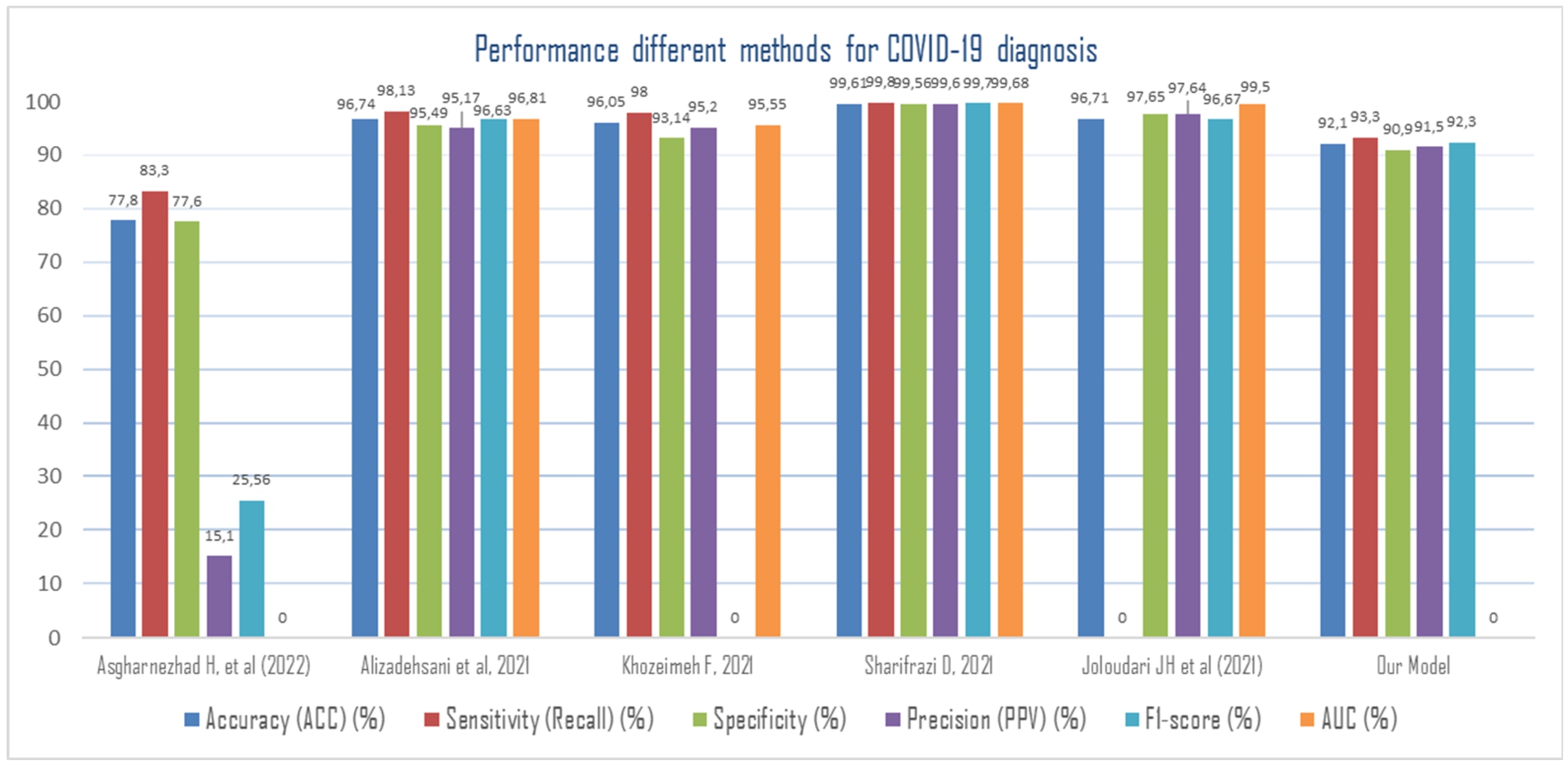
Performance obtained using different methods for Covid-19 diagnosis.
The complexity of designing ubiquitous systems is increasing in parallel with the growing needs of users. In this context, Model-Driven Engineering presents itself as a response to meet this challenge. This article suggests the use of a model-driven approach to design ubiquitous applications.
The advent of assistants like ChatGPT has given rise to a new generation of no-code development environments that allow generating an application from its description. Usually, other works focus on defining a single model that integrates business logic and context. We have presented a proposal that focuses on a quasi-separation. It allows us to study all contextual information separately and prevents as well the need to re-perform the entire development process due to context changes. To do this, we are situated in the standard technical context of the MDA domain, and we will employ a tool-chain from this domain: EMF for defining the meta-model, Sirius for graphically creating models, and Acceleo for code generation.
With the recent development of OpenAI Codex, optimized for programming languages, we conducted a preliminary investigation to assess the capabilities of OpenAI Codex and ChatGPT in generating a source code with minimal intervention. We have provided the Codex model and ChatGPT with the same requirements and requested to generate the source code for the COVID-19 application to compare it with the application generated by our workshop. The results indicate that the Codex and ChatGPT has significant capacity to generate software code. However, it requires intervention to ensure the accuracy and completeness of the generated code.
List of acronyms
We evaluated the deep learning model, a model for corona disease classification, which was developed using the concurrent neural network model. The model achieves a prediction accuracy of 91% on the test dataset. Our model offers fast, accurate, and low-cost testing methods that can be efficient alternatives of PCR testing method.
Due to the paucity of COVID-19 data, Neural Recurrent Networks sometimes require vast volumes of data for computer models to consume and collect knowledge and drive disease-fighting discoveries. In this vein, it should be noted that the main focus of our work is on code generation from models, but the results obtained are very encouraging.
As future works, we will consider other factors that effect on the COVID-19 severity such as background disease (like diabetes, etc.). these features have useful information can be used to increase the accuracy of our model. As well as we will increase the number of datasets. We will add other machine learning models. We also aim to explore the extension and integration of generative AI into our proposed modeler. Furthermore, we plan to expand this study to other generative AI technologies such as Microsoft Bing and Google Bard.
Conflict of interest
None to report.