
Abstract
We are moving towards ‘smart’ world in which industries, such as healthcare, smart cities, transportation, and agriculture have started using IoT (Internet of Things). These applications involve huge number of sensors and devices that generate high volume of real time data. To perform useful analytics on this data, location and spatial awareness characteristics of devices need to be considered. Wide range of location-based services and sensors in GIS have to manage moving objects that change their position with respect to time. These applications generate voluminous amount of real time geospatial data that demands an effective query processing mechanism to minimize the response time of a query. Indexing is one of the traditional ways to minimize the response time of a query by pruning the search space. In this paper, we performed a detailed survey of the literature regarding the indexing of real time geospatial data generated by IoT enabled devices. Some major challenges relevant to indexing of moving objects are highlighted. Various important index design considerations are also discussed. The goal is to help researchers in understanding the principles, methods, and challenges in the indexing of real time geospatial data. This will also aid in identifying the future research opportunities.
Introduction
IoT characterize the future in which devices are connected to each other using the Internet and allow human-to-machine and machine-to-machine interaction. IoT involves large number of devices connected with each other to capture enormous amount of data. Processing this huge amount of data is a crucial aspect in performing a valuable spatiotemporal analytics. Nowadays, idea of Bring Your Own Device (BYOD) has been propagated that has revolutionized the way devices are used. With extensive use of location-based services and sensors, geography has been inevitably linked with modern technologies. Smart building devices, car navigation systems, and autonomous vehicles must be equipped with location intelligence to function properly. For example, in order for smartphones to correctly predict the directions they must have to embed spatial awareness within them.
Wide range of IoT based applications have to manage spatial objects that change their position with respect to time. Examples of such objects include oil tankers, cars, and air planes. These objects are used in number of GPS and location based applications including crowd tracking, robot path planning, and traffic monitoring. Utilization of such spatiotemporal data plays an important role in addressing many societal issues. Majority of applications in the domain of transportation, military, agriculture, and business acquire massive amount of spatiotemporal data from sensors that need effective management. Indexing techniques emerged as a solution to prune the search space and minimize the response time of spatial query operations.
This paper discusses the challenges faced during spatial query processing. We begin with describing an integration of GIS and IoT, the query model involved in this integration, and brief background of spatial data processing. Challenges, design considerations, and research opportunities are discussed in the context of spatial query processing. In many real life applications such as Didi, the number of queries approach up to several millions during peak hours. This makes spatial query processing a challenging task. The sooner the queries are entertained the better will be the validity of results returned. For example, a quick response time is needed in a disaster management applications such that appropriate measures are taken on time. Many spatial indexing methods have been designed to date. But, all of them have not addressed some critical challenges in spatial index design and query processing. Particularly, in case of indexing of moving objects, the read/write query conflicts have not been addressed. To design an indexing solution, one must focus on some important design considerations and challenges to make the solution suitable for real life applications. Therefore, it is significant to have a study in place that discusses these design considerations and challenges.
Difference from existing surveys
To the best of our knowledge, there is no study in place that has thoroughly reviewed the domain of indexing of real time geospatial data generated by IoT devices and highlighted the challenges, index design considerations, and research opportunities. This paper has covered all of these shortcomings of existing research works. This survey is focused on reviewing the literature and domain of spatial indexing.
The survey [100] provided a summarized view of recent research efforts made on spatial data mining. Background of spatial data mining is presented while briefly discussing the structure of spatial data and data structures involved in handling it. The discussion is focused on machine learning based methods for knowledge discovery in spatial databases. Generalization, clustering, and many other variants are discussed in the light of spatial data mining. The challenges in spatial query processing has not been put into focus.
The paper [45] surveyed the whole big spatial data domain briefly. As the focus of this survey is not on some specific module of big spatial data domain (e.g., spatial query processing), therefore various aspects of big spatial data processing, namely, visualization, underlying architecture, implementation approaches, and indexing are reviewed very briefly. Only some recent works have been highlighted with regard to each component.
In [221], a brief overview of modeling and management of spatiotemporal data is presented. The discussion includes only some of the research efforts made for modeling and management of moving objects. However, the discussion of challenges in query processing with moving objects and description of landscape of literature is missing.
The spatiotemporal access methods used for indexing past, current, and future locations of moving objects have been discussed in [125]. However, the challenges with each data access methods have not been discussed.
In view of the above discussion, the need for a survey on spatial indexing is obvious. Most of the existing surveys are focused on the review of big spatial data domain. The focus of survey [100] is on spatial data mining. Spatial indexing and query processing has not been discussed in this survey. The research work [45] reviewed some spatial indices very briefly but didn’t consider spatiotemporal data in its discussion. The research works, [221] and [125] have not extensively evaluated spatial indices. As opposed to these research works, we have provided a complete overview to the domain of spatiotemporal indexing. We discussed the challenges in query processing in this domain. We have also extensively reviewed the literature starting from early 90s till to date. Our main contributions are presented as follows.
Detailed review of background on spatiotemporal query processing. The significance of spatial indexing is highlighted and extensive literature review is done. Comparative review of the literature is performed on spatial indexing with regard to number of view points and design considerations. Challenges and research opportunities related to spatiotemporal query processing and indexing are discussed.
The rest of the document is organized as follows: Section 2 introduces the domain of IoT and spatiotemporal data processing and various major concepts covered by these domains. Section 3 reviews the existing research works related to the spatial querying and indexing of moving objects. Section 4 describes the challenges associated with spatial indexing. Section 5 describes the important design considerations relevant to spatial indexing. Section 6 discusses research opportunities. Section 7 concludes the paper.
Integration of IoT and GIS
IoT data is unstructured and has heterogeneous formats as it is usually acquired from diverse sources. Huge amount of data with spatiotemporal characteristics will be generated by these diverse sensors. This has made information representation, retrieval, management, and processing of spatiotemporal data a complex process. Typical IoT based solution has three layers: 1) edge technology to acquire data using embedded technology, 2) platform involved in manipulation of data and extraction of intelligence from it, and 3) applications that use this intelligence. Figure 1 depicts this layered architecture. At edge, there are sensors, actuators, and devices for sensing the environment. Platform layer involves processing, management, and analytics aspects.
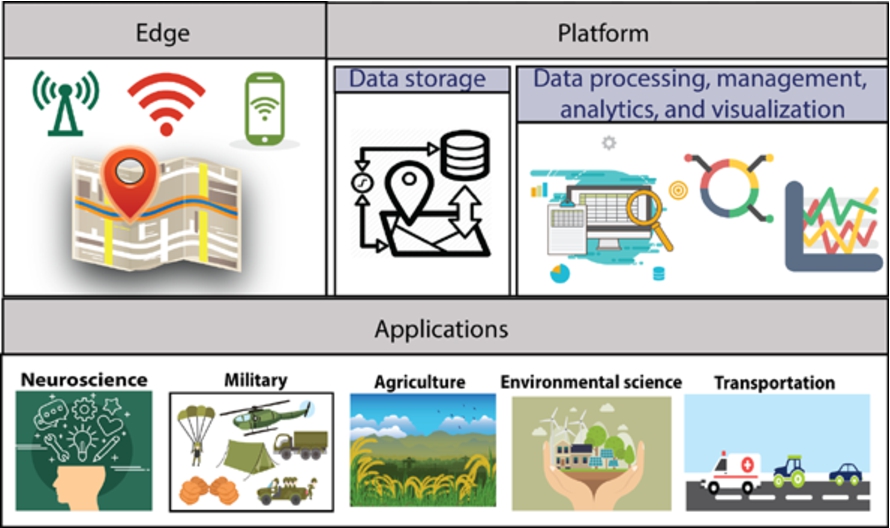
Layered architecture of IoT based solution.
The scope of this paper lies within layer 2 in which processing of spatiotemporal data with moving objects will be considered. Typically, the query model involves sensors or GPS based devices deployed in the environment and moving objects that report their location to the server continuously. This has been depicted in Fig. 2.
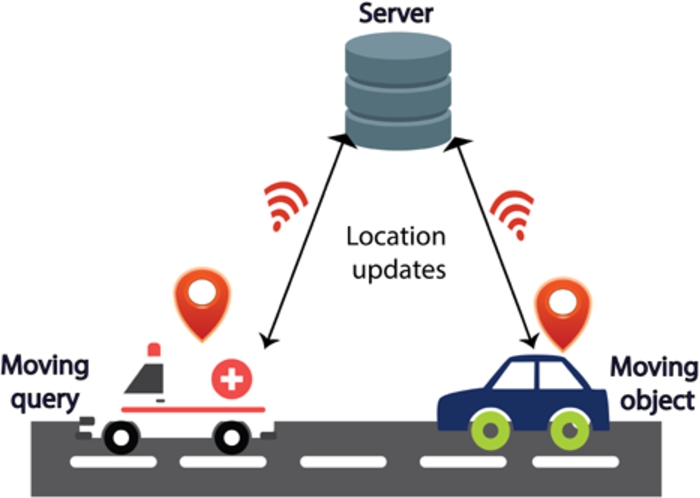
Query model.
Processing of this spatiotemporal data should consider the crucial aspects and issues in IoT domain, such as limited battery life of sensors. With limited battery life, sensors would not be able to do extensive processing. Therefore, it is important to minimize the query processing time and communication among sensors and the server. The primary focus of this paper is therefore on query processing and indexing of spatiotemporal data generated by sensors distributed in the environment. Indexing is essential to minimize the processing costs in platform layer of IoT. The upcoming sections introduce the domain of spatial query processing and indexing and major concepts and applications involved in it.
A vast amount of spatiotemporal data is collected in various applications in the domain of transportation, neuroscience, agriculture, military, healthcare, and environmental science. The motivation for analysis of data involving moving objects in various application domains have been described in this section. Figure 3 illustrates some common spatial applications.
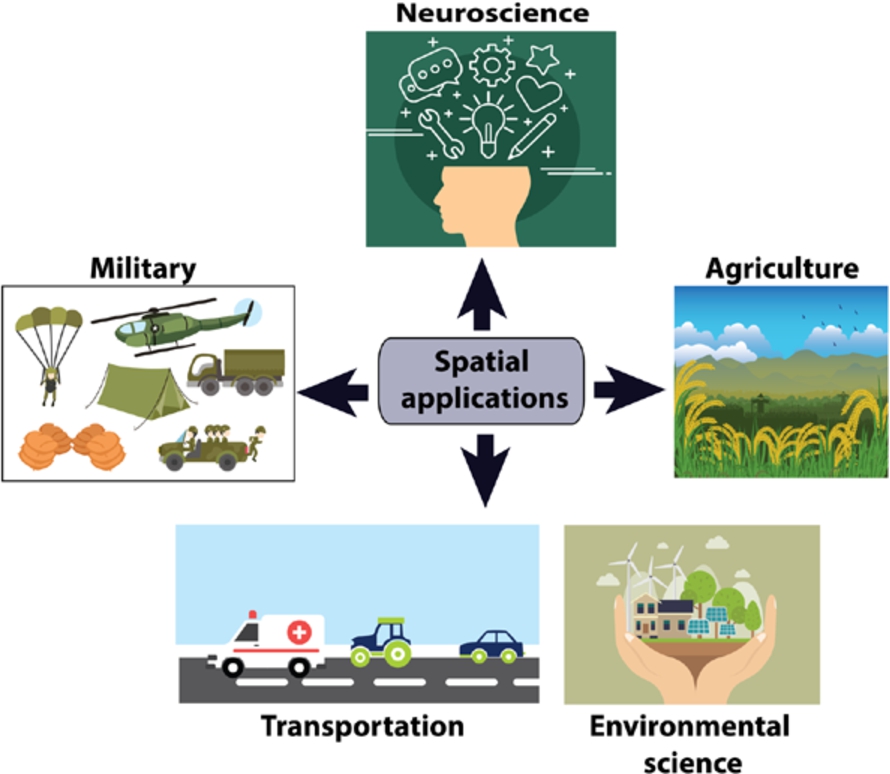
Spatial applications.
Transportation: Taxi pick and drop applications have been used increasingly across the world. Nearby taxis can be found by employing spatial query processing techniques.
Neuroscience: Temporal neural activities occurring in brain can be analyzed to understand the principles of brain and identify the mental disorders that made disruption to the normal working behavior of brain. This will help in diagnosis of various neural problems and devise therapeutic plans for patients.
Agriculture: Remote-sensing images of agricultural area taken at regular timestamps can help in analyzing the relationships between various factors such as application of fertilizer, planting procedure, and quantity of weeds. This will help to devise strategies to increase crop yield.
Military: In the domain of military, there are many applications involving spatiotemporal data. One such application is to find the shortest route for supplying food and weapons to the militants. Health care. Temporal data related to diagnosis made to patients and environmental features can be analyzed to discover patterns and spread of epidemic. Effective strategies can be developed for the well-being of humans.
Environmental science: The spatiotemporal data regarding atmosphere such as pressure, humidity, and temperature can be analyzed to identify important patterns and devise mitigation strategies for adverse scenarios that might occur in future. For example, the prediction about flow of wind or tornado can be made before the calamity happens in actual. In addition to this, various sensors can be employed in air and water that record data related to particles, ozone, oxygen, and carbon dioxide. This data can be utilized in measuring the quality of air and water in terms of level of pollution calculated using the data from sensors.
Spatial point is represented with the help of two coordinates, longitude and latitude. Spatiotemporal data is a spatial data with an additional temporal attribute to define the evolution of object over some period of time. Spatial query extracts the information about the spatial objects present in our environment. Broadly, we can group the spatial queries into three categories, as illustrated in Table 1 that briefly describes each category along with an example query.
The structure of spatial data makes it difficult to be processed by traditional data processing methods. Traditional data model such as relational data model suits in scenarios when the schema and structure of data is fixed and the data is one-dimensional. However, spatiotemporal data is multi-dimensional in nature that makes it difficult to apply traditional techniques to process it. This is because the structure and nature of spatiotemporal data introduce a number of challenges from processing and management perspective. One such challenge is reduction of continuous updates.
Categories of spatial queries
Categories of spatial queries
The eminence of big spatial data has made the management and processing of spatial data, a pervasive component for research. The massive data generated by majority of the GIS applications need an efficient spatial query techniques to keep the response time low. Moreover, the overhead of huge number of update operations performed to track the up to date spatial location of moving objects must be decreased.
Indexing methods aim at minimizing the cost of searching large number of spatial objects and improving the response time of queries. Traditionally, indexing has been used to deal with one-dimensional data. These one-dimensional indices cannot be used in spatial data processing. This is because the structure and nature of spatial data introduce a number of challenges from processing and management perspective. As the data related to moving objects has multiple dimensions, therefore typical one-dimensional indices that are created based on a single dimensional value such as ‘salary’, cannot handle multi-dimensional values. Therefore, to deal with spatial data, indices must be designed considering the multi-dimensional nature of spatial data. Further, unlike static spatial data, the management and processing of data with dynamic nature (moving objects) needs special consideration. As the moving objects continuously change their position at each time instant, therefore constant updates to indexing structure are required that highly degrades the performance of an application.
Primarily, there are two sub branches of spatial indexing methods: space driven and data driven. In space driven structures, spatial objects present in a 2D space are divided into a rectangular grid of cells. Geometric criterion is used as a basis for mapping the spatial objects to cells. Fixed grid had been proposed as a basic space driven structure. It partitions the space into a fixed number of equal sized cells with each cell depicting a secondary storage block. This structure cannot handle skewed data well due to its static data distribution. Therefore, many variations of space driven structures have been proposed to overcome the limitations of basic fixed grid structure. Quadtree, grid file, k-d tree, and various space filling curve techniques have been proposed such as z-order curve, Peano curve, and Hilbert curve. Space filling curves transform a spatial proximity problem from a higher dimensional space to one dimensional space. In contrast to space driven structures, data driven structures are focused on the distribution of spatial objects rather than partitioning of space. R-tree is a data driven structure proposed to handle the indexing of multi-dimensional data. It is a tree based structure that works on the concept of minimum bounding rectangles (MBRs) that hold a group of spatial objects. Leaf node of a tree holds MBR and an object’s identifier. It has several limitations such as high overlap among MBRs resulting in high response time of a query. To address these limitations, several variations of R-tree have been proposed in the literature such as R+ Tree, parametric R-tree, FNR R-tree, and X-tree.
With regard to timeline, the indexing of spatiotemporal data can be categorized into three groups. These are: indexing with past spatial locations, indexing with current spatial locations and indexing with future spatial locations. Brief description and distribution of literature with regard to this grouping is defined in Table 2.
Categories of spatial indices
Categories of spatial indices
The continuously changing data related to moving objects cannot be managed well using traditional database management systems. In traditional relational databases, the data remains unchanged otherwise unless explicitly updated. For example, if the value in employee’s age field is 25 then the database will retain this value unless it is explicitly updated. In case of moving objects such as cars, the positional information needs to be updated continuously. Otherwise, this can result in outdated query results. Continuously updating the information results in high performance overhead. Frequent updates cannot be afforded in many real life scenarios. For example, in wireless networks domain, excessive bandwidth will be consumed due to frequent updates. Tracking large number of objects (e.g. millions of cars in a city) becomes a challenge due to frequent update issue. The indexing of moving objects is more challenging due to the overhead of repeatedly updating the index structure in case of location updates. This must be addressed in the design of index to gain performance benefits. Sampling the position of moving object along its trajectory emerged as a traditional way of representing moving objects in indices. One of the earliest research contributions in this regard is presented in [140]. The sampled object location is indexed using an R-tree index. Following it, a few efforts [163,206] are made to update the existing spatial indices to make them handle moving objects. The sampling methods have an overhead of frequent location updates resulting in an overhead of high workload on the system. To overcome this, significant number of efforts are done that model the moving objects using linear functions of time and velocity [9,34,77,156,190,235], and [98]. In this scenario, location update is required only when the velocity of an object changes. This minimizes the number of updates to some extent. The existing studies focused on making predictions during query processing suffer from performance and functional deficiencies. Most of the research works [71,205,217,245] have considered movement of objects in Euclidean space. However, in realistic scenarios such as road networks, we have to deal with network distances. Many solutions involve prediction models that need to be trained on massive amount of data in the form of trajectories to produce accurate and realistic predictions [8,8,71,81,89,198,205,217,245], and [208]. But, historical data is not available due to privacy concerns.
Movement possibilities for indexing moving objects: The continuous spatial query processing systems use a client-server paradigm, consisting of data and query objects. The query objects initiate the query about data objects. There are three possibilities of movement of objects as illustrated in Table 3. These objects share their updated location and query to the server. The server maintains the moving objects and process the initiated queries.
Possibilities in movement
Possibilities in movement
Recently, the attention of research community has been directed towards integration of spatiotemporal locations and sensor data. The research works related to Geo-IoT integration can be categorizes into five groups: edge computing, device integration, data acquisition and management, service provider, and application related solutions. Recently, a short survey based on this classification has been presented in [96]. The focus of this paper is primarily on indexing of spatiotemporal data generated by IoT devices. It should be noted that existing surveys that have discussed data management issues in Geo-IoT integration have not considered spatiotemporal query processing and indexing data aspects. Therefore, it is vital to have a study in place that explores this domain and its challenges. In this paper, we extensively reviewed the domain of spatiotemporal data indexing (also known as moving objects indexing, interchangeably).
The problem of spatial query processing and management has gained huge attention in recent times. In this section, an overview of whole literature in the light of spatial query processing and management is presented. Some recent solutions have also been discussed briefly. A qualitative comparison of these solutions with regard to design considerations will be presented in the next section.
A thorough study of domain is carried out. There are approximately up to 250 research works that contributed in spatial indexing. The main challenges identified in spatial querying of moving objects include maintaining consistency, enhancing performance, and reducing updates. These will be discussed in detail later. The research works on spatial indexing (for both static and moving objects) starting from early 90s till to date are explored. During exploration of research works on spatial indexing, we focused on both data processing and management aspects. After detailed study, we identified three important concerns that are relevant in spatial indexing. These are mobility of spatial objects, multi-user environment, and massive data processing. Mobility defines whether the spatial objects are moving or static. In real life applications, both static and moving objects play an important role. Some examples of static and moving objects in real life scenarios are defined in Table 3. Multi-user environment is the second most important concern that must be considered while designing an indexing solution. Real life applications are usually designed not only for one user, but for multiple users. Multiple users might initiate queries related to same data items/objects. Thus, synchronization and scheduling of these concurrent queries must be performed to report reliable results to queries. If the scheduling is not performed then this might result in inconsistent query results. Third important factor is the scale of data to be processed. As discussed in the last section, applications in today’s era generate huge volume of data that must be processed quickly. Returning the results in timely manner is crucial for many real life applications. For example, in any disaster management application, the results must be processed and disaster alarms must be disseminated timely. Thus, these three characteristics or concerns are quite important to consider for an indexing solution. We defined four features for review and categorization of indexing solutions proposed in the literature. The research works have been grouped into four categories: Concurrency control, distributed and parallel processing, pure moving objects indexing, and hybrid. The percentage of research contributions in the literature regarding each category is shown in Fig. 4.
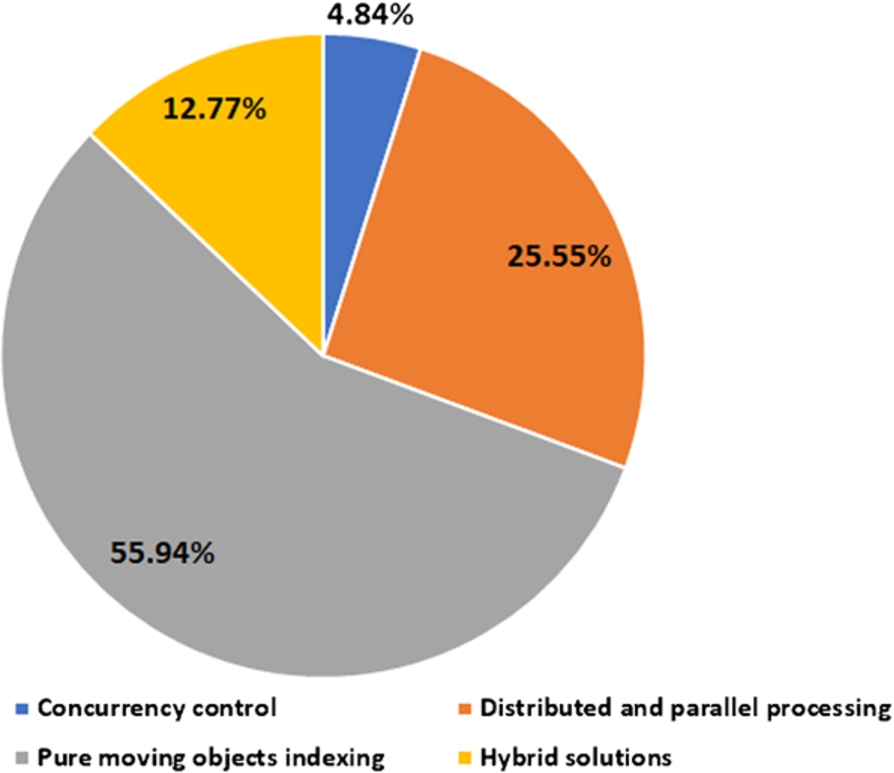
Categorization of literature.
Table 4 provides a comparative view of literature in the light of categories defined.
Timeline view of the research articles reviewed
(Continued)
The concurrency control category encloses the research works that have discussed concurrent multi-user queries on spatial data. The distributed and parallel processing category discusses the research works that are focused on processing of spatial data and queries in distributed and parallel way. The pure moving objects indexing category encloses the research works that are focused primarily on the indexing and query processing of moving objects, i.e. spatiotemporal data. The hybrid category encloses the research works that are two or more of the above mentioned categories. Primarily, the works in this category consist of survey and review papers, discussing the domain of spatial query processing generally. The timeline view of these research works with relevant categorization is defined in Table 4. The timeline view of literature is depicted in Fig. 5.
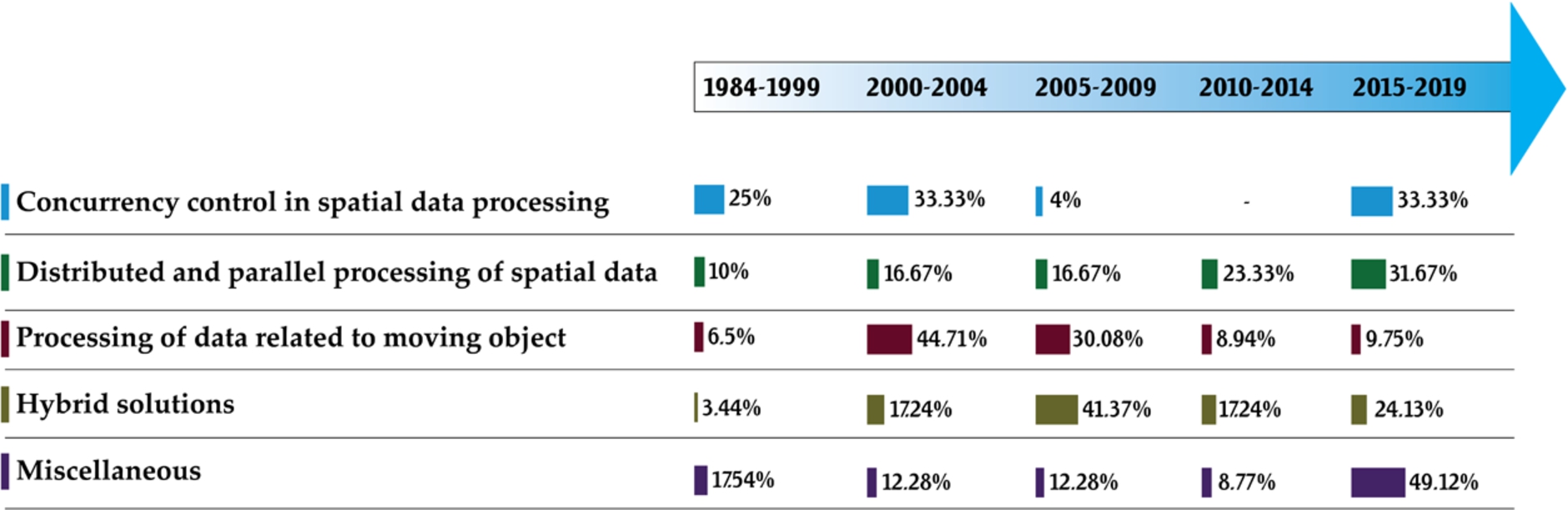
Timeline view of the research articles reviewed.
The paper [88] addressed the issue of maintaining high concurrency in multi-dimensional indices. A new protocol is proposed to eliminate the overhead of blocking during node splits. A top down index region modification approach is proposed that avoids simultaneous locks on nodes at multiple levels. The dataset for experimental evaluation includes multi-dimensional feature vectors fetched from Corel Image Collection. These feature vectors are indexed in R-tree. The experiments are conducted on shared memory system with multiple processors. Varying workloads for insert and search operations are considered. Insert ratio and disk access ratio is varied and response time of the query is estimated. Scalability is also tested. Experimental results indicate that the proposed scheme provides higher throughput than the state-of-the-art technique, CGist. It also scales well with the increase in number of processors.
Node splits and MBR updates are the two major factors that increase the delay of search operations and degrade the concurrency of indices. To lessen the query delay, an enhanced concurrency control scheme is proposed in [195]. Latches are held only during physical node split. A partial lock coupling method is introduced that enhances concurrency by allowing lock coupling only for shrink MBR operations. MBR shrink operations occur less frequently than expansion operations therefore the proposed solution is more effective in eliminating excessive query delay. For evaluation of proposed method, comparison is made with the existing link technique, CGIST. Dataset with 20 dimensional feature vectors is involved in comparison. Parameters involved in experiments are throughput, response time, varying database and node size, page buffer size, number of dimensions and processes, and the parameter k in kNN queries. The results indicate that the proposed algorithm outperforms the existing algorithms with regard to response time and throughput and also scales well.
The thesis work [35] is focused on the design of an effective concurrency control and indexing method for spatial data. Both stationary and moving objects are put into focus. The main contributions of this research work are: 1) design of an efficient spatial indexing method with object clipping, ZR+-tree. It eliminated the overlap problems in leaf nodes.; 2) concurrency control protocol for object clipping: GLIP; 3) concurrency protocol for linear spatial access indices: CLAM; 4) concurrent query processing for moving spatial objects; 5) Disposable index for Moving Objects (DIME) that eliminates the need for expensive delete operations. In evaluation, compaison of query performance and throughput of ZR+-tree and state-of-the art techniques, R+-tree and R-tree is carried out. To evaluate proposed schemes for moving objects, datasets are generated by Brinkhoff network based moving objects generator. Three range queries related to bicycles, vehicles, and pedestrians are defined for moving objects. Throughput and mobility is evaluated. Correctness analysis of concurrency control protocol is also performed. Findings indicate that proposed protocols provide better results as compared to existing solutions.
In [101], a concurrency control mechanism for R-tree is proposed that is capable to store multi-dimensional spatial data. R-link tree (a variant of R-tree) is implemented and its comparison is performed with R-tree. Illustra database engine is deployed with multiple users sending requests concurrently to a database server. Each client process has its own server in Illustra architecture. To evaluate the performance of proposed protocol, two dimensional dataset with 30600 non-overlapping rectangles is considered. Throughput and response time for insert and search operation is evaluated that indicates that the proposed solution outperforms the existing R-tree index.
In [258], a non-blocking scalable concurrent spatial index is proposed. A decoupling approach for structural adjustment is presented that isolates logical removal and physical adjustment of nodes. The protocol is theoretically evaluated using lemmas and correctness proofs. Experiments are conducted on a single machine with hyper threading. State-of-the-art solutions: ctrie, kary, and patricia are involved in comparative analysis. Two dimensional and uniformly distributed point objects dataset is used in experimentation. Performance in terms of throughput is evaluated for both high and low contention scenarios. The results indicate that the proposed index is better in terms of throughput than the existing solutions.
Distributed and parallel processing
In [95], a novel GPU and tree based parallel index: G-tree is proposed that overcome the issue of curse of dimensionality. Existing tree-based methods conventionally use stacks and queues to handle results with GPUs. G-tree uses a novel data structure: structure of arrays for traversals. Breadth first search based traversals are employed instead of depth first search based traversals that resulted in maximization of parallelism over indexing nodes. G-tree use a selective dimensionality filtering approach in which few dimensions out of total number of dimensions are extracted to work on. The extracted set of dimensions are processed on GPUs in a parallel way. The time complexity of a proposed index on range query is theoretically evaluated. Dataset of size up to 9.6 Gb is involved in experiments. Two types of datasets are considered. One dataset is real world dataset involving SURF features with skewed distribution. The other one is a synthetic dataset uniformly generated with dimensionality of up to 256. Experimental results indicate that the performance of the parallel index proposed in this research work is better than the state-of-the-art indexing methods for multi-dimensional data.
The paper [92] proposed a tree based index focussed on both CPU and GPU architectures. CPU is involved in navigation of internal nodes of a tree. Navigation of leaf nodes is performed by GPUs in a linear way utilizing large number of processing units. Host memory of CPU and device memory of GPU is utilized in storing internal and leaf nodes. Various opportunities and guidelines for making balance of the workload between CPU and GPU architectures and co-processing of queries by both the architectures are studied. Three-dimensional point datasets are taken from National Climate Data Center. The datasets have two dimensional longitude and latitude points along with time and number of sensor values such as wind speed, temperature, and precipitation. Various parameters are involved experimental evaluation. These are amount of memory assessed, scan size, average query response time, number of GPU blocks, speed up, average count of conditional instructions with respect to each query, load throughput, number of concurrent queries, query execution time, selection ratio, and number of GPU blocks. The results indicate that the proposed hybrid index provides 12× faster response time for queries as compared to the existing algorithms for traversals.
The paper [116] proposed two different indexing schemes to deal with high communication cost problem in moving object querying. Hybrid distributed solution involving both on-demand and broadcast operations helps in effective querying of moving objects. The server broadcasts the query information repeatedly. Grid of cells are used to represent object movement. During the movement, spatial object downloads the query related information by tuning to broadcast channel without interrupting the server for information. Simulator is designed in Java for evaluating the proposed solution. Parameters varied in simulation are packet size, cell size, and number of objects and queries. Comparison is performed with MobiEyes. The results show that the proposed solution saves 30%–60% of the communication cost.
Two designs of indices: two level hierarchical index and centralized global index are proposed in [139]. To enhance the scalability, replication protocol is proposed for both the index designs. The proposed index extends GMIL to distributed storage. In the proposed scheme, local index is held by each data server. Global index holds MBRS of root nodes and decides about the traversal of local index. To evaluate the two proposed schemes, dataset with three dimensional satellite images of size 30 GB is considered. Storage Resource Broker (SRB) is used to implement distributed indexing schemes. The results indicate that centralized indexing scheme introduces scalability issues for insert and search operations. On the other hand, two level hierarchical index allows better scalability. Replication, however makes centralized scheme faster than the two level hierarchical scheme.
Pure moving objects indexing
An efficient range query processing method is proposed in [147] for moving objects. The aim is to minimize the computation and communication cost. Moving objects change their location dynamically, server must be contacted which increases the communication cost. Existing methods use a concept of safe region which ensures that moving object affect the result of query only if it is moving within it. Design of safe region is another challenging task. To avoid this, pruning rules are introduced in this research work. A spatial index: partition retrieved list is proposed that helps in efficiently constructing safe region. Dataset considered for performance evaluation consists of 100K moving objects in LosAngeles. The results show that the computation and communication cost of the proposed solution is low.
The research work [103] proposed an R-tree based index: LUR-tree to deal with moving objects. It reduces unnecessary update operations by ensuring that index gets updated only if the object leaves its corresponding MBR. A sample application of automobile tracking is considered. To evaluate the performance of proposed index, its performance for update and search operation is compared with R∗-tree on the basis of number of page accesses. Spatiotemporal data is considered for performance evaluation. The datasets are synthetically generated with uniform and Gaussian distribution. Update query, kNN query, and range search query performance is evaluated. LUR-tree is better in terms of its update performance than R∗-tree. Whereas, R∗-tree is better with respect to its search performance.
The paper [175] proposed an efficient R∗-tree based indexing method to deal with moving objects. With respect to continuous object movement indexing, there are two scenarios. One is to index positions of objects in future and the other one is to index the history of object’s movement. Primary focus is on indexing the future movements of objects and making future predictions. Timeslice and window queries are discussed. A skewed 2D data is simulated using a workload generation script Generalized Search Tree Package (GiST). Number of destinations, number of data points, update interval length, querying window size, are query size are considered as workload parameters in simulation.
A hybrid solution is proposed in [117] that can reduce the communication cost incurred during location updates. Two different index structures are proposed, Grid and direction index. Grid of cells is labeled using Hilbert curve. The processing if a query is distributed among moving objects. When a query arrives, the server finds the monitoring region for it. It then updates the relevant data bucket. The server then communicates new monitoring region for this query with the resident objects of an old monitoring region. The proposed index is compared with MobiEyes. The findings indicate that the access time grows linearly with the increase in number of objects.
In [37], a new indexing scheme: MON-tree for moving objects is proposed. Two models of network: edge oriented and route oriented are used. MON-Tree deals with storage and retrieval of past states of moving objects. The index structure is focused on polyline based bounding boxes and movements of objects along them. The bounding boxes make the top of R-tree whereas indexing of movements is performed at the bottom part of the R-tree. The proposed index overcome the problem of high dead space in polyline MBBs. A hash structure is used at the top level of R-tree consisting of identifier for polyline and a pointer for the bottom part of the tree. While inserting an object, polyline identification is used to fetch the bottom R-tree. MBB approximations are utilized in indexing polylines. The bottom part of R-tree stores movement of object represented by a position and time interval. To experimentally evaluate MON-Tree, network based moving objects generator is used consisting of road network of Germany. Dataset contains three models: edge, segment, and route. The comparison is made among the proposed MON-Tree (edge and route model) and FNR-tree. Number of disk accesses are estimated with varying page size, window size, time interval size, speed, number of objects. As per the results, MON-Tree has shown good performance and scalability.
The paper [163] introduces two access structures, TB-tree and STR-tree. The movement of an object is depicted with a polyline representing its trajectory. Two types of spatiotemporal queries are involved in study. These are coordinate and trajectory based queries. The proposed technique overcome the limitation of high overlaps in R-tree. In addition to spatial closeness in R-tree, STR-tree allows trajectory preservation. That is, line segments that belong to same trajectory are kept together. TB-tree preserves trajectories in more strict manner than STR-tree. It bundles up the geometries to trajectory bundle. This trajectory preservance introduces an overhead of minimized spatial discrimination. Combined query processing involving STR-tree and TB-tree is also discussed. Synthetic datasets of line segments are generated using GSTD generator. Comparison of STR-tree and TB-tree is done with R-tree. TB-tree proved out to be more efficient in dealing with trajectory-based queries.
In [226], a tree-based index named as Q+R-tree is proposed for indexing moving objects. It is a combination of Quadtree and R∗-tree. The aim is to minimize the cost for update operation. Two types of object movements: fast movement and quasi-static is considered. Quasi-static is defined as a state in which object is neither static nor moving fast. The performance degradation happens mainly due to fast moving objects. Quasi-static and fast moving objects are indexed on R∗-tree and Quadtree respectively. Quadtree is better in terms of update performance as compared to R∗-tree. On the other hand, R∗-tree has better query performance than Quadtree. The combination of these two approaches helps in an efficient indexing. Datasets with moving objects ranging from 100K to 1M are generated for experimentation. Comparison of R-tree, Quadtree, and proposed index is done with respect to insert and search time. Q+R-tree has shown best performance among the rest of the indices.
The paper [77] designed a an indexing scheme: B+tree to index moving objects efficiently. Linearization of moving objects’ locations is performed by using space filling curve technique. Subsequently, B+tree indexing is performed. Partitioning of index is done on the basis of update time. Time axis is divided into intervals whose duration is approximated with maximum duration between the two update operations. The update operation is located in a partition defined by a timestamp of a phase during which it occurred. Efficient algorithms for range and KNN queries are defined and discussed. Two versions of index are implemented. One with Z-curve as a space filling technique and other using H-curve. Dataset of moving objects is synthetically generated. Page size, node capacity, maximum update and predictive interval, query window size, dataset size, k for KNN, and number of queries are used as parameters in experimental evaluation. Storage efficiency is also evaluated. The results indicate that proposed index outperformed the rest of the indices. The effects of concurrent access are also estimated. Multi-user environment is simulated by multi-thread programs varying from 1 to 8. Throughput and response time is evaluated. The results indicate that proposed index is more effective as compared to existing index, TPR tree.
In on-demand querying method, client sends their location to server that processes the query and sends the results back to client. If there are large number of simultaneous queries, then service delays are introduced. On-demand environments face a challenge of congestion on server for complicated queries with moving objects. Distributed indices involving client/server model have several limitations such as compromise on privacy, server dependency, and insufficient support for moving objects. In [153], an indexing algorithm is proposed for moving objects in a broadcast environment. It processes queries efficiently by using grid cells. An energy efficient query processing algorithm is also proposed. Cost model is presented and simulation based experiments are performed to evaluate the proposed solution. The comparison is made with Hilbert-curve index. Access and tuning time is involved in comparison. Dataset consisting of 39231 MBRs of Montgomery Country Roads is considered. The results indicate that the proposed algorithm scales well for kNN and range queries and is also energy efficient.
In [17], a scalable kNN query processing technique is proposed that is based on in-memory structure. The focus is on road network with moving objects. R-tree is used to store road network topology. Grid model manages the movement of objects. In kNN, proposed technique: SIMkNN incrementally expands the search region based on distance based evaluation of nearest neighbors. Real and synthetic datasets are involved in experiments. Road network of CA, Los Angles, and USA with 193320 nodes and 264521 edges is taken as real dataset. Moving objects on a network of road are synthetically generated using Brinkhoff road network generator. Overall, simulation of 1 million moving objects is performed. Average performance on random queries is reported. Memory usage, estimation time, I/O count, update time, and response time is evaluated. Results show that SIMkNN performs better in terms of memory and time efficiency as compared with baseline algorithm, MOVNet and IER-PHL.
Hybrid
[173] addressed the indexing issue with moving objects for KNN and range queries. The authors proposed a hybrid index based on both grid and R-tree based index structures to provide better performance on search, insert, and update operations. The proposed technique is scalable and robust. R-tree is used at root node and grid based index is used at leaf nodes to aggregate the benefits of the two indexing schemes. R-tree is beneficial for search operations whereas uniform grid based indices are efficient in processing update operations. To experimentally evaluate the effectiveness of the proposed index, comparison is made with R-tree and U-Grid based indices. The comparison is based on the response time of each of the indices with KNN and range based queries. CPU time utilized in update operation is also taken into consideration. Bucket size, node size, grid cell length, number of objects, and percentage of selectivity area is varied and the effect is analyzed. Datasets generated by Open source moving object trace generator (MOTO) are used in experiments. Findings indicate that the proposed solution is scalable with respect to varying number of moving objects.
In [146], authors proposed a GPU based parallel indexing scheme: G-PICS that supports concurrent query processing. The queries are grouped and assigned to a thread. G-PICS supports range query, point query, within-distance query, kNN query, and spatial joins. The performance is evaluated on two types of datasets: real and synthetic with 9.5 million data points each. Real dataset constitutes of molecular simulation of lipid bi-layer system. The data points in real dataset are uniformly distributed whereas synthetic data generated by Zipf distribution is highly skewed. The parameters involved in experimentation include speedup, processing time for range query, and percentage of moving data points. As per the results, the proposed scheme makes good use of resources of GPU by processing large datasets.
The paper [7] proposed an extensible index: SP-GIST supporting space partitioning trees. Space partitioning trees is a class of data structures that hierarchically divide the search space to disjoint portions. With one framework dealing with variety of tree structures is attractive from the database design view point. In this paper [7], common characteristics of spatial space partitioning tree based indices are studied to develop a framework that can represent various tree based structures and eradicate the complexities that hinder the adoption of such tree based structures in database engines. To enhance query performance, interface method named as Cluster is proposed. Three clustering algorithms are presented: fill factor clustering, deep clustering, and breadth clustering. To evaluate the proposed framework, extensions of PR quadtree, MX quadtree, Patricia trie, and trie are implemented. Results indicate that applying clustering techniques help in reducing the number of pages accessed.
In [154], authors proposed a quadtree based index that expresses location of each object as a sequence of bits. It uses a grid based hierarchical division of quadrant. Location of each object is represented with point of interest. Both kNN and range based search algorithms have also been presented. The proposed index is evaluated with both real and synthetic datasets. Real dataset consisting of around 39K data objects represented with MBRs is considered. Access and tuning time is evaluated by varying the size of data. The proposed index is compared with Hilbert curve based distributed spatial index and exponential sequence scheme. It is found that proposed binary index has fastest access time. Hilbert curve based distributed index performed worst among all.
The research works related to moving objects indexing differ from one another on the basis of type of index used (data structure followed in index design), dataset considered (real dataset/simulated workload), and mobility pattern followed. Table 5 provides a comparative view of solutions in the literature regarding moving objects indexing with regard to features: index type, dataset involved in evaluation of proposed index, and movement type supported by each solution.
Comparison of literature on moving objects query processing
Comparison of literature on moving objects query processing
(Continued)
In view of the above discussed literature, we have identified some research gaps and challenges in the design of index for moving objects. The challenges are discussed in detail later in the next section. First, it can be seen that both the spatial and spatiotemporal data have been explored well for indexing. However, these research works have not considered the read/write concurrency conflicts in detail. The effect of multi-user environment and concurrent read/write requests has been studied very briefly. Some research studies that have considered this consistency aspect have used lock based concurrency control schemes, that have an overhead of high latency due to locks. Especially, in case of moving objects, consistency is very critical to maintain because the objects continuously update their locations and proper scheduling of read/write operations is mandatory. Otherwise, inconsistent and outdated results might be reported. Most of the concurrency control protocols in the literature have been designed for static data, typically based on a flat transaction model of a relational database. The protocols proposed for conflict resolution (which is a core component in concurrency control solutions) can be divided into four categories: Pessimistic techniques (2PL) with variants, Optimistic concurrency control techniques with variants, hybrid of 1) and 2), and multi-versioning. Each of these categories has its own pros and cons. Pessimistic techniques have an issue of cascade of blocking and deadlocks. Optimistic concurrency control techniques overcome these issues but have a serious issue of resource wastage. Multi-versioning techniques do not seem fit for long running transactions such as spatial range queries as it results in an overhead of excessive versions. The management of large number of versions is a very challenging task. Therefore, the only feasible solution will be to have a hybrid solution of 1) and 2), covering positive aspects of these techniques. Second, mostly, tree-based indices have been used in which MBRs are used enclose moving objects. Overlapping in these indices has been identified as a very serious issue that can have a negative impact on consistency and performance. Due to overlapping, a single search or update operation might need to traverse multiple nodes of a tree, thus degrading the overall performance. Third, the amount of updates that must be performed as a result of change in object’s location must be reduced. In that case, previous obsolete location must be updated with the up to date location. Forth, it is important to note that majority of the contributions in the literature considered only small or medium sized datasets with few million data points only. However, most of the applications in today’s era have to deal with huge volume of data. Further, majority of the proposed indices have been evaluated on a single machine architecture. Evaluation in distributed environment is necessary to test scalability of indices. Fifth, in terms of data structure used in indexing, trees and grids have been used in the literature. Both these structures have their own pros and cons. The primary issue with tree based structures is the poor handling of updates. The reasons include expensive operations of split and overlap. Grid based structures, on the other hand, is better in terms of update performance. The idea of integrating these two data structures to implement the benefits of both of these structures has recently got attention in the literature. One such proposal is presented in [173], in which a hybrid index consisting of both tree and grid structures in its design is proposed. Tree based structure helps in achieving good search and query performance whereas grid based structure supports efficient updates. Sixth, the nature of movement considered in moving objects indexing is a very important aspect to consider. Many efficient solutions have been proposed but they only support movement of one of the entities (data object and query object) with the other one assumed as static. These indices are feasible for applications that have either static data objects and moving query objects or static query objects and moving data objects. Sample queries and applications of such scenarios have already been discussed in 3. However, many real life applications have dynamic data objects and query objects. To deal with such applications, solutions proposed in [59,132,135,230], and [175] can be utilized.
Challenges
Overall, five major challenges in continuous spatial indexing are highlighted from the existing literature. These are 1) maintaining consistency, 2) eliminating phantom updates, 3) enhancing performance, 4) avoiding overlap issue, and 5) reduction of updates. These are discussed as under:
Maintaining consistency
There are multiple isolation levels in data management systems to ensure isolated execution of simultaneous read/write. Serializable isolation level is the most protective of all that provides high protection for concurrent queries on one-dimensional data, but they are not optimal for spatial indexing due to underlying expensive locking techniques. Lock based concurrency methods end up in either locking the resource for long, or locking more resources than necessary. The lockable granules have a high overhead due to maintenance of locks. The lock duration must be minimized to improve the throughput. For example, consider the Fig. 6 in which objects are indexed by R-tree index. One solution to ensure consistent results would be to have the search and update windows place shared locks on leaf nodes, A and B. As both the leaf nodes share the object C, therefore another feasible solution would be to have object level locking. This could result in huge number of locks in case of high volume of data. For example, if the search query has to return 1 billion objects as a result, then it means 1 billion locks will be placed at the search time. Thus, no efficient concurrency control techniques exists to ensure serializable operations in moving objects’ indexing.
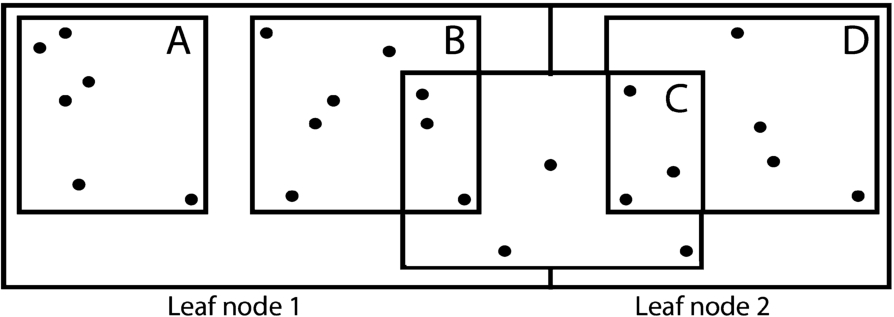
Lock-based concurrency control in R-tree index.
Phantom update is defined as an update operation occurring before the search operation commits, thereby returning inconsistent results. Consider an example of R-tree index in Fig. 7. A delete operation is performed on data points covered by object C as specified by update window, U. Objects that should be returned by search query window, S are C and E. However, as the delete is performed before the search commits, the deleted object C is also returned as a result. This update/delete operation is referred to as phantom update. One solution to this problem is to lock the area spanned by a update window U to stop search window from accessing the deleted object. In-existence of proper concurrency control measures causes incorrect results returned by a query due to phantom update issue. Figure 8 considers a scenario in which inconsistent results are returned by the query due to lack of concurrency control mechanisms in place. A vehicle S has to keep track of all the ambulances that are traveling within 2 miles range. The query is evaluated at two consecutive timestamps t1 and t2. Two ambulances (ambulance A and ambulance B) are initially traveling outside the query range of S. Ambulance A must be returned as a result at timestamp t2 if everything goes fine. However, if there are no concurrency control mechanisms adopted then this will lead towards following scenarios exhibiting inconsistent results.
Pseudo disappearance: The query returns null result if it is evaluated before ambulance A updates its new location after deleting previous one. Back order: Back order is an issue in which obsolete results are returned by the query. In this case, ambulance B or both ambulances A and B will be returned as an answer to the query.
These inconsistencies can be avoided if a well-designed concurrency control protocol is employed in query processing engine.
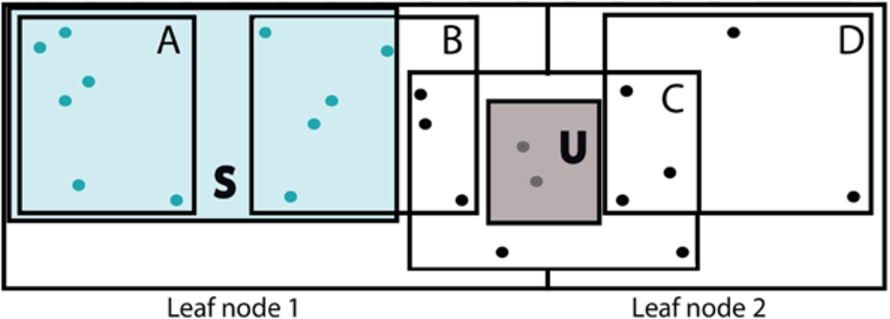
Inconsistent results due to phantom update issue.
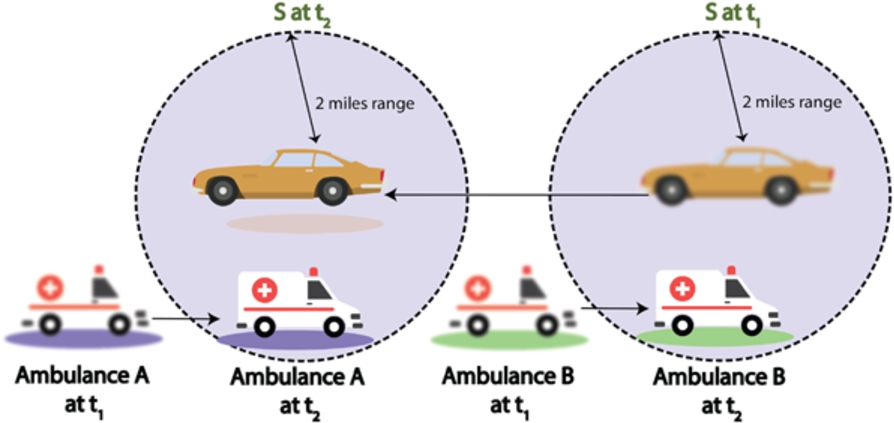
Phantom update issue in querying of moving objects.
Executing the results of a query in a parallel way can certainly result into high performance gain. However, lock-based concurrency control algorithms introduces difficulties to introduce parallelism in query solution. The queries and location updates occurring at the same time on the shared data item can give inconsistent results. With lock based concurrency control mechanisms, query has to wait for the update operation that holds an exclusive lock. This highly deteriorates the parallelism. Moreover, a long running query on one core introduces long idle period due to locks despite the available resources on other cores of a CPU. As a result of this, workloads comprising of queries and updates cannot scale well as the cores of a CPU will be under-utilized.
Avoiding overlap issue
Overlapping is major concern in evaluating a query performance in multi-dimensional index trees. Due to overlapping, a point query might need to go through multiple index tree’s branches if the point exists in an overlapped area.
Reduction of updates
Unlike static spatial objects, moving objects must have to update their old location with the new one. As the moving objects continuously change their position at each time instant, therefore constant updates are required to indexing structures that highly degrades the performance of an application. To overcome this challenge, pruning rules and effective algorithms must be designed that reduces the number of positional updates relevant to a moving object.
Design considerations
In this section, some important considerations that are relevant in the design of spatial index are discussed. The comparative view of some recent and potential research works related to indexing of spatial objects is provided in Table 6. The comparison is made with respect to some important design considerations. These design consideration are identified by reviewing the literature and assessing the important aspects related to management and processing of spatial data. We also identified the aspects that are crucial to the workflow of spatial query processing. After thorough analysis, we identified some spatial index design considerations. These design considerations have been discussed in the next sub sections. The motivation for considering these design features is also discussed along with. The relevant research works are also cited that discuss the respective design feature and its significance. This weighs the reliability of our feature selection and justifies the need for considering these design features during spatial index design. The comparative review helps in identification of research gaps for doing research in the domain of spatial indexing.
Comparison with regard to index design considerations
Comparison with regard to index design considerations
(Continued)
As previously discussed, the read/write conflicts must be resolved during spatial query processing to obtain consistent results. The spatial index must have concurrency control protocol embedded to ensure consistency. The core aspect in concurrency control protocol’s design is conflict resolution. It can be divided into four categories: Pessimistic techniques (2PL) with variants, Optimistic concurrency control techniques with variants, hybrid of 1) and 2), and multi-versioning. Pessimistic techniques have an issue of cascade of blocking and deadlocks. Optimistic concurrency control techniques overcome these issues but have a serious issue of resource wastage. Multi-versioning techniques do not seem fit for long running transactions such as spatial range queries as it results in an overhead of excessive versions. The management of large number of versions is a very challenging task. Therefore, the only feasible solution will be to have a hybrid solution of 1) and 2), covering positive aspects of these techniques. The need and significance of concurrency control measures for spatial indexing has been discussed in [35] in which phantom update issue, occurring due to simultaneous query processing has been explained. A concurrency control method is proposed for R-tree based spatial index..
Read/write conflicts
When multiple spatial queries run, there is a chance of conflict among them. The conflict is resolved using various schemes such as blocking or use of time stamps. It is also important to note whether the conflicting transaction (or query operation) is read or write. This is closely related to the semantics of query results and their consistency. Handling of conflicts among two read queries is different and more critical as compared with that of read write query pair. Because, the updates made by the write operation must be made visible to the simultaneous read operation to ensure consistent results. These conflicts must be minimized in the designed spatial index.
Spatial query operation
The multidimensional spatial queries are more complex to handle as compared to one dimensional queries. As discussed earlier, there are three categories of spatial query operations: distance, direction, and topological. Various spatial querying methods specific to these query categories have been proposed in the literature. Various indices have also been designed keeping in view the particular spatial query operation such as nearest neighbor query. The spatial index calculates and stores the shortest paths to various data points and query points. It is important to note that calculating these shortest paths is of no use in range based query operation. Thus, the working of spatial index has to be adjusted according to particular query operation under focus. For example, [92,95], and [83] have proposed indices that can handle range queries only. Method proposed in [17] works only for kNN queries. However, in [173], algorithms for both range and kNN queries have been proposed.
Geometry/dimension of data
The core aspect in the design of spatial index is the structure of geometry and dimensions of spatial data with respect to which the spatial index is to be designed. It is highly important to consider this factor as the overall structure and working of spatial index is dependent on the nature of spatial data. For example, the index designed to query data points will not work to query the regions and line-oriented data such as a road path. Thus, it is very important to consider this factor while the design of spatial index. For example, the index proposed in [17] assumes that the data model consists of multi-dimensional points and moving objects do not have any extent. This index cannot at any case store and process moving objects with some extent such as polygons. To deal with polygons we need indices that have been proposed specifically for polygons, e.g. [83].
Nature of movement (data object and query)
For moving data objects, the three possibilities of movements as described earlier are important to consider. One index designed with regard to moving data objects and static query objects cannot be used to support the querying of moving data objects and moving query objects. Thus, while designing a spatial index for an application. All the possible movements must be taken into consideration in index design. The various possibilities of movement of objects along with real life application scenario is illustrated in Table 3. For example, [173] proposed an index for scenario with static data objects and moving query objects. As this index assumes that data objects will not move, therefore location updates for data objects will simply be ignored. This will cause the queries to report inconsistent results with this index. Thus, this index will only work in scenarios where we have static data objects. If the environment has moving data and query objects then indexing solutions that have a support for it must be considered, e.g. [135].
Data model (past trajectories/current locations)
Data model is the essential component in data processing and management. The whole semantic of a spatial query is dependent on the underlying data model. The justification for considering this feature while index design is the same as we discussed for the geometry of data. The extent of spatial object changes the way it is stored and managed by indexing structure. Apart from extent, timeline of queries also heavily affects the design of index. Specifically, in case of query processing with moving objects, the timeline of movement of these objects is very relevant to focus on. For example, if we consider historical data of moving objects, then this data will be in the form of trajectories represented with lines and object identifier. On the other hand, the current location data of moving objects will have longitude and latitude locations with associated timestamp value and object identifier. Thus, the structure of index will highly be dependent on the data model. This must be evaluated while designing of a spatial index.
Scalability
The designed query processing algorithm or index must be able to deal with massive data and scalability demands of an application. The increase in amount of data inserted must not cause the insert operation’s performance to degrade. The problem of scalability has been studied with regard to scalable incremental query processing [131,132,230], and [142]. The solutions proposed use a shared execution mechanism or a moving object grouping mechanism to reduce usage of resources. However, the challenge of scaling to multiple servers is not considered. Moreover, the incremental processing seems inappropriate in terms of performance considerations.
Skewness
It is a well-known fact that moving objects have a skewed distribution [107,255], and [193]. If we use a grid based index, then the capacity of cells in a grid structure varies significantly that deteriorates the performance of a query processing algorithm. Consider an example of 4KNN query initiated by query point q. S0 depicts the search space initially explored. This grid encloses only two set of points p1 and p2. The search space needs to be expanded to fetch the other two closes points apart from these two points. When we expand the search space to S1, the network/Euclidean distance must be found from 15 points. Thus, for processing 4KNN query we need a large number of distance calculations which is very expensive computationally. If we can reduce the grid cell size then we will end up in minimizing the number of nearest neighbor calculations. But, this increases the number of grid cells. We have to consider the tradeoff between query performance and storage usage while designing a spatial index.
Communication cost
For both tree and grid like structures, there is a communication mechanism that is initiated whenever a merge/split operation occurs on a cell or a node. Whenever a new cell or a node enters or leaves during these operations, the neighborhood must be updated about it. While designing a spatial index, this cost incurred during neighbor communication must be evaluated. Strategies must be designed that can help to improve the performance and minimize the communication cost. It should be noted that communication cost overhead is not only associated with node split or merge operations. The communication aspect goes along all the phases of query processing such as parallel data broadcasting, parallel query processing, intra-cluster communication, grid cells’ communication, and communication during location updates. For instance, when the data and query objects move, they have to communicate with the server to send their location updates. Thus, the focus should be to reduce the overhead of communication happening at any phase of spatial query processing. The problem of minimizing the communication cost while spatial query processing has been discussed in [17].
Overlap
Overlapping is major concern in evaluating a query performance in multi-dimensional index trees. Due to overlapping, a point query might need to go through multiple index tree’s branches if the point exists in an overlapped area. [35] discussed the overlapping issue and proposed a spatial index with zero overlap (ZR-tree).
Parallelism
To cater the massive amount of spatial data, there is a need to exploit the modern computational hardware by employing parallelism to increase the performance of a query. Some recent research works, [95,114,185,187], and [48] have discussed the need for parallelism and proposed parallel spatial indexing methods.
Research opportunities
The domain of spatial data processing can be classified into two groups: modeling and querying. In data modeling sub group, the existing works revolve around proposing a new query language mapped to a real life scenario or designing a better moving object’s location prediction function. For example, in [260] range query based on complex shaped obstacles in environment has been proposed. In the second sub group, the focus is primarily on designing an efficient query processing algorithm or index. Some important research opportunities are discussed as under:
Propose an efficient algorithm or pruning rule (such as safe region techniques) that can cater all the possible movements of data and query objects. This will help in reducing the amount of updates required when the object moves. As discussed earlier, the proposed indices are not evaluated with regard to read/write conflicts. It is therefore significant to incorporate read/write conflict resolution mechanisms in the indexing algorithm designed. This can be done by mapping the existing concurrency control solutions in the literature to the spatial indices. Majority of the indices designed till date have been evaluated on small datasets on a single machine. However, considering the dynamic nature of spatial data and big data characteristics, it is very important to evaluate these indices for huge data volume in a distributed environment to highlight and test their scalability. Parallelism is an effective tool to speedup the response time of any algorithm. At hardware level, parallelism can help to equally utilize all the cores of the system. In the domain of spatial indexing, parallelism can help in meeting the challenges of high update cost and excessive computations. It would be an interesting work to parallelize the spatial indexing solution and overcome the challenges previously discussed and highlighted in this paper.
Conclusion
IoT has gained prevalent attention across the globe. It consists of billions of sensors and devices connected through the Internet to acquire, process, manage, and analyze data. Integration of geospatial technology with these sensors has transformed the ways of data processing and management. The use of these sensor nodes and mobile devices has been backed up with issues such as limited network bandwidth and energy consumed by these devices. Thus, the real time spatiotemporal data processing need to use indexing mechanisms to minimize the overhead of extensive query processing. In this paper, we performed a detailed survey of the literature regarding the indexing of real time geospatial data generated by IoT devices. After a thorough review of literature, some major challenges relevant to query processing and indexing of moving objects are highlighted. Various important index design considerations are discussed in detail. The goal is to help researchers in understanding the principles, methods, and challenges in the indexing of real time geospatial data. This will also aid in identifying the future research opportunities.