
Abstract
Research at the Interaction Lab focuses on human-agent communication using conversational Natural Language. The ultimate goal is to create systems where humans and AI agents (including embodied robots) can spontaneously form teams and coordinate shared tasks through the use of Natural Language conversation as a universal communication interface. This paper first introduces machine learning approaches to problems in conversational AI in general, where computational agents must coordinate with humans to solve tasks using conversational Natural Language. It also covers some of the practical systems developed in the Interaction Lab, ranging from speech interfaces on smart speakers to embodied robots interacting using visually grounded language. In several cases communication between multiple agents is addressed. The paper surveys the central research problems addressed here, the approaches developed, and our main results. Some key open research questions and directions are then discussed, leading towards a future vision of conversational, collaborative multi-agent systems.
Keywords
Introduction
Conversational interaction in Natural Language between humans and artificial agents is a long-standing goal of AI research, depicted in popular culture in many different ways, ranging from HAL to C3PO, and beyond. One of the first and most well-known conversational systems was ELIZA [69], a text-based psychotherapist bot, developed in the 1960s. Since then, conversational systems research has flourished and become a mainstream aspect of real-world applications of AI, with deployed speech systems such as Siri, Alexa, and Google Assistant. While these deployed real-world systems are not (yet) great conversationalists, since they often fail to maintain context and coherence over multiple dialogue turns, current research attempts to make such systems more useable, more natural and human-like, more accurate, and safer. While most conversational systems have been built with 2 agents in mind (human and AI), recent work also explores how to extend methods to multi-agent settings, for example several humans interacting with a robot, or a human interacting with multiple conversational agents, for example in a smart home. In addition, recent efforts attempt to make such systems multimodal, situated, and embodied, meaning that they should be aware of visual and spatial aspects of the interaction context. This paper will outline the main research challenges and approaches in these areas, focusing on recent work at the Interaction Lab,1
Interaction Lab website:
Broadly, conversational AI research can be broken down into several types of systems, each generating a collection of related research questions:
Goal-driven cooperative communication: humans and agents need to coordinate on shared tasks, driven by the human’s goals e.g. book a flight, find a restaurant, get information.
Situated and embodied communication: humans and agents coordinate to complete tasks within a shared visual and spatial environment e.g. a robot directing people around a building, a smart camera finding an object for a partially-sighted person.
Social open-domain conversation: general conversation about topics of interest (movies, music, news, etc). This is not driven by any specific task goal, other than user engagement, information provision, and entertainment. See for example the open-domain conversational system Alana, in Figure 1.

This paper will largely focus on the first two types of system and the research problems and directions that they generate, as they are most closely related to research in Multi-Agent Systems.2
See [11] for our work on social open-domain conversation.
In general we model each human conversation partner as an agent which has goals, plans, and preferences, and which can send signals (usually Natural Language speech or text3
Though sometimes also gesture and facial expressions etc.
The computational agents involved in the conversation then need to decode sequences of signals from humans to infer goals, plans, information needs, and so on. They then need to decide what to say or do next in the interaction, and they need to encode their decisions in Natural Language4
Combinations of language with gestures, movement, graphics etc are also considered in work on multimodal output generation.
More recently NLU is sometimes called “semantic decoding’ or “intent recognition’, context maintenance and updating aspects of DM are sometimes called “state tracking”, and NLG is also sometimes called “Response Generation”.
This paper will introduce research results and perspectives developed at the Interaction Lab, related to each of these topics.
The Interaction Lab was founded in 2009 at the Department of Computer Science, Heriot-Watt University, Edinburgh, Scotland. We also work with the recently formed National Robotarium within the Edinburgh Centre for Robotics (ECR). The group currently consists of 8 faculty, 8 postdoctoral researchers, and 16 PhD students. We are well-known for pioneering machine learning approaches in several different aspects of conversational AI, dialogue systems, and human-robot interaction. In particular we were one of the main groups working on Reinforcement Learning approaches to dialogue management and Natural Language Generation [24,38,51] – methods which have now become widespread. We have been involved in a number of EC projects developing machine learning approaches to conversational AI (FP6 TALK and CLASSiC) and human-robot interaction (e.g. FP7 JAMES, H2020 MuMMER, H2020 SPRING), and researchers in the Interaction Lab also work in the EPSRC ORCA Hub in Robotics and Autonomous Systems, which explores trust-worthy, interpretable, and explainable AI. We were also twice finalists in the Amazon Alexa Prize (2017, 2018), deploying an open-domain social conversational system to millions of Alexa users in the US for 2 years.We work with several robot platforms (ARI, Furhat) for HRI research, as well as smart speaker systems (Alexa, Google home etc), within a purpose-built instrumented experimental space. In terms of industry collaborations and applications we have worked with Amazon, Google, Apple, PAL Robotics, Softbank Robotics, France Telecom, and BMW, amongst others. The Interaction Lab works closely with its spin-out company Alana AI,6
Alana AI Ltd:
The research questions addressed in our work fall into the following broad areas, often associated with the particular processing modules (e.g. language understanding, dialogue management, language generation) needed to build a working conversational system (see below). In general, our deployed systems necessarily address all of these problems. As well as developing modular approaches, we also build end-to-end systems as described in e.g. [18,62]. Specific projects often focus on one of more of the following research areas:
Data collection and annotation
This work involves collecting audio, video, or text examples of human-human or human-machine interaction behaviour in the domain or task to be modelled, and is often a necessary pre-requisite to developing a system, although it may be possible to use existing datasets of which there is an increasing number [55,66]. The data collected is generally used to train models and develop components for Natural Language understanding and generation, and dialogue management, or sometimes to build simulations in which to train7
User simulations are also useful in avoiding expensive and time-consuming evaluations with real users, although real-user evaluations are always the ultimate test of developed systems and modules.
Research here also involves analysing and sometimes transcribing and/or annotating data for specific interactive phenomena of interest (e.g. negotiation, gaze, gesture, interruptions, pauses, disfluency, feedback, clarification ....) [76]. Designing effective data collection methods is a key topic [46], and “Wizard-of-Oz” data collection setups are often deployed where a hidden operator controls a system or robot in order to elicit complex interactions.
This research area involves building semantic decoders – models which mapping from Natural Language user input to a formal meaning representation for use in state tracking and dialogue management (e.g. “I want to fly to Paris” could map to a formal representation such as
In recent deep learning end-to-end approaches these sorts of explicit intermediate semantic representations are not used, and mappings are directly learned between input sequences (user utterances) combined with context (encodings of previous turns of the dialogue), and output sequences (system utterances). Here, semantic representations are distributed in hidden layers of deep neural networks, and a number of important research questions concern the properties of such representations [64].
State tracking
This topic concerns the representation and updating of dialogue or interaction state [70], which can contain several types of contextual information on which Dialogue Management decisions can later be made. State information usually includes representations of user goals (perhaps with confidence scores due to uncertainty in both speech recognition and/or NLU [21]) and can also contain aspects of interaction history (e.g. mentioned topics or entities, agreed information so far, open questions, etc). If using Reinforcement Learning approaches to dialogue management, the state must be encoded in a suitable manner [24]. An accurate representation of state needs to be maintained as new information and observations accumulate [68]. Again, in recent deep learning approaches, no explicit state representation is developed, and the state information is encoded using sequences of prior turns in the interaction [10,62,65].
Dialogue Management (DM)
Dialogue or Interaction Management concerns the decision of ‘what to say’ next in an interaction, based on the current state [34], in order to achieve an end goal. This is generally a mapping (either learned, or designed using rules, or approached using planning) from dialogue states S to dialogue acts A. For example the system could in some states decide to explicitly confirm the user’s destination – a dialogue act such as
Natural Language Generation (NLG)
The decision of ‘how to say it’ [34] in Natural Language (sometimes including gestural or graphical output) given a dialogue act chosen by the DM. For example mapping
Evaluation
Here we develop datasets, methods, and metrics for evaluating performance of each of the above processes and modules, or of full end-to-end systems, or of deployed systems with end users. We have been involved in or have driven community-wide benchmarking shared tasks such as the Spoken Dialog Challenge [6], Dialogue State Tracking (DST) shared tasks [68], and the End-to-end NLG challenge (E2E-NLG) [18].
Evaluation can involve comparison against benchmarks [40], the development of new evaluation metrics and frameworks for evaluation [64], online and/or in-situ lab-based experiments [9,26] with e.g. smart speakers [11], multimodal interactive systems, or robots [30,44]. For evaluations of deployed systems we generally use efficiency metrics based on a combination of full or partial task completion (e.g. did the user book the right flight?/choose a suitable restaurant?/select the correct object in an image?, etc) along with some penalties for dialogue length, repetition, and errors of various types. However for social open-domain dialogue systems longer dialogues are generally considered to be better as they show more engagement from the user [11,56].
Main approaches and key results
The main approaches pursued in the Interaction Lab concern the following key themes and methods:
Machine learning models of language processing
Most of our projects involve the development of statistical machine learning approaches to the research questions described above. For example we learn mappings from Natural Language to meaning representations [5,32,40,67], and statistical models for Natural Language Generation (NLG) [18,27,53] and Dialogue Management (DM) [24,52,53,56]. An important concern is to build data-efficient methods for learning goal-oriented conversational systems from small amounts of data [19,58,59].
We have generally used features from representations of the dialogue context (i.e. what has already been said in the conversation) as additional signal for model training and decision-making. One example of this is re-ranking speech recognition or semantic interpretation hypotheses based on predicted next dialogue acts from the user (e.g. based on the context, are we expecting a question or an answer?) [36]. Another example is using context to re-rank possible system responses – either at the level of DM or NLG decision-making [56]. A particular recent focus is on the use and adaptation of large pre-trained vision-and-language models in interactive systems [63,65].
Reinforcement Learning (RL) for DM and NLG
In particular, we have explored and developed the use of RL methods for decision-making in interactive systems. Decisions can be made at the level of dialogue acts [24,34,52], words [18], gestures, or robot actions, or combinations of these [28]. We have also used Deep RL for learning communication policies in strategic non-cooperative games8
See the STAC project
Since RL requires large amounts of data for training, a particular focus has been on the development of simulated users for training and testing RL policies. This work ranges from rule-based to statistical simulations of user behaviours [52]. We also developed a simulation for multi-agent conversation in [29]. Evaluation of user simulations is also a key topic [49].
Incremental processing
Human language is produced and understood word-by-word (it is ‘incremental’), and people can interrupt each other and even complete each other’s utterances. However, most systems need to wait until the perceived end of a user utterance (which is often not accurate since humans often pause mid-utterance) before they start processing its meaning or deciding on a next action. As well as increasing latency in a system, this is not natural or fluid dialogue behaviour for humans. Related to this, spontaneous human language production is often disfluent – it contains many fillers (um, er, uh etc), pauses, re-starts, and repairs. We therefore work on incremental language processing in understanding and generation, and the handling of disfluencies [57], often using the framework of Dynamic Syntax [2,19].
Vision and language
A recent research focus has been on systems that include visual as well as linguistic information in the interaction, and which in some cases learn visually-grounded word meanings [61,64,65], seeking to address the classic ‘symbol-grounding’ problem of AI [23]. Such setups are also known as ‘multi-modal’ interaction systems, as they combine the information modalities of language and vision. Figure 2 shows an example of a recently-developed deep learning model for learning visually grounded language [65]. Researchers in the Interaction Lab have shown that previous work on so-called ‘Visual Dialog’ does not really require taking dialogue context into account, and proposed new visual dialogue datasets where linguistic context matters [3]. We are currently working to further develop interactive systems for learning grounded language, for example within the 2022 Amazon Alexa SimBot challenge [47,63].
Assistive visual conversational systems for blind and partially sighted people
We have developed several conversational systems where the interaction context includes visual and spatial information about objects and people. This allows us to create conversational systems which can assist blind and partially sighted people to find objects and access descriptions of places and scenes [4]. We have also developed interactive robots with the same capabilities [48]. Our spin-out company Alana AI is developing a visual conversational system for blind and partially sighted people in collaboration with the RNIB (Royal National Institute for the Blind).
Interactive visual language learning
We have developed self-play approaches to learning visually grounded language from data [65] as well as approaches that use conversational feedback from humans such as repairs (“no that is not red it’s blue”) to learn grounded word meanings [75]. In future human interactions with robots and smart devices, the ability to learn from such conversational feedback will be crucial [35]. Conversational feedback provides fine-grained signals which van be used to coordinate tasks and recover from mis-understandings, as well as in teaching agents the meanings of words.
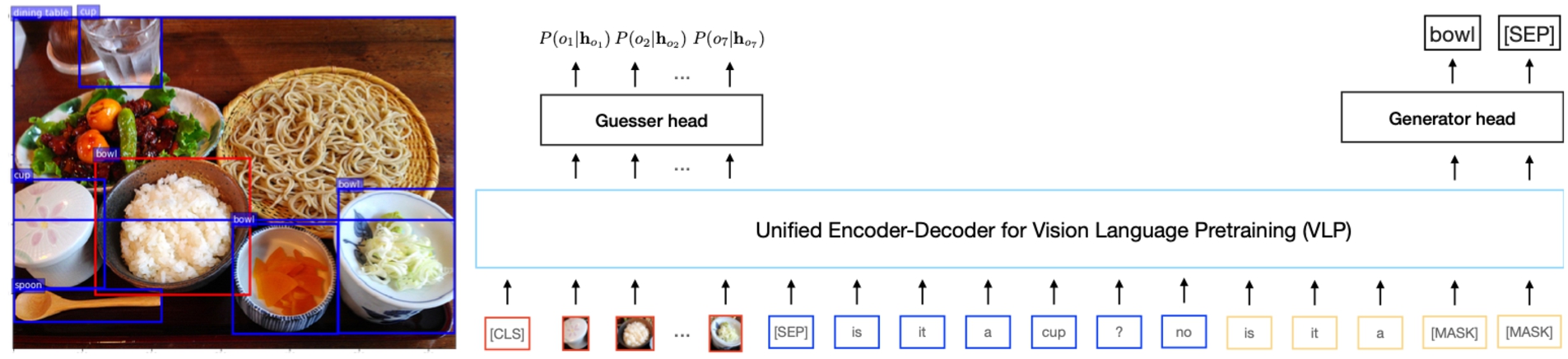
Example of a vision-and-language conversational learning system (SPIEL) from [65]. Visual and conversation context (red, blue, yellow signals) are input to the VLP model. The Guesser head computes a probability distribution over possible target objects given the input, and the Generator head generates output language tokens word-by-word for an agent asking questions to find the target object e.g. “is it a bowl?”
Many of our systems are developed with HRI use cases as their ultimate goal. These systems involve multimodal information in interaction, for example considering user gestures and facial expressions as well as speech [44], and they are situated and embodied, meaning that visual and spatial information must be considered [48]. Some systems involve multiple humans, meaning that multi-agent social information and decision-making needs to be modelled.
For example, the JAMES project developed a robot bartender, and focussed on multi-user social interaction such as managing queuing behaviour [28]. The MuMMER project developed a socially entertaining conversational robot for single users at a time, adapting our Alexa Prize system Alana [11] on a Pepper robot (see Fig. 1) in a shopping mall scenario, and it was also able to give spatial and visual directions involving gestures as well as speech [20]. The SPRING project currently works on socially intelligent HRI in a multi-user scenario, in the context of a hospital waiting room. Here we deal with visual dialogue about the room (where to sit, lost objects etc) [48] as well as multi-party conversations tracking the individual goals of different users (e.g. one needs a coffee, another wants to check in) within the interaction context. The NLU, DM, and NLG processes then need to consider multiple agents in combination (see Section 4.1).
Ethical issues: Safety and factuality in language generation and conversation
Recent years have seen the exploration of large language models such as GPT-3 for generation of linguistic output in conversational systems. However, such models are known to hallucinate information, provide non-factual information, and encode various types of negative bias – providing serious ethical barriers to real-world deployment. Researchers in the Interaction Lab therefore work on methods to enhance the safety of such models [16]. In particular work on summarization and data-to-text generation seeks to make NLG systems more accurate and controllable [73]. On the other hand, human users can often be offensive towards conversational agents, and researchers in the Interaction Lab also work on ways to handle this, relating to the design of conversational personas [1].
Embodied interaction
Related to visual and spatial systems, as well as to HRI, we need to take into account conversational interaction with embodied systems which can take actions on objects situated in the world. We have developed methods that allow for conversationally interactive monitoring, negotiation, and execution of plans and activities with duration and resource use [17,37]. More recently, researchers in the Interaction Lab have developed deep learning systems such as ‘Embodied BERT’ (EmBERT) [62] which combine video streams and language to learn grounded language and action execution. Related to this work, we are currently the only European team participating in the Amazon Alexa SimBot challenge9
We also work on fundamental issues regarding how the performance of various conversational AI models, modules, and whole systems should be evaluated. For example researchers in the Interaction Lab have proposed new evaluation methods and metrics for NLG [18,45,72], user simulations [49], open-domain conversation [11,71], and visually grounded language learning [64]. In general, the proposed NLG metrics seek to better measure accuracy and faithfulness with respect to source documents or data-structures, reducing “hallucination” of false or unsupported information. Work on metrics for open-domain conversation seeks to promote coherence, diversity, and the user-engagement of the conversations. Our work on visually grounded language learning proposes a multi-task evaluation framework [64] where aspects of learned representations such as attribute learning, generalizability, and compositionality are also evaluated as well as task performance.
Open problems/future work
We next survey some of the open research directions that researchers in the Interaction Lab are pursuing in conversational human-agent interaction.
Multi-party and multi-agent interaction
As mentioned above, the great majority of work on conversational AI has focused on bi-lateral interaction, between a human and a system. However, this perspective has broadened in recent years, with some recent work on multi-agent conversational interaction. We have worked on so-called “multi-party” dialogue systems, where a computational agent needs to interact with two or more humans (see [7] for some of the earliest work on this problem). Such a system cannot simply be modelled as several bi-lateral systems running in parallel, since there are important interactions between the humans (discussed below) which the system will need to track accurately – for example maintaining dialogue states not only for each individual but also representing information which has been agreed between them, or is still under discussion. There are several important research problems to be addressed here:

Example of a simulation environment for data collection and evaluation: the SimBot challenge using the TEACh dataset, from [47]. An Instructor (top) guides a Follower (with egocentric perspective in the main window) in a realistic 3D home environment to complete tasks such as “put all the forks in the sink”. Our EMMA system competes in this challenge [63].
Multi-party and multi-agent data collections – for model development and training we need to collect significant amounts of realistic data on multiple humans interacting with conversational systems, or more generally, mixtures of AI and human agents collaborating on tasks. This is more challenging than standard bilateral conversational data collections, since humans (and AI agents) may have conflicting or complementary tasks, goals, and information. For example we have recently designed a multi-party wizard-of-oz data collection with 2 humans and an ARI robot, where the humans can have shared goals (e.g. both want a coffee), or complementary information (e.g. A wants a coffee and B knows where the cafe is), or even conflicting information (e.g. A thinks the next meeting is in room 15, B thinks it is in room 17). Such considerations require careful design of tasks and methods to elicit natural, spontaneous, and complex multiparty dialogue phenomena. Recent online tools such as SLURK [22] also support multi-party data collections.
Speaker diarization: “who is saying what”? – the problem of determining which human is speaking. Speech recognition systems are able to perform speaker recognition to some level of accuracy but multimodal information may also be used to assign speech signals to a particular speaker. Researchers in the Interaction Lab have recently performed an evaluation of current speech recognisers to perform this task [2].
Multi-party NLU and addressee identification: “who did they say it to?” – once we know who said what, we need to determine which agent the utterance was addressed to. This can sometimes be explicit in the speech signal (“Jimi can you pass me the guacamole?”) but can also be signalled by gaze, body pose, and gesture (I look at Jimi, point towards the table and say “Guacamole please?”). Utterances can also be broadcast to multiple people, or overheard by people that were not addressed – and in such cases the content of the utterance still updates their dialogue states.
Incrementality: a challenging further aspect of multi-party NLU is that humans can complete each other’s utterances. For example, in a hospital waiting room scenario from the SPRING project10
See
Multi-party state tracking: “Who has which goals and information? What is agreed so far between participants? What issues are under discussion?” – Following on from speaker diarization and NLU, multi-party state tracking needs to maintain an accurate representation of each individual agent’s goals, plans, and information. Moreover, new representations need to be built and tracked for issues which have been agreed between 2 agents (or between a group of agents), and issues which are still ‘live’ in the conversation. For example Patient and Companion may have agreed that they both want a coffee, while a new person just joining the conversation will not be aware of this context. A conversational system needs to track all of this state.
Multi-party DM and turn-taking: “Who is going to speak next? What should I say? Who should I say it to?” – as well as the state tracking aspects described above, a key aspect of state for interaction management with multiple agents is turn-taking i.e. who gets to take the conversational floor and how this turn-taking is managed and signalled. This is due to the constraint of there being only one audio channel resource available for signalling. Sometimes the current speaker will explicitly signal who the turn is being passed to (“Jimi do you know?”). Speakers can also bid for the floor and try to take the next turn though gaze and gesture. These aspects of multimodal turn-taking are very challenging and the community is only beginning to work on them. Further aspects from the DM decision point of view are whether or not to remain silent and allow others to speak, and who to address when speaking.
Social behaviours: related to the above multi-party DM decisions, social behaviours in turn-taking sometimes need to be modelled. For example, in the JAMES project,11
Multi-party simulations – in order to train and test models without expensive and time consuming human interactions and evaluations, we will need facilities to simulate realistic multi-party user behaviours. This will involve extending bilateral approaches, such as in the Multi-User Simulation Environment (MUSE) model of [29], using tools and methods such as [60] or [31].
Multi-party NLG – conversely to NLU, we will also need to ensure that system NL output is adapted to be able to explicitly address one or more humans, and there may need to be additional verbalisations to handle turn-taking and interruptions (e.g. “Excuse me, I think I know where you can get a coffee”). Template-based approaches to NLG can be fairly easily adapted on a case-by-case basis, but more general learned response generation models will require more extensive collections of multi-party training data.
The considerations mentioned in Section 4.1 are important for multi-agent communication consisting of a single agent and multiple humans, but some different issues arise when we consider multiple agents interacting with humans. Possible scenarios for such communication could be multiple autonomous vehicles, or smart home devices, which communicate amongst themselves (perhaps in some inter-agent protocol) but where there are also practical, legal, and/or ethical requirements for explainable AI such that humans be kept “in the loop” regarding their information and/or decisions.
Here some aspects of the agent-agent communication will need to be transparently communicated to the humans (e.g. if the agents have adopted a plan or collated some information which the humans need to be informed of [37]). In some simple cases this could be done by visual or gestural means (e.g. indicator lights on vehicles) but in general we will need mechanisms for agent-agent communication to be ‘translated’ into Natural Language. This perspective implies that at least some agent-agent communication must be explainable in Natural Language, and some recent research begins to explore this possibility [33,35].
New data collections for multi-agent conversational collaboration
A central reason for the lack of work on conversational collaborative interaction in multi-agent systems is that current datasets do not contain semantic coordination phenomena of the type that will allow such skills to be learned. This is because (as argued by [8,25,35,41,54]) these datasets do not focus on agents with different goals and/or knowledge of the task that needs to be coordinated. The few exceptions, such as Cups [41] and MeetUp [25], have only small volumes of data, and almost no datasets go beyond pairs of agents. Moreover, while work on visually grounded language learning commonly uses shared real images [14,61], prior work on coordination in conversational grounding in visual tasks (such as [75]) has almost exclusively used simulated, artificial, and abstract data (e.g. using abstract shapes [39,43,77]). Note that the ‘Visual Dialog’ work of [12] does use agents with different visual information (one agent can see the image, one cannot) but there is no shared task here, making the whole dataset problematic [3,42].
Further, AI systems trained and tested only in simulation and on abstract images may not transfer well to real-world use cases – the ‘sim-to-real’ problem [15]. Therefore, an important first objective for our future work is to collect new data and create shared tasks in more realistic environments and to ensure that results and models are ecologically valid [13], i.e. involving more realistic tasks such as [47] which should better transfer to real-world settings. This argument is further developed in [35].
Conclusion
This paper surveyed the main research questions in conversational AI in relation to multi-agent interaction, which are being explored at the Interaction Lab. We first described the key concepts and research questions in such work, ranging over Natural Language Understanding, State Tracking, Dialogue Management, and Natural Language Generation, and we also described key research questions in data collection and evaluation methods. We then surveyed recent research methods and results from the Interaction Lab, involving the development of machine learning approaches for Natural Language Processing, visual conversational systems, grounded language learning, incremental language processing systems, end-to-end NLG, explainable AI, and safety. Along the way we briefly described several of our deployed systems, for example the Amazon Alexa Prize system ‘Alana’ and several embodied human-robot conversational systems in the social robots of the JAMES, MuMMER, and SPRING projects.
We then focused on conversational AI issues that are most important from a multi-agent point of view, specifically the issues involved in ‘multi-party’ conversational systems and our approaches to them.
In terms of our future perspective on important open challenges related to multi-agent systems research, we highlight two main areas: embodied conversation with visual context, and multi-agent communication in Natural Language. We are ultimately working towards systems where humans and AI agents (including embodied robots) can spontaneously form teams and coordinate shared tasks through the use of Natural Language conversation as a flexible and transparent common communication interface.
Footnotes
Acknowledgements
This work is partially funded by the EU Horizon 2020 program under grant agreement no. 871245: the SPRING project.![]()