
Abstract
Semantic Web services frameworks provide the means to automatically discover, rank, compose and invoke services according to user requirements and preferences. However, current preference models offer limited expressiveness and they are tightly coupled with underlying discovery and ranking mechanisms. Furthermore, these mechanisms present performance, interoperability and integration issues that prevent the uptake of semantic technologies in these scenarios. In this work, we discuss three interrelated contributions on preference modeling, discovery optimization, and flexible, integrated ranking, tackling specifically the identified challenges on those areas using a lightweight approach.
Introduction
Semantic Web Services (SWS) have become a widely studied research area, where various underlying frameworks, e.g. WSMO or OWL-S, define semantic Web ontologies to describe Web services, so that they can be automatically discovered, ranked, composed, and invoked according to user requirements and preferences [5]. Specifically, several service discovery and ranking techniques have been envisioned, and related tools have been made available for the community. However, existing approaches offer a limited expressiveness to define preferences that are highly dependent on underlying techniques. Furthermore, discovery and ranking mechanisms usually suffer from performance, interoperability and integration issues that prevent a wide exploitation of semantically-enhanced techniques.
In order to address these issues, current research focus is on developing lightweight SWS descriptions, which enable interoperability of existing approaches, and corresponding discovery and ranking solutions that offer a better performance with a contained loss on precision and recall. In this work, we address those challenges by proposing SOUP, a fully-fledged preference ontological model that serves as the foundations for the development of lightweight tools, namely EMMA and PURI, to both improve discovery performance and integrate current ranking proposals, correspondingly. A more detailed description of our contributions and their evaluation can be found at [1].
Contributions
The main objective of our research work is to improve SWS discovery and ranking processes, focusing not only on conceptual aspects enabling user preferences modeling and interoperability, but also on implementation level improvements, regarding performance, scalability, and integrability of discovery and ranking mechanisms. Therefore, we developed three interrelated proposals that led to the lightweight, integrated architecture shown in Fig. 1 that tackles these challenges.
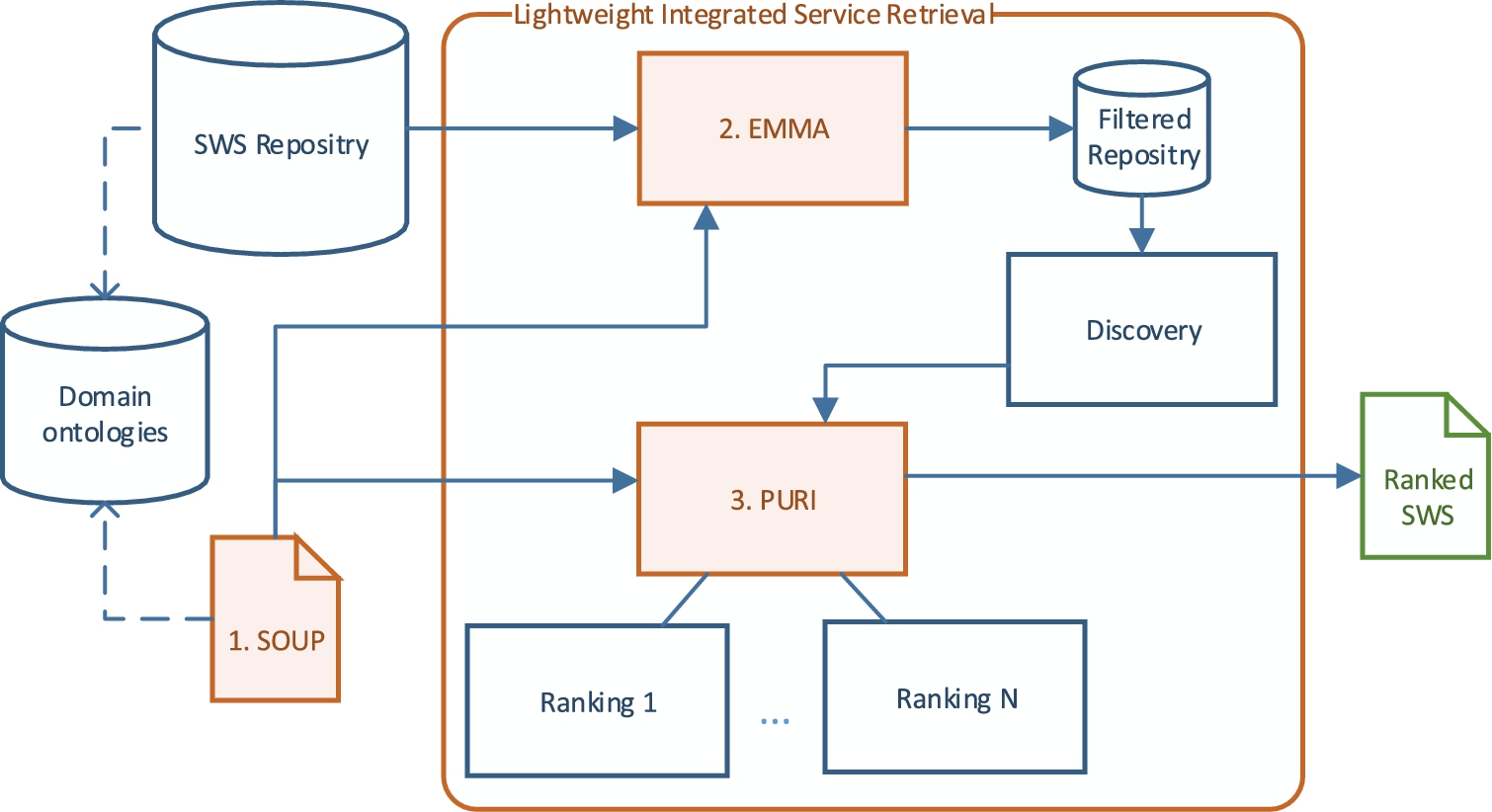
A lightweight, integrated service retrieval architecture. (Colors are visible in the online version of the article;
First, we developed SOUP (a Semantic Ontology of User Preferences, no. 1 in Fig. 1) [3], a comprehensive model to define service requests including user preferences, independently of the underlying formalisms used for describing, discovering and ranking services. Its intuitive semantics, based on strict partial orders, ease the definition of preferences by users, while providing complex facilities that allows the combination of atomic preferences. This model effectively decouples the conceptual definition of preferences from the discovery and ranking implementation to be used, providing users with a higher reusability, flexibility and expressiveness for their preference definitions.
Our proposed preference model serves as the foundations for the rest of our research work. Using this model as a vocabulary and an upper ontology to abstractly define both service descriptions and user requests, we designed EMMA (an Enhanced MatchMaking Addon, no. 2 in Fig. 1) [4], a generic optimization framework that analyzes service requests to automatically generate filters that are applied to service repositories before actually performing discovery and ranking processes. As a result, both processes are significantly improved, offering better performance and scalability at a small cost on precision and recall. Moreover, the abstract descriptions provided by our model enable the application of our optimizations to any available SWS framework.
Furthermore, the inherently better interoperability provided by our preference model enables the integration of different discovery and ranking mechanisms. Consequently, we devised PURI (Preference-based Universal Ranking Integration, no. 3 in Fig. 1) [2], a framework and integrated architecture for SWS discovery and ranking that further improve the flexibility to define and evaluate user preferences, taking a hybrid approach that integrates corresponding ranking mechanisms. This architecture offers a unique, lightweight interface to the whole discovery and ranking process, while maintaining a low level of coupling with the actual mechanisms that perform these tasks.
Our contributions have been thoroughly evaluated and validated with both synthetic and real-world scenarios. First, SOUP preference model expressiveness and independence has been validated by completely describing complex scenarios from the SWS Challenge.1
In conclusion, this research work provides an independent, lightweight preference model that serves as the foundation for an optimized and integrated solution to SWS discovery and ranking. Our approach successfully tackles existing challenges in this area, concerning expressiveness of preference models, coupling with discovery and ranking mechanisms, performance of discovery processes, interoperability and integration between different discovery and ranking solutions.
Footnotes
Acknowledgements
This work has been partially supported by the European Commission (FEDER), the Spanish and the Andalusian R&D&I programmes (P12-TIC-1867 (COPAS), TIN2012-32273 (TAPAS), TIC-5906 (THEOS)).