
Abstract
Technical analysis is the art of identifying patterns in historical data with the belief that certain patterns foretell future price movements. An empirical evaluation of the effectiveness of technical analysis is confounded by the subjectivity involved in identifying patterns. This work presents a robust framework for pattern identification using probabilistic neural networks (PNN). The thirty components of the Dow Jones Industrial Average and a set of ten indices are considered. Fourteen patterns are analyzed. In order to test the possibility that technical patterns are more predictable in certain market environments, the period under study (1990 – 2015) is partitioned into bull and bear markets and the statistical significance of profits earned by identified patterns observed in each environment is analyzed. A range of holding periods from 10 to 50 trading days is considered and a simple model of transaction costs is added. The study reveals that no pattern produces statistically and economically significant profits for a cross-section of stocks and indices analyzed, though a few patterns are more successful predictors. Bullish (bearish) patterns are more reliable predictors in bullish (bearish) market environments. These observations can be explained by the Adaptive Market Hypothesis with certain patterns becoming more accurate predictors in specific market environments.
Introduction
Technical analysis is the art of identifying geometric patterns in historical prices – often supplemented with volume-based signals – with the belief that occurrence of patterns are reliable predictors of price movement in the immediate future. Academic professionals and fundamental analysts typically scoff at technical analysis because of its paucity of quantitative justification. Recent works dealing with profitability of technical analysis based trading strategies have given some credence to the assertion that technical analysis may not be a complete farce. Brock et al. (1992) test the profitability of moving average rule (buying when shorter period moving average rises above longer period moving average, and selling when it falls below longer period moving average) and trading-range break out (buy when price rises above the observed local maximum and sell when it falls below the observed local minimum). They find statistically significant profits that cannot be explained using three null models of efficient market hypothesis – random walk, AR(1) and GARCH-M models. They observe further that volatility of returns following a buy signal is lower than volatility of returns following sell signal, thereby refuting the notion that higher returns for these strategies compensate higher inherent risks.
Osler and Chang (1995) test the profitability of head and shoulders pattern in foreign-exchange markets. They find the strategy yields economically significant profit in German Mark and Yen markets but not in other exchange rate markets studied in the work. They use a bootstrap method using random walk null model of efficient market hypothesis to conclude that returns from head and shoulders trading strategy are incompatible with the null hypothesis for German Mark and Yen exchange markets. Rejection of null model could either imply inefficiency of those exchange markets or the existence of a different null model compatible with efficient market hypothesis (for example, time varying mean). Other works Logue et al. (1978), Sweeney (1986), and Levich and Thomas (1993) also report statistically significant profits using technical analysis.
Savin et al. (2007) use pattern recognition method presented by Lo et al. (2000) to test if head-and-shoulders pattern has predictive power. After examining data for S&P 500 and Russell 2000 from 1990 to 1999, they conclude that the pattern has negligible predictive power when used as a stand-alone trading strategy, but has power to predict risk-adjusted excess returns over market portfolio returns. They conclude that the period studied in their work coincided with a bull market, and head-and-shoulders being a reversal pattern would not be a profitable stand-alone trading strategy.
Researchers have noted the failure of macro-economic models in explaining exchange rate volatility. Neely et al. (1997) and Stephan (2009) have assessed the effectiveness of technical patterns in explaining exchange rate fluctuations. Neely et al. (1997) apply genetic algorithm to study the profitability of technical patterns in foreign exchange markets. Genetic algorithm is used to design superior trading strategies based on filter rules and moving-average rules. The rule is tested in an out-of-sample period from 1981 – 1995 and found to generate statistically and economically significant profits. Neely et al. (1997) further show that the higher profits are not a compensation for bearing higher risks by examining betas. The significance of technical patterns in foreign exchange markets has been examined by Stephan (2006), Stephan (2008) and Stephan (2009). Stephan (2009) attributes the prevalence of technical analysis in foreign exchange markets to a virtuous circle whereby traders use it as a tool to form an expectation of current trends, in turn making technical analysis a more commonly used tool and increasing its effectiveness as a predictor. Neely et al. (2009) examine the time-varying effectiveness of technical patterns as predictors in foreign exchange market. They observe that filter-rules and moving-average technical rules produce statistically and economically significant profits from early 1970 to late 1980; however, by early 1990 such rules no longer produce statistically significant profits. They explain the observation as being consistent with Adaptive Market Hypothesis (Lo, 2004). Olson (2004) arrives at a similar conclusion, noting that moving-average trading rule profits (risk-adjusted) have declined from 3.5% during 1970 to around 0% from 1990 to 2000 across 18 exchange rate series. Chavarnakul and Enke (2008) employ generalized regression neural network (GRNN) to construct two trading strategies based on equivolume charting that predict the next day’s price using volume and price based technical indicators. They observe that using neural network improves the profitability of a moving average based trading rule in trending markets. However, the time period studied is rather limited - one year - and they only consider S&P 500 index. Furthermore, the difference in profitability between neural network based strategy and buy-and-hold strategy is not too large. Other works (Enke and Thawornwong 2005), (Li and Kuo 2008), (Leigh et al. 2005), (Chenoweth et al. 1996) have studied the application of neural networks in finance. Enke and Thawornwong (2005) test the hypothesis that neural networks can provide superior prediction of future returns based on their ability to identify non-linear relationships. They employ only fundamental measures and do not consider technical ones. Their neural network provides higher returns than buy-and-hold strategy, but they do not consider transaction costs. Scalar vector regression (SVR) has also been used in creating automated trading strategies: (Hong et al. 2010; Huang 2012; Kazema et al. 2013; Wang and Pardalos 2014).
A challenging aspect for any work attempting to perform an empirical assessment of technical analysis based trading strategies is the automated identification of technical pattern. Osler and Chang (1995) employ a method based on peaks and troughs. They define a peak as a local maximum of closing price that is at least χ percent higher than the preceding trough and a trough as a local minimum at least χ percent lower than the preceding peak. χ is selected based on standard deviation; in their work they select a set of values for the cutoff parameter χ. Lo et al. (2000) use a novel method based on kernel smoothing. They use a Gaussian kernel in smoothing, with a constant smoothing parameter chosen by visual inspection of smoothed price curve. Approach used by Lo et al. (2000), and Osler and Chang (1995) has the shortcoming of using a constant smoothing parameter over the entire price history. Heteroskedasticity in stock prices is a well documented phenomenon (Bollerslev, 1987). Lo et al. (2000) acknowledge this shortcoming. Methods employed by Osler and Chang (1995) and Lo et al.(2000) use sequence of successive local maximum and minimum to identify patterns. In addition, they use a number of tests to make sure there is close fidelity to the technical patterns they recognize, for example, Lo et al. (2000) require the tops in a double-top pattern to be within 1.5% of their mean. It is conceivable for a double-top pattern to occur with successive tops being slightly more than 1.5% of their average. Further, it is distinctly possible that a different smoothing in an area may reveal part of a pattern. An approach that insists on observing local extrema in a specific order while using a constant smoothing parameter is likely to miss such pattern occurrences.
This work applies neural networks for recognizing technical patterns in stock prices and evaluates the performance of patterns as predictors of future price movements. Neural networks are uniquely suited to the task of character recognition, and pattern recognition has distinct similarities to character recognition (Beymer and Poggio 1996). A class of neural networks called probabilistic neural networks or PNN is employed. PNN were introduced by Specht (1990). The process of constructing a PNN is simpler than that required for a back-propagation neural network. PNN is used to identify the following patterns: ascending-triangle, descending-triangle, head-and-shoulders, cup-and-handle, double-top, double-bottom, triple-top, triple-bottom, broadening-top, down-price-channel, rising-wedge, falling-wedge, up-symmetric-triangle, down-symmetric-triangle and down-price-channel for ten indices and for the thirty components of Dow Jones Industrial Average. To evaluate the empirical performance of a trading strategy based on each of the patterns, 15 years of history for indices (from 2000 to 2015) and 25 years of history for Dow Jones components (from 1990 to 2015) is considered.
Technical analysts also resort to the use of volume-based indictors as confirming signals during pattern formation phase. However, there is little agreement between technical analysts on the exact definition of confirming signals. The confirming signals rarely constitute the defining aspect of the pattern. To illustrate this point, consider the definition of head-and-shoulders pattern from two sources Investopedia (2016) and Wikipedia (2016). While Investopedia (2016) mentions nothing about the role of volume, Wikipedia (2016) qualifies its description of the pattern using volume: “The left shoulder is formed at the end of an extensive move during which volume is noticeably high.”. However, Wikipedia (2016) further qualifies the role of volume in left shoulder by mentioning that the breakout below neckline in that region may occur on high or low volume. “The drawn neckline of the pattern represents a support level, and assumption cannot be taken that the Head and Shoulder formation is completed unless it is broken and such breakthrough
The remainder of this paper is organized as follows: Section 3 describes the algorithm used in identifying the patterns, Section 4 describes the probabilistic neural network used, Section 5 discusses the application of the probabilistic neural network in identifying the patterns for ten indices and thirty Dow Jones components. Section 6 concludes the work.
Algorithm for identification of technical patterns
To recognize a pattern using neural networks, a representation of the pattern is required that is robust to local noise. As a first step, prototypes of price patterns are first created manually. The prototypes are very geometric, with prices rising and falling along straight lines. Figures 1–3 show the manually generated prototypes on a plot. These prototypes are referred as prototype patterns in this work. All prototype patterns are twenty days in length. Next, Gaussian noise is added to each day’s price in prototype pattern. The standard deviation of noise is selected to be smaller than the maximum daily price change in the prototype plots. In the present work, standard deviation of added noise is taken to be 0.3. 200 realizations of random variable are obtained at each point, thereby yielding 200 perturbed plots corresponding to each prototype pattern. An example of perturbed plot for head-and-shoulders pattern is shown in Fig. 4. Next, each point in the unperturbed price plot is moved to the left by one day. First and last points corresponding to the first and last day are kept at their original positions. The third days price displaces the second day’s price and so on. 200 realizations of Gaussian noise with mean = 0 and variance = 0.09 are added to each day’s price yielding 200 new perturbed plots. An example of left-shift perturbed plot for head-and-shoulders pattern is shown in Fig. 4. In a similar manner to the left-shift, right shift is performed on unperturbed base price pattern, keeping the first and last day’s prices at their original location. After right-shifting by one day, 200 realizations of Gaussian noise are added to each day’s price yielding another 200 perturbed plots. Gaussian noise has mean = 0 and variance = 0.09. An example of right-shift perturbed plot for head-and-shoulders pattern is shown in Fig. 4. This procedure produces 601 examples of price patterns corresponding to each technical pattern under consideration. These 601 plots (six hundred perturbed plots and one prototype plot) corresponding to each pattern comprise the training set for the probabilistic neural network. PNN are simpler to construct as compared with multi-layer back-propagation neural networks. For example, back-propagation neural network implementation in R package neuralnet (Fritsch et al. 2012) fails to converge for the data set in this work (14 × 601 plots). Increasing the number of hidden neurons or the maximum iterations does not help to overcome the problem of non-convergence during training. Also, increasing the number of hidden layers or hidden neurons increases the time taken by back-propagation neural network during learning. This demonstrates the attractive feature of network simplicity for a PNN. Details regarding construction of PNN are presented in Section 4.
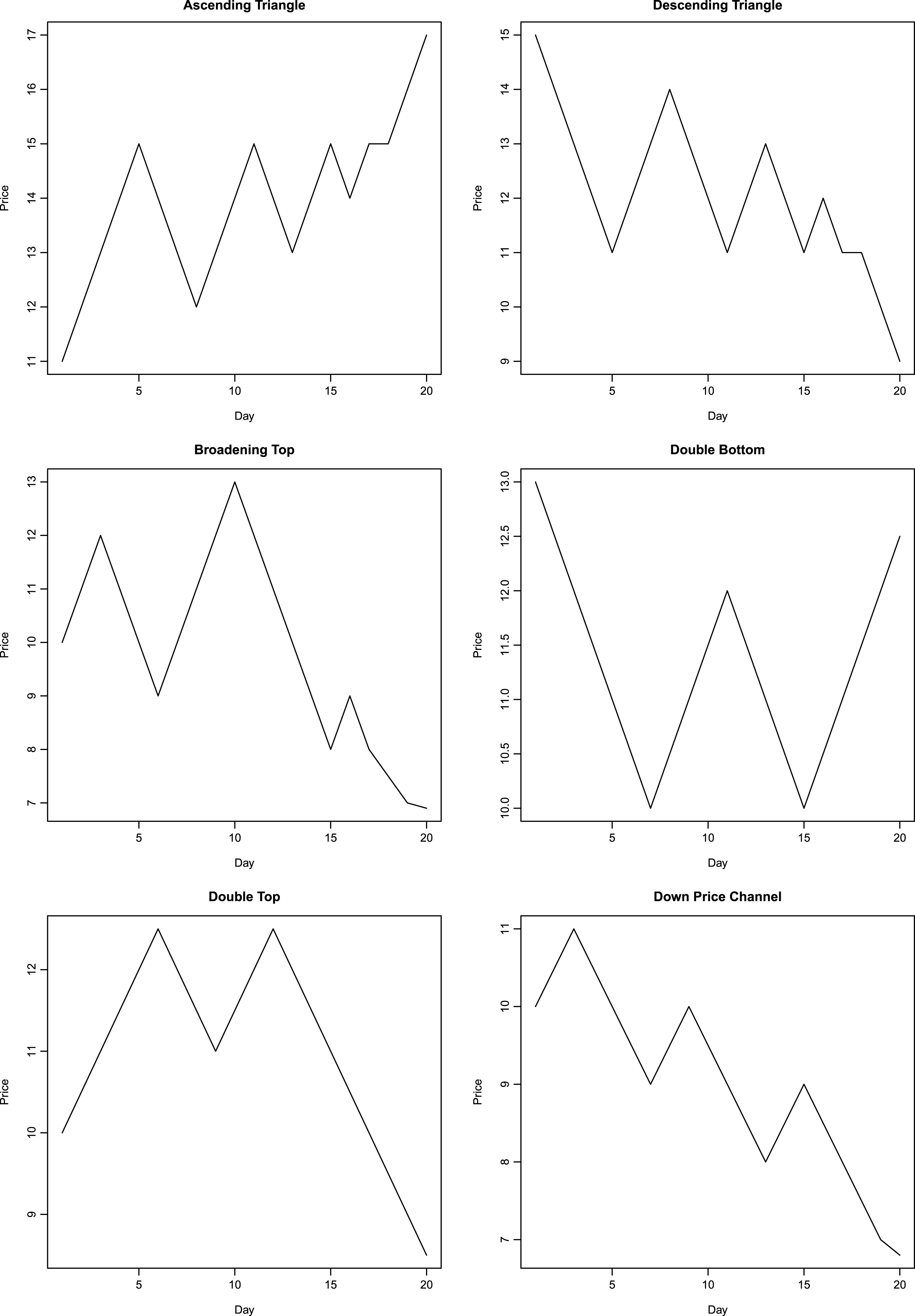
Manually generated pattern shapes.
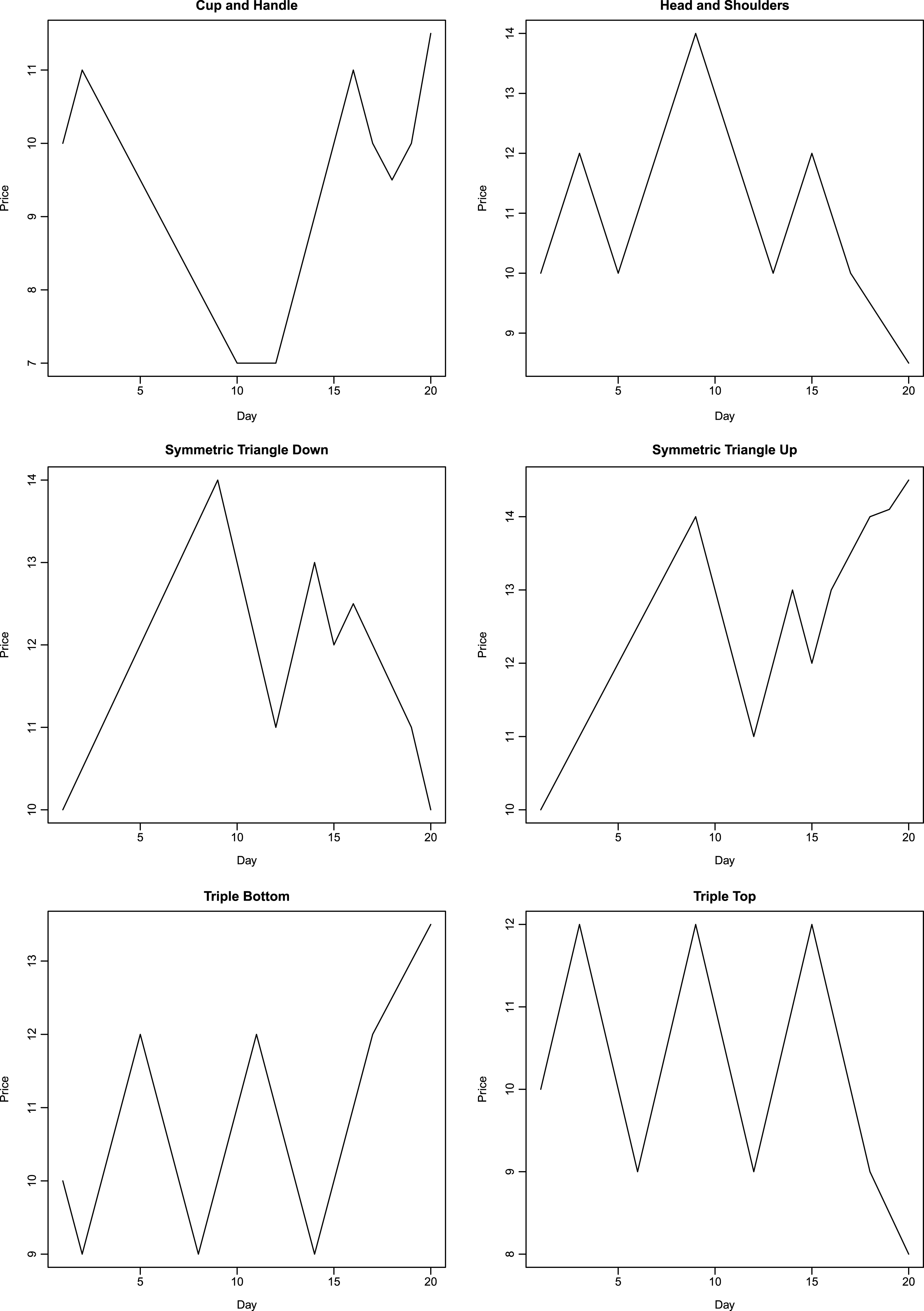
Manually generated pattern shapes.
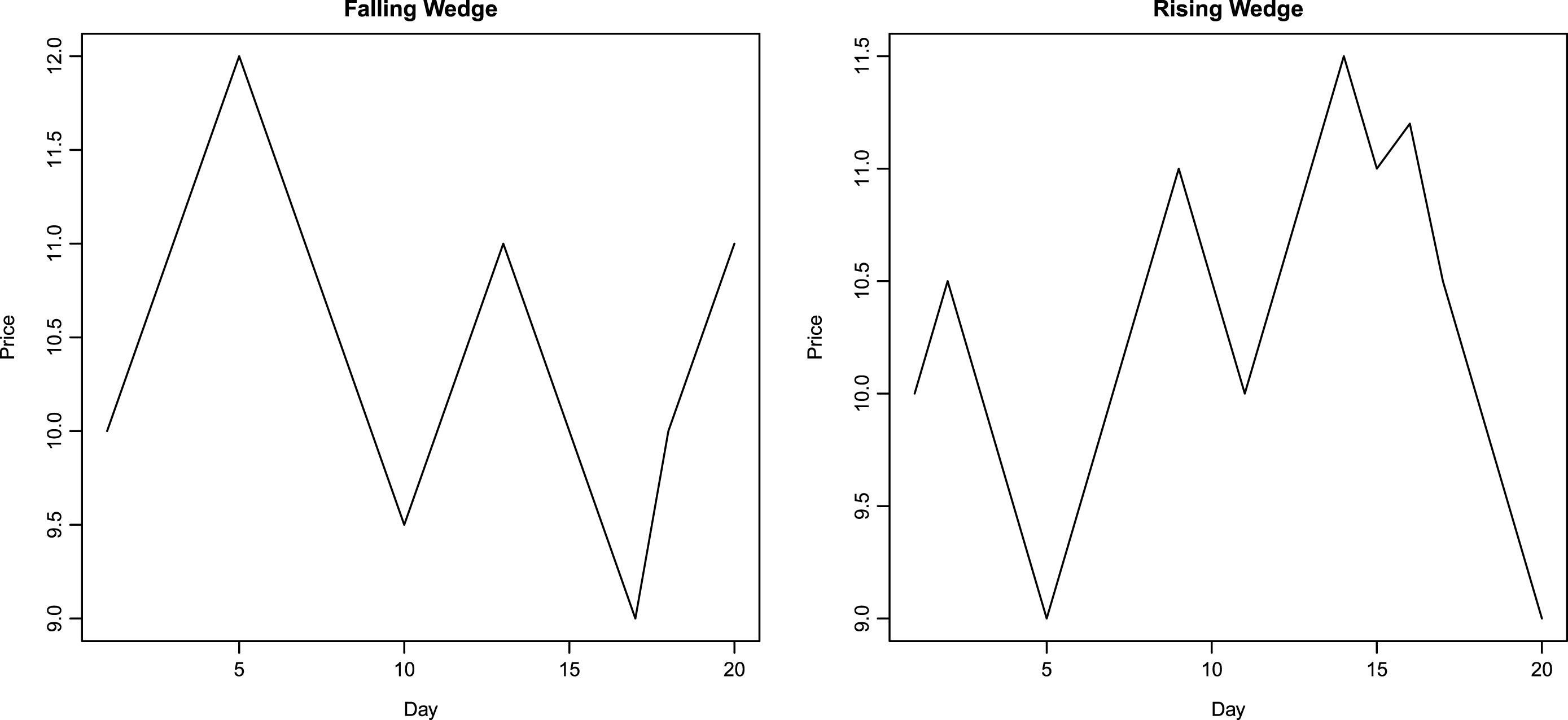
Manually generated pattern shapes.
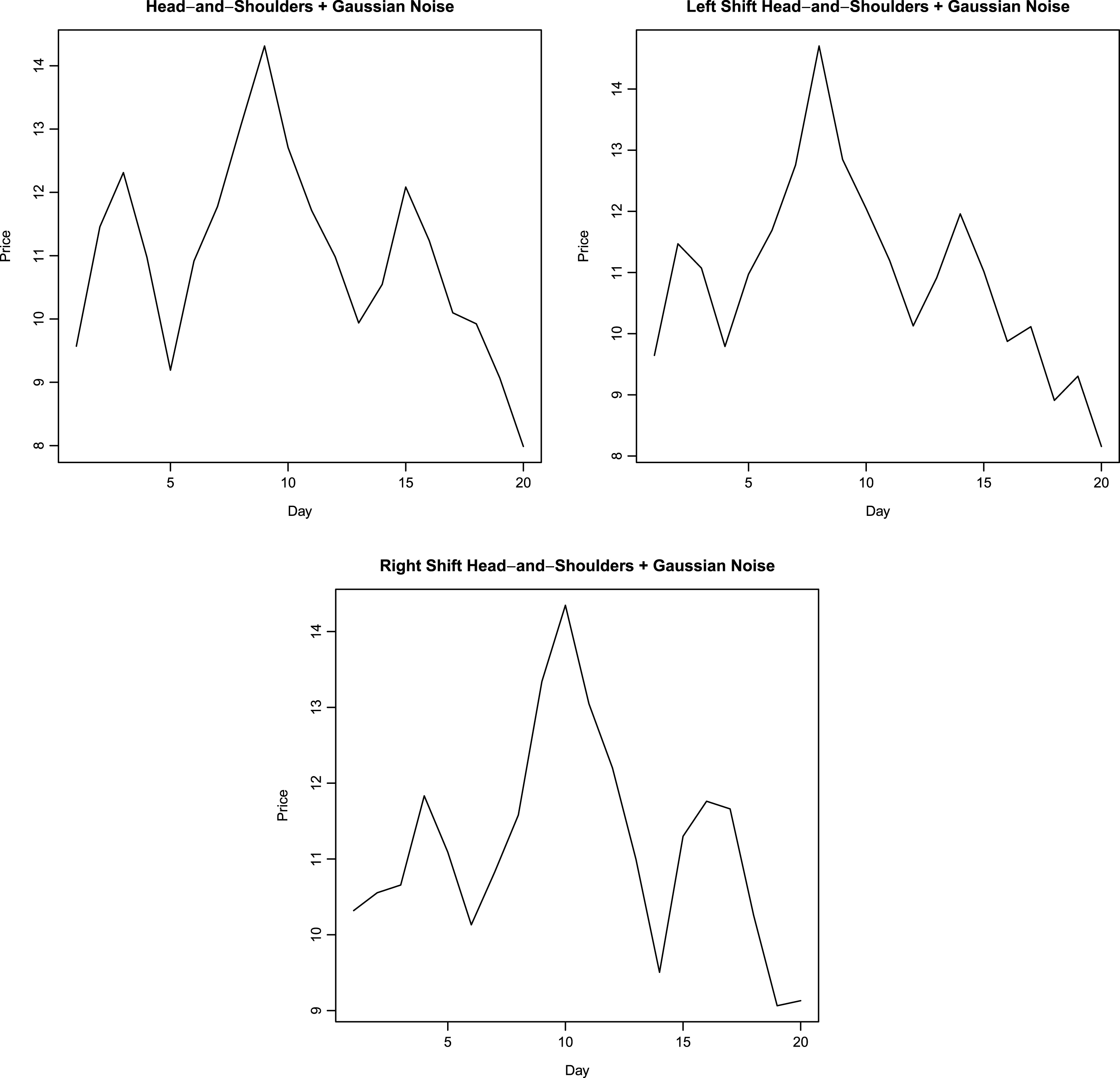
Perturbed head-and-shoulders pattern with left and right shift.
In order to classify a pattern into one of several classes under consideration, or to determine that it does not belong to any of the classes, a representation of pattern is required. This representation is akin to a fingerprint: patterns belonging to one class should produce similar representations. This task is similar to the task confronted in character recognition where a handwritten character must be matched to one of several known characters. However, unlike in character recognition where a character must belong to one of several classes (alphabets), one also needs to discriminate the case where a pattern does not match any of the classes. To that end, the algorithm for pattern recognition presented in this work can also be used for character recognition.
The prototype patterns and their perturbations are constructed to have the same length, i.e. they have same number of days. This is true of all patterns considered. In this work, the prototype patterns are chosen to be 20 days in length. This requirement does not impose any restriction on the length of patterns that can be classified using this algorithm. Further, because window sizes considered are greater than or equal to 20 days, resizing the series down to a length of 20 days does not introduce significant interpolation inaccuracy. The prices are normalized. Let p min denote the minimum price, p the daily price and p max the maximum price observed over the twenty day length of a pattern. Normalized prices are calculated using equation (1).
This set of twenty normalized prices is the fingerprint of the pattern. The perturbations of a pattern will have fingerprints that are closer to the fingerprints of prototype (unperturbed) pattern. Distance is defined as Euclidean distance in the twenty-dimensional space. More formally, distance between two patterns is given by equation (2). x i and y i are the normalized prices.
A probabilistic neural network (PNN) is constructed to classify patterns belonging to the types considered in this work. Details of constructing the network are presented in the next section. In order to identify a pattern, a range of window lengths varying from twenty days to sixty days are considered. Let l denote the window length, L denote the price series length and i denote an index in price series. For each window length, the algorithm checks price pattern between i and i + l days, where index i ranges from the beginning of price series to L - l - 1 (inclusive range). The price list observed between days [i, i + l] is scaled to a new price list with 20 elements; the scaled price list now has the same length as the prototype patterns. The price series length scaling is performed using equation (3). Rescaling is analogous to resizing the price series length to 20 days. Price for day j in actual price series becomes the price on day d j in rescaled price series where d j is given by equation (3). Price for days between d j and dj+1 are interpolated.
Fingerprint of each rescaled price series is calculated as a tuple of twenty normalized prices using Equation (1). This fingerprint is presented as input to PNN for classification. In order to identify the case where a pattern does not match any of the types considered in this work, the PNN uses a threshold. Details are presented in the next section.
Probabilistic neural networks were first introduced by Specht (1990) as a four-layer neural network capable of representing non-linear decision boundaries for a classification problem and offering significant speedup as compared to the training time of a back-propagation multi-layer feed-forward neural network. Prababilistic neural networks have four layers: input layer, pattern layer, summation layer and output layer. The first layer is the input layer. The number of input units is equal to the dimensionality of the problem. In this work, a pattern is represented by a set of twenty normalized prices, hence the first layer of PNN is comprised of twenty input units. The input units transmit their input as output, without applying any other transformation. The second layer of the PNN, known as pattern layer, is defined by the training set data. In this work, the training data consists of 14 × 601 inputs – each pattern type has 600 perturbations and one base price series, giving 601 training data points for each pattern type, and there are fourteen patterns types examined. The second layer therefore consists of 14 × 601 units. Units in second layer of a PNN network are grouped into classes the PNN network is meant to classify. In this work, second layer units are grouped into fourteen groups. Each group consists of 601 units. Each unit applies a Gaussian activation function to its input. If the input is denoted as x, output generated by m unit in second layer pattern j is given by equation (4). x m denotes the normalized price vector corresponding to mth training input. x m and x are vectors of size 20.
In Equation (4), x i refers to the training data point corresponding to i pattern unit. It is the normalized price. σ is the variance-covariance matrix defined on training data belonging to a pattern type. It is calculated as shown in Equation (5). There are fourteen variance covariance matrices used in the PNN network, one corresponding to each pattern type.
The third layer of a PNN is the summation layer. Summation layer sums up the output from second layer’s units belonging to a group. There are fourteen summation layer units in this work, each producing an output corresponding to the likelihood of the data matching a pattern type. Input for a summation layer unit is the set of outputs generated by second layer units belonging to a particular group. Summation layer unit’s output is shown in equation (6). m denotes the index of pattern type, there are 14 types of pattern considered in this work.
The fourth layer of a PNN is the output layer, it picks the group having the maximum value and classifies the data as belonging to that group. The fourth layer has one unit, its output is given in Equation (7).
A PNN always classifies a data into one of the classes. In order to identify the case where a data set does not match any pattern, this work requires the maximum output to be greater than 100 times the output from other groups. Let z m denote the maximum output from third layer and z i denote an output from another unit in third layer. m denotes the third layer unit having maximum output and i is another third-layer unit. For the data to be classified as matching pattern m, this work requires that Equation (8) hold for all i ≠ m.
The threshold value of 100 is an empirical parameter, higher values of threshold will produce very close matches to the pattern while rejecting potential matches that do not comport with the threshold. Low values of threshold parameter will produce greater number of matches while producing an occasional false positive by identifying a data to match a pattern when it does not (i.e. a technical analyst would disagree with the classification).
A diagrammatic representation of the probabilistic neural network is shown in Fig. 5.
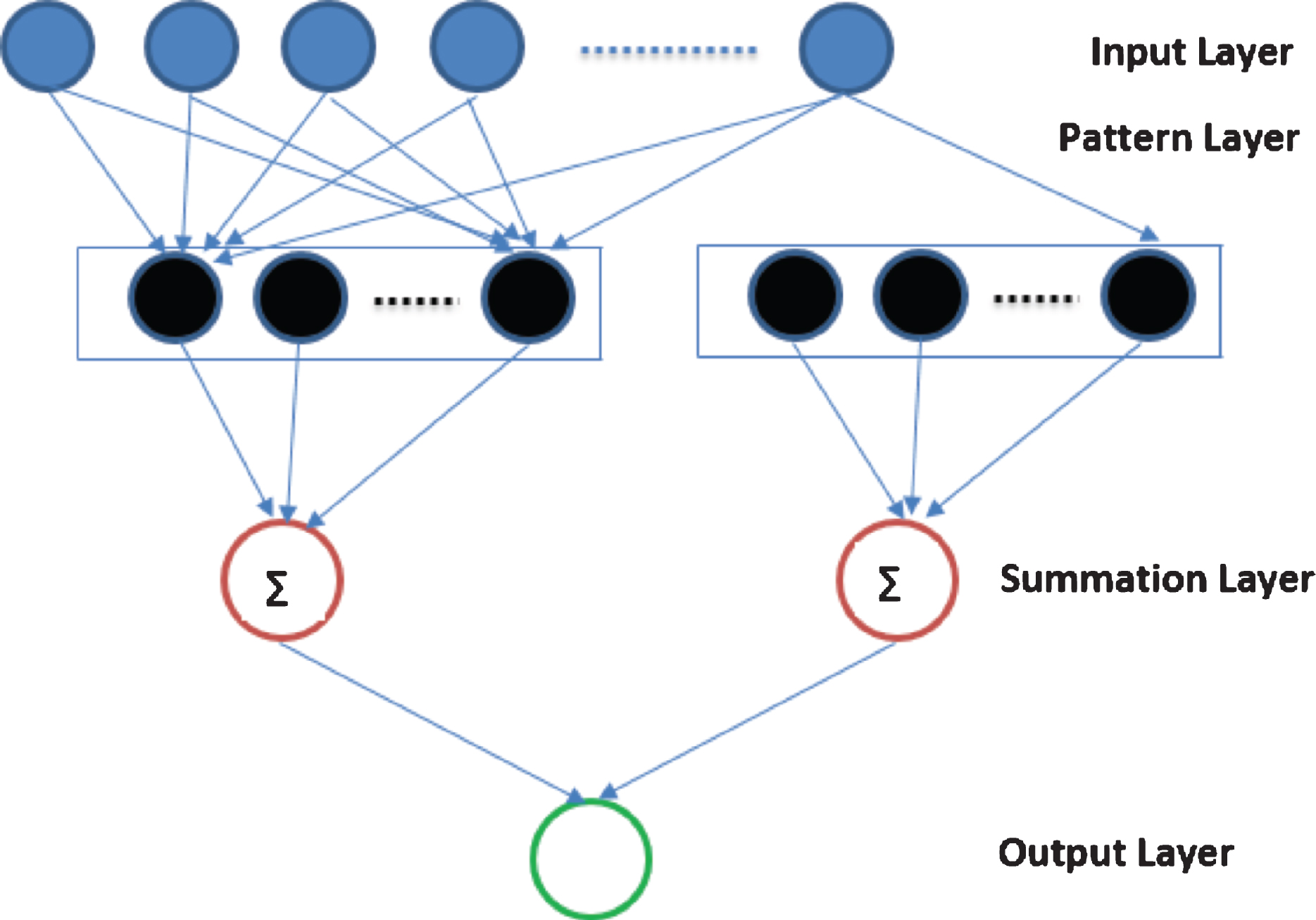
Representation of PNN.
This work attempts to identify technical patterns enumerated earlier in prices of thirty Dow Jones components and in ten indices: S&P 500 index and nine Russell indices (Table 1). For Dow Jones components and S&P 500 index, price history from 1990 to 2015 is analyzed. For Russell indices, price history from 2000 to 2015 is studied because prices for these indices are available from 2000 onwards. Patterns with length ranging from 20 trading days to 40 trading days are considered (40 trading days is around two months). Manifestations of patterns with longer duration are not identified. This restriction reflects a compromise between reducing computation time and considering a window length that covers common occurrences of patterns. Bulkowski (2005, p. 805) observes average length of falling-wedge pattern to be less than two months, average length of flag pattern to be less than two weeks (Bulkowski 2005, p. 903), average length of broadening tops and bottoms to be two months (Bulkowski 2005, p. 81), average length between left and right shoulder tops of head-and-shoulders pattern to be two months (Bulkowski 2005, p. 415) and average length of an island pattern to be just over a month (Bulkowski 2005, p. 491). According to Bulkowski (2005, p. 143), pattern length can vary depending on bull or bear market. A range of holding periods (10, 20, 30, 40 and 50 trading days) is considered in order to test the possibility that some patterns may need longer holding periods for price to move in accordance with the pattern’s prediction.
On each day, the PNN based pattern identification algorithm is applied to price series of 30 Dow components and 10 indices to see if a pattern can be identified over the window length. Dividend and split adjusted closing prices for the 30 Dow components and 10 indices are used. After identification, the pattern is validated using an independent test (described below). Once a pattern is identified and validated, its return is recorded over the holding period. Return is calculated as , where N is the holding period length. In order to examine the possibility that technical patterns may be more effective predictors in certain market environments, the period from 1990 to 2015 is partitioned into bull or bear markets depending upon the market performance (S&P 500 index) during the period. The periods were selected using publicized dates for the onset of bull and bear markets widely reported in media. This selection entails some in-sample bias because the partitions are selected ex-post, though the bias is alleviated to a certain extent by the relatively long duration of periods selected compared to the length of patterns and holding periods considered. A study conducted for the entire period yields similar qualitative results. Since the patterns are either bullish or bearish in their predictions, it is appropriate to partition the period between bullish or bearish markets and test the predictive power of all patterns in the two market environments. The classification is shown in Table 2. Returns observed for different patterns are tabulated in tables presented. Examples of identified patterns are presented in Figures 6, 7 and 8.
Indices analyzed
Indices analyzed
Partition by market trend
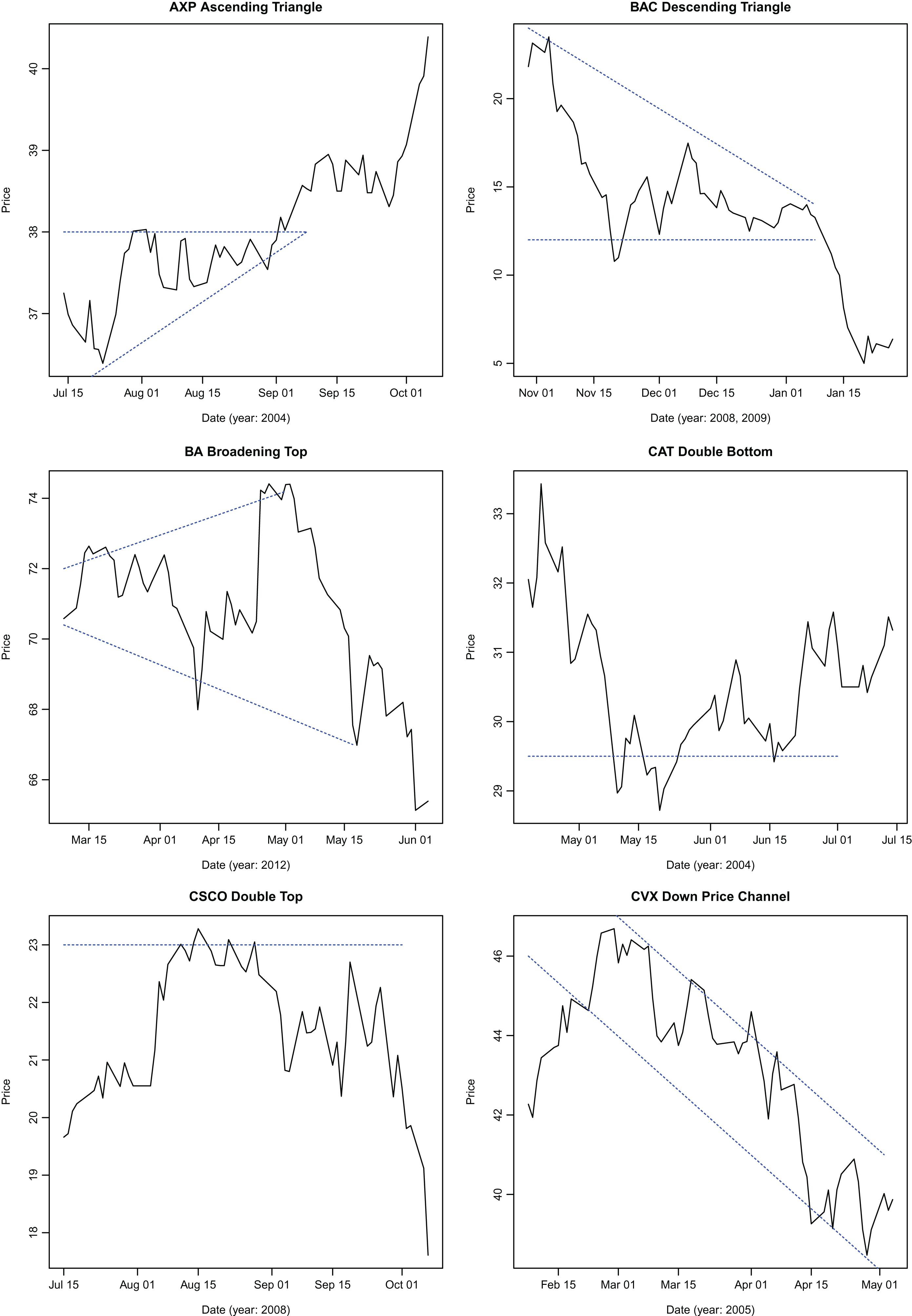
Specimen patterns identified by the algorithm.
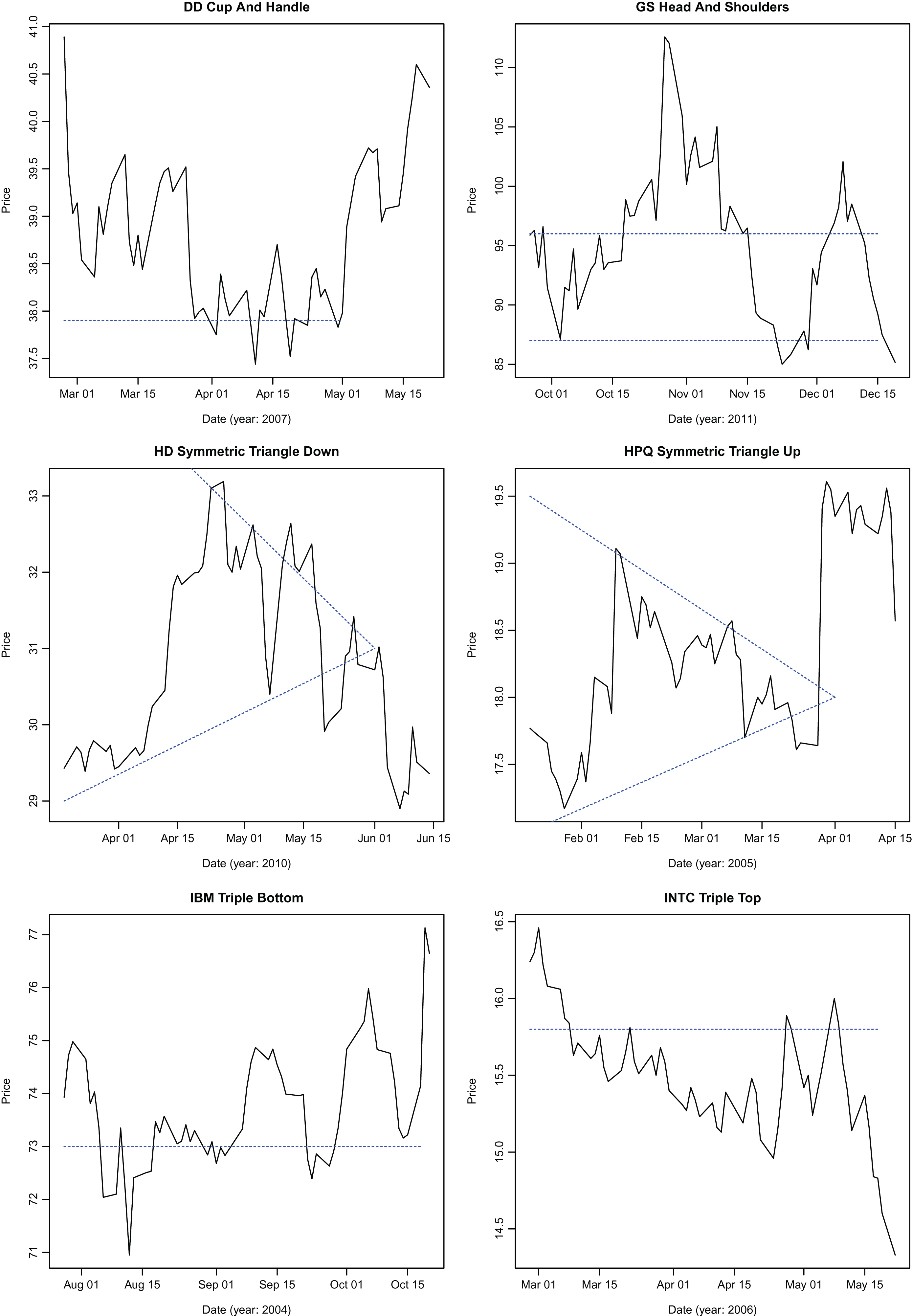
Specimen patterns identified by the algorithm.
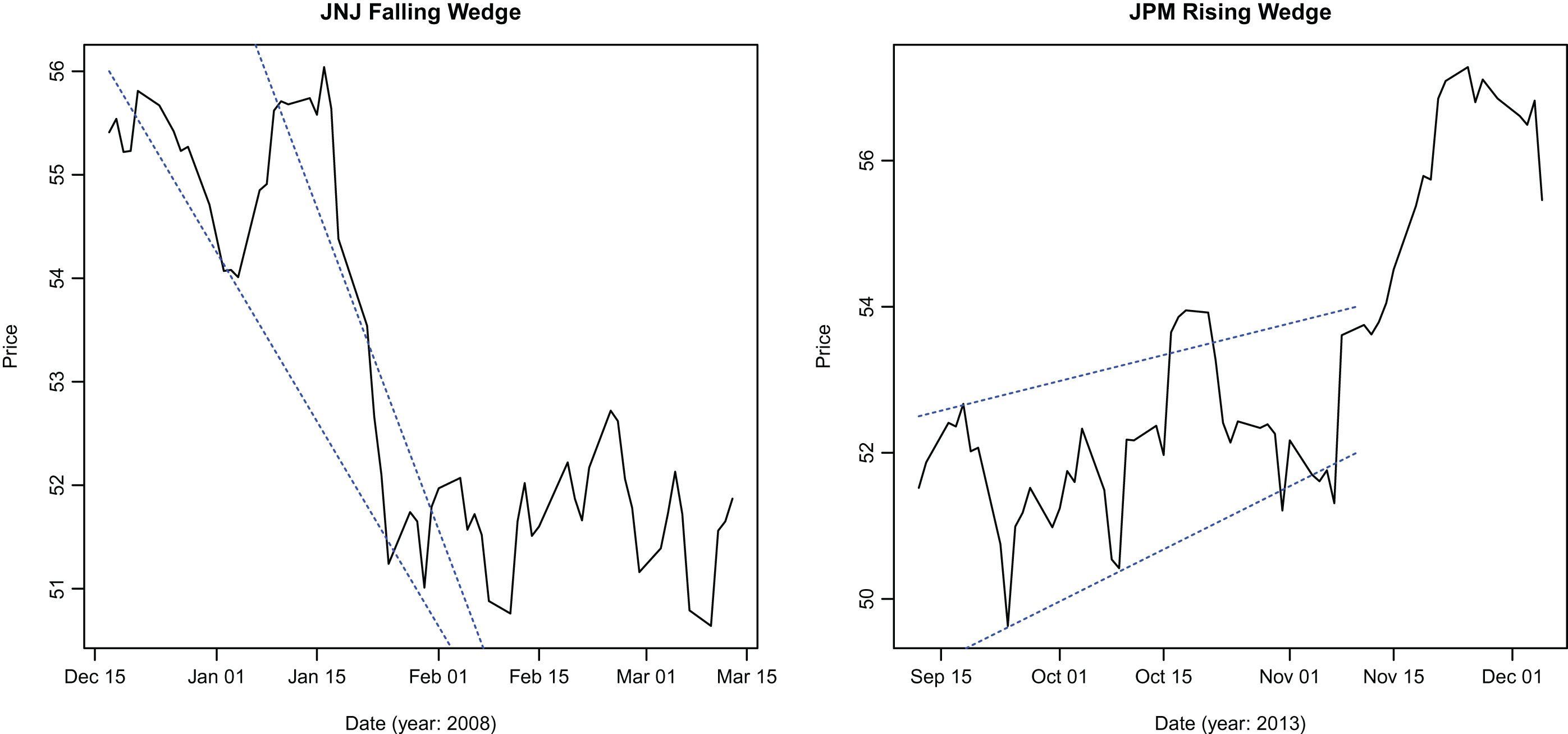
Specimen patterns identified by the algorithm.
Bullish and bearish environments are selected to coincide with changes in S&P 500 index over a period of a year or more, marked by well publicized market events (Table 2). Shorter periods – less than a year – were not used in order to reduce in-sample bias because the partitions are being selected ex-post. The period from 1990 – 1999 is marked by a steady rise in markets, without any major market black-swan event like Black Monday (crash of 1987) or technology crash. 2002 – 2003 partition is widely recognized as the period of technology bubble burst. 2003 – 2007 partition is recognized as the bull market spawned by brisk growth of mortgage lending; 2007 – 2009 partition is the ensuing period now referred as the Great Recession and 2009 – 2015 is the period of recovery from the Great Recession.
In order to validate identified patterns, a price-based test is added. The validation test is based on observing a set of high and low prices in a certain order. A technical pattern is characterized as an ordered set of high and low prices attained during the pattern’s observation period. Lo et al. (2000) have used kernel smoothing techniques to identify local price maxima and minima. Locally weighted scatter-plot smoothing algorithm (LOESS) with a quadratic polynomial employed for local fitting is used for price smoothing. Smoothed daily prices are compared to their neighboring prices to identify local extrema (maximum or minimum) by comparing the closing price for a day with the closing price of preceding and following trading days. If the closing price is higher than its neighbors, the price is a local maximum. Likewise, if it is lower than its neighbors, it is a local minimum. The identified pattern must have an occurrence of high-low price sequence characterizing the pattern. If an identified pattern fails the validation test, it is rejected. The high-low sequence for the patterns is shown in Table 4. Parameters employed in locally weighted scatterplot smoothing algorithm are tabulated in 3.
Parameters used in LOESS smoothing
Validating identified patterns
Recognized and validated patterns are not manually evaluated to ensure correct classification. Technical analysts employ additional tests for classifying a price series as a technical pattern. To the extent that those validation tests are not employed, certain price series may have been misclassified.
Trading strategies based on technical patterns are often associated with trading rules. Trading rules are diverse, ranging from simple price increase or decrease based decisions to complex conditions involving volume. In order to study the impact of trading rules on the ability of technical patterns to forecast future price movements, a simple trading rule is applied: following the identification of the pattern, closing price is observed after three days. If the close price has not moved in accordance with the prediction of the technical pattern, no trading is done for that pattern instance. As an example, let i denote the day on which a technical pattern is recognized. Closing price is observed for i + 3 day and compared with closing price for i day. If the price change is not in accord with the bullish or bearish price prediction of the pattern, no trading is done for that pattern occurrence. Holding period begins from i + 4 day and ends on i + 13 day (both days inclusive) to ensure there is no in-sample bias. Three-day period is an empirical parameter; it is meant to test the accuracy of technical patterns as a price predictor. Increasing this period can increase the reliability of patterns at the expense of foregoing trading for more days following pattern identification.
Figures 6, 7 and 8 demonstrate the effectiveness of the algorithm in identifying patterns.
After a technical pattern is identified by the algorithm, price change is recorded for one unit of asset for the duration of the holding period. In order to ensure that there is no in-sample bias, holding period begins after pattern identification, validation and application of trading rule. A range of holding periods – 10, 20, 30, 40 and 50 trading-days – are considered. Technical analysis categorizes the technical patterns as bullish or bearish – bullish patterns are supposed to presage bullish price movement and bearish patterns are harbingers of future price declines. Table 5 shows this classification. In order to assess the statistical significance of profits for the trading strategy based on respective technical patterns, a one-sided t-test is performed. One-sided test is appropriate to test the bullish or bearish characterization of the patterns. 95% significance threshold is used; thestatistically significant patterns observed during bull and bear markets are reported in Tables 6 and 7 for Dow Jones components and in Tables 8 and 9 for indices respectively. Other patterns were not statistically significant. Null hypothesis for the test is that the technical patterns have no predictive power for future price movements.
Bullish or bearish classification of technical patterns
Statistically significant patterns observed during bull markets for dow components
Statistically Significant Patterns Observed During Bear Markets for Dow Components
Statistically significant patterns observed during bull markets for indices
Statistically significant patterns observed during bear markets for indices
It can be observed from the tables that only a few technical patterns from the set of fourteen patterns considered in this work produce statistically significant profits for a specific ticker. Falling wedge is the most common pattern occurring in the price charts for the Dow components that produces profits in line with the technical analyst’s predictions. It is followed by triple bottom and symmetric triangle up patterns, each of which produces statistically significant profits for 10 tickers. Cup-and-handle pattern produces statistically significant profits for 9 tickers. It can be observed that no pattern produces statistically significant profits for more than half the tickers considered.
More technical patterns produce statistically significant results during bull markets – this is in part accounted by the longer duration of bull markets. During bear markets, bearish technical patterns are observed to produce statistically and economically significant profits for Dow Jones components. For indices, Table 9 illustrates that both bullish and bearish patterns produce statistically significant profits. Cup-and-handle pattern is observed to produce statistically significant profits more frequently for indices than for assets, as can be seen by comparing the occurrences of that pattern between Tables 8 and 6. Also, most patterns require a holding period greater than 20 trading days to produce statistically significant profits.
Previous works (Allen and Karjalainen 1999; Lo et al. 2004) have shown transaction costs to be an important factor in the profitability of a trading strategy, particularly the ones with high turnover. Transaction costs include trading commission, bid-ask spread and market-impact costs (Lo et al. 2004). A simple model of transaction costs is introduced in order study how many patterns remain statistically and economically significant predictors of future price movements. Allen and Karjalainen (1999) model transaction costs as 0.1%, 0.25% or 0.5% of the notional. Here, transaction cost is modeled as 0.5% of the trade notional.
Transaction costs reduce the profits earned (or increase the losses incurred) by a trading strategy. By virtue of knowing the bullish or bearish nature of a technical strategy, a one-sided T-test is used to assess the statistical and economic significance of a strategy. For bullish patterns, the transaction costs are subtracted from profit (or loss); for bearish patterns, they are added to loss (or profit). If a bullish pattern yields a loss, transaction costs will increase the loss; if a bearish pattern produces a profit, transaction costs will increase the profit. In both of these cases, the pattern will contribute to a rejection by the one-sided T-test. When transaction costs are accounted for in this manner, and a pattern produces profits that are opposite to those predicted by the bullish or bearish nature of the pattern, one cannot conclude that taking an opposite position in the pattern may open the possibility of profitable trading using the pattern. This is because transaction costs always reduce the profits.
As expected, Tables 10, 11, 12 and 13 show that fewer patterns cross the threshold of 95% significance as predictors of future price moves after transaction costs are accounted for. Falling wedge pattern is a more reliable predictor of future price moves for Dow Jones components during bull markets as compared with other patterns, as is rising wedge pattern during bear markets. Cup-and-handle pattern is a more reliable pattern for indices considered in this work than it is for Dow Jones components.
Inclusive of transaction costs (0.5%), statistically significant patterns observed during bull markets for dow components
Inclusive of transaction costs (0.5%), statistically significant patterns observed during bear markets for dow components
Inclusive of transaction costs (0.5%), statistically significant patterns observed during bull markets for indices
Inclusive of transaction costs (0.5%), statistically significant patterns observed during bear markets for indices
Adaptive Market Hypothesis proposed by Lo (2004) helps understand the results observed here: it is possible that certain technical patterns are more aggressively traded by market participants leading to a greater degree of predictability for those patterns. No technical pattern is consistently profitable across all securities examined in this work, this could point to disappearing opportunities for earning easy profits from following one pattern due to increasingcompetition in the niche. Neely et al. (2009) report similar conclusions in foreign-exchange markets where they observe that filter rule based moving-average strategies have largely lost their profitability by 1990. Todea et al. (2009) report that profitability of a moving-average based strategy in six Asian markets from 1997 to 2008 is episodic. Hsu et al. (2010) report that technical patterns (moving averages, filter rules) loose much of their predictive power as market matures.
This work presents an empirical assessment of accuracy of a set of technical patterns as future price change predictors. It considers a set of fourteen patterns for the Dow Jones Index components and a set of ten indices, looking at closing prices for the last 25 years for Dow Jones components (and S&P 500 index) and 15 years for remaining indices. Technical pattern occurrences ranging from 20 trading days (one month) to 40 trading days (2 months) are analyzed. Period under consideration is partitioned into bear or bull markets depending upon the market (S&P 500) trend during the period in order to examine the possibility that certain patterns are more reliable predictors in a particular market environment. A locally-weighted scatterplot (LOESS) based rule is employed to validate a pattern once it has been identified by the neural network. Holding periods ranging from 10 to 50 trading days after a pattern is observed and validated are used. Data analyzed in the study does not support the proposition of sustained profitability following technical trading rules for a cross section of stocks comprising the Dow Jones Index and the set of indices. There are a few instances where the rules generate statistically and economically significant profits that are in accord with the predictions of the rule. However these comprise a clear minority, being outnumbered by the cases where such rules do not generate economically or statistically significant profits. Some patterns, like cup-and-handle pattern, are more reliable predictors of future price moves for indices than they are for Dow Jones components. Bullish patterns are more reliable predictors in bullish market environments, with falling wedge being the most frequently observed pattern. Likewise, bearish patterns (like rising wedge) are more reliable predictors in bearish market environments. This observation suggests that a portion of a technical pattern’s predictability can be attributed to the market environment. Transaction cost of 0.5% reduces the number of statistically significant patterns observed, but the foregoing conclusions stand. The results support Adaptive Market Hypothesis (Lo, 2004): some technical patterns are more effective predictors of future price movements in certain market environments and for certain assets.
Role played by volume as a confirming signal for pattern identification has not been examined in this work and is a topic for future study. Technical analysts employ additional tests to validate classification of a technical pattern; including those tests will enhance the recognition algorithm. The algorithm outlined is able to identify the patterns, as confirmed by the plots of identified patterns; but any claim to accuracy must be qualified with the details of pattern definition employed. Technical analysis literature abounds in elaborate identification rules for the patterns – like confirming signals – and rules for when to unwind the trade. Adding these elaborate definitions to the algorithm may yield cases where such rules generate reliably significant profits. This study outlines an algorithm that can be effectively used in such an effort.