
Abstract
This article presents the findings of a systematic qualitative analysis of research in the ethics of digital trace data use in learning and education. From the resulting analysis of 77 peer-reviewed studies, we (1) map the characteristics of research by study type, academic community, institutional setting, and national context; (2) identify the primary ethical concerns and related responses; and (3) highlight the research gaps. Four areas of focus are identified in this emerging area: (1) privacy, informed consent, and data ownership; (2) validity and integrity; (3) ethical decision making; and (4) governance and accountability. We highlight the lack of evidence particularly for preschool and school-aged children and the disparate communities working in this domain, and we suggest a more cohesive approach, where the wider learning and educational ecosystem is recognized, explicit engagement with ethical theory is central, and mid- to long-term ethical issues are considered alongside immediate concerns.
Digital trace data—the data generated when people use digital technologies—are playing a progressively central role across informal and formal education contexts, such as the home, school, museums, and higher education institutions. In an educational system now mediated by digital technologies, data are being generated, recorded, manipulated, and distributed on an unprecedented scale and scope. These kinds of data have been incorporated into a variety of learning scenarios and can be seen, for example, in the creation of real-time learning dashboards, the use of predictive analytics of learner performance, the development of educational apps and games, and data-driven decision making in education institutions. Digital trace data have been heralded as a means to improve the quality, efficiency, and, in some cases, equality of educational systems.
Despite the evidence for these claims remaining a significant focus of debate (e.g., Selwyn, 2015), digital trace data are now a feature of many education systems across the globe. At the same time, there is increasing attention to the ethical considerations surrounding the use of such data for learning and education. Such considerations include privacy and data protection as well as the assumptions that drive algorithms used in data analytics. These ethical challenges must be addressed across the complex networks of actors of the educational landscape—between policy, politics, administration, schools, commercial software providers and third party data “mediators,” who are often responsible for technical data services around software and databases. This context raises important questions about legal regulation, governance, agency, and who (and for what) each actor is accountable when it comes to ethical practice.
Although these issues have attracted debate for some time, answers to these questions are becoming increasingly pressing at the time of writing due to the significant switch to the use of digital technologies to provide access to learning opportunities during the COVID-19 (coronavirus disease 2019) pandemic. Although these moves were made to solve an immediate problem, there are likely to be long-lasting impacts on the use of technology, including the ethical implications of the use of digital trace data in education that require academic scrutiny (Williamson et al., 2020).
While the body of literature addressing and responding to these ethical concerns is certainly growing, research fields in these areas are still emerging. There are few integrated and coherent attempts to map ethical concerns and challenges related to the use of digital trace data in learning and education. Different researchers are exploring the issue within particular academic communities or focusing their analysis within a particular stage of education or stage of development, and through use of particular and varied terminology.
This article details a systematic search of the academic literature relating to digital trace data and ethics in education and learning. The review seeks to identify and analyze all relevant conceptual and empirical work in the field, with a view to identifying the key ethical issues and their social implications, any responses to such ethical issues (including guidance and frameworks), and areas for further research and policy development. Given the emerging nature of this topic, we address three key aims: (1) to map the landscape of research in the ethics of digital trace data use in learning and education (specifically by study type, academic community, institutional setting, and national context); (2) to provide a thematic analysis of the ethical issues and responses that are highlighted in existing research on the ethics of digital trace data use in education and learning; and (3) to identify research gaps and an agenda for future research in this area.
Digital Trace Data in Education
What Is Digital Trace Data?
For decades, education researchers have used technologies to capture data. However, there has been an exponential interest since the early part of this century in the availability and potential to use “digital trace data.” Digital trace data are the data that are generated as people interact with any kind of digital device. For example, when students complete an assessment, read a page, write a response to a forum post, or compose an essay, digital systems capture an array of data about these activities. Such data may include the time taken to carry out the various stages of the task, patterns of engagement, who responds to whom, what was written and edited out, and what images were uploaded and when. These and other digital activities, that in the past were often not directly measurable by researchers, can now all be routinely captured by digital systems—potentially offering insights into how students are thinking or understanding a particular concept (Regan & Jesse, 2019). These forms of data relevant to learning are not only captured by keystrokes but can include other kinds of engagements with digital devices such as movement (e.g., via the growing use of activity trackers), speech (e.g., providing commands to digital “personal assistants”), or eye movements and facial expressions (e.g., captured via webcams or smart glasses), and include the metadata from each interaction (see Boellstorff, 2013). Such data can be generated within a particular system (e.g., maths game, learning management system, search engine, social media site) but this data collection is not confined to one site or one location. The use of cookies, IP addresses, and the availability of GPS tracking enables activities to be further tracked across contexts and time (Mayer-Schönberger & Cukier, 2014; Regan & Jesse, 2019).
The examples summarized above demonstrate that digital data may originate from three principal sources. First, data can be deliberately collected, which Kitchin (2014b) terms directed data, such as the measurement of pupil progress against particular benchmarks or standards, as well as more covert forms of institutional monitoring, surveillance, and evaluation of individuals. In each case, the nature of the data collected has been predetermined by a person or institution. Second, data can be gathered and archived automatically through the ‘routine operations” of digital devices and systems, including, for example, patterns of engagement within learning platforms (Selwyn, 2015). Third, data may also be input by users of digital systems, for example, by providing information as part of personal “profiles” on social media, or participating in discussion forums (Kitchin, 2014b). As technology becomes increasingly embedded in everyday life and learning, there has been an exponential rise in the use of the latter two sources of digital data.
These data, that we and others have called digital trace data, can also be referred to as Big Data, and is viewed as uniquely different to previous forms of data collection. Kitchin (2014a) characterizes such data as huge in volume, consisting of terabytes or petabytes of data; high in velocity, being created in or near real-time; diverse in variety, being structured and unstructured in nature; exhaustive in scope, striving to capture entire populations or systems; fine-grained in resolution; and flexible, so that it may be extended and expanded easily (Kitchin, 2014a; see also boyd & Crawford, 2012).
While the majority of these data will be generated in its “raw” form of alphanumeric symbols, it can then be processed and manipulated through “data work” (Selwyn, 2015), when data are processed into “more socially meaningful ‘data entities’—i.e., representations, models, calculations and visualisations” (Kitchin, 2014a, p. 65). As such, the term Big Data are used to refer not only to the sheer size of datasets themselves but also to their internal complexity and the complexity of associated analytics (Clayton & Halliday, 2017).
Thus, there are a number of properties of digital trace data that are distinctively different from other kinds of data that we typically see in education (Eynon, 2013; Selwyn, 2015; Williamson, 2017b). Such data are particularly valuable in collecting real-time longitudinal data about learning processes that tend to be difficult to capture in other forms of education research. It enables the opportunities to link multiple forms of data together to understand learning and education, and lends itself to more computational approaches to analyses (Pardos, 2017). These characteristics present distinct ethical challenges which we discuss below.
For the purposes of this review, we deliberately use the term digital trace data to reflect these trends instead of the term Big Data that reflects a current “hype cycle” in education and is likely to date quickly.
It should also be made clear that academics from many social spheres are exploring the ethics of systems that use digital trace data. In particular, the Human Computer Interaction (HCI), Computer Supported Cooperative Work (CSCW), and Computer-Supported Collaborative Learning (CSCL) communities are areas where substantial work on the ethics of the use technology has already been explored, particularly in terms of the ways ethics can be incorporated into the design of technological systems (see, e.g., Friedman & Kahn, 2003; Gray & Boling, 2016; Shilton, 2018). In addition, Science and Technology Studies (STS) communities have conducted substantial work on data bias and algorithmic accountability, especially focusing on algorithmic bias, to understand, and ultimately challenge, the kinds of data-driven inequality and discrimination that can play a part in many spheres of social life (see, e.g., Ananny & Crawford, 2018; Martin, 2016). Furthermore, new methods across the social sciences (e.g., “trace ethnography,” which is premised on extracting information about users and their actions, and subsequent analysis and manipulation of these data to understand and describe behaviors more clearly; Geiger & Ribes, 2011) are also encouraging researchers to examine ethical practice in relation to the use of digital trace data.
The purpose of this review is to establish the evidence base and conceptual discussion within the particular fields of learning and education. There are two academic communities engaged in such debates: those from data analytics (learning analytics, educational data mining) and sociological scholars of datafication and digital governance.
Data analytics
The increasing prevalence of digital data work within education is apparent in the growing adoption of data analytics, often termed learning analytics: “The measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimising learning and the environments in which it occurs” (Long & Siemens, 2011, p. 34). Broadly speaking, this body of work has originated out of the learning science community, and those particularly focused in understanding online learning in the context of higher education.
Interactive digital educational tools, such as those mentioned above, generate immense quantities of granular information or “digital trails” about students, including view and download commands, start and end time, time on task, and correctness. Although not yet operational in most systems, applications that can monitor bodily movements and indicators such as heart rate, eye movement, and facial expressions already exist and can also provide data concerning students’ physical reactions while performing educational tasks (Effrem, 2016).
Analytics dashboards now appearing in most virtual learning environment/learning management system online learning platforms present a range of graphs, tables, and other visualizations used by learners, educators, administrators, and data analysts. Learners may receive basic analytics such as how they are doing relative to the cohort average (e.g., test scores, forum contributions) as well as summaries of their other online activity, such as library loans, purchases, and participation in social networks (Harel Ben Shahar, 2017).
Learning analytics can thus provide learners with insight into their own learning habits and give recommendations for improvement, or, for example, help identify “at risk” learners. Through learners’ static (e.g., demographics or past attainment) and dynamic (e.g., pattern of online logins; quantity of discussion posts) data, researchers have tried to “classify” learners’ trajectories (e.g., “at risk,” “high achiever,” “social learner”) or predict which students are likely to succeed or drop out of a particular course (Dodman et al., 2019) with a view to offering more timely interventions (e.g., extra social and academic support; more challenging tasks). As such learning analytics is focused both on the processes and outcomes of learning.
Educational data mining (EDM) is an emerging discipline that draw significantly from methods in computer science and engineering (Romero & Ventura, 2010) to optimize learning systems, where optimization typically relates to learning efficiency (Eynon, 2013). Such approaches may not always provide insights into the process of learning (which can often remain as a “black box”) but can nonetheless offer insights into how to improve outcomes. Many of the methods used are similar to those in learning analytics, although EDM historically has a greater focus on automated methods and learning analytics has a greater focus on human interpretation and visualization (Siemens & Baker, 2012).
Indeed, as both communities mature and collaborate, the distinctions between EDM and learning analytics are becoming less clear. As such, the use of data analytics within education can be seen to serve purposes for learners, teachers, administrators, institutions, and policymakers. These include providing feedback to teachers and learners about their understanding of key concepts, likely exam performance, and dropout risk (e.g., Clayton & Halliday, 2017); seeking to improve student success through predictive models and visualizations (Essa & Ayad, 2012); creating a shared understanding of the institutional successes and challenges through more transparent data and analysis (e.g., Dietz-Uhler & Hurn, 2013); finding unexpected patterns in the data, beyond those detectable through human observation (boyd & Crawford, 2012); and improving administrative decision-making and organizational resource allocation (Rios-Aguilar, 2015). The precise ways these goals can be achieved may include learning analytics and/or EDM despite each community having its own distinctive parameters.
Digital education governance
A quite separate academic community are those from the Sociology of Education, who have a relatively long history of discussion and critique of the growing “datafication” of education. Scholars from this community have argued that education has been subjected to a process of “digitally driven datafication,” whereby schools, colleges, universities, and commercial institutions now collate masses of digitized data on a daily basis and function increasingly along “data-driven’ lines. While there has been an intensification of more “traditional” digital data recording (e.g., surveys, exams, collection of performance data, etc.), there has also been a broadening of the use of digital trace data collected by digital devices. For example, Manolev et al. (2019) describe how a process of “datafication” of discipline and student behavior has taken place through ClassDojo, a classroom management and communication platform with a “gamified” behavior shaping function.
An important issue within this area of research is the significant role of commercial stakeholders within this space. Companies such as ClassDojo, along with Google, McGraw Hill, Knewton, and Pearson, are using data-driven methods in the educational products they market to educational institutions or to parents/guardians. In addition, data are at the heart of the business model of many other mainstream platforms that young people may use for learning such as YouTube, Facebook, or Twitter that can be used to facilitate informal learning, or indeed have become reconceptualized as learning spaces and “course management systems” for schools and higher education institutions (Tess, 2013). This is taking place in an environment where digital datasets have become increasingly commercially valuable and appropriated by the digital knowledge economy (Zuboff, 2019).
The growing commodification and commercial value of digital data sets, and their use in these domains, are blurring the boundaries between the roles of the private and the public sector in determining educational policy and practice. Internet empires—such as Google, Apple, Amazon, and Facebook—now have major control over the ways in which knowledge is generated and accessed (Andrejevic, 2013; Kitchin, 2014b; Mayer-Schönberger & Cukier, 2013; Williamson, 2016a). Such observations have important ethical consequences, as the ethical practices of companies tend to be less transparent than public institutions, which, in turn, can have significant implications for public trust. Digital data are not neutral and objective truths, but rather the products of human decision-making and technological design features that are embedded within wider social, cultural, and economic arrangements (e.g., Cheney-Lippold, 2011). There are thus further implications concerning whose judgments are informing and supporting learning processes and educational practices. The ethics of this direction of travel requires significant and careful scrutiny.
The Ethics of Digital Trace Data
There was early acknowledgment from scholars and practitioners of digital data that the use of digital trace data in education and learning posed significant ethical challenges (e.g., Eynon, 2013; Ferguson, 2012). Before examining this work it is useful to consider existing approaches to ethics in education.
Traditional approaches to ethics in education
There are well-established ethical guidelines across the field of education research. These include the guidelines on ethics from British and American Educational Research Associations (BERA and AERA) and the Australian Association for Research in Education (AARE).
However, while there has been some recognition by professional associations in the field of education about the need to examine the ethical implications for research using digital data (e.g., a useful bibliography provided by BERA), to date there have been limited professional resources for researchers in the field of education who are engaged in the collection and use of digital data, especially those focused on the use of digital trace data, to guide their ethical choices (Moore & Ellsworth, 2014).
A new ethics? Returning to ethical theory
West et al. (2016) suggest that engaging in an ethical decision-making process should prompt consideration and acknowledgement of our values (which each individual/institution has) and context (legal/cultural/political/economic) to identify the ethical issues relating to the decision-making process. Ethics as a discipline has deep and contested theoretical groundings. It is thus important to acknowledge the position and value base from which ethical issues arise in order to examine their relationship with data use in education.
There are a number of well-established schools of ethical thought, which serve as “alternate lenses with which to view specific contexts, individuals, and social relationships” (Gray & Boling, 2016, p. 969). These strands include (1) deontological, (2) virtue, (3) consequentialist, and (4) pragmatist ethics (see also Becker & Becker, 2001). Each strand brings with it a rich intellectual tradition, but can be briefly summarized as follows: Deontological ethics are based on the idea of duty, connected to rights, and are derived from the work Kant, Rawls, and Ross. A deontoglogical perspective addresses human action itself, assuming that an act can be seen to be inherently good, insofar as it references a formalized set of rules. This “duty-based” perspective focuses on the motives of the human actor rather than the results of that act. In the Kantian view there is the “idea that there are moral absolutes in the world . . . things which are quite simply wrong, morally, just as there are things which are wrong logically or arithmetically” (Reamer, 1993, p. 30). In the context of data in education, it could be argued that people have the right to data privacy, to know that their data are being collected, and/or that they have the right to access and amend their own data. Yet rights (e.g., the basic human right to privacy) are interpreted differently in different jurisdictions (Reidenberg, 2000), as well as individuals’ expectations and beliefs about these rights, making use of digital data across in education in different countries challenging.
Virtue ethics date back to Aristotle. As Reamer (1993, p. 41) explains, “An action is the right thing to do, not because of some sort of calculation as to its consequences, or because it concurs with a ‘duty’, but because it is consistent with virtue.” As an example, Clayton and Halliday (2017) discuss the way in which digitization threatens social integration (a virtue): Schooling and university is largely about training for citizenship in ways that require interaction with peers from different social groups. . . . If digitisation threatens the sharing of space in the learning process, it may destroy one of the most valuable means through which societies pursue integration. (p. 299)
Consequentialist ethics can be understood as addressing the consequences of an act as the primary basis for ethical analysis. This perspective, as set out by Jeremy Bentham and John Stuart Mill in the form of utilitarianism, focuses on the effect of an act on society has been, often focusing on the potential of an act to affect the happiness of everyone. Consequentialist ethics thus prioritizes the social group over the individual. From this perspective, the benefits to the various players are considered and action is related to benefit for the largest number of people (Beauchamp & Childress, 1994). For example, if the majority of students benefits from presenting progress data to assist them in their progression, then all students should provide their data for this purpose. Willis (2014) suggests that much of the current state of ethics in learning analytics has a basis in utilitarianism, which says that we ought to do what causes the most good for the most people. Willis (2014) highlights the inescapable connection between utilitarianism and the law, as both attempt to provide a means to take individual information and serve the greater good. Willis (2014) suggests this is why legal frameworks and ethical discussions are generally dealt with together.
However, Willis (2014) suggests that utilitarianism has pragmatic problems, especially where implementation creates conflicts between individual users and larger groups and does not account for difficulties in predicting consequences. Discussions of learning analytics and ethics are problematic, because of their binary approach: actions are deemed either “right” or “wrong,” most often in legalistic terms (see also Kay et al., 2012). Willis (2014) suggests that determining the most good for the most people, a utilitarian perspective, is a responsible way forward, but often difficult to achieve when faced with unintended outcomes. Indeed, scholars have recognized that the ethical domain is one in which power is contested: “Who gets to decide what ethics is will determine much about what kinds of interventions technology can make in all of our lives, including who benefits, who is protected, and who is made vulnerable” (Moss & Metcalf, 2020, n.p.).
As a response to these problems, there has been a rise in what can be grouped as pragmatist approaches to ethical scholarship. The introduction of feminist theory has, for example, strongly influenced the development of care ethics, which prioritizes the interpersonal domain of interaction over notions of consequentialism (Gilligan, 1982). From this perspective, individuals are understood to have varying degrees of dependence and interdependence on one another, and through this ethical lens it is possible to explore the power relationships and the relative vulnerability of actors. Individuals affected by the consequences of one’s choices must be considered in proportion to their vulnerability, and contextual details determine how to safeguard and promote the interests of those involved. This perspective accounts for acts as facilitating the giving or receiving of care, emphasizing the interpersonal and affective nature of ethics in individual contexts (Gray & Boling, 2016). In educational contexts, care ethics help set the limits of what may or may not be harmful for students to know, especially when in the theoretical construct of predictive analytics (Willis & Strunk, 2017).
The particular ethical challenges of digital trace data
There are some characteristics of digital trace data that present particular ethical challenges. As technology evolves as a space for learning, the methods necessary to capture and document such activities are also emergent (Eynon et al., 2017). Indeed, legal frameworks often trail behind technical innovation; thus, the legal advice that serves to inform a utilitarian approach may not be sufficient or appropriate (Markham & Buchanan, 2002, 2012). For example, scholars must consider the relevance of the human subjects model versus a more humanities-based model to guide ethical decision making. In a number of contexts, digital trace data could be viewed as text as opposed to a human interaction or dialogue that requires consent from research subjects (Bassett & O’Riordan, 2002). However, this is not a straightforward decision in many cases. This is further complicated by the fact that often ethical advice on using digital data are not specific to young people (cf. Livingstone et al., 2015) or to the context of learning and education. The specific context for ethical decision making is thus of the utmost importance (West et al., 2016).
As noted above there are a number of properties of digital trace data that are distinctively different from other kinds of data that we typically see in education (Selwyn, 2015; Williamson, 2017b). The most well cited of these are the “three types or 3Vs of ‘volume, velocity, and variety’ (Laney, 2001; Zikopoulos et al., 2012)” (Kitchen, 2014b, p. 67) that are particularly valuable when researchers wish to collect real-time longitudinal data, link multiple forms of data together, and utilize advanced data techniques to capture parts of the learning or education process that have been difficult to measure with “traditional” social science methods.
These characteristics present distinct ethical challenges. The possibilities to aggregate and combine data sources lead to risks of de-anonymizing individuals (Oboler et al., 2012); and often these data are reused and decontextualized to answer new questions, but in ways that divorce the data from an understanding of its original social context, which is sometimes used as a heuristic for developing ethical practices that are socially and culturally appropriate (Eynon et al., 2017). Furthermore, such data enable data scientists to develop proxies for all kinds of categories (such as gender, race, and age) that may not be explicitly collected (or consented to) within the system itself (Regan & Jesse, 2019). Given the multiple ways these data can be used, there are also questions about the extent to which it is reasonable/possible for individuals to fully understand the implications of agreeing to the use of these data (Ananny & Crawford, 2018; Tsai et al., 2019).
To assist in developing ethical arguments that take account of this fluid and highly complex domain, Floridi (2018) describes the important interactions between digital ethics, also known as computer, information or data ethics, digital governance, and digital regulation. Digital ethics, Floridi (2018) suggests, is “the branch of ethics that studies and evaluates moral problems relating to data and information, algorithms and corresponding practices and infrastructures” (pp. 3–4). Floridi (2018) asserts that digital ethics shapes both digital regulation and digital governance through moral evaluation.
Digital governance, Floridi (2018) argues, is the practice of establishing and implementing procedures, policies, and standards for the use and management of data. This might include the processes and methods used to improve the data quality, reliability, access, security, and availability of data services, or setting out accountabilities with respect to data-related processes in a particular institution, often enacted by designated data “stewards” or “custodians.”
Digital governance may include guidelines and recommendations that overlap with, but are not identical to, digital regulation. “A system of rules elaborated and enforced through social or governmental institutions to regulate the behaviour of the relevant agents” (Floridi, 2018, p. 3). The EU’s General Data Protection Regulation (GDPR), introduced in 2018, represents a significant piece of digital regulation that introduces legally enforceable standards relating to privacy and data protection. It imposes legal obligations onto all organizations within its jurisdiction, providing they target or collect data related to people in the European Union. Harsh fines can be levied against those who are not compliant with the GDPR’s strict standards. Floridi (2018) argues that compliance is the crucial relation through which digital regulation shapes digital governance. That is to say, an institution’s digital governance policies and practices determine the extent to which it is compliant with a piece of digital regulation.
However, Floridi (2018) suggests that compliance is necessary but insufficient to steer society in the right direction. Digital regulation indicates the boundary between legal and illegal practice, but it does not cover what might be considered the best moral course of action. This, Floridi suggests, is the task of both ethics, on the side of moral values and preferences, and of digital governance, on the side of best management. This discussion is summarized in Figure 1.
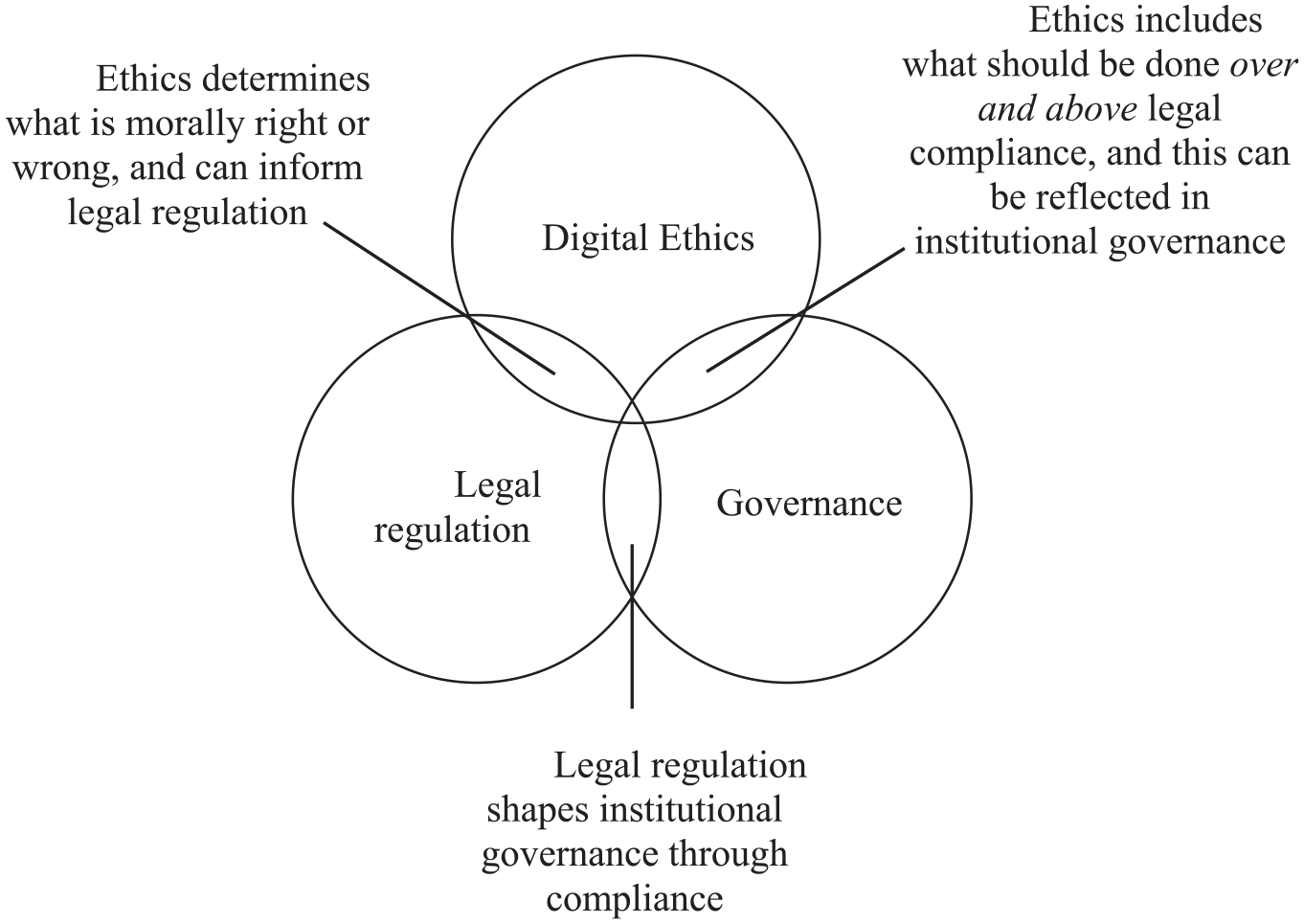
The interrelationships between digital ethics, governance, and legal regulation, based on Floridi (2018, p. 2).
There is thus significant need to bring together the existing advice on this topic, to understand the ethical issues that are arising as digital data are increasingly central to the educational landscape, to identify the emerging responses to these challenges in relation to both governance and legal regulation, and to question the ethical theories and values upon which they are based.
We therefore ask three questions about the emerging domain of research on the ethics of digital trace data use in education and learning: (1) What are the characteristics of research in this domain by study type, academic community, institutional setting, and national context? (2) What are the primary ethical concerns and related responses in this domain? (3) What research gaps are there in this domain and how might these be addressed?
Method
In this study, due to the new and emerging nature of the research field, and the diverse presentation of research evidence, a meta-analytic systematic review, such as Fong et al. (2017) or Dietrichson et al. (2017), has not been possible. Instead, a systematic qualitative/thematic analysis, similar to the approach employed by Tieken and Auldridge-Reveles (2019) has been conducted. The specific methods employed for this review are set out below.
Searching for Relevant Studies
Searches for relevant studies for this review were conducted using three principal databases: (1) EBSCOHost (a discovery service searching the following databases: British Education Index, Child Development & Adolescent Studies, Education Abstracts [H.W. Wilson], Educational Administration Abstracts, ERIC, Family & Society Studies Worldwide, Library, Information Science & Technology Abstracts, Teacher Reference Center); (2) ProQuest (a specialist index and full-text social sciences databases, incorporating 900 journal titles, covering subject areas including politics, sociology, education, linguistics, and criminal justice); and (3) the advanced search function in Google Scholar.
The searches were conducted using sets of search terms set out in Table 1a and limited to those studies published since 2000. The evolution of digital trace data has a long and complex history. For decades, in subfields such as in the AI and Education (AiED) community, researchers have been able to use the data generated by the systems they were developing to better understand learning processes. However, excitement around the potential for these kinds of data—typically termed “Big Data” accelerated in the early 2000s due to advances in new technologies and the current social, economic, and political landscape (boyd & Crawford, 2012). This was galvanized within the field of education with the introduction of Massive Open Online Courses (MOOCs) designed for tens of thousands of students in 2011, which provided opportunities for many researchers to access digital trace data about learning. Given this complex background, we therefore set our starting point to search for studies to 2000. The terms for Categories A (relating to digital data), B (relating to ethics), and C (relating to education and learning) were compiled iteratively through several trial searches, scanning relevant article abstracts for additional keywords and identifying key terms from reading, and revising the terms accordingly. A particular challenge was to identify the range of appropriate terms that were sufficiently far-reaching so as to identify all relevant studies, but also targeted enough to yield appropriate search results (e.g., a search for “education” AND “data” would yield far too many irrelevant search results). Where search engines would facilitate an advanced search, search terms were applied through groups using Boolean logic. The sensitivity of different combinations of search terms were trialed and reviewed by two researchers. The final list of search terms is set out in Table 1a.
Review search terms

Searching and Screening Studies
All searches were carried out between March and June 2019. Retrieved articles underwent three phases of screening. First, the titles and abstracts of retrieved studies in each database were scanned for relevance to the present review according to the inclusion criteria (Table 1b). The first 500 studies in each set of search results (sorted by relevance) from each of the three principal databases were scanned, after which point it was consistently found the studies retrieved by the databases did not have abstracts or key words that met any of the inclusion criteria for this review. This stage was carried out by a single reviewer, but an additional reviewer was available to discuss titles and abstracts that presented some uncertainty or ambiguity.
Selection criteria for included studies

In a second phase, the selected articles were reviewed in accordance with the inclusion criteria set out in Table 1b, and this process was aided by using the “search in document” function to locate keywords in passages of text. This stage was conducted by two reviewers, and articles subject to disagreement were discussed against the inclusion criteria until consensus was reached. Finally, the reference sections of included studies were scanned to locate additional studies. It was decided that nine articles, while initially appearing to fit the inclusion criteria, did not detail sufficient discussion or empirical detail that addressed the review questions to contribute to the review. These stages, and the retrieved results, are set out in Figure 2.
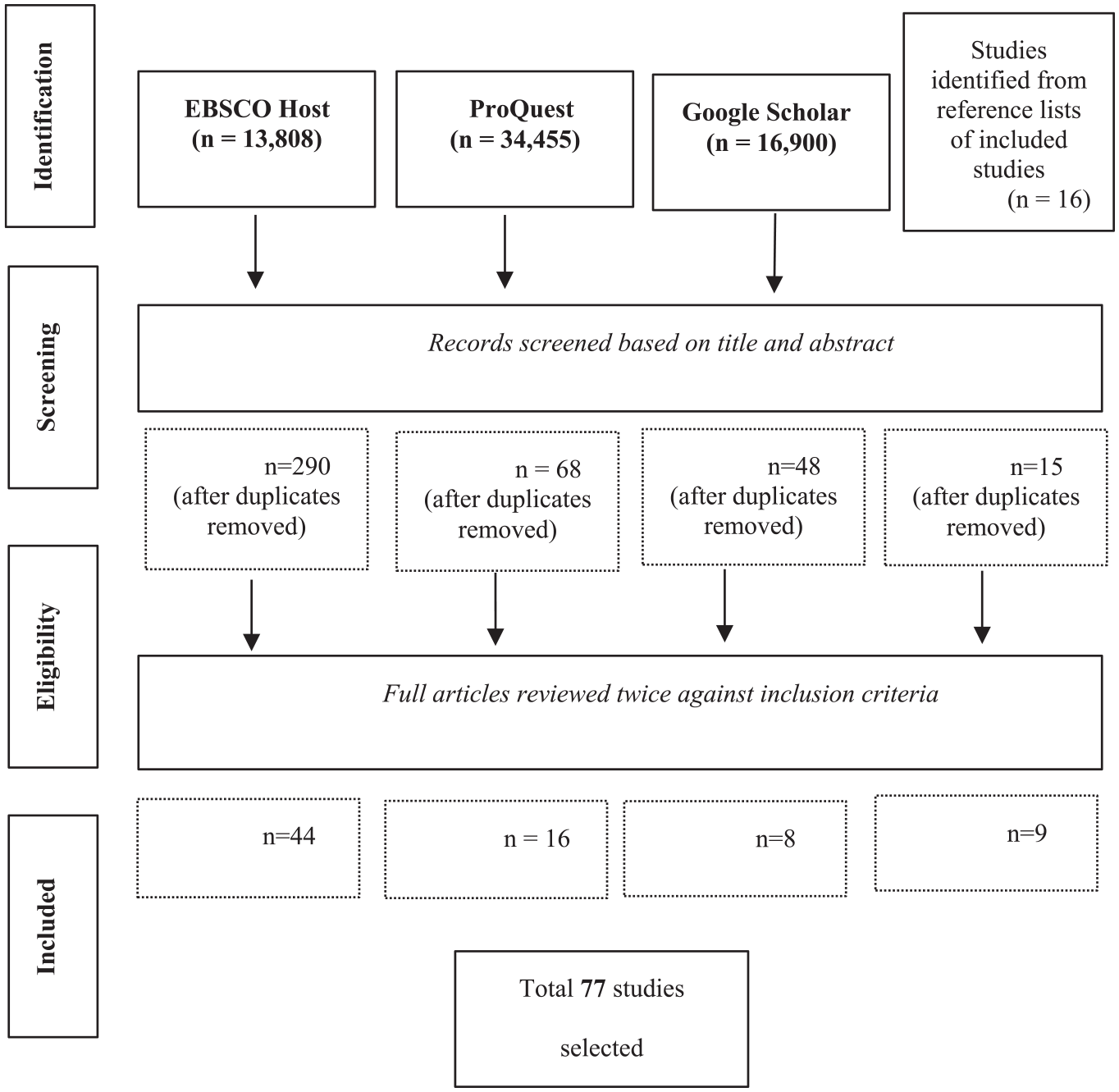
A flow chart illustrating the retrieval and exclusion of articles from electronic databases.
Criteria for Inclusion
Studies were included if they focused on educational contexts or issues and devoted significant attention to ethical issues. Studies were also included if they focused predominantly on fields beyond that of education (e.g., sociology, Big Data, etc.) but made reference to educational contexts and devoted significant attention to ethical issues. Studies were excluded if they focused on ethical issues and digital trace data but did not relate specifically to educational contexts (see, e.g., Herschel & Miori, 2017; Mai, 2016). Studies were excluded if they made only passing reference to ethical issues. For example, a number of excluded studies suggested that ethical principles were important, or listed concerns related to “privacy and ethics” but did not discuss them in detail (see, e.g., Avella et al., 2016; Picciano, 2012; Reyes, 2015). Studies were excluded if there were discussions relating to the ethics of data use in education but the data used were not explicitly “digital trace data,” that is, the data were derived from more traditional means of data collection (see, e.g., Roberts-Holmes, 2015; Roberts-Holmes & Bradbury, 2016). Studies were excluded if the discussion related to the ethics of data collected specifically for research purposes (see, e.g., Metcalf & Crawford, 2016), and included only if the collection, use, and analysis of data was specifically embedded within the business of supporting learning and educational institutions. While there were a number of studies relating to data ethics within the context of libraries (see, e.g., Jones & Salo, 2018), these related less to the support of learning within educational institutions and more to archiving and data management, and so were excluded from this review.
Outcomes of Screening Process
As indicated by Figure 2, a total of 77 published studies were selected following the sorting and screening process. Despite the parameters, all included studies were published between 2012 and 2019. Given our understanding of the field we were unsurprised that the ethical implications of digital trace data were not a focus of papers until the second decade of this century, and began shortly after the introduction of MOOCs.
It is important to note that there was no attempt to evaluate the quality of the selected articles. Despite this being a common approach in systematic reviews, it was not appropriate in this case given the relative newness of the topic. When reviewing emerging research areas, there is a risk of omitting articles, and by extension important topics of research that are developing in this area, if the inclusion criteria are too stringent. We addressed this issue by restricting the review to peer reviewed papers.
We recognize the relatively fast-moving nature of the topic. In some senses, it means that reviews of this kind can become quickly dated. However, our intention is to highlight principles that endure rounds of innovation and provide a foundation for others to build upon. This is particularly important in research that explores aspects of education and new technologies, which typically neglects to learn from history (Selwyn, 2012).
Analysis and Coding of Selected Studies
As noted in the introduction, research exploring the ethics of using digital trace data are still in its infancy, and is relatively dispersed across academic communities, educational contexts, and definitions of ethics. We therefore coded each study according to its characteristics alongside the ethical issues raised to assist in mapping the field and providing insights for future work. Specifically, each selected study was coded according to educational context (early years, school, higher education, etc.); academic community (learning analytics; Big Data); study type; ethical issues raised; responses to ethical issues proposed; and engagement with (ethical) theories.
Papers associated with each code were then subject to a process of thematic analysis, used to draw out ethical issues and social implications that form the basis of the following discussion. This thematic analysis involved rounds of qualitative coding to create categories of papers that fit well together in terms of topic (Dey, 2003; Saldaña, 2015). Next, an open coding process was used to “chunk” the summaries into areas of convergence across the included studies (Corbin & Strauss, 2007). We coded for broad themes and related subthemes, including ethical issues and challenges, as well as proposed responses to these challenges. Just as adopted in the thematic review by Tieken and Auldridge-Reveles (2019), we focused on findings with support from multiple sources, and we also looked for any thematically relevant counterevidence or divergent findings, either within or between contexts. We drafted and revised summative memos in order to develop and refine the synthesis of our findings. The results of this process are presented in the next section.
Results
Study Characteristics
To provide an initial mapping of the landscape of research in the ethics of digital trace data use in learning and education, and address Research Question 1, we examined the articles by study type, academic community, institutional setting, and national context.
Study Type
The type of study gives an important overview of the nature of the research evidence in this particular field. Table 2a presents the included studies according to study type and shows that the majority (n = 53) were conceptual discussion papers, some of which also engaged with a variety of academic theories (see Table 9 for a summary of theoretical engagements). Only one of the included studies was a systematic review (Nunn et al., 2016), which sought to present the methods, benefits, and challenges of learning analytics in higher education. Nearly a fifth of the papers were classified as empirical. Studies were classed as empirical if they included some form of data collection or analysis, or if they included an in-depth case study, rich with empirical detail (n = 14). Table 3 sets out the nature of these empirical studies, and the educational contexts in which they were conducted.
Included study types

Academic field

Type of institution

Note. MOOC = massive open online courses.
Origin of research
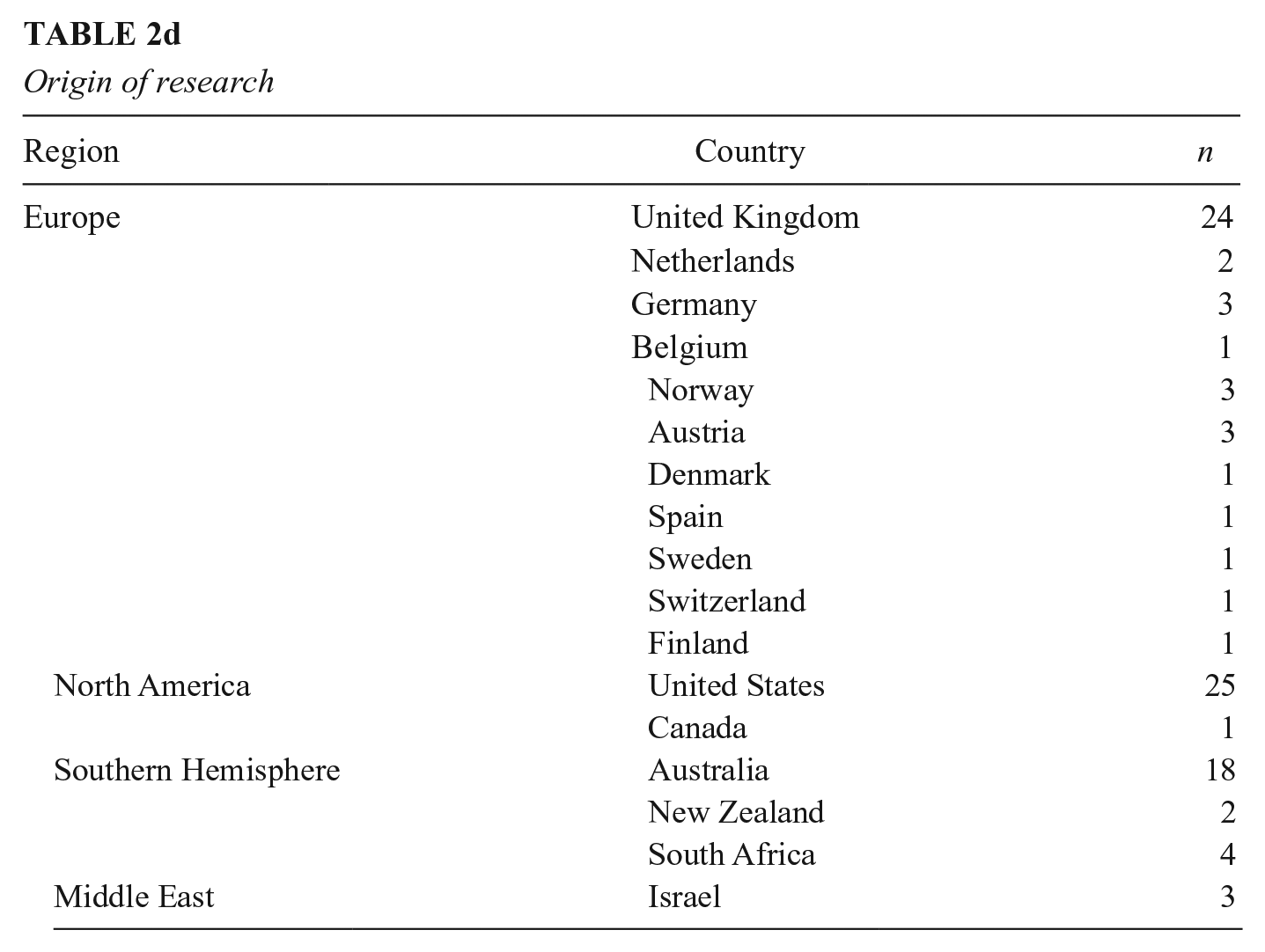
Studies reporting empirical work and case studies
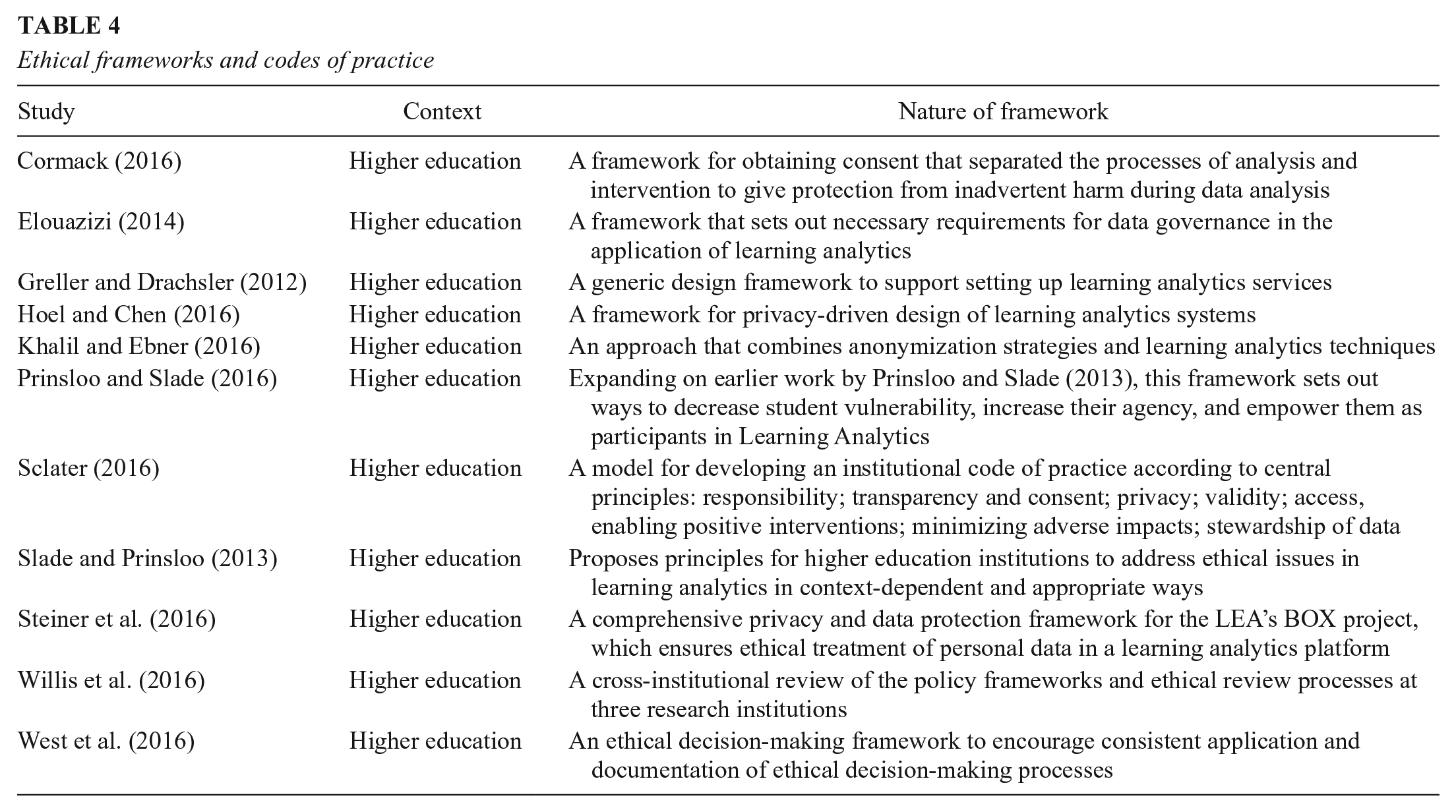
The remaining papers were codes of practice, frameworks for understanding ethics, engaging with ethical principles, or carrying out ethical decision making in educational institutions (n = 11). These were almost exclusively situated within the context of higher education institutions and are set out in Table 4.
Ethical frameworks and codes of practice
Academic Communities
It is important to note the broad academic communities from which the included studies arise, so as to identify the most active research groups in the field (and to understand the extent to which they are connected). The data were based on study keywords and bibliographic tags and are set out in Table 2b. It is clear that studies linked to learning analytics were dominant within the included sample (n = 37). As Siemens and Baker (2012) have observed, learning analytics has become a relatively well-defined academic community with its own dedicated journals, conferences, and so on, and given its emphasis on informing institutional practice it is perhaps not surprising that many of the ethical studies emerge from this tradition. A relatively large number of studies (n = 19) were positioned within a Big Data community, encompassing a larger number of studies from outside higher education, although it was possible for a study to engage with both learning analytics and Big Data. Only a few studies (n = 4) referred explicitly to EDM techniques, and this may reflect that a lot of researchers who engage with EDM tend to be from the computer and engineering sciences, where data are likely to be seen in a numerical or textual sense, not as part of a human subject—thus ethics have in the past been seen as less pertinent. However, as the field is developing, this is changing. 1 Indeed, two of the studies that have data mining as keywords also refer to learning analytics, suggesting a blurred distinction between the two approaches to analyzing digital trace data.
The remainder of the included studies were more sociological in focus (n = 21). A significant number of these engaged with the concepts of datafication and digital governance in education, the increasing role of corporate and third party agencies in the production, analysis and visualizations of data across the educational landscape, and the associated ethical challenges. A number of studies (n = 8) engaged extensively with legal regulations and frameworks in their analysis, and in most cases were at least partly written by legal scholars. This indicates the clear interconnections between ethics and legalities. As the discussion below will explore, these legal reflections were particularly linked to privacy and data protection concerns.
It is thus clear that discussions relating to ethics and digital trace data use in education originate from a number of relatively distinct academic communities. In the section of ethical issues below, we look across these communities for themes, commonalities, and gaps.
Institutional Context
Given the wide range of institutions across which education and learning may take place, it is important to identify the context in which the included studies situated their conceptual discussions and empirical work. Table 2c illustrates that discussions of ethical issues for digital data in education are most common within the sphere of higher education (n = 41). The field of learning analytics is most commonly associated with higher education institutions (as well as MOOCs), which explains the similar number of studies in Tables 2b and 2c. There were a substantial number of studies that discussed the ethics of digital trace data in a school context (n = 17). However, although one article (Lupton & Williamson, 2017) discussed ethical issues relating to the use of digital data through different life stages and in different educational contexts, from infancy to adulthood, there was a general absence of research literature addressing the ethical issues associated with the education of younger children, and with games and informal learning outside the classroom. There were a large number of conceptual papers that discussed ethical issues in a broad sense, without engaging with a particular type of educational institution or age group (n = 14). If, as the section on ethics above described, ethical considerations must take into account context, this lack of focus on educational context is problematic and will be discussed later in this article.
The peer-reviewed literature has started to engage with the ethical challenges relating to the increasing role played by software companies and other data mediators (n = 14). This growing field is important, as understanding how companies are making ethical decisions is central to future discussions of the use of digital data for learning and education.
National Context
Ethical practice is inevitably linked to the laws that govern data use, and thus the national and regional jurisdiction within which included studies were carried out has potential importance. Table 2d sets out the national data according to institutional affiliation of authors, showing a dominance of studies from the United States the United Kingdom, and Australia.
Ethical Issues and Responses: A Thematic Analysis
From the thematic analysis of all the papers, we identified four overarching categories of ethical issues. They were privacy, informed consent, and data ownership; validity and integrity of data and algorithms; ethical decision making and the obligation to act; and governance and accountability. In this section, we will address each of these four ethical topics, implications, and author proposals to respond to these ethical issues in turn.
Privacy, Informed Consent, and Data Ownership
Notions of privacy, informed consent, and the extent to which digital data can and/or should be anonymized represent the most commonly and extensively discussed ethical issues across the selected papers. Scholars widely recognized the ethical challenges of informing and obtaining appropriate consent for collecting a range of types of digital data, subjecting it to analytics, and interpreting it. Of the 50 papers that discussed these issues, more than half were from the learning analytics tradition, which tends to be focused on HE institutions. Only four papers talked explicitly about privacy in relation to a school-aged context. The remaining papers, which made reference to Big Data, did not position the discussion within a specific context of education. Rather, they were broad, conceptual papers that discussed the issues of privacy and consent in relation to education and education policy in general. As this review will set out below, it is problematic that these discussions have been taking place without a great deal of attention to specific educational contexts, given the recognition that ethical issues must be considered in a context-specific manner (see, e.g., West et al., 2016).
Conceptualizing privacy
Several studies acknowledged that definitions of privacy, and related theories are contested (e.g., Heath, 2014; Rubel & Jones, 2016) and have a legal basis that varies according to national or regional jurisdiction. Privacy, in this sense, is the right to control and limit the flow of personal information. From this perspective, Rubel and Jones (2016) suggest that privacy is a function of autonomy; that is, to be able to make decisions for oneself, based on one’s own reasons and one’s own values, when one wishes to. Hoel and Chen (2016) emphasize privacy as a sociocultural concept and observe that the boundaries around personal and private data are social, contextualized agreements. As a final point, Regan and Jesse (2018) and Ferguson et al. (2016) note a tendency among scholars and practitioners to characterize ethical concerns under the general rubric of “privacy,” which can serve to oversimplify the concerns and make it too easy for advocates to dismiss them. Indeed, MacCarthy (2014) suggests that privacy disputes are acting as a proxy for more basic clashes in educational values.
Yet researchers such as Cormack (2016) and Ifenthaler and Schumacher (2016) suggest uses of personal data may be increasingly accepted, even expected, both by individual learners and by society. Pardo and Siemens (2014) argue that “society seems to be evolving toward a situation in which the exchange of personal data are normal” (p. 440). Thus, privacy, and how best to conceptualize it, remains open areas of debate by authors within the included studies.
Threats to learner privacy
A significant number of authors in the included studies recognize that privacy of student information is important for education because of the adverse impact that inappropriate uses or disclosures may have on student learning and social development (e.g., Regan & Jesse, 2018; Reidenberg & Schaub, 2018). The mass collection and centralization of student information have been argued to pose significant threats to learner privacy and raise questions about data ownership and consent: who owns the data and who has the right to use and/or profit from it (Cope & Kalantzis, 2016; Cormack, 2016; Jones, 2019; Lynch, 2017; Steiner et al., 2016).
Several studies highlight that the process of data aggregation can mean data are combined from many different sources, is used and/or shared by many actors and for a wide range of purposes (e.g., Wang, 2016). Lawson et al. (2016) cite an example of the use of data in a regional university in Australia in which there was an institutional assumption that student data, consensually gathered at enrolment, could be analyzed beyond the scope of the original consent. Yet, as Cormack (2016) and several others make clear, the potential value of the gathered data becomes apparent only after they are subjected to analysis by computer algorithms, not beforehand. Many scholars recognize that it is hard to predict what correlations will emerge from the data, let alone what their impact on the individual will be (Cormack, 2016). Thus, a number of scholars (e.g., Aguilar, 2017) have emphasized the potential unexpected consequences of data use and the related implications for privacy.
In addition, several studies recognize the possibility that new personal information may be deduced or inferred by employing data analytics on already gathered data. This broadened approach needs to address both whether or not individuals’ consent was secured for data collection in the first place, and privacy issues arising from the development of new information on individuals’ likely behavior through analysis of already collected data. Johnson (2017) argues that this new information can violate privacy but does not call for consent.
Reidenberg and Schaub (2018) suggest, for example, that tools may provide recommendations on which students may need a tutor’s attention or specific interventions. Such early warning systems aim to identify at-risk students with the goal of providing them with needed support and, particularly with respect to higher education, increasing student retention rates. Yet students and parents may not be aware of the existence of learning analytics dashboards or what information is employed within them (Pardo & Siemens, 2014; Reidenberg & Schaub, 2018).
Also of concern within a number of the included studies is the flow of information to private vendors or mediators who combine institutions’ data for analysis, such as the controversial InBloom project in secondary education (Pardo & Siemens, 2014; Polonetsky & Tene, 2014). A number of scholars problematize the sharing of student data with commercial technology vendors, with concerns ranging from inadequate security controls to monetization of student’s information. Indeed, Russell et al. (2018) explore the U.S. marketplace for student data.
Data ownership and legalities
Several studies include specific reference to the challenges relating to the ownership of digital data. Greller and Drachsler (2012) highlight a lack of legal clarity with regard to data ownership. Elouazizi (2014) suggests data ownership is inherently distributed. For example, the instructional designer and/or faculty can own the learning process data, the Learning and Content Management System (LCMS) team (in some institutions) can own the processes and procedures for configuring and collecting the data, and the administrative staff owns part of the learner educational experience data. When it comes to ethical data sharing or analytics, the privacy issues discussed above must be negotiated across this range of actors.
A significant number of studies (n = 8) explore the relationship between digital trace data, ethical issues, and legal regulation. Although Khalil et al. (2018) present the European Union as an example of a fast-evolving legal framework, scholars acknowledge that there is generally a low level of legal “maturity” (Kay et al., 2012, in Pardo & Siemens, 2014), as legal systems are still at the early stages of commenting on privacy, ethics, and data ownership. Making cross-cultural comparisons between the United States and China, Hoel and Chen (2019) note that privacy is handled very differently in different parts of the world. This is a challenge when designing tools and approaches for the use data analytics in a potentially global education market.
Privacy and surveillance
A number of studies linked data privacy to the concept of surveillance, or “dataveillance” (e.g., Hope, 2018). Selwyn (2015) suggests that dataveillance entails the monitoring, mining, and processing of data, which in turn allows for the identification, classification, and representation of social entities in the form of automated data profiles—sometimes described as “data doubles” or “data shadows” (p. 73). Manolev et al. (2019) comment that ClassDojo’s datafying system of school discipline intensifies and normalizes the surveillance of students. Furthermore, it creates a culture of performativity and serves as a mechanism for behavior control. Watson et al. (2017) uses the case of an individual student to problematize dataveillance, suggesting that such practices threatened trust and student autonomy.
Responses
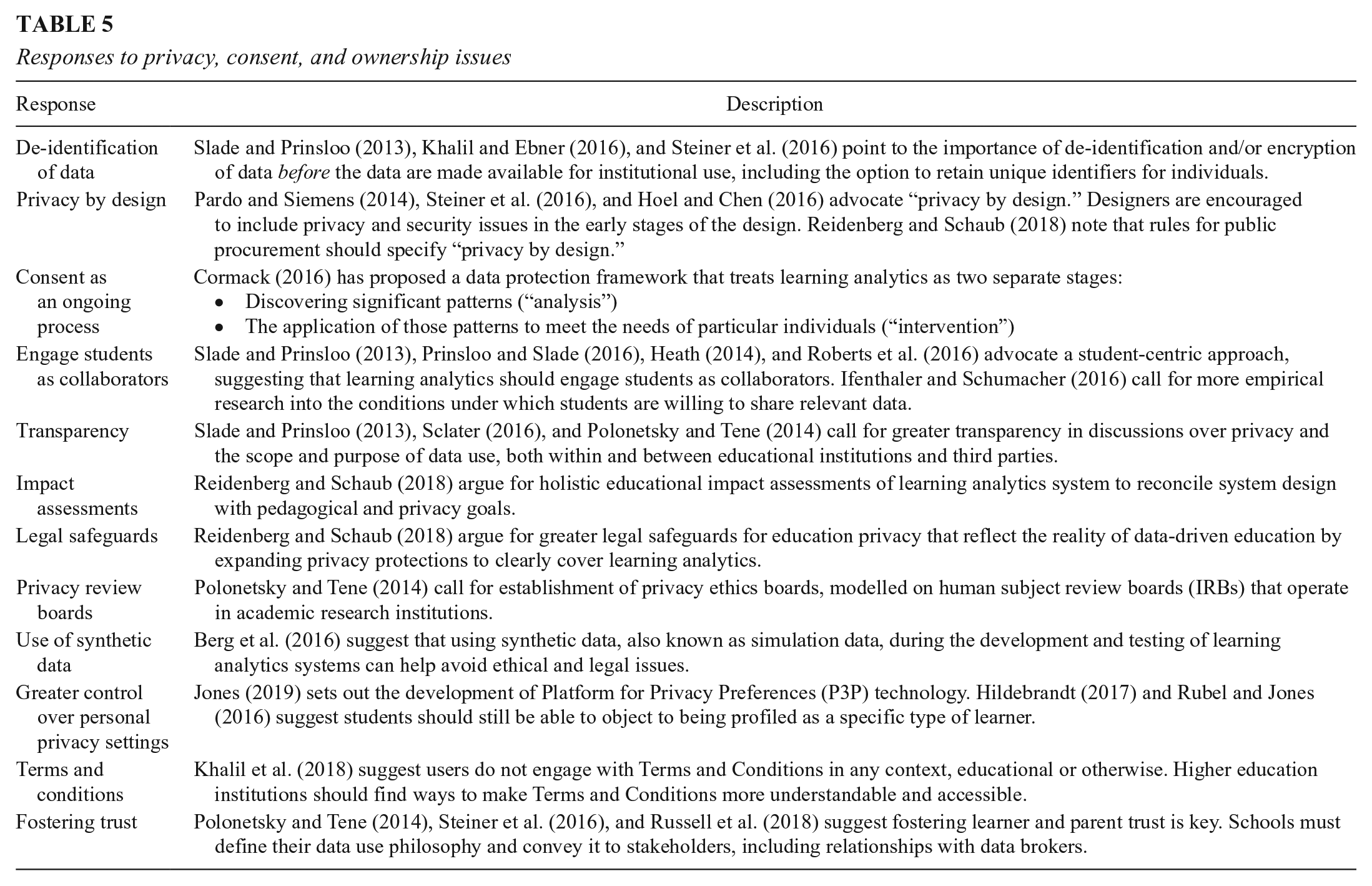
The included studies suggest a number of possible responses to the privacy-related ethical challenges, as set out in Table 5. Some scholars point to specific strategies to digital governance structures and legal regulation, such as privacy review boards, impact assessments, and greater legal safeguards that are better tailored to the particular privacy issues. Others point to better transparency, trust, and learner engagement, including a framework for an ongoing process of consent (Cormack, 2016), ways to encourage active engagement with Terms and Conditions, and ways that learners can have greater control over their own privacy settings. A final group of scholars identify a need to embed privacy issues into system design, including the de-identification of data or using data simulations to preempt and address ethical issues (Hoel & Chen, 2016; Pardo & Siemens, 2014; Reidenberg & Schaub, 2018; Steiner et al., 2016). Despite these numerous helpful responses, there is a very limited focus on what privacy and consent means for younger age groups, or how to involve parents as mediators of consent in the home and school settings, or what privacy means at a household level. Indeed, Rodríguez-Triana et al. (2016) emphasize how such considerations are markedly different and more complex (given interaction between parents, schools, and legal regulations regarding young people) when considering data use with children, compared to students attending a higher education institution.
Responses to privacy, consent, and ownership issues
Validity, Integrity and Interpretation of Digital Data
A significant proportion (n = 35) of included studies identified ethical concerns that relate to the nature of the digital trace data itself and the various assumptions that are intertwined with the processes of data analytics. The included studies address both the validity (i.e., the extent to which the products of data analytics truly represent the phenomenon they claim to measure) and the integrity (i.e., the completeness, accuracy, and consistency) of the digital data within education and learning systems. Similar numbers of these studies were derived from learning analytics, Big Data, and sociological literatures, suggesting that ethical problems with the nature and manipulation of data are receiving attention across the three broad academic communities identified in this review. There were similar numbers of studies addressing these issues in both higher education (15) and schools (10), while three studies made reference to corporate or third party organizations and seven studies did not make reference to a specific educational context.
The reductionist nature of digital trace data
Clayton and Halliday (2017) and Perrotta (2013) highlight that Big Data only tends to include information that is easily measurable and readily quantifiable: test scores, attendance rates, time on task, and completion rates during exercises (cf. Zeide & Nissenbaum, 2018). Slade and Prinsloo (2013) suggest that fixating on data that show what can be measured sometimes leads to a failure to remember that the information is, at best, a partial representation of what one wishes to know about. For example, Veletsianos et al. (2016) highlight three important domains of the experience of MOOC students that are absent from MOOC tracking logs: the practices at learners’ workstations, learners’ activities online but off-platform, and the wider social context of their lives beyond the MOOC. Watson et al. (2017) use the case of an individual student to highlight aspects of a student’s online learning practices that are not reflected in learning analytics data. While the student felt out of his depth and was left “dangling,” these feelings were certainly not reflected in his apparently purposeful learning behaviors. A significant number of the included studies thus discussed the reductionist nature of digital trace data and its analytics (see Selwyn, 2015; Slade & Prinsloo, 2015), providing a snapshot view of a learner at a particular time and context (see Harel Ben Shahar, 2017; Lundie, 2016).
Having clearly highlighted the ethical problems with what is captured by data, and when the data are captured, a significant number of studies note that much of the data require extensive filtering, classification, and standardization to transform the digital trace data into databases, and the ways in which complex data are represented (see, e.g., Edwards, 2015). Similarly, correlations between different variables may be assumed when dealing with missing and incomplete data around usage of, for example, an institution’s learning management system. Such assumptions may be influenced by the analyst’s own perspectives and result in subconsciously biased interpretations. The ethical implications of this are that such approaches risk inadvertently shifting learning and educational processes in ways we do not fully understand (Eynon, 2013). Indeed, Williamson and Piattoeva (2019) problematize the “precarious construction of objectivity” of digital trace data and its analytics and the way it informs “evidence-based” education governance.
Bias and discrimination
The included studies further suggested ways in which the use of digital data in education could serve to increase bias and discrimination toward certain learner groups. For example, predictive tools can produce discriminatory results because they include demographic data that can mirror past discrimination included in historical data. Harel Ben Shahar (2017) suggests algorithms used in educational enrolment can favor recruiting wealthier students over their less affluent peers simply because those are the students the college has always enrolled (Harel Ben Shahar, 2017). Students from a privileged background may also have greater digital skills, which results in more successful engagement in a digital environment. These disparities do not reflect an actual gap in academic ability but could cause the algorithm’s prediction to be biased against young people from low-income families or ethnic minorities (Har Carmel & Harel Ben Shahar, 2017).
Data analytics models that rely on demographic data (or that do not take into account disparate outcomes based on demographics) may also unintentionally entrench disparities in achievement among particular groups. For example, early-alert and program recommender systems can disproportionally flag certain ethnic or economically disadvantaged groups for poor achievement or steer them away from more challenging and/or economically rewarding paths, thus potentially exacerbating their disadvantage (see, e.g., Har Carmel & Harel Ben Shahar, 2017). Stahl and Karger (2016) suggest that a digital record of the student’s negative behaviors or poor academic performance, and being profiled as a particular type of learner, could ultimately interfere with future educational and/or employment opportunities. These concerns may be more pronounced with respect to students with disabilities in light of the potentially sensitive nature of the data being collected. Schouten (2017) emphasizes that data are often used to profile students who are regarded as vulnerable or educationally at risk, thus these particular ethical concerns may disproportionally affect disadvantaged students.
Several scholars also contend that algorithmic decision making may create new groups that are systematically unfairly disadvantaged. For example, if children who are color blind or who engage in after-school sports are less likely to succeed on computerized tasks, the algorithmic predictions are less favorable for them, this may be detrimental to their educational prospects, and they may be discriminated against in ability grouping processes (see, e.g., Har Carmel & Harel Ben Shahar, 2017; Harel Ben Shahar, 2017).
Scholes (2016) argues that at the heart of the analytics is the concept of categorizing students according to the statistical risk that can be attached to them, and subjecting students to different treatment on this basis. Scholes (2016) emphasizes the possible discriminatory effects of such practices. For example, a prediction that leads to a decision about a student’s educational future does more than indicate the student’s ability: it constitutes it (Harel Ben Shahar, 2017). It is extremely hard, therefore, to verify the algorithm’s predictions and to expose any inaccuracies and falsehoods (Clayton & Halliday, 2017).
Responses
The included studies highlighted a number of responses to the ethical challenges of data validity and integrity (see Table 6), which included deeper and more regular interrogation of the data; better training for a wider workforce in data interpretation, so that it may be more effectively interrogated; and adoption of such ethical principles and practices from the outset of any project as part of an “ethics by design” approach. Once again, scholars call for greater transparency in the underlying algorithms in educational software, and better communication surrounding their limitations, in order to improve trust and credibility.
Responses to challenges to data validity and integrity

Ethical Decision Making and the Obligation to Act
The obligation to act was discussed most explicitly within the context of learning analytics in higher education (see Daniel, 2019; Greller & Drachsler, 2012; Howell et al., 2018; MacFadyen, 2017; Roberts et al., 2016; Sclater, 2016; Slade & Prinsloo, 2013) (n = 7).
The insights provided by Big Data and data analytics can inform students to adjust their behaviors, and institutions to provide additional support to individuals and groups. More than ever before institutions have rich and detailed, albeit incomplete, pictures of students’ learning journeys. As discussion in this article has set out, there is widespread acknowledgment that having access to data does not, per se, translate into complete or necessarily accurate information or knowledge and the wider educational implications of using this data are still subject to debate. Yet, where such data does flag a likely outcome which might result in student harm, if, for example, a student is at risk of underperforming or dropping out of a course, it does raise the obligation to act, whether on moral and/or legal grounds.
As the above included studies have recognized, this raises a number of important questions: What obligation does the institution have to intervene when there is evidence that a student could benefit from additional support? What obligation do students have when analytics suggest actions to improve their academic progress? How are the appropriate interventions decided upon? While the included studies make clear the challenges relating to obligations to act, there remains a need for greater attention to the ways in which we should respond to insights about our students’ dispositions, learning behaviors, and risk profiles (given the recognized limitations to the uses of digital trace data). These issues are not only relevant to those working in the formal educational sector. Institutions developing analytics for use in the home have responsibilities related to when and how to alert parents and young people to potential learning issues.
A small number of the included studies proposed some possible ways forward (see Table 7), including the careful consideration in advance (and in hindsight) of the circumstances, nature of possible interventions, and their possible impacts. Scholars also identify the importance of taking into account additional qualitative data when considering an individual learner (see Greller & Drachsler 2012). Yet responding to the analyses and insights provided by digital data analytics is often constrained by a range of factors, such as lack of political will, gaps in performance contracts, and/or a lack of financial or human resources.
Responses to the obligation to act

Governance and Accountability Across the Educational Landscape
The studies addressing the phenomena of datafication, digital governance, and accountability (n = 19) were split between those predominantly discussing increasing forms of datafication in schools (n = 5), those looking at institutional governance in learning analytics (usually part of a code of practice or framework; n = 5), and those addressing accountability and governance through examining the role of corporate entities and data mediating agencies (n = 9).
A significant number of scholars (Fenwick & Edwards, 2016; Hartong, 2016; Lupton, 2015; Manolev et al., 2019; Ratner et al., 2019; Selwyn 2015; Williamson, 2015a, 2015b) raise important issues regarding the increasing power of software companies (Williamson 2016b), nonstate actors and centers of data analytics (see Lindh & Nolan, 2016; Ratner et al., 2019) in the sphere of data and education, where there is often “the predictive analytics capacities to anticipate and pre-empt educational futures” (Williamson, 2016a, p. 123).
In this way, Fenwick and Edwards (2016) assert that digital technologies are not simply technical solutions to enhancing the quality, efficiency, and effectiveness of practices but can also be powerful “value-embedded socio-technical interventions” in the attempted shaping of practices, accountabilities, and responsibilities. Scholars report the way in which educational institutions are conducting their work practices in this context of “algorithmic governance” (e.g., Williamson, 2015b), often without fully realizing how the data they generate are taken up and used by other actors and agencies and what the broader implications are of becoming entangled within these digital knowledge systems (Lupton, 2015). Despite the potential problems with validity and integrity of digital trace data for education, such data science practices are at risk of being presented as “objective ways of knowing,” making calculations about intervening in educational practices and learning processes (Perrotta & Williamson, 2018, p. 6). MacGilchrist (2019) notes that no matter how good the motives, and how pedagogically well-founded the decisions, it is a post-democratic moment when the ability to make these decisions has shifted from publicly accountable government officials, policy-makers or educators, to developers, programmers, designers and other staff in private edtech organisations. (p. 83)
In addition, despite the increasingly complex partnerships with different global and national data service contractors (Lupton, 2015), these have rarely been the subject of in-depth analysis or ethical scrutiny (Hartong, 2016). While codes of practice and ethical frameworks such as Slade and Prinsloo (2013) and Sclater (2016) have highlighted the need for appropriate data management and interpretation skills, this guidance is generally to be implemented at the level of the educational institution. Indeed, all but one of the frameworks identified as part of this review originate from the field of learning analytics (which is generally associated with higher education institutions). Some initial responses to these observations have been suggested in the included studies (see Table 8), including a move away from thinking about from institutions as isolated data spheres but rather a network of publicly accessible data, a greater transparency in the way that these data have been produced and consumed by different actors across this network. Yet very few studies have discussed ways in which ethical practices of institutions should relate to third parties, or governance polices across these actors.
Responses to ethical challenges of governance and accountability

Engagements With Theories of Ethics
As discussed earlier in this review, West et al. (2016) suggest that engaging in an ethical decision-making process should involve consideration and acknowledgement of our values (which each individual has) and context so as to identify the ethical principle(s) that are being applied to the decision-making process. As such, it is essential that such principles are understood and de-constructed to acknowledge the position and value base from which they arise (West et al., 2016). However, as is clear from Table 9, it is relatively rare for authors in this domain to acknowledge these assumptions or to attempt to articulate those assumptions that underpin their ethical decisions and prompt their questions about ethics.
Theoretical engagements in included studies
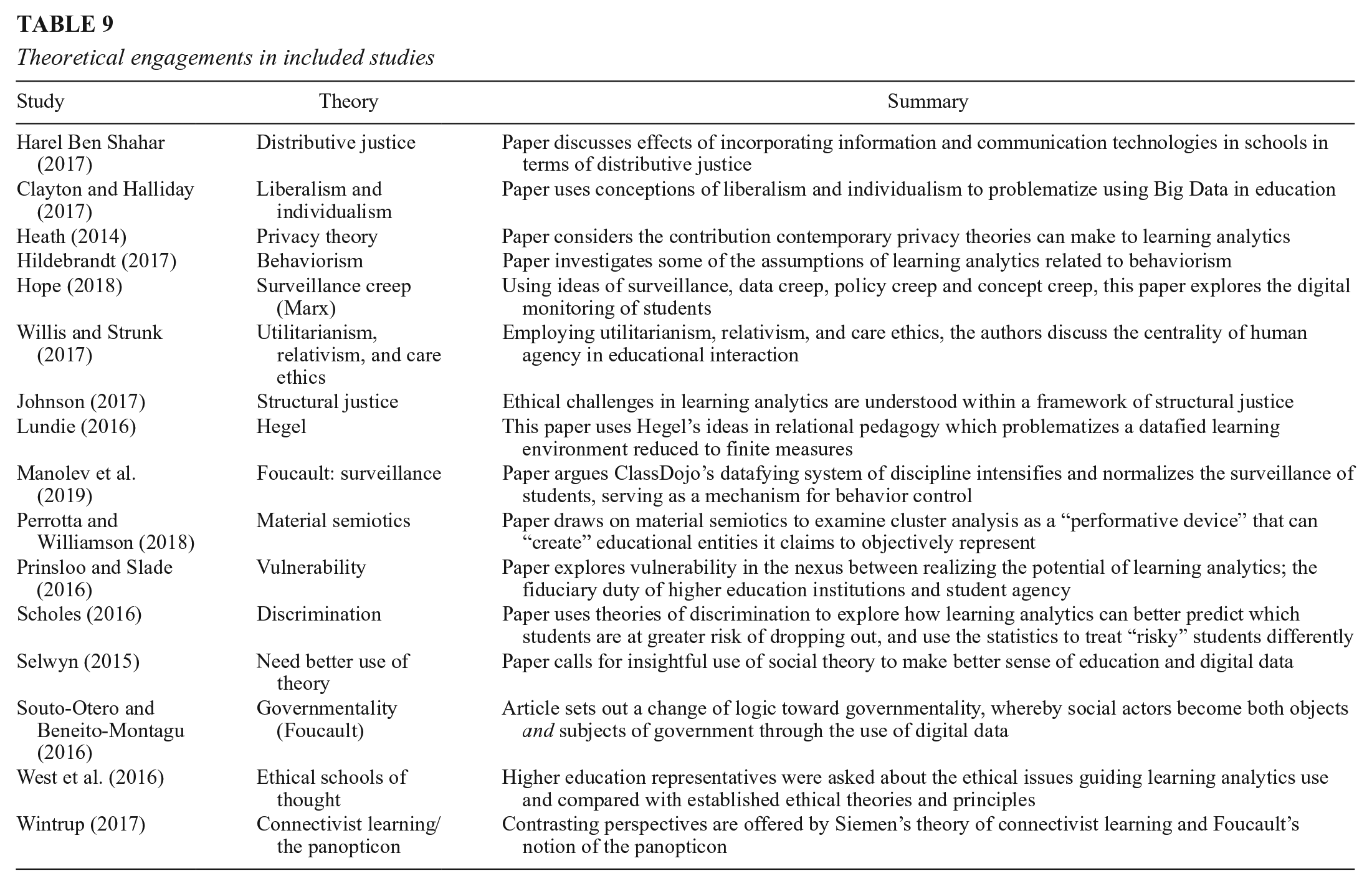
Across the included studies, the engagement with theoretical literature to discuss ethical concerns was broad, and often drawing on concepts of surveillance, governmentality, structural justice, discrimination, and vulnerability to explore the power imbalances presented by ethical issues. While discussion of these individual theories is beyond the scope of this article, it is clear that scholars have used different theoretical frameworks. However, there was often limited or no attempt to define what scholars understood as ethics, perhaps because it is assumed that everyone has a shared understanding of the term. A minority of studies made explicit the values and/or theories through which they arose. In particular, Har Carmel and Harel Ben Shahar (2017) and Harel Ben Shahar (2017) situate their discussions of Big Data use in education with a framework of distributive justice and employ (and critique) consequential logic to their discussion and problematization of ethical issues in data-driven ability grouping in schools. Slade and Prinsloo (2013) pose a question with a strongly utilitarian emphasis: At some point, all institutions supporting student learning must decide what their main purpose really is: to maximize the number of students reaching graduation, to improve the completion rates of students who may be regarded as disadvantaged in some way, or perhaps to simply maximize profits. (p. 1514)
Similarly, Cormack’s (2016) “balancing test” to determine the outcome of ethical decisions in learning analytics could be understood as driven by consequentialist ethics, considering all relevant interests for involved parties.
Willis and Skunk (2017) and Prinsloo and Slade (2016) both seek to move beyond utilitarianism toward an ethics of care, which holds that moral action centers on interpersonal relationships and views care or benevolence as a virtue. While consequentialist and deontological ethical theories emphasize generalizable standards and impartiality, an ethics of care emphasizes the importance of response to the individual. The distinction between the general and the individual is reflected in their different moral questions: “What is just?” versus “How to respond?” This links to the discussion earlier in this review relating to the obligation to act.
In practice, the values underpinning ethical practice are rarely set out clearly, justified, or interrogated (Ferguson et al., 2016). Yet values are not consistent from country to country, from institution to institution, or even from classroom to classroom (Ferguson et al., 2016). Rodríguez-Triana et al. (2016) suggest that ethical considerations need to be context specific, noting that different ethical issues arise in higher education and primary school settings.
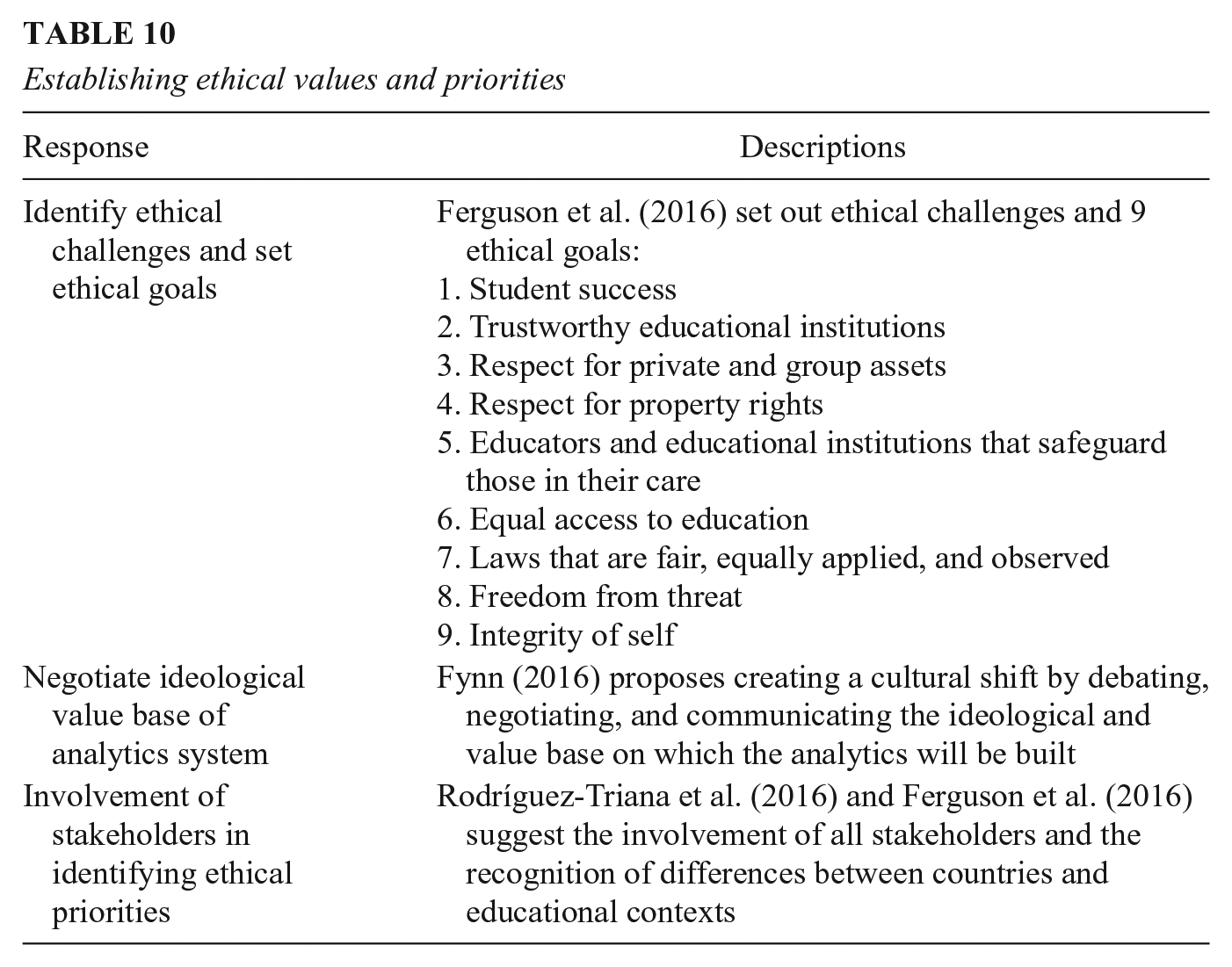
From these selected papers, there were some specific proposals to address these issues (see Table 10). Rodríguez-Triana et al. (2016) call for greater stakeholder involvement to better incorporate differences in ethical priorities across cultures and contexts. Fynn (2016) suggests the need to negotiate the ideological value base of learning analytics systems, and Ferguson et al. (2016) suggest we should strive for specific ethical goals. Willis and Strunk (2017) argue that the ethics of technology and, more specifically, of learning analytics ought to be deeply ingrained in innovation, implementation, and assessment. At each critical juncture of development, a set of principled frameworks should be employed to think through possible outcomes, unintended consequences, and how those ethical decisions could affect future inventions. (p. 61)
Establishing ethical values and priorities
The papers suggest moves in a positive direction, but without a strong conceptual underpinning and more explicit guidance on how ethical practice might be achieved, it is difficult for a collective response from the education community to be developed.
Discussion
In this article, we have mapped the current landscape of research in the ethics of using digital trace data in learning and education, specifically by study type, academic community, institutional setting, and national context. As would perhaps be expected, many papers are conceptual in orientation and located in specific geographic areas (notably the United States, the United Kingdom, and Australia). This geographical focus partly reflects where a lot of research using digital trace data are carried out, but also reflects the parameters of our search. Activities in other parts of the globe, notably India, China, and parts of South America, will be important to examine in future research.
A very large proportion of the existing research is focused on higher education. There is a distinct lack of attention on ethical requirements in schools, particularly early years and informal contexts of learning. Clayton and Halliday (2017) suggest that some of the most important challenges related to using digital trace data in education relate to preschool and school-aged contexts. Indeed, outside of education there has been a significant discussion about the needs for children’s rights to be firmly integrated into the agendas of global debates about ethics and data science (Berman & Albright, 2017; Livingstone et al., 2015; Lupton & Williamson, 2017). Special legal and cultural considerations need to be in place for children and young people both in school and in informal contexts of learning including the home. From the mapping phase we can see that the two broad academic communities set out at the beginning of the article, that is, those engaged in learning analytics and EDM and those focused on digital education governance, are clearly identifiable in the data. There is limited overlap between them. This is a missed opportunity, as Floridi (2018) notes both would benefit from stronger links in order to understand ethics as part of a wider system of governance and regulation in this constantly shifting landscape (as shown in Figure 1).
The thematic analysis has shown that there are four main areas of focus in this domain. The first theme—privacy, informed consent, and data and ownership—formed a central focus of the majority of papers, followed by issues related to the validity and integrity of data and algorithms, then governance and accountability, with a small number focused on the theme of obligation to act. For each theme, authors proposed multiple ways forward to address the ethical challenges that were highlighted: yet were relatively disparate in approach.
We would like to draw attention here to two broader issues cut across all four thematic themes: transparency and power. Across the included studies, there are discussions relating to the need for greater transparency in data privacy, access, and ownership (i.e., students knowing what data are being collected and having access to their own data), in data interrogation (having access to and understanding the processes and algorithms to which the data are subjected), and in the activities of corporate and third party actors.
Independent reviews of educational software that utilizes algorithms prior to their use in schools may be one way to help address some of these issues (Boninger et al., 2017; Regan & Jesse, 2018). Others, such as Greller and Drachsler (2012), Nunn et al. (2016), Fenwick and Edwards (2016), and Perrotta (2013), call for better training for education professionals on the interpretation of data. However, transparency and associated interventions are not straightforward. In the terms of Barocas and Nissenbaum there is the problem of the “transparency paradox”: simplicity and fidelity cannot both be achieved because the details necessary to convey properly the impact of the information practices in question would be far too complex to be accessible and understood by the majority (Barocas & Nissenbaum, 2014). Furthermore, as Tsai et al. (2019) note, drawing on Ananny and Crawford (2018), total transparency is not only very difficult but also positions individuals as solely responsible for their decision to use a system. However, the inherent imbalance in the power relationships in the various contexts in which data are collected poses questions about the extent to which individuals can truly make informed decisions about the use of their data.
Recognition of issues of power was a consistent theme throughout the articles we have reviewed above. Moss and Metcalf (2020) suggest the ethical domain is one in which power is contested: who gets to decide what ethics is will determine much about what kinds of interventions technology can make in all of our lives, including who benefits, who is protected, and who is made vulnerable. Within the review, a number of theoretical perspectives well known to critical scholars of education were evoked to explore issues of power and vulnerability (e.g., Foucault, Hegel, Marx). Issues raised above included the power institutions yield over learner data, and the means to address power imbalances through increased learner engagement. Others highlighted the power of data systems and algorithms to introduce bias and discrimination in interpretation of digital trace data, the power of software companies and other third party agencies due to their role in data collection, storage and mediation, and the limits of the power educators had to act based upon these data.
In other areas of social life, individuals have some (although often admittedly limited) power, in terms of the decision whether or not to use a certain system or to determine settings that mean less of their data are tracked. Yet the context of learning and education can often be quite different as in many cases students and other stakeholders have far less agency. For example, sharing data can be synonymous with course enrolment, with students being unable to opt-out and still enroll in the class. Parents may be similarly coerced, as they can feel that they may place their child at a disadvantage if they opt out from them using particular education software (Zeide, 2017). Thus, the need to provide specific attention on digital trace data does not just derive from the characteristics of the data, but also the unique context of the field of education itself.
The importance of this issue is further highlighted by another significant finding from this review, that many of these papers did not engage explicitly with theoretical debates in the field of ethics. “Ethics” in many of the papers is presented as a given, as if all authors and readers have a shared understanding, but often scholars do not elaborate on what is meant or intended by this term. Yet, as we have discussed ethics is a rich field, there is a need to make explicit the theoretical/epistemological underpinnings of those studying this question in relation to digital trace data and education to help provide strong foundations to future work in this domain. As a community and as a field, we need to make our values and the basis for those values far more explicit.
The reviewed papers demonstrate an emerging recognition and exploration of the ethical challenges posed by the use of digital trace data and the accompanying renegotiation of legal, accountability, and governance structures in education. In the results sections above relating to our thematic analysis: privacy, informed consent and data and ownership, validity and integrity of data and algorithms, governance and accountability, and the obligation to act we have summarized potential responses to each ethical concern, and we hope that the responses set out in Tables 5 to 9 provide a useful guide for policymakers, practitioners, and researchers seeking to make ethical choices at this time.
However, we also wish to suggest three broad lines of future work that are much needed. At present, the educational literature on this topic is less advanced than in other related fields and intellectual traditions, where there has been a much deeper engagement with ethical concerns, frameworks, and implications for future technology development.
First is the need to increase the awareness of the wider ecosystem of learning with digital technologies that lead to the production and use of digital trace data. Lupton and Williamson (2017) present a means to think across the life course of a learner (from early years onwards), and this ensures a more developmental perspective to such debates; and also to recognize that learning and education of this kind may take place across an array of settings both in formal and informal contexts of learning, across geographical settings with different legal and social rules, norms, and regulations.
As part of this, it is important to attend to the ever-increasing role of corporate and third party actors in the collection and storage and processing of data for learning and education. Education is distinct from other domains in which Big Data are being applied and needs special consideration (Clayton & Halliday, 2017). There needs to be a more holistic view of how and where learning and education takes place, and by whom, to ensure that all institutions engaged in learning (not just formal educational institutions) are accountable, and that the rights, needs, and experiences of all learners are recognized. This includes the incorporation of additional contextual data when making decisions concerning individual learners. Given the parameters of our review, it is likely that the role of the commercial sector and private actors and their practices are even more prevalent than indicated here. Thus, this area is an essential focus of future enquiry.
Next is the need to develop a more explicit engagement with existing theoretical framings that could be used as a lens to explore this specific domain. Without it, there is a risk that the development of a meaningful and coherent body of research that outlines the ethics of the use of digital trace data for learning and education will not be realized due to the lack of theory explicitly used in these studies. At present, many of the studies seem to emerge from a relatively “short term” vision of such debates, where immediate institutional needs (often those of a higher education institution) predominate. As Boden et al. (2009) warned, this can risk an overemphasis on the creation of procedures, rules, and regulations, with philosophical debates on matters pertaining to morals, ethics, standards, and principles having been sidelined. Future papers need to pay attention both to local context and to broader theoretical principles. Relatedly, we would encourage a more long-term vision in many of these debates. There is a lack of attention and exploration of future orientated questions (e.g., issues of measurement and the obligation to act). In this way, ethical debates tend not to anticipate future challenges, and often lag behind what it is technically feasible and tend not to recognize or build on past understandings in other areas of education.
At present, the relationships between ethics, governance, and legal regulation as set out by Floridi (2018) in the introduction to this paper are not synchronized in the domain of digital trace data in learning and education. In order to create greater synchronicity we need stronger explicit discussions of theoretical orientations, to unpack “ethics as a keyword” (Moss & Metcalf, 2020), clearer discussions of contexts and audiences and why these matter, and a strong focus on considering these issues within the specific case of learning and education. These all need to be considered in a holistic way that builds on previous analyses and theoretical arguments where different communities work together.
The synthesis suggests that one way to achieve this in such a rapidly emerging field may be to take an “ethics by design” approach (see, e.g., Har Carmel & Harel Ben Shahar, 2017; Harel Ben Shahar, 2017; Rodríguez-Triana et al., 2016); that chimes with many of the proposed ways forward identified in the thematic analysis above. In other words, to incorporate ethical considerations from the outset of any initiative or intervention that involves the use of digital trace data as part of the research endeavor that recognizes that ethical decisions within educational contexts requires continuous renegotiation. The included studies suggest that this process needs to involve key stakeholders and take contextual factors into account when defining ethical priorities. Although there remains relatively little instruction as to how these laudable goals might be achieved, there is helpful guidance emerging. For example, franzke et al. (2020) set out an enhanced framework to engage in a “processes of deliberation” to empower ethically informed research practices. Researchers could also draw on similar activities and approaches in other fields such as HCI (Gray & Boling, 2016).
Such an approach should take into account, in a research informed way, the context in which ethical decision making occurs, and should incorporate a complex network of actors across the educational landscape. Scholars would be encouraged to make ethical decisions in a more iterative, collaborative, and transparent way that links stakeholders across settings, practices, and policies. In a similar way to participative design, a well-established approach in some areas of education, research can be actively linked to both changing practice and developing theory at the same time. This research domain could then develop in ways that takes into account the wider ecosystem of learning, to set a proactive, forward-looking ethical agenda.
Conclusion
In this article, we have carried out a systematic qualitative analysis of the emerging research in the ethics of digital trace data use in learning and education. From our systematic search of three databases, we identified 77 peer-reviewed studies. In order to address the first research question we examined the articles by study type, academic community, institutional setting, and national context and found a significant overrepresentation of higher education, and two relatively disconnected academic communities working in this space. We then carried out a thematic analysis of the ethical issues and responses that are highlighted in existing research on the ethics of digital trace data use in education and learning; and reported on the findings and arguments from four identified themes of work: privacy, informed consent, and data transparency and ownership; validity and integrity of data and algorithms; governance and accountability; and ethical decision making and the obligation to act. From this process we also found important gaps in the literature. Given the importance of this area, and the likely growth in the use of digital trace data for learning and education, we suggest there is a need for future research to begin to work toward a more cohesive community of thought, where the wider learning and educational ecosystem is recognied, explicit engagement with ethical theory is central, and mid- to long-term issues are also considered alongside immediate concerns. In so doing, the academic community can build a proactive ethical agenda in this developing domain. This review provides an important foundation to these discussions.
Footnotes
This work was supported by Ferrero International, Grant Number R52124/CN001.
Notes
Authors
LAURA HAKIMI is a researcher affiliated with the Department of Education and the University of Oxford, Oxford, UK; email:
REBECCA EYNON is a professor of education, the Internet and society at the University of Oxford, Oxford, UK; email:
VICTORIA A. MURPHY is a professor of applied linguistics at the Department of Education, University of Oxford, Oxford, UK; email: