
Abstract
Many novice teachers learn to teach “on the job,” leading to burnout and attrition among teachers and negative outcomes for students in the long term. Preservice teacher education is tasked with optimizing teacher readiness, but there is a lack of causal evidence regarding effective ways to prepare new teachers. In this paper, we use a mixed-reality simulation platform to evaluate the causal effects and robustness of an individualized, brief, and highly directive coaching model for candidates enrolled in a university-based teacher education program as well as for undergraduates considering teaching as a profession. Across five conceptual replication studies, we find that short, targeted, and directive coaching significantly improves candidates’ instructional performance during simulated classroom sessions and that coaching effects are robust across different teaching tasks, study timing, and modes of delivery. However, coaching effects are smaller for a subpopulation of participants not formally enrolled in a teacher preparation program. These participants differed in terms of prior experiences learning about instructional methods, suggesting that coaching in isolation is not as effective without corresponding coursework on targeted practices. Taken together, our five studies provide encouraging evidence that teacher preparation can be an important time for rapid skill development when candidates are given targeted practice opportunities and corresponding support. Although we often think that practice has to happen in real classrooms with real students, we provide robust evidence that “the work of teaching” can be incorporated into teacher education coursework. We highlight implications for research and practice.
Keywords
Considerable evidence suggests that teachers improve dramatically in their early years of classroom experience (Atteberry et al., 2015; Harris & Sass, 2011; Kraft & Papay, 2014). This on-the-job learning is stressful for beginning teachers, and the majority report entering the classroom feeling underprepared, leading to burnout, attrition, and negative outcomes for students (Ingersoll, 2001; Papay & Laski, 2018). A central question for the field has been whether—and how—some of this rapid skill development could be moved into preservice teacher education, before teachers become solely responsible for students. Teachers who start their careers with a solid foundation in critical instructional skills are better poised to stay in the classroom and contribute to positive student outcomes. Unfortunately, researchers lack robust, causal evidence about methods for promoting this kind of rapid skill development during preservice preparation.
Given that teachers get better “with practice,” a potential avenue for development is having preservice teachers (termed candidates) repeatedly practice teaching skills, with feedback and support (Grossman, Compton, et al., 2009; Hoffman et al., 2015). Traditionally, candidates are intended to practice these skills during their clinical placements, working alongside experienced mentor teachers. Unfortunately, sole reliance on this apprenticeship model has clear downsides. Candidates do not always have chances to practice all the skills they need as teachers of record. Mentors also vary in the degree to which they model strong teaching (Ronfeldt, 2015) and may not provide necessary feedback (Matsko et al., 2020). Thus, preparation program developers have been studying whether practice with targeted feedback could also occur in coursework. Such “approximations of teaching”—role-plays, rehearsals, and simulations—have been shown in qualitative work to support candidates’ ability to translate theoretical knowledge about “effective teaching” into practice (Grossman, Hammerness, & McDonald, 2009b; Kavanagh & Rainey, 2017; Reisman et al., 2019). However, little work has looked at the causal effects of such approximations or whether different supports surrounding approximations enhance their utility (Cohen et al., 2020).
Coaching is a promising option for expediting skill development during approximations (Kraft et al., 2018). Theory suggests that coaches serve as experts who can observe teachers, evaluate strengths and weaknesses, and develop individualized strategies to promote improvement (Coburn & Woulfin, 2012). Coaching is increasingly common for in-service teachers (Cilliers et al., 2020; Stahl et al., 2016) and has been shown to improve teachers’ attitudes toward teaching, feelings of self-efficacy, instructional skills, and student achievement (Castro et al., 2021; Desimone & Pak, 2017; Kretlow & Bartholomew, 2010).
Despite this compelling evidence, coaching is underutilized during preservice preparation. Although mentors in clinical placements sometimes provide directive coaching and feedback, candidates are often asked to learn by observation and osmosis (Matsko et al., 2020). Given the short duration of teacher preparation, more standardized, frequent, and explicit feedback on developing skills could be a powerful and efficient complement to more variable clinical placements. Although the literature on preservice coaching is nascent, a handful of studies have associated coaching with improvements in candidates’ satisfaction with preparation and skill development (e.g., Albornoz et al., 2020; Bowman & McCormick, 2000). We theorize that coaching could be especially useful earlier in a teacher’s development, when skills are only emergent and ideas about effective practice are less ossified (Ericsson & Pool, 2016).
In this study, we examine the immediate causal effects of short, 5-minute, highly structured and directive coaching sessions delivered in the context of mixed-reality simulations (MRS). The simulation platform featured a virtual classroom and student avatars that were remotely controlled by an actor trained to facilitate realistic classroom interactions. The simulation sessions were integrated with candidates’ coursework and served as a practice space and an assessment platform in our research. Designed to be complementary to candidates’ field placements, the simulation sessions provided candidates with opportunities to “try out” new teaching skills before practicing them in live classroom settings. In prior work, we have found compelling experimental evidence that even brief, 5-minute, directive coaching sessions can dramatically improve candidates’ classroom management skills, as observed in the MRS (Cohen et al., 2020). What was less clear, however, was whether such findings would replicate in additional experimental evaluations with systematic variations in participant characteristics (units), pedagogical outcomes, settings, and times (Cronbach, 1982).
To examine the efficacy and robustness of a standardized coaching protocol on candidates’ instructional performance in the MRS, we conducted a series of conceptual replication studies in which we randomized candidates to receive coaching or to self-reflect on their performance in the MRS. The replication studies were designed to introduce systematic sources of variation to evaluate the robustness of coaching effects across different time periods, teaching tasks and associated outcomes, participant characteristics and course experiences, and delivery modes.
This study makes two unique contributions to the education literature. First, we find that directive coaching caused much more dramatic improvement in participants’ teaching in simulations than did the more common preparation practice of self-reflection (Hatton & Smith, 1995; Sato, 2014). This finding is important, given that nearly 100 teacher preparation programs in the United States use this simulation technology to enhance practice experiences, and yet our study is the only one to date to have experimentally evaluated the benefits of offering different supports to promote candidates’ skill development (Ireland, 2021). Second, this study demonstrates the role that experimental and conceptual replication designs could play in causally identifying methods for supporting teachers and the conditions in which these supports could be most effective. In our study, we used conceptual replication designs to systematically test hypothesized sources of effect variation. The goal of the conceptual replication effort was to develop foundational knowledge about one potential mechanism—coaching—for supporting teacher candidates who are robust across different populations, pedagogical outcomes, contexts, and settings.
Combined, we view these findings as a critical first step in identifying an evidence-based promising practice—brief, directive coaching—to support candidates’ development of core instructional skills (Blazar & Kraft, 2015; Hill et al., 2013; Ronfeldt, 2015). We conclude our paper with discussion about ongoing research designed to determine the degree to which these improved practice sessions could translate to more distal outcomes of candidates’ instructional quality in live classrooms.
Background
Coaching to Support Practice-Based Learning in Teacher Education
Preparation programs have long relied on an “apprenticeship” model of clinical practice wherein candidates learn by observing, practicing, and co-teaching with experienced mentors (Clift & Brady, 2005; Grossman et al., 2011). Although they are useful in affording classroom experience, apprenticeship models can be problematic when candidates do not have chances to practice important skills and/or when mentors model weaker teaching that contradicts principles emphasized in coursework (Feiman-Nemser & Buchmann, 1985; Grossman, Hammerness, & McDonald, 2009b). Moreover, during clinical placements, candidates often receive feedback about their teaching skills during “triad meetings” with mentors and university-based supervisors that may occur days or weeks after classroom observations (Grossman et al., 2011). In contrast, practice in university settings affords scaffolded and uniform opportunities to develop classroom skills in more controlled and less complex environments, while also allowing candidates to receive immediate feedback from expert teacher educators (Ball & Forzani, 2009; Grossman, Hammerness, & McDonald, 2009b).
The traditional model of practice in teacher education also involves attempting larger “chunks” of instruction—for instance, a morning meeting, an entire mathematics lesson, a small-group discussion of a text (Clift & Brady, 2005). University-based supervisors are the figures typically conceptualized as the “coach” and work with candidates over the course of a semester or year. Often that “coaching” is more reflective than directive, and the coach asks candidates to identify strengths and areas for growth (Jay & Johnson, 2002; Larrivee, 2008; Warford, 2011). The goals of reflective coaching are often amorphous and distal, improving clinical assessments that may occur months after observations and coaching (Darling-Hammond, 2014). Although this modal form of teacher education coaching can be helpful, little work—and no causal work, to our knowledge—has suggested that this model of reflective feedback from university supervisors contributes to meaningful changes in candidates’ instructional practices (Grossman et al., 2011).
Many additional forms of coaching necessitate differing levels of time and relational trust between the coach and the individual being coached (Cornett & Knight, 2009; Ericsson & Pool, 2016). Sometimes, coaches provide support over extended periods of time (Gibbons & Cobb, 2016). On other occasions, coaches are brought in for shorter durations to target very specific and immediately felt needs (Stahl et al., 2016; Stapleton et al., 2017). Some coaches focus on the entirety of a professional practice, such as a lead basketball coach. Other coaches concentrate on more specific aspects of practice, such as free throws.
Just as there are multiple forms of coaching, there are multiple forms of practice in which coaching might be integrated. On some occasions, a “full scrimmage” is useful, so that learners can practice coordinating the complex set of skills needed to engage in high-quality classroom instruction (Reich, 2022). On other occasions, more focused “drills” and aligned coaching help learners “focus on improving more discrete elements” by “abstracting away the complexity of the whole” (Reich, 2022, p. 220)—that is, teacher candidates likely need more opportunities to practice and receive coaching on more decomposed aspects of teaching, alongside chances to “recompose” those aspects into entire lessons (Janssen et al., 2015).
When learning a complex practice, such as teaching, novices often struggle to improve when practice opportunities are longer and more multifaceted (Van Merriënboer & Kirschner, 2017). In fact, Ericsson and colleagues’ (1993) model of deliberate practice hinged on the notion that learners needed frequent, low-stakes practice and coaching about focused aspects of the targeted skill. Moreover, practice was shown to be more “deliberate” and useful at leveraging sustained improvements when the coach was clear about the particulars of the desired goal and explicit in communicating those goals to the learner. Across a wide array of studies, learners have benefited from immediate, detailed feedback that compared their performance with those desired goals (Ericsson et al., 1993).
We argue that coaching in teacher education could and should also involve more goal clarity around what “good” looks like, coupled with coaching that is tightly aligned with those goals. This shift means that beginning teachers would practice specific instructional tasks with well-defined goals. Coaches and candidates alike would understand what they were working toward and receive feedback aligned with meeting those goals. This kind of directive, performance-based coaching is modal in sports, where considerably more robust evidence has shown the effectiveness of the approach compared to coaching models in education (Lyle & Cushion, 2016).
The Potential of Simulated Teaching Environments
Digitally mediated simulations, used widely in other professions, such as aviation and medicine, offer realistic and standardized practice spaces that can be embedded into coursework, providing a platform to practice, receive coaching, and “try again” (Slater, 2009). Voice actors (termed interactors) who control “student” avatars are trained to respond in real time to candidates’ instructional cues in ways real students would. Importantly, studies have shown that simulations feel more realistic than other approximations, such as role-plays, and that candidates’ responses are closely aligned with classroom performance (Arora et al., 2011; Dieker et al., 2014).
Simulations are also useful for conducting causal, “basic science” research in applied settings because they provide a standardized platform for observing candidates and opportunities to systematically vary conditions. Sessions can be delivered in controlled ways, allowing teacher educators and researchers to focus on developing specific skills while limiting other sources of variation, such as instructional content (Cohen et al., 2018), the influence of mentors (Goldhaber et al., 2020), or the composition of students (Steinberg & Garrett, 2016). The short duration of simulations also allows candidates opportunities to repeatedly “do over” teaching scenarios in ways that are impossible in classrooms, while affording real-time coaching that would be logistically challenging during a school day.
Standardized Practice Sessions With Directive Coaching
Because candidates lack the background knowledge and experience to recognize their own strengths and weaknesses, simulated practice alone is likely insufficient to improve candidates’ instructional skills. Candidates also need feedback from experienced coaches who have opportunities to observe the candidates’ practice and can provide concrete, actionable strategies for improvement (Albornoz et al., 2020; Deussen et al., 2007; Hammond & Moore, 2018). This type of directive coaching can also help candidates understand the impact of instruction on students (Cohen et al., 2020).
Although one might assume that more coaching is “better,” there is no empirical clarity around whether higher dosage coaching is associated with greater observable improvements in instruction (Blazar & Kraft, 2015; Desimone & Pak, 2017; Kraft et al., 2018). In fact, one of the few randomized control trials in this area found no relationship between coaching dosage and teacher outcomes (Pas et al., 2015). Our coaching model—focused on short 5-minute sessions with directive feedback in service of tightly aligned, proximal outcomes—is conceptually similar to many widely used approaches to coaching. For example, “bug-in-the-ear” technology is used in classrooms across the country to provide very short (typically less than 20 seconds) in-the-moment coaching for teachers and has been shown to improve teacher outcomes in the short (Scheeler et al., 2009) and long terms (Rock et al., 2014). Recent work by Hanno (2021) provided additional support for the immediate positive associations between short, individual coaching sessions and improvements in teaching. Although some of those observed improvements faded over time, others did not.
To support candidates’ practice and learning in the simulation sessions, we employed a directive, 4-step coaching model wherein coaches provided targeted feedback on a specific set of instructional skills. The coach first observed the candidate’s simulated practice and diagnosed the instructional needs along a skill progression (see example in online Appendix A1). Second, the coach gauged the candidate’s perception of their performance (e.g., “How are you feeling about the simulation?”) before identifying strengths and improvement targets. Third, the coach provided detailed information about the features of high-quality enactment of the targeted skill, how and why it would support positive student outcomes, and specific strategies the candidate could utilize in subsequent simulations. Finally, the coach engaged in a role-playing exercise with the candidate, providing opportunities to rehearse a targeted skill. A recent experimental evaluation of this directive coaching model with 100 teacher candidates found large and statistically significant effects on candidates’ observed quality of practice in simulated classroom settings (ES = 1.70 SD) as well as on their perceptions of the student avatars (Cohen et al., 2020).
Robustness of Coaching Effects Across Key Sources of Variation
Although these experimental results suggest that directive coaching can improve candidates’ teaching, teacher educators also need evidence on the contexts and conditions under which this type of coaching would be beneficial (or not) for helping candidates improve. To this end, we identified four theoretically relevant sources of variation in study, participant, and setting characteristics that we hypothesize would moderate the magnitude of coaching effects in the MRS:
Conceptual Replications for Identifying Sources of Variation
In this study, we tested hypothesized sources of effect variation described above through a series of prospectively planned conceptual replication designs (Steiner et al., 2019; Wong et al., 2021). The conceptual replication studies were designed according to the causal replication framework, which describes five conditions under which replication studies can be expected to produce the same effects (please see online Appendix A6). The assumptions may be understood broadly as replication design requirements (R1–R2, online A6) and individual study design requirements (S1–S3, online A5). Replication design assumptions include treatment and outcome stability (R1) and equivalence in the causal estimand (R2) across studies. Combined, these two assumptions ensure that the same causal estimand—or a well-defined treatment-control contrast, target population, and setting—is compared across all studies. Individual study design assumptions ensure that valid research designs are used for identifying and estimating unbiased study-specific effects (S1–S2) and that effects for each study are correctly reported (S3)—they are standard assumptions in most individual causal studies. When one or more of the replication and/or individual study assumptions are not met, replication of effects usually fails.
An implication of the causal replication framework is that it is straightforward to derive different types of research designs for replication as well as the assumptions required for these designs to yield valid results. Conceptual replications examine whether two or more studies with intentionally varied causal estimands yield the same effect. Here, the researcher introduces systematically planned violations in replication assumptions, such as variations in treatment conditions, population characteristics, settings, or outcome measures. Conceptual replication designs include switching replication designs with variations in settings across alternating intervention intervals, multiple cohorts and stepped-wedge designs with variations in when treatments are introduced across time, and multi-arm treatment designs with variations in treatment dosage levels (Wong et al., 2021). In each of these designs, if replication failure is observed, it is because of systematic differences in participants, treatments, outcomes, settings, or time.
Research Methods
To examine the robustness of coaching effects in MRS settings, we used data from five randomized controlled trials (RCTs) to construct four conceptual replication designs that introduced systematic variations on the dimensions noted above. Figure 1A describes the timing of each of the five individual studies conducted from the spring of 2018 to the spring of 2020.
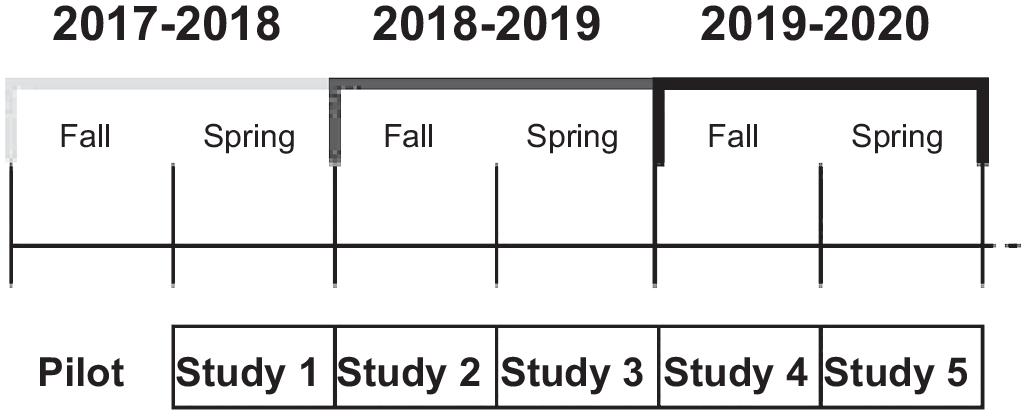
Planned replication studies from 2017 through 2020.
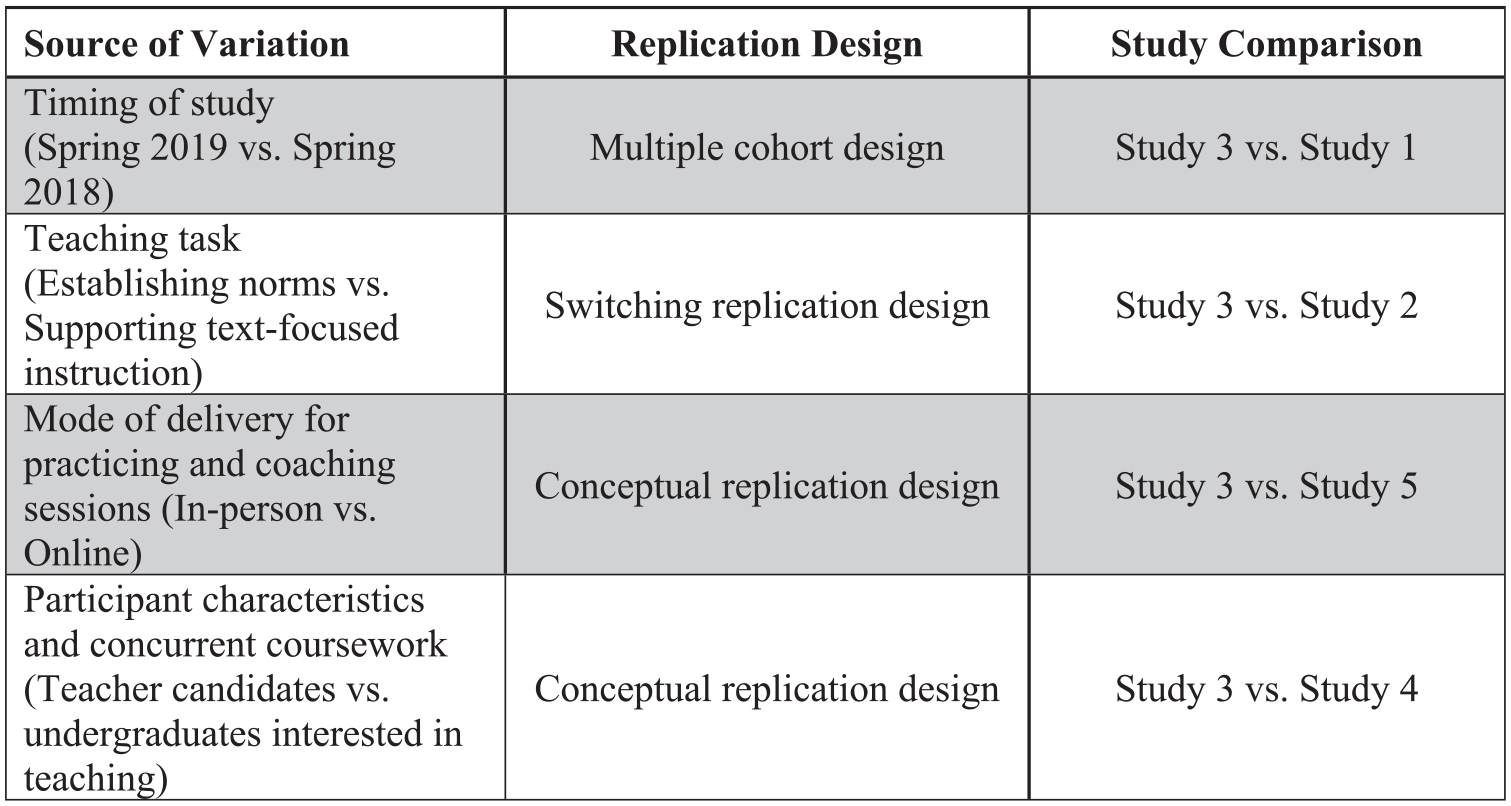
Conceptual replication designs for understanding sources of systematic variation.
Population and Settings
All studies were conducted at a large, selective, public university in the southeast United States. Participants in four of the five experimental studies (Studies 1, 2, 3, and 5) were enrolled in a teacher preparation program that graduates approximately 100 teachers each year. Participants in Study 4 were enrolled in the same university but recruited through an undergraduate course exploring teaching as a profession. 1
Candidates in Studies 1, 2, 3, and 5 were generally representative of new teachers—that is, they were mostly White and female and had college-educated parents. The undergraduate sample in Study 4 was less White (60%) and less predominantly female (58%), although these candidates also had mostly college-educated parents. Approximately 43% of the undergraduates reported an interest in teaching, and 63% reported prior experience working with children (e.g., babysitter, coach; see Table 1 for baseline and setting characteristics for the five studies).
Descriptive Statistics Across Replication Studies
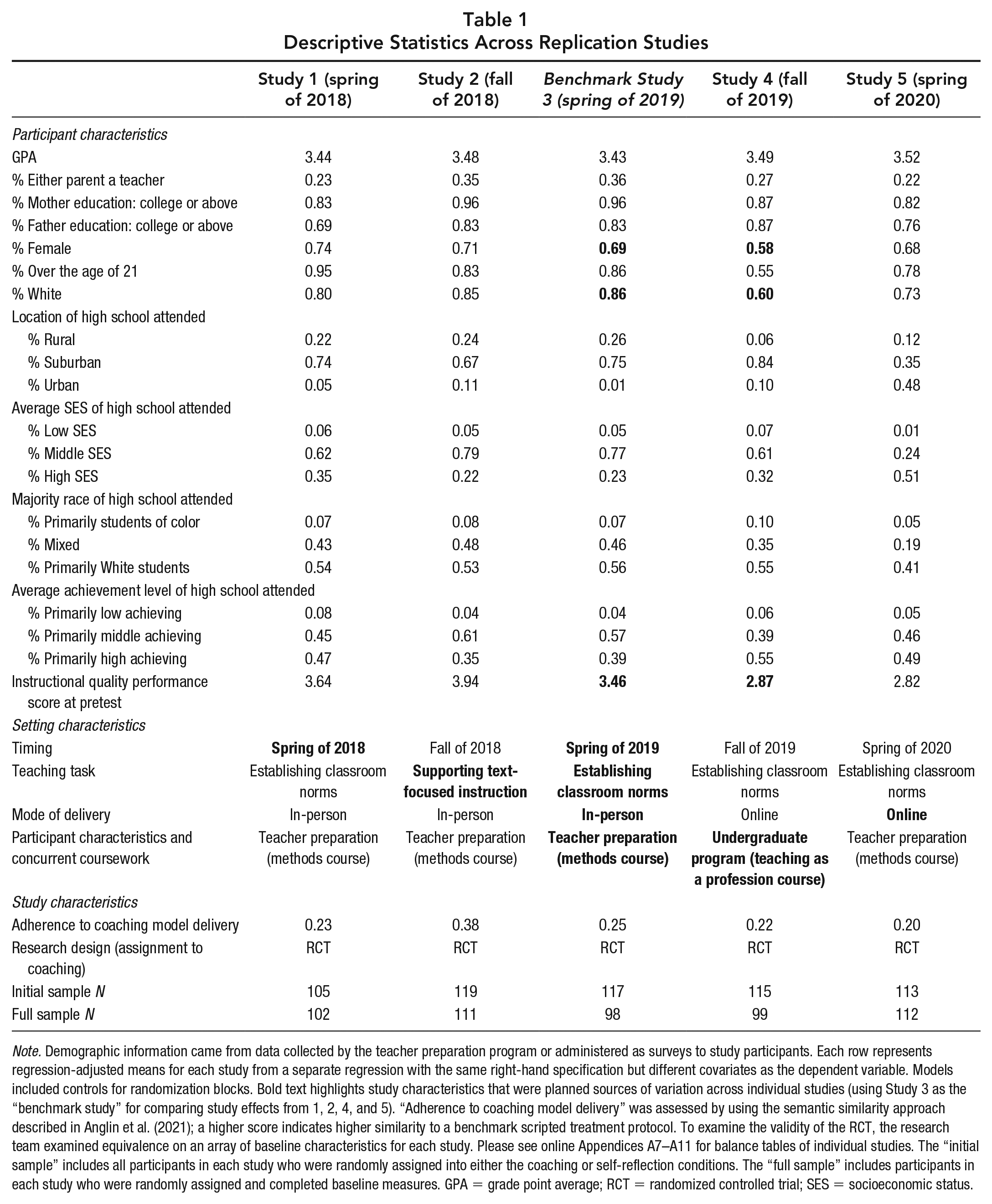
Note. Demographic information came from data collected by the teacher preparation program or administered as surveys to study participants. Each row represents regression-adjusted means for each study from a separate regression with the same right-hand specification but different covariates as the dependent variable. Models included controls for randomization blocks. Bold text highlights study characteristics that were planned sources of variation across individual studies (using Study 3 as the “benchmark study” for comparing study effects from 1, 2, 4, and 5). “Adherence to coaching model delivery” was assessed by using the semantic similarity approach described in Anglin et al. (2021); a higher score indicates higher similarity to a benchmark scripted treatment protocol. To examine the validity of the RCT, the research team examined equivalence on an array of baseline characteristics for each study. Please see online Appendices A7–A11 for balance tables of individual studies. The “initial sample” includes all participants in each study who were randomly assigned into either the coaching or self-reflection conditions. The “full sample” includes participants in each study who were randomly assigned and completed baseline measures. GPA = grade point average; RCT = randomized controlled trial; SES = socioeconomic status.
Experimental Design of Individual Studies
For each study, participants were randomly assigned within course sections to receive coaching or to engage with a self-reflection protocol between simulation sessions. Coaches and interactors were scheduled to ensure sufficient variation across course sections, days, and session timings, allowing the research team to control for possible differences due to coaching and interactor effects. Interactors and coaches were shared across study periods, with approximately four coaches per study. Diagnostic results showed that for each of the five studies, random assignment was well implemented. Balance checks of baseline covariates indicated that groups were equivalent after randomization (please see balance tables for each study in online Appendices A7–A11). There were no instances of treatment noncompliance when participants failed to “show up” for coaching sessions or “crossed over” from the intervention to control conditions (Angrist et al., 1996). For each of the studies, attrition was minimal (less than 15%), with no evidence of differential attrition between groups (see online Appendices A7–A11 for balance tables and sample sizes for the “full” and “analytic” samples for each study).
Data Collection Procedures
Figure 2 summarizes the data collection procedure for each individual RCT. At Time 1, participants completed questionnaires about their demographic characteristics and teaching experiences as well as baseline simulation sessions during which they practiced teaching tasks but did not receive either coaching or self-reflection prompts. Participants were then randomly assigned within course sections to coaching or self-reflection. Approximately 2 months after the baseline sessions, participants completed a second simulation (Time 2). Immediately after Time 2, half of the participants received 5 minutes of coaching with an expert trained coach, while the other half completed a 5-minute series of reflection prompts. After the 5 minutes of coaching or self-reflection, participants completed a third simulation (Time 3), during which their pedagogical performance was observed and scored as the outcome.
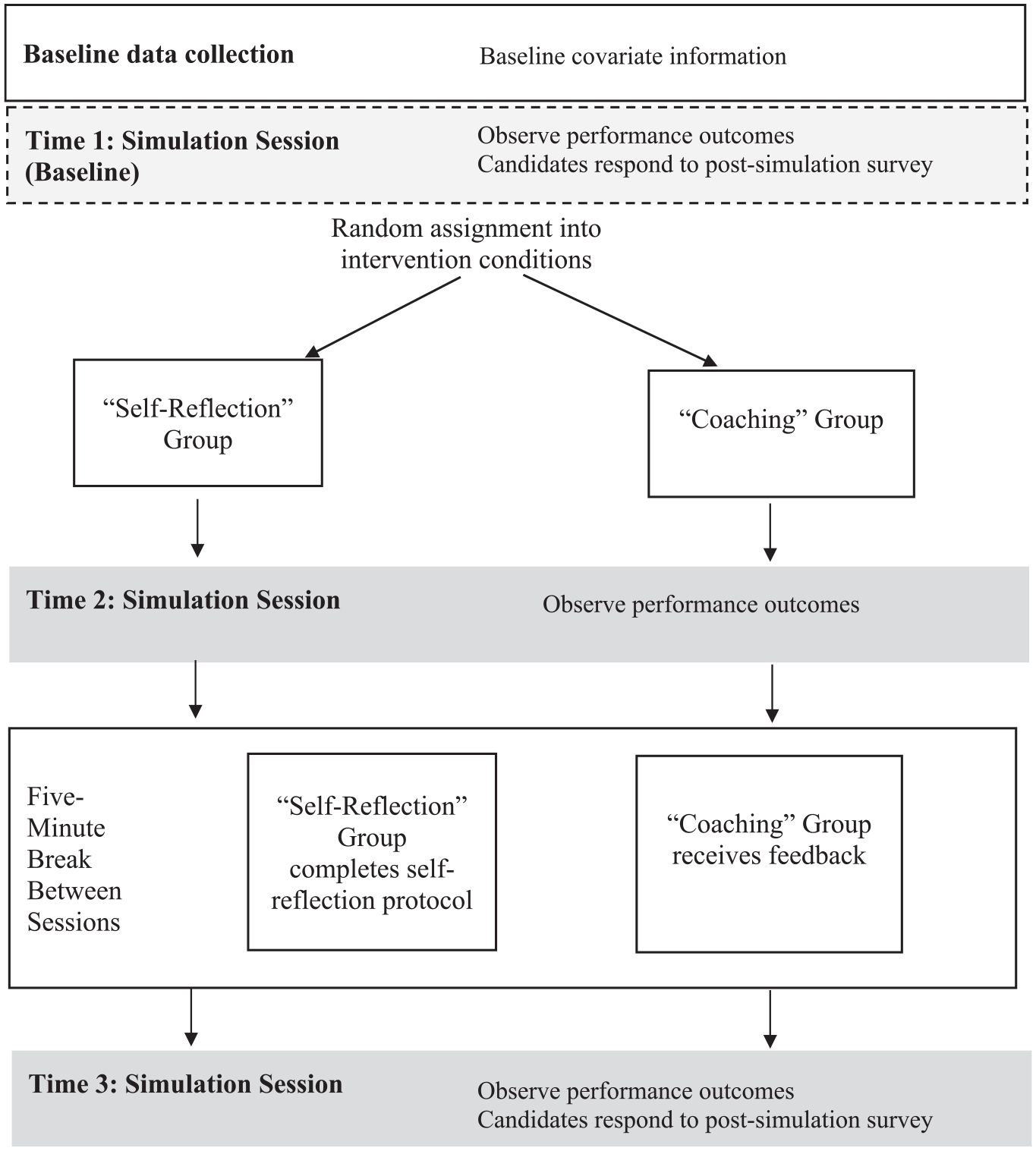
Data collection procedure for individual RCT studies.
Simulation Sessions
In each study, participants practiced one of two teaching scenarios. In Studies 1, 3, 4, and 5, participants had to “redirect off-task behaviors” while establishing classroom norms; in Study 2, participants focused on “supporting text-focused instruction” while leading a small-group discussion. For each scenario, participants engaged in a series of “parallel” simulation sessions, meaning that although student avatar responses differed across sessions at Times 1, 2, and 3, they were consistent in terms of the number, type, and intensity of responses. Implementation measures ensured that simulation sessions were delivered consistently across sessions. 2
Treatment Contrast
Coaching Condition
After observing participants at Time 2, coaches provided feedback according to our 4-step protocol. Although feedback focused on different instructional skills and areas of strength and weakness, the structure of the coaching was consistent across studies. Coaches were doctoral students in education who had trained intensively to ensure that the protocol would be implemented with fidelity (see footnote 8 for how implementation fidelity of the coaching protocol was assessed).
Self-Reflection (Business-as-Usual) Condition
Instead of receiving coaching after Time 2, participants in the control condition engaged in a researcher-designed self-reflection protocol that asked participants to identify perceived strengths and weaknesses and goals for the subsequent simulation session (Yost, 2006). The control condition was consistent across studies.
Measures
To ensure comparability of baseline and outcome measures across studies, we administered the same survey measures in similar settings for each study. Measures were coded by using the same protocols and were analyzed in similar ways.
Baseline Characteristics
Baseline surveys included information about participants’ high school grade point average, parental education, and characteristics of the high school attended (average achievement level, average socioeconomic-status level, and urbanicity of school). Participants also completed personality and belief measures, including the NEO Five-Factor Inventory (McCrae & Costa, 2004), Teacher Sense of Self-Efficacy (Tschannen-Moran & Hoy, 2001), and multicultural attitudes surveys (Munroe & Pearson, 2006; see online Appendix A4 for a descriptive summary of baseline measures and their psychometric properties).
Outcome for “Redirecting Off-Task Behaviors.”
The primary outcome measure (Studies 1, 3, 4, and 5) was designed by the research team to align with the Responsive Classroom (2014) framework used across the K–12 schools in which candidates participated in clinical experiences (i.e., student teaching). (For details, see Cohen et al. [2020]; online Appendix A2 includes the rubric.) Responsive Classroom describes an effective redirection as timely, occurring as close as possible to the start of an off-task behavior, thereby minimizing the likelihood of escalation (Landrum & Kauffman, 2006). Effective redirections also specify what a teacher would like a student to do (Good & Brophy, 1995) as succinctly as possible (Levin & Nolan, 2003) to preserve student dignity (Sun, 2015) and instructional time (Doyle, 2009). Finally, to preserve a positive learning environment, redirections are delivered calmly, ideally with a positive tone and warm affect (Responsive Classroom, 2014). Simulations were also scored with additional rubrics focused on more discrete aspects of redirection, such as how quickly (in seconds) did participants redirect off-task behavior or what percentage of the responses provided to student ideas were “perfunctory” (e.g., “good job,” “okay”). The overall coaching effects shared here were consistent among these additional outcome measures. Results and rubrics are available upon request. 3
Scores for the “redirecting off-task behavior” outcome ranged from 1-low to 10-high (see online Appendix A2). 4 A team of trained and certified raters, blinded to participants’ condition, scored videos of all simulation sessions. Fifteen percent of videos were double-scored, with Krippendorff’s alpha scores for reliability ranging from 0.75 to 0.88 across studies. Coder drift was addressed with weekly calibration checks and rater agreement reports.
Outcome for “Supporting Text-Focused Instruction.”
We developed the rubrics for the supporting text-focused instruction scenario (Study 2; online Appendix A3 includes the rubric) from seminal work on teacher feedback by Hattie and Timperley (2007) and a wealth of reading comprehension research that has foregrounded the importance of teacher facilitation of meaningful student interactions with a text (Boardman et al., 2018; Dewitz & Graves, 2021; Duke et al., 2011). In particular, we focused on teachers’ text-based questions that (a) supported active engagement with text, (b) helped students revise textual misunderstandings, and (c) made text-based arguments (Deshler et al., 2007; Hillocks, 2010; McKeown et al., 2009; Reznitskaya et al., 2009; Shanahan et al., 2010). Teacher feedback during these text-focused interactions is crucial, and Hattie and Timperley (2007) underscored the difference between perfunctory, low-level feedback and descriptive, high-level feedback in which a teacher names the specific, positive features of student contributions—in this case, engaging with a literary text. 5
Scores for this outcome measure ranged from 1-low to 10-high (see online Appendix A3 for rubrics). Certified raters scored videos by using the same procedures as described above, with Krippendorff’s alpha scores for reliability ranging from 0.75 to 0.88.
Effect Variation
To identify why heterogeneity in coaching effects may occur, we conducted a series of replication designs that introduced systematic sources of variation across studies, while attempting to ensure that all other study conditions remained the same (Wong et al., 2021). For ease of interpretation, we selected Study 3 as the “benchmark” study and introduced systematic variations in conceptual replication Studies 1, 2, 4, and 5 for comparing effects. To examine the robustness of coaching effects due to variations in the timing of the study, we used a multiple cohort design to compare impacts for candidates from one year (spring of 2018, Study 1) with impacts the following year (spring of 2019, Study 3).
To examine the robustness of coaching effects across different teaching tasks, we used a modified switching replication design wherein participants were randomly assigned to receive coaching at different intervention intervals in alternating sequence such that when one group received coaching, the other group served as the control, and vice versa (Shadish et al., 2002). 6 We compared coaching effects for two intervention intervals, wherein candidates practiced “supporting a text-focused discussion” (Study 2) in the first period and “redirecting off-task student behaviors” (Study 3) in the second. Here, we assessed the replicability of coaching effects across different teaching tasks and pedagogical outcomes with the same sample of participants. To examine the robustness of effects across different modes of delivery, coaching effects were compared for in-person simulation and coaching sessions (Study 3) and online through Zoom (Study 5). Finally, to evaluate effects across different target populations, we compared results for candidates enrolled in the teacher education program (Study 3) with undergraduates considering careers in teaching but without preparation coursework (Study 4). Figure 1B summarizes sources of variation, replication designs, and study comparisons.
Despite our design-based approach to introduce systematic sources of variation across studies, deviations may have occurred (and did), where study features differed in more ways than originally intended. For example, participant characteristics may have changed across studies in a multiple cohort design, fidelity to the coaching protocol may have changed with in-person versus online delivery, or constructs represented in an outcome measure of quality pedagogical practice may have deviated when intervention sessions were focused on different teaching tasks. When study findings were replicated, variations in study populations, contexts, measures, and features provided evidence about the robustness of coaching effects. However, when study findings differ—and there were multiple sources of planned and unplanned variation—it can be difficult for the researcher to determine why replication failure occurred (Steiner & Wong, 2018; Steiner et al., 2019; Wong et al., 2021).
To investigate validity threats to our replication designs—or alternative explanations for why replication failure may have occurred—we present diagnostic information that characterized the extent to which assumptions were addressed or varied under the causal replication framework. We summarized each study’s participant and setting characteristics, fidelity and adherence to the coaching protocol, and study design features (Table 1), along with joint tests of statistical significance (online Appendix A5). The diagnostic results presented here are akin to balance statistics commonly reported in experimental designs to demonstrate the comparability (or lack of comparability) across groups. Online Appendix A6 summarizes the conclusions of all our diagnostic results, evaluating the extent to which replication assumptions were met or violated.
Analysis
To examine the robustness of coaching effects across the five conceptual replication studies, we began by estimating the conditional average treatment effect of coaching on participants’ pedagogical performance for each individual RCT separately. Coaching effects for each study were estimated by using the following model:
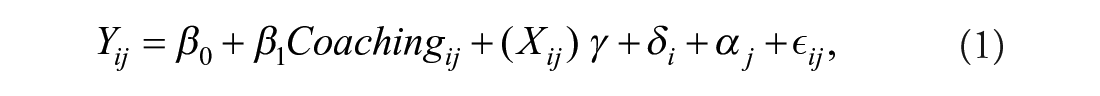
where Yij represented the pedagogical performance for participant i in course section j and was a function of participant i’s coaching status (where Coaching = 1 if assigned to receive coaching and Coaching = 0 if assigned to participate in self-reflection), as well as a vector of characteristics (Xij) measured at baseline and indicators for any missing baseline information. The model also included fixed effects for each course section (αj), which served as blocking factors for random assignment in each study, and for the interactor (δi) delivering the simulation session. The coefficient β1 represented the conditional average treatment effect for each study (see Table 2).
Coaching Effect Sizes by Study
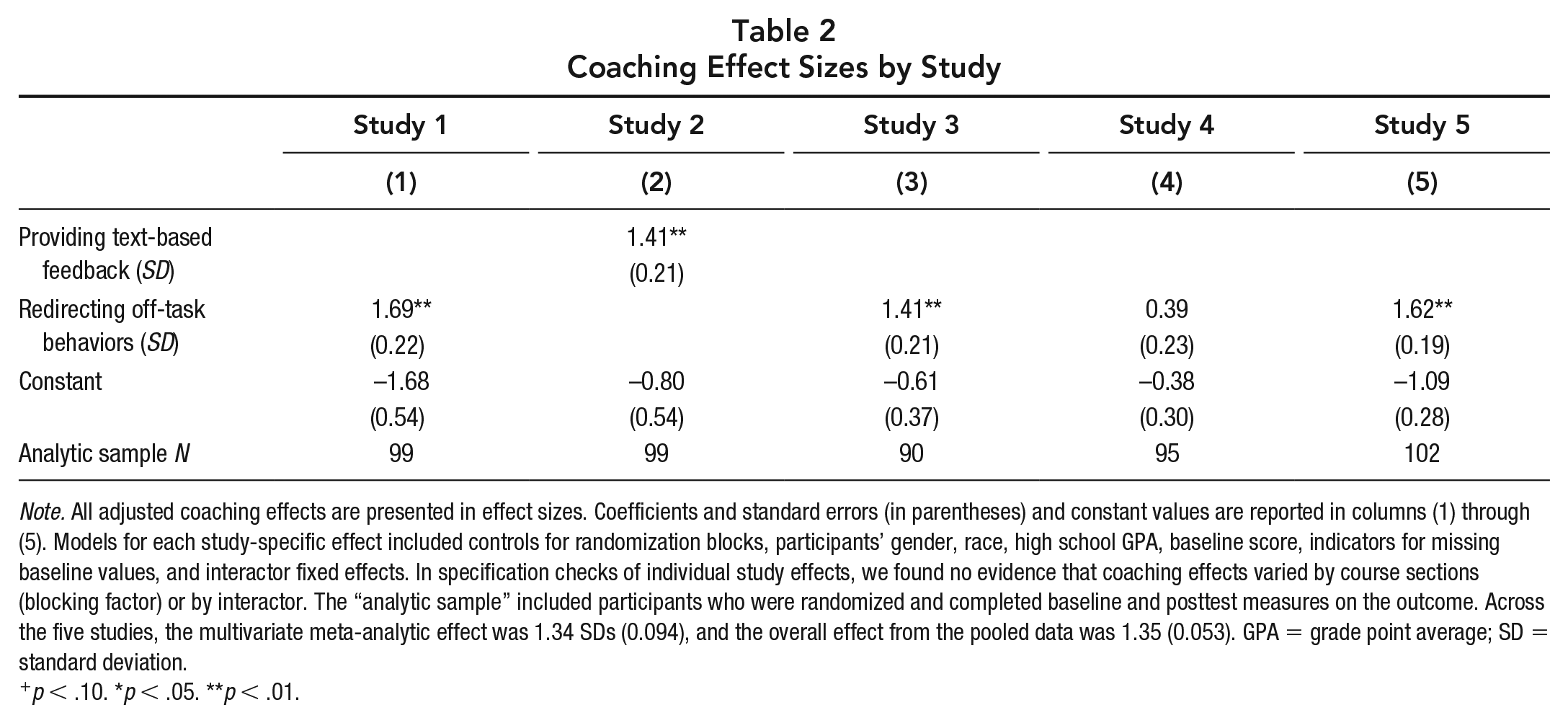
Note. All adjusted coaching effects are presented in effect sizes. Coefficients and standard errors (in parentheses) and constant values are reported in columns (1) through (5). Models for each study-specific effect included controls for randomization blocks, participants’ gender, race, high school GPA, baseline score, indicators for missing baseline values, and interactor fixed effects. In specification checks of individual study effects, we found no evidence that coaching effects varied by course sections (blocking factor) or by interactor. The “analytic sample” included participants who were randomized and completed baseline and posttest measures on the outcome. Across the five studies, the multivariate meta-analytic effect was 1.34 SDs (0.094), and the overall effect from the pooled data was 1.35 (0.053). GPA = grade point average; SD = standard deviation.
p < .10. *p < .05. **p < .01.
Next, we estimated the overall average treatment effect across the five studies by using a fixed-effects multivariate meta-analytic approach, wherein each study’s effect size was weighted by the inverse variance of the effect estimate. 7 To evaluate effect heterogeneity across studies, we examined the Q-statistic for the test of homogeneity (Hedges & Schauer, 2018). If the null hypothesis was rejected and effect heterogeneity was inferred, we compared coaching effects for each set of replication studies to identify the source of the effect variation (see Figure 1B for a summary of study comparisons). If diagnostic results from our balance tables indicated differences in participant characteristics across our pairwise comparison of studies, we used propensity score estimation to reweight samples to be observationally similar to our “benchmark” Study 3. We then assessed the replicability of “adjusted” coaching effects for observationally similar study samples. If differences in intervention effects persisted, we concluded that setting characteristics—as well as unobserved participant characteristics—resulted in treatment effect variation across studies. 8
Finally, we assessed replication success in study results by comparing the direction, magnitude, and statistical significance patterns of effects as well as results from a correspondence test that combined statistical tests of difference and equivalence in the same framework (Steiner & Wong, 2018; Tryon, 2001; Tryon & Lewis, 2008). We used the correspondence test because a test of difference could yield ambiguous conclusions when it is underpowered to reject the null hypothesis of no difference in study effects. To address this concern, the correspondence test combined statistical tests of difference and equivalence into the same framework to distinguish between results that were statistically different (significant difference, nonsignificant equivalence), statistically equivalent (nonsignificant difference, significant equivalence), statistically indeterminate (nonsignificant difference and equivalence), or trivially different (significant difference and equivalence). 9 We reported conclusions by using a stringent threshold (0.2 standard deviation [SD]) for equivalence (Steiner et al., 2023) and a more generous threshold (1 SD), given prior evidence that directive coaching effects were larger than 1 SD (Cohen et al., 2020).
Results
Diagnostic Results of Replication Assumptions
Variations in Participant and Setting Characteristics
Table 1 summarizes participant and setting characteristics for each study to demonstrate the extent to which these factors systematically varied and/or replicated across studies. The bold text highlights systematic differences in participant and setting characteristics introduced across replication efforts. Online Appendix A5 displays the effect size difference in study sample characteristics for each conceptual replication as well as results of joint tests of statistical significance comparing differences in characteristics across sets of studies. We found that for Studies 1, 2, and 3, teacher candidate samples were qualitatively similar in terms of demographic characteristics and contextual experiences (Table 1). Although our balance statistics and F-test results indicated differences between samples (online Appendix A5), they were due to a few participants who indicated variations from an overall homogeneous sample that consisted of mostly White women who had attended suburban high schools and had college-educated parents.
Participant and setting characteristics for Study 4, however, deviated substantially from those of the other three studies. Participants in Study 4 had different undergraduate course experiences and were younger, more male, and less White than the participants (teacher candidates) in other studies. Because they were enrolled in an undergraduate course that explored teaching as a profession (and not in the teacher preparation program), they also lacked prior course experiences on pedagogical methods. The deviations reflected differences in the underlying target populations and contexts from which the research team sought to sample. Participants in Study 5 were also different from those represented in Studies 1, 2, and 3—they were younger, less White, and more likely to have attended an urban high school or a high school with majority high-achieving students. This compositional shift reflected a policy change for the preparation program between the two periods. In Studies 1, 2, and 3, the preparation program included a combined bachelor’s/master’s degree program, while in Study 5, the combined degree program was separated into distinct bachelor’s and master’s degree programs. Although students in both degree programs underwent a similar sequence of coursework, undergraduate and graduate students had different participant characteristics.
Variations in Coaching Delivery
To examine the extent to which the coaching intervention was delivered consistently across studies, the research team used a natural language processing method to quantify the semantic similarity between a benchmark coaching protocol and transcripts of coaching sessions as delivered. Anglin et al. (2021) demonstrated that semantic similarity scores could be used to assess intervention fidelity in evaluation settings with highly standardized protocols that were delivered through verbal interactions with participants. 10 Adherence scale scores obtained from the method ranged from 0 to 1, with transcripts of coaching sessions with high adherence to the coaching protocol having higher scores and those that strayed from the protocol having lower scores. Adherence scores in Table 1 indicate that fidelity to the coaching protocol was similar across studies, although coaching fidelity was higher in Study 2 (0.38) relative to the other studies, which ranged in scores from 0.20 to 0.26.
Summary
Combined, these results suggest that although the conceptual replication studies succeeded in introducing systematic variations in time (Study 1 vs. Study 3), teaching task and outcome (Study 2 vs. Study 3), participant and setting characteristics (Study 3 vs. Study 4), and online versus in-person delivery (Study 3 vs. Study 5), there were also unplanned deviations from the original replication designs. To investigate the role of participant characteristics in moderating coaching effects across studies, we will examine the replicability of results for samples that have been adjusted to appear observationally similar on participant characteristics.
Impact of Coaching on Participants’ Instructional Practices
Table 2 presents effect size estimates of coaching on the quality of participants’ pedagogical practices in the simulations. Columns 1–5 in Table 2 provide separate effect estimates in SD units for each study. Effect sizes ranged from 0.39 SD (p value = ns, Study 4) to 1.69 SD (p value < 0.01, Study 1). Coaching effects for candidate samples (Studies 1, 2, 3, and 5) were consistently large and statistically significant (ranging from 1.41 SD in Studies 2 and 3 to 1.69 SD in Study 1), while the coaching effect for undergraduates (Study 4) was 0.39 SD and not statistically significant. Across the five studies, the multivariate meta-analytic coaching effect was positive, large, and statistically significant (1.34 SD, p value < 0.01). 11 However, the test of homogeneity indicated significant differences in effect estimates across studies (Q-statistic = 21.99; df = 4; p value < 0.01).
Robustness of Results Across Systematic Sources of Effect Heterogeneity
Given the evidence of effect heterogeneity, we also examined results from our replication studies to identify sources of effect variation. Table 3 summarizes results from each set of replication comparisons (with unadjusted and adjusted effects), with ✓ indicating replication success by a prespecified criterion (magnitude, sign, statistical significance pattern of results) and × indicating replication failure by the prespecified criterion. We also report the estimated difference in effects and whether they were statistically different and conclusions from the correspondence test (difference, equivalence, indeterminant, trivial difference).
Replication Success Across Series of Systematic Replication Studies
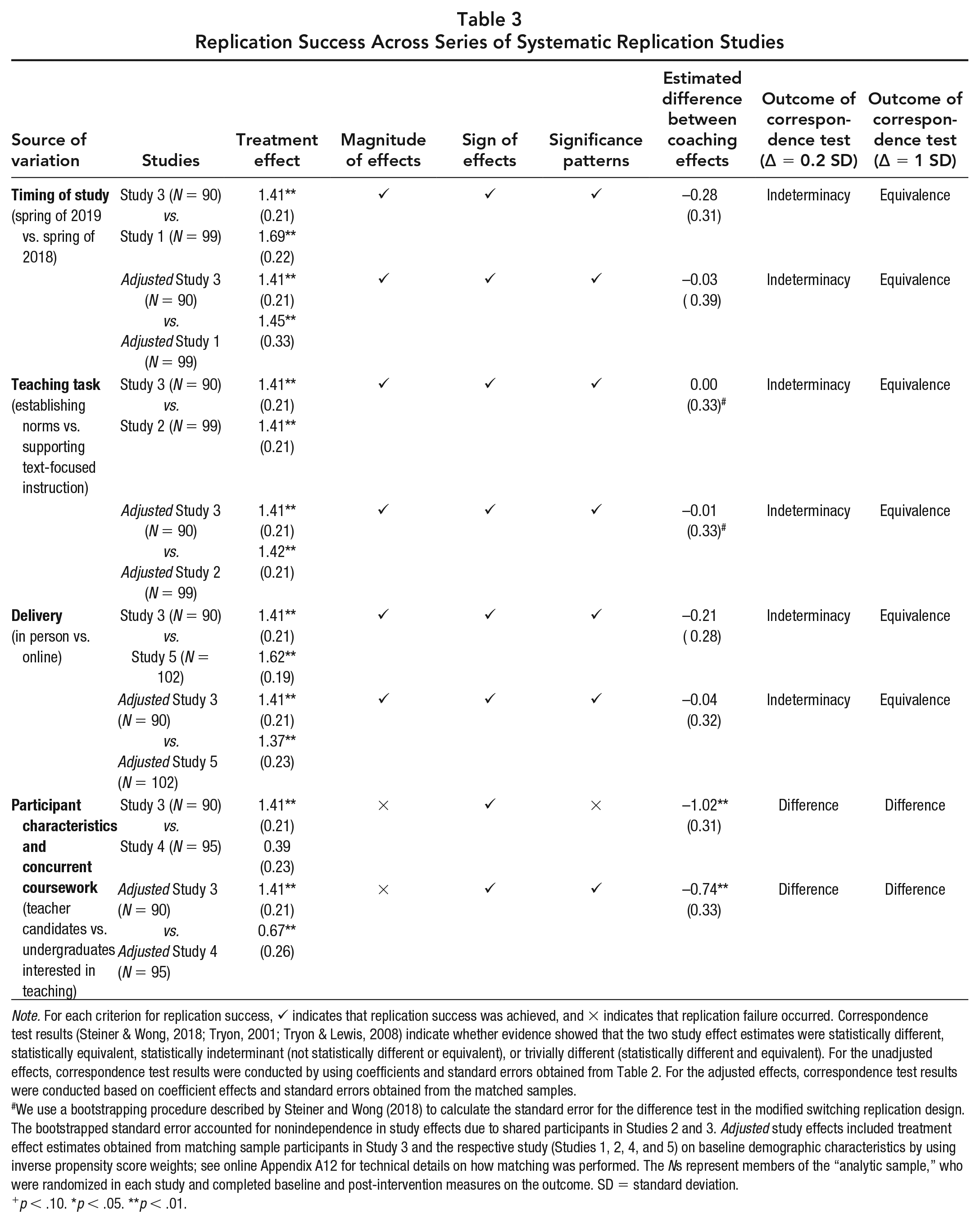
Note. For each criterion for replication success, ✓ indicates that replication success was achieved, and × indicates that replication failure occurred. Correspondence test results (Steiner & Wong, 2018; Tryon, 2001; Tryon & Lewis, 2008) indicate whether evidence showed that the two study effect estimates were statistically different, statistically equivalent, statistically indeterminant (not statistically different or equivalent), or trivially different (statistically different and equivalent). For the unadjusted effects, correspondence test results were conducted by using coefficients and standard errors obtained from Table 2. For the adjusted effects, correspondence test results were conducted based on coefficient effects and standard errors obtained from the matched samples.
We use a bootstrapping procedure described by Steiner and Wong (2018) to calculate the standard error for the difference test in the modified switching replication design. The bootstrapped standard error accounted for nonindependence in study effects due to shared participants in Studies 2 and 3. Adjusted study effects included treatment effect estimates obtained from matching sample participants in Study 3 and the respective study (Studies 1, 2, 4, and 5) on baseline demographic characteristics by using inverse propensity score weights; see online Appendix A12 for technical details on how matching was performed. The Ns represent members of the “analytic sample,” who were randomized in each study and completed baseline and post-intervention measures on the outcome. SD = standard deviation.
p < .10. *p < .05. **p < .01.
Timing of Study
Results from Table 3 show that coaching effects were robust across variation in study timing under most criteria for replication success. The coaching effect for Study 3 was 1.41 SD (p value < 0.01), while the coaching effect was 1.69 SD (p value < 0.01) for Study 1. When the Study 1 sample was reweighted to be observationally similar to participants in the benchmark Study 3, the adjusted coaching effect for Study 1 was 1.45 SD. Overall, we found that effects were replicated in terms of direction, magnitude, and statistical significance patterns. The difference in effect estimates was also not statistically significant. In looking at results from the correspondence test, we found that effects were statistically indeterminant (neither statistically different nor equivalent) with the more stringent tolerance threshold (0.2 SD), but statistically equivalent with the empirically based threshold of 1 SD. 12
Teaching Task
When participants practiced “establishing classroom norms,” coaching improved their performance by 1.41 SD (p value < 0.01, Study 3); when they practiced “text-focused instruction,” coaching improved performance by 1.41 SD (p value < 0.01, Study 2) or by 1.42 SD (p value < 0.01, Study 2) for the adjusted coaching effect. Coaching effects were comparable in terms of magnitude, direction, and statistical significance patterns, and the correspondence test again indicated indeterminacy for the equivalence test at the 0.2 SD threshold but equivalence for the 1 SD threshold.
Mode of Delivery
The coaching effect for the face-to-face sessions was 1.41 SD (p value < 0.01, Study 3). The unadjusted coaching effect for sessions delivered on Zoom was 1.62 SD (p value < 0.01, Study 5), and the adjusted coaching effect was 1.37 SD. These results indicate that although reweighting the Study 5 sample to be more observationally similar to the Study 3 sample produced an effect closer to the benchmark study result, coaching effects for the weighted and the unweighted samples were comparable. Across most criteria—direction, magnitude, statistical significance, and difference—replication success was achieved. Although the correspondence test yielded a conclusion of statistical indeterminacy for a tolerance threshold of 0.2 SD, it concluded that effects were equivalent for the larger tolerance threshold of 1 SD.
Target Population and Concurrent Coursework
Finally, for candidates who were enrolled in methods classes, the coaching effect was 1.41 SD (p value < 0.01, Study 3), but for undergraduates not enrolled in preparatory courses, the effect was smaller and not statistically significant (0.39 SD, Study 4). When the participant sample in Study 4 was reweighted to appear similar to that of the Study 3 sample, the adjusted coaching effect was 0.67 SD. Combined, these results suggest that differences in observable participant characteristics explained some of but not all the variation in coaching effects across Studies 3 and 4. Instead, coaching effects were likely also moderated by contextual characteristics (including concurrent course experiences) and other unobserved participant characteristics. For the unadjusted and adjusted effects, we concluded replication failure of results in terms of magnitude of effect and statistical significance pattern. The correspondence test yielded a conclusion of statistical difference for the more stringent 0.20 SD tolerance threshold and for the larger 1 SD threshold (significant difference, nonsignificant equivalence).
Discussion and Implications
Teacher preparation needs more evidence, particularly causal evidence, about promising practices for expediting teacher learning and skill development. Coaching—used extensively with practicing teachers—has been shown to improve a range of outcomes, from instructional skills to student achievement (Allen et al., 2011; Cilliers et al., 2020; Kraft et al., 2018). Our early work in a preservice context suggested that targeted, individualized, and directive coaching could also improve candidates’ instructional skills (Cohen et al., 2020). Given the resource-intensive nature of coaching, however, we needed more causal evidence about the robustness of coaching effects as well as the contexts and conditions under which this type of brief, directive, performance-oriented coaching was likely to be effective.
Here, we used conceptual replication research designs to implement five RCTs that evaluated the impact of directive coaching, using simulated classrooms to approximate and assess teaching. Across four studies, we saw significant performance improvements because of coaching. This result provided encouraging evidence that teacher preparation could be an important time for rapid skill development, if candidates are given targeted practice opportunities and corresponding supports. Although we often think that practice has to happen in real classrooms with real students, we have provided robust evidence that “the work of teaching” could be incorporated into coursework (Ball & Forzani, 2009). Rather than waiting until candidates are in clinical placements, providing structured practice and targeted feedback in ways that are integrated across coursework could better prepare candidates for skills with which they often report struggling (Grossman, Compton, et al., 2009).
We also found that directive, performance-oriented coaching could leverage large improvements, even absent long-standing relationships between candidates and coaches. Although many have argued for the value of responsive coaching, where coaches cultivate trust with the teachers they support, we found robust evidence that coaches who did not know candidates—and supported them in only brief, directive, skill-focused sessions—could promote rapid skill developments (Killion, 2016; Kowal & Steiner, 2007). This is not to argue that relationships are not important in teacher education or that other, more reflective approaches to coaching are not also helpful. However, our data suggest that performance-oriented coaching with clearly defined goals could also be effectively layered onto practice experiences. This coaching model would be less time-intensive than many approaches, and it would have an attendant benefit of candidates being able to “feel themselves improve” because they would know what they were working toward and could practice again immediately following the coaching session. We recognize that our model of coaching, with the candidate and the coach working toward clearly defined and articulated goals, is not the norm in teacher education. That said, our data suggest that teachers, like all learners, could benefit from a clear understanding of what they are working toward and why (Ericsson & Pool, 2016). These cycles of repeated practice with coaching around tangible and well-articulated goals are the norm in many professional fields, including sports and medicine, and we see no reason why the same could not be true in teacher education (Reich, 2022).
This study is the first to our knowledge that used a series of systematic replication studies to inform theory about how, when, and for whom coaching “works” in a field where we have next-to-no causal evidence. Because each study was designed prospectively, the research team introduced systematic sources of variation to examine heterogeneity in observed coaching effects across different teaching tasks, timing of study, targeted participants, and modes of coaching (Wong et al., 2021). Our findings suggest that our model of skill-focused, directive coaching significantly improved candidates’ teaching skills and that coaching effects replicated across pedagogical tasks, timing, and modes of delivery. These results are encouraging for program developers looking for ways to integrate simulations and shorter and more directive coaching (Dieker et al., 2014).
We also found that coaching effects were not robust across participants and contextual experiences. Undergraduates did not improve from coaching as much as candidates enrolled in concurrent methods coursework focused on the practices targeted in simulations. Although our data did not allow for definitive conclusions about mechanisms, we theorized that smaller coaching effects for the undergraduate sample, even after controlling for observable characteristics, may have been explained by the candidates’ lack of schema or prior knowledge about the skills targeted in coaching. This result suggests that coaching in isolation, without corresponding coursework on targeted practices, is not as effective (Kraft et al., 2018). It also underscores the importance of coherent and coordinated learning experiences where candidates engage with the theory underlying teaching practices, have opportunities to observe and analyze use of such practices, and then have chances to enact those practices with coaching supports (Grossman, Compton, et al., 2009). That is, approximations of teaching should not be stand-alone experiences, where skills are decoupled from their conceptual bases (Kennedy, 2016). This thought is in line with previous studies that highlighted the importance of grounding in-service coaching with corresponding instruction about related skills (Albornoz et al., 2020; Kraft et al., 2018; Scheeler et al., 2009). Preservice coaching programs might want to develop cycles of learning that ensure that skills practiced and coached build on a robust foundation of knowledge about the skills, what they look like in use in classrooms, and how and why they support positive student outcomes.
However, these study results have limitations, particularly in that we were not able to observe the longer term effects of our coaching model on less tightly aligned measures of teaching quality in K–12 classrooms. That said, the primary purpose of this work has been focused on causally identifying supports for improving teacher practice in simulated settings, before we invest much more substantial resources in tracking the development of those skills in more applied contexts. Nearly 100 teacher preparation programs are using the simulation technology we relied on here. And yet, prior to our work, the field knew next to nothing about the utility of different approaches to simulated practice. The vast majority of programs were asking candidates to practice without additional supports (Ireland, 2021), assuming the accuracy of the adage “practice makes perfect.” Many other programs were asking candidates to self-reflect on their performance in the simulated classroom (Ireland, 2021). This focus on “self-reflection” as a lever for improvement is a central tenet of much teacher education practice and policy, as demonstrated by the fact that one of the most common licensure exams, edTPA, primarily assesses prospective teachers’ reflection skills (Sato, 2014).
Thus, our central goal across the studies presented here was to understand whether this model of directive coaching could help teachers improve more in simulated contexts than could other less-resource intensive approaches to simulation, as well as the contexts and conditions in which coaching could help more or less. In other words, we wanted to understand how to get simulated practice “right” before looking at the robustness and transferability of our methods.
The effect sizes presented here were large—much larger than what is typically observed in educational research generally (Kraft, 2020; Lipsey et al., 2012) and in the study of coaching interventions specifically (Kraft et al., 2018). We acknowledge that our large effect sizes were likely bolstered by the proximal and aligned nature of the outcome measures, although we also present evidence of coaching effects on less tightly aligned measures, such as the IOWA Connor’s rating scale. It will be important to analyze the degree to which our observed coaching effects persist across the teacher preparation period or fade over time. We are in the midst of this work, although it has been affected by shifts in teacher preparation during the COVID-19 pandemic. We also need to build more robust evidence about correspondence between improved teaching in simulated classrooms and improvements in the more distal outcomes of teaching real students in real classrooms. This work is also currently underway. Finally, all of our work has been done at a single university with a specific population of candidates. At present, we are in the middle of partnering with other university-based teacher preparation programs to examine the robustness of coaching effects across different populations of candidates, working in diverse geographic locations and classroom settings. Extending the evidence base about the degree to which targeted, directive coaching could improve teaching practices across sites, samples, and teaching outcomes is a critical area for ongoing and future work. Despite these limitations, we see these results as an important first step in identifying simulations and directive coaching as an efficient and effective method for helping candidates develop important teaching skills. Given the short duration and crucial importance of teacher preparation, building a robust evidence base about such methods is imperative.
Supplemental Material
sj-pdf-1-edr-10.3102_0013189X231198827 – Supplemental material for Experimental Evidence on the Robustness of Coaching Supports in Teacher Education
Supplemental material, sj-pdf-1-edr-10.3102_0013189X231198827 for Experimental Evidence on the Robustness of Coaching Supports in Teacher Education by Julie Cohen, Vivian C. Wong, Anandita Krishnamachari and Steffen Erickson in Educational Researcher
Footnotes
Authorship Note
Vivian Wong and Julie Cohen contributed equally to the work.
Notes
Authors
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.