
Abstract
Attempting to describe a face can lead to subsequent recognition impairments, i.e., verbal overshadowing. A new explanation of the verbal overshadowing effect was tested by manipulating whether participants described features that were more or less salient for face identification. To manipulate the distinguishing features, distractor faces were created with gray scale photographs of men identical to the targets except for the eyes and mouth (Study 1) or eyebrows and nose (Study 2). In both studies, participants (Study 1: N = 177, 81 men, M age = 18.9 yr.; Study 2: N = 144, 133 men, M age = 20.5 yr.) were assigned to one of two verbalization conditions or a control condition. After a target face was presented, participants in the two verbalization conditions were asked to describe specific features—either eyes and mouth, or eyebrows and nose—before a recognition test. Participants in the control condition completed a filler task. The measure of recognition was whether participants could recognize the target correctly. Results showed that describing the eyes and mouth did not cause significant verbal overshadowing in either Study 1 or 2, while describing the eyebrows and nose caused statistically significant verbal overshadowing in Study 2. Verbalizing information important for face identification did not cause verbal overshadowing regardless of the distinguishability of described features.
In a seminal study, Schooler and Engstler-Schooler (1990) demonstrated that verbally describing a target's appearance led to impaired recognition performance. They termed this phenomenon “verbal overshadowing.” Recent research has suggested that verbalizing memories disrupts recognition (Kitagami, Sato, & Yoshikawa, 2002; Wickham & Swift, 2006; Nakabayashi, Lloyd-Jones, Butcher, & Liu, 2012). The present study examines how differences in the verbalized information influence verbal overshadowing—in particular, how describing salient and distinguishing features influences face recognition.
One of the main questions about verbal overshadowing is whether verbal overshadowing occurs when participants describe features that are salient for face identification. According to research on face identification, eyes are more salient than other facial features and they are processed more efficiently (Fraser & Parker, 1986). Because of this increased saliency, it has been argued that information from the upper portion of the face, especially the eyes, is important for face identification (Goldstein & Mackenberg, 1966; Ellis, Shepherd, & Davies, 1975; Haig, 1986). In line with this view, McKelvie (1976) found that masking the eyes of a target increased face recognition errors more than masking the mouth. Hills, Ross, and Lewis (2011) found that recognition performance was better when participants' attention was directed to a target's eyes than to the mouth in the study phase. Eye movement studies have also shown that participants spend the most time looking at the eyes when a face is presented (Althoff & Cohen, 1999; Henderson, Williams, & Falk, 2005; Williams & Henderson, 2007).
Despite these studies suggesting the presence of salient features for face identification, it is unclear whether verbally describing these facial features impairs subsequent face recognition in verbal overshadowing studies. The transfer inappropriate processing shift (TIPS: Schooler, 2002; Chin & Schooler, 2008) hypothesis is the primary explanation for verbal overshadowing. According to this hypothesis, the verbal process required for verbal descriptions inhibits nonverbal face recognition processes (i.e., holistic processing) and consequently reduces recognition performance. Similarly, Schooler (2002) argued that the cause of verbal overshadowing is not the content of the verbal description, but that local information processing is enhanced by verbalization (i.e., featural processing). Therefore, TIPS assumes that the specific facial feature described should not affect verbal overshadowing, so most verbal overshadowing studies do not examine effects of describing salient facial features on subsequent face recognition. Many different studies support the TIPS (Dodson, Johnson, & Schooler, 1997; Brown & Lloyd-Jones, 2002, 2003), and some studies have demonstrated that there is no correlation between description accuracy and recognition performance (Fallshore & Schooler, 1995; Finger, 2002; Kitagami, et al., 2002). However, some previous studies have shown that differences in described content modulate the occurrence of verbal overshadowing (Meissner, Brigham, & Kelley, 2001; MacLin, 2002; Meissner, Sporer, & Susa, 2008). Thus, it is not clear whether differences in the salience of verbalized information might affect verbal overshadowing.
A number of studies have shown that paying specific attention to certain (salient) facial features is necessary for subsequent face identification. A face is better recognized when participants first fixate the eyes than other areas (Hills, et al., 2011). In addition, Althoff and Cohen (1999) demonstrated that people usually attend to eyes rather than to other features. In their experiment, participants' eye-movement patterns were measured while they viewed familiar or unfamiliar face images. The results showed that the eyes were fixated more than other features regardless of the familiarity of the presented face. Thus, one might expect that participants pay attention to specific information (i.e., eyes) during a face recognition test if they do not verbalize the target. In sum, because people attend to eyes during face identification in normal situations, participants whose attention is directed to those salient features (e.g., eyes) during verbalization should be able to recognize the target as well as participants who do not engage in any verbalization. Thus, describing salient features should prevent verbal overshadowing.
Whether the described information is a distinguishing feature for discriminating the target from distractors may affect recognition performance. Which facial features distinguish between the target and distractor stimuli depends on how the stimuli and distractors are constructed, while the salience of a feature to later recognition is not dependent on the recognition stimulus set. Kitagami, et al. (2002) demonstrated that verbal overshadowing was influenced by the distractors' appearance in the recognition test. They reported that verbal overshadowing was likely to occur when distractors were similar to the target. This result suggests that verbal overshadowing may occur when the verbalized information, i.e., the description of certain features, is not useful for distinguishing the target from distractors. Therefore, both the salience and distinguishability of verbalized information should be considered in verbal overshadowing studies.
It is unclear how verbalizing distinguishing features affects verbal overshadowing. There appear to be two possibilities. First, if the verbalized information is distinguishing, verbal overshadowing may not occur. Another possibility is that people do not rely on non-salient information (e.g., the nose) when they identify faces (Ellis, et al., 1975; McKelvie, 1976; Hills, et al., 2011). Therefore, when people describe distinguishing but non-salient features, they might not be able to use the verbalized information for target recognition, leading to verbal overshadowing. Thus, facial features with different saliency (eyes and mouth vs eyebrows and nose) should have different effects on verbal overshadowing. Although some studies have demonstrated that describing facial features can enhance face recognition (Winograd, 1981; Brown & Lloyd-Jones, 2005; Jones, Armstrong, Casey, Burson, & Memon, 2013), most of these studies asked participants to describe a target face during or immediately after the encoding phase. In the verbal overshadowing paradigm, participants are asked to describe a target face a certain amount of time after the encoding phase.
Study 1
In the current study, to manipulate feature distinguishability, morphed distractors were created that had the same features as the target except for the eyes and mouth. These manipulations represent alterations in which feature is distinguishable. Although the mouth may be less salient to face recognition than the eyes, both these features were changed because the recognition test might be too difficult if only one feature was changed. To avoid presenting the altered features disproportionately in the upper or lower half of the face, eyes and mouth were modified. Participants were assigned to either a condition where they were instructed to describe the eyes and mouth, the eyebrows and nose, or make no description.
Hypothesis 1. Describing the eyes and mouth will not cause verbal overshadowing because eyes are more salient for face identification than the other features.
Hypothesis 2. Because the eyebrows and nose tend to contribute less to face identification than the eyes (they are less salient features), describing the eyebrows and nose should cause verbal overshadowing.
Method
Participants
One hundred and seventy-seven undergraduates (81 men) participated in the experiment for course credit. The mean age was 18.9 yr. (SD = 1.2). Participation occurred during a class. This study was approved by the university institutional review board. The voluntary nature of the study was explained to participants.
Materials
One target and seven distractor faces were created. The target face was a photograph of a Japanese male with a neutral expression. The target was chosen because he did not have any distinctive features, such as a scar or beard. The distractor faces were composite faces that were almost identical to the target face except that their eyes and mouths were taken from seven other Japanese male faces. This allowed manipulation of whether the verbally described features were distinguishing (modified) features between target and distractors. A single target face was used because most verbal overshadowing studies use one test set (Finger & Pezdek, 1999; Meissner, et al., 2001; Finger, 2002; Kitagami, et al., 2002; Itoh, 2005). All stimuli were presented in gray scale. In the encoding phase, the target was 10.2 cm × 8.2 cm. In the recognition test, the target and distractors were 7.3 cm × 5.9 cm. Semantic images of target and distractors are shown in Figure 1. In the recognition phase, it was necessary to present eight images (the target and distractors) in one page to imitate the form of photo lineup (Schooler & Engstler-Schooler, 1990; Kitagami, et al., 2002). In the encoding phase, only the target face was presented in one page and the target face needs to be observed carefully by participants. Therefore, the images presented in the recognition phase were smaller than the target image of the encoding phase.
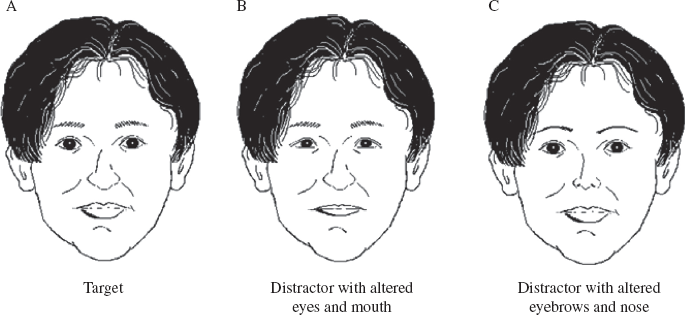
Semantic images of target and distractor faces. A: target image. B: distractor image altered eyes and mouth. C: distractor image altered eyebrows and nose. These images were created at http://www.vector.co.jp/soft/dl/win95/art/se305589.html.
Adobe Photoshop Elements 10.0 was used to create the distractors. The eyes and mouths of different faces were put on the target face. The positional relations between features were changed as little as possible. The research materials were presented in a seven-page booklet that included a cover sheet, the target face, a crossword puzzle, a description or filler task, and the recognition task. In the encoding phase, the target face was presented in the center of the page. In the description or filler task, answer space was located under the instruction. In the recognition task, the target and distractors were printed in the upper half of the page. The recognition array consisted of two rows and four columns. The location of items in the recognition set was counterbalanced. An answer space was located under the recognition array. In this experiment, participants could see the whole face, including hair and facial contour, but not the neck.
Procedure
Participants were tested in a group, and were randomly assigned to one of three conditions: distinguishing features verbalization, non-distinguishing features verbalization, or control. To control the time spent on each task, all participants were told to only turn pages in the booklet when instructed to do so. In addition, participants were not allowed to go back to previous pages.
All participants viewed the target face for 10 sec. and were told to look at it carefully to prepare for the recognition task. Following target presentation, all participants engaged in a crossword puzzle task for 3 min. Then, participants in the distinguishing features verbalization condition were asked to describe the target's distinguishing features (eyes and mouth) in as much detail as possible for 3 min. Participants in the non-distinguishing features verbalization condition were asked to describe non-distinguishing features (eyebrows and nose) in as much detail as possible for 3 min. In both verbalization conditions, participants wrote the target's feature under the instruction of the task in the booklet. The target face was not presented at the page. In other words, they described the target's features by their memory. Participants in the control condition engaged in an unrelated verbal listing task for 3 min. At the end of the experiment, all participants completed a recognition task in which they were asked to identify the target face presented among seven distractor faces. Participants were given as much time as they needed to choose the correct face. The entire experiment took about 10 min.
Analysis
Recognition performance (hits and false alarms) and verbalization conditions (distinguishing features verbalization, non-distinguishing features verbalization, and control) were entered into a binary logistic regression. In previous studies, when participants chose a distractor, this response was counted as a “false alarm,” and when participants chose a “not-present” option, this response was counted as a “miss.” Following previous studies, all incorrect responses on the recognition test were considered false alarms.
Results and Discussion
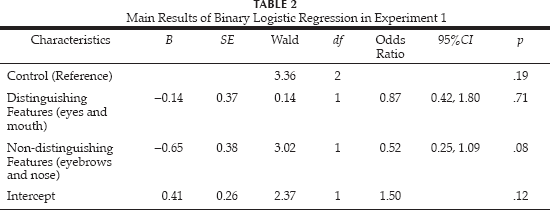
Table 1 shows the proportion of correct responses. The effect of verbalization conditions was not significant (χ2 = 3.39, p = .18; Nagelkerke R2 = .03). The main results of the binary logistic regression analysis are shown in Table 2. In addition, partial regression coefficients did not significantly differ between the control and non-distinguishing features verbalization conditions (W = 3.02, p = .08; OR = 0.52, 95% CI = 0.25, 1.09). Furthermore, the partial regression coefficients were not significantly different between the control and distinguishing features verbalization conditions (W = 0.14, p = .71; OR = 0.87, 95% CI = 0.42,1.80).
Recognition Accuracy (Proportion Correct) as a Function of Verbalization Condition in Experiment 1

Main Results of Binary Logistic Regression in Experiment 1
To assess whether description accuracy was related to identification accuracy, two independent coders examined each description for the number of correct, incorrect, and other details. All participants in both verbalization conditions described instructed features. Objective and correct details were classified as Correct. Objective and incorrect details were classified as Incorrect. Details that were subjective and could not be classified into either category were classified as Other. Acceptable inter-rater agreement was obtained (κ = .76). Although this kappa coefficient is not high, a previous study considered the range of 0.61 to 0.80 kappa coefficients as substantial inter-rater agreement (Viera & Garrett, 2005). Table 3 shows the mean numbers of Correct, Incorrect, and Other details. There were significantly more Incorrect details in the distinguishing features vs non-distinguishing features verbalization condition (t1 = 6.51, p < .01, Cohen's d = 1.21). In contrast, there were significantly more Other details in the non-distinguishing features verbalization vs distinguishing features verbalization condition (t1 = −3.49, p < .01, Cohen's d = −0.65). There were no significant differences in the mean number of correct details (t1 = 0.24, p = .80, Cohen's d = 0.05) or the mean total number of details between the two verbalization conditions (t1 = 0.73, p = .46, Cohen's d = 0.14). Although there were some differences between the two verbalization conditions in the number of details, the numbers of Correct, Incorrect, and Other details were not correlated with recognition performance (rs < .15, ps > .12). In sum, the quality of participants' descriptions did not influence recognition accuracy. This suggests that how participants describe the target face may not be critical.
Mean Number of Correct, Incorrect, and Other Details (SD) as a Function of Verbalization Condition in Experiment 1

There was no significant difference in recognition performance between the control and non-distinguishing features verbalization conditions. However, the odds ratio (0.52), a measure of effect size in logistic regression analyses, indicates that recognition performance was lower in the non-distinguishing features verbalization condition than the control condition. The odds ratio was converted to Cohen's d (d = −0.36) (Borenstein, Hedges, Higgins, & Rothstein, 2009) and then to Fisher's Zr (Zr = −0.18). Because this effect size is comparable to the effect size obtained in a meta-analysis of verbal overshadowing (Zr = −0.12; Meissner & Brigham, 2001), the result is likely robust. Further studies are necessary to confirm this effect. In contrast, Cohen's d was −0.07 for the distinguishing features verbalization condition. Therefore, describing the eyes and mouth did not cause verbal overshadowing. This may be because eyes are salient for face identification. These results suggest that the whether individual features are salient for face identification and whether distinguishing features are described should be considered when examining effects of verbalized information.
Study 2
In Study 1, the salient information (eyes and mouth) was also distinguishing. To disentangle the effects of verbalizing salient and distinguishing features, Study 2 examined whether verbal overshadowing occurs when verbalized information is non-salient (eyebrows and nose) but distinguishing in the recognition phase. If description of distinguishing and salient features inhibits verbal overshadowing, describing the eyes and mouth should cause verbal overshadowing in Study 2 where these features are salient but not distinguishing. If describing salient features can inhibit verbal overshadowing, describing the eyes and mouth should not cause verbal overshadowing.
Hypothesis 3. If the distinguishing features (those modified in the distractor images) are also salient for face recognition, describing the distinguishing features (eyebrows and nose in Study 2) may not cause verbal overshadowing.
Hypothesis 4. If describing distinguishing but non-salient features causes verbal overshadowing, describing the eyebrows and nose will cause verbal overshadowing regardless of how much these features were changed to create distractors.
Method
Participants
One hundred and forty-four undergraduate students (133 men) participated in the experiment in exchange for course credit. The mean age was 20.5 yr. (SD = 2.0). Participation occurred during two classes.
Materials and Procedure
One target and seven distractor faces were created. The target face was identical to Experiment 1. To examine the effect of verbalizing distinguishing features, the distractor faces were composite faces that were identical to the target face, except that their eyebrows and noses were taken from seven different Japanese male faces. Stimuli were the same size and color as Study 1. Semantic images of target and distractors are showed in Fig. 1(a, c).
As in Study 1, seven-page booklets were prepared for the experiment. The booklets contained the following research materials: a cover sheet, the target face, a crossword, a verbalization or filler task, and the recognition task. These research materials were identical to Study 1, except for the distractors. Participants were tested in a group. They were randomly assigned to one of three conditions: distinguishing features (eyebrows and nose) verbalization, non-distinguishing features (eyes and mouth) verbalization, or control. Participants in the distinguishing features verbalization condition were asked to describe the eyebrows and nose. Participants in the non-distinguishing features verbalization condition were asked to describe the eyes and mouth. The rest of the procedure was identical to Study 1.
Analysis
Recognition performance (hits and false alarms) and verbalization conditions (distinguishing features verbalization, non-distinguishing features verbalization, and control) were entered into a binary logistic regression.
Results and Discussion
Table 4 shows recognition accuracy (proportion correct). The effect of verbalization conditions was significant (χ 2 = 6.217, p = .05; Nagelkerke R2 = .06). Table 5 shows the main results of the binary logistic regression analysis. There was a significant difference in the partial regression coefficients between the control and distinguishing features (eyebrows and nose) verbalization condition (W1 = 6.47, p = .02; OR = 0.36, 95% C7 = 0.16, 0.82). In contrast, the partial regression coefficients did not differ between the control and non-distinguishing features (eyes and mouth) verbalization condition (W1 = 2.00, p = .13; OR = 0.54, 95% C7 = 0.24,1.20).
Recognition Accuracy (Proportion Correct) as a Function of Verbalization Condition in Study 2

Main Results of Binary Logistic Regression in Study 2

Two independent coders scored each description for the number of Correct, Incorrect, and Other details (Table 6), as in Study 1. Adequate inter-rater agreement was obtained (κ = .66). Although this is moderate, the previous study also considered it as substantial inter-rater agreement (Viera & Garrett, 2005). No significant differences were observed between the two verbalization conditions in the mean total number of details (t93 = 0.58, p = .56, Cohen's d = 0.12). There was also no significant difference in the mean number of Correct details (t93 = 0.41, p = .67, Cohen's d = 0.09) and Other details (t93 = −1.23, p = .22, Cohen's d = −0.25). Only the mean number of incorrect details differed significantly between verbalization conditions (t93 = 3.14, p < .01, Cohen's d = 0.65). Participants in the non-distinguishing features verbalization condition described more Incorrect details than those in the distinguishing features condition. However, the numbers of Correct, Incorrect, and Other details were not significantly correlated with recognition performance (rs < .15, ps > .30). As in Study 1, the accuracy of participants' descriptions did not influence recognition accuracy.
Mean Correct, Incorrect, and Other Details as a Function of Verbalization Condition in Study 2

In Study 2, there was a significant difference in recognition performance between the distinguishing features (eyebrows and nose) verbalization and control conditions. In other words, describing the eyebrows and nose led to verbal overshadowing, even though this information was distinguishing in the recognition task: the differences between the target and distractors were the eyebrows and nose. Therefore, paying attention to the eyebrows and nose was a reasonable strategy for discriminating the target from distractors. However, facial recognition is not driven by reasoned choice. When people identify individual faces, they are less likely to use information from the eyebrows and nose, and are more likely to use information from the eyes (McKelvie, 1976). Verbalizing information about eyebrows and noses may be incongruent with real-world face identification, and so did not help participants identify the target.
In contrast, the difference in recognition performance between the non-distinguishing feature (eyes and mouth) verbalization and control conditions was not statistically significant. Describing the eyes and mouth did not impair face recognition, even though these features were identical in the target and distractors. Eyes are the most salient features for facial identification (McKelvie, 1976). Other studies have also demonstrated that eyes play a more important role in face recognition than other features (Ellis, et al., 1975; Haig, 1986). Describing eyes may direct participants' attention to the eyes during the recognition phase. Detecting subtle differences in eyebrows in Study 2 may have required focusing on the eyes. It is possible that participants may have been able to recognize the target's eyebrows by attending to the relationship between eyes and eyebrows. Therefore, describing the eyes did not cause verbal overshadowing.
General discussion
The present study examined whether verbalized information about different facial features affected verbal overshadowing. The focus was how verbalizing information about salient and distinguishing features influences verbal overshadowing, and which feature plays a stronger role in face recognition. A facial feature's salience is not dependent on the distractors' appearance, whereas which feature is distinguishable was modified in the distractors. The results showed that verbally describing the eyes and mouth did not impair face recognition in either Study 1 or 2. In Study 2, describing the eyebrows and nose caused significant verbal overshadowing. Contrary to the TIPS hypothesis, verbalizing different information influenced the extent to which verbalization impaired face recognition.
Information salient to face identification plays a more influential role than distinguishing features in face recognition after verbalization. Verbally describing the eyes and mouth did not lead to verbal overshadowing, although the experimental manipulation made this information non-distinguishing for recognition in Study 2. In contrast, verbal descriptions of other features (eyebrows and nose) in Study 2 caused verbal overshadowing. This suggests that describing salient features (eyes) does not cause (or possibly counters) verbal overshadowing. The effect of describing non-salient features (eyebrows and nose) is still unclear. In Study 1, the difference in recognition performance between describing the eyebrows and nose and the control condition was not significant. However, the effect size (Cohen's d = −0.36) suggests that describing the eyebrows and nose causes verbal overshadowing. The effect of describing eyebrows on verbal overshadowing could be clarified in future studies.
Further Research and Design Issues
The present study has important implications for the controversy about whether the content of verbal descriptions affects memory performance (Meissner & Brigham, 2001; Schooler, 2002; Meissner, et al., 2008). Most previous studies investigated the correlation between description quality and recognition performance to examine how differences in verbalized information influence verbal overshadowing (Schooler & Engstler-Schooler, 1990; Fallshore & Schooler, 1995; Meissner, et al., 2001; Meissner & Brigham, 2001; Kitagami, et al., 2002; Meissner, et al., 2008). However, examining description accuracy is not sufficient. In the present study, participants who described the eyes and mouth gave more incorrect details than those who described the eyebrows and nose, but there was no correlation between description accuracy and recognition accuracy. These results suggest that, even if description accuracy is low, verbalizing salient information may not cause (or may counteract) verbal overshadowing. This may explain why previous studies produced inconsistent results: verbal overshadowing might not be found if differences in the salience of the verbalized information for face identification are not taken into account. In addition, the present results may partly explain why several studies have failed to observe significant verbal overshadowing (Meissner & Brigham, 2001; Nakabayashi & Burton, 2008; Wickham & Lander, 2008). 2 Several previous studies did not control what information was verbalized (Schooler & Engstler-Schooler, 1990; Fallshore & Schooler, 1995; Dodson, et al., 1997). The present results suggest that describing salient features (i.e., eyes) can attenuate or counter the negative effects of verbalization. This may contribute to the low replicability of the verbal overshadowing effect.
According to the TIPS hypothesis, verbalization turns participants' attention to featural information. In the present study, although participants' attention may have been directed to featural information, describing salient features may have reduced the detrimental effect of this processing shift on recognition performance by directing participants' attention to the salient features. Verbal enhancement effects on face recognition have been reported (Winograd, 1981; Brown & Lloyd-Jones, 2005; Jones, et al., 2013); however, participants in those studies verbalized information about targets in an encoding phase or immediately after target presentation (but see Itoh, 2005). The effect of verbalization may differ depending on the timing. Verbally describing targets after a delay may not facilitate later target face recognition, even when salient features for face identification (e.g., eyes) are described.
The similarity of the target and distractors is also important. In the present study, the recognition test may have been more difficult in Study 2 vs Study 1 because less salient features (eyebrows and nose) were changed in Study 2. However, recognition performance was comparable. Therefore, the similarity of the recognition set was likely higher in Study 1, which could have influenced whether verbal overshadowing was observed. In addition, feature distinctiveness of the target face should also be considered. If feature distinctiveness is high, the feature may draw attention in the encoding phase regardless of the feature's salience or distinguishability. The target faces used here did not have any distinct features such as a scar or beard. However, the importance of controlling feature distinctiveness should be explored in future studies.
In the present study, feature distinguishability was manipulated by using composite distractors in a recognition test where either the eyes and mouth or eyebrows and nose were changed. However, eyes and mouths may differ in salience (McKelvie, 1976). Recognition performance when the eyes are described should be examined with intact faces in future research. Furthermore, facial features are not completely independent of each other (Tanaka & Farah, 1993; Tanaka & Sengco, 1997; Maurer, Le, & Mondloch, 2002; Halberstadt, 2005). Although describing a specific feature affected verbal overshadowing, the effect of feature distinguishability should be examined with intact faces. In addition, there was no control group where participants described the target without any specific instructions about what to describe. Including this condition would have allowed evaluation of which features participants tended to describe in the standard verbal overshadowing paradigm.
The present study suggests that describing features that are salient to face identification (e.g., eyes) does not cause recognition impairment. These results suggest that such verbalization of visual information does not always have a negative effect on nonverbal (visual) memory. Verbal overshadowing may be more likely when information non-salient to face identification is verbalized. Future studies should examine whether these results generalize to memory for intact faces or other nonverbal information.