
Abstract
In practical linguistic multi-criteria group decision-making (MCGDM) problems, words may indicate different meanings for various decision makers (DMs), and a high level of group consensus indicates that most of the group members are satisfied with the final solution. This study aims at developing a novel framework that considers the personalized individual semantics (PISs) and group consensus of DMs to tackle linguistic single-valued neutrosophic MCGDM problems. First, a novel discrimination measure for linguistic single-valued neutrosophic numbers (LSVNNs) is proposed, based on which a discrimination-based optimization model is built to assign personalized numerical scales (PNSs). Second, an extended consensus-based optimization model is constructed to identify the weights of DMs considering the group consensus. Then, the overall evaluations of all the alternatives are obtained based on the LSVNN aggregation operator to identify the ranking of alternatives. Finally, the results of the illustrative example, sensitivity and comparative analysis are presented to verify the feasibility and effectiveness of the proposed method.
Keywords
Introduction
A multi-criteria group decision-making (MCGDM) problem is defined as a decision problem where several experts (judges, decision makers (DMs), etc.) provide their evaluations on a set of alternatives regarding multiple criteria and seek to achieve a common solution that is most acceptable by the group of experts as a whole (Kabak and Ervural, 2017; Wang et al., 2021). One important issue in MCGDM is to depict the ratings of experts. As the socio-economic environment becomes increasingly complex, it becomes difficult for DMs to specify their preferences with crisp values. Zadeh (1965) pioneered fuzzy sets (FSs), which are characterized by membership functions and considered as an effective tool to capture uncertain information. In order to capture DMs’ imprecise preferences, Atanassov (1986) introduced the concept of intuitionistic fuzzy sets (IFSs), which are considered as an extension of Zadeh’s fuzzy sets (Zadeh, 1965). IFSs have been widely applied to address impreciseness and uncertainty information in MCGDM problems (Chen et al., 2020; Garg and Kumar, 2019; Ohlan, 2022; Seikh and Mandal, 2022; Wan et al., 2020; Zhao et al., 2021). For an overview of IFSs and their extensions in MCGDM, one can refer to Xu and Zhao (2016).
Although FSs and IFSs have been extended to manage various MCGGDM problems, they failed to effectively handle a situation where the indeterminate and inconsistent information are involved. To manage such issues, Smarandache (1999) pioneered neutrosophic sets that consider the truth, indeterminacy and falsity memberships, simultaneously. Neutrosophic sets are regarded as a flexible tool in coping with information involving uncertainty, incompleteness and inconsistency (Peng and Dai, 2020). However, without specific description, neutrosophic sets are hard to be applied in actual situations. Wang et al. (2010) introduced single-valued neutrosophic sets (SVNSs), which are considered as an extension of neutrosophic sets. Moreover, various extensions of neutrosophic sets, such as interval neutrosophic sets (Liu et al., 2022; Wang et al., 2005), trapezoidal neutrosophic sets (Liang et al., 2018b; Sarma et al., 2019), type-2 neutrosophic sets (Gokasar et al., 2022), multi-valued neutrosophic sets (MVNSs) (Ji et al., 2018; Ye et al., 2022), probability MVNSs (Liu and Cheng, 2019; Peng et al., 2018), interval-valued fermatean neutrosophic sets (Broumi et al., 2022) and complex fermatean neutrosophic sets (Broumi et al., 2023) have been proposed and applied to address various neutrosophic multi-criteria decision making (MCDM) problems, such as investment decision, personnel selection, disaster management and designing a stable sustainable closed-loop supply chain network (Kalantari et al., 2022). Among various forms of neutrosophic sets, SVNSs are considered as one of the most concise tools to capture DMs’ evaluations (Peng and Dai, 2020).
Over the past years, lots of studies have been witnessed focusing on MCDM and MCGDM based on SVNSs and their extensions, which can be roughly grouped into two categories (Nguyen et al., 2019; Peng and Dai, 2020). The first category is based on various neutrosophic aggregation operators, such as single-valued neutrosophic number (SVNN) generalized power averaging operator (Liu and Liu, 2018), SVNN weighted geometric averaging (WGA) operator (Refaat and El-Henawy, 2019), and SVNN ordered weighted harmonic averaging operator (Paulraj and Tamilarasi, 2022). The second category is based on kinds of neutrosophic measures (Hezam et al., 2023; Karabasevic et al., 2020; Kumar et al., 2020; Peng and Dai, 2018; Sun et al., 2019; Tian et al., 2020; Zhang et al., 2023). For example, Hezam et al. (2023) proposed a neutrosophic discrimination measure-based COPRAS framework, and applied it to evaluate the sustainable transport investment projects. Karabasevic et al. (2020) developed an extended TOPSIS method based on the SVNN Hamming distance measure, and applied it to e-commerce development strategies selection. Sun et al. (2019) developed a new distance measure for SVNNs, based on which an extended TODIM and ELECTRE III methods were proposed and applied in physician selection.
The above-mentioned approaches are effective when copying with MC(G)DM problems with SVNNs. However, specific numerical evaluations cannot always accurately reflect DMs’ behaviour and opinions because of the limitation of their cognition. Actually, DMs usually prefer to elicit their evaluations with linguistic terms, such as “poor”, “good” and “perfect” due to the prominent advantages of linguistic terms for characterizing ambiguous and inexact assessments (Zadeh, 1975). Recently, Li Y. et al. (2017) proposed linguistic single-valued neutrosophic sets (LSVNSs) which employ a triple-tuple linguistic structure to characterize the truth, indeterminacy and falsity memberships of LSVNSs. Since LSVNSs integrate the advantages of SVNSs and linguistic term sets (LTSs), various MC(G)DM methods on the basis of linguistic single-valued neutrosophic numbers (LSVNNs) have been proposed. For example, Fang and Ye (2017) developed a linguistic neutrosophic MCGDM method based on the LSVNN weighted arithmetic averaging (WAA) and WGA operators. Garg and Nancy (2018) proposed the LSVNN prioritized WAA and WGA operator-based MCGDM method. Moreover, several comprehensive MCGDM methods that integrate with the LSVNN power WAA and WGA operators and TOPSIS (Liang et al., 2018a), and the EDAS (Li et al., 2019) were developed. These linguistic neutrosophic MCGDM methods have been applied to the university human resource management evaluation and property management company selection, respectively.
Although great efforts have been made to improve and extend the application of linguistic neutrosophic MCGDM methods, there still exist some challenges. The existing methods seem to overlook the semantics of individual DMs and the consensual solution. In the existing methods, numerical values are identified through calculating the index values of linguistic terms. In this way, the numerical values cannot indicate experts’ personalized individual semantics with respect to linguistic terms.
When tackling linguistic MCGDM problems, it is argued and accepted that words indicate different meanings for various DMs in computing with words (Mendel et al., 2010). Considering the issue of personalized individual semantics (PISs) is necessary. For example, two referees are invited to express evaluations about a manuscript. Both of them provide comments with “good”. However, linguistic term “good” may indicate different numerical semantics for them. Recently, different attempts have been made to copy with this issue, which can be roughly classified into three groups, including type-2 fuzzy set model (Mendel and Wu, 2010), multi-granular linguistic model (Morente-Molinera et al., 2015), and consistency-driven models (Li et al., 2017). Compared with the first two types of models, the consistency-driven model can effectively characterize the specific semantics of individuals, and becomes a popular tool to manage PISs in linguistic GDM. Thus, various consistency-driven models have been designed to assign personalized numerical scales (PNSs) based on linguistic preference relations (LPRs) (Zhang and Li, 2022), incomplete LPRs (Li et al., 2022a), distribution LPRs (Tang et al., 2020), and hesitant fuzzy LPRs with self-confidence (Zhang et al., 2021). In these models, DMs’ PISs can be explored according to their linguistic preferences in terms of a set of alternatives. The traditional PIS models are valid in the situations where the evaluations are expressed with LPRs or their extensions. However, they will fail to work when DMs’ evaluations are in forms of linguistic MCGDM matrices.
Recently, Li et al. (2022a) designed a data-driven learning model to investigate the PISs of DMs in MCGDM. In this model, two objectives are achieved through maximizing the minimum overall deviation among alternatives between any two consecutive categories, and minimizing the overall deviation among alternatives in a category. Inspired by the idea of Li et al. (2022b), this study aims to propose an improved framework to handle PISs and GDM, where the evaluations are presented in forms of MCGDM matrices with LSVNNs. The main novelties and contributions are summarized as follows:
A novel discrimination measure for SVNNs is proposed, based on which a discrimination-based optimization model is constructed to assign PNSs. The proposed framework is the first attempt to manage PISs in linguistic GDM, where DMs’ assessments are presented with linguistic neutrosophic MCGDM matrices.
An extended consensus-based optimization model is constructed to identify the weights of DMs considering group consensus. The proposed approach can cautiously assign DMs’ weights to guarantee a level of agreement among members regarding the final solution, and reveal the differences among alternatives with the optimal discrimination degrees.
The rest of the paper is organized as follows. Section 2 introduces some concepts about 2-tuple linguistic model and numerical scale (NS) model, neutrosophic sets and LSVNSs. Section 3 presents the concept of distance and discrimination measures for LSVNNs and develops a discrimination-based optimization model to obtain PNSs. Section 4 presents a comprehensive linguistic neutrosophic MCGDM framework considering the PIS and group consensus. Section 5 presents an illustrative example, followed by the comparative analysis to valid the proposed framework. Finally, Section 6 concludes this study.
2-Tuple Linguistic and Numerical Scale Models
(Herrera and Martínez, 2000).
Let
The inverse function of Δ,
Let
If
The inverse operator of
(Smarandache, 1999).
Let X be a space of points, where
(Wang et al., 2010; Ye, 2013).
An SVNS in A is characterized by
Linguistic Single-Valued Neutrosophic Sets
(Li Y. et al., 2017).
Let
(Fang and Ye, 2017).
Let
Let
This section presents the concepts of distance and discrimination measures of LSVNNs, based on which a programming model is constructed to derive the PNSs of each DM.
For convenience, assume that
Assume that the standardized matrices are denoted by
Let
Particularly,
Let
If
It is obvious that Properties (1) and (2) hold. Thus, the proof of Property (3) is provided.
Since
Thus, we have
In GDM, a panel of experts are invited to provide their evaluations about a set of alternatives. It is required that an expert should be qualified with the ability to differentiate between cases which are similar but not identical (Herowati et al., 2017). Motivated by the idea of maximizing deviation method (Wang, 1997), the total deviation among all alternatives is considered an effective tool to measure the discrimination of an expert (Tian et al., 2019). Let Although the discrimination measures defined in this study and Tian et al. (2019) are both used to measure experts’ discrimination degrees among alternatives, there are differences in application. The discrimination measure in Tian et al. (2019) is defined for measuring experts’ discrimination degrees among alternatives with evaluations in forms of interval type-2 fuzzy numbers. However, the discrimination measure defined in this study is suitable for experts who elicit qualitative ratings with LSVNSs. Assume that LSVNN evaluations of Example 1.
As mentioned above, an expert is expected to be skilled and have the ability to discriminate the differences between cases. When experts are required to express linguistic ratings, their PISs of linguistic terms are embedded in the evaluations, which implicitly indicate the subtle differences among alternatives distinguished by experts. Therefore, an optimization model by maximizing the discrimination degree can be considered as a good solution to derive the PISs of DMs.
By resolving Model (9), a set of possible PNSs of linguistic terms for DM Assume that Without loss of generality, ρ is set as By resolving Model (10), the PNSs of linguistic terms for DM
Results derived from without considering and considering PISs.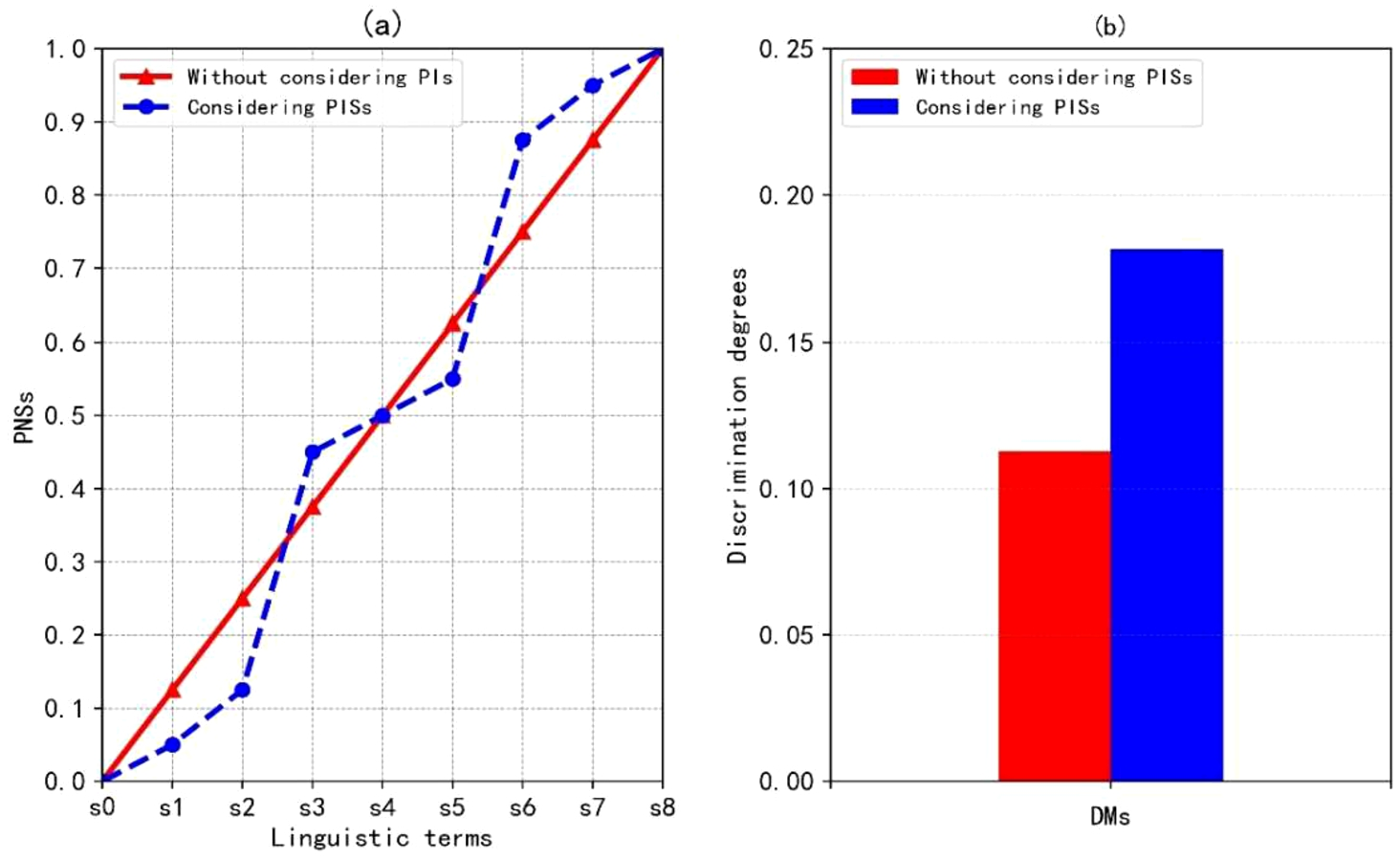
This section develops a comprehensive linguistic neutrosophic MCGDM framework that considers the PIS and group consensus.
Consensus Measure
Let
For a MCGDM problem, let
In order to merge the group consensus into the MCGDM, an optimization model is established to derive the weights of DMs by maximizing the group consensus as follows:
Set
By resolving Model (14), the weight vector of DMs Take the numerical example with LSVNN decision matrices First, the PNSs of linguistic terms for each DM can be derived based on Model (9). The obtained results are presented in Table 2. Second, the weights of each DM can be identified based on Model (14) By resolving the above model with the software MATLAB or LINGO, the weight vector of DMs is PNSs of linguistic terms for DMs in Fang and Ye (2017).
This subsection presents a framework for managing MCGDM with LSVNNs considering the PIS and consensus, which is described in Fig. 2. The detailed steps are as follows:
Each member provides evaluation information with LSVNNs and the individual decision matrices are normalized based on Eq. (6), i.e.
The PNSs
The weight vector
The overall evaluations
The ranking of alternatives can be identified based on the score values
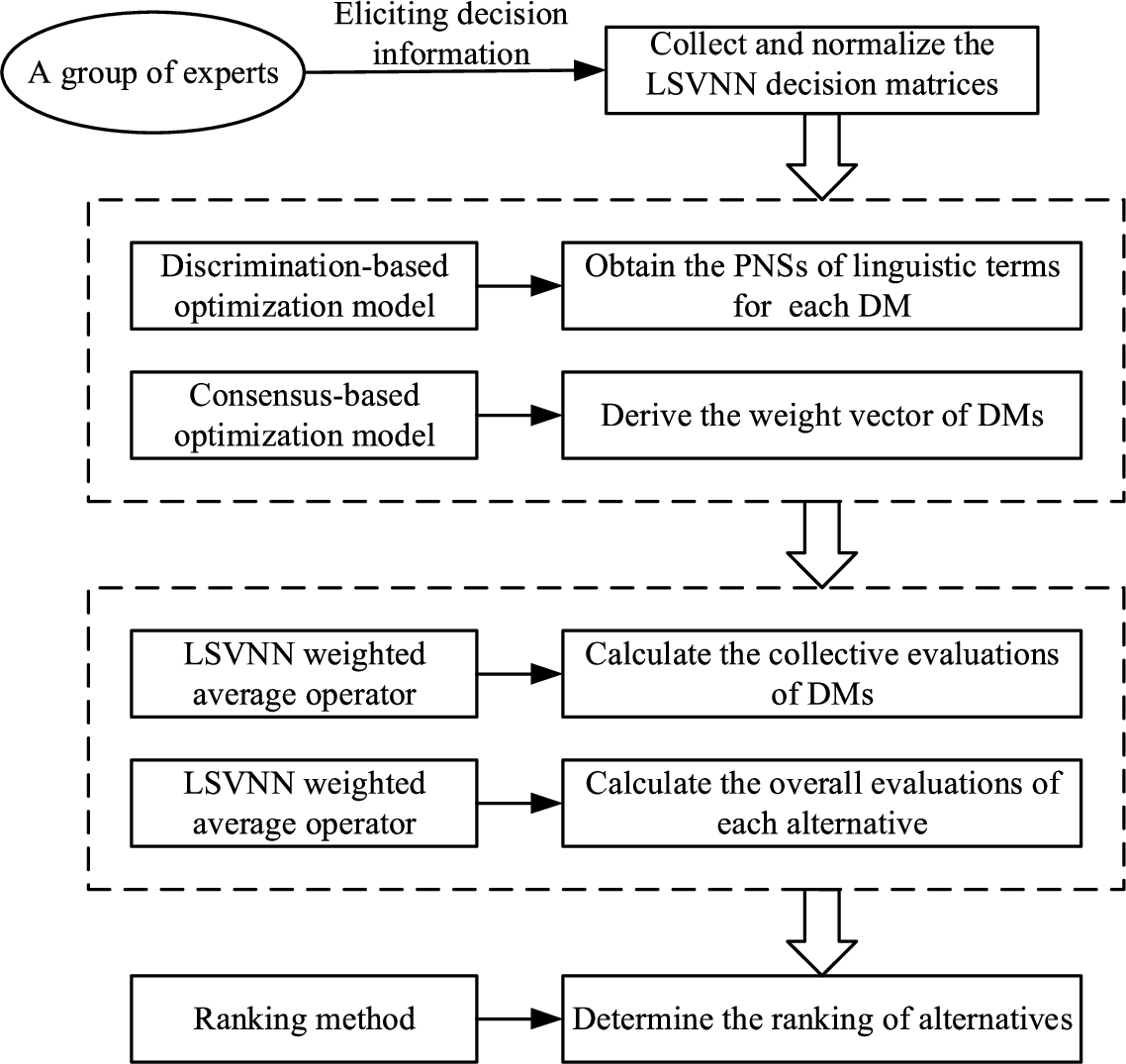
Flowchart of the proposed approach.
This section presents an illustrative example adapted from Garg and Nancy (2018) to demonstrate the application of the proposed approach.
Illustration of the Proposed MCGDM Method
A panel involving five experts are invited to express their evaluations and select the best internet service provider(s). After conducting the preliminary investigation, four internet service providers, namely, Bharti Airtel (
The proposed approach is employed to deal with the above linguistic neutrosophic MCGDM problem. Let the parameter
LSVNN evaluations given by DM
.
LSVNN evaluations given by DM
LSVNN evaluations given by DM
LSVNN evaluations given by DM
Each member provides evaluation information with LSVNNs and the individual decision matrices are normalized based on Eq. (6), as presented in Tables 3–7.
The PNSs
By resolving the above model with the software MATLAB or LINGO, the PNS
LSVNN evaluations given by DM
LSVNN evaluations given by DM
PNSs of linguistic terms.
A consensus-based optimization model can be established based on Model (14) as follows:
By resolving the above model with the software MATLAB or LINGO, the weight vector of DMs is
Overall evaluations of alternatives in terms of each criterion.
The overall evaluations
Overall values of each alternative.
The score and accuracy values
In order to investigate the influence of parameter ρ on the final result, different values of ρ are assigned, namely,
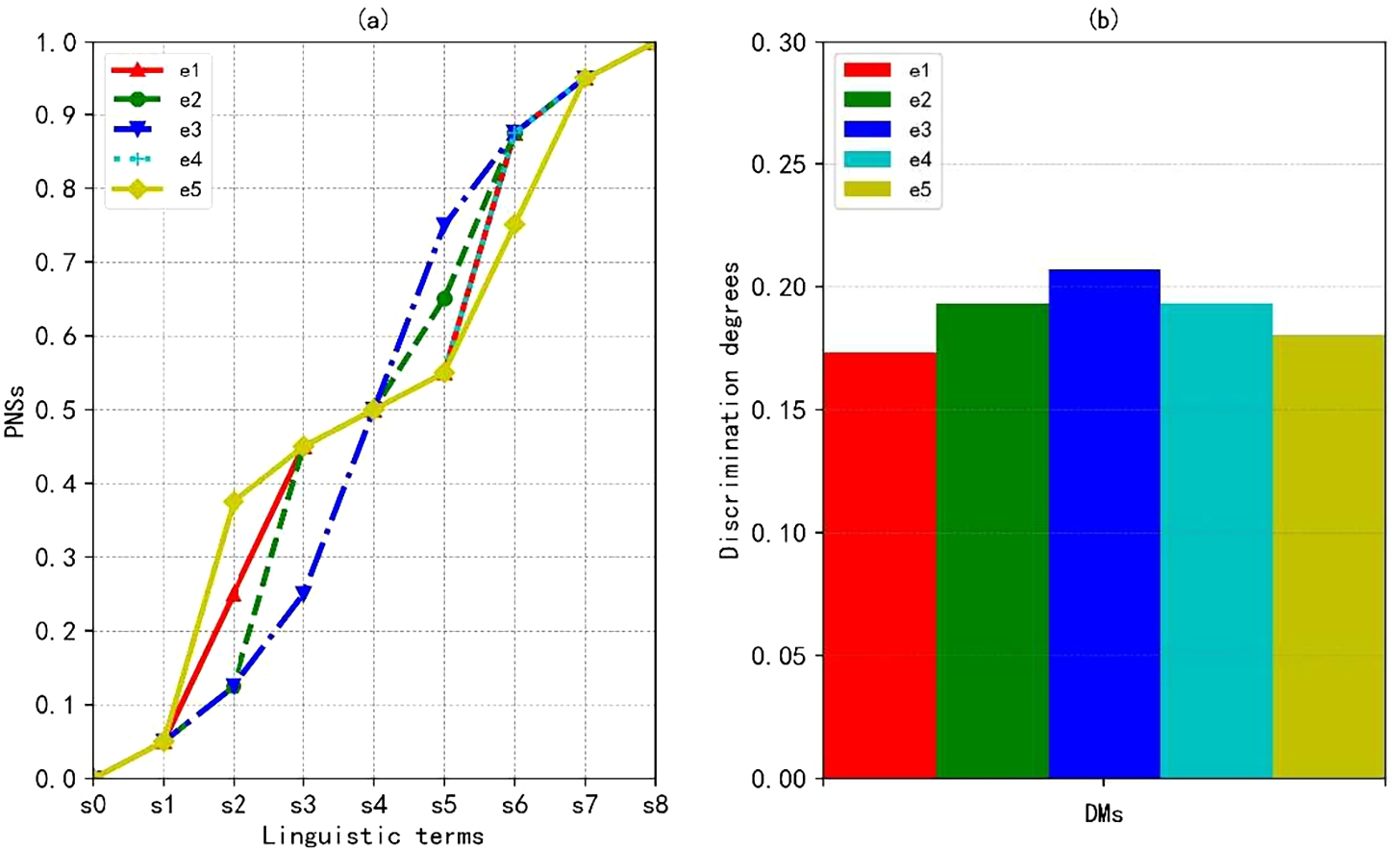
PNSs of linguistic terms and discrimination degrees with
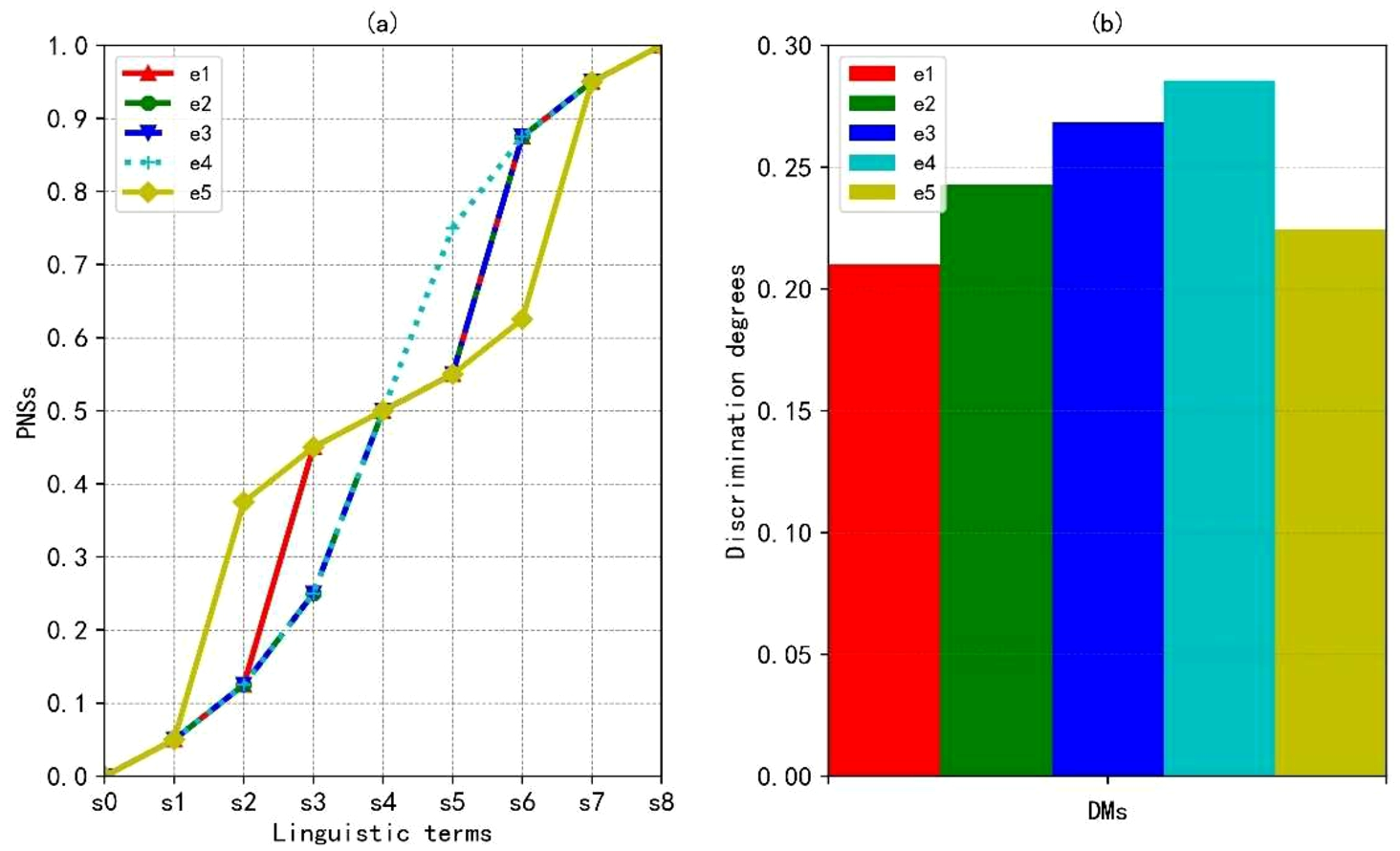
PNSs of linguistic terms and discrimination degrees with
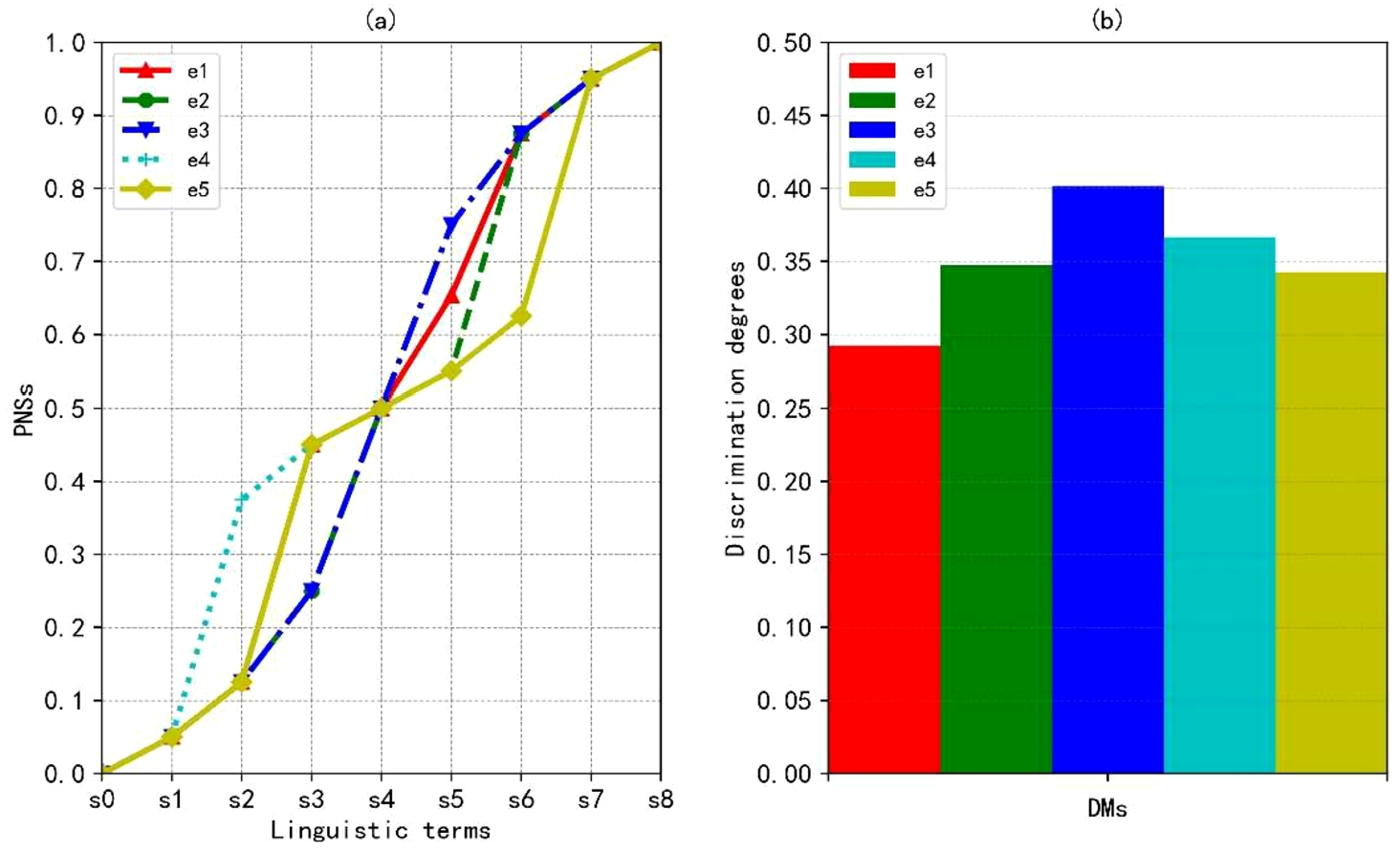
PNSs of linguistic terms and discrimination degrees with
A comparative analysis is conducted between the existing MCGDM and the proposed approaches with LSVNNs. Two common MCGDM methods are employed in this comparison, and they are the LSVNN WAA and WGA operator-based method (M1 for short) (Fang and Ye, 2017) and the LSVNN prioritized WAA and WGA operator-based method (M2 for short) (Garg and Nancy, 2018).
The proposed approach is employed to solve the MCGDM problems in Fang and Ye (2017) and Garg and Nancy (2018), where the criterion weights keep the same as M1 and M2, respectively. The ranking results obtained by different methods are presented in Table 12. The sorting results obtained from the first group of comparative analysis are consistent, all of which are
Rankings of alternatives with different values of ρ.
Rankings of alternatives with different values of ρ.
Rankings of alternatives yielded by different methods.
Comparisons between the existing and the proposed methods.
In order to highlight the characteristics of considering PISs, the discrimination degrees of decision matrices are calculated. Since the PISs of DMs are overlooked in M1 and M2, the fixed NSs for LTS S are set, namely,
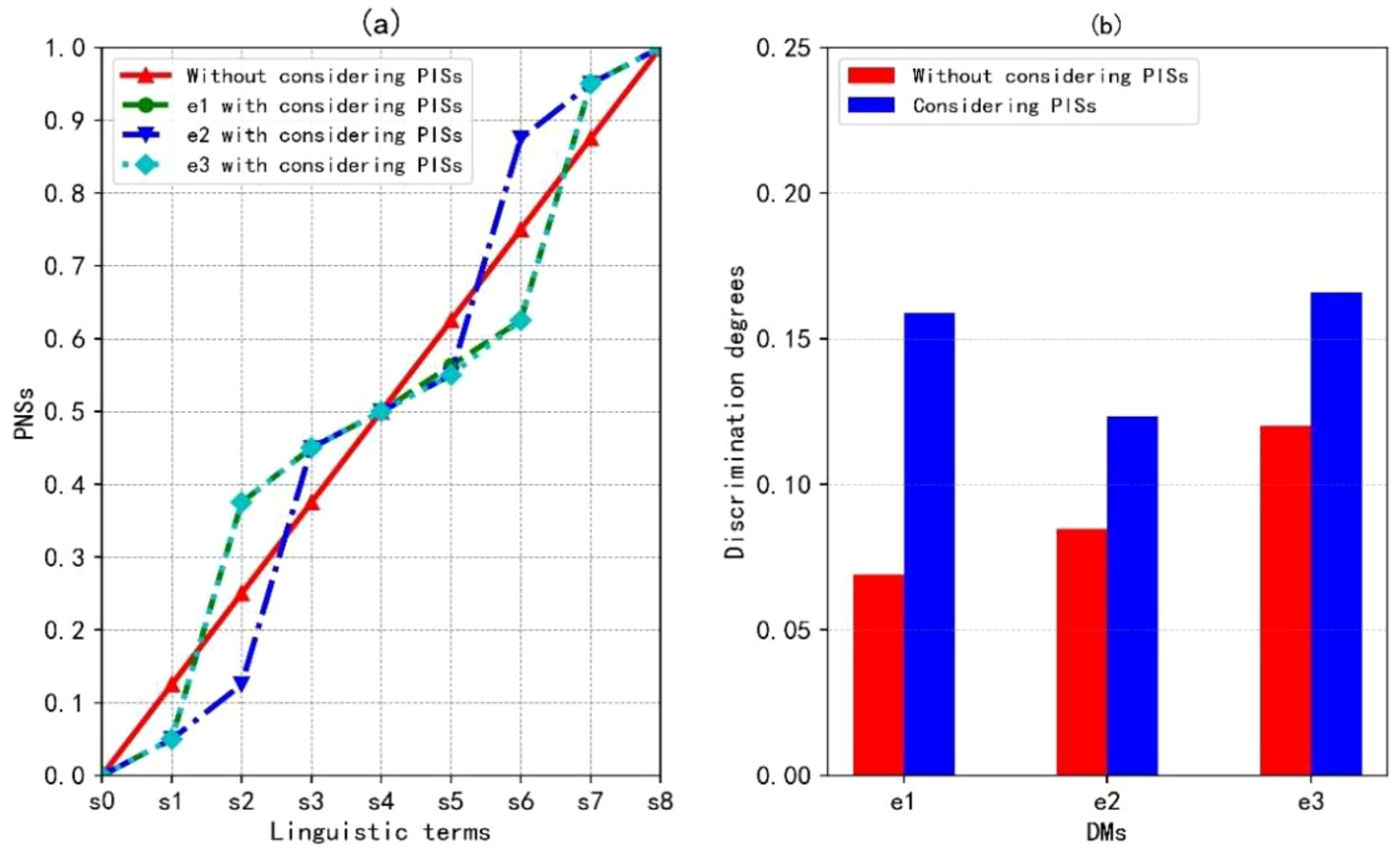
Comparisons between M1 and the proposed approach.
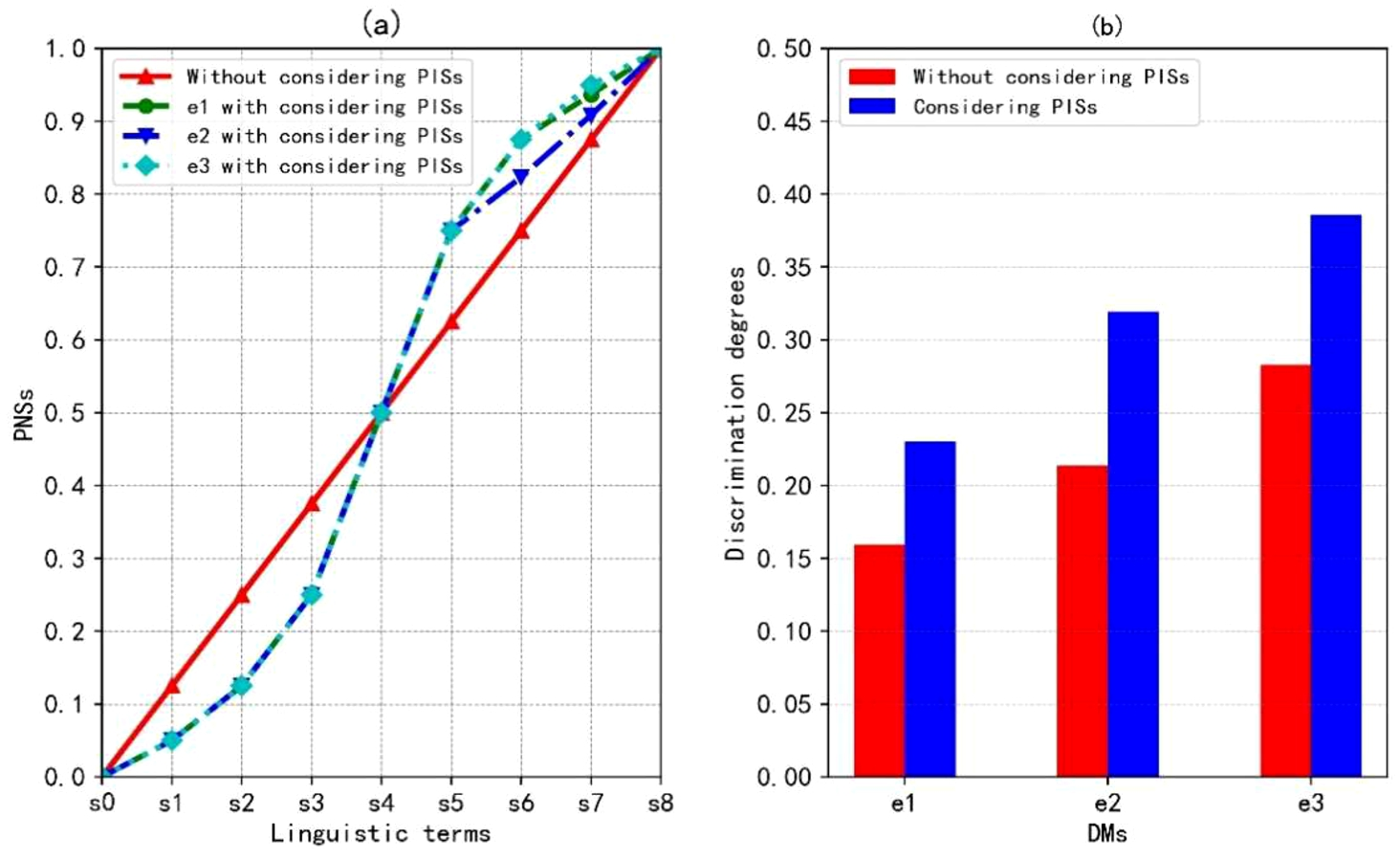
Comparisons between M2 and the proposed approach.
Furthermore, comparisons are conducted between the existing LSVNN MCGDM methods and the proposed approach. The comparison results are summarized in Table 13. The results reflect that the existing methods aggregate LSVNNs based on the indices of linguistic variables of them. In this way, various virtual linguistic terms will be output and they may fail to be mapped to any original linguistic terms, reducing the readability. By contrast, the proposed approach considers the PISs of DMs and employs an NS-based 2-tuple linguistic model to address LSVNNs. The proposed approach can effectively avoid generating virtual linguistic terms. Meanwhile, the group consensus considered in the proposed approach can yield a final solution that is highly accepted by the group. In summary, the suggested method is better compared to other approaches.
Based on the discussion in the illustrative example, sensitivity and comparative analysis, the prominent features of the developed framework are summarized as follows:
An effective solution for addressing PISs. The proposed PIS model can provide an effective solution to assign PNSs of linguistic terms for DMs, characterizing their personalized semantic preferences regarding linguistic MCGDM with LSVNNs.
A cautious method to assign the weights of DMs considering group consensus. The developed consensus-driven optimization model is utilized to identify the weights of DMs, guaranteeing a high level of agreement among members in terms of the final solution.
A robust method to determine the differences among alternatives. The proposed approach can not only consider the PISs of DMs, but also provide a robust method to reveal the differences among alternatives with the optimal discrimination degrees.
However, although the proposed approach equips outstanding characteristics in dealing with linguistic MCGDM problems with LSVNNs, DMs may have to derive the PNSs and weights of DMs by resolving some mathematic programming models. Compared to the existing methods without considering PISs, the proposed approach is intricate and time-consuming.
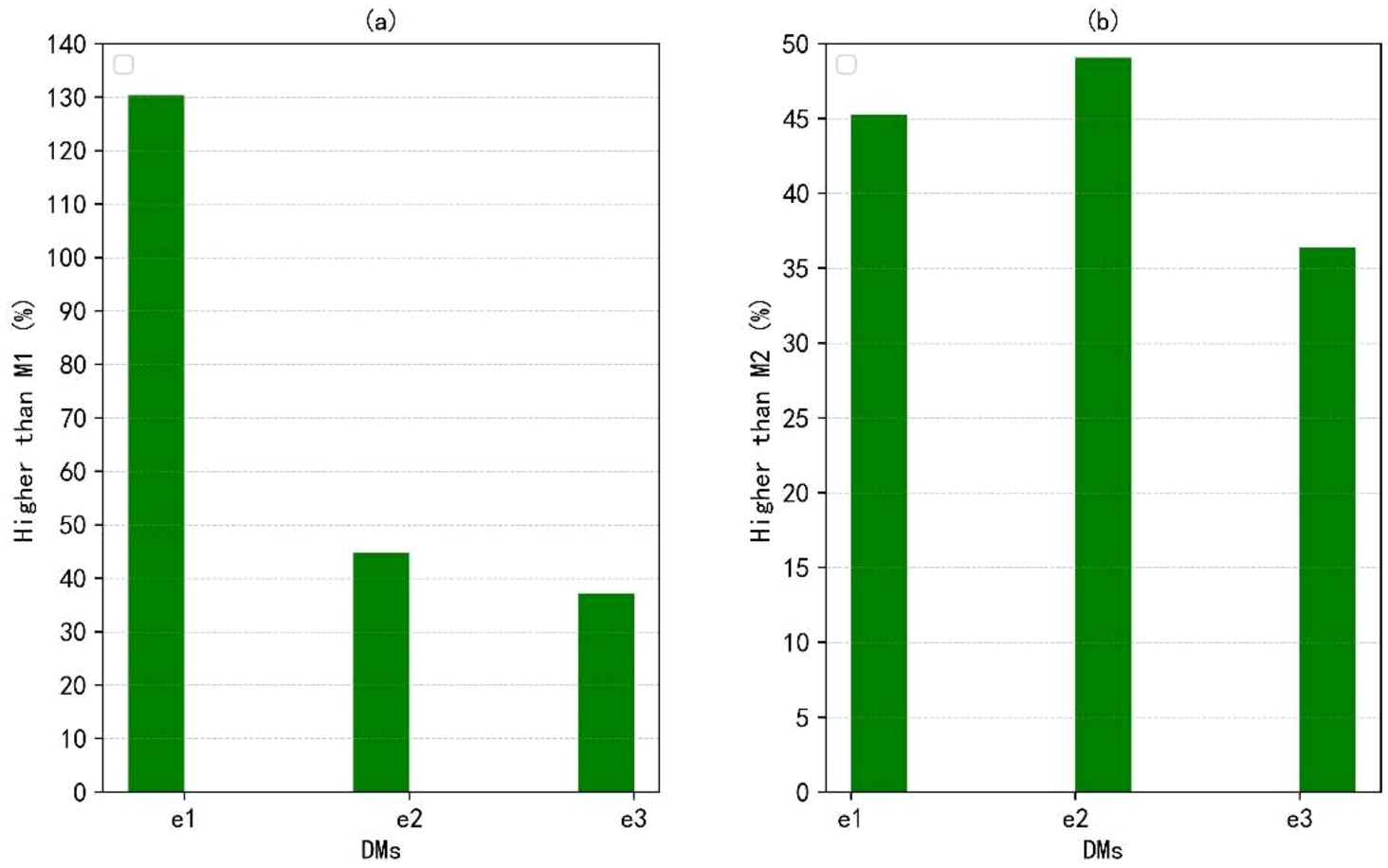
Discrimination degrees derived from considering and without considering PISs.
LSVNNs are valuable for describing qualitative ratings involving uncertain, incomplete, and inconsistent information. When eliciting linguistic evaluations, words may be assigned different meanings for various people, that is, DMs have PISs with regard to linguistic terms. Considering PISs of DMs can lead to a realistic and effective methodology for addressing linguistic neutrosophic MCGDM problems. This study firstly develops a discrimination-based optimization model to assign PNSs of linguistic terms on LTS for DMs, and effectively describe their personalized semantic preferences regarding linguistic MCGDM with LSVNNs. Then, an optimization model on the basis of group consensus is constructed to identify the weights of DMs, which guarantees a high level of agreement among members in terms of the final solution. Subsequently, an LSVNN WAA aggregation operator and PNSs-based score and accuracy functions are utilized to determine the ranking of alternatives. Finally, by comparing with existing methods, the results demonstrate that the proposed approach which developed PIS can effectively derive PNSs of linguistic terms on LTS for DMs and lead to higher discrimination degrees than those without considering PISs.
In the future study, it would be an interesting topic to investigate the PIS-based approach for addressing incomplete MCGDM problems with LSVNNs. Moreover, complex MCGDM involving large-scale members and considering their social relationships has attracted much attention (Liao et al., 2021). It would be an interesting extension of the proposed framework for tackling social network large-scale MCGDM problems.
Footnotes
Appendix
The notation used in this study is summarized in Table 14.
Acknowledgements
The authors are very grateful to the editors and the anonymous referees for their valuable comments and suggestions.