
Abstract
The focus of this paper is on the criteria weight approximation in Multiple Criteria Decision Making (MCDM). An approximate weighting method produces the weights that are surrogates for the exact values that cannot be elicited directly from the DM. In this field, a very famous model is Rank Order Centroid (ROC). The paper shows that there is a drawback to the ROC method that could be resolved. The paper gives an idea to develop a revised version of the ROC method called Improved ROC (IROC). The behaviour of the IROC method is investigated using a set of simulation experiments. The IROC method could be employed in situations of time pressure, imprecise information, etc. The paper also proposes a methodology including the application of the IROC method in a group decision making mode, to estimate the weights of the criteria in a tree-shaped structure. The proposed methodology is useful for academics/managers/decision makers who want to deal with MCDM problem. A study case is examined to show applicability of the proposed methodology in a real-world situation. This case is engine/vehicle selection problem, that is one of the fundamental challenges of road transport sector of any country.
Keywords
Introduction
This paper concerns the problem of determination of numerical weights for different criteria indicating their relative importance in Multiple Criteria Decision Making (MCDM). Different methods have been suggested in the literature and can be classified very roughly into three approaches: subjective, objective and integrated (Ahn, 2011; Hatefi, 2019). The subjective methods assign the weights to the criteria solely according to the preferential judgments by the DM, for example, Direct Rating (DR) (Doyle et al., 1997), Step-Wise Weight Assessment Ratio Analysis (SWARA) (Kersuliene et al., 2010), and belief-based Best Worst Method (BWM) (Liang et al., 2021). On the other hand, in the case of objective weighting methods, the DM may not be willing or able to give any preference information on the criteria, for instance, entropy (Hwang and Yoon, 1981), Correlation Coefficient and Standard Deviation (CCSD) (Wang and Lou, 2010), and Simultaneous Evaluation of Criteria and Alternatives (SECA) (Keshavarz Ghorabaee et al., 2018). The integrated methods determine the weights of the criteria using both subjective and objective information, for instance, Simple Product Aggregation (SPA) (Hwang and Yoon, 1981), Factor Relationship (FARE) (Ginevičius, 2011), and Block-Wise Rating the Attribute Weights (BRAW) (Hatefi, 2021).
In the current paper, we put emphasis on the Barron and Barrett (1996)’s notion who stated that various subjective methods for eliciting the exact weights from the DM may suffer on several counts, because the results are highly dependent on the elicitation method and there is no agreement as to which weighting method generates more valid weights. On the other hand, we know that in recent years, the multi-criteria group decision making situations have received extensive attention (Diao et al., 2022). In such situations, reaching a consensus regarding the weights of several criteria is difficult particularly when precise weights are required from the DMs (Sureeyatanapas et al., 2018; Danielson and Ekenberg, 2016; Ahn and Park, 2008a). Furthermore, the larger the number of criteria, the lower the accuracy of their subjective evaluation (Ginevičius, 2011). On the other hand, it is much easier for the DM to prioritize the criteria rather than to give specific numerical values (Alfares and Duffuaa, 2016). To relieve such issues, a family of the integrated methods called approximate (or surrogate) weighting methods has been developed. The methods in this family are shown by typology notation I/+SW, i.e. Integrated & Surrogate Weighting (Hatefi, 2022). The approximate weighting methods assume that the exact values of the weights are not known and only a ranking structure of the criteria (i.e. ordinal information about criteria importance) is given by the DM. An approximate weighting method begins with a simple sort where the DM arranges the criteria in the order of his/her preference. Secondly, an ordinal number called rank order is assigned to each criterion ranked, starting with the highest ranked criterion as 1. Finally, the criteria weights are estimated using a predetermined function or procedure. Clearly, the approximate weighting methods convert ranks of the criteria into quantitative weights. For the ranked criteria, the weights should be according to criteria weight space as in equation (1) in which
Definitely, in situations such as time pressure, lack of enough knowledge, imprecise or incomplete DM’s information, and DM’s limited attention, an approximate weighting method could be used as a surrogate for subjective methods. In fact, an approximate weighting method generates the weights that are substitutes for the exact values that cannot be drawn out directly from the DM. Hence, the relevant researchers seek to devise new methods that generate approximate weights as close as possible to real-world exact values, and this is why several methods are investigated and suggested. There even may be a slight significant difference between the weights generated by two methods; in this regard, Bottomley and Doyle (2001) proved that whilst several weighting methods may appear to be minor variants of one another, these nuances may have substantial consequences for inference and decision making. Such a result was confirmed by Zizovic et al. (2020). As a matter of fact, although there are several methods in the literature, but a new method may generate a more appropriate weight vector which may be slightly different than the others, and this slight difference may even change decision making results. Thus in line with the abovementioned researches, the major motivation of the current paper is to improve the ROC method, and to reinforce its theoretical foundations. In Section 2, the paper explains how the ROC method can be improved to a new version called Improved ROC (IROC). In Section 3, the procedure of a methodology to employ the IROC method is offered. In the proposed methodology, we assume a group of subject matter experts (i.e. the DMs), who are faced with the problem of weighting a variety of the criteria. To overcome multiplicity of the criteria, a Criteria Breakdown Structure (CBS) is provided. The CBS is a tree-shaped (in 1st level, 2nd level, 3rd level, etc.) description of all the criteria which should be weighted. The IROC method is used in weight assignment of each level of the CBS. In Section 4, the paper applies the proposed methodology in a real-life study case taken from transportation industry. Finally, some conclusions are provided in Section 5.
The Proposed Idea
Definitely, each feasible point in the weight space is a solution to assign the weights to the ranked criteria. Among these solutions, the defining vertices of the convex polyhedral of the weight space can be considered as Vertex Methods (VM) which are
Two approaches can be used to obtain the coefficients
In order to estimate the coefficients, a set of systematic simulation experiments was performed, with regard to MADM problem. MADM problem refers to selecting the most appropriate candidate among m predetermined alternatives or prioritizing them in the presence of usually conflicting n criteria (Hwang and Yoon, 1981; Hatefi, 2021). Generally, a MADM problem is shown by matrix
The systematic simulation study was firstly proposed by Barron and Barrett (1996), and is a broadly accepted framework to address the performance of any approximate weighting method. Many investigations have employed such a simulation study, such as Hatefi (2019), Ahn (2017), and Ahn and Park (2008a). According to the basic notion of this approach, there exists a set of true weights as the reference weights in the DM’s mind which are not accessible in its pure form by any elicitation method. The decision made by the true weights is called true decision. The idea is to generate the weights by the method to be examined (herein the IROC method) as well as the true weights from an underlying random distribution and address how well the decision made by the method match the true decision in terms of a given efficacy measure. To this end, Hit Ratio (HR) and Rank order Correlation (RC) have been widely used as efficacy measures. The HR evaluates how frequently a method selects the same best alternative as the true weights. Equation (5) presents the HR function for a given method in which π is the total number of simulation runs, and γ is the number of simulation runs in which the method selects the same best alternative as the true weights do. The HR ranges from 0 to 1, in the way that 1 means the best alternative of the two rank orders are the same, throughout whole simulation runs. The RC indicates the similarity of the overall rank structures of the alternatives made by the true weights and by the method. This measure is calculated by Kendall’s formula as equation (6) (Winkler and Hays, 1985). In this function, m is the number of alternatives, and θ is the number of pairwise preference violations between the rank structures of the alternatives by the method and by the true weights. Obviously, the values range from −1 to 1 for the RC, the value 1 stands for perfect correspondence between the two rank orders.
The simulation was designed with four levels of the alternatives (
The simulation experiment was conducted with the use of a Visual Basic for application in the Excel programming language on a personal computer. The simulation runs (i.e. 15000 times) were made in five rounds. Finally, the averages HR and RC of 5 rounds were considered. Calculation of the Pearson’s correlation coefficients between the HR and RC data for 96 combinations showed that the performance values for the two efficacy measures HR and RC were highly correlated, with overall average of 0.9815. Hence, we employ only the HR to derive the coefficients. We chose the HR because it is easier to understand and simpler to handle.
To calculate the coefficients of the VMs, this procedure was done: First, for each combination of the number of alternatives and the number of criteria, the HR values are normalized to add up to 1. As an instance, in combination with
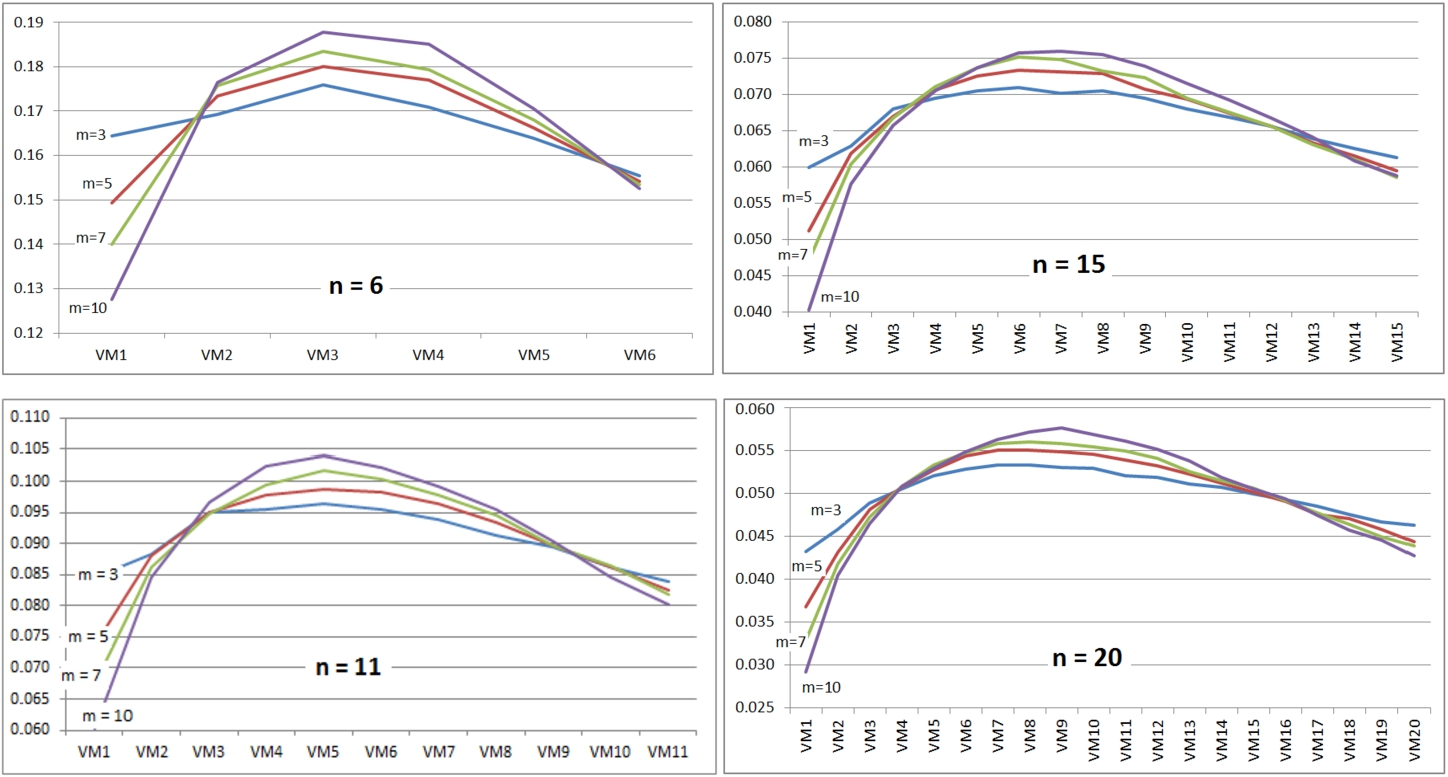
Typical trends of the normalized HR at various VMs.
Correspondingly, geometric mean was then used over the combinations with identical number of the criteria. By way of example, in combinations
The default coefficients for the VMs in the weight space.
The coefficients in the IROC function have been portrayed in Fig. 2. As a major consequence from this figure, we can conclude that the curves are not uniform. Moreover, each set of the coefficients tends to follow a concave shape with the maximum at point
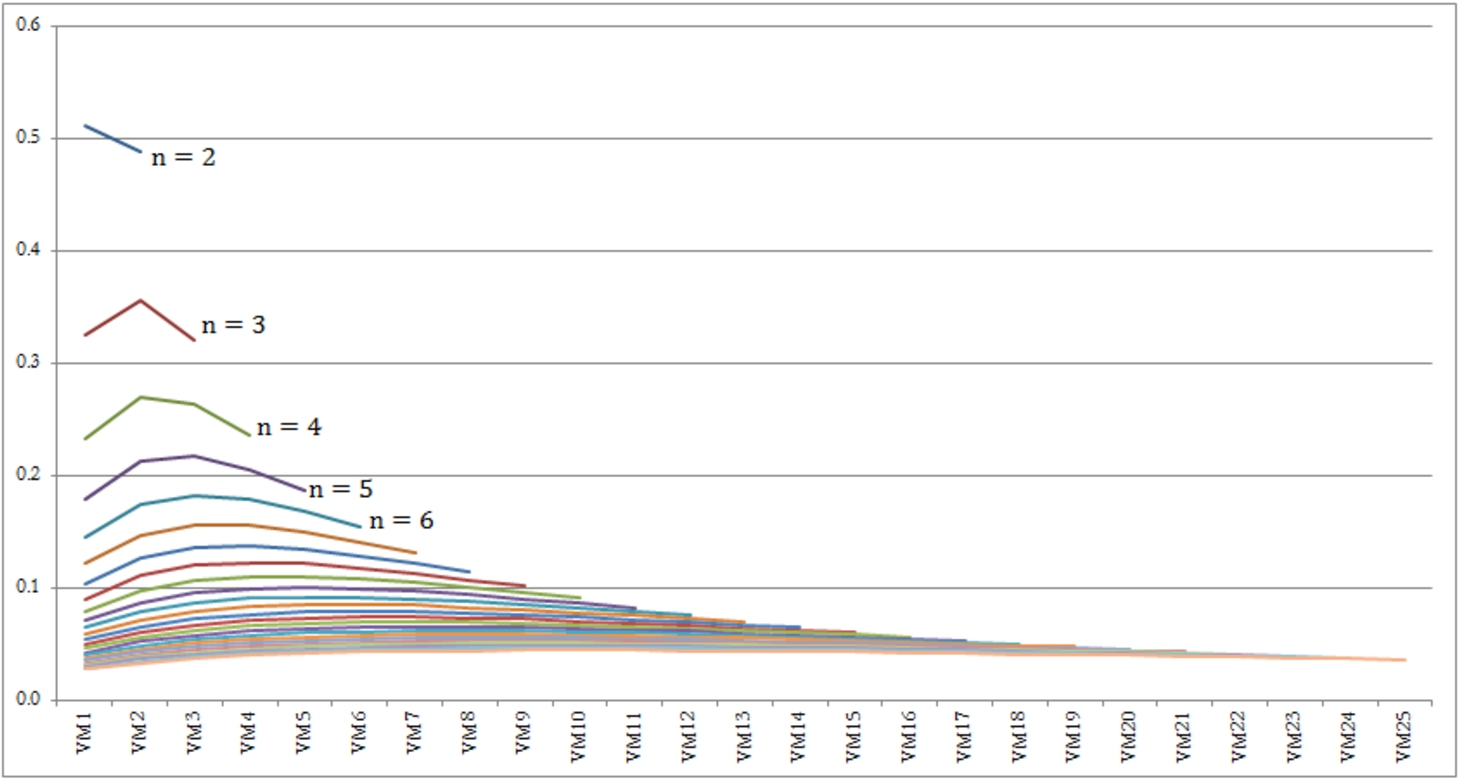
Variations of the IROC coefficients for different number of the criteria.
In this section, we report a set of simulation experiments that was conducted with the purpose of comparing the behaviour of the ROC method versus the IROC method. All the characteristics of this simulation scheme were like the previous simulation experiments (described in Section 2.2), unless: (I) the two methods ROC and IROC were considered to be tested simultaneously, and (II) four levels of the alternatives (
Table 2 depicts the efficacy measures data obtained from the experiments. To sum up, throughout the simulation results, we can conclude that the IROC method appears to be a better performer than the ROC method as expected. In respect to the HR, the data indicates that the IROC method outperforms the ROC method over 17 out of 20 (= 85%) cases. Among these 17 cases, in 14 cases the numerical data for the IROC method and ROC method differ only in the third decimal place, and in 3 cases (
Simulation results of the average HR and RC measures for the ROC and IROC methods.
Simulation results of the average HR and RC measures for the ROC and IROC methods.
Even though Table 2 obviously shows the superiority of the IROC method over the ROC method; two tests as equation (8) and equation (9) are built, the former to compare the ROC HR population mean and the IROC HR population mean, and the latter o compare the ROC RC population mean and the IROC RC population mean.
Table 2 shows that the data as for the ROC HR/RC minus the IROC HR/RC are paired. In fact, there are two samples in which each observation in one sample is paired with one observation in another sample. Hence, firstly, we employ the Shapiro–Wilk tests (Shapiro and Wilk, 1965), as seen in equation (10) and equation (11), to survey whether the HR/RC differences are normally distributed.
In equation (10), the test statistic equals 0.9563, and the Shapiro–Wilk critical value using 99% confidence is 0.868. Because
Both the HR differences and the RC differences are normally distributed. Thus, the one-way paired t-student test is applied for the tests in equation (8) and equation (9). For equation (8), the t-student test statistic is calculated as −4.0986, and the critical range at 99% confidence level is
The ROC and IROC weights for
The weights produced by the ROC and IROC methods for
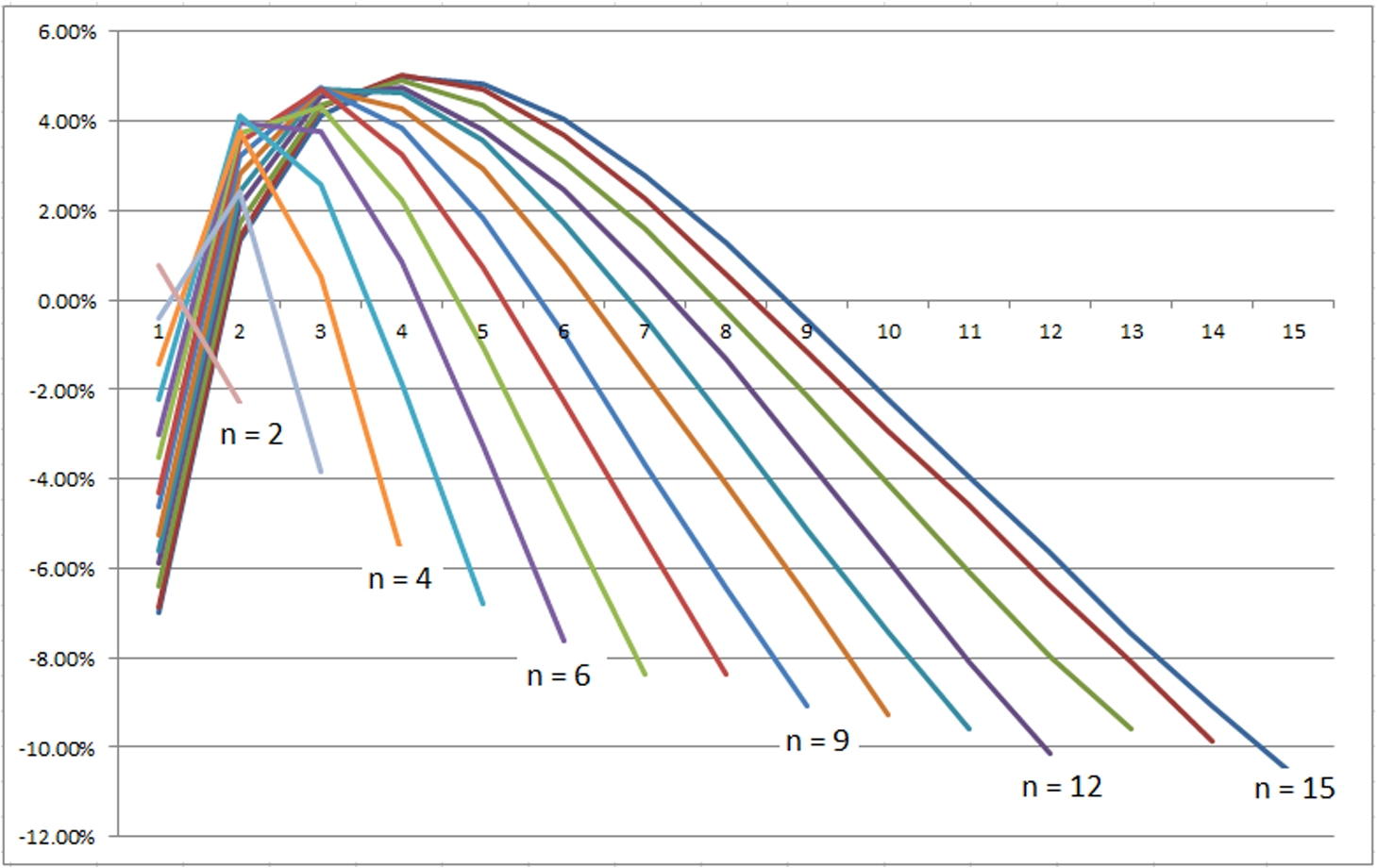
Variation of the difference percentage between the ROC weights and the IROC weights.
The procedure of the proposed methodology is briefly shown as follows:
Step (A): Determine a panel of the related subject matter experts, who adequately realize the problem, and their knowledge/skills are sufficient to make proper judgments. The expert number is denoted by E (
Step (B): Draw up a Criteria Breakdown Structure (CBS). This structure is made using a Delphi method or superior documents/approvals. Figure 4 represents a schematic CBS diagram. Assume that there are P parent boxes (
Step (C): Consider the 1st box of the CBS (i.e.
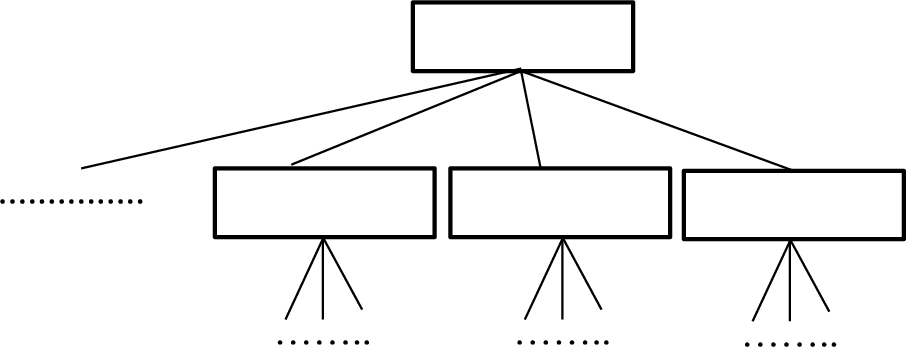
A schematic CBS.
Step (D): Assume that n criteria
Step (E): Measure the degree of consensus among the panelists using Kendall’s coefficient of concordance (Kendall and Gibbons, 1990). The Kendall’s coefficient ranges from 0 (no agreement) to 1 (complete agreement). To calculate the coefficient, a total rank for each criterion is firstly computed by equation (12). After that, the mean value of the total ranks is computed by equation (13). Finally, the Kendall’s coefficient is defined as equation (14), where the sum of squared deviations is the numerator in equation (14).
Table 4 shows a guideline to interpret the Kendall’s coefficient.
Step (F): If T indicates a strong or higher consensus in the ranks, go to the next step, otherwise it is necessary to revise the individual ranks by the experts in another meeting, to emerge a higher consensus. This action is repeated until a strong or higher consensus is built.
Interpretation of the Kendall‘s coefficient.
Step (G): Extract the concordant ranks from the total ranks computed by equation (12). The bigger value of the total rank indicates the lower concordant rank of a criterion.
Step (H): Use the IROC method to estimate the criteria weights.
Step (I): If
Step (J): Use simple product formula (SPA) to determine the final weight of each criterion at the lowest level of the CBS. In point of fact, the final weight of a criterion is simply obtained by multiplying its weight by its sequential parent’s weights in the CBS.
A Brief Introduction
Public transport development often requires participatory decision making procedures (Duleba et al., 2021). One of the major decision making context is energy management. Energy is the fundamental and essential core of the public transport in countries. Experts have estimated that the global need for energy may rise by more than 50% up to 2030 (Singh et al., 2018). The Energy Information Administration (EIA) outlook report 2020 shows that the public transport accounts for about 25% of all energy consumption in the world. Today, countries are faced with several technologies for their public transport vehicles. These technologies, among others, are (Sperling, 1995; Morita, 2003; Tzeng et al., 2005; Patil et al., 2010; Mousaei and Hatefi, 2015; Erdogan et al., 2019; Rani and Mishra, 2020; Andersson et al., 2020; Cui et al., 2022; Abbasi and Hadji-Hosseinlou, 2022):
Diesel engines/vehicles such as conventional diesel, ultra-low-sulfur diesel, bio-diesel (e.g. vegetable oil biodiesel, and animal fat biodiesel).
Gas engines/vehicles such as Compressed Natural Gas (CNG), Liquefied Propane Gas (LPG), Liquefied Natural Gas (LNG), Dimethyl Ether (DME), Gas-To-Liquid (GTL), and hydrogen fuel cell.
Blend engines/vehicles such as methanol & gasoline blend, hydrogen & CNG blend or hythane, and bio-CNG blend.
Electric engines/vehicles such as opportunity charging, direct electric charging, and exchangeable-battery electric.
Hybrid engines/vehicles such as electric & gasoline hybrid, electric & diesel hybrid, electric & CNG hybrid, and electric & LPG hybrid.
From the above list, some kind, e.g., conventional diesel engine/vehicle, are based on burning fossil fuels (Bhan et al., 2022), which generates carbon dioxide and other air pollutants such as unburned hydrocarbons and oxides of nitrogen, resulting in global warming and climate unwelcome changes. On the contrary, the modern technologies, e.g., exchangeable-battery electric engine/vehicle, have cleaner engines, which do not use fossil resources. Governments always need to choose the proper engine/vehicle technology to invest in and to develop in their public transport network. This challenge is often modelled as a MADM problem. In this regard, governments often have to respond the two following preliminary important questions:
Which criteria have to be involved in the engine/vehicle selection problem?
How much is the weight factor of each criterion?
The proposed methodology (explained in Section 3) is employed to answer the above questions. There are a number of researches related to the current case, most of them have determined list of the related criteria. Let’s review some samples. Poh and Ang (1999) used Analytic Hierarchy Process (AHP) in order to evaluate the transportation fuels in Singapore. Winebrake and Creswick (2003) employed the AHP method to analyse the outlook of hydrogen-based engines for transportation systems. Tzeng et al. (2005) is a seminal work in the field of the current study case. They used Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) for the sake of determining the best alternative fuel buses compatible with urban area circumstances. Patil et al. (2010) developed a framework to model the interactions between different aspects of a transportation system, and showed up the strategies which affect decision making about engines/fuels with regard to public transport. For fuel selection in public transport, a fuzzy decision making framework was developed by Vahdani et al. (2011). Scott et al. (2012) carried out a review of those academic investigations attempting to deal with issues arising within the bioenergy, using MCDM techniques. Asilata and Keswani (2015) addressed a systematic analysis for selection of fuel by using the AHP method. Shah et al. (2017) presented an overview of available liquid and gaseous fuel, commonly used as transportation fuel in Bangladesh, and illustrated the potential of bio-CNG conversion from biogas. Oztaysi et al. (2017) concentrated on the alternative fuel selection problem of a company in the USA. They developed a multi-expert MCDM technique using Interval-Valued Intuitionistic Fuzzy Sets (IVIFS) with linguistic data. Erdogan and Sayin (2018) performed a study to choose the best fuel for the compression ignition engine. They employed the SWARA method to determine the criteria weights, and used Multi-Objective Optimization on the basis of Ratio Analysis (MULTIMOORA) to rank the selected fuels. Erdogan et al. (2019) used hybrid models SWARA-MOORA and ANP-MOORA to select the optimum fuel for the compression ignition engine/vehicle. Karasan and Kahraman (2020) made use of Interval-Valued Neutrosophic (IVN) ELECTRE I method to select renewable energy alternative for a municipality. Rani and Mishra (2020) proposed a novel decision making model based on the operators of q-Rung Ortho-Pair Fuzzy Sets (q-ROFSs), weighted aggregated sum product model, score function and similarity measure to deal with the alternative-fuel technology selection problem, wherein the decision experts and the criteria weights were completely unknown. Andersson et al. (2020) evaluated which criteria have an influence on the fuel choice between ethanol and gasoline for owners of Flex-Fuel Vehicles (FFVs) in Sweden. Major results showed that price, perceptions about quality, age and environmental attitudes influence the willingness to choose ethanol.
This section reports findings of the criteria identification in the engine/vehicle selection problem. A complete criteria list is founded based upon both the published literature and the expert’s judgments. We did the best to extract all the criteria reported in the relevant literature, among others, Poh and Ang (1999), Winebrake and Creswick (2003), Tzeng et al. (2005), Patil et al. (2010), Vahdani et al. (2011), Scott et al. (2012), Farkas (2014), Mousaei and Hatefi (2015), Asilata and Keswani (2015), Shah et al. (2017), Oztaysi et al. (2017), Hatefi (2018), Erdogan and Sayin (2018), Erdogan et al. (2019), Karasan and Kahraman (2020), and Rani and Mishra (2020). After that, a Delphi evaluation, using 9 related participants who were experts in the field of various engines/vehicles, was preformed to reach consensus on the criteria. In each round of the process, the respondents had to answer the questions to refine the criteria, i.e. to screen, to add, to combine, or to decompose them. We made use of the advantage of being performed by email in the Delphi process. The type of attendance meeting was not selected for the reason of Covid-19 conditions. In Table 5, let’s review the final list of the criteria obtained from the above-mentioned process. This list includes main criteria (1st level) and sub-criteria (2nd level).
The engine/vehicle selection criteria.
The engine/vehicle selection criteria.
A sample country is considered to be analysed using the proposed methodology. Regarding all the criteria displayed in Table 5, a decision making group including 9 experts
1st level criteria ranked by 9 experts.
1st level criteria ranked by 9 experts.
The criteria weights in the study case.
This paper focused on weighting the criteria in MCDM problem. To assign the weights to the criteria, the paper concentrated on the approximate weighting approach, in which the criteria weights are estimated based on the ranks of the criteria given by the DM. The reason for this selection is this fact that in complex MCDM models, most subjective methods for eliciting the exact weights often may cause that the DMs cannot give reliable information. Although there are various approximate weighting methods in the literature, it was shown that the ROC method is still known as the best method compared with the existent methods. Notwithstanding, the paper depicted the theoretical means of the ROC method is under an unrealistic assumption, i.e. the corner weight vectors of the weight space are equal in the DM’s preference. In order to resolve this drawback, as the major contribution of the paper, a different coefficient for each corner was obtained. Next, the ROC function was reformulated to involve the new coefficients. This new function was named the IROC method. Two series of simulation experiments were performed in this study. The first set of experiments was conducted to adjust the IROC parameters. By means of the second set of simulations, the improvement of the IROC decision quality than that of the ROC method was proved.
A group decision making methodology was suggested to estimate the criteria weights in a breakdown structure of the criteria called CBS. This methodology benefits from the IROC method. Under a real-life study case about the engine/vehicle selection problem, the paper reviewed the respected literature to extract the criteria, and conducted a Delphi analysis to finalize the criteria register including 8 criteria at the first level and 27 criteria at the second level. Later, the proposed methodology was used to estimate the criteria weights in each level.
The current paper tried to establish default values for the IROC coefficients. A future research may focus on the extraction of these coefficients from the DM’s preferences. Except for this future research direction, it is also interesting to investigate establishment of a reliable model to analytically/theoretically compare different weight approximation methods. Such a model has not been studied so far.
At the end, we hope that employing the proposed methodology helps the relevant country’s DMs to take proper policies/decisions in a productive manner.