
Abstract
The data-driven approach is popular to automate learning of fuzzy rules and tuning membership function parameters in fuzzy inference systems (FIS) development. However, researchers highlight different challenges and issues of this FIS development because of its complexity. This paper evaluates the current state of the art of FIS development complexity issues in Computer Science, Software Engineering and Information Systems, specifically: 1) What complexity issues exist in the context of developing FIS? 2) Is it possible to systematize existing solutions of identified complexity issues? We have conducted a hybrid systematic literature review combined with a systematic mapping study that includes keyword map to address these questions. This review has identified the main FIS development complexity issues that practitioners should consider when developing FIS. The paper also proposes a framework of complexity issues and their possible solutions in FIS development.
Keywords
Introduction
Fuzzy sets have been used greatly in different scientific areas. In their study, authors of Kahraman et al. (2016) found many application areas in theoretical and practical studies, like engineering, arts, humanities, computer sciences, health science, life sciences, physical sciences, etc. They present a comprehensive literature review on the fuzzy set theory realization covering 50 years since Zadeh had proposed it in 1965. The authors have not analysed any complexity issues of the fuzzy set theory application and realization. However, the authors have highlighted the need for a standard notation of the fuzzy set theory. Various authors frequently encounter different notations for the same concepts of the theory in their publications. A standard notation will improve the theory’s value and will be a significant step to provide the condition that has already been implemented in the classical logic. Another problem defined by the authors of Kahraman et al. (2016) is the segregation between classical logic publications and fuzzy logic publications. Moreover, there can be found too many different fuzzy models and approaches in the literature without sufficient discussions about their correctness or deficiencies that may create a doubtful point of view to the theory (Kahraman et al., 2016). One of the main reasons for these problems is the complexity of the fuzzy set theory and its application in different areas. Therefore, there is a need for a more comprehensive study of the fuzzy inference systems development complexity issues and their systematization in this context.
We can find plenty of approaches to develop FIS in the literature automatically (Ruiz-Garcia et al., 2019; Lee, 2019; Mirko et al., 2019; Askari, 2017). Authors of these approaches point out various limitations, issues, or drawbacks of developing FIS because of its complexity, like the sparse rule base (RB) (Antonelli et al., 2010), high dimensional data (Alcalá et al., 2009b), a vast number of linguistic terms (Askari, 2017; Ephzibah, 2011), etc. All those complexity issues complicate the automatic development of FIS and need to be solved. However, in the fuzzy set theory application field, they are not investigated sufficiently in a systematic and comprehensive way. Authors of the analysed papers have focused on solving a particular task, like reducing computational complexity through decreasing the number of fuzzy rules (Ruiz-Garcia et al., 2019; Zhu et al., 2017; Harandi and Derhami, 2016; Bouchachia and Vanaret, 2014) or reducing MFs (Fan et al., 2019; Ibarra et al., 2015), etc. This lack of understanding of a general situation hampers progress in the analysed field since academics offer limited approaches (Ivarsson and Gorschek, 2011).
Consequently, the following research questions arise: 1) “What complexity issues exist in the context of developing fuzzy inference systems (FIS)?” (RQ1) and 2) “Is it possible to systematize existing solutions of identified complexity issues?” (RQ2). In order to answer the defined research questions, this paper presents a synergy of two well-known research methods – a systematic literature review (SLR) and a systematic mapping survey (SMS). SLR is used to perform in-depth analysis and obtain answers for the defined research questions (Kitchenham et al., 2009; Mallett et al., 2012), and SMS with a keyword map – for providing more general research trends and detecting topics that exist within the analysed field (Petersen et al., 2015; Kitchenham et al., 2011; Ramaki et al., 2018). Moreover, a keyword map allows us to visualize (Linnenluecke et al., 2019) and better understand each concept’s real meaning in FIS development, systematize existing solutions of identified complexity issues, and develop the framework of complexity issues and their possible solutions in FIS development.
This research increases the body of knowledge on FIS development theory by providing a systematic view of complexity issues and their existing solutions. New trends in developing FIS are uncovered as well. Additionally, the results of this research can help researchers and practitioners become familiar with found FIS complexity issues and their possible solutions. Our main scientific contribution and advantages of this paper are as follows:
The complexity issues in FIS development are found and systematized.
The solutions for the found complexity issues in FIS development are discovered.
The framework of FIS development complexity issues and their solutions is proposed.
The hybrid SLR and SMS approach with a keyword map is employed to answer the research questions at various depths.
The novelty of this research is the systematic view of the found complexity issues in FIS development, the proposed framework of FIS development complexity issues and their solutions. The rest of this paper is structured as follows. Section 2 introduces the main concepts and explains their use in the paper. Section 3 presents related works. Section 4 presents the review method. Section 5 shows the obtained results of hybrid systematic review approach on complexity issues. Section 6 provides the developed framework of FIS development complexity issues and their possible solutions. At last, the discussion is drawn in Section 7, and conclusions in Section 8.
Here, the concept of complex is relevant to the context of software systems. Odell (2002) defines a system as complex, if it cannot be fully understood by analysing its components, i.e. the interaction among the components must also be considered. As Battram (1998) defines: “Complexity refers to the condition of the universe which is integrated and yet too rich and varied for us to understand in simple common … ways. We can understand many parts of the universe in these ways, but the larger more intricately related phenomena can only be understood by principles and patterns—not in detail.” According to Corning (1998), Benigni et al. (2012), a system is complex, if it exhibits the following properties: 1) it is composed of many interconnected parts; 2) the parts are highly interdependent; and 3) their behaviour produces synergies (combined effects) that are not easy to predict from the behaviour of the individual parts by analysing them in isolation. Here, we understand a system to be complex if it consists of a number of components interacting with each other in different ways that allow new properties to emerge (Waldrop, 1993).
Further, we analyse the complexity of a fuzzy inference system (FIS) that uses fuzzy set theory to map inputs to outputs and consists of the following main components (Askari, 2017; Mamdani, 1974; Takagi and Sugeno, 1985; Miliauskaitė and Kalibatiene, 2020a) (see Fig. 1). Fuzzification is converting the data input into fuzzy linguistic variables by applying a particular fuzzification method. This method presents a way of determining the degree to which input variables belong to each of the appropriate fuzzy sets via the membership functions (MFs). Fuzzy Inference involves applying a set of (fuzzy) rules from a Knowledge base to fuzzy inputs in order to generate a set of fuzzy outputs. Defuzzification translates the obtained fuzzy output for the final user into an understandable crisp output, using a particular defuzzification method.
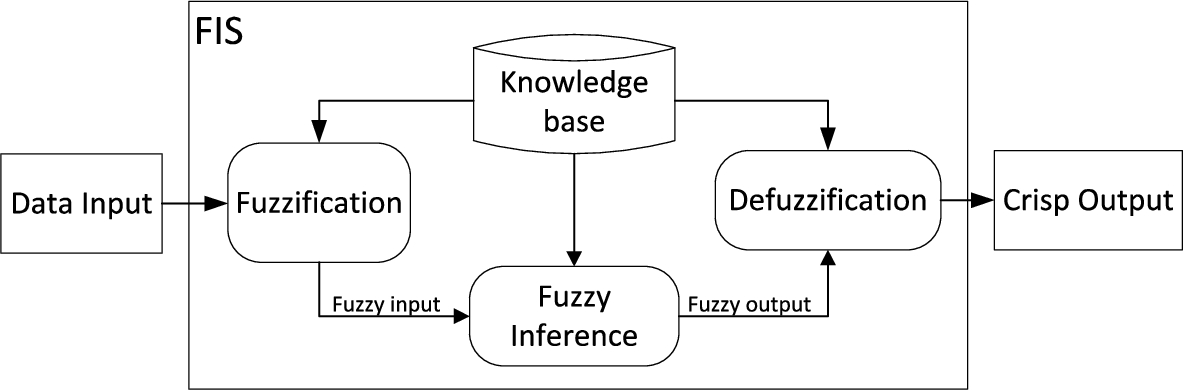
The reference schema of FIS.
In a data-driven FIS, the underlying MFs and fuzzy rules are generated automatically from synthetic or real data streams but not defined by an expert manually (Miliauskaitė and Kalibatienė, 2020b) (Fig. 1).
Authors of Antonelli et al. (2011) understand complexity as interpretability of rule base (RB), and interpretability of fuzzy partitions as integrity of the database. Data complexity is measured in terms of the average number of patterns per variable (i.e. data density) for pattern recognition (Ephzibah, 2011). FIS suffers from exponential complexity, manifested through some linguistic terms (number of subspaces on the universe of discourse of input variables) and some input variables (Askari, 2017). Complexity is also measured by counting the number of operations (Ephzibah, 2011) or the number of RB elements, including the number of MFs, rules, premises, linguistic terms, etc. (Askari, 2017). Selecting a small number of right linguistic terms is essential for better interpretability. The total number of parameters of the fuzzy RB is also a measure of interpretability. A system with a smaller number of parameters is more interpretable and less complex (Ishibuchi and Nojima, 2009). In Askari (2017), Kaynak et al. (2002), authors suggest reducing the exponential complexity of FIS by reducing the number of fuzzy (linguistic) terms or the number of fuzzy (linguistic) variables or both. The model interpretability is measured in terms of complexity (Antonelli et al., 2016): “Complexity is affected by the number of features used for generating the model: the lower the number of features, the lower the complexity”. RB complexity is measured as the total number of conditions in the rules’ antecedents (Alcalá et al., 2009b).
The most related reviews to the present review are summarized in Table 1. The authors of Liu et al. (2017) have suggested developing hierarchical structure-based vague reasoning algorithms to handle complex systems and to reduce its complexity through decomposition and reuse of the whole system. Other findings in Liu et al. (2017) are related to the need of the adoption of existing knowledge inference systems for big data and real-time applications, increasing the accuracy of models while reducing reasoning efficiency and computational cost. Authors of D’Urso (2017) have stated that the higher type fuzzy systems are increasingly complex; therefore, they only focus on type-2 fuzzy sets to reduce the computational complexity. The authors of Shahidah et al. (2017) note the importance of a fuzzy system in correlated node behaviour detection with emphasis on the enhancement of the computational complexity and accuracy detection. In Sanchez-Roger et al. (2017), authors have mentioned uncertainty of information in the complex environment of the financial field, where fuzzy logic helps to manage those complexities. The authors Rajab and Sharma (2018) have found in their review that for improving the performance of neuro-fuzzy systems (NFS), various data pre-processing methods, higher order neuro-fuzzy methodologies and various optimization mechanisms were combined with these systems to improve the overall performance. In future, newer efficient input and output processing techniques and different optimization techniques can be applied with various NFS approaches (Rajab and Sharma, 2018).
Summary of the analysed literature reviews on complexity issues in FIS.
Summary of the analysed literature reviews on complexity issues in FIS.
However, the complexity issues of FIS development are not analysed in detail in the presented papers. Consequently, there is no systematic and comprehensive review of FIS complexity issues and their solutions, i.e. the analysed papers differ from this study by research questions and their aim.
SLR was adopted as proposed by Kitchenham et al. (2009), and SMS from Petersen et al. (2015), Kitchenham and Charters (2007), Linnenluecke et al. (2019), Ramaki et al. (2018). The hybrid SLR and SMS approach used in this review is presented in Fig. 2. It consists of four main stages: review design, review conduct, review analysis, and quality assurance (i.e. reducing threats to validity). The first, second, and third stages are done sequentially one after the other with some iterations, if necessary, and the fourth stage is interleaved with the first, second, and third stages. In the rest of this section, the details of those stages are described.
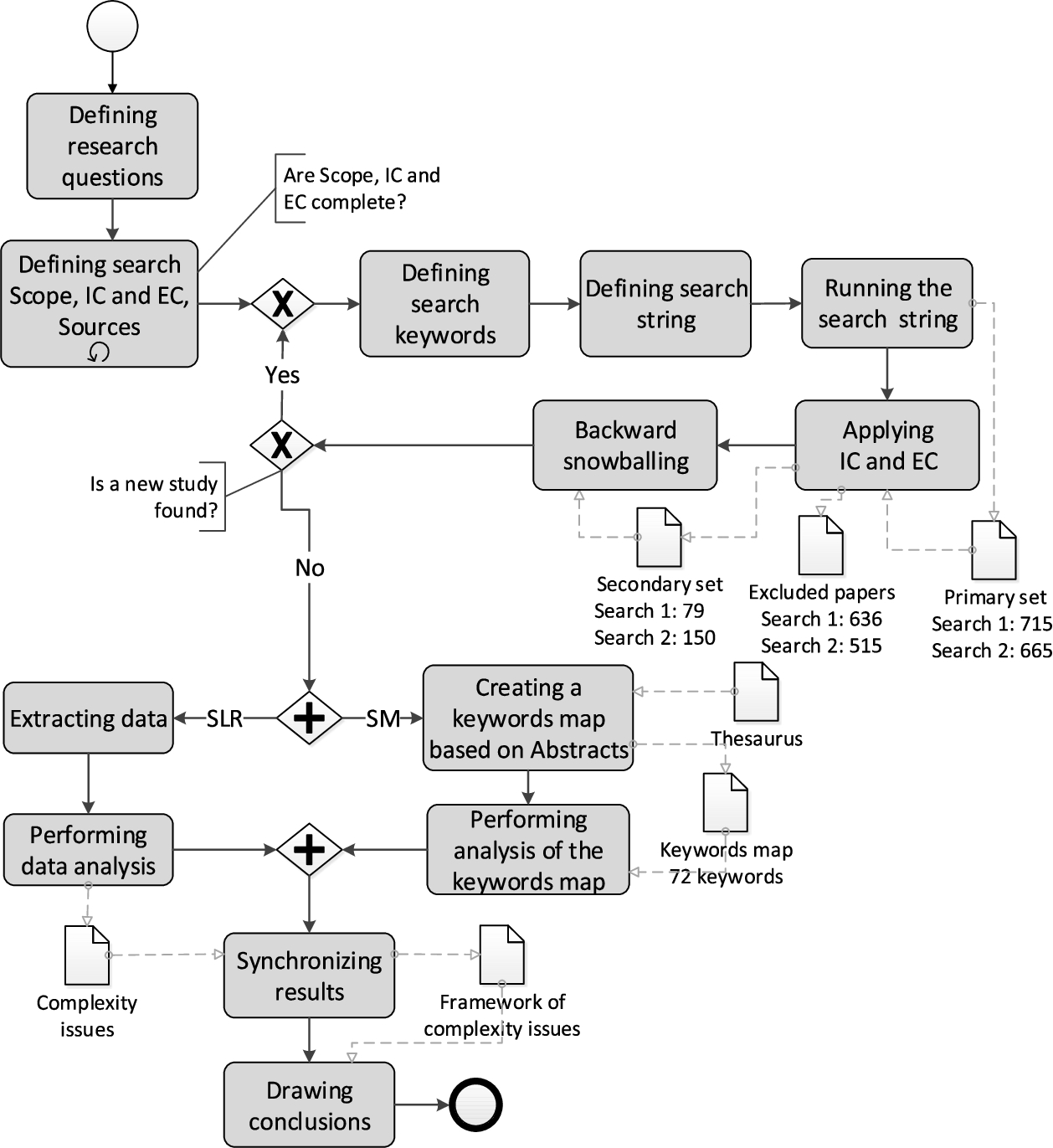
The hybrid SLR and SMS approach schema.
1. Defining research question. The review begins from the definition of the research questions, which were described in Introduction. This review was conducted from December 2019 until April 2020, so we considered the papers that have been published until January 2020.
2. Defining research scope, inclusion (IC) and criteria (EC), search sources. The scope of our review is all papers that have been prepared in Computer Science (CS), Information Systems (IS), and Software Engineering (SE). Web of Science (WoS) database was chosen as the search source. For more motivation, see Section “Source evaluation”.
Based on the defined scope of the research, papers’ IC and EC are defined as the following:
3. Defining search keywords. In this step, we define relevant keywords, which together with selected sources are going to be used to formulate a search string. The following keyword hierarchy was established in Table 2.
Keyword hierarchy.
Note: some general terms, which refer to FIS development and complexity issues, like data, input, output, etc., were excluded, since their inclusion into the search string increased the number of papers found, but additional papers did not expand the knowledge provided on the research topic. Therefore, they were excluded from the search but are still found together with the keywords used.
4. Defining search string. Here, we have specified the following two search strings:
Search string 1 is the primary search string used for the initial search. Search string 2 is the secondary search string developed using keywords from Table 2 and refined, by adding reduc* and optimiz*, after backward snowballing.
5. Running the search string. In this step, the defined search strings are running in WoS engine. For the first iteration, we have used the search string 1. The output of this search is a primary set of the papers. For the second iteration, we have used the search string 2, which was developed after applying backward snowballing strategy. The results of the search are presented in Table 3.
6. Applying IC and EC. Here, the predefined IC and EC were applied to the primary set to obtain only relevant papers on the analysed topic. The input of this step is the primary set of papers. The output is the secondary set of papers. The results of the application of IC and EC are presented in Table 3.
Number of obtained papers (Articles (A) or Proceedings Papers (PP)).
*Duplicate papers are excluded.
7. Backward snowballing. In this review, we have applied backward snowballing technique (Jalali and Wohlin, 2012) for searching relevant keywords in titles, abstracts and keywords of the secondary set of papers to improve and refine search strings. As the result of the first iteration, the secondary search string (Search string 2) was developed.
The direct inclusion of the backward snowballing technique in the review method allows us to iteratively evaluate the secondary set of papers. It supplements the search process with additional keywords, including new relevant papers that may be omitted due to too many papers. The backward snowballing technique should be applied until new papers are found or time runs out. In this review, two iterations were performed, since new iterations do not increase the number of relevant papers.
8. Extracting data. This step is conventional to the data extraction in SLR (Petersen et al., 2015). It covers extracting initial data from Abstracts and tabulating it. The input of this step is Abstracts of the secondary set of papers. The output is the primary set of complexity issues (see Fig. 4).
9. Performing data analysis. This step covers the analysis of the extracted data. The data extracted from the papers was tabulated and plotted to present basic information on RQs. The obtained initial set of complexity issues was grouped into categories, based on Fig. 1.
10. Creating a keyword map based on abstracts. This step corresponds to the keyword mapping activity. It is described in detail in Section 5.3. The input of this step is abstracts of the secondary set of papers and the fuzzy keyword thesaurus specially developed for this review (see Section 5.3). The output of this step is the keyword map (see Fig. 5).
11. Performing analysis of the keywords map. This step covers analysis of the keyword map. For more details, see Section 5.3. The input of this step is the keyword map. The output is the main trends (see Section 5.3). The main results of this step are presented in Section 5.
12. Synchronizing results. In this step, we are synchronizing the obtained results and developing the complexity issues framework (see Section 6).
13. Drawing conclusions. Here, the final conclusions and discussion regarding RQs are drawn.
In Fig. 3, the trend of the research on the topic is illustrated. The number of papers on FIS complexity issues has risen in the period during 2011–2019.
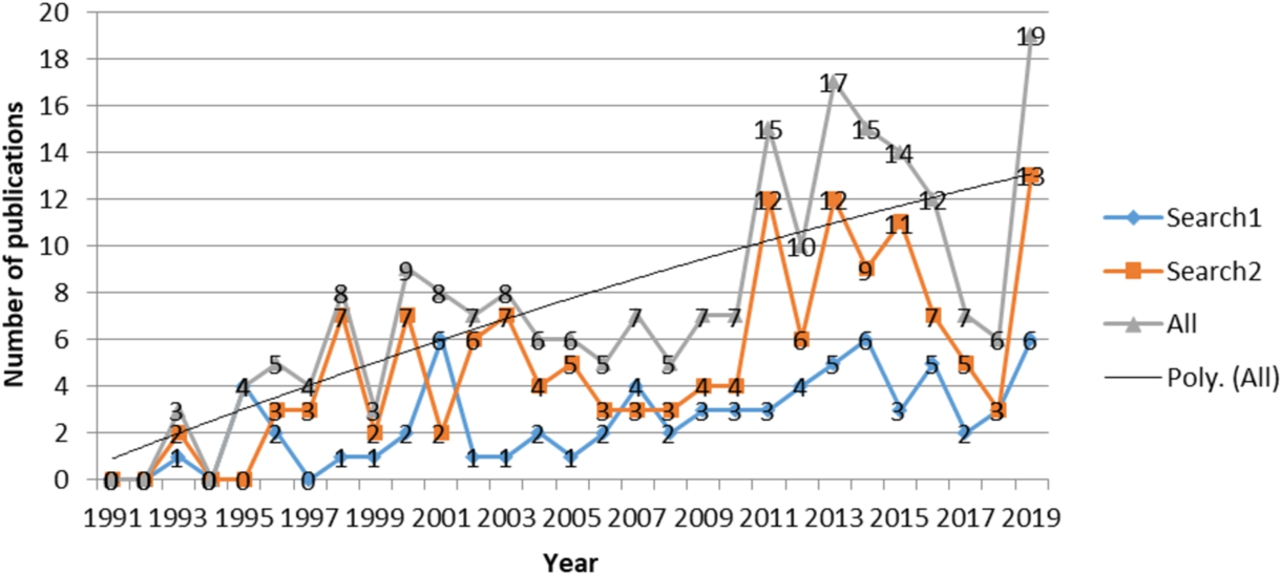
Number of obtained papers (Poly. (All) – is a trend line).
BASE is useful for users without access to paywalled content (Gusenbauer, 2019), which means that large portions of the academic web are not represented. The publisher Elsevier owns both ScienceDirect and Scopus, but Scopus provides possibility to writing more sophisticated strings than ScienceDirect. According to Martín-Martín et al. (2018), WoS and Scopus databases are not overlapping only 12,2% of documents in Engineering and Computer Science. ACM Digital Library, BASE and Wiley Online Library, having a large number of proceedings publications, lose their advantage because of our predefined EC2, EC3 and EC4 (Dybå and Dingsøyr, 2008). For ensuring quality of publications, databases use different types of impact factors as the following: WoS has an Impact Factor (IF), Scopus has its own CiteScore, which is an alternative to WoS IF. ACM Digital Library and Wiley Online Library count only total citations for each publication. The analysis of the possibility for full download of search results shows that WoS and Scopus have the most carefully arranged bibliographic data. WoS allows downloading up to 500 items per time, Scopus – full downloading. Summing up all advantages and disadvantages and taking into consideration time and performance constraints, WoS was chosen for this review.
Found Complexity Issues in FIS (RQ1)
According to the in-depth content analysis of the abstracts of the secondary set of papers presented in Annex 32, four main FIS development complexity issues are found (RQ1) as the following: computational complexity (CC) (1) (i.e. the huge number of calculations in all FIS components); complexity of fuzzy rules (CFR) (2) (i.e. extraction of fuzzy rules, modification and optimization of fuzzy RB, fuzzy RB interpretability); complexity of MF development (CMF) (3) (i.e. MF development, optimization, simplification, partition integrity, comparison of fuzzy numbers, determining MF shape, definition of FOU, aggregation/approximation of information represented by MF); and data complexity (DC) (4) (i.e. related to big data and high-dimensional data issues, balancing of a data set, incomplete input data).
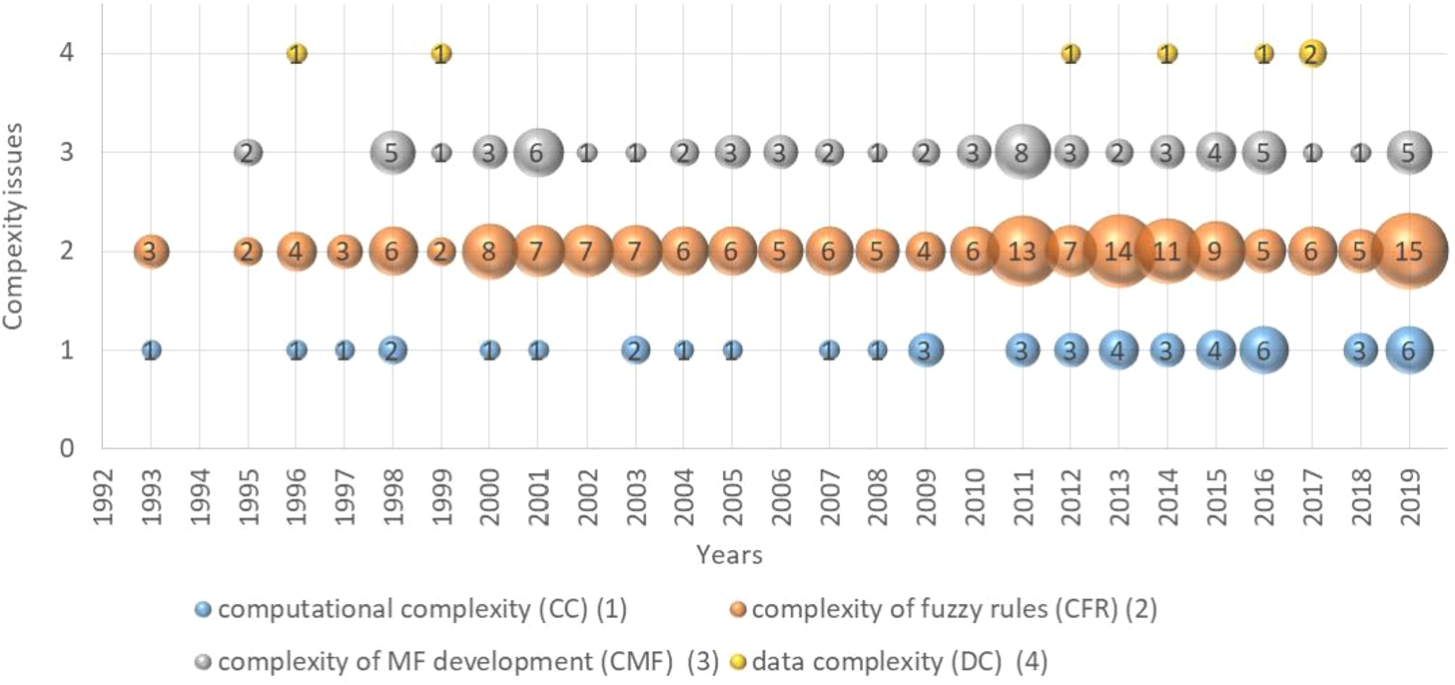
Found complexity issues according to years.
The temporal distribution of the four complexity issues (CC (1), CFR (2), CMF (3), DC (4)) is given in Fig. 4 as follows: x-axis presents years, y-axis presents four complexity issues, and bubbles indicate the number of papers dealing with a particular complexity issue in a given year. The larger the bubble, the more significant number of papers dealing with a specific complexity issue in a given year.
As can be found from Fig. 4, the computational complexity (CC) issue originated in 1993. CC of each method may be different. It is commonly referred to as time complexity (Banaeian et al., 2018). Authors of Aghaeipoor and Javidi (2019) evaluate the average running time for each stage of MOKBL (Multi-Objective Knowledge Base Learning through a fuzzy feature selection and slight tuning of MFs) + MOMs (Multi-Objective Modifications through a rule pruning process and main tuning of MFs). The running times are different for different datasets. The authors said that their proposed method was not time-consuming since they applied efficient strategies for rule generation, objective estimation, new rule pruning, and tuning. The relatively short running time demonstrates the model’s efficiency and scalability, especially for the most complicated datasets (Aghaeipoor and Javidi, 2019). Authors of Cavalieri and Russo (1998) mention computation complexity together with acceptable memory resource requirements. In Hata et al. (2016), authors analyse tuning of fuzzy rules using a neuro-fuzzy learning algorithm. However, as they state, increasing the number of inputs greatly increases the number of parameters. Thus, learning time increases and learning accuracy decreases. Authors of Ruiz-Garcia et al. (2019) consider the practical implementation of general type-2 fuzzy logic systems (GT2-FLSs) and state that the type-reduction operation still presents a challenge for GT2-FLSs because of its CC. They introduce new equations for the meet and join operations, type reduction procedure for the type-2 fuzzy logic system, fuzzification, inference, type-reduction, and defuzzification to reduce CC. Summing up, the CC issue is closely related to other identified complexity issues. It remains relevant from the beginning of the development and application of fuzzy set theory until now; since fuzzy set theory application involves many computations because of its complexity.
The second row in Fig. 4 presents the complexity of fuzzy rules (CFR). As can be mentioned, it is the most significant and relevant issue among others. As stated by some authors, like (Marimuthu et al., 2016; Rajeswari and Deisy, 2019; Hilletofth et al., 2019), the optimal number of the premise and consequent parameters along with the reduced number of rules should be made to achieve more accuracy and reduce the computational complexity by triggering a smaller number of nodes for each activity in fuzzy logic systems (FLS). The significant issues that affect the accuracy of fuzzy-based methods are fixing appropriate MF and validating the fuzzy rules before extracting outliers (Rajeswari and Deisy, 2019). Authors of Hilletofth et al. (2019) investigate the possibility of increasing the interpretability of fuzzy rules and reducing the complexity when designing fuzzy rules. They advocate using of three novel fuzzy logic concepts (i.e. relative linguistic labels, high-level rules and linguistic variable weights) in a fuzzy logic system for re-shoring decision-making and, consequently, increasing the interpretability of fuzzy rules and reducing the complexity when designing fuzzy rules while still providing accurate results.
An essential issue in the design of fuzzy rule-based classification is the automatic generation of fuzzy if-then rules and MFs (Ravi and Khare, 2018), i.e. choosing the type of MFs, the number of MFs, and defining the parameters of MFs. Authors propose a brain genetic fuzzy system (BGFS) for data classification by newly devising the exponential genetic brain storm optimization, i.e. MFs and rules are derived using the exponential brain storm optimization algorithm. So, CFR stands together with other complexity issues, especially the complexity of MF development (CMF). It remains relevant from the beginning of the development and application of fuzzy set theory until now. Its slight increase is visible in 2011–2019.
The third row in Fig. 4 presents the historical evolution of the CMF issue. As was mentioned before, it concerns choosing the type of MFs, the number of MFs or partitioning, defining parameters of MFs, the integrity of partitions (Aghaeipoor and Javidi, 2019; GaneshKumar et al., 2014), and comparison of fuzzy numbers (Matarazzo and Munda, 2001). As the selected papers’ analysis shows, this issue is analysed in tandem with complexity issue of fuzzy rules, like in Rajeswari and Deisy (2019), Ravi and Khare (2018), Barsacchi et al. (2019).
The fourth row in Fig. 4 presents the data complexity (DC) issue. Its occurrence in this research is weak. This limitation can be explained by the fact that the fuzzy set theory is mostly used to solve DC, like high dimensional or spatial data, noisy data, and big data (Chang et al., 2016; Chan et al., 2018; Wang et al., 2017; Feng et al., 2019), but not viewed as a complexity issue in FIS development.
Summing up, those complexity issues found are a relevant research area from the beginning of the development and application of fuzzy set theory until now. Moreover, they evolve with the origin of new technologies and approaches, like neural networks and genetic algorithms, to optimize fuzzy rules and MFs. Additionally, they correlate with each other. Therefore, they should be analysed in tandem.
Figure 5 presents a co-relationship analysis between different pairs of complexity issues.
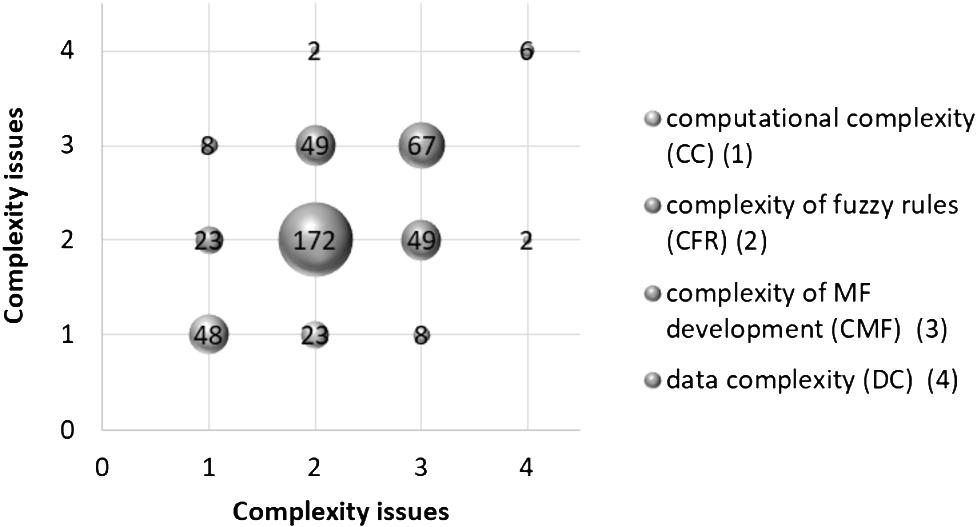
Co-relation of the found complexity issues.
The x-axis and y-axis present the same four complexity issues in the figure, and bubbles indicate the number of papers dealing with a pair of complexity issues. The larger the bubble, the more significant number of papers dealing with a pair of complexity issues. Moreover, Fig. 5 is symmetric since the logical AND of two sets provide symmetric results.
As can be seen in the figure, the most related complexity issues are CFR and CMF (analysed in 49 papers), the second relevant – CC and CFR (in 23 papers), the third relevant – CC and CMF (in 8 papers), and the least relevant – CFR and DC (in 2 papers). CC and DC, CMF, and DC are not found to be related. A co-relationship analysis among three complexity issues shows that the most related triplet is CC–CFR–CMF (in 5 papers). A co-relationship analysis among the found complexity issues indicates that no papers analyse all four issues in co-relationship.
Summing up, it is found that one particular complexity issue is analysed in 147 papers from 217 selected papers (67.74%), two complexity issues in tandem are analysed in 64 papers (29.49%), three – in 6 papers (2.76%), and four – not found. This comparison allows us to conclude that authors tend to analyse one particular issue, less prone to two related issues, and do not analyse all the issues in conjunction.
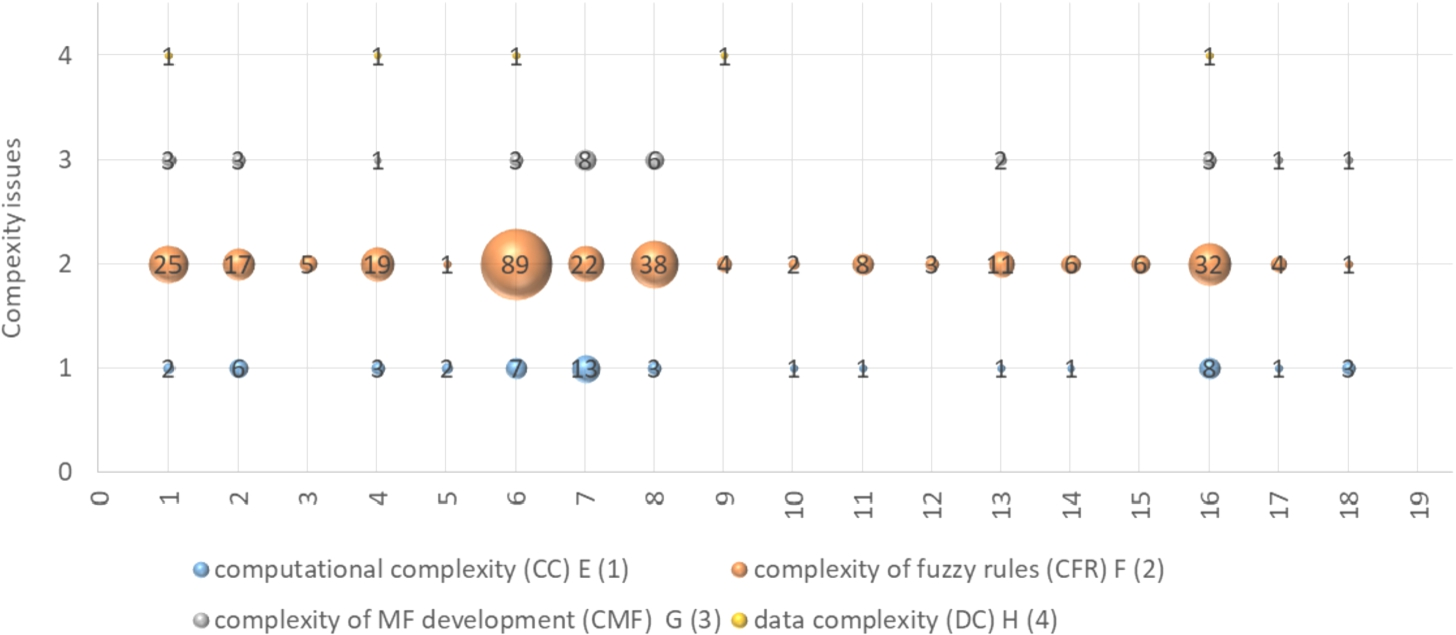
Found solutions for complexity issues (x axis: 1 – genetic algorithm, 2 – neural network, 3 – particle swarm, 4 – other evolutionary algorithm, 5 – MFs type reduction, 6 – fuzzy rule reduction, 7 – MFs reduction, 8 – optimization, 9 – decision table/tree, 10 – granularity, 11 – mining, 12 – Pareto, 13 – similarity, 14 – least square, 15 – fitness function, 16 – approximation techniques, 17 – aggregation, 18 – fuzzy c-means, 19 – other).
Fig. 6 depicts found solutions for complexity issues in FIS. The detailed primary information is presented in Annex 1 2 . The 19 practical solutions have been found in the analysed papers (RQ2). They are as follows: 1) genetic algorithm, 2) neural network, 3) particle swarm, 4) other evolutionary algorithms, 5) MFs type reduction, 6) fuzzy rule reduction, 7) MFs reduction, 8) optimization, 9) decision table/tree, 10) granularity, 11) mining, 12) Pareto, 13) similarity, 14) least square, 15) fitness function, 16) approximation techniques, 17) aggregation, 18) fuzzy c-means, and 19) other. As can be seen, some solutions are general, like optimization (Guély et al., 1999) or reduction (Lin et al., 2015); others, on the contrary, are specific techniques, like fuzzy c-means (Fu et al., 2019), Pareto (Alcalá et al., 2009b), etc. Therefore, they should be systematized into a hierarchy. To understand the complexity issues found and possible solutions, they are analysed and organized further in Section 6.
The CC issue (Fig. 6) is solved by: MFs reduction (7) (Lee et al., 2011; Akbarzadeh-T et al., 2000) (i.e. when there are less MFs, there are fewer computations), using different approximation techniques (16) (i.e. the techniques are used to interpolate and simplify MFs in inference/reasoning process; consequently CC is reduced), fuzzy rule reduction (6) (Lin et al., 2015; Ang and Quek, 2005; Tikk and Baranyi, 2000; Kóczy and Hirota, 1993) (i.e. when there are less fuzzy rules, the inference/reasoning process is simpler; consequently we need fewer computation resources), neural networks (2) (i.e. neural networks are used to achieve dynamic rule formation in FIS (Marimuthu et al., 2016; Lin et al., 2015; Ang and Quek, 2005; Kóczy and Hirota, 1993), thus reducing CC), etc.
The CFR issue (Fig. 6) can be mitigated by the following means: 1) reducing the number of fuzzy rules (6) (Lin et al., 2015; Ang and Quek, 2005; Tikk and Baranyi, 2000; Kóczy and Hirota, 1993), 2) optimizing the number of fuzzy rules (8) by choosing only appropriate (Bouchachia and Vanaret, 2014; Renhou and Yi, 1996), 3) applying a particular approximation technique (Rojas et al., 2000); 4) using genetic algorithms (Akbarzadeh-T et al., 2000; Balazs and Koczy, 2012; Ishibuchi and Yamamoto, 2003); 5) MFs reduction (Akbarzadeh-T et al., 2000), etc.
The CMF issue (see Fig. 6) can be resolved by the following means: 1) reducing MFs (7) (Lee et al., 2011; Akbarzadeh-T et al., 2000), 2) optimization (8) (Akbarzadeh-T et al., 2000), 3) neural network (2) (Lee et al., 2011; Galende-Hernández et al., 2012), etc. The data complexity is reduced using genetic algorithms (1), other evolutionary algorithms (4), fuzzy rule reduction (6), approximation techniques (16) (for explanations, see below in this section) and decision table/tree (9) (Antonelli et al., 2016).
As can be seen from the analysis of the found solutions for complexity issues, some issues are solved through minimizing others (like the computational complexity is minimized by reducing rules, etc.). Therefore, the synergy effect between complexity issues is observed, like the positive synergy between rule selection and tuning techniques to enhance the capability to obtain more accurate and compact fuzzy logic controllers (Alcalá et al., 2009a). The synergy among application of several techniques leads to a positive result, like successful scoping with large and high-dimensional data sets (Antonelli et al., 2013), a positive performance is achieved when applying genetic tuning after the application of the proposed method (Sanz et al., 2012); fuzzy c-means clustering and granularity with weighted data is implemented for enhancing the performance of the classifier (Fu et al., 2019).
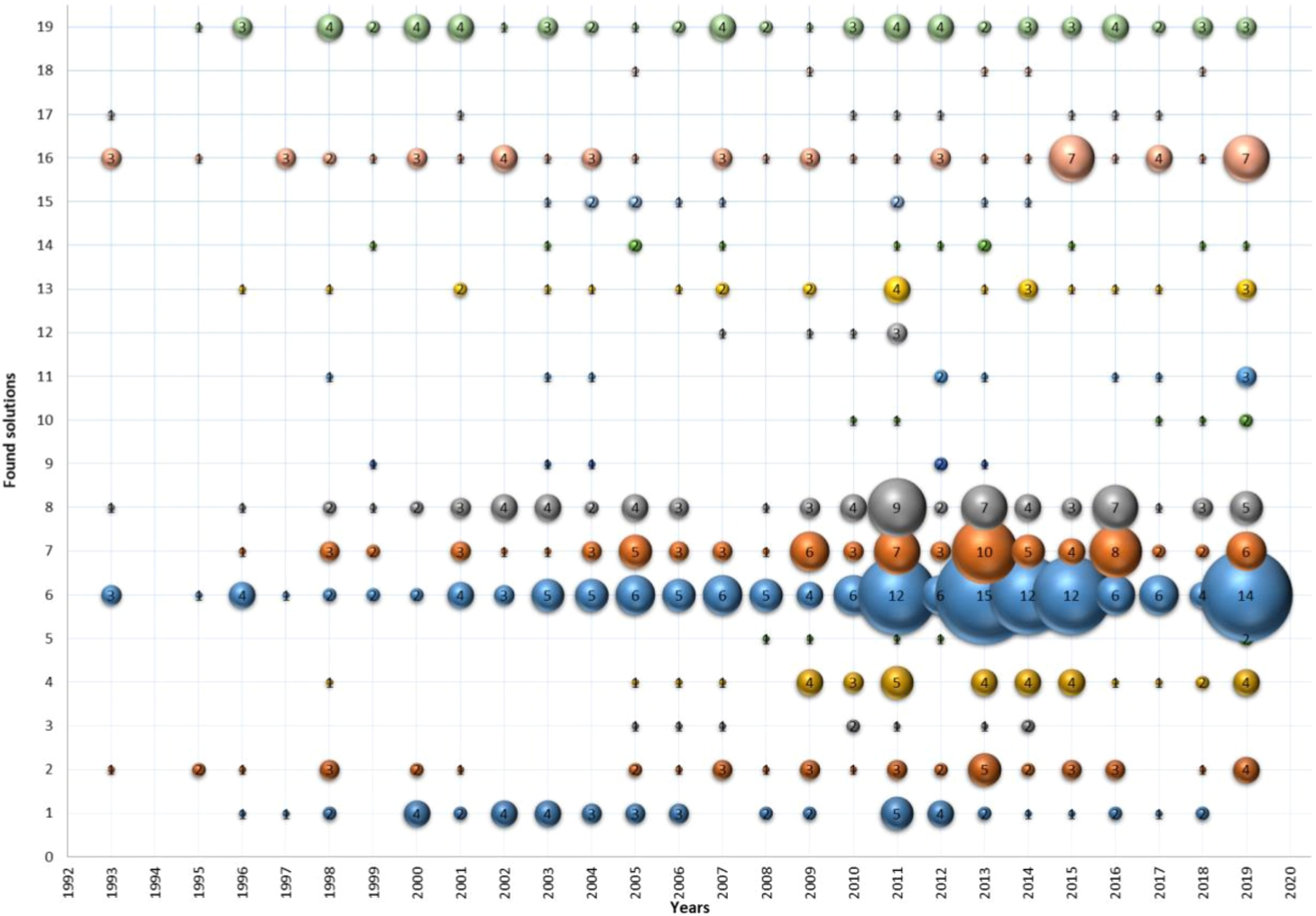
Distribution of applied solutions for complexity issues according to years (y axis: (y axis: 1 – genetic algorithm, 2 – neural network, 3 – particle swarm, 4 – other evolutionary algorithm, 5 – MFs type reduction, 6 – fuzzy rule reduction, 7 – MFs reduction, 8 – optimization, 9 – decision table/tree, 10 – granularity, 11 – mining, 12 – Pareto, 13 – similarity, 14 – least square, 15 – fitness function, 16 – approximation techniques, 17 – aggregation, 18 – fuzzy c-means, 19 – other).
In Fig. 7, the distribution of applied solutions for complexity issues is presented by years. As can be seen, genetic algorithms (1) are used in conjunction with fuzzy logic theory continuously throughout the analysed years. According to Lee et al. (2014), a genetic fuzzy system hybridizes the FIS approximate reasoning with the learning capabilities of evolutionary algorithms to improve the overall behaviour of the resulting system. Authors of Stavrakoudis et al. (2012), Sanz et al. (2011), Casillas et al. (2005), Kim et al. (2006b) have used genetic tuning to improve the performance of fuzzy rule-based classification systems. In Rey et al. (2012), relevant rules were selected using a genetic algorithm that took into account the information obtained by an orthogonal transformation.
Neural networks (2) are integrated into FIS to enable effective handling of the fast and rapidly changing data streams (Ferdaus et al., 2019). The author Chen (2015) has proposed a neuro-fuzzy approach with a learning strategy, which allows us to add or prune fuzzy rules and allocate suitable positions of MFs to perform subsequent optimization efficiently. Authors of Farag et al. (1998) have used a fuzzy neural network to find initial MFs of the fuzzy model and to extract fuzzy rules, and a genetic algorithm to optimize tuning of the found initial MFs.
Since 2009, some evolutionary algorithms (4) have been used to solve different complexity issues. Authors have not mentioned the names of evolutionary algorithms in their abstracts but have just said that they used evolutionary algorithms in their research. We have distinguished them from other approaches, but there is a high probability that most of them are neural networks or genetic algorithms.
Since 2005, a particle swarm (3) optimization have been employed to manage the clustering task for a complex, irregular, and high dimensional data set (Feng et al., 2006); to simultaneously tune the shape of MFs and the rule consequences for the entire fuzzy rule base (Chatterjee and Siarry, 2007); to explore the fuzzy rule sets, fuzzy sets and MFs to its optimal or the approximately optimal extent (Huang et al., 2010); to optimize the parameters (i.e. premise (antecedent) parameters, consequent parameters and structure of fuzzy rules) of the proposed fuzzy classifiers (Elragal, 2014).
MFs type reduction (5) becomes popular since 2008. It can be explained by the more active usage of type-2 fuzzy sets, which are more complex and require more computational efforts. Consequently, different MFs type reduction procedures are proposed, like in Ruiz-Garcia et al. (2019), Lee et al. (2011), Shahparast and Mansoori (2019).
Fuzzy rule reduction (6) and MFs reduction (7) are the most popular complexity issue solving approaches. They encompass evolutionary lateral tuning of MFs and fuzzy rules in Alcalá et al. (2007), eliminating some of the rules by combining different kinds of reference inputs (Kondratenko et al., 2013), introducing a set of governing equations for designing MFs and fuzzy rules to preserve the monotonicity property in Jee et al. (2013), using the Hebbian learning mechanism for rule pruning in Nguyen et al. (2015).
Different optimization (8) procedures are used widely for solving complexity issues as well. In Marimuthu et al. (2016), authors have proposed an optimized adaptive neuro-fuzzy inference system (ANFIS) using frequent pattern mining (see also mining (11) in Fig. 7) and FIS for recognition of activities of a person. Authors make initial rule identification through MFs of each activity, and the number of rules is reduced using the frequent pattern mining (FPM) approach. During the learning phase, the optimal premise parameters are selected using the gradient descent method (other (19) in Fig. 7), and the choice of consequent parameters is based on the least-square (least square (14) in Fig. 7) estimation method. In Ravi and Khare (2018), MFs and rules are devised using an exponential genetic brainstorm optimization algorithm. Authors of Altilio et al. (2018) have used the Adaptive Neuro-FIS to optimize the generalization capability of the resulting model, i.e. to estimate numerical parameters of each fuzzy rule (i.e. MFs) and the whole number of rules to be used. In Almasi and Rouhani (2016), authors have proposed a method based on optimization to generate appropriate MFs and solve classification problems simultaneously. MFs are built based on dynamic class centres.
Decision tables/trees (9) are not so popular for solving complexity issues. Several authors have used them to derive fuzzy if-then rules and MFs from a set of given training examples (Hong and Chen, 1999) or for generating an initial rule base (Barsacchi et al., 2019). Since 2010, a granularity approach (10) has been used for fuzzy partition granularity (Barsacchi et al., 2019; Ishibuchi et al., 2011) and information granularity (Zhu et al., 2017; Fu et al., 2019). Mining techniques (11) have been weakly used for solving FIS development issues, except pattern mining for the reduction of rules in Marimuthu et al. (2016), fuzzy rule mining in Aghaeipoor and Eftekhari (2019), Olufunke et al. (2013), fuzzy association rule mining in Antonelli et al. (2016). Since 2008, Pareto optimization (12) has been used in a few studies, like (Alcalá et al., 2009b; Ishibuchi et al., 2011; Gacto et al., 2010).
Similarity measure (13) is continuously used in some studies for the following goals: for cluster merging utilizing both similarities of the adapted clusters and their centre closeness (Alaei et al., 2013), for partition integrity measure by using an index based on the similarity between the partitions (Antonelli et al., 2011), to alleviate overlap among MFs and to reduce the complexity of the obtained system (Leng et al., 2009), to combine similar input linguistic term nodes for fuzzy sets that indicate the degree to which two fuzzy sets are equal (Chao et al., 1996), for measuring similarity between two fuzzy terms, by their closeness derived from their distance (Kóczy and Hirota, 1993).
Some studies have used the least square method (14). In Pratama et al. (2013), the optimal fuzzy consequent parameters are updated by the time localized least square method. An orthogonal least squares method and a total least squares method are used for rule selection in nonlinear plant modelling problems (Yen and Wang, 1999). In Wang et al. (2005), a recursive least square together with fitness function (15) (Fig. 7) is used to obtain the optimized fuzzy models. The fuzzy rule parameters of antecedents (i.e. MFs) are randomly generated, and the rule consequents are estimated using a regularized least-squares algorithm (Altilio et al., 2018).
A fitness function (15) has been found among other rarely used methods for solving different complexity issues, like to reduce the number of rules and to maintain the performance of FIS (Pal et al., 2003), optimize parameters of antecedent MFs and rule structures (Kim et al., 2006a). Authors of Kim et al. (2005) have used a new fitness function to optimize a fuzzy model, i.e. to obtain modelling accuracy, rule compactness, and interpretability of input MFs. Approximation techniques (16) were used for fuzzy mapping (Tikk and Baranyi, 2000; Kóczy and Hirota, 1993; Rojas et al., 2000), approximating the secondary MF (Melin et al., 2019), and approximating reasoning characteristics of FIS (Golestaneh et al., 2018). Aggregation (17) is found rarely, like (Gegov et al., 2015; Mesiarová-Zemánková and Ahmad, 2012; Eslamkhah and Hosseini Seno, 2019). Fuzzy c-means (18) have been used for process fault detection and diagnosis (Alaei et al., 2013), solving data clustering problems (Ramathilaga et al., 2014), generating fuzzy rules (Emami et al., 1998), forming an initial fuzzy model (Fu et al., 2019). Other (19) approaches were found in the analysed papers only once. Some of them are discussed previously in this section. They are not mentioned again to avoid duplication.
Summing up, from Fig. 7, we can conclude that artificial intelligence approaches (i.e. genetic algorithms, neural networks, other evolutionary algorithms), simplification and generalization techniques (i.e. reduction, similarity, etc.), optimization techniques (i.e. Pareto), similarity techniques (i.e. fitness function, least square) are used for solving different complexity issues in FIS development.
In this section, we provide the keyword co-occurrence analysis to present the main content of the selected papers and the range of researched areas in complexity issues. The co-occurrence analysis of the keyword map is performed using the authors’ abstracts.
VOSviewer selects keywords using an automatic keyword identification technique (van Eck et al., 2010) and creates the keyword map by considering the closeness and strength of existing links. The closeness and strength are calculated from the number of papers, in which both keywords have occurred together (i.e. using binary counting). VOSviewer also clusters keywords and portrays the topic by colours. The size of the bubbles presents the density of occurrence of keywords. VOSviewer uses a unified approach to keywords’ mapping and clustering (Khalil and Gotway Crawford, 2015). In this research, it has identified 4566 keywords, occurring at least 7 times in the abstracts of 217 papers, and develop the keyword map (Fig. 8). A fuzzy keyword thesaurus was created to perform data cleaning as follows:
merge different spellings of the same word, like “membership function” and “membership functions”;
merge abbreviations with full keywords, like “membership functions”, “MFs” and “MF”;
merge synonyms, like “rule premise” and “rule condition”;
exclude general keywords, like article, aim, paper, etc., since these keywords provide very little information, and the usefulness of a map tends to increase when they are excluded.3
The thesaurus consists of 226 merged and 215 excluded keywords (see Annex 2 2 ).
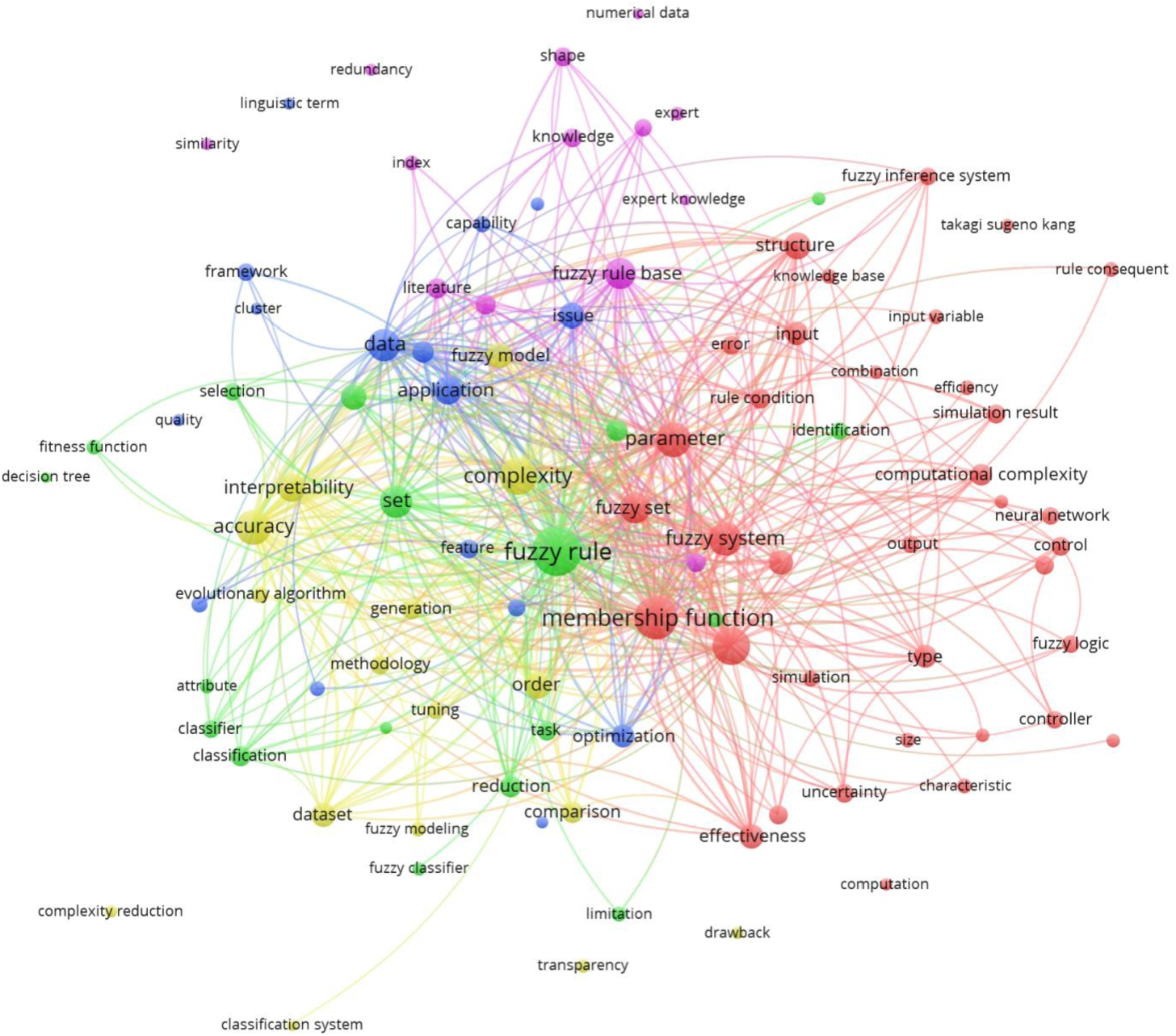
Co-occurrence network of keywords on the topic of complexity issues.
Finally, 100 keywords that seemed most relevant and most interesting were presented in the keyword map (Fig. 8) and used for in-depth analysis. We have analysed the keyword map based on the complexity issues that are named as complexity (78 occurrences found in the abstracts), issue (37), computational complexity (28), limitation (14), drawback (8) and redundancy (8). The most relevant co-occurred complexity issue keywords are the following:
Co-occurrence of the keyword “issue”.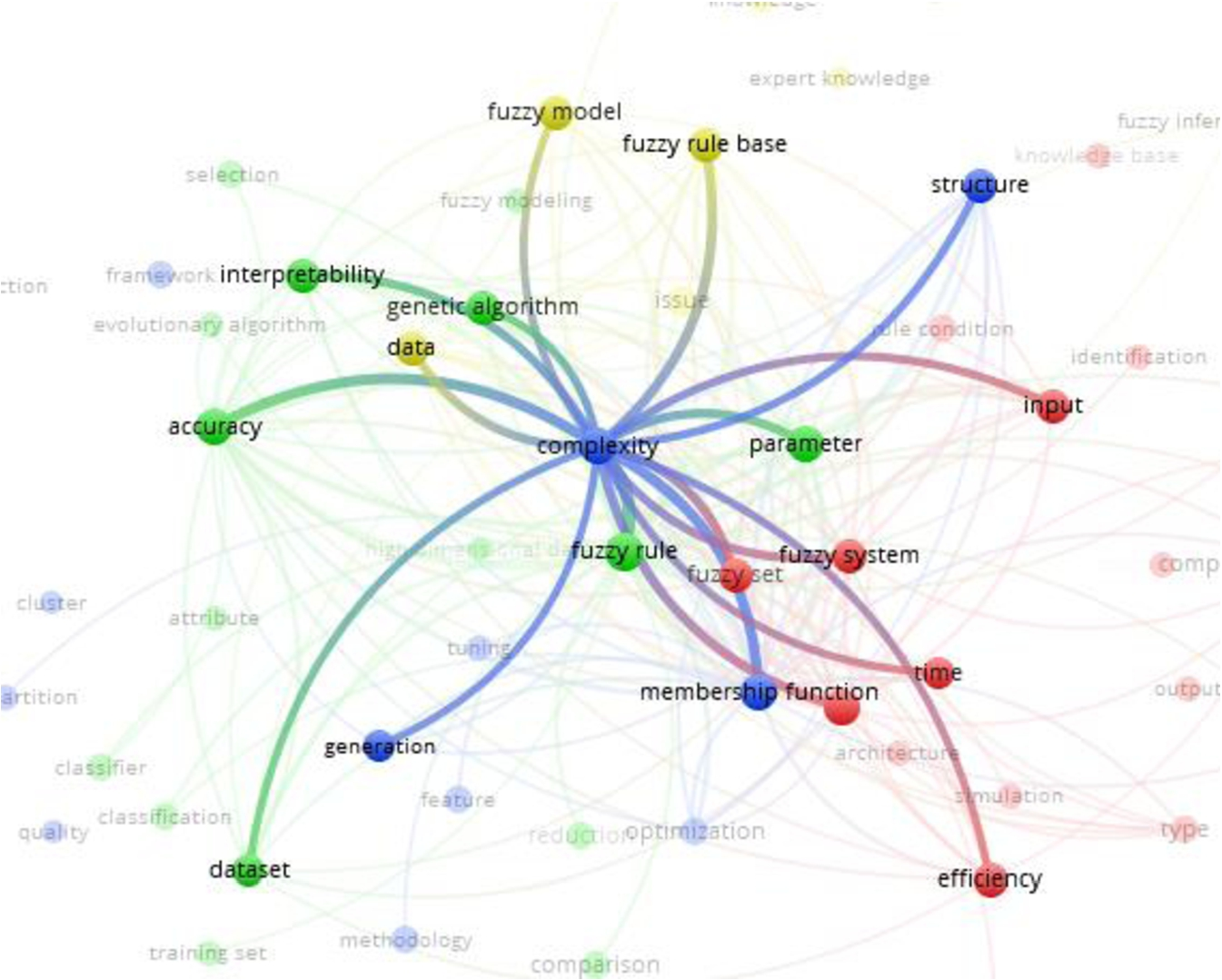
(a) Co-occurrence of the keyword “issue”. (b) Co-occurrence of the keyword “limitation”. (c) Co-occurrence of the keyword “drawback”.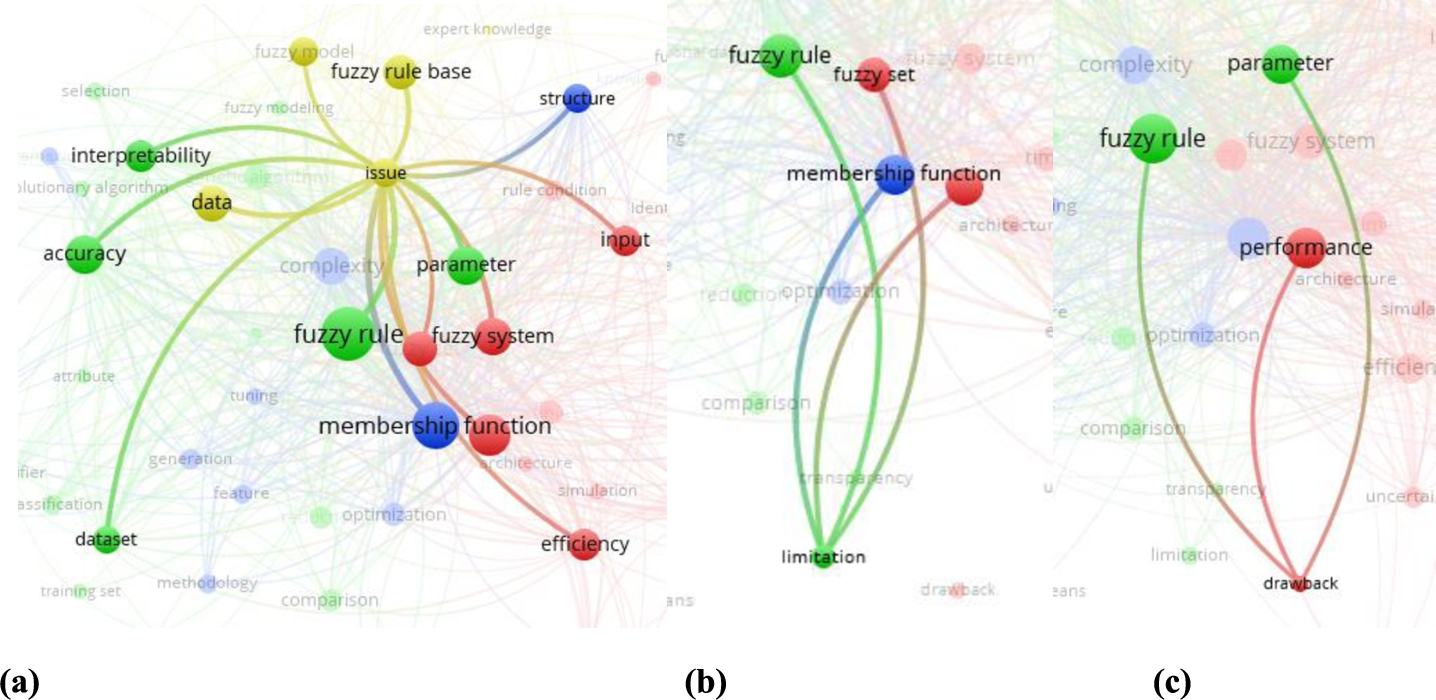
Co-occurrence of the keyword “computational complexity”.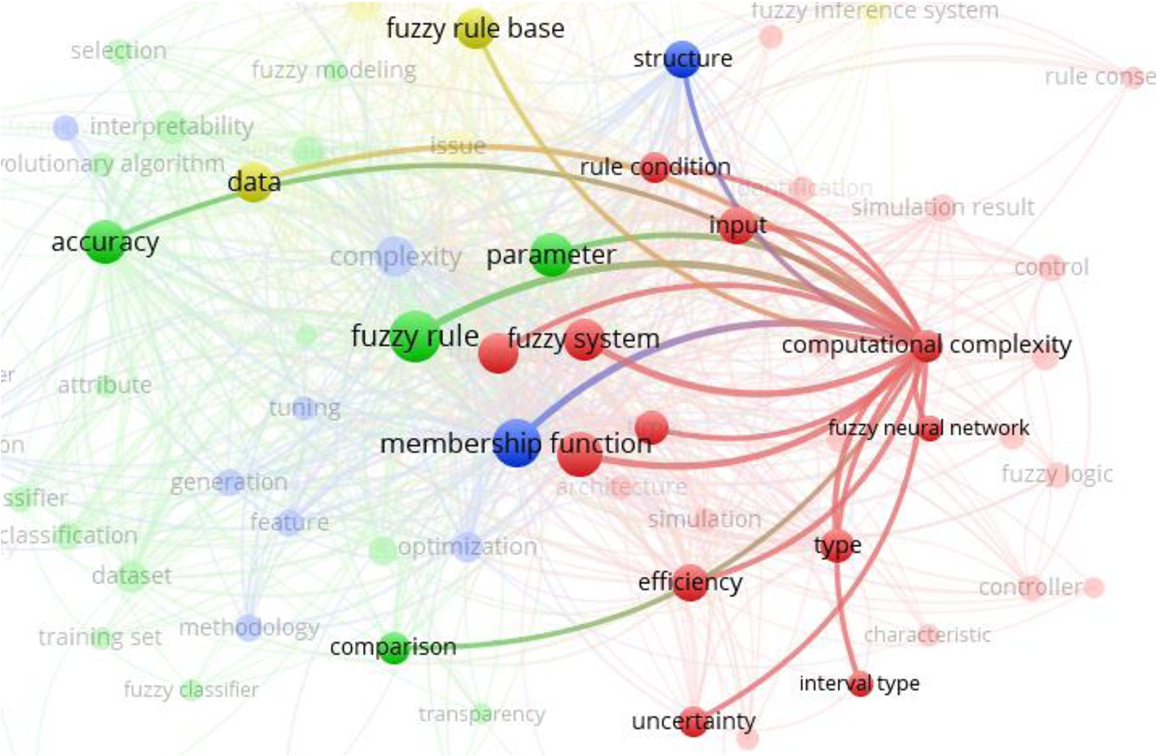
Summing up, the following main complexity issues can be highlighted: computational complexity, complexity of fuzzy rules, complexity of MFs, and data complexity, which are the same as obtained during SLR (Table 3).
In this section, we present a framework of complexity issues and their possible solutions in FIS development. The developed framework serves as a map for identifying, understanding and solving complexity issues in FIS development. It (Fig. 12) consists of two following dimensions:
Based on the obtained results and FIS reference architecture (see Fig. 1), all found complexity issues can be classified as presented in Fig. 12. They are the following:
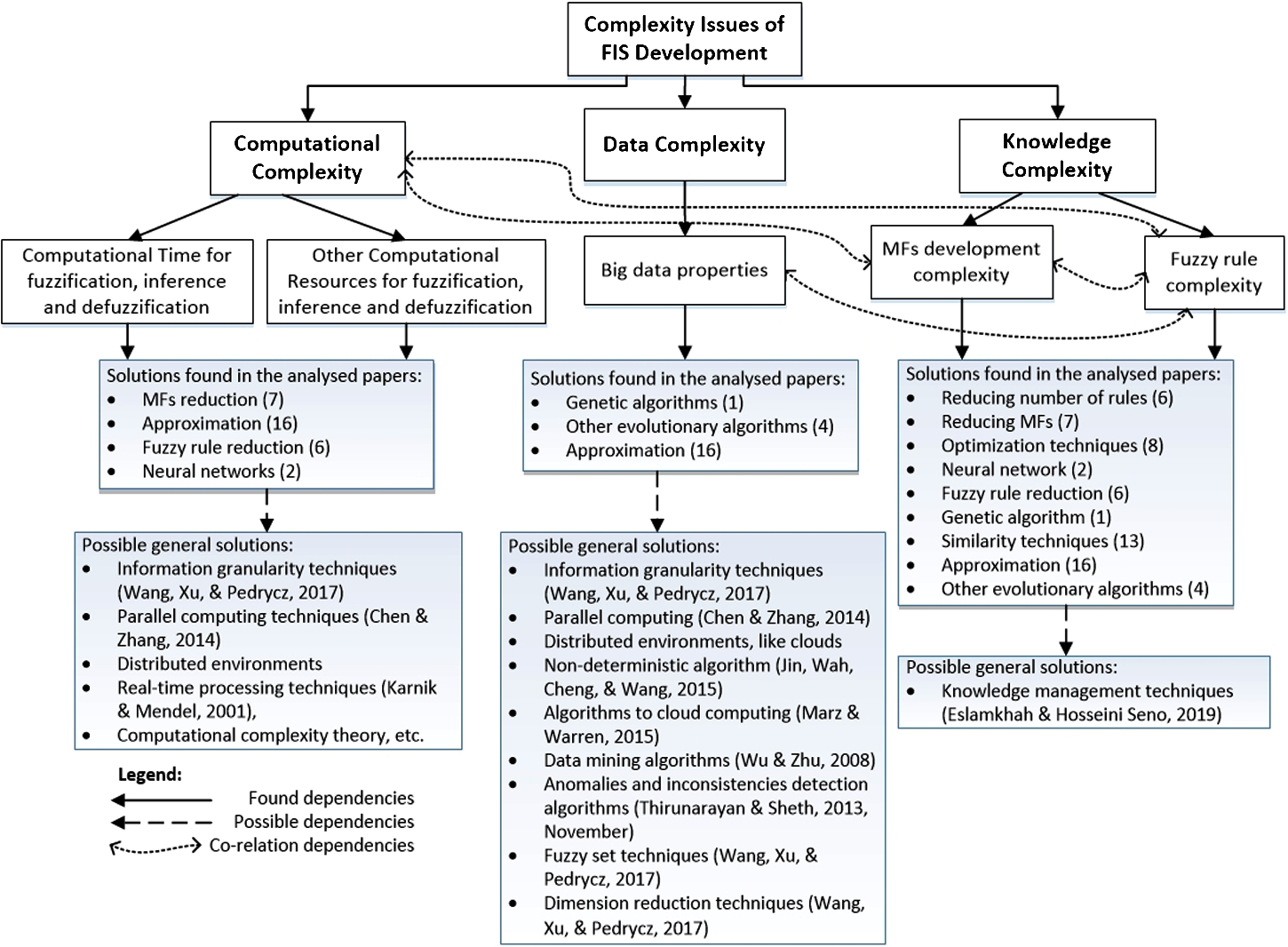
The framework of complexity issues and their possible solutions in FIS development.
As FIS become increasingly complex because of their application domain and tasks being solved, FIS development complexity issues need to be systematized and classified to ensure its development efficiency and effectiveness. In this research, we have applied a hybrid SLR and SMS to answer the defined research questions: (RQ1) What complexity issues exist in the context of developing fuzzy inference systems (FIS)? and (RQ2) Is it possible to systematize existing solutions of identified complexity issues? The conducted review on the topic shows an increase of papers analysing different complexity issues in FIS development. It can be attributed to technological development and raise the applicability of fuzzy theory to present uncertainties in various application domains.
Finally, we can summarize the obtained results and answer the research questions. Four main issues have been found in the reviewed papers (RQ1): 1) computational complexity (CC), 2) complexity of fuzzy rules (CFR), 3) complexity of MF development (CMF), and 4) data complexity (DC). These complexity issues did not occur with equal frequency in the analysed papers as the following: CFR had the highest occurrence, CMF – high occurrence, CC – moderate occurrence, and DC – low occurrence. Here, it is necessary to discuss why we have this phenomenon of circumstances. CFR and CMF have occurred mostly, since MFs and fuzzy rules development are central in developing FIS (Fig. 1). The defined MFs and fuzzy rules form a fuzzy model impacting the FIS inferencing results. Thus, the more precise the definition of MFs and fuzzy rules is, the more accurate results and the more efficient FIS we will get. Moreover, we express domain knowledge through MFs and fuzzy rules. Therefore, in our proposed framework of complexity issues and their possible solutions in FIS development, CMF and CFR are generalized as Knowledge Complexity. CC has occurred moderately. It is an important complexity issue in FIS development, since we have to perform numerous calculations in each FIS component. However, in the analysed papers, not all authors mention this complexity issue in their abstracts. They highlight CFR and CMF and believe that their solution enables the reduction of CC. Although solving CFR and CMF does not entirely reduce CC, it depends on calculations in other components of FIS, like defuzzification, but reduces it significantly. Consequently, to increase CC, we need an efficient way of developing all FIS components. DC has the lowest occurrence in the analysed papers. DC is a global issue going beyond FIS. Since we limit our search strings to FIS but not to all software systems, we got a small number of papers highlighting DC. Moreover, as observed, FIS is usually used to address DC, rather than DC being the FIS development complexity issue. Therefore, we need to extend the review with new keywords, like “high-dimensional data,” “big data,” “noisy data,” etc., to analyse DC more accurately. However, it is outside the scope of this review.
We have performed the co-relationship analysis between different pairs, triples, and quadruples to determine the most related complexity issues. One particular complexity issue is most relevant in the analysed papers (found in 217 papers, 67.74%). Pairs of complexity issues are analysed in 64 papers (29.49%), triplets – in 6 papers (2.76%), and a quadruple – not found. This comparison allows us to state that authors tend to analyse one particular issue, less often – two or three related issues, and do not analyse all the issues in conjunction. The authors choose the complexity issues that are most relevant to their research and reduce them using a particular approach. Besides, they expect that reducing the most relevant complexity issue will reduce other related complexity issues. Therefore, in the domain for in-depth knowledge elicitation, a deeper analysis of causal relationships among complexity issues is necessary by applying the causality-driven methods (Gudas et al., 2019) and determining fuzzy relations (Ferrera-Cedeño et al., 2019) among complexity issues.
This paper has proposed the framework of complexity issues and their possible solutions in FIS development (RQ2). It allows us to systematize existing solutions for each complexity issue found in RQ1. As can be seen, the same solutions, like genetic algorithms, neural networks, approximation and optimization techniques, etc., are used to solve different complexity issues. From a global perspective, the found complexity issues are not new in CS. Therefore, to solve those complexity issues, we propose to employ well-known Possible general solutions (Fig. 12). Moreover, they show the directions in which FIS can and should be developed and refined. Summarizing, complexity issues in FIS development should be solved by searching for new and applying already known approaches from more general fields, like computational complexity theory, parallel computing techniques, information granularity techniques, knowledge management techniques, etc.
One more result of this review is the application of the hybrid SLR and SMS approach. The advantage of the applied approach is that it includes SLR’s advantageous properties to perform in-depth analysis for answering the defined research questions and SMS with a keyword map visualizing and better understanding each concept’s real meaning in FIS development.
The overall advantage of the results obtained in this paper is that they enhance knowledge on FIS development and help the researchers and practitioners become familiar with the found FIS development complexity issues and their possible solutions.
Limitations of the Review
The most common limitations of systematic reviews are related to coverage of search and to possible biases introduced during study selection, data extraction, and analysis. These are also the main limitations of this review. The coverage of the searching threat is related mainly to the search Source of this review, since for the search, we have chosen only one search engine, i.e. WoS. However, in Section 3, we have argued WoS selection. Moreover, our iterative search allows us to obtain a significant number of the primary set of papers (1380), which is a sufficient size of an initial set to perform the review. Moreover, we concentrate on the papers published in Computer Science, Information Systems, and Software Engineering. Although performing a systematic review of other fields was not the aim of our review, we understand that important papers might have been excluded from our discussions. A systematic review performed manually across all fields may not be feasible. Consequently, we intend to conduct a systematic review focusing on a field related to FIS development and keeping the review process feasible.
We addressed potential research bias in assessing papers, data extraction, and data analysis by strictly following the predefined review protocol, assessing the obtained results independently, and then combining them to minimize the researcher’s bias. Two researchers performed all tasks independently and then merged the results.
Finally, since the review process is described in detail, it allows us to ensure the review’s replicability. However, there is no guarantee that other researchers will obtain the same results (but similar ones) as presented in this work since subjectivity cannot be eliminated.
Lessons Learned
The lessons learned from this review can be organised according to two factors: those related to the performing of a systematic review and those related to the complexity issues and their possible solutions in FIS development.
Another lesson learned is related to the step of performing data analysis. Most systematic reviews in Computer Science, Information Systems and Software Engineering are exploratory and based on a quantitative approach. In our study, we have calculated the frequency of complexity issues in the analysed papers. Therefore, different quantitative analysis approaches, like statistical analysis, should be used for the data analysis. However, note that a sufficiently large sample needs to be studied to apply statistical methods.
Conclusions
The analysis of the related works in the field of FIS development shows that there is plenty of approaches to develop FIS. Their authors point out various limitations, issues, or drawbacks of developing FIS because of its complexity. All those complexity issues complicate the automatic FIS development and need to be solved. In the literature, they are not investigated sufficiently in a systematic and comprehensive way. Consequently, there is a need to determine what complexity issues exist in FIS development and which solutions are applied to solve them.
To answer the defined research questions, we have applied SLR and SMS with a keyword map review. SLR allows us to perform an in-depth analysis. SMS with a keyword map is employed to visualize and better understand each concept’s real meaning in FIS development, systematize existing solutions of identified complexity issues, and develop the framework of complexity issues and their possible solutions in FIS development.
The obtained analysis results of RQ1 show four main complexity issues: 1) computational complexity, 2) complexity of fuzzy rules, 3) complexity of MF development, and 4) data complexity. The occurrence of those complexity issues in the analysed papers are the following: the complexity of fuzzy rules have the highest occurrence, the complexity of MF development – high occurrence, computational complexity – moderate occurrence, and data complexity – low occurrence. The obtained analysis results of RQ2 show that the same solutions, like genetic algorithms, neural networks, approximation and optimization techniques, etc., are used to solve different complexity issues.
Based on the found answers to the defined research questions, we have proposed a framework of complexity issues and their possible solutions in FIS development. It allows a better understanding of FIS development complexity issues and their possible solutions for the developers. It encourages further research directions on a more effective and efficient FIS development by researchers.
In future research, we are going to do the following:
extend our review to several search sources;
extend our research to examine the synergy effect in FIS;
apply other techniques, like clustering analysis, etc., for co-relationship analysis of complexity issues and their solutions; and
analyse FIS development and deep learning possibilities.
Footnotes
Note that for each complexity issue keyword co-occurrence strength differs. The same cannot be chosen because of different occurrence of complexity issue keywords, which are shown in the brackets.