
Abstract
Industry 4.0 solutions are composed of autonomous engineered systems where heterogeneous agents act in a choreographed manner to create complex workflows. Agents work at low-level in a flexible and independent manner, and their actions and behaviour may be sparsely manipulated. Besides, agents such as humans tend to show a very dynamic behaviour and processes may be executed in a very anarchic, but correct way. Thus, innovative, and more flexible control techniques are required. In this work, supervisory control techniques are employed to guarantee a correct execution of distributed and choreographed processes in Industry 4.0 scenarios. At prosumer level, processes are represented using soft models where logic rules and deformation indicators are used to analyse the correctness of executions. These logic rules are verified using specific engines at business level. These engines are fed with deformation metrics obtained through tensor deformation functions at production level. To apply deformation functions, processes are represented as discrete flexible solids in a phase space, under external forces representing the variations in every task’s inputs. The proposed solution presents two main novelties and original contributions. On the one hand, the innovative use of soft models and deformation indicators allows the implementation of this control solution not only in traditional industrial scenarios where rigid procedures are followed, but also in other future engineered applications. On the other hand, the original integration of logic rules and events makes possible to control any kind of device, including those which do not have an explicit control plane or interface. Finally, to evaluate the performance of the proposed solution, an experimental validation using a real pervasive computing infrastructure is carried out.
Introduction
Industry 4.0 (Lasi et al., 2014) refers to a new industrial revolution where current production solutions and robots are being replaced by Cyber-Physical Systems (Bordel et al., 2017b) and other innovative engineered systems such as pervasive computing or sensing infrastructures (Ebling and Want, 2017). Traditionally, in industrial scenarios, managers define at a very high abstraction level processes to be executed and supported by production systems (Sánchez et al., 2016). Dashboards and other graphic environments are employed for this purpose. In these models, actions to be performed at low-level together with their input parameters are indicated. Connections among tasks and their temporal organization are strict and cannot be modified. Moreover, sometimes valid ranges for task outputs may also be defined as common industrial systems and robots are very predictable and precise (Bordel et al., 2018c). This top-down approach employs technologies such as YAWL (Van Der Aalst and Ter Hofstede, 2005) or BPMN (Geiger et al., 2018) to create and validate processes and assumes that every low-level infrastructure is following a request-actuation design paradigm. In this paradigm, every low-level system is provided with an interface through which requests may be received. After each request, the hardware system performs a certain action or actuation and, after that, stops its operation waiting for a new request (Bordel et al., 2018b). These systems, then, are totally controllable by external agents and match perfectly the request sequences that are created through modelling technologies such as YAWL (Bordel et al., 2017a).
However, Industry 4.0 scenarios are different. Cyber-Physical Systems and pervasive computing infrastructures are not typically provided with open interfaces, and they tend to act autonomously according to deterministic algorithms or, even, learning technologies (Bordel et al., 2020b). Dense environments where thousands of agents with heterogeneous capabilities are deployed and working together are the most common application scenarios for Industry 4.0. This context, furthermore, can get more complex if humans are considered (Bordel et al., 2017c). In fact, Industry 4.0 is inclusive, and many manufacturing companies produce handmade products where human labour is essential. Production systems including humans are even more heterogenous, as people’s behaviour is very variable and dynamic. And, obviously, human agents are not externally controllable (Bordel et al., 2017c). Thus, in Industry 4.0, complex tasks and services are provided through the choreographed coordination of heterogenous agents acting in an autonomous way (Bordel et al., 2018a). This bottom-up approach is also compatible with computational processes defined at high-level, if decomposition and transformation engines are considered. However, it is a very costly and inefficient approach, as many false negative alarms are triggered. When autonomous agents are included, processes may be executed in a very anarchic but still correct manner.
Therefore, traditional industrial control mechanisms are not valid for these scenarios, and innovative technologies are needed (Bordel et al., 2020a). Then, in this work we propose a new supervisory control mechanism for Industry 4.0 scenarios, matching the special characteristics of distributed processes supported by coordinated autonomous and heterogeneous agents. This new technology defines (at prosumer level) processes using soft models where flexible logic rules and general deformation metrics guarantee the correctness of executions. These rules are verified in a passive manner at business level using specific engines. These engines receive information (events) from lower layers and run a validation procedure to analyse if minimum rules are being met by low-level agents. These events are enriched with information at production level, describing if tasks are being correctly executed or not. Finally, at production level, the physical parameters or tasks under execution are being monitored. Using tensor deformation functions (Bordel et al., 2017a), the global similarity between the expected executions and the real actions is measured. To allow these calculations, processes are represented as discrete flexible solids in a multidimensional phase space. This generalized approach is focused on reducing the false negative alarms observed in traditional control systems. All information is acquired through observation and recognition mechanisms, which are not described in this paper, but already existing (Bordel et al., 2019).
The rest of the paper is organized as follows: Section 2 introduces the state of the art on control mechanisms for Industry 4.0 scenarios. Section 3 presents the proposed technology, including the three abstraction levels (prosumer, business, and production) and their associated mechanisms. Section 4 provides an experimental validation of the proposal. Finally, Sections 5 and 6 explain some results of this experimental validation and the conclusions of our work.
State of the Art
Industry 4.0 is one of the most popular research topics nowadays (Lu, 2017), thus, many different control solutions for these new scenarios have been reported. In fact, almost every existing control mechanism has been already applied and integrated into Industry 4.0 technologies and scenarios: from traditional monolithic instruments (Kretschmer et al., 2016) to most modern intelligent algorithms (Meissner et al., 2017). Besides, a large catalogue of specific control solutions for Industry 4.0 scenarios have been also reported (Dolgui et al., 2019).
Two basic types of control solutions for Industry 4.0 have been described: supervisory control (Wonham and Cai, 2019) and embedded control (Aminifar, 2016) solutions. In supervisory control mechanisms, a surveillance system monitors the behaviour of hardware infrastructures and actuates and intervenes in the production process if it goes outside an acceptable variation margin. On the other hand, embedded control mechanisms are integrated into the production processes themselves and are continuously regulating the evolution and behaviour of the hardware platform.
One of the most popular supervisory control mechanisms in Industry 4.0 are SCADA systems (Mohammad et al., 2019) (Supervisory Control And Data Acquisition). SCADA solutions can manage heterogeneous infrastructures, through complex and heavy modular software tools (Calderón Godoy and González Pérez, 2018). Traditionally, SCADA solutions were built as monolithic platforms where specific industrial protocols, such as OPC, were employed (Boyer, 2016). Initial applications for Industry 4.0 also followed this paradigm (Merchan et al., 2018). Nevertheless, recently, new and different modules for slightly distributed SCADA solutions have been reported (Branger and Pang, 2015), and even cloud-based platforms may be found (Sajid et al., 2016). Furthermore, some SCADA mechanisms for industrial scenarios based on Internet-of-Things have been described (Wollschlaeger et al., 2017). The main problem of SCADA systems is their security weaknesses: many different reports about security problems of SCADA systems in the context of Industry 4.0 scenarios have been reported (Igure et al., 2006; Chhetri et al., 2017). Moreover, in largely distributed production systems, communication delays usually create complex malfunctions in SCADA control functions. Then, different stability analyses (Foruzan et al., 2016), mathematical models to compensate delays (Silva et al., 2018) and evolution analyses (Gu et al., 2019) to detect problems have been reported. In any case, these problems are still present and only distributed solutions including a small number of devices are working nowadays.
Other supervisory control solutions for future industrial scenarios based on autonomous agents have been described. These mechanisms are typically defined as Discrete event systems (Wonham et al., 2018) and are focused on autonomous robots (Gonzalez et al., 2018) and similar mobile machines (Roszkowska, 2002), although other applications to real-time solutions (Sampath et al., 1995) and fault diagnosis (Moreira and Basilio, 2014) may be found. Logic rules have been also employed to implement robot navigation frameworks (Kloetzer and Mahulea, 2016) and different mechanisms to optimal (Fabre and Jezequel, 2009) or clean paths (Iqbal et al., 2012) in robotized Industry 4.0 have been also reported. Works on this area are also evaluating, in a formal way, the scalability (Hill and Lafortune, 2017) and software characteristics (Goryca and Hill, 2013) of supervisory software solution for Industry 4.0.
Contrary to all these previous works, the problem and scenario addressed in this work is more general. First, we are considering not only robots and similar devices but also pervasive infrastructure and humans; what introduces an important challenge. Besides, all previous supervisory control solutions assume there is an interface so the surveillance system can intervene and act in the production process; however in most future engineered solutions (and, of course, when humans are considered), that’s not a realistic assumption.
Embedded control solutions can be classified into two different groups: vertical and horizontal architectures (Dolgui et al., 2019). Vertical architectures are, probably, the genuine approach for Industry 4.0 applications. In this approach, computational processes are transformed and decomposed (Ivanov et al., 2016a; Bagheri et al., 2015), so executable units may be transferred and delegated to remote production infrastructures or, even, cloud services (Bordel et al., 2018c). On the contrary, horizontal architectures are traditional embedded control paradigms, which have been adapted to Industry 4.0 (Lalwani et al., 2006). Feedback control systems are the most traditional approach. In these mechanisms, a complex production system is represented through a block diagram where different key indicators are calculated at each step (Disney et al., 2006). Feedback loops guarantee that if any deviation is detected, that information is considered in previous steps to correct the situation. Feedback control solutions for traditional linear production schemes (Bensoussan et al., 2009; Lin et al., 2018) are very popular, but additional proposals for new non-linear schemes (Spiegler and Naim, 2017; Zhang et al., 2019) may also be found. Furthermore, different studies about how randomness (Garcia et al., 2012), disturbances (Scholz-Reiter et al., 2011), and fluctuations (Yang and Fan, 2016) affect the global behaviour and performance of these feedback control mechanisms have been published. On the other hand, optimal control applications have been reported. Optimal control is the most common technique in horizontal control architectures for Industry 4.0 (Dolgui et al., 2019). In these scenarios, cloud production systems are the most common application for these technologies (Frazzon et al., 2018; Rossit et al., 2019). Optimal control is characterized by a process evolution that is not allowed to belong to certain states or areas in the phase state. With this view, solutions for optimal planning (Sokolov et al., 2018) and efficient activity scheduling (Ivanov et al., 2019) in Industry 4.0 may be found. As in previous topics, works on robustness and resilience analyses have also been reported (Aven, 2017; Ivanov et al., 2016b).
The main problem of embedded control mechanisms in Industry 4.0 applications is that they require a total access to every component in the industrial system; as control modules must be integrated in every component and all of them must be interconnected to generate the global expected behaviour. Contrary to these systems, the proposed approach in this paper is also valid for proprietary solutions (very usual in industrial applications) which cannot be accessed or easily modified, as only a supervisory transversal component is able to support the whole control policy.
Finally, control mechanisms based on modern technologies such as artificial intelligence and fuzzy logic may be found (Diez-Olivan et al., 2019). Although fuzzy logic is not a recent technology (Nguyen et al., 2018), new solutions for industrial scenarios have been recently reported. These solutions are sparse, but some new proposals for nonlinear and event-driven processes may be found (Pan and Yang, 2017). In this context, case studies about real implementations are also a relevant contribution (Theorin et al., 2017; Golob and Bratina, 2018). These technologies are very powerful but are not flexible enough to deal with anarchist executions caused by human behaviour, as learning algorithms need to previously observe every execution model to be accepted.
Table 1 shows in a systematized manner the main advantages and disadvantages, and differences in terms of the problem addressed, of previously described works.
Systematized state of the art review.
Systematized state of the art review.
This section describes the new proposal for supervisory control in Industry 4.0 scenarios, where processes are described using soft models, logic rules and deformation functions and metrics. Section 3.1 describes the global overview of the proposed solution. Section 3.2 presents the new soft models to represent processes at prosumer level. Section 3.3 analyses how logic rules (at business level) may be employed to verify in a flexible manner the process execution performed by autonomous agents and humans. And Section 3.4 describes proposed technologies for production level, where deformation functions and metrics are deployed to evaluate workflows and feed verification engines at business level.
General Overview
Figure 1 shows the proposed architecture for the described new control mechanism. At the highest level, managers are defining processes ① using any of the existing process description technologies, such as BPMN or YAWL. Industrial production processes are usually very large and complex, including many activities and tasks which may be partially related (or not). Besides, some technologies enable defining quality indicators for tasks’ outputs, so the activity execution may be rejected if those indicators are not met. Process definitions at this level (named as prosumer level, as managers act as producers and consumers in the proposed technology) are typically graphic, and only relations among tasks and quality measurements are described.
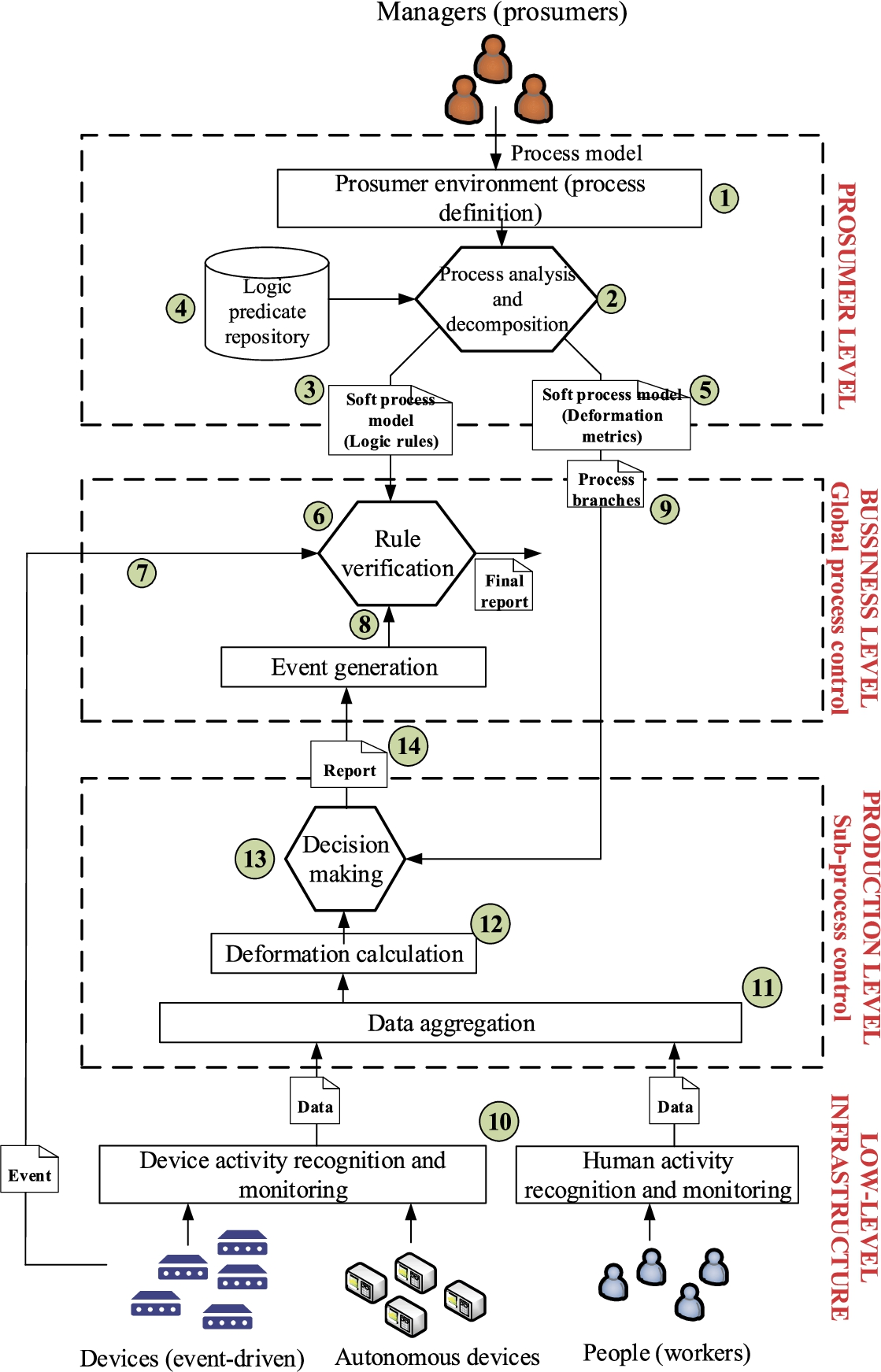
Proposed architecture for new supervisory control solution in Industry 4.0 scenarios.
The process model based on standard technologies (hereinafter we are considering YAWL language) is then analysed and decomposed ② to “soft” and relax the model. The idea is to transform a hard or rigid process definition where deformations and variations are not expressed (and, then, not accepted by the control solution) into a soft model ③ where global quality and organization restriction are equivalent but dynamic changes, variations and deformation are admissible.
To perform this transformation, a specific engine ② analyses the YAWL process model and identifies the key branches or subprocesses whose exterior structure cannot be modified. For example, a subprocess generating a subproduct as output which is the input of a second subprocess must be executed strictly before the second subprocess. However, tasks inside both subprocesses could be executed in any order, and the same subproduct is created.
After this analysis and decomposition procedure, two different soft process descriptions are generated. The first one is a global description based on logic rules ③. To generate this description, each subprocess is represented by a discrete state. And the global state map is regulated by a set of logical rules extracted and instantiated from a logic predicate repository ④, where different general conditions are stored (temporal order, necessary conditions, etc.). Those logical rules represent the minimum restrictions that the production process must fulfill, but all additional restrictions artificially introduced by the limitations or graphic process representations are removed. The second one is a set of reports ⑤ where deformation metrics about each subprocess are indicated. Quality indicators about each task are considered together and three global metrics for the whole subprocess are obtained: stiffness, strength and ductility.
The global soft description is transferred to a verification engine ⑥, where logical rules are validated (or not) at real-time. This global understanding about the process takes place at business level, where information from managers (process models) and from autonomous hardware platforms are matched to determine if production processes are being correctly executed or not. This verification engine takes as input two information sources: events directly generated by hardware devices ⑦ following an event-driven paradigm; and events generated ⑧ by control component in lower layers (the production layer). These events are employed to validate logical rules and determine if minimum conditions to consider the process execution is valid are being met.
All reports about subprocesses ⑨ are transferred to a lower level (the production level), where low-level (physical) information is collected to evaluate if process deformation is above the proposed global metrics. To do that, information from different recognition technologies (human-oriented, device-oriented, etc.) is collected ⑩. These recognition technologies are not addressed in this paper, as any of the previously existing mechanisms may be integrated (Bordel et al., 2019; Bordel and Alcarria, 2017). All information sources are integrated ⑪ to perform a global evaluation of process deformation. To obtain those global metrics a mathematical algorithm ⑫ is employed. This algorithm is deducted by understanding production processes as discrete flexible solids in a generalized phase space. Dynamic behaviour of autonomous devices is represented as external forces acting on the solid (process) and deforming it. Using different deformation functions (and the provided deformation metrics), it is evaluated if the final process execution is similar enough to the model to be considered as a valid execution or not. A decision-making engine ⑬ performs these functions. A report ⑭ and event-like result (whose format may be adapted in an event generation module) is sent to the rule verification engine ⑥ (as one of the information sources described before).
Using YAWL language, managers may define processes in a very easy manner with graphic instruments (see Fig. 2). At the highest level (prosumer level) managers (prosumers) are defining a complex production process or workflow W. This workflow is an ordered sequence T of
Besides, in YAWL, tasks may be labelled with a list
Moreover, bifurcation conditions can be considered in YAWL process definitions (see Fig. 2). These conditions are modelled as lists

Graphic representation of a YAWL process.
A key subprocess is characterized by only one input point (only one task receives inputs from the physical world) and only one output point (only one task generates a physical service or product). Besides, relations among tasks within the subprocess do not have associated subproducts
On the other hand, annotations
The set of states

Key subprocess identification and Kripke structure creation
A second element is generated in the analysis and decomposition engine. For each key subprocess
Stiffness (F) represents the ability of a process to resist to deformations. In other words, it presents how much a process may absorb variations in the input parameters and conditions and still keep the planned values in the state variables.
Strength (G) represents the ability of a process to prevent unsatisfactory executions. It describes how resistant the internal organization of the process is, producing correct executions even if inputs and/or state variables suffer great changes with respect to the original model.
Ductility (D) represents the ability of a process to be deformed and, still, produce correct executions. This parameter indicates how flexible a process is, so even large changes in the state variables are considered as valid executions.
Stiffness is related to security margins and safeguards between consecutive tasks in the process model (11). As these security margins are larger, it is easier for the process to resist to global deformations, as the effect of inputs on the first tasks are absorbed by security margins. Function calculating the stiffness of a process
Strength is related to the number of restrictions and indicators in the list
Finally, ductility is obtained from the tolerances and relative errors in the list
Then, the subprocess descriptions
At business level, a Kripke structure (9) describing the process model is received. On the other hand, from this level, the control solution is viewed as a discrete event system (DES),
In this DES,
Moreover, in this scenario, events and states in the low-level platform are unknown and, probably, infinite. Then, supervisory control cannot be performed directly over the workers and hardware devices, but over the Kripke structure. Actually, this structure is a fair Kripke structure are two additional conditions are met in every process model:
Justice or weak fairness requirements: Many states
Compassion or strong fairness requirements: If many states
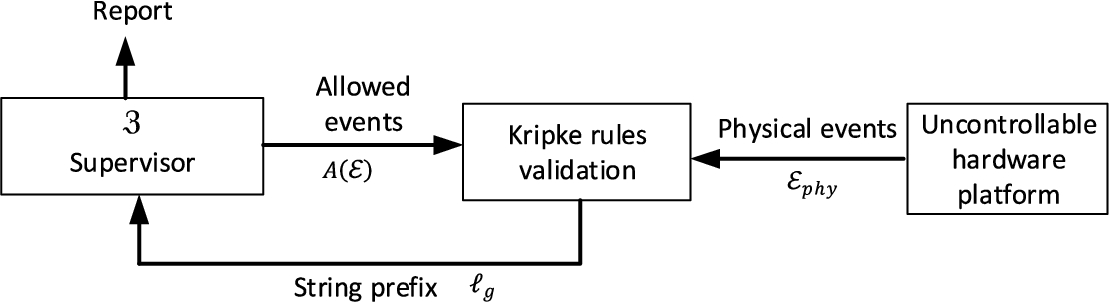
Supervisory control solution.
In that way, a two-level verification is performed in the “rule verification engine” (see Fig. 3). In this solution, states
In those conditions, the proposed supervisory control algorithm operates as follows. First, physical events

Supervisory control
Different solutions to validate logic rules have been reported (Leucker, 2017), any of them may be integrated into the proposed mechanism.
Finally, at production level, a collection of labelled key subprocess
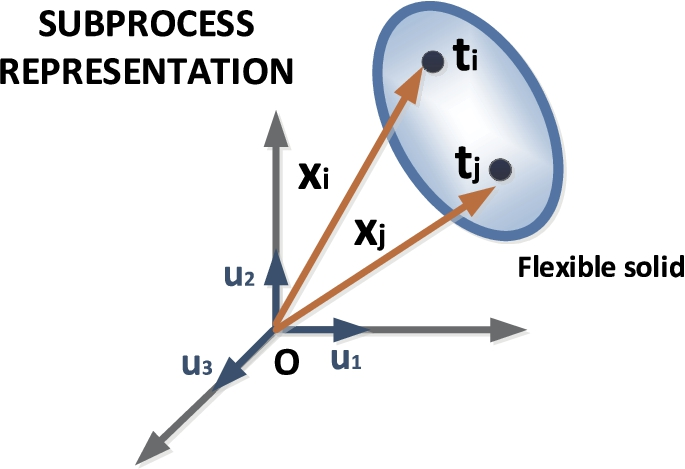
Subprocess representation in a general phase space.
The question to address, then, is if the suffered deformation is high enough to consider whether the execution is unsatisfactory or not.
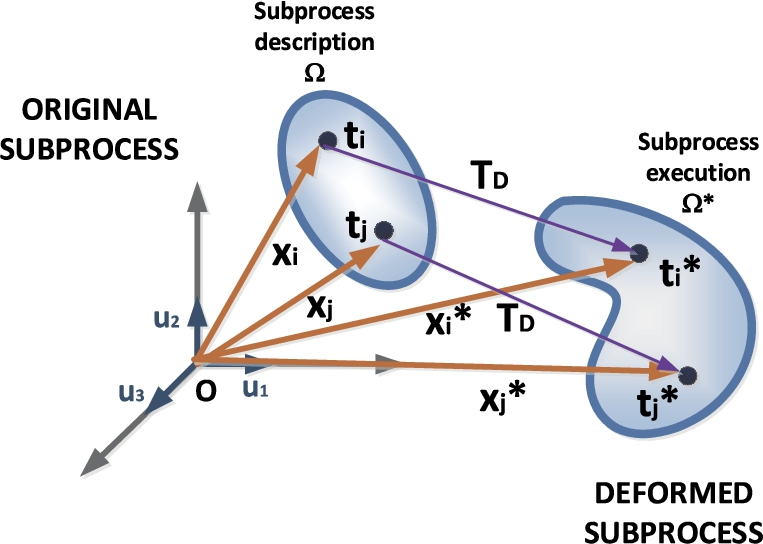
Subprocess representation in a general phase space.
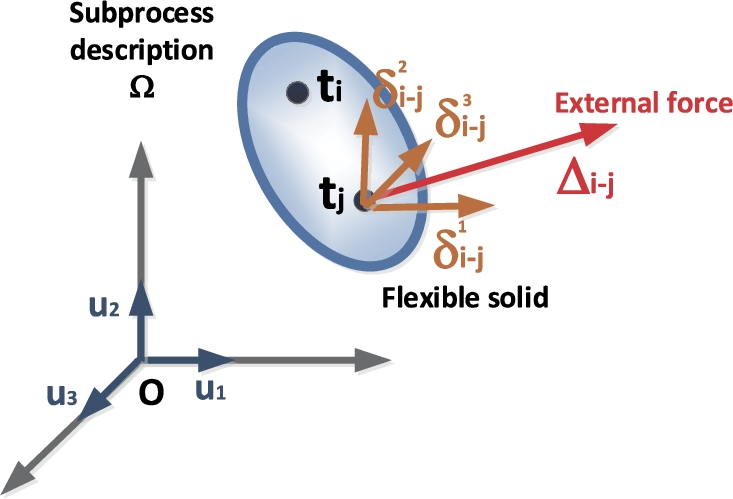
External forces acting on the flexible solid in the phase space.
In the proposed model, a set of external forces
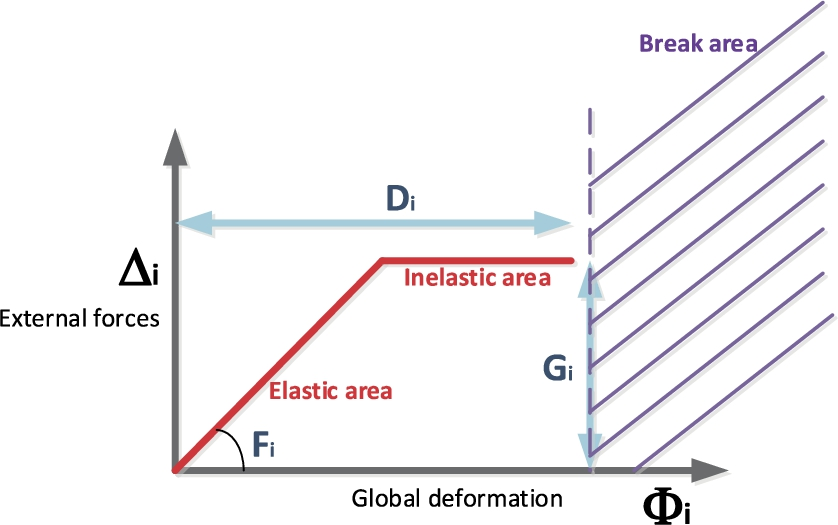
Generalized Hook law for process verification.
As can be seen in Fig. 7, it is not necessary to evaluate the external forces
On the one hand, in the inelastic area, small variations in the estimated global deformation
Thus, we proposed a two phases deformation evaluation: in the first step, a very simple algorithm where all state variables and quality indicators are considered independent is employed; only if this algorithm places the global deformation in the inelastic area, a second step where a complex and much more precise algorithm is employed would be triggered.
To calculate the first and approximate global deformation
As can be seen in Table 2, using the unitary deformation we can evaluate the subprocess rotation and absolute deformation. Then, for processes where rotation and large deformation values are present, Hencky function is the most precise calculation method. Equally, for null rotation and large deformation values, specific logarithmic algorithms and expressions may be proposed depending on the scenario. Finally, for small values of deformation we can use the Green or Almansi function (as desired) if rotation is present, or the unitary deformation if no rotation and small deformation values are observed.
After calculating the global deformation

Deformation evaluation
Different deformation calculation expressions.
Module calculation (34), in this case, will refer to the tensor module calculation; contrary to the previous case where vector module was employed.
With this much more precise value, the caused deformation is finally evaluated. If it remains in the inelastic area, the execution is approved. In the contrary event, the execution is rejected. Algorithm 3 describes the entire described solution at production level.
In order to evaluate the performance of the proposed solution, an experimental validation was designed and carried out. The experiments were based on pervasive sensing and computing platforms, deployed in a laboratory, emulating an Industry 4.0 manufacturing environment. In this environment, workers and work automation devices were expected to perform a certain workflow along the day, composed of certain production activities, taken from food manufacturing companies such as baking companies (see Table 4). These production activities, besides, are composed of a quite large collection of tasks, which are finally monitored.
The scenario was deployed at Universidad Politécnica de Madrid, where a 30 m2 space was conditioned as working environment. Because of sanitary restrictions during 2020 in Europe, only three people could be at the same time in the laboratory. Then, if a large amount of people were involved in the experiment, different experiment realization (each one with only three participants) would be performed. Electronic devices present in this installation were configured to simulate a food production environment.
Three different information sources and devices were considered in order to monitor people and device activities: RFID tags, infrared barriers and accelerometers and general sensors (temperature, humidity, light, etc.). Table 3 shows the composition of the deployed infrastructure. All these elements were built together with an Arduino Nano platform and connected through Bluetooth technologies to a gateway supported by a Raspberry Pi device. This gateway, finally, communicates all information to a central server in the cloud for data storage and back-end deployment. The server was deployed in a Linux architecture (Ubuntu 18.04 LTS) with the following hardware characteristics: Dell R540 Rack 2U, 96 GB RAM, two processors Intel Xeon Silver 4114 2.2G, HD 2TB SATA 7,2K rpm.
Autonomous devices in the proposed scenario belonged to three different types (see Table 3):
Autonomous robots: Cleaning robots and software-based robots, acting in an autonomous manner to help workers in the management of production facility. Software-based robots consisted on agents interacting with virtual PLCs simulating bakery processes, service interruptions, etc.
Electronic ink displays: Low-cost and low consumption devices employed to display information about next activities to be performed, warning and alerts, etc. All these displays were controlled from the Raspberry local gateway.
Cyber-Physical Systems and pervasive system to control living conditions: All environmental conditions, such as temperature or humidity, were monitored by pervasive computing platforms and traditional feedback control loops.
Infrastructure composition during the experimental validation.
In order to recognize activities being performed, two different technologies were employed. To recognize human activities, we are using a two-phase solution composed of different machine learning and pattern recognition layers (Wonham and Cai, 2019). To recognize activities performed by autonomous devices we employed previous works on artificial intelligence mechanisms for Internet-of-Things applications based on signal processing (Bordel et al., 2020b). These components were deployed together with the proposed solution in the referred cloud server. This server also offered a prosumer webpage, where YAWL-based workflows of production activities could be generated. Workflows are based in bakery production activities of the state of the art (Katz et al., 1963), and most common activities are showed in Table 4.
The experiment considered four different workflows with a variable number of tasks and production activities. All workflows were executed by autonomous devices and twelve people in an eight-hour session (standard labour schedule). People were selected as a homogenous community, with respect to the gender and age parity. The experiment included three different phases:
Training phase: Participants received some training about the activities and workflows they had to perform and the context and experiment conditions.
Process execution phase: Each participant was interviewed in this phase. The participant was asked to execute a certain process, which is described in a short document, as any company would do.
Evaluation phase: In this phase, experts evaluated the records obtained by the system about the validity of executions, and they were compared to observations made by experts (which finally determined whether an execution was correct or not).
Most common production activities in the experimental validation.
Two different experiments were performed using the described infrastructure. During the first experiment, the precision and success rate of the proposed supervisory control mechanism was evaluated. The number (percentage) of activities and workflows correctly detected as successful or unsatisfactory executions is calculated, including the percentage of false positives and false negatives. Experiments are repeated for workflows with different number of tasks, and they are also compared to traditional top-down control approaches (Bordel et al., 2018c). During the second experiment, the scalability of the proposed control solution with respect to the complexity (number of tasks) of the executed workflow and quality indicators in the task description is analysed. The main indicator analysed in this second experiment is the processing delay.
Figure 8 shows the results from the first experiment, comparing the success rate in the proposed control mechanism (rule verification engine) ⑥ to previously existing traditional solutions [5], for workflows with a different number of tasks
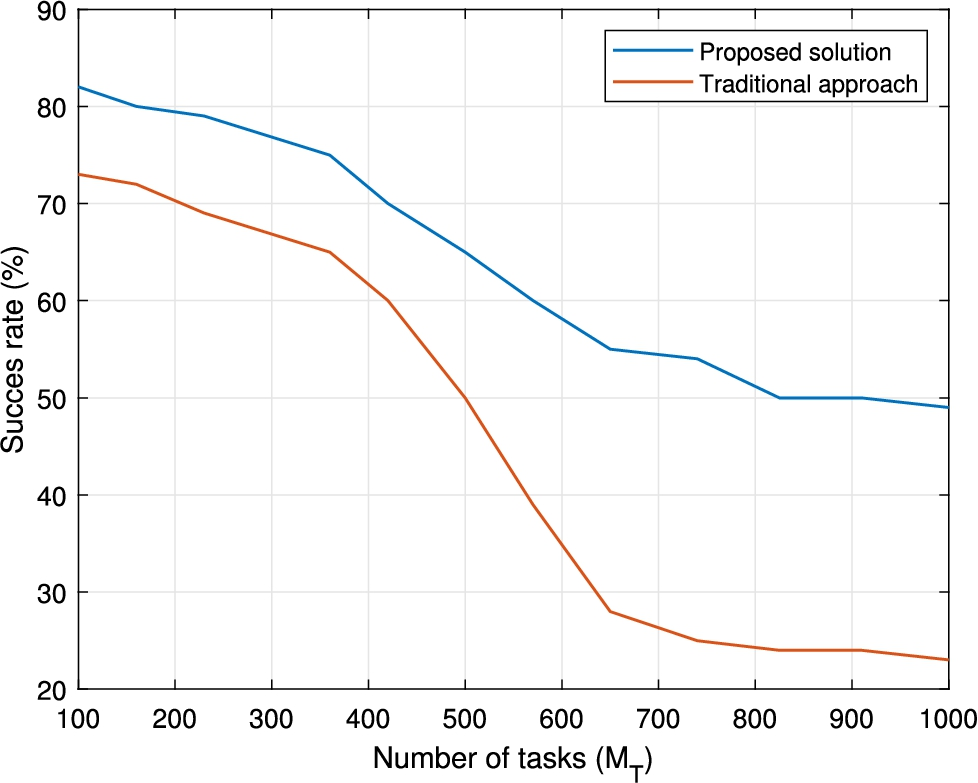
Execution correctly valuated and accepted (or rejected).
As can be seen, the proposed supervisory control mechanism reaches a higher successful rate in all cases. In a first zone, for workflows where
An interesting result to be evaluated is how the wrongly evaluated process executions are split into false positive detection and false negative detections. Figure 9 shows those results.
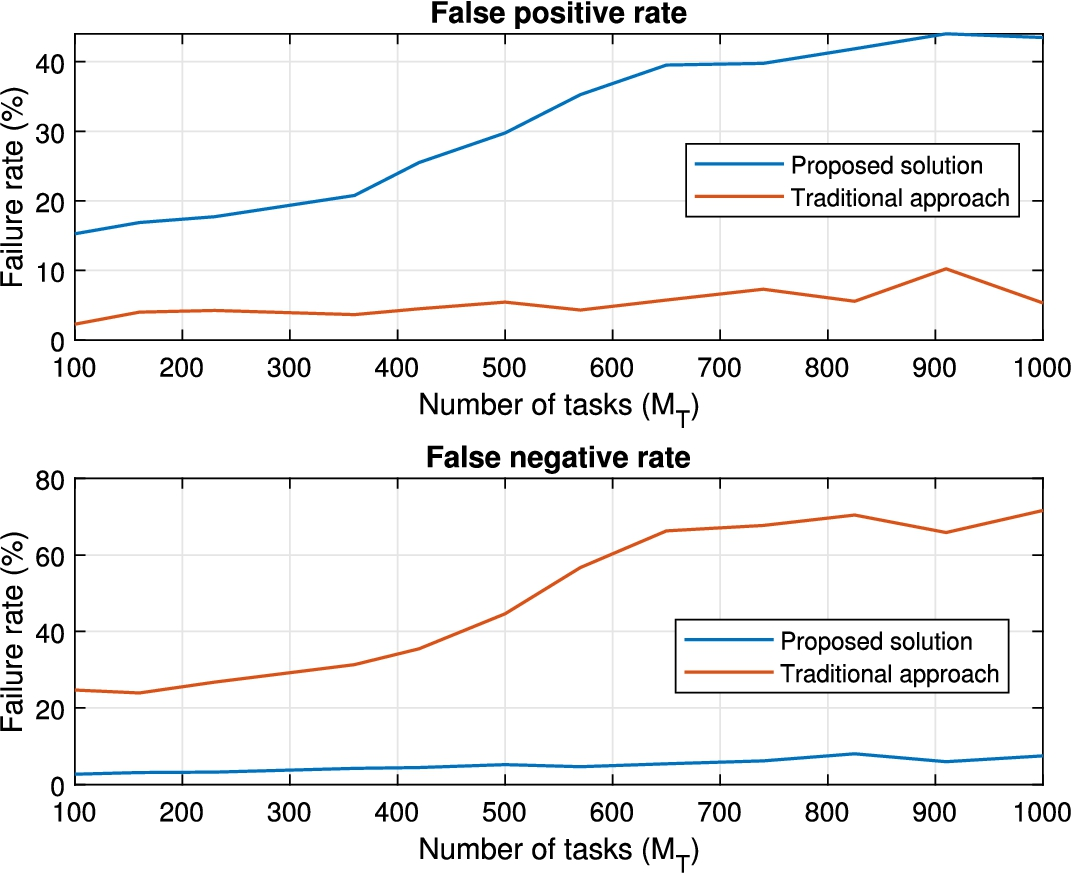
Distribution of errors in the first experiment.
In general, as can be seen, traditional approaches present a much higher number of false negative detections (executions that are valid are considered unsatisfactory), while the proposed solution tends to create false positive evaluations (executions that are not valid but are finally accepted) in a higher rate than state of the art technologies.
Finally, Fig. 10 shows the results from the second experiment. The scalability in terms of processing delay (from deformation calculation ⑫ to rule verification ⑥) is analysed, considering different number of tasks
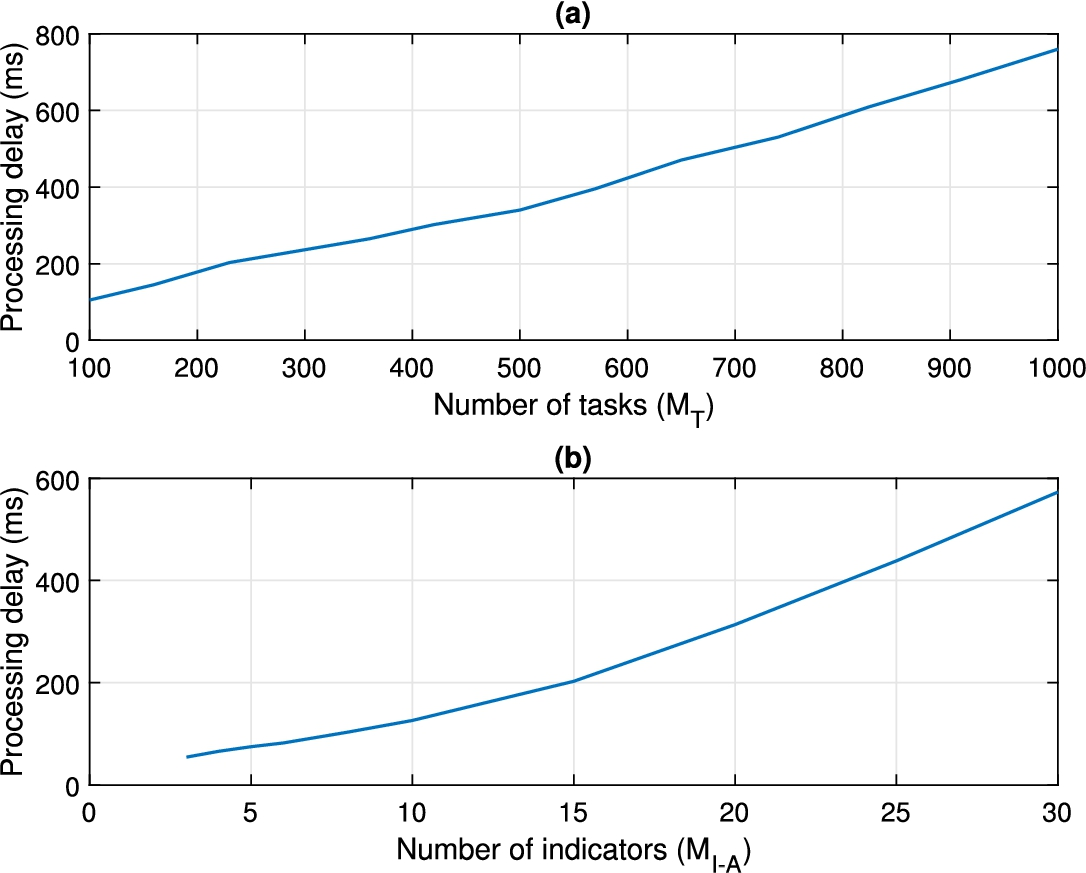
Processing delay evolution: scalability. (a) Number of tasks in the workflow. (b) Number of quality indicators describing each task.
Industry 4.0 solutions are composed of autonomous engineered systems where heterogenous agents act in a choreographed manner to create complex workflows. In this work, supervisory control techniques are employed to guarantee a correct execution of distributed and choreographed processes in Industry 4.0 scenarios. At prosumer level, processes are represented using soft models where logic rules and deformation indicators are used to analyse the correctness of executions. These logic rules are verified using specific engines at business level. These engines are fed with deformation metrics obtained through tensor deformation functions at production level. To apply deformation functions, processes are represented as discrete flexible solids in a phase space, under external forces representing the variations in every task’s inputs.
Experimental validation shows that the proposed mechanism improves the performance of traditional control solutions in a percentage between 10% and 300%, depending on the workflow to be executed. Besides, scalability of the proposed solution is almost linear with respect to the number of tasks in the workflow, and
As future works, it is intended to do a proof of concept in a relevant environment, a real food processing facility for the monitoring of production activities in a non-intrusive way. For this, it is necessary to consider, in addition to the technical challenges of integration with sensorization devices present in this relevant environment, ethical and privacy considerations for the workers who are in these facilities. For these tests and the continuation of this line of research we have a research framework with relevant food processing companies, established in accordance with the DEMETER project.