
Abstract
Ligand Based Virtual Screening methods are widely used in drug discovery as filters for subsequent in-vitro and in-vivo characterization. Since the databases processed are enormously large, this pre-selection process requires the use of fast and precise methodologies. In this work, the similarity between compounds is measured in terms of electrostatic potential. To do so, we propose a new and alternative methodology, called LBVS-Electrostatic. Accordingly to the obtained results, we are able to conclude that many of the compounds proposed with our novel approach could not be discovered with the classical one.
Introduction
The constant increase in the size of the databases used in Drug Discovery requires efficient techniques and methods that can be used to select the compounds most similarly to a query molecule and at the lowest possible cost. One of these techniques is Virtual Screening (VS). VS is an in-silico technique that allows large libraries with millions of compounds to be processed in order to find new compounds related to a pharmacological query based on one or more features (Hamza et al., 2012; Boström et al., 2013; Kumar and Zhang, 2016; Wang et al., 2009). This represents a great advantage over experimental methods such as High-Throughput Screening (HTS) in terms of efficiency, budget, time and development cost (Kar and Roy, 2013). The resulting compounds from VS are subsequently acquired and empirically tested in the laboratory. In addition, VS techniques are often used as a pre-filter for HTS (López-Ramos et al., 2009). All these advantages have increased the popularity of these techniques, which have experienced great advances over the last two decades. The interested reader is referred to previous works (Lešnik et al., 2015; Kalászi et al., 2014; Liu et al., 2011; Dou et al., 2018; Schmidt et al., 2018) for a description of different methods and tools currently used on VS.
However, there is still room for improvement regarding the accuracy of VS predictions so as not to discard promising compounds, or to reduce the time and error of calculations that compute the different features of the studied compounds (Böhm and Stahl, 2003). VS applied to the electrostatic similarity of compounds is a clear example of this. Contrary to what happens when VS is applied to select the most similar compounds in shape or pharmacophore properties, where the tools base their predictions on scoring functions that measure these particular features (Lešnik et al., 2015; Puertas-Martín et al., 2019; Yan et al., 2013), the predictions in this field are not exclusively based on this descriptor, but on both the similarity of the three dimensional shape and electrostatic similarity (Tresadern et al., 2009; Chu and Gochin, 2013; Kim et al., 2015; Kossmann et al., 2016; Woodring et al., 2017; Maccari et al., 2011; Kim et al., 2016; López-Ramos and Perruccio, 2010; Hevener et al., 2012; Kaoud et al., 2012; Tiikkainen et al., 2009; Massarotti et al., 2014; Oyarzabal et al., 2009).
Broadly speaking, all the previous works follow the same methodology, called LBVS-Shape throughout this paper, although they may differ in the selection procedure used to determine the compounds proposed as best predictions. Essentially, they initially optimize the compounds in the database against the query in terms of shape by using ROCS (OpenEye Scientific Software, 2019a). After that they select a number N of compounds with the highest shape similarity values and then finally evaluate them in terms of electrostatic similarity.
The value of N is not fixed, as it depends on the particular study. Usually, N is less than
Additionally, we also believe that using a more realistic description of compound bioactivity during the optimization procedure may help to obtain better predictions. As such, we propose a new approach as part of this work, named LBVS-Electrostatic, which involves the direct optimization of the electrostatic similarity. To do so, a new version of the algorithm OptiPharm, called OptiPharm_ES, has been implemented. OptiPharm (Puertas-Martín et al., 2019) was initially designed to optimize the shape similarity between two given molecules, but now it has been adapted to maximize the electrostatic similarity. As results will show, the new LBVS-Electrostatic methodology is able to obtain better solutions than the ones obtained with the classical LBVS-Shape approach.
The rest of the paper is organized as follows. Section 2 gives a brief description about the mathematical formulation of the scoring functions. Sections 3 and 4 describe the two methods used for virtual screening based on electrostatic similarity, both the literature approach and the novel proposal. The former is currently the method most frequently used in the literature. In short, it computes a sublist of molecules with the highest three-dimensional shape similarity. Usually, such a sublist is only composed of less than
Scoring Functions to Measure Similarity Between Compounds
This section is devoted to defining the mathematical functions used to guide the searching processes. The figures in which the values of these objective functions are graphically represented have been created with VIDA v4.4.0 (OpenEye Scientific Software, 2019b) using the default configuration.
Shape Similarity
The shape similarity of two compounds is calculated as follows:
Notice that the accuracy obtained from (1) depends on the number of atoms in the two compared molecules, i.e. the higher this number, the longer the value of
The electrostatic similarities are obtained by numerical solution of the Poisson equation (Böttcher et al., 1974), viz:
Again the accuracy obtained by (5) depends on the number of atoms in the compared molecules. As such, similarly to what was done previously, the Tanimoto Similarity (Jaccard, 1901) value has been computed as follows:
This method bases its predictions on a previous pre-filtering process consisting of identifying the N candidate compounds from the database with the highest shape similarity. After that, for each selected compound, the electrostatic similarity is calculated at the optimum superimposition obtained in the previous stage. Finally, the molecule with the highest electrostatic similarity value is selected as the one for the solution.
In this work, we have used the tool ROCS (OpenEye Scientific Software, 2019a) to optimize the shape similarity between two molecules. ROCS is a parametrized piece of software used to maximize volume overlapping similarity and utilizes the previously described (3) to represent molecules by means of Gaussian functions (Grant and Pickup, 1995; Grant et al., 1996). Electrostatic similarity has been calculated using the ZAP Toolkit (see (6)). This software has been downloaded without modification from the original website (OpenEye Scientific Software, 2019c). It is worth mentioning that ROCS and ZAP are, by far, the most widely used tools in the literature for VS based on shape and electrostatic similarity (Ellingson et al., 2010; Thomas et al., 2013; Hawkins and Stahl, 2018; Connelly et al., 2015; Gowthaman et al., 2015). For this reason they have been selected as part of this study; i.e. a fair and complete study must be carried out by making a comparison with the state-of-the-art methods.
The New Approach: A LBVS Method Guided by Electrostatic Similarity (LBVS-Electrostatic)
Our main aim when using this approach is to obtain the compound(s) with the highest electrostatic similarity values. Thus, an optimization problem must be defined with this aim in mind. Broadly speaking, any tool, method or algorithm used will be better guided towards the optima if the objective function is a numerical model representing the real objective. Until now, most methods focus on prioritizing the search of compounds with the same global shape, while they place electrostatic similarities at much lower priority. Consequently, they solve a shape similarity optimization problem instead of focusing on the electrostatic similarity, which may be more useful from the drug discovery point of view.
The new approach being presented here is based on the idea that the scoring function used to guide the optimization method must be mainly based on electrostatic similarity, since it is very likely that compounds with very high electrostatic similarity will share very similar chemical properties. The same can not be said while just focusing on shape similarity. In the latter, the search may converge to a sub-optimal solution (Ivorra et al., 2018; Fernández et al., 2017, 2019). OptiPharm (Puertas-Martín et al., 2019), a recent algorithm proposed for working on LBVS problems, is used to prove our hypothesis. The interested reader is referred to as Puertas-Martín et al. (2019) for an in-depth description of this algorithm. For the sake of completeness, some of its main strengths and important features are briefly described in the following.
OptiPharm is a global evolutionary optimizer that can solve any optimization problem that concerns the computation of the similarity of two compounds, named query and target. It implements procedures to increasingly adjust the query molecule to the target, which remains fixed throughout the optimization method. A solution s represents the rotation and translation of the query with respect to the target. The parameters associated with s are dynamically bounded for each particular instance to reduce as much as possible the feasible region.
OptiPharm analyses the entire search space looking for likely areas where the local and global optima can be. To do so, it runs on a set of M solutions, called population, on which it applies a sequence of reproduction, selection and improvement procedures during several iterations.
Each solution in the population has a radius value that delimits a multidimensional subarea of the search space where the reproduction and improvement methods are applied. The radius corresponding to a solution depends on the iteration i where it was created. The real strength of the radius is that it allows us to focus the search on different subareas since many solutions with different radii can coexist simultaneously during the optimization procedure. Therefore, at the same stage of the optimization procedure, new promising regions are systematically analysed, while others are examined thoroughly. Besides, the maximum number of initial solutions M, the number of iterations
Figure 1 shows the main stages of the algorithm and a brief description of the procedures implemented.
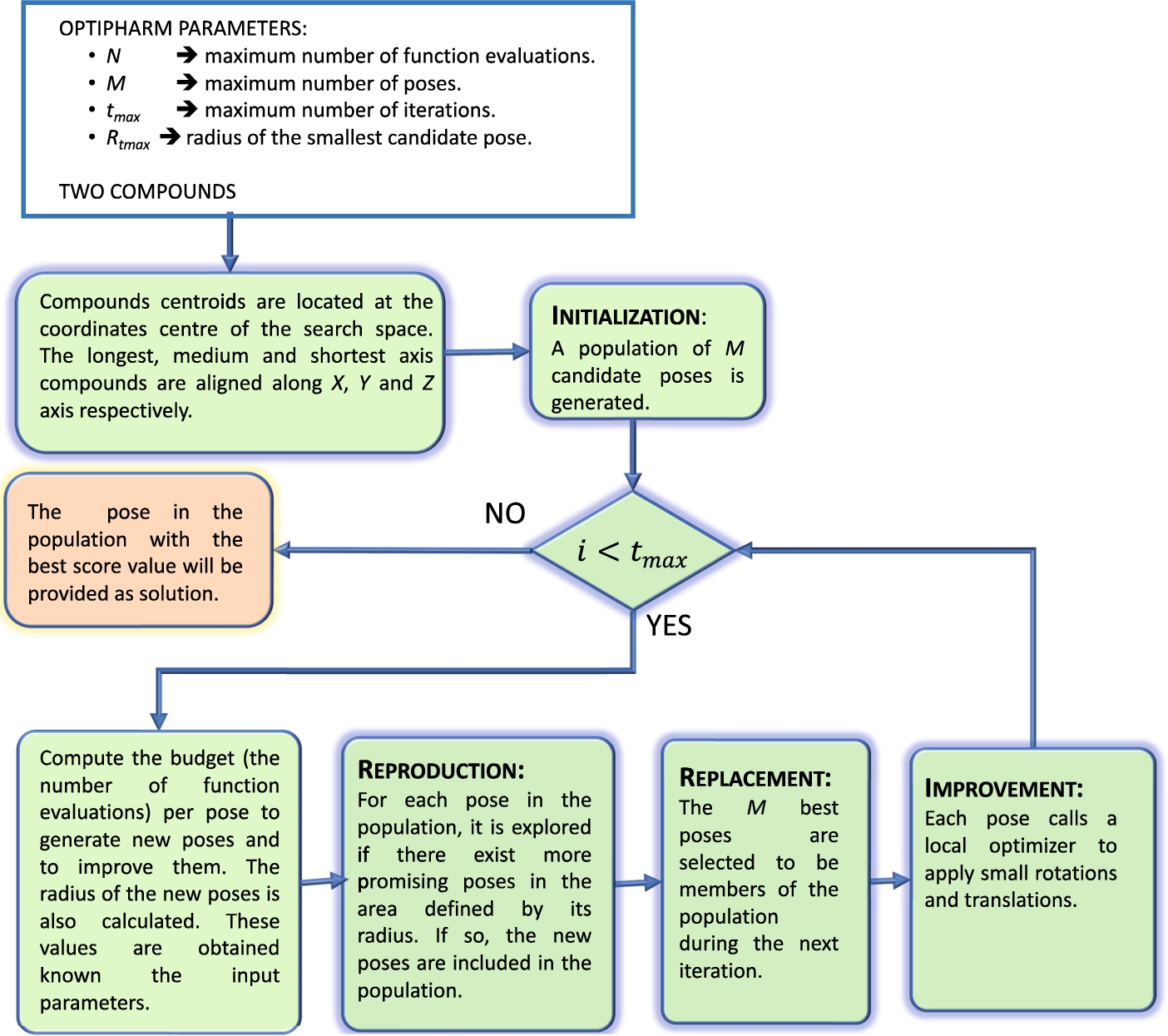
OptiPharm algorithm: main stages.
During this work, the scope of its functionalities has been extended to include the electrostatic potential as the scoring function. The new version has been called OptiPharm_ES. The electrostatic similarity between two compounds has been computed by using the source code of the ZAP Toolkit, also downloaded from
All the experiments in this work have been executed using a Bullx R424-E3, which consists of 2 Intel Xeon E5 2650v2 (16 cores), 128 GB of RAM memory and 1 TB HDD (
Benchmarks
In this work, a database provided by The Food and Drug Administration has been used (FDA). The Food and Drug Administration is a federal agency of the United States Department of Health and Human Services responsible for protecting and promoting public health by controlling, among other things, prescription and over-the-counter pharmaceutical drugs (medications). This agency provides a data set containing 1751 compounds, which represents approved medicines that can be safely used on humans in the USA. This database is useful since in the high similarity cases it would directly contribute to drug re-purposing. This is of relevant utility given the clear trend regarding re-purposing drugs observed over the last 5 years (Dakshanamurthy et al., 2012; Kumar and Zhang, 2018; Yuan et al., 2017).
The version of the database used in this work was obtained from DrugBank v5.0.1 (Wishart et al., 2018) and necessary mol2 files for the VS calculations were set up by using AmberTools (Case et al., 2017) by removing salts and neutralizing their protonation state, computing partial charges by MMFF94 force field, adding hydrogen atoms and minimizing energies (default parameters) (Halgren, 1995).
A comprehensive computational analysis may cover a representative sample of the database. The compounds included in the FDA database have different attributes, one of the most relevant for the study at hand being the number of atoms. In this work, a selection of 50 compounds has been made in the following way: the compounds in the database have been sorted by the number of atoms, including hydrogen, and then divided into 24 intervals (see Fig. 2). From each sector, at least one compound was chosen at random and proportional to the number of compounds in the sector.
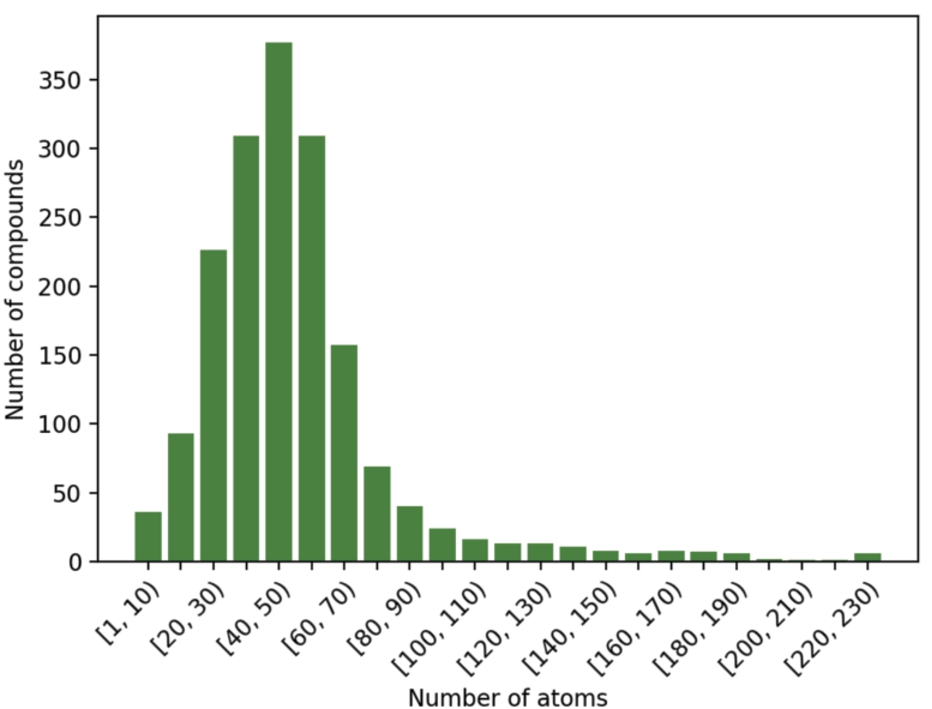
Number of compounds included in the FDA database, according to their number of atoms.
Finally, these comparisons between compounds have been run using OptiPharm_ES with the following input parameter configuration:
Influence of the Size List of Top-Ranked Compounds in the LBVS-Shape Method
As previously mentioned, the LBVS-Shape bases its predictions on a pre-selection of the first best compounds in terms of superimposition score (N). In this subsection, a study has been conducted to know how the value of N affects the final results from the point of view of electrostatic similarity. In particular, the LBVS-Shape has been performed on the selected 50 queries and for five different values of N, i.e. N has been set to 175, 438, 876, 1313 and 1751 compounds. It means that for each query, we have selected either
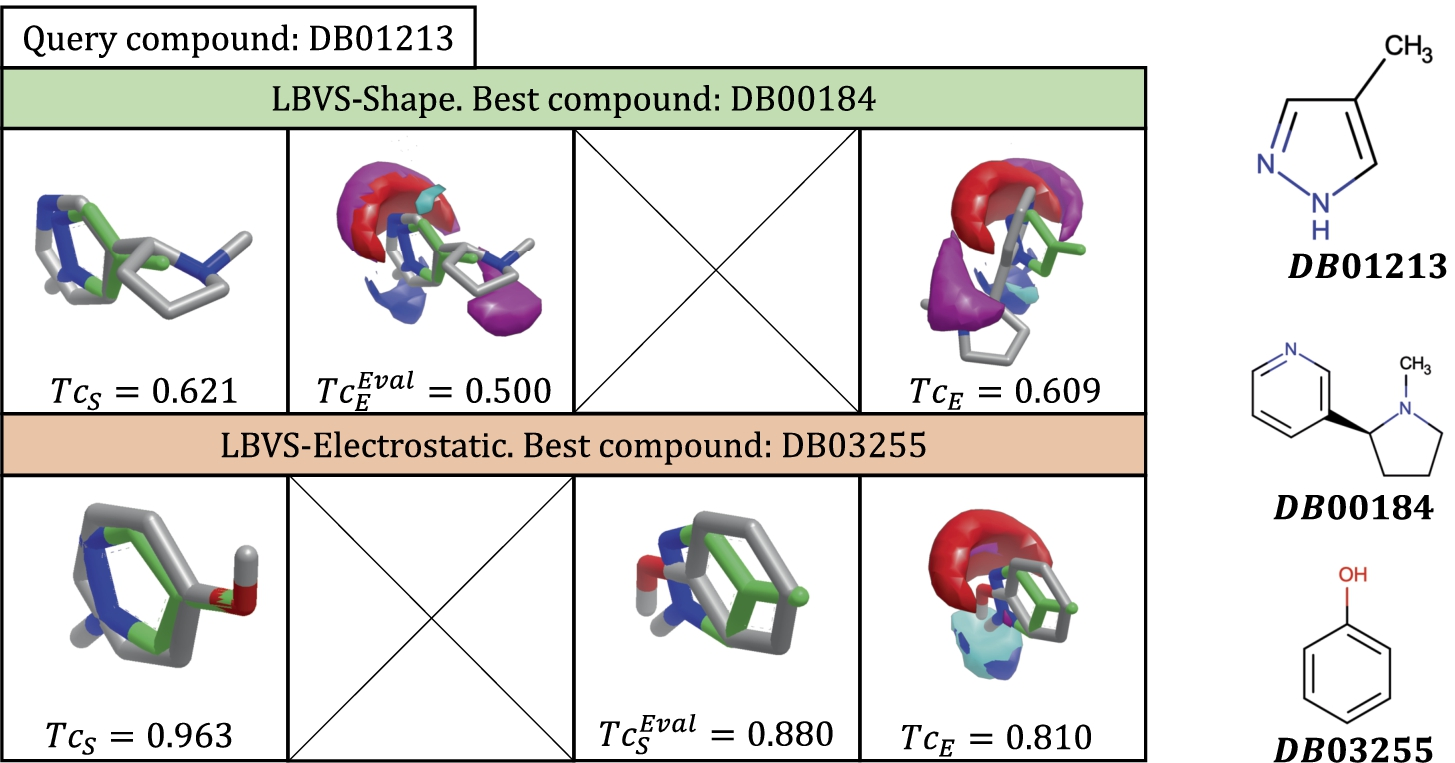
Figure 3 illustrates a toy example of the main steps of the LBVS-Shape method for the
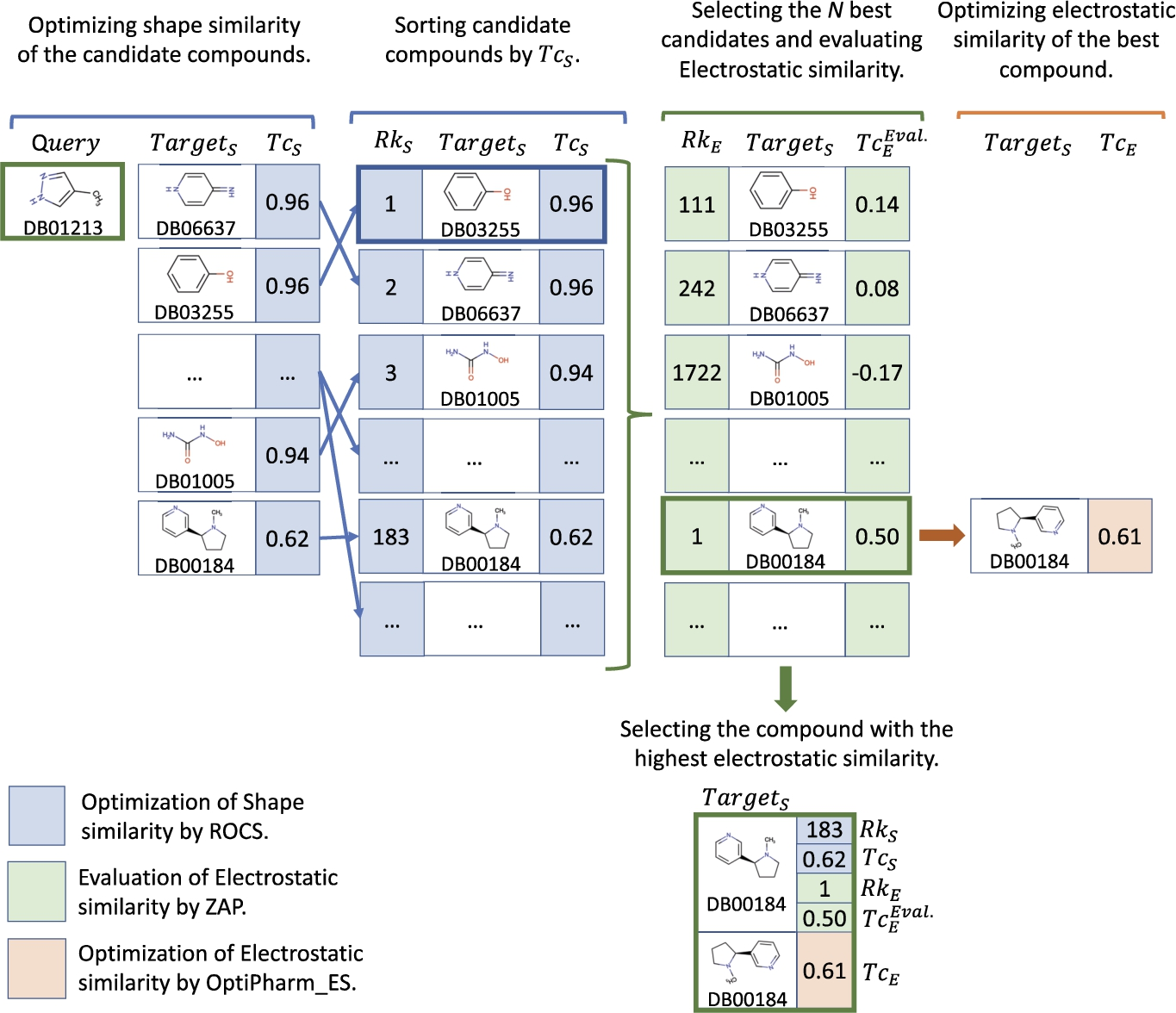
Toy example of the performance of the LBVS-Shape method for a particular case where
To get an overview of the results, average values of the BestComp found for the 50 queries and each value for N have been computed, and shown in Table 1. In particular, the average position
As it can be seen, the predictions seem to improve in term of electrostatic similarity as the number N of selected molecules in the sorted list increases (see columns
Influence of the parameter N in the results obtained by the LBVS-Shape method. For each value of N, the following average values from the 50 queries, are shown: position in the shape ranking (
To analyse the performance of both methods, we have conducted a study in which the selected 50 molecular queries are processed with reference to the FDA database. Notice that comparing a query with itself always reaches the maximum similarity value, both for electrostatic potential as well as for shape. Subsequently, these results were removed when ranking the compounds. In other words, the compounds given as a result are not the most similar ones, but the second compounds in the ranked list. Additionally, as previously mentioned, the traditional method has been carried out considering the total number of compounds in the database
To illustrate how we generate the later summarizing tables, a sample of the results obtained by both methods when comparing a query to the molecules in the dataset is studied. In particular, the instance
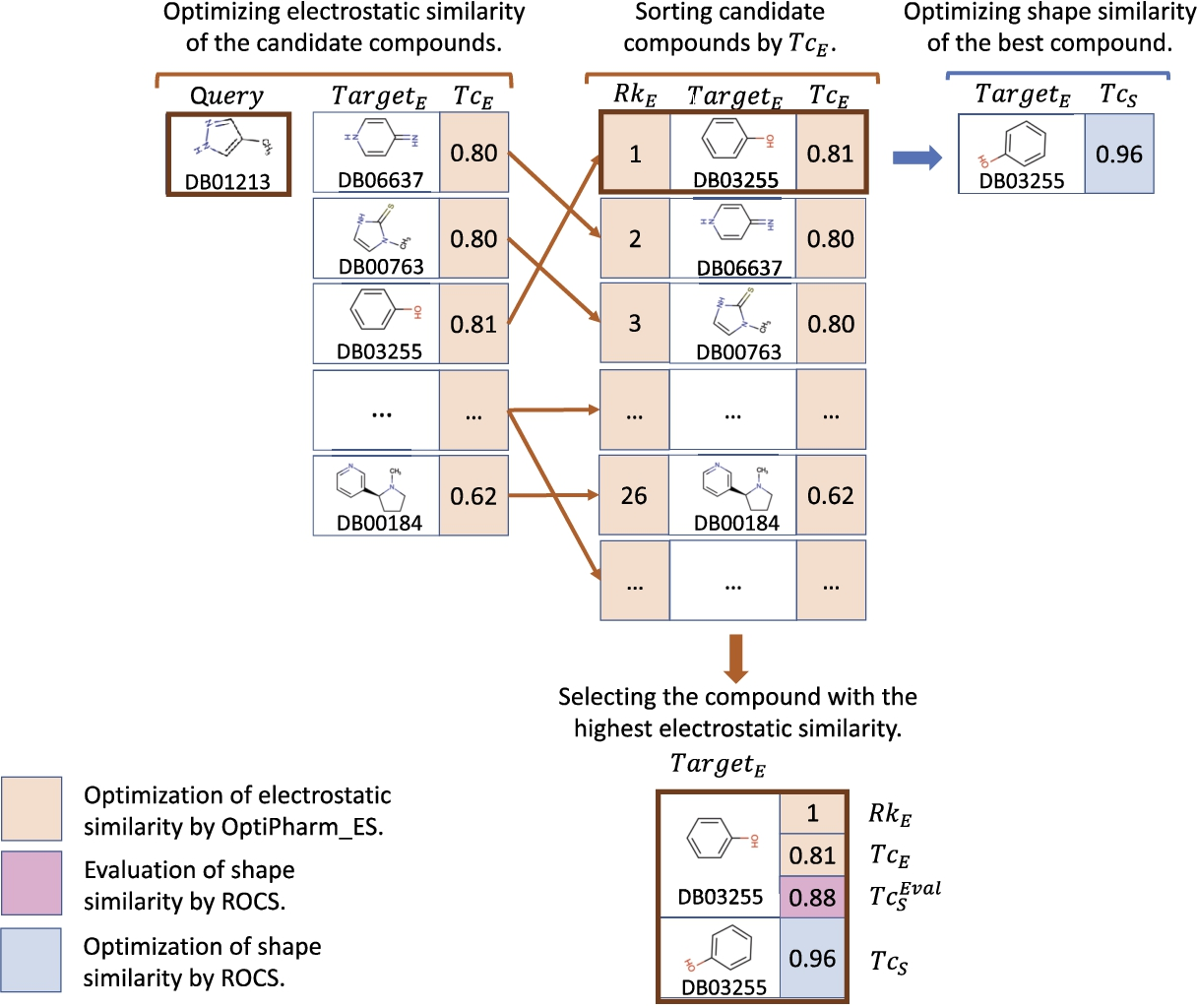
An example of the performance of the LBVS-Electrostatic method for a particular case where
For the sake of clarity and comparison, the results shown in Figs. 3 and 4 are summarized in Table 2. The meaning of the columns as well as the particular values in the tables, are the ones previously explained and shown in each figure. The last row corresponds to the values associated with the best predictions. As can be observed, each method obtains a different compound as a top solution. LBVS-Shape provides the DB00184 molecule with a
Summary of the results obtained for both LBVS-Shape and LBVS-Electrostatic methods for the query compound DB01213. The column notation, the colours included and the corresponding results come from Figs. 3 and 4, i.e. they maintain the same meaning as shown previously for those pictures. The last row indicates the results associated with the top solution selected for each method.
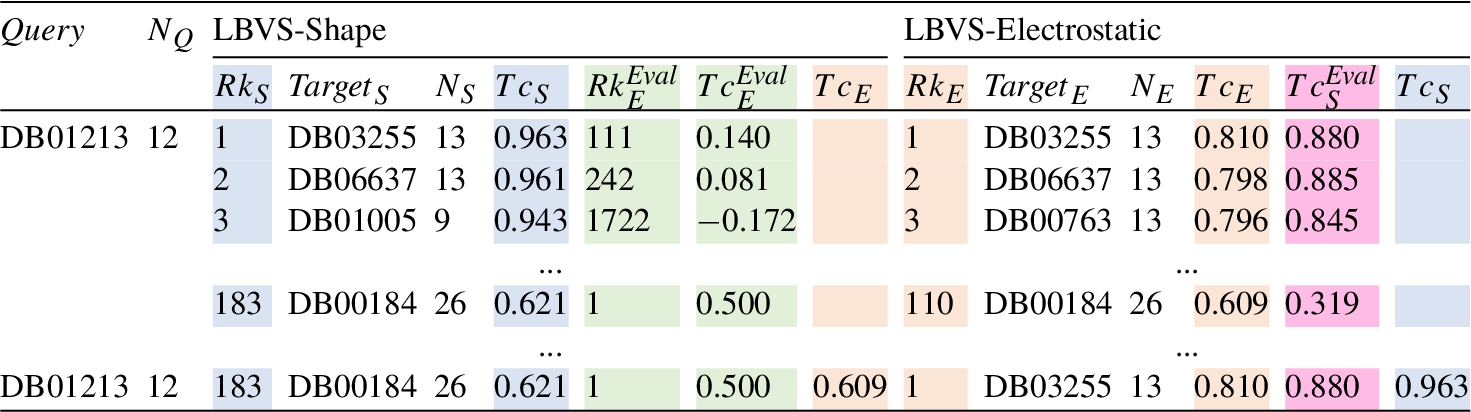
Summary of results of LBVS-Shape and LBVS-Electrostatic where
Rows are sorted by the number of atoms of queries. For each query, the same procedure explained in Table 2 is followed. The last row summarizes the average values for each column.
Once the specific case of DB01213 has been explained in detail, the results of the 50 queries have been summarized in Table 3. Columns
As evidenced, LBVS-Electrostatic obtains on average
Regarding shape similarity, it is possible to infer that, on average, the methods are equivalent in terms of accuracy of the predictions, i.e. LBVS-Shape obtains an average value of
Making a somewhat more detailed approach for compounds smaller than 50 atoms, which means the first 23 query compounds in the table, there are 5 cases where the difference is less than 0.05 (DB00529, DB00173, DB00331, DB00915 and DB01352) and in another 3 cases the difference is 0.1 (DB01043, DB07615 and DB01268). Considering the values of these 7 cases in which the shape LBVS-Electrostatic is smaller than that of LBVS-Shape, the average difference is 0.048, while the mean gain in electrostatic similarity for those 7 compounds is 0.271. In large compounds, which includes 27 queries, there are only two cases with similar characteristics, which are compounds DB09236 with a difference of 0.07 and DB06699 with a difference of 0.013, both of them for shape similarity. In view of these results, the LBVS-Electrostatic method seems to be justified when proposing new solutions for small compounds.
However, not all the improvements are related to electrostatic fields. The optimization of electrostatic potential using OptiPharm_ES might allow a better solution to be found in terms of shape too. Compounds DB01119 and DB1213 in Table 3 are some outstanding examples. For example, in the case of
The ZAP Toolkit has been widely used in the literature to calculate the electrostatic similarity score for two compounds (Boström et al., 2013; Tresadern et al., 2009; Chu and Gochin, 2013; Kim et al., 2015; Kossmann et al., 2016; Woodring et al., 2017; Maccari et al., 2011; Kim et al., 2016; López-Ramos and Perruccio, 2010; Hevener et al., 2012; Kaoud et al., 2012; Tiikkainen et al., 2009; Massarotti et al., 2014; Oyarzabal et al., 2009; Haque and Pande).
In this subsection we would like to remark that the ZAP Toolkit can return an erroneous value, which was discovered when using OptiPharm_ES. During the optimization procedure, OptiPharm_ES can progressively separate two input compounds aimed to escape from local optima and explore the searching space in depth. In fact, it is possible to analyse cases where no overlap exists between the input molecules. During the analysis of the results, we discovered that cases exist where the ZAP Toolkit can overflow, mainly when situations such as the previously mentioned happen. See Fig. 6 to see a particular example. Herein, compound DB01365 remains fixed on the left while compound DB00459 occupies three positions (red, blue and pink). The red compound obtains an electrostatic similarity value of 1. The light blue compound is displaced half a unit to the left, i.e. closer to the reference compound and its similarity value is 0.38. The pink compound is shifted 0.5 units to the right, that is, away from the reference compound. Its similarity value is 0. Calculations can be made using the ZAP Python script available at
This problem has been solved in OptiPharm_ES by considering the poses with the previously mentioned problem unfeasible. It means that they are no longer considered during the optimization process.
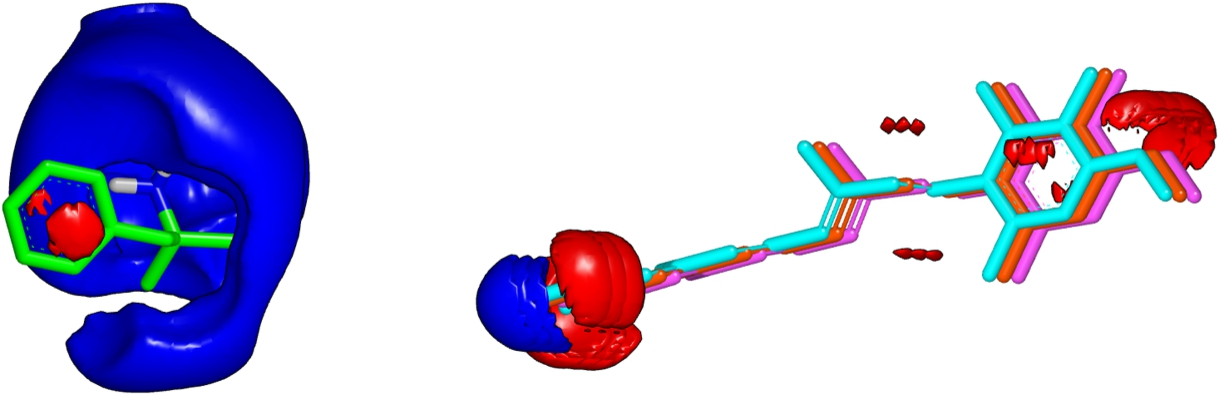
Compound DB01365 is printed green. Compound DB00459 is represented in three coloured figures: light blue, red and pink. Electrostatic fields are printed in dark blue and red using VIDA.
In this work, a new approach to solve the LBVS problem based on the electrostatic similarity has been put forward. It has been called LBVS-Electrostatic. This methodology is based on the direct optimization of electrostatic similarity. For this purpose, a new version of OptiPharm has been used. Conversely, the method proposed in the literature, which has been named LBVS-Shape throughout the paper, looks for a sublist of the top compounds with the highest shape similarity by using ROCS, to later evaluate their electrostatic similarity with ZAP. In this work, a study to analyse the influence of the number of compounds in such a sublist has been carried out. As the results have shown, the larger the number of molecules considered, the better the prediction obtained in terms of electrostatic similarity. From this conclusion, a computational study has been carried out to compare the new method LBVS-Electrostatic with the one in the literature LBVS-Shape. To increase the probability of finding good predictions, LBVS-Shape has been executed taking into account the whole database prior to the electrostatic similarity evaluation. Even so, LBVS-Electrostatic performs better than LBVS-Shape, achieving better predictions in electrostatic potential for the 50 queries included in the study. Regarding the shape similarity, both methods behave in a similar fashion, on average obtaining compounds with similar shape similarity values. It is important to mention that the new methodology proposed in this paper is novel, which means that the predictions proposed have not been analysed previously.
Finally, we have shown that ZAP can return erroneous values. This is an important discovery, since it is the most commonly used software in the literature to measure the electrostatic similarity.
In the future, we have plans to implement this objective function from scratch, but for the study at hand, we considered that it was more important to compare it with the state-of-the-art software. Additionally, other functions measuring the pharmacophore similarity will be implemented. Finally, we will analyse the problem from a multi-objective perspective, where shape an electrostatic similarity are optimized simultaneously.
Footnotes
Appendix Availability of data and materials
Project name: OptiPharm_ES. Project home page: Project source code repository: Operating system(s): Linux and MacOS. Programming language: C++. License: Mozilla Public License 2.0. Any restrictions to use by non-academics: licence needed, contact with the authors.
The databases belong to their authors and access to them depends on any applicable restrictions.
Acknowledgments
Powered@NLHPC: This research was partially supported by the supercomputing infrastructure of the NLHPC (ECM-02). This research was also partially supported by the supercomputing infrastructure of Poznan Supercomputing Center and by the e-infrastructure program of the Research Council of Norway, and the supercomputer center of UiT – the Arctic University of Norway. The authors also thankfully acknowledge the computer resources and the technical support provided by the Plataforma Andaluza de Bioinformática of the University of Málaga. This work was partially supported by the computing facilities of the Extremadura Research Centre for Advanced Technologies (CETA–CIEMAT), funded by the European Regional Development Fund (ERDF). CETA–CIEMAT belongs to CIEMAT and the Government of Spain. Additionally, the authors would also like to thank N.C. Cruz and J.J. Moreno for their technical support.