
Abstract
Many image translation methods based on conditional generative adversarial networks can transform images from one domain to another, but the results of many methods are at a low resolution. We present a modified pix2pixHD model, which generates high-resolution tiled clothing from a model wearing clothes. We choose a single Markovian discriminator instead of a multi-scale discriminator for a faster training speed, added a perceptual loss term, and improved the feature matching loss. Deeper feature maps have lower weights when calculating losses. A dataset was specifically built for this improved model, which contains over 20,000 paired high-quality tiled clothing. The experimental results demonstrate the feasibility of our improved method and can be extended to other fields.
Introduction
Today, the world has entered the information era. E-com-merce has also achieved great progress and is increasingly becoming an indispensable component of our daily life. In the past, it was necessary for people to go to physical stores and have a try-on before buying. However, it's inconvenient to go to a clothing store every time we feel like purchasing clothes. Online shopping makes it possible to trade in the absence of going outside. For most individuals, purchasing garments of interest on e-commerce platforms (e.g., Taobao, http://www.taobao.com) is a desirable choice. In daily life, we often see models or celebrities like film stars wearing good-looking costumes on TV or advertisements, but we don't know where to find them. A very prevalent practice is to put the model pictures on the e-commerce platform to retrieve the same clothes. However, it is obviously an unwise choice to use the clothes worn on the models because a model in a bad pose could have a devastating impact on retrieval performance. A tiled clothing picture taken of a model can truly improve the accuracy of clothing retrieval.
Generating images from a conditional image is a typical image transformation problem. Therefore, we can use image-to-image translation methods to tackle this typical issue, producing tiled clothes images from model images.
Several years ago, researchers first proposed generative adversarial networks (GANs). 1 GANs consists of two parts: a generator and a discriminator, and both of them composed of a multi-layer perceptron. The generator deceives the discriminator by learning the data distribution of the whole dataset to synthesize pictures that have the same data distribution as the dataset, while the discriminator makes all efforts to distinguish the generated image from the real image by training and learning. The training process is like a minimax two-player game, eventually reaching the Nash equilibrium.
GAN's learning style gives it great potential because neural networks can be used to fit arbitrary data distributions. In the field of computer vision, GANs have been widely used. Based on the GANs model, it has been successful in some computer vision problems, such as text-to-image translation,2-4 image-to-image transformation,5-13 super-resolution,9-13 and realistic natural image generation.
There are three mainstream directions for GAN research. First, for the purpose of improving the quality of generated images.5,6 Second, for stabilizing the training process and shortening the convergence time.14-20 Third, to apply generative adversarial networks theory into practice.2-4
In this study, we are committed to the practical application of GANs, and present a novel modified pix2pixHD network, which can synthesize high-resolution and detail-rich tiled clothing images conditioned on model images.
The paper is organized as follows. We briefly introduce some other work related to our network, including GAN and its derivative models,21,22 and image-to-image translation. Our detailed network architecture is then illustrated, and we introduce the improved loss functions, including the perceptual loss9,23 term and the improved feature matching loss 12 term. Dataset production, implementation details, and final results are then presented. Finally, the conclusion is presented and future work is discussed.
Related Work
GANs
Training a GAN is tricky, and the training process is unstable and difficult to converge, which is a notorious shortcoming. What's more, the generated images are sometimes far from the real picture. Further efforts14,15,18–21 were made to improve the image generation performance. For example, DCGAN 21 is the first combination of a convolutional neural network (CNN) 24 and GANs to solve the training instability problem, but the mode collapse occurs after long time training. Further attempts have been made by other scholars; they propose a novel metric to evaluate the discrepancy between the synthesized picture and the target picture in place of the Jensen-Shannon (JS) divergence: the Wasserstein distance, 14 which is also called the Earth-Mover (EM) distance. Wasserstein GAN 14 can also mitigate the problem of training instability and reduces mode collapse. WGAN-GP 22 is an improved version that points out problems with weights clipping in 14 and adds a gradient penalty term to further alleviate training instability. LSGAN 17 replaces the loss of the original GAN with a novel least squares loss. The discriminator of BEGAN 22 applies an encoder-decoder structure to solve the imbalance problem between the generator and the discriminator. In addition, GANs generate samples in a random fashion and cannot be made full use of in practical applications. Conditional GAN 25 can generate pictures of specific categories, but it requires us not only to input random noise during training, but also to input the conditional information.
Image-to-Image Translation
Many scholars now use generative adversarial nets to implement image-to-image translation tasks. Most of them are based on conditional GAN, 25 which is characterized by using the input image as a condition to translate the input image into the target image in another domain. One reason why adversarial learning is favored is that compared to L1 or L2 losses, which makes generated images over-smoothing, 8 adversarial losses can produce more realistic details. Image transformation is mostly cross-domain, for example, day-to-night, sketch to shoes, and so on. Pix2pix 8 is an excellent conditional GAN-based image translation model, and a large amount of experiments have proved its feasibility. It uses a modified U-net 26 as its generator, adding skip connections between the mirror layer of the encoder and decoder, which shares low-level information such as shape between the conditional image and the generated image. pix2pixHD 12 is proposed to generate high-resolution images conditioned on input images. Both of the previous two methods require a massive number of image pairs for training. However, paired picture data is difficult to obtain and is expensive in both human and material resources. Unlike pix2pix and pix2pix-HD, CycleGAN 11 can realize cross-domain image translation without paired images as the training set (e.g., image style transfer).11,23 In addition, it introduces cycle-consistent loss to enhance the performance of the network. Similar work is also used in image super-resolution, like SRGAN 9 and ESR-GAN, 13 to synthesize a corresponding high-resolution image given a low-resolution image.
Our Method
pix2pixHD was used as a basic framework to generate high-resolution images of realistic tiled clothing from a model wearing clothes. The discriminator tries to distinguish the ground-truth (GT) and the generated image as much as possible.
Network Architectures
Generator
Similar to the original pix2pixHD, our generator consists of two modules: the coarse module and the fine module. Both of them contain three parts: convolutional blocks, n residual blocks, 27 and transposed convolutional blocks. The network architecture of our generator is visualized in Fig. 1. The input of the fine module image resolution is 1024×512, while the coarse module works at a resolution of 512×256, which is obtained by downsampling the input image. The coarse module works at a lower resolution, which consumes less computing resources while acquiring global information, such as shape and color. After the input image passes through the convolutional blocks in the fine module, the obtained feature maps are combined with the last feature map of the coarse module before being fed into the residual blocks, which fuses global information and local information together to generate high-resolution images.
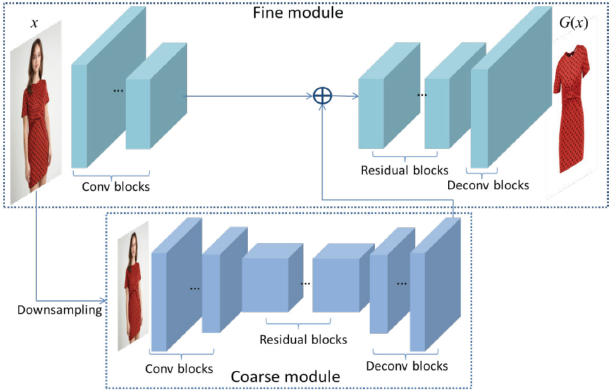
Network architecture of generator. There are two components: coarse and fine modules. The input of residual blocks in fine module is the addition of the last feature map of coarse module and the last feature map from convolutional blocks of fine module.
Discriminator
As for the discriminator, we did not use the multi-scale dis-criminators. 12 High-resolution images mean larger size images and will increase the amount of computation. Multi-scale discriminators determine whether the picture is real at three scales (×1, ×1/2, ×1/4), which inevitably results in a longer training phase. Instead, we use the single Markovian discriminator, PatchGAN 8 , which determines whether each N×N patch in the whole image is real or fake. N is a hyper-parameter, representing the size of each patch. An image can be divided implicitly into dozens of patches, and the authenticity of the whole picture is determined by mean of all patches. Using the Markovian discriminator as the discriminator reduces the amount of parameters and training time of the entire network, and more importantly, it can process images in arbitrarily size. Fig. 2 shows our discriminator architecture.
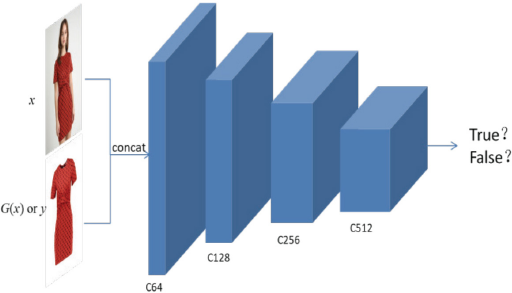
Network architecture of discriminator. Our discriminator is a 4-layer fully convolutional network, whose input is the concatenation of x and G(x) or y in channel. Ck represents the number of channels.
Perceptual Loss and Improved Feature Matching Loss
Perceptual Loss
Perceptual loss has been widely used for style transfer and super-resolution. To enhance the perceptual similarity between generated images and targets, perceptual loss is used to constrain the difference of feature maps of different images in the high-dimensional feature space. We used the pre-trained VGG1928 model on the ImageNet dataset to obtain a high-level representation of the image. ϕi, j represents the feature map within VGG19, where i and j indicate before the i-th pooling layer and the j-th convolu-tional layer (after activation function) respectively. So, our perceptual loss can be formulated as the L1 distance between generated images G(x) and target images.
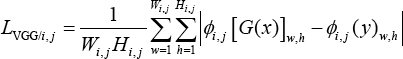
x is the conditional image, and Wi,j and Hi,j denote the width and height of the feature map obtained from the VGG19 network.
Improved Feature Matching Loss
In addition to adding perceptual loss, we improved the feature matching loss by weighting every intermediate layer. The feature matching loss was first proposed to dispose of the imbalance problem that the discriminator is inclined to overtrain during training by matching the representation of images generated by the generator and ground-truth in the intermediate layer of the discriminator. 14 In multi-scale discriminators, 12 the weights of all intermediate layers are the same when calculating the feature matching loss. Inspired by previous work 29 we set a greater weight for the shallower layer feature map to obtain better performance. Assume that Dk represents the feature map after the k-th convolutional layer within the discriminator. Therefore, our improved feature matching loss LFM is expressed as Eq. 2.
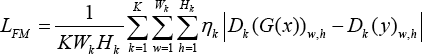
K is the number of convolutional layers in the discriminator, ηk indicates the weight of the k-th layer, and Wk and Hkare the width and height of the feature map after the k-th convolutional layer.
Objective Function
The loss function of traditional conditional GANs can be represented as in Eq. 3.
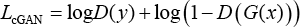
But in this study, we fed respectively transformed clothes images and ground -truth images into the discriminator after concatenation with conditional images in the channel. Hence, our conditional GAN loss is represented by Eq. 4.
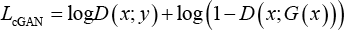
(x; ∙) indicates concatenation with x.
To further improve the performance of the network, we combined adversarial loss with a traditional loss, such as L1 or L2 loss. A traditional loss encourages the generated tile image to be closer to the ground-truth in pixel-wise level. Many previous solutions exhibit that L1 loss is less prone to bring out blurry results compared to L2 loss, which is mainly caused by the greater penalties for pixels with large differences. The L1 distance between G(x) and y, which we denote as Lcontent can be expressed as Eq. 5.
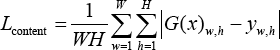
W and H are width and height of generated images.
Therefore, our final objective function is expressed in Eq. 6.
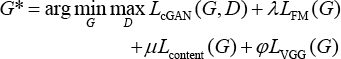
λ, μ, and φ are the importance of each loss term. Different weight of each kind of loss λ, μ, and φ are defined as 10, 100, and 1, respectively.
Experiments
Dataset
Currently available open clothing datasets like DeepFash-ion 30 and MVC 19 cannot satisfy our demands: paired model images and tiled clothes worn by models. Therefore, we exploited a WebCrawler program to collect images from the Internet and create our own dataset. All images in our data-set were acquired from the German e-commerce platform Zalando (http://www.zalando.com). Clothing pictures exhibited at this (big e-commerce platform are of high quality, complete in variety, and are high resolution. The obtained images were manually screened by us, the appropriate pictures selected, and pair model pictures and corresponding garment pictures obtained individually. After preparation, our dataset contained 22,777 pairs of images, of which 20,119 pairs were used as training sets and the remaining 2,158 pairs were tested. There are seven categories of clothing in the dataset, namely T-shirts, shirts, jackets, trousers, jeans, skirts, and dresses. Toalleviate the influence of the unbalanced sample amount of each class on the experimental results, each type of image pairs was greater than 2000. Part of our dataset image pairs are shown in Fig. 3.

Example image pairs of our built dataset. There are seven categories of clothing included in it.
Implementation
The implementation of this study was based on Google's deep learning framework TensorFlow. Our network trained on NVIDIA TITAN V in an end-to-end manner. Like most other GANs, Adam Solver is adopted as optimizer with a learning rate of 0.0002 and momentum of 0.5. There was no learning rate decay during training. We initialized network weights with a normal distribution with a mean of 0 standard deviation of 0.02. The network trained for 200 epochs with a batch size of 1. The resolution of the original images was 1280×762, and were resized to 1024×512 before being fed into the network. In addition to the size change, the image was also augmented (such as horizontal flip) to increase the amount of data. Hyper-parameter i and j were predefined as 5 and 4. Patch size N was set to 70. The quantity of convolutional layer K is 4, and weight of each layer from η1 to η4 was 3, 1.5, 1.5, and 1. The amount of residual blocks in coarse module and fine module were 9 and 3 respectively. Different weight of each kind of loss λ, μ, and φ were defined as 10, 100, and 1, respectively. The hyper-parameters were set in this way to ensure that the content loss accounted for the largest proportion in the entire loss function.
Result Analysis
We compared our improved model with the original model pix2pix-HD, which was regarded as the baseline in our experiment. We tested our trained model on the test dataset, which contained 2,158 image pairs different from training dataset. We display part of our experimental results in contrast with baseline in large size in Fig. 4. Other result images are shown in Figs. 5 and 6 in a relatively small size. By contrasting our results with baseline and ground-truth in terms of perception, our produced clothing images were very close to ground-truth and performed well in generating details.

Example results of our network and other network. Our network produced high-resolution images with subtle details. The 3rd and 7th columns are our generated images.

Example generated images of our network, part I.

Example generated images of our network, part II.
Evaluation Metrics
Assessing the quality of images genera ted by GAN is an intricate issue. A desired GAN model not only requires the quality of generated images, but also the diversity. Inception Score (IS) 14 and Fréchet Inception Distance (FID) 31 are prevalently adopted as the evaluation metric of GANs. However, our object was to encourage the generated clothing image conditioned on a model as close as possible to the ground-truth, which did not require diversity of the generation model. Consequently, we used peak signal to noise ratio (PSNR) and structural similarity (SSIM), 32 which are widely chosen as evaluation metrics for image super-resolution, instead of IS or FID. PSNR is a method that assesses the pixel-wise difference between two images, which can be formulated as Eq. 7.
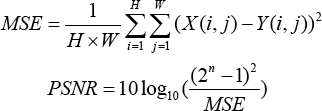
MSE is mean square error between X and Y, n is the number of bits per pixel. In our work, n is 8. The larger value of PSNR indicates that the discrepancy between generated images and ground-truth is smaller, and the quality is better.
Another method, SSIM, measures image similarity from the aspects of brightness, contrast, and structure, which can better reflect the subjective feelings of human eyes. It is defined as Eq. 8.
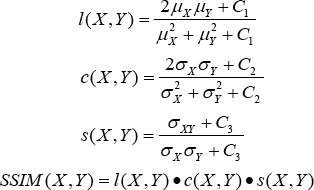
μX, μY, σX, σY, and σXY indicate the mean of X, Y, the variance of X, Y, and the covariance of X and Y, respectively, and l(X, Y), c(X, Yi), and s(X, Y) represent brightness, contrast, and structure similarity, respectively. The SSIM value ranged from 0 to 1; the larger the value, the smaller the image distortion.
Quantitative Comparisons
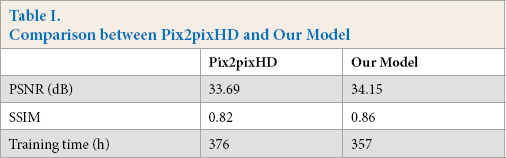
To quantify the performance of our produced clothing images, we calculated PSNR on both test results of pix2pixHD and the results of our improved version. Apart from this, we measured the training time of our model and the original model. Quantitative results are displayed in Table I. The training time of our model was shorter than pix2pixHD by almost one day (19 h), and the PSNR value was higher than that obtained with pix2pixHD, which justifies the superiority of our improved algorithm.
Comparison between Pix2pixHD and Our Model
There are also portion failure examples shown in Fig. 7. It was difficult to produce a clear boundary or a good result when the garment image contained the same color as the background and had a steep change in color. This tricky issue will be settled in future work.

Failure example images of our network.
Conclusion
This study investigated the practical application of an image-to-image translation model, which transforms model images into high-resolution tiled clothing images. Our modified method shortened the training time by changing the multi-scale discriminator to a single discriminator, and we introduced perceptual loss and improved the feature matching loss of the original pix2pixHD to improve the performance of the model. The experimental results test on our trained model show that those modifications strengthened the performance of original model significantly and that the method is of strong feasibility. At the same time, our results demonstrate that our method was promising and can be extended to other applications and fields.
Footnotes
Acknowledgements
This work is partially supported by the National Key Research and Development Program of China (2019YFC1521300), by the National Natural Science Foundation of China (61971121), by the Fundamental Research Funds for the Central Universities of China, and by the DHU Distinguished Young Professor Program.