
Abstract
Background
Interference in immunoassays may cause both false-negative and false-positive results. It may be detected using a number of affirmative tests such as reanalysis of certain samples using different assay platforms with known bias, after the addition of blocker antibodies, or assessment of linearity and parallelism following serial doubling dilutions.
One should look for interference where it is likely and has high medical impact. Probabilistic Bayesian reasoning is a statistical tool to identify samples where interference is most likely. But when looking for interference where it is likely, do we find it where it has the largest population health consequences?
Methods
We used information theory to quantify the effect of assay interference by calculating the Shannon information content (using logarithms with base 2). We then obtained lower bounds of the population health consequences of a particular test and combined these expressions to get lower bounds of the population health consequences of interference.
Results and conclusion
We suggest that assays having a low frequency of true positives should be the primary target of retesting because: (i) assays with a low frequency of true positives exhibit a high likelihood of interference and (ii) the population health consequences of false-positive results are generally higher for assays with a low frequency of true positives. Finally, we give a worked example having a realistic frequency of interference and test costs. In some immunoassays (e.g., tumour markers), adding a blocker to all tests can be a more cost-efficient mean than retesting positive samples.
Introduction
In a recent article, Ismail et al. 1 used Bayes’ theorem to show that the relative number of false positives tends to be higher when using immunoassays with a low rate of true positives to diagnose disorders with low prevalence. The expression obtained by probabilistic Bayesian reasoning for the probability of identifying a false-positive test result by retesting the sample with a different assay is f/(t + f) and thus dependent both on the frequency of false positives (f) due to interference and on the frequency of true positives (t). In non-Bayesian terms, we would refer to this expression as the positive predictive value of interference detection by retesting. Such retesting will, in practice, identify most of the interferences, but not all. For simplicity, our calculations will be based on retesting for interferences as previously described. 1
Probabilistic Bayesian reasoning provides a statistical basis for identifying the samples where interference is most likely a posteriori (post-test, i.e. it may be applied only when a test result, e.g. ‘positive’/'negative’ is available). However, probabilistic Bayesian reasoning is not an a priori measure (pre-test, i.e. a measure that may be applied before a test result is available), so it is not an informative measure when reducing interference in an assay, where an a priori measure is needed. Furthermore, it does not estimate the population health consequences of interference. Depending on the assay, the population health benefits of test results vary greatly. The detection of human immunodeficiency virus (HIV) antibodies by an immunoassay has much greater impact on population health (since a positive HIV test may both reduce further spreading of the disease and offer the affected individual an opportunity to receive effective treatment) than an immunoassay test result suggesting slightly elevated testosterone concentrations in a male adult.
This paper introduces information theory both as an a priori measure of interferences and as a tool to identify assay interference with the most substantial population health consequences. After a brief introduction into information theory, we show that retesting positive samples from assays with a low frequency of true positives makes double sense because of both a higher likelihood of interference being present in these tests and generally higher population health consequences of a true-positive test result.
Preliminaries of information theory
Information theory is the aspect of quantitatively treating information content, or knowledge. The theoretical foundations were first laid by Claude Shannon 2 and can be found in different standard text books. 3,4 Like in several previous scientific papers published by others, 5–8 we will concentrate on information theory in the context of diagnostic tests. The framework of information theory is as follows.
When performing a test for a diagnostic purpose, we gain knowledge after having received the test result. This knowledge, in a mathematical aspect, should be additive. If the same information is obtained by either two sequential tests or a single test, the sum of knowledge of the two sequential tests should equal the knowledge obtained by the single test. Furthermore, if we get to know something that seemed unlikely before testing (i.e. had a low probability a priori), it will count more compared with a more likely result. The impact of a test must thus be a monotonically decreasing function of the probability of the test result. Mathematically, the only way to combine additivity and a decreasing function of the probability is to apply a logarithmic function. A commonly used base of the logarithm is 22, with the resulting unit of measurement being bits. The Shannon information content of the test outcome is thus:
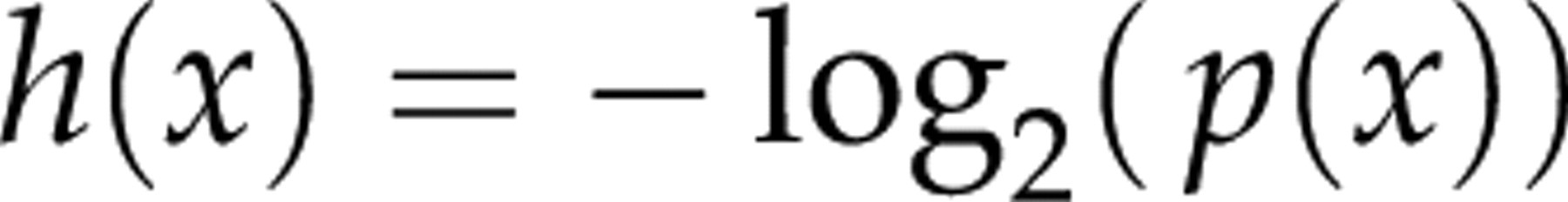
Information theory and diagnostic tests
A definitive test may be considered as a test with the highest accuracy; thus, it entails no false results (positive or negative) and provides a final answer irrespective of the disease prevalence in the tested population. Therefore, the information content of a definitive test solely depends on the prevalence of the disease in the tested population. If hepatitis C antibodies are to be found in 1.7% of the Norwegian population, a definitive immunoassay test for demonstrating them will have an information content of h(x) = −log2(0.017) = 5.88 bits. Ruling out hepatitis C antibodies will have an information content of h(x) = −log2(0.983) = 0.025 bits. An immunoassay test result stating the absence of hepatitis C antibodies thus adds little to our knowledge, since the disease has low prevalence and the negative result was highly likely a priori. A result stating the presence of hepatitis C antibodies is less likely a priori and would thus add more to our knowledge.
Before taking the test, we do not know the outcome. However, we can ask for how much information we can expect to be returned by the test, i.e. the expectancy of a test. The expectancy of a definitive test P is the entropy H of the disease states D with the prevalence p(d) and expressed by:
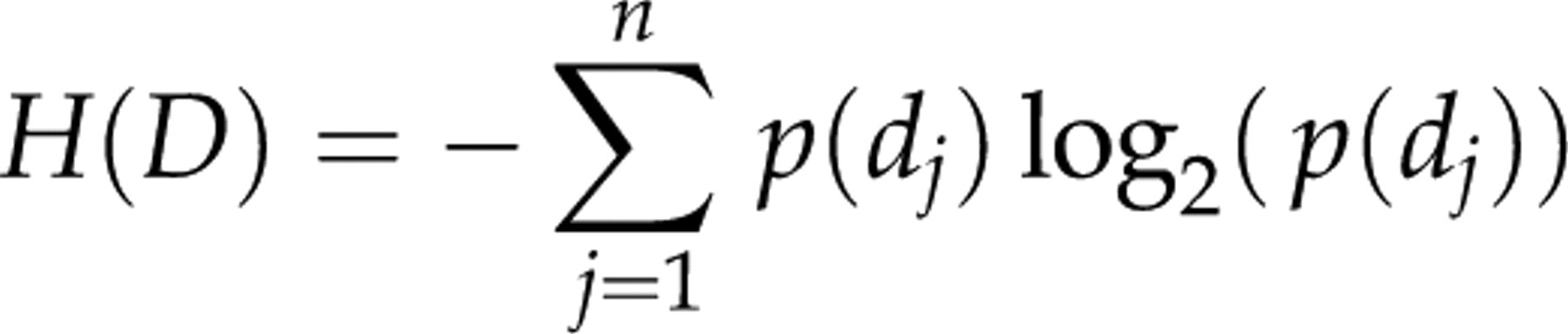
The expected information H is referred to as the Shannon entropy of the test/disease and can be regarded as an a priori measure of a test. For a test with only two outcomes (true positives and true negatives) occurring with probabilities t and (1 − t) we have:
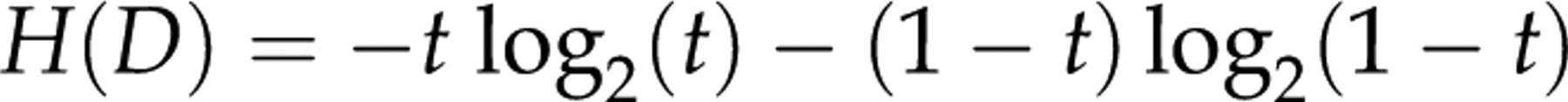
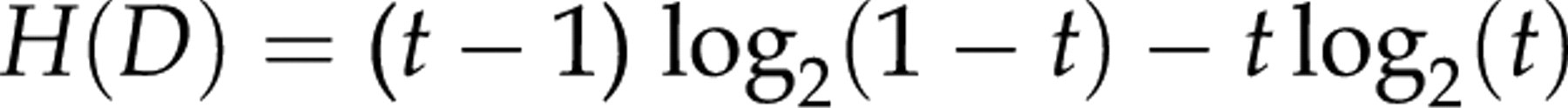
A definitive immunoassay test for hepatitis C antibodies thus has the entropy:
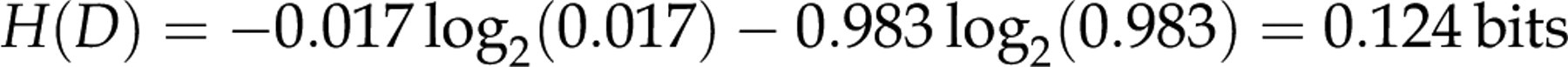
The highest entropy is reached when all outcomes are equally probable. With two outcomes, the highest entropy is 1 bit and is reached at P= 0.5, and lowest when P approaches 0 or 1.
In tests fraught with false positives, i.e. tests having specificities less than 100%, it seems appropriate to distinguish between two categories. In the first case, the test is optimal, but a fraction of healthy individuals also exhibits the same biochemical markers as the test is intended to identify. An example not related to immunoassays is diagnosing bacterial pharyngotonsillitis by throat culture, where some healthy children and adults are asymptomatic carriers. 9 For such tests, the aetiological predictive value has been discussed as an alternative Bayesian a posteriori measure of the test. 10 In the second case, the test is clearly suboptimal, i.e. the test gives a false-positive result in individuals which do not express the biochemical marker that the test is intended to identify. For this latter case, it makes sense to calculate the gains of improving/fixing a test, and the term ‘suboptimal’ will refer to such a test.
The true prevalence of thyroid disease in a young population is 1%. However, testing for thyroid disease (in the youth) by measuring thyroid-stimulating hormone (TSH) typically yields a rate of true negatives of 98.6%, a rate of true positives of 1.0% and a rate of false positives due to assay interference of 0.4%. 11,12
If the TSH test was definitive, having no false positives, the entropy would be equal to the information entropy of the disease:
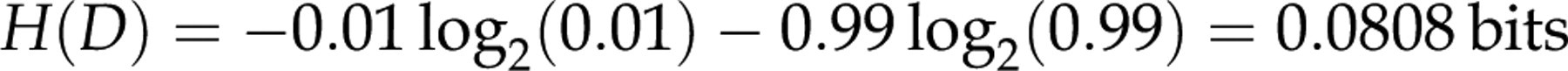
We now consider a suboptimal test R having true positives (the fraction of true positives denoted t) and false positives (denoted f). After having performed this test, we have separated samples into one set of true negatives (1 − t − f) and one set of samples containing both true positives and false positives (t+ f). We have the entropy:
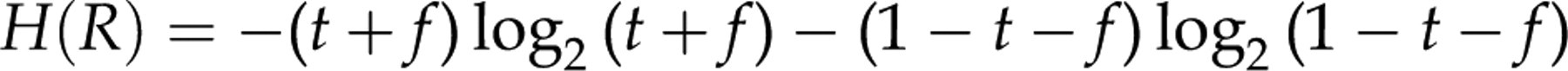
Surely we are not satisfied yet, so we now apply an additional, affirmative test A on all positive samples (t+ f). This test is to be regarded as a definitive test, and may separate the positives into true positives and false positives.
We now have the complete information on which samples are true negatives, false positives and true positives. This information has the entropy:
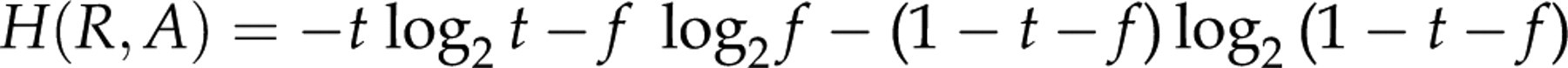
The second test A has then contributed with the entropy:
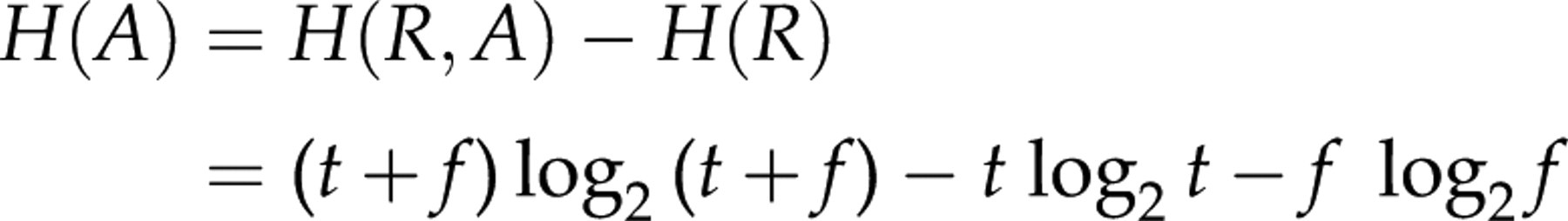
For completeness, we finally state that the entropy shared between a definitive test and the suboptimal test, their mutual information, I(D;R) is:
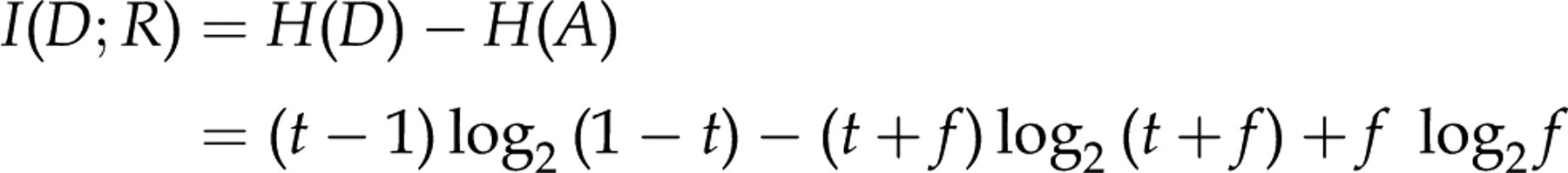
For the TSH test, we have:
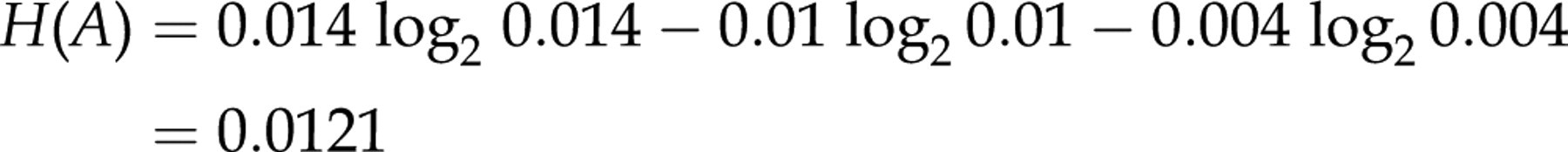
The mutual information is:
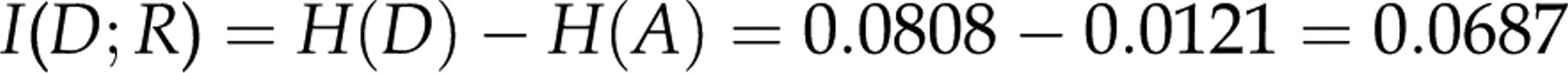
As the information content of a definitive TSH test is 0.081, interference thus reduces the information content by approximately 15% in the suboptimal test.
If we do the same exercise for elderly women having a rate of true negatives of 82.6%, a rate of true positives of 17% and a rate of false positives of 0.4%,
11,12
we get:
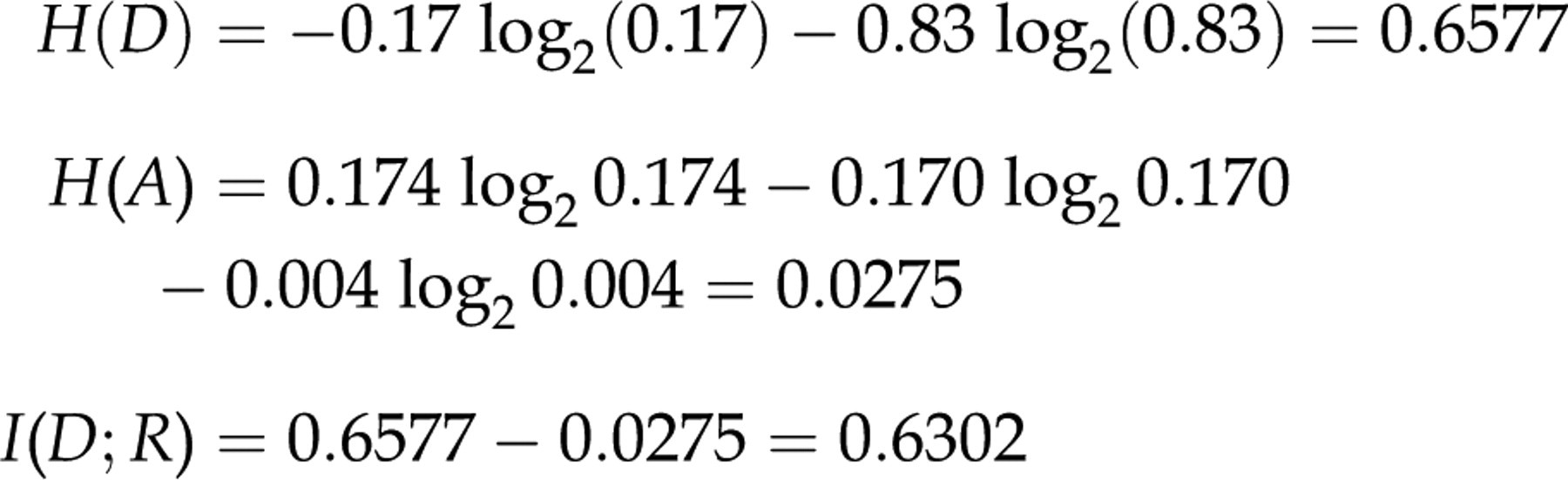
If we consider to eliminate interference by retesting all positive samples with a definitive test, this will increase the average information content by 4% in the elderly population (having a high prevalence of the disease) compared with an increase by 18% in the young population (having a low prevalence of the disease).
Thus, the results so far are close to what may be obtained with Bayes’ theorem. It should be noted that we are giving a value, albeit small, not only to ‘ruling in’ diseases but also to ‘ruling out’ diseases.
The concept may be further generalized to samples having false negatives as well. Finally, we may be interested in applying the concept on quantitative tests. The Shannon information is not defined for continuous probability densities, but there exists a generalized expression for the asymmetric information gain from R to D, defined on continuous probability densities, denoted the Kullback–Leibler information. To clarify, we must emphasize that we here refer to the asymmetric Kullback–Leibler information in the original sense, and not to the symmetrised version, i.e. the Kullback–Leibler divergence. 13 An overview of the proper use of the Kullback–Leibler divergence for diagnostic tests is given in ref. 8
An a priori measure and population health benefit of a diagnostic test
Information theory shows that our efforts on reducing interference at the sample level will be most efficient when concentrating on retesting a few positive samples in an assay with a low rate of true positives. On the assay level, we have demonstrated how to calculate the gain in information content of applying a definitive test over a suboptimal test. However, in order to calculate the population health benefit of a definitive test over a suboptimal test, we must first know the population health benefit for a unit of information content of a particular assay. We must simply calculate the ‘benefit per bit’ for our assays!
A brief and simplified model of health economics is provided by Claxton et al. 14 in a report commissioned by the Department of Health, UK. Every technology, when adopted, infers an additional cost, Δc, on the health-care sector. However, with the adaption of the technology follows a population health benefit, Δh. Since the health budget is not infinite, there exists a threshold, k, for what a society is willing to pay for health. So only techniques where Δc≤ kΔh will be adapted.
A diagnostic test result provides a road to a potential health benefit, but a diagnostic test result is by no means a health benefit per se. Hence, how can we translate a diagnostic test result into a quantitative health benefit? We see two possibilities. The first one is to assign the value of the upcoming health intervention to the test. The second one is to use the direct value of information content of the diagnostic test. In this paper, we follow the second one. For further discussion on prognostic tests and their cost–benefit, we recommend the paper by Moons et al. 15
For the least cost-effective tests in the laboratory, the ratio between cost and benefit will approximate k. Tests having a higher cost per unit of benefit than this threshold should be abandoned. Highly cost-effective tests may have a cost per unit of benefit considerably lower than the threshold k, which can be reflected in willingness-to-pay, i.e. even if this test were more expensive, it would still be in use.
We now split the population health benefit Δh of a test into the information content gained in bits (ΔH) and the population health benefit of a bit of information content for this particular test (Ut
):
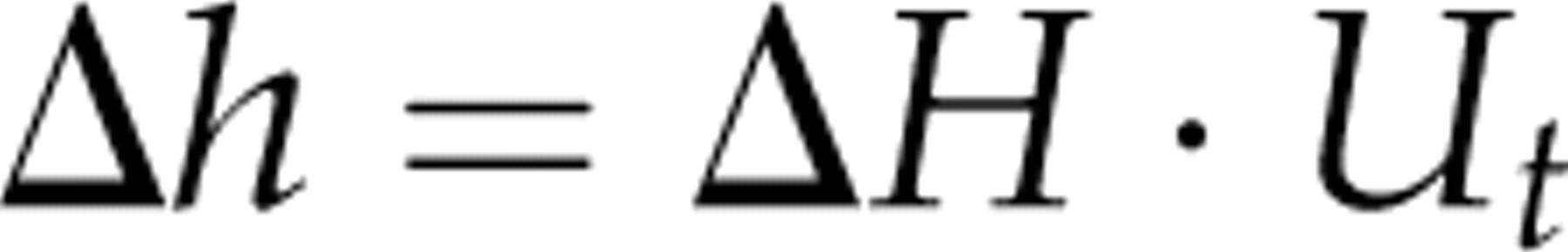
We thus have:
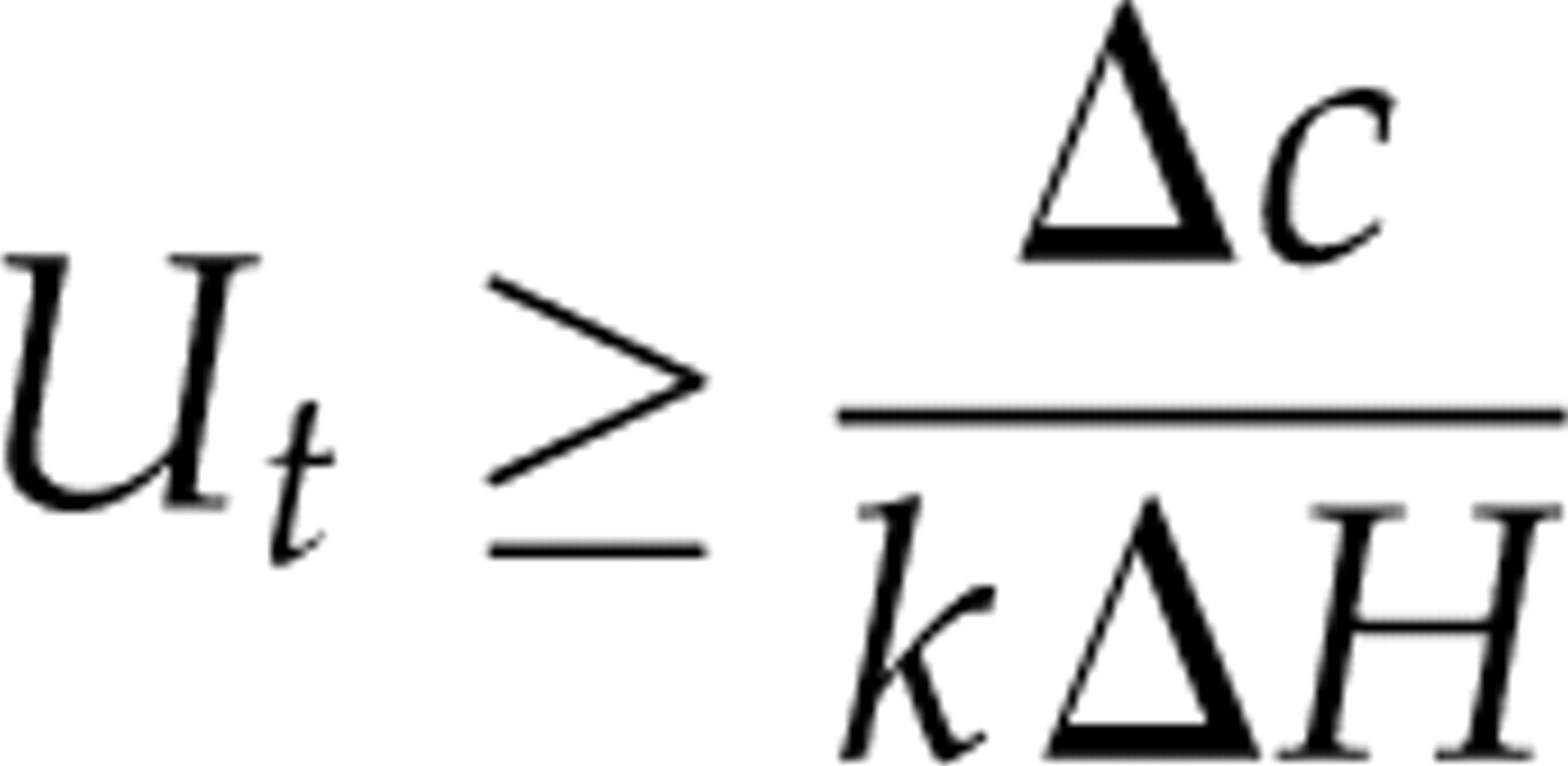
There must be some sort of trade-off in the laboratory between the population health benefit and the disease prevalence. It is not tested for rare diseases unless they are important! For diagnosing thyroid disease, the cost per TSH test is equal for the young and elderly. If we believe that cost-effectiveness is equal for both young and elderly subjects, then the population health benefit of a bit of information content must be higher for the younger subjects (where the disease prevalence is lower and hence the information entropy ΔH is lower). Knuteson
16,17
discusses a similar trade-off in the context of scientific experiments with unknown outcome, and concludes that under equal cost-effectiveness, the benefit must be proportional to the inverse of the information entropy. We have the following expression for the benefit of a bit of information from a particular test:
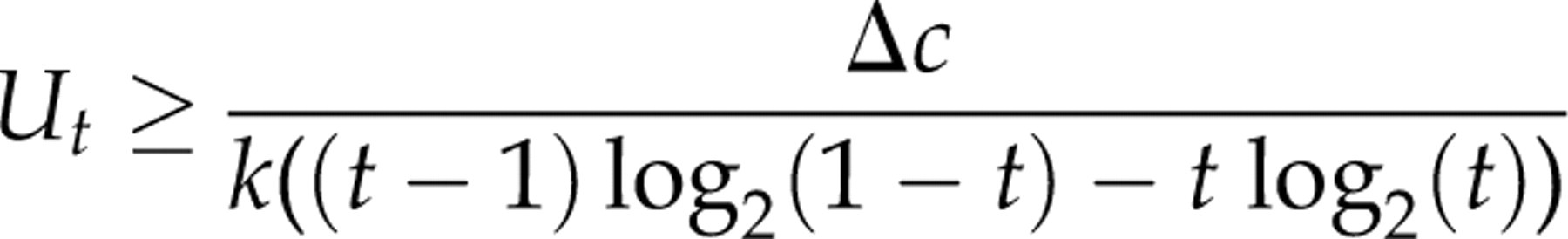
Quantitatively, the ratio between the benefit of a bit of information in the young and elderly, respectively, is: U(TSH − younger)/U(TSH − elderly) 0.6577/0.0808 = 8.14. Hence in fact, the population health benefit of a bit of information on ruling in or ruling out thyroid diseases is considered far more worth (eight times) in younger than in elderly subjects.
We now have expressions both for the population health benefit of a bit of information content in an assay (Ut
) and for the loss of information content by interference measured in bits calculated as the difference of the information content between a definitive and a suboptimal test. Combining these two expressions, we get the following expression for the population health benefit of having a definitive test rather than a suboptimal one (assay level):
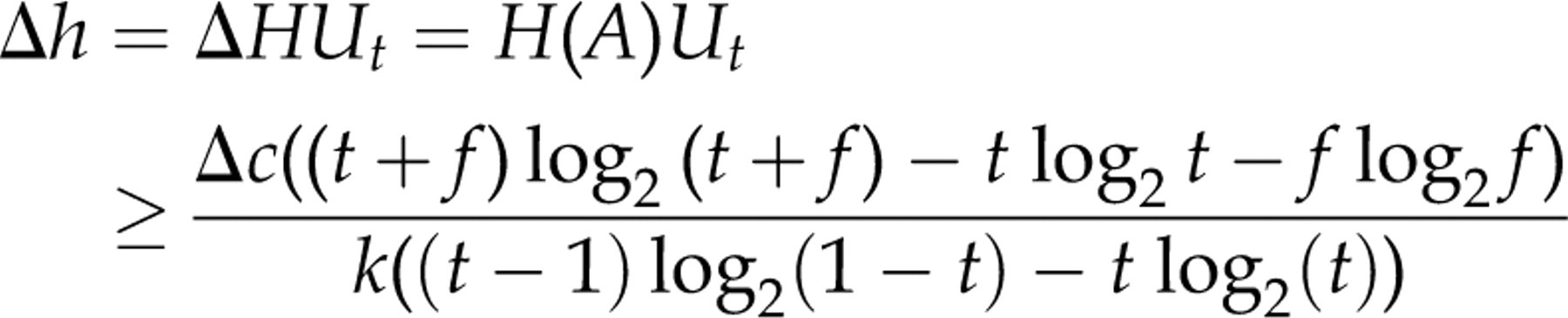
For the young population, we have:
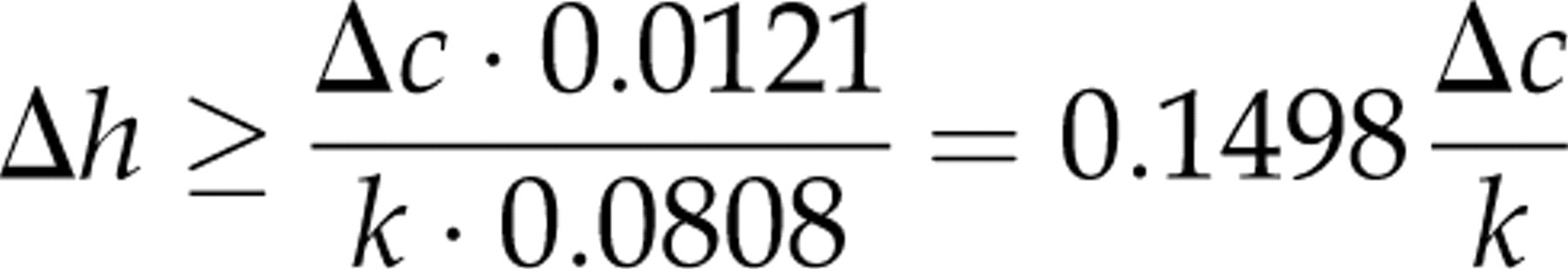
and for the elderly population:
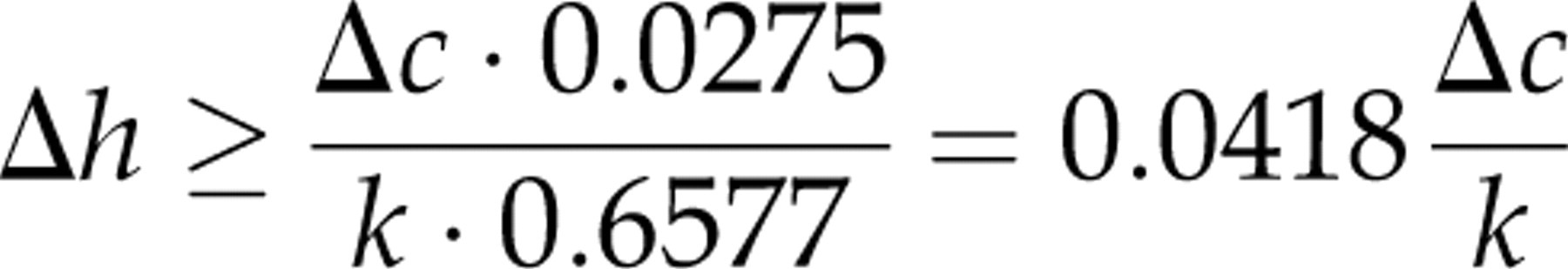
To illustrate how the benefit depends on the rates of false and true positives, we have plotted false-positive rates (interferences) ranging from 0.001 to 0.020 and true-positive rates ranging from 0.01 to 0.50 and calculated the greatest lower bounds of the population health benefit of having a definitive test rather than a suboptimal one (Figure 1).
The greatest lower bounds of the gain of eliminating interference from an assay is illustrated as a function of the rate of true positives (p) and false positives (f)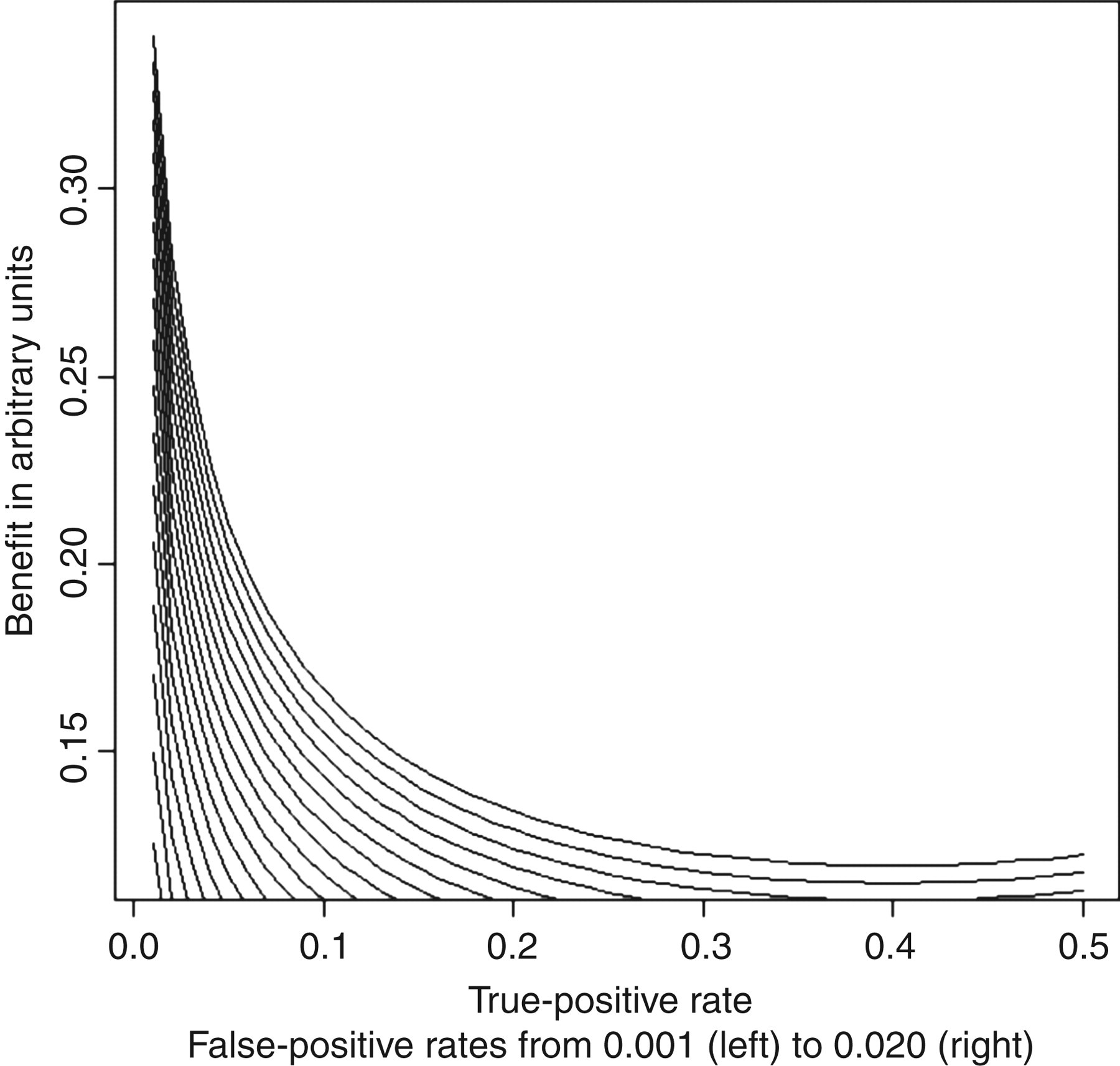
We want to underline that our calculated and graphically presented benefits are actually the greatest lower bounds of the benefits. Some tests are more cost-effective than others, i.e. the willingness-to-pay greatly for those tests greatly exceeds the threshold. Cost-effective tests will probably be tests for common diseases having large clinical consequences. Examples are troponins (for myocardial infarction), glycated haemoglobin (for diabetes) and D-dimer (for thromboembolic events), which are all tests for common diseases where the test outcome has immediate influence on the future care of the tested patient.
An a posteriori measure of the benefits of eliminating interference from a single sample
As pointed out by Ismail et al.,
1
the a posteriori (i.e. given that the sample is tested positive) probability of finding interference (the positive predictive value of interference) is:
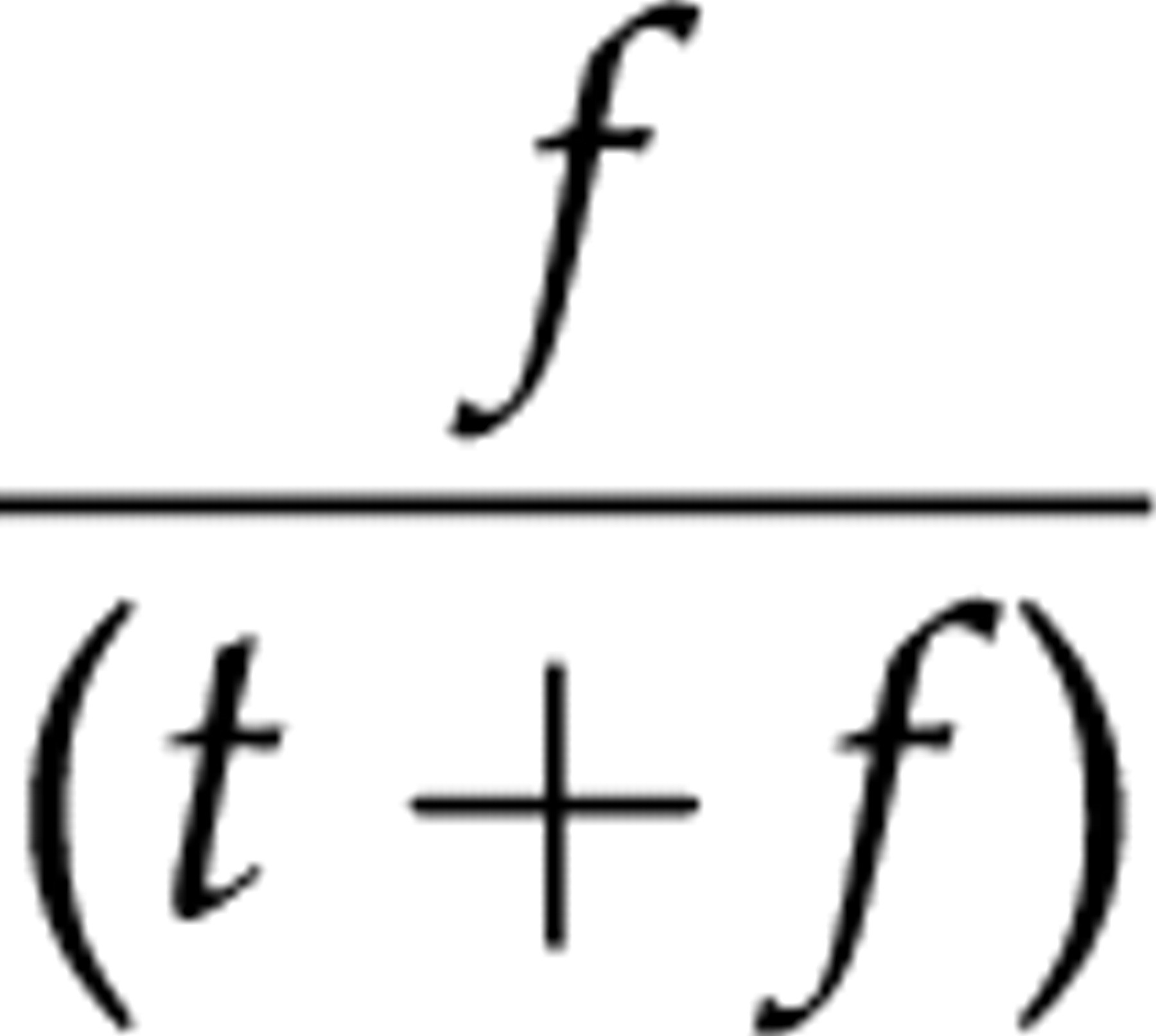
But when considering where to look for interferences, we not only have to take the probability of finding interference into account, but also the population health benefit, Δh. We thus have an a posteriori benefit of retesting a positive sample exceeding:
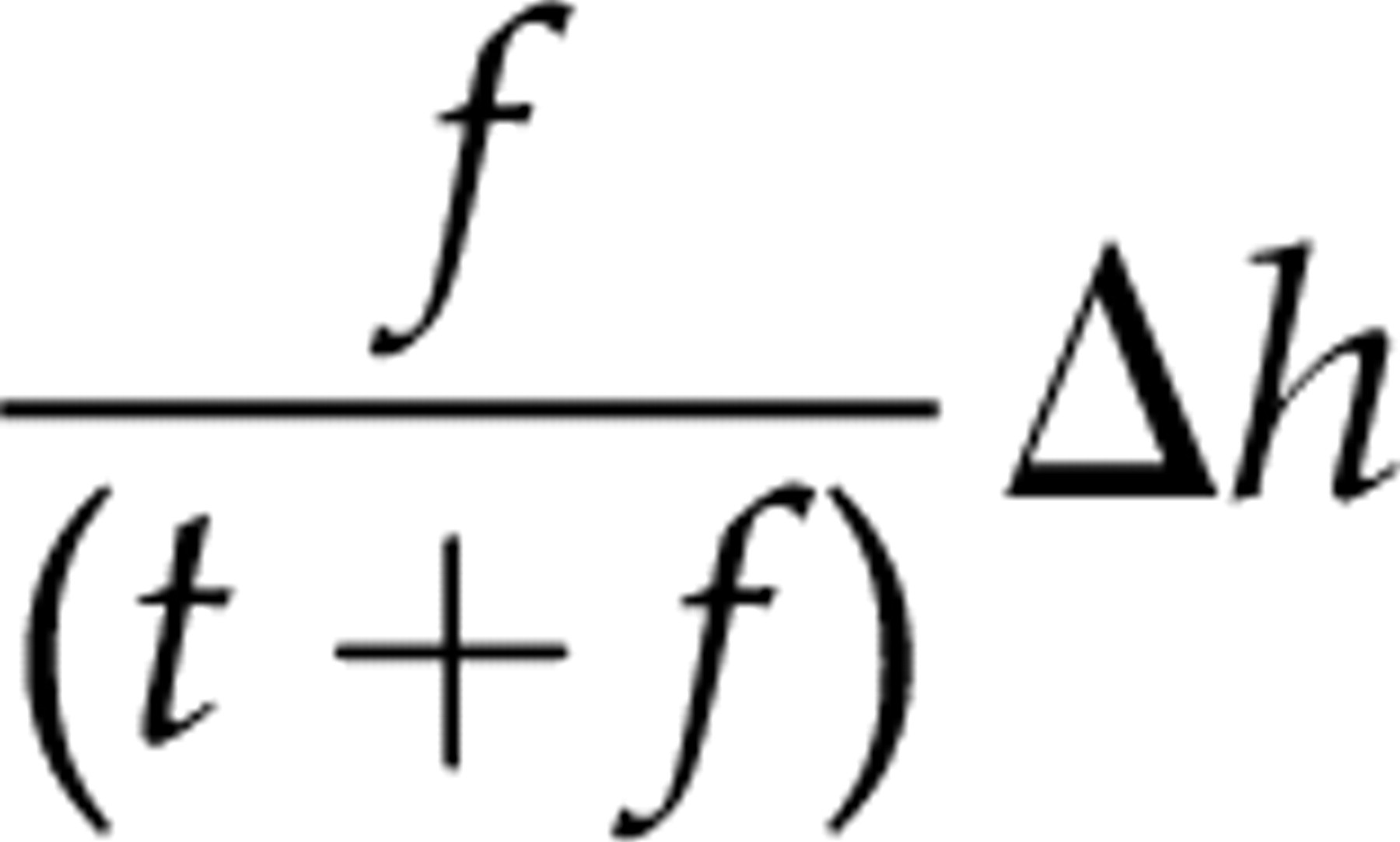
Thus, the population health benefit of retesting a positive sample steeply increases when the prevalence of true positives is low (Figure 2). This is due to both an increasing probability of identifying interference upon retesting and higher population health benefits of identifying interferences in diagnostic tests for diseases having low prevalence.
The greatest lower bounds of the gain of eliminating interference from a single sample by retesting it using an assay devoid of interference is illustrated as a function of the rate of true positives (p) and false positives (f)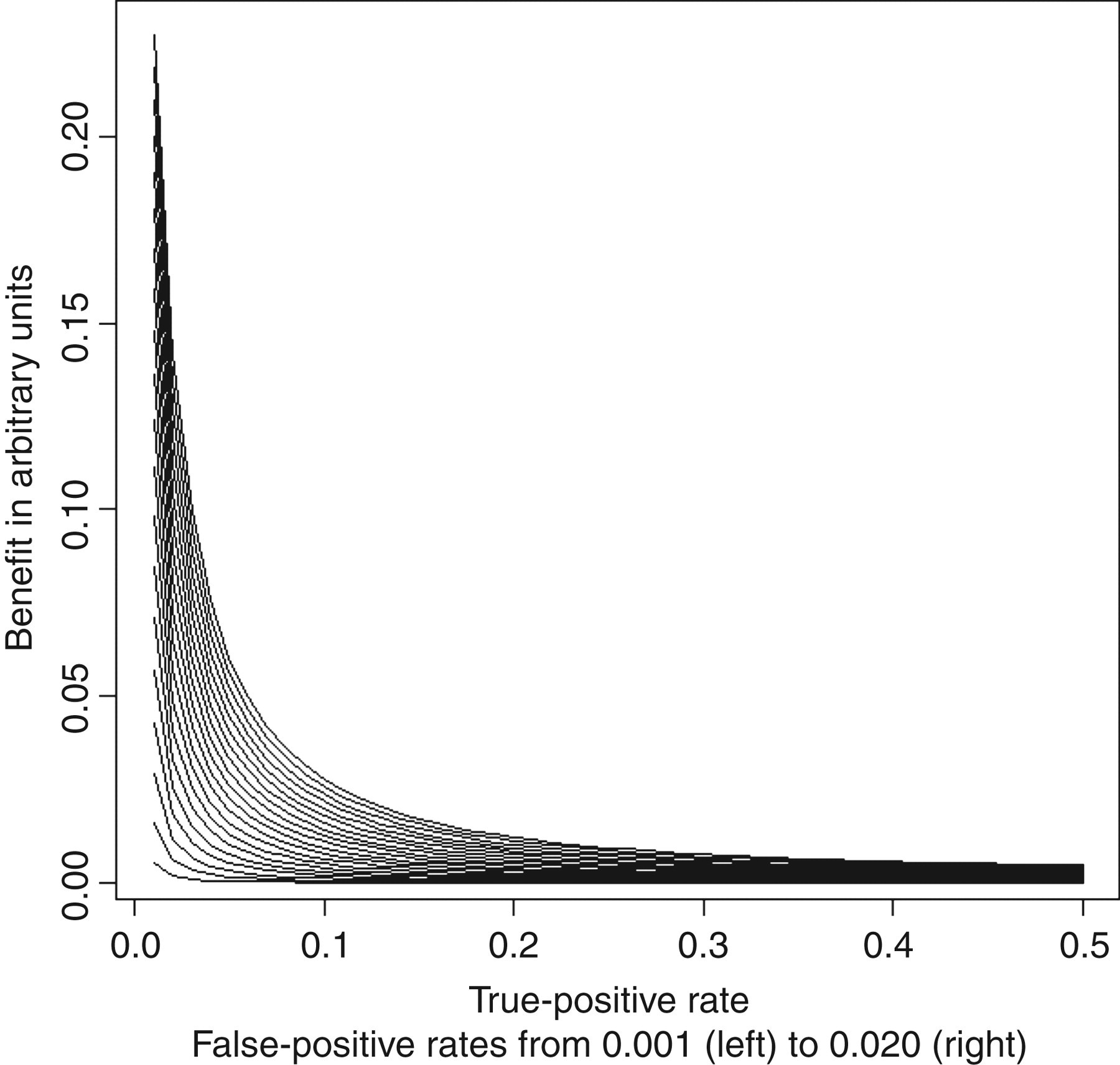
Adding blockers a priori or a posteriori?
So far, we have succeeded in finding expressions for the population health benefit of applying definitive tests rather than suboptimal ones. But what constitutes a definitive test? We may eliminate interference a priori (by adding blockers to all tests) or a posteriori (by adding blockers to all positive tests only and retest). Three sources of cost associated with the definitive test may be: the direct cost of the test Δc, the cost Δc b of blockers and finally extra costs Δc e associated with retrieving positive samples and adding blockers.
If we add blockers a priori, the cost will be:
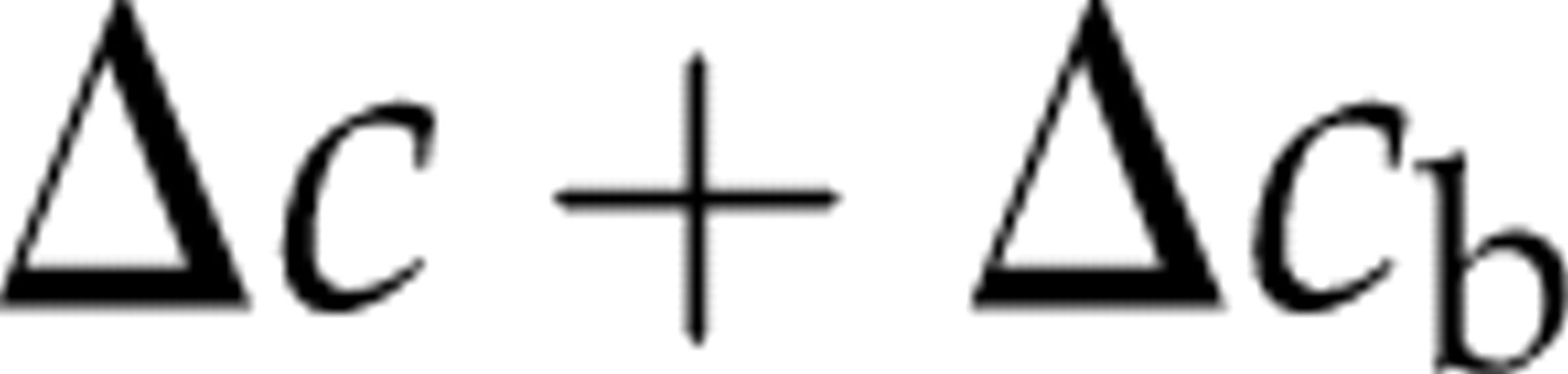
If we add blockers a posteriori, we only have to add blockers to positive tests. The cost of adding blockers a posteriori will be:
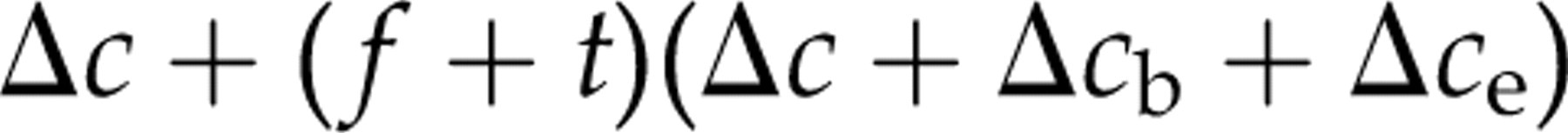
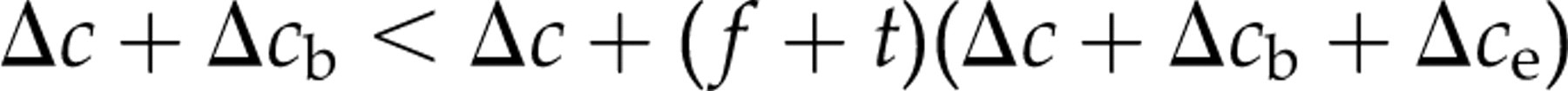
which can be expressed as:
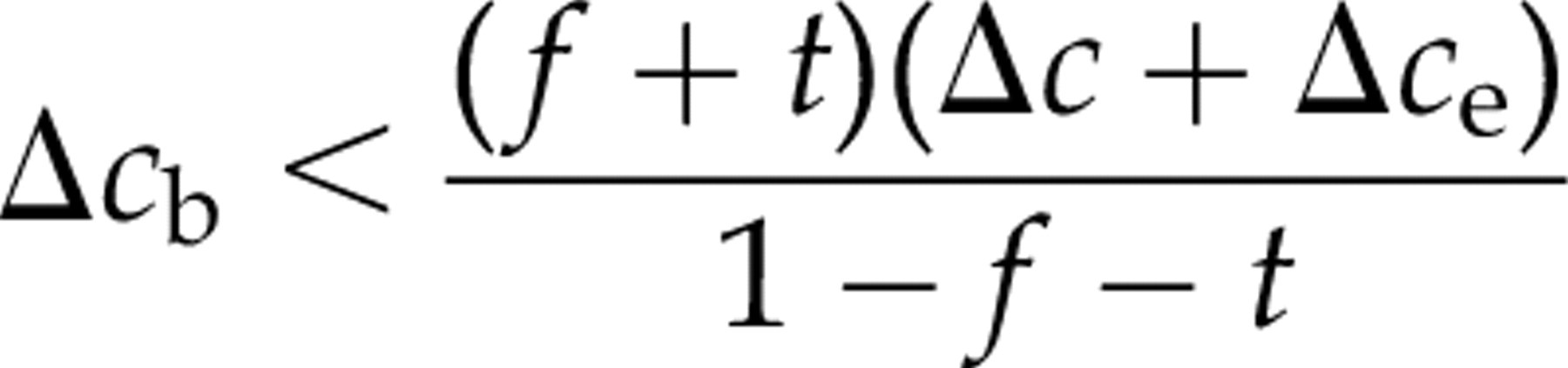
We previously found a prevalence of heterophilic antibody interference in an in-house assay for carcino-embryonic antigen (CEA) of 4.0%. 18 We conservatively assume the costs Δc of our CEA test to be £3, the blocker Δc b 20p and extra costs Δc e £3 per test. If 10% of samples in our hospital have results over the upper reference limit, adding blockers a priori would be an cheaper option (at 20p when costs are shared by all samples) than the a posteriori retesting with blockers added (at 87p when costs are shared by all samples).
Although heterophilic antibody interference may be considered a heterogeneous entity, most interference could be eliminated by simple and inexpensive means such as adding immunoglobulins to the buffer, 18 removing the interference-prone Fc-fragment from assay antibodies 18 or deliberately combining antibodies from different subclasses in assays. 19
Thus, in our view, the high extent of heterophilic antibody interference and the low cost associated with avoiding them strongly favours general a priori over a posteriori means.
Discussion
The antigen–antibody interaction in an immunoassay takes place in serum samples obtained from different patients who have a huge range of endogenous immunoglobulin antibodies of different classes and subclasses. The vast heterogeneity of these potentially interfering antibodies makes it almost impossible to eliminate all interferences from this unpredictable source. Because of this, the described information theory must be regarded as a relatively blunt but nevertheless useful tool which helps in understanding some of the important features and consequences of heterophilic antibody interference. In a recent paper, we have tried to take a more integral approach on assay interference by looking for interference simultaneously in several immunoassays. 20 Information theory has here helped us to understand some aspects of heterophilic antibody interfence. Some of this knowledge is summarized below.
Most, but not all, interferences may be eliminated by retesting all positives. 1 However, given the observed high prevalence of such false positives, assay design and buffer additives, i.e. a priori measures, are the most cost-effective and realistic primary line of defence.
As noted previously, we will probably have some residual interference even if we have optimal assay design and buffer additives. Such interference is most likely when the rate of true positives is low (as shown previously by probabilistic Bayesian reasoning). 1 In such a test, the population health benefit of identifying interferences also tends to be higher (as shown in the present paper by information theory).
There is thus good reason to believe that assay interference reporting is biased to tests with a low frequency of true positives, where the outcome has large clinical consequences, such as tumour markers and certain hormones. In these cases, interference is easy to identify (by probabilistic Bayesian reasoning) and considered sufficiently important to report (by information theory).
In assays with a high rate of true positives, interference is difficult to identify by probabilistic Bayesian reasoning, and the gains of eliminating interference are smaller as shown by information theory. A more cost-effective approach is to increase test robustness a priori as demonstrated by information theory.
DECLARATIONS