
Abstract
Collecting and analyzing observational data are essential to learning and implementing lessons in earthquake engineering. Historically, the methods that have been used to analyze and draw conclusions from empirical data have been limited to traditional statistics. The models developed using these techniques are able to capture associative relationships between important variables. However, the intervention decisions geared toward seismic risk mitigation should ideally be informed by an understanding of the causal mechanisms that drive infrastructure performance and community response. This article advocates for a paradigm shift in earthquake engineering where the language, tools, and models that have been (and continue to be) developed to draw causal conclusions from observational data are adopted. Several categories of data-driven earthquake engineering problems that can benefit from causal insights are examined. Two widely adopted frameworks from the broader causal inference literature are presented and linked to hypothetical earthquake engineering problems. The critical role of semi-parametric models and sensitivity analysis in justifying causal claims is also discussed. The article concludes with a discussion of specific opportunities and challenges toward the widespread use of causal inference as a tool for knowledge discovery in earthquake engineering. The ability to leverage the underlying physics of a problem within a causal inference framework is identified as both an opportunity and challenge for earthquake engineering researchers.
Keywords
Introduction
Drawing insights from empirical data is essential to earthquake engineering research and practice. Statistical analysis of observational data (i.e., data that are not generated by a controlled experiment) permeates every area of earthquake engineering including (but not limited to) ground motion hazard characterization, analysis and design of new structures, evaluation and retrofit of existing structures, and regional risk and resilience assessments. In structural engineering (a subdomain of earthquake engineering), there is a long history of using data from physical experiments to develop statistical models to estimate response parameters such as component stiffness, strength, and/or deformation capacity. These models are then used in the design, analysis, retrofit (in the case of existing facilities), and performance evaluation of individual or distributed infrastructure. Post-earthquake field reconnaissance is also key to advancing earthquake engineering research and practice. Lessons learned from field investigation data range from identifying the presence and criticality of specific seismic vulnerabilities (e.g., captured columns, unbraced, and/or unbolted cripple walls) to the effectiveness of different risk mitigation measures (e.g., seismic retrofits (SRs)). Field observations also inform the development of ground motion models (GMMs) and provide insights into the effects of different risk mitigation policies. Structural health monitoring (SHM) is another area where observational data and analysis are used in earthquake engineering. SHM uses different sensors to measure the response of structures to ground shaking, which is then used to infer the type, location, and extent of damage. Linking measured structural response to actual damage often involves some type of statistical analysis.
For the most part, the data-driven models that have been developed in earthquake engineering are based on statistical relationships where concepts such as correlation, regression, conditional independence, and association are adopted (Pearl, 2019). Linear and nonlinear regression are commonly used to develop models that predict the response parameters for structural components, including reinforced concrete (RC) (Dai et al., 2020; Haselton et al., 2016) and steel (El Jisr et al., 2022; Lignos and Krawinkler, 2011), beam-column elements, and RC shear walls (Abdullah, 2019; Abdullah and Wallace, 2019). The resulting equations allow engineers to estimate the parameters that are used in computational or analytical models. The GMM, a core component of seismic hazard characterization, uses regression (usually linear in logarithmic space) to estimate shaking intensity and duration parameters conditioned on features related to the earthquake formation process and geophysical properties of the path taken by the waveform and the local site of interest (Abrahamson et al., 2014; Boore et al., 2014; Campbell and Bozorgnia, 2014; Chiou and Youngs, 2014). Currently, there is a growing trend to use machine learning (ML) algorithms as the basis for developing predictive models within the aforementioned application areas of earthquake engineering. This has largely been motivated by the ability of ML to detect complex patterns in observational data and produce predictions that are often more accurate than those obtained from traditional statistical models. A detailed state-of-the-art review on the application of ML in earthquake engineering problems is provided in Xie et al. (2020).
The models described in the previous paragraph provide associational relationships, which, by themselves, cannot be used to infer cause and effect. In fact, traditional statistics does not include a coherent language for describing causal effect, much less the methods and tools of analysis (Pearl, 2019). Within the earthquake engineering domain, while useful for predictions, such models are limited in their ability to provide fundamental causal insights on the phenomena being studied. A reasonable counterargument is that, when coupled within our understanding of the physical laws that generate the associated observational data, these statistical models do inform cause and effect. Yet, this approach to elucidating causal knowledge is typically unsystematic and not rigorously justifiable. However, the last two decades have seen significant advances in developing techniques that can be used to draw causal conclusions from observational data. This body of knowledge, which has been developed in fields that include statistics, computer science, and the social sciences (e.g., political science, economics), is at the heart of modern scientific research. This set of circumstances raises the question of whether the foundational principles and methods that have been advanced in the broad area of causal inference can be used to solve earthquake engineering problems.
The goal of this article is to begin the process of answering the question posed at the end of the previous paragraph. Specifically, we discuss some specific types of earthquake engineering inquiries that can potentially benefit from being viewed through the lens of causal inference. The following problem categories are considered:
Drawing fundamental insights from datasets generated by structural component and sub-assembly experiments.
Untangling the effects of specific ground motion characteristics (e.g. duration, pulses) on structural response and damage using computational models.
Quantifying the average (over the entire inventory) benefits of seismic retrofit interventions using observational data from real earthquakes.
Evaluating the factors (e.g., building or site-related) that are most responsible for the observed damage using a real event.
The next section considers potential causal inference applications in earthquake engineering through the lens of these four problem categories. Within these specific areas of inquiry, the state-of-the-art in data-driven modeling and inference is summarized and the limitations of existing approaches in terms of their ability to produce causal conclusions are highlighted. Two foundational causal inference frameworks are then presented with an acute focus on their ability to provide fundamental insights into specific earthquake engineering questions. The same section also addresses the importance of semi-parametric models and sensitivity analysis tools for justifying causal conclusions. Subsequently, we discuss the opportunities and challenges in conducting causal investigations using observational data within the domain of earthquake engineering.
Potential causal inference applications in earthquake engineering
Infrastructure earthquake risk mitigation often takes the form of a physical intervention that is intended to enhance seismic behavior at the system or component level through some causal mechanism. The effectiveness of those interventions is often informed by data-driven models and analysis of empirical data from past events. However, in earthquake engineering, the state-of-the-art in modeling and analysis of empirical data is based on traditional statistical methods where associative (or correlation) effect of the intervention is quantified. Ideally, such investigations should be underpinned by data-driven techniques which can be seamlessly integrated with our knowledge of physics to extract causal information about the effect(s) of interventional changes to the system.
This section discusses four categories of earthquake engineering problems that can benefit from causal inference. In particular, a review of the state-of-the-art in data-driven modeling and inference within each subdomain is presented while emphasizing the shortcomings in terms of the ability of existing methods to elucidate cause and effect from observational data.
Data-driven investigations based on physical structural experiments
The physical laboratory experiment is a primary tool in advancing our fundamental understanding of structural component and system-level behavior under seismic loading. For a given experimental project, the results from one or a small set of physical experiments are used to understand how different structural properties or design strategies affect behavior. The results from a given physical experiment can also be used to anecdotally validate a particular modeling strategy. The last few decades have accumulated hundreds (or more than 1000 for some component types) of structural experiments for various types of components and sub-assemblies. Also, with the creation of cyberinfrastructure systems such as DesignSafe (Rathje et al., 2017), these datasets are being widely shared and used among structural/earthquake engineers. A single dataset would typically include comprehensive information from experiments conducted on a particular type of component or sub-assembly. Examples of such components and datasets include RC and steel beam-column elements (Berry et al., 2004; Lignos and Krawinkler, 2013), RC shear walls (Abdullah, 2019), RC and steel frames with masonry infill (Huang et al., 2020; Liberatore et al., 2017), and RC and steel frame panel zones (Skiadopoulos and Lignos, 2021).
The increase in the collection and curation of data from physical experiments has spurred the development of data-driven approaches for estimating the parameters that are used in structural analysis models. Such studies use data from largely disparate experiments (i.e., each performed with a different goal in mind) and various forms of regression to develop predictive models, typically for macro-element modeling parameters. In fact, macro-elements are commonly used in nonlinear structural models because they are often easy to implement, and the associated parameters can be calibrated from the results of physical experiments. Linear and nonlinear regression models have been developed to predict the behavior of components, such as RC shear walls (Abdullah, 2019; Abdullah and Wallace, 2019), steel beam-column elements (El Jisr et al., 2022; Lignos and Krawinkler, 2011), RC beam-column elements (Dai et al., 2020; Haselton et al., 2016), and masonry-infilled frames (De Risi et al., 2018; Huang et al., 2020; Liberatore et al., 2018; Sirotti et al., 2021).
The typical workflow to develop a predictive model begins with a visual examination of any trends between the potential input variables (e.g., component material or geometric properties) and the parameter of interest (e.g., the capping strength of the element). Quantitative metrics, such as correlation and statistical significance tests, are also used to evaluate the feasibility of a particular structural property as an input into the statistical model. Once the input variables have been chosen, an appropriate statistical model is implemented. Finally, the developed model is evaluated using the plots of the predicted versus observed values of the parameter of interest and quantitative metrics, such as the coefficient of determination
A more recent trend has been to use ML algorithms as the primary engine for developing predictive data-driven models using structural component data from physical experiments. Some studies have compared the predictive performance of models developed using a suite of algorithms (Jeon et al., 2014; Mangalathu and Jeon, 2018; Rahman et al., 2021). Others use a single algorithm that is targeted toward addressing a specific concern with data-driven models (e.g. small datasets) (Luo and Paal, 2019, 2021). ML has also been used to develop models that predict the failure mode of specific structural components. These are classification models that take in various structural features as input and predict the type of failure that would occur under seismic loading (Huang and Burton, 2019; Mangalathu and Jeon, 2018, 2019; Mangalathu et al., 2020).
The data-driven models summarized in this section are useful for predictions but are unable to provide fundamental insights about the behavior of the component or system of interest. For the purpose of illustration, consider the study by Abdullah and Wallace (2019) that used a dataset of 164 experiments on RC shear walls to develop a statistical model for predicting the drift capacity. One of the considered input variables was the configuration of the boundary transverse reinforcement. The dataset included various types of overlapping and non-overlapping hoops. The article provided a detailed discussion on the importance of overlapping hoops and provided supporting evidence from individual experiments. However, due to the presence of many confounding variables, there was no attempt to quantify the benefits of overlapping hoops using the assembled dataset. The principles and methods of causal inference described later in the article can be used for such an assessment.
Structural response simulation-based data-driven investigations
Nonlinear structural response analysis is widely used to simulate the behavior of different types of infrastructure under earthquake ground motions. In the performance-based earthquake engineering (PBEE) methodology (Moehle and Deierlein, 2004), nonlinear response analysis is used to evaluate the performance of structures in terms of metrics that are of interest to stakeholders, that is, collapse risk, economic losses, and functional recovery. Within this type of assessment, questions arise about the effect of specific earthquake ground motion features (e.g. duration, spectral shape, and pulse effects) on seismic structural response and performance. These types of evaluations are typically achieved through statistical analysis of seismic response and performance data that are generated in simulation models. Note that while the data generated from a simulation model can be viewed as coming from a “controlled” experiment, the variable of interest (e.g., ground motion duration) is typically linked to the ground motion data, which is observational.
Consider an area of research that has been of growing interest to the earthquake engineering community—the effect of ground motion duration on the seismic structural collapse risk of buildings. This area of inquiry was spurred by large magnitude earthquakes that have occurred within the last two decades (e.g., 2011
Another approach that has been adopted to quantify the effect of duration on collapse performance is to subject the same structure (or set of structures) to “short” and “long” duration ground motions that are “spectrally equivalent” (Chandramohan et al., 2016a, 2016b). This strategy recognizes that the SS of a ground motion is a possible confounding variable that would also influence collapse risk. The strategy is analogous to the “matching” approach (discussed more later in the article) that has been used in early causal inference literature (Stuart, 2010). However, there are several limitations to matching, both as a general strategy for dealing with the effects of confounders (discussed later in the article) and in the specific application in the aforementioned studies focused on the effect of duration of structural collapse risk. Regarding the latter, obtaining a one-to-one spectral match for a single pair of long and short duration motions is a difficult proposition, which only increases in complexity when trying to assemble a record-set for collapse performance assessment. This approach also brings the quality of the matching into question, an issue that is not explicitly addressed in the aforementioned studies. Finally, the univariate matching approach essentially ignores the potential effect of other confounders (e.g., pulse effects). Later in the article, we discuss techniques used in the broad area of causal inference that are designed to address these specific limitations.
Statistical evaluations of structural response simulation data have also been used to study the effects of other types of ground motion features, including spectral shape (Eads et al., 2016; Haselton et al., 2011), pulses (Champion and Liel, 2012; Liapopoulou et al., 2020), and sedimentary basins (Bijelić et al., 2019; Marafi et al., 2017). In general, these studies have adopted one of the two approaches (matching or statistical trend analysis) described in the previous paragraph. It is worth mentioning that these statistical analyses are supported by fundamental insights into the physics of ground motions and the structural response of infrastructure to earthquake-induced shaking. Together, these lines of inquiry provide justification for any causal claims that are made in the findings. However, it is also important to distinguish between qualitative and quantitative causal insights. The latter cannot be inferred from statistics alone (Pearl, 2019).
Evaluating the benefits of seismic structural mitigation using observational data
A review of the earthquake engineering literature found only a single study (discussed later in this section) that sought to systematically evaluate the overall (i.e., across a set of buildings) benefits of seismic retrofit using observational data (i.e., through field reconnaissance following real events). In other words, the overwhelming majority of field observational studies that have highlighted the benefits of seismic retrofit have all been anecdotal. In a report written for a “lay audience,” the Pacific Earthquake Engineering Research (PEER) documented the performance of two similar (based on pictures taken from the exterior) 2-story homes that experienced ground shaking from the 2014
For structural engineers, providing a causal link between seismic retrofit and earthquake damage may seem obvious since many laboratory experiments have been conducted to answer this question. However, making the link between the results of these experiments and a systematic quantification of the mitigating effect of the retrofit during an actual earthquake is not a trivial endeavor. This partly explains why the insights drawn of the effect of seismic retrofit on building performance during real earthquakes have mostly been either anecdotal (as described earlier in this section) or derived from detailed numerical analyses of individual buildings. A recently published study by Rabonza et al. (2022) used “counterfactual analysis” to quantify the benefit of seismic risk interventions. The authors combined observed data from the 2015
Elucidating the factors that contribute to observed seismic building damage
Post-event field reconnaissance is a primary tool for understanding the factors that most influence seismic damage to infrastructure. The earliest missions relied almost exclusively on in-person one-at-a-time inspections that enable engineers and scientists to collect and document perishable data that could inform various aspects of seismic risk mitigation and resilience-building. Whereas, more modern reconnaissance efforts combine in-person and virtual inspections with remote sensing at different scales (e.g., satellite, unmanned aerial vehicles). The Earthquake Engineering Research Institute (EERI) Learning from Earthquakes (LFE) (EERI-LFE, 2022) program alone has collected and curated datasets from over 300 earthquakes over a period of more than 70 years. More recently, the Structural and Geotechnical Extreme Event Reconnaissance (GEER, 2022; StEER, 2022) programs routinely spearhead earthquake field investigations. In addition, entities such as the RAPID Center (Berman et al., 2020) and DesignSafe Cyberinfrastructure (Rathje et al., 2017) have advanced the use of modern technology in the collection and curation of earthquake reconnaissance data.
Detailed post-earthquake inspections of individual infrastructure (e.g. buildings) can reveal critical insights about the factors that influence seismic damage. These factors can range from specific structural and non-structural deficiencies, soil–structure interaction, or amplification of ground shaking triggered by a myriad of possible effects (e.g., geological features of the local site and/or seismic wave path, near-source and/or directivity effects). It is well understood that generalizing the findings from in-person (or virtual) inspections requires systematic analysis of the collected data. This has led to numerous studies in the literature on the statistical (or quantitative trend) analysis of the damage to specific system or component types, including bridges (Basöz et al., 1999), non-structural elements (Giaretton et al., 2016), and buildings (Aguilar et al., 1989; Boatwright et al., 2015; Jünemann et al., 2015; Scholl, 1974; Sun and Zhang, 2011). A typical analysis of this type would quantify the empirical distribution of specific types of damage and establish associative relationships (qualitative and quantitative) with potential causal factors (i.e. shaking, structural/non-structural vulnerabilities). Depending on the size and quality of the data, empirical fragility curves may be developed to link the ground shaking intensity to the probability of different types and severity of damage (Basöz et al., 1999).
Similar to other data-driven studies in earthquake engineering, there is a growing trend toward using ML to develop models for predicting the geographic distribution of damage following an event. Buildings (Harirchian et al., 2021; Mangalathu et al., 2020; Roeslin et al., 2020; Stojadinović et al., 2021) and the components that comprise a water distribution system (Bagriacik et al., 2018; Winkler et al., 2018) are the two types of infrastructure that have been considered in this regard. These types of studies primarily focus on the predictive accuracy of the considered model(s).
Like the other application areas, the analyses and models that are applied to infrastructure damage data from real earthquakes cannot provide explicit quantitative information on causal effects. For illustration purposes, we consider a study by Boatwright et al. (2015) that performed an investigation of the factors that most influenced the overall distribution of observed building damage during the 2014 South Napa earthquake. In the end, the authors were only able to conclude that “the distribution of red and yellow tags is well-correlated with the pre-1950 development of Napa and with the underlying sedimentary basin but poorly correlated with the most recent alluvial geology.” In other words, because of the methods adopted (from traditional statistics), no causal claims could be made. In another study by Mangalathu et al. (2020), ML models were developed to predict the distribution of building damage during the same earthquake. As part of that study, the authors quantified the relative importance of different features used in a Random Forest algorithm. This was done by computing importance scores for each input parameter, which is a measure of the amount of predictive power the parameter adds to the model. Note, however, that this is an associative metric that cannot be used to draw causal insights.
Foundational principles and frameworks in causal inference
This section describes two foundational frameworks that have dominated the causal inference literature. Sensitivity analysis is also discussed as a means of justifying key assumptions in causal investigations. The objective is to initiate a dialogue about which underlying principles, tools, and methods can be adapted (and how) to data-driven inquiries within the domain of earthquake engineering. To this end, the two frameworks (and sensitivity analysis discussion) are presented while simultaneously establishing links to some of the problem types described in the previous section.
Potential outcome framework
The potential outcome (PO) framework is one of the two methodological developments that have dominated research and practice in causal inference. The initial concepts are attributed to the work of Jerzy Neyman (1923) but have since been advanced by Don Rubin (2005). In any causal inference problem, the primary goal is to evaluate the effect of some “treatment”
POs are defined as the outcome variable values that each unit takes on under the treatment and control conditions. Specifically, for unit
Causal estimand array for the hypothetical seismic retrofit problem

One potential strategy for computing the causal estimand is to “match” pairs of treatment and control units with similar covariate values and compare their POs. Revisiting our earlier hypothetical problem, we would need to find pairs of retrofitted and unretrofitted buildings with similar structural properties that have also experienced comparable shaking characteristics. Several matching methods have been proposed in the causal inference literature, particularly in the social sciences (Stuart, 2010). In real observational studies, it is almost impossible to obtain pairs of treatment and control units that are exactly or even closely matched because it is often the case that we are dealing with large numbers of covariates that could potentially affect the outcome. As such, even after matching, there could still be significant covariate imbalance between treatment and control units. To address this issue, several techniques have been developed to statistically adjust the outcomes based on the covariate distribution of the treatment and control units through “weighting” or “balancing.” Examples of such methods include bias-corrected matching (Abadie and Imbens, 2011) and kernel balancing (Hazlett, 2020).
The randomized control trial (RCT) is known to be the ideal approach for dealing with covariate mismatch. In RCTs, the treatment is randomly assigned to a portion of the units and their mean outcome values
Several important assumptions are embedded in the PO framework. The “consistency” assumption says that the observed outcome (denoted as
The “Pearl” framework
The second framework is primarily attributed to Judea Pearl (2019), who describes three hierarchical levels of causal inference. The first and most basic level is association, which reflects the act of “seeing,” where a set of statistically related variables is merely observed. The relations are quantified based on conditional dependencies. For example,
Central to the Pearl framework is the use of directed acyclic graphs (DAGs) and structural causal models (SCMs) to conceptualize both the causal and statistical dependencies between the variables in an observational dataset. A DAG is a graph that only contains directed edges and has no cycles (i.e., there is no path from a single node that leads back to itself) (Geiger et al., 1990). Consider the simple DAG shown in Figure 1 that is based on the “effect of seismic retrofit” problem introduced in the PO framework section. The goal is to isolate the causal effect of seismic retrofit (SR) (the treatment) on seismic damage (SD) (the outcome) using data collected after a real earthquake. For illustration purposes, we will consider the peak ground acceleration (PGA) (shaking intensity) and the building age (AGE) as the only two covariates or “confounders.” Confounding refers to a situation where a common cause obscures the causal relationship between two or more variables. More precisely, the causal effect of
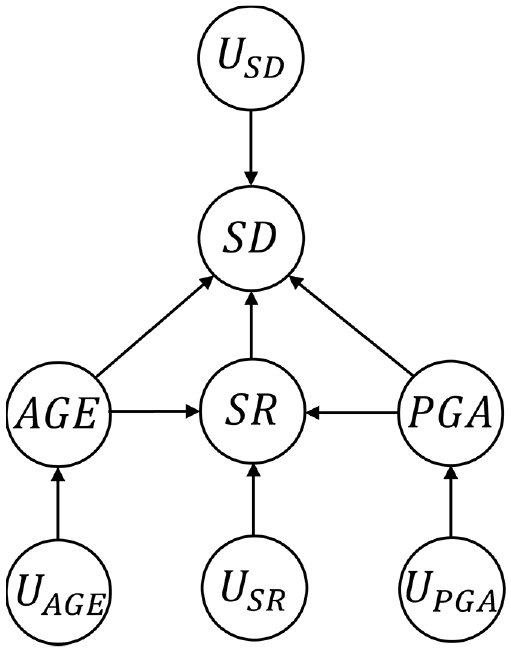
DAG corresponding to the seismic retrofit problem introduced in the PO framework section.
It should be noted that, within a DAG, the causal assumptions are encoded in the links (arrows) that are missing, not the ones that are shown (Pearl, 2019). The links that are included are used to represent the possibility of a causal influence, which is determined and quantified by the data. In Figure 1, for example, the missing arrows between the exogenous variables indicate the assumption of joint independence. Additional causal assumptions that are encoded in Figure 1 are (1) AGE does not influence PGA, (2) SR does not influence AGE or PGA, (3) PGA does not influence AGE, and (4) SD does not influence any of the endogenous variables.
SCMs integrate features of structural equation models (Duncan, 2014; Goldberger, 1972), the PO framework, and graphical models for probabilistic reasoning and causal assessment (Pearl, 1988). A SCM contains a set of endogenous and exogenous variables linked by a set of functions, which capture the causal relationships between the variables. The SCM corresponding to the DAG in Figure 1 is shown in Equation 1:




where
A causal analysis using data, DAGs and SCMs can be viewed as having two objectives: identification of a causal effect and quantification of the strength of that effect. Recall that the presence of an arrow in a DAG represents the possibility of a causal link that is determined by the analysis. For some problems, especially in domains such as earthquake engineering, the causal link may be identifiable based on our knowledge of the physical system being studied. For example, we know based on structural engineering principles that there is going to be some causal effect of the retrofit on damage, so we may want to focus on quantifying the strength of that effect. However, there are other problems, even within earthquake engineering, where the presence of a causal link is less obvious.
As noted earlier, the
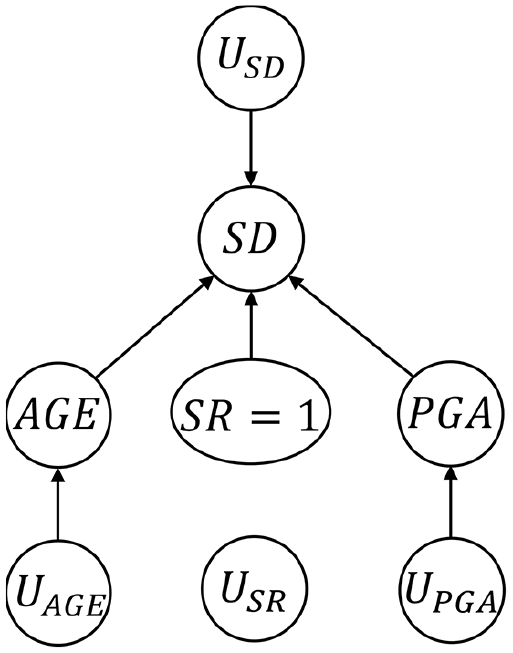
DAG corresponding to the

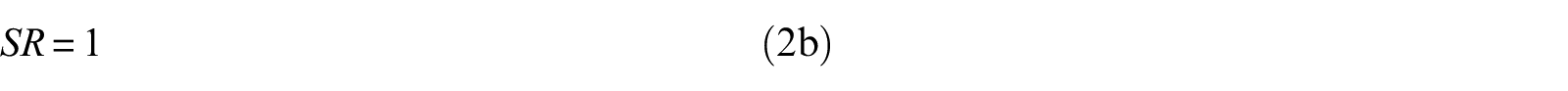


Identifying and quantifying the strength of a causal effect in a graph is feasible when the Markovian assumption—error terms are jointly independent, and the graph is acyclic—is a reasonable one. Identification and effect quantification in non-Markovian models (e.g., with correlated errors) are also possible, but with additional complications (see Pearl (2019). Here, we will deal with the former case. A model

where
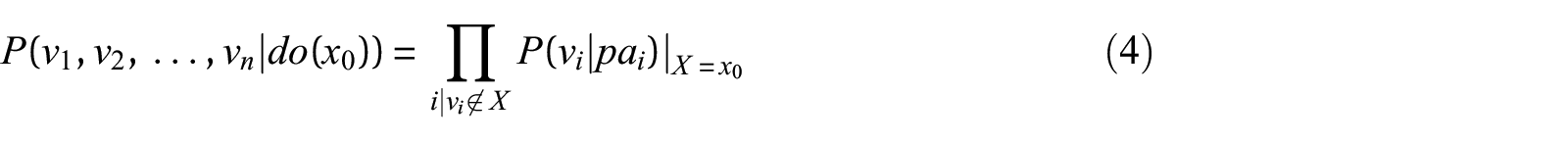
where
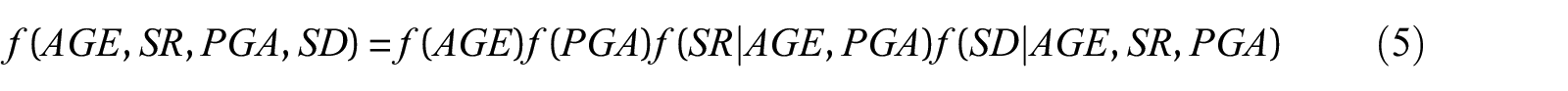
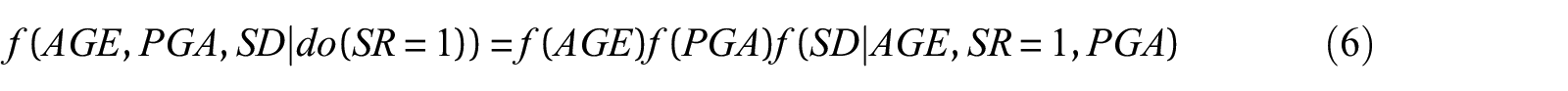
Then,
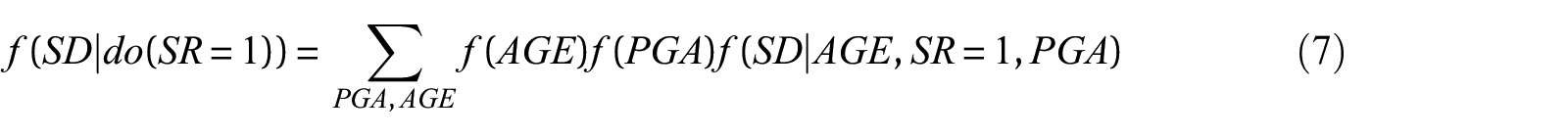
Equation 7, which is often described as “adjusting” for the confounding variables, coincides with the objectives of the “weighting” or “balancing” techniques mentioned in the PO section. Additional details on estimating causal effects using DAGs and SCMs are provided in Pearl (2019), where other complicating issues such as dealing with unmeasured confounders and counterfactual analysis (the third level of the causal hierarchy) are discussed.
Semi-parametric models
Semi-parametric models have been applied to a broad range of causal inference problems (usually within the PO framework) and have been shown to be especially useful in dealing with high-dimensional confounding (i.e., a large number of covariates). This body of work is largely attributed to James Robins and his collaborators (Robins, 1994; Robins and Tsiatis, 1991; Robins et al., 1992). As described in the PO framework, the general problem is defined with the goal of determining the effect of some treatment
One approach to estimating the causal effect for the “ground motion duration” problem is to fit regression models with SD (outcome) as the dependent variable and


In Equations 8 and 9,
A strategy that has been receiving significant recent attention in the causal inference literature is to use ML models for
For our ground motion duration problem, we would generate our dataset of observations using response history analysis. Each ground motion in the record-set will be used to analyze the building structural model, which will yield a performance outcome SD. We will also be able to compute the duration, DR (treatment), SS, and first-mode spectral acceleration,
This section discussed a single specific approach (semi-parametric models) to estimating treatment effects in the presence of confounders within a broader causal inference framework. It is noted that several alternative approaches exist in the broader literature (Imbens and Rubin, 2015).
Sensitivity analyses
In general, causal inference on observational data (as opposed to a controlled experiment) requires the unavoidable assumption that there is “no unobserved confounding” or “ignorability” conditional on observables (also described as “conditional ignorability”) (Imbens and Rubin, 2015; Pearl, 2019; Rosenbaum and Rubin, 1983). In fact, the need for assumptions that are unverifiable by the collected data is fundamental to causal inference (Pearl, 2019). In earthquake engineering problems, the ignorability assumption can be placed in two broad categories. The first is one where conditional ignorability is justifiable based on an understanding of the physical mechanisms that drive the problem. In this scenario, it is still advisable that the investigator provides as much evidence as possible to justify that the estimated causal effects are not due to confounding. This is especially true if the underlying physics of the problem is not fully understood. The second is the situation where the ignorability assumption is not fully justifiable but necessary simply because of a lack of data on potential additional confounders. In this case, it is even more important that the modeler investigates the implications of these unmeasured confounders to the causal estimates.
In the causal inference literature, sensitivity analysis is the primary means for assessing the implications of unobserved confounding to causal inference results. Specifically, sensitivity analyses are used to determine whether an unobserved confounder can substantively alter the conclusions about an estimated causal effect. Two metrics are widely used for this purpose: the robustness value (RV) and partial coefficient of determination (or partial

where
The partial
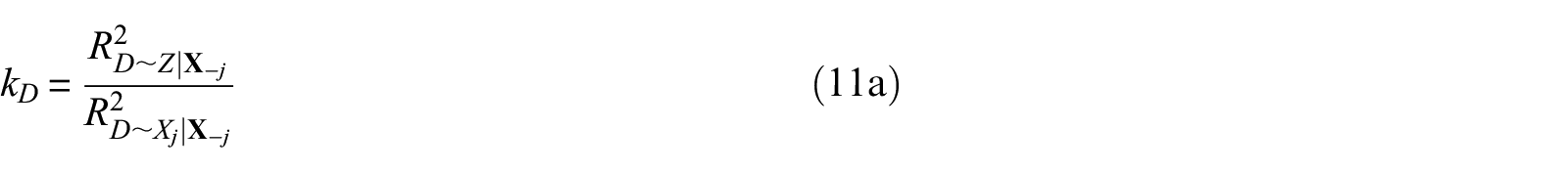
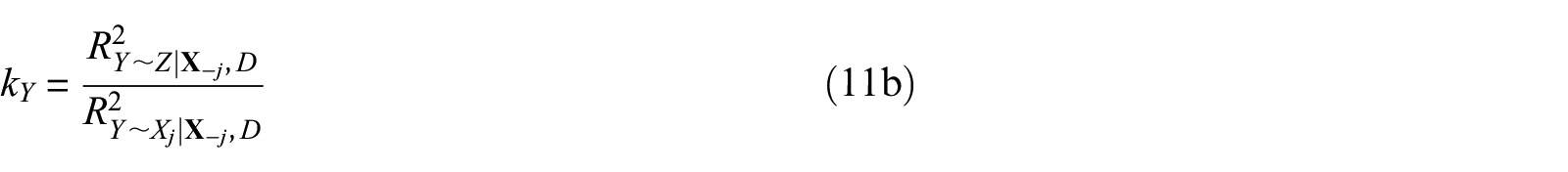
where


where
Revisiting the “ground motion duration” problem described in the previous subsection, the argument can be made that spectral shape and
Opportunities and challenges
Statistical analysis of observational data is a primary tool in earthquake engineering research and practice. Furthermore, the present access to multiple data streams (e.g., field reconnaissance, simulation, and remote sensing), coupled with recent advancements in computing and statistical learning, have only intensified data-driven efforts in the domain. However, as a community, we are yet to broadly leverage the principles, tools, and techniques that have been developed and disseminated in the field of causal inference. While it is generally accepted that seismic risk mitigation should ideally be based on a causal understanding of the effects of earthquakes and any intervention strategies, the overwhelming majority of data-driven investigations do not rigorously address the issue of confounding. This can be viewed as an opportunity for the earthquake engineering community, which already has a long history of interdisciplinary (or more recently, transdisciplinary) research and practice.
A general area that is ripe for research is an overall investigation of what principles, tools, and methods in the broad area of causal inference (on observational data) are adaptable to solving problems in earthquake engineering. This article presented four categories of domain-specific problems and two frameworks that have dominated the causal inference literature. While an attempt has been made to link the two, understanding which method(s) is most appropriate for a given problem (or category of problems) is still an open question. For instance, one can inquire about whether there are common or distinct strategies needed when addressing causal problems where the data are generated from physical experiments, numerical simulations, or field reconnaissance after real earthquakes. Another open question is in regard to the most appropriate causal inference method(s) (e.g., PO, semi-parametric model-based) for binary (e.g., retrofitted or not retrofitted) versus continuous (ground motion duration) treatment variables. In contrast to the social sciences (e.g., economics and political science) where causal inference methods are widely used, earthquake engineering problems are often supported by an understanding of the underlying physics (to different degrees). This knowledge can serve as a base of support for the many unavoidable assumptions that are needed when trying to elucidate cause and effect.
The last 5 years has seen a broad embrace of the use of ML methods in the earthquake engineering domain. However, the applications have generally been toward developing predictive models, where capturing associative relationships between the features and outcome variable is sufficient. There is a need for a broad assessment within the domain to understand how ML algorithms can be leveraged in causal inference problems that involve high-dimensional confounding. For ease of illustration, the hypothetical problems presented in the previous section were limited to two confounders. However, a realistic appraisal of these problems can quickly lead to the recognition that the number of confounders is much greater. Consider the hypothetical seismic retrofit problem presented earlier. The confounders can be placed into two categories: those related to the building characteristics and those related to the ground shaking intensity. Besides the age, other building-related confounders include the number of stories, floor area, plan layout, and wall density. On the shaking intensity side, there may be a need to consider multiple types of intensity measures to ensure that the confounding is rigorously addressed. With that many confounders, using ML (specifically double ML) as the “adjustment” strategy almost becomes a necessity. In contrast to their use in predictive models, the application of ML within a causal context is much more suited to the advancement of fundamental knowledge and/or discovery of new insights.
So far, we have highlighted several sub-problems within earthquake engineering that can derive potential benefits when viewed through a causal lens. Some high-level questions were also presented as “opportunities” toward a full embrace of causal inference as a tool for advancing the field. However, like any new area of inquiry, this pursuit does not come without challenges. The proposed paradigm shift is centered around the use of observational data to extract causal information. Therefore, having access to high-quality data is paramount to realizing this goal. As emphasized in early sections, a causal claim that is derived from observational data relies heavily on the validity of the conditional ignorability assumption. In other words, the need to adjust for all significant confounders implies that the dataset should contain the necessary information. Because of differences in the data-generating process, this will be more of a challenge for some problem categories than others. Problems that rely on data from physical experiments will be limited by the information that was documented and provided by the investigators. However, for problems involving existing infrastructure, while collecting the necessary data may prove to be a challenge, it is usually possible with the appropriate amount of effort.
In general, the domains that have advanced the field of causal inference (i.e., social science, public health, and statistics) are much more reliant on purely data-driven methods. Comparatively speaking, mechanistic models play a much bigger role in developing solutions to earthquake engineering problems. A major challenge in this regard is establishing methods that integrate mechanistic modeling with causal inference principles and data-driven techniques. This strategy was the centerpiece of the Rabonza et al. (2022) study which used counterfactual analysis to quantify the benefit of disaster risk reduction interventions.
Summary and conclusion
This study is rooted in the hypothesis that the foundational principles, concepts, language, and methodological advancements in the broad area of causal inference can enhance the way that knowledge is gleaned from data-driven earthquake engineering models. To advance this proposition, four categories of problems that are prevalent within the domain are discussed, highlighting the limitations in the state-of-the-art with respect to the inability to make quantitative and justifiable causal claims. The problems vary based on the data-generating process (e.g., physical experiments, numerical simulations, and field reconnaissance) and types of investigations (e.g., average benefit of interventions and effect of seismic and structural properties on damage). Next, two distinct but fundamentally related “schools of thought” in the broad area of causal inference are presented. Using hypothetical examples related to the aforementioned problem categories, we begin to forge direct connections with the earthquake engineering domain and highlight limitations and capabilities in terms of advancing the field. The importance of sensitivity analysis as a means to justifying the unavoidable conditional ignorability assumption is also examined.
Through the state-of-the-art review of domain-specific problems, we elucidate opportunities for using causal inference to advance earthquake engineering research and practice. In addition, more general questions that are agnostic to the discussed problem categories are presented as opportunities for future research. One such question is centered around the adaptability of the causal inference frameworks to earthquake engineering problems in general. For instance, some methods are more suitable to dichotomous treatment variables (e.g., retrofitted versus unretrofitted building) while others are more suited to continuous variables (e.g., significant duration of a ground motion). The potential for ML models as a tool for addressing the challenge of high-dimensional confounding in causal earthquake engineering problems is also discussed. Because of the need for information that captures all (or most) possible confounders, the current lack of high-quality data was recognized as a major challenge. Given that the methods from the broader causal inference literature are centered around fully empirical (or data-driven) analyses, we also identified the need to develop integrative causal frameworks that also incorporate engineering models.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.