
Abstract
Single image super-resolution (SR) aims to reconstruct high-resolution (HR) images from their low-resolution (LR) counterparts. Although recent transformer-based SR methods have achieved impressive performance, their substantial computational complexity and memory requirements severely restrict practical deployment. To address these challenges, we propose the gated multi-scale interaction network (GMIN), a lightweight convolutional neural network architecture that effectively integrates transformer design principles. GMIN introduces the gated multi-scale interaction module, which comprises a spatially adaptive mixing layer (SML) and an enhanced spatial gated feed-forward network (EGSFN). The SML dynamically filters less informative features and aggregates multi-scale spatial information through innovative gating mechanisms, while EGSFN employs large-kernel convolutions with gating operations to capture rich spatial dependencies, significantly enhancing feature representation capabilities. Comprehensive experimental results demonstrate that GMIN achieves an exceptional balance between SR quality and computational efficiency, outperforming the transformer-based ESRT by 0.14 dB in peak signal-to-noise ratio while utilizing fewer parameters and requiring 77% fewer floating-point operations per second. These findings establish GMIN as a novel and practical solution for lightweight image SR, making a significant contribution to the development of efficient SR models suitable for resource-constrained environments.
Keywords
Introduction
Image super-resolution (SR) aims to reconstruct high-resolution (HR) images from low-resolution (LR) observations using learning-based approaches (Dong et al., 2016; Kim et al., 2016; Lim et al., 2017; Zhang et al., 2018). Due to the inherent resolution discrepancy between LR inputs and HR outputs, SR models are required to infer missing high-frequency spatial information, which inevitably introduces uncertainty. Moreover, the image degradation process is generally noninvertible, such that a single LR image may correspond to multiple plausible HR reconstructions. These characteristics make single image SR a highly ill-posed inverse problem (Zhu et al., 2022).
Current SR methods confront two primary challenges.
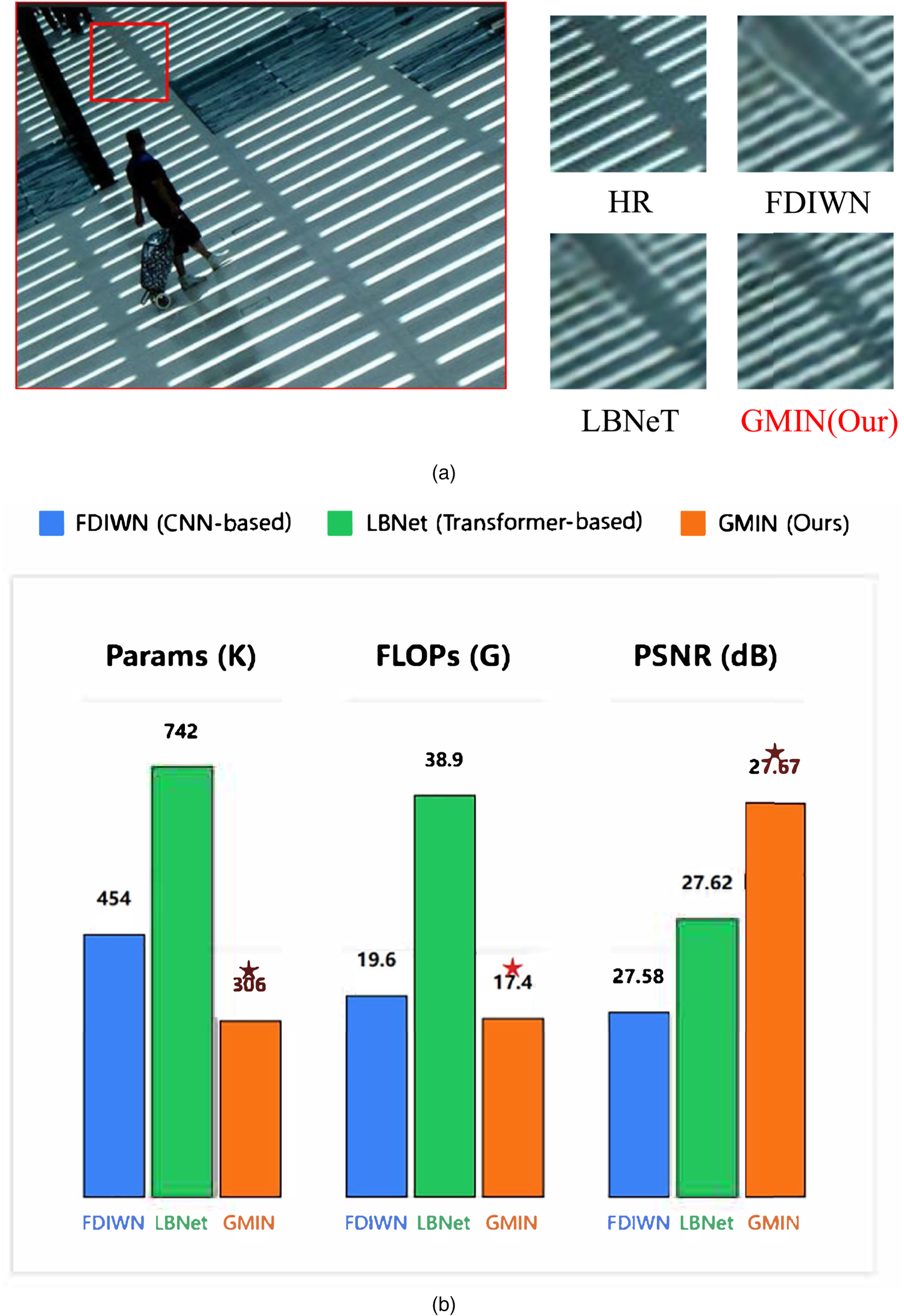
Motivation for GMIN: Addressing the dual challenges of texture fidelity and computational efficiency in image super-resolution. We illustrate (a) the visual superiority of GMIN in avoiding common artifacts and (b) its quantitative advantage in achieving high performance with reduced computational resources. (a) Visual quality: Comparison of texture recovery. Conventional CNNs often suffer from over-smoothing, while transformers may introduce ringing artifacts. In contrast, GMIN produces sharper and cleaner details. (b) Efficiency analysis: Tradeoff between model size (parameters), computational cost (FLOPs), and reconstruction quality (PSNR). GMIN achieves a superior balance, offering high performance with significantly lower computational overhead. Note. GMIN = gated multi-scale interaction network; CNN = convolutional neural network; FLOPs = floating-point operations per second; PSNR = peak signal-to-noise ratio.
To systematically address these challenges, we draw inspiration from MetaFormer’s insight that “architecture matters more than attention” (Yu et al., 2022) and recent advances in efficient feature interaction (Li et al., 2022a; Qian et al., 2024; Rao et al., 2022; Xie et al., 2021). We establish core design principles: (1) replace computationally expensive global attention with efficient feature interaction mechanisms while preserving transformer-like architectural advantages; and (2) achieve balanced modeling of local texture and global context through dynamic multi-scale interaction.
Based on these principles, this paper proposes the gated multi-scale interaction network (GMIN). The core component is the multi-level GMIM. Specifically, we design a spatially adaptive mixing layer (SML) that filters redundant features through spatial adaptive units (SAUs) and utilizes gated multi-scale interaction blocks (GMIBs) to extract local and global features in parallel. To further enhance spatial modeling without the cost of MHSA, we introduce an efficient gated spatial feed-forward network (EGSFN) that employs large-kernel convolutions and gating branches. Additionally, GMIN adopts a lightweight design by removing layer normalization and redundant skip connections to optimize inference efficiency.
The main contributions of this paper include: We introduce an efficient GMIN tailored for addressing image SR reconstruction challenges. In comparison to existing advanced methods, our approach significantly enhances network performance while striking a superior balance between lightweight design and overall performance (as shown in Figure 2). We design an innovative GMIB module that effectively integrates local texture information with global contextual information through gated multi-scale branch architecture and adaptive feature fusion mechanisms, significantly suppressing ringing artifacts while successfully recovering fine texture details (as shown in Figure 1(a)). We propose an efficient EGSFN module that enhances the network’s spatial modeling capabilities through large-kernel convolution operations and pixel-level gating mechanisms, while fully preserving the inherent advantages of feed-forward networks (FFNs) in channel nonlinear transformations.
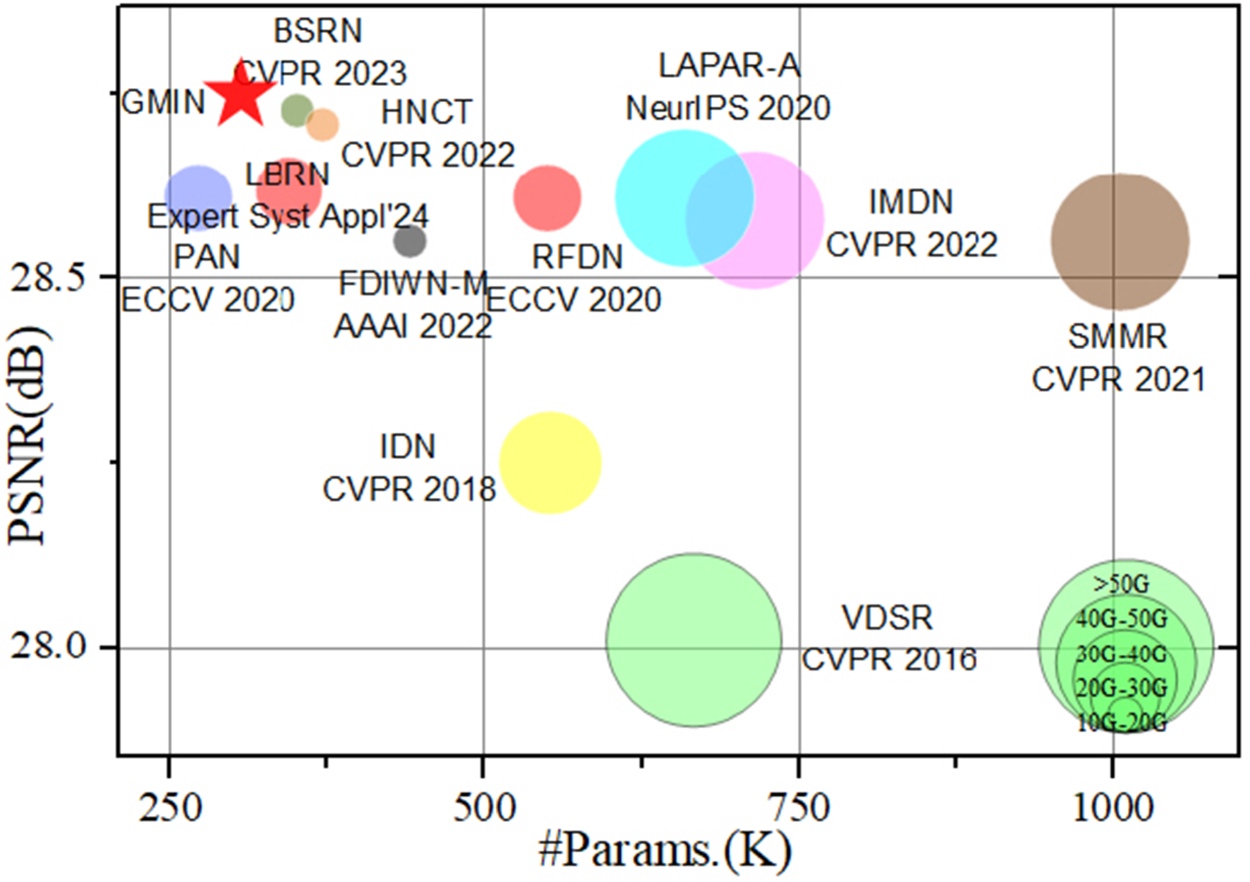
Performance-complexity tradeoff comparison of state-of-the-art SR methods on the Set14 dataset for
CNN-Based Lightweight SR Model
In recent years, there has been considerable interest in lightweight SR models due to their smaller model size and reduced computational resource demands. To achieve lightweight SR models, researchers have explored various methodologies. Ahn et al. (2018) introduced an efficient neural network called cascading residual network (CARN), employing a cascading network structure and grouped convolutional operations. Compared to the then state-of-the-art methods, the network demonstrated significant reductions in parameters and computational effort, while maintaining comparable performance. Hui et al. (2019) proposed a lightweight information multi-distillation network (IMDN) by constructing cascaded information multi-distillation blocks. This network gradually extracts hierarchical features and utilizes the information distillation mechanism during training. However, the network’s parameter count is relatively high, and the efficiency of channel information distillation needs improvement. Addressing these issues, Liu et al. (2020) redesigned the architecture of IMDN and introduced a method named residual feature distillation network (RFDN). This network utilizes feature distillation connections instead of the information distillation mechanism, enhancing SR performance without introducing additional parameters.
More recently, researchers have focused on optimizing architectural efficiency further. For instance, Hao et al. (2024) proposed the lightweight blueprint residual network (LBRN), which leverages blueprint separable convolutions to minimize redundancy. Similarly, Gendy et al. (2024) introduced EConvMixN, a network based on extended convolution mixers that effectively balances local and global feature processing.
Despite the notable progress achieved by these lightweight SR networks, they all rely on CNN structures, capable only of extracting local features and facing challenges in learning global information. This limitation hinders the recovery of global texture details in images. Moreover, as network depth increases, these methods demand more computational resources and memory consumption, posing challenges for deployment on embedded terminals such as mobile devices.
Transformer-Based Lightweight SR Model
The successful adoption of transformer architecture in natural language processing has spurred significant interest in its application to computer vision. In contrast to traditional CNNs, the transformer model employs a self-attention mechanism, enabling it to capture long-distance dependencies between sequence elements, making it adept at processing sequence data. Dosovitskiy et al. (2020) introduced the visual transformer for image recognition, directly taking sequences of chunked image blocks as inputs, and pre-training it on a large dataset, achieving performance comparable to CNN-based methods. Touvron et al. (2021) combined transformer with distillation methods, proposing an efficient image transformer (DeiT) suitable for training on medium-sized datasets with enhanced robustness. Liang et al. (2021) pioneered the application of the transformer to hyper segmentation by introducing the Swin transformer network. This network utilizes multiple Swin transformer layers for local attention and cross-window interaction, incorporating a convolutional layer for feature enhancement. Through the synergistic integration of transformer and CNN, SwinIR surpasses other state-of-the-art SR methods.
Recent efforts further specialize transformer designs for lightweight SR. Zhang et al. (2022) presented an efficient long-range attention network (ELAN) for image SR, employing shift convolution and grouped multi-scale self-attention modules to leverage remote image dependencies, yielding superior results with much lower complexity than existing transformer-based models. To reduce the quadratic complexity of self-attention, Shi et al. (2023) introduced the efficient striped window transformer (ESWT), which utilizes a striped window mechanism to capture long-range dependencies with reduced computational overhead. Wang et al. (2023) introduced omni self-attention, which concurrently models pixel-per-pixel interactions in both spatial and channel dimensions, exploiting the potential of existing transformer-based models. Interactions are considered in both spatial and channel dimensions, capturing correlations between space and channel. The interaction between local propagation and global scale is facilitated using full-scale aggregation groups. Experiments demonstrate that the Omni-SR architecture achieves a peak signal-to-noise ratio (PSNR) of 26.95 dB at upscaling factor
Method
Network Architecture
Our GMIN builds upon MAN (Wang et al., 2022b) to effectively reconstruct HR images. As illustrated in Figure 3, GMIN comprises four essential components: shallow feature extraction, cascaded GMIMs, multi-stage feature fusion (MSFF), and image reconstruction.
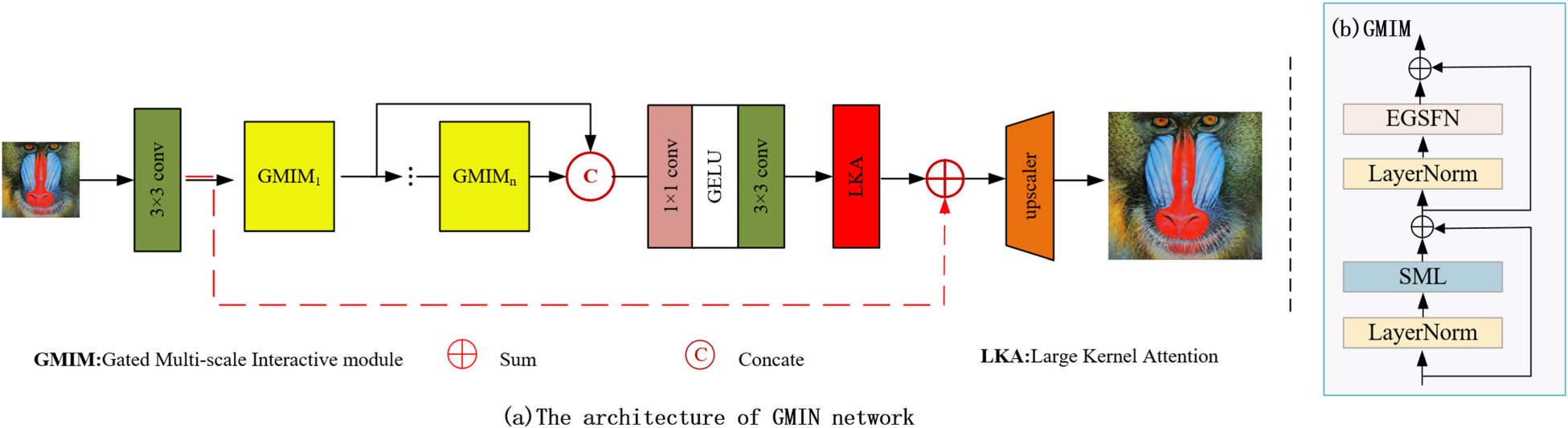
Overview of our GMIN. (a) The architecture of GMIN and (b) GMIM. Note. GMIN = gated multi-scale interaction network; GMIM = gated multi-scale interaction module.
The network first extracts shallow features from the LR input

These features then flow through

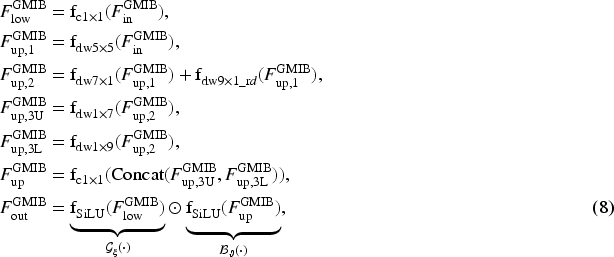
To maximize information utilization across different feature levels, we employ an MSFF module that integrates all GMIM outputs. The MSFF applies a
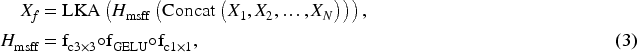
The reconstruction module combines the refined features with the shallow features via a residual connection, followed by pixel-shuffle upsampling:

We train the network using

Recent transformer-based models have shown remarkable potential in image SR. Yu et al. (2022) proposed MetaFormer, a general architecture abstracted from a transformer without specifying a particular token mixer. Their research demonstrated that the overall architectural framework contributes more significantly to model performance than the specific token mixing mechanism.
Following this insight, we designed our GMIM based on the MetaFormer architecture (Figure 4), achieving superior results compared to traditional CNN-based approaches. By intentionally omitting LayerNorm and skip connections for computational efficiency, our GMIM consists of two primary components: the spatially adaptive mixer layer (SML) for spatial information encoding and the efficient gated spatial feed-forward network (EGSFN) for channel information processing.
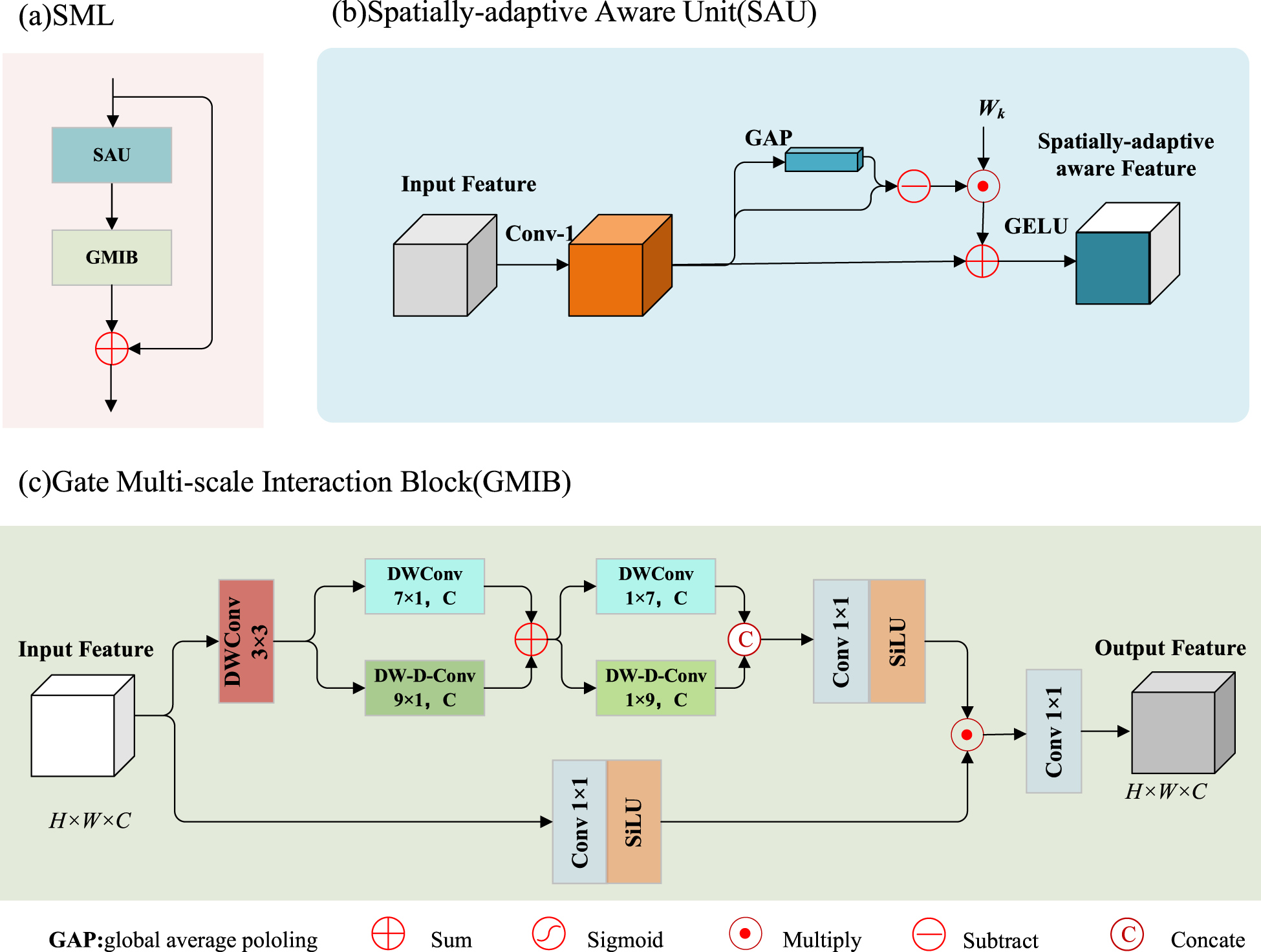
Architectures of our GMIM. (a) SML, (b) SAU, and (c) GMIB. Our SML primarily consists of two components: SAU and GMIB. SAU is designed to dynamically exclude less critical feature information to enhance performance in the SR tasks. GMIB employs gated units for the effective aggregation of multi-scale contextual features. Note. GMIM = gated multi-scale interaction module; SML = spatially adaptive mixing layer; SAU = spatial adaptive unit; SR = super-resolution; GMIB = gated multi-scale interaction block.
The MHSA mechanism is central to transformer architectures, dynamically generating weights to mix spatial tokens. However, its quadratic complexity significantly limits transformer applicability in low-level vision tasks. To address this limitation, we propose the SML with a lightweight spatially adaptive awareness unit (SAU). This design efficiently filters redundant low-frequency information while capturing critical high-frequency details, substantially reducing computational complexity. Furthermore, SML achieves effective multi-scale feature aggregation through the synergistic combination of gating units and depthwise convolution (DWConv).
The SML consists of two cascaded components: SAU and GMIB:

Spatially adaptive Aware Unit ( SAU. Natural images exhibit inherent spatial redundancy due to their localized structures. To efficiently capture essential spatial information for SR, we introduce the SAU, which dynamically suppresses less critical feature information. As shown in Figure 4(b), SAU processes both local texture features within each patch (via
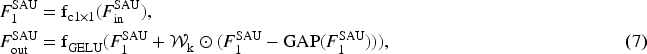
The lower branch serves as a gating mechanism that captures pixel-wise activation states using a
While conventional FFNs effectively model channel-wise feature relationships, they often neglect spatial information and introduce redundancy through channel expansion. To address these limitations, we propose the EGSFN, as shown in Figure 5.
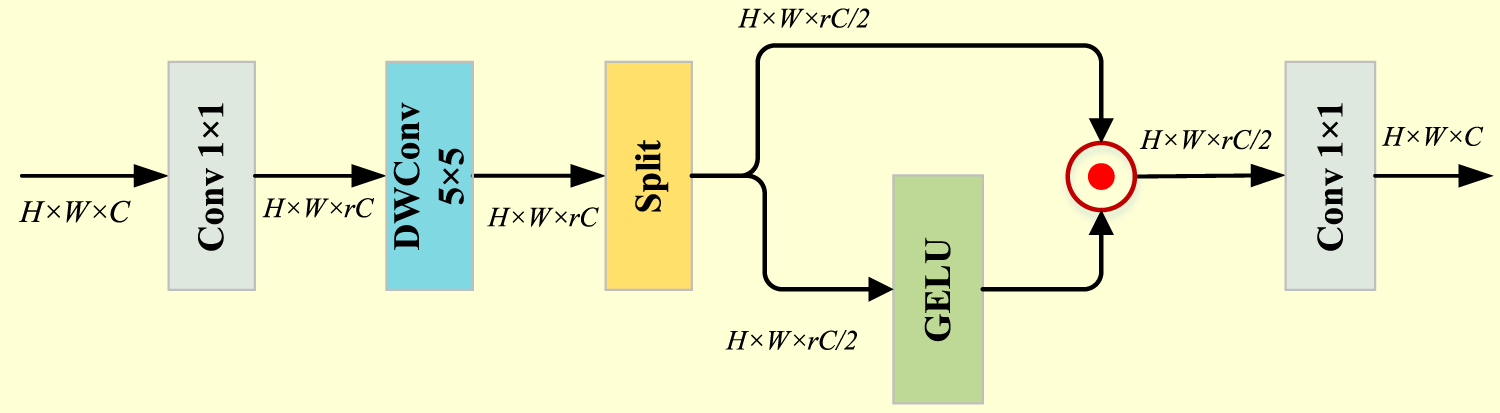
Architecture of the efficient gated spatial feed-forward network (EGSFN). The network combines depthwise convolutions for local structure learning with a channel-split gating mechanism that selectively filters information, enhancing spatial feature capture while maintaining computational efficiency.
EGSFN first applies a

Research by Guo et al. (2023) demonstrates that LKA modules effectively expand the receptive field for image restoration tasks, significantly enhancing network representation capabilities. In our GMIN architecture, we incorporate LKA at the end of the deep feature extraction backbone to capture long-range dependencies before reconstruction. The LKA module is formulated as:
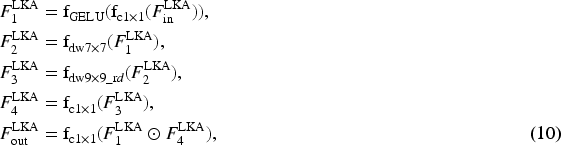
Experimental Settings
Datasets and Evaluation Metrics
We train GMIN following the standard procedure on DIV2K (Agustsson & Timofte, 2017) and Flickr2K (Lim et al., 2017) datasets. In addition, we conducted testing using five commonly employed benchmark datasets, namely Set5 (Bevilacqua et al., 2012), Set14 (Zeyde et al., 2010), BSD100 (Martin et al., 2001), Urban100 (Huang et al., 2015), and Manga109 (Matsui et al., 2017). To measure the quality of restoration, we convert the SR image to the YCbCr color space and compute the PSNR and structural similarity (SSIM) metrics on the luminance channel. PSNR represents the ratio of the maximum possible power of the signal to the destructive noise power that affects its representation accuracy, and is commonly expressed in logarithmic decibels (dB) units. The value range of SSIM is
Training Details
In line with prior research, we used the original HR training images to generate corresponding LR image pairs through bicubic downsampling (BI). To augment the training dataset, we applied random horizontal flips and rotations of
For optimization, we employed the Adan optimizer with
Comparison With Lightweight SR Methods
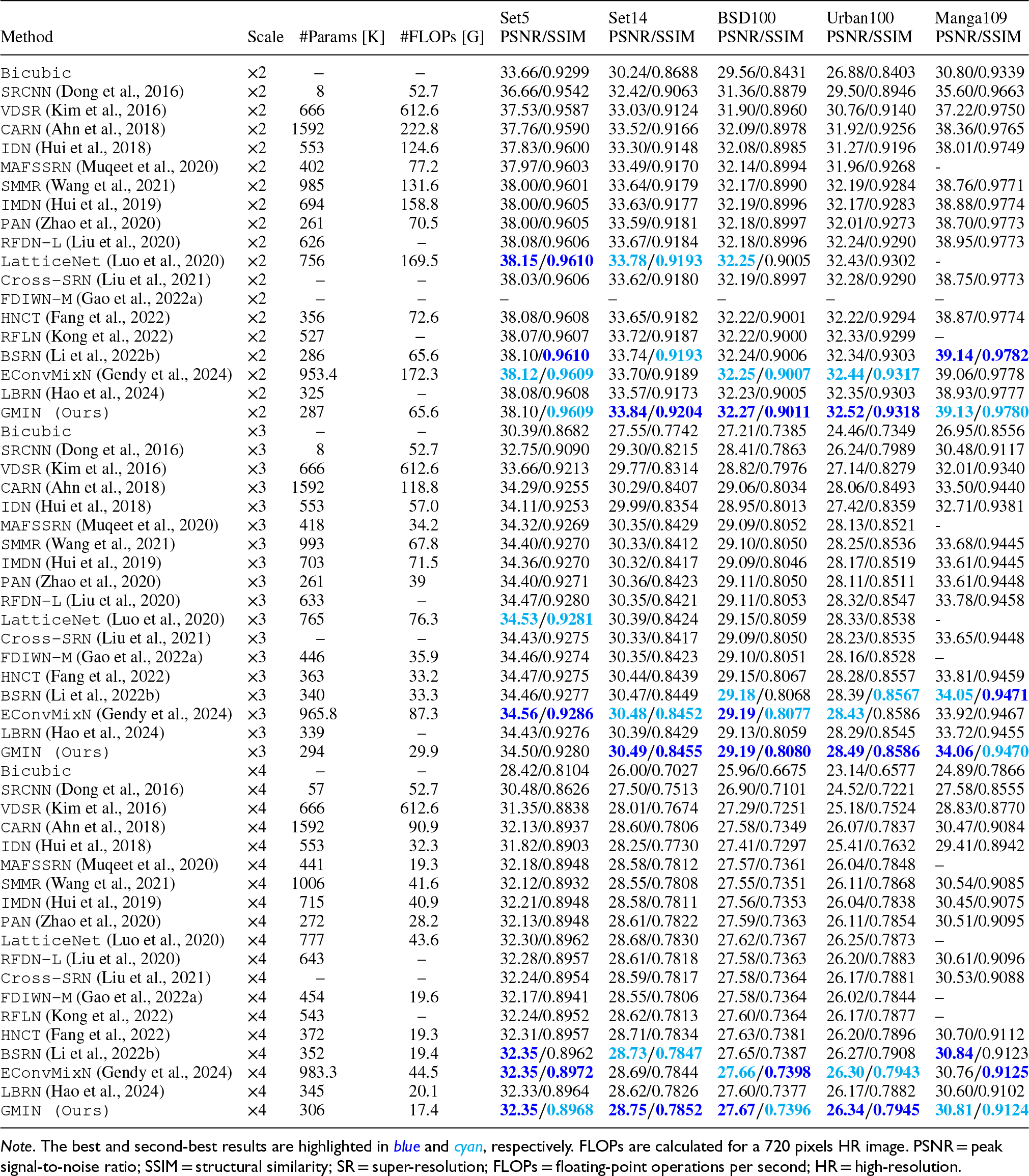
To evaluate the effectiveness of our GSIN, we conducted a comprehensive assessment that included both quantitative objective comparisons and subjective visual evaluations. Our goal was to benchmark GSIN against several leading lightweight SR methods. The methods included in this analysis are Bicubic, SRCNN (Dong et al., 2016), VDSR (Kim et al., 2016), CARN (Ahn et al., 2018), MAFSSRN (Muqeet et al., 2020), SMMR (Wang et al., 2021), IDN (Hui et al., 2018), IMDN (Hui et al., 2019), PAN (Zhao et al., 2020), LatticeNet (Luo et al., 2020), RFDN-L (Liu et al., 2020), Cross-SRN (Liu et al., 2021), FDIWN-M (Gao et al., 2022a), RFLN (Kong et al., 2022), HNCT (Fang et al., 2022), BSRN (Li et al., 2022b), EConvMixN (Gendy et al., 2024), and LBRN (Hao et al., 2024). We evaluated upscaling factors of
Quantitative Comparison (Average PSNR/SSIM) of State-of-the-art Lightweight SR Methods for
,
, and
Upscaling.
Quantitative Comparison (Average PSNR/SSIM) of State-of-the-art Lightweight SR Methods for

Visual comparison of state-of-the-art lightweight SR methods for upscaling factor
Table 1 compares GMIN with state-of-the-art methods including RFLN (Kong et al., 2022), BSRN (Li et al., 2022b), and HNCT (Fang et al., 2022). For
Subjective Visual Effect Assessments
Visual comparisons between our approach and several state-of-the-art methods are presented in Figure 6. The experimental results demonstrate the enhanced reconstruction quality achieved by GMIN, particularly at the
Comparison With Transformer-Based SR Methods
We developed an extended version of our architecture, GMIN-L, by stacking nine GMIMs with a channel width of 64. This transformer-style CNN variant was evaluated against leading transformer-based methods, including SwinIR (Liang et al., 2021), ESRT (Lu et al., 2022), LBNet (Gao et al., 2022b), ELAN-light (Zhang et al., 2022), and ESWT (Shi et al., 2023).
Quantitative Objective Comparisons
Table 2 presents a comprehensive comparison, demonstrating that GMIN-L achieves competitive or superior performance while requiring significantly fewer parameters and computational resources. At a
Quantitative Comparison (Average PSNR/SSIM) With Other Advanced Transformer-Based SR Methods.
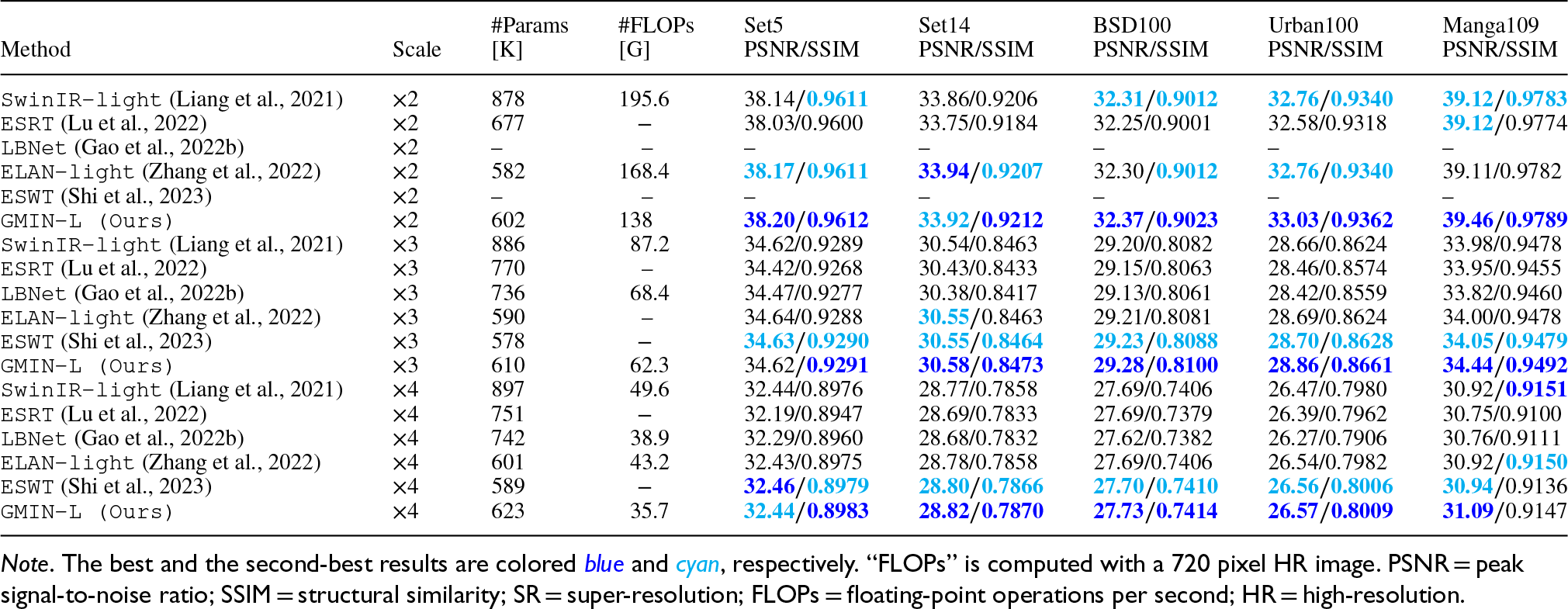
Quantitative Comparison (Average PSNR/SSIM) With Other Advanced Transformer-Based SR Methods.
Figure 7 presents visual comparisons at

Visual comparison with other transformer-based super-resolution (SR) methods for upscaling factor
For the BSD100:253027 sample, competing methods including HNCT (Fang et al., 2022), FDIWN (Gao et al., 2022a), and BSRN (Li et al., 2022b) incorrectly reconstructed the building line orientations. By contrast, GMIN-L produced reconstructions that closely preserve the geometric structures present in the original HR images.
Similarly, for Urban100:img033, alternative approaches failed to accurately capture the ground line patterns, exhibiting noticeable blurring and geometric distortion. GMIN-L, however, generated reconstructions with substantially higher fidelity and minimal artifacts, resulting in superior visual quality.
These examples across diverse architectural and structural patterns demonstrate GMIN-L’s enhanced capability to preserve critical high-frequency details and geometric structures during SR reconstruction.
Effect of SAU
To evaluate the effectiveness of the SAU, we conducted experiments with two comparative configurations within the SML framework. The first configuration completely removed the SAU component, denoted as “w/o SAU.” The second retained only a
As illustrated in Figure 8, incorporating SAU leads to measurable performance improvements. We further analyzed the computational complexity of SAU, with results presented in Table 3. While removing SAU (“w/o SAU”) slightly reduces model parameters and computational complexity (FLOPs), it simultaneously causes significant degradation in reconstruction quality as measured by PSNR and SSIM metrics. Similarly, when comparing with the simplified “w/Conv-1” configuration, which maintains nearly identical parameter count and computational overhead, we observe performance decreases of 0.01 dB in PSNR and 0.004 in SSIM. These experimental results demonstrate that SAU maintains a favorable balance between computational efficiency and performance enhancement, providing substantial quality improvements while introducing minimal additional computational burden.
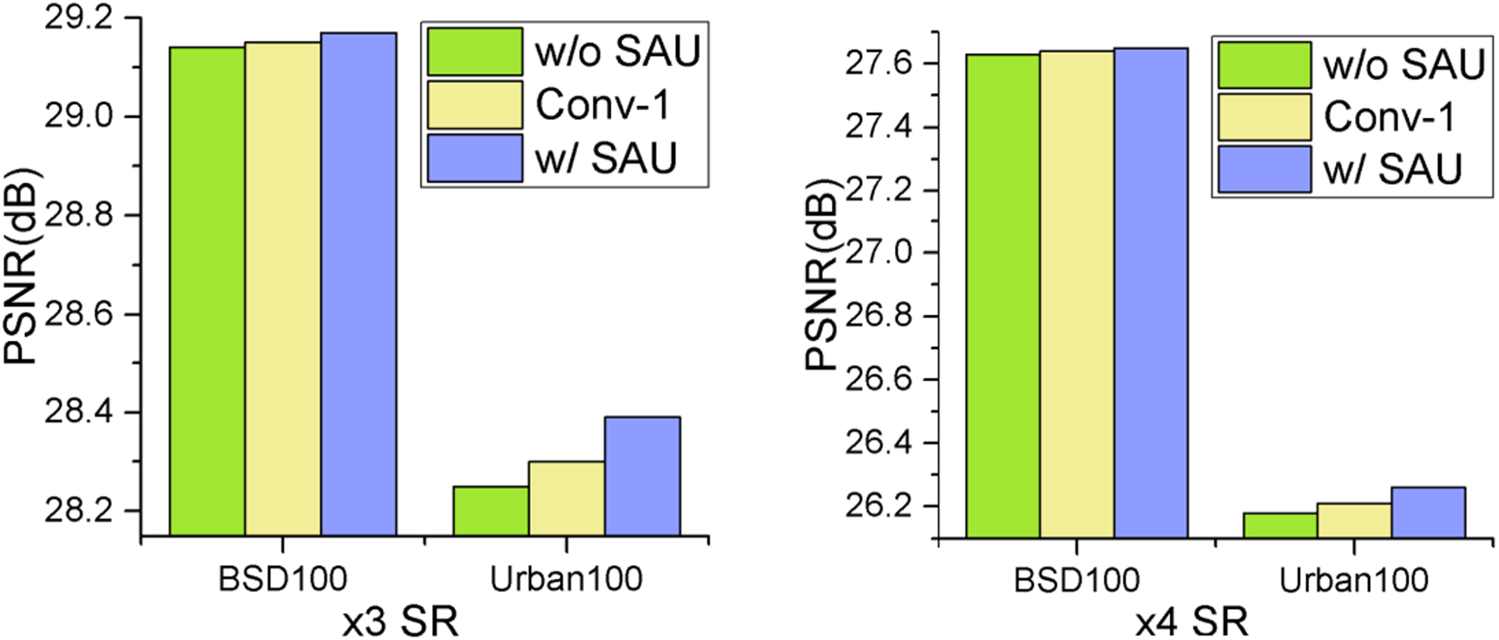
Ablation study about the effectiveness of SAU. The study was performed on the BSD100 and Urban100 datasets at
Impact of SAU Presence in the SML Module for
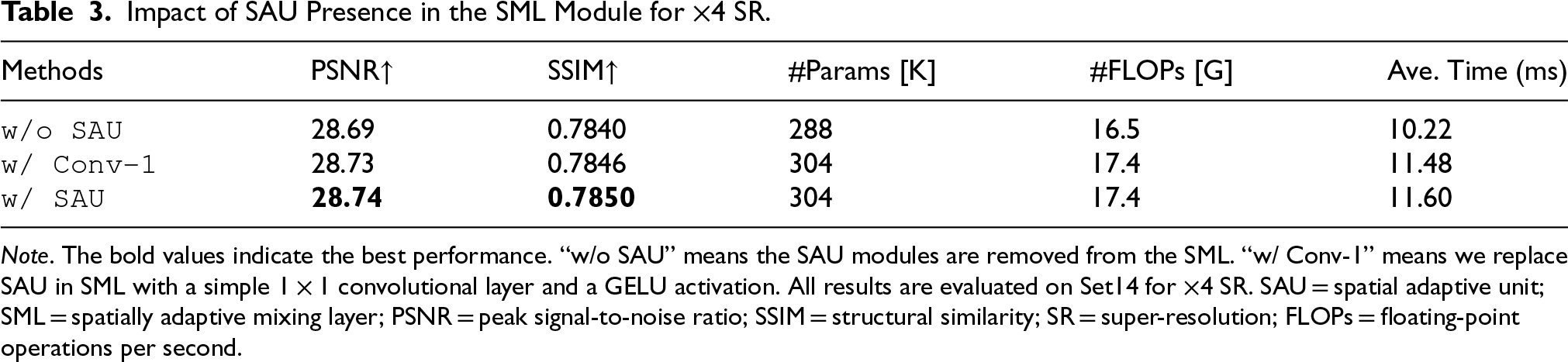
Note. The bold values indicate the best performance. “w/o SAU” means the SAU modules are removed from the SML. “w/ Conv-1” means we replace SAU in SML with a simple
The GMIB serves as a critical component of GMIM, offering both reduced computational demands and strong performance characteristics. To quantitatively evaluate its effectiveness, we conducted comparative experiments replacing GMIB with established feature extraction modules from other lightweight SISR architectures, specifically ESDB (excluding ESA and CCA; Li et al., 2022b) and MLKA (Wang et al., 2022b).
As shown in Table 4, GMIB demonstrates superior efficiency with lower parameter counts and computational complexity (FLOPs) compared to alternative approaches, while simultaneously achieving higher reconstruction quality. This performance advantage stems from GMIB’s effective multi-scale interaction mechanism, which captures both local and global image features. The significant performance-to-complexity ratio makes GMIB particularly valuable for developing efficient, lightweight SR models, confirming its effectiveness as a feature extraction module for image SR tasks.
Performance Comparisons of GMIB and Other Basic Units on Benchmark Datasets for
SR.

Performance Comparisons of GMIB and Other Basic Units on Benchmark Datasets for
To assess the effectiveness of EGSFN, we conducted an ablation study with results presented in Table 5. We compared our proposed EGSFN against three alternative architectures: the original feed-forward network (FFN; Dosovitskiy et al., 2020), gated linear unit FFN (GLU-FFN; Chen et al., 2022), and convolutional FFN (Conv-FFN; Wang et al., 2022a).
Performance Comparisons of EGSFN, FFN (Dosovitskiy et al., 2020), GLU-FFN (Chen et al., 2022), and Conv-FFN (Wang et al., 2022a) on Benchmark Datasets for
SR.
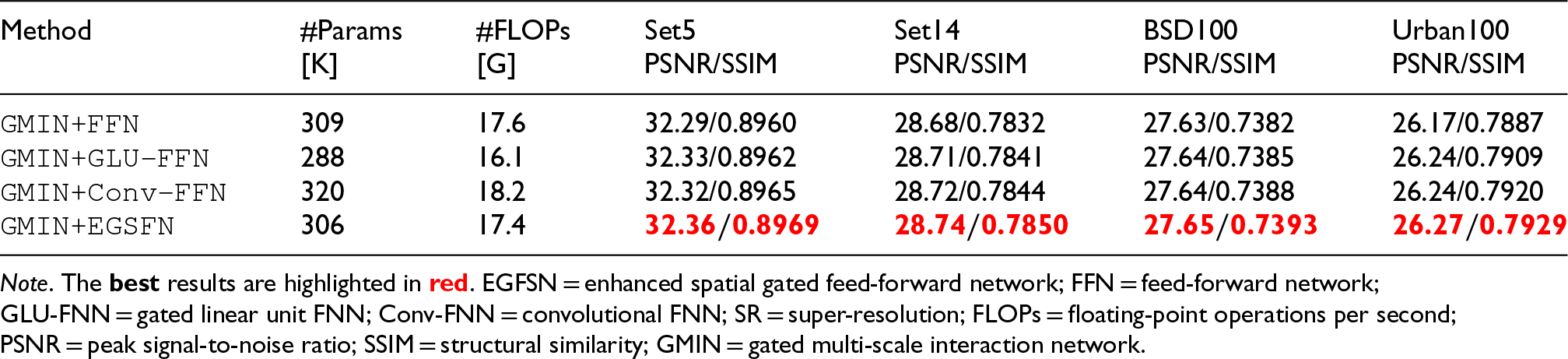
Performance Comparisons of EGSFN, FFN (Dosovitskiy et al., 2020), GLU-FFN (Chen et al., 2022), and Conv-FFN (Wang et al., 2022a) on Benchmark Datasets for
The experimental results demonstrate that EGSFN outperforms FFN while maintaining a comparable parameter count. Compared to GLU-FFN, EGSFN incorporates DWConv, which enhances local perception capabilities and consequently improves overall performance, despite a modest increase in parameters and FLOPs. When compared to Conv-FFN, EGSFN not only achieves superior performance but also exhibits a more efficient parameter utilization due to the integration of the split operation.
To accurately assess the complexity of our GMIN, we compared the inference speed of several lightweight SR methods on the BSD100 dataset (
Quantitative Tradeoff Comparison Between Model Performance and Complexity of Image SR on BSD100 Dataset (
).
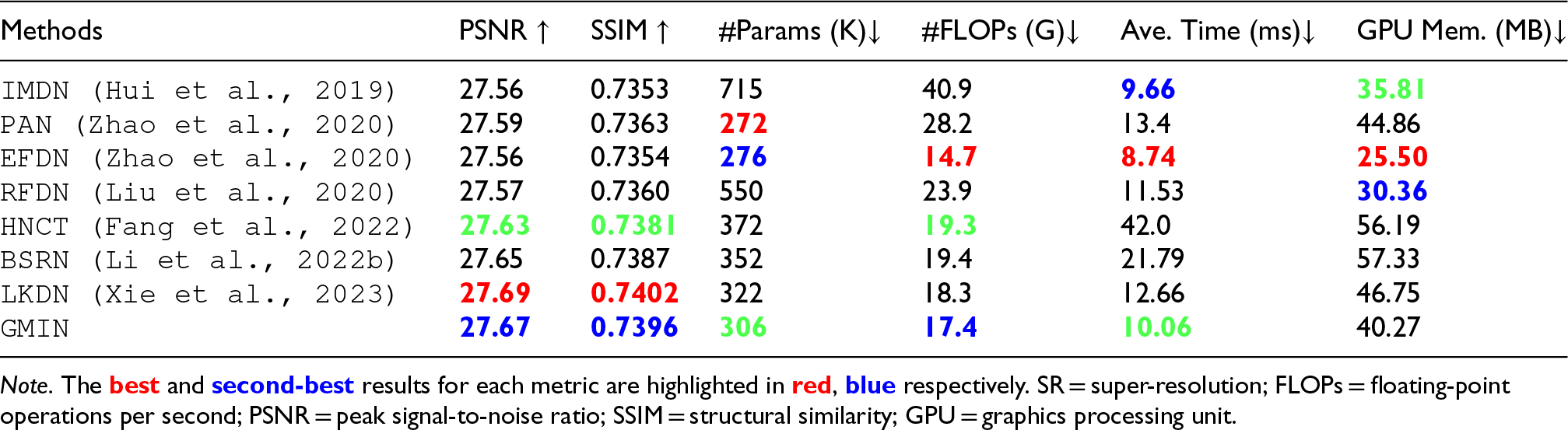
Quantitative Tradeoff Comparison Between Model Performance and Complexity of Image SR on BSD100 Dataset (
With comparable FLOPs, the proposed GMIN achieves a PSNR value of 27.67 dB, surpassing HNCT (Fang et al., 2022) by 0.04 dB and BSRN (Li et al., 2022b) by 0.02 dB, while requiring fewer parameters and shorter inference times. Even when compared to lightweight algorithms such as EFDN (Wang, 2022), which have fewer parameters and shorter inference times, GMIN maintains significantly higher performance.
Furthermore, when compared to LKDN (Xie et al., 2023), the current state-of-the-art lightweight SR method, GMIN, exhibits only a marginal 0.44% reduction in performance, while offering substantial efficiency gains: a 4.97% reduction in parameters, a 4.92% decrease in FLOPs, and a 20.54% reduction in inference time. This experimental evidence underscores the exceptional efficiency of GMIN when considering the balance between parameters, performance, and inference time.
To evaluate the generalization capability of our GMIN and its SR performance in real-world applications, we conducted SR experiments at a scale factor of

Visual comparison with the state-of-the-art methods for
As demonstrated in Figure 9, GMIN effectively enhances both the resolution and visual quality of real-world images. Compared to other methods, our proposed model produces images with more distinct textures, fewer artifacts, and greater detail preservation, resulting in an overall superior visual quality. These results highlight GMIN’s exceptional generalization capability and effectiveness for real-world SR applications, even when trained without access to ground truth HR images.
LAM is an attribution analysis method for SR results proposed by Gu et al. (Gu & Dong, 2021). This technique highlights pixels that have the most significant impact on SR outcomes. For a given local patch, a larger attribution area in the LAM indicates that the SR network extracts and utilizes information from a wider range of pixels.
We employed LAM to compare GMIN with RFDN (Liu et al., 2020), HNCT (Fang et al., 2022), and BSRN (Li et al., 2022b), as illustrated in Figure 10. Our analysis reveals that GMIN achieves a higher distribution intensity value, demonstrating its superior capability to effectively utilize information from a broader range of pixels in the input LR image. This enhanced information utilization directly contributes to improved SR performance. Furthermore, these results confirm that our proposed GMIN possesses a larger effective receptive field, which is a critical factor for achieving superior SR results.

The LAMs are visualized for RFDN (Liu et al., 2020), HNCT (Fang et al., 2022), BSRN (Li et al., 2022b), and the proposed GMIN. A larger highlighted area indicates that it captures more pixels associated with the input patch. Note. LAM = local attribution map; GMIN = gated multi-scale interaction network.
Despite GMIN's efficiency, its static convolution kernels lack the content-dependent dynamic adaptability of Transformer-based MHSA, potentially leading to suboptimal performance on images with extremely complex non-local patterns. Additionally, the domain gap between synthetic training and real-world degradations remains a challenge for robust deployment. In future research, we will investigate model compression techniques, such as integer quantization and structural reparameterization, to optimize deployment on resource-constrained edge devices. Furthermore, we intend to extend GMIN's efficient feature interaction to video SR by incorporating temporal alignment modules to exploit multi-frame redundancy.
Conclusion
In this paper, we introduce GMIN, a lightweight CNN based on the transformer framework, specifically designed to enable efficient image SR. To enhance feature extraction and integration, we propose the GMIB, which incorporates gated units and a dual-branch structure to simultaneously capture and interact with local and global features. Multi-scale feature representations are first generated through feature concatenation and a