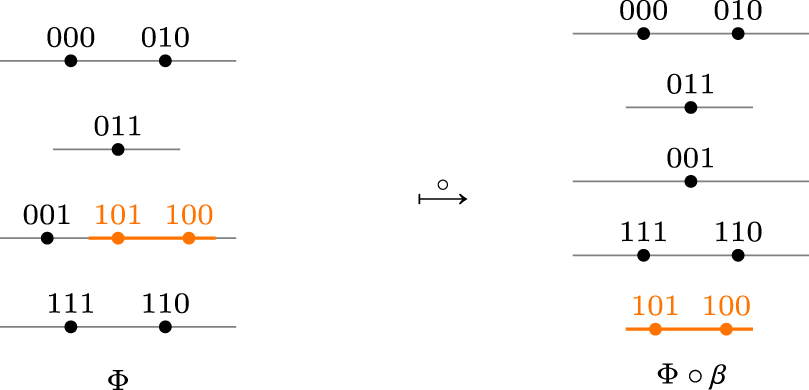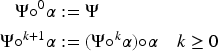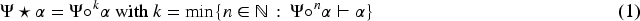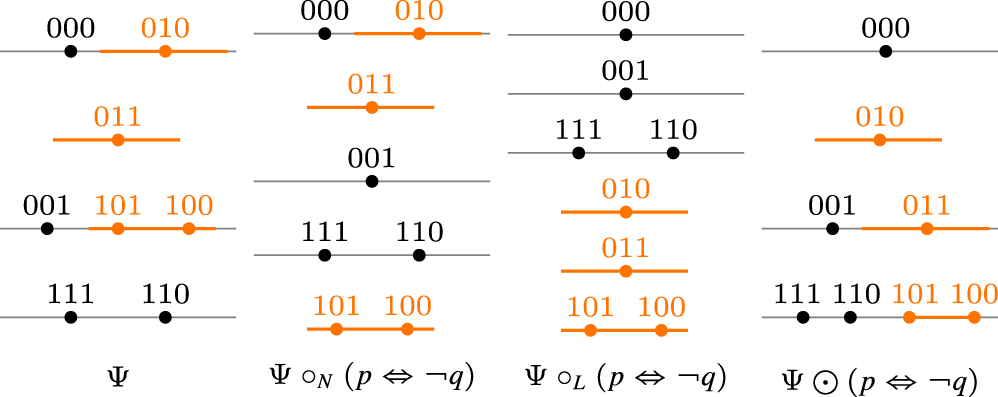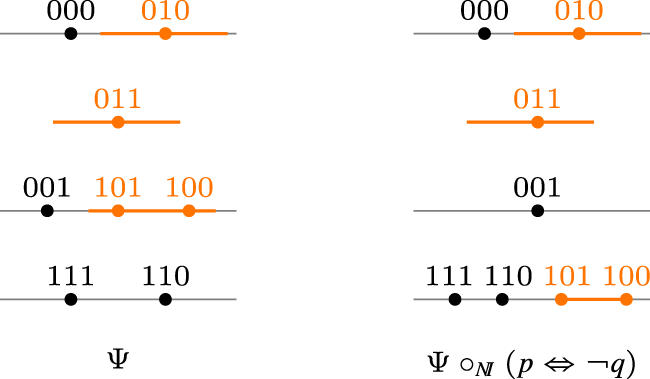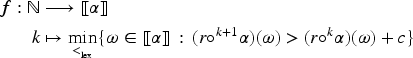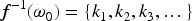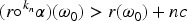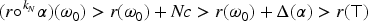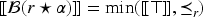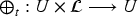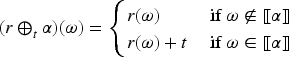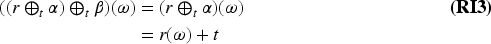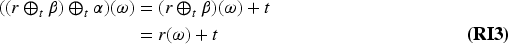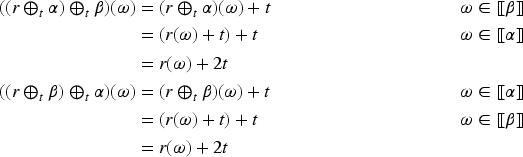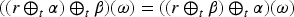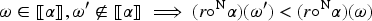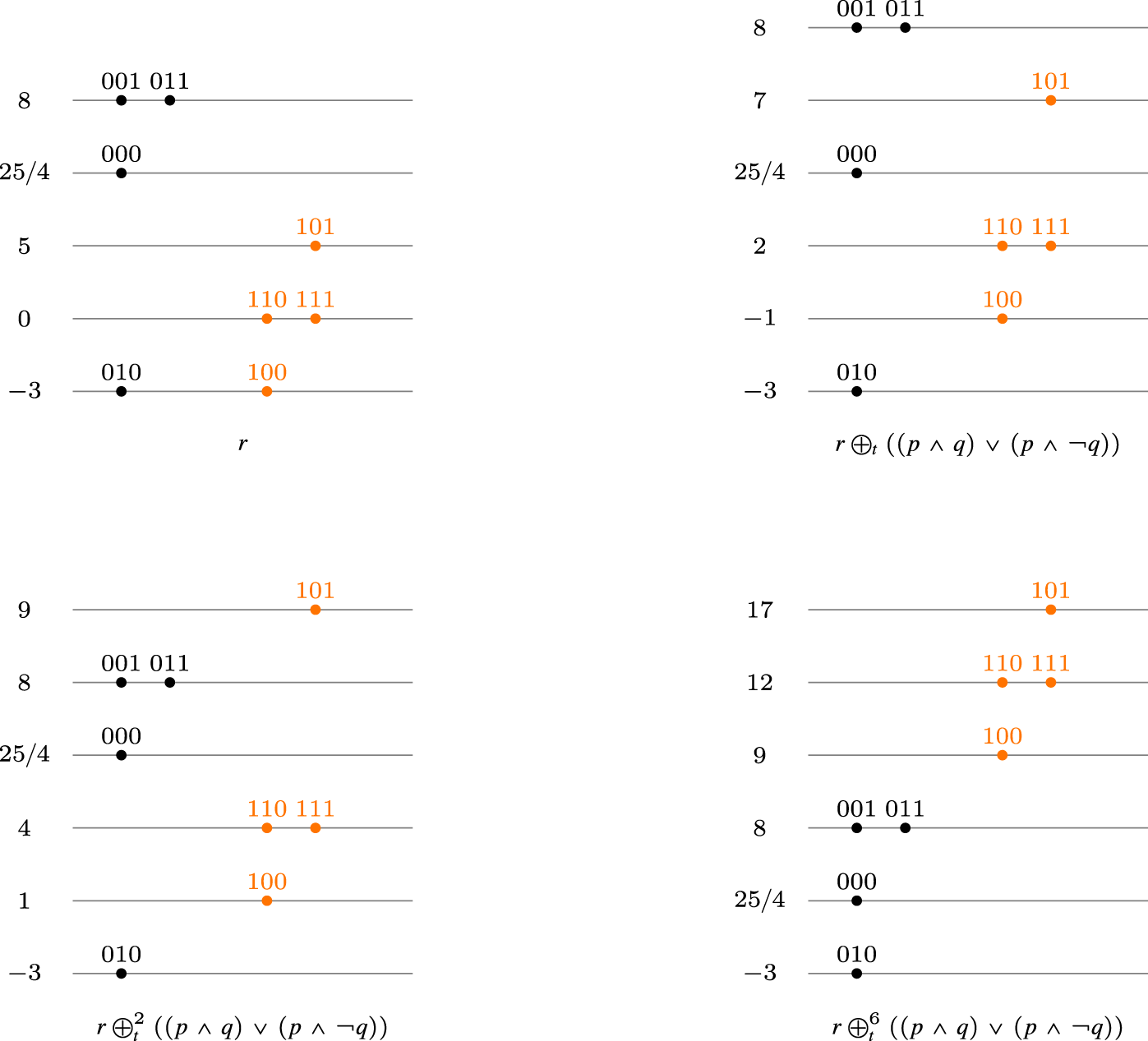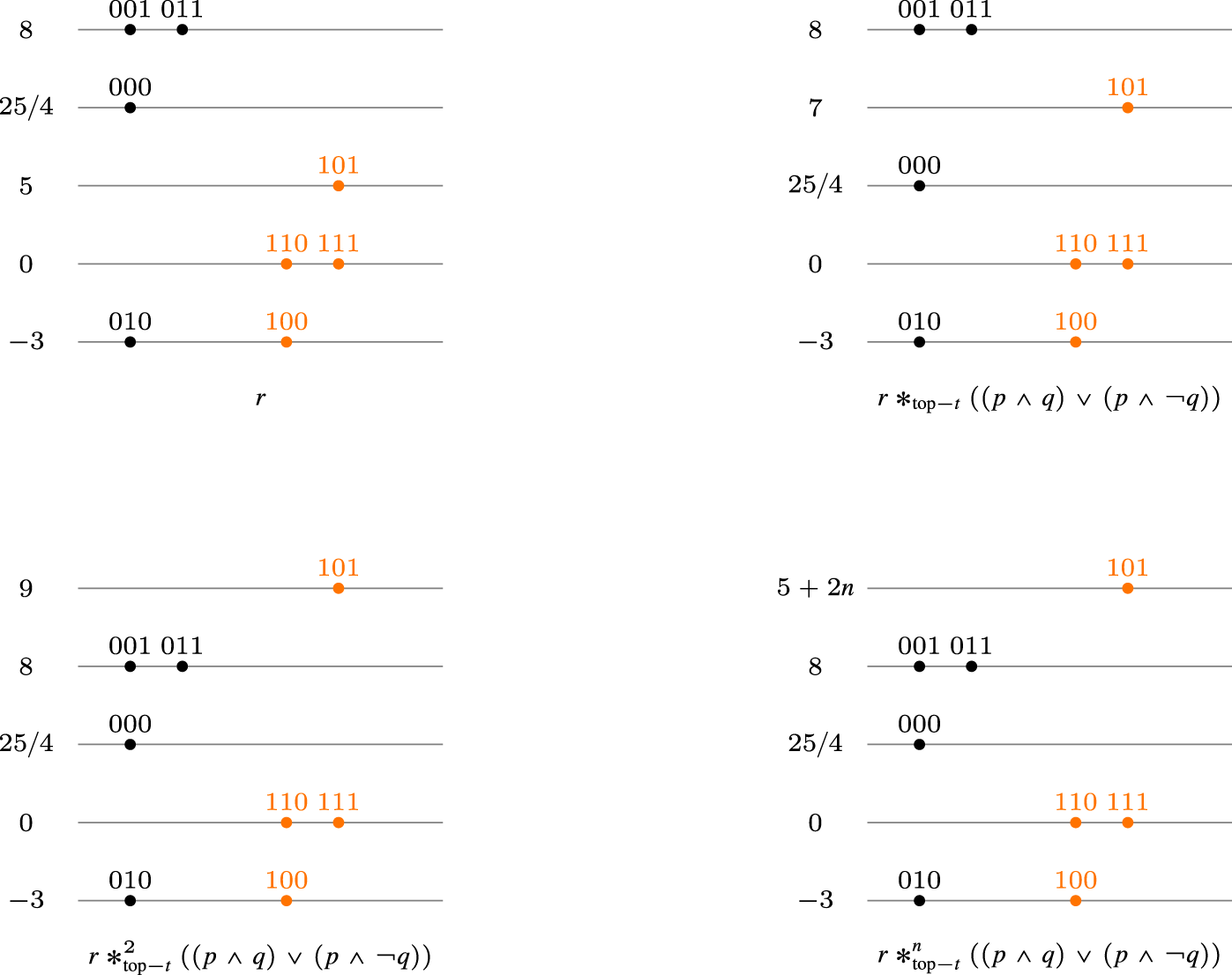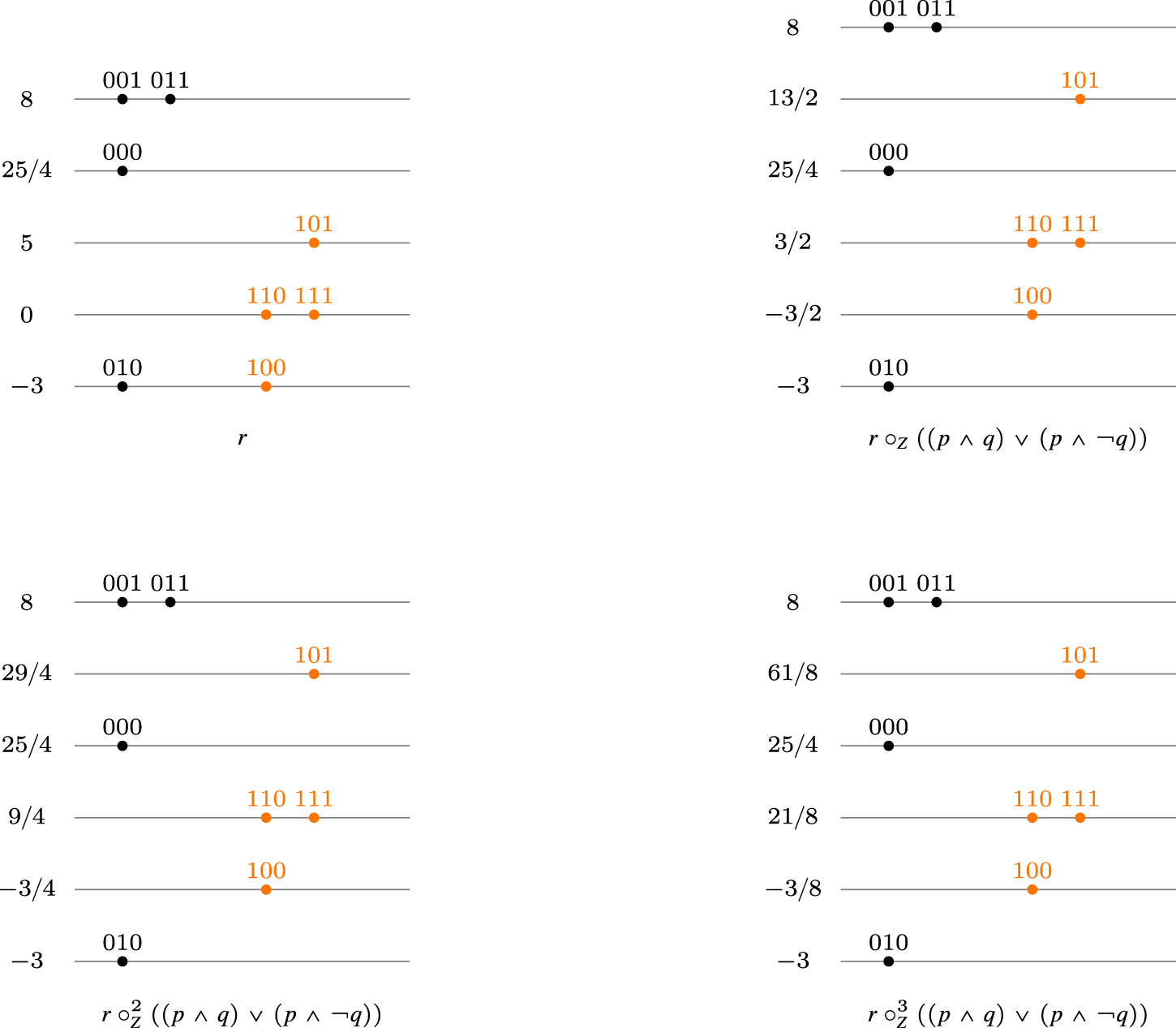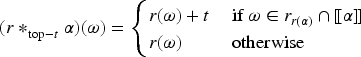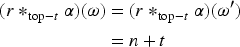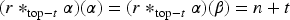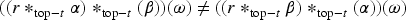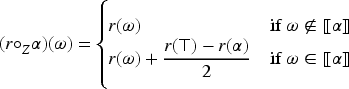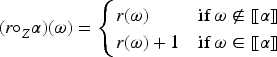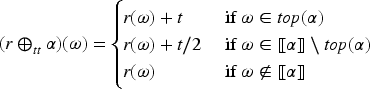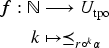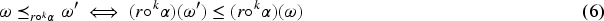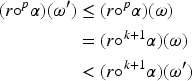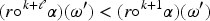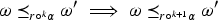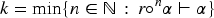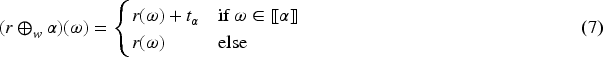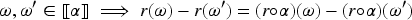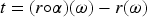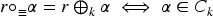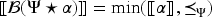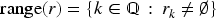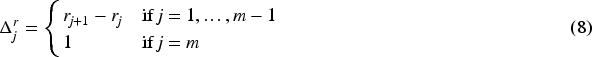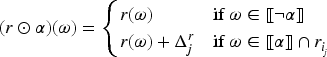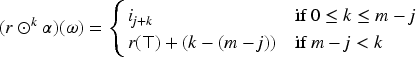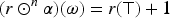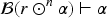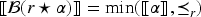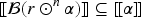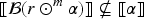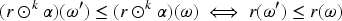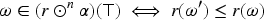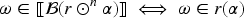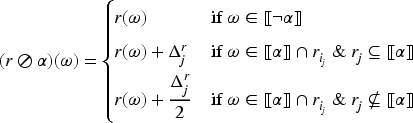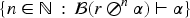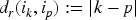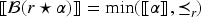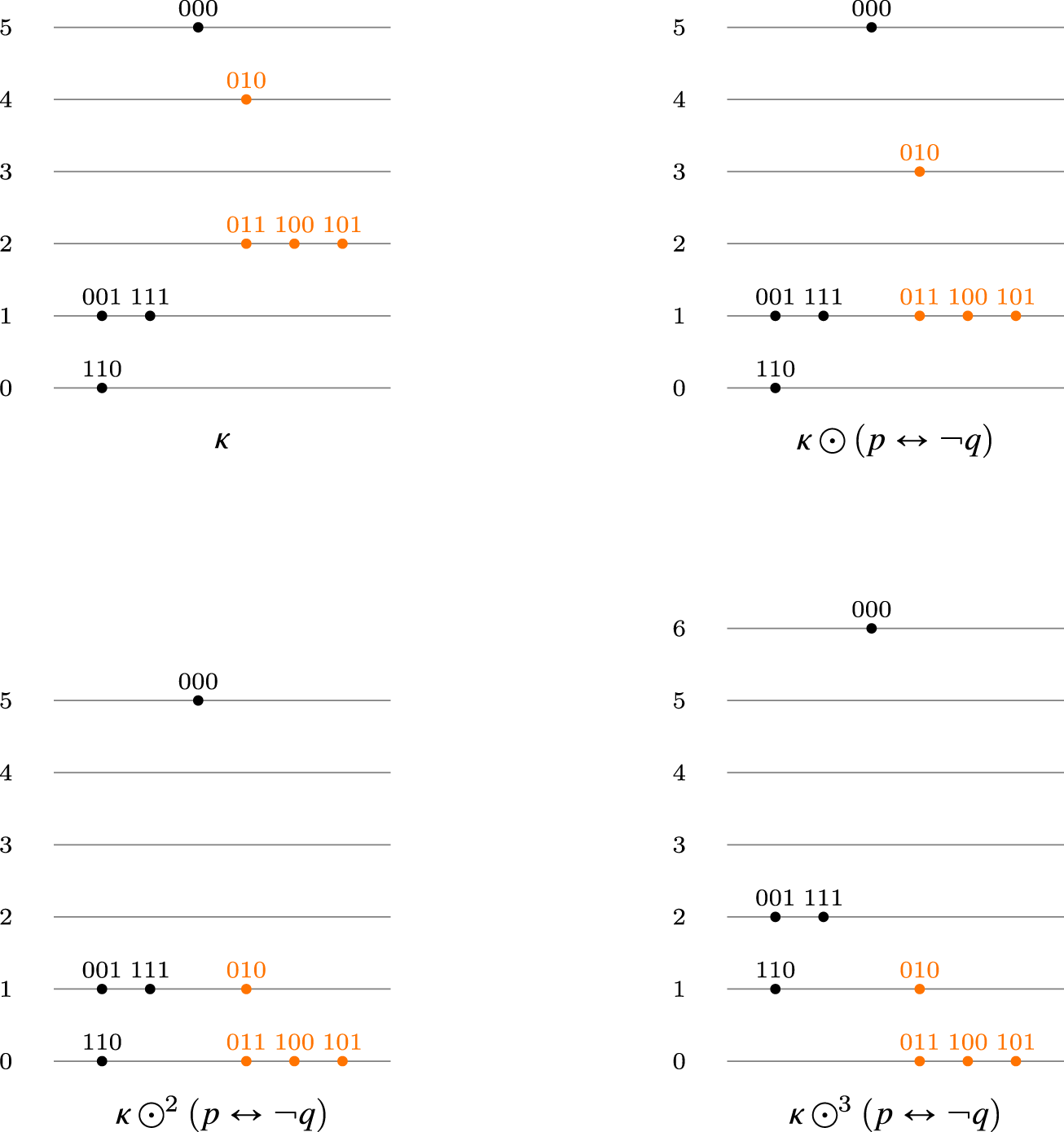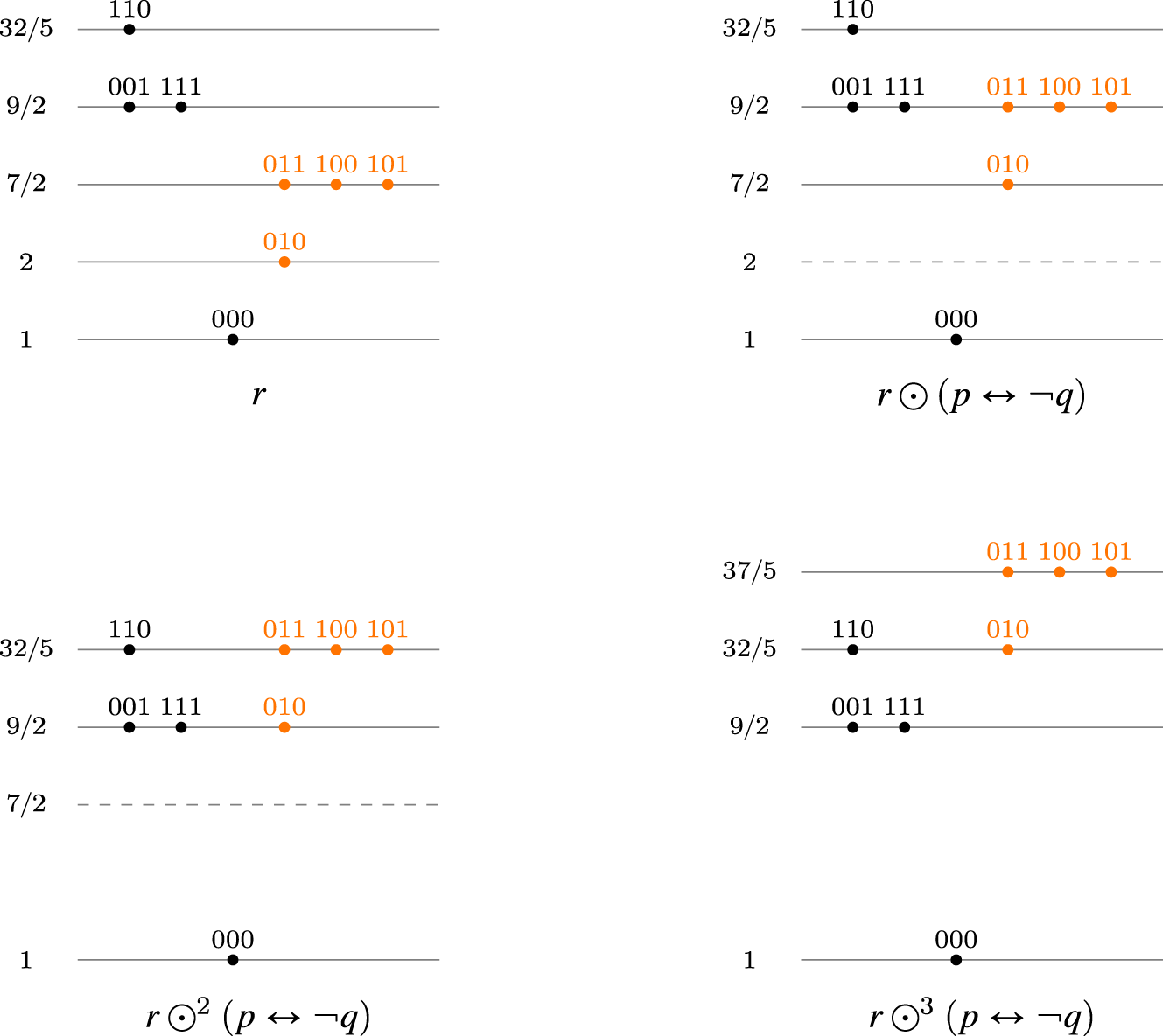With the aim of providing a natural and expressive domain for defining change operators, we introduce the epistemic space of rational rankings. We show that this epistemic space is highly useful for understanding various aspects of belief dynamics, particularly those related to the improvement of new information. It enables us to define certain classes of improvement operators, a generalization of iterated revision operators, in a natural and intuitive way. A key feature of rational rankings is the possibility of defining improvement operators in such a way that the negation of the new information does not worsen. This is impossible within the frameworks of total preorders or ordinal conditional functions, two well-known epistemic spaces. Another notable aspect of this space is that the behavior of these operators can be characterized by a few simple equations and inequalities, whose meaning remains transparent. Additionally, there are no stationary states: The epistemic state resulting from applying an operator to a prior epistemic state and new information is always distinct from the prior state. Finally, we prove that this class of operators is indeed a subclass of improvement operators. Consequently, we show that these operators exhibit desirable behavior when iterated sufficiently, ultimately converging to Darwiche and Pearl revision operators.
No man ever steps in the same river twice, for it’s not the same river and he’s not the same man.
Heraclitus
Introduction
Unlike Heraclitus’ quote, in many models of belief revision, the new information might not affect the epistemic state (Alchourrón et al., 1985; Darwiche & Pearl, 1997). Thus, the epistemic state remains the same even if one piece of information arrives multiple times. However, this is not always true, and we would like to model situations in which new information always produces a change. Another behavior observed in widely used models of belief revision (total preorders (TPOs) or ranking functions as an instantiation of epistemic states) is that, in general, after revision, there is a loss of plausibility of the negation of the input. However, one might want the plausibility of the negation of the input to remain the same before and after revision, following the minimal change principle.
Let us show some concrete situations in which the phenomena pointed out in the previous paragraphs are realized.
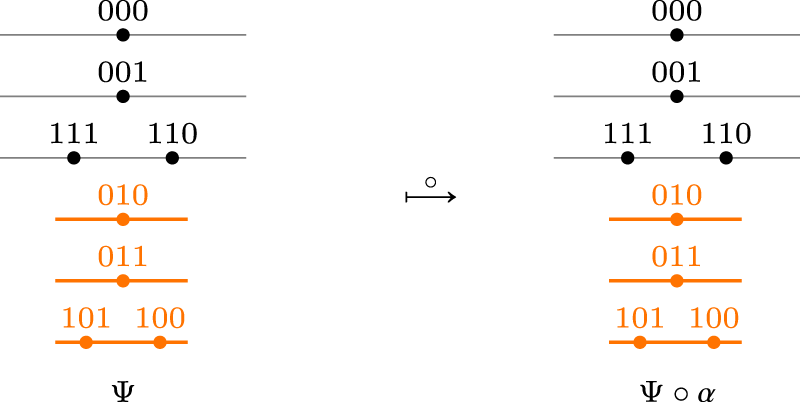
The situation depicted in Figure 1, shows a example in which we have an epistemic state represented as a TPO and a formula , the new piece of information, such that for any revision operator that complies with Darwiche and Pearl’s postulates, necessarily . As usual, TPOs over worlds are outlined graphically putting the worlds on layers and the lower the level, the more plausible it is. In our example we take the worlds over the propositional language the formula has exactly as models those appearing in the the three lowest levels, drawn in orange, for instance . The reason why any revision operator satisfying the Darwiche and Pearl postulates does not produce change in the situation depicted in Figure 1 is that the plausibility order of models of does not change (postulate DP1), the plausibility order of models of does not change (postulate DP2), and finally the plausibility order of models of does nor worsen with respect the models of (postulates DP3 and DP4). And since in all models of are strictlty more plausible than the models of the only possible output for is .
No movements: A situation in which no Darwiche and Pearl (DP) operator produces change.
The other situation which is unavoidable in representations of epistemic states as TPOs or ranking functions, the loss of plausibility of the models of the negation of the new piece of information, is illustrated in next example.
Suppose we have the epistemic state represented by the TPO of Figure 2 and the new piece of information is the formula having as set of models . Then any revision operator satisfying the postulates of Darwiche and Pearl, produces as output the TPO of Figure 2 in which the minimal models are those of and the models of conserve the same relations as in . What is important to stress is that the models of are less plausible in than in .
Loss of plausibility of counter-models of the new information.
In the following example, we present a situation in which permanent change is desirable and, at the same time, it illustrates why we don’t want the plausibility of the negation of the new piece of information to decrease after the change:
Dr. Roberts, MD, has been practicing medicine for 20 years. Since he began his practice, he has applied treatment A to the common cold. Treatment A always works, so he has great confidence in this treatment, and this confidence increases with every successful case even when its effectiveness against the common cold was already part of his beliefs. One day he observes a case of common cold where treatment A did not work. Backed by all his experience, his confidence in treatment A does not decrease, but he gives some credit to the idea that treatment A might not work in some cases.
The epistemic states and operators we introduce in this work allow modeling this kind of situation where the degree of confidence in treatment A does not change in numerical terms after receiving the information that the treatment does not work. However, after receiving the information that treatment A does not work, the degree of confidence in this new information increases. Of course, if this new information is repeated a sufficient number of times, the doctor must change his opinion about the benefits of treatment A.
Another feature that one would like to model is that the changes are produced little by little (and sometimes very little by little!) as in the following example:
Carlos is learning English. He has only rudimentary knowledge. He takes an initial test and doesn’t even manage to obtain the A1 certificate. Due to work requirements, he needs to obtain the C2 certificate, the highest level. He knows that to achieve this, he will have to keep working hard every single day. Every day, he checks how his English level is progressing. He knows he is improving—but very slowly. So he thinks that one way to measure his improvement is as a small daily epsilon that, after many days, will allow him to reach the C2 level.
We claim that the structures we are going to introduce, rational rankings, allow us to perform revisions and improvements without worsening in an absolute way. However, even if the plausibility values remain unchanged, some models that were previously believed may fall out of the beliefs after an update. This can be interpreted as their relative plausibility has worsened from the perspective of the more entrenched beliefs. That said, the richness of our numerical epistemic states could be used beyond belief change, namely, to other logic-based AI applications where absolute or conditional plausibility values are directly exploited. For example, it could make sense to reuse those rational rankings as such in other contexts as in Bauters et al. (2017), Casini et al. (2023), Ma and Liu (2011) or van Eijck and Kai Li (2017) where epistemic states are used not to model change, but as a foundation for inference/prediction/interaction. In such settings, plausibility information is valuable in its own right independent of belief revision.
Having given these previous examples to illustrate our motivations, we will now establish the context of our work in detail and where it fits within the current lines of research.
Our starting point is the logical model for belief change proposed by Alchourrón, Gärdenfors, and Makinson (Alchourrón et al., 1985), known as the AGM framework. This framework adheres to three main principles: Coherence, success, and minimal change. Specifically, when dealing with the incorporation of new information into a corpus of beliefs (belief revision), these principles form the foundation of the revision process (revision operators). These operators are functions that map the epistemic state of an agent and the new information into a new epistemic state that is coherent (i.e., free of contradictions), incorporates the new information, and remains as close as possible to the original epistemic state. In the logical AGM framework, epistemic states are represented as logical theories (sets of sentences closed under logical deduction), and the new information is represented by a logical formula. Typically, propositional logic serves as the underlying logic. When the logic is finite propositional logic, Katsuno and Mendelzon (Katsuno & Mendelzon, 1991) proposed a simplified model (the KM framework) where the epistemic state corresponds to a propositional formula, and the new information is also a propositional formula. The KM framework provides an easily understandable set of rationality principles and includes a useful representation theorem: Revision operators are characterized as functions mapping a formula (an epistemic state) into a TPO over the set of interpretations.1
Both the AGM and KM models are effective for explaining a single step of revision. However, the KM representation theorem led Darwiche and Pearl (Darwiche & Pearl, 1997) to demonstrate that these frameworks are inadequate for iterated revision processes. Consequently, they proposed a new model for iterated revision, referred to as the Darwiche and Pearl (DP) framework. The core concept in the DP framework is the notion of a (complex) epistemic state. These epistemic states differ from formulas and theories; they are objects associated with certain beliefs. For instance, the simplest examples of epistemic states are TPOs over interpretations, where the beliefs associated with a TPO are represented by a formula whose models are precisely the minimal models of the TPO.
While TPOs provide a natural and straightforward setting for studying DP revision operators, more general settings exist where DP revision operators can be defined. For example, ordinal conditional functions (OCFs) proposed by Spohn (Spohn, 1988) offer such a general setting. Indeed, there are DP revision operators defined on OCFs that cannot be described in terms of TPOs (see Aravanis et al., 2019 and Schwind et al., 2022). It is crucial to recognize that a belief change operator, such as a DP revision operator, must be defined within a specific “epistemic space,” and numerous epistemic spaces, including some quite uncommon ones, exist (Schwind et al., 2022).
Another important area of research in belief change, particularly in belief revision, involves non-prioritized change operators (Hansson, 1997, 1999). In these operators, the success postulate is relaxed. This category includes credibility-limited revision operators (Booth et al., 2012; Hansson et al., 2001), where only information from a credible set is incorporated, and information not in this set is rejected with no impact on the current belief state. Another family of non-prioritized revision operators aims to capture the idea that the plausibility of new information increases. These improvement operators (Konieczny et al., 2010b; Konieczny & Pino Pérez, 2008; Medina Grespan & Pino Pérez, 2013) uniquely achieve success after several iterations of the same information, contrasting with credibility-limited revision operators, where some pieces of information are never incorporated even after multiple iterations. However, these two approaches have been successfully merged in credibility-limited improvement operators (Booth et al., 2014). Notably, research on these operator families has been primarily conducted within the framework of TPOs as the epistemic space, though some improvement operators have also defined in the space of OCFs (Konieczny & Pino Pérez, 2008).
In this paper, we introduce a novel complex epistemic space called rational rankings, where rankings are represented by rational numbers. This exploration is motivated by the idea that studying structures beyond TPOs and OCFs can offer deeper insights into the properties that improvement operators should possess in broader contexts. The framework of rational rankings is both rich and intuitive, allowing us to define operators on this space that capture the increase in plausibility of new information. This behavior is characterized by a set of simple equations and inequalities with clear, intuitive meanings. We show that these operators fit within the class of improvement operators proposed in the literature and demonstrate that, after sufficient iterations, they function as Darwiche and Pearl’s revision operators.
Preliminaries
We consider a finite set of propositional variables and the set of propositional formulas, built up from and the usual connectives. denotes the set of consistent formulas from . The symbols and denote respectively the tautology and the contradiction. The set is the set of all interpretations (or worlds) that is the classical truth functions on . Propositional formulas will be denoted in general by lower case Greek letters like and their set of models is denoted by .
Let be a a total pre-order, that is a reflexive (), transitive () and total () relation over . The corresponding strict relation is defined as iff and , and the corresponding equivalence relation is defined as iff and . We denote when and there is no such that .
Operators of change adequate to iteration (Darwiche & Pearl, 1997) have to be defined in epistemic spaces (Schwind et al., 2022). Let us recall their definition more precisely.
An epistemic space is an ordered pair where is a set whose elements are called epistemic states and is a projection function that maps each to a consistent propositional formula that represents the belief set associated with .
Thus an epistemic state is just an element of an epistemic space, very much as a vector is just an element of a vector space.
The two more typical examples of epistemic spaces are the tpo epistemic space, (tpo is the abbreviation of TPO) and the ocf epistemic space, (ocf is the abbreviation OCF).2 More precisely, where is the set of all TPOs over and maps each TPO in to a consistent formula such that . And where is the set of all ocfs over and maps an ocf to a consistent formula such that .
Given an epistemic space , a change operator is a function of the form . General epistemic states are noted by upper case Greek letters like . The output of an operator is noted in infix notation. Thus, is the epistemic state obtained from with the change produced by the information .
Given a change operator we define for every formula :
The improvement operators proposed in Konieczny and Pino Pérez (2008) have an important property, the success at iteration (I1), which allows stating postulates in terms of a corresponding revision operator. More precisely, given a change operator of the form defined in an epistemic space , which satisfies (I1): For all and , there exists such that , we can define the operator associated to the operator in the following way:
Then, improvement operators are defined as follows:
The operator is an improvement operator if it satisfies the following postulates:
There exists such that
If , then
If , then
For any positive integer if for all then
If , then
If then
If then
If then
In Konieczny and Pino Pérez (2008), a representation theorem of improvement operators in terms of TPOs over worlds is provided.
It is worth remarking that postulate (I4) is stronger than the DP postulate (R4), that is, whenever ; for a discussion on this, see Konieczny and Pino Pérez (2008). Actually, (I4) aims to code at the level of beliefs the fact that if , then and are exactly the same epistemic state, which is clearly stronger than (R4) (Darwiche & Pearl, 1997).
(Gradual assignment)
Given an epistemic space and an operator over this space, a mapping associating each epistemic state with a TPO over worlds is called a gradual assignment for if the following conditions are satisfied:
If , then
If and , then
For any positive integer , if for any ,
then
If then
If then
If then
We have the following representation theorem for the class of improvement operators:
A change operator is an improvement operator if and only if there exists a gradual assignment such that for each epistemic state and each formula , .
Note that conditions 4 and 5 align with Darwiche and Pearl’s conditions (CR1) and (CR2) respectively (Darwiche & Pearl, 1997). Condition 6 corresponds to condition (P) introduced in Booth and Meyer (2006), Jin and Thielscher (2007) for defining admissible DP revision operators. Consequently, the operator associated with an improvement operator is an admissible DP revision operator.
The natural revision operator is defined on the epistemic space mapping each tpo and each formula into the tpo that satisfies along with the following condition:
If , then ,
where denotes and denotes .
That is, Boutilier’s natural revision operator on selects the set of all minimal models of according to an input tpo and defines this set as the first level of the revised tpo, leaving the rest of the tpo unchanged.
Nayak’s lexicographic operator is defined also in the epistemic space by putting , plus conditions 4 and 5 of a gradual assignment, and:
If and , then
Lexicographic revision reorders all models of to be higher than all models of , while preserving the internal relationships within the worlds of and within the worlds of .
The one-improvement operator is defined also in the epistemic space by mapping each tpo and each formula into the tpo () that satisfies conditions 4, 5 and 6 of a gradual assignment, and the following additional conditions:
If then
If then
These additional conditions characterize the behavior of . They state that the models of at a level just above a level with models of move down to this level.
Let us now illustrate how the behavior of these operators differs from each other.
Let . Figure 3 shows a tpo over worlds3, and the revised tpos , and . We have , , but and the three associated tpos are very different. Therefore, it is easy to identify scenarios (sequences of input formulas) that result in different beliefs for each tpo.
The natural revision operator , the lexicographic revision operator and the one-improvement operator at work.
Note that there are other improvement operators defined in , the space of OCFs, which can not be represented in the space of tpos (see Schwind et al., 2022).
Generalized Improvement Operators
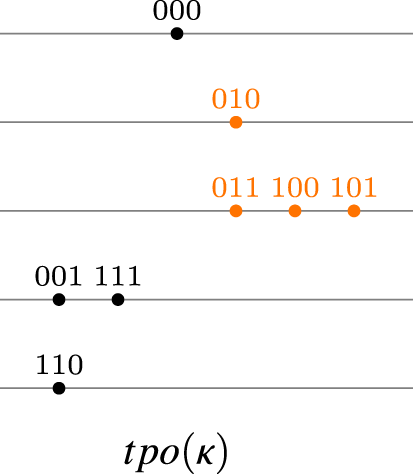
We would like to consider operators that improve only a portion of the new information (for instance, only the most plausible models of the new information). This approach could lead to a “natural improvement” operator reminiscent of Boutilier’s natural revision. To clarify this idea, we will define the operator on the space , which emulates this behavior. First, given a tpo and a formula , let be a formula such that . Then define . Figure 4 illustrates the behavior of this operator at work.
The natural improvement operator at work.
It is easy to see that the operator does not satisfy (I9), which corresponds to condition 6 of a gradual assignment. This is evident from Figure 4 where the world 010 remains at the same level as the world 000 after the change. However, the operator satisfies postulate (I1), which is central to the improvement principle. In fact, it is clear that the operator associated with is indeed the natural revision operator . Thus, it is reasonable to replace postulate (I9) with “non-worsening postulates”, those corresponding to postulates (C3) and (C4) of Darwiche and Pearl. This leads to the following definition, which extends the class of improvement operators:
(Generalized Improvement Operator)
The operator is a generalized improvement operator if it satisfies the postulates (I1-I8) plus the following ones:
If then
If , then
Obviously enough, if an operator sastisfies (I9), then it satisfies (I9a) and (I9b). As a consequence, every improvement operator is a generalized improvement operator.
From the semantic perspective, we have the following:
Given an epistemic space and an operator over this space, a mapping associating each epistemic state with a TPO over worlds is called a generalized gradual assignment if it satisfies conditions 1–5 of a gradual assignment and the following conditions:
If and then
If and then
Conditions 6a and 6b above correspond to Darwiche and Pearl’s conditions (CR3) and (CR4) (Darwiche & Pearl, 1997). Then, we can prove with a technique similar to the proof of Theorem 1 the following result for the class of operators satisfying (I1):
A change operator is a generalized improvement operator if and only if there exists a generalized gradual assignment such that .
It is easy to see that if is a generalized improvement operator, then its corresponding operator is a DP revision operator. More interestingly, we obtain the following correspondence:
An operator is a generalized improvement operator satisfying (R1) if and only if it is a DP revision operator satisfying (I4).
Rational Improvement Operators
The goal of this section is to better understand the behavior of various improvement operators within a specific epistemic space: The space of rational rankings. Given that the order on is dense and unbounded, it more naturally captures the dynamics of improvement operators. The density of is particularly advantageous because it enables the insertion of an intermediate layer between two existing layers without altering their ranks. This capability is not possible with OCFs when the layers are consecutive. This approach aligns with the principle of improving without changing the rank of models that contradict the new information.
Although rankings into real numbers have been studied in Spohn (2009), there are key differences, which we will explore in Section 7.
A rational ranking is a function . The set of all rational rankings is denoted by . For a given rational ranking , we denote as the preimage for , that is, . The (possibly empty) set represents the th level of the ranking .
Given any consistent formula and a ranking , we define the rank of in , denoted by , as:
The following notation, , which denotes the set of most plausible models of in , will be useful:
The epistemic space of rational rankings, is defined by taking as the set of rational rankings and as the function from to defined as:
The intended meaning of a rational ranking as an epistemic state is that indicates that the world is more plausible than the world . The beliefs associated with correspond to a formula whose models are precisely those with the highest rank.
In this work, we adopt the perspective that the value assigned to a world in a rational ranking directly represents its plausibility, in contrast to OCFs. We find it natural to associate higher ranks with greater plausibility.
A significant difference from OCFs is that rational rankings are not normalized, meaning that a rational ranking can have beliefs with arbitrarily high ranks. This characteristic allows for the plausibility of models representing new information to be increased without altering the plausibility of models representing the negation of that information.
Given a rational ranking , its underlying preorder is defined by:
The canonical assignment on rankings is the function mapping each ranking to its underlying preorder .
Since , we have that
(Rational Improvement Operators)
is a rational improvement operator if there is a rational number such that the following properties are satisfied for all rational ranking , all consistent formulae and all worlds , :
If then
there is a such that
if , then
if then
If and then
Postulate (RI1) states that for any ranking function , the plausibility of the models of does not decrease after a rational improvement by . (RI2) asserts that at least one model of sees its plausibility strictly increased after a rational improvement by . Moreover, this increase has a lower bound for any formula in any rational ranking . (RI3) requires that a rational improvement by does not alter the plausibility of the models of . This can be seen as a strengthening of condition 5 of a gradual assignment, which requires that the relative plausibility between the models of is not altered after revision by . This is also a somewhat extreme account of minimal change principle: While we improve the plausibility of new information , we are specifically told not to move any possible world unrelated to . (RI4) ensures that the relative order of the models of should remain unchanged after a rational improvement by . Lastly, (RI5), together with (RI3), ensures the independence of syntax: A rational improvement by a formula or an equivalent one should result in the same ranking function.
It is important to note that postulates (RI1-RI5) are both natural and flexible, allowing for the definition of a wide variety of rational improvement operators, including those with a uniform behavior. But, one could also define an operator such that, for some models of , the plausibility increases only from the second time is encountered in a series of consecutive inputs of : .
The next result is crucial in proving that rational improvement operators are indeed generalized improvement operators.
If is a rational improvement operator, then it satisfies (I1).
Let . Since each element in is a binary sequence, we can well-order this set with lexicographic order. Now define the function:
This function is well defined since (RI2) implies that the set is non-empty. Since is finite, the pigeonhole principle implies there is some with . Hence
Now, using (RI1), it is easy to that
By the Archimedean property, there is a natural number such that , hence
As , we have that . Since for every and every , we have that . Thus, the models in are a subset of hence . That is, satisfies (I1).
We can now state that:
Every rational improvement operator is a generalized improvement operator.
The idea of the proof is to show that the canonical assignment is a generalized gradual assignment. This, along with Theorem 4, allows us to apply Theorem 2 to reach our conclusion.
Let be a rational improvement operator. Theorem 4 implies that the associated revision operator is well-defined. Hence , thus . Since , it follows from the definition of that
We now want to prove that is a generalized gradual assignment for . Properties (1.) and (2.) are immediate from the definition of and the definition of . To prove Property (3.), it is enough to prove it for and then apply an inductive argument. To do so, suppose . Then, (RI3) along with (RI5) implies that , thus . Property (4.) follows directly from (RI4). Property (5.) is an immediate consequence of (RI3). Properties (6a.) and (6b.) follow from (RI1) and (RI3). Therefore, is a generalized gradual assignment for and Theorem 2 implies that is a generalized improvement operator.
Since every rational improvement operator is a generalized improvement operator, it follows that its associated operator is a DP revision operator.
Examples and Properties
In this section, we introduce several families of rational improvement operators, discuss some of their properties, and provide characterizations for some of them.
Let . The -translation is the operator
such that, if is a ranking function and is a sentence, the operator is defined as
Satisfaction of (RI1), (RI3) and (RI4) is a direct consequence of the definition of . Taking any and , we get that , hence satisfies (RI2). Lastly, if we have that for every since , and we also have for every since , so (RI5)) is satisfied. Therefore, is a rational improvement operator.
These operators are named -translations because they uniformly move the entire set of models of “upwards”. Translation operators are reminiscent of -conditionalization (Spohn, 2009). However, while conditionalizations are revision operators, translations are not.
We can model the case presented in Example 3 using -translations. First, fix a positive rational number . Let be a formula such that is exactly the set of all possible worlds where treatment A cures common cold. Suppose is a ranking representing the epistemic state of Dr. Roberts when he began his practice. Assume is a state of “complete ignorance” that is all possible worlds are in the same level. Moreover, we can assume they are at level . Suppose is the ranking representing the epistemic state of Dr. Roberts right before he observes some scenario where treatment A did not cure common cold. Then for some (large) . We also know that is a part of Dr. Roberts beliefs, thus with . Moreover, for every . Hence for every and for every .
We can also model the situation showed in Example 4 using -translations as follows:
First, fix a positive rational number such that where is big enough. Let be a formula such that is exactly the set of all possible worlds where the English is fluent. As before, suppose is a ranking representing the epistemic state where Carlos begin his training. We can assume that is a state of “neutral” where all possible worlds are at level . After days of training, we can expect that the level of Carlos has improved to . This can be modeled by . Thus, in that state the English level of Carlos is . Then, if we suppose that the level of the C2 certificate is , a very large number, we know (by the Archimedean property) that there will be a number of days such that . Therefore the beliefs in the state is with a degree bigger that , that is in such state Carlos is assured to obtain the C2 certificate.
It is interesting to note that the -translations satisfy the following interesting commutativity property:
This property a two-step adaptation to rational rankings of the commutativity property introduced in Schwind and Konieczny (2020).
When an operator satisfies (Com) for every ranking and formulas and , it is called a commutative operator.
The operator is a commutative operator.
Let . The proof is direct by (RI3) in the case when .
Now suppose that . Then
and
Hence,
The proof is similar for the case when . The remaining case is when :
Thus for every :
This shows that satisfies (Com).
By the previous proposition and the results in Schwind and Konieczny (2020) (Proposition 9 therein) the t-translation operators can not be representable as improvement operators in the space of tpos. And the impossibility also remains for the revision operators corresponding to the translations.
An interesting behavior of this family of operators is captured by the following definition:
A rational improvement operator is a Nayak operator iff for each formula , there is some such that:
These operators are named as such because, with a sufficient number of iterations, the underlying preorders behave similarly to the lexicographical revision proposed by Nayak (Nayak, 1994).
Notice that is a family of Nayak operators.
However, not all Nayak operators belong to this family. For instance, in Example 15, one can see operators that fall outside this classification.
More generally, we have the following definition:
An operator defined in the space of rational rankings represents an operator defined in the space of TPOs when for any ranking and any formula we have , that is, if the underlying TPO of coincides with the TPO of changing by the underlying TPO of with the operator . In other words, if the following diagram commutes:
where is the canonical assignment of Definition 8.
An interesting observation is that when a revision operator defined on rational rankings represents a revision operator defined on TPOs in the sense of the previous definition then is an instantiation of in the sense of Schwind et al. (2022). However, previous definition not only concerns revision operators, it concerns also improvement operators (Figures 5 to 7).
Iterative behavior of with .
Iterative behavior of with .
Iterative behavior of .
Now, given a translation operator , define the operator associated to it, in the following way: First, for a ranking and a formula define as and second put where . Note that is well defined because is a translation and moreover it is easy to see that represents the lexicographical revision operator of Nayak within the meaning of Definition 11.
Another interesting family of rational operators exhibits behavior inspired by Boutilier’s natural revision operator (Boutilier, 1996). First let us define what is a Boutilier operator in our framework.
A rational improvement operator is a Boutillier operator if the operator associated to it, represents the operator , that is, the diagram 5 holds for and .
Given with , the top--translation is the operator
assigning to each ranking and each sentence the ranking given by
It is easy to see from this definition that is a rational improvement operator. Moreover, the operator associated to represents the operator of revision natural in the sense of Definition 11.
Summarizing we have:
is a family of Boutillier operators.
However, as we will see in Example 14, not all Boutilier operators belong to this family.
The operator is not commutative.
Consider a ranking and formulas such that . Let , and let , such that . Now
Now since we have
and since . However, and . As , this means that , hence and . Therefore
It is important to note that simply increasing the plausibility of models of new information does not necessarily result in a rational improvement operator. The manner in which this increase is implemented is crucial. The following example illustrates this point.
Consider the operator that associates each pair with a new ranking defined as follows: If , then
and if :
Notice there is no such that this operator satisfies (RI2), so it is not a rational improvement operator. Clearly, when , the models of are “improving” with repeated applications of . However, this operator does not generally satisfy (I1), meaning there is no associated revision operator. Therefore, is not an improvement operator in the usual sense. This demonstrates that simply increasing the ranks of models of new information is insufficient to define an improvement operator.
Operators exhibiting this behavior can be referred to as Zeno operators, as their behavior resemble the phenomena of Zeno Paradox. There is a goal that is approached but never fully achieved: If and then for every , .
We can use the concept from Example 13 to define a Boutilier operator that is not part of the family described in Example 12. In Example 14, the operator is designed so that the highest-ranked models of always improve by , while some lower-ranked models of move in a Zeno-like manner.
The idea of the operator , which we are going to define, is very simple: The top models of improve by . The “isolated” models of (those in a layer with only models of ) improve by half of the distance to the consecutive upward rank, while the rest of the models don’t move. More precisely, let be the image of the ranking where . Define . Then, fix as a positive rational number and define as follows:
if ,
if and there is no with ,
in any other case.
It is easy to see that is a rational improvement operator. Moreover, it is clear from the definition of that it is a Boutillier operator because its associated operator represents .
With a similar idea we can define a Nayak operator which is not a -translation for any .
The idea of the operator we are about to define is very simple: The top models of improve by . The other models of improve by . More precisely,
It is easy to see that is a rational improvement operator. And it is quite simple to verify that it is a Nayak operator different from for any .
Although epistemic states always change with applications of rational improvement operators, the underlying preorders have a fixed point.
Let be a rational improvement operator, a rational ranking and a propositional formula. Then there is some such that for every .
Let be the set of all TPOs on . Since is a finite set, is also a finite set. Now, define a function
Hence, there is some preorder on that has an infinite preimage . Suppose is the least element of . We are going to prove, using induction, that , that is, is a final segment of thus is the desired fixed point.
Suppose , then . Given any two we have to prove that . This is immediate if by (RI3) and when by (RI4).
If and :
Since we have that and since we have that , thus implies that hence .
If , and , suppose . Then . Since is infinite, there is some such that that is such that .
Since , we have that for every thus
thus . Since , there is some , , such that , therefore
which is impossible because of (RI1).
Hence, for every pair and every :
In order to prove the reciprocal statement, suppose . Since is a TPO, this implies that , but by the previous discussion this implies , hence . Thus we have proved by contraposition.
Therefore, for every we have that , that is, is a final segment of as we wanted to prove.
Let us call the minimum satisfying Theorem 6. Then the following observation is easy to see:
where
When is a Boutillier operator . If is Nayak, then generally .
Consider the relation ‘’ of logical equivalence between formulas in . Since is a finite set and each formula in can be identified with its set of models, the logical equivalence relation partitions on a finite set of equivalence classes.
Let be a function mapping each equivalence class in to a positive rational number. Denote by the image of the equivalence class of via . Now we define the operator :
Suppose . Take . Then it is straight forward to prove that is a rational improvement operator. We can call a weighted translation and a weight function.
Weighted translations generalize translations. Consider a fixed positive rational number , then translation is where is the weight function such that for every .
A Characterization of Translations
The translation operators are the operators introduced in Example 9. More formally we have the following definition:
A rational improvement operator is a translation if it is for some .
There are two additional postulates we can include in order to capture all the homogeneity behind the translations: For any rankings , , any formulas , and any worlds and
If and then .
.
(T1) says that the increment of the rank of a given model does not depend on the formula and (T1) says that said increment does not depend of the ranking.
Postulate (T1) implies
First, notice that replacing by in (T1) we obtain precisely (T1W), thus .
Let be a rational improvement operator. Then is a translation iff it satisfies properties (T1) and (T2).
It is easy to check that every translation satisfies (T1) and (T2). On the other hand, suppose is a rational improvement operator satisfying (T1) and (T2). We prove it is a translation. First, take any ranking , any consistent formula , and take a model of with (which exists by (RI2)). Define
Postulate (T2) implies that is independent of . (T1W) implies that is also independent of and (T1) implies that does not depend on . Hence depends only on . (RI3) entails that for every . By the very same definition of , we have that for every . Therefore for some and we can conclude that postulates (T1) and (T2), together with the postulates for rational improvement, characterize translations.
Note that Postulate (T1W) is strictly weaker than (T1). To prove this, enumerate the (finite) set of equivalence classes of under the relation given by . We have classes with . Define :
It is easy to see that this is a rational improvement operator that satisfies (T1W) but not (T1), hence .
One can wonder whether postulates (T1) and (T1) are independent of each other or not. The answer is positive:
Postulates (T1) and (T1) are independent.
Notice that satisfies (T2) thus .
Finally, given an enumeration of rankings, consider the function defined as iff . This is a rational improvement operator satisfying (T1) but not (T2), therefore .
Let us finish this section about translations with one observation about them.
Note that is the the ranking obtained from by shifting the rank of all the models by . Thus, clearly, but the underlying preorder of both rankings is the same. Moreover, we have the following:
Given and , if we have that . Thus, and have the same underlying preorder but . In other words, the operator has a cancelation property at the level of underlying orders.
Weighted translations, defined in Example 16, are not translations because their very definition violates postulate (T1) of translations when there are two formulas with different weights.
One Improvement and Half Improvement Operators in the Setting of Rational Rankings
An interesting feature of the epistemic space of rational rankings is its richness and flexibility. This allows us to define some operators appearing in the literature in an easy and natural way. As examples of our claim, we will define the one-improvement and half-improvement operators4Konieczny et al. (2010b); Konieczny and Pino Pérez (2008) on the epistemic space . Nevertheless, these operators will not be rational improvement operators, but they are going to be improvement operators.
Given an epistemic space , consider a gradual assignment for some change operator .
The assignment is a systematic enhancement if it satisfies:
A change operator in some epistemic space is a one-improvement (resp. a half-improvement) operator iff there is a systematic enhancement (resp. a half-gradual assignment) for such that
Now we define operators and and prove that they are, respectively, the one-improvement and the half-improvement operators in our epistemic space.
Since systematic enhancements and every half gradual assignments are gradual assignments, we have that one-improvement and half-improvement are indeed improvement operators.
Given a ranking , its range is the set:
Since is a finite set, is also finite for every ranking that is there is some and some finite sequence of rational numbers such that .
For each , define
We define the operator on the epistemic space as the function mapping each pair to the ranking defined by
This function is well defined since each element of is in exactly one non-empty level of the ranking .
Equivalently, if and with then . In the other hand, if then .
The one-improvement operator is not a rational improvement operator since it is impossible to find a constant as in Definition 9 that suits every ranking.
For every ranking and every consistent formula , there exists a natural number such that that is operator is defined for .
Let be a rational ranking and any consistent formula. Let be the range of with . Suppose for some . By the definition of and an inductive argument it is easy to see that, given a natural number :
If , then
for . Since for every we have that
that is the revision operator associated to is defined.
The canonical assignment is gradual for .
The canonical assignment satisfies properties (1) to (6) in Definition 3:
Properties (1) and (2) are immediate consequences of the definitions of canonical assignment and . Property (3) follows easily by induction on . Properties (4), (5) and (6) follow directly from the definitions of the operator and the canonical assignment.
The canonical assignment is a systematic enhancement for operator .
By Lemma 3, we know the canonical assignment is gradual for . It remains to prove that it satisfies (S4) and (S5). These is immediate from the Definition of . Let and , then:
If , we have that . Suppose , then for some pair such that . If , then and hence . If then and , then . Hence implies thus and the cannonical assignment satisfies (S4).
Now, if , we have that and . Thus , hence therefore and (S5) is satisfied.
If is the canonical assignment, then
for every ranking and every formula , if is the revision operator associated to .
By Lemma 2, the revision operator is defined for the operator . Thus, given any ranking and a formula , there is some such that
and
for every .
Since the canonical assignment is gradual, it is easy to check, for every and every pair of worlds , that
Therefore
for every . As , we have
Operator on rational rankings is a one-improvement operator.
Direct from Lemmas 2, 3, 4 and 5.
It is worth to note that Lemmas 2, 3, 4 and 5 prove formally that the operator defined on rational rankings represents the one improvement operator6 defined on TPOs within the meaning of Definition 11.
We can also define a half-improvement operator in this setting but, as in the one-improvement case, it can not be a rational improvement operator but a (generalized) improvement operator. This is not the only way to define a half-improvement operator in this epistemic space but it is natural.
We define the half-improvement operator on the epistemic space as the function mapping each pair to the ranking defined by
For every ranking and every consistent formula , there exists a natural number such that therefore the revision operator is defined for .
Let be a ranking, and a formula. It suffice to find a natural number such that for every such that . Then the set
is non empty, so it has a least element and this means that the operator is defined.
Let . It is enough to prove that there is some such that for every with and for each . Define the -distance between and as
We proceed by induction on the -distance between and .
Suppose . Then . There are two cases: Either or . In the first case, there is nothing to prove and . In the second case, given , we have that while for every . Thus in this case .
Now suppose . For simplicity, say for some suitable , then . Again, we have two cases. If , then for every . Now, since and for every , we have such that and .
Notice that the -distance between and is , hence we can apply the inductive hypothesis to , thus there is some natural number such that and for every and we are done.
If , then and we can prove the conclusion of the theorem similarly as we did in the first case.
We are going to prove that, indeed, is the half-improvement operator in this setting by proving that the canonical assignment is a half gradual assignment such that where is the revision operator associated to (Konieczny et al., 2010a).
The canonical assignment is a gradual assignment for . Moreover, it is a half gradual assignment.
Similar to the proof of Lemma 3.
If is the canonical assignment, then
for every ranking and every formula , if is the revision operator associated to .
Similar to the proof of Lemma 5.
The operator on rational rankings is a half improvement operator on rational rankings.
Immediate from Lemmas 6, 7 and 8.
It is worth to note that Lemmas 6, 7 and 8 prove formally that the operator defined on rational rankings represents the half improvement operator7 defined on TPOs within the meaning of Definition 11.
Something interesting here is that rational improvement operators are not the only improvement operators defined on the epistemic space .
When we restrict the domain of the operator to rankings with for each , then the behavior of is identical to the behavior of .
One-improvement on OCF Versus One-improvement on Rational Rankings
One-improvement and half-improvement operators are defined this way, because they are indeed respectively one-improvement and half-improvement operators on the underlying preorders of ranking functions. An advantage of working on rational rankings is that we can define a one-improvement operator such that for every ranking and every formula , we have that whenever that is we only “move” the models of the new information, which is in accordance with the minimal change principle. To illustrate this point, consider the ocf depicted in Figure 8. The domain of is the set of all possible worlds on variables considered in this order. The one-improvement operator on OCFs is defined in Konieczny and Pino Pérez (2008). Figure 8 shows its behavior.
The one-improvement operator at work on a ordinal conditional function (OCF).
Following Schwind et al. (2022), the TPO associated to is depicted on Figure 9. Although there are infinite rational rankings associated to this TPO we choose one and apply one-improvement operator three times on a particular ranking in Figure 10.
The total preorder associated to .
The one-improvement operator on rational rankings.
Related Work
Soft Improvement
The notion of soft improvement operators introduced in Konieczny et al. (2010b) can be translated to the context of rational rankings as follows:
(r-Soft) If , and , then
This means that the increase in plausibility cannot result in the rank of a model being strictly greater than that of a counter-model which was more plausible in the initial ranking.
Unfortunately, our rational improvement operators cannot satisfy (r-Soft). The reason is that if an operator satisfies (RI2), it necessarily violates (r-Soft). Specifically, we can find a rational ranking where the underlying order is linear and the difference between and the minimum rank in the image of is less than the constant given by property (RI2). If we choose an such that , then it is clear that if is the model of given by (RI2), it violates (r-Soft) because .
Nevertheless, for certain inputs, rational improvement operators can exhibit soft behavior. For instance, if is a rational ranking such that the image of consists of the set with , then displays soft behavior. In such cases, its behavior resembles that of the half improvement operator (Konieczny et al., 2010b).
Decrement Operators
The decrement operators introduced by Sauerwald et al. (Sauerwald & Beierle, 2019) are related to soft changes aimed at achieving contraction. The idea is to decrease the plausibility of the input until it is no longer believed. Related to this, we can define in the space of rational rankings operators that we call regressions. They are defined similarly to translations but use a negative rational number .
These operators will generally not be soft, but for certain inputs, they behave like decrement operators. For example, if is a rational ranking where the ranks in the image have a difference of 1 between consecutive ranks, then the regression operator behaves as a decrement operator.
General Properties for Iteration
In Schwind et al. (2023), some generalized DP postulates were proposed for revision. These postulates aimed to ensure homogeneity in the behavior of operators. In the space of TPOs, these postulates characterized a family reduced to only three operators: Nayak lexicographic revision, Boutilier natural revision, and the restrained revision of Booth and Meyer (Booth & Meyer, 2006). The semantic aspect of these postulates is satisfied by the translations. A natural question is whether these (or similar) postulates can characterize the family of translations.
Expressive Power of Rankings
Rational rankings are not more expressive than OCFs, under standard hypotheses (postulate (G) in Schwind et al., 2022). However, in this paper we aim to work with a meaningful, unnormalized structure and consider a framework with rationality postulates directly applied to these structures, rather than just at the level of beliefs. Within this context, OCF-based operators are clearly not rational improvement operators in the sense of Definition 9. In particular, we have seen in Example 2 that in normalized structures as OCF’s, it is unavoidable to worsen the plausibility degree of countermodels of the new information. On the contrary, in structures such as rational rankings is possible to improve or even revise without worsening the countermodels of the new information.
Spohn’s Work on Rankings
There are some important differences between our work and Spohn’s work (Spohn, 2009): First, Spohn defines normalized rankings into the positive real numbers, while our rational rankings are not normalized. Additionally, he defines rankings into the set . In Spohn’s framework, negative ranks model degrees of disbelief, which is not the intention in our work. Moreover, the density of is a key property for our development, which is overlooked in Spohn’s work.
JLZ System
Weydert proposes in Weydert (2003) the JLZ System for default reasoning with the aim of building a canonical ranking for any given default base. In Weydert (2012), he defines a formalism for iterated belief revision where belief states are modeled by ranking measures and inputs are sets of graded doxastic conditionals.
The general structures considered in Weydert (2012) are also normalized unlike our structures. Moreover, both Spohn -see for instant Hild and Spohn (2008)- and Weydert consider ranks taking the value . We don’t need this value.
Another important difference between our work and the work of Spohn and the work of Weydert is that we study mechanisms of very gradual changes that we call improvement. We have indded characterized a class of this operators for space of rational rankings.
Conclusions and Future Work
A first contribution of this work is the introduction and characterization of the class of generalized improvement operators. We have defined the epistemic space of rational rankings and the associated rational improvement operators. These operators consistently produce changes, and notably, improving new information does not require decreasing the plausibility of models that do not satisfy this new information. This framework effectively models scenarios such as the evolution of Dr. Roberts’ beliefs in Example 3.
The epistemic space of rational rankings allows to define in a simple and natural manner operators that represent one-improvement and half-improvement operators (Konieczny et al., 2010b) defined on TPOs (see Definitions 15 and 16). The definition of the one-improvement operator on OCFs is very complex in comparison (Konieczny & Pino Pérez, 2008). Half-improvement operators on OCFs has not been defined.
By working within the space of rational rankings, we can define -translations with very small values of . This flexibility allows us to model Carlos’ evolving beliefs in Example 4, demonstrating the need for many iterations to achieve a goal.
Another notable feature of using rational rankings is the ability to define regressions simply with negative numbers.
Through a few equations and inequalities with clear meanings, we have established a class of operators that captures the notion of improving the plausibility of the input: The rational improvement operators. Additionally, we have provided two independent postulates that characterize the translation operators.
The space of rational rankings can be very useful as a field of experimentation in order to find the properties characterizing well behaved operators. For instance, we can define operators as the Zeno operators (Example 13) which show that it is not enough to increase the plausibility of certain models of the input, for being a real improvement operator (to achieve success iterating the input enough number of times).
Some concepts, such as the softness of operators, are intrinsically contextual. As demonstrated, this is incompatible with (RI2). Future work should explore more relaxed notions than (RI2) that accommodate contextual operators, particularly postulates compatible with (r-Soft).
An important direction for future research is to determine the syntactic characterization of the classes of operators defined in this work. Additionally, investigating whether rankings on real numbers would provide a richer framework, potentially incorporating properties such as completeness, could be a valuable avenue for exploration.
Footnotes
Acknowledgments
The authors thank many participants of the BRAON 2024 Workshop, where a preliminary version of this work was presented, for their questions, suggestions, and lively discussions. For sure, they helped us improve the presentation and the scope of this work.
A short version of this work (Borges et al., 2024) was presented at KR 2024.
ORCID iDs
Nerio Borges
Nicolas Schwind
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work has benefited from the support of the AI Chair BE4musIA of the French National Research Agency (ANR-20-CHIA-0028). Dr. Borges whishes to thank Yachay Tech University for support through research project MATH24-03.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
References
1.
AlchourrónC. E.GärdenforsP.MakinsonD. (1985). On the logic of theory change: Partial meet contraction and revision functions. Journal of Symbolic Logic, 50, 510–530.
2.
AravanisT. I.PeppasP.WilliamsM. (2019). Observations on Darwiche and Pearl’s approach for iterated belief revision. In Proceedings of the twenty-eighth international joint conference on artificial intelligence, IJCAI 2019. (pp. 1509–1515).
3.
BautersK.McAreaveyK.LiuW.HongJ.LacasaL. G.SierraC. (2017). Managing different sources of uncertainty in a BDI framework in a principled way with tractable fragments. The Journal of Artificial Intelligence Research, 58, 731–775.
4.
BoothR.FerméE.KoniecznyS.Pino PérezR. (2012). Credibility-limited revision operators in propositional logic. In Proceedings of the Thirteenth international conference on the principles of knowledge representation and reasoning, KR 2012. (pp. 116–125).
5.
BoothR.FerméE.KoniecznyS.Pino PérezR. (2014). Credibility-limited improvement operators. In Proceedings of the Twenty-First European conference on artificial intelligence, ECAI 2014. (pp. 123–128).
6.
BoothR.MeyerT. (2006). Admissible and restrained revision. Journal of Artificial Intelligence Research, 26, 127–151.
7.
BorgesN.KoniecznyS.Pino PérezR.SchwindN. (2024). Belief change on rational rankings. In P. Marquis, M. Ortiz & M. Pagnucco (Eds.), Proceedings of the 21st International conference on principles of knowledge representation and reasoning, KR 2024, Hanoi, Vietnam. November 2-8, 2024.
8.
BoutilierC. (1996). Iterated revision and minimal change of conditional beliefs. Journal of Philosophical Logic, 25(3), 262–305.
KatsunoH.MendelzonA. O. (1991). Propositional knowledge base revision and minimal change. Artificial Intelligence, 52, 263–294.
18.
Kern-IsbernerG.Skovgaard-OlsenN.SpohnW. (2021). Ranking theory. In M. Knauff & W. Spohn (Eds.), The handbook of rationality. (pp. 337–345). MIT Press.
19.
KoniecznyS. (2009). Using transfinite ordinal conditional functions. In Proceedings of the Tenth European conference on symbolic and quantitative approaches to reasoning with uncertainty, ECSQARU 2009. (pp. 396–407).
20.
KoniecznyS.GrespanM. M.Pino PérezR. (2010a). Taxonomy of improvement operators and the problem of minimal change. In Twelfth International conference on the principles of knowledge representation and reasoning.
21.
KoniecznyS.Medina GrespanM.Pino PérezR. (2010b). Taxonomy of improvement operators and the problem of minimal change. In Proceedings of the Twelfth international conference on principles of knowledge representation and reasoning, KR 2010. (pp. 161–170).
22.
KoniecznyS.Pino PérezR. (2008). Improvement operators. In Proceedings of the Eleventh international conference on principles of knowledge representation and reasoning, KR 2008. (pp. 177–187). http://www.aaai.org/Library/KR/2008/kr08-018.php.
23.
MaJ.LiuW. (2011). A framework for managing uncertain inputs: An axiomization of rewarding. International Journal of Approximate Reasoning, 52(7), 917–934.
24.
Medina GrespanM.Pino PérezR. (2013). Representation of basic improvement operators. In E. L. Fermé, D. Gabbay & G. R. Simari (Eds.), Trends in Belief revision and argumentation dynamics (pp. 195–227). College Publications.
25.
NayakA. C. (1994). Iterated belief change based on epistemic entrenchment. Erkenntnis, 41, 353–390.
26.
SauerwaldK.BeierleC. (2019). Decrement operators in belief change. In Proceedings of the Fifteenth European conference on symbolic and quantitative approaches to reasoning with uncertainty, ECSQARU 2019. (pp. 251–262).
27.
SchwindN.KoniecznyS. (2020). Non-prioritized iterated revision: Improvement via incremental belief merging. In Proceedings of the Seventeenth international conference on principles of knowledge representation and reasoning, KR 2020. (pp. 738–747). https://doi.org/10.24963/kr.2020/76.
28.
SchwindN.KoniecznyS.Pino PérezR. (2022). On the representation of Darwiche and Pearl’s epistemic states for iterated belief revision. In Proceedings of the Nineteenth international conference on principles of knowledge representation and reasoning, KR 2022. (pp. 320–330). https://proceedings.kr.org/2022/32/.
29.
SchwindN.KoniecznyS.Pino PérezR. (2023). Iteration of iterated belief revision. In Proceedings of the 20th International conference on principles of knowledge representation and reasoning, KR 2023. (pp. 625–634). https://doi.org/10.24963/kr.2023/61.
30.
SpohnW. (1988). Ordinal conditional functions: A dynamic theory of epistemic states. In W. L. Harper & B. skyrms (Eds.), Causation in decision: Belief change and statistics (pp. 105–134). Kluwer.
31.
SpohnW. (2009). A survey of ranking theory. In F. Huber & C. Schmidt-Petri (Eds.), Degrees of Belief (pp. 185–228). Springer, Dordrecht. https://doi.org/10.1007/978-1-4020-9198-8 8
32.
van EijckJ.LiK. (2017). Conditional belief, knowledge and probability. In J. Lang (Ed.), Proceedings Sixteenth conference on theoretical aspects of rationality and knowledge Liverpool, UK, 24-26 July 2017. (pp. 188–206).
33.
WeydertE. (2003). System jlz–rational default reasoning by minimal ranking constructions. Journal of Applied Logic, 1(3-4), 273–308.
34.
WeydertE. (2012). Conditional ranking revision: Iterated revision with sets of conditionals. Journal of Philosophical Logic, 41(1), 237–271.