
Abstract
Intent detection, a fundamental text classification task, aims to identify and label the semantics of user queries, playing a vital role in numerous business applications. Despite the dominance of deep learning techniques in this field, the internal mechanisms enabling recurrent neural networks (RNNs) to solve intent detection tasks are poorly understood. In this work, we apply dynamical systems theory to analyze how RNN architectures address this problem, using both the balanced SNIPS and the imbalanced ATIS datasets. By interpreting sentences as trajectories in the hidden state space, we first show that on the balanced SNIPS dataset, the network learns an ideal solution: the state space, constrained to a low-dimensional manifold, is partitioned into distinct clusters corresponding to each intent. The application of this framework to the imbalanced ATIS dataset then reveals how this ideal geometric solution is distorted by class imbalance, causing the clusters for low-frequency intents to degrade. Our framework decouples geometric separation from readout alignment, providing a novel, mechanistic explanation for real world performance disparities. These findings provide new insights into RNN dynamics, offering a geometric interpretation of how dataset properties directly shape a network’s computational solution.
Introduction
RNNs and the Interpretability Challenge
Modern recurrent neural networks (RNNs) 1 are widely used to tackle problems involving sequential data. These networks have demonstrated strong performance in various natural language processing (NLP) tasks, such as sentiment analysis (Liu, 2015), intent detection and slot filling (Hakkani-Tür et al., 2016), and machine translation (Sutskever et al., 2014). However, despite their widespread success, the exact nature of the internal mechanisms by which RNNs solve specific tasks remains an open question. This lack of understanding is partly due to the nonlinear nature of RNNs and the high-dimensionality of their hidden layers, which together obscure the computational processes underlying their behavior. Moreover, the trend in practical applications leans toward increasingly complex architectures (Bahdanau et al., 2015; Sutskever et al., 2014), making it even more challenging to understand what is happening inside the nets. The integration of RNNs into applications with significant societal impact, such as healthcare, legal systems, and autonomous decision-making, has made the demand for interpretability more pressing than ever. Understanding how these models detect patterns, solve problems, and make decisions is no longer merely a theoretical concern but a practical necessity. Enhancing the interpretability of neural networks decision-making is crucial to ensure their robustness, fairness, and accountability in real-world applications (Hamon et al., 2020). Addressing this challenge is key to bridge the gap between the impressive capabilities of RNNs and the trust required for their deployment in high-stakes environments.
Analysis Approaches for Understanding RNNs
Understanding the behavior of RNNs has been a persistent challenge in machine learning research. Early studies focused on visualizing the activity of specific network components, such as memory gates, during NLP tasks (Karpathy et al., 2016; Strobelt et al., 2018). Although these unit-level analyses offer localized functions, they often fail to provide a comprehensive interpretation of the network’s overall behavior. The inherent feedback connections between RNN neurons allow these networks to be viewed as nonlinear dynamical systems (Martelli, 1999), allowing the application of well-established tools from dynamical systems theory (Strogatz, 2015). Based on this perspective, several studies have derived analytic expressions for aspects of network dynamics such as bifurcations in the parameter space of small networks and convergence properties (Haschke & Steil, 2005; Yi & Tan, 2004). These efforts have enhanced our understanding of the mathematical underpinnings of RNN behavior but remain limited in their ability to explain task-specific computations in large, real-world networks. Recently, a new reverse engineering paradigm has emerged to analyze RNNs at a higher level of abstraction. Instead of focusing on the microdetails of individual neurons or gates, this approach examines the state space of trained RNNs. Fixed points are identified and the dynamics of the system is linearized around them, revealing a key computational mechanism embedded within the network (Sussillo & Barak, 2013). This perspective has yielded significant insights, particularly in the context of text classification tasks, where state space analyses have demonstrated promising results (Aitken et al., 2021; Maheswaranathan et al., 2019). A recurring theme in these works is the discovery that trained RNNs often converge to highly interpretable, low-dimensional representations associated with attractors in the state space. The geometry and dimensionality of these attractors manifolds are intricately linked to the structure of the dataset and the nature of the task being solved. In summary, this attractor-based view provides a powerful framework for understanding how RNNs encode information and implement computations.
A Comparison With Other Interpretability Paradigms
Our analysis adopts a dynamical systems framework to seek a mechanistic understanding of RNN computation, offering insights distinct from other valuable interpretability paradigms. Contrasting our global, dynamic approach with other common methods clarifies its unique contributions.
In contrast, our dynamical systems approach provides a different and complementary level of insight. Revealing dynamic processes: Unlike static attribution maps, this framework visualizes computation as a dynamic process. It allows us to model sentences as trajectories within the hidden state space, revealing how evidence is accumulated token-by-token, rather than just identifying which tokens were most influential. Characterizing global geometry: Where other methods are local, our approach characterizes the global geometry of the task learned by the network. This enables the analysis of holistic properties such as the intrinsic dimensionality of the problem and the organization of the decision space into meaningful regions. Uncovering mechanistic principles: Most critically, this perspective moves from correlation to mechanism. It seeks to explain why the network functions as it does, framing classification as a process governed by the stable and unstable dynamics of a fixed-point topology. Therefore, our approach complements other methods by providing a unique lens into the internal, dynamic, and geometric nature of how RNNs solve tasks.
Intent Detection: A Case Study Domain
Within the field of NLP, intent detection is a horizontal foundational operation, providing instrumental support for a wide range of applications. Broadly defined, intent detection is an NLP task aimed at recognizing and classifying the underlying purpose or operational goal (a.k.a. intention) expressed in an user’s utterance. It serves as a critical component in the functional architecture of language understanding systems (Qin et al., 2021), addressing the challenge of mapping a large and diverse set of linguistic expressions onto a predefined set of semantic intentions. This challenge is complex, requiring the operation of multiple linguistic levels simultaneously. From diverse lexical realizations and syntactic structures, to semantic ambiguities and pragmatic contexts, intent detection must integrate diverse dimensions of language processing to deliver accurate results. Despite progress in academic research and industrial applications, intent detection remains a theoretical and practical challenge. Different lines of interest include: detecting multiple intents within a single utterance (Kim et al., 2017), integrating intent detection with entity recognition (t, 2022; Song et al., 2022; Weld et al., 2022), managing out-of-domain intents (Capuano, 2021; Lang et al., 2023), and developing robust models that support explainability and transparency in classification decisions (Zhuang et al., 2024). These challenges, combined with the intrinsic characteristics of intent detection: (a) operation on a low-dimensional semantic space, despite the high-dimensionality of the architectures involved, and (b) a topologically inspired convergence towards different semantic kernels, make it an ideal domain for analysis using dynamical systems theory. This work leverages a combined mathematical, computational, and linguistic framework rooted in dynamical systems theory to propose a novel approach to understanding the nature of the intent detection process. This framework also constitutes the starting point for tackling some of the challenges indicated.
Our Contributions and Paper Organization
Our key contribution is the pioneering study of the state-space dynamics of trained RNNs applied to the SNIPS and ATIS intent detection problems. We show that the state space can be characterized as a low-dimensional manifold whose intrinsic dimensionality is related to the size of the embedding layer and the number of neurons in the hidden layer. We show that input sentences traverse discrete trajectories through the state space, progressing from initial states toward specific outer regions. A crucial finding is the identification of distant regions within the state space, where these trajectories terminate. These peripheral areas are aligned with the directions defined by the rows of the readout matrix, allowing for the generation of predictions. In addition, we uncover the fixed-point topology underlying the network dynamics. Unlike other tasks, such as sentiment analysis or document classification, we find that RNNs trained for intent detection exhibit an unexpected fixed-point structure (Aitken et al., 2021). The number and nature of attractors, saddle points and other critical points in the state space are shown to depend on network parameters and the type of RNN cell (e.g., LSTM or GRU). We first established this geometric framework on the balanced SNIPS dataset, and then use it as a diagnostic tool to test its generalizability on the complex, imbalanced ATIS dataset. This analysis reveals how the ideal geometric solution is distorted by class imbalance on low-frequency intents. We introduce a novel diagnostic framework that decouples geometric separation from readout alignment, allowing us to identify four distinct, mechanistic patterns that explain real-world performance disparities.
The rest of the article is organized as follows: Section 2 introduces the problem of intent detection, discussing various aspects and current lines of research in this field, as well as how the dynamical systems approach fits into this context. Section 3 explores how RNNs can be interpreted as nonlinear dynamical systems. Section 4 outlines the specific objectives to be addressed through the experiments. Section 5 describes the datasets selected for this study. Section 6 details the experimental setup and methodology, while Section 7 provides an in-depth analysis of the results obtained. Finally, Section 8 presents the conclusions and suggest potential directions for future research.
Intent Detection: Domain Characterization and Research Challenges
Intent detection is a cornerstone in several areas of NLP, playing a vital role in numerous industrial applications, particularly in conversational systems, virtual assistants, and question-answering environments. At its core, intent detection addresses one of the most fundamental syntactic–semantic challenges in natural language understanding: to collaborate effectively in conversational interactions, a conversational agent must accurately identify and unambiguously classify the user’s intent. This task depends on various linguistic components and levels. From lexical and morphological units to syntactic, semantic, and even pragmatic and acoustic nuances. In particular, even non-verbal cues, such as silence or pauses, can convey relevant intentional meanings.
Evolution of Intent Detection Approaches
The field of intention recognition has evolved significantly since its inception. Three main paradigms can be distinguished, starting with simple dictionary-based and rule-based methods (Niimi et al., 2001). A second major approach focuses on statistically based classification methods (Jansen et al., 2007). In the current landscape, intent detection is experiencing a remarkable moment of dynamism, adopting the most advanced techniques in deep learning and natural language processing. Different neural network architectures, from RNNs to transformer-based models, have been applied, including proposals based on models such as BERT (Abro et al., 2022; Wu et al., 2024; Yolchuyeva et al., 2019).
Current Research Challenges
Despite significant progress, intent detection remains a challenging task due to the complexity of human interactions. Given the foundational nature of intent detection, as a core component of different language technology systems, research must address different challenges. Multi-intent detection: User utterance in conversational interactions often includes multiple intents simultaneously (Kim et al., 2017). For example, in the sentence: ‘Hello good morning, I would like to cancel the medical appointment I had and ask for a new one’ the user expresses three different intents: greeting, cancelation and rescheduling. Moreover, temporal dependencies between intents can arise, as in: ‘I want to make a transfer but first I would like to know my balance’. In this case, the execution of the second intent depends on the completion of the first. In addition, operational or interpretative dependencies may exist, as in: ‘Turn off all the lights that are on and turn on all the lights that are off’. In this case, determining which lights are affected by the second intent must be resolved before executing the action associated with the first intent. Integration of intent detection and entity recognition: The tasks of intent detection and entity recognition are deeply interconnected but have traditionally been treated as separate problems within the language understanding pipeline (Abro et al., 2022; Song et al., 2022; Weld et al., 2022). Entities may be linked to different intents according to semantic or pragmatic relationships. Hence, a correct identification of entities may depend to a large extent on the recognition of intents. For example, in the sentence ‘I would like to book the flight departing at 9’, the value ‘9’ should be classified as a time, while in ‘I would like to order 9’, the same value ‘9’ represents a quantity. Furthermore, entity recognition can clarify ambiguous intents, as in ‘From Paris to New York next Monday’. Out-of-domain intent management: Effective handling of out-of-domain intents is essential for real-world applications, particularly in domains like banking, public administration, and customer service (Capuano, 2021; Lang et al., 2023). Users often express intents that fall outside the operational scope of a system, posing a challenge for intent detection. This complexity is amplified by a high level of overlap in the way intents can be expressed. For example, a citizen may request the renewal of a document from the wrong administration, but linguistically, the request resembles a legitimate query. Detecting and accurately classifying these cases remains a significant challenge. Model explainability: In many critical applications, it is not sufficient for a conversational system to simply classify the intent but also to provide a clear and understandable explanation associated with the decision (Zhuang et al., 2024). Moreover, explainability contributes to ensure the robustness and reliability of conversational systems and the identification of potential biases.
Suitability for Dynamical Systems Analysis
The analysis of the intention detection task, together with its current research directions and the associated methodological and technological challenges, suggests that it is a highly suitable domain for the application of dynamical systems analysis. As we show in this article, intent detection models typically operate on low-dimensional manifolds, even though they are implemented using high-dimensional neural architectures. This feature reflects the intrinsic nature of intent detection, which at a high level of abstraction can be described as a mapping operation from complex linguistic expressions to a relatively small catalog of semantic intents. The objective is to maintain strong robustness and flexibility across with respect to variability of expressions at all linguistic levels, including lexical-morphological, syntactic, and semantic variability. On the other hand, modeling based on specific fixed-point topologies with attractors and saddle points aligns well with the inherent structure of intent classification problems. The targets in the intent catalog can ultimately be interpreted as convergence points of the entire set of linguistic variants that express or represent the same meaning (semantic-level cataloging) or are associated with the execution of the same operation (pragmatic-level cataloging). This mathematical and computational framework provides a suitable approach for addressing one of the key characteristics of human language, such as ambiguity and the transition between different interpretations.
A key intuition underlying this article is that the process of understanding, which underpins intent classification, can be viewed as a trajectory in a multidimensional space defined by word embeddings as they are processed and transformed by the network in the hidden layer for each token of an input expression. Analyzing these trajectories through space offers valuable insights into the comprehension process, which can be seen as a nonlinear accumulation of information received from the input signal in sequential nature. Within this framework, attractor points can be interpreted as the centers of regions that represent the intents defined in the catalog of the working domain. This approach integrates motivations of a computational nature (rooted in deep learning models with architectures ranging from RNNs to Transformers), mathematical (through the use of a topological model that enables operations such as comparison, trajectory analysis, proximity assessment, sudden changes in direction and speed), and linguistic (addressing issues like ambiguity, synonymy, polysemy, and dependencies between linguistic levels). This work also offers a starting point for tackling the challenges in the field of intent detection. For instance, the state space topology provides a new perspective for addressing multi-intent detection and out-of-domain intent identification. Additionally, the low-dimensional manifold structure serves as a foundation for analyzing the interaction between intent detection and entity recognition within a unified semantic space. Crucially, this framework’s ability to provide a mathematical foundation for understanding the internal workings of intent detection systems enhances their explanatory power, addressing the limitations of black-box models and promoting greater transparency.
Background
Recurrent Neural Networks Computations
Feedforward networks (FFNs) analyze inputs under the assumption that the order in which samples are processed does not carry meaningful information. However, in many real-world scenarios, the order of the components, or their temporal or spatial relationships, is crucial. For example, NLP problems are studied as token sequences, and weather forecasting relies on time series data (Han et al., 2021). In such cases, a mechanism for retaining and learning temporal dependencies is required. To address this limitation, FNNs can be enhanced with feedback connections, as illustrated in Figure 1. This enhancement gives rise to the architecture known as recurrent neural networks (RNNs) (Goodfellow et al., 2016).
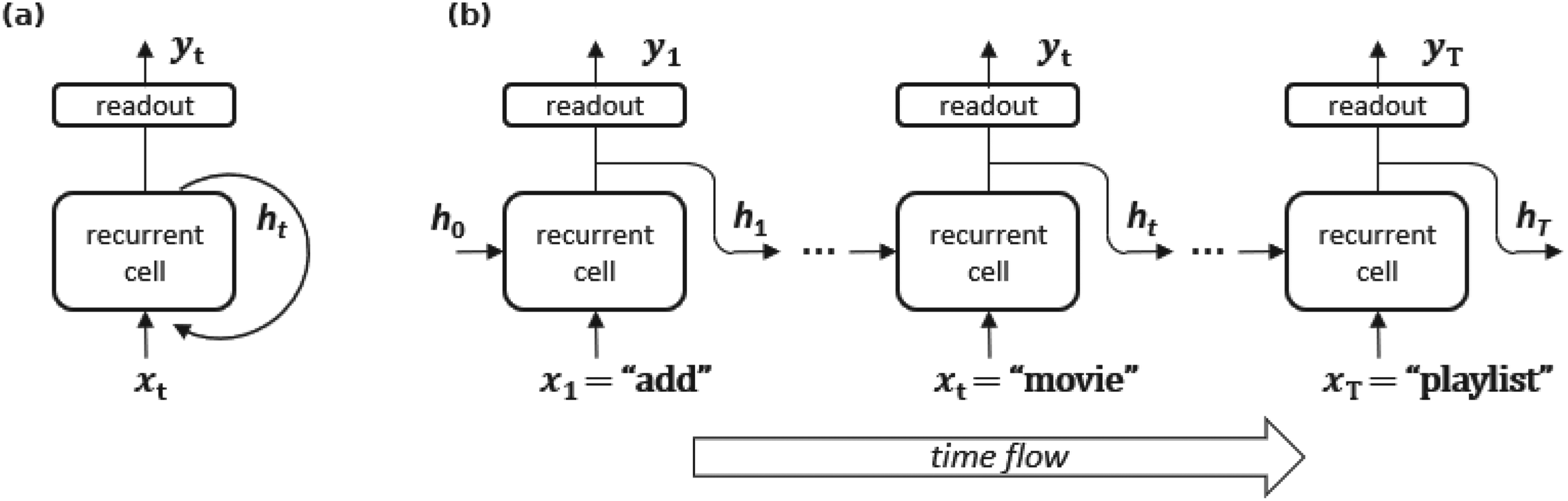
(a) Folded representation of a Recurrent Neural Network (RNN), highlighting the recurrent connection within the architecture. (b) Unfolded representation of an RNN, explicitly showing the flow of time. At each time step
In general, the computations performed by RNNs can be summarized using the following pair of equations in difference:


Systems governed by difference equations as in Equation (1) are called discrete-time dynamical systems, with their state represented by
A fixed point or equilibrium point, denoted as
Linearization
Fixed points have a key property; the Hartman–Grobman theorem (Hartman, 2002) states that the behavior of an NLDS near a fixed point
From this decomposition, the state of a
Basins of Attraction and Saddle Points
In many systems without external input, the dynamics naturally evolves toward specific regions of the state space. These converging points or regions are known as attractors. Among the attractors, the simplest type is the stable fixed point. The region of the phase space (i.e., the set of all initial states) from which the system evolves toward a particular attractor is called the basin of attraction of an attractor. Any initial condition within this region will eventually lead the system to the attractor through the iterative dynamics of the system. The state space is typically partitioned into basins of attraction, each associated with a specific attractor. Saddle points play a crucial role in governing the boundaries and interactions between these basins. Typically, a saddle point will have a dominant set of stable modes (or manifolds) with only a small number of unstable modes. This configuration makes saddle points critical for state space management, as they influence how trajectories transition between basins of attraction. For example, a region of state space may be funneled through the stable modes of a saddle point, only to be directed toward different attractors by its unstable modes. In this way, saddle points act as gateways or intermediaries that connect different basins of attraction. As a result of this interaction, the stable manifold of a saddle point often forms the boundary between the basins of attraction (Ceni et al., 2020). The complexity of a saddle point can be quantified by its index, defined as the number of unstable manifolds (or directions) associated with the fixed point. A saddle point with a higher index has a greater number of directions in which the trajectories diverge, which can lead to more intricate dynamics and transitions between basins.
Reverse Engineering RNNs of Classification Tasks
Recurrent Neural Networks, as nonlinear discrete-time dynamical systems, can be analyzed using tools from dynamical system theory. Modern RNN architectures are made up of hidden layers with hundreds of neurons, resulting in high-dimensional hidden states. Traditional dynamical system analysis often treats individual neurons as system parameters, but this high dimensionality poses significant challenges for standard state-space analysis. A recent line of research adopts a higher-level perspective to study the computational mechanisms learned by RNNs (Sussillo & Barak, 2013). These reverse engineering techniques aim to uncover how trained RNNs implement specific tasks by analyzing the geometry and dynamics of their state space. This approach focuses on key dynamical features, such as fixed points, their linearized dynamics, and the interactions between equilibrium points, to infer the behavior of the network.
For example, tasks such as binary sentiment analysis and general text classification exhibit a common underlying dynamical mechanism (Aitken et al., 2021). In such tasks, the hidden state trajectories of RNNs largely lie in a low-dimensional subspace of the full state space, despite the high dimensionality of the hidden states. Within this subspace lies an attractor manifold, which serves as a repository for accumulating evidence for each class as the network processes tokens sequentially. The exact dimensionality and geometry of this attractor manifold depend on the structure of the dataset and the complexity of the task. For binary sentiment classification, hidden states typically evolve along a line of stable fixed points, reflecting the network’s progression as it processes input text (Maheswaranathan et al., 2019). More generally, for categorical classification tasks with
Objectives
RNNs are nonlinear dynamical systems with high-dimensional state-space structures. These structures can be analyzed by examining fixed points, attractor manifolds, and trajectories within the state space. Recent advances in reverse engineering techniques have provided valuable insight into how RNNs implement task-specific computations. These studies suggest that RNNs encode evidence in low-dimensional manifolds, using an integrative mechanism to track and accumulate information over time to facilitate accurate classification. Although significant progress has been made in understanding RNN dynamics for tasks such as binary sentiment classification and generic text classification, these techniques have not yet been systematically applied to intent detection. Intent detection presents unique challenges due to its diverse and semantically rich set of intent classes. As a result, it remains unclear how state-space dynamics manifest in intent detection tasks and how architectural parameters affect the underlying trajectories and manifold geometry. The primary objective of this study is to investigate how RNN architectures encode intent detection tasks in their state space. Specifically, our goal is to analyze the structure of the state space, determining its intrinsic dimensionality, and comparing it with previous findings for generic categorical text classification tasks. We also examine the behavior of hidden state trajectories as the RNN processes input sequences, uncovering the internal mechanism that lead to accurate predictions. To address these objectives, we performed experiments using the SNIPS and ATIS datasets and analyzed the state-space dynamics of various RNN architectures.
Datasets
Several benchmark datasets have been widely used to evaluate the performance of intent detection models. Among them, three prominent datasets are SNIPS, ATIS, and MASSIVE, each with distinct characteristics and challenges. The SNIPS dataset (Coucke et al., 2018) developed for English voice assistant systems consists of 7 balanced intents. This simplicity, combined with the absence of significant class imbalance, makes SNIPS an ideal choice for analyzing the state space dynamics of intent detection models without introducing side effects due to imbalance or an excessive number of classes. In contrast, the ATIS (Airline Travel Information System) dataset (Hemphill et al., 1990) contains real customer conversations about flight information. Although ATIS includes 26 intentions, almost 74% of its samples belong to a single intent, making it challenging to analyze model performance fairly across all classes. Furthermore, some utterances in ATIS are annotated with multiple intents. The recently introduced MASSIVE dataset (FitzGerald et al., 2022) is a multilingual localization of the SLURP dataset (Bastianelli et al., 2020). It spans 51 languages and includes 60 intents in 18 domains. However, the MASSIVE dataset exhibits both a large number of intents and a degree of class imbalance, with some intents having very few samples. This makes MASSIVE more suitable for multilingual and large-scale evaluations.
Given our focus on understanding the state space dynamics of RNNs in intent detection tasks, we select two complementary datasets for our experiments: SNIPS and ATIS. SNIPS serves as our baseline. Its reduced number of intents, balanced class distribution, and manageable complexity allow for a controlled investigation of the underlying computational mechanisms. ATIS serves as our generalizability test. Its significant class imbalance and larger number of intents provides a challenging, real-world scenario to validate our framework. Table 1 compares the key characteristics of these datasets, highlighting differences in class distribution, imbalance, and scale.
Comparison of Intent Detection Datasets, Summarizing Key Characteristics, Including the Number of Languages, Utterances per Language, Domains, Intents, Slots, and Class Imbalance Measures (Number and Percentage of Samples in the Largest and Smallest Intent Classes for Each Dataset).
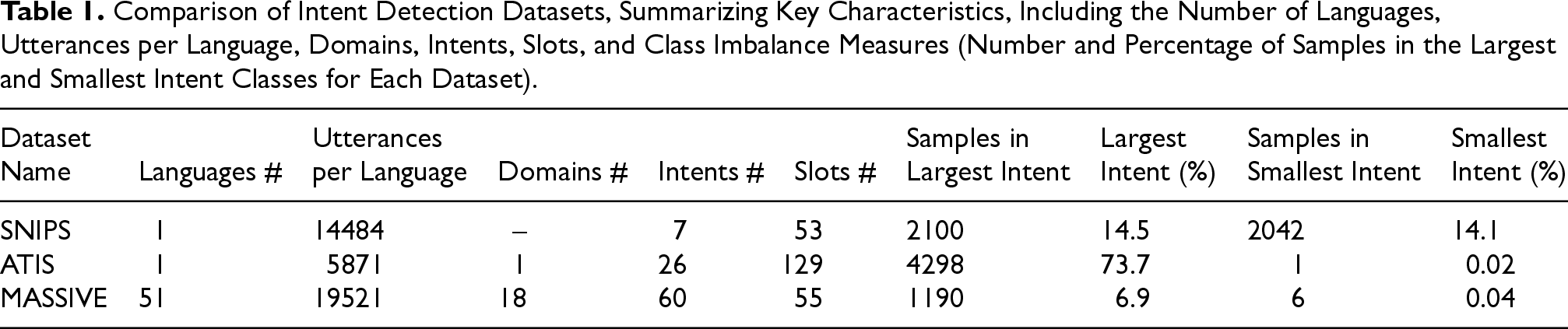
Comparison of Intent Detection Datasets, Summarizing Key Characteristics, Including the Number of Languages, Utterances per Language, Domains, Intents, Slots, and Class Imbalance Measures (Number and Percentage of Samples in the Largest and Smallest Intent Classes for Each Dataset).
Our analysis is structured into four steps: a) train different RNN architectures to solve the intent detection task on the SNIPS and ATIS datasets; b) extract and visualize the state space learned by the RNNs; c) analyze the manifold structure in which the state space is embedded; and d) investigate the fixed-point structure underlying the RNNs.
We implemented and trained the RNN models using TensorFlow 2 (Abadi et al., 2016). Each RNN consisted of a trainable embedding layer with embed_dim neurons (without pre-trained embeddings), a unidirectional recurrent layer with hidden_dim neurons, and a final dense layer for output. Tokenization was performed using Tensorflow’s TextVectorization layer. Three types of recurrent cells were evaluated: standard (vanilla) RNN, LSTM (Hochreiter & Schmidhuber, 1997), and GRU (Cho et al., 2014). The models were trained on the SNIPS and ATIS intent detection dataset. The training process optimized the multiclass cross-entropy loss function, used for classification tasks. We used Adam optimizer (Kingma & Ba, 2015) for all experiments. Training was performed with early stopping based on validation accuracy (Prechelt, 1996) (patience=2 epochs) to prevent overfitting.
It is important to note that our goal was not to achieve state-of-art optimized performance, but rather to obtain a reasonably high-performance (e.g., >93% accuracy). This ensures the models are competent and their learned dynamics, which are the focus of our study, are meaningful. To this end, hyperparameters were tuned independently for each dataset. For the SNIPS dataset we used a learning rate of
Results
Intent Detection Low-dimensional Dynamics
In this section, we show that the state space learned by an RNN during the intent detection task is constrained to a low-dimensional hypersurface, or manifold, embedded within the high-dimensional space of the hidden layer. Before sentences are processed by RNNs, a tokenization mechanism transforms each natural language phrase into a sequence
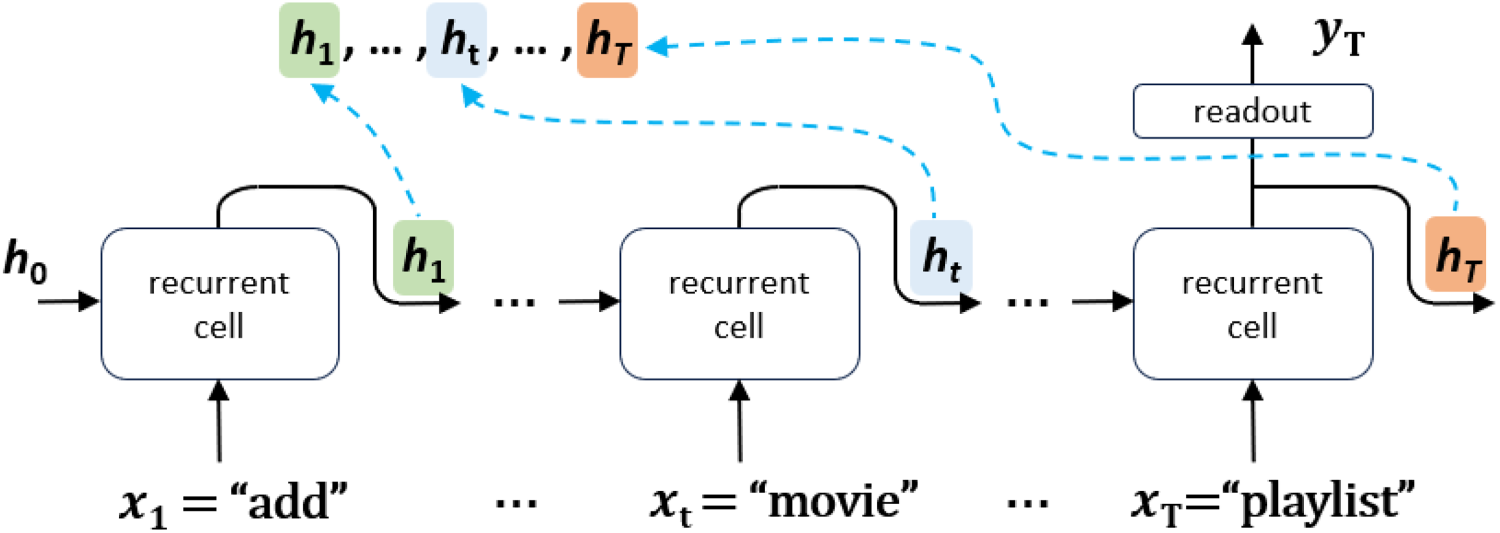
Sequence of hidden states
Given that the state space points may lie on a manifold embedded within a higher-dimensional space, the natural question is to determine the intrinsic dimensionality of this manifold. Intrinsic dimensionality refers to the minimum number of dimensions required to accurately represent the variability of the data. Several methods exist to estimate this dimensionality (Camastra & Vinciarelli, 2002; Levina & Bickel, 2004). Previous studies suggest that the variance-explained threshold is a robust and empirically validated approach, particularly for classification tasks (Aitken et al., 2021). This method involves performing Principal Component Analysis (PCA) (Jolliffe, 2002) and determining the number of principal components required to explain a fixed percentage (typically 95%) of the total variance.
Using this approach, we analyzed the state space learned by RNNs trained on the SNIPS dataset. All sentences from the SNIPS test dataset were processed by trained RNNs, and the resulting hidden states were concatenated to form the state space. PCA was then applied to these hidden state points to compute the cumulative variance explained by each principal component. Figure 3 illustrates the results for different RNN architectures with
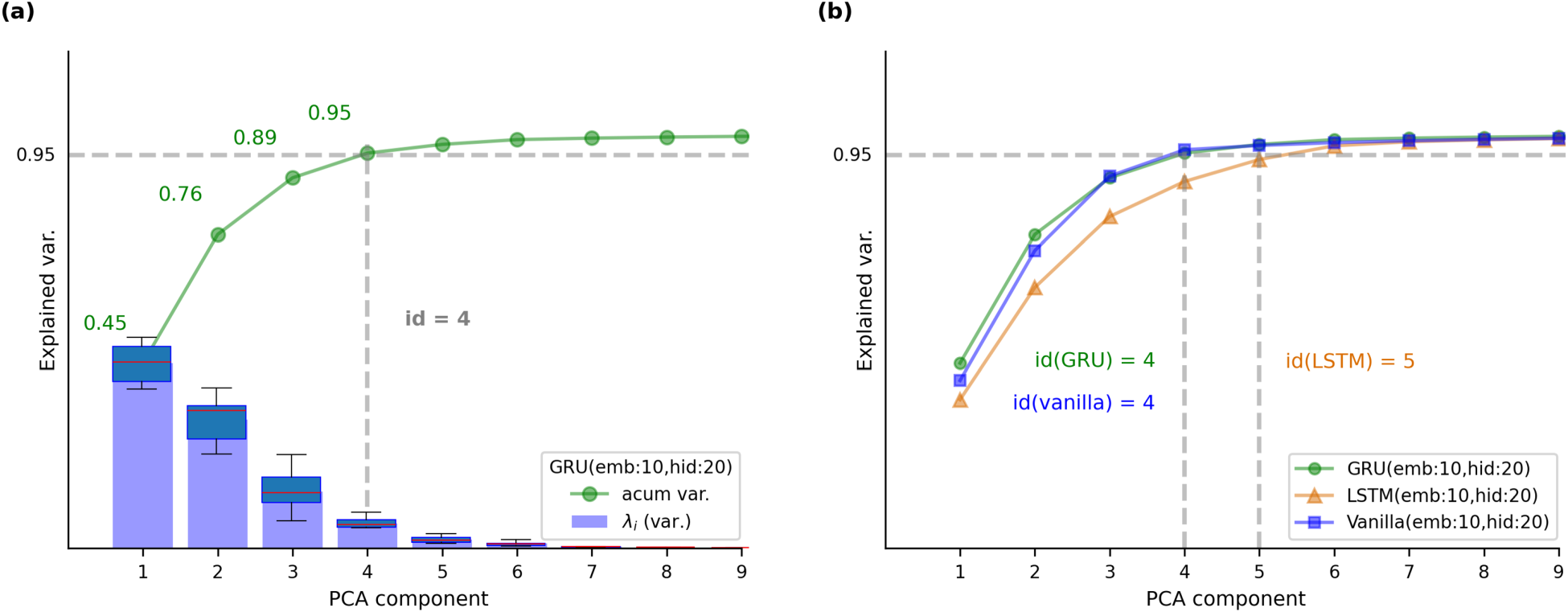
Variance explained by principal components for the hidden states of RNNs trained on the SNIPS dataset. (a) PCA analysis for a GRU-based RNN with embedding size
From related work, it is known that the state space dimensionality of RNNs solving categorical text classification tasks is
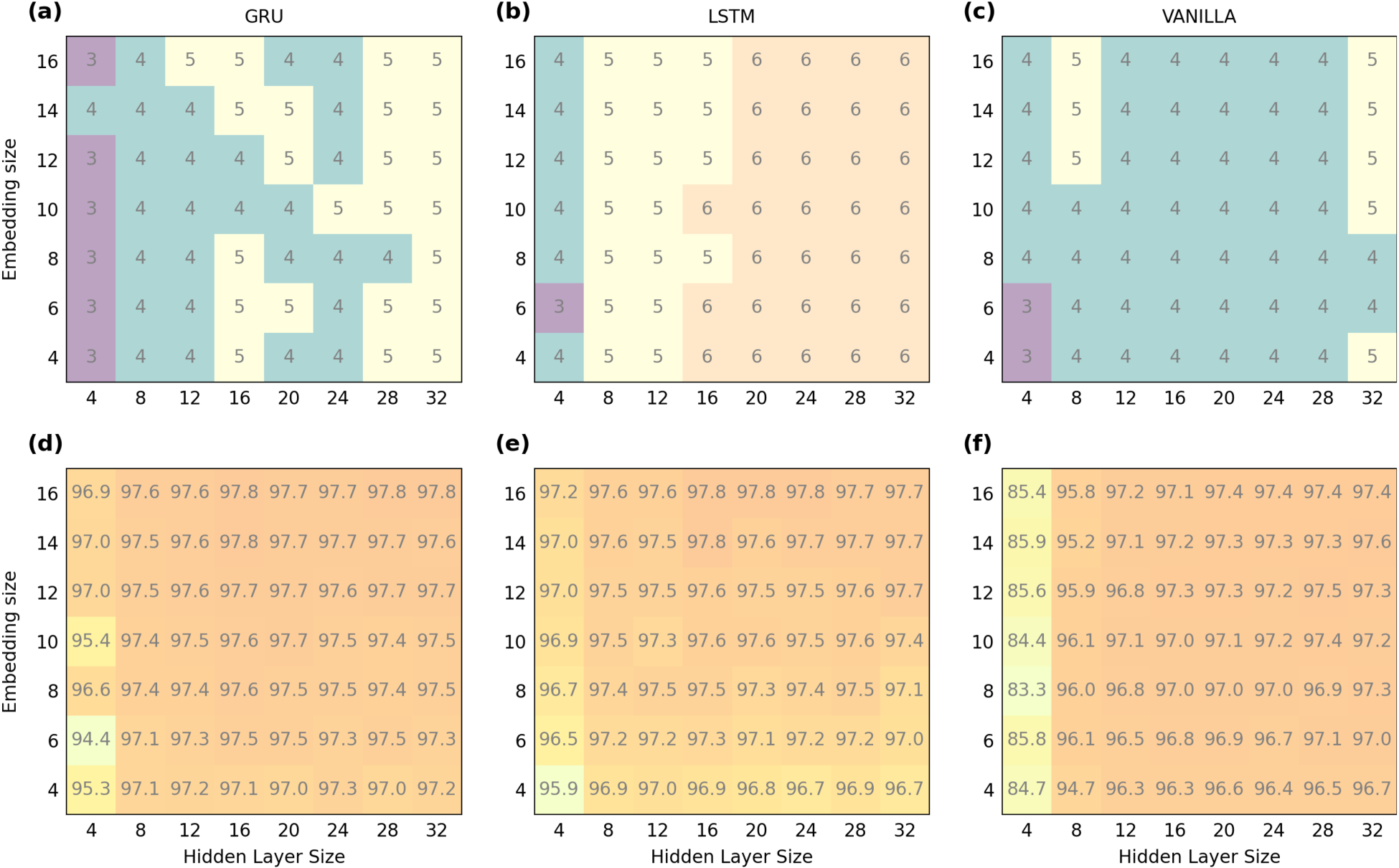
State space dimensionality and accuracy of RNNs trained on the SNIPS dataset for different combinations of embedding and hidden layer size. The top row shows the intrinsic dimensionality (id) of the state space for (a) GRU RNNs, (b) LSTM RNNs and (c) Vanilla RNNs. The bottom row displays the corresponding classification accuracy for the same architectures: (d) GRU, (e) LSTM, and (f) Vanilla RNNs.
In the following section, we analyze the spatial organization of hidden states in trained RNNs, taking advantage of the low intrinsic dimensionality (
Given a state space, its hidden states can be projected onto a lower-dimensional subspace defined by the top 
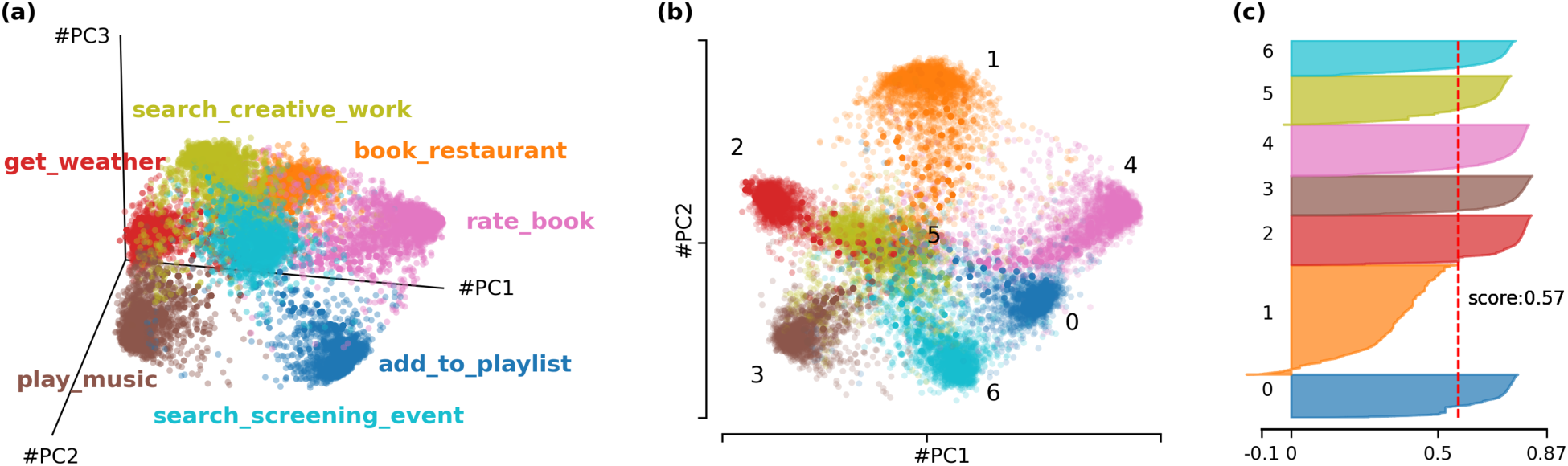
Top-2 and top-3 PCA projections of the state space of a GRU(emb:16,hid:16) trained on the SNIPS dataset. The hidden states are colored based on the intent label of its corresponding sentence. (a) 3D PCA projection. (b) 2D PCA projection, highligting intent clusters. (c) Silhouette score from a K-means clustering analysis of the state space, showing a score of 0.57 indicating a moderate level of cluster separation.
To numerically verify the presence of clusters in the state space, we applied the classical K-means clustering algorithm (Lloyd, 1982), configured with 7 clusters (matching the number of intents in the SNIPS dataset), random initialization of centroids and the Euclidean distance metric. The resulting state space partition was evaluated using the silhouette technique (Rousseeuw, 1987) which provides a measure of the quality of the clustering. The silhouette coefficient of a point quantifies its separation from other clusters by comparing the average intra-cluster distance (distance to points within the same cluster) to the nearest-cluster distance (distance to points in the closest neighboring cluster). The silhouette coefficients range from
Cluster Analysis of Final Hidden States for Various RNN Configurations. Silhouette Scores for State Space Partitioning and Final States Clustering, Evaluated in Both the Original High Dimensional State Space and the Intrinsic Low-Dimensional (id-Projected) Space. Statistics for Cluster Centroid Distances and Cluster Radii. Mean Cosine Similarity Between Readout Vectors and Cluster Centroids (Alignment).
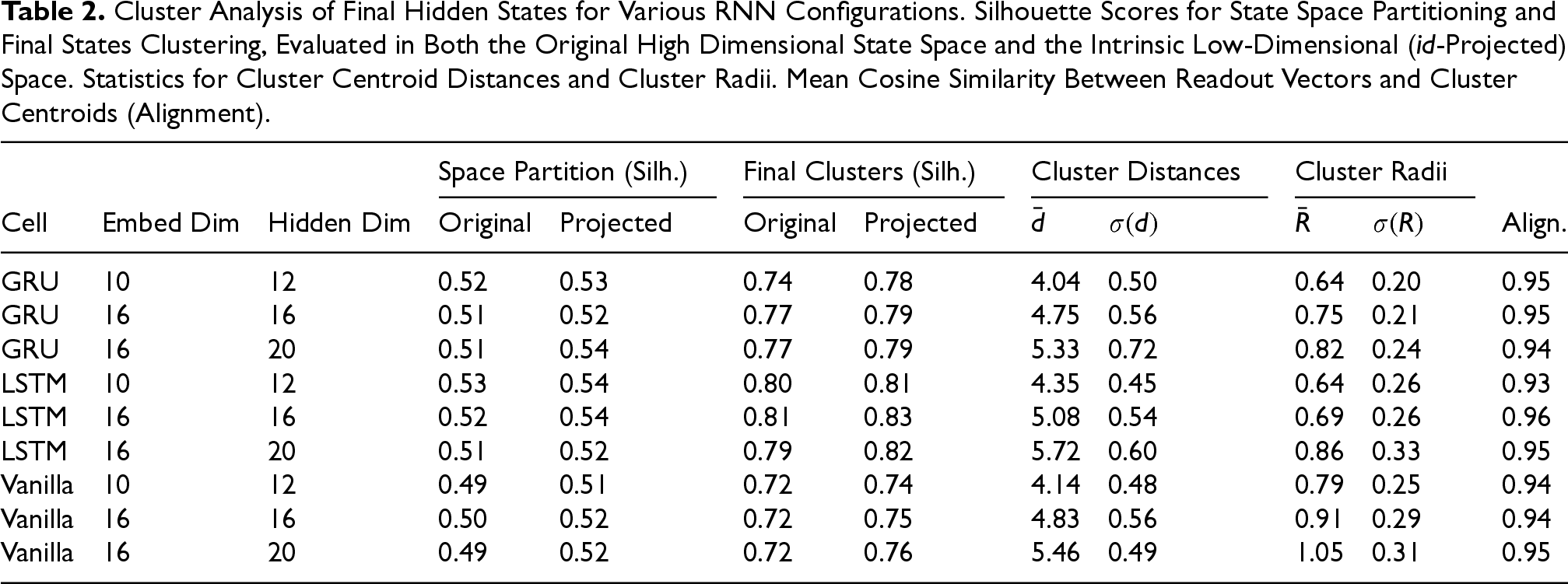
This result confirms the existence of a well-defined partition in the state space, where hidden states corresponding to sentences with the same intent are grouped into distinct regions. Furthermore, this partition can be analyzed without requiring the full-dimensional hidden state space. Instead, the structure of the state space can be captured by examining its intrinsic manifold through the top-
In this section, we analyze how input sentences are processed as trajectories through the state space of a trained RNN, revealing structured and predictable behavior within the state space. Sentences evolve along paths, reaching distinct regions of the state space that can be numerically identified as clusters. These regions enable the RNN to classify sentences based on the semantic patterns captured in the final hidden states.
For each input token
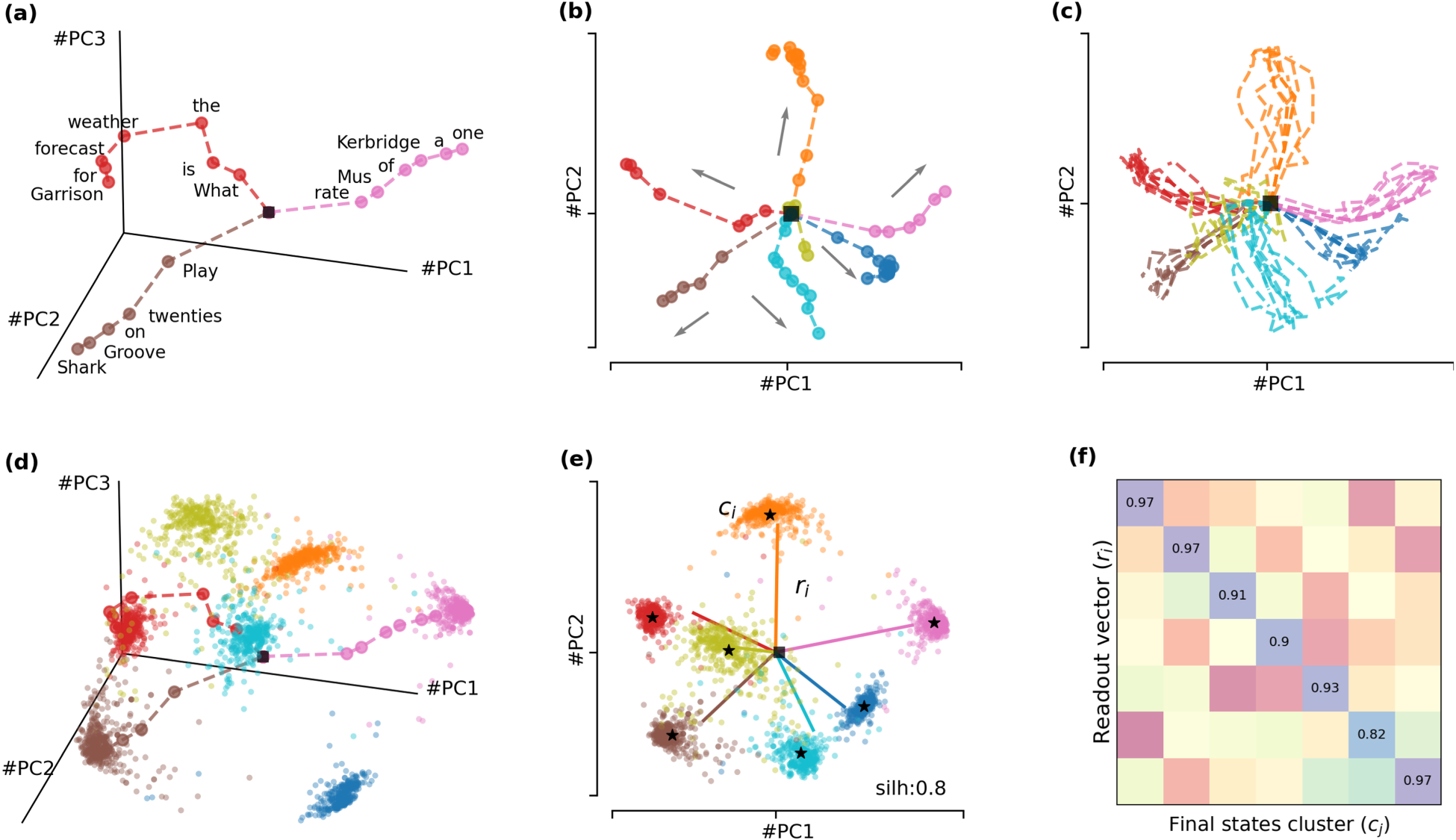
State space visualizations of a GRU(emb:16,hid:16) trained on the SNIPS dataset, projected onto the top principal components. (a) Example trajectories for three individual sentences. Each point represents a hidden state corresponding to a token (labeled) in the sentence, a black square marks the initial hidden state. Dashed lines show transitions between states. (b) A representative trajectory for each intent, with arrows indicating the direction of movement. (c) Overlay of multiple trajectories sharing the same intent. (d) Three example trajectories embedded in the 3D state space, superimposed on the final hidden states of all test sentences. (e) Clusters of final states with centroids marked as black stars. Readout vectors (
This behavior generalizes across all intents and sentences, as shown in Figure 6(b) and (c), respectively. Here, individual bullets have been removed for a cleaner representation, and arrows have been added to emphasize the sense of movement along the trajectories. These trajectories appear to direct the hidden states toward specific regions of the state space depending on the intent associated with the sentence. The final hidden state
As shown in Figure 2, for prediction purposes, intermediate states are discarded, and only the final hidden state 
This formulation enables the RNN to classify sentences based on the semantic patterns encoded in the final hidden states. For a sentence with true intent
In this section, we analyze the spatial arrangements of the final hidden state clusters in the RNN state space. The results reveal a robust structure across different configurations, with cluster centroids located approximately equidistant from the initial hidden state and clusters remaining compact, enabling effective intent classification.
For each network configuration, we calculated the Euclidean distances
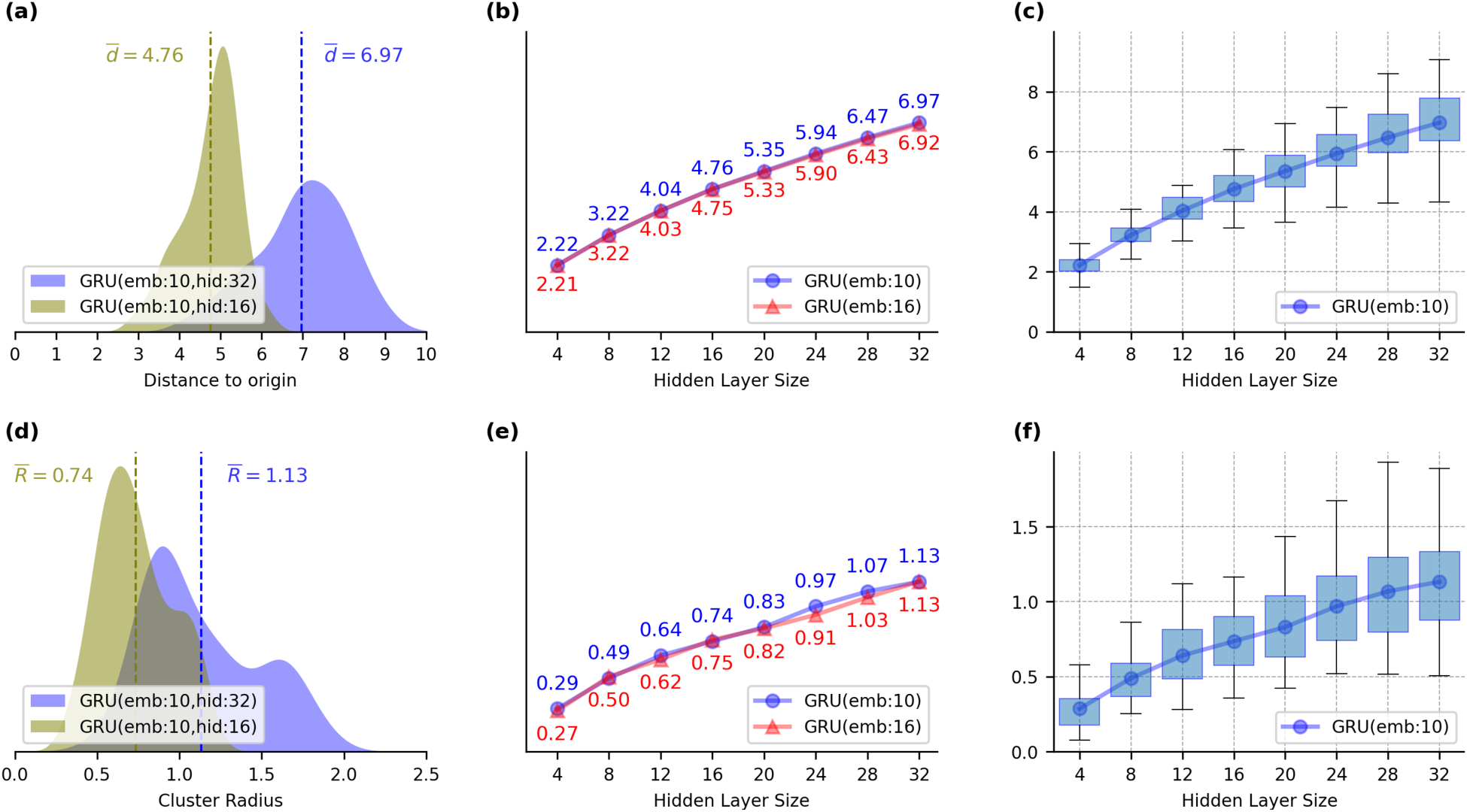
Analysis of the spatial characteristics of final hidden states clusters for different GRU configurations. (a) Distribution of the distances (
In addition, we measured the cluster radii
In the previous section, we show how sentences traverse a low-dimensional state space, guided by the RNN toward final state clusters. This structured behavior suggests the presence of an underlying fixed point topology in the network dynamics. To investigate this, we use the first-order approximation of the RNN dynamics around an expansion point 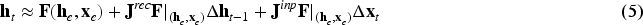
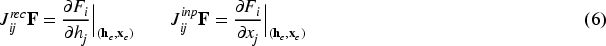
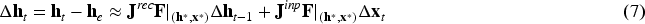
In this section, we focus on the first step: identifying the fixed point structure. Fixed points 

Summary of Approximated Fixed Points (
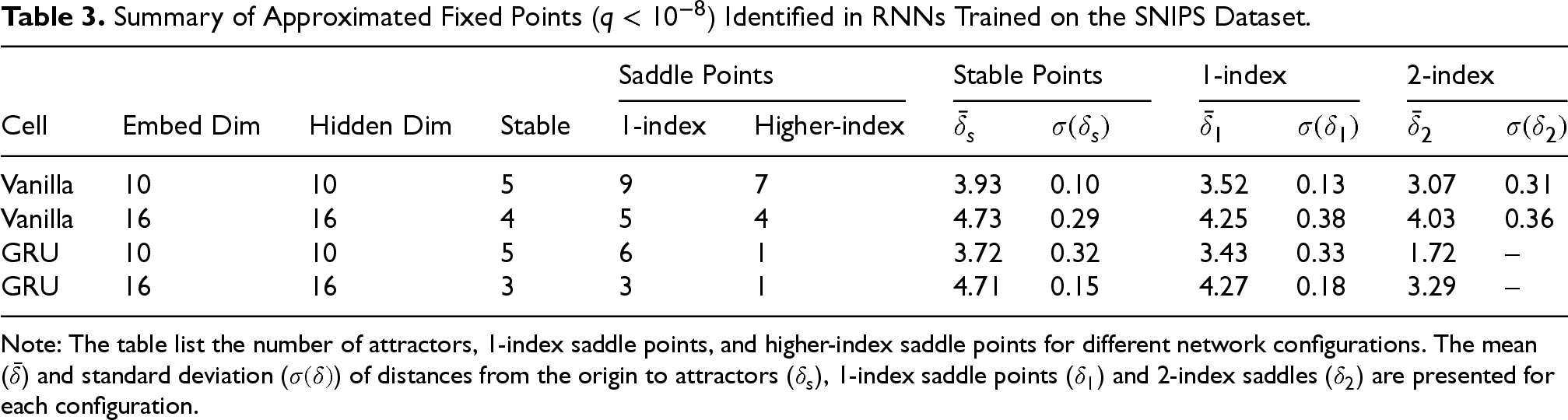
Note: The table list the number of attractors, 1-index saddle points, and higher-index saddle points for different network configurations. The mean (
To address the generalizability of findings beyond the balanced SNIPS dataset, we replicated our analysis on the ATIS dataset. As detailed in Section 5, ATIS presents a more realistic and challenging scenario characterized by a severe class imbalance, with 26 intents (compared to 7) and the top intent (flight) accounting for 73.7% of samples. This allows us to test if our dynamical systems framework can provide insights under less-controlled conditions.
We trained a GRU(emb:64,hid:64) architecture on the imbalanced ATIS dataset. To clarify the scope of the analysis: the full ATIS dataset contains 26 intents, but the standard training set contains only 22 of these. The 4 intents that appear only in the test dataset were excluded from our analysis as they represent an out-of-scope task. Furthermore, 6 of the 22 training intents have no samples in the provided test dataset. Our analysis, therefore, focuses on the 16 intents (shown in Table 4) for which samples were present in both the training and the test data. On this 16-class task, the model achieved a high aggregate accuracy (93.7%), this single metric obscures severe performance disparities. For instance, as shown in Table 4, high-frequency intents like flight achieve an F1-score of 0.97, while low-frequency intents like meal (6 training samples) fail completely with a 0.00 F1-score. Standard metrics show that the model fails on rare classes, but our framework can help explain why by analyzing the learned state space.
Per-intent Performance and State Space Diagnostics for a GRU(emb:64,hid:64) Model Trained on the ATIS Dataset. F1-Score and the Two Metrics from Our Framework Are Shown: Silhouette Score (Geometric Separation) and Cosine Similarity (Readout Alignment), Computed Within the 95% PCA Projected State Space.
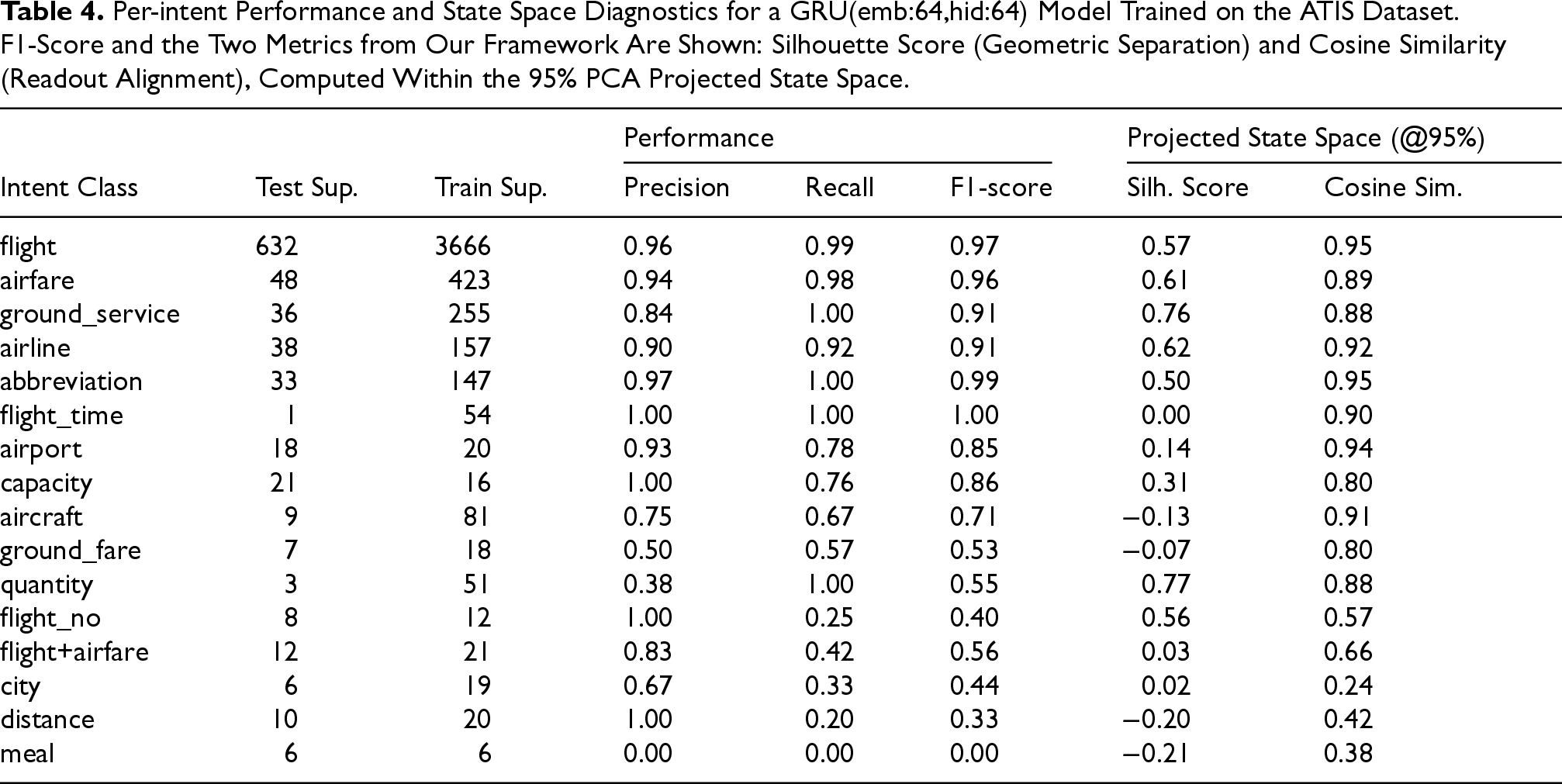
Per-intent Performance and State Space Diagnostics for a GRU(emb:64,hid:64) Model Trained on the ATIS Dataset. F1-Score and the Two Metrics from Our Framework Are Shown: Silhouette Score (Geometric Separation) and Cosine Similarity (Readout Alignment), Computed Within the 95% PCA Projected State Space.
Consistent with our findings on SNIPS, the computation of a GRU(emb:64,hid:64) on ATIS operates on a low-dimensional manifold. A PCA analysis of the test hidden states revealed that only 9 components are required to explain 95% of the variance, a dimensionality far lower than the model's actual hidden and embedding size (64) and the number of classes (16). However, the geometry of this manifold is significantly influenced by the class imbalance. As visualized in the 2D and 3D projections in Figure 8(a) and (b), the state space is dominated by large, well-separated clusters for high-frequency intents (e.g., flight, airfare). In contrast, most low-frequency intents do not form distinct clusters but instead coalesce into a dense, undifferentiated region.
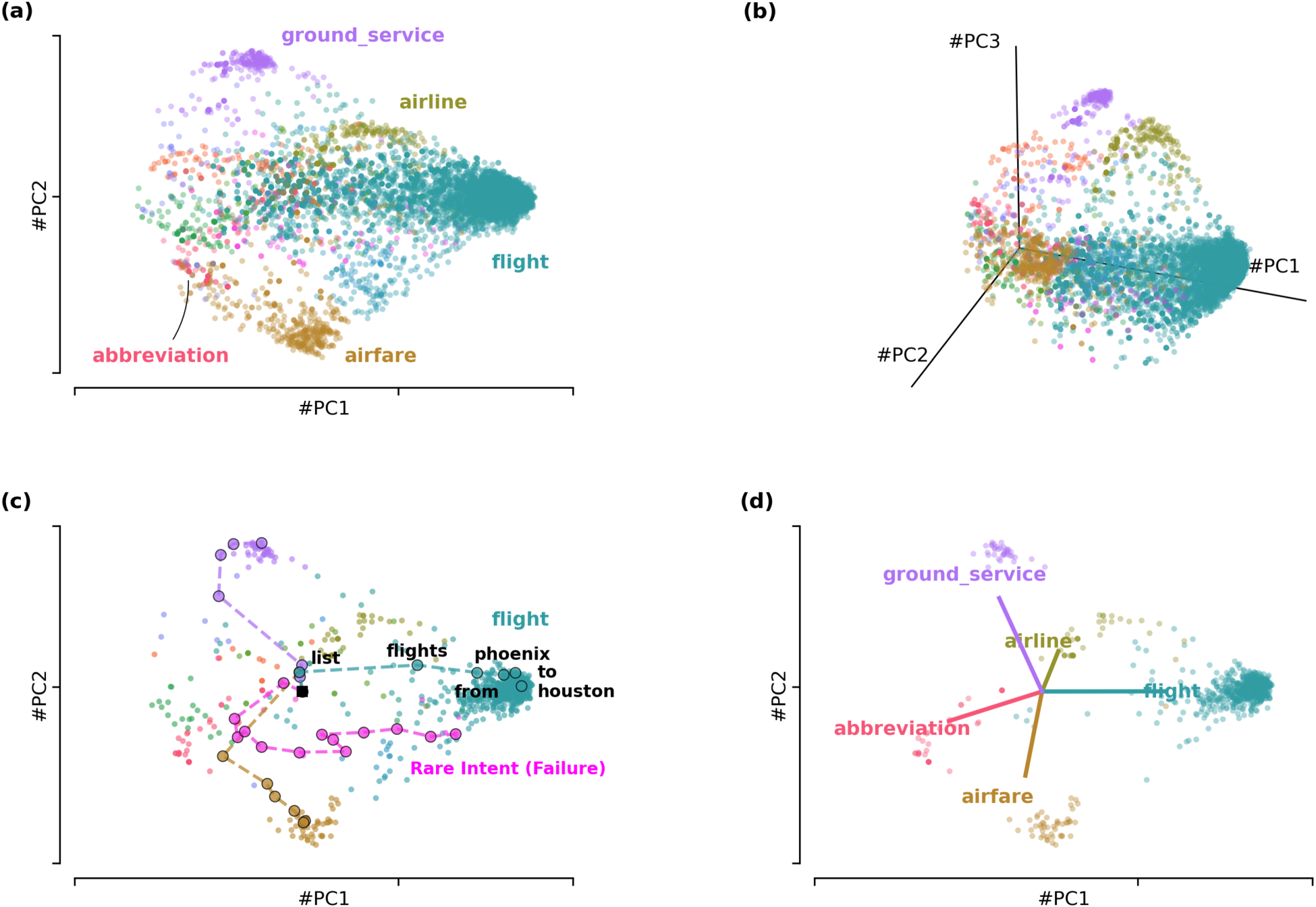
State space visualizations of the GRU model trained on the imbalanced ATIS dataset. (a) 2D projection of the final hidden states, showing a few large distinct clusters for high-frequency intents (e.g. flight, airfare). (b) 3D projection, confirming the geometric separation of the major clusters. (c) Example 2D trajectories. A “success” (teal) steers to the flight cluster, while a “failure” (magenta) for a rare intent wanders into the wrong cluster. (d) Alignment of readout vectors (colored lines) with their corresponding high-frequency clusters (colored dots).
This “geometric collapse” of rare classes makes standard clustering algorithms like K-means ill-suited for this analysis. K-means, which seeks to find well-defined centers, would fail to partition this dense region and would misrepresent the landscape. Therefore, to properly quantify the quality of the partition the network was supposed to learn, we used a methodology based on the ground-truth labels. We posit that this geometric structure provides a powerful lens to diagnosing classification performance. We use this lens to test our hypothesis that successful classification requires the network to accomplish two distinct tasks, which we evaluated consistently within the 95% variance projected space: Geometric Separation: The network must guide trajectories for a given intent to a unique and coherent region of the state space. This dynamic steering process is visualized in Figure 8(c), which contrasts a successful flight trajectory with a failed one for a rare intent. Readout Alignment: The network must correctly align the corresponding readout vector
A failure in either step can lead to a poor F1-score. Analyzing these two metrics, as shown in Table 4, reveals distinct, interpretable patterns of model behavior that are invisible to a standard F1-score analysis. These four patterns are visualized in Figure 9:
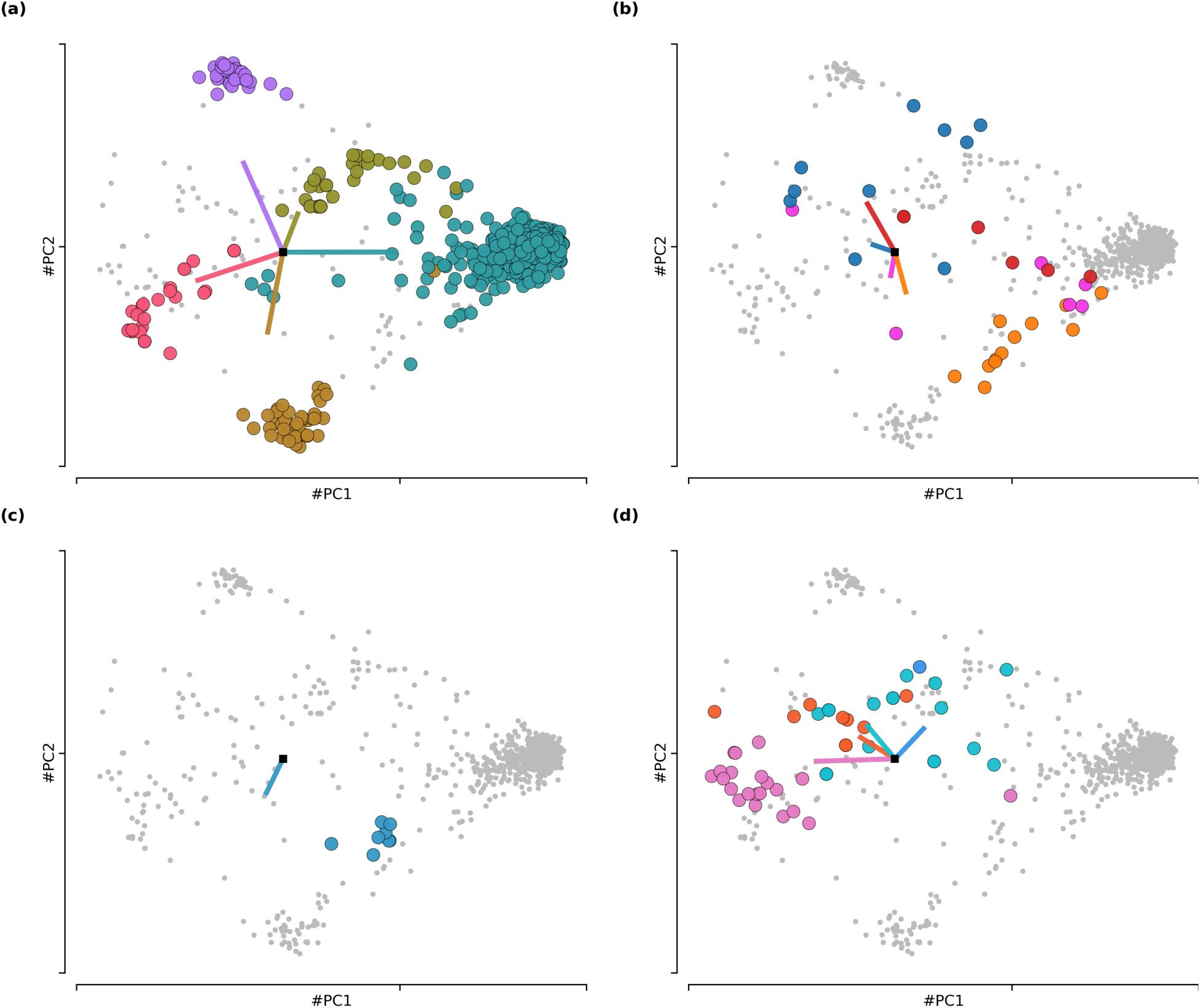
The four patterns of model behavior in the imbalanced ATIS PCA state space. Final states for analyzed intents (colored dots), all other final states (Gray dots) and readout vectors for analyzed intents (colored lines). (a) Pattern 1: Convergent High Performance. High separation and strong alignment. (b) Pattern 2: Geometric Collapse. Poor separation and weak alignment. (c) Pattern 3: Alignment Failure. Good separation but poor alignment. (d) Pattern 4: Alignment-Driven Classification. Poor separation but strong alignment.
Other low-frequency intents, such as quantity and ground_fare, show other combinations of metric failures. While these represent complex failure modes, the four primary patterns identified and visualized cover the most distinct and interpretable modes of model success and failure.
This case study on ATIS shows the robustness and explanatory power of our framework. It reveals how dataset properties like class imbalance are not abstract statistical issues but are directly encoded into the geometric and topological structure of the network’s learned dynamics.
Intent detection remains a challenging problem that has yet to be fully solved. Conceptually, one can think of intent as evolving dynamically: as more words are processed, the potential intent becomes more constrained, as if moving between interpretations. Our approach embraces this notion, modeling the search for the final intent as a dynamical process within the state space of a recurrent ceural network.
In this article, we applied reverse engineering techniques to study the computational mechanisms of RNNs trained for intent detection. Our analysis of the balanced SNIPS dataset revealed that networks converge to an elegant and highly interpretable solution: they partition their state space into a low-dimensional manifold of distinct, well-separated clusters corresponding to each intent. We showed that sentences evolve along structured trajectories, steering the network’s hidden state toward the correct cluster. To test the generalizability of this framework, we extended our analysis to the imbalanced ATIS dataset. This more challenging, real-world scenario revealed how this ideal geometric solution is distorted by class imbalance. Our two-part diagnostic framework (Geometric Separation and Readout Alignment) allowed us to move beyond simple accuracy scores and identify four distinct, mechanistic patterns of model success and failure, explaining why certain intents perform well while others fail.
While other interpretability methods can identify which input token are salient, our dynamical systems approach provides a unique, mechanistic understanding of how the network’s internal state evolves over time and arrive at a decision. This perspective opens several promising avenues for future research. This geometric framework can be extended to address related, high-stakes problems in conversational AI. Our finding in the ATIS dataset provides a concrete empirical basis for this. For example, in out-of-scope (OOS) detection, utterances would likely produce trajectories that fail to converge to any of the established, high-frequency clusters, terminating instead in a dense, undifferentiated central region. This geometric distance from a final state to the nearest cluster could thus serve as a robust signal for OOS detection. The framework could also be adapted to analyze the joint intent detection and slot filling task. this would make it possible to explore how the state space dynamics dor intents and slots interact and mutually influence one another. Additionally, the geometric separation of clusters could serve as a new metric for model robustness, or be used to probe for demographic biases in how different user utterances are processed (Sanchez-Karhunen et al., 2025). Finally, a critical and exciting line of work involves adapting this dynamical systems framework from RNNs to the modern Transformer architectures. Understanding the state-space geometry and attractors within these more complex models is a key challenge for the field of interpretability.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.