
Abstract
Road extraction from satellite imagery is vital for urban planning, transportation, and disaster response. While deep learning models like U-Net, LinkNet34, D-LinkNet, MACU-Net, and RCFSNet have advanced this field, they still struggle with road connectivity, multi-scale feature capture, and complex scenes. To address these challenges, we introduce GeoLinkNet, a novel deep learning architecture for improved road segmentation. GeoLinkNet features four innovations: local context attention (LCA) to enhance spatial coherence; geometric feature extractor (GFE) using directional convolutions for better structural recognition; adaptive fusion module (AFM) for effective multi-level feature integration; and residual refinement module (RRM) to sharpen segmentation with residual learning. Experiments on the DeepGlobe road extraction dataset show that GeoLinkNet outperforms existing methods, achieving better road continuity, segmentation accuracy, and feature representation. The model successfully balances fine detail preservation with global structural awareness, offering a scalable and robust solution for satellite-based road extraction.
Introduction
Road network extraction from satellite imagery is one of the most critical and challenging tasks in remote sensing today (Wang et al., 2016, 2022a; Yuan et al., 2024). With the advent of high resolution satellite images, the potential for automatically extracting detailed road maps has expanded tremendously, impacting a wide range of applications from smart city planning and autonomous navigation to disaster response and infrastructure monitoring (Imam et al., 2024a; Liu et al., 2024). Despite these opportunities, accurate road extraction remains a formidable challenge due to the inherent complexity of the scenes, which include diverse environmental conditions, varying road widths, occlusions from natural and man-made objects, and dramatic differences in appearance between urban and rural areas (Huang et al., 2025; Imam et al., 2024a). In modern urban settings, roads are frequently interwoven with dense clusters of buildings, trees, and other structures, leading to frequent occlusions and discontinuities (Mo et al., 2024). In contrast, rural areas often present roads with subtle contrasts against the background and irregular geometries. Such variability necessitates that any effective segmentation model must be robust enough to extract roads accurately under both favorable and adverse conditions. Moreover, the extracted road networks must maintain continuous connectivity even small breaks in the predicted road segments can significantly impair subsequent applications such as navigation and route planning (Wu et al., 2021). Another layer of complexity arises from the need to capture both fine grained details and global contextual information. For instance, a segmentation model must detect narrow road boundaries while also understanding the broader structure of the road network to ensure connectivity over long distances (Wu et al., 2021). Traditional methods often fell short in this regard because they relied on handcrafted features and lacked the capacity to generalize across varying scales and contexts (Darweesh et al., 2019; Kass et al., 1988). The emergence of deep learning has provided new opportunities by automatically learning hierarchical features from the data, but even state of the art models still encounter difficulties in preserving both local details and global road continuity (Liu et al., 2022a). While recent advances in convolutional neural networks (CNNs) have led to significant improvements in segmentation performance, many existing CNN-based models fail to preserve road topology due to insufficient geometric awareness. We hypothesize that combining semantic encoding with explicit geometric feature extraction improves road continuity and connectivity (Liu et al., 2022a, 2024; Wang et al., 2016). To address these challenges, we propose GeoLinkNet, a novel architecture that balances local detail preservation with global structural awareness through four innovative modules, achieving state-of-the-art performance on benchmark datasets. The proposed GeoLinkNet model builds upon recent advances in deep learning for remote sensing to overcome the long-standing trade-off between local detail and global consistency in road extraction. GeoLinkNet introduces a geometry-aware architecture that integrates four complementary modules designed to jointly capture semantic and geometric information. The combination of these modules enables the precise delineation of road structures while preserving network continuity and topological coherence.
Local context attention (LCA): Enhances spatially significant features and suppresses background noise, allowing the model to focus on fine-scale road structures and reduce irrelevant activations. Geometric feature extractor (GFE): Reinforces directional and geometric cues through strip convolutions, effectively capturing the elongated and linear patterns characteristic of road networks. Adaptive fusion module (AFM): Dynamically balances semantic and geometric feature streams, ensuring coherent integration of contextual and structural information across multiple scales. Residual refinement module (RRM): Refines edge boundaries and improves topological continuity, resulting in smooth and connected road predictions even in occluded or complex urban environments
The rest of the paper is organized as follows. Section 2 reviews the related works. Section 3 introduces the methods and loss functions. Section 4 shows the experimental settings and results. Section 5 discusses the ablation study. Finally, Section 6 makes a conclusion.
Related Works
Early research in this area predominantly relied on handcrafted features and classical algorithms such as edge detection (Kass et al., 1988), morphological operations, and active contour models (Darweesh et al., 2019). These methods were initially effective in controlled environments but suffered from a lack of robustness when faced with varying illumination, noise, and occlusions (Liu et al., 2015). Their dependence on predefined features limited their ability to generalize to different geographic regions and diverse imaging conditions. The limitations of traditional methods paved the way for machine learning approaches that leveraged statistical classifiers like support vector machines (SVMs) and Random Forests (Bakhtiari et al., 2017; Kumar et al., 2017). These models incorporated features such as texture descriptors, color histograms, and shape information to improve road classification. Although this represented a step forward, the reliance on manual feature engineering remained a critical bottleneck, as the handcrafted features often failed to capture the complex patterns inherent in satellite imagery (Bakhtiari et al., 2017).
The introduction of deep learning, particularly fully convolutional networks (FCNs), marked a turning point in the field of road extraction. U-Net, introduced by Ronneberger et al. (2015), is one of the earliest successful deep learning architectures for segmentation. It employs an encoder–decoder structure with skip connections to retain spatial details (Di Benedetto et al., 2023). Its ability to learn rich, hierarchical features directly from the data led to significant improvements in segmentation performance (Abderrahim et al., 2020). However, despite its groundbreaking results, U-Net was not without shortcomings. Its standard convolutional operations struggled to capture multi-scale context and long-range dependencies, which are crucial for delineating continuous road networks (Di Benedetto et al., 2023). Building upon the successes of U-Net, LinkNet34, developed by Chaurasia and Culurciello (Chaurasia & Culurciello, 2017), integrates a ResNet-34 backbone that leverages residual learning to enhance the training of deeper networks. The use of residual connections (Zagoruyko & Komodakis, 2017) allowed LinkNet34 to better propagate gradients and extract more robust features (Imam et al., 2024a). Nonetheless, while LinkNet34 improved the overall feature extraction process, it still encountered difficulties in handling roads with varying scales and in maintaining connectivity in areas with heavy occlusion or discontinuities. Further advancements were made with D-LinkNet, introduced by Zhou et al. (2018a), which incorporated dilated convolutions into the bridge between the encoder and decoder (Imam et al., 2024b; Zhou et al., 2018a). The dilated convolutional layers expanded the network receptive field without increasing the number of parameters, enabling a more effective capture of contextual information across multiple scales (Xu et al., 2024; Zhou et al., 2018a). This approach proved beneficial for segmenting roads of varying widths however, it did not fully resolve the challenge of maintaining continuous road connectivity, particularly in complex urban environments. Recognizing the need to capture a broader global context, NL-LinkNet, designed by Wang et al. (2022b), integrated Non-Local Blocks (Wang et al., 2018) to model long range dependencies between distant regions in the image. This mechanism allowed the network to consider interactions between remote pixels, enhancing the continuity of road predictions (Wang et al., 2022b). More recently, connectivity aware approaches have been designed to explicitly preserve road topology. CoANet, proposed by Mei et al. (2021), incorporates a connectivity attention (CoA) module and a strip convolution module (SCM) to enhance the continuity of road networks. The CoA module models the relationship between neighboring pixels, ensuring that road segments are predicted as continuous entities, while the SCM captures long-range dependencies through directional convolutions. Although CoANet effectively preserves connectivity, it faces challenges in balancing fine detail extraction with global contextual understanding Similarly, SPIN Road Mapper, proposed by Bandara et al. (2021), enhances road segmentation by utilizing a spatial and interaction space graph reasoning (SPIN) module, which builds graphs in both spatial and interaction spaces to model dependencies between road segments. This approach improves road connectivity and mitigates the risk of fragmented predictions, particularly in occluded or low contrast areas, while also employing a pyramid structure to capture multi-scale features (Bandara et al., 2021). Additionally, MACU-Net, developed by Li et al. (2022), incorporates multi-scale attention mechanisms within a U-Net framework (Zhou et al., 2018b) to refine segmentation across different scales, enhancing road delineation while maintaining a lightweight design. However, despite its improved feature extraction capabilities, MACU-Net remains sensitive to complex road patterns and occlusions, limiting its effectiveness in highly cluttered urban environments (Li et al., 2022).
Method
In this section, we describe the proposed GeoLinkNet architecture in detail. First, we present the overall architecture, followed by a comprehensive description of each component. We then provide mathematical formulations that justify the placement and design of each block within the network, demonstrating how these innovations contribute to improved road segmentation performance.
GeoLinkNet Architecture
GeoLinkNet is designed for road network extraction from satellite images by integrating both semantic feature extraction and explicit geometric modeling. Unlike traditional encoder–decoder architectures, which rely solely on a single encoding stream, GeoLinkNet introduces a dual-branch encoding strategy. The first branch, referred to as the semantic encoder, captures high level contextual information, while the second branch, the geometric encoder, explicitly models the linear and directional structure of roads, as illustrated in Figure 1. These two complementary feature streams are then adaptively fused within the decoder, ensuring that road connectivity and structural integrity are well preserved throughout the segmentation process. The process begins with an input image that is first processed by the initial layers of a pretrained ResNet-34 backbone (He et al., 2016). These initial layers consist of a convolution, batch normalization, ReLU activation, and max-pooling, which together generate a coarse feature map. This feature map is then sequentially passed through four encoder blocks, denoted as encoder1 to encoder4. Each encoder block itself is composed of two essential sub-components, as shown in Figure 2. The first component is the ResNet layer, which extracts hierarchical semantic features at increasing levels of abstraction (Chaurasia & Culurciello, 2017; Imam et al., 2024a). The second component is the LCA module, which immediately follows the ResNet layer and serves to refine the extracted features by enhancing spatially relevant regions while suppressing noise (Tan et al., 2020). By integrating LCA directly after each ResNet layer, the network ensures that features critical to road extraction, such as elongated structures and road boundaries, are consistently emphasized (Xu & Wan, 2024). This mechanism improves feature coherence and strengthens road connectivity across different scales.
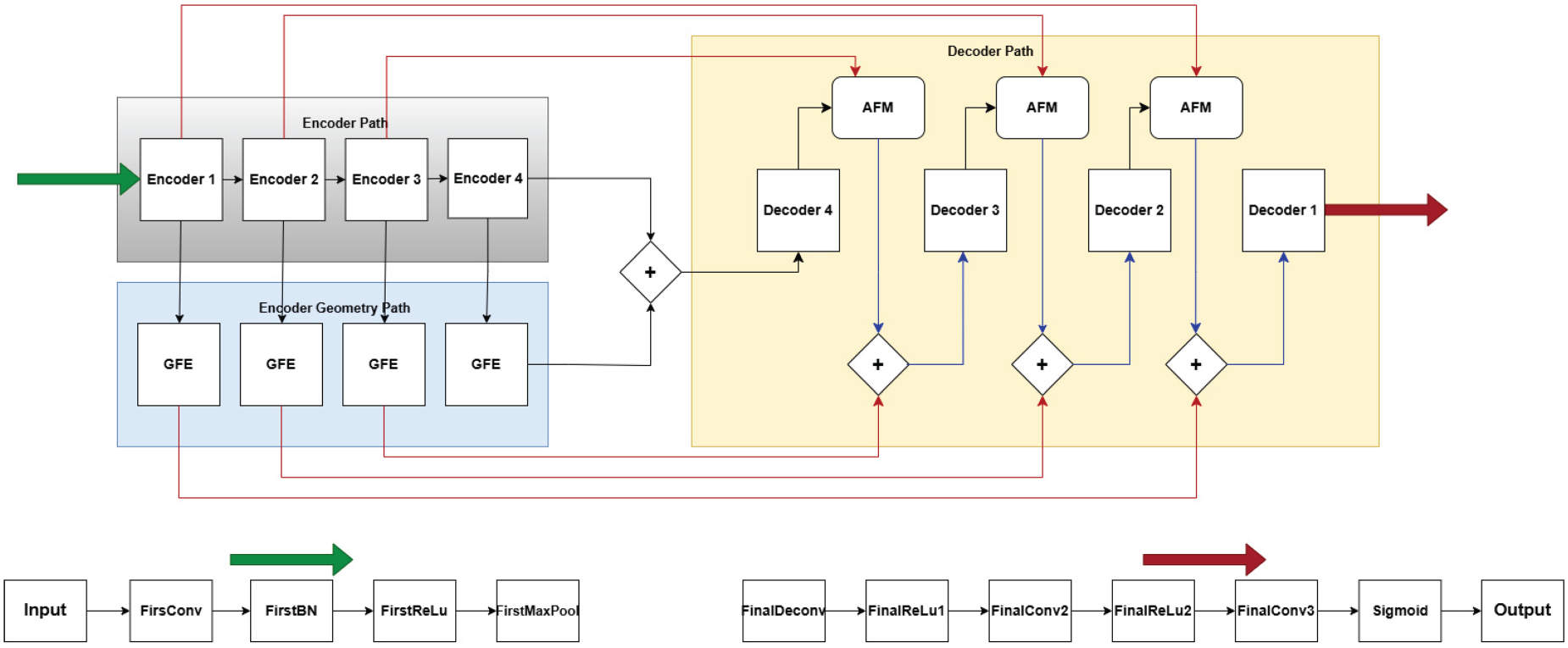
Global architecture of GeoLinkNet.
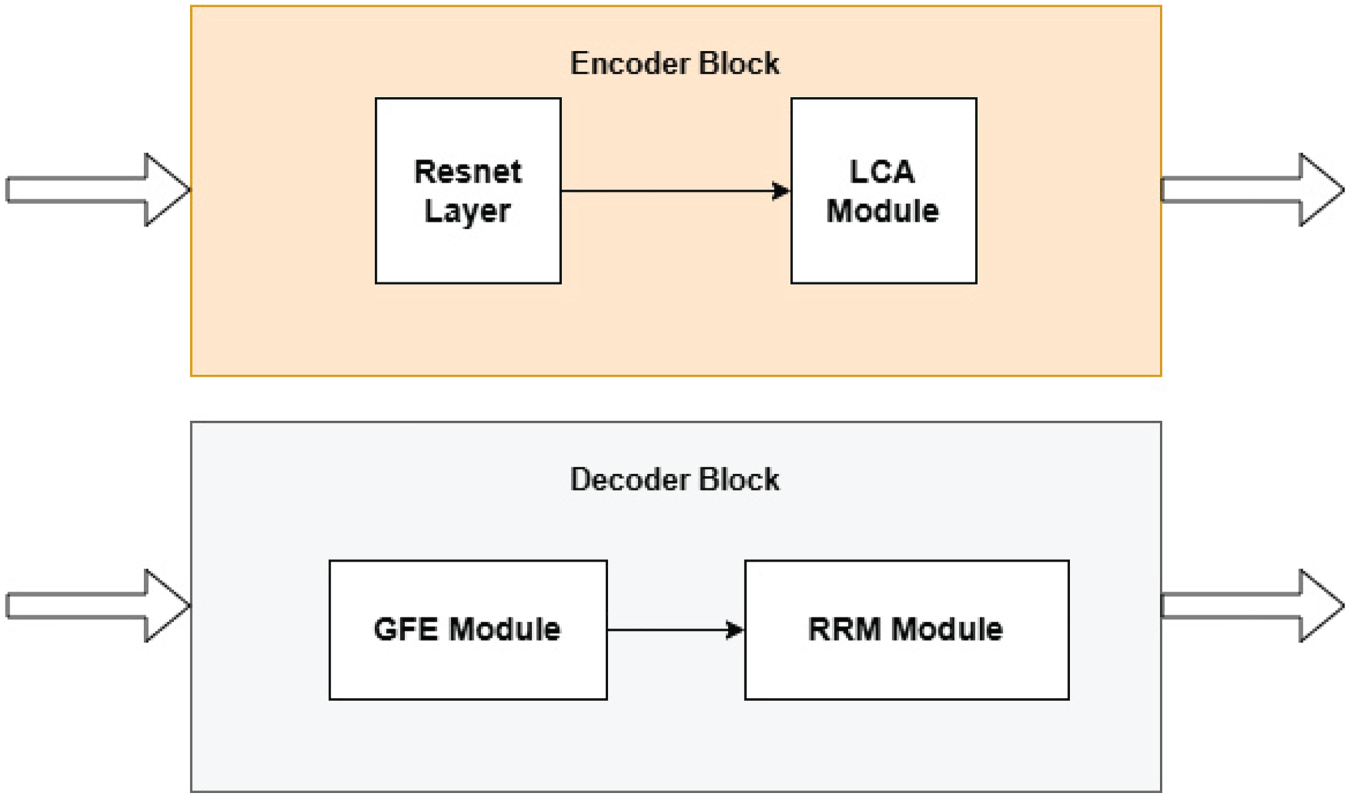
The structure of encoder and decoder block.
Simultaneously, while the semantic encoder processes and refines feature representations, a parallel encoding branch, referred to as the GFE path, operates on the same outputs from each encoder. In other words, each output from the semantic encoder serves as the input to each block in the geometric encoding path. This geometric pathway is specifically designed to extract road aligned features using directional convolutions (Wang et al., 2021; Zhong et al., 2025). Unlike standard convolutional layers, which apply square kernels, the GFE module employs strip convolutions operating in four orientations: horizontal, vertical, and two diagonal directions. This targeted filtering enables the model to explicitly capture the geometric structure of roads, which typically follow elongated and linear patterns (Zhong et al., 2025). These geometric features complement the rich semantic representations learned by the primary encoder, allowing GeoLinkNet to better handle challenging conditions such as occlusions, variable road widths, and disconnected segments. Once both semantic and geometric features have been extracted, they must be carefully fused before being passed to the decoder. Rather than merging these two streams immediately, GeoLinkNet employs a progressive fusion strategy to ensure optimal feature integration. At each decoder level, the network first fuses the upsampled decoder features with the corresponding semantic encoder outputs using the AFM. The role of AFM is to selectively combine high-level semantic features with information recovered during decoding, (Zheng et al., 2024) ensuring that only the most relevant features contribute to the reconstruction process. Instead of directly injecting geometric features into the decoder, GeoLinkNet applies a delayed fusion mechanism that prioritizes semantic information in the earlier decoding stages before incorporating geometric cues. A crucial step occurs before the fourth decoder block (decoder4) begins processing: the final output of the geometry encoder (i.e., the GFE feature map from encoder4) is added to the final semantic encoder output (encoder4) before entering the decoder. This delayed fusion of geometric features ensures that the highest-level structural information is retained and used effectively, preventing early over dependence on low level geometry and allowing semantic features to guide the initial reconstruction process. The decoder itself consists of four levels, corresponding to the hierarchy of the encoder. Each decoder block, from decoder4 to decoder1, is structured in two key stages. The first stage applies a strip convolution module (GFE), which further refines the upsampled features by reinforcing directional cues at each scale (Zhong et al., 2025). The second stage applies a residual refinement module (RRM), which restores fine grained details and enhances road continuity (Cheng et al., 2023), as show in Figure 2. By explicitly modeling geometric refinements at each decoding step, GeoLinkNet ensures that road structures remain well defined even in complex scenarios. At the final stage of the architecture, the output from decoder1 undergoes additional deconvolution and convolution layers, followed by a sigmoid activation to produce the final probability map for road segmentation. This final step ensures that the model outputs a refined binary mask where each pixel is assigned a probability representing its likelihood of belonging to a road segment.
The LCA module is a lightweight attention mechanism applied immediately after each ResNet block in the encoder. Its primary function is to suppress irrelevant background activations while enhancing spatially significant features associated with road structures (Mei et al., 2021; Tan et al., 2020). By selectively amplifying meaningful responses and filtering noise (Liu et al., 2022b), LCA refines the encoder feature representations, ensuring improved spatial coherence across all abstraction levels (Zagoruyko & Komodakis, 2017; Zhang et al., 2018). As shown in Figure 3, the LCA module consists of three primary components: a feature compression layer, which applies a 1

Architecture of LCA module.
First, the number of channels is reduced to half using a

An attention map is then generated using another

Finally, the original feature map

The GFE Module captures road-aligned structures using directional convolutions (Zhong et al., 2025), as illustrated in Figures 4 and 5. Unlike standard convolutional layers that process spatial features isotropically, GFE applies anisotropic convolutions to emphasize horizontal, vertical, and diagonal structures, making it highly effective for detecting elongated road segments.
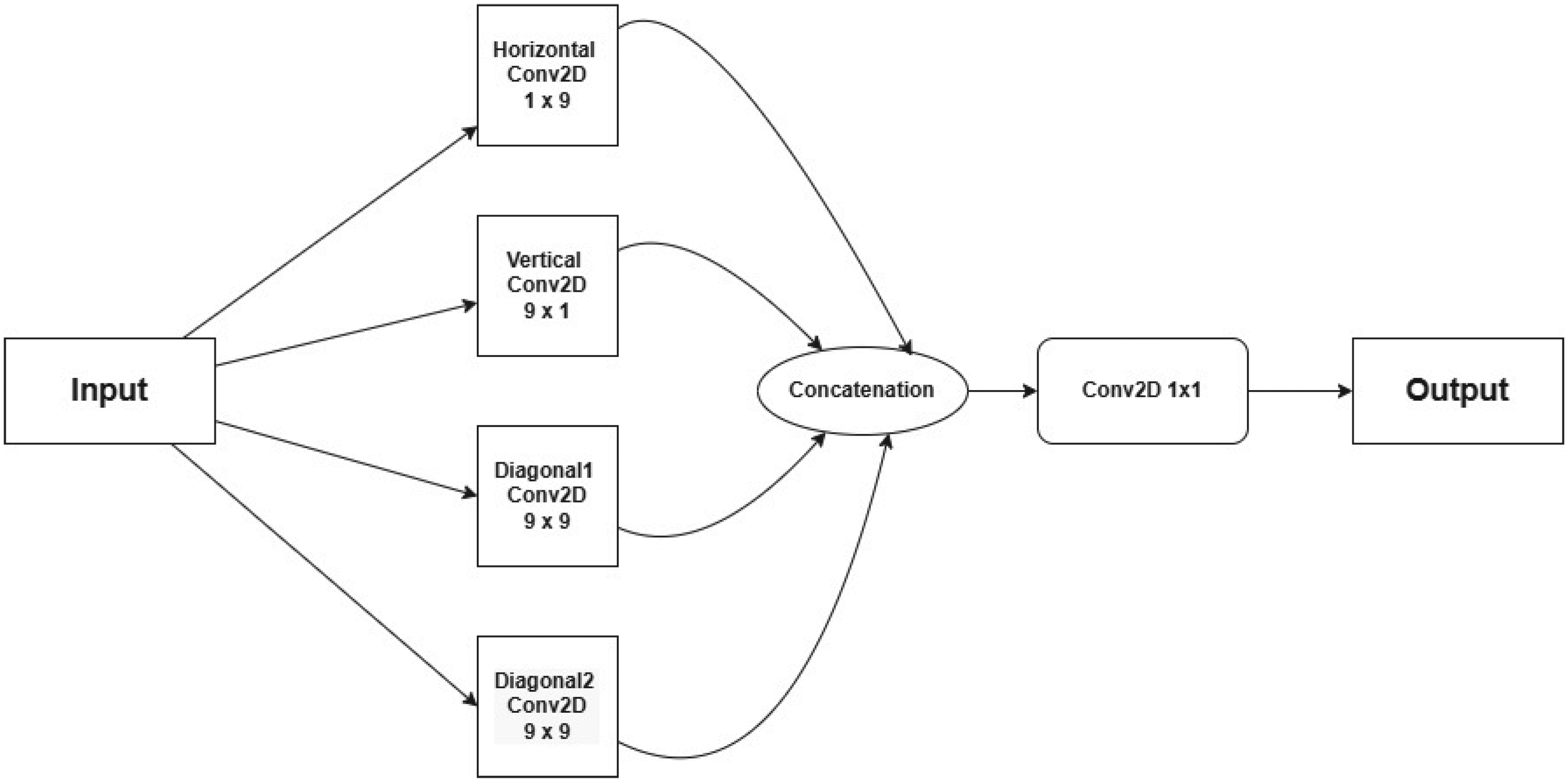
Architecture of geometric feature extractor block.
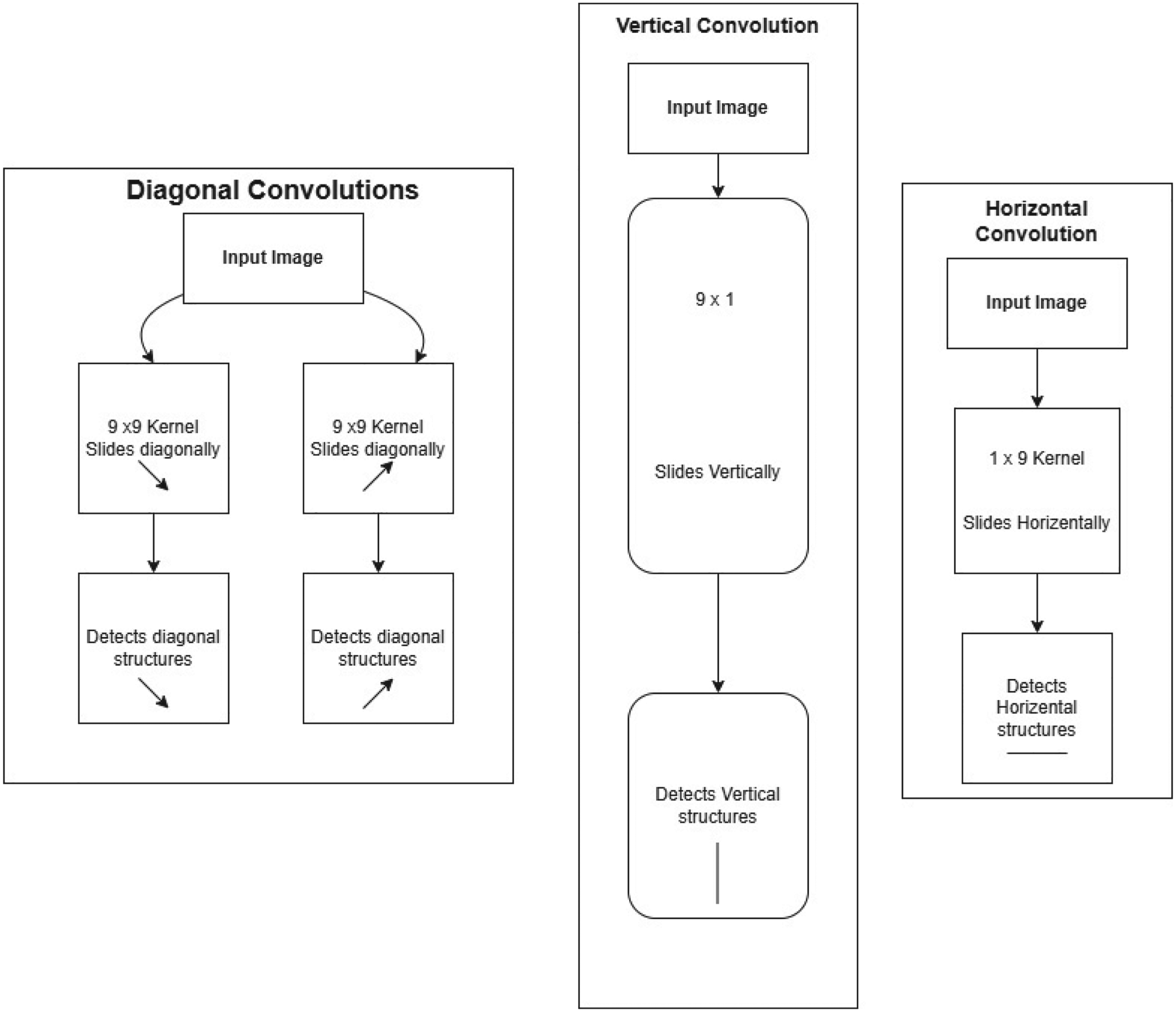
Different types of convolutions used in the GFE module.
The AFM dynamically integrates encoder and decoder features through attention-based weighting, as shown in Figure 6. Unlike traditional skip connections that simply concatenate or add encoder and decoder features, AFM dynamically reweights and fuses these features to enhance road connectivity and structural consistency in the final segmentation map. The feature summation layer serves as the initial step of the AFM and is responsible for merging semantic features extracted from the encoder (refined by the LCA module) with the corresponding decoder feature maps. This fusion is performed through element wise addition, allowing hierarchical details from the encoder to be effectively preserved throughout the reconstruction process.
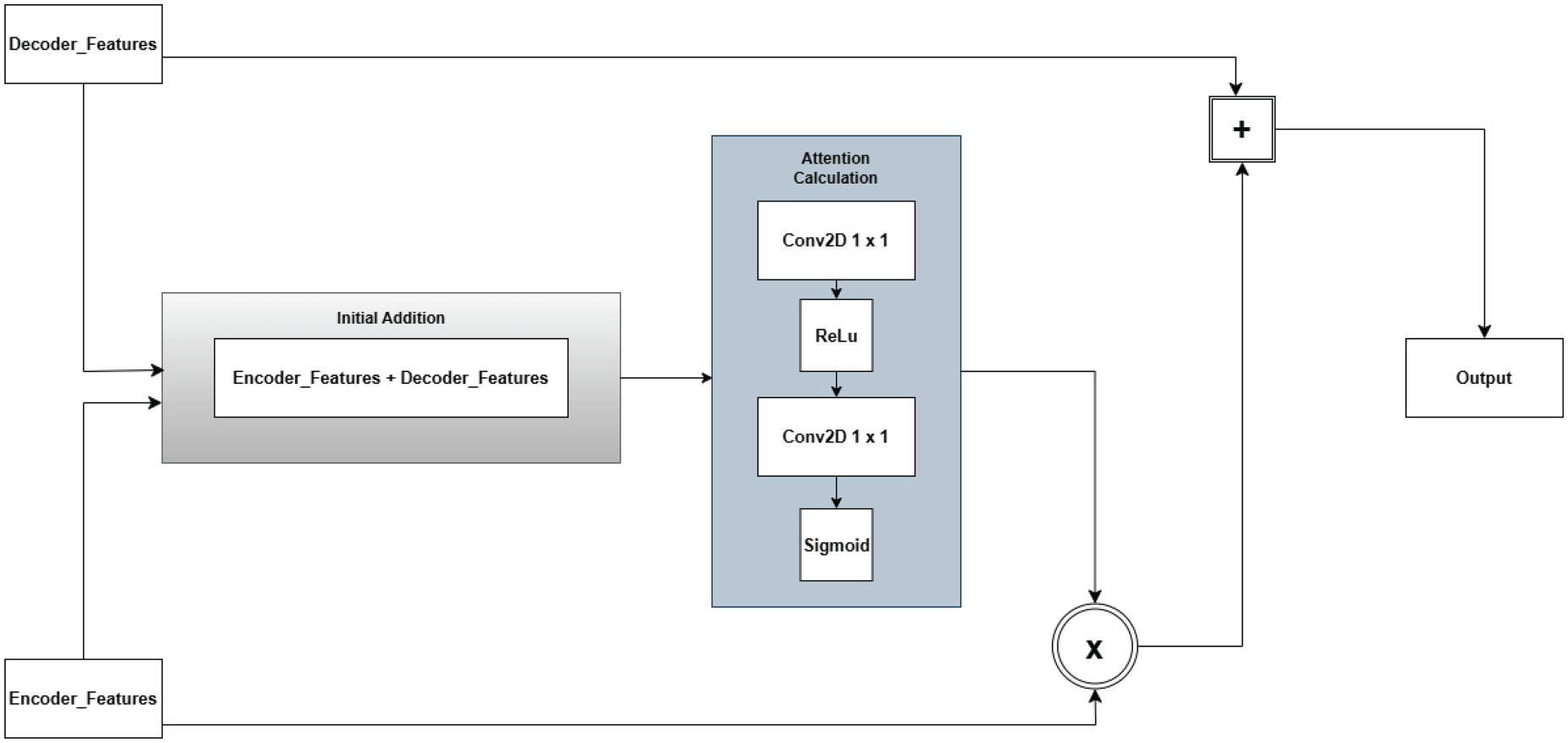
Architecture of adaptive fusion module.
Following the summation step, the attention-based feature reweighting mechanism refines the merged features by applying a lightweight channel attention mechanism (Chen et al., 2017; Liu & Yin, 2019). This attention mechanism learns adaptive scaling factors that selectively emphasize the most informative feature maps while suppressing less relevant activations (Mei et al., 2021). The process begins with a 1
Instead of relying on a naïve feature fusion strategy, where encoder features are indiscriminately merged with decoder outputs, the AFM adapts its feature weighting dynamically at each resolution level. This design allows the network to make finer distinctions between road structures and background elements, ensuring that the segmentation predictions remain highly accurate across different scales. By progressively integrating semantic information from the encoder while refining it through attention based weighting, the AFM significantly enhances the preservation of road connectivity and improves structural consistency in the final segmentation map.
Let



By dynamically adjusting the contribution of encoder and decoder features, AFM significantly enhances the spatial precision of road predictions, preserving fine details while maintaining the global structure of road networks.
The RRM, illustrated in Figure 7, is responsible for enhancing fine details at the final stage of the decoder. Since deep networks tend to lose small-scale structures during upsampling, RRM is designed to restore road continuity by learning residual corrections (Cheng et al., 2023; Xie et al., 2017). As depicted in Figure 6, the RRM is designed to enhance the final segmentation output by recovering fine details that may have been lost during earlier upsampling operations in the decoder. The RRM consists of two successive 3
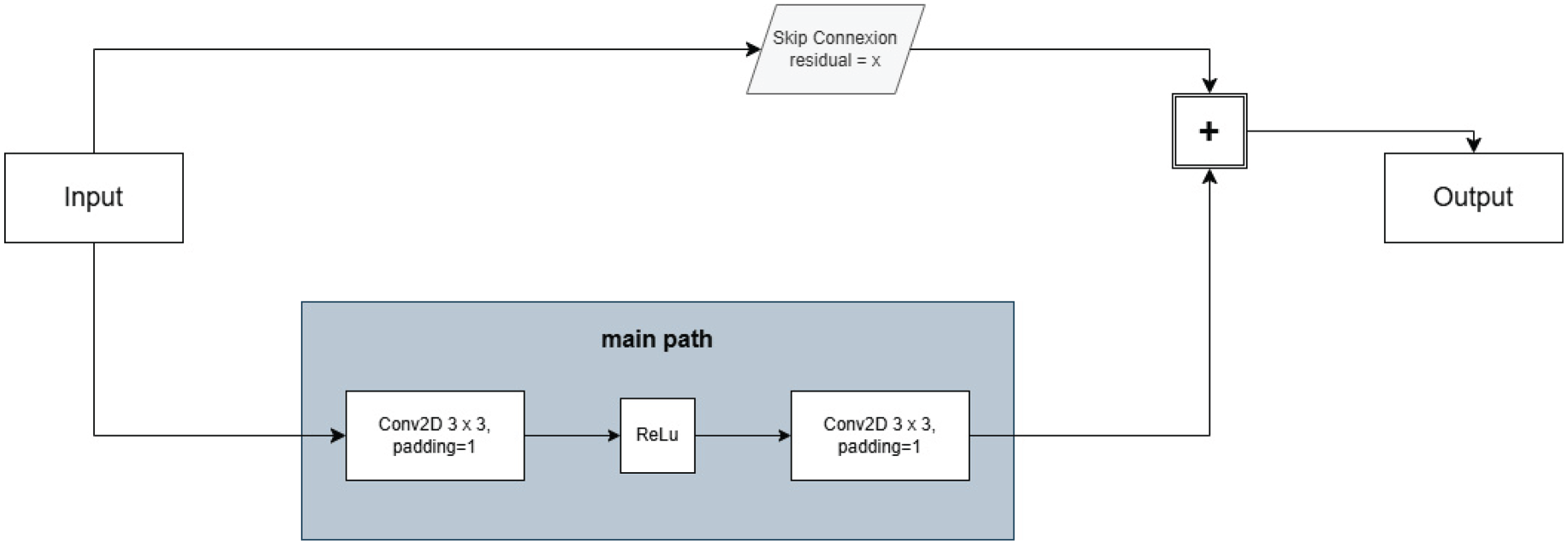
Architecture of the residual refinement module.
The RRM is strategically placed at the final stage of the decoder, directly before generating the output segmentation map. This placement ensures that its refinements are applied only to the final prediction, rather than interfering with earlier feature transformations. Since road segmentation tasks require high precision in delineating narrow roads and maintaining connectivity, applying the RRM at the last stage helps to mitigate blurring effects, correct small-scale discontinuities, and improve overall segmentation sharpness. By leveraging residual learning, RRM enhances feature preservation, stabilizes training, and refines the segmentation output without introducing unnecessary modifications to well-predicted regions.
We engineered a custom loss function (Imam et al., 2024a) by integrating two complementary metrics to enhance the training of GeoLinkNet. This unified loss computation approach was strategically implemented across our architectural framework, allowing the model to benefit from the combined strengths of both evaluation metrics. The fusion of these loss functions proved particularly effective in guiding the training process, ensuring that GeoLinkNet maintains both segmentation accuracy and road connectivity.
Binary Cross Entropy (BCE Loss) Imam et al. (2024a)
BCE Loss serves as our primary metric for evaluating binary predictions in road extraction. This fundamental loss function, widely recognized in the field of binary segmentation, calculates the logarithmic difference between predicted and actual road pixels. The mathematical representation quantifies how well GeoLinkNet distinguishes between road and non-road regions in satellite imagery. This loss metric has been extensively validated in previous research and is particularly well-suited for our binary road segmentation objective.
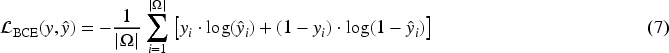
For foreground pixels (
The Soft-Dice Loss function is a refined adaptation of the traditional Dice Loss metric, designed to improve segmentation accuracy. While originally developed for binary classification, its flexibility extends to multi-class applications. In our road extraction framework, this loss metric effectively quantifies the overlap between predicted road segments and ground truth annotations. It computes a smooth, differentiable measure of spatial similarity between two pixel sets, making it particularly valuable for our segmentation objectives in GeoLinkNet.
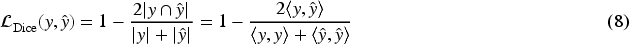
This loss decreases as the overlap between the predicted and ground-truth masks increases, promoting better spatial alignment and handling class imbalance more effectively than standard loss functions like binary cross-entropy.
Dataset Description
We conducted our evaluation using two benchmark datasets. The first one is the DeepGlobe dataset (Demir et al., 2018), which contains images captured by DigitalGlobe satellites with a spatial resolution of 50 cm per pixel and a dimension of 1024
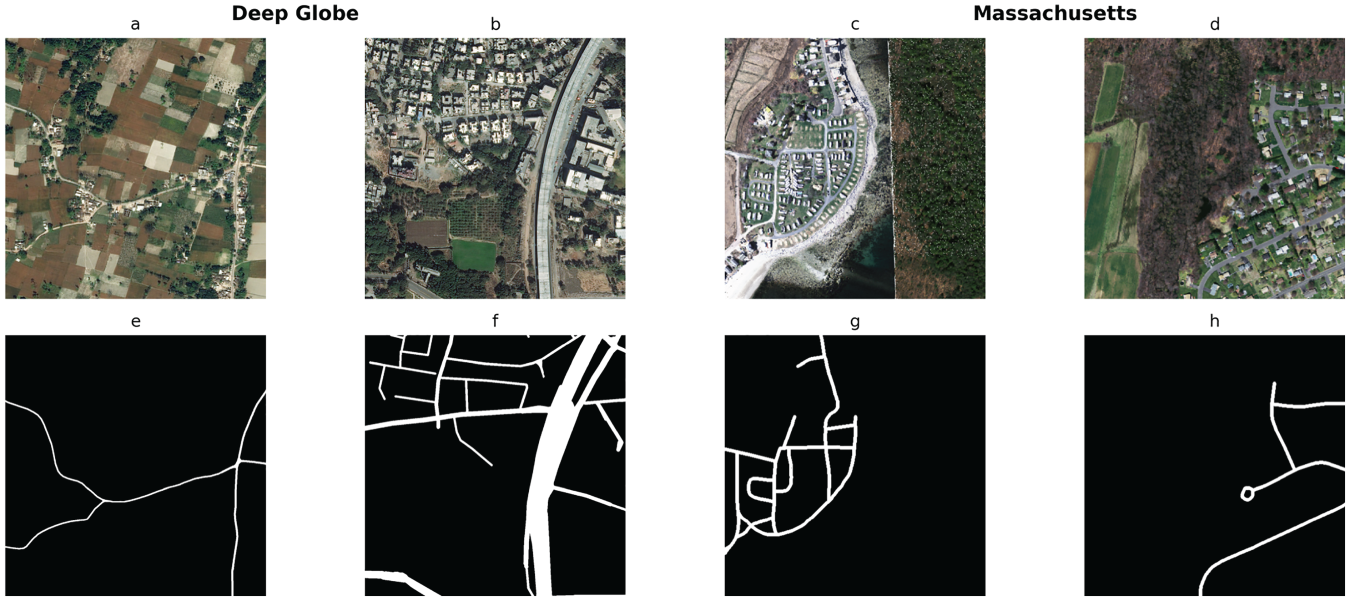
Examples of challenging road network scenes from the two benchmark datasets. Figures (a) and (b) correspond to satellite images from the DeepGlobe dataset, while (e) and (f) represent their corresponding segmentation masks. Figures (c) and (d) correspond to satellite images from the Massachusetts Roads dataset, and (g) and (h) show their respective masks.
To evaluate the performance of GeoLinkNet, we used standard segmentation metrics commonly employed in road extraction, including Precision, Recall, F1-score (Powers, n.d), and intersection over union (IoU) (Rezatofighi et al., 2019). These metrics collectively assess both the accuracy and spatial consistency of the predicted road masks with respect to the ground truth annotations.
Experimental Settings
To effectively tackle the challenges associated with road extraction, we implemented our experiments using the PyTorch framework, a highly flexible and powerful deep learning environment. PyTorch provides an optimal platform for designing, training, and testing our model, enabling efficient implementation of complex architectures while ensuring scalability and adaptability for extensive experimentation.
For computational efficiency, we utilized the Nvidia GeForce RTX 3080 GPU, equipped with 12 GB of VRAM, to accelerate model training and inference. The substantial memory capacity of this high-performance GPU allows for the seamless processing of large-scale satellite imagery, reducing training time and optimizing resource utilization. This computational setup enables our model to handle extensive datasets effectively, facilitating faster convergence and a more comprehensive analysis of road extraction from satellite images.
Experimental Results and Discussion
In this section, we evaluate GeoLinkNet road segmentation performance through comprehensive comparisons with existing architectures. To ensure a fair comparison, we implemented and trained ten models under identical experimental conditions: seven baseline architectures (U-Net, LinkNet34, D-LinkNet34, NL3-LinkNet, NL4-LinkNet, NL34-LinkNet, and NL-LinkNet-DotProduct) and three state-of-the-art methods (LinkNet34++, MACU-Net, and RCFSNet). Additionally, we compare our results with CoANet-UB and SPIN Road Mapper, whose results are taken from recent literature.
Our evaluation is conducted on two benchmark datasets: the DeepGlobe (Demir et al., 2018) and Massachusetts Roads datasets (Mnih, n.d). We assess the segmentation performance using both quantitative and qualitative metrics. This comprehensive analysis measures segmentation accuracy, road connectivity, and structural coherence, providing a detailed assessment of GeoLinkNet effectiveness across different spatial resolutions and geographic contexts. By benchmarking our model against these diverse datasets and existing architectures, we aim to demonstrate its superior performance in extracting road networks with higher precision, better continuity, and improved robustness across varying terrains and imaging conditions.
Quantitative Results
Performance Comparison of Baseline Models With GeoLinkNet.

Performance Comparison of Baseline Models With GeoLinkNet.
Among the baseline models, U-Net exhibits the lowest performance on both datasets, with F1-scores of 79.12% and 70.07%, and IoU values of 66.74% and 58.21% for DeepGlobe and Massachusetts, respectively. Its simple encoder–decoder architecture struggles to preserve road connectivity, often resulting in discontinuities in segmented road networks. The absence of residual connections also limits its ability to capture deeper hierarchical features. In contrast, LinkNet34 and D-LinkNet34, which leverage residual learning, show notable improvements. On DeepGlobe, they achieve F1-scores above 85% and IoU values above 75%, while on Massachusetts, F1-scores reach around 77% with IoU values exceeding 65%. However, these models still have limitations in integrating multi-scale contextual features, which affects segmentation accuracy in occluded or low-contrast regions. By comparison, GeoLinkNet consistently outperforms all baseline models across both datasets. It achieves F1-scores of 89.88% and 85.27%, and IoU values of 81.96% and 76.45% for DeepGlobe and Massachusetts, respectively. This superior performance is primarily attributed to its multi-branch encoding strategy, which effectively preserves both local geometric structures and long-range dependencies, ensuring higher precision, better road continuity, and more robust segmentation across diverse terrains and imaging conditions.
Performance of NL-LinkNet Variants Compared to GeoLinkNet.
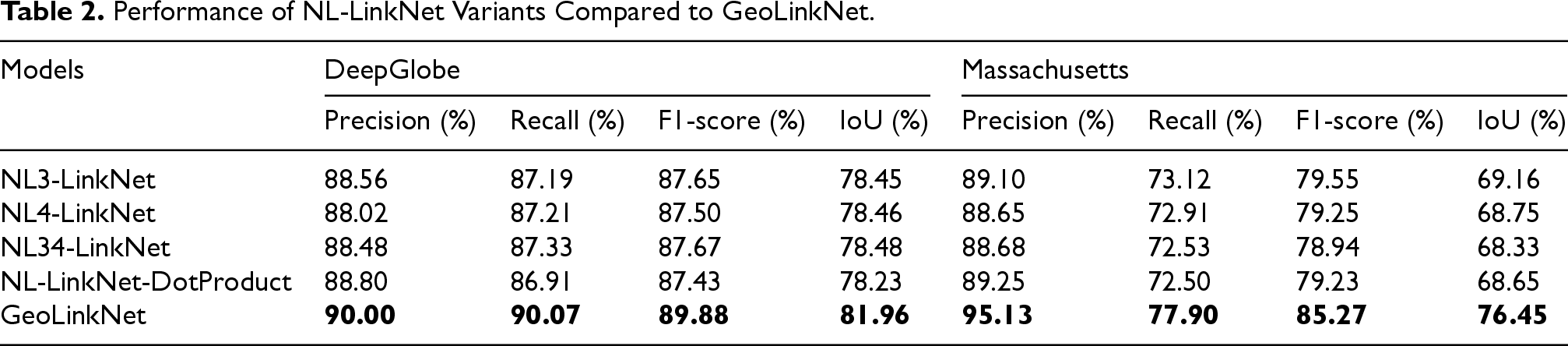
The NL-LinkNet variants consistently outperform traditional architectures by effectively modeling global dependencies, which improves the segmentation of long, continuous roads. On DeepGlobe, these models achieve F1-scores around 87.5–87.7% and IoU values around 78.2–78.5%, while on Massachusetts, F1-scores range from 78.9% to 79.6% and IoU values from 68.3% to 69.2%. However, despite these gains, limitations remain. For example, NL-LinkNet-DotProduct, while achieving a high precision of 88.80% on DeepGlobe and 89.25% on Massachusetts, shows relatively lower recall (86.91% and 72.50%, respectively), indicating that some roads are still missed due to over-aggressive feature filtering.
In contrast, GeoLinkNet surpasses all NL-LinkNet variants across both datasets. It achieves F1-scores of 89.88% and 85.27%, and IoU values of 81.96% and 76.45% on DeepGlobe and Massachusetts, respectively. This superior performance is attributed to the synergistic integration of local and global features, enabled by the LCA, GFE, and AFM, which together enhance road continuity, precision, and robustness across different terrains and imaging conditions.
GeoLinkNet vs. State-of-the-Art Road Segmentation Models.
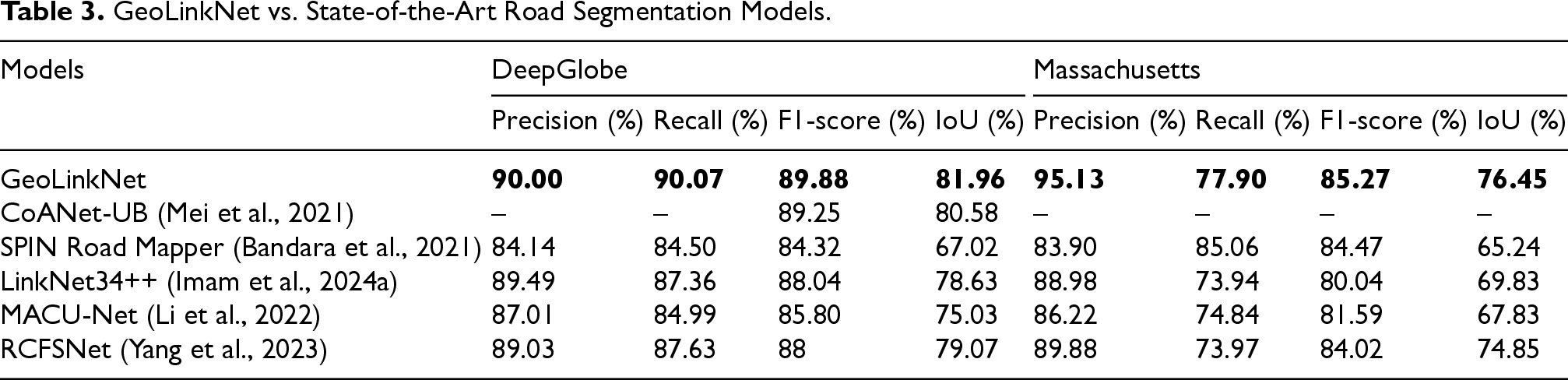
Among the state-of-the-art models, CoANet-UB demonstrates strong performance on the DeepGlobe dataset with an F1-score of 89.25% and an IoU of 80.58%, reflecting effective feature extraction capabilities. However, no results are reported for the Massachusetts dataset, limiting the assessment of its generalization across different geographical contexts. SPIN Road Mapper achieves balanced performance across both datasets, with F1-scores of 84.32% and 84.47% on the DeepGlobe and Massachusetts datasets, respectively, and IoU values of 67.02% and 65.24%, respectively. Despite achieving a high recall score of 85.06% on the Massachusetts dataset, its precision score remains relatively lower at 83.90%, indicating a tendency toward over segmentation in challenging regions. For the models that we implemented and trained, LinkNet34++ substantially improves upon the original LinkNet34. It achieves an F1-score of 88.04% and an IoU of 78.63% on the DeepGlobe, with a precision of 89.49% and a recall of 87.36%. On the Massachusetts dataset, LinkNet34++ reaches an F1-score of 80.04% and an IoU of 69.83%. Although it benefits from extensive data augmentation strategies, it still struggles with long-range dependency modeling and occasionally produces fragmented road predictions in complex scenarios. MACU-Net achieves F1-scores of 85.80% and 81.59% on DeepGlobe and the Massachusetts dataset, respectively, with corresponding IoU values of 75.03% and 67.83%. Its multi-scale attention mechanisms improve feature extraction, however, the model remains sensitive to occlusions and complex road patterns in densely populated urban environments. RCFSNet demonstrates competitive performance, achieving F1-scores of 88% and 84.02%, and IoU values of 79.07% and 74.85% on the DeepGlobe and Massachusetts datasets, respectively. Its road context and full-stage feature integration approach yields strong results, particularly in Massachusetts, where it achieves a high precision of 89.84%. However, it still struggles to maintain connectivity in heavily occluded regions. In contrast, GeoLinkNet outperforms all baseline and state-of-the-art models consistently across both datasets. On DeepGlobe, GeoLinkNet achieves an F1-score of 89.88% and an IoU of 81.96%, with balanced precision and recall at 90.00% and 90.07%, respectively. These scores surpass those of the second-best model, CoANet-UB, by 0.63 percentage points in terms of the F1-score and 1.38 points in terms of the IoU. On the Massachusetts dataset, GeoLinkNet achieves an even more remarkable performance with an F1-score of 85.27% and an IoU of 76.45%, significantly outperforming all other methods. Its precision of 95.13% on Massachusetts represents the highest value across all models and datasets, demonstrating an exceptional ability to minimize false positives while maintaining reasonable recall (77.90%). GeoLinkNet superior performance stems from its multi-branch architecture, which synergistically integrates semantic and geometric features, setting a new state-of-the-art benchmark for road extraction from satellite imagery.
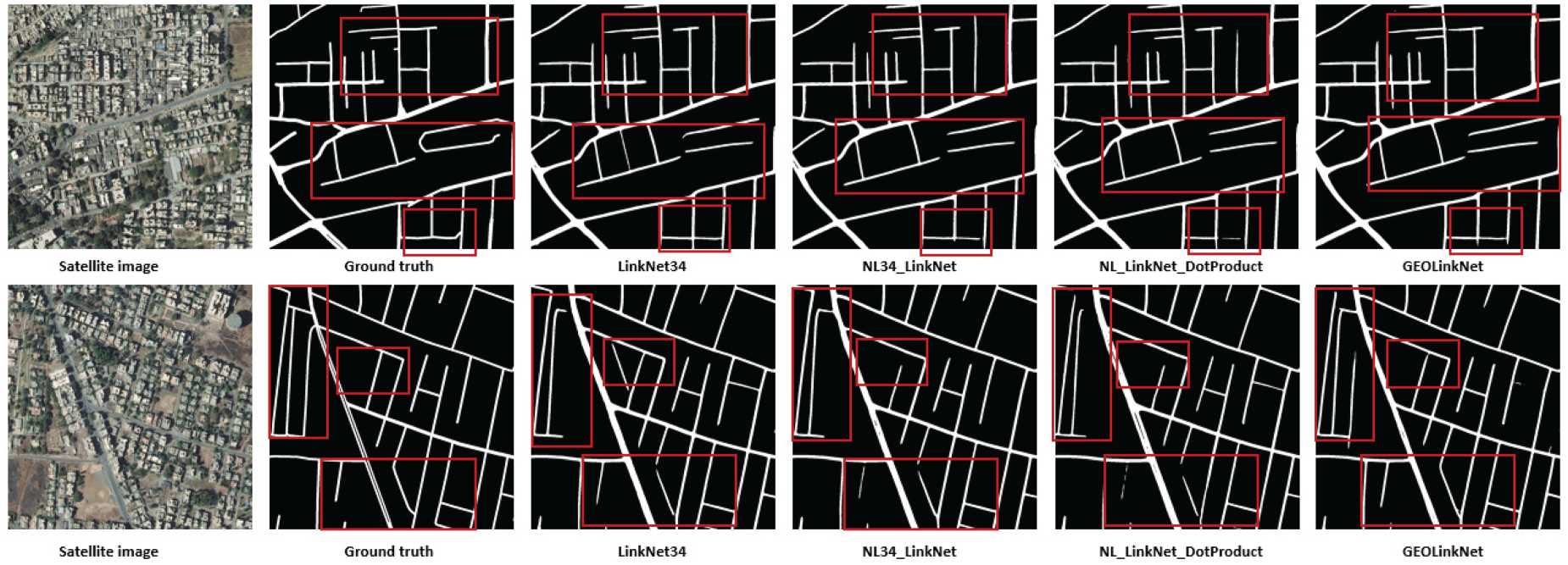
GeoLinkNet segmentation quality is assessed by comparing its outputs with LinkNet34, NL34-LinkNet, and NL-LinkNet-DotProduct across various challenging environments on both DeepGlobe and Massachusetts datasets, as illustrated in Figures 9 to 16. These comparisons highlight GeoLinkNet ability to extract roads more accurately and maintain connectivity even in complex scenarios across different geographical contexts. In dense urban environments (Figures 9 and 10), road networks often feature narrow streets, sharp intersections, and significant occlusions from buildings, trees, and vehicles. Traditional models such as LinkNet34 struggle in these conditions, frequently breaking road continuity in shadowed or obstructed areas. NL34-LinkNet and NL-LinkNet-DotProduct improve upon this by capturing long-range dependencies, but they still exhibit gaps in segmentation, particularly in intersections. As shown in Figure 9 on the DeepGlobe dataset, GeoLinkNet produces the most complete road network in urban settings, effectively reconstructing occluded roads while maintaining clear separation between adjacent structures. Similarly, Figure 10 demonstrates that on the Massachusetts dataset, GeoLinkNet maintains superior performance in dense urban areas, where residential neighborhoods with tree-lined streets and closely packed buildings present significant challenges. While baseline models produce fragmented road segments with numerous disconnections, GeoLinkNet successfully preserves road continuity even in heavily occluded regions. This improvement is primarily due to the LCA module, which enhances feature discrimination in crowded areas, preventing road discontinuities across both datasets.
Road extraction in dense urban areas on DeepGlobe datasets: overcoming occlusions and intersection challenges.
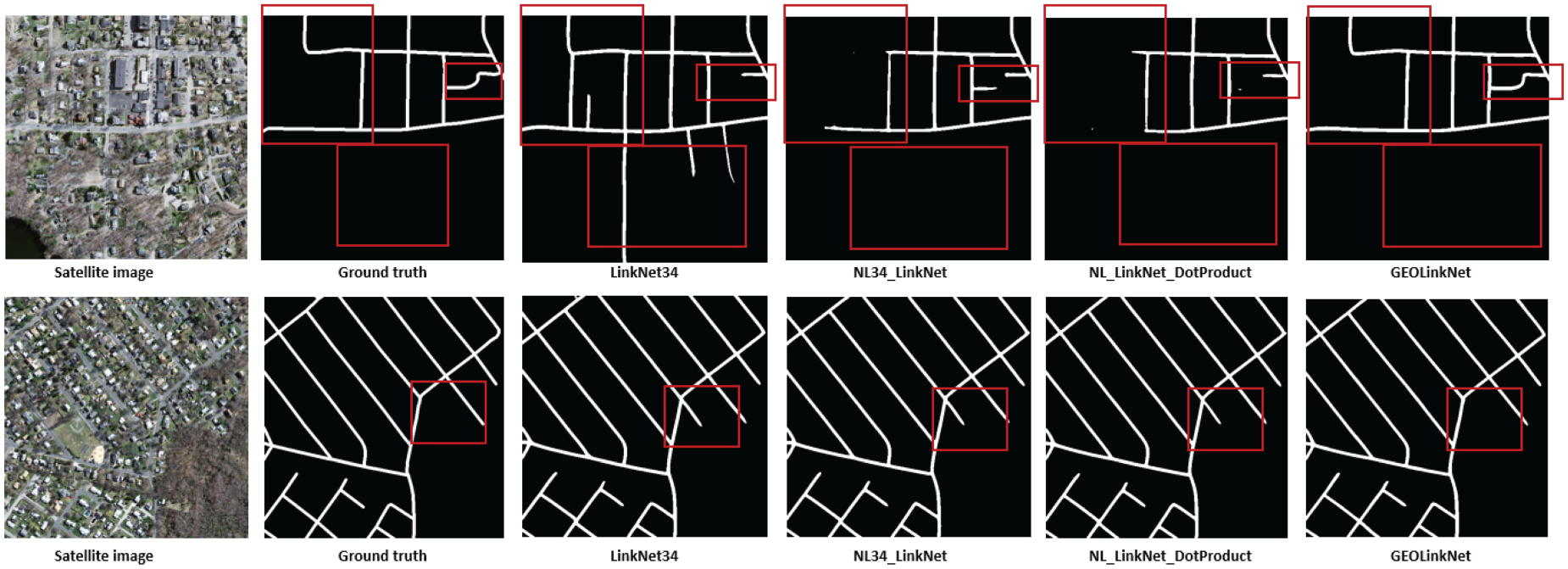
Road extraction in dense urban areas on Massachusetts dataset: overcoming occlusions and intersection challenges.
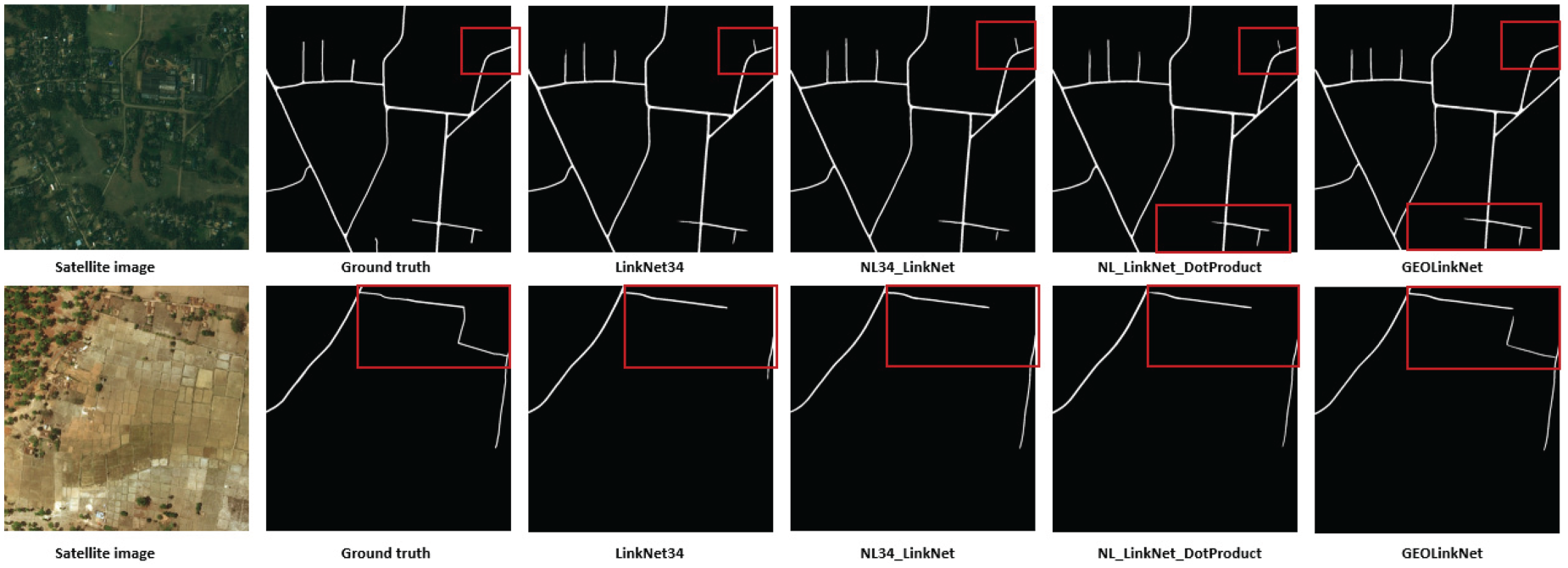
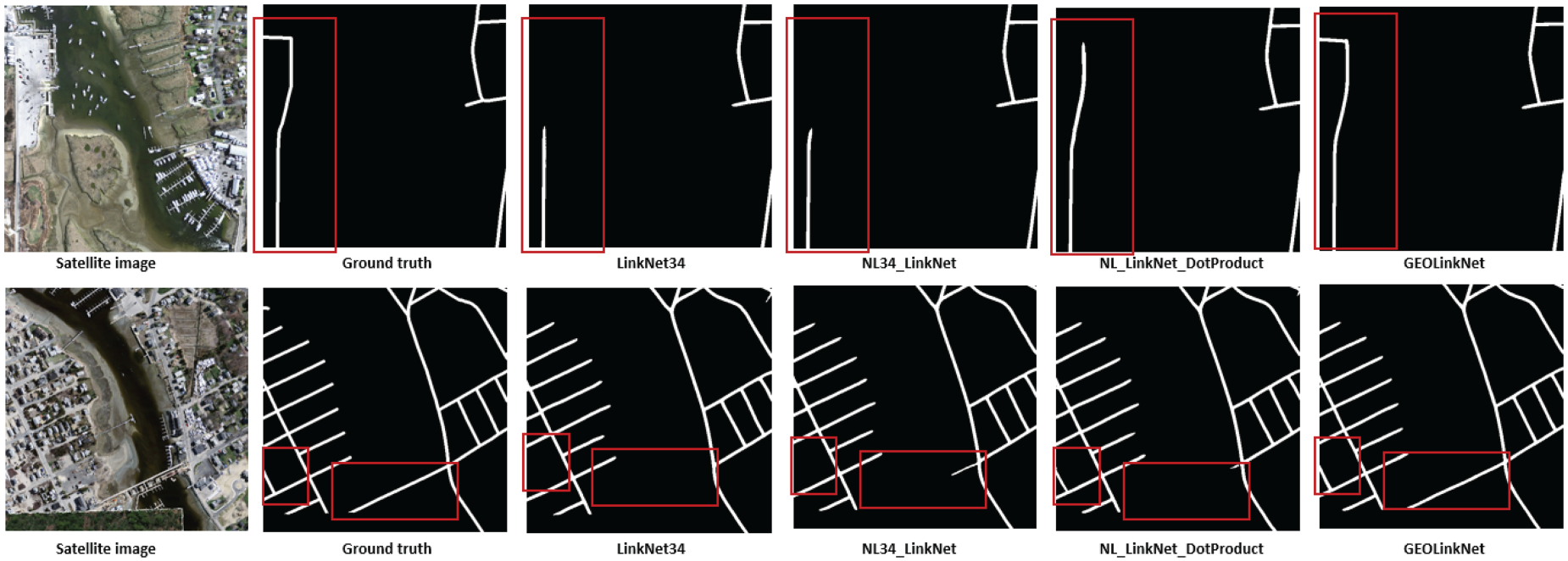
Road extraction in low contrast rural landscapes on DeepGlobe datasets: enhancing road background distinction.
Road extraction in low contrast rural landscapes on Massachusetts dataset: enhancing road background distinction.
Road extraction in sparsely populated rural regions on DeepGlobe datasets: addressing thin and fragmented roads.
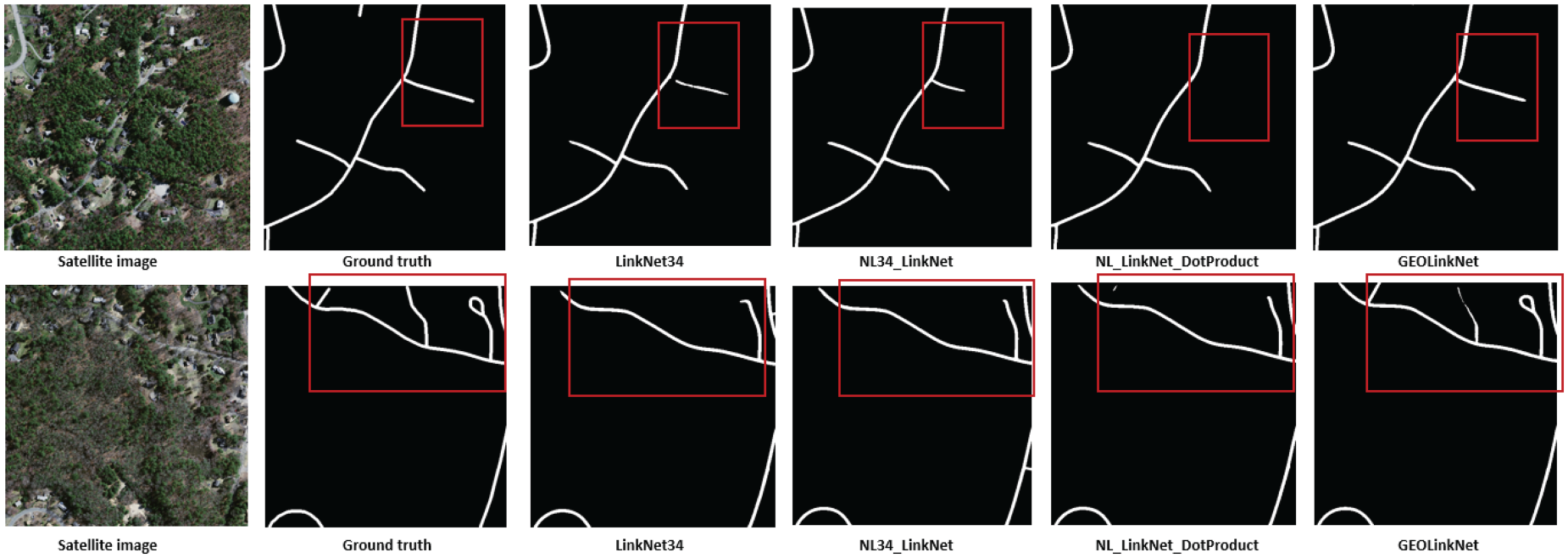
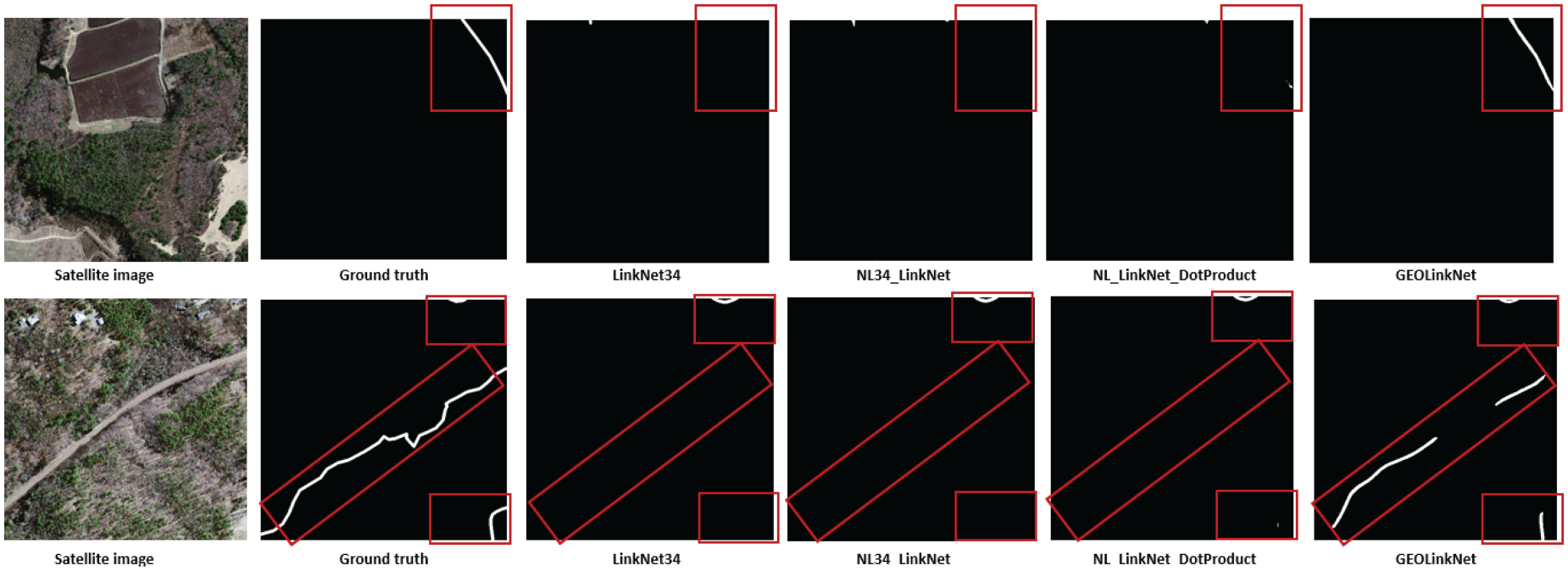
Road extraction in sparsely populated rural regions on Massachusetts dataset: addressing thin and fragmented roads.
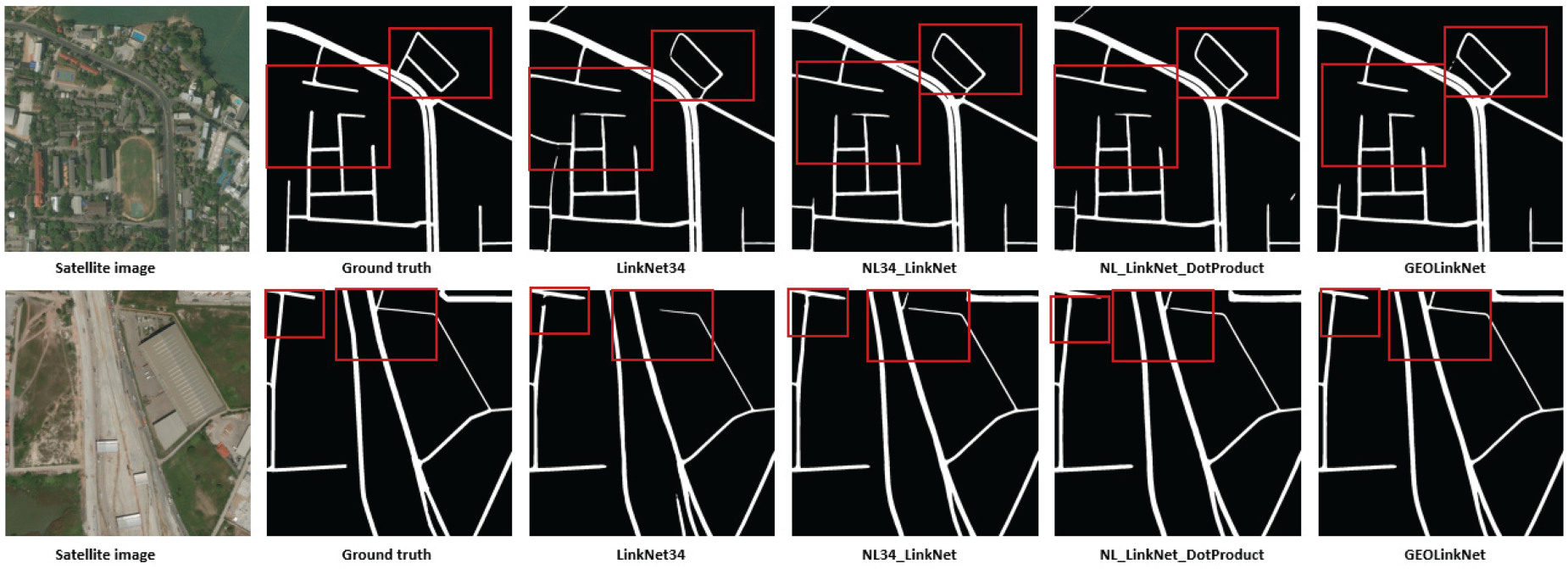
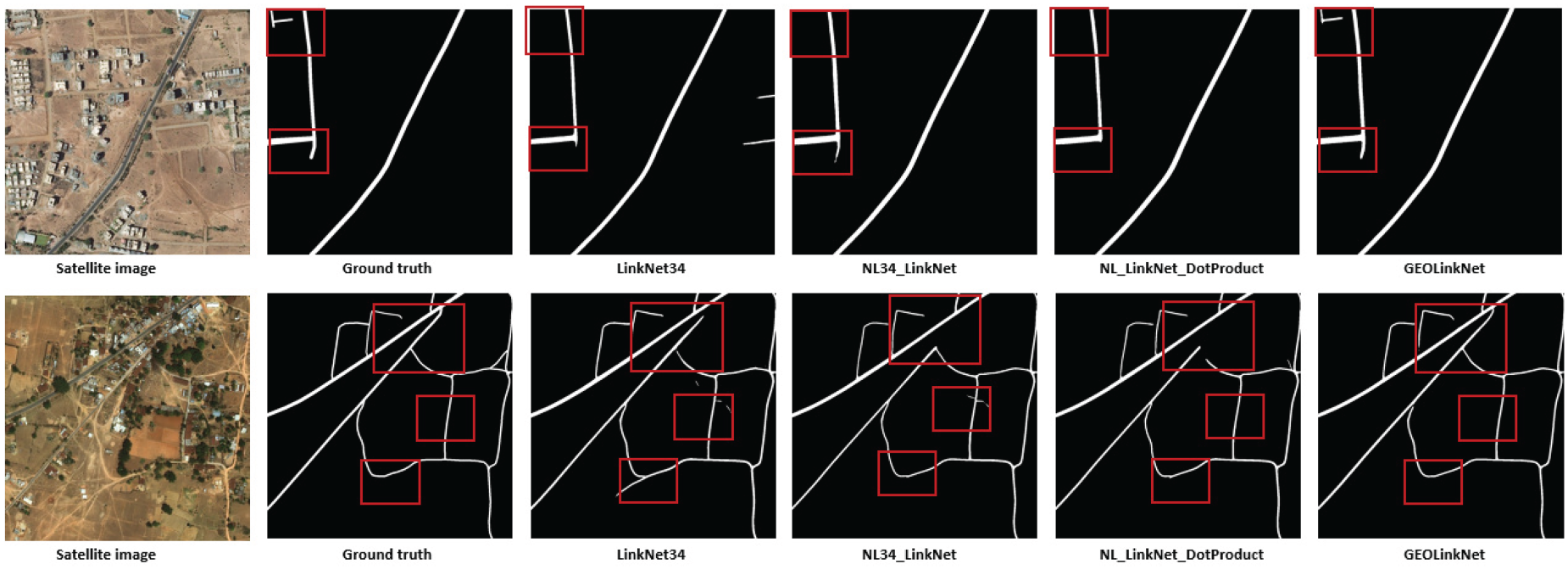
Handling complex road patterns on DeepGlobe datasets: overpasses, multi-lane roads, and curved highways.
Handling complex road patterns on Massachusetts dataset: overpasses, multi-lane roads, and curved highways.
In low-contrast rural roads (Figures 11 and 12), distinguishing road surfaces from their surroundings is particularly challenging due to similar pixel intensities between roads and adjacent terrain. LinkNet34 often misclassifies roads as background, leading to incomplete segmentation, while NL34-LinkNet and NL-LinkNet-DotProduct suffer from false positives, detecting non-road elements as part of the network. Figure 11 shows that on the DeepGlobe dataset, GeoLinkNet maintains superior road delineation, detecting roads even in low-contrast conditions where the road surface blends with surrounding agricultural fields or bare soil. Figure 12 further confirms this capability on the Massachusetts dataset, where rural roads with subtle color variations against grass and vegetation backgrounds are accurately extracted. In both cases, GeoLinkNet demonstrates significantly reduced background noise and more precise road boundary detection compared to competing models. This is achieved through the GFE, which reinforces directional features and improves the model’s ability to distinguish roads from background noise, regardless of contrast levels.
In sparsely populated rural areas (Figures 13 and 14), road structures are often thin, fragmented, and partially obstructed by vegetation, making segmentation difficult. LinkNet34 fails to reconstruct many road sections, leading to broken road segments. NL34-LinkNet and NL-LinkNet-DotProduct show some improvements but still struggle with curved roads and intersections. As illustrated in Figure 13 on the DeepGlobe dataset, GeoLinkNet outperforms all models in extracting narrow country roads with inconsistent visibility, especially where vegetation partially covers the road surface. Figure 14 demonstrates similar superiority on the Massachusetts dataset, where rural roads traversing through forested areas and open fields are extracted with remarkable continuity. In both datasets, GeoLinkNet generates more continuous road extractions, maintaining structural integrity even in areas with inconsistent road visibility caused by shadows, vegetation cover, or seasonal variations. The RRM plays a key role here, correcting small-scale segmentation errors and reinforcing road boundaries, ensuring finer details are preserved across diverse rural landscapes.
In complex road patterns (Figures 15 and 16), such as overpasses, multi-lane roads, and curved highways, standard models struggle with road separation and proper connectivity. LinkNet34 often fails to distinguish intersecting roads, leading to incorrect merges. NL34-LinkNet and NL-LinkNet-DotProduct improve on this but still misclassify overlapping road structures. Figure 15 shows that on the DeepGlobe dataset, GeoLinkNet maintains precise segmentation of complex highway interchanges and curved arterial roads, effectively capturing lane separations and geometric variations that confuse other models. Figure 16 extends this validation to the Massachusetts dataset, where intricate road networks including highway on-ramps, complex intersections, and multi-lane thoroughfares are accurately segmented. In both cases, GeoLinkNet preserves structural coherence in challenging scenarios where roads cross at different elevations or merge at acute angles. The AFM is crucial in this process, dynamically merging semantic and geometric features, ensuring that roads remain clearly delineated and properly connected across diverse road geometries.
To complement the quantitative analysis in Table 3, we present visual comparisons between GeoLinkNet and state-of-the-art methods on two benchmark datasets. Figures 17 and 18 show representative segmentation results that validate the superior performance of GeoLinkNet across diverse scenarios.

Qualitative comparison on DeepGlobe dataset. Each row shows: satellite image, Ground truth, LinkNet34++, MACU-Net, RCFSNet, and GeoLinkNet (left to right). Red boxes highlight regions of interest.

Qualitative comparison on Massachusetts roads dataset. Layout identical to Figure 17, demonstrating consistent performance across datasets.
As shown in Figure 17, each row of the DeepGlobe dataset displays the original satellite image, ground truth, and predictions from LinkNet34++, MACU-Net, RCFSNet, and GeoLinkNet (left to right). Red boxes highlight critical regions where performance differences are most evident. The examples span diverse challenges, including dense urban areas with building occlusions (row 1), curved roads with low contrast (row 2), complex suburban neighborhoods with varying road widths (row 3), rural intersections with acute-angle road branches (row 4), and vegetation-covered roads with subtle color variations (row 5). Across all scenarios, LinkNet34++, MACU-Net, and RCFSNet produce fragmented road segments, incomplete extractions, and irregular boundaries, especially in occluded or low-contrast regions. In contrast, GeoLinkNet demonstrates superior road continuity, accurate boundary delineation, and the ability to maintain topological structure under challenging conditions.
Similarly, Figure 18 on the Massachusetts Roads dataset extends this analysis, demonstrating GeoLinkNet generalization across different geographical contexts. The figure follows the same structure, providing examples of curved multi-lane highways (row 1), isolated rural roads with minimal features (row 2), residential areas with vegetation occlusions (row 3), narrow, low-contrast rural roads (row 4), and complex urban intersections with dense buildings (row 5). As observed in DeepGlobe, baseline methods exhibit similar limitations, including fragmented predictions, incomplete road detection, and sensitivity to occlusions. In contrast, GeoLinkNet produces complete, continuous road extractions with well-defined boundaries and minimal false positives. It achieves an exceptional precision of 95.13% while maintaining structural integrity.
These qualitative results strongly corroborate the quantitative findings in Table 3, confirming that GeoLinkNet is a state-of-the-art method for handling diverse road extraction challenges, including occlusions, low contrast, complex geometries, and varying road widths across different datasets and imaging conditions.
To validate the contribution of each component in GeoLinkNet, we conducted a comprehensive ablation study on the DeepGlobe dataset. This analysis systematically evaluates the impact of removing or isolating individual modules, including the LCA, GFE, AFM, and RRM. By comparing these variants against the full GeoLinkNet architecture, we demonstrate how each component contributes to the overall segmentation performance. Table 4 presents the quantitative results of the ablation study, where each variant represents a specific architectural modification. The full GeoLinkNet model serves as the baseline, achieving an F1-score of 89.88% and an IoU of 81.96%, establishing the benchmark for comparison.
Impact of the AFM. When AFM is removed and replaced with simple element-wise addition for skip connections, the model experiences a notable performance drop, with F1-score decreasing from 89.88% to 88.36% and IoU dropping from 81.96% to 79.57%. This degradation represents a loss of 1.52 percentage points in F1-score and 2.39 points in IoU. The ”Without AFM” variant demonstrates that naive feature fusion fails to effectively integrate multi-scale semantic and geometric information. Without the attention-based weighting mechanism, the model cannot adaptively prioritize relevant features at different decoder levels, resulting in suboptimal feature combination and reduced segmentation accuracy. This validates that AFM plays a crucial role in ensuring that encoder features are selectively integrated with decoder outputs, preventing information loss and maintaining road continuity across multiple scales.
Impact of the RRM. The removal of RRM results in a relatively modest but significant performance decrease, with F1-score dropping from 89.88% to 89.38% and IoU from 81.96% to 81.18%. Although this represents a smaller degradation compared to other ablations (0.50 percentage points in F1-score and 0.78 points in IoU), the impact remains meaningful. The ”Without RRM” variant shows that while the model can still achieve strong segmentation through LCA, GFE, and AFM, the absence of residual refinement leads to less precise road boundaries and minor connectivity issues. RRM enhances final segmentation quality by iteratively correcting small-scale errors and sharpening road edges through residual learning. Without this refinement stage, the model produces slightly blurrier segmentations with less defined boundaries, particularly in complex urban scenes where fine-grained details are critical.
Ablation Study Results on DeepGlobe Dataset Showing the Impact of Each Module.

Ablation Study Results on DeepGlobe Dataset Showing the Impact of Each Module.
Impact of Geometric Feature Extraction (Only LCA). The ”Only LCA” variant, which excludes the GFE module and its parallel geometry path, shows a significant performance drop, with F1-score falling to 87.12% and IoU to 77.77%. This represents a decline of 2.76 percentage points in F1-score and 4.19 points in IoU compared to the full model. Notably, this variant performs worse than ”Only GFE” (F1: 89.10%, IoU: 80.03%), revealing that geometric feature extraction provides a more substantial contribution to segmentation performance than local attention alone. Without the explicit geometric modeling provided by strip convolutions, the network loses its ability to effectively capture directional road structures. The GFE module is specifically designed to detect elongated, linear features characteristic of road networks through horizontal, vertical, and diagonal convolutions. Its absence forces the model to rely solely on semantic features refined by LCA, which, while improving local coherence and spatial attention, cannot fully compensate for the lack of explicit geometric priors. This results in decreased accuracy in detecting narrow roads, maintaining continuity in occluded regions, and preserving structural alignment in complex road patterns, particularly for curved highways and multi-lane intersections.
Impact of Local Context Attention (Only GFE). The ”Only GFE” variant, which removes LCA from the encoder while retaining the geometry path, shows a moderate performance decrease. With an F1-score of 89.10% and IoU of 80.03%, this configuration underperforms the full model by 0.78 percentage points in F1-score and 1.93 points in IoU. Interestingly, this variant achieves better performance than ”Only LCA” (F1: 87.12%, IoU: 77.77%), demonstrating that geometric feature extraction through strip convolutions provides stronger baseline performance than attention mechanisms alone. However, the performance gap between ”Only GFE” and the full model reveals that while geometric features effectively capture road directionality and linear structures, they benefit significantly from the spatial refinement provided by LCA. The LCA module enhances encoder features by suppressing irrelevant background noise and emphasizing spatially coherent road-related activations, ensuring that the features passed to both the decoder and the geometry path are more discriminative. Without this attention-based refinement, the network can still detect major road structures through directional convolutions, but struggles with fine-grained segmentation in cluttered environments, leading to reduced precision in complex urban scenes and areas with significant occlusions.
Synergistic Effect of Combined Modules. The ablation study clearly demonstrates that the superior performance of GeoLinkNet is not attributable to any single component but rather to the synergistic integration of all four modules. A key finding is that GFE provides the strongest individual contribution, as evidenced by ”Only GFE” achieving better performance (F1: 89.10%, IoU: 80.03%) than ”Only LCA” (F1: 87.12%, IoU: 77.77%). This confirms that explicit geometric modeling of road structures through directional convolutions is more critical than attention mechanisms alone. However, the full model’s superior performance (F1: 89.88%, IoU: 81.96%) demonstrates that combining both LCA and GFE yields significant additional improvements, with LCA refining the quality of features processed by GFE. Each component addresses a specific limitation in road segmentation: LCA enhances spatial coherence and suppresses noise, GFE captures geometric structure and road directionality, AFM ensures effective multi-scale fusion through adaptive weighting, and RRM refines final segmentation boundaries with residual learning. The performance degradation observed in each ablation variant confirms that removing any of these components compromises the model’s ability to accurately extract road networks from satellite imagery. The full GeoLinkNet architecture, which integrates all modules in a carefully designed pipeline, achieves the best balance between precision, recall, and structural consistency, validating the effectiveness of our multi-component design strategy.
These results conclusively establish that GeoLinkNet architectural innovations are essential for achieving state-of-the-art road segmentation performance, with each module contributing meaningfully to the overall accuracy and robustness of the model.
In this study, we presented GeoLinkNet, a geometry-aware deep learning architecture that enhances road extraction from satellite imagery by jointly leveraging semantic and geometric information. The model integrates four key components: the LCA for spatial refinement, the GFE for directional structure recognition, the AFM for multi-scale feature integration, and the RRM for final segmentation enhancement. Extensive experiments on the DeepGlobe and Massachusetts Roads datasets demonstrate the superiority and generalization capability of GeoLinkNet across diverse geographic contexts. The model achieves state-of-the-art results, with F1-scores of 89.88% on DeepGlobe and 85.27% on Massachusetts, and IoU values of 81.96% and 76.45%, respectively, surpassing contemporary architectures such as CoANet-UB and LinkNet34++. The ablation study further confirms the crucial contribution of each module, revealing that the synergy between LCA, GFE, AFM, and RRM is essential to achieving optimal performance. GFE provides the most significant individual impact by enhancing geometric awareness, while AFM and RRM contribute to improved multi-scale consistency and refined boundaries. Qualitative and quantitative analyses validate GeoLinkNet’s robustness in handling complex urban occlusions, low-contrast rural regions, and intricate road geometries, maintaining superior road continuity and accuracy across scales. Although the model exhibits higher computational cost than lightweight baselines, the trade-off yields substantial accuracy and structural gains, making it highly suitable for applications where precision is paramount, such as urban mapping, GIS updating, and autonomous navigation.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the General Directorate of Scientific Research and Technological Development of Algeria (DGRSDT).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.