
Abstract
The need for personalized content has grown considerably with the increasing amount of online information. User profiles, as structured collections of user characteristics and interests, are essential for personalization because they help systems better understand individual preferences and deliver more relevant content. This review examines methods for user profiling and their adaptation over time. We organize existing literature into five categories: User Profile Modeling, Profile Dynamics, Recommendation Systems, Personalized Systems, and Adaptive Systems. Key findings highlight the importance of combining explicit and implicit data collection methods, differentiating between short- and long-term user preferences, and employing techniques such as evolutionary algorithms, context-awareness, and explainability. Additionally, we identify promising areas for future research, including multimodal data integration, scalability, privacy preservation, contextual adaptation, and universal user models. This review aims to help readers navigate the extensive literature and provide insights to support the development of practical applications based on user profiling techniques.
Introduction
User profiles consist of a set of characteristics that describe how users interact with a given system. These profiles represent users’ interests, needs, preferences, demographic traits, and desires (Amato & Straccia, 1999). User profiles are created and managed through a process called User Profile Modeling, which consists of two main steps (Lops et al., 2019, p. 9). First, it is necessary to define what user information is to be stored and how this information will be represented. Second, it is required to establish an appropriate methodology for constructing, updating, and maintaining these profiles over time.
To build accurate user profiles through user modeling, systems must collect relevant data about users. Typically, user data can be gathered in two ways: explicitly and implicitly. Explicit data collection typically involves directly asking users to provide ratings or feedback on items. Implicit data collection, on the other hand, involves observing and analyzing users’ behavior without direct input. Examples of implicit data include monitoring songs played, applications downloaded, websites visited, or books read (Isinkaye et al., 2015).
User profiles can be categorized into two main types: static and dynamic. Static profiles contain fixed information about users that does not change over time. Such static information, however, carries the risk of becoming outdated, potentially leading to ineffective personalization (Hawalah & Fasli, 2015). Indeed, users’ interests, preferences, and needs often evolve. To address this issue, the concept of Profile Dynamics was introduced. Profile dynamics refers to techniques that account for the evolving nature of user profiles. These techniques allow systems to detect both short- and long-term changes in user interests and characteristics. By identifying and incorporating these changes, systems can maintain updated user profiles. Consequently, profile dynamics ensures that the personalization provided by the system remains accurate, relevant, and helpful.
User modeling is important for personalized systems, especially given the current data explosion where the amount of digital data being generated and stored is growing exponentially. In this context, user modeling enables systems to understand users’ characteristics and adapt their behavior dynamically. Such adaptation typically involves tailoring the content to individual users or groups of users according to their specific behaviors, needs, and preferences. Furthermore, user modeling can also help identify and suggest new interests to users, that is, interests they may not be aware of but that align closely with their existing preferences (Moukas, 1997).
One of the primary applications of user modeling is information filtering, which is, in turn, used, for example, in Recommender Systems (RSs) across various domains. These domains include web personalization, computational advertising, e-learning systems (Hawalah & Fasli, 2015; Le et al., 2009; Wu et al., 2022; Yin et al., 2015), and search engines (Eke et al., 2019). A RS collects information about users’ preferences regarding specific items, such as movies, songs, or books. Using this information, the system suggests new items that closely align with users’ interests and needs (Bobadilla et al., 2013; Isinkaye et al., 2015).
User modeling also benefits prediction systems. In these systems, user modeling can help estimate ratings for items even without explicit user feedback (Farid et al., 2018). Furthermore, adaptive systems can also rely on user modeling to customize the user interface. Customization might include adapting font sizes or displaying context-aware information, thus improving the effectiveness of the interaction between the system and the user (Browne, 1990).
In order to provide context for how the selected studies were identified and organized, the next section describes the methodological approach used to conduct this narrative review.
Methodology
This article adopts a narrative review approach to synthesize and organize the existing literature on user profiling and its dynamics. The literature search and retrieval process started in March 2023 and concluded in June 2025, using Web of Science, ACM Digital Library, and Google Scholar databases. The search used combinations of keywords such as “user profile,” “profile dynamics,” “recommender systems,” and “adaptive systems.” No restrictions were applied regarding publication dates. Additionally, further relevant publications were identified through references cited within the initially retrieved articles.
Publications were reviewed for relevance based on titles, abstracts, and full texts. Works were included if they contributed to understanding how user profiles are constructed, maintained, or applied in personalized and adaptive systems. In total, 117 publications were selected, and their full texts were extracted and analyzed. Among these publications, 53 were conference articles, 51 were journal articles, 3 were books, 3 were book chapters, and 7 were pre-prints.
The publications have been grouped into five categories, namely: User Profile Modeling (
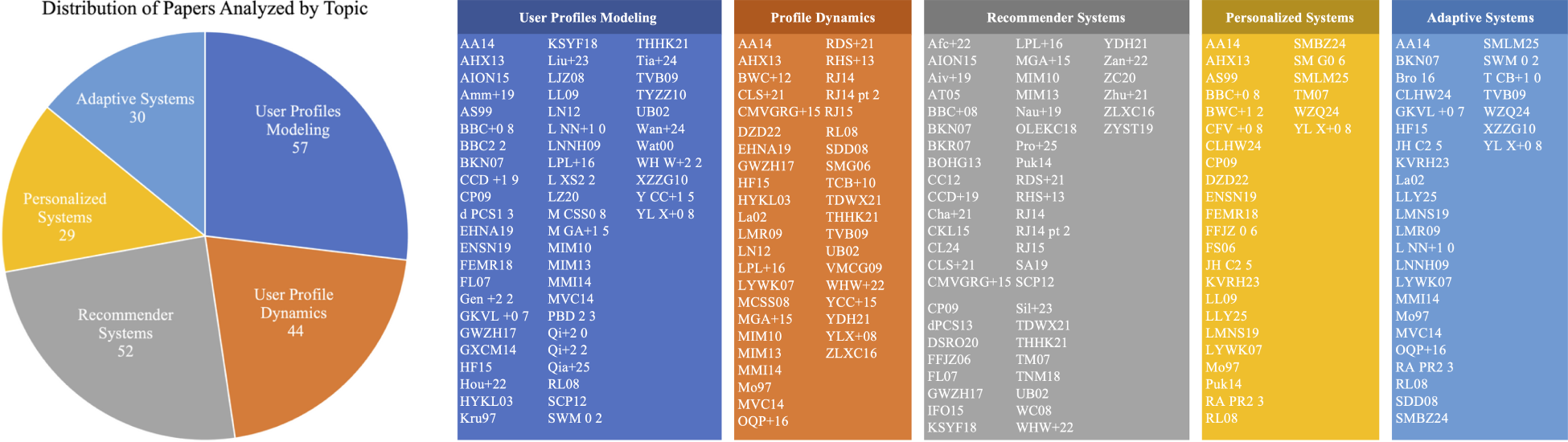
Distribution of the papers analyzed by topic. The alphanumeric labels (e.g., MIM10, DZD22) correspond to the list of selected studies provided in Online Appendix.
This article follows a structured approach, in which the relevant literature for each stage of user profile modeling is introduced. While the suggested taxonomy improves the understanding of the different domains associated with user modeling and profile dynamics, the systematic step-by-step approach facilitates developing user profile modeling applications. Therefore, following the introduction, we first discuss user profile modeling, focusing on relevant topics such as information retrieval and feature representation. The next section addresses profile dynamics and summarizes techniques for handling evolving user preferences and interests. This discussion is followed by a section on recommendation systems, including their definition and important sub-classifications. We then describe personalized/adaptive systems, highlighting their relationship with both user profiles and profile dynamics. Finally, we close the review with the concluding remarks and directions for future work.
User profiles play a fundamental role in RSs (Isinkaye et al., 2015) and personalized or adaptive systems (Brusilovski et al., 2007). They provide a comprehensive representation of individual users or user groups. A user profile is an instantiation of a user model within the system (Eke et al., 2019). Typically, user profiles consist of two main components: demographic information, such as age, gender, and occupation, and a set of keywords or concepts associated with corresponding values. These keywords and concepts serve to represent and estimate user intentions, interests, and other pertinent information for profile modeling, both for long-term and short-term time frames (Deng et al., 2022). However, some profiles can be more complex, using users’ behavioral data, such as clicking behavior or time spent on a web page (Abdel-Hafez & Xu, 2013).
While there is a consensus in the literature that a profile represents a set of characteristics for individual users or user groups, there exists a gap when it comes to a formal definition of what constitutes a profile and its inherent structure. An exception to this gap can be found in Fermé et al. (2024), where a user profile
As mentioned earlier, user profiles are generated through a process known as user modeling, which is subsequently employed for inferring unobservable information about users. The user modeling process involves several distinct steps, namely information retrieval, feature extraction and representation, profile construction, preference learning, and profile dynamics (also referred to as profile maintenance) (Razmerita & Lytras, 2008; Zhou et al., 2012). Figure 2 provides an overview of these different stages. The subsequent sections provide a comprehensive description of each step.

User modeling phases required to build user profiles (Razmerita & Lytras, 2008).
User profiling can raise concerns regarding data privacy. These concerns have become increasingly important since the introduction of the General Data Protection Regulation (GDPR). One possible solution to address these privacy issues involves federated systems. In federated systems, users do not need to share their raw data directly. Instead, they only share model parameters through a decentralized approach. These parameters can then be aggregated centrally to build an overall model, thereby improving privacy protection for users. Liu et al. (2023) proposed a solution that employs hierarchical information for user profiling. The resulting user profiles are then aggregated to build an overall model. Federated RS that uses graph neural networks (Luo et al., 2022; Tian et al., 2024) can also be a solution to protect user privacy. Other approaches exist where a federated collaborative filter is introduced (see, e.g., Qi et al., 2020 or ud din et al., 2019).
In order to accurately identify users’ needs and interests, the system needs to collect as much information about the user as possible; therefore, the information retrieval phase is important to make an effective user personalization. Information retrieval can be classified as explicit, collected by getting users’ feedback or manually editing their profile; implicit, collected by analyzing users’ interaction and behavior within the system; or hybrid, combining explicit and implicit information (Isinkaye et al., 2015).
Information about users may include demographic data, such as age, gender, and education. These data can be utilized to classify users and generate baseline recommendations based on demographically similar individuals. This technique is known as Demographic Filtering (Adomavicius & Tuzhilin, 2005) and can be particularly useful for addressing the data sparsity problem, which occurs when limited information about users is available.
In addition to demographic characteristics, the user’s behavior within the system, their past searches, and previously expressed preferences can also be used to infer their interest in specific items or particular needs. Such information can be represented using graph structures, in which nodes represent entities such as users or items, and edges refer to interactions or relationships between these entities (Purificato et al., 2023). However, user profiling systems typically concentrate only on users’ positive interactions with the system, overlooking other relevant information. In fact, relying solely on positive signals might not be sufficient to fully capture the user’s interests and preferences. As argued by Leung and Lee (2009), incorporating knowledge about negative user preferences can provide a broader perspective on the user profile, allowing systems not only to understand what users like but also to explicitly represent what they dislike.
In any case, the collected data undergoes a preprocessing process to extract label values, known as user profile features. These features are then employed in constructing the user profile (Eke et al., 2019), which can apply to either an individual user or a group of users.
As already mentioned, the information used for profiling can be categorized as explicit (provided by users), implicit (automatically collected), or hybrid. In the following subsections, we will explore these techniques in detail. The highlighted papers for this subsection are presented in Figure 3.
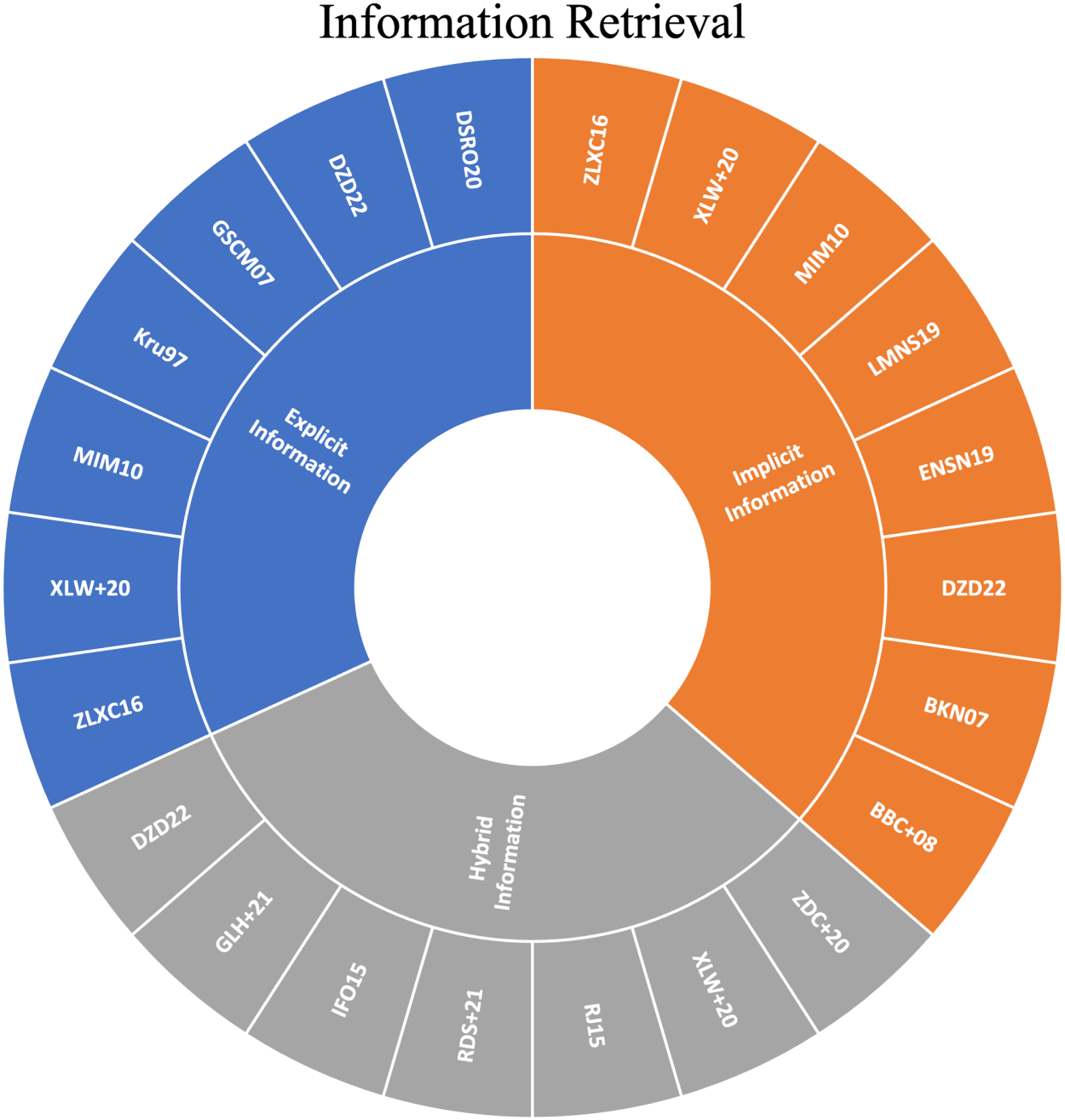
Highlighted papers on Information Retrieval. The alphanumeric labels (e.g., MIM10, DZD22) correspond to the list of selected studies provided in Online Appendix.
Explicit information retrieval relies on information explicitly provided by users. This may include demographic information, such as age, gender, and place of residence, which can be used to create demographic clusters and infer users’ preferences (Krulwich, 1997).
Users can also provide positive or negative feedback information using ratings or dislike buttons (Da’u et al., 2020; Deng et al., 2022; Xie et al., 2020). Additionally, users can provide information about their interests (Gauch et al., 2007) and manually assign weights to or order their preferences within the system.
Although simple and highly effective (Zhang et al., 2016), this information retrieval strategy has areas for improvement. The process is time-consuming and requires users to have domain knowledge of the concepts used to describe preferences and the rating scale for weighting preferences (Da’u et al., 2020). Furthermore, not all users are willing to spend time providing feedback and information to the system, even when encouraged to do so (Marin et al., 2010). For these reasons, implicit information retrieval methods have arisen.
Implicit Information
Implicit information retrieval occurs when the user’s information is collected automatically without user intervention in the process (Brusilovski et al., 2007). There are many ways to implicitly collect information about users’ preferences, feedback, and interests.
One method is by analyzing browsing behavior, including the websites visited by the user, their contents, timestamps, and duration of the visit on each website (Deng et al., 2022). Another approach is to analyze the user’s query logs, examining their past searches and creating query-flow graphs to represent a user’s search behavior. This technique is particularly useful for identifying logical sessions and recommending new queries (Boldi et al., 2008).
Additionally, observing which options the user selects or clicks can provide valuable insights (Lops et al., 2019). For instance, if a system presents options sorted by preference level and the user does not choose one of the top options, a comparison can be made between the selected option and the top ones to identify differences. This information can then be used to modify the weights of a given model, ensuring that similar options to the selected one are prioritized in the subsequent recommendation process (Zhang et al., 2016).
This method requires, however, considerable computational power due to the large amount of data collected, as well as data mining techniques. Furthermore, the implicitly collected data may be noisy (Xie et al., 2020), and the confidence in the obtained results is occasionally low (Marin et al., 2010), especially in the initial stages. On the other hand, this information retrieval process has the advantage of being capable of collecting data continually, and thus, receiving updated information (Eke et al., 2019).
We argue that contextual information can also be categorized as implicit information, which can be used effectively for user profile modeling (Ravi et al., 2021). Contextual information refers to any details that help describe the user’s current situation. Typical examples include the user’s location, current activity, and social relationships (He et al., 2016).
Hybrid Information
Hybrid information retrieval is a methodology that makes use of the strengths of both explicit and implicit feedback to verify collected information and strengthen the effectiveness of the system, particularly in the context of user profile dynamics (Rana & Jain, 2015). One way to obtain hybrid feedback is by using implicit feedback to verify the veracity of explicitly collected information (Isinkaye et al., 2015). This methodology creates unbiased user models by considering both positive and negative feedback during the training phase of the model (Xie et al., 2020), enabling the same model to better capture the user’s intention (Deng et al., 2022).
Logesh and colleagues (Ravi et al., 2021) argue that the optimal performance of RSs requires the use of both implicit behavior and explicit feedback information from users. By incorporating both of these information retrieval approaches, the authors suggest that the resulting models will become more transparent and trustworthy. This increased transparency and trustworthiness is expected to encourage users to provide more information, thereby enabling the model to be trained more effectively.
Still within the domain of RSs, Interactive RSs aim to integrate feedback into the recommendation process. These systems suggest items and subsequently receive feedback from users, which can be utilized to generate more refined and personalized recommendations (Zhou et al., 2020). A similar application can also be found in Conversational RSs (Gao et al., 2021), where implicit interaction can be used as a means to evaluate recommendation models.
Step 2—Feature Extraction and Representation
After the information retrieval phase, the feature extraction is conducted. Feature extraction involves extracting, from the raw data, the features that can potentially be used to model the user profile. For example, an important aspect of this phase is to identify and extract the most relevant keywords present within a document (Lau, 2002). Another example is categorical features, which can be represented using encoding techniques such as one-hot encoding. In one-hot encoding, each category is converted into a binary vector; this strategy can be applied to both users and items (Wu et al., 2022). Eke et al. (2019) summarized the possible features to extract depending on the application.
Following feature extraction, feature representation is the next step for user profile construction. In this step, the previously extracted information is encoded into a latent representation (embeddings), transforming features into a format suitable for further analysis, such as user profile modeling. Feature representation has received increased attention, especially due to the recent emergence of deep learning techniques (Ben Hassen et al., 2022), and has been successfully applied across various systems for multiple purposes.
Li and Zhao (2020) suggested that feature representation can be performed using either structured datasets (e.g., matrices) or unstructured sequences (e.g., purchase histories). And it is important to note here that feature extraction, and later feature representation, can be applied to both users and items.
The highlighted papers of this subsection are displayed in Figure 4.
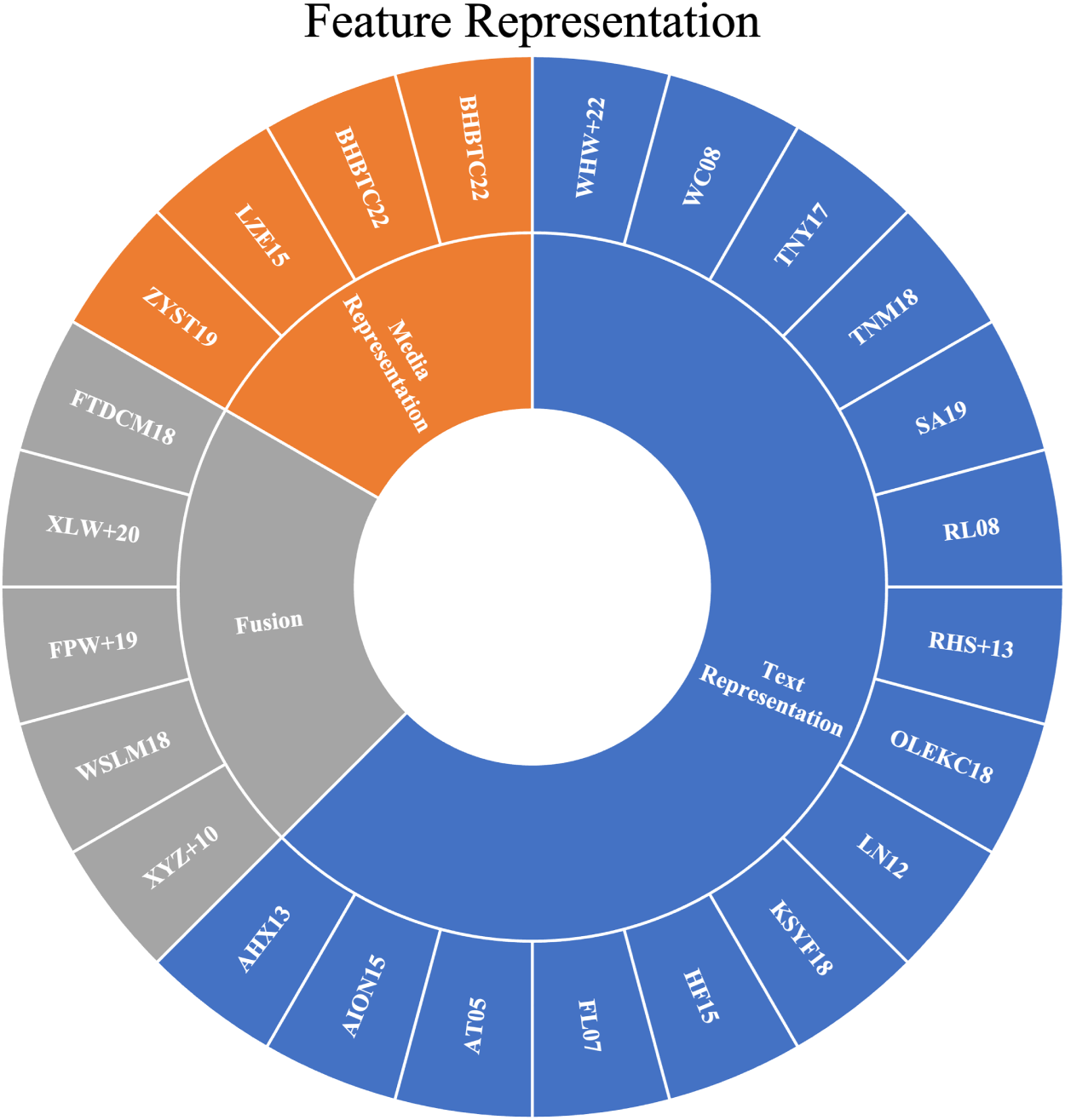
Highlighted papers on Feature Representation. The alphanumeric labels (e.g., MIM10, DZD22) correspond to the list of selected studies provided in Online Appendix.
For text representation, one widely used method is the Term Frequency–Inverse Document Frequency (TF-IDF) classifier, a text vectorization technique that calculates the weight of a keyword in a document based on its frequency within that document (Adomavicius & Tuzhilin, 2005). For instance, in a study by Lauschke and Ntoutsi (2012), the TF-IDF classifier was utilized to extract features (in this case, keywords) in a system designed to monitor user profiles and their evolution on the social platform X (formerly known as Twitter).
Another approach, known as the Bag-of-Words method, is a simpler alternative to TF-IDF. It analyzes the frequency of words input by users to generate a set of keywords representing their interests. This autoencoder technique is particularly effective in systems that rely on explicit data, such as microblog text (Abdel-Hafez & Xu, 2013). Moreover,
An ontology, on the other hand, is a formal knowledge representation of a specific domain in a structured manner that can be understood by both humans and machines (Obeid et al., 2018). One of the key characteristics of ontologies is their capability to establish and describe relationships between classes (Felden & Linden, 2007). As a result, ontologies can be considered a form of feature representation, more specifically, a representation of semantic features (Razmerita & Lytras, 2008), which can be shared and reused in different systems. Moreover, ontologies can solve the cold-start problem, that is, when there is insufficient information about the user to make accurate user profiles (Tarus et al., 2017).
Ontologies represent entities, such as users, products, or services, within the system (Tarus et al., 2018) and concepts. Subsequently, these ontologies are compared to predict users’ needs, particularly in the context of recommendation systems (Ruotsalo et al., 2013; Weng & Chang, 2008). For instance, Liu et al. (2018) developed a framework where the ontology structure incorporates both the Point of Interests (POIs) and the users. Recommendations are then generated by evaluating the similarity between the POIs and the users’ ontologies using the Jaccard index.
Similarly, Obeid et al. (2018) implemented a semantic RS wherein ontologies were employed to represent higher education institutions, employment, and students. However, machine learning techniques were utilized to generate tailored recommendations for university degrees for students.
Reference ontologies, such as Open Directory Project (ODP), also serve an important role in representing semantic features since they provide an improved and standardized framework for defining, representing, and relating entities and concepts (Tarus et al., 2018). As a result, they provide a richer representation of information when compared to ontologies developed from scratch.
For example, Hawalah and Fasli (2015) mapped web pages to concepts present in a reference ontology for web personalization. Interestingly, these authors also proposed techniques that utilize the established mapping for constructing and maintaining ontological user profiles (including session-based, long-term, and short-term profiles). These profiles were subsequently used to adapt the system according to user behavior.
Amini et al. (2015), on the other hand, integrated various reference ontologies into a unified and more comprehensive ontology for profiling scholars’ knowledge.
Finally, with the advent of Large Language Models (LLMs), semantic embedding has also emerged as an effective option for text representation (Geng et al., 2022; Wang et al., 2024), enabling the implementation of a new RS paradigm called Generative Recommendation, which will be explored later in this paper.
Media Representation
Features from other sources, such as images, text, audio, and video, are often extracted and projected into latent spaces using Convolutional Neural Networks (CNNs) (Ben Hassen et al., 2022) for user modeling. These networks are well-suited to process and model unstructured multimedia data through convolution and pooling operations (Zhang et al., 2019).
For instance, in the study conducted by Ben Hassen et al. (2022), a transfer learning technique and an autoencoder were employed to extract the latent features of the images representing items. This was not the first study to use pre-trained models to represent features at a high-level abstraction (Liang et al., 2015).
Attention mechanisms are extensively employed in the field of Natural Language Processing (NLP), as well as in the extraction of visual features. These mechanisms are applied to the input data to allow the predictions to focus on the most relevant components of the inputs (Zhang et al., 2019), thereby improving the quality of predictions generated.
From this perspective, a potential strategy could involve employing two attention mechanisms to extract pertinent features associated with users and multimedia items (see, for instance, Liu et al., 2019 and Chen et al., 2017). Subsequently, this extracted information can be incorporated into, for example, recommendation models.
Fusion
Equally important are deep fusion methods, which have been suggested as a viable approach for modeling multiple data sources in user profiling, as shown by Farnadi et al. (2018). This technique is capable of integrating data from multiple sources (i.e., heterogeneous information (Zhao et al., 2017)), such as the integration of implicit and explicit feedback (Xie et al., 2020), into a unified representation. This integration can occur either at the decision level or at the feature level (Fu et al., 2019).
Wen et al. (2018) proposed an effective visual background recommendation for dance performances that combined textual information with the visual content of images. In addition, Xiang et al. (2010) suggested a method named Injected Preference Fusion (IPF) for combining long- and short-term user profiles in recommendation calculations.
Moreover, with more recent multimodal LLM architectures, one can also develop multimodal feature extraction and representation. We argue that this represents a promising research opportunity and suggest exploring it further in future work, following proposals similar to the one presented by Qiang et al. (2025).
Step 3—User Representation
Various methodologies can be used to represent the user profile based on the information collected in the previous step. The Matrix Factorization (MF), or more generally, Tensor Factorization, serves as an initial point of reference. It is an embedding model that encompasses the diverse interactions, such as ratings, between users and items (Ben Hassen et al., 2022), and can be employed to construct the user profile, considering both the current and predicted interactions. This matrix can be further expanded by incorporating Knowledge Graphs (KGs), for instance, to identify higher-ordered relationships (Yang et al., 2021). MF gained wide popularity due to the Netflix Prize Contest (Bennett & Lanning, 2007).
Three other main methods are commonly used in the literature to represent user profiles (Brusilovski et al., 2007; Eke et al., 2019). These three methods can be further categorized into keyword-based and knowledge-based methods (Thomsen et al., 2009). The first approach involves the creation of keyword profiles (see, e.g., On-At et al., 2016), where user profiles are constructed as vectors consisting of pairs of keywords and their respective weights (Abdel-Hafez & Xu, 2013) according to the degree of interest. The keyword profiles may comprise explicit and implicit information covering long-term and short-term preferences. Furthermore, the weights associated with these profiles can be determined through various methods, such as employing the TF-IDF, and a similarity measure (Farid et al., 2018) is then utilized to identify the contents of interest to the user.
However, keyword-based profiles are susceptible to the inherent ambiguity of natural languages (Lops et al., 2019). Specifically, relying solely on keywords may not capture the complete contextual information, polysemy, or underlying intention behind a statement or a textual segment (de Paiva et al., 2013). Due to these limitations, novel approaches were suggested, including semantic network profiles. Semantic network profiles represent user profiles as weighted semantic networks of nodes, where the weights of the nodes and their interconnections denote the user’s level of interest (Gao et al., 2014). In this methodology, each node within the network corresponds to a set of keywords that can be mapped to a specific higher-level concept (Brusilovski et al., 2007), either manually or by using lexical databases such as WordNet (Miller, 1995), or ontologies (Hawalah & Fasli, 2015; Thomsen et al., 2009). This mapping is user-specific and helps to overcome challenges associated with keyword profiles, particularly those associated with polysemy (Gauch et al., 2007), as words related to the same concept are clustered within the same node.
Like semantic network profiles, concept-based profiles analyze the interrelationships between words to identify abstract topics or concepts that represent the user’s interests (Farid et al., 2018). Nevertheless, unlike semantic network profiles that construct user profiles through the mapping process, concept-based approaches utilize pre-existing concept mappings (Brusilovski et al., 2007). In essence, concept-based profiles can be viewed as an expansion of keyword-based profiles, in which concepts replace keywords, and the weights continue to signify the extent of user interest in a specific concept.
It is also important to mention the work by Hou et al. (2022), who proposed a universal user and item representation that can be transferred to other systems (e.g., new recommendation systems) without the need to retrain the models for each specific context.
Step 4—Preference Learning
After collecting the user’s information and determining how the profile will be constructed, weights can be calculated and associated with the user’s preferences. The values of these weights can be static or dynamic. In a later part of this article, the process of profile dynamics will be explored in more detail. For now, the most common (Tang et al., 2010) preference-learning techniques are listed below.
Machine learning techniques such as
Support Vector Machines (SVMs), also a machine learning technique, are powerful models that operate by identifying the optimal hyperplane to separate data points of distinct classes while maximizing the margin between them. In the literature, SVMs have been employed to, for example, update user profiles using positive and negative feedback (Zhang et al., 2016), as well as to identify relevant documents for users from the Web (Tang et al., 2010).
Moreover, CNNs can also be effectively applied to preference learning tasks. Although CNNs were originally developed and widely adopted in computer vision for extracting visual information, their capability to detect local patterns and relationships also makes them applicable to other types of data. Recent studies have confirmed, for instance, that CNNs can capture relevant textual features for preference modeling (Qi et al., 2022). At the same time, their visual feature extraction capabilities continue to be highly relevant for RSs, as illustrated by their effective use in visual preference learning scenarios (e.g., Ben Hassen et al., 2022).
In the area of statistical methods, Naive Bayes (NB) employs Bayes’ theorem in order to compute the probability of an event happening, given prior information about the conditions associated with the event. In the context of user profiling, NB can be applied to classify unrated Web pages (Adomavicius & Tuzhilin, 2005), predict the web pages that are likely to capture a user’s interest (Isinkaye et al., 2015), and model user preferences (Brusilovski et al., 2007, p. 390).
In a multi-agent system developed for the purpose of user profiling, diverse agents collaborate and interact during distinct personalization phases, such as information collection (Eke et al., 2019). As a result, the system is capable of identifying hidden structures and capturing the inherent complexity of user behavior.
There are several filtering techniques used in recommendation systems for preference learning (Isinkaye et al., 2015). These techniques include content-based filtering, collaborative-based filtering, and hybrid-based filtering (Rana & Jain, 2014a). Content-based filtering involves recommending items based on their attributes and users’ characteristics. Collaborative-based filtering, on the other hand, recommends items based on the preferences of similar users. Hybrid-based filtering combines different filtering techniques to provide more accurate recommendations.
Finally, it is relevant to mention here the use of KGs for user profiling. Ontologies were mentioned in Step 2 as a means for textual representation, as they enable knowledge to be represented in a structured manner. Associated with the ontologies are the KGs. If, on the one hand, ontologies are semantic data models that serve as a schema layer for a KG, on the other hand, the KG represents the population of this schema, containing the actual entities and relationships defined by the ontology. As Di Noia et al. (2018) mentioned, KGs represent an advantage in selecting the most relevant features to constitute a user profile (c.f., Step 2), since the use of the ontological schema enables selecting the features by semantic relationships. However, they can also be used for preference learning using data summarization techniques, which find subsets of the KG that are most representative of a user’s preferences.
In a recent review, Zhang et al. (2024) categorized methods for Knowledge-Based (KB)-based preference learning in recommender systems into three main groups. The first is the two-stage learning method, where representations for entities and relations are learned from the KG first and then used as input for a separate recommendation model. The second is the joint learning method, which combines the objective functions of the KG embedding and the recommendation algorithm into a single objective for preference learning. The third is the alternate learning method, which alternates the training of KG embeddings and the recommendation model.
It is also important to highlight here that the use of KGs has the advantage of addressing some limitations of the traditional recommendation systems, such as data sparsity and the cold-start issue. Furthermore, they can make the recommendations explainable, which increases user trust and acceptance (Cao et al., 2019; Zhang et al., 2024).
KGs also have applications in mobile user profiling. For example, the recent work by Liu et al. (2023) showed that KGs can be constructed to model mobile users’ interactions with their urban environment, and with this, move beyond basic mobility features to also include semantic knowledge.
Another approach consists of combining KGs with reinforcement learning (Wang et al., 2020; Zhou & Wang, 2025) in order to enable dynamic, incremental user profiling (c.f., Step 5), where the KG provides a structured semantic representation of entities and relations while reinforcement learning continuously refines user models through interaction feedback. With the advent of LLMs with reasoning capabilities, a new research direction has emerged that explores the integration of LLMs with KGs, as it allows for evaluating the content generated by LLMs and reducing hallucinations. Cui and collaborators (Cui et al., 2025) reviewed this new research direction for healthcare applications, for example, for personalized clinical decision support.
Step 5—User Profile Dynamics
Profile modeling can be considered complete at this stage. In this case, user profiles are regarded as static entities, meaning they remain unchanged over time. Nonetheless, it is important to acknowledge that user profiles can rapidly become obsolete, making personalized systems ineffective over time. For instance, in social networks (Lauschke & Ntoutsi, 2012), user profiles may undergo updates due to age, new hobbies, and qualifications. If these updates are reflected in the user profile, they can lead to an accurate representation (Hawalah & Fasli, 2015) of their current short- or long-term interests.
To address that issue, profile dynamics techniques have been devised to accommodate the dynamic nature of users’ interests and requirements, thus creating dynamic profiles. Profile dynamics enables a system to identify short-term and long-term alterations in user characteristics and incorporate them into their profiles. This ensures the system can provide up-to-date and pertinent personalized recommendations, enhancing user experience and system effectiveness.
The highlighted papers of this subsection are displayed in Figure 5.
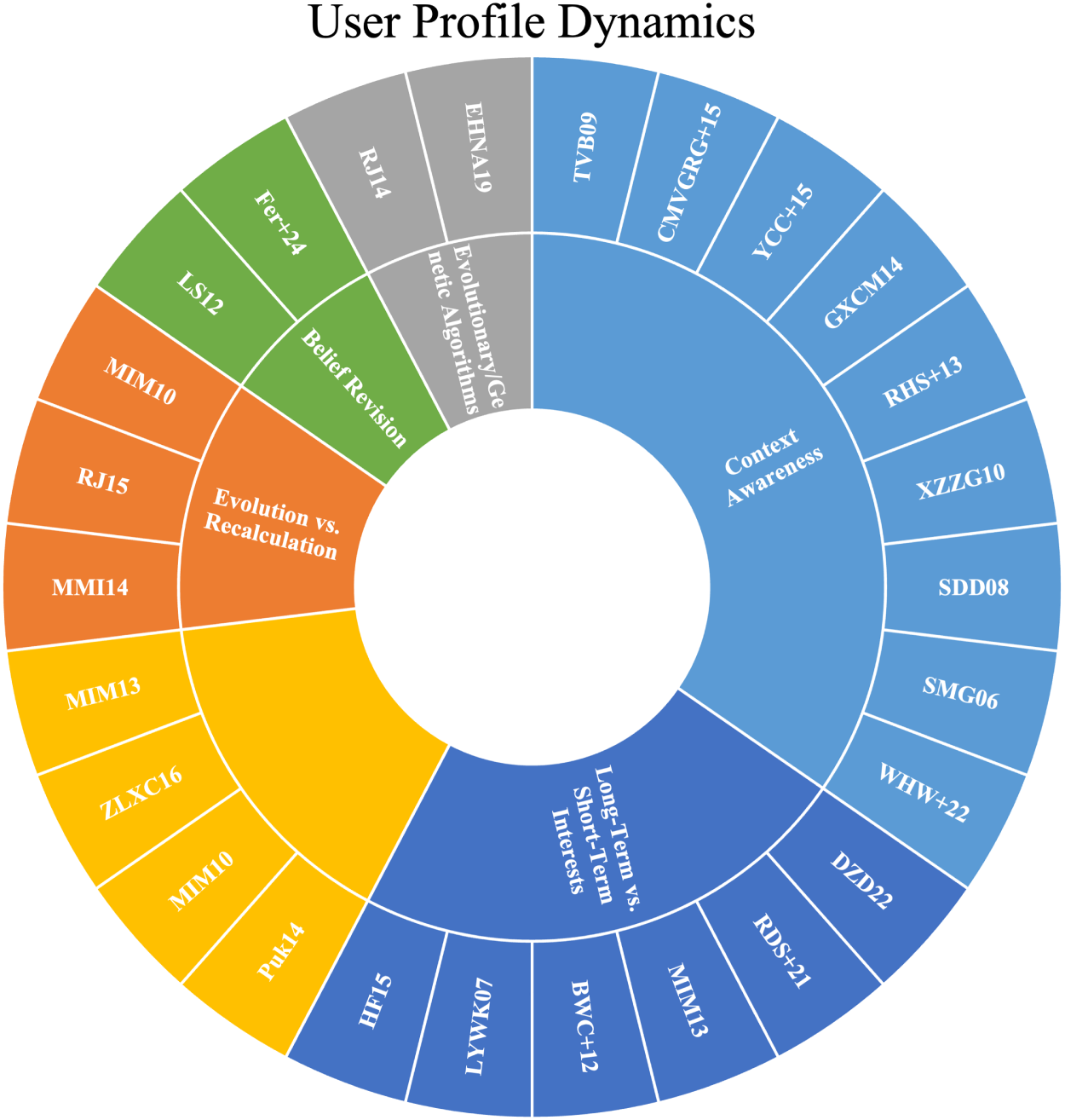
Highlighted papers on Profile Dynamics. The alphanumeric labels (e.g., MIM10, DZD22) correspond to the list of selected studies provided in Online Appendix.
One way of obtaining a dynamic user profile is by creating a user profile, based on weights, for the user’s long-term interests—which contains user interests that tend to be more stable over time—and another for the user’s short-term interests—which represents users’ current interests that change constantly. Short-term interests are usually constrained to periods, such as the previous month, week, or last session (Hawalah & Fasli, 2015).
Several works have used this technique, making relevant conclusions about the functionality of long- and short-term behavior in identifying user preferences. For example, Li et al. (2007) used independent models for both short-term and long-term user preferences. The long-term model integrated a taxonomic hierarchy, whereas the short-term model exploited the user’s recent search history. In order to accommodate evolving user preferences, the researchers implemented dynamic user profile strategies based on click-history data.
Bennett et al. (2012) studied long- and short-term activity interactions. Their findings showed that long-term interests are most helpful at the beginning of a search process, while short-term interests become increasingly valuable during extended searches. Moreover, the researchers suggested that combining both short-term and long-term profiles leads to superior outcomes compared to using either profile in isolation.
Marin et al. (2013) introduced an algorithm that incorporates dynamic user profiles by analyzing both short-term user changes (in this case, the latest user interactions) and long-term data, that is, the user’s several interactions with the system. Their study concludes that, similarly to the findings of Bennett et al. (2012), combining these two approaches improves both adaptation speed and robustness.
In the context of location recommendations, Ravi et al. (2021) proposed a recommendation framework that used two distinct agents for long-term and short-term user interests. The suggested approach prioritizes the short-term agent as it captures the user’s current preferences more effectively.
Deng et al. (2022) present a model that integrates positive and negative feedback to enhance personalized search. The model is divided into long-term and short-term modules. The long-term module analyzes users’ historical search logs, while the short-term module investigates the specifics of the user’s ongoing search interactions in the current session.
Context information at a given moment, such as the user’s current location, can also be considered a component of short-term user profiles (Yin et al., 2015). In other words, the system will use this information to adapt its behavior according to the user’s needs in that given context and circumstance. Additionally, it has been proposed that visualization of temporal graphs (Tchuente et al., 2010) can be employed to construct long- and short-term profiles rather than solely focusing on preference weights at specific time instances.
Evolution vs. Recalculation
When user interests or preferences change, user profiles must be updated accordingly to maintain accurate personalization. Generally, there are two main approaches for updating user profiles over time: recalculation and evolution (Marin et al., 2010, 2014; Rana & Jain, 2015).
In recalculation, the user profile is recalculated entirely at fixed periodic intervals (e.g., monthly), without explicitly using previous profiles. Suppose we have two consecutive profiles
In contrast to recalculation, the evolution approach progressively adjusts the existing profile by incorporating recent user activities, thus explicitly considering the user’s profile history. At any given moment, the new profile is calculated incrementally by integrating the previous profiles with recent information. Typically, the evolution approach can be summarized in the following steps: Calculate intermediate profiles at fixed intervals by applying, for example, machine learning techniques. Integrate these intermediate results with previous profile information: Gather information about user actions or interactions that occurred between profiles Convert the gathered information into training data (or training rules). Repeat steps 3 and 4 until the profile stabilizes and reaches convergence.
To make the distinction between evolution and recalculation clearer, consider a movie recommendation scenario in which a user’s preferences are modeled over time. Initially, the user profile may fluctuate as new interactions (such as watching action films or rating romantic comedies) alter the weight of genre preferences. However, as the system collects sufficient data, the profile begins to stabilize, that is, to converge toward long-term user preferences, with subsequent interactions only slightly adjusting the preference vector. In contrast, with recalculation, the system periodically recalculates the entire profile from scratch using only the most recent data. In this case, stability may be disrupted; however, the resulting profile will more accurately reflect short-term or context-dependent preferences.
Another example could be the analysis of an academic CV. The evolutionary approach looks at a researcher’s entire history to show their long-term expertise. In contrast, the recalculation approach focuses only on the last five years to highlight their current activity and recent trends.
Evolutionary/Genetic Algorithms
Evolutionary algorithms are based on the concept of evolution, such as the natural selection process, as popularized by Charles Darwin. In user profile modeling and evolution, these algorithms are used to find and update users’ interests by constantly applying, for example, genetic operators like selection, mutation, and crossover until an optimal solution is obtained.
El Houda et al. (2019) proposed a genetic algorithm that updates the user’s interests by using their queries and current interests. In the proposed algorithm, the weight of the queries or interests is used to create genes, which are then used to create chromosomes. Chromosomes are iteratively transformed by applying genetic operators until an optimal solution is found or a stopping criterion is satisfied.
Rana and Jain (2014b), on the other hand, propose an evolutionary clustering algorithm called EVAR (Evolution VARiance clustering algorithm). This algorithm aims to group similar users into clusters and then evolve these clusters to accurately represent the users’ evolving preferences over time.
Adaptation Algorithms/Rules
In this algorithm class, algorithms adapt their behavior based on the information fed to them before they are run. Several works (Marin et al., 2013; Zhang et al., 2016) propose an adaptation algorithm where the options selected by the user are constantly analyzed to make items similar to those selected rank higher and nonselected items rank lower in the future.
Marin et al. (2010) introduced a similar algorithm. In their algorithm, adaptation occurs in two phases, namely: 1) an online phase where the preference is decreased for undesired attributes and increased for desired attributes; 2) an offline phase where the over-ranked items collected over time are analyzed to find which characteristics appear more frequently (over a certain threshold) and then increase the preference for them.
López-Jaquero et al. (2009) developed adaptation rules and applied them to interface development, whereas Pukkhem (2014) worked on a set of adaptation rules for a system in the e-learning context.
Context Awareness
Another way to achieve dynamic user profiles is through context awareness, a technique that presents the system with information about the context in which the user is inserted (e.g., location). Several studies have shown the successful application of context-awareness systems, even in the domain of profile evolution (Thomsen et al., 2009). For instance, Wu et al. (2022) introduced a method that incorporates contextual information as a part of user data, with the objective of making content-enriched models also context-aware. Schaefer et al. (2006) presented a context-aware framework designed for the customization of smart home environments with multiple devices situated in diverse contexts within the home. Similarly, SMARTMUSEUM (Ruotsalo et al., 2013) is a context-aware ubiquitous RS designed specifically for tourists. This system offers real-time recommendations of cultural information, catering to the unique needs of each individual tourist.
Ontologies have shown their efficacy as tools for modeling user context, with the proposal of standard ontologies in the process of modeling user context (Golemati et al., 2007). Sutterer et al. (2008) introduced a user profile selection method that selects a profile based on the user’s current environment. This method also leverages ontologies to facilitate the modeling of context.
In the domain of content selection and presentation, Xu et al. (2010) proposed a method that handles various types of contextual information. This method goes beyond conventional context attributes such as time, device, and location, also making use of sensor data such as temperature and ambient light levels, as well as outputs from other context-reasoning systems, such as user activity recognition and mood detection.
In the domain of user modeling, Gao et al. (2014) developed a context-aware personalized approach that tracks users’ digital behavior and query patterns to update their preference profiles. Yin et al. (2015), on the other hand, proposed a temporal context-aware mixture model that combines intrinsic user interests with temporal context to analyze social media behavior.
Furthermore, Colombo-Mendoza et al. (2015) presented the RecomMetz, a context-aware, knowledge-based mobile movie recommendation system. Interestingly, this system takes into account location, time, and crowd information for recommendations, incorporating a domain ontology as the main component of its recommendation process.
Belief Revision
The AGM belief revision model (Alchourrón et al., 1985; Fermé & Hansson, 2018) is a formal framework to represent the dynamics of the belief of a rational agent. To the best of our knowledge, there are not many works that relate belief revision to users’ profiles. In particular, we can mention two papers: Fermé et al. (2024) proposed a method, based on AGM, for creating and dynamizing user profiles to represent and review information about users’ interests. It also focuses on defining and enforcing the principle of consistently making minimal changes to the user profile. That means ensuring that changes to users’ interests do not happen abruptly and that no significant changes can happen; instead, changes to the knowledge base should be slow and steady (Lau, 2002). That article also proposed a way to create, represent, and update user profiles by presenting and characterizing four operators to achieve profile dynamics through a belief revision-inspired approach.
The second paper is by Lau and Song (2012). In that paper, the authors developed a service recommendation agent based on belief revision logic to handle the non-monotonicity problem in web service recommendation. They applied belief revision-based reasoning to determine the most suitable context for the initial service request based on the beliefs stored in the user’s profile. After service request reasoning, the set of potential web services is identified and ranked. The highest-ranked services are considered to be the most desirable ones that match the user’s specific interests.
Applications
User profiles are primarily used in two main types of systems: RSs and personalized/adaptive systems. RSs use information from user profiles to suggest specific items (such as products, songs, or movies) that align closely with users’ interests and preferences. On the other hand, personalized or adaptive systems use user profiles in a broader sense. They not only deliver personalized content but also dynamically adjust their behavior, interfaces, and functionalities according to users’ characteristics, needs, and context.
Recommendation Systems
RSs are systems that use the information provided by the user profile about the user’s interest in a particular item (e.g., movie, song, or book) to recommend other similar items to the user (Bobadilla et al., 2013). This study area emerged in the mid-1990s when researchers focused on predicting the ratings of items the user had not yet seen.
It is important to highlight that RSs have been successfully applied in various heterogeneous, human-centered, and socially relevant fields. Examples include applications in education (da Silva et al., 2023), healthcare (Chang et al., 2021), and social media (Aivazoglou et al., 2019).
RS can be classified as Collaborative Filtering (CF) Recommendation, Content-Based (CB) Recommendation, and KB Recommendation. Additionally, hybrid recommendation approaches exist, combining these different recommendation techniques. Hybrid methods aim to overcome the limitations of one approach by leveraging the strengths of another, thus achieving more effective results (Adomavicius & Tuzhilin, 2005; Isinkaye et al., 2015).
Before describing the different recommendation approaches, we highlight the Cross-Domain Recommendation (CDR) systems. CDR systems integrate user preferences and interaction data collected from multiple domains to enhance recommendation quality. Since they can integrate data from multiple domains, these systems can also help reduce common issues such as data sparsity and the cold-start problem (Zang et al., 2022).
It is worth mentioning here the work by Berkovsky et al. (2007), which represents, to the best of our knowledge, one of the earliest studies addressing CDR systems in the context of collaborative filtering. More recently, Chen and Lee (2024) integrated the notion of profile evolution into a CDR system. We note that if a CDR system aims to improve recommendation accuracy across multiple domains simultaneously, it is referred to as a multi-target recommendation system. For an in-depth exploration of CDR systems, we refer the reader to the recent survey by Zhu and team (Zhu et al., 2021).
Collaborative Filtering Recommendation
CF compares the target user to other users and finds similarities between them. The users with greater similarity are then grouped into neighborhoods or clusters. The previous ratings of these groups are analyzed to find items that have not yet been rated by the user but might be of interest based on the positive ratings.
This is the most widely used recommendation technique and is best suited for recommending items that are difficult to describe in an objective manner, such as movies, art pieces, or music (Isinkaye et al., 2015).
CF can be classified as Model- and Memory-based. Memory-based methods consist of heuristics that use the information collected about the interests stored in the user profile to make predictions (e.g., similarity metrics to obtain the distance between users and items). On the other hand, model-based methods use the interests information to fit a model that will later be used to make recommendations by predicting their effectiveness in satisfying the user’s needs (Adomavicius & Tuzhilin, 2005; Bobadilla et al., 2013).
Table 1 presents some of the most common techniques used in CF according to their classification. In this table, clustering appears as both a model- and memory-based method. This is because clustering builds abstract user or item groups that function as models, yet its construction and updating rely directly on stored interaction data to compute similarities and reassign members. Other approaches, such as regression or neural networks, cannot be considered hybrid since their learned parameters replace the need for direct access to historical data during inference, while purely memory-based methods rely exclusively on those stored interactions.
A List of the Most Used CF Techniques (Adomavicius & Tuzhilin, 2005; Bobadilla et al., 2013).
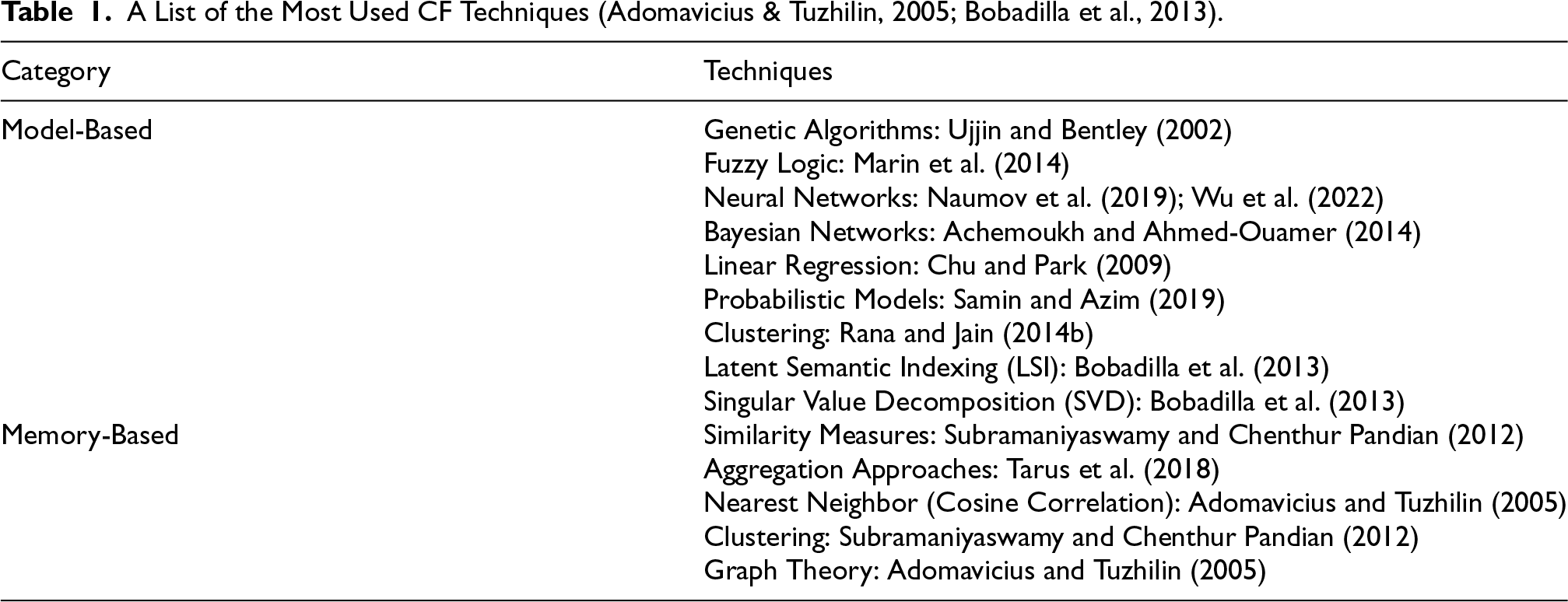
A List of the Most Used CF Techniques (Adomavicius & Tuzhilin, 2005; Bobadilla et al., 2013).
CF strategy works well when dealing with difficult items (such as non-objective items) to describe because they depend on factors like opinions. It can also make new and effective recommendations that are not represented in the user profile by detecting interests that the target user has yet to show, but that similar users have already expressed.
However, one of the main limitations in CF is known as the cold-start problem, which happens at the beginning of the interaction when the system does not have enough information about the user to find their neighbors and make accurate recommendations (Bobadilla et al., 2013). Data sparsity is also a common problem because users are often unwilling to spend time writing reviews or providing feedback. As a result, a lot of information is missing from the database (Isinkaye et al., 2015). Due to the processing of vast amounts of data, scalability is also considered a problem, especially when the number of users grows. MapReduce can, however, minimize this problem (Chen et al., 2015). Finally, synonymy problems or polysemy may occur when similar items have different names in the database but similar meanings, making it challenging to distinguish similar items (Isinkaye et al., 2015).
Nevertheless, several studies have explored the use of CF for real-world recommendation problems. For example, Chu and Park (2009) proposed a recommendation framework for Yahoo! News that applied CF and addressed the cold-start issue by enriching user profiles with dynamic features. Rana and Jain (2014a, 2014b), on the other hand, introduced an evolutionary clustering algorithm designed to identify groups of similar users more accurately.
In the context of digital libraries, Chen et al. (2015) proposed an RS based on pairwise user similarity computed via an ontology model. Additionally, Da’u et al. (2020) developed a deep learning model for extracting product features, aiming to improve CF-based recommendations.
In another study, Ravi et al. (2021) presented a location recommendation system built upon a multi-agent framework, which also integrated short- and long-term user behaviors for dynamic recommendations. Finally, Lu et al. (2016) proposed a method called Collaborative Evolution (CE), which integrates MF and autoregressive vectors into a unified learning framework. In their method, users’ latent interests at different points in time are iteratively learned through CF, and the temporal evolution of these interests is explicitly modeled to guide the learning process further.
This method analyzes past user interactions with the system, identifies which items the user liked in the past, and searches for similar ones to recommend. This type of recommendation is ideal for document recommendations, such as books and news.
CB systems can be classified into case-based reasoning and attribute-based techniques. Case-based reasoning recommends items that are most related to items the user previously liked. On the other hand, the attribute-based technique focuses on the features of the items liked in the past and recommends new items with those same features (Tarus et al., 2018). Some of the techniques used in this kind of system are Bayesian Classifiers, Clustering, Decision Trees, and Artificial Neural Networks.
These systems have the benefit of not depending on the information from other users, thus relying only on the information of the target user; to adapt their recommendations quickly; to be more private because users do not have to share their profile information for the system to function; to support explainable recommendation since they base their recommendations on item features which facilitate explainability (Isinkaye et al., 2015). However, they depend on the items being described accurately and extensively to make practical and accurate recommendations. They can also suffer from overspecialization, which happens when users get similar items consistently and cannot discover new interests. The cold-start problem can also challenge the usability of these systems (Adomavicius & Tuzhilin, 2005).
Several studies have applied CB recommendation methods. For instance, Mehrpoor and collaborators (Mehrpoor et al., 2015) presented a RS designed to facilitate knowledge accessibility in an engineering environment, benefiting from both CB and collaborative filtering techniques. Additionally, Liu et al. (2018) proposed a CB RS that leverages ontological information.
Knowledge-Based Recommendation
This method performs a deep analysis of the items and uses this knowledge to find ways to satisfy specific user needs (Felfernig et al., 2006). This deep knowledge is sometimes accomplished by using ontologies to represent it because they can be used to describe objects semantically without the constraints of other models (Colombo-Mendoza et al., 2015; Tarus et al., 2018).
These systems have an advantage over CF and CB systems. More specifically, they do not suffer from problems that stem from new users and new items (e.g., cold-start problems) or rating sparsity problems because they make use of the deep knowledge acquired on the items to calculate recommendations (Adomavicius & Tuzhilin, 2005; Tarus et al., 2018).
Some limitations of KB systems are the need for an understanding and knowledge of engineering skills (Tarus et al., 2018) and the need for deep knowledge acquisition of the problem at hand. For this reason, the majority of these types of systems are developed for areas where domain knowledge is easily available (Adomavicius & Tuzhilin, 2005).
Applications of KB recommendation methods can be found in the literature. For example, Felfernig et al. (2006) developed a KB recommender called CWAdvisor, illustrating its use in two distinct scenarios: as a digital camera advisor and as a financial service advisor. Another study by Codina and Ceccaroni (2012) presented KB RSs that use semantic relationships between items to enhance recommendation performance, describing various approaches for creating semantically enriched models. Additionally, Ruotsalo et al. (2013) proposed a KB recommender focused specifically on tourism sites, such as museums. Finally, Colombo-Mendoza et al. (2015) introduced a context-aware KB recommendation system designed to recommend movie showtimes.
Explainability in Recommender Systems
Over time, user profiling methods have evolved from simple rule-based systems toward more complex machine learning models (Prottasha et al., 2025). With this increasing complexity, the resulting recommendation systems have also become less transparent, often behaving as black-box models lacking clear explanations about how they generate recommendations.
This lack of transparency motivates the need for explanations in RSs, leading to the emergence of eXplainable Artificial Intelligence (XAI) techniques in the area of recommendations. Explanations help users better understand why (Zhang & Chen, 2020) certain items were recommended to them. Besides improving the overall user experience (Afchar et al., 2022), explanations can provide several additional benefits, according to the literature (Tintarev & Masthoff, 2007), namely: Transparency—Show the user how the system chose the recommended item. Scrutability—Give the user the ability to correct the system in the case of an ineffective recommendation (e.g., “not interested” button). Trust—Measure how much the user trusts the system, which can be achieved by questionnaires or by analyzing customer loyalty and sales numbers. Persuasiveness—The ability of the system to convince the user to choose an item they would typically not be interested in. Effectiveness—Help users make the correct decision according to their preferences. Additionally, the level of satisfaction with the item before and after an action can be analyzed to see if it really was a good fit for the user. Efficiency—The user should be able to use the system and select recommendations quickly. This can be measured by seeing how long the user took to complete a task. Satisfaction—Aims to increase the users’ satisfaction with their choices and with the system.
Additionally, Zhang and Chen (2020) proposed categorizing explainable recommendation system problems according to the dimensions of what, when, who, where, and why (5W).
There are several examples of systems that incorporate explanations into their recommendation processes. One example is a General Knowledge Enhanced Framework for Explainable Sequential Recommendation (GFE) (Yang et al., 2021). This system captures users’ preferences along with the evolution of their dynamic interests. Another example is the User-Centric Path Reasoning (UCPR) (Tai et al., 2021). This framework creates explainable recommendations by guiding the recommendation search process according to user demands, thereby enhancing the diversity of explanations provided. Lastly, a system called Temporal Meta-path Guided Explainable Recommendation (TMER) (Chen et al., 2021) achieves explainable recommendations by sequentially modeling evolving user-item interactions within a dynamic KG.
Generative Recommendation
Unlike traditional discriminative models that rank a fixed set of candidates, generative recommendations utilize LLMs to formulate recommendations as a language generation task. These recommendations are typically interactive, explainable, and contextually adaptive. Nevertheless, Wu et al. (2024) categorize LLM-based recommendation systems into discriminative and generative LLMs. In discriminative approaches, the model serves as an encoder that extracts semantic embeddings to improve ranking or matching accuracy. This means that LLMs can also perform feature extraction tasks, producing representations that serve as input for RSs. In contrast, generative models operate as autonomous sequence generators that synthesize personalized outputs directly from text prompts containing user, item, and contextual features.
Several studies have explored how LLMs can maintain and update user profiles over time (Jiang et al., 2025; Sabouri et al., 2025). Jiang et al. (2025), for example, evaluated how LLMs can construct, remember, and adapt evolving user personas across multiple interactions. Sabouri and team (Sabouri et al., 2025) suggested an explainable temporal user profiling framework in which a LLM generates concise natural-language representations of short- and long-term user histories.
Chen et al. (2024) argue that LLMs will enable current recommendation systems to be more than content filtering, transforming them into interactive service generators where models can plan, reason, and create customized responses through natural language. Kirk et al. (2023), with the focus on model alignment, complements this view and suggests applying reinforcement learning with human feedback as a mechanism for fine-grained adaptation of model outputs to user preferences and values.
Regarding user segmentation, Li et al. (2025) applied a generative model to consumer segmentation, and showed that LLMs can synthesize realistic persona-driven conversations and predict segment-specific preferences with high consistency. Similarly, Salemi et al. (2024) introduce a benchmark, which evaluates an LLMs’ capacity to adapt its outputs across seven personalized text classification and generation tasks. These two works suggest that LLMs can simultaneously encode user intent, retrieve relevant historical data, and generate adaptive recommendations.
A natural extension is to use the multimodality capacity of some of these models to improve the task of user profiling (in other words, to make the user profile richer in information). Indeed, these models can be used for multimodal embedding fusion, in which image, audio, and text features are aligned within a shared latent space to support generative recommendation (Qiang et al., 2025; Shen et al., 2024). This multimodal capacity aligns closely with emerging paradigms of Artificial Intelligence (AI) agents (Zhang et al., 2025), where, through collaboration within an ecosystem of multimodal agents, one can obtain enriched user profiles with contextual, multimodal information, thus enabling better generative and adaptive recommendations. For example, Zhang et al. (2025) considered users and items as intelligent agents capable of perceiving, reasoning, and interacting across modalities, while continuously exchanging information to co-evolve their understanding of preferences and contexts. In other words, this allows each agent to continuously learn and collaboratively refine user profiles and recommendations.
Personalized/Adaptive Systems
Personalized systems use information from user profiles to adapt their interface and behavior according to users’ needs and preferences. Typically, personalization aims to display content that interests users and filter out irrelevant items. Additionally, personalization can include other more detailed adaptations, such as adjusting the font size and style based on the user profile (Browne, 1990). According to Fan and Poole (2006), personalization can be described across three main dimensions: (a) what is personalized, referring to the type of content presented, the presentation style, the information delivery channel, or the functionality itself; (b) the target of personalization, referring either to specific user groups (e.g., pet owners, families with small children) or individual users; and (c) who performs the personalization, reflecting the degree of automation involved in the user-modeling process. When users explicitly provide information to the system, personalization is called explicit personalization. Conversely, if the system automatically performs profile adaptation, this is known as implicit personalization.
Various studies have explored personalization approaches in different domains, including personalized search and e-learning. In the area of personalized search, Moukas (1997) introduced a system called Amalthaea, which provides personalized search capabilities through information filtering. Achemoukh and Ahmed-Ouamer (2014) proposed a method for modeling and representing long- and short-term user profiles based on Dynamic Bayesian Networks. Similarly, Hawalah and Fasli (2015) presented a multi-agent personalized search system, which dynamically builds user profiles by analyzing both short-term and long-term user interests inferred from previously visited web pages.
In the context of e-learning, several personalization approaches can also be found. For example, Le et al. (2009) proposed a generic model capable of providing personalized learning resources and services within blended learning contexts. Razmerita and Lytras (2008) introduced an ontology-based user modeling framework, tested within the context of a semantic learning portal, highlighting the explicit use of user modeling in adaptive systems. Another work by Le et al. (2010) discusses the application of user profiles in Adaptive Instructional Systems, aiming for improved utility in blended-learning scenarios.
It is important to note that although many authors use the terms “personalized” and “adaptive” systems interchangeably (Le et al., 2010), a key difference separates the two concepts. Adaptive systems explicitly take into consideration changes in user profiles over time; in other words, adaptive systems explicitly incorporate profile dynamics.
In this context, LLMs have started to be considered as promising systems capable of combining personalization (via, e.g., personas) and adaptation capabilities. User profiles constructed from previous interactions with these models can be used to personalize the model’s future outputs and responses (Salemi et al., 2024). Besides user segmentation (Li et al., 2025), LLMs can also perform feature extraction tasks, producing representations that serve as input for RSs, or even directly generating recommendations expressed in natural language (Wu et al., 2024). Another recent approach involves reinforcement learning based on human feedback, which helps to better capture the user profiles, thus providing higher-quality recommendations (Chen et al., 2024). Nonetheless, existing techniques still face limitations in effectively capturing users’ current situations and the dynamic nature of user preferences (Jiang et al., 2025). On the positive side, recommendations and user profiles generated by LLMs tend to be easier to explain compared to traditional deep learning models (Sabouri et al., 2025). However, it is important to highlight recent concerns regarding alignment issues in LLMs, emphasizing the need for careful system design and evaluation to avoid undesired system behaviors (Kirk et al., 2023).
Conclusion
This review has explored the literature on user profile modeling and profile dynamics. We believe that the proposed taxonomy, which includes user profile modeling, user profile dynamics, RS, personalized systems, and adaptive systems, has helped clarify the discussion and provided a structured overview of existing research in the field.
We highlighted how accurate and frequently updated user profiles enhance the effectiveness of personalized and adaptive systems. Specifically, we discussed several methodologies for creating user profiles, techniques for keeping them up-to-date over time, and the primary application domains where these profiles are employed.
Several conclusions can be drawn from our analysis. First, user profiles play a key role in enabling personalization across different systems, such as RS, personalized interfaces, and adaptive applications. Second, both explicit and implicit data collection methods provide valuable input when creating user profiles. Hybrid approaches, in particular, help improve profile quality by combining the strengths of implicit and explicit user information. Third, differentiating between short-term and long-term user interests is important for dynamic user profiling, as capturing both timeframes leads to better personalization and recommendation accuracy. Fourth, profile dynamics techniques, such as context-awareness methods and belief revision frameworks, help address natural user profile evolution effectively. Fifth, explainability has become increasingly important for recommendation systems, as it can make recommendations easier to understand, improve user trust, and provide greater user satisfaction. Finally, recent developments involving LLMs have shown promise for achieving advanced user modeling and producing personalized natural-language recommendations. However, alignment and ethical considerations still need further attention.
Although substantial progress has been made, some important research directions remain open for exploration. First, it is worth exploring multimodal and heterogeneous data integration further. In particular, new approaches leveraging multimodal deep learning architectures may help create richer and more informative user profiles. Second, developing scalable user profile update methods that can handle dynamic changes in real-time is another significant challenge, especially as personalized systems continue to grow in size and complexity. Third, given the rising concerns about user privacy and regulations such as the GDPR, research into privacy-preserving approaches, for example, federated learning, is expected to become more important. Fourth, more effective methods to capture contextual and situational information will enhance the adaptation of user profiles, particularly in mobile and ubiquitous computing scenarios. Finally, another promising research direction would be the development of universal and holistic user profiles capable of generalizing across multiple platforms, applications, and usage contexts.
The word cloud presented in Figure 6 was generated from the corpus of extracted articles and visually highlights the most frequently occurring terms related to user profiling. In the word cloud, the size of each term directly reflects its frequency in the analyzed literature.

Word cloud showing the most frequently used terms in the extracted papers.
As illustrated in the figure, the terms “recommendation” and “recommendation systems” appear frequently, suggesting that recommendation systems represent one of the primary applications of user profiling. Within the scope of recommendation systems, several studies propose approaches that dynamically adapt recommendations to the user’s current contextual environment.
Supplemental Material
sj-pdf-1-eai-10.1177_30504554251407092 - Supplemental material for User Profiling and Its Dynamics: A Narrative Review
Supplemental material, sj-pdf-1-eai-10.1177_30504554251407092 for User Profiling and Its Dynamics: A Narrative Review by Diogo Nuno Freitas, Katherin Varela and Eduardo Fermé in The European Journal on Artificial Intelligence
Supplemental Material
sj-pdf-2-eai-10.1177_30504554251407092 - Supplemental material for User Profiling and Its Dynamics: A Narrative Review
Supplemental material, sj-pdf-2-eai-10.1177_30504554251407092 for User Profiling and Its Dynamics: A Narrative Review by Diogo Nuno Freitas, Katherin Varela and Eduardo Fermé in The European Journal on Artificial Intelligence
Footnotes
Acknowledgements
We would like to thank the reviewers for their constructive comments, which have improved the quality and readability of our manuscript.
Funding
The authors received the following financial support for the research, authorship and/or publication of this article: This paper was partially supported by FCT (Fundação para a Ciência e a Tecnologia), Portugal, through the project PTDC/CCICOM/4464/2020 and by project M1420-01-0247-FEDER-000073 in the Operational Program for the Autonomous Region of Madeira (Madeira 14–20). E.F. was partially supported by FCT through project UIDB/04516/2020 (NOVA LINCS). D.N.F was supported by the Portuguese Foundation for Science and Technology with the grant number 2021.07966.BD (![]() ).
).
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.