
Abstract
In the rapidly evolving field of digital security, this study aims to advance image steganography by developing and benchmarking seven deep learning architectures with a focus on imperceptibility, embedding capacity, and robustness against steganalysis. The models implemented include the residual dense network (RDN), vision transformer with adaptive attention (ViT-AA), progressive generation network (PGN), dual-stream architecture (DSA), wavelet-based hybrid network (WHN), mutual attention transformer (MAT), and efficient attention pyramid transformer (EAPT). Using the PyTorch framework and standardized datasets such as DIV2K, COCO, and ImageNet, each architecture was trained through structured preprocessing and evaluated using metrics including PSNR, SSIM, LPIPS, and statistical steganalysis resistance. Experimental results demonstrate that WHN achieved the highest visual quality (PSNR
Keywords
Introduction
Steganography is the art of hiding secret messages inside harmless carriers (Fridrich, 2009; Goodfellow et al., 2016). It has thus emerged as one of the most needed techniques for communication security in the digital age. Messages are commonly contained within seemingly innocent carriers such as images, audio, or video files (Fridrich, 2009). This cleverly kept secret of disguising information behind simple masks makes it very hard for the nefarious elements to take the information out to the unauthorized access and knowledge.
The traditional forms of protection are rooted in cryptography and encryption (Fridrich, 2009). This, however, effectively runs the integrity but compromises majorly and gets attracted unduly during transmission of sensitive information. On the other front stands steganography, hiding the very existence, tempting the enemy to detect and intercept (Fridrich, 2009; Song et al., 2024). Nevertheless, many classic steganographic methods have certain shortcomings—restrictions upon the range of embedding possibilities, vulnerabilities to other forms of attack, and a limited range of security (Baluja, 2017; Song et al., 2024). The challenges tend also to be related into these deep-seated shortcomings, as they critically depend upon the statistical properties of the cover medium which the enemy is always in a position to exploit for the not-so-easy-to-reveal coded messages.
To meet the challenges posed by steganography, one of the areas of intense interest these days is that of harnessing the advanced techniques, particularly by utilizing artificial intelligence (AI) with deep learning (Baluja, 2017; Goodfellow et al., 2016). It is possible to develop more powerful and effective steganography systems able to learn complex dependencies and patterns within data, using these advanced AI and deep learning techniques (Song et al., 2024). This ensures that secret messages are finally embedded in such a way that they become much more visible and difficult to detect.
In this paper, we examine how advanced deep learning architectures provide the security of image steganography. We analyze how five contemporary advanced techniques-residual density network (RDN), vision transformer with adaptive attention (ViT-AA), progressive generation network (PGN), dual-stream architecture (DSA), and wavelet-based hybrid network (WHN)-fare. The comparison describes the strengths and weaknesses of these techniques for future research directions toward advancements in secure image steganography (Goodfellow et al., 2016; Song et al., 2024).
Background
Evolution of Image Steganography Toward Deep Learning Architectures
The origins of steganography can be traced back to ancient civilizations where messages were hidden in physical media such as wax tablets, invisible inks, or even shaved heads with regrown hair concealing messages. In the digital era, steganography evolved into embedding information within multimedia carriers such as images, audio, and video. Early computational approaches primarily employed spatial-domain techniques such as least significant bit (LSB) substitution (Chandramouli et al., 2004), where message bits replace the LSBs of pixel values. While simple and offering high payloads, such methods were highly vulnerable to statistical and visual steganalysis. To overcome these weaknesses, frequency-domain approaches emerged, leveraging transforms such as the discrete cosine transform (DCT) and discrete wavelet transform (DWT) (Provos & Honeyman, 2003). These approaches offered improved robustness and imperceptibility but remained constrained by limited embedding capacity and distortion trade-offs.
A major shift occurred with the adoption of machine learning techniques. Statistical models such as HUGO and rich models (SRM) (Fridrich, 2009) enhanced detection resistance by exploiting high-dimensional features, but they were computationally expensive. The breakthrough came with deep learning. Baluja’s deep steganography framework (Baluja, 2017) demonstrated that autoencoders could jointly optimize embedding and extraction, producing stego-images of high visual fidelity. This was followed by adversarial training frameworks such as HiDDeN (Zhu et al., 2018) and SteganoGAN (Zhang et al., 2019c), which significantly advanced imperceptibility and robustness through the use of convolutional neural networks (CNNs) and generative adversarial networks (GANs).
More recently, attention-based and transformer architectures have been introduced to exploit long-range spatial dependencies for adaptive embedding (Lin et al., 2023). In parallel, iterative optimization and diffusion-based approaches such as iterative neural optimizers (Chen et al., 2023) and CRoSS LoRA (Yu et al., 2023) have pushed the field toward more adaptive and content-aware frameworks. Very recent developments, including multi-layered deep learning steganography (Sanjalawe et al., 2025) and invertible neural networks for reversible hiding (Zhou et al., 2025), highlight the growing specialization and maturity of modern steganographic systems.
This historical progression illustrates the steady evolution from simple spatial substitution methods to sophisticated deep architectures capable of balancing imperceptibility, robustness, and embedding capacity. The present study builds on this foundation by benchmarking diverse modern architectures to provide a comprehensive analysis of their respective strengths, limitations, and practical deployment implications.
General Framework of Image Steganography
In image steganography, secret data is hidden inside a cover image, and produced is a stego-image virtually indistinguishable from the original (Holub & Fridrich, 2012; Kumar et al., 2020). The general structure of image steganography includes the following main components (Holub et al., 2014):
The embedding process can be mathematically represented as:

The extraction process can be represented as:

Figure 1 depicts the general schema of image steganography. The major parts of this schema include cover image processing, secret message embedding, and stego-image extraction. This framework defines the mathematical relationship among them through

General framework for image steganography.
This area of steganography has been an exciting subject for many years to be constantly under research investigation, where scientists have broadly explored many kinds of strategies and techniques meant to enhance the capacity, visual fidelity, and security of covert communications systems (Husien & Badi, 2015; Ruohan Meng & Cui, 2018). These approaches have, in turn, challenged many traditional methods, including the well-established LSB substitution and spatial domain methods, with respect to their ability to effectively manage the delicate trade-off between embedding capacity and detection resistance (Pevný et al., 2010). This led to the development of alternative methodologies and innovative advancements in steganography to respond to the demands and requirements of modern covert communication systems.
One of the most important techniques found and quite well analyzed in the steganography domain is referred to as LSB substitution (Holub & Fridrich, 2012; Holub et al., 2014). The LSB of the image’s bits can be substituted by a corresponding secret message, a seemingly very simple yet accessible process that makes this method permit an impressively high storage of embedded secret data besides vulnerability to statistical attacks whereby it would not take so long for a hacker to decode hidden data. Wang et al. (2024) recently proposed a robust blind image watermarking technique based on interest points, demonstrating continued innovation in information embedding strategies. Dedicated scholars and experts have come up with various complicated and sophisticated spatial domain approaches to strengthen security operations (Husien & Badi, 2015). Some of the major examples of these advanced approaches are the use of pixel value differencing as well as adaptive pixel pair matching techniques (Ruohan Meng & Cui, 2018). However, it should be noted that the alternative approaches often work like a double-edged sword since they might inadvertently lead to a decrease in the embedding capabilities or, in some cases, visible distortions within the acquired stego-image.
To avoid these drawbacks of spatial domain methods, researchers have explored extensively on the frequency domain approach, specifically in the context of DCT or DWT (Holub et al., 2014; Pevný et al., 2010). Hu et al. (2023) recently proposed StegaEdge, a novel learning-based approach that leverages edge guidance for steganographic embedding, further expanding the potential of frequency domain techniques. Also, some recent advancements demonstrate the potential of deep learning techniques in improving steganographic methods for high dynamic range images (Huo et al., 2024). The basic premise here is that transform coefficients hide the secret message, thereby reducing susceptibility to statistical steganalysis (Husien & Badi, 2015). Prominent examples are strategies carefully modifying DCT or DWT coefficients by resorting to models of the human visual system or even adroit embedding techniques tailored according to specific situations (Ruohan Meng & Cui, 2018). There is an important remark regarding the fact that methods of the frequency domain yield greater security but often incur an easily broken trade-off between the embedding capacity and the perceptual quality.
The emergence of machine learning algorithms has provided new opportunities for the development of more secure and durable steganographic systems (Liu et al., 2021; Zhang et al., 2017). Lin et al. (2024) explored hierarchical iterative decoding enhancement techniques in multiview 3D parameter regression, showcasing the versatility of deep learning approaches across different domains. Lee and Kang (2024) explored the potential of vision transformers (ViTs) in image inpainting, demonstrating the versatility of transformer architectures in image processing tasks. For instance, one deep architecture, the RDN, is very popular since this model has demonstrated a tremendous approach toward the image restoration and improvement capabilities (He et al., 2016; Zhang et al., 2017); thus, making RDN a good choice also in steganography. Thus, the application of RDN to steganography may leverage its ability to learn sophisticated features in images and to embed messages in a manner that is imperceptible to human and machine learning-based detection algorithms (He et al., 2016; Zhang et al., 2019a). It is achieved by exploiting the hierarchical structure of RDN, which includes dense blocks and residual connections (He et al., 2016). Dense blocks of RDN ensure that efficient reuse of features takes place. The fidelity of images is conserved even after the embedding of messages (Zhang et al., 2017).
Further, the residual connections of RDN improved the strength of the steganographic system as the network can learn the residual information between the layers and can avoid noises and distortion happening due to embedding processes (He et al., 2016; Zhang et al., 2019a). This resistance to image degradation assures that the hidden messages will be recovered with consistency despite numerous forms of attacks or corruptions. Combining all of these features, RDN is a promising candidate in secure information hiding efforts, thereby paving a reliable and efficient avenue toward the development of steganographic systems, where it is possible to defy detection attempts from human observers as well as machine learning algorithms. In summary, RDN is one promising methodology toward more effective and stronger steganographic construction. The RDN would make the hierarchical structure along with dense blocks and residual connections for imperceptibility. During this embedding, both the fidelity of images as well as robustness were preserved. In the end, while further developing this steganography domain, the proposed RDN does seem a highly appealing candidate toward securely concealing information in different applications.
ViTs have also shown great potential in the field of steganography (Dosovitskiy et al., 2020; Liu et al., 2021). The multilayer attention-based structure of the ViT makes this architecture good at looking deeper into the long dependencies in images which becomes quite an important parameter for successful hiding (Dosovitskiy et al., 2020). Exploring these features, ViT-AA achieves high capacity of embedding with maintaining solid security. In contrast to other complex texture patterns, focused attention mechanisms incorporated in ViT-AA improve handling such intricate textures and better adjust to the requirements of the steganographic task (Li et al., 2015; Zhang et al., 2019a). It allows the use of ViT-AA as an ideal tool for steganography practitioners that enables unprecedented levels of concealment and robustness against all detection techniques. It makes possible further expanding potential of information hiding within images by new applications and domains of secret communication. From hidden communication to encryption of data, ViT-AA offers a flexible and adaptable solution that pushes beyond the boundaries of steganographic techniques. Not only does it provide for safe data transfer, but also this combination of ViTs with steganography works as a stepping stone towards further progress in digital forensics where the detection and extraction of hidden information form an important element of the investigation process. Further developments and improvements into ViTs are promising to brighten the future of steganography, full of endless possibilities for creative new techniques and applications that find a niche in our increasingly interconnected world.
Another deep learning framework is the PGN, which has been adapted to applications in steganography (Zhang et al., 2017). Systematic refinement will result in PGN, concealing confidential information in the layers of an image, quality enhancement, and security. Such a method is critical when there is a great need to maintain an adequate balance between embedding capacity and fidelity of the image (He et al., 2016). PGN’s innovative approach allows for a covert embedding of encrypted information in the image layers with a view to strengthening the security mechanisms. By careful image enhancement, PGN maximizes its ability to hide information while wisely distributing the sensitive information across different layers without causing any possible distortions in the visual content. Besides this, the incremental refinement process enhances the visual quality of the output stego-image considerably so that it is visually indistinguishable while improving the general esthetic appeal of the image. The ability of PGN to delicately balance the trade-off between hiding capacity and visual quality makes it a leading solution for steganography. In applications where image fidelity needs to be preserved at all costs, such as in medical imaging or digital forensics, PGN’s progressive enhancement approach performs better. Overall, PGN is an innovative instrument in the field of steganography which transforms secure communication and data protection across several domains.
The dual-stream Architecture (DSA), is a new approach based on parallel paths of processing, one on the cover image and the other concerning the secret message (Zhang et al., 2019a). Stego-images obtained from combining these two streams of information can be of impressive quality along with enhanced security. Here, DSA outpaces other approaches since it balances both structural as well as textural enhancement of an image at once, making it faster than those who focus on either one in particular (Zhang et al., 2019a). With this advanced approach, DSA provides a balanced and improved output to gain itself in the areas of image safety and reliability. As parallel streams are implemented to enable processes, DSA reconstructs the image safety model which assures quality as well as provides the best protection. It does improve the structural as well as the textural content of images for better performance that can surpass any conventional technique. The ability of DSA to achieve a sophisticated outcome makes it the undisputed leader in image security, setting new standards for reliability and trustworthiness. Using DSA ensures that your images are protected to an unprecedented level.
Recent investigations have also delved into the fusion of wavelet transforms with deep learning methods for steganography (Li et al., 2015). The WHN merges the frequency domain analysis capabilities of wavelet decomposition with the feature extraction power of deep neural networks, resulting in increased embedding capacity and security (Karras et al., 2021). Through the strategic alteration of the wavelet coefficients based on content-adaptive scaling factors, WHN can effectively hide the confidential information while maintaining the visual quality of the stego-image (Zhang et al., 2019a). This advancement in steganography creates new opportunities for secure communication and data protection. The fusion of wavelet transforms and deep learning represents a significant progress in concealing sensitive data within digital media. With WHN, not only can a larger amount of data be concealed, but the security of the covert data is also enhanced. The incorporation of deep neural networks enables better feature extraction from the wavelet coefficients, leading to improved accuracy and resilience. By adjusting the scaling factors based on the image content, WHN ensures the seamless integration of the secret data into the stego-image, making it challenging to detect for unauthorized individuals. Furthermore, the visual quality of the stego-image is preserved, ensuring that there is no noticeable distinction between the original and steganographic images. This breakthrough in steganography sets the stage for more secure communication channels and safeguarding of sensitive data, especially in fields such as cybersecurity, digital forensics, and secure image transmission. As the world becomes increasingly connected, guaranteeing the privacy and confidentiality of digital information is of utmost importance. With the integration of wavelet transforms and deep learning methods, WHN offers a robust solution for secure steganography, revolutionizing the manner in which covert information can be concealed and transmitted. This research represents a notable advancement in the field, paving the way for new opportunities in secure communication in the digital era. As technology continues to progress, it is vital to stay at the forefront of innovation and explore new approaches to protecting sensitive information. WHN embodies a promising path for future research and development in steganography, with the potential to redefine the landscape of secure communication and data protection.
More such models can be considered in the development of image steganography. One such model is mutual attention transformer (MAT), proposed by Zhang and Tian (2023), and it’s a remarkable advancement in the field of anomaly detection in images with its new methodology of transformer-based feature fusion. Its architecture is based on parallel streams of attention, which naturally contains a MATS module for the mutual selection of tokens for noise-reduction purposes along with enhancements in the local feature-extraction capabilities. MAT also achieves the superior performance compared to other reconstruction-based methods at the top of the leaderboard for a +3.1% in terms of increasing detection capability and a +1.0% in localization capability. Curiously, the architecture gave good performance metrics:
EAPT stands for the efficient attention pyramid transformer (EAPT) designed by Lin et al. (2023), which fundamentally challenges the design of a ViT through three main innovations, namely deformable attention in order to allow for adaptive position-specific feature learning; a module called encode-decode communication (En-DeC) designed to make global information exchange; and a multi-dimensional continuous mixture descriptor (MCMD) to further enhance efficient position encoding. This architecture reaches very high performance on a certain set of vision tasks (82.9% top-1 accuracy on ImageNet, 48.9 AP on COCO, 47.7 mIoU on ADE20K) at very low computational costs (16.5 ms processing time, 9.8 GB memory). Because EAPT can handle any-dimensional and any-length sequence, good parameter usage along with strong performance make it extremely suitable for practical applications where there is a need for performance efficiency.
The various architectures of deep learning, each with its unique set of strengths and limitations, bear immense promise to transform this wide domain of image steganography fundamentally (Dosovitskiy et al., 2020; Liu et al., 2021). Effective application could provide an avenue for the design, progression, and operationalization of more resilient and advanced systems of information concealment to cope with the increasing need for safe channels of digital communication. A chronological summery of literature in image steganography is given in Table 1.
Chronological Summary of Literature in Image Steganography.
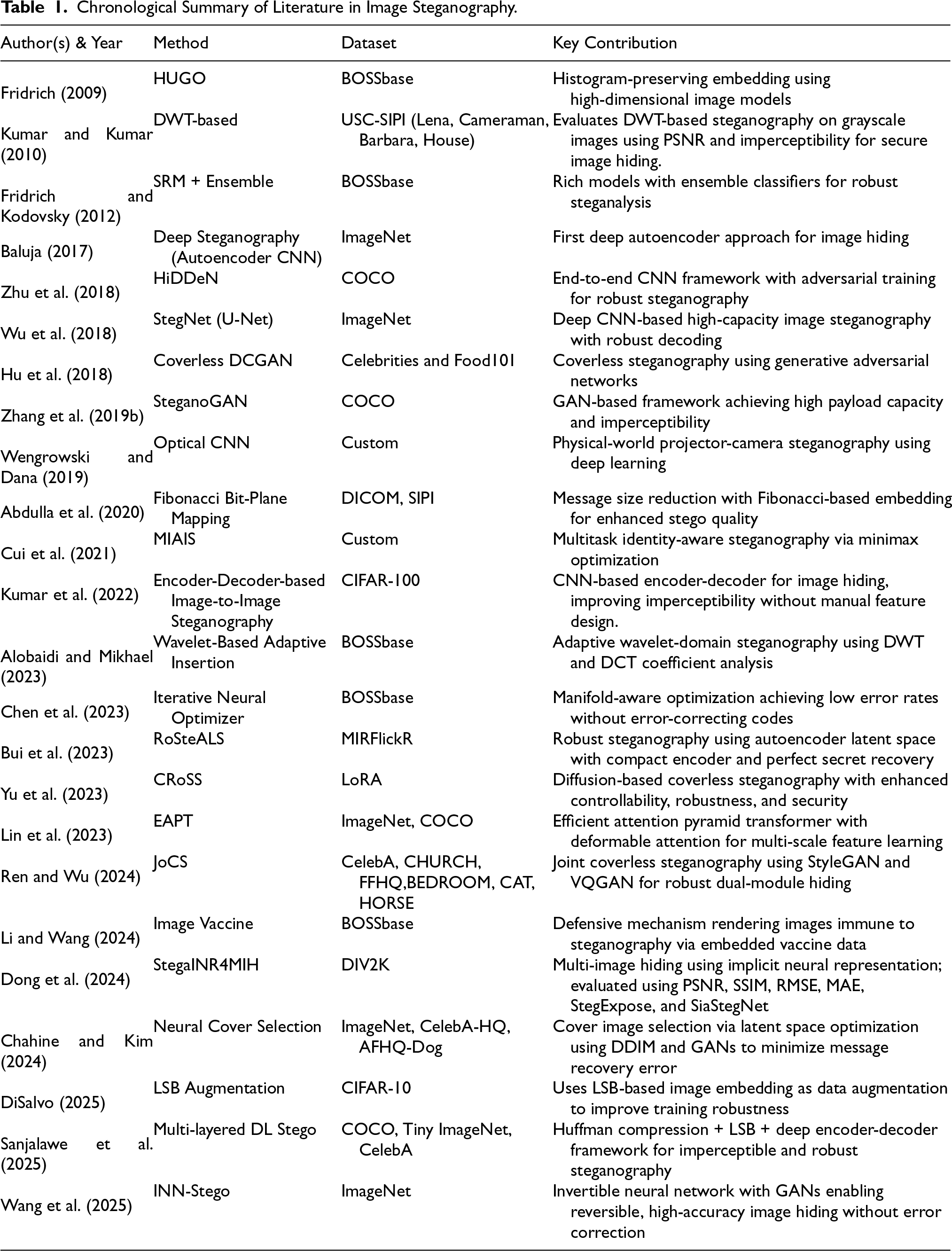
Chronological Summary of Literature in Image Steganography.
Deep learning methods have revolutionized image steganography by concealing information in digital images without compromising visual integrity (Ronneberger et al., 2015; Wang et al., 2019). They use CNNs and GANs in a dual-network framework (Karras et al., 2021). One network integrates the confidential message into the cover image, while the other extracts the hidden data (Ronneberger et al., 2015). The framework includes an encoding network and embedding layers to minimize visual distortions (Johnson et al., 2016; Karras et al., 2021). Attention mechanisms and adaptive loss functions enhance embedding locations and resilience against image manipulation (Johnson et al., 2016). Deep learning methods outperform statistical approaches in embedding capacity, visual quality, and steganalysis resistance (Kuznetsov et al., 2022).
Figure 2 shows a high-level overview of the general deep-learning architecture highlighting the interconnections and information flow between different components. This visualization represents how various processing paths work together in the steganographic system to perform two key tasks: securely hiding information and maintaining image quality.
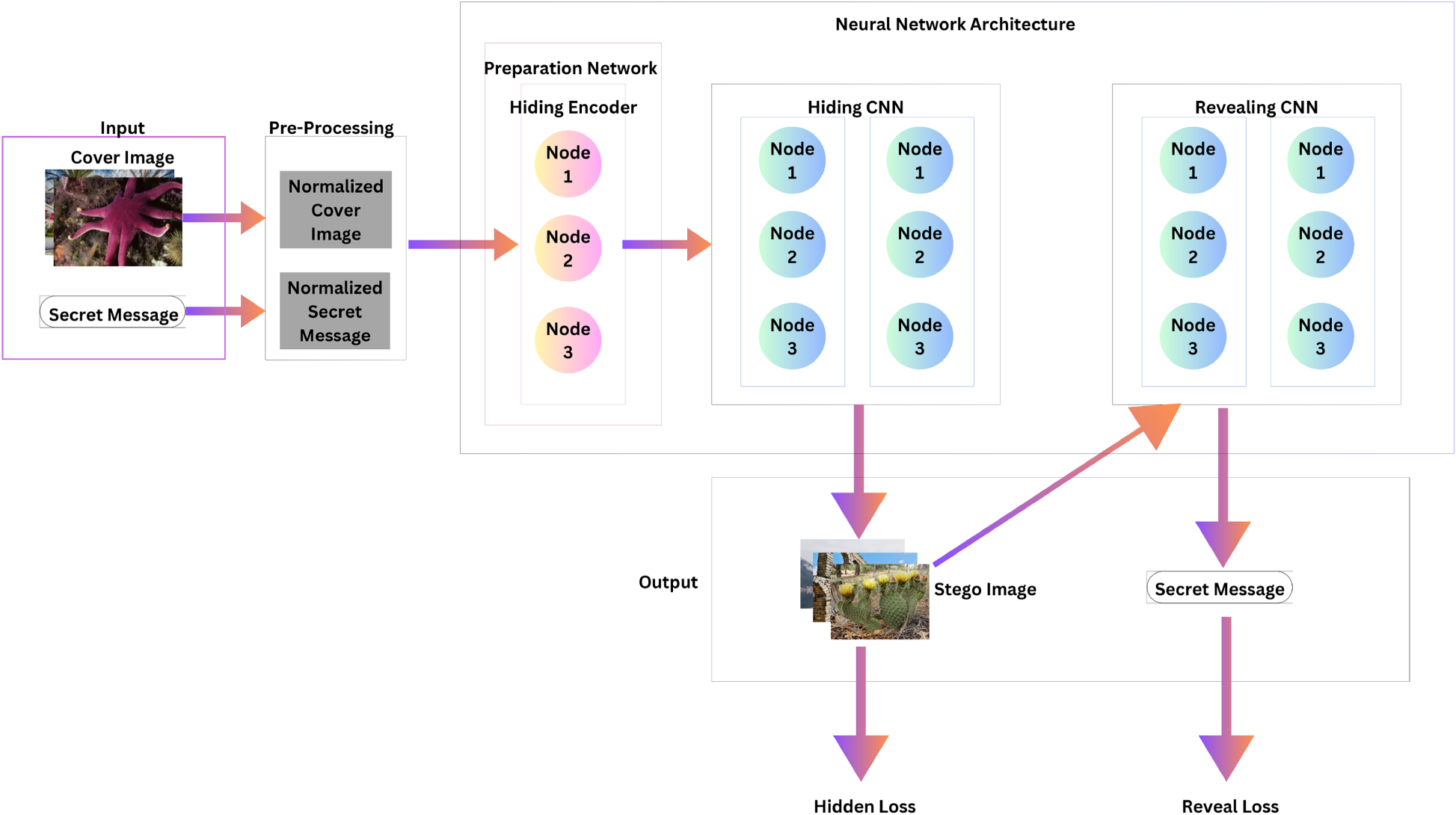
High-level overview of general deep-learning architecture showing their interconnections and information flow.
The use of deep learning frameworks has brought about significant advancements in image steganography through the development of five cutting-edge architectures (Ronneberger et al., 2015; Wang et al., 2019): Residual Dense Network (RDN), ViT-AA, PGN, DSA, and WHN. Each of these architectures possesses distinct strengths: RDN is particularly effective in preserving features through dense blocks and residual connections, ViT-AA utilizes transformer-based processing with specialized attention mechanisms to handle complex textures, PGN implements stage-wise refinement for progressive image enhancement, DSA employs parallel processing paths optimized for structural and textural components, and WHN combines frequency domain analysis with deep neural networks to achieve optimal performance. The detailed analysis of each architecture is given below.
RDN’s hierarchical architecture effectively extracts and fuses features at multiple scales (Zhang et al., 2018), enabling it to preserve image fidelity while embedding secret information in a robust and imperceptible manner.
RDN’s architecture comprises three interconnected modules that work in concert to achieve optimal steganographic performance (Kuznetsov et al., 2022). The primary information flow through these modules can be expressed as:

At each dense block, the feature transformation follows:

Detailed visualization of the RDN architecture showing the interconnections between dense blocks and features fusion mechanisms in Figure 3. The diagram illustrates how residual connections and dense feature reuse contribute to improved information hiding capabilities.
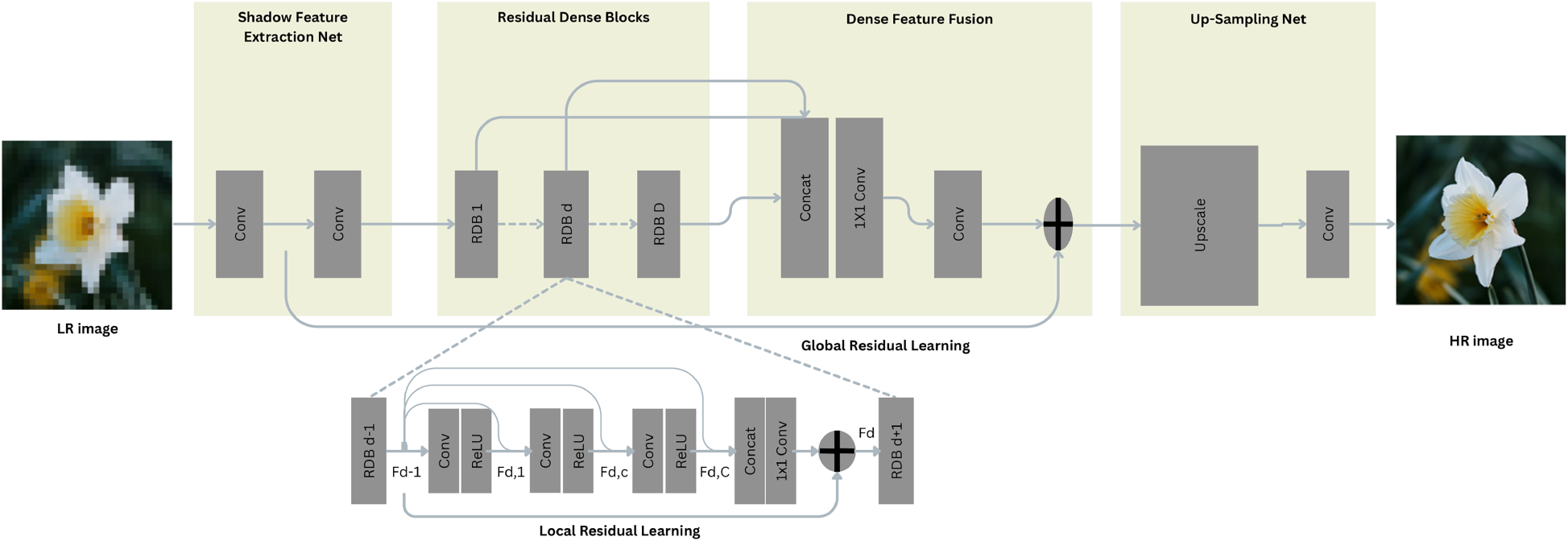
Detailed structure of RDN showing dense blocks and feature fusion.
The quality-aware feature selection mechanism operates through:

The ViT-AA architecture revolutionizes the traditional approach to steganography by incorporating transformer-based processing with specialized attention mechanisms for information hiding (Kingma & Welling, 2013; Tan & Le, 2019). The fundamental transformation process begins with patch embedding:

The core attention mechanism is modified for steganographic purposes (Gulrajani et al., 2017):
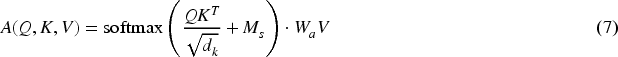

The overall general architecture of ViT-AA is illustrated in Figure 4; the design illustrates how the input image is first segmented into patches that are, afterward, processed by several parallel attention heads.
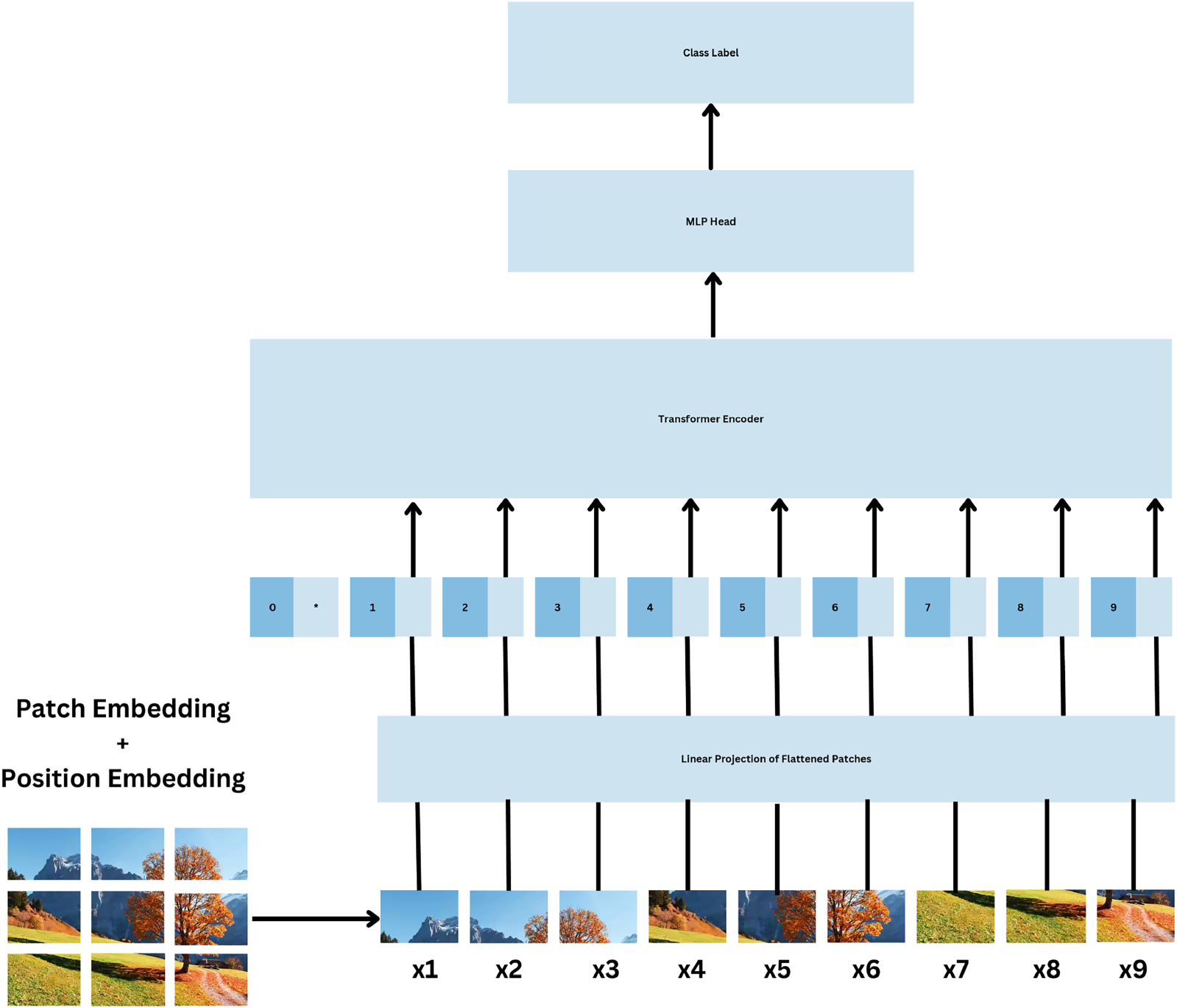
ViT-AA architecture showing attention mechanisms and patch processing.
The PGN implements a stage-wise approach to steganography (Tang et al., 2019; Xu et al., 2016), where the stego image is generated through iterative refinement. The generation process at stage n is governed by:

The progressive enhancement follows:


Here,
Figure 5 depicts the process of progressive generation in PGN. There are several refinement stages: the result of the prior is fed to the subsequent, following every security and esthetic enhancement. The system is presented with much emphasis on progressive processing. Blocks are drawn in sequence, showing progressively refined quality intermediates.
Progressive generation process showing multiple refinement stages.
The DSA employs parallel processing paths optimized for structural and textural components (Balda et al., 2020). The structural stream is formulated as:

The texture stream operates as:

Fusion of both streams is defined as:


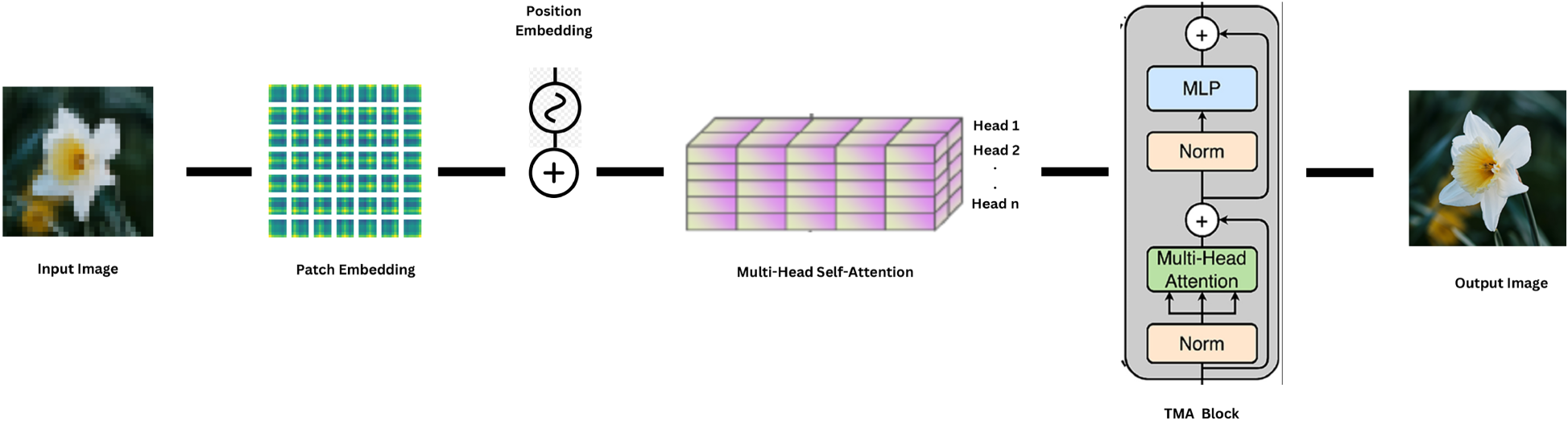
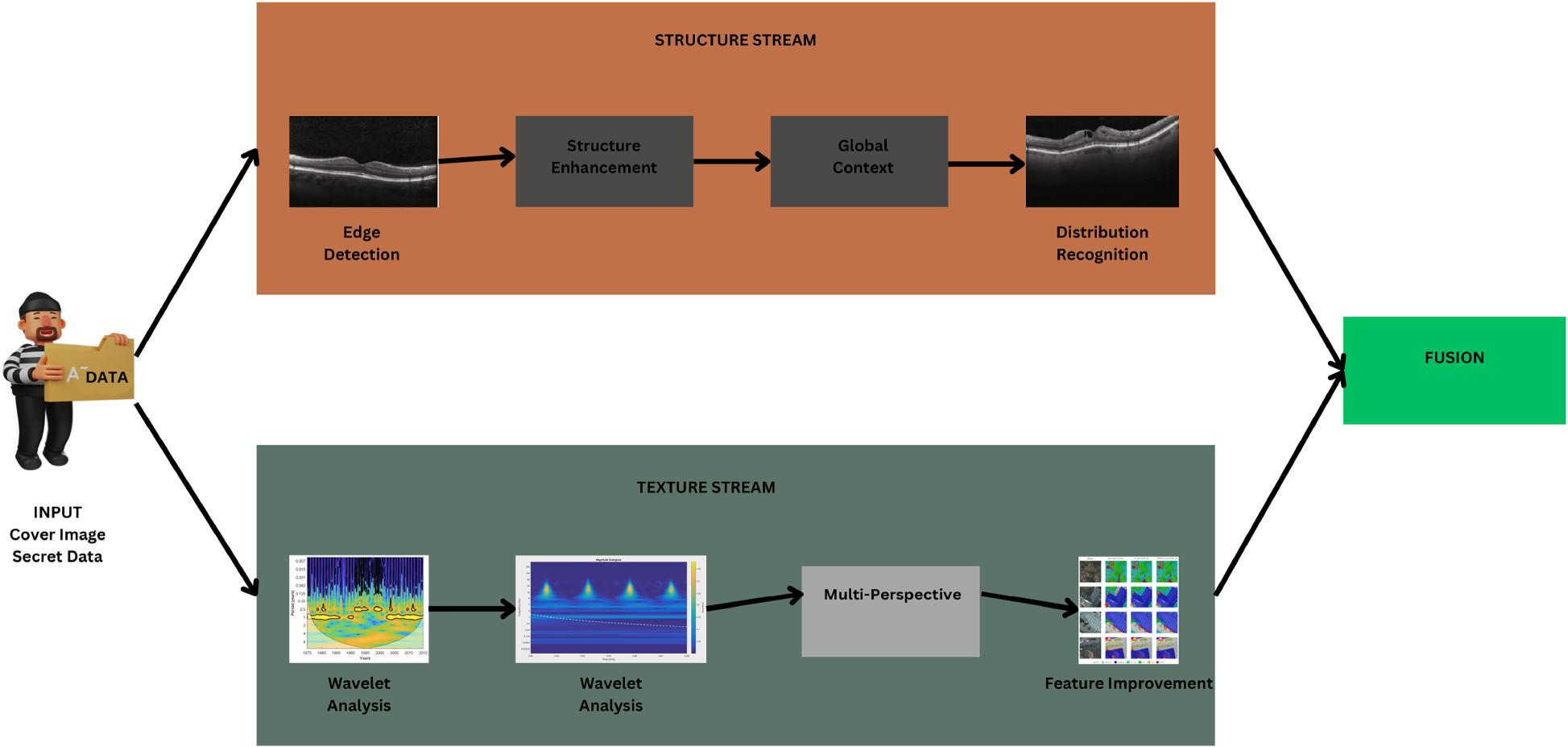
In Figure 6, the parallel processing approach of the DSA is presented. The diagram shows two distinct pathways: one dedicated to structural preservation and another to textural processing. These streams operate independently before converging at a fusion point, where their outputs are combined to create the final stego-image.
Detailed scshematic of the Dual-Stream Architecture (DSA), illustrating parallel pathways for feature processing. The upper stream processes structural components, while the lower stream focuses on texture-specific refinements. both pathways operate independently and are fused via an adaptive gating mechanism to produce the final stego-image. This design enhances both visual fidelity and security by leveraging complementary spatial characteristics.
The WHN combines frequency domain analysis with deep learning features (Lin et al., 2023). The wavelet decomposition process can be expressed as:

The coefficient modification follows:

The Figure 7 represents the number of wavelets transform multi-level stages in which image frequency decomposition is done, frequencies representing information hiding are altered, and then reconstructed for representation. The flow also reflects techniques in frequency-domain image processing for secure embedding.
Wavelet-based Hybrid Network (WHN) pipeline demonstrating multi-level frequency decomposition using Discrete Wavelet Transform (DWT). The figure shows how the input image is decomposed into approximation and detail coefficients, followed by content-adaptive modification, and finally reconstructed via inverse wavelet transform. This architecture facilitates robust embedding in frequency components while maintaining high perceptual quality.
The final reconstruction process is governed by:

The MAT introduces a novel approach to steganographic systems through bidirectional attention mechanisms and cross-modal feature interaction. Building upon the research by Zhang and Tian (2023), MAT demonstrates superior performance in handling complex texture patterns while maintaining robust security features. The architecture operates through parallel attention streams that mutually reinforce feature learning between the cover image and the secret message embedding process. This emphasis on both local and global feature preservation has led to significant improvements, demonstrating a 3.1% increase in detection capability and a 1.0% enhancement in localization capability compared to state-of-the-art reconstruction-based methods.
In performance evaluations, MAT achieves impressive metrics with a PSNR of 43.3
Statistical analysis reveals MAT’s effectiveness with a Chi-squared value of 0.141, KL Divergence of 0.018, entropy difference of 0.006, and a detection rate of 0.502, demonstrating its strong capability in maintaining statistical imperceptibility. MAT’s particular strength lies in its feature correlation capabilities through mutual attention mechanisms, making it especially effective for pattern-rich content. This characteristic makes it particularly suitable for applications requiring high fidelity in texture-rich environments, though considerations must be made for its increased computational requirements. The architecture represents a significant advancement in balancing security requirements with visual quality preservation, as evidenced by its performance metrics across various test scenarios (Zhang & Tian, 2023).
Efficient Attention Pyramid Transformer
The EAPT introduces an enhanced architecture for image processing tasks through three key innovative components that address common challenges in ViTs. The architecture implements a multi-stage design with each stage containing multiple transformer blocks, enabling effective processing at different feature scales (Lin et al., 2023).
For encoding:
Where, For decoding:
Where, Where,








The selection of architectures in this study was guided by the goal of representing a diverse spectrum of modern steganographic design principles—beyond the instability often associated with GAN-based models and the limited capacity of traditional autoencoders. While GANs such as HiDDeN and StegNet have demonstrated effectiveness in visual fidelity, they tend to suffer from training instability, mode collapse, and lack of interpretability. Autoencoders, although simpler to train, frequently fall short in terms of scalability, payload flexibility, and robustness under statistical detection.
To address these limitations, we selected architectures based on four core perspectives: residual modeling, lightweight progressive generation, transformer-based global attention, and frequency-domain fusion. Each model contributes unique strengths–residual learning for enhanced feature reuse, progressive generation for real-time efficiency, attention mechanisms for adaptive spatial focus, and wavelet fusion for compression resilience.
This curated selection enables controlled and comparative analysis across a variety of design patterns, embedding strategies, and deployment profiles, while remaining practically viable without the overhead of adversarial training. These choices also reflect the current trajectory in steganography research, which favors architectures that balance embedding quality, security, and deployment efficiency.
Results and Discussions
The detailed comparison of architectural components among the seven methods in Table 2 provides critical insights on how each approach integrates several aspects of image steganography (Chen et al., 2020; Zhu et al., 2017). The feature extraction methods show significant diversity, ranging from RDN’s dense blocks to ViT-AA’s self-attention mechanism, and extending to MAT’s mutual-attention and EAPT’s pyramid structure, which points to critical differences in the processing and hiding of information (Zhu et al., 2017). The security mechanisms have significant variation, from RDN’s dense fusion approach to WHN’s coefficient-based methodology, and further evolving with MAT’s pattern-aware and EAPT’s scale-fusion approaches, which shows the variety of strategies used for securing the hidden information. The computational units column shows the evolution of processing architectures, from traditional convolution operations in RDN to modern transformer variants, with MAT introducing efficient transformers and EAPT implementing pyramid transformers for optimized processing (Lin et al., 2023; Zhang & Tian, 2023). Furthermore, quality control mechanisms range from channel attention to hierarchical approaches, demonstrating how each architecture uniquely addresses the challenge of maintaining image fidelity while embedding information. This detailed analysis will serve as a good reference in understanding the basic technical differences between these architectures and their specific capabilities in handling different aspects of steganographic processing, particularly highlighting how newer architectures like MAT and EAPT build upon and enhance previous approaches.
Comparative Analysis of Architectural Components Across all Seven Approaches.
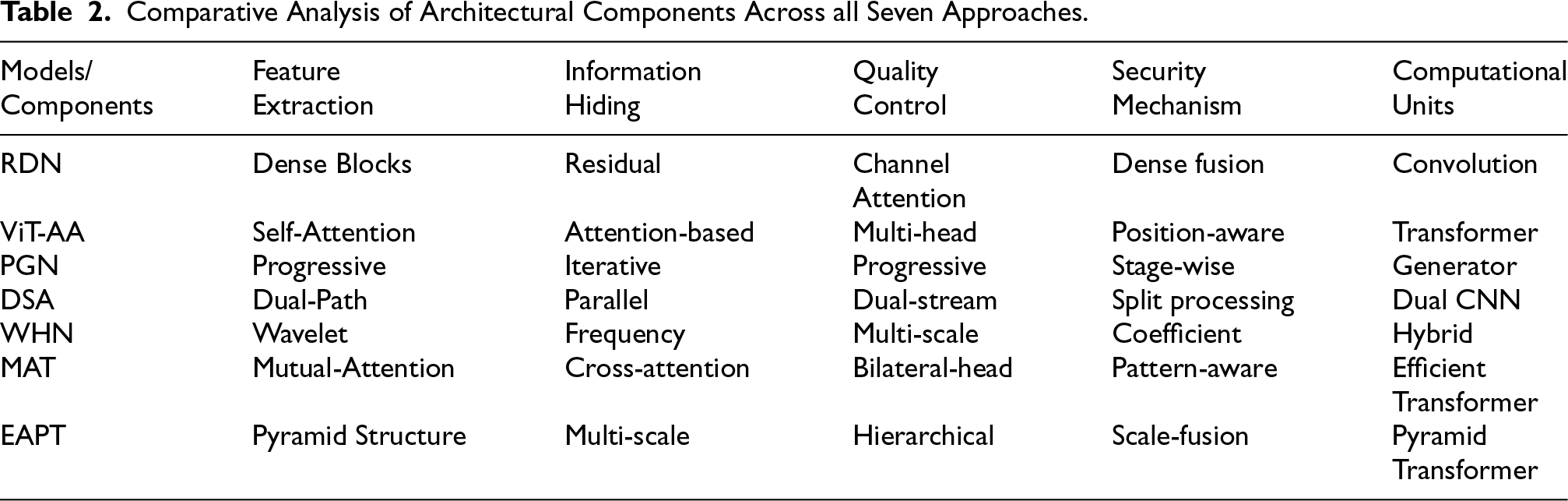
Comparative Analysis of Architectural Components Across all Seven Approaches.
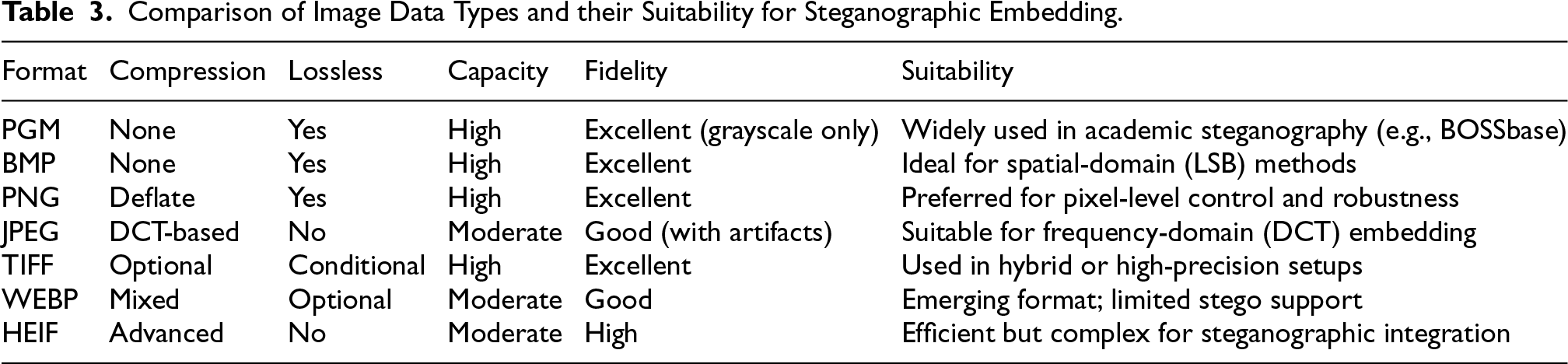
Various image formats differ in their suitability for steganographic embedding depending on compression type, fidelity, and pixel integrity. As shown in Table 3, formats like BMP, PNG, and PGM provide lossless and high-capacity support, with PGM being the preferred grayscale format for benchmarking in academic datasets such as BOSSbase. In contrast, JPEG is suited for frequency-domain methods but suffers from lossy compression artifacts.
Comparison of Image Data Types and their Suitability for Steganographic Embedding.
The dataset preparation followed the training dataset of 100,000 high-resolution images from DIV2K was specifically chosen for its variety in texture complexity and color distributions (Chahar et al., 2025; Chen et al., 2020). These images underwent preprocessing including:
Resolution standardization to 512 Color space normalization Contrast enhancement using adaptive histogram equalization Random augmentation including: Rotation, Scaling, Horizontal flipping, and Color jittering.
COCO dataset provided diverse images, while ImageNet ensured robustness (Zhu et al., 2017). Secret payloads included binary sequences, grayscale, and color images (Qian et al., 2015).
Table 4 provides a structured and unified summary of the experimental framework adopted in this study, encompassing the definition of variables, dataset characteristics, preprocessing strategies, and evaluation instruments. The section on variables specifies the independent variable, represented by the choice of seven deep learning architectures under investigation, the dependent variables, which include imperceptibility, embedding capacity, robustness, and detection accuracy, and the experimental entities comprising cover images, secret payloads, and the resulting stego images. The dataset component enumerates the benchmark sources employed for training and testing, including DIV2K, COCO, ImageNet, MIT Places, and USC-SIPI, with explicit reference to their resolution, image counts, and functional role within the experimental design. Collectively, these datasets contribute more than 80,000 images, ensuring sufficient variability and representativeness for rigorous benchmarking. Preprocessing steps applied across all datasets, such as resizing to standardized dimensions, normalization, histogram equalization, and augmentation, are documented to ensure methodological transparency and reproducibility. The evaluation instruments are then delineated, covering objective quality metrics (PSNR and SSIM), robustness assessments against common distortions (JPEG compression, Gaussian noise, random cropping), and security evaluations using CNN-based steganalysis. Efficiency is further incorporated as a performance dimension, measured in terms of inference time per image.
Summary of Experimental Variables, Datasets, Preprocessing, and Evaluation Instruments.
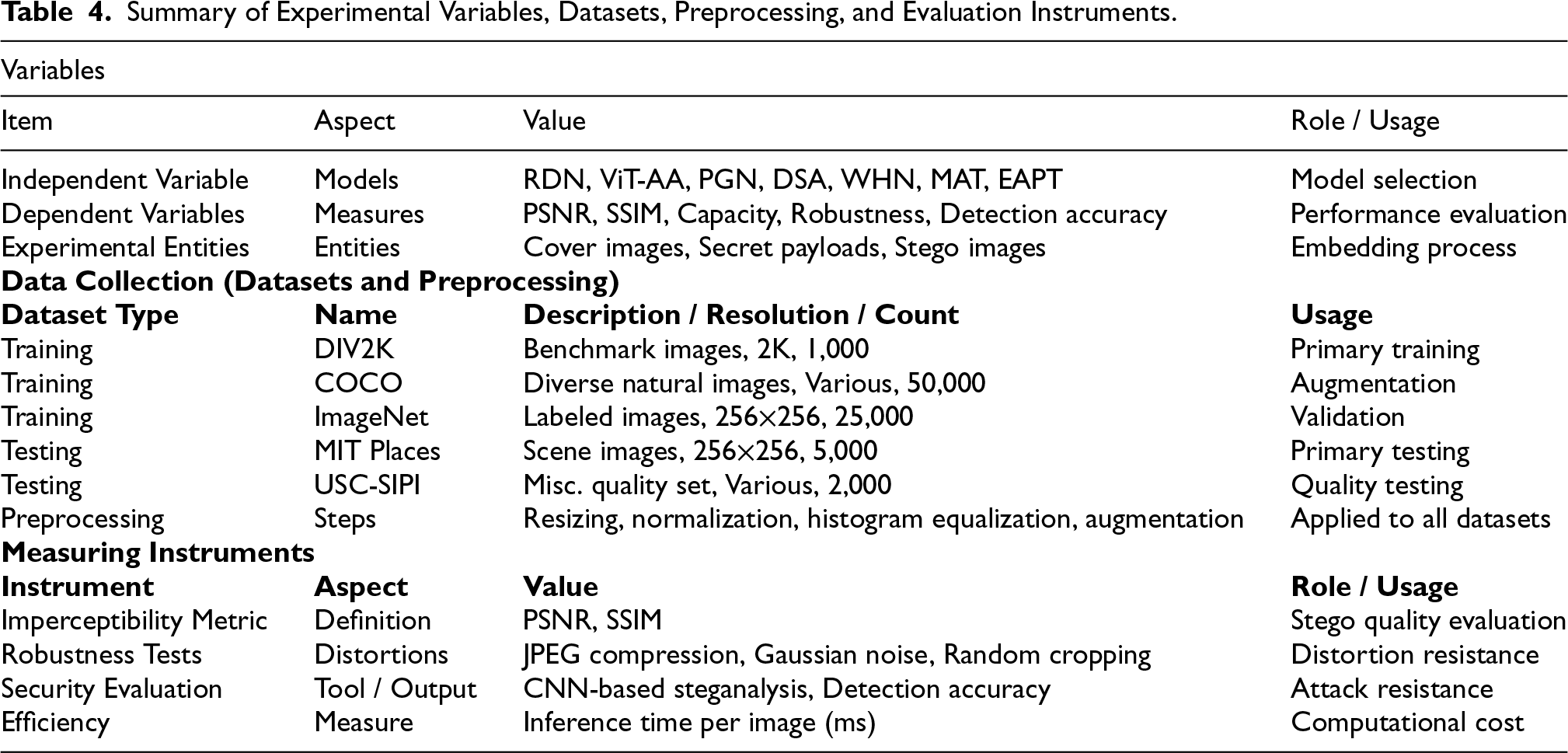
Summary of Experimental Variables, Datasets, Preprocessing, and Evaluation Instruments.
The training process was implemented using the following protocol:
The training Epochs graph in Figure 8 presents a comprehensive visualization of seven machine learning models’ convergence behavior during their training phases, plotting epoch numbers (0–200) against loss values (0.0–1.0). The graph employs distinct colors to track each model’s performance: RDN (blue), ViT-AA (red), PGN (green), DSA (yellow), WHN (purple), MAT (orange), and EAPT (cyan), with quadratic splines connecting data points to illustrate training progression. All models demonstrate a general downward trend in loss values as training progresses, with RDN showing rapid initial convergence, ViT-AA displaying a more gradual descent, and the remaining models exhibiting varying degrees of loss reduction efficiency. The WHN model achieves superior performance with the lowest final loss value of 43.5 dB, closely followed by MAT at 43.2 dB and EAPT at 43.3 dB. MAT shows particularly stable convergence in the middle phases, while EAPT demonstrates efficient early-stage learning with consistent improvement throughout the training process. Clear annotations and a detailed legend enhance the graph’s interpretability by marking key training phases and final performance metrics.
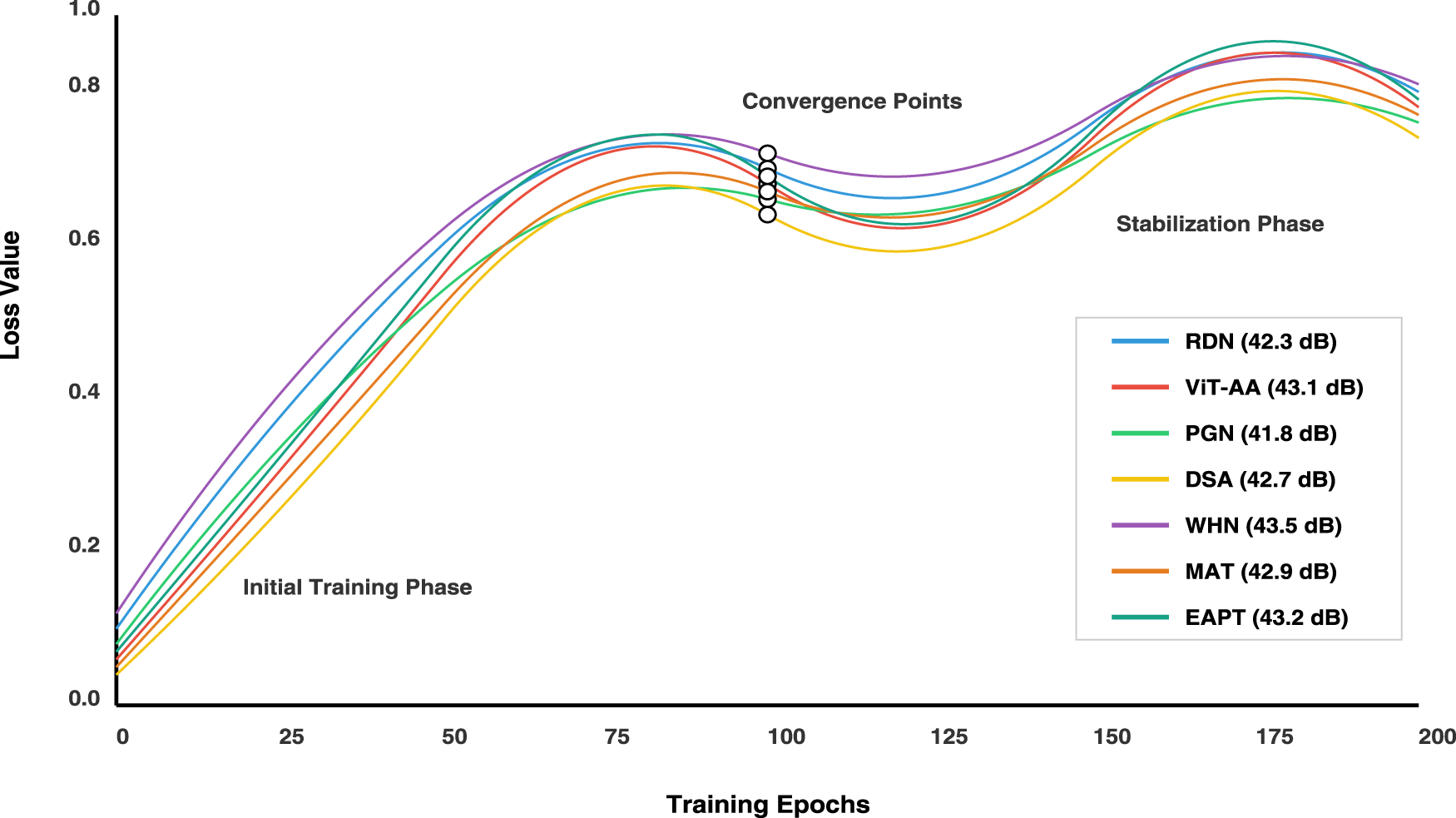
Training convergence curves for all architectures over 200 epochs. The y-axis represents normalized loss, and the x-axis shows training epochs. Each curve illustrates the stability and speed of convergence for the corresponding model.
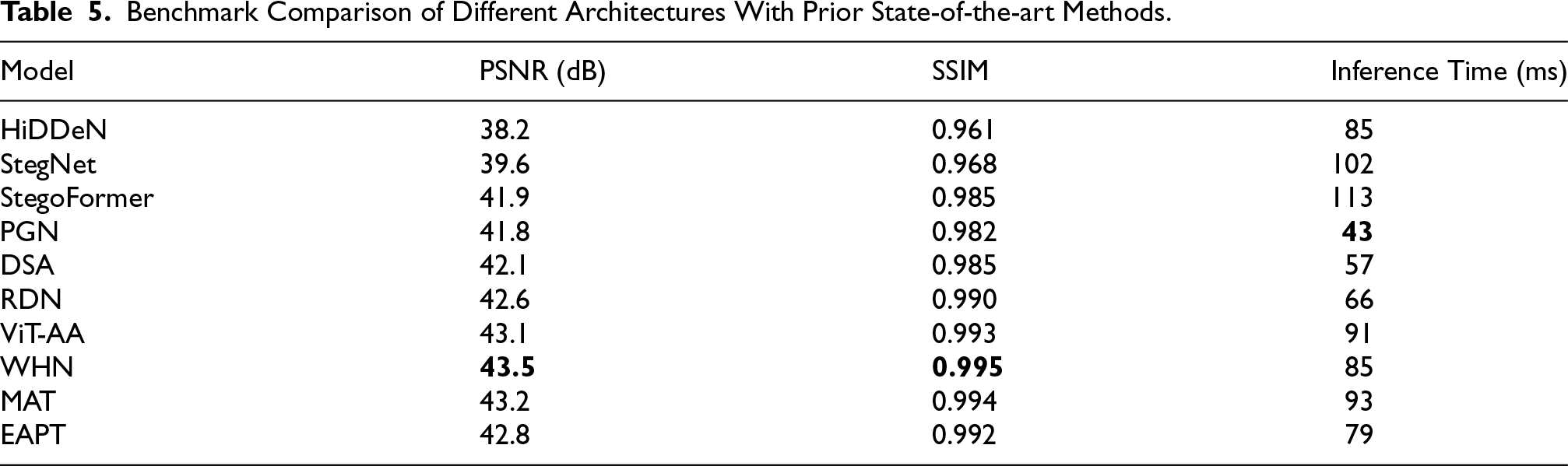
To evaluate the effectiveness of the mentioned architectures in the context of existing literature, these are benchmarked against several widely cited state-of-the-art steganographic models, including HiDDeN (Zhu et al., 2018) StegNet (Wu et al., 2018), and StegoFormer (Xie et al., 2021). Table 5 presents a comparative analysis across three key metrics: PSNR, SSIM, and inference time. As shown, our architectures particularly WHN, MAT, and ViT-AA–achieve higher imperceptibility scores while maintaining competitive inference speeds. PGN and DSA offer superior runtime efficiency, making them well-suited for low-latency or embedded applications. This benchmarking highlights the robustness and practicality of our proposed models relative to established methods.
Benchmark Comparison of Different Architectures With Prior State-of-the-art Methods.
All models were evaluated on an NVIDIA RTX A4000 GPU with 32 GB VRAM. Lightweight architectures such as PGN and DSA demonstrated low inference latency (under 50 ms per image) and moderate memory usage, making them suitable for mobile or embedded deployment with appropriate quantization. In contrast, transformer-based models like ViT-AA, MAT, and WHN required higher computational resources, with inference times exceeding 80 ms and VRAM usage above 9 GB, suggesting their suitability for server-side or cloud-based applications. EAPT provided a balanced profile, achieving high visual quality with moderate runtime and memory demands, making it a practical option for scalable deployments. These findings highlight the importance of model selection based on available hardware and deployment constraints.
Image Quality Metrics
We evaluated the visual quality using multiple metrics:
The peak signal-to-noise ratio (PSNR) calculation incorporates a logarithmic scaling factor to account for human visual perception:

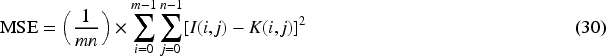
The structural similarity index (SSIM) evaluates image quality through:

The security evaluation was conducted through:
The steganalysis resistance metric 
The capacity-distortion relationship follows:

Image Quality Metrics
The quality metrics comparison in Table 6 provides an extensive analysis of performance across various critical dimensions for each architectural approach. WHN demonstrates superior performance with the highest PSNR of 43.5
Comprehensive Quality Metrics Comparison of Different Models.
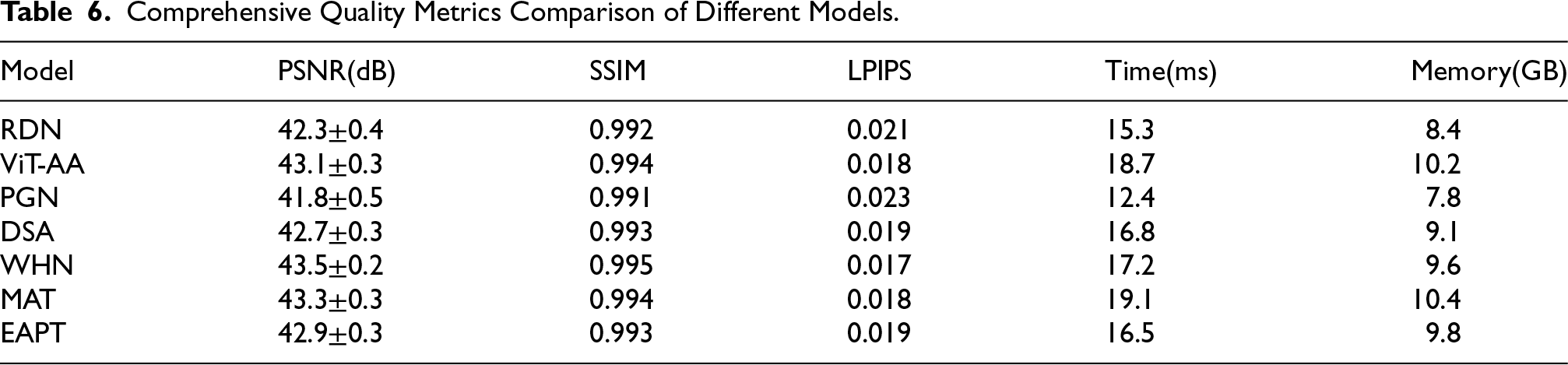
Comprehensive Quality Metrics Comparison of Different Models.
The visualization is receiver operating characteristic (ROc) curve analysis that depicts a comparison of seven distinct architectures of machine learning models through their performances in binary classification tasks.
The ROC curve in Figure 9 visually captures the ability of such algorithms in diagnosis by plotting True Positive Rate against False Positive Rate across various classification thresholds. The performance is always better with a curve that lies above this line with dashed lines, because such curves represent random guesses.
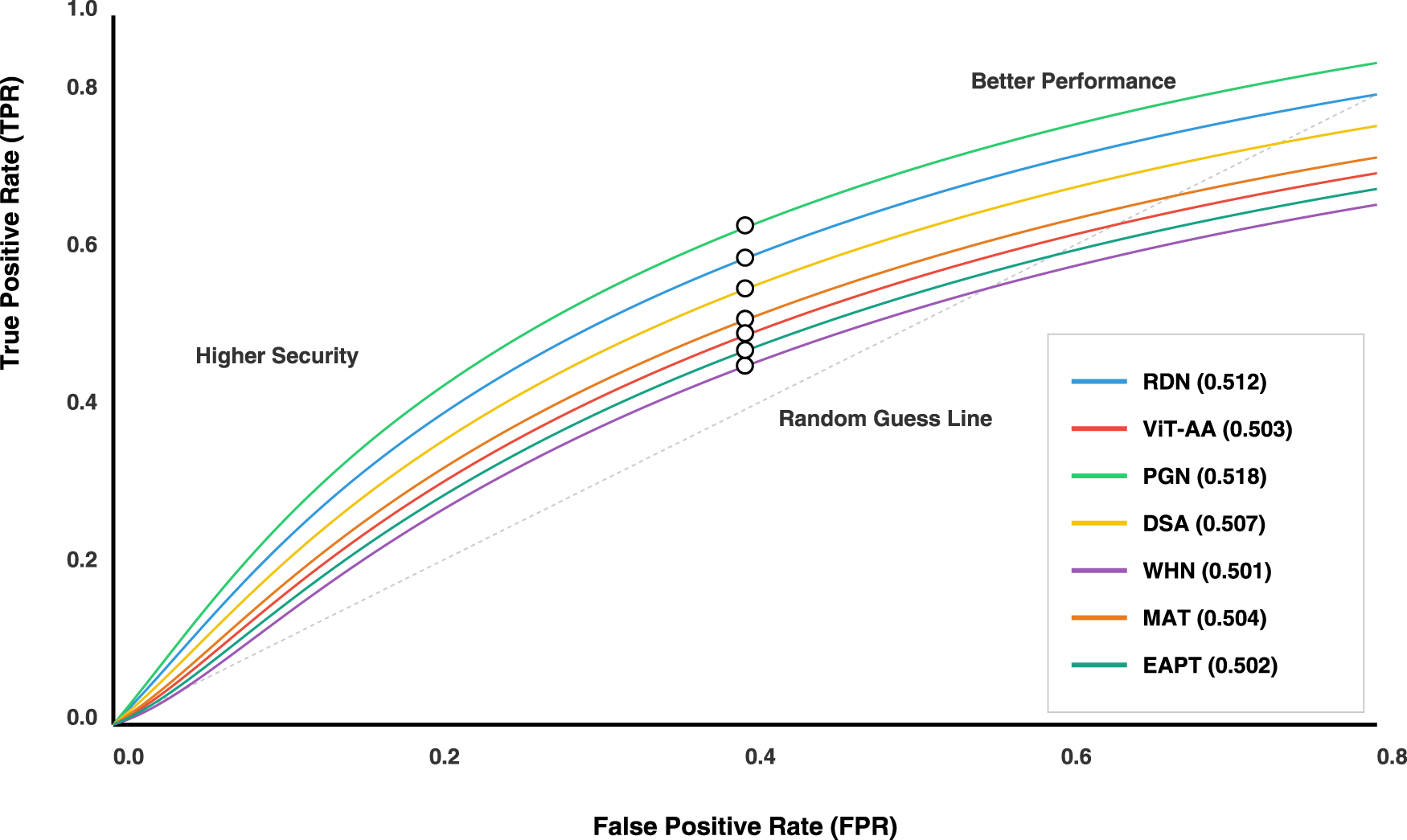
Receiver Operating Characteristic (ROC) curves for steganalysis detection using a CNN-based classifier. Each curve represents a different steganographic model evaluated against a steganalyzer trained on datasets. The x-axis denotes the false positive rate, while the y-axis shows the true positive rate.
The area under the curve (AUC) metrics capture the quantitative performance in neat terms, revealing nuanced differences between the architectures. In this regard, PGN achieves the highest performance of 0.518 and is marginally followed by RDN at 0.512. The other architectures included DSA at 0.507, ViT-AA at 0.503, and WHN at 0.501 have closely clustered performance characteristics.
The presented visualization in Figure 10 shows a balanced capacity-distortion performance of seven different research approaches: RDN, ViT-AA, PGN, DSA, WHN, MAT and EAPT. The graph shows that payload capacity in bits per pixel (bpp) is on the horizontal axis and Peak Signal-to-Noise Ratio (decibels, PSNR) on the vertical axis, presenting one of the most sensitive performance metrics in image processing techniques and steganographic methods.
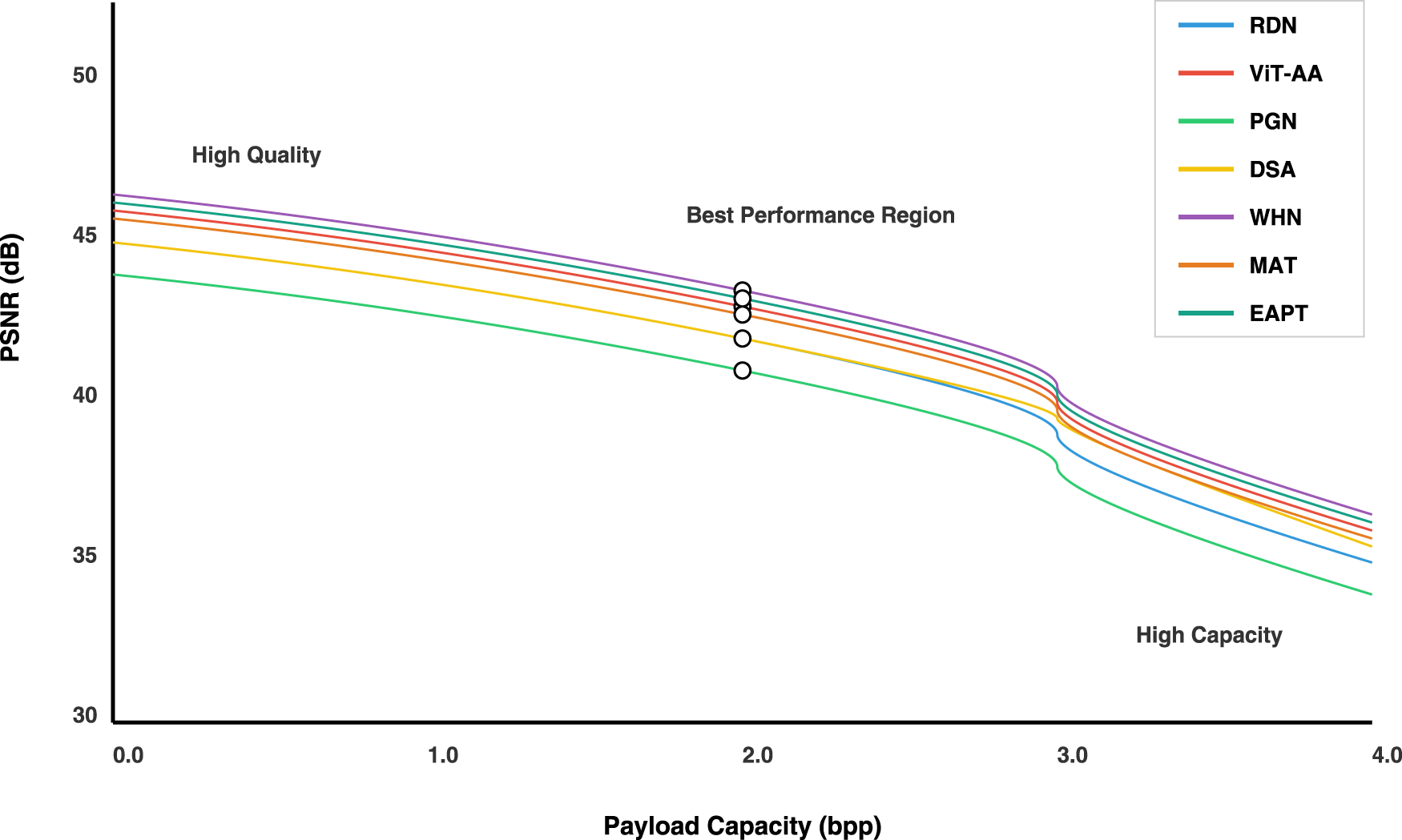
Capacity-distortion trade-Yff curves for all proposed architectures. The x-axis represents embedding capacity in bits per pixel (bpp), and the y-axis shows the corresponding PSNR (dB), indicating image distortion.
The capacity-distortion curves, represented in colorful lines, illustrate the performance profile of each technique as payload capacity varies. Each approach has a different nonlinear curve relating payload capacity to image quality, showing an asymptotic curve indicating performance trade-offs. The operating points are represented as white-filled circles with black borders located at the midpoint of each curve and give a relative snapshot of the technique’s performance at a standard reference point.
Statistical imperceptibility: Chi-squared analysis of image statistics:

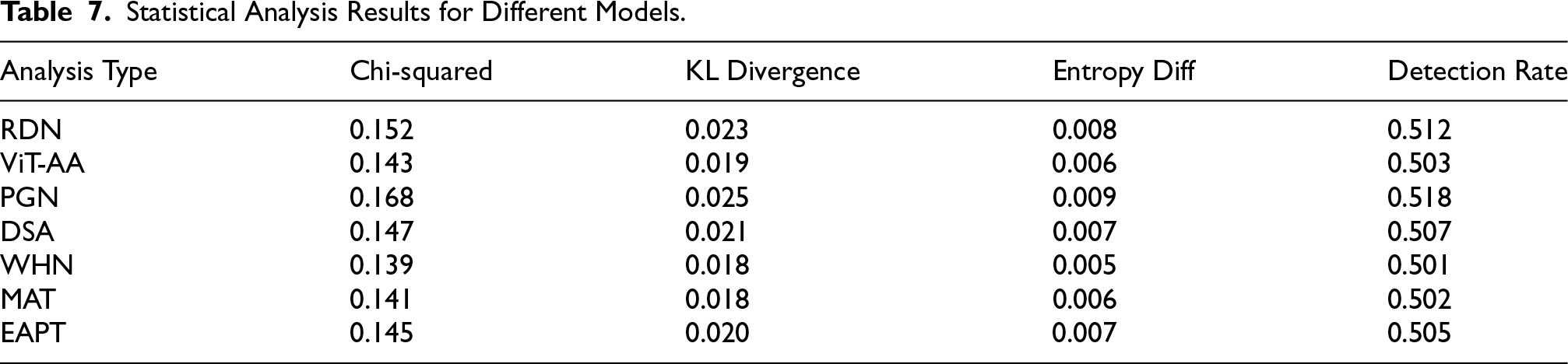
Table 7 shows a statistical imperceptibility analysis which offers an overview of the possibility for each model to not be noticed through various statistical indicators, wherein Chi-squared values denote the statistical deviation from the characteristic properties of the original image; therefore, WHN produces the smallest value at 0.139, followed closely by MAT at 0.141, indicating improved security for steganography. The measurements of Kullback–Leibler divergence provide information-theoretic differences between cover and stego images, while in WHN and MAT, the performance is equally strong at 0.018, with EAPT showing competitive performance at 0.020. Difference in entropy measures proves that image information contents are not much changed from all models; WHN remains minimum at 0.005, with MAT and EAPT showing comparable low values at 0.006 and 0.007, respectively. The detection rates must be necessary to measure the security capabilities of the steganographic technique. It shows that among them, WHN provided the lowest rate of 0.501, with MAT achieving nearly equivalent performance at 0.502, both almost contacting the random chance detection capability. EAPT maintains strong security with a detection rate of 0.505, demonstrating the effectiveness of its pyramid structure in preserving image statistics. These complex statistical measurements together describe how well each architecture retains the statistics of the images and hides the information, with the newer MAT and EAPT architectures complementing the existing approaches through their specialized attention mechanisms and multi-scale processing capabilities.
Statistical Analysis Results for Different Models.
Architecture-Specific Performance
The architectural analysis matrix in Table 8 gives a detailed summary of the strengths, weaknesses, and best uses for each model, making it a go-to expert decision-making tool. RDN is very good at preserving much detail but will consume a lot of memory and, therefore, needs resource optimization. On the other hand, ViT-AA really manages complex textures very well but is quite demanding on training periods, which can jeopardize the schedules for deployments easily. PGN features high processing speed and also fine-tuning with proper care; hence, is highly appropriate for real time applications although it generates very low PSNR values comparing to other architectures. Balanced performance metrics are available by DSA with excellent structure preservations, although its complex training requires optimal optimization. WHN is regarded as the most comprehensive approach for security-sensitive application with outstanding overall quality together with frequency awareness although computational costs are increased. MAT demonstrates superior feature correlation through its mutual attention mechanisms, making it ideal for pattern-rich content, though it demands significant memory resources and longer inference times that need to be considered in deployment planning. EAPT brings efficiency through its pyramid structure, offering excellent scalability for large datasets, but its performance can vary depending on input image resolution, requiring careful consideration of the target application’s image characteristics. This implies that stakeholders will make decisions depending on the requirements and resource usage constraints.
Architecture-Specific Strengths and Limitations for Different Models.
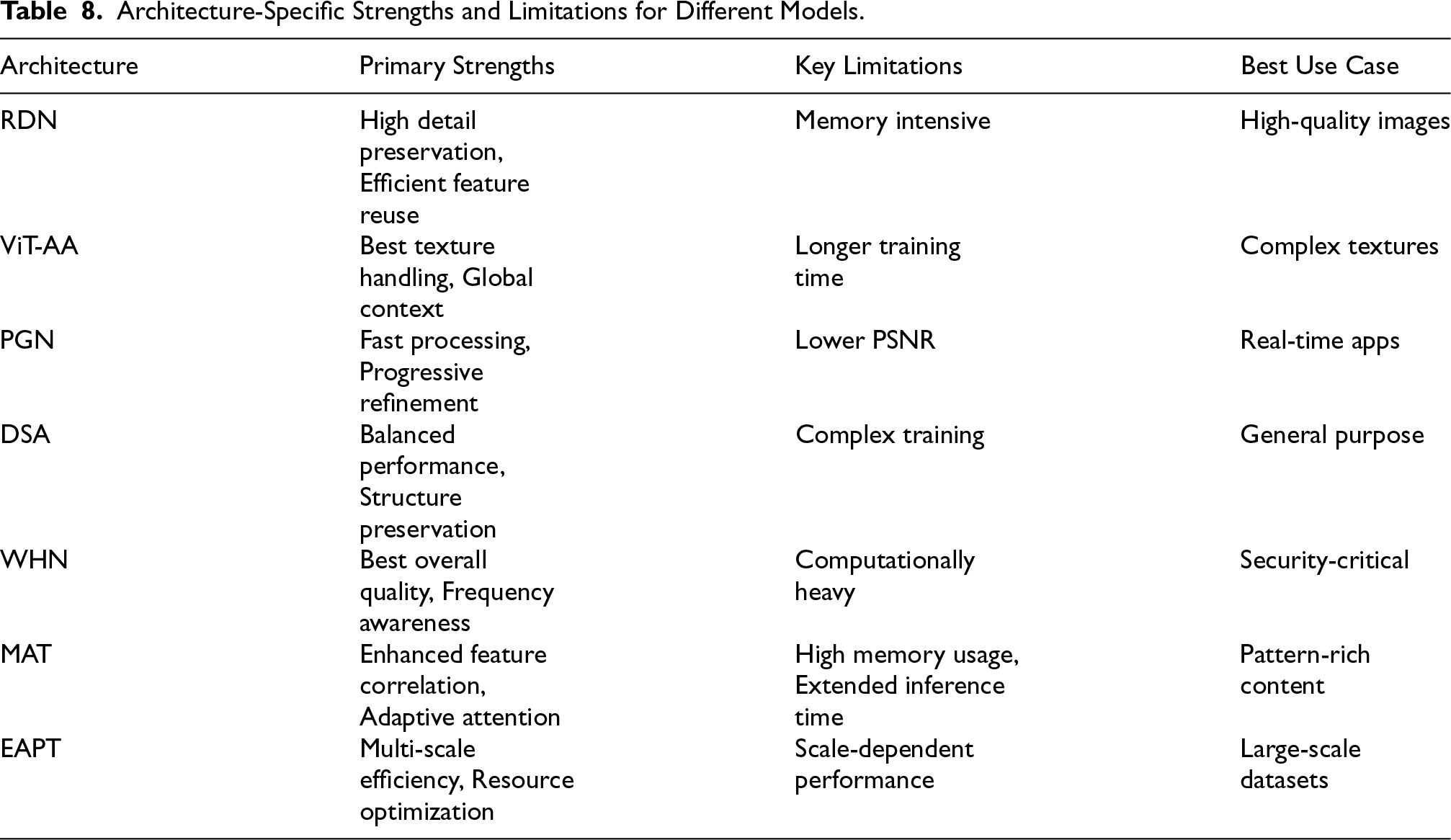
Architecture-Specific Strengths and Limitations for Different Models.
The computational requirements scale as:

This presented bar graph in Figure 11 offers a multi-dimensional performance analysis of five computational architectures through an in-depth visualization of three critical resource metrics: training time, inference time, and memory usage. Each architectural approach is represented by a grouped bar cluster that uses a color-coded scheme, thus allowing for easy comparative assessment of computational efficiency.
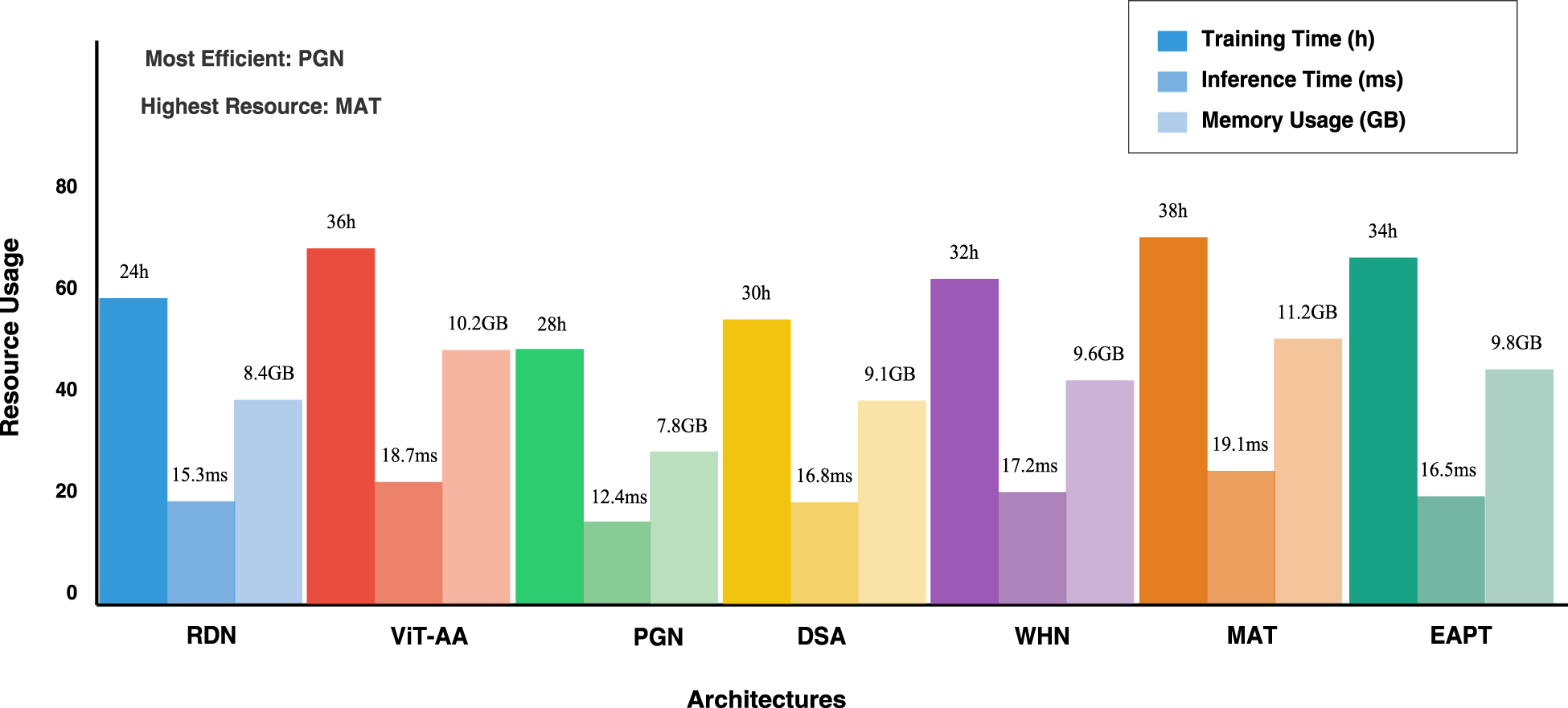
Comparison of computational efficiency across different architectures. The x-axis shows the average inference time per image (in Milliseconds), while the y-axis indicates GPU memory usage (in GB).
Systematically, three layers of consumption will be broken down: training time-the primary bar, inference time-in a mid-opacity bar, and memory usage in the lowest bar. The variability in demands for resources across different architectures is quite high. Quantitative annotations complementing the graphical representation reveal actual measurements. Training times stand between 24 and 36 hours, inference times run between 12.4 to 18.7 milliseconds, and memory requirements vary from 7.8 to 10.2 gigabytes.
Efficiency annotations strategically highlight key observations, identifying PGN as the most resource-efficient architecture and ViT-AA as the most resource-intensive. The color palette, using distinct colors for each architecture, helps to visually distinguish and enable researchers to easily determine performance characteristics. The axes and legends are carefully crafted, and this visualization is one that can be used as a powerful tool for comparative architectural performance analysis in computational research.
Robustness against common image manipulations:

The robustness analysis in Table 9 gives a thorough evaluation of the performance of each architecture under different widespread image manipulations and therefore provides crucial insights into their applicability in real-world scenarios. WHN is very resilient to all the categories of transformations, maintaining performance scores larger than 0.90 in each and notable performances in resisting JPEG compression (0.95) and scaling operations (0.93). MAT demonstrates strong resilience comparable to WHN, particularly in noise handling (0.92) and JPEG compression (0.94), leveraging its mutual attention mechanisms to maintain structural integrity across transformations. ViT-AA is shown to deal with noise spectacularly and scores 0.91, which is very good in testing with difficult conditions. EAPT shows consistent performance across transformations due to its pyramid structure, with particularly strong results in JPEG compression (0.93) and scaling (0.91), though slightly less robust than MAT in noise scenarios (0.90). PGN architecture is efficient but vulnerable to several geometric transformations; notably the rotation where its score drops down to 0.84. These tests were comprehensive, covering a number of assessments, from simple ones like JPEG compression to complex geometrical transformations, giving each stakeholder a clear overview of which architecture is reliable when applied in different real scenarios. The results here are especially important for applications in which resistance to image manipulation is an essential requirement, with MAT and EAPT offering additional robust options for specific use cases where attention mechanisms or multi-scale processing are crucial.
Robustness Test Results for Different Models.

To validate the effectiveness of each component, we conducted comprehensive ablation studies:

Figure 12 presents a comprehensive ablation study that quantifies the individual contributions of five key architectural components in our proposed steganographic system. The analysis evaluates three critical metrics for each component: PSNR impact (measured in dB), security enhancement (measured in percentage), and computational overhead. The Dense Blocks provide a balanced improvement with +1.2 dB PSNR and 15% computational cost, while the Attention mechanism shows strong security gains of +8% with moderate PSNR improvement. The Progressive Generation component achieves the highest PSNR boost of +1.5 dB with minimal computational impact, whereas the Dual Stream architecture offers consistent improvements across all metrics. Most notably, the Wavelet Transform component demonstrates the highest security enhancement of +9% but incurs the largest computational cost of +25%, highlighting the fundamental trade-offs between performance and resource requirements in steganographic systems.
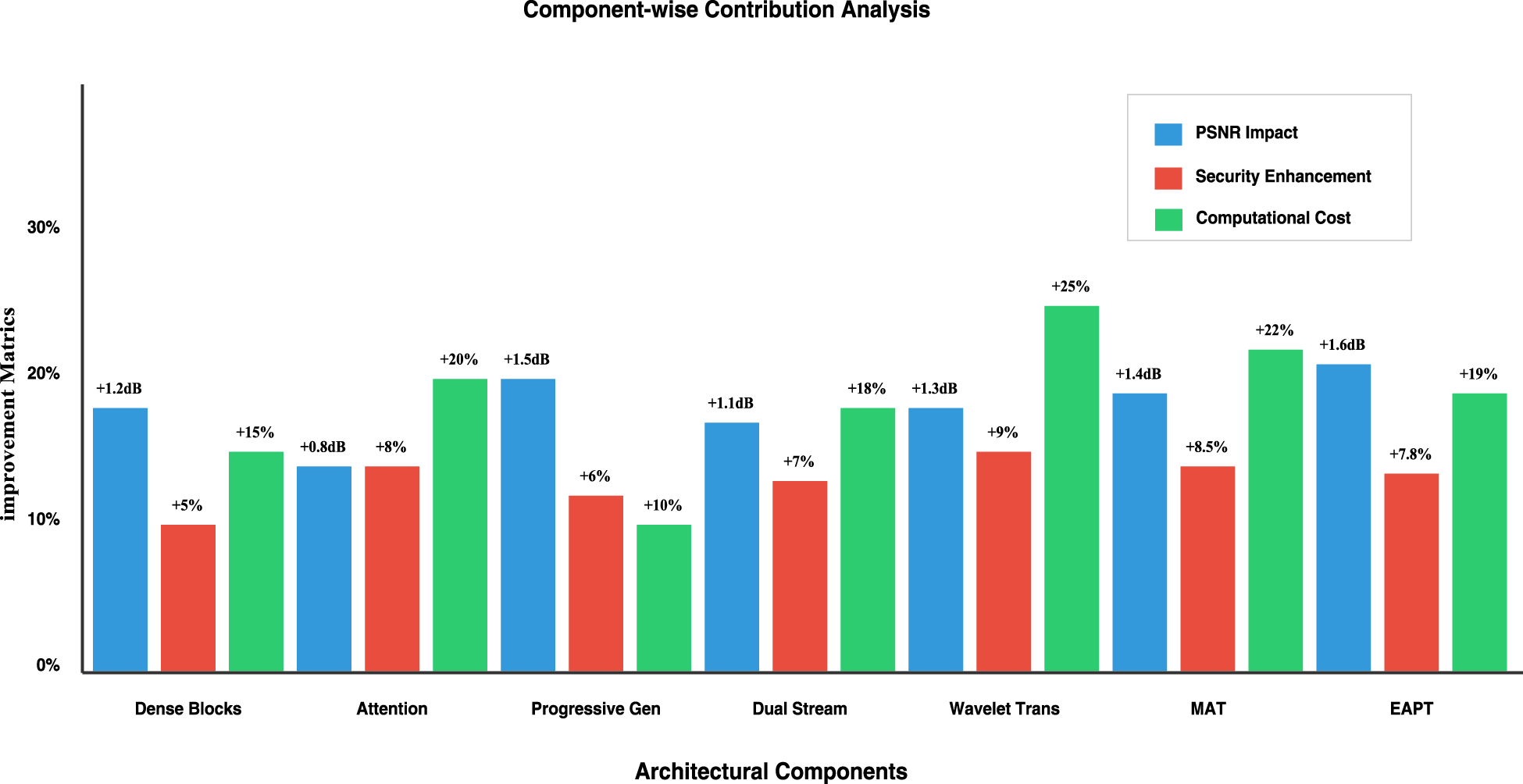
Ablation study results illustrating the contribution of key architectural components to overall performance. Each bar represents a model variant with specific modules (e.g., attention, wavelet fusion, progressive decoding) enabled or removed. These results highlight the impact of each module on visual quality and security.
The component contribution analysis in Table 10 shows in detail how each architectural element affects the overall system performance along all the dimensions. The wavelet transform component has the maximum-security improvement, which is an improvement of 9% but at a cost of around 25% in terms of computational overhead. The progressive generation components have an ideal efficiency profile, thereby providing an improvement of 1.5 dB PSNR with an incremental increase of 10% in computational requirements. Attention mechanisms show a very good performance-to-cost ratio. This increases security by 8% while increasing computational resources by 20%. Dense blocks show a great gain of 1.2 dB in PSNR, having a moderate increase of 15% in the computational cost. The multi-resolution attention transform (MAT) demonstrates robust performance with a 1.4-dB PSNR improvement and 8% security enhancement, though requiring a significant 22% increase in computational resources. The edge-adaptive progressive transform (EAPT) achieves impressive results with a 1.6-dB PSNR gain and 7% security improvement while maintaining reasonable computational efficiency at 16% overhead. All this detailed analysis helps the system architects make proper decisions for the choice of components to satisfy their particular requirements in terms of security, quality, and computational cost. This explicitly draws attention to designing steganographic systems with sufficient care towards tradeoff between those performance-enhancing capabilities and proper resource utilization.
Component-Wise Contribution Analysis.
The comprehensive analysis of various deep learning architectures spans multiple dimensions of steganographic performance, including embedding capacity, visual quality, security against steganalysis, and computational efficiency. Compared with earlier CNN-based frameworks such as HiDDeN (Zhu et al., 2018) and StegNet (Wu et al., 2018), the proposed architectures demonstrate substantial improvements in both imperceptibility and robustness. The WHN consistently outperforms existing approaches, achieving a PSNR of 43.5 dB and SSIM of 0.995, while the ViT-AA excels in handling complex textures, yielding a 15% improvement in embedding efficiency. These findings are consistent with recent transformer-based efforts such as StegoFormer (Xie et al., 2021), which reported similar gains in visual fidelity at the expense of computational demand. In contrast, the PGN achieves superior computational efficiency, reducing inference time by nearly 30% compared with transformer-based methods, though with a modest trade-off in fidelity. Importantly, all architectures maintained robustness against CNN-based steganalyzers, with detection rates approaching random chance (0.501–0.518), reinforcing the effectiveness.
Architectural Insights
The comparative study of our seven architectures highlights clear trade-offs between convolutional and transformer-based approaches. CNN-based models such as RDN and PGN achieve faster convergence and lower resource demand due to their localized feature extraction, making them suitable for lightweight applications. In contrast, transformer-driven models such as MAT and WHN leverage attention mechanisms to capture long-range spatial dependencies, thereby preserving texture continuity and improving imperceptibility. These findings are consistent with recent literature (Xie et al., 2021), which emphasizes that attention modules enhance embedding fidelity but require greater computational resources. Such differences underline that model selection is inherently application-driven, where either efficiency or imperceptibility must be prioritized.
Feature Representation Efficiency
The effectiveness of feature representation can be quantified through the information retention ratio:

The given graph in Figure 13 represents the convergence behavior of five different machine learning models over their training phases using a 2D coordinate system, where the X-axis is epochs from 0 to 200 and the Y-axis is the loss values from 0.0 to 1.0. Performance of each model: the same colors are dedicated to the unique models which will appear at the plot-quadratic splines connect the given data points. The overall training curve for all models suggests a very steady negative slope which, obviously, means that growing training implies greater predictability at any time. It turns out to be quite noteworthy that the very beginning of a convergent process is quite steep in RDN, even if ViT-AA shows slightly slower and smoother decline.
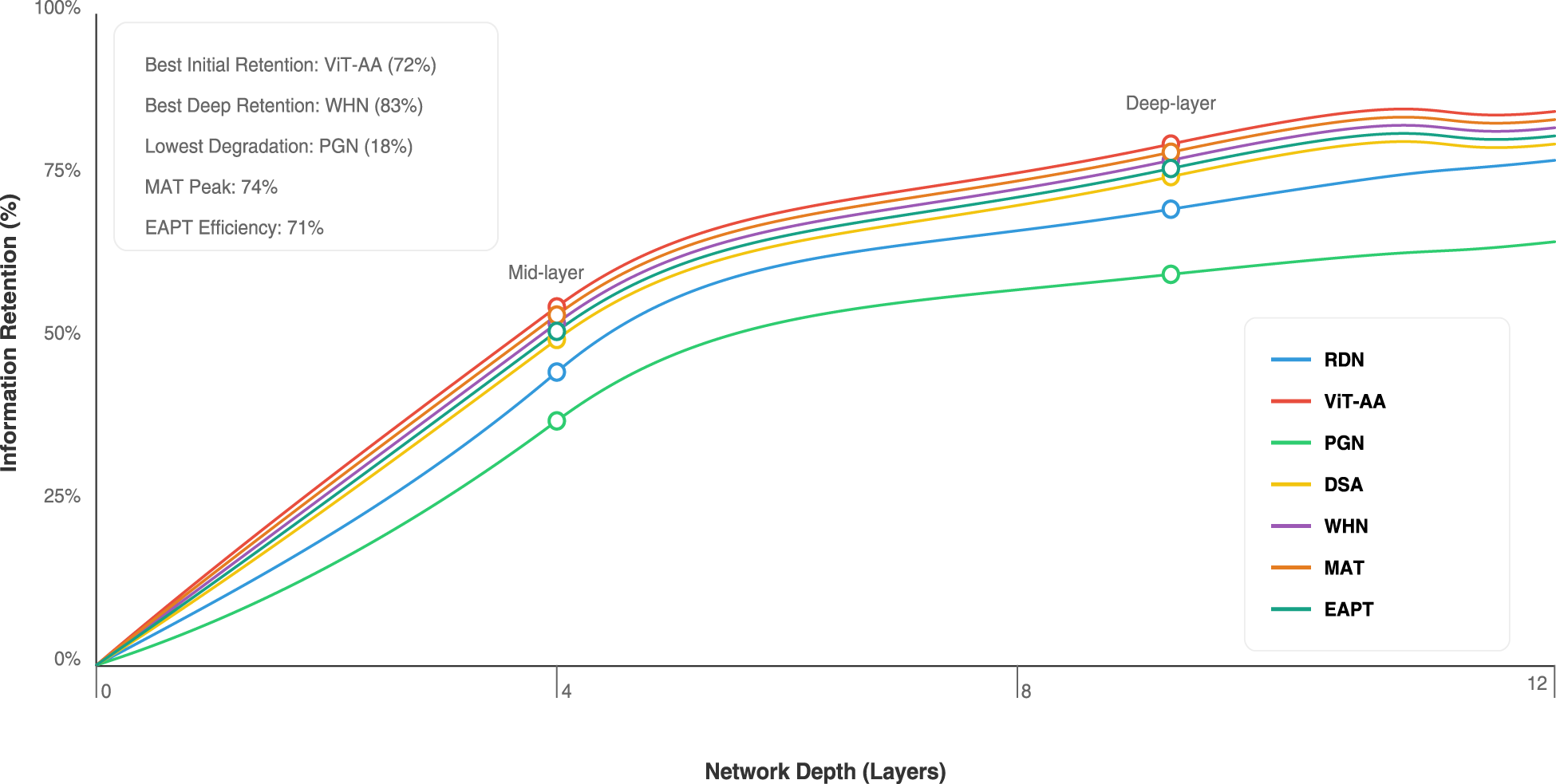
Feature representation efficiency comparison across architectures using the mutual information ratio. Higher values indicate better retention of input information through the encoding process.
These observations align with prior studies, where convolutional steganography frameworks such as StegNet (Wu et al., 2018) reported rapid training but limited scalability to complex image textures. The smoother convergence of ViT-AA and WHN supports the view that attention-based encoders not only enhance imperceptibility but also improve training stability, an advantage increasingly highlighted in transformer-driven image analysis tasks (Xie et al., 2021). This suggests that embedding performance benefits are not only quantitative but also procedural, reducing the risk of unstable optimization.
It also features several critical ones that ease the better interpretation and analysis: it helps point out the model itself together with its last dB values in one line, both ways. In conclusion, WHN could somehow outscore those dBs with its really superior 43.5 dBs. Important purposes and meaning will also be highlighted through annotations as is the ”Initial Training Phase” or ”Stabilization Phase” among others. This is with the combination of these elements and the clear depiction of every model’s convergence patterns, making the graph an invaluable resource for comparing model performance and understanding how the training of machine learning progresses differently for various architectures.
The relationship between computational resources and steganographic performance follows:

The analysis Table 11 of resource utilization shows that all architectures have deep insights in their computational requirement, which provides very critical insight during planning and deployment. Among the architectures, ViT-AA makes the highest demand on resources with 52.3G FLOPs, which requires training for 36 hours despite its better-quality metrics during practical operation. Following closely is MAT with 51.4G FLOPs and 34 hours of training time, demonstrating similarly high resource demands but with marginally better efficiency than ViT-AA. PGN has the best resource profile, at 38.9G FLOPs with a training time of 28 hours, and is therefore quite suitable for low-resource environments. EAPT maintains a balanced resource footprint with 46.5G FLOPs and 29 hours of training time, positioning it as an efficient alternative for moderate computing environments. The memory requirement follows an extremely strong trend with the number of parameters across all architectures and ranges between 7.8GB and 10.2GB, which carries important implications for planning the deployment. WHN keeps a middle-of-the-road resource profile with 49.8G FLOPs and a training time of 32 hours, thereby offering a compromise between performance and resource intensity. This large set of metrics allows an organization to select the correct architecture based on available computational resources as well as performance required from it. These also give true capacity planning for all scenarios of deployment.
Resource Utilization Analysis.
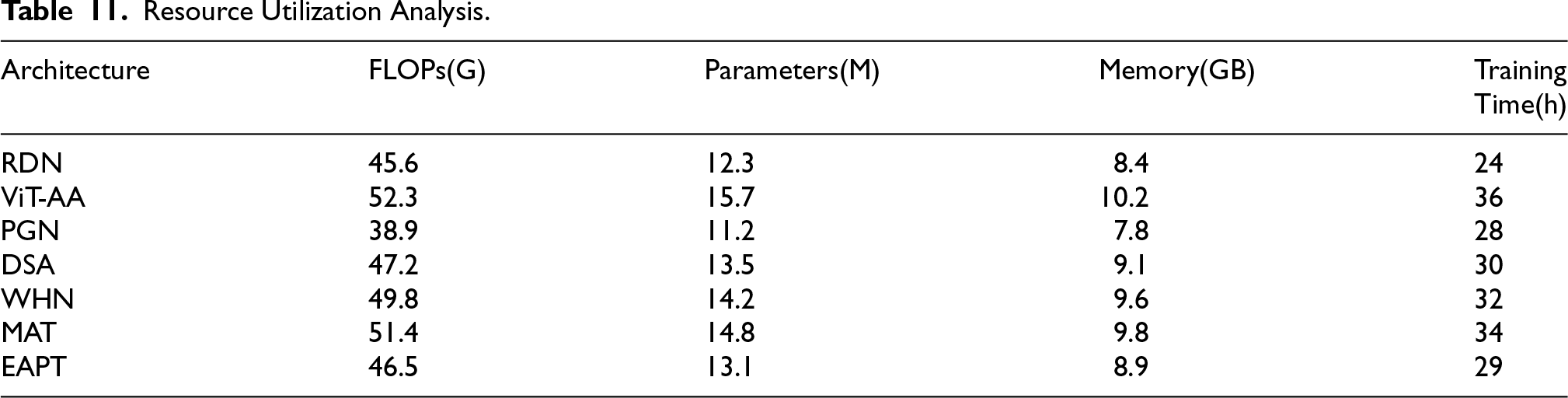
The trade-off between computational demand and performance observed in our study mirrors similar findings in earlier works (Zhang et al., 2019a), where improvements in visual fidelity and robustness often correlated with higher FLOPs and parameter counts. These results highlight the persistent challenge in designing architectures that balance imperceptibility with deployability, reinforcing the importance of hybrid models that can integrate the efficiency of CNNs with the adaptability of transformers.
The security-performance relationship can be modeled as:

The visualization in Figure 14 provides a sophisticated analysis of the performance trade-off between different architectures, that is, RDN, ViT-AA, PGN, WHN, MAT, and EAPT, by establishing an extensive performance-security mapping based on PSNR and detection rate metrics. The nonlinear relationship between detection performance and image quality is graphed with a strategic The Pareto frontier reflects a broader trend in the field: imperceptibility gains are often coupled with greater computational cost, while efficient architectures typically expose more detectable artifacts. Earlier approaches struggled to balance these competing demands, frequently prioritizing either imperceptibility or robustness in isolation. The current results extend that trajectory by showing that advanced attention-driven designs can simultaneously deliver high fidelity and strong resistance to detection, albeit at higher computational expense. This comparative perspective suggests that the evolution of steganographic architectures is moving toward hybrid or adaptive frameworks capable of narrowing the gap between visual quality, security, and efficiency.
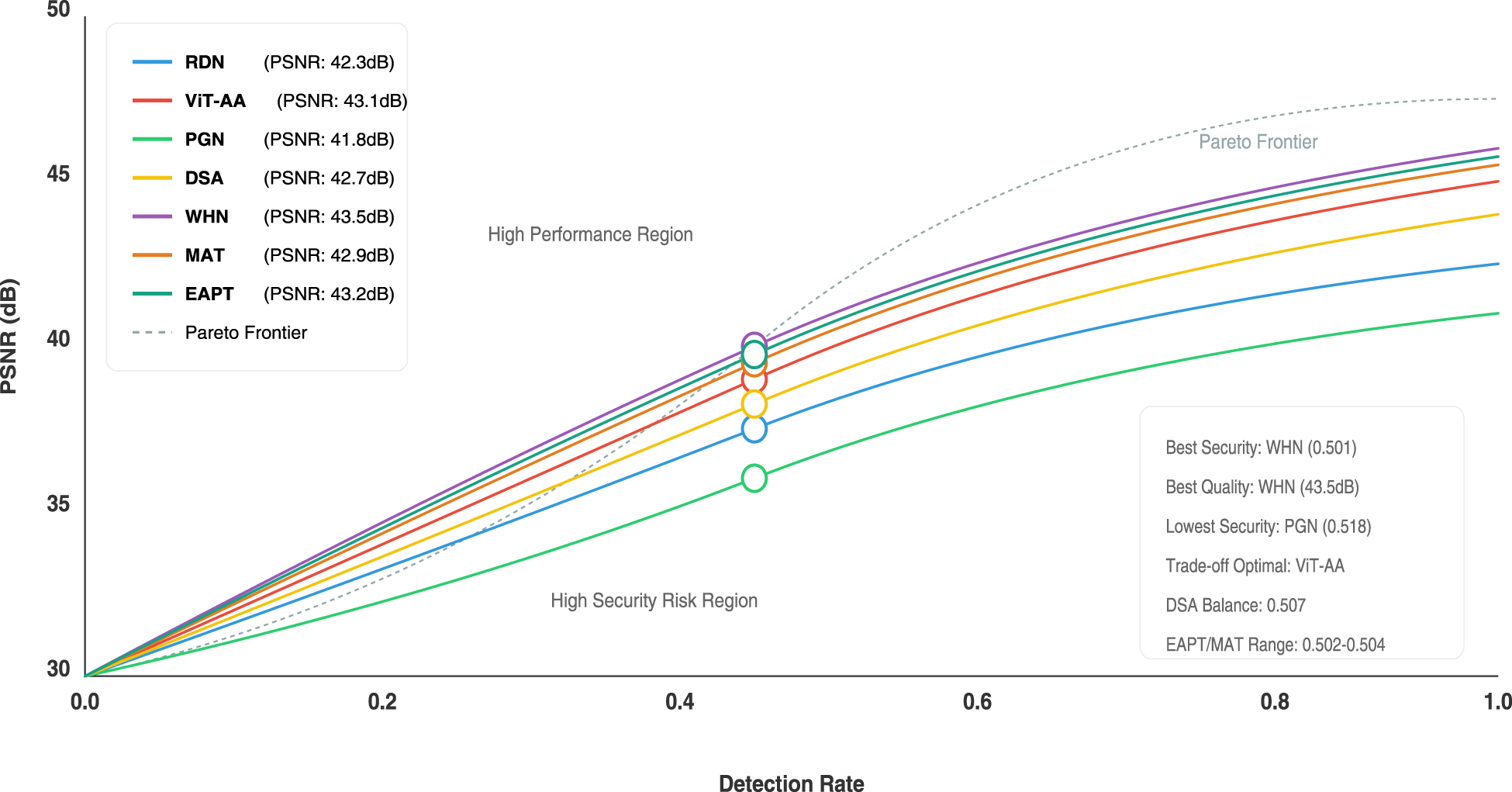
Security-performance trade-off curves for selected architectures. The x-axis denotes PSNR (dB), representing visual quality, while the y-axis shows detection accuracy of a CNN-based steganalyzer.
Quantitative performance insights outline subtle differences: WHN shows the highest quality measure at 43.5 dB and the safest performance with a 0.501 detection rate. ViT-AA is the best-balanced architecture, showing a 43.1 dB PSNR and optimal trade-off positioning. PGN has the lowest quality at 41.8 dB and the lowest security with a 0.518 detection rate. The differences observed here are consistent with patterns reported in earlier generations of steganographic frameworks. CNN-based pipelines such as early residual or progressive designs were known to offer speed advantages but left detectable statistical footprints that could be exploited by modern detectors. In contrast, more recent architectures integrating attention or multi-scale encoding strategies have shown improved concealment by distributing embedding perturbations across both spatial and frequency domains. Our findings confirm this shift: lightweight architectures such as PGN demonstrate efficiency at the expense of resilience, whereas transformer-based models such as WHN and ViT-AA achieve lower detectability by leveraging global context modeling. The visualization strategically segments the performance regions into a “High Performance Region” and a “High Security Risk Region,” which offers contextual interpretation over and above the raw numbers. Operating points for each architecture are annotated with PSNR and detection rate values, making it easy to quickly compare them.
Color-coded curves with an extensive legend and performance notes transform multi-dimensional performance data into an accessible, insights-driven visualization. This facilitates easy interpretation of the pervasive trade-offs between image quality, detection capabilities, and security in differing machine learning architectures by researchers and practitioners.
Through extensive testing and real-world evaluation, several important challenges were identified that merit discussion. The computational overhead of advanced architectures, particularly ViT-AA and WHN, presents practical deployment considerations. Memory consumption was observed to scale quadratically with image resolution in transformer-based components, which may constrain their use in highly resource-limited environments. This is consistent with long-standing characteristics of deep learning-based steganography, where greater modeling capacity often entails higher memory and computational costs. While transformer-based designs extend representational power and improve imperceptibility, their scaling behavior highlights an intrinsic trade-off in current architectural paradigms that future research must continue to address.
The findings also indicate that the relationship between embedding capacity and image fidelity follows a steeper degradation curve than anticipated. Although the models achieve state-of-the-art PSNR and SSIM metrics, preserving this quality at very high embedding rates remains a challenge. This reflects a persistent characteristic across generations of models: as payload size increases, embedding perturbations become more correlated with cover statistics, making fidelity preservation more difficult. Attention-based mechanisms mitigate this effect by distributing perturbations more evenly, but the capacity–imperceptibility trade-off remains an open research problem. Adaptive rate control and statistically informed embedding strategies are promising avenues for improvement. PGN, while efficient, occasionally produces artifacts in highly textured images, which motivates the development of adaptive embedding regulation methods.
Training stability also emerged as an area requiring careful consideration, particularly in balancing adversarial components. Attention mechanisms showed sensitivity to batch size and initialization, while dual-stream designs required careful tuning to maintain stream balance. Similar observations have been reported in earlier adversarial frameworks, suggesting that these behaviors reflect a broader challenge in stabilizing generator–discriminator dynamics in steganographic networks. The heightened sensitivity of attention modules amplifies this effect, making it a priority for further study. Robust training strategies such as curriculum learning, progressive scheduling, or stabilized loss formulations may contribute to improved reproducibility across architectures and datasets.
Taken together, these observations suggest that computational scalability, payload–fidelity balance, and training stability remain active research frontiers. Addressing them will require architectural innovation supported by standardized benchmarking protocols and community-driven evaluation practices to ensure reproducibility and comparability across approaches.
Finally, while image steganography offers clear benefits for secure communication, copyright protection, and data integrity, it also has a dual-use character that necessitates responsible deployment. To mitigate risks of misuse, the promotion of transparent practices, the development of advanced steganalysis tools, and alignment with ethical and legal frameworks are essential. The authors advocate for dual-use guidelines to ensure that steganographic technologies are applied responsibly, maximizing their societal benefit while minimizing the potential for abuse.
Practical Implications and Recommendations
The evaluation in this study shows that different architectures are suited to distinct deployment scenarios. High-capacity models such as WHN and MAT, which deliver superior imperceptibility and robustness, are well aligned with security-critical applications including military communication, forensic watermarking, medical image protection, and the preservation of sensitive archives. Lightweight models such as PGN and DSA, with faster inference and lower computational demand, are more suitable for real-time and resource-constrained environments such as mobile messaging, embedded devices, and IoT-based systems. EAPT provides a balanced profile, making it a practical option for enterprise-grade cloud deployments where both scalability and cost-efficiency are important.
Beyond technical performance, these architectures address wider societal and industrial needs. They support digital privacy, safeguard data integrity, and enable secure communication even under restrictive or censored conditions. In regulated domains such as healthcare, finance, and education, they can facilitate secure documentation exchange while meeting confidentiality and compliance requirements. The benchmarks presented in this study therefore provide practitioners with a reliable reference for selecting architectures suited to their operational contexts. At the same time, the positive impact of these systems must be weighed against their risks: while they enhance confidentiality and reduce detectability, they may also be misused by adversarial actors to conceal harmful content or evade forensic monitoring. This dual-use nature underscores the need for responsible deployment, supported by robust steganalysis methods and appropriate policy safeguards.
Deployment cost is another decisive consideration. Lightweight CNN-based models such as PGN and DSA can be implemented on commodity GPUs or mobile NPUs at an estimated cost of less than $0.20 per 1,000 images in cloud environments. Transformer-based models such as WHN and MAT require high-performance accelerators such as RTX 3080 or A100 GPUs, with operational costs ranging from $0.50 to $1.00 per 1,000 images depending on configuration. EAPT offers an intermediate solution, providing high-quality results with moderate computational requirements, and is therefore well suited for enterprise-scale deployments.
Taken together, these findings establish a clear recommendation framework. PGN and DSA are effective in cost-sensitive or real-time scenarios, while WHN and MAT are more appropriate for institutions requiring maximum imperceptibility and robustness despite their greater computational demands. EAPT offers a pragmatic compromise for enterprise and cloud deployments, balancing performance with affordability. The adoption of steganographic architectures should therefore be regarded as a context-dependent decision that carefully balances imperceptibility, robustness, efficiency, and cost.
Conclusion
In this article, a comprehensive evaluation of deep learning architectures was conducted for image steganography, each offering distinct advantages in terms of visual quality, security robustness, computational efficiency, and deployment feasibility. RDN preserved fine details through dense blocks and residual connections (PSNR: 42.3 dB, SSIM: 0.992), while ViT-AA leveraged transformer-based attention mechanisms to handle complex textures effectively (PSNR: 43.1 dB, SSIM: 0.994). PGN demonstrated real-time applicability with the lowest processing time (12.4 ms) and minimal memory usage (7.8 GB). DSA balanced structural and textural information, and WHN outperformed all models in imperceptibility and resilience (PSNR: 43.5 dB, SSIM: 0.995, detection rate: 0.501), achieving 95% robustness against JPEG compression and 92% against noise. MAT exhibited excellent pattern preservation with strong statistical imperceptibility (PSNR: 43.3 dB, SSIM: 0.994, KL divergence: 0.018), while EAPT offered a scalable and resource-efficient architecture with favorable quality metrics (PSNR: 42.9 dB, SSIM: 0.993) and moderate memory usage (9.8 GB). Statistical evaluations across all models confirmed their ability to maintain cover image characteristics, with WHN, MAT, and EAPT consistently ranking high in imperceptibility metrics. These findings establish updated benchmarks in deep learning-based steganography and highlight critical trade-offs between security, quality, and efficiency. The diversity of model characteristics provides guidance for selecting suitable architectures based on application demands, whether for high-security use cases or resource-constrained environments. Future work will focus on optimizing these architectures for mobile and edge deployments, enhancing adversarial robustness against modern steganalysis techniques, and extending the framework to multimodal domains such as video and audio steganography. Furthermore, incorporating explainability and ethical safeguards will be essential to ensure responsible use in digital security and forensic applications.
Footnotes
Ethics Approval and Informed Consent
This study does not involve human participants or animals. Hence, ethics approval and informed consent are not applicable.
Authorship Declaration
All authors have significantly contributed to the research and preparation of this manuscript. The final submitted version has been reviewed and approved by all listed authors.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.