
Abstract
In the field of unpaired image-to-image (I2I) translation, enforcing consistency through similarity constraints on features from corresponding stages of the encoder and decoder has led to state-of-the-art performance. However, this simple similarity constraint, typically based on mean-squared error, is limited in terms of feature alignment, spatial information utilization, and global context modeling. These limitations result in suboptimal detail preservation and global structure in the generated images. To address these issues, we propose RFA-GAN, an I2I translation framework that integrates noise injection and attention mechanisms. To enhance the generator’s ability to preserve fine details, we propose a channel shuffle dual attention module. Although generative adversarial networks have achieved remarkable progress in generating high-quality samples, the presence of noise and distortion still impairs translation performance. To mitigate this, we inject Gaussian noise into the model, which not only improves performance under noisy conditions but also reduces sensitivity to noise. Furthermore, to compensate for the insufficient capture of local details and the lack of global style information, we design a focal-frequency residual block. Extensive experiments on multiple benchmark datasets demonstrate that our method significantly improves the quality and detail preservation of generated images while enhancing model robustness. These results suggest that our approach provides an efficient and stable solution for unpaired I2I translation.
Introduction
Image-to-image (I2I) translation aims to transform an image from a source domain to a target domain while preserving its structural content and semantic integrity. This paradigm has been widely applied in diverse computer vision tasks, including style transfer (Zhang et al., 2023), image dehazing (Dong et al., 2020), image restoration (Liang et al., 2021), and semantic segmentation (Yu et al., 2017). I2I tasks can be broadly categorized into information-symmetric and information-asymmetric scenarios. In symmetric translation (e.g., horse-to-zebra or seasonal changes), input and output images share similar structures, differing primarily in style or texture. In contrast, asymmetric translation requires the model to hallucinate missing structures and synthesize fine-grained details under large domain gaps—such as generating photorealistic scenes from semantic layouts, reconstructing realistic images from artistic paintings, or translating edge maps into natural images—posing significantly greater challenges in feature representation, cross-domain alignment, and generative fidelity.
Despite notable progress, existing methods still struggle in highly asymmetric settings. Convolutional networks, limited by local receptive fields, often produce blurry textures and structural artifacts due to their inability to model long-range dependencies. While transformer-based models improve global context modeling, they suffer from high computational cost and insufficient local detail refinement (Qin et al., 2023). Moreover, most approaches operate solely in the spatial domain, underutilizing the rich structural priors embedded in the frequency domain, which hinders high-frequency detail reconstruction and structural coherence. Although generative adversarial network (GAN)- and diffusion-based frameworks have demonstrated strong generative capabilities, they remain sensitive to input noise, domain shifts, and training instabilities, limiting their robustness and generalization in real-world applications (Du et al., 2023; Zhang et al., 2023).
To address these limitations, we propose RFA-GAN, a novel unpaired I2I translation framework that integrates noise injection and attention mechanisms to enhance detail preservation and structural reasoning. Our key insight is that effective feature modeling in asymmetric translation requires both multi-scale spatial-channel interaction and frequency-aware contextual aggregation. To this end, we design the channel shuffle dual attention module (CSDAM), which jointly enhances spatial and channel features through a dual-attention mechanism. By integrating a channel shuffle operation, CSDAM promotes cross-channel information exchange, reduces feature redundancy, and strengthens inter-channel interactions, enabling the generator to capture fine-grained textures and deliver richer, more discriminative representations.
Furthermore, to balance local detail generation with global style consistency—a common challenge in tasks such as cat-to-dog translation—we introduce the focal-frequency residual block (FFRB). FFRB combines a frequency-domain channel attention mechanism (Qin et al., 2021) with the multi-scale focal modulation strategy from FocalNets (Yang et al., 2022). This design allows the model to adaptively emphasize informative frequency components, suppress noise and redundancy, and aggregate multi-scale contextual features in a hierarchical manner. Additionally, Gaussian noise is injected during training to simulate real-world data variability, improving model robustness and mitigating overfitting. Together, these components enable RFA-GAN to achieve superior performance in preserving structural integrity and generating photorealistic details under challenging asymmetric conditions.
Our contributions are summarized as follows: We propose a CSDAM that enhances fine-grained texture and structural feature capture across scales by combining channel shuffling with dual attention mechanisms. Gaussian noise is injected at the input stage to improve model robustness and cross-domain generalization. We design a FFRB that strengthens global frequency-domain representation and performs multi-scale local modulation, leading to better preservation of fine details and improved visual fidelity compared to traditional residual blocks. We propose the RFA-GAN framework and conduct comprehensive experiments on several widely used unpaired I2I translation datasets. Quantitative and qualitative results demonstrate that our method outperforms existing approaches in terms of visual quality and detail preservation of the generated images.
Related Works
I2I Translation
GANs (Goodfellow et al., 2020; Isola et al., 2017; Karras et al., 2019) have become a foundational paradigm in the field of image generation, enabling the synthesis of highly realistic images across a variety of tasks. Among these, I2I translation has emerged as a prominent application, where the objective is to learn a mapping between two visual domains to convert an image from a source domain to a target domain while preserving its semantic content and spatial structure. I2I translation methods can be broadly categorized into supervised and unsupervised learning frameworks. In the supervised setting, Pix2Pix (Isola et al., 2017) pioneered the first conditional GAN-based I2I model, which leverages adversarial loss along with an L1 reconstruction loss, relying on a large corpus of paired training data. Although highly effective in scenarios where paired samples are available, this approach is limited in scalability due to the impracticality and high cost of collecting such paired data in real-world applications. To overcome this limitation, unsupervised I2I translation approaches have gained significant attention. Notably, CycleGAN (Zhu et al., 2017) and DiscoGAN (Kim et al., 2017) introduced the concept of cycle-consistency, employing two generators and two discriminators to perform bidirectional domain mapping. The cycle-consistency loss ensures that an image translated from domain A to domain B and then mapped back to domain A should closely reconstruct the original image, even without paired supervision. This framework significantly expands the applicability of I2I models by enabling training with unpaired datasets. However, the cycle-consistency constraint enforces strict pixel-level alignment, which may hinder the model’s ability to capture high-level semantic transformations, often leading to suboptimal results in more complex translation scenarios. Building upon this, the UNIT framework (Zhan et al., 2022) proposed a shared latent space assumption, suggesting that images from different domains that are semantically aligned can be projected into a common latent representation. This approach facilitates cross-domain alignment in the feature space, allowing for more flexible translation. Similarly, GcGAN (Fu et al., 2019) introduced a geometric consistency loss that preserves spatial relationships between the source and translated images, improving structural coherence during domain translation. In parallel, AttnGAN (Chen et al., 2018) incorporated attention mechanisms into the generation process by requiring the model to learn foreground masks, thereby focusing translation only on relevant object regions. Although this technique enhances localization and translation accuracy, the explicit estimation of masks introduces considerable computational overhead, making it less efficient for high-resolution or large-scale applications.
More recently, motivated by the remarkable success of transformers in natural language processing and vision tasks, several works have explored their integration into I2I translation pipelines. For instance, ITTR (Zheng et al., 2022) and InstaFormer (Kim et al., 2022) embed transformer architectures into the generator design to capture long-range dependencies and global context. These models leverage self-attention mechanisms to enhance semantic alignment between source and target domains, achieving state-of-the-art performance in terms of translation quality and generalization.
Collectively, these advances have significantly pushed the boundaries of I2I translation. However, challenges such as preserving fine-grained texture details, ensuring structural consistency, and improving computational efficiency remain open problems, motivating the continued exploration of novel architectures and training strategies in the field.
Contrastive Learning
Contrastive learning is based on discriminative principles, aiming to learn feature embeddings by pulling together positive pairs and pushing apart negative pairs in the embedding space. The first method to introduce contrastive learning into I2I translation was CUT (Park et al., 2020). In the following years, researchers focused on improving CUT. QS-Attn (Hu et al., 2022) changed the negative sample selection strategy of CUT by dynamically selecting relevant anchors as positive and negative samples through the computation of Query, Key, and Value matrices. Spectral Normalization and Dual Contrastive Regularization (Zhao et al., 2025) further improved upon QS-Attn by introducing spectral normalization and dual contrastive regularization; however, its semantic contrastive loss relies on features extracted by VGG16, which may limit model generalization and increase computational overhead. MoNCE (Zhan et al., 2022) proposed adaptively reweighting negative samples according to their similarity to the anchor, promoting contrastive learning with more informative negatives. Unlike methods such as SimCLR (Chen et al., 2020) that rely on a large number of negative samples, BYOL (Grill et al., 2020) achieves strong performance without the need for negative samples. Inspired by BYOL, EnCo (Cai et al., 2024) introduces a multistage contrastive loss that enforces similarity constraints in the latent space between patch-level features at corresponding stages of the generator’s encoder and decoder to ensure content consistency. We incorporate this multistage contrastive loss into our framework to enhance content preservation in generated images. However, the feature constraints in EnCo still exhibit limitations in retaining fine-grained details and maintaining global structural consistency.
Noise Injection
At the theoretical level, previous studies have explored unconditional GANs, demonstrating that introducing noise during training can effectively improve learning stability and mitigate model overfitting. Recently, this strategy has shown promising experimental results in enhancing system robustness and adversarial resistance (Cohen et al., 2019; Lee et al., 2019). However, although this approach has proven effective for classification, it is not directly applicable to I2I translation, as the two tasks differ fundamentally: classification outputs discrete labels, whereas I2I models must synthesize entire images—a task that is considerably more demanding.
In the context of I2I translation, Chrysos et al. (2020) proposed a robust conditional GAN (RoCGAN) that adopts a dual-path generator structure with a shared decoder. RoCGAN demonstrated stable and consistent outputs even under noisy and adversarial conditions in tasks such as face super-resolution and image inpainting.
Nevertheless, the high computational demand and extended training time introduced by the dual-path architecture raise concerns about its scalability to larger generation models, especially in applications requiring high computational efficiency. Moreover, although Jia et al. (2021) and Wang et al. (2021) explored noise injection strategies within GAN frameworks, their experiments were conducted under supervised I2I settings (i.e., using paired training samples), leaving the effectiveness of such techniques in unsupervised I2I scenarios uncertain.
Recent advances in diffusion probabilistic models (Dhariwal & Nichol, 2021; Song et al., 2021) have also attempted to introduce controlled Gaussian noise during the diffusion process, achieving positive results in both supervised (Batzolis et al., 2021) and unsupervised (Su et al., 2022) I2I tasks. Inspired by these findings, we inject Gaussian noise into our GAN-based I2I translation framework, and extensive experiments demonstrate that this strategy significantly enhances model robustness while simultaneously improving the quality of image translation.
Attention Mechanism
The human visual system is capable of rapidly identifying salient regions within complex scenes, which has inspired the incorporation of attention mechanisms in the field of computer vision (Zhao et al., 2025). Essentially, an attention mechanism is a strategy that adaptively adjusts weights based on input features (Bello et al., 2019), allowing the model to focus more on critical regions while suppressing redundant information. Since the introduction of channel attention by SENet (Hu et al., 2018), subsequent studies such as convolutional block attention module (CBAM; Woo et al., 2018) have further extended attention modeling into the spatial dimension, enabling joint channel–spatial attention representations. Numerous follow-up works have explored diverse attention module designs and fusion strategies, and their extended applications in generative models.
In the domain of image generation, the integration of attention mechanisms with GANs has also yielded notable results. The self-attention GAN (Zhang et al., 2019) was the first to introduce self-attention to capture long-range dependencies within images, thereby enhancing the global consistency and structural coherence of generated images. Subsequent approaches embedded attention modules into various components of GANs. For instance, CBAM-GAN (Ma et al., 2019) incorporated the CBAM module to enhance fine-grained feature modeling, while MA-GAN (Jia et al., 2022) combined multi-scale convolutions with channel attention to adaptively adjust residual scales for optimized feature representation.
In the context of I2I translation, an increasing body of research demonstrates that attention mechanisms not only improve semantic consistency and detail preservation, but also enhance the robustness of cross-domain feature modeling. SelectionGAN, proposed by Tang et al. (2019), integrates multi-channel attention and a cascaded semantic guidance module to improve the quality of cross-view image translation. Moreover, it introduces a result selection mechanism to refine the final output. Tang et al. (2019) later proposed AGGAN, which constructs a dual-branch architecture for source and target domains. It leverages attention modules to enhance the model’s focus on salient regions, thereby achieving more accurate content transfer.
U-GAT-IT, developed by Kim (2019), combines attention mechanisms with adaptive normalization strategies, improving the disentanglement of style and structure information. This method demonstrates strong generative performance in unsupervised image translation tasks. RABIT, proposed by Zhan et al. (2022), introduces a dual-level feature alignment structure that aligns low-level details and high-level semantics separately. It also incorporates attention-guided exemplar learning, making it suitable for high-resolution scenarios where both style preservation and semantic consistency are crucial.
To address the limitation of conventional convolutions in capturing long-range dependencies, MixerGAN (Cazenavette & De Guevara, 2021) employs an multilayer perceptron (MLP)-Mixer architecture to facilitate global interaction between image patches, improving contextual modeling while balancing efficiency and performance. Building on this idea, CWT-GAN (Lai et al., 2021) introduces a cross-model weight transfer mechanism that dynamically transfers discriminative features learned by the discriminator to the generator. By integrating a residual attention mechanism and class activation maps, this approach significantly enhances translation quality between domains with large structural differences.
It is also worth noting that spatial attention mechanisms, in addition to channel attention, have proven effective in image translation. By modeling spatial relationships among features, spatial attention automatically isolates key regions within an image and has been successfully integrated into various GAN architectures. For example, the bidirectional attention GAN proposed by Yang et al. (2021) effectively models spatial dependencies in traffic flow images, while self-attention modules have also been used to detect latent structural defects in input data (Ali & Cha, 2022).
In summary, due to their strong transferability and representational power, attention mechanisms have become an indispensable component in I2I translation tasks. Ongoing research continues to explore novel attention designs and integration strategies, further advancing the quality and reliability of image translation models.
Method
Overall Architecture
Given an input image
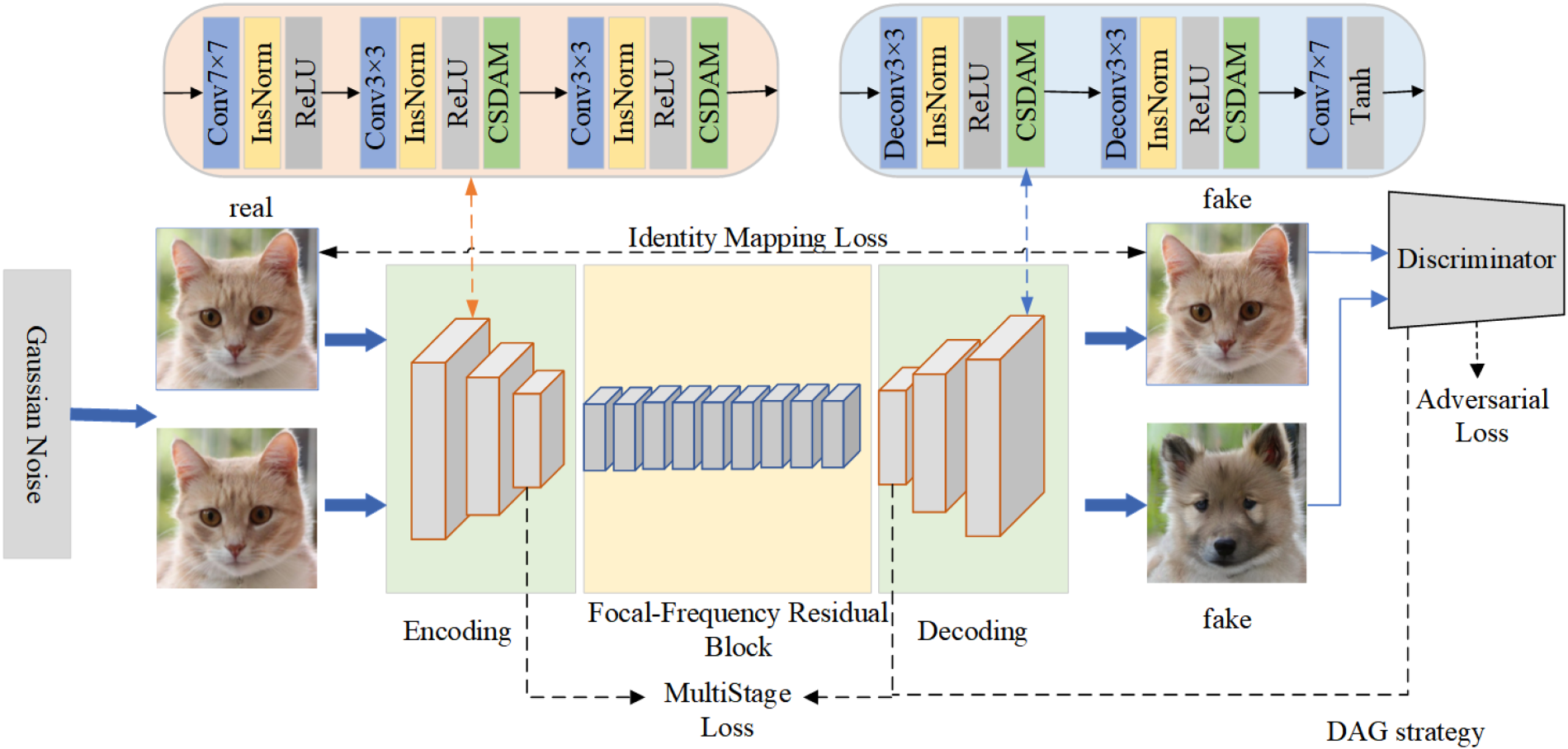
Overall Framework of Our Proposed RFA-GAN: A Cat Image Is First Reconstructed as a Cat Image Through the Identity Mapping Loss, While It Is Also Translated Into a Dog Image by the Generator. During the Generation Process, We Incorporate the Channel Shuffle Dual-Attention Module, the Focal-Frequency Residual Block, and Gaussian Noise Injection to Enhance the Quality and Robustness of Image Translation.
To enhance the feature representation capability of the generator in I2I translation tasks, we propose a novel CSDAM, as illustrated in Figure 2. This module is designed to simultaneously capture dependencies across channels and spatial regions, enabling adaptive and dynamic modulation of diverse feature responses. CSDAM consists of three main components: a channel attention submodule, a channel shuffle operation, and a spatial attention submodule. In the channel attention submodule, given an input feature map
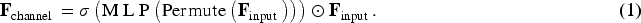
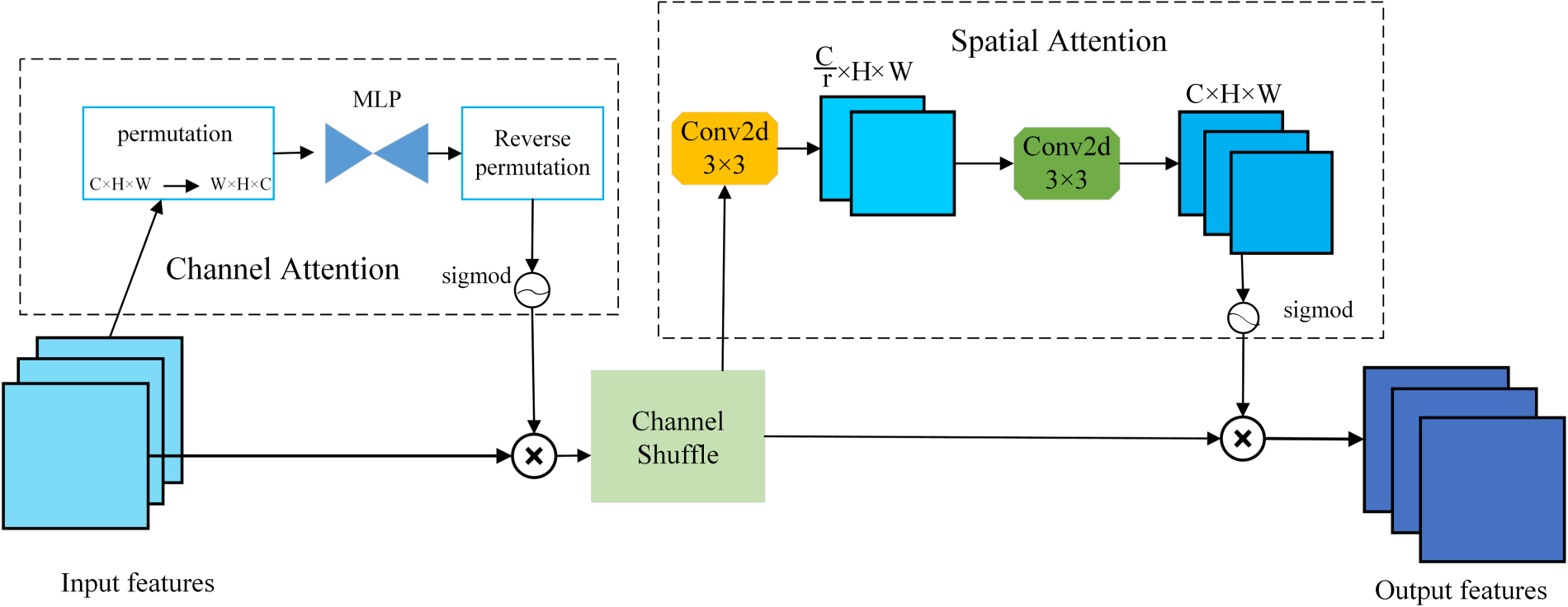
Detailed Architecture of the Proposed CSDAM: The Module First Applies Channel Attention by Permuting and Reordering Features Through an MLP, Followed by a Channel Shuffle Operation to Enhance Inter-Channel Interaction. Subsequently, Spatial Attention Is Employed Using Convolutional Layers to Capture Spatial Dependencies. The Combination of Channel and Spatial Attention Enables CSDAM to Adaptively Emphasize Informative Features and Suppress Irrelevant Ones, Thereby Generating Refined Output Features. Note. CSDAM = channel shuffle dual attention module; MLP = multilayered perceptron.
Among them,
After the channel attention operation, to facilitate cross-group information flow and further alleviate potential redundancy in convolutional layers, we introduce a channel shuffle mechanism. The enhanced feature map is first divided into eight groups, with each group containing (c/8) channels. A transpose operation is then applied to shuffle the channel order across different groups. After shuffling, the feature map is reshaped back to its original dimensions. This operation effectively encourages semantic feature mixing across channels, thereby enhancing the model’s capacity to represent complex feature interactions. The channel shuffle operation can be formally defined as:

After the channel information is remixed, to further enhance the model’s ability to capture local spatial semantic information, a spatial attention submodule is designed. Specifically, two
To highlight the distinctiveness of CSDAM, we compare it with three representative attention or feature enhancement modules—SENet (Hu et al., 2018), CBAM (Woo et al., 2018), and ShuffleNet (Zhang et al., 2018)—and analyze their applicability to I2I translation tasks. SENet generates channel attention weights via global average pooling (GAP), effectively enhancing channel discriminability. However, this approach compresses spatial dimensions, discarding fine-grained spatial details that are crucial for tasks requiring local fidelity (e.g., fur textures in cat-to-dog translation). Moreover, the absence of interaction between channel and spatial attention can lead to misalignment between salient channels and their corresponding spatial regions, undermining local consistency. CBAM models both channel and spatial attention but adopts a sequential fusion strategy, which limits its ability to capture joint channel–spatial dependencies. ShuffleNet reduces computational costs through group convolution and employs channel shuffling to promote information exchange between groups. Yet, its fixed, input-agnostic shuffling strategy lacks adaptability, making it less effective for dynamically enhancing semantic regions in high-fidelity generation tasks.
In contrast, CSDAM employs a dual-attention mechanism with adaptive channel shuffling to jointly and dynamically enhance channel and spatial representations. The channel attention branch leverages dimension permutation and MLP-based modeling to capture complex inter-channel dependencies, while the adaptive shuffling strategy, guided by learned attention weights, facilitates content-aware feature fusion and redundancy suppression. The spatial attention branch utilizes a lightweight
To enhance the robustness of the 12I translation model against real-world noise interference, we introduce isotropic Gaussian noise into the input images during the training phase. Unlike conventional approaches that address noise through denoising modules applied only during inference or as a separate post-processing step, our method incorporates noise directly into the learning process. This allows the model to be exposed to and adaptively learn from noisy inputs throughout training, thereby encouraging it to capture more resilient and generalizable feature representations. As a result, the model maintains high-fidelity translation performance even under challenging, noise-contaminated conditions, which is particularly important for practical applications where input images are often degraded by various forms of environmental noise. Specifically, let


The noise injection operation is applied only during training, ensuring computational efficiency and real-time performance during inference. In our experiments, we set
In this study, we propose a novel residual module called FFRB, as shown in Figure 3, which is designed to enhance the performance of image translation tasks such as cat-to-dog translation. Building upon the traditional residual block structure, FFRB adopts a two-step feature enhancement strategy.
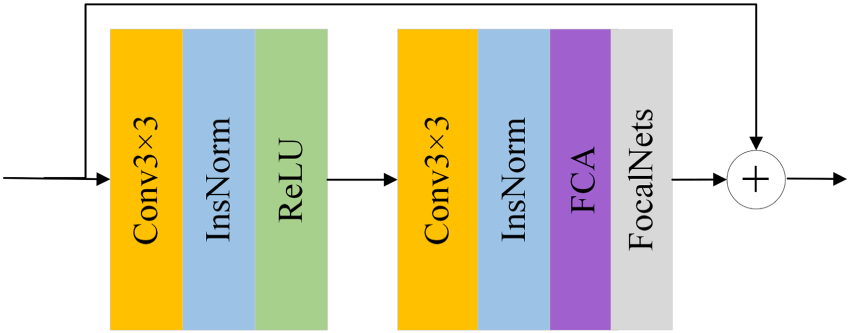
Diagram of the FFRB: The Module Adopts FCA to Emphasize Informative Frequency Components While Suppressing Redundancy, and Integrates FocalNets’ Focal Modulation to Aggregate Multi-Scale Context, with Residual Connections Preserving Spatial Details and Stabilizing Training.Note. FFRB = focal-frequency residual block; FCA = frequency channel attention.
In the first stage of our model, we employ a combination of a convolutional submodule and a frequency channel attention (FCA) module to enhance feature extraction and channel-wise information modeling. Initially, the input image passes through a two-layer convolutional block for preliminary feature extraction. The first convolutional layer, coupled with normalization and ReLU activation, is designed to capture low-level features such as edges and textures. The second convolutional layer further enhances the semantic representations. To enrich the channel representation and leverage frequency-domain cues critical in image translation tasks, we incorporate the FCA module, proposed in frequency channel attention network (FcaNet), immediately after the second convolutional layer. While conventional channel attention mechanisms typically rely on GAP to compress features into scalars, GAP only retains the lowest frequency components, leading to loss of valuable high-frequency information. This limitation often results in blurred textures or missing details in image translation tasks. The FCA module addresses this issue by modeling channel attention in the frequency domain using the discrete cosine transform (DCT). It splits the input channels into several groups and applies DCT to extract different frequency components across groups, thereby capturing richer and more diverse channel features. This multi-spectral approach allows the model to better preserve fine-grained details, textures, and structures in the translated images. By integrating FCA (Qin et al., 2021), our model gains enhanced capability to distinguish and emphasize informative channels, leading to improved visual quality and reduced perceptual distortion.
After frequency modulation, we integrate the FocalNets module into the proposed residual block, FFRB, to enable multi-scale local context modeling. Specifically, FocalNets (Yang et al., 2022) employs a hierarchical structure of depthwise separable convolutions to encode features across varying receptive fields, thereby capturing contextual information ranging from local to global scales. On top of this, a dynamic gating mechanism is introduced to adaptively assign content-aware weights to each contextual level based on the query location. These multi-level contexts are then effectively fused into the current feature representation through an element-wise modulation process. The incorporation of this module enhances the model’s ability to represent fine-grained local structures while preserving sensitivity to long-range dependencies. This is particularly advantageous for image-to-image translation tasks, where precise rendering of textures, edges, and other spatial details is crucial. The overall operation of the FFRB can be mathematically formulated as:


The component ConvBlock(
Finally, FFRB fuses the features processed by FocalNets with the original input features through a residual connection, leading to richer and more expressive feature representations. This two-stage feature enhancement design takes full advantage of the complementary strengths of global frequency information and multi-scale local detail, which not only preserves the expressiveness of the original features but also significantly improves the capture of fine-grained information. Experimental results demonstrate that the FFRB module, while maintaining high computational efficiency, significantly improves the visual quality and detail fidelity of generated images, providing stronger feature support for image translation tasks.
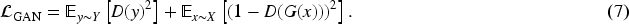

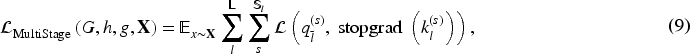
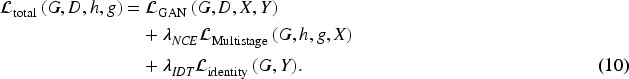
Experiment Setup
Comparison With Other Methods
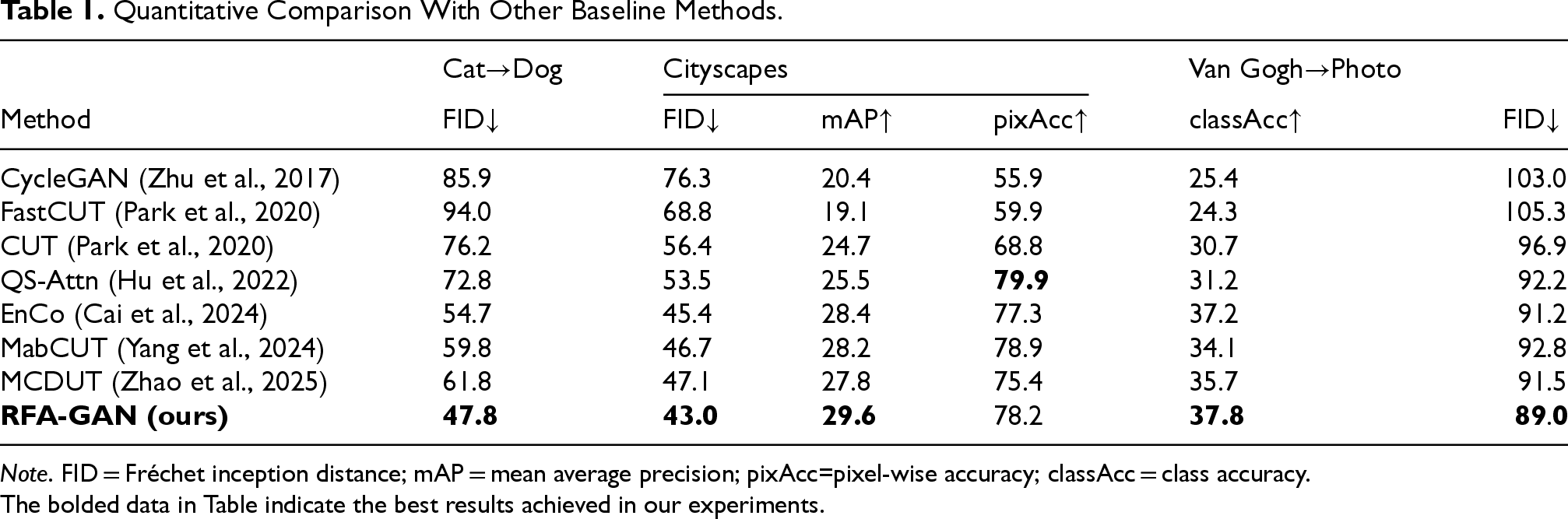
Table 1 presents the quantitative comparison between our proposed RFA-GAN and several baseline methods on the Cat
Quantitative Comparison With Other Baseline Methods.
Quantitative Comparison With Other Baseline Methods.
Note. FID = Fréchet inception distance; mAP = mean average precision; pixAcc=pixel-wise accuracy; classAcc = class accuracy.The bolded data in Table indicate the best results achieved in our experiments.
As shown in Figure 4, we present the image translation results of our method on the Cat

Visual Results Comparison with All Baselines on the Cat
Compared with other methods, our model achieves better performance in terms of completeness, clarity, and realism of the generated results. Specifically, it produces more accurate structural reconstructions in key facial regions such as the ears and mouth, with clearer contours and more natural shapes. This effectively avoids common issues observed in other methods, such as structural distortion or missing parts. Furthermore, our model excels in restoring fine-grained fur textures, resulting in synthesized images that are more visually faithful to real animal appearances and significantly enhancing perceptual image quality.
As illustrated in Figure 5, we present the visual results of our proposed method on the Cityscapes dataset, along with comparisons against several representative baseline models. The results clearly demonstrate that our model, guided by semantic labels, can generate high-quality images containing various typical urban scene elements such as cars, buildings, and trees. Moreover, it achieves superior performance in both detail fidelity and overall image sharpness compared to existing approaches.

Visual Results Comparison with All Baselines on the Cityscapes Dataset: Red Boxes Highlight Key Regions Such as Vehicles and Trees, to Facilitate Comparison of Different Methods in Terms of Edge Sharpness, Detail Realism, and Semantic Consistency. Our Method Produces Sharper and Structurally More Coherent Details While Maintaining Accurate Semantic Alignment with the Input.
In particular, our method exhibits stronger generation capability for complex structural elements, such as vehicles. While other methods often suffer from issues such as structural fragmentation, blurred edges, or missing textures, our model produces cars with clearer contours, more complete shapes, and richer texture details. These characteristics result in a perceptual quality that is closer to that of real-world images. This indicates that our method strikes a more effective balance between structural preservation and style translation.
Figure 6 presents the visual comparison results on the Van Gogh

Visual Results Comparison with All Baselines on the Van Gogh
Compared to existing approaches, our method excels at capturing fine-grained, style-relevant features—such as shading, color tone, and spatial consistency—that are crucial for high-quality style transfer. In particular, the generated images from our model exhibit clearer textures, more realistic lighting, and well-preserved scene structures, whereas other methods often produce artifacts, overly smoothed regions, or distorted compositions. These results highlight the effectiveness of our model in achieving a better balance between structural fidelity and style adaptation, thereby validating its robustness and superiority in cross-domain image translation tasks.
Through comparative experiments, our method outperforms all baseline models. In the proposed RFA-GAN framework, the generator integrates the CSDAM and FFRB modules, and Gaussian noise is injected into the input images during training. To evaluate the impact of the number of channel shuffle groups in the CSDAM module on model performance, we conducted an ablation study on the Cat

Qualitative Ablation Results: The Leftmost Column Shows the Input Images, While the Remaining Columns Present the Translated Outputs from Models A to G.
Ablation Experiment on the Number of Channel Shuffle Groups in the Cat

Note. FID = Fréchet inception distance.
FID Scores Under Varying Gaussian Noise Variances During Training on the Cat
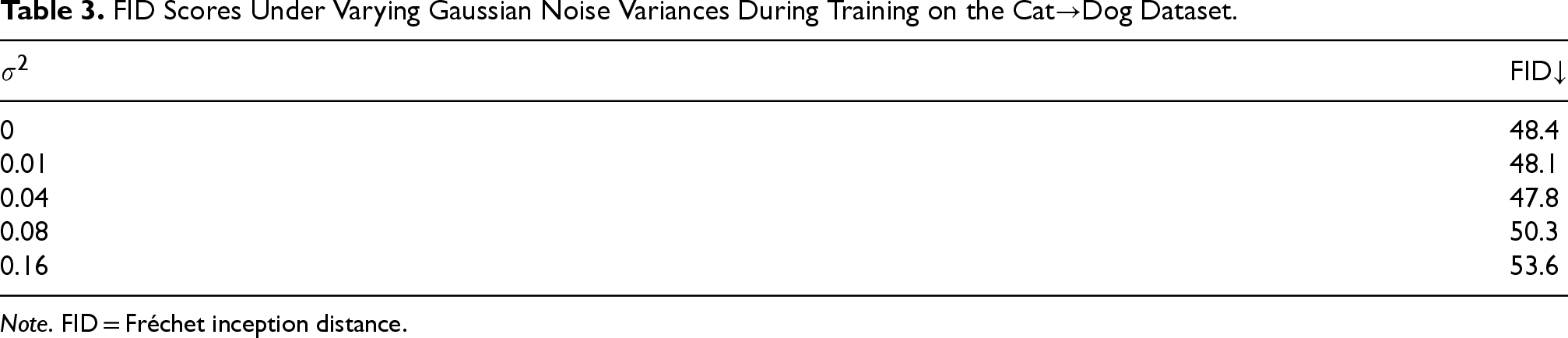
Note. FID = Fréchet inception distance.
Quantitative Results for Ablation Study.

Note. CSDAM = channel shuffle dual attention module; FFRB = focal-frequency residual block; FID = Fréchet inception distance.The bolded data in Table indicate the best results achieved in our experiments.
As shown in the ablation results in Table 2, when the number of channel shuffle groups is set to 8, the model achieves the lowest FID score, indicating the best image generation quality.
As shown in Table 4, Model A introduces the CSDAM module into the generator; Model B adds Gaussian noise to the image before feeding it into the generator; and Model C replaces the traditional ResNet residual blocks with the proposed FFRB module. Compared with EnCo, all three models (A, B, and C) demonstrate improved performance, validating the effectiveness of each design component. Model D, which combines the CSDAM module with noise injection, further enhances performance relative to Models A and B, indicating that CSDAM not only strengthens feature representation but also improves robustness against noise. Model E outperforms both Models B and C, showing superior adaptability in capturing local details while resisting noise or distortion. Model F integrates both CSDAM and FFRB, surpassing the individual performance of Models A and C, which confirms the complementary effects of the two modules in balancing local detail restoration and global style consistency. Model G integrates all components and outperforms all comparative models, demonstrating the overall superiority of the proposed approach.
To clarify the independent contributions of each subcomponent within CSDAM, we conducted a more fine-grained ablation study. As illustrated in Table 5, removing any subcomponent from CSDAM consistently leads to performance degradation, confirming its necessity. In particular, eliminating the channel attention branch results in the most significant decline, underscoring its critical role in selective feature modeling for preserving content fidelity and style consistency. Similarly, the removal of spatial attention causes a considerable drop, highlighting its importance in capturing fine-grained structural details. The exclusion of the channel shuffle operation also leads to moderate degradation, suggesting that cross-channel interaction is beneficial for reducing redundancy and enhancing feature expressiveness. Overall, the full CSDAM configuration consistently achieves the best performance across all evaluation metrics, further validating that the synergy among its subcomponents is essential to the effectiveness of the module.
Ablation Study on CSDAM Subcomponents.

Note. CSDAM = channel shuffle dual attention module; FID = Fréchet inception distance.
To validate the effectiveness of the proposed CSDAM module, we conducted comparative experiments by replacing CSDAM in the encoder and decoder of the RFA-GAN framework with representative attention mechanisms, including CBAM (Woo et al., 2018) and efficient multi-scale attention (EMA; Ouyang et al., 2023). The quantitative results, summarized in Table 6, demonstrate that CSDAM outperforms these alternatives under the same experimental settings, confirming its effectiveness in enhancing feature representation for I2I translation tasks.
Quantitative Results for Ablations Compared With Other Attention Mechanisms. +CBAM and +EMA Indicate Replacing CSDAM in our Generator with the Corresponding Attention Modules.

Note. CSDAM = channel shuffle dual attention module; FID = Fréchet inception distance; EMA = efficient multi-scale attention; CBAM = convolutional block attention module.
Additionally, we visualized the attention maps produced by CSDAM, CBAM, and EMA for both cat and dog images to provide a more comprehensive comparison. As illustrated in Figure 8, our CSDAM module exhibits a sharper and more semantically aligned focus on discriminative regions, which facilitates better preservation of structural consistency and style details in the I2I translation process.

Visualization Comparison of Attention Maps Produced by Different Attention Mechanisms (CSDAM, EMA, and CBAM) on Cat and Dog Images: (A) Attention Maps for Cats; (B) Attention Maps for Dogs.Note. CSDAM = channel shuffle dual attention module; EMA = efficient multi-scale attention; CBAM = convolutional block attention module.
However, despite CSDAM’s strong performance in most scenarios, we also observed its potential limitations. In extreme cases of highly complex image translation tasks (e.g., Van Gogh

Extreme Cases in Highly Complex Image Translation Tasks.
In the FFRB, we integrate FcaNet and the focal modulation module (FocalNets). Ablation studies on the cat
Ablation Study on the Key Components of FFRB.

Note. FFRB = focal-frequency residual block; FID = Fréchet inception distance.
To further evaluate the practical effectiveness of our model in unpaired I2I translation tasks, particularly in terms of human visual perception, we conducted a user study focused on subjective visual quality assessment. This experiment aimed to assess the perceptual realism and visual quality of the generated images based on feedback from human observers.
A total of 30 volunteers with basic image discrimination capabilities were recruited for this study. All participants were capable of evaluating image quality from a perceptual standpoint. To ensure the representativeness and fairness of the evaluation, we selected three representative datasets and randomly sampled 20 images from each dataset. These images were translated using our proposed model (RFA-GAN) as well as several mainstream baseline models. The generated images corresponding to each original input were presented to the participants in a randomized order to prevent any model-related bias during the evaluation.
Participants were instructed to rank the translated results of each image set based on criteria such as image clarity, detail preservation, style consistency, and overall visual realism. The ranking was performed from “most consistent with real-world perception” to “least consistent.”
As shown in Figure 10, the results indicate that our proposed RFA-GAN consistently received higher user ratings across most samples. Specifically, RFA-GAN was ranked first in 65% of the image sets evaluated by participants, significantly outperforming other baseline methods. These findings demonstrate the clear advantage of our model in terms of perceived visual quality in unpaired image translation tasks.
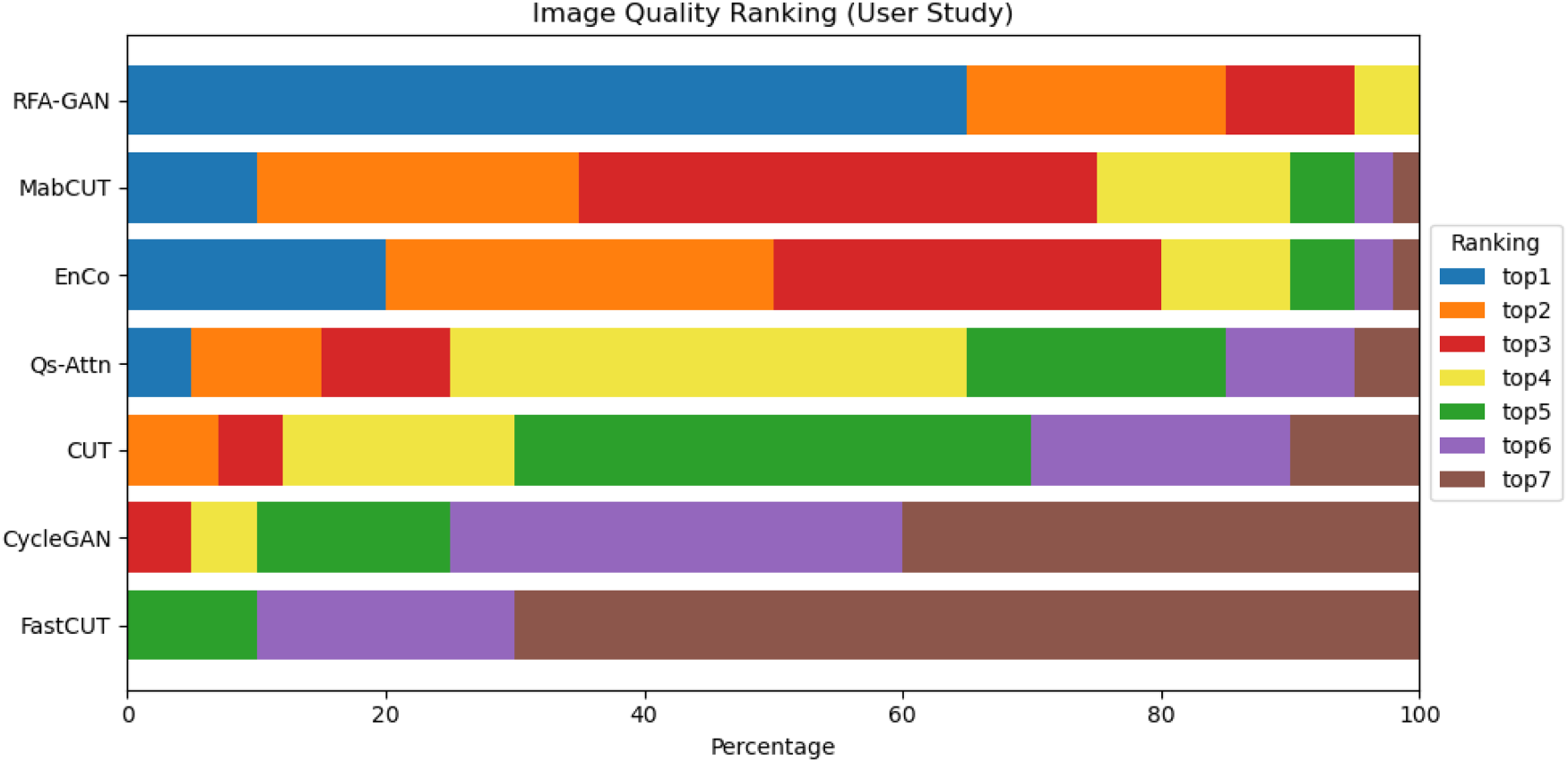
User Study Results: We Aggregated and Computed the Proportional Rankings of User Preferences Across Models, and Visualized the Results to Assess Performance. The Horizontal Axis (X-Axis) Represents the Ranking Percentage (%), While the Vertical Axis (Y-Axis) Lists the Evaluated Models.
Although RFA-GAN achieves competitive performance in various I2I translation tasks, its computational complexity remains a limitation. The integration of dual attention and frequency-aware modules increases model overhead, potentially restricting deployment in resource-constrained or real-time applications.
For future work, we plan to investigate lightweight architectures and model compression techniques—such as neural pruning and knowledge distillation—to improve inference efficiency. Furthermore, extending RFA-GAN to high-resolution video translation and specialized domains, such as medical image synthesis, represents a promising direction for broader impact.
Conclusion
This paper proposes a novel I2I translation framework, RFA-GAN, which integrates noise injection and attention mechanisms to effectively alleviate the problem of detail loss during the translation process. To enhance the model’s ability to capture fine-grained features, we design the CSDAM. A novel FFRB is proposed to overcome the limitations of traditional residual blocks in preserving texture and detail features, achieving enhanced reconstruction fidelity for target domain images. Furthermore, we incorporate Gaussian noise at the input stage to improve the model’s robustness and generalization capability. Extensive experiments on multiple mainstream datasets demonstrate that the proposed method significantly outperforms existing state-of-the-art methods in terms of image quality and detail preservation. Ablation studies further validate the effectiveness of each module design, and comparisons with various mainstream attention mechanisms highlight the superior performance of CSDAM. We hope this research provides new insights and valuable references for unpaired I2I translation tasks.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Scientific Research Project of Jilin Provincial Education Department (grant no. JJKH20250520KJ), the Natural Science Foundation of Jilin Province (grant no. 20230101179JC), the National Natural Science Foundation of China (grant no. 61702051).
Declaration of competing interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.