
Abstract
We present the architecture of a fully autonomous, bio-inspired cognitive agent built around a spiking neural network (SNN) implementing the agent’s semantic memory. This agent explores its universe and learns concepts of objects/situations and of its own actions in a one-shot manner. While object/situation concepts are unary, action concepts are triples made up of an initial situation, a motor activity, and an outcome. They embody the agent’s knowledge of its universe’s action laws. Both kinds of concepts have different degrees of generality. To make decisions the agent queries its semantic memory for the expected outcomes of envisaged actions and chooses the action to take on the basis of these predictions. Our experiments show that the agent handles new situations by appealing to previously learned general concepts and rapidly modifies its concepts to adapt to environment changes.
Keywords
Introduction
The ability of a cognitive agent to act adequately in a given environment depends on its ability to predict how performing a given action will affect its current situation; that is, it depends on the agent’s knowledge of the laws of the universe that determine the effects of its possible actions on its environment (hereafter the action laws of the universe). How artificial agents can acquire these laws and how these should be updated if their environment changes has proved a difficult question. In the case where the intended environment is open—that is, where the agent’s designer cannot foresee all the situations the agent might encounter in the future—, providing a suitable set of action laws to the agent “by hand” is unfeasible. The only viable solution is that the agent continuously learns the relevant laws from experience, just as natural agents (humans and animals) do. Crucially, this learning process should allow for generalization over disparate experiences, so that the agent is able to behave appropriately in new situations. It should also allow for rapid modification of the learned action laws to accommodate environment changes. Finally, it should address the fact that however big its memory resources may be they will always be finite, while the number of distinct objects and situations it may encounter in an open world is unbounded.
The aim of the present article is to show how such a learning (autonomous, online, achieving generalization and rapid updating while being adapted to open universes), could be done. Solving this problem would be useful in applications such as mobile autonomous robots (e.g., service robots) living in open worlds.
The proposed approach’s main hypothesis is that natural agents’ ability to perform well in our open and changing world largely relies on the fact that they store their knowledge in the form of rapidly updatable concepts with various degrees of generality. Presumably, natural agents first form concepts about the encountered objects/situations, and then use these as elements for composing more complex concepts, notably concepts of action. The latter constitutes their knowledge of their environment’s action laws. Concepts are a very compact way to store information, as more general concepts can apply to a whole range of distinct cases while being usable in new similar situations. They also allow for efficient updating, as the adjustment of a single concept modifies all the inferences and further decisions that can be made on its basis. Another important hypothesis is that natural agents’ endless ability to learn new concepts despite having finite brains relies on some efficacious management of forgetting. Forgetting is inevitable for an agent with finite memory living in an open world; but it needs to avoid catastrophic forgetting, that is, some kind of forgetting that would severely affect its ability to act judiciously in its current world. Most likely, natural agents avoid catastrophic forgetting by selectively forgetting their less important knowledge (such as, e.g., details and old, unused memories) and reallocating the corresponding neurons to encode new useful knowledge. We suggest that artificial agents could take inspiration from these strategies and use some artificial neural network to learn and store concepts, and query this network to make predictions about the outcome of envisaged actions.
To test this idea, we here build an artificial agent with an SNN at its core. This agent lives in a very simple virtual world, composed of rooms which may be, or not, accessible (hence, knowable) to it. At first, the agent is confined to one single room and learns by itself how to act in it according to its own interests. Then at some point a door opens to a new room containing some never encountered before objects and situations. Yet, although these are new to the agent, some general laws are preserved from one room to the other. Our experiments show that having learned these laws in the first room allows the agent to act by and large properly in the second one, as soon as it enters it. They also show that the agent is able to learn new laws holding in the second room without catastrophic loss of previous knowledge. Finally, some changes are introduced in the second room, rendering some of the previously learned rules obsolete while some new rules become true. Again, experiments show that the agent quickly updates its knowledge to account for these changes.
The article is organized as follows. Section 2 discusses related work and Section 3 presents the agent and its universe. Section 4 gives a general overview of the neural network, while Section 5 details its functioning. Section 6 describes the agent’s workings and Section 7 presents the experiments conducted on the agent and discusses the results. Section 8 concludes and outlines future possible developments of the framework.
Related Works
The research problem addressed in this work is autonomous online learning, updating and generalization of concepts and action laws in an open universe. To our knowledge, no existing approach addresses this problem in all its dimensions, but these are investigated in separate research fields.
Agents living in complex open environments (such as the real world) can be confronted with a huge amount of information in the course of their life. Retaining the totality of that information and further processing it to use it does not seem a practical option, as this would be extremely costly in terms of memory, computational power and energy consumption. This is especially true in the case of agents such as autonomous mobile robots, for which frugality regarding these same resources can be critical. For these agents, memorizing the whole of the experienced objects and events cannot be taken as a reasonable goal or criterion. Rather, forgetting appears as the unavoidable counterpart of continual learning, and the question is how to manage it so as to preserve the agent’s performance as much as possible. The most natural way to do this is by ensuring that the previous knowledge that is lost through new learning is the agent’s less useful knowledge at the time of the learning. How to characterize “less useful knowledge” and how to preferentially select it for deletion is a key issue to address to efficiently manage forgetting. In turn, such an efficient management of forgetting appears as a necessary condition for making lifelong learning autonomous agents in complex open environments possible.
The present article aims at providing a proof of concept of a cognitive agent satisfying the above requirements. As a first step, it focuses on the learning of concepts and only uses them in some basic decision making to demonstrate the agent’s learning abilities. However the agent is designed so as to allow the retrieval of the learned concepts and action laws, which could then be encoded in symbolic format and used in more complex decision making involving explicit reasoning and action planning. The implementation of such complex reasoning abilities in the agent is left to future work.
In the absence of studies investigating the considered research problem in all its dimensions, comparing the proposed setup with existing approaches seems inappropriate. Indeed, this would only take into account some of the dimensions of the problem and fail to evaluate the proposal relative to its goal. It should also be remarked that the standard metrics commonly used to assess neural networks’ learning performance cannot be used in the present case. Notably, notions such as Average Accuracy, Forward and Backward Transfer (Chaudhry et al., 2018; Lopez-Paz & Ranzato, 2017) used in the field of Continual Learning to assess learning accuracy, generalization and resistance to catastrophic forgetting cannot be used. Indeed, these metrics were devised to assess the performance of classifiers and are built upon a basic notion of accuracy that consists in checking whether two objects (generally the predicted class and the actual class of a sample item) are identical. But in the present proposal a prediction is not a single object but a set of objects (namely a set of predicted features), which is to be compared with another set of objects (the actual situation’s set of features). Simply checking whether these two sets are identical would be a rather crude way to assess the prediction’s accuracy: a more fine-grained comparison is needed, based on set inclusion properties. For these reasons, a suitable set of experiments and metrics was devised (see Section 7).
The Agent and Its Universe
This section describes the universe the agent lives in and gives a general overview of the agent. It also clarifies the notions of concepts and action laws used in the sequel.
The Universe
The universe is designed so as to support a set of experiments intended to assess the agent’s abilities. It presents a number of challenges for the agent to face, while being kept as simple as possible to allow the precise monitoring of the agent’s performances.
The universe is built over a grid of boxes, which we (not the agent) identify using an orthonormal coordinate system (see Figure 1). Each box represents a particular location in the agent’s universe and possesses a particular set of features the agent is able to perceive, drawn from the set LF = {OK, KO, NorthWall, EastWall, SouthWall, WestWall, Cold, Sound, #0, #1,…, #24}. For example, the box with coordinates
The rooms are made out of boxes, and delimited with impassable walls. For instance, Figure 1A shows the first room, which is composed of 25 boxes. Opening a door amounts to removing the wall features from the corresponding boxes’ feature sets (as in Figure 1B, where the EastWall feature has been removed from boxes
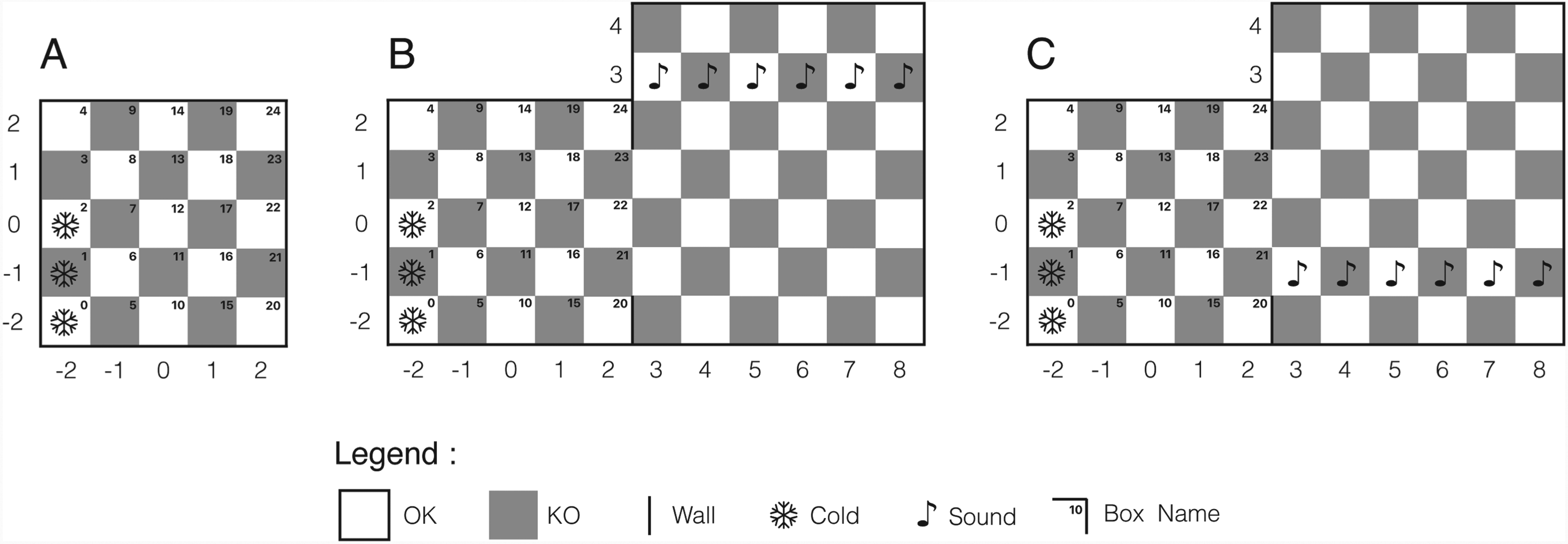
The agent’s accessible world: (A) In the first phase, room 1 only; (B) After opening the door, rooms 1 and 2; (C) After the sound feature is moved downwards (from row 3 to row
When considering the agent’s universe, at any point in time we only consider the boxes to which it has access, the set of which is always finite. Note that this does not contradict the unboundedness of the universe: although each possible room is finite (as are rooms in real world), the number of possible rooms the agent may discover in its life and the number of new objects it may encounter in them, as well as the number of changes that may occur in these rooms, are unbounded. Being able to handle these novelties (react appropriately and update its knowledge on the fly) is the agent’s main challenge.
As regards the features, KO corresponds to some unpleasant stimulus the agent spontaneously wants to avoid, and OK to the absence of such a stimulus. The other features convey some indifferent information. It should be stressed that OK and KO are not rewards in the sense of RL, as they play no role in the neural network’s learning process (see section 5 for details). Their only purpose is to motivate the agent’s choices and to allow us to assess its ability to make appropriate decisions.
The distribution of OK and KO boxes, which is common to both rooms, provides some general (non-monotonic) laws of the universe (such as “going North-East from an OK box leads to another OK box”), the learning of which is the agent’s second challenge. Boxes’ names in the first room are specific features (i.e., they apply to one single object). They are used to check that the agent also forms particular concepts of individual boxes and uses them to learn particular rules (such as “going North-East from the OK box with name ‘#12’ leads to the OK box with name ‘#18’’’). Cold is a feature common to a small number of boxes. It is mainly used to increase the number of features boxes may have (from two to five), and also to check that the agent can form concepts with an intermediate degree of generality such as, for example, the concept of cold OK boxes with a West Wall (see Section 3.3 for a formal definition of generality). Being able to handle concepts with various degrees of generality is a third challenge. Sound is used to test the agent’s ability to use the learned general rules in the presence of novelty, and also to check that it can learn new concepts and action laws without suffering catastrophic forgetting. Notably, after the door opens (Figure 1B) the agent is expected to learn new general rules such as “going North from a box with sound leads to a box with a north wall”. Moving the Sound feature from its “up” position (Figure 1B) to its “down” position (Figure 1C) is used to test the agent’s ability to update its knowledge when the environment changes.
The agent is composed of a set of sensors, a perceptual system, a semantic memory, a decision system, a motor system and a set of actuators (see Figure 2). Sensors collect data from the external world and feed it to the perceptual system, which performs feature/object recognition. Neural networks doing this while relying on unsupervised learning from unlabeled data already exist (e.g., Kheradpisheh et al., 2017, Thiele et al., 2018), so we simply suppose that the agent’s perceptual system operates as intended and provides the semantic memory with the appropriate inputs, namely, the correct and complete set of features of the agent’s current location. Semantic memory forms concepts by binding together sets of features, and stores them for further retrieval. Its modeling is the main focus of the article. The decision system is the other important part: it queries the semantic memory to predict the outcome of possible actions, and decides which one to take on the basis of these predictions. This decision is then sent to the motor system, which activates the actuators to perform the corresponding motor activity. Information from the actuators is sent back to semantic memory through proprioception, allowing the agent to memorize the motor-related features of the realized actions.
The agent’s possible actions consist in steps from one box to another adjacent box, in any of the eight directions. Formally, an action is a triple made up of a depart location, a motor activity, and an outcome. By “motor activity” we mean the fact that the agent’s actuators are activated so as to make it move to the immediate next box in the selected direction. The set of the agent’s possible motor activities is therefore the set MotAct = {North, North-East, East, South-East, South, South-West, West, North-West}. The set of motor activity features the agent is able to perceive by proprioception is the set MF = {N, NE, E, SE, S, SW, W, NW, Diag, Orth}, where the first eight are specific to each particular motor activity, while Diag and Orth are more general features shared by all motor activities yielding diagonal/orthogonal moves. In cases where there is a wall at the edge of the depart box in the selected direction, the agent bumps into it and remains at the same place. We then say that the action’s outcome is a failure. Otherwise, the action’s outcome is the agent’s new location.
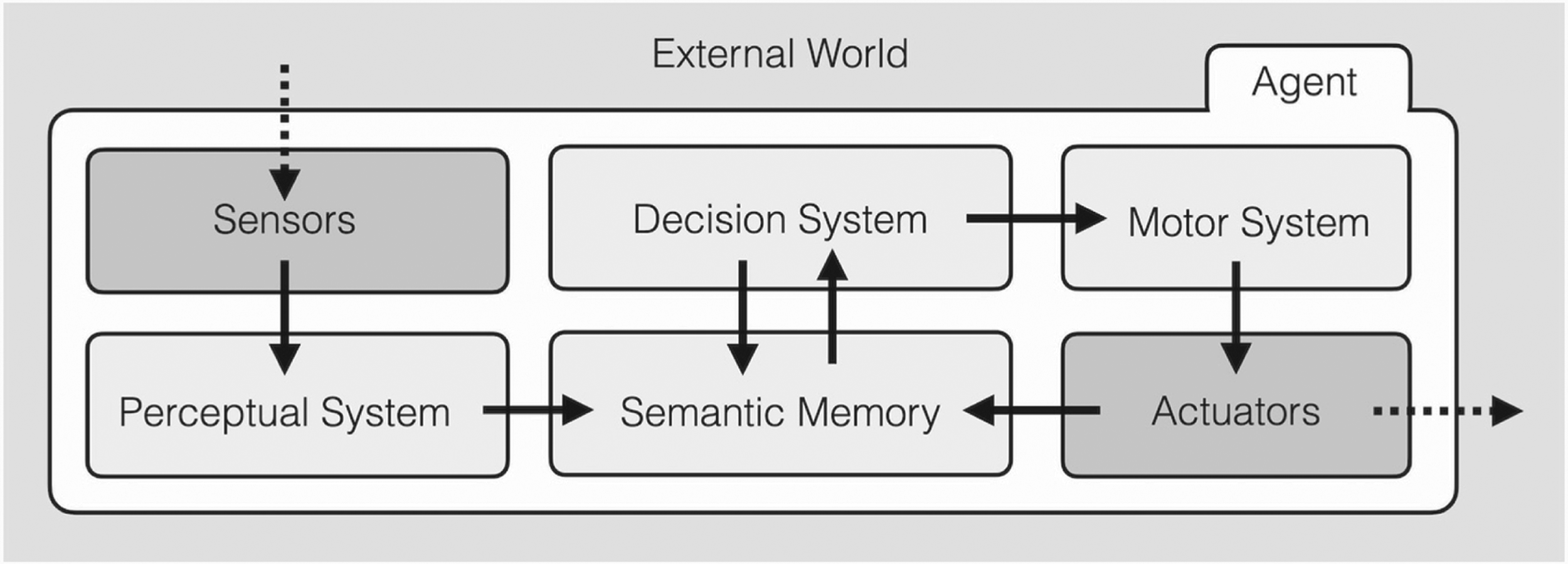
Schema of the agent.
The agent can form two kinds of concepts. First, concepts of “things,” in the broad sense. These concepts bind together co-occurrent features and can be seen as some sort of conjunction in which conjuncts have different “weights,” reflecting the fact that some features are more important than others in a concept’s definition (Freund, 2008). They store the agent’s knowledge about locations and more generally about any object, so we call them object concepts. The second kind is relational concepts. These take other concepts as elements and bind them together into tuples. Concepts of actions are of this kind: they bind together the agent’s concepts of a depart location, a performed motor activity, and a subsequent outcome, in the order in which they were experienced.
An object concept X is said to be general, as opposed to particular, if there is another concept Y such that the set of features composing X is a strict subset of the set of features composing Y. Y is then said to be more particular than X. These definitions capture the fact that if X is more general than Y then the set of objects X applies to is a superset of the set of objects Y applies to. In line with this idea, in this work an action concept is said to be general if the object concept of its initial situation is general or its motor activity component only contains Diag or Orth (thus, if X and Y are action concepts such that X is more general than Y, then the set of actions X applies to is a superset of the set of actions Y applies to). Generality of both kinds of concepts is understood relatively to the set of concepts the agent possesses at some point, so no concept is general or particular in itself.
For example, when visiting the box
It should be mentioned that this representation of action laws is slightly different from the one used in the AI field of planning (see e.g., Fikes & Nilsson, 1971), which involves a notion of executability that specifies the conditions that need to hold for an action to be possible. Yet the notion of executability can readily be recovered from action concepts by stating that the action represented by the action concept
Implementing the Agent’s Semantic Memory in the Neural Network: Overview
This section presents the neural network implementing the agent’s semantic memory. It first gives an overview of SNNs, and more particularly of the neural models and the learning rules which are relevant for that purpose. Then it presents the network’s general architecture.
Spiking Neural Networks
Spiking neural networks (SNNs) are artificial neural networks in which information is transmitted between neurons by the means of spikes fired by neurons at other neurons. At each time step the activation level of each neuron is computed as a function of both its previous activation level and the amount of activation received by the neuron at this time step. If this activation level reaches a certain threshold (the neuron’s spike threshold) the neuron fires a spike and its activation level is reset to some base value. Emitted spikes are conveyed from one neuron to another through weighted connections that modulate the amount of input transmitted by spikes to the receiving neuron. Learning consists in adjusting these weights.
SNNs are well suited for autonomous learning in open worlds because they allow for spike time dependent plasticity (STDP), a family of biologically plausible learning rules which can achieve unsupervised online learning from unlabeled data (Thiele et al., 2018). There are a number of STDP variants, but all have in common that the modification of the connection’s weight between two neurons depends on the relative timing of their spikes. In the most popular version, the connection between two neurons is reinforced if the input neuron spikes just before the output neuron; it is decreased if it spikes just after the output neuron; and it is left unchanged otherwise.
There are also many different implementations of STDP in SNNs, ranging from highly detailed and biologically accurate models to drastically simplified ones. Simplified versions are known for being rapid and energy-efficient (Yamazaki et al., 2022), which are interesting properties for autonomous robots.
The JAST learning rule (Thorpe, 2023; Thorpe et al., 2019) is certainly one of the simplest STDP implementations one can find. In this family of models, connections between neurons are binary (i.e., weights are either 0—meaning no connection—or 1) and each neuron has a fixed number of incoming connections. Learning is achieved through the replacement, at each time step, of a number
Although this learning rule is appealing for its simplicity, it cannot be used as it is for the present purpose. Obviously, freezing neurons is not suitable for continual learning and updating. Furthermore, neurons having both binary connections and a fixed number thereof would be unable to encode concepts having a variable number of features, which is required since an object’s number of features may vary over time (for instance, when the door is closed the box
For this reason, the neural network implementing the agent’s semantic memory only retains some of the JAST learning rule’s ideas, while relying on a more refined modeling of the neurons’ internal dynamics to address these issues. Retained ideas are mainly the use of binary synapses, and the fact that learning consists in swapping a number of these so that the sum of the connections’ weights on any given neuron remains constant through learning. This character ensures that there can be no “dead” neurons, that is, neurons having lost most of their incoming connections and which are therefore unable to respond to any input. However here a same input neuron may have multiple synapses onto a same output neuron, which means that the connections’ weights are in fact integers. Another retained idea is the use, in some specific cases, of dynamic spiking thresholds, to ensure that a given input always has a number of neurons responding to it.
The article’s original contribution regarding SNNs mainly concerns the use of some internal metrics of the neurons to regulate learning and modulate information transmission. For instance, the input neurons’ ability to establish new synapses onto output neurons depends on the number of synapses they already have, which facilitates the learning of rare or new features (such as e.g., Sound). Another example is that the choice of the neurons recruited for learning a new concept depends on the time of their last spike. This allows to preferentially select less used neurons for new learning and to prevent in this manner the forgetting of more used—and therefore presumably more useful—knowledge. A third example is the modulation of information transmission between neurons in the querying process, which depends on the weight sum of input neurons’ connections onto output neurons. This modulation favors the transmission of more specific information over that of less specific information, which is critical in non-monotonic contexts (see Section 6.1). It should be remarked that these methods do not depend on the specific type of spiking neurons used in the proposal and could thus be applied to regulate learning and forgetting and to balance information retrieval in other contexts.
The Neural Network’s Architecture
The network is composed of an interface, which communicates with the agent’s other components, and a body of hidden neurons which is itself divided into two layers (see Figure 3). The first layer learns object concepts and the second learns action concepts. For this reason we call their neurons, respectively, object concept neurons (O-neurons for short) and action concept neurons (A-neurons). This architecture draws on neuroanatomical studies according to which concepts are represented in the brain by hierarchically organized concept neurons, each receiving information from some lower neurons and sending reciprocal connections to these same neurons so that it can reactivate them for information retrieval (Bausch et al., 2021; Quiroga, 2012; Shimamura, 2010). For simplicity these reciprocal connections are not modeled as such, but instead information is allowed to flow in both directions along the same connections: from interface neurons to O-neurons and from there to A-neurons for learning and querying, and the other way round for retrieving information. A key point is that interface neurons are both input and output neurons, depending on the phase of the computation.
Interface neurons (I-neurons for short) mainly support the representation of features, be it of the visited locations or of the agent’s own motor activities. An additional neuron acts as a failure detector, specifically firing when the agent bumps into a wall and remains at the same place. All of them have their labels fixed from the start. I-neurons encoding mutually exclusive features have fixed reciprocal inhibitory connections which prevents them from firing together in a same computing process: as soon as one has fired, the others are shut down for the rest of the process. The
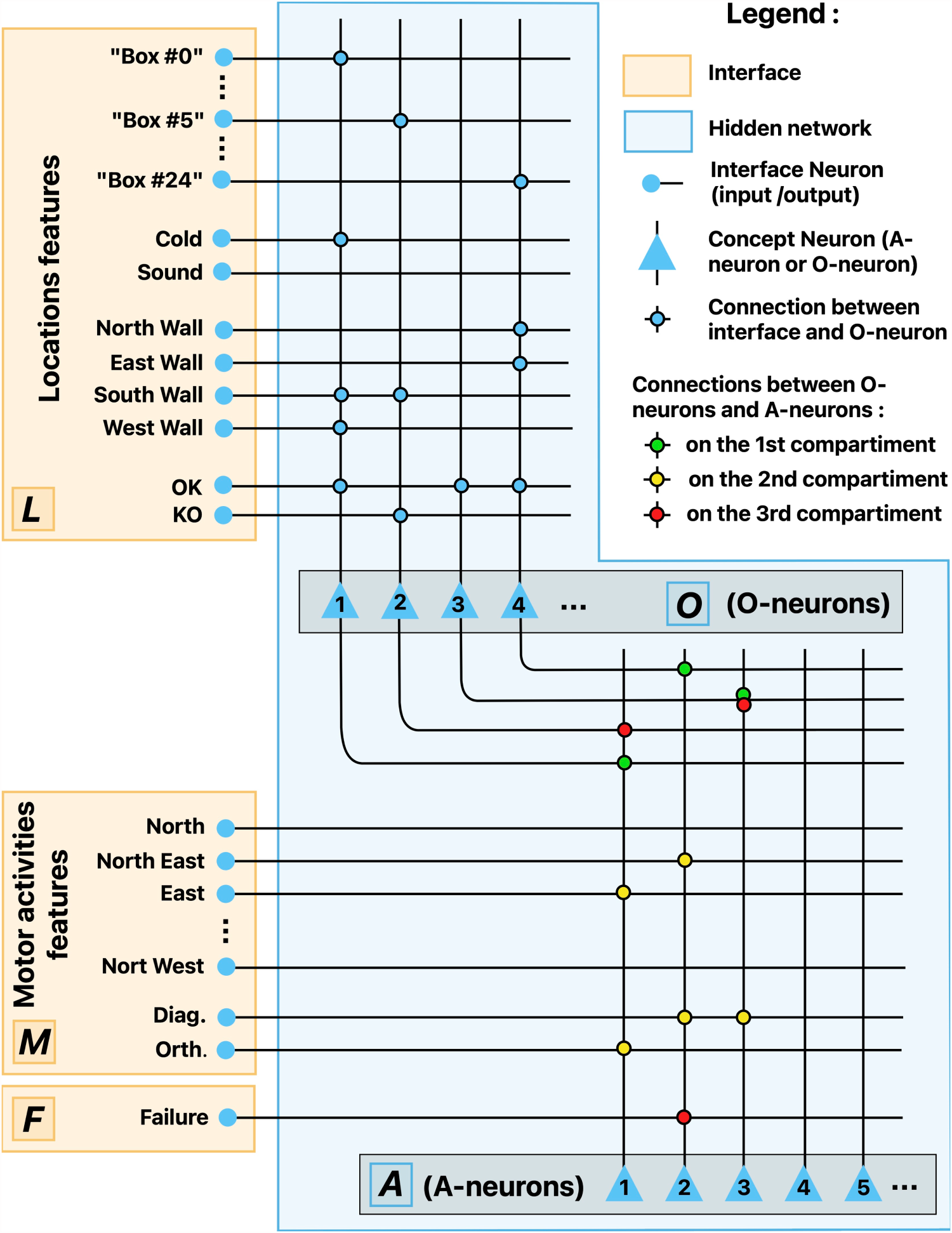
Schema of the SNN. O-neurons #1 and #2, respectively, encode the concepts
The first layer of hidden neurons (O-neurons) is composed of 100 neurons with a differentiated dynamics depending on whether their input source is I-neurons or A-neurons. O-neurons learn co-occurrences of features. The second layer is composed of 400 compartment neurons with three separate input compartments. The first compartment receives connections from O-neurons, the second from motor activities I-neurons, and the third from O-neurons and the
This section describes the neural network’s functioning and details its implementation. For readability, inessential algorithms and parameters settings are relegated in Appendices.
General Notions
Let
Connections
Synapses between any two neurons always have a weight of
These arrays are initialized at random, in such a way that for any O-neuron
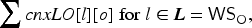
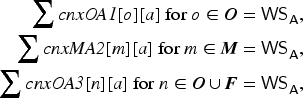
Spike Thresholds
Each O-neuron
Last Spikes
The number of steps performed by the agent since the last spike of each O- and A-neuron is stored in separate vectors
Synapses’ Growth Rates
While the number of incoming synapses on O- and A-neurons is strictly constrained by
Implementation Apparatus
In the algorithms provided in the sequel we introduce and use dictionary structures in which each value
We also use Python’s Numpy function
Forward Firing of O-Neurons
The set of L-neurons that fire in response to an input from either the perceptual system (if the agent is observing its current location) or the decision system (if the agent is querying its semantic memory) is noted

Information Retrieving
Given a set
Learning of O-Neurons
Learning of object concepts (see Algorithm 2) occurs after each observation by the agent of its current situation. The set of O-neurons selected for learning is noted

However, it may happen that there are not enough of them, which is materialized by the fact that a target number
When this happens, the network seeks additional neurons to make learn by “boosting” the input received by O-neurons (see Algorithm 3).

In practice, for each non-firing O-neuron a boosting coefficient

The learning process then depends on the accuracy of the agent’s knowledge relative to the current situation. To assess it, the O-neurons from
If, on the contrary,
A-Neurons
Inputs
The sets of neurons from
A-Neurons’ Forward Spiking
Let

A-Neurons’ Learning
Learning of action concepts (see Algorithm 6) takes place after each step made by the agent. In this case,
The set of A-neurons selected for learning is noted

For each input set
For each neuron
The learning process then depends on the accuracy of the agent’s expectations relative to the action’s outcome. If these expectations were both correct (i.e., all predicted features are actually present) and complete (i.e., all actually present features were predicted), then for any learning neuron
If the agent’s expectations were not correct, then for any learning neuron
If the agent’s expectations were not complete, then for any learning neuron
The Agent’s Functioning
This section first explains how the agent queries its semantic memory to predict the outcomes of envisaged actions, and then how the agent uses these predictions to make its decisions. Finally, it describes the whole process of making a step.
Querying the Network
To query the neural network, the decision system first sends an input to the L-neurons that encode the features of the considered initial situation, bringing a set
Now, among the A-neurons that receive connections from
Each time an A-neuron spikes, it sends a backward input to O- and
Due to input modulation, the input sum received by a given A-neuron

Making Decisions
Suppose that the agent is at some location and wants to make a step. The process by which it decides which motor activity to perform (i.e., in which direction to go) is run by its decision system (see Algorithm 8). First, the agent decides whether to exploit its current knowledge about its environment, or to explore its environment to improve its knowledge. The exploration/exploitation dilemma is a well-known problem in online learning Sutton and Barto (2018); Watkins (1989), and changing environments make it even more difficult. For this reason we do not try to reach an optimal solution here, but we simply make the agent’s decision system choose at random with equal probability between an Exploration and an Exploitation mode.

The agent then makes predictions about the outcome of each possible action. To do so, it successively queries its semantic memory for the outcome of the action having the current location as initial situation and one of the eight possible moves as motor activity (see Algorithm 9).

After each such querying process, a coefficient
The prediction process thus returns a set (dictionary)
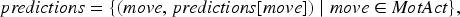
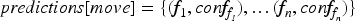
The agent then rates each motor activity 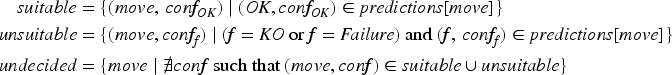
Making a Step
Let

First, it decides in which direction to go by running the decision process described in Section 6.2.
The agent’s move is simulated by a function
Once the action is learned, the input pair
Experiments and Results
The testing of the agent’s abilities was carried out by placing it at location
The results presented here are averaged over 50 trials. Three distinct groups of tests (“Experiments”) were carried out. The code provided in supplementary material allows to reproduce the experiments while varying the number of trials, sequences, steps in sequences, and others parameters.
Experiment #1
In a first group of tests, trials were sequences
Post-Learning Predictions Percentages (Mean over 50 trials). CC: Correct and Complete predictions, MF: Missed Features, PE: Prediction Errors.
Post-Learning Predictions Percentages (Mean over 50 trials). CC: Correct and Complete predictions, MF: Missed Features, PE: Prediction Errors.
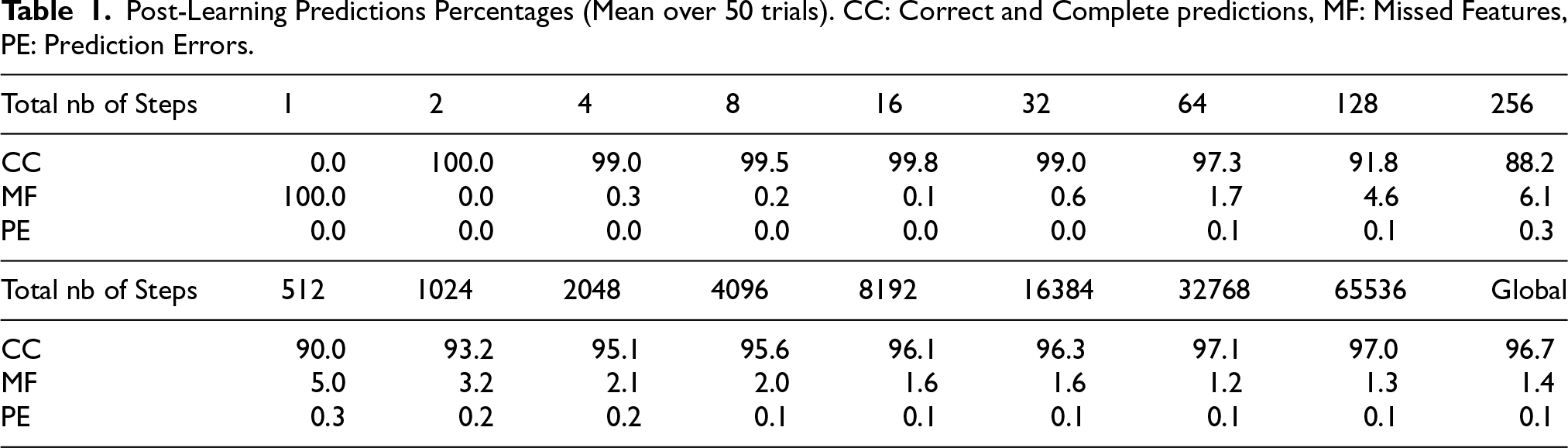
A first test concerned the agent’s ability to learn an action over one single experience (“one-shot learning”). To assess it, after each step the agent was asked to redo the prediction that led to the just realized action, and this new prediction was compared with the action’s actual outcome (see Table 1). A prediction is said to be Correct and Complete (CC) if the predicted features are exactly those of the arrival location. The table’s first line shows the percentage of performed steps leading to a CC post-learning prediction for each series of steps.
At each step, the arrival location’s features (“features to predict”) were listed and counted, and those among them that the agent failed to predict (“Missed Features”) were counted. The table’s second line (MF for “Missed Features”) shows the percentage of features to predict that the agent failed to predict for each series of steps.
The features predicted by the agent were also listed and counted at each step, and those among them that were wrongly predicted (i.e., that did not belong to the arrival location’s feature set) were counted. The table’s third line (PE for “Predictions Errors”) shows the percentage of predicted features that were wrongly predicted for each series of steps.
These results show a good performance at immediate recall after learning. The fact that the network does not learn anything at the first step is expected, as there is no previous step hence
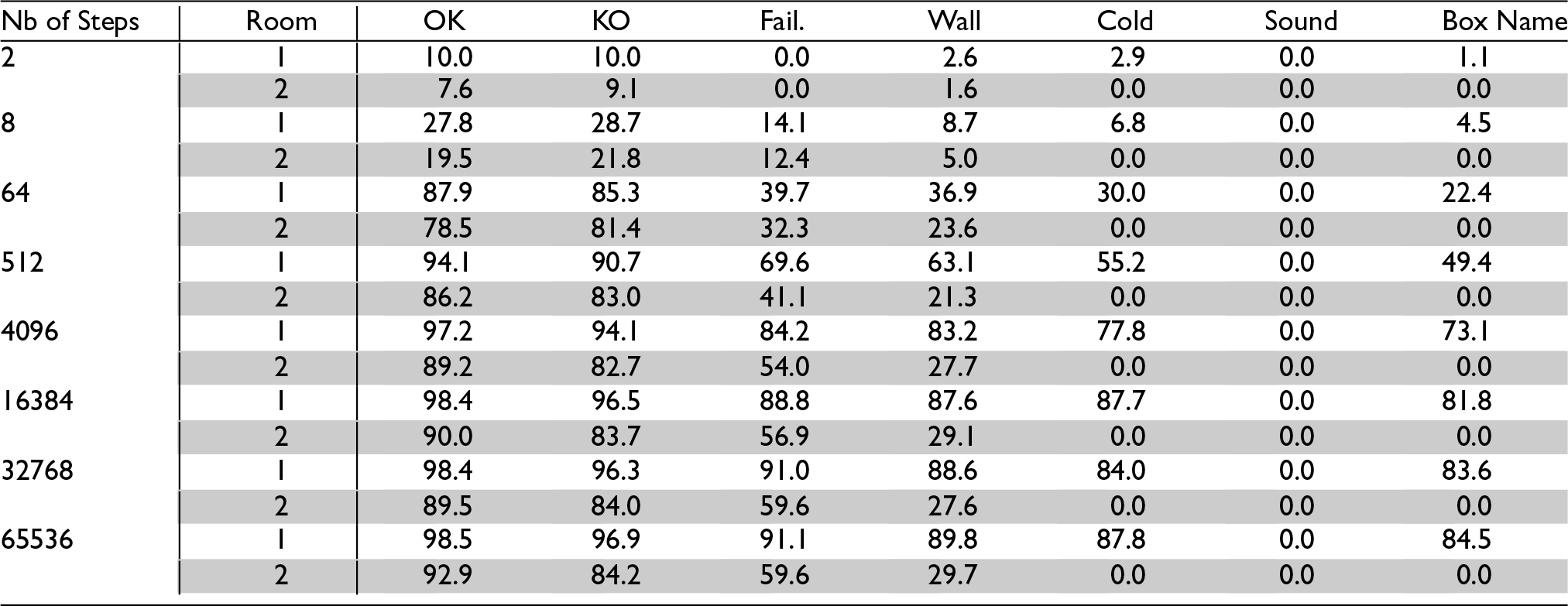
To test whether the acquired knowledge was retained in the long run, after each series of steps the simulation was frozen and learning was deactivated, and the agent was placed successively in each location of each room. There, it was queried for its predictions for each of the eight possible motor activities. Its predictions were recorded and compared with the actions’ actual outcomes. Tables 2 and 3 show each feature’s mean Hit Rate (that is, its chances of being predicted when effectively present), and Correctness (its chances of being effectively present when predicted) 1 for each room.
Predictions’ Hit Rates after
Predictions’ Correctness after
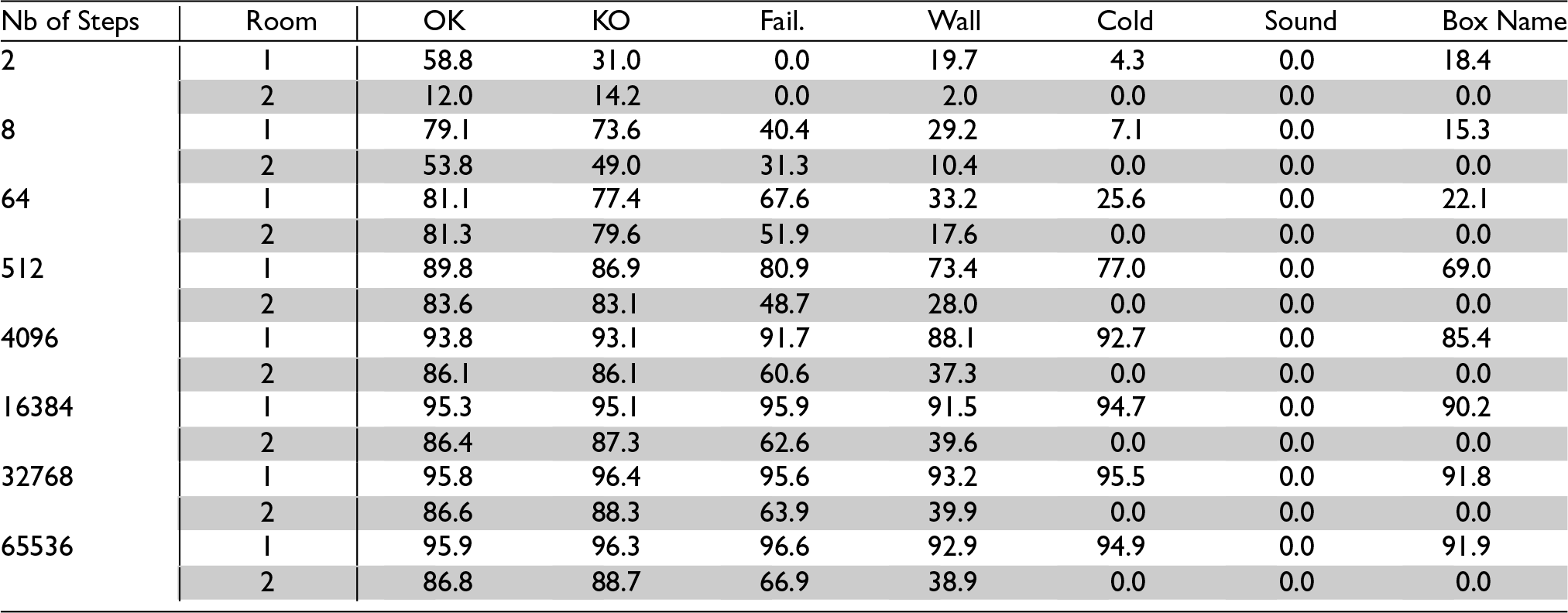
Values for the first room (white lines) show that learned actions are indeed recalled long after having been performed. Values for the second room (grey lines) show that despite never having been in this room (since the door was kept closed) the agent was able to correctly predict OK and KO features and to a lesser extent Failure—and this, even though locations from the second room have different sets of features, including for some of them a new feature, Sound. The poor performance at wall prediction is due to the lack of general rules of the universe observable in the first room regarding the presence of walls in adjacent boxes. The agent thus relies on concepts of particular actions (i.e., action concepts involving particular concepts of individual boxes) to predict walls in the first room, but these cannot be reliably used in the second room. The mixed result at failure prediction comes from a competition between general action concepts, the control of which needs to be improved.
To test the agent’s ability to use its knowledge to make appropriate decisions, the outcome of each action taken in Exploitation mode was recorded throughout the trials. Figure 4.A shows the percentages of OK, KO, and Failure outcomes obtained in this manner for each series of steps (“no data” corresponds to trials for which no steps were taken in Exploitation mode in the considered series). Visited locations were logged to check that the agent was not looping indefinitely on the same boxes: all boxes kept being visited, be it very rarely, at any point of the trials, due to the Exploration mode. In average, most visited boxes were visited in about 10% of the taken steps, versus 2% for the least visited ones. Most visited locations are the OK boxes with no walls, which is expected since they are visited in both Exploration and Exploitation modes and can be accessed from all directions. Least visited locations are KO boxes with walls, which are less accessible and are mostly visited in Exploration mode.
Finally, the agent’s ability to use the knowledge acquired in the first room to act judiciously in the second room was tested. At the end of each series of steps the agent was asked to chose a move from each of the second room’s type of locations (where two locations are said to be of the same type if they have exactly the same features). Figure 4.B shows the percentages of OK, KO, and Failure outcomes obtained in this manner. These results reflect the agent’s performance at making predictions about the second room’s locations: it successfully predicts OK and KO boxes, but has more difficulties predicting failure.
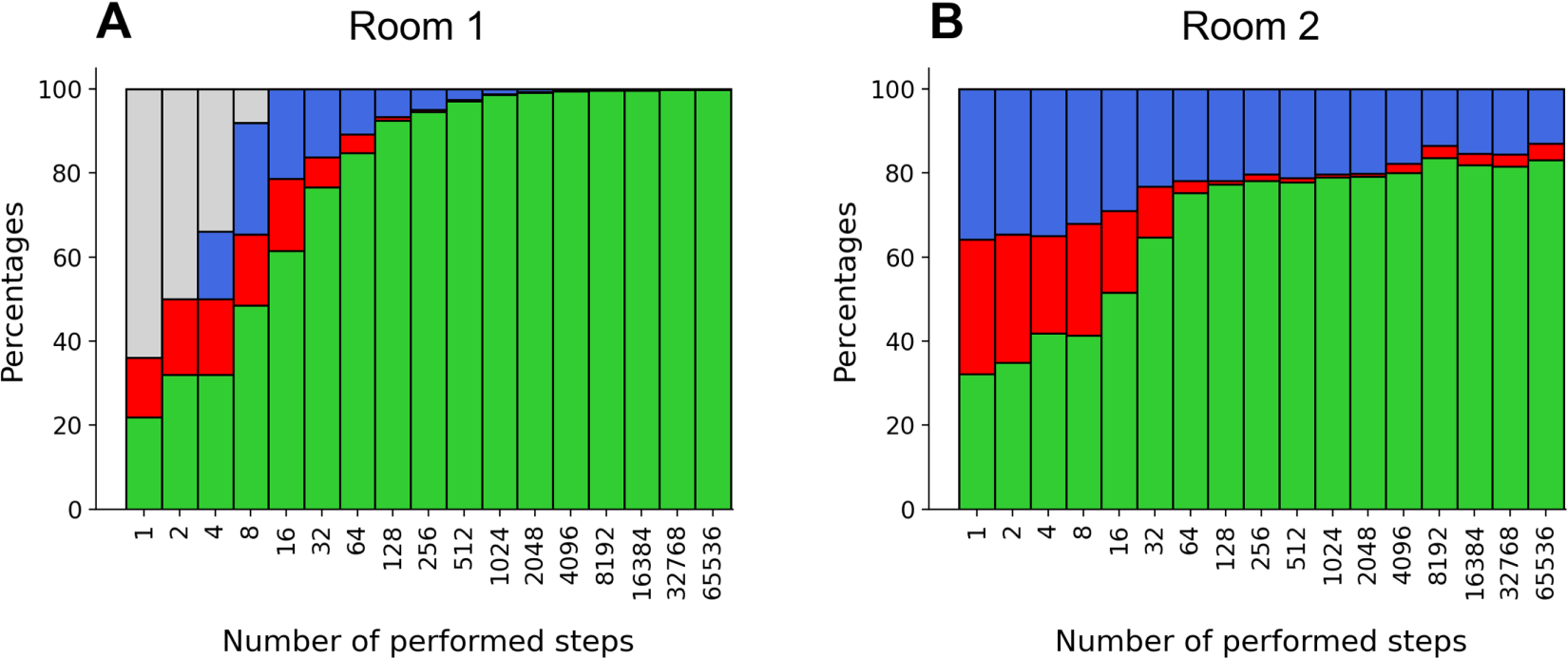
Action’s mean outcomes with door closed; Green: OK, Red: KO, Blue: Failure, Grey: No Data.
To test the agent’s ability to handle changes, a second group of tests was carried out. The setup was the same as in Experiment #1, except that the door was opened at the 2048
Predictions’ Hit Rates after
Steps, with the Door Opened at the 2048
Step.
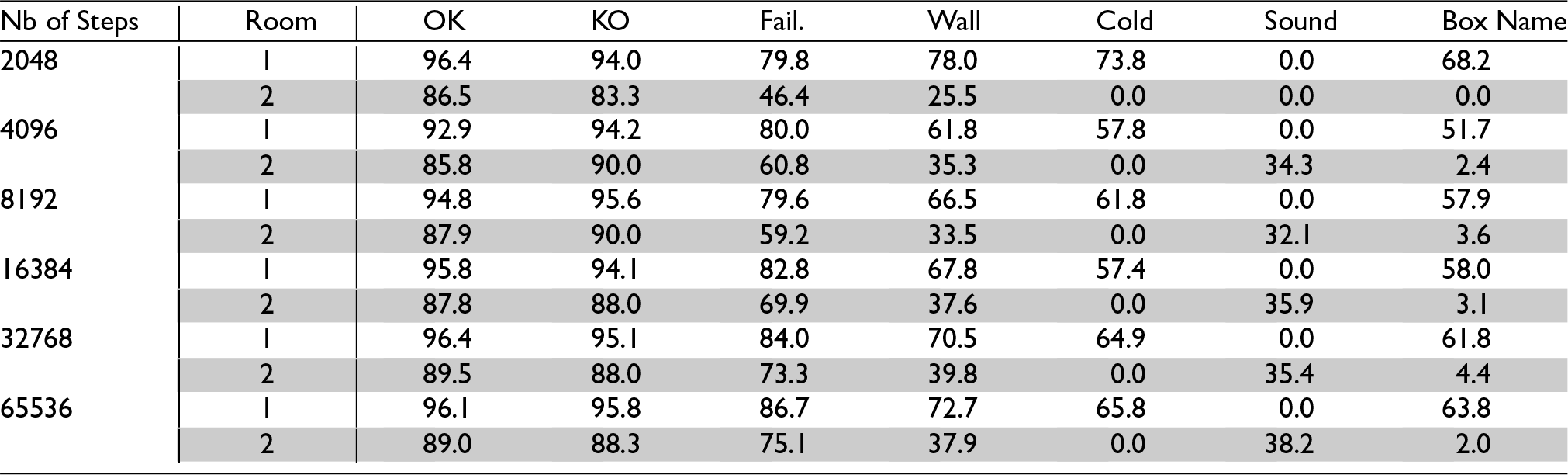
Predictions’ Hit Rates after
Predictions’ Correctness after
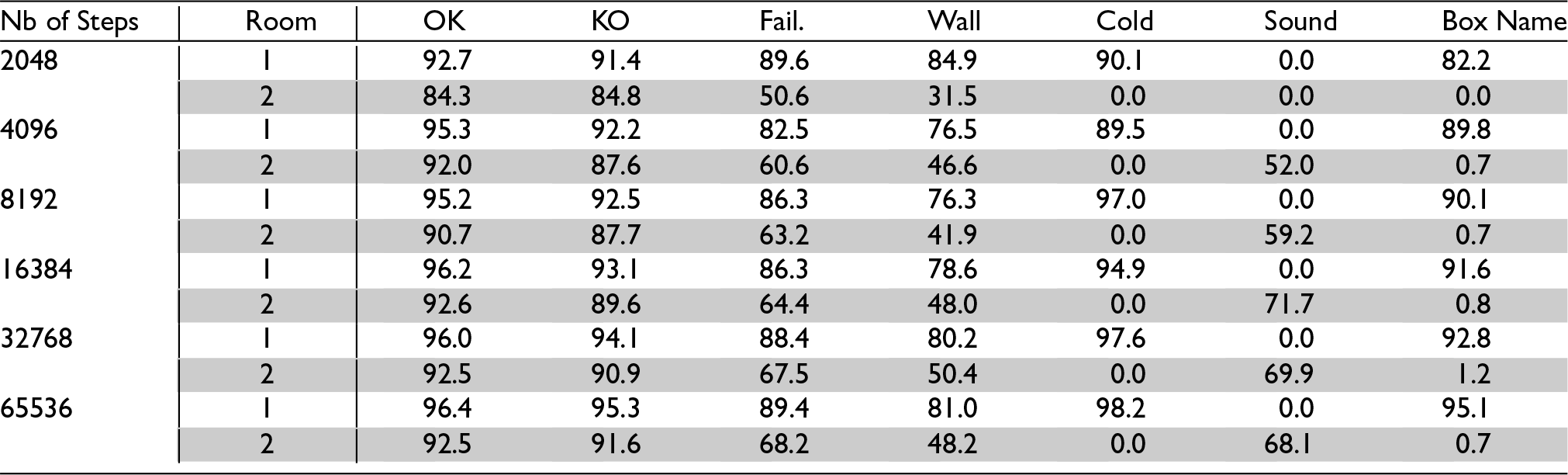
It should be remarked that this learning did not lead to significant loss of previous knowledge regarding the first room: a moderate drop in Hit Rates can be observed for boxes’ names, Cold and walls, but not for OK, KO, and Failure. Furthermore, Correctness is barely impacted. This is due to the use of selective forgetting in the learning process (remember O- and A- neurons’ boosting of inputs in Section 5). As neurons encoding more particular concepts (such as detailed descriptions of particular locations) are less often reactivated, they tend to be reallocated over time, which leads to the loss of the particular features they encode. But neurons encoding more general concepts are more often reactivated, which preserves them from reallocation and forgetting. As a result, particular and less-used concepts tend to fade out over time, while more general and well-used concepts are preserved.
Accordingly, the agent’s ability to make appropriate decisions in the first room was not impacted by the door being opened. In fact, the bar chart of OK, KO, and Failure outcomes obtained in this second run of tests showed no visible difference with the one obtained with the door closed shown in Figure 4.A.
To better assess the agent’s ability to update its knowledge to accommodate environment changes, a third experiment was conducted. As previously, the agent was kept in the first room for 2048 steps before the door was opened, but then it was prompted to run 50 series of 100 steps. Half way through these, the Sound feature was moved from the boxes
Figure 5 shows the percentage of NorthWall (resp., SouthWall) predictions after each series of steps. These results show that after the door opened the agent first learned to predict a north wall in the arrival box when considering a north move, but that once the Sound feature was moved to its “down” position it stopped doing so and learned to predict a south wall in the arrival box when considering a south move instead. This learning was both fast and robust, considering that the agent had very few learning occasions. Indeed less than 0.6% (on average) of taken steps were north moves from a box with sound, and similarly for south moves from a box with sound. This means that very few experiences were enough for the agent to update its knowledge, which is consistent with the results obtained in the first experiment.
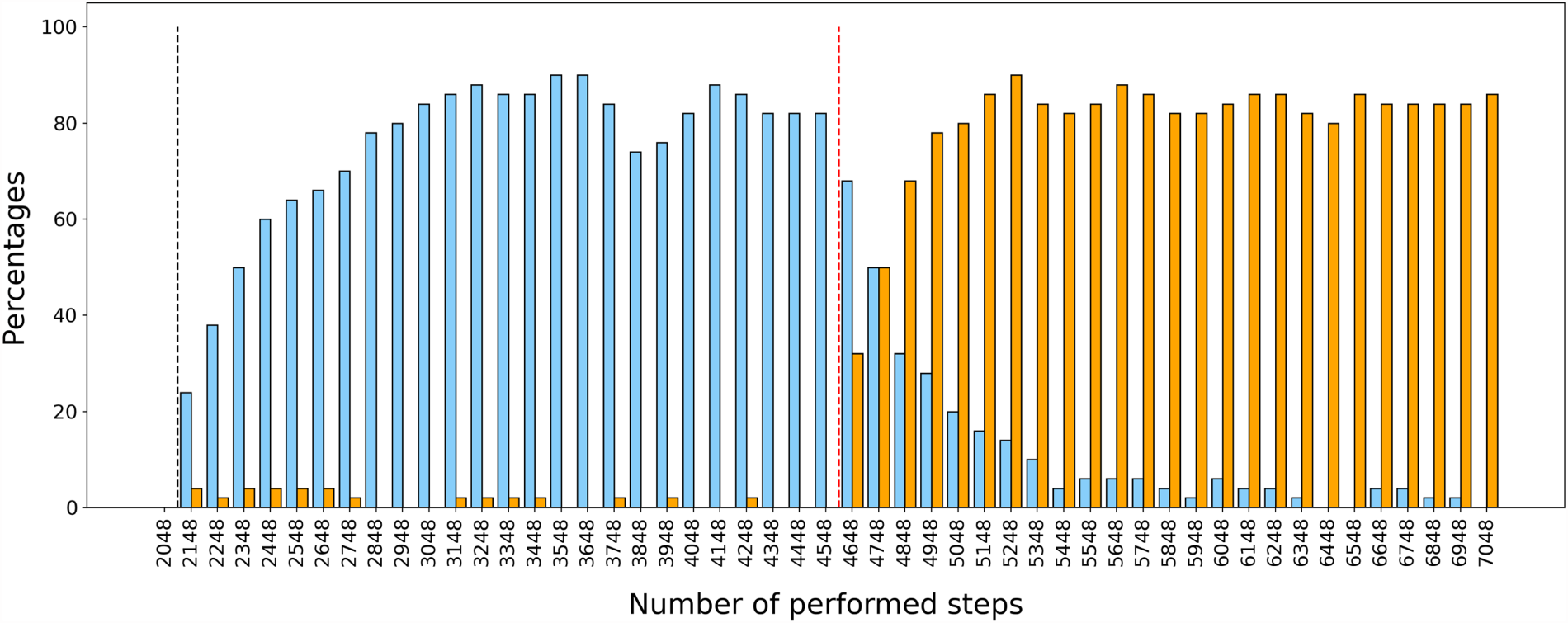
Prediction of walls in arrival boxes given Sound as information about the depart location. Black dotted line: door opens; red dotted line: sound changes location; blue: NorthWall predictions considering a north move; orange: SouthWall predictions considering a south move (percentages over 50 trials).
Computing time was simply estimated by running trials consisting in a single series of 2024 steps. An average of 5.9 seconds (standard deviation 0.16) was obtained on a conventional computer. However this is to be taken as an upper bound, since for practical reasons some testing carried out in the course of the series was not deactivated. No attempt to optimize the computing time was made, as it seems less critical in the case of online learning of autonomous agents which can learn while physically performing their actions.
Conclusion and Future Developments
In this article, a proof of concept of the architecture of a fully autonomous agent learning action laws online and accommodating environment changes was provided. This agent relies on general concepts to handle new situations and dynamically adjusts its concepts to its current environment. This makes it well suited for open worlds: if a new door were to open to a third room with new objects and laws, it would learn them just as it did in the second room. Of course, this would come at the cost of the forgetting of its least used concepts, but these are precisely the ones it needs the less. In fact, the agent’s ability to selectively forget its least used knowledge ensures that it will always be able to adapt to new environments by replacing old unused concepts by new useful ones.
It should be stressed that this architecture does not crucially depends on the specific type of spiking neurons used to implement it nor on the details of its implementation. Any similar architecture based on a SNN using some STDP-like learning rules would probably work, provided that it retains the approach’s main ideas. Notably, strict constraints on output neurons’ connections weight sums associated with flexible constraints on input neurons’ forward connections weight sums allow to regulate learning and keep the network balanced; target numbers of neurons for spiking and learning associated with dynamic learning thresholds ensure that the network will always have neurons to learn a new input; boosting the inputs received by the neurons having not spiked for a long time allows to preferentially select those encoding less used knowledge for learning new inputs, and to prevent in this manner catastrophic forgetting; forcing a few neurons to learn particular concepts counterbalances STDP’s tendency towards generalization and favors the representation of concepts with diverse degrees of generality; finally, input modulation in the querying process promotes the firing of neurons encoding the most specific information, thus helping the agent to make accurate predictions in non-monotonic contexts. All these methods rely on individual neurons’ properties such as the weight sum of their incoming/forward connections, the time of their last spike and other similar metrics.
As regards scalability to larger environments, the number of neurons needed in each layer of the network (interface, O-neurons, A-neurons) grows linearly with the number of items (features, object concepts, action concepts) to encode; the number of synapses needed on each O-neuron grows linearly with the maximum number of features to be learned for a given object/situation. However, it is important to observe that these are upper bounds: the agent’s ability to form general concepts out of individual experiences and to use them to make decisions makes that it is not necessary to encode each individual object with all its features and each performed action.
Future developments of the architecture include endowing the agent with planning abilities. To do so, a notion of executable action law should be defined (see Section 3.3). The agent would also need to build its own set of possible situations (states) online (the set of its object concepts could probably be used to this end). Finally, the decision system should be augmented to represent goals and embed a cost function and a planning algorithm.
However further work remains to be done to allow the agent to live in more realistic environments. Notably, it would be necessary to make the agent able to use incomplete information as input for learning and querying, as real-world agents’ observations are rarely complete. It would then be interesting to make the agent able to query its semantic memory for object properties given some partial input. It would also be useful to implement negation in the network to allow the agent to represent the fact that a given object does not have a given feature. Neural inhibition could probably be used for this, but the appropriate learning rules remain to be found. It seems that taken together these two improvements would bring the agent to draw non-monotonic inferences in the spirit of (Grimaud, 2016). It would also be suitable to make the agent able to distinguish between objects and their locations, as actions can modify one, the other, or both. Biological brains process the “what” and the “where” components of observations in two separate pathways before reunifying them, and this could be an inspiration source. A further line of research would be to investigate how an agent should decide between Exploration and Exploitation modes in an open world. Intuitively, it seems that the choice between these two modes should depend on the agent’s estimation of the risk associated with an explorative behavior, and that the agent should refrain from entering in exploration mode in situations where the assessed risk is high, while allowing itself more exploration in situations where it is low. Yet a correct formalization of this idea remains to be found.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the ANR (Agence Nationale de la Recherche) project ALoRS (“Action, Logical Reasoning and Spiking networks”) [ANR-21-CE23-0018-01]
Declaration of Competing Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendices
The network’s parameters were set as follows:
Interface neurons:
Lowering these spike thresholds increases the predictions’ Hit Rates while decreasing their Correctness. Reciprocally, increasing these spike thresholds increases the predictions’ Correctness but decreases their Hit Rates. O-neurons:
For For Upper bound for A-neurons:
upper bound for
Research was carried out on a MacBook Pro with Apple M1 Max chip (2022). Operating System: macOS-15.6-arm64-arm-64bit. We used Python with Spyder IDE.
Spyder version: 6.0.5 (standalone) Python version: 3.11.11 64-bit Qt version: 5.15.8 PyQt5 version: 5.15.9