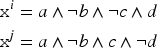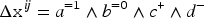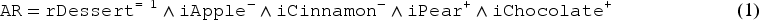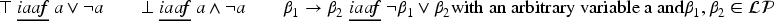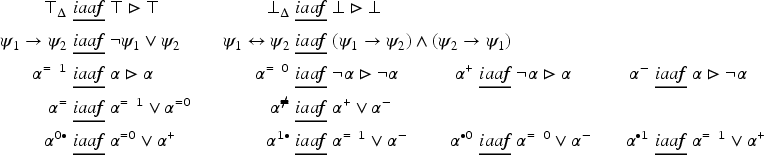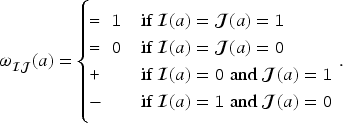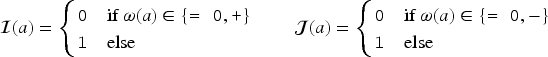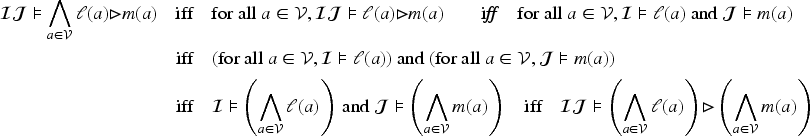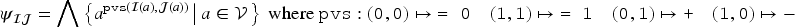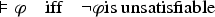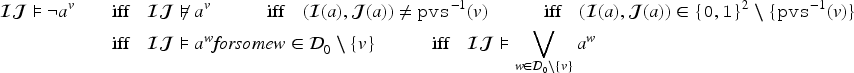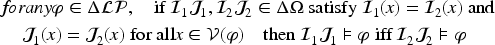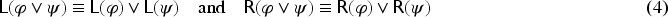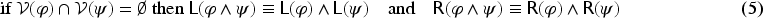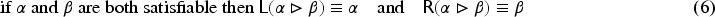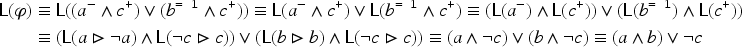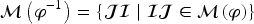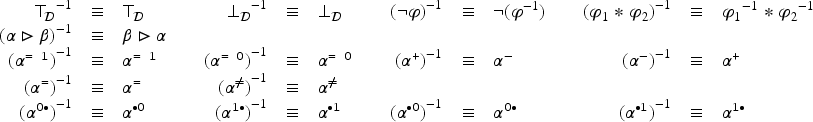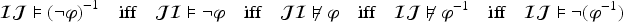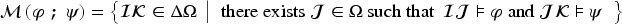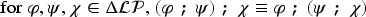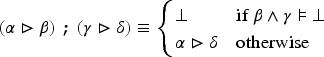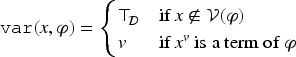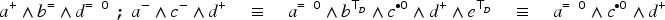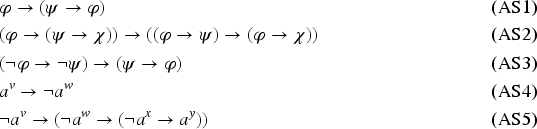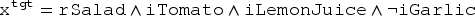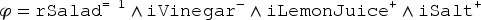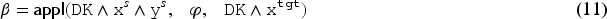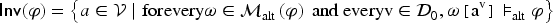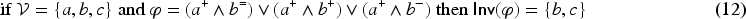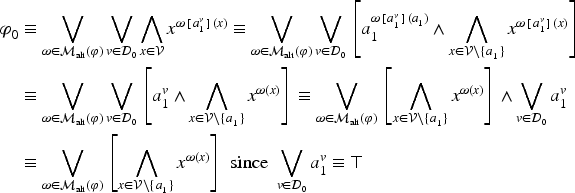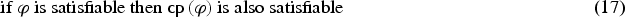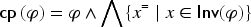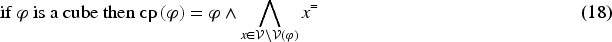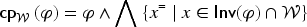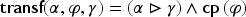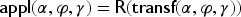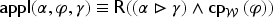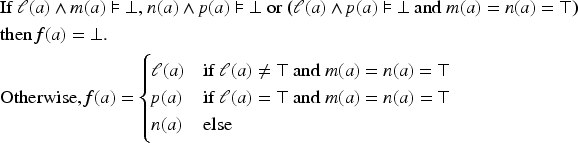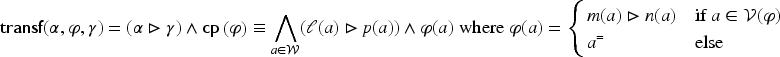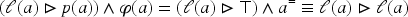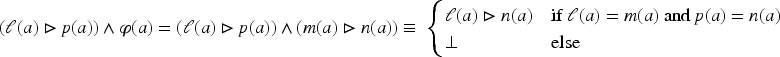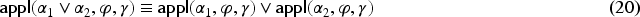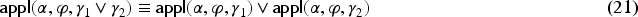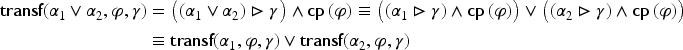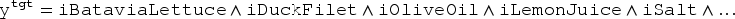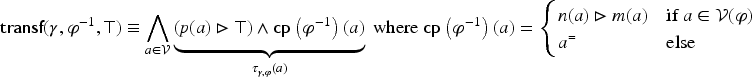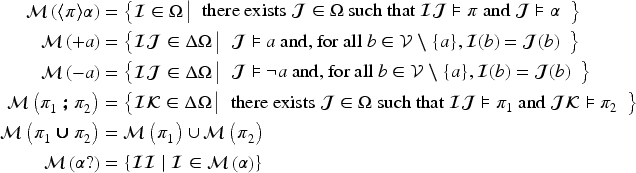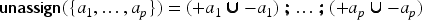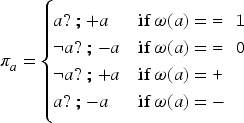Propositional logic (as other logics) can be seen as a way to represent sets of states of the world (by the sets of models of formulas). Representation of variations from a set of states of the world to another is motivated by studies on case-based reasoning (CBR): the comparison of two problems and the way a solution is transformed into another solution can be seen as variations from a set of states to another. This has led to a notation for representing these variations (a syntax) and this article studies how to associate to this notation a semantics based on model theory in which an interpretation is an ordered pair of interpretations in propositional logic. The article presents a classical study of this logic (syntax, semantics, properties, a formal system, etc.). It also explains how CBR can benefit from this logic, in particular through the representation of adaptation rules and to a case-based inference algorithm using such rules.
Case-based reasoning (CBR; Riesbeck & Schank, 1989) is a reasoning based on a case base where a case is, in general, given by an ordered pair where represents a problem (of the application domain under consideration) and represents a solution to this problem. A CBR session takes as input a problem to be solved (the target problem) and consists usually of two reasoning steps: retrieval and adaptation. Retrieval consists in selecting a case such that is deemed similar to . Adaptation consists in modifying with the aim of solving the target problem. A principle often used for adaptation is based on the intuitive notion of variations between problems and between solutions:
Computation of the variation from to , denoted by ;
Computation of , the variation from to the solution to be found, on the basis of ;
Computation of , from and , where is a plausible solution to . Note that, in general, CBR is a hypothetical reasoning: the solution it provides solves plausibly the target problem.
Step (2) above is typically based on adaptation knowledge which is often represented by adaptation rules. In general, the premises of such a rule contain the variation between problems and, its conclusion, a variation between solutions: “If two problems change according to then their solutions change according to .” Such rules can be learned from the case base, according to a principle introduced in Hanney and Keane (1996) and that is sometimes called the case difference heuristics (e.g., in Leake et al., 2021). The idea is to apply a learning process using as learning set the ordered pairs where and (resp., ) is the variation from to (resp., from to ).
In some applications of CBR, problems and solutions can be represented by Boolean properties (or translated into this representation), that can be coded as conjunction of literals in propositional logic. For example, let us consider the two following problems:
The variation from to has been noted in the following way in some studies on adaptation knowledge learning using the case difference heuristics:
where means that the Boolean property varies according to , where (resp. ) means “stays true (resp. false)” and (resp. ) means “change from false to true (resp. from true to false).”
For instance, adaptation knowledge learning has been studied for , a CBR system in the cooking domain (Cordier et al., 2014). Suppose that, in a recipe book (constituting a case base), ordered pairs of dessert recipes can be found such that, has apple and cinnamon as ingredients and has pear and chocolate (but no pear and chocolate in and no apple and cinnamon in ). From these ordered pairs, the following adaptation rule can be learned:
In recipes of desserts with apples and cinnamon, these ingredients can be replaced by pears and chocolate.
This adaptation rule can be written by the following expression:
(where is the property to be a recipe of dessert, , the property to be a recipe with apple as ingredient, etc.)
The expressions such as the one presented above were only used as notations: the syntax was defined but not the semantics that would enable to draw inferences. The first objective of this article is to define this semantics and to study its properties. Starting from finite propositional logic , the logic is defined, such that its syntax contains formulas such as the one introduced above and semantics is defined in a model-theoretic way. Then this logic is studied according to various aspects. The second objective is to study some benefits of using this logic for CBR, beyond the mere notation from which it originates.
The article is organized as follows. After some preliminaries (Section 2), the logic is presented: its syntax, its semantics, and some general results related to it (Section 3). In Section 4, a formal system for this logic is presented, which is proven to be sound and complete. Section 5 deals with algorithmic aspects of this logic. This work originates from a notation used in CBR and Section 6 details two important issues of CBR through this logic: the representation of adaptation rules and a novel algorithm for CBR, including an efficient case retrieval step that is exact with respect to adaptation. Section 7 discusses some related works and Section 8 concludes the article and presents some future work. For some results, the proofs are given in Appendix Section A, in order to improve the readability of the article.
Preliminaries
These preliminaries are about propositional logic (Section 2.1) and CBR (Section 2.2).
Propositional Logic
is the basic logic on which will be defined.
Let be a finite set of symbols; an element of is called propositional variable (or simply variable). A formula of is either a propositional variable or has one of the following forms: , , and , where , , and are propositional formulas. The following abbreviations are used ( is read “is an abbreviation for”):
A literal of is a formula or (for an ). A cube in this logic is a conjunction of literals where every variable occurs at most once. A cube is complete if every variable occurs in it. The set of variables occurring in is denoted by .
The semantics in model theory is defined as follows. An interpretation in propositional logic is a mapping , where is the set of Booleans ( stands for false and stands for true). Let be the set of interpretations. Let and . The relation “ satisfies ” (also read “ is a model of ” and denoted by ) is defined recursively as follows:
if for a variable ;
if for an ;
if and for ;
if or for .
The set of models of is written . If is a finite set of formulas, is the intersection of the for , which allows to assimilate to the conjunction of its elements. The relation entails () is defined by , and the relation is defined by . A formula is satisfiable when (which is equivalent to ). A formula is a tautology (denoted by ) if . Finally, with , if .
Case-Based Reasoning
Generalities. CBR is a type of reasoning relying on a case base, where a case is a representation of a problem solving episode. An application domain for CBR is given by a triplet where and are sets and is a binary relation on . An element is called a problem, an element , a solution, and is read “ has for solution ” or “ solves .”
In general, the relation is not completely known by the CBR system: the objective of the latter is to build a hypothesis of solution to a given problem, the target problem, denoted by .
It is often assumed (in particular, in this article) that a case is given by an ordered pair where : the relation is only known for a finite set that constitutes the case base. An element of the case base is denoted by and is called a source case ( is the source problem).
The most common process of CBR consists in a retrieval step (selection of elements of the case base deemed similar to the target problem) and an adaptation step (reuse of the retrieved cases for solving ). In this article, only single case retrieval and single case adaptation are considered, that is, . This means in particular that an adaptation problem is given by a source case and a target problem: it is noted in the following.
Two ways of considering adaptation exist, that are inspired by the difference between transformational analogy and derivational analogy, two notions introduced by J. G. Carbonell (see Carbonell, 1983, 1986):
Transformational adaptation aims at solving the adaptation problem by reading it under the form “The solution searched for, , is to as is to .” It can be interpreted as follows: from variations between and , denoted by , the variation between the solution and the unknown , denoted by , is inferred, then, is inferred from and .
Generative adaptation aims at solving the adaptation problem by reading it under the form “The solution searched for, , is to as is to .” It relies on the highlighting of the links between and and on the “replay” of this link on .
This article focuses on transformational adaptation: the study of the application of to generative adaptation constitutes a potential future work.
CBR Knowledge Model. Usually, it is considered that the knowledge base of a CBR system is composed of four knowledge containers: the case base , the domain knowledge , the retrieval knowledge , and the adaptation knowledge (Richter & Weber, 2013). and have been mentioned above. is often represented by a similarity measure or a distance function between problems. can be considered as a conjunction of integrity constraints, where each of these constraints gives a necessary condition for a case to be licit. The inferences in the case representation formalism are usually made according to the domain knowledge: the relation is used instead of simply .
Representing Cases in Propositional Logic. In some applications, cases can be represented in : the set is partitioned into and a problem (resp. a solution ) is represented by a formula whose variables belong to (resp. to ). A source case is represented by the conjunction . Sometimes, as it will be seen in the running example of Section 6, the partitioning in problem variables and solution variables is only done once the adaptation problem is specified: knowing and the source case , and are determined and then, can be written .
In many applications, the source cases and the target problem are considered as specific, that is, coming from a particular experience and thus completely instantiated. In this situation, for a source case and a target problem , the problems and can be written under the form and the solution under the form , where . Then, the formula is a complete cube so .
Adaptation Knowledge Learning. Adaptation is often based on adaptation knowledge. This knowledge can be acquired from experts (see, e.g., d’Aquin et al., 2006). It can also be learned from the case base, according to the principle called “difference heuristics” in Jalali et al. (2017) and initially defined in Hanney and Keane (1996). This principle relies on the principle of transformational adaptation: given two different source cases and , the variations , from to , and , from to , are built. Adaptation knowledge learning uses a set of ordered pairs to produce a model of a mapping , which makes it possible, from a problem variation to obtain a solution variation, which is useful during a transformational adaptation process.
Some work in this framework has used the notation , where is a problem or solution attribute and where represents a relation between values of the domain of this attribute. Then, this notation makes it possible to encode these variations, for the purpose of adaptation rule learning using techniques such as closed itemset extraction (see d’Aquin et al., 2007, for a description of such a process). For example indicates a variation of for the attribute . The result of a frequent closed itemset extraction is a set of itemsets, an itemset in this adaptation rule learning process being a set of expressions . Considering only Boolean attributes, these are formulas of the logic , which motivates the study of this logic.
The Logic of Propositional Variations
This section presents the logic : its syntax (Section 3.1), its semantics (Section 3.2), some general results associated with it (Section 3.3), and two operators on this logic (Section 3.4).
Syntax of
A formula is an expression of one of the following forms: (that can be read “ becomes ”), , and , where and . The following abbreviations are used:
When the context is not ambiguous, and are simply noted and . Let ; the elements of are called primitive variation symbols. The set is the set of non primitive variation symbols. is therefore the set of variation symbols.
A literal of is a formula of the form where and . A cube of this logic is a conjunction of literals in which any variable appears at most once. A cube is said primitive if every variation symbol occurring in it is primitive. A cube is complete if it is primitive and if every variable occurs in the cube.
For , and , is the result of the substitution of with in defined in the usual way. The set of variables occurring in is denoted by . The size of , noted , is the number of occurrences of connectives of . A knowledge base of is a finite subset of .
Semantics of
Two definitions of the semantics are given below: one with interpretations based on propositional logic interpretations and an alternative one based on the primitive symbols of variation. They define the same entailment relation. The former will be used more often, the latter is used mainly in some proofs.
A First Definition of Entailment
Let . An element of is called interpretation (for this logic) and is simply written . For , is defined as follows (where , ):
if and .
if .
if and .
if or .
The set of models of is denoted by . It can be noted that . The notions of satisfiability, logical entailment (), tautology, and logical equivalence () are defined in the same way as in propositional logics.
An Alternative Definition of Entailment
The relation between a knowledge base and a formula of propositional variation logic can be redefined using four “truth values” given by the elements of .
Let be the set of functions . Let be the relation between an and a defined by:
Let . For example, if , where , , and . For a knowledge base , let . Then, the relation between a knowledge base and a formula is defined by if .
This relation does not define a new semantics of the logic of variations as the proposition below show; it only gives an alternative definition of this semantics.
For every knowledge base of and every , iff .
Given , let be such that, for ,
The function is bijective and its inverse function is defined as follows. To , it maps such that, for :
(it can be shown that it is a bijection by using the fact that and by checking that, for , by associating to it as described above, the equality holds).
It is shown then that, for and , iff .
Finally, for a knowledge base and , it is shown that iff using the bijective function introduced above and (2).
General Results
This section presents some general results on the logic .
Some Equivalences
The following proposition entails that if and are cubes of then can be written as a cube of .
For all , let . Then .
From the definition of the semantics, it yields that, for :
Some definitions of formulas in the article are given by the set of their models, thus up to equivalence. This kind of definition is acceptable because every subset of is representable in :
For every subset of , there exists such that .
Let , and let the formula
(for and two Booleans, is the primitive variation symbol associated with ). It can be shown first that, for every , (just consider the four cases). Conversely, if for every , entails and , then . Consequently, . Now, with , .
Results Borrowed from Propositional Logic
The following results (and their proofs) are easily transposed from results in proposition logics.
Deduction theorem and its corollary (for ):
Link between tautologies and satisfiable formulas ():
De Morgan’s laws.
Let be a finite set of formulas of , such that is a subformula of and . Let obtained by replacing an occurrence of in with . If then .
Involutivity of , commutativity of and , associativity of and , distributive property of over , distributive property of over , and so on (all these properties being verified up to logical equivalence).
Let , and . If then .
Alternative Syntaxes and Normal Forms
In many formal logics, it is possible to choose a set of primitive constructors to define the syntax of the logic and defining other constructors as abbreviations. In Section 3.1, the syntax of has been defined with the primitive constructors , , , and , and then, the constructors (where and ) where introduced as abbreviations. Then, it is possible to choose another set of primitive constructors, for various purposes (e.g., for algorithmic issues). In propositional logic, it is possible to choose as a (non-minimal) set of primitive constructors, but other choices can be made, among which the minimal sets of connectives , , and . The following result defines different sets of constructors that can be chosen as primitives constructors for the logic .
Let be a set of connectives of propositional logic that is sufficient for defining the syntax of this logic (e.g., for every , there exists such that and the connectives of belong to ). Examples for are , , and . Then, the following syntax restrictions of does not restrict its semantics (every formula can be rewritten in an equivalent formula with the considered syntax restriction):
Connectives of , where and
(hence no , , no , , no occurrence of );
Connectives of , where and ;
Connectives of , , where and are literals of .
Then, some normal forms can be defined.
(normal forms)
A clause of is a disjunction of literals (, ). A primitive clause is a disjunction of primitive literals ().
A formula of is under negation free normal form (NFNF) if it is built syntactically with the only connectives are and and with the literals ().
A formula of is under disjunctive normal form (DNF) if it is a disjunction of primitive cubes.
A formula of is under conjunctive normal form (CNF) if it is a conjunction of primitive clauses.
An empty disjunction (resp. conjunction) is assimilated to (resp. to ): and .
Every can be put under NFNF, DNF, and CNF.
Sketch of proof.
First, the following result is proven (for ):
Let be the inverse function of the bijective function introduced in the proof of Proposition 3.
For , the following sequence of equivalences holds:
Let . is equivalent to a formula under SR4 (cf. Proposition 4) with the connectives , , and . Then, can be removed from using De Morgan laws ( and ) and equivalence (3), from left to right, as long as it is possible. The result of this transformation is a formula equivalent to and under NFNF.
Using distributive property of over (resp. on over ) on as long as it is possible, gives a formula under DNF (resp. under CNF).
Left and Right Parts of a Variation Formula
For , and denote propositional formulas (unique up to logical equivalence) such that
is called the left part of and its right part.
To compute and , a method consists in putting into disjunctive normal form (disjunction of cubes) and to apply Proposition 6 below: an example at the end of the section illustrates this. To prove this proposition, the following lemma is used, stating something that may seem obvious but that may deserve to be stated nonetheless.
Only the variables occurring in formulas of may play a role in a deductive inference:
Sketch of proof.
The proof of this lemma can be done by a simple mathematical induction.
For and ,
The example below shows the computation of for :
Inverse and Composition on Variation Formulas
A formula can be seen as a representation of a binary relation on , since . Therefore, operations on binary relations can be defined on variation formulas, in particular, the inverse of a formula and the composition of two formulas.
Inverse of a Variation Formula
For , let semantically defined by
The following proposition shows how can be syntactically defined, whatever the choice of syntactic constructors of are chosen according to Proposition 4:
Let , and . Then:
Sketch of proof.
The proof of each of these equivalences is rather straightforward. As an example, the equivalence can be proven as follows (for ):
Composition of Two Formulas
Let . The composition of and is a formula defined semantically by
In other words, is the composition of the binary relations and on : .
The following result is a direct consequence of associativity of binary relation composition:
This allows to omit parentheses in compositions.
The research of a formula equivalent to is studied via the following propositions, whose proofs are given in Appendix Section A.2.
Let us start with the case where the formulas to be composed are of the form .
Let . Then:
We focus next on the links between composition and disjunction:
Let . The following equivalences hold:
Two additional variation symbols are introduced: and such that, for all , and .
To a variable and a cube of is associated as follows:
The following proposition allows to compute the composition of two literals of built on the same variable.
There exists a binary operation over such that for and , .
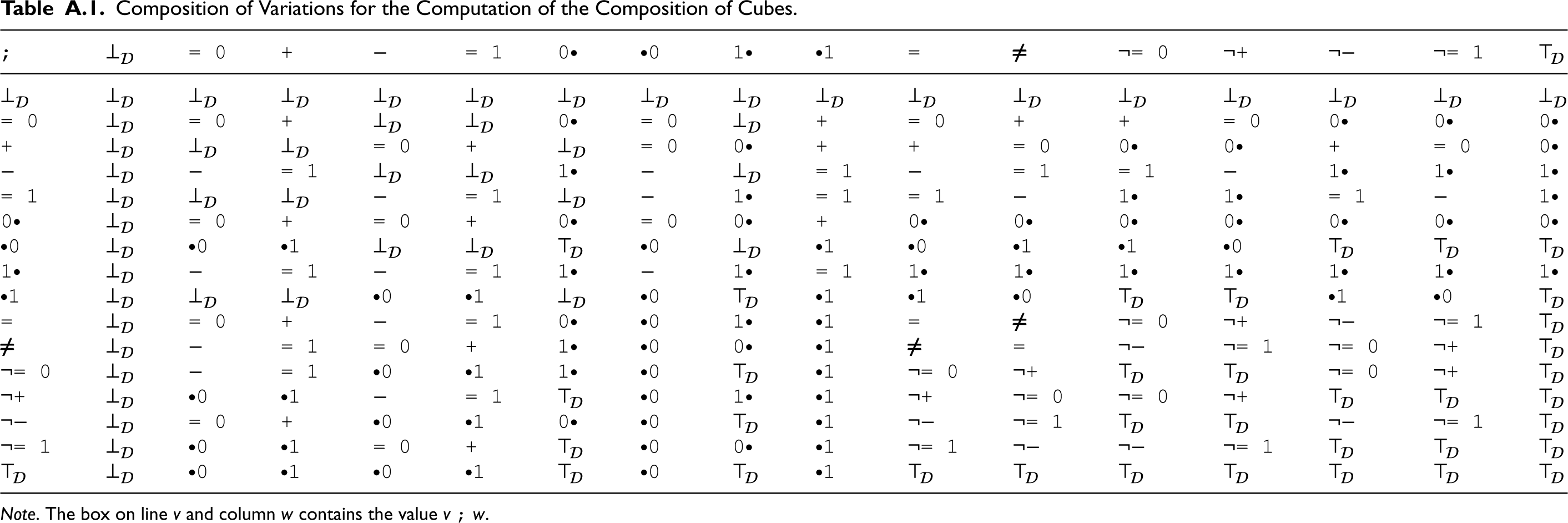
Now, the composition of cubes can be computed thanks to the following proposition:
Let and be two cubes of . Then
To compose two cubes, Proposition 11 is applied and then a simplification is made by remembering that and . For example, if the set of variables is then, according to Table 2 in Appendix Section A.2:
More generally, a way to have a syntactical expression of consists in putting these two formulas of under DNF, and then applying the equivalences of Proposition 9 as long as it is possible, and finally applying Proposition 11 to eliminate completely the symbol .
A Sound and Complete Formal System for
In this section, , a formal system sound and complete for is presented and studied that is strongly inspired by , the formal system of Hilbert that is sound and complete for .
Definition of the Formal System
, as any Hilbert style formal system, is defined by a triple where is the set of the well-formed formulas (wffs) of , is the set of its axioms and is the set of its inference rules.
Proposition 4 shows that every formula can be written with some syntactical restrictions. In particular, every formula can be written only with the atoms where and , and with the only connectives and (the other connectives being defined as abbreviations, e.g., is an abbreviation for ). A wff is a formula of with these syntactical restrictions.
The set of axioms, , is a subset of defined by the following axiom schemes:
where , , and have to be replaced with any wffs, has to be replaced with any variable, and , , , have to be replaced by primitive variation symbols that are pairwise distinct. The axioms schemes (AS1), (AS2), and (AS3) are directly taken from Hilbert formal system. The axiom schemes (AS4) and (AS5) translate the fact that is a partition of .
: the only inference rule of is the modus ponens that is also the only inference rule of : .
Soundness of for
Let be the entailment relation associated with whose definition is recalled now. Let be a subset of and . A proof of from is a finite sequence such that and, for each , is either an axiom, or an element of , or is obtained by application of the inference rule on formulas where . Then, is defined by the existence of a proof of from .
The formal system is sound for : for every finite set of wffs of and every , .
Sketch of proof.
The soundness is proven in the usual way. First, it is shown that every axiom of is a tautology of . Then, the soundness of modus ponens is shown: if is a model of and of (for and , two wffs) then is a model of . Using these two results, it is shown by mathematical induction that, if is a proof of from and then for each . So, (since ). Therefore, if then .
Completeness of for
The formal system is complete for : for every finite set of wffs of and every , .
The proof of this result is given in Appendix Section A.3.
Algorithmic Issues
This section explores two algorithmic aspects of satisfiability in . First, it is shown that the problem of satisfiability in is NP-complete. Second, a semantic tableaux algorithm to test the satisfiability of a formula is presented.
Satisfiability Checking in is NP-Complete
Let be the decision problem which, given a formula of , determines whether is satisfiable. The problem is NP-complete. It is shown by proving that is in NP, then that it is NP-hard. The detailed proof is given in Appendix Section A.4.
A Semantic Tableaux Algorithm for Satisfiability Checking in
Semantic tableaux form a family of methods for satisfiability checking applicable to many logics (e.g., propositional logic and first order logic (Smullyan, 1995), and description logics (Baader & Sattler, 2001)). This section presents a semantic tableaux algorithm for based on an adaptation of a semantic tableaux algorithm for .
Description of the Algorithm
Given a knowledge base of and , the deduction test “?” is equivalent to the test of unsatisfiability of . So, deduction amounts to satisfiability checking.
The input of the algorithm is a formula of . Its output is the answer to the question “Is satisfiable?”
The first step of the algorithm consists in putting in NFNF (connectives and , connective-free subformulas of the form , , ): the result of this step is a formula under NFNF such that .
The second step of the algorithm is the development of a tree whose nodes are labeled by formulas. A branch of such a tree is frequently assimilated in the following with the set of the formulas labeling the nodes of this branch.
The tree of formulas is developed in the following way. Initially, has only one node labeled by . Then, the following modifications of are applied (the algorithm is non-deterministic: the order of application of these modifications changes neither the termination nor the result but has an impact on the computing time):
If a branch of contains a conjunction such that for at least one , , then the tree is updated by extending with every : the new value of the branch is .
If a branch of contains a disjunction such that for every , , then the branch is “forked” in branches .
The development of a branch is stopped if contains two literals and with , and then is said to end with the clash . It is also stopped if neither (A) nor (B) apply to the branch. In both cases, is said complete.
The algorithm stops when every branch of is complete, and returns “ is unsatisfiable” if every branch ends with a clash and “ is satisfiable” otherwise.
Properties of the Algorithm
This algorithm always terminates (Proposition 14) and returns the expected result (according to Propositions 15 and 16). The proofs of these results are given in Appendix Section A.5.
The tableau algorithm described in Section 5.2.1 always terminates.
If the algorithm of Section 5.2.1 ends with a clash in every branch, then is unsatisfiable.
If is unsatisfiable then every complete tree derived from the algorithm of Section 5.2.1 ends with a clash.
Application to CBR
The study of the logic has been motivated by a notation used in CBR, a syntax that has not been associated with a semantics before. Now, this section presents an application of this logic to CBR that is centered on the notion of adaptation rule. Section 6.1 introduces an example of adaptation problem in CBR that can be solved thanks to the application of an adaptation rule. Section 6.2 describes the representation of adaptation rules. Such a rule is based on a formula of and the handling of a rule is based on the notion of application of a variation formula on a propositional formula which is described in Section 6.5. This requires the notion of ceteris paribus which is introduced before, in Section 6.4, and this latter requires the notion of invariant variables of a formula, introduced even before, in Section 6.3. Then, the application of an adaptation rule on the example is described (Section 6.6). From this study, an algorithm for performing CBR (including retrieval and adaptation) based on the notion of adaptation rules is presented (Section 6.7). Finally, an open problem related to the composition of adaptation rules is presented in Section 6.8.
Introduction of an Example
An example in the cooking domain is considered: a problem represents a query of recipe and a solution, a recipe. The problems and solutions are assumed to be expressed in propositional logic. It is assumed in this example that the domain knowledge is empty: . The adaptation problem is where
is the source case of a salad recipe, with batavia lettuce, duck filet, tomatoes, olive oil, and vinegar:
where is read “salad recipe,” , “recipe with the ingredient ‘something”’ and is a notation for the conjunction of negative literals such that cannot be deduced from the start of the formula: . In particular, . It can be noticed that is a complete cube of propositional logic.
is the target problem “I want a recipe of salad with tomatoes, lemon juice but no garlic.”:
Knowing the adaptation problem makes it possible to partition in : and . Therefore, can be written with
(“” corresponds to the conjunction of literals where and is not a positive literal of ).
An itemset is also considered, that is obtained by an itemset extraction system (e.g., a frequent closed itemset system, see, e.g., Zaki and Hsiao (2002)) for the adaptation knowledge learning. Such an itemset contains a finite set of literals indicating “simultaneous” variations between cases and is interpreted by the conjunction of its elements. can be written as a cube of : if there are several literals , , …built with the same variable that occur in , it can be shown that they can be replaced with a sole (e.g., ). In the example, the following formula is considered:
The itemset from which is built reflects the fact that there is a sufficient number of ordered pairs of salad recipes with vinegar in the first recipe but not in the second one, and lemon juice and salt in the second one but not in the first one. Therefore, if is interpreted as an adaptation rule, then applicability and application of on the adaptation problem have to be studied.
Representing an Adaptation Rule
An adaptation rule is defined as a pair where and is a nonnegative real number called cost of .
What does it mean that is applicable to an adaptation problem and how can the result of this application be defined? To answer these questions, a mapping is considered that associates to a formula , the application on of under constraint . This mapping is defined and studied further. Since the source cases and the target problem have to be considered with the domain knowledge , the following formula will be computed:
If then is said to be non-applicable to the adaptation problem. Else, this result can be written where is the solution proposed for by application of for this adaptation problem.
CBR is usually a hypothetical inference and adaptation does not necessarily produce a correct solution to the target problem. In particular, the application of an adaptation rule may output an incorrect solution. In order to make a selection among a set of adaptation rules applicable to the same adaptation problem, is used: the cost associated with a rule is indicative of the plausibility of the application of this rule. The higher the is, the least the confidence on the application of the rule will be. For instance, this can be interpreted in a probabilistic setting: if estimates the probability that a rule produces a correct result (under some given probability distribution), then could be a reasonable choice.
Thus, the representation of an adaptation rule amounts to the definition of the mapping, which requires preliminary definitions presented in the next two sections.
Before that, a preliminary remark on the representation of source cases and on adaptation rules is made: although the study that follows makes no theoretical restriction on the form of source cases and adaptation rules, a reasonable assumption is that , , and are cubes, and that justifies that these situations are considered with some importance. Since a source case usually represents a specific problem-solving episode, it means that every (problem or solution) variable is assigned a Boolean value for this case: either or , so and can both be written as cubes. For , if it is obtained by a frequent itemset extraction system, then for an itemset which is a set of literals , and so, is a cube.
Invariant Variables of a Variation Formula
In this section, the variables that leave a formula unchanged are defined. The subset of is defined using the alternative definition of the semantics of introduced in Section 3.2.2. The idea is that means that the value of does not influence the satisfiability of by , for any . Formally, this leads to the following definition:
For , and , is defined by .
For , the set of invariant variables of is
For example,
This notion is independent from syntax: if then . It can be shown, using Lemma 1, that if a variable does not occur in then it is invariant. Thus:
As example (12) shows, a variable occurring in can be invariant for . The following proposition shows that a formula transformation makes it possible to link more tightly non-occurrences of variables to .
For every , there exists such that and .
First, the case where is considered. In this case, the result is immediately verified with as an immediate consequence of (13).
Then, the case where is considered. can be put under the form of a disjunction of complete cubes: with . Let . By definition of , , for all . Therefore, as soon as a occurs in the disjunction , every for occur in . Then, by repeating and gathering elements in the disjunction (which is possible since is associative and commutative modulo logical equivalence and for every formula ), it yields that:
Let be the last formula of the equivalence sequence above. Because and , the proposition is proven with .
In the case where , the process above can be applied on in order to obtain such that does not occur in , then, by repeating it with the set of variables on , the formula is obtained, being a formula equivalent to with no occurrence neither of nor of . Then, the process is repeated to result in a formula equivalent to with no occurrence in . With , this concludes the proof of the proposition.
The particular case of the following proposition will be useful in the remainder of the article.
If is a cube of then .
In this proof, for a cube , is a cube such that if then , else, is obtained by replacing the conjunct of by . Since (cf. (13)), it is sufficient to show that if then , which will be proven by contraposition. Let . Let be such that is a literal of having as variable. Let be such that (if is a primitive variation symbol, , else, there are several possible choices for , e.g., if then ou can be chosen). Let . Then and (because, by hypothesis on the cubes, a variable occurs at most once in a cube which involves that cubes are satisfiable). Therefore, and so .
Operator Ceteris Paribus
Consider the formula : it indicates that “goes” from to , the other variables being free to vary in any way. So, if then . It appears useful in some cases to express for example that goes from to , the other variables remaining unchanged. For this purpose, this will be expressed by a formula that, with the example with two variables, gives : in the models of this formula, “stays” at or “stays” at ( stands for ceteris paribus, i.e., “All things being equal”), in other terms, . In this example, is a variable whose interpretation does not change the interpretation of : .
More generally, an operator is searched for such that, for :
The following definition of is proposed and then, it is proven that it satisfies these properties and that is the most general formula (according to ) satisfying these properties.
is the mapping from to defined, for by
satisfies (14), (15), (16), and (17). Moreover, if satisfies these properties then .
Equations (14), (15), and (16) follow immediately from the definition.
Equation (17) can be proven in the following way. Suppose is satisfiable. Then it is also satisfiable according to the alternative definition of the semantics: there exists such that . Let , ,…, be such that . Let . By definition of , . Besides, for all and so . Now, for every variable , . Therefore, . So, and so, is satisfiable.
Now, let verifying the properties (14), (15), (16), and (17) of . Then, according to (14) and (15), .
An immediate consequence of Proposition 18 is:
Moreover, the models of are the for .
It can be noted that is non-monotonic in the sense that for some , and . For example, and .
A practical issue is raised with this operator: for , is in where and this may involve a long computing time. This problem turns theoretical if the logical framework is extended to an infinite set of variables: the definition of given above cannot be applied, formulas being necessarily of finite sizes. A future work to address this issue will be the study of a possible extension of the logic by a connective (rather than an operator ).
It is sometimes useful to restrain the ceteris paribus to a predefined set of variables, hence the following definition.
Let and . The ceteris paribus of restrained to the set of variables is:
And, of course, .
Applying a Variation Formula to a Propositional Formula
This section aims at defining a notion of application of a formula to a formula , given an integrity constraint on the result.
The application of on under constraint is denoted in the following (as mentioned in Section 6.2). In order to reach its definition, first, a formula is considered, called the transformation of by under constraint , and whose result (its right part, obtained by application of the operator ) will be .
The three following conditions are proposed for an to be a model of : , and . These three conditions can be written as one:
Is this condition sufficient? To answer this question, let us consider the following example: , , and . If (19) was a necessary and sufficient condition for then would be equivalent to , that is, to . So, whether or would not change the application of on . On the contrary, it is assumed that if a variable (in this example ) is invariant in , its value should not be changed by the transformation, hence the use of the ceteris paribus (and an a posteriori justification of its study): so, it is assumed that . The idea is that the formula represents in a compact manner a transformation and that when it expresses nothing about a variable , this latter is unchanged by the transformation: if and (resp. ) then, with , (resp. ). This leads to the following definition:
For and , the transformation of by under constraint is defined by:
The application of on under constraint is the result of this transformation:
is said to be applicable on under constraint if . Two necessary (but not sufficient) conditions of applicability are and .
Despite the use of the ceteris paribus, if , , and contain few variables (wrt to ), the computation of can be performed without considering all the variables of , as shown in the following proposition:
Let and , and let . Then
Let and . The goal is to prove that .
Since , it can be deduced that (in particular because if then for every ).
Let us show that . Let : what remains to be shown is that . By definition of , there exists such that . Then, let defined (for ) by . It will be shown that , which implies that . For this purpose, it is sufficient to show the following assertions:
;
;
For all , .
Because the only difference between and concerns variables that are not in (since they are not in ) and because , it yields that . As , (A1) holds.
Similarly, the only difference between and concerns variables that are not in (since they are not in ) and because , it yields that , hence (A2).
Let . To prove (A3), it is sufficient to prove that . If , by definition of , this holds. If , , so (according to Definition 8). As , , that is, . Now, since . Therefore, , which proves (A3) and finishes the proof.
The following proposition gives a way to compute in the application of on under constraint when and are cubes and is a primitive cube.
Let and be two cubes of and be a primitive cube of . Let . Thus, it is possible to write , , and , where , , and belong to , for every . It can be noted that iff , iff and iff or (equivalently) (since is a primitive cube).
For , is defined in the following way:
Then .
Therefore, is applicable on under constraint iff for all , .
Sketch of proof.
The idea of the proof consists in computing for every variable . Indeed, can be written as a conjunction over as shown below:
The complete proof consists in considering all the possibilities for a variable , depending on whether belongs or not to , to and to . So, there are cases to consider, but since , one of these cases is removed. Below, only two cases are detailed:
, and . Then and . So:
. Then , so:
The five remaining cases are studied similarly and this leads to the conclusion of the proposition.
Finally, the following proposition makes it possible to compute where is a primitive cube but where and are any propositional formulas, using transformations under disjunctive normal form of and and Proposition 21.
Let and . The following equivalences apply:
Equivalence (20) can be proven using Proposition 6(4), Section 3.3.4, and the following sequence of equivalences:
Consider the adaptation problem and the formula of Section 6.1, along with the adaptation rule where is chosen arbitrarily. By applying (11) to this example, a satisfiable is obtained, and verifies with
which is the expected result on this example (“” represents a conjunction of negative literals).
An Algorithm for CBR
An approach to CBR used in particular in the system (Cordier et al., 2014), consists in performing a retrieval relying on a minimal transformation of the target problem, such that it corresponds exactly to at least one source case, then using an “inverse transformation” on a retrieved case to obtain a solution.
In the representation setting of this article, the transformation of the target problem is built thanks to adaptation rules. Assume the adaptation knowledge of a CBR system is represented by the set of available adaptation rules . may also contain the rules for each problem variable : such a rule states that, given an adaptation problem such that the only difference between the two problems and is related to the value of , the solution is reused as such. The role of these additional adaptation rules is to ensure that the system proposes a solution (possibly with a high adaptation cost).
In order to implement the proposed algorithm, the transformations considered apply to the target problem, so are based on the rule for each (where is the inverse of , as defined in Definition 3). Assuming that costs are additive, the retrieval returns not only an but also a sequence of rules that relates the target problem to this retrieved case. Formally, let , , …, defined by and , for and . Then, the retrieved case is such that and such that the transformation cost is minimal. Algorithmically, it amounts to a best-first search in a state space where states are propositional formulas, is the initial state, the goal is to have a state that matches at least one source case (which can be done efficiently if source cases are specific), the successors of a state being obtained by inverse adaptation rules , and the search being controlled by the cost.
Once a source case retrieved with an associated sequence of adaptation rules , ,…, the idea is to apply the inverse sequence of these rules to to solve : with such that , ,…, , are computed successively: for , . Then such that is a proposition of solution of , adapted in q steps from the retrieved case. It can be noted that above, the (resp., the ) are not necessarily problems (resp. solutions). For example, and may contain variables from .
For such an adaptation to give a consistent result, the adaptation rules must be applicable. This is ensured by the following proposition, in the case where , and are cubes:
Let and be two cubes of and be a cube of . Then:
Sketch of proof.
The conditions for the direct computation have already been seen in Proposition 21.
For the “inverse” computation, it yields that:
The computation of the right part of , and its conjunction with , are done the same way it was done in the proof of Proposition 21, partitioning the set of variables according to , and .
For example, if , .
The compatibility condition of this conjunction is . The right part of this term is then , and the compatibility condition with is . The same conditions are met in the direct computation.
This computation is done the same way in the six other cases, and it is easy (but tedious!) to check the equivalence: iff .
It can be shown that is satisfiable for all by starting from the end:
Since, by definition, is equivalent to the complete cube and cubes are satisfiable, .
that, according to Proposition 23, is satisfiable iff is satisfiable, with . Now, by definition of , , which is satisfiable (cf. case ), thus is satisfiable and hence .
that, according to Proposition 23, is satisfiable iff is satisfiable, with . Now, by definition of , which is satisfiable (cf. case ), thus is satisfiable and hence .
that, according to Proposition 23, is satisfiable iff is satisfiable, with . Now, by definition of , which is satisfiable (cf. case ), thus is satisfiable and hence .
Since , is satisfiable: adaptation gives a consistent result.
It can be noted that this algorithm can be used to solve an adaptation problem (when a case has already been chosen). For this purpose, it only requires to apply the algorithm to the singleton case base .
A final but important remark has to be made. In the system , retrieval was based only on a minimum generalization of the literals of the target problem according to a taxonomy, that is a set of formulas (). Such generalization, expressed with the logic developed in this article, corresponds to adaptation rules . After that, a first raw adaptation was proposed (following the inverse of these taxonomy-based adaptation rules). Then, a rule-based adaptation using more sophisticated rules was performed. With the algorithm presented above, retrieval and adaptation are more tightly linked: once retrieval is done, adaptation just follows backward the adaptation rule chain. Therefore, the retrieval of this algorithm follows a strong version of the adaptation-guided retrieval principle (AGR; Smyth & Keane, 1996). In the usual version of AGR, the retrieved case has to be adaptable. Here, not only is it adapted, but the retrieved case is the source case that requires the least adaptation effort (measured by the costs of adaptation rules) to solve the target problem. Moreover, for this algorithm, retrieval knowledge and adaptation knowledge coincide: the rules are used both for retrieval and for adaptation.
Toward a Composition of Adaptation Rules
The algorithm of Section 6.7 relies on a sequence of applications of adaptation rules. The open issue that is raised here is the computation of a composition of adaptation rules: given two rules and , can a rule be defined such that the application of corresponds to the successive applications of and ? The composition of formulas introduced in Section 3.4 should be useful here, but no definitive answer to this question has been found at this time.
The interest in defining such a composition of rules would be to use it during the post-treatment of learning these rules. If, for example, a frequent closed itemset extraction system is used, a large number of itemsets that can be interpreted as adaptation rules may be produced. If it was possible to find a minimal generating family for the composition of these rules, it would lower their number (and computing time) without changing the algorithm.
Discussion and Related Works
This section discusses some formalisms with connections with the logic of propositional variables presented in this article. Section 7.1 considers briefly several of these formalisms. Dynamic logics are considered separately, since they have stronger similarities with . For discussing these similarities (and differences), two types of inferences are highlighted first, in Section 7.2, namely observations and actions. Then, on this basis, is related with DL-PA, a dynamic logic with propositional variables (Section 7.3).
A Few Related Formalisms and Other Studies
The notion of propositional variation may evoke the notion of differences between Boolean functions that have been studied in the work of Thayse (1981). Indeed, a formula can be seen as a representation of a function from to . In Thayse work, the differences between two Boolean variables is calculated by an exclusive or and this work leads to a differential calculus on Boolean functions inspired from studies in analysis on real numbers (Taylor developments, etc.). However, considering the original goal of this work described in this article, that is, representing variations, useful in particular for CBR, the sole use of exclusive or appears insufficient. In particular, the symmetry of () does not make it possible to express directed variations, for example, to distinguish going from to and going from to , whereas the variation symbols and makes this distinction.
The alternative definition of the semantics of (Section 3.2.2) is based on the set of truth values . This motivates to study the relationships between and the logic of Belnap (2019) which is also based on four truth values which are often represented by ordered pairs of Booleans. From a semantic viewpoint, the link is not straightforward since is most of the time considered as a logic with two truth values (the alternative definition of the semantics has mainly been introduced for practical purpose). Moreover, the number of truth values is at the basis of Belnap–Dunn logic whereas, for variation logic, it appears only as a consequence of choosing propositional logic as a starting point to build this logic: other choices could have been made, which would have led to a set of primitive variations of cardinal different from four. Now, relations between these two logics could be investigated, in particular, at an algorithmic level. This study has not been carried out and constitutes a potential future work.
Observations and Actions
The mechanisms linked to adaptation presented in Section 6 can be divided into observations and actions. The observations occur during the adaptation knowledge learning process (described in Section 2.2) during which are observed variations between source cases. Given an adaptation rule and an adaptation problem , the application of on can be seen as an action mechanism: a plausible solution of is created, starting from . So, assimilating a case to a state and an adaptation rule to an action, an adaptation rule can be considered as the application of an action on a state, to reach a new state (knowing that this new state is constrained by ). The application of adaptation rules is an invitation to study action-related formalisms and inferences (cf. the synthesis Dupin de Saint-Cyr et al., 2020). In this framework, the actions are considered as deterministic: if an action is applicable on a state, it generates exactly one state. The next section studies the links between a dynamic logic and .
A last remark can be done. A link between observations and epistemic actions (also studied in Dupin de Saint-Cyr et al., 2020) could be considered. However, the study of the links between observations as considered here (observing variations between cases) and the epistemic actions (acting for observing and acquiring/modifying knowledge about the current state) has not appear fruitful (or not yet).
and DL-PA
DL-PA (dynamic logic of propositional assignments) is a dynamic logic whose atomic programs are assignments of propositional variables, that is, expressions and for , corresponding to assignment of by, respectively, and (Balbiani et al., 2013). Formulas of DL-PA are the propositional variables, formulas build with other formulas using the connectives of propositional logic, and the formulas of the form where is a program and is a formula. Programs are either atomic programs, or of one of the forms , , , and (where , , and are programs and is a formula).
The semantics of a formula is given by a subset of and the semantics of a program by a subset of , which suggests to study the link between DL-PA programs and formulas. This semantics is defined in an usual way for propositional variables and formulas build on connectives, and for the other formulas and for the programs, in the following way (for , , a formula, , and , programs):
Finally, if there exists a sequence () such that , and for all and .
Ceteris paribus on formulas is useful to establish a relationship from formulas of this logic to DL-PA programs. An operation on DL-PA programs can also be defined to establish a link in the other direction. For this purpose, it will be assumed in the remainder of this section that the set of propositional variables is finite, contrary to the assumption of a countable set of variables made in Balbiani et al. (2013).
It can be remarked that the program (for ) does the opposite of an assignment: even if is assigned to a value ( or ) in the state preceding the application of this program, the execution of this program has for effect that does not have any assignment after this execution. This can be generalized to a set of variables:
The execution of has for effect that it reaches a state in which no variable of has an assignment (so this state is a formula having at least models).
Table 1 gives equalities between sets of models of some formulas of and set of models of some programs of DL-PA. It can be noted that, in this table, some operations of correspond to constructors (syntactical elements) of DL-PA; for example, in the symbol belongs to the syntax of the logic whereas in , is an operator. Moreover, for (which is also a formula of DL-PA), where is defined in Appendix Section A.4, related to the proof of the NP-completeness of . Finally, for , , and a DL-PA program such that , .
Relations Between Formulas of and DL-PA Programs.
Let , , and and DL-PA programs such that and .
For each line of the following tables, :
DL-PAdynamic logic of propositional assignments.
Composition of Variations for the Computation of the Composition of Cubes.
Note. The box on line and column contains the value .
In general, every can be translated into a DL-PA program so that , as explained below, at least under the assumption of a finite set of variables. It must be noticed however that the proposed translation is not efficient and that there is little hope to find one that is, since the satisfiability in is NP-complete whereas the satisfiability of formulas in DL-PA is EXPTIME-hard (even if this complexity is about DL-PA formulas and not programs, this is an indication of the relative complexity of inferences of the two logics).
A simple proof that can be translated into is linked to the fact that every subset of is representable by a program (still under the assumption of a finite set of variables). A more constructive proof associates first to each complete cube of a DL-PA program. Let be a complete cube of : for an . For , let be the program
With , let . It can be shown that . More generally, every can be written as a disjunction of complete cubes: . By associating to each cube a program as described above, it is possible to build the program . Then .
So, there are strong links between and DL-PA that should be studied further. It seems that is more useful for observing variations (and that is why this logic has been initially defined) whereas DL-PA which, in a sense, integrates naturally the ceteris paribus, is more appropriate for acting with these variations (considering the application of an adaptation rule as the execution of a program). So, reasoning with adaptation rules could be done in for their learning and with DL-PA (or one of its fragments) for their application.
Conclusion
CBR uses two types of knowledge. The knowledge of what holds (in a particular state) is represented by the source cases and by the domain knowledge. The knowledge of what changes is represented by retrieval and adaptation knowledge. The former type of knowledge can be expressed in well-studied formalisms, such as propositional logic. The study of formalisms for the second type of knowledge has received less attention, particularly when the tight relation between knowledge representation and reasoning is considered. The first goal of this article has been the systematic study of one of these formalisms, the logic of propositional variations which is suited when cases and domain knowledge can be represented in propositional logic. Although the logics for representing variations (such as ) and dynamic logics are related, the objectives of their studies are different. For logics of variations, our first objective has been to represent this notion of variations in order to study how to draw inferences with them: starting from a notation introduced for some studies on adaptation knowledge learning, a semantics has been added to it, which has made possible to reason on variations. The second objective of this article has been to “go back” to CBR, to study the potential impact of this logic of variations, beyond its mere notation. The logic has been used for representing adaptation rules for CBR and a CBR algorithm based on adaptation rules has been designed. This algorithm has the property that it retrieves the best source case, that is, the one that minimizes the adaptation effort and it is our claim that it should be quite efficient. Indeed, it is rather similar to an implementation of a CBR algorithm for the system (which does not have this property of optimal retrieval though) and that was efficient, with a case base of about cases.
There are many potential future studies following this work, including the ones that are mentioned all along the paper, such as the use of the logic of propositional variations for generative adaptation. However, we will limit ourselves here to describe three directions of research that are of particular interest for us.
The first direction of research is quite obvious: it consists in studying other logics of variations, based on other formalisms than propositional logic. In particular, we are interested in using as base logic a logic of propositional closure on linear constraints (on integer and real variables), a logic studied on another (and complementary) line of work on CBR (Diebold et al., 2024). So, a variation logic based on this logic would, in particular, represent variations between two constraints. An important difference with the study presented in this article is that the set of variation symbols would not be finite, but defined by a language.
A second direction of work is the study of the implementation of and its practical application to a CBR system. The complexity of the inference may be an issue here, since is NP-complete. One way to address this difficulty is to define a translation mechanism from to SAT solver and using an efficient solver for SAT (it could also be for another well-studied decision problem than SAT). Another way to address this difficulty is to consider polynomial fragments of . For example, it is easy to define a Horn fragment of this variation logic and to reuse the backward chaining algorithm for the Horn fragment of propositional logic, but it remains to be proven that this algorithm remains complete.
A third direction of work is the study of links existing with proportional analogies, that is, quaternary relations between four objects , , , and that are read “ is to as is to ” and that are bound by some set of postulates (see, e.g., Prade & Richard, 2013). In the past few years, several studies have made connections between CBR and proportional analogies (e.g., Lepage & Lieber, 2018; Lieber et al., 2021), thus this may have an impact on CBR as well. An intuition behind proportional analogies is that if a quadruplet is in an analogical proportion then some well-chosen transformation from to coincides with some well-chosen transformation from to . Such transformations could be represented by variation formulas, hence the link with the current study. In particular, one question that can be raised is what are the mappings such that the quaternary relation , for would define proportional analogies on ?
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their remarks, which have contributed to improve the quality of this article. Some of their suggestions could not be taken into account, in particular, because they involve many more research, but they are potential future directions of work, as acknowledged in the conclusion section. The authors also wish to thank Tiago de Lima and Pierre Marquis who gave them relevant pieces of advice that were useful for this work.
ORCID iDs
Thomas Laure
Jean Lieber
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A. Proofs of Some Results
References
1.
BaaderF.SattlerU. (2001). An overview of tableau algorithms for description logics. Studia Logica, 69, 5–40.
2.
BalbianiP.HerzigA.TroquardN. (2013). Dynamic logic of propositional assignments: A well-behaved variant of PDL. In 28th Annual ACM/IEEE Symposium on Logic in Computer Science (pp. 143–152). IEEE.
3.
BelnapN. D. (2019). How a computer should think. New essays on Belnap–Dunn logic (pp. 35–53). Springer.
4.
CarbonellJ. G. (1983). Learning by analogy: Formulating and generalizing plans from past experience. In R. S. Michalski, J. G. Carbonell, & T. M. Mitchell (Eds.), Machine learning, an artificial intelligence approach (Chap. 5, pp. 137–161). Morgan Kaufmann, Inc.
5.
CarbonellJ. G. (1986). Derivational analogy: A theory of reconstructive problem solving and expertise acquisition. In Machine learning (Vol. 2, Chap. 14, pp. 371–392). Morgan Kaufmann, Inc.
6.
CordierA.Dufour-LussierV.LieberJ.NauerE.BadraF.CojanJ.GaillardE.Infante-BlancoL.MolliP.NapoliA.Skaf-MolliH. (2014). Taaable: A case-based system for personalized cooking. In S. Montani & L. C. Jain (Eds.), Successful case-based reasoning applications-2. Volume 494 of Studies in Computational Intelligence (pp. 121–162). Springer.
7.
d’AquinM.BadraF.LafrogneS.LieberJ.NapoliA.SzathmaryL. (2007). Case base mining for adaptation knowledge acquisition. In M. M. Veloso (Ed.), Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI’07) (pp. 750–755). Morgan Kaufmann, Inc.
8.
d’AquinM.LieberJ.NapoliA. (2006). Adaptation knowledge acquisition: A case study for case-based decision support in oncology. Computational Intelligence (an International Journal), 22(3/4), 161–176.
9.
DieboldE.KabritY.KrilA.LieberJ.MalvaudP.NauerE.SippJ. (2024). Olaaaf: A general adaptation prototype. In J. A. Recio-Garcia, M. G. O. Orozco-del-Castillo, & D. Bridge (Eds.), Case-based reasoning research and development. Volume 14775 of Lecture Notes in Computer Science (pp. 223–239). Springer Nature Switzerland.
10.
Dupin de Saint-CyrF.HerzigA.LangJ.MarquisP. (2020). Reasoning about action and change. A guided tour of artificial intelligence research: Volume I: Knowledge representation, reasoning and learning (pp. 487–518). Springer.
11.
HanneyK.KeaneM. T. (1996). Learning adaptation rules from a case-base. In I. Smith & B. Faltings (Eds.), Advances in case-based reasoning—Proceedings of the Third European Workshop, EWCBR’96, LNAI 1168 (pp. 179–192). Springer Verlag.
12.
JalaliV.LeakeD.ForouzandehmehrN. (2017). Learning and applying adaptation rules for categorical features: An ensemble approach. AI Communications, 30(3–4), 193–205.
13.
LeakeD.YeX.CrandallD. J. (2021). Supporting case-based reasoning with neural networks: An illustration for case adaptation. In AAAI spring symposium: Combining machine learning with knowledge engineering (Vol. 2). CEUR.
14.
LepageY.LieberJ. (2018). Case-based translation: First steps from a knowledge-light approach based on analogy to a knowledge-intensive one. In ICCBR 2018—26th International Conference on Case-Based Reasoning, Stockholm, Sweden.
15.
LieberJ.NauerE.PradeH. (2021). When revision-based case adaptation meets analogical extrapolation. In 29th International Conference on Case-Based Reasoning (ICCBR 2021), Volume 12877 of Lecture Notes in Computer Science book series (LNCS) (pp. 156–170). Springer.
16.
PradeH.RichardG. (2013). From analogical proportion to logical proportions. Logica Universalis, 7(4), 441–505.
17.
RichterM. M.WeberR. O. (2013). Case-based reasoning, a textbook. Springer.
18.
RiesbeckC. K.SchankR. C. (1989). Inside case-based reasoning. Lawrence Erlbaum Associates, Inc.
19.
SmullyanR. M. (1995). First-order logic. Courier Corporation.
20.
SmythB.KeaneM. T. (1996). Using adaptation knowledge to retrieve and adapt design cases. Knowledge-Based Systems, 9(2), 127–135.
21.
ThayseA. (1981). Boolean calculus of differences. Springer.
22.
ZakiM. J.HsiaoC.-J. (2002). CHARM: An efficient algorithm for closed itemset mining. In Proceedings of the 2002 SIAM International Conference on Data Mining (pp. 457–473). SIAM.