
Abstract
Personalized news recommendation aims to address information overload problems and find interesting news for users, which is essential for online news portals and platforms nowadays. Existing deep neural networks and pretrained language models require some labeled data to train end-to-end models or fine-tune object functions. More recently, prompt-tuning methods have been proposed to minimize the gap between the knowledge acquired during pretraining and the fine-tuned model. Although these methods have achieved fairly good results in news recommendation, how to take the personalized characteristics of items into template construction and achieve competitive performance compared to hand-crafted prompts through soft prompt-tuning is still an important academic and practical challenge. In this article, we propose a soft prompt-tuning method for personalized news recommendation. The side information of news is introduced to learn the characteristics of items in the recommendation, and different strategies of verbalizer optimization are designed for performance improvement. Specifically, the summaries and subcategories of news are first introduced for template construction to consider the characteristics of news, which can provide a more comprehensive and accurate description of news. Secondly, three different strategies are designed to expand the label word space for modifying soft prompts, and the integration of these strategies is used for final verbalizer optimization, which can significantly reduce additional noise and improve recommendation accuracy. Extensive experiments conducted on the MINDsmall and MINDlarge datasets validated the effectiveness of the proposed method compared to other state-of-the-art prompt methods.
Introduction
With the rapid development of the internet, online news portals and platforms have played an important role in people’s daily life. Users can easily access all kinds of news whenever and wherever possible, which brings convenience but also leads to the serious problem of “information overload.” To address these issues, personalized news recommendation aims to help users find their most interesting news from the huge amounts of news, which can be an effective filtering tool for users and an essential function for online news platforms nowadays (Wang et al., 2018; Zhang & Wang, 2023).
The research paradigm of news recommendation evolved from deep neural networks to pretrained language models (PLMs), which both show substantial performance in this task. Existing news recommendation methods based on deep neural networks mainly focus on learning the higher-level and abstract feature representations of users and items, which aim to find the connections between users and items to help personalized recommendations. The main intuition behind these methods is to learn the similarities between users and items in different networks. For example, Wang et al. (2018) proposed a deep knowledge-aware network for news recommendation (DKN) that incorporated knowledge graph representation for news recommendation, which introduced a convolution neural network and attention module to discover latent connections among news. Wu et al. (2019b) proposed a news recommendation method based on multihead self-attention (NRMS), where the representations of news and users are learned from news titles and users’ browsing, respectively. However, the static word vectors, such as Word2Vec and GloVe, are predominantly utilized as initializations in these deep-based news recommendation methods, which primarily focus on extracting information inside the recommendation dataset itself, while often neglecting the wealth of semantic and linguistic information available in real-world large-scale corpora.
Recently, there have already been some efforts in devoting PLMs to personalized news recommendation. In these methods, some popular PLMs (e.g., BERT and RoBERTa) have been introduced to fine-tune downstream recommendation tasks on pretrained knowledge. The PLMs are utilized as the news encoder, and the specific function for news recommendation is used to train the model, which has achieved substantial performance compared to deep-based methods. For example, Sun et al. (2019) proposed a sequential recommendation named BERT4Rec, the masked language model is introduced to learn the representations of user behaviors, and the masked items are predicted using both left and right context. However, due to the significant gap of objective forms in pretraining and fine-tuning, these fine-tuned pretrained language model (PLM) methods cannot stimulate the abundant and rich knowledge distributed in a large-scale pretrained model for news recommendation.
To address the huge gap between the knowledge acquired during pretraining and the fine-tuned model, the prompt-tuning model is proposed and has achieved awesome performance in various natural language processing (NLP) downstream tasks, especially for few-shot and even zero-shot learning scenarios, including machine translation (Zhang et al., 2023), question answering (Chappuis et al., 2022), sentiment analysis (Mao et al., 2022), and text classification (Zhu et al., 2024). In the prompt-tuning, the input statements are converted into the cloze-style tasks, which introduced the natural language template and adapted the masked model (Ding et al., 2021). For instance, given the news
Motivated by the recent success of the prompt-tuning model, in this paper, we propose a Soft Prompt-tuning method for Personalized News Recommendation (SP-PNR), which aims to take the personalized characteristics of items into template construction and achieve competitive performance compared to hand-crafted through soft prompt-tuning. Specifically, firstly, all the side information of news, including the summaries and subcategories, is introduced to learn the characteristics of news, which can provide a more comprehensive and accurate description of news for personalized recommendation. Secondly, several strategies are designed to capture different characteristics of expanded words, and the integration of these strategies is used for final verbalizer optimization, which can significantly reduce additional noise and improve recommendation accuracy (Acc) for modifying soft prompts. Extensive experimental results conducted on the MINDsmall and MINDlarge datasets validate the effectiveness of our SP-PNR compared to other state-of-the-art methods. The contributions of our method can be summarized as follows:
To take the personalized characteristics of news into template construction, a prompt-tuning model with the summaries and subcategories of news is proposed. To achieve better recommendation performance by soft prompt-tuning, several strategies are employed to capture different characteristics of the expanded words for verbalizer optimization. The experimental results on the MINDsmall and MINDlarge datasets confirm that our SP-PNR can achieve state-of-the-art performance compared to other news recommendation methods based on deep neural networks and prompt-tuning.
Related Work
Personalized News Recommendation
Personalized news recommendation methods have played critical roles in almost all online news platforms to alleviate the information overload problems of users.
In the past few years, deep neural networks have exhibited powerful advantages in multilevel feature extraction, implicit feature learning, sequence modeling, and attention mechanisms. Most popular deep neural networks, such as convolutional neural network (CNN), recurrent neural network (RNN), long short-term memory (LSTM), and autoencoder, have been applied to news recommendation tasks and achieved significant performance improvements. For example, Wu et al. (2019a) proposed a neural news recommendation approach (neural attentive multiview learning for news recommendation [NAML]), which can learn informative representations of users and news by exploiting different kinds of news information. Zhu et al. (2019) proposed a deep attentional neural network, which employed a parallel CNN that enhanced with attention to condense user interest features, then the method introduced an RNN fortified by attention to delve into intricate sequential patterns within user click behaviors. An et al. (2019) proposed a neural news recommendation method with long- and short-term user representations (LSTUR), which effectively fused the user’s long-term and short-term interests to provide an effective method for modeling user interest. While deep neural network methods demonstrate remarkable performance, they often fail to fully exploit the rich semantic structures within news articles. In light of this, recent advancements in natural language processing have paved the way for the integration of PLMs into personalized news recommendations.
Recently, fine-tuned PLMs such as BERT (Devlin et al., 2018), ALBERT (Lan et al., 2019), and BioGPT (Luo et al., 2022) have emerged as a powerful tool for exploiting rich knowledge in NLP tasks. By fine-tuning PLMs with specific downstream tasks, the latent information can be learned, and these models have achieved tremendous success in various NLP tasks. Unlike traditional models that are typically trained directly on labeled data for specific tasks, PLMs first undergo pretraining on a large-scale unlabeled corpus using self-supervised learning to encode universal text information. Consequently, PLMs usually offer a more advantageous starting point for fine-tuning in downstream tasks (Qiu et al., 2020). Considering the superior performance, fine-tuning PLM methods have been widely applied to acquire richer semantic information for news recommendation. For example, Wu et al. (2021) explored to model news with PLMs and fine-tuned them with the news recommendation task. Yu et al. (2021) proposed the Tiny-NewsRec framework, which effectively improved the performance and efficiency of news recommendation systems based on PLMs by reinforcing the model’s understanding of domain-specific features and optimizing the knowledge transfer process. Zhang et al. (2021) proposed the User–News Matching BERT for News Recommendation (UNBERT) approach, which employed a multilayered transformer architecture to enhance text representation through pretrained models with rich linguistic knowledge. Despite fine-tuning PLMs has achieved sound performance in personalized news recommendation, the significant gap between objective forms in pretraining and fine-tuning has restricted taking full advantage of knowledge in PLMs.
Prompt-Tuning
In response to the challenges of the huge gap between pretraining and fine-tuning in fine-tuning PLM methods, more recently, prompt-tuning has been advanced, influenced by GPT-3. Prompt-tuning streamlines the process by constructing natural language templates and strategically inserting input statements, followed by fine-tuning the masked model to transform tasks into cloze-style completion tasks, which aims to reduce the reliance on manual customization and enhance the consistency and reliability of evaluations. Prompt-tuning has shown impressive performance in various downstream NLP tasks, including relation extraction (Chen et al., 2022), data augmentation (Wang et al., 2022), and sentiment analysis (Li et al., 2021), particularly in few-shot learning scenarios.
The success of the prompt-tuning methods relies heavily on appropriate templates and suitable label words. The hand-crafted templates are first designed, which refer to discrete prompts that are manually specified and remain unchanged during training. For instance, Brown et al. (2020) created manually crafted prefix prompts to handle a wide variety of tasks, including question answering, translation, and probing tasks for common sense reasoning. Han et al. (2022) applied logic rules to construct prompts with several sub-prompts for relation classification, consistently outperforming existing state-of-the-art baselines without introducing additional model layers, manual annotations, or augmented data. Li et al. (2023) designed a series of personalized templates specifically to accommodate the unique preferences among different users, thereby enhancing the personalization level of news recommendations and ultimately optimizing the overall performance of the recommendation system. While the strategy of hand-crafted templates is intuitive and does allow solving various tasks with some degree of Acc, there are also several issues to be addressed: (1) Creating and experimenting with these prompts is an art that takes time and experience, particularly for some complicated tasks such as semantic parsing (Shin et al., 2021); (2) even experienced prompt designers may fail to manually discover optimal prompts (Jiang et al., 2020).
To address these problems, several methods have been proposed to automate the template design process. Soft templates are continuous prompts, usually presented as vectors, that can be continually optimized during training to obtain optimal results. For example, Shin et al. (2020) proposed a gradient-based prompt search method to automatically generate templates in prompt-tuning. Su et al. (2021) enhanced prompt-tuning via prompt transfer and investigated the transferability of soft prompts across distinct downstream tasks. Liu et al. (2022) proposed an automatic prompt generation method that achieved promising performance in Natural Language Understanding tasks by identifying the template suitable for downstream tasks and incorporating learnable vectors into the template while continually optimizing it during training. Zhang and Wang (2023) designed a diverse array of prompt templates consisting of discrete, continuous, and hybrid types, and correspondingly built answer spaces for each template to systematically examine and validate the efficacy and applicability of their proposed Prompt4NR framework.
Besides the generation of templates, the mapping from label words to categories, that is, the verbalizer, has proven effective in addressing the discrepancy between text and label space. For example, Hu et al. (2021) demonstrated the effectiveness of knowledge-enhanced tuning by enriching their label vocabulary with external knowledge bases and subsequently refining the augmented set of labels through meticulous processing. Wei et al. (2022) proposed a prototypical network that aggregates the semantic information of labels to construct a prototypical prompt verbalizer, thereby enabling the generation of prototypical embeddings for various labels within the feature space. Cui et al. (2022) proposed an evolutionary verbalizer search algorithm, which aims to improve prompt-based tuning with the high-performance verbalizer.
Methods
In this section, we will sequentially and meticulously outline the comprehensive framework, the automatic template generation, the construction of the verbalizer, and the news recommendations. The whole framework of the proposed SP-PNR is illustrated in Figure 1.
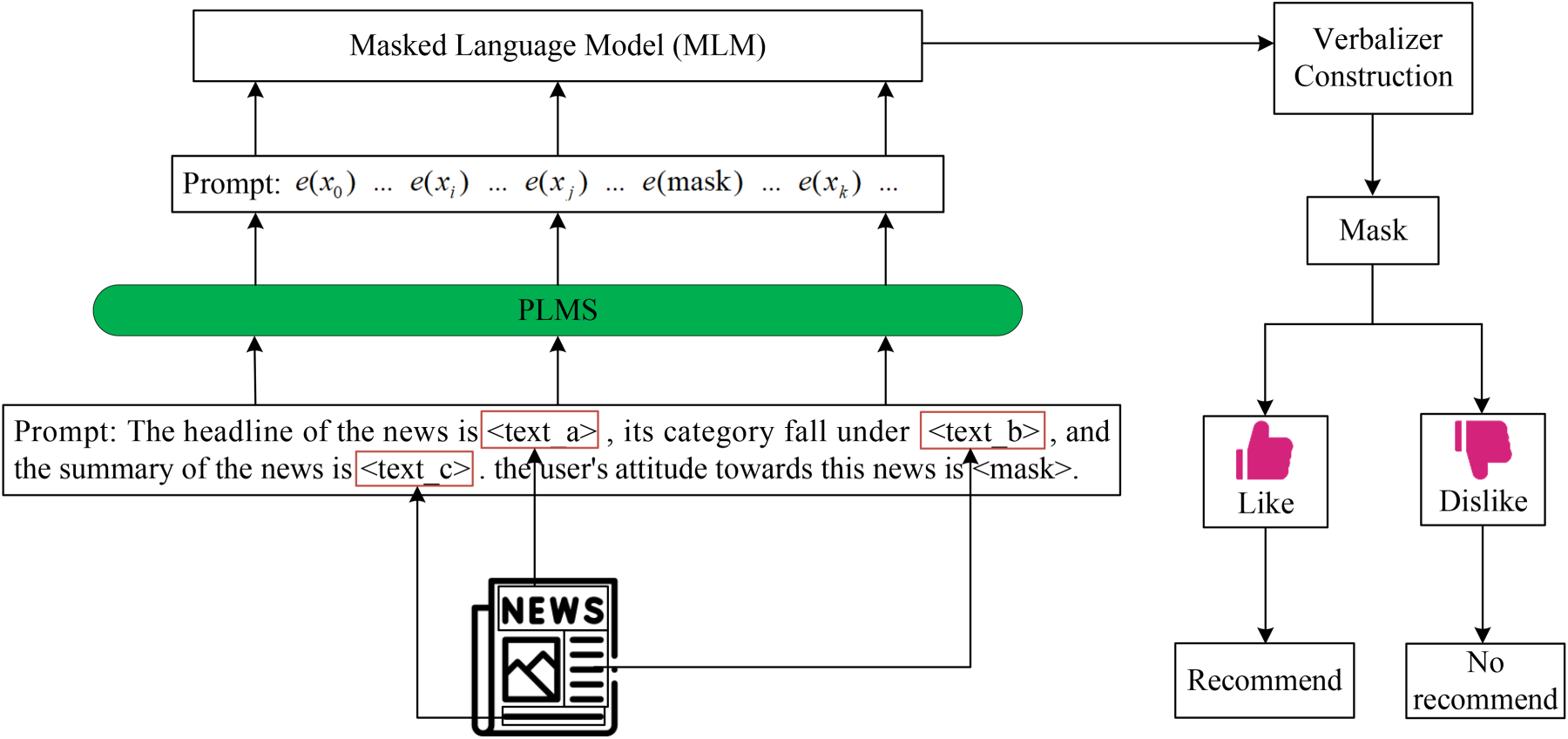
The Whole Framework of our Soft Prompt-Tuning Method for Personalized News Recommendation (SP-PNR).
The insightful observation of prompt-tuning motivates us to complete the soft prompt-tuning method for personalized news recommendations. To ensure the personalization of recommendations, we train a separate model for each user. As shown in Figure 1, there are three main components in our SP-PNR: automatic template generation, verbalizer construction, and news recommendation. Firstly, in the experiments, we obtain the titles, subcategories, and summaries from the news, which aims to obtain as much comprehensive semantic information as possible from the news. These three are then taken as inputs and denoted by
Automatic Template Generation
In our SP-PNR, news titles, subcategories, and summaries are denoted as
As an example, to accurately predict user U730’s attitude toward the candidate news, we take the following news: Title: “Young and the Restless” star William Wintersole passes away at 88, Category: TV news, Summary: Well-known soap opera actor William Wintersole passes away at age 88. We incorporated all the detailed semantic information of the above news, including title, category, and summary, into our predefined template. Through this process, we aim to accurately determine user U730’s attitudinal inclination toward the candidate news.
For the task of automatic template generation, the PLMs are represented as
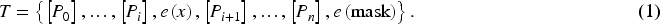
Different from the hand-crafted template, we employ the neural network in the experiments for training soft tokens, and the template we use can be represented as (2):
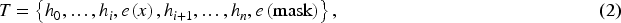
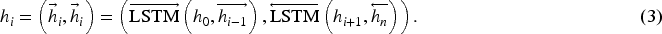
Notably, a significant advantage of soft prompt templates lies in their ability to dynamically adjust their parameters based on specific task contexts. This characteristic endows soft prompts with enhanced adaptability and generalization capabilities across diverse scenarios and tasks, eliminating the need for manual design or tedious modification of fixed token templates. In contrast, hard-crafted templates are constrained by their inherent rigidity and limited vocabulary selection, potentially hindering the full expression of rich model semantics and thereby increasing the risk of over-fitting. On the other hand, soft prompts effectively generate appropriate tokens through refined parameter optimization processes, allowing them to capture and convey complex semantic nuances more accurately, which significantly reduces the likelihood of over-fitting. In a word, the mechanism of generating prompts via parameter optimization not only enhances the understanding and representation of intricate semantics but also, to a large extent, mitigates the occurrence of over-fitting issues.
Prompt-tuning entails a procedure in which a verbalizer systematically assigns label words to their corresponding categories, serving as a valuable strategy for enhancing the performance of downstream tasks. Our approach began with a focus on elementary sentiment-bearing terms, such as “like” and “dislike,” initially augmenting our vocabulary collection by compiling their synonymous counterparts. Subsequently, we employed an advanced large language model to uncover emotionally charged label words derived from user reactions to candidate news items, thereby further enriching the content of our label repository.
Furthermore, our SP-PNR incorporates three additional strategies for extending the range of label words. These methods not only mitigate potential noise within the expanded label words but also boost overall efficiency by abbreviating execution times. Each strategy distinctively addresses a particular attribute of the enlarged words’ nature. The following provides a detailed account of these three strategies:
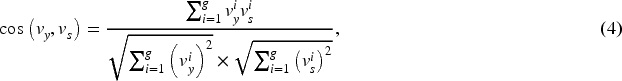
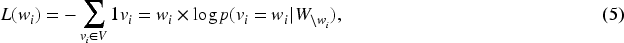

All the expanded words are sorted based on their corresponding sequence loss
It is worth noting that
Upon successfully constructing the final verbalizer through a variety of strategies, a crucial subsequent step involves appropriately mapping the predicted probabilities for each label word to their respective categories. This mapping process can be effectively represented by an objective function
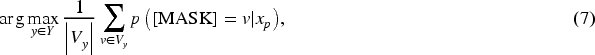
Based on precise modeling of user interests, following the application of objective function
In this section, we conduct extensive experiments on a classic news dataset to evaluate the effectiveness of our proposed personalized recommendation method. Specifically, we first provide a detailed description of the datasets used in the experiments. Secondly, the compared methods and evaluation metrics of the experiment are introduced. Then, we introduce the results of the experiments and their observations.
Dataset
We followed the approach in the HDNR (Wang et al., 2023) and selected MINDlarge and MINDsmall as our experimental datasets (Table 1). The following section provides an introduction to these two datasets.
MINDsmall-488: The MINDsmall dataset is a widely used news recommendation dataset derived from anonymous user behavior logs from Microsoft’s news website. We created the MINDsmall-488 subset by selecting 488 users with historical click volumes between 160 and 320, ensuring sufficient interaction records without excessive redundancy. The dataset was processed by merging and deduplicating the training and testing sets, allocating 70% for training and 30% for testing. Each user’s data was formatted into combinations of user IDs, news titles, categories, and summaries.
MINDlarge-1138: The MINDlarge dataset is also derived from the same source. We constructed the MINDlarge-1138 subset by selecting 1,138 users with click volumes between 200 and 500, following the same criteria and processing methods as MINDsmall. This subset captures richer user–news interactions while maintaining focused user interests.
Furthermore, we have made our dataset and source code publicly available on “https://github.com/zhuyiYZU/SP-PNR.”
Compared Methods and Evaluation Metrics
Compared Methods
We compare SP-PNR with the following deep learning and fine-tuning PLM methods for news recommendation to demonstrate the effectiveness of our method:
NRMS (Wu et al., 2019b). The NRMS method employs the multihead self-attention mechanism in the Transformer architecture to capture the long-distance dependence of news headlines and content and the complex patterns of historical user behavior. Neural News Recommendation with LSTUR (An et al., 2019). The LSTUR method provides a powerful and flexible approach to modeling user interests for recommender systems by effectively fusing long-term and short-term user interest features by utilizing user IDs and recent behavioral sequences, respectively. NAML (Wu et al., 2019a). The method designs a semi-automatic encoder-based hybrid collaborative filtering recommendation method that utilizes multiperspective learning and attention mechanisms to process complex information for news recommendation. DKN (Wang et al., 2018). The method improves the Acc and relevance of recommendations by fusing knowledge graph information with deep learning techniques to better understand and capture the complex semantics and diversity of user interests in news content. UNBERT (Zhang et al., 2021). The UNBERT model employs a multilayered Transformer architecture to enhance the textual representation by pretrained models with rich linguistic knowledge.
Implementation Details and Parameter Settings
We utilize BERT (Devlin et al., 2018) as the backbone PLMs, and the BERT-base-cased model is used in our experiments. Acc, recall (Rec), and missing alarm rate (MAR) are adopted as the metrics. In our SP-PNR, the learning rate, the batch size, the hidden size, and the dropout rate are set to
Details of Dataset Used in our Experiments.

Details of Dataset Used in our Experiments.
All experimental results were obtained on a server with an NVIDIA Geforce RTX 3090 Founders Edition GPU, an Intel(R) Core(TM) i9-10980XE CPU running at 3.00 GHz, and 64 GB of memory. In addition, we employed Python version 3.7 in conjunction with PyTorch version 1.13.1 and OpenPrompt version 1.0.1.
In the experiments, Acc, Rec, and MAR are used to evaluate the effectiveness of our proposed SP-PNR and all compared methods; these three evaluation metrics are defined as (8), (9), and (10). The bigger the values of Acc and Rec, the better the performance of the methods. The smaller the values of MAR, the better the performance of the methods. Increased Acc signifies a closer alignment between our predictions of users’ news preferences and the actual situation. In a news recommendation system, a higher Rec ensures that our predicted results increasingly encompass all the news content that genuinely interests users. Rec and MAR work in tandem, both contributing to maximizing the provision of potentially favored content for users, which is the central goal of a news recommendation. By synergistically coordinating and optimizing these three evaluation metrics, we can more effectively achieve this objective.


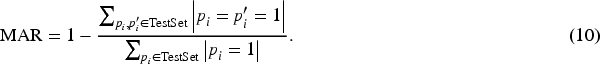
For both datasets, we train each user independently to fully demonstrate the personalized characteristics of the recommendation system. Considering the large number of users and the uneven distribution of information among individuals, we adopt the average value of all users as the comprehensive performance index. The results of Acc, Rec, and MAR on all the methods are presented in Table 2. By analyzing the results of the experiments, we can make the following observations: While deep neural network methods, such as NAML, NRMS, LSTUR, and DKN, have presented fairly good and competitive results on both datasets, they often fail to fully exploit the rich semantic structures within news articles. We believe that is why these methods cannot achieve the best performance in the two datasets. Moreover, the results of these deep neural networks fluctuate greatly on different datasets, indicating that these methods have a strong dependence on training data, and their robustness and generality are relatively poor. Despite the fine-tuning PLMs, such as UNBERT, can acquire richer semantic information for news recommendation, the significant gap between objective forms in pretraining and fine-tuning restricts taking full advantage of knowledge in PLMs, which can be validated from the results in two datasets. In contrast, our SP-PNR achieved superior performance on both datasets, reflecting a marginal advantage in introducing prompt-tuning. Furthermore, our SP-PNR still demonstrates optimal performance when comparing multiple types of news recommendation methods on both Rec and MAR. The results on both datasets strongly suggest that our method can successfully incorporate the deep semantic information of news to a greater extent than other approaches, which empowers the method to more accurately capture user interests and significantly enhances the personalization level of the recommendation system.
The Performance of Acc, Rec, and MAR on MINDsmall-488 and MINDlarge-1138.
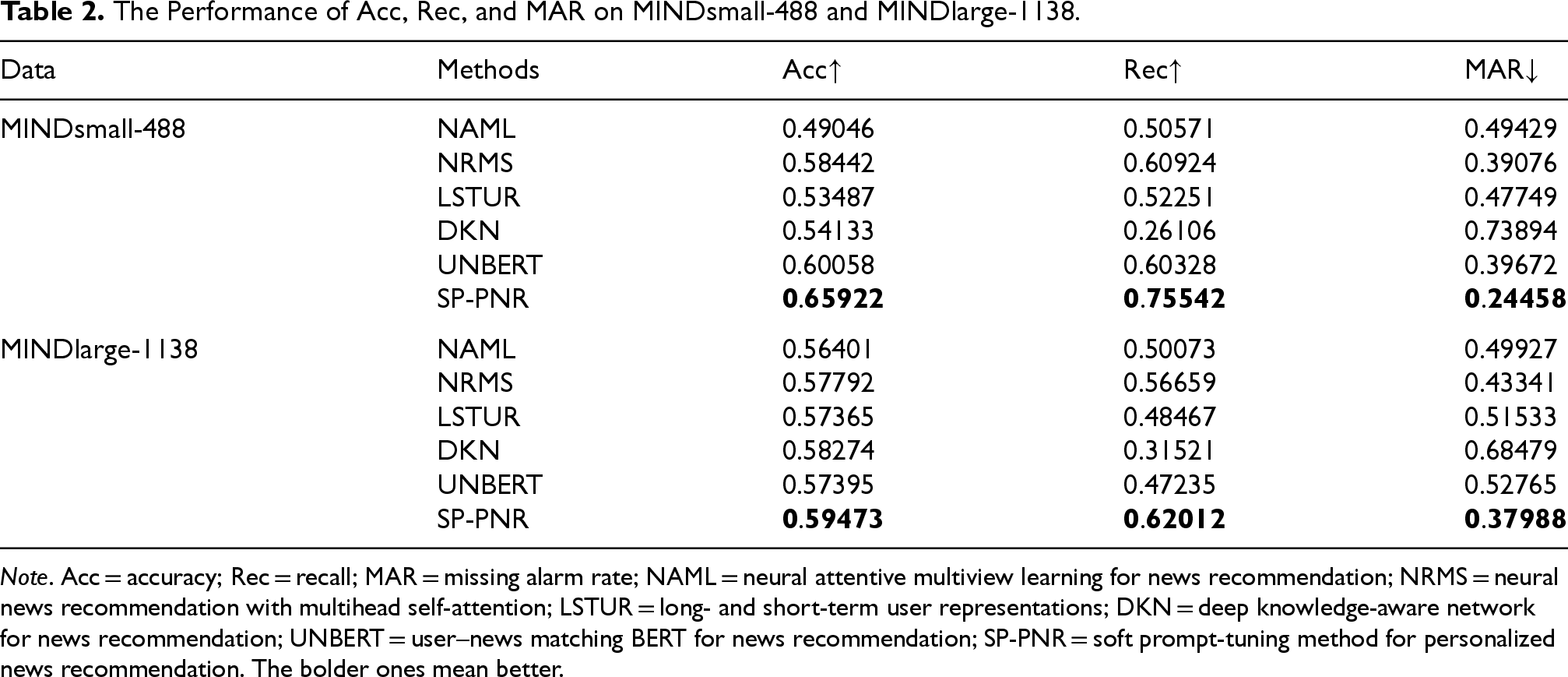
The Performance of Acc, Rec, and MAR on MINDsmall-488 and MINDlarge-1138.
Note. Acc = accuracy; Rec = recall; MAR = missing alarm rate; NAML = neural attentive multiview learning for news recommendation; NRMS = neural news recommendation with multihead self-attention; LSTUR = long- and short-term user representations; DKN = deep knowledge-aware network for news recommendation; UNBERT = user–news matching BERT for news recommendation; SP-PNR = soft prompt-tuning method for personalized news recommendation. The bolder ones mean better.
To systematically validate the effectiveness of our SP-PNR in integrating news content, we conducted an in-depth comparative analysis, especially incorporating the experimental results from multiple hand-crafted templates. Three manual templates conducted in the dataset are listed in Table 3, and the experimental results are shown in Table 4.
The Information of Different Hard Templates.

The Information of Different Hard Templates.
The Performance of Different Templates.
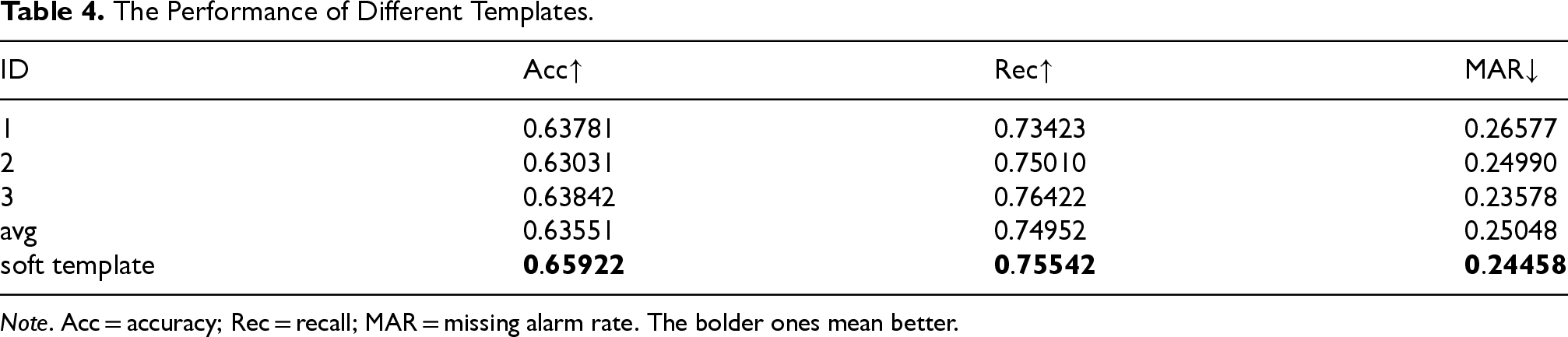
Note. Acc = accuracy; Rec = recall; MAR = missing alarm rate. The bolder ones mean better.
From the results in Table 4, we can observe that the manual templates can achieve fairly good results, and even obtain a high level of Acc in controlled experiments. However, these methods exhibit limitations, mainly in terms of the difficulty of flexibly responding to the diverse and personalized interest tendencies of a wide range of users. Moreover, testing and matching numerous customized templates individually for each user in real scenarios is undoubtedly a resource-intensive and operationally difficult challenge.
On the contrary, our proposed soft template generation strategy shows significant advantages. With excellent flexibility and generalization capability, the method can adapt to the diversity of user needs and tailor more accurate and efficient information matching solutions for a wide range of user groups. In the experiments, we designed three different hand-crafted templates and conducted relevant experiments to compare the average of the obtained results with our soft templates, which further highlights the great potential of our approach in improving the efficiency and user experience of personalized news recommendation.
To gain insight into the substantial impact of the completeness of news semantic information on the performance of a personalized news recommendation method, we systematically removed the subcategory and summary parts of each news from the entire dataset, called SP-PNR(-sub) and SP-PNR(-sum), respectively, thereby reducing the overall semantic information of the news. The purpose of the experiment is to quantify the specific impact of reducing semantic information on recommendation effectiveness, primarily by reducing the semantic richness of the news.
The experimental results are presented in Table 5, which clearly shows that the richness of news semantic information is crucial for ensuring recommendation Acc and enhancing user experience. It also reflects the nonnegligible role of rich semantic content in accurately matching user interests.
Representation of Different Semantic Information.

Representation of Different Semantic Information.
Note. Acc = accuracy; Rec = recall; MAR = missing alarm rate; SP-PNR = soft prompt-tuning method for personalized news recommendation. The bolder ones mean better.
To investigate the influence of different PLMs on personalized news recommendation, we further introduced RoBERTa and DeBERTa as the backbone model to our SP-PNR, which aims to assess how varying PLMs affect recommendation Acc and effectiveness.
The experimental results are presented in Table 6, showing that SP-PNR with BERT generally provides the best performance in terms of Acc. RoBERTa-base and DeBERTa-base, while showing competitive Rec, performed relatively lower in Acc and MAR, especially on the MINDlarge dataset. These results indicate that while BERT excels in overall recommendation performance, RoBERTa-base and DeBERTa-base also contribute to competitive Rec, particularly in certain datasets.
The Influence of Different PLMs.
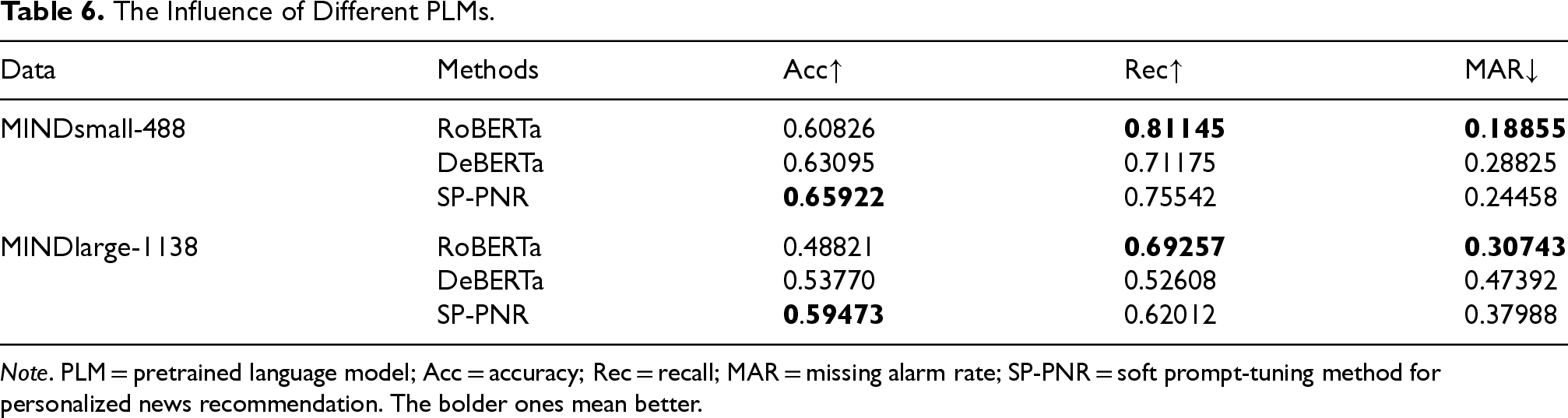
The Influence of Different PLMs.
Note. PLM = pretrained language model; Acc = accuracy; Rec = recall; MAR = missing alarm rate; SP-PNR = soft prompt-tuning method for personalized news recommendation. The bolder ones mean better.
To further validate the generalizability of our SP-PNR, we conduct experiments on the classical MovieLens-1M dataset. Due to the special characteristics in the MIND dataset, including news title, content, and the reading timestamp, the baselines, including NRMS, LSTUR, NAML, DKN, and UNBERT, cannot be applied in the MovieLens dataset. Thus, we introduced classical recommendation methods as baseline methods. The detailed descriptions of the dataset, baselines, and experimental results are as follows.
Nonnegative Matrix Factorization (NMF; Wang & Zhang, 2012). A basic matrix factorization method for recommendation, using the generalized Kullback–Leibler divergence for updates in our experiments. Singular Value Decomposition Plus (SVD++; Koren, 2008). A model that combines both explicit and implicit feedback from users, integrating latent factor and neighborhood models for recommendation. Personalized Recommendation With Knowledge Graph via Dual-Autoencoder (PRKG; Yang et al., 2022). This method uses auxiliary information from item knowledge graphs, encoded into low-dimensional representations via a semi-autoencoder to enhance recommendations. LLaMA (Touvron et al., 2023). A large language model based on the Transformer architecture, trained on a dataset containing 2 trillion tokens, demonstrates strong performance across various benchmarks.
Notably, the PREA toolkit (Lee et al., 2014) 2 is adopted for the implementation of NMF and SVD++. For PRKG, the default parameters as reported in Yang et al. (2022) are used in the experiments. It is worth noting that the existing experimental results reported in their papers are directly copied into our tables. For LLaMA, recommendations are made directly through a conversational approach.
The experimental results on the MovieLens-1M dataset are presented in Table 7. Our SP-PNR outperformed other baseline methods across all evaluation metrics, including Acc, Rec, and MAR. In contrast, other methods such as NMF, SVD++, and LLaMA had lower performance, particularly in Rec and MAR, with SP-PNR models significantly outperforming them.
The Performance of Acc, Rec, and MAR on MovieLens-1M Dataset.
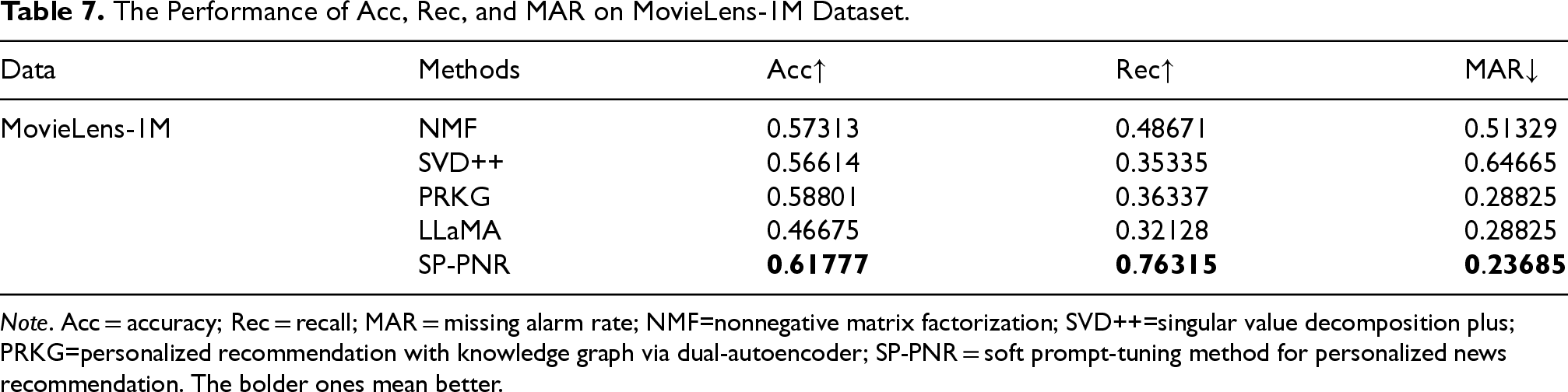
The Performance of Acc, Rec, and MAR on MovieLens-1M Dataset.
Note. Acc = accuracy; Rec = recall; MAR = missing alarm rate; NMF=nonnegative matrix factorization; SVD++=singular value decomposition plus; PRKG=personalized recommendation with knowledge graph via dual-autoencoder; SP-PNR = soft prompt-tuning method for personalized news recommendation. The bolder ones mean better.
We conducted a case study to evaluate the effectiveness and robustness of our SP-PNR method. User U13234 demonstrated a strong preference for news articles in the “lifestyle” category, with their clicking behavior highly concentrated on this category. In our experiments, the prediction Acc for this user reached an impressive 96.7%, indicating that our SP-PNR method performs exceptionally well for users with focused interests. In contrast, User U25769 exhibited a more diverse interest profile, with clicking behavior spanning over 10 different categories. However, further analysis revealed that the user rarely clicked on news articles from the “auto” category, despite this category frequently appearing in the recommendations. This suggests that the “automation” category does not align with the user’s interests. The SP-PNR method effectively identified both the user’s preferences and the categories they were less inclined to engage with, contributing to more targeted and accurate recommendations. Additionally, we observed more targeted interest patterns. For example, User U2237 showed a strong interest in news related to “basketball-NBA,” but did not engage with news in the “football” category, indicating that some users may only be interested in a specific subcategory within a larger category. In contrast, User U15631 demonstrated interest in “lifestyle” news, along with a notable interest in “movies,” “music,” and “travel” news, highlighting that this user enjoys a broad range of topics related to leisure and lifestyle. The SP-PNR method can effectively identify these varying interest patterns, whether they are highly concentrated or span multiple categories, providing more precise and personalized recommendations.
Our prompt-tuning templates demonstrated strong robustness by effectively capturing the multidimensional semantic information in news articles. For users with concentrated interests, the templates achieved high prediction Acc. For users with diverse interests, the templates still succeeded in identifying their primary preferences, showcasing adaptability across different user profiles. This robustness ensures that the SP-PNR method performs reliably across varying types of user behavior. However, as more semantic information is integrated, the interests of some users may become less distinct, indicating that the templates still have limitations in fully capturing complex user preferences.
Overall, the SP-PNR method, supported by a robust template design, exhibits strong flexibility and adaptability in capturing user interests, making it a reliable foundation for personalized recommendations. In future work, we aim to further enhance the coverage and flexibility of the templates to better address the needs of users with complex or highly diverse interests.
Parameter Sensitivity
The parameters in the experiments can significantly impact the experimental results, including the learning rate and batch size. In this section, we conducted parameter sensitivity experiments on the MINDsmall-488 News dataset. The results are presented in Figures 2 and 3, respectively. Notably, when we change one parameter, the rest others are fixed in the experiments.
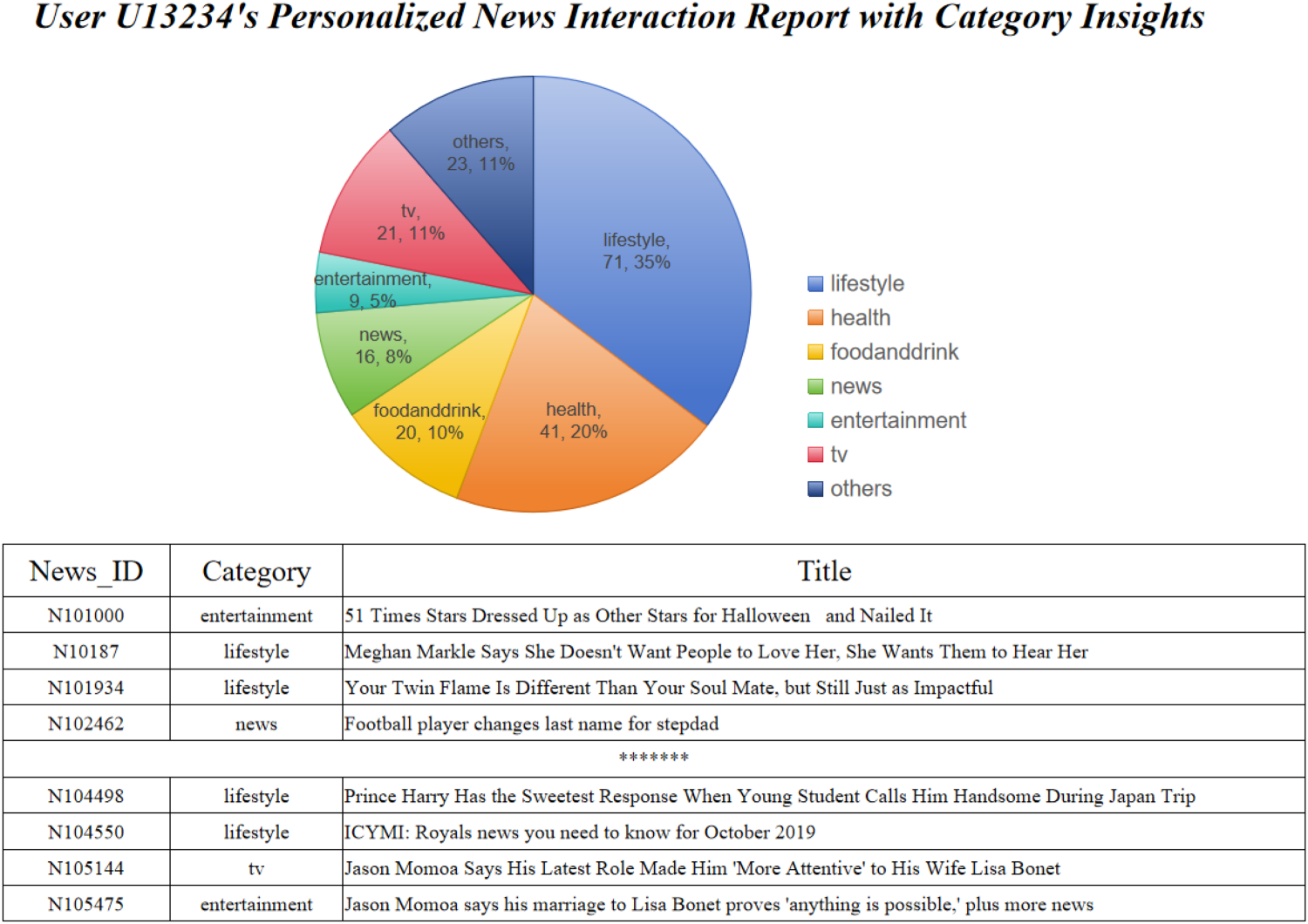
User U13234’s Personalized News Interaction Report With Category Insights.
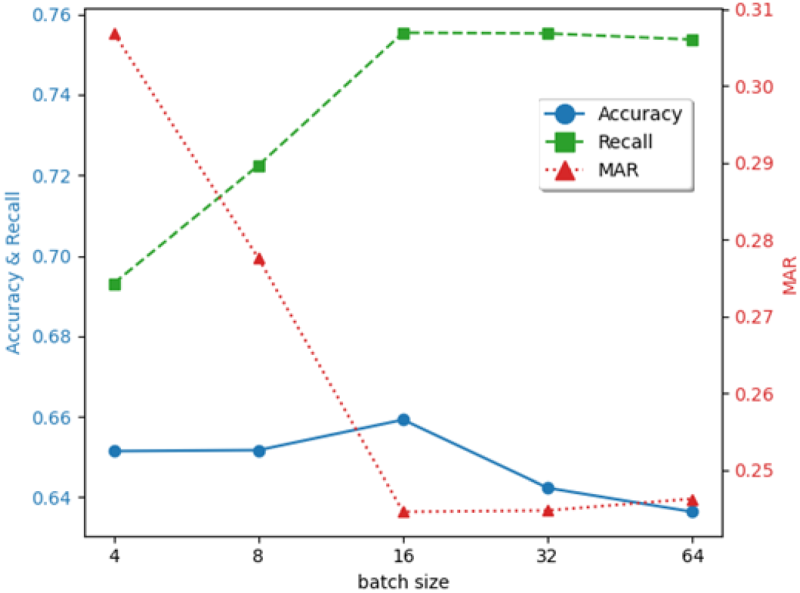
The Effect of Batch Size on Experimental Results.
Batch size is a pivotal hyperparameter in news recommendation systems, governing the quantity of samples processed per training iteration. Its selection critically influences both the efficiency and effectiveness of model training, with the specific impacts delineated in Figure 2.
The experimental results show that the model performance is optimal when the batch size is set to 16, with the Acc and Rec reaching the peaks of 0.65922 and 0.75542, respectively, while the MAR is as low as 0.24458, indicating the comprehensiveness and Acc of the model in capturing the information in this configuration. The small-scale batches
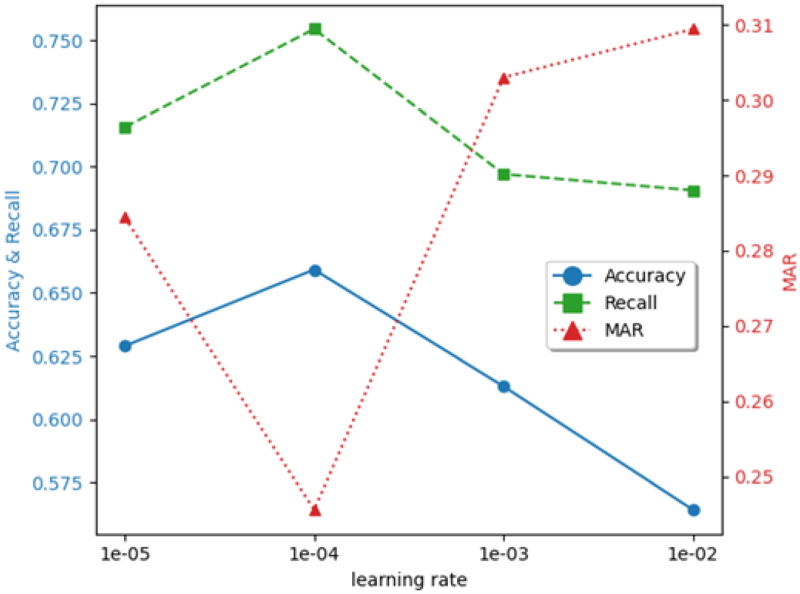
The Effect of Learning Rate on Experimental Results.
From the results of the experiments, it can be found that when the learning rate is
Conclusion
In this paper, we propose an SP-PNR. It improves previous methods by taking the personalized characteristics of items into template construction in a prompt and achieves competitive performance compared to hand-crafted through soft prompt-tuning. All the side information of news, including the summaries and subcategories, is introduced to learn the characteristics of news, and three strategies are designed to capture different characteristics of expanded words for verbalizer optimization. Finally, extensive experiments show the effectiveness of our presented method.
In the future, we will extend our research work in the following two directions. Firstly, we aim to incorporate more auxiliary information from external knowledge for personalized news recommendations. Secondly, we plan to explore better methods for automatic template construction.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Graduate Student Scientific Research Innovation Projects in Jiangsu Province of China (SJCX23_1896), the National Natural Science Foundation of China under grants (62076217), the Key Research and Development Program of Jiangsu Province in China (BE2023315), and the Open Project of Anhui Provincial Key Laboratory for Intelligent Manufacturing of Construction Machinery (IMCM-2023-01).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.