
Abstract
Neural network-based treatment effect estimation algorithms are well-known in the causal inference community. Many works propose designs and architectures and report performance metrics over benchmarking data sets, in a machine learning manner. Nevertheless, most authors focus solely on binary treatment scenarios. This is a limitation, as many real-world scenarios have a multivalued treatment nature (for instance, multiarmed clinical trials, or health technology assessment processes). In this work, a novel approach is presented, where a top-performing, neural network-based algorithm for binary treatment effect estimation is generalized to a multivalued treatment setting. This approach yields an estimator with desirable asymptotic properties that delivers very good results in a wide range of experiments. To the best of the authors’ knowledge, this work is opening ground for the benchmarking of neural network-based algorithms for multivalued treatment effect estimation.
Introduction
Machine learning and neural networks are becoming a common choice for performing causal analysis tasks (causal inference and causal discovery) due to their power and flexibility for modelling complex functions, especially when dimensionality of the data is high (Hernán & Robins, 2020). Several authors have investigated specific network architectures, loss functions, regularization methods, etc., to tackle the task of inferring causal quantities using neural networks (Johansson et al., 2018; Nair et al., 2022; Yoon et al., 2018). The performance of those algorithms is being benchmarked in the scientific literature, by using specific data sets and common metrics to achieve comparable results (Lin et al., n.d; Shimoni et al., 2018). These advancements are happening almost exclusively in binary treatment scenarios. Nevertheless, often real-life applications have multiple-valued treatments, for instance, multiarmed clinical trials, or health technology assessment (Lampe et al., 2009; Li et al., 2021) processes where the health technology or intervention being evaluated can take multiple values (Cattaneo et al., 2013; Li & Li, 2019). This highlights the need to explore neural network-based causal inference methods for multivalued treatments, both at the theoretical and empirical levels. In the present work, a top-performance, neural network-based, binary average treatment effect (ATE) estimation algorithm named Dragonnet (Kiriakidou & Diou, 2022; Shi et al., 2019) is selected, and its generalizability to a multivalued treatment setting is tested. To the best of the authors’ knowledge, Velasco et al. (2022) is one of the first attempts to establish a benchmark for this type of algorithm in the aforementioned setting. Other works found in the literature focus on specific data morphologies (Kaddour et al., 2021), do not use neural networks (Künzel et al., 2019), or can be considered meta-methods (Schwab et al., 2019). In the remainder of this text, the problem statement, the network architecture, and the associated mathematical formulations, a framework for experiments, the results obtained in different scenarios, and a critical evaluation of those results are presented. The code of the algorithm and the experiments can be found in https://github.com/BorjaGIH/Hydranet.
Problem Statement
Let the treatment of interest be a discrete random variable
Let the conditional outcome be defined as the expectation of the outcome given the treatment and the covariates,
In a binary treatment setting, under the identifiability conditions, the ATE is one of the most common causal quantities of interest, and it is defined as
The subject of interest in this paper is the estimation of the vector of ATEs
From Dragonnet to Hydranet
Dragonnet is a high-capacity, end-to-end neural network architecture for estimating binary treatment effects (Shi et al., 2019). In this section, the variation of the architecture, mathematical formulations, and proofs for adapting Dragonnet to a multivalued treatment setting are presented. This adaptation is called Hydranet.
Architecture
The architecture of Hydranet can be seen in Figure 1. It consists of two parts: the representation part, formed by the input layer and two hidden layers, and the heads, formed by
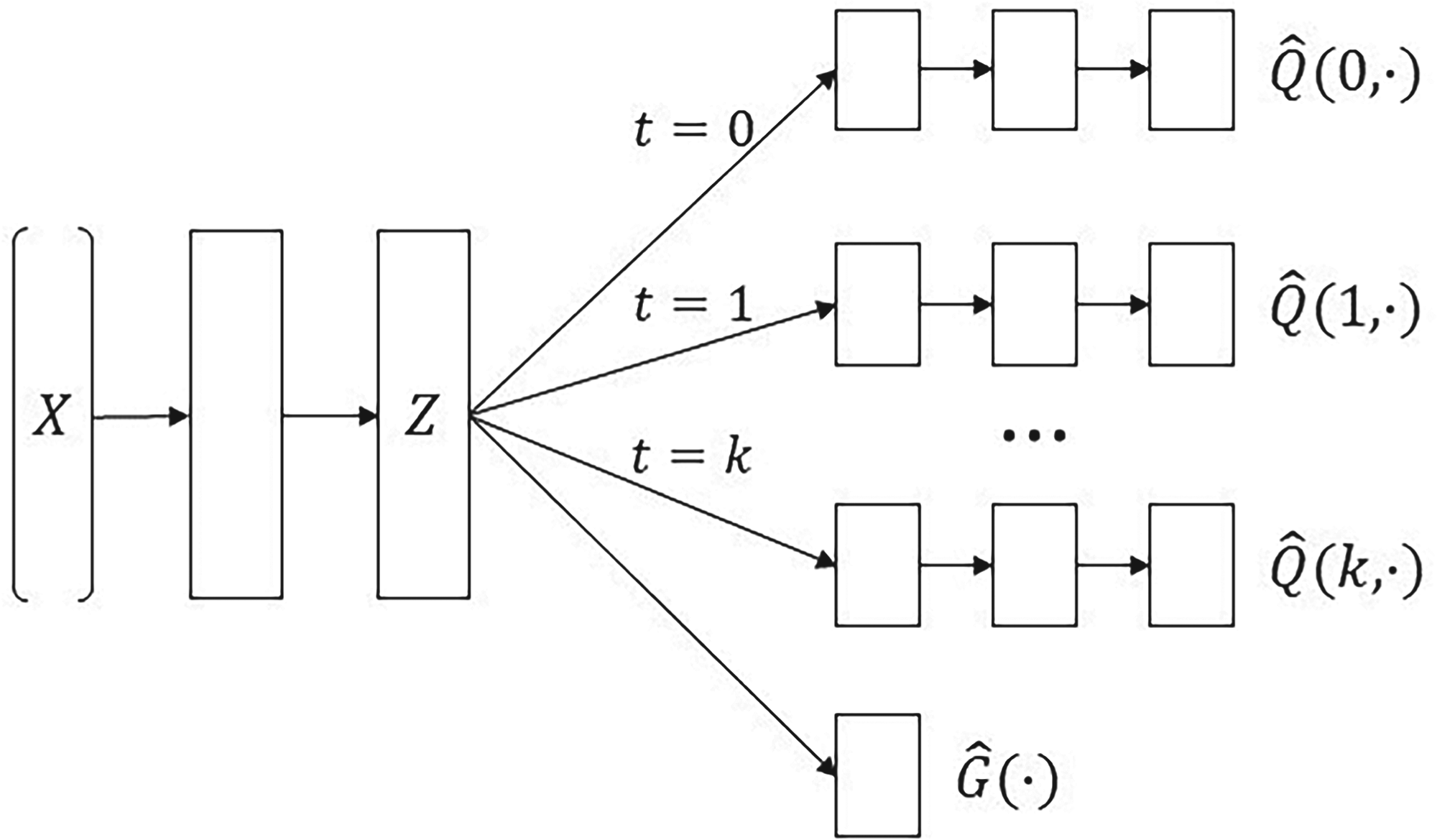
Hydranet Architecture, where
The baseline objective function has the shape


Now, following the reasoning in Shi et al. (2019), we present targeted regularization. Targeted regularization is a modification of the objective function, obtained with the introduction of an extra parameter,
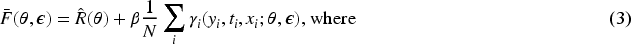

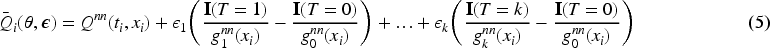
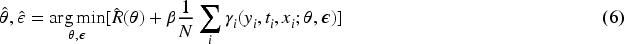
What is the rationale behind this modification of the objective function? It lies in targeted maximum likelihood estimation (TMLE) (Lendle, 2015) and in the semiparametric estimation theory (SET; Kennedy, 2016). On the one hand, SET provides us with mathematical conditions and guarantees that if those are fulfilled, the estimator
First, note that the aforementioned conditions are simply the nonparametric estimating equations, defined as
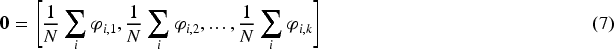
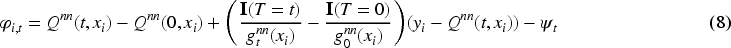
Then, recall that what is desired is that the minimization of the modified objective function (3) ensures the fulfillment of the nonparametric estimation equations (7). This is mathematically expressed as
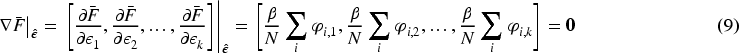
Hydranet has been tested in two data sets, a fully synthetic one and a semisynthetic one. In the remainder of the text, they will be referred to as the synthetic dataset and the IHDP dataset, respectively. In order to generate these datasets, algorithms mimicking different data-generating processes (DGPs) have been designed and implemented. For the synthetic data set, the covariates, treatments, and outcomes have been synthetically generated, taking inspiration from Kaddour et al. (2021). For the IHDP data set, the covariates are taken from a study with real participants, while the treatments and outcomes are synthetically generated. Those real covariates were collected for a randomized controlled trial carried out in 1985 (Gross, 1993; Multisite, 1990), and are routinely used for benchmarking causal inference algorithms, usually following the configuration in Dorie et al. (2018). A similar strategy has been followed in the current work, but adapting the DGP to the present needs (a multivalued treatment scenario). With both data sets, the number of treatments has been set to 5. In the remainder of this section, a more detailed explanation of the DGP of each dataset and its output is provided.
Synthetic Dataset DGP
For generating fully synthetic data, DGPs with tunable parameters of bias size
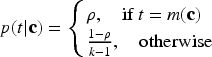
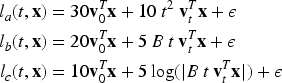
Several data sets have been generated under varying values of the four parameters of interest, bias size
IHDP Dataset DGP
For generating the IHDP dataset, a similar strategy has been followed, but fixing
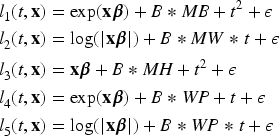
Metrics
For performance benchmarking purposes, the sum of errors of the vector of ATEs has been employed. This is computed as the sum of the absolute values of the differences of all estimated ATE components with respect to their true values,
Experiments and Results
In the case of binary treatment settings, there are de facto benchmarking data sets and metrics, that is, data sets and metrics that are widely used in the literature and thus serve for algorithmic performance comparison purposes. The IHDP data set and the metrics presented in Dorie et al. (2018) are an example of this. This is not the case in multivalued treatment settings, where comparators are scarce. Nevertheless, algorithms that can be considered comparable to Hydranet have been developed and implemented to benchmark its performance. Thus, in every experiment, the results of the following algorithms are included: (1)
Synthetic Data Experiments
Figure 2 and Table 1 show the error of the different algorithms for increasing values of the bias size. As it should be expected, the error of the naive algorithm increases with the bias size, and the out-sample error is bigger than the in-sample error. The comparators also suffer from bigger errors with the increase of the bias. Hydranet outperforms all the comparators, and is very robust in front of the bias increase. It also shows a similar performance in-sample and out-sample, both for the baseline algorithm and for the targeted regularization version.
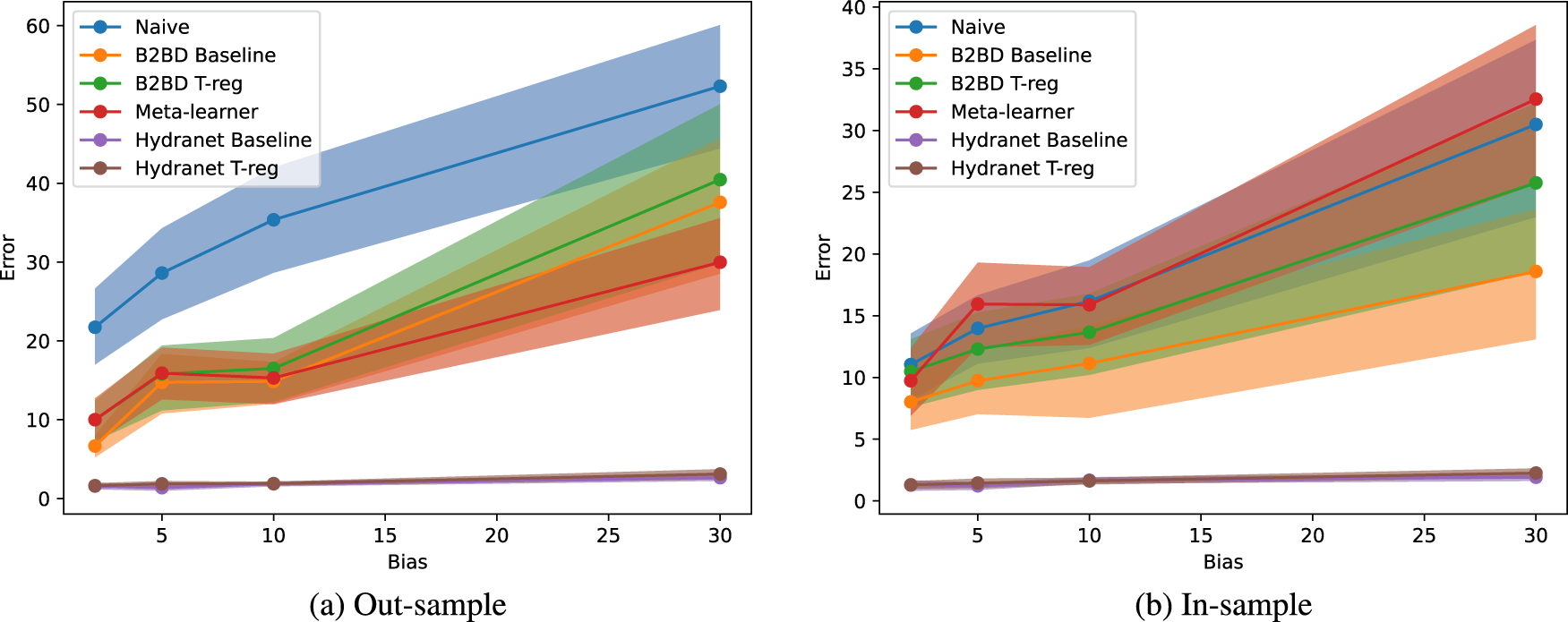
Errors w.r.t. Bias Size. (a) Out-Sample and (b) In-Sample.
Errors of the Different Algorithms w.r.t. Bias Size.
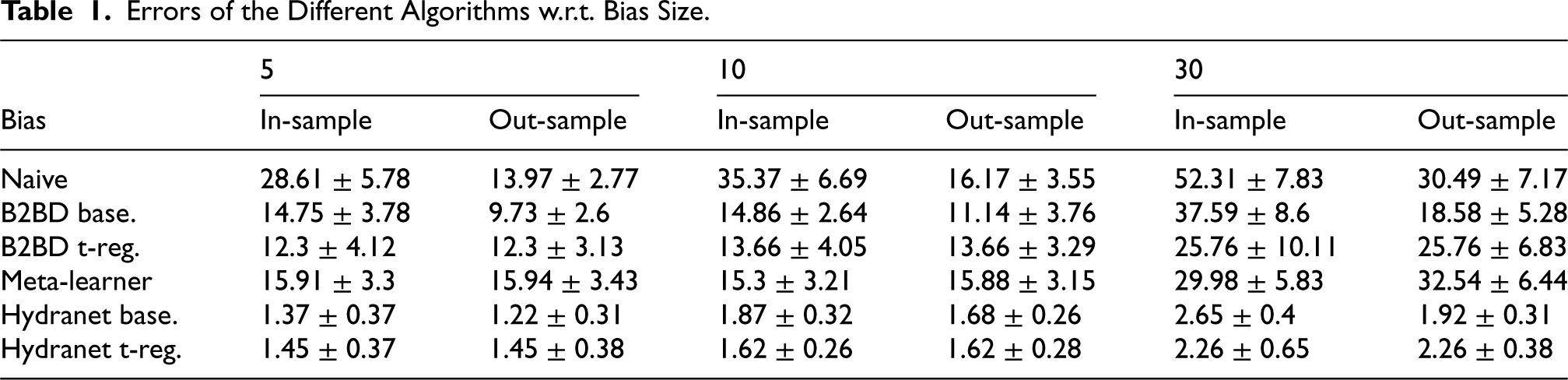
Figure 3 and Table 2 show the error of the different algorithms for increasing values of the degree of positivity
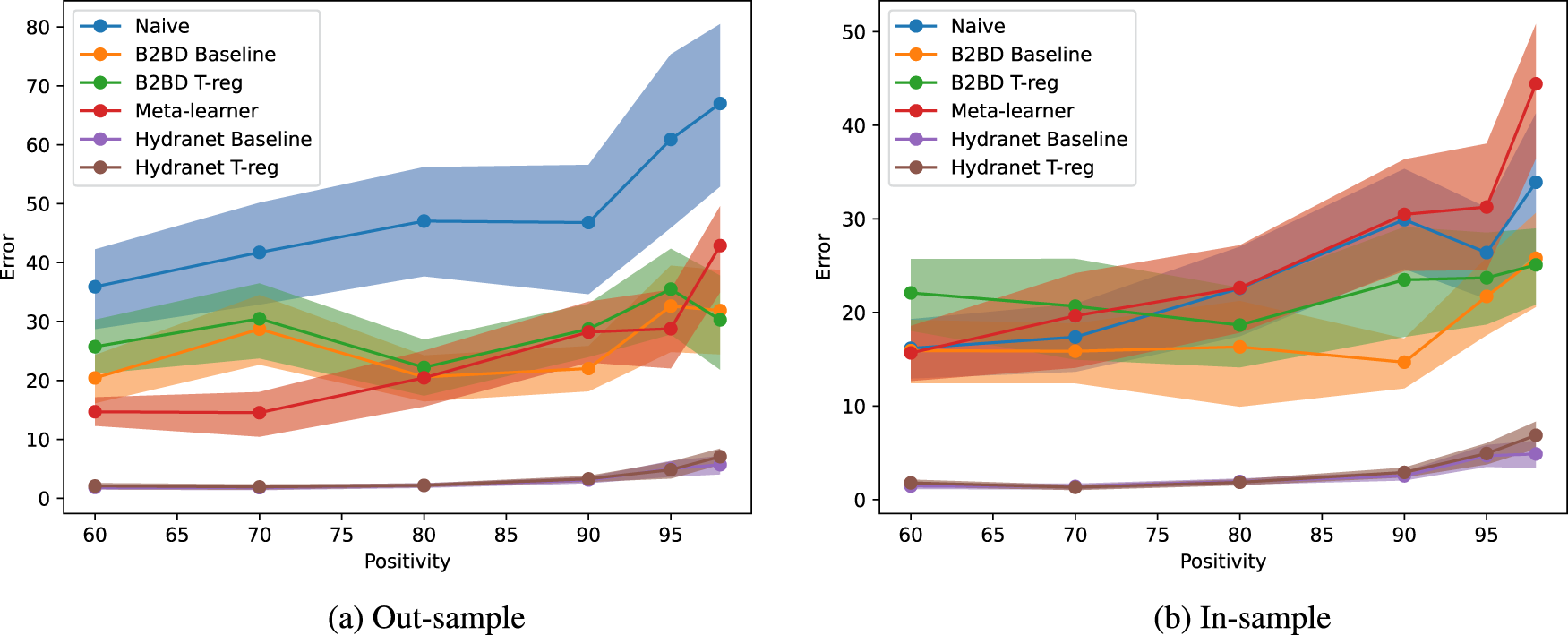
Errors w.r.t. Degree of Positivity. (a) Out-Sample and (b) In-Sample.
Errors of the Different Algorithms w.r.t. Degree of Positivity.
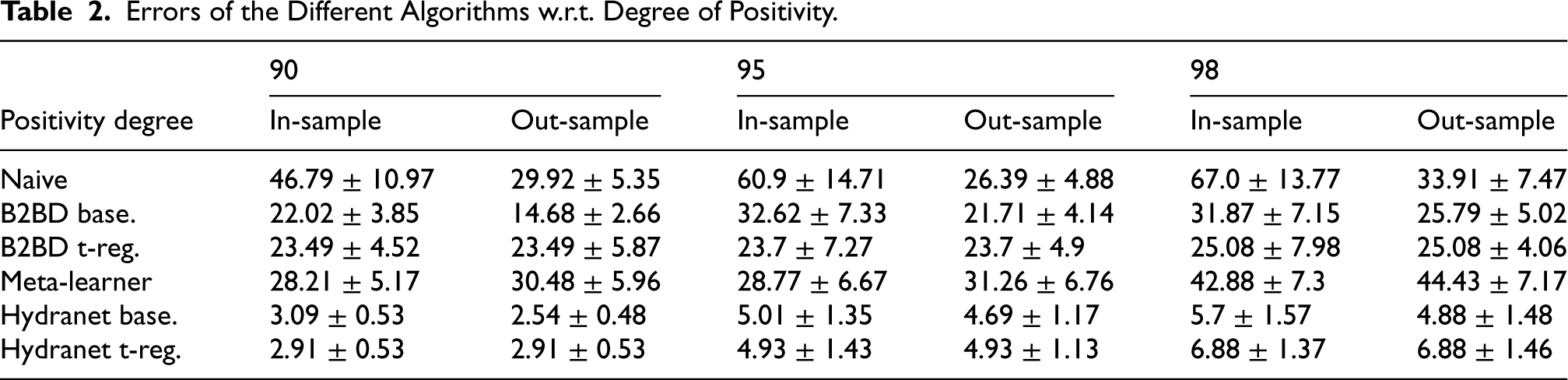
Errors w.r.t. Dataset Size. (a) In-Sample and (b) Out-Sample.
Figure 4 and Table 3 show the performance of the algorithms for varying dataset sizes. As expected, all algorithms reduce their error with bigger data sets, but Hydranet with targeted regularization outperforms them all, and shows a smaller error even for small dataset sizes, proving its efficiency. Recall that data efficiency was one of the desired properties ensured for our estimator, thanks to targeted regularization. It must be highlighted that in this experiment, the estimations of the baseline Hydranet have been plugged into a naive doubly-robust estimator, the augmented inverse probability of treatment weighted (A-IPTW) estimator. The resulting estimations show big error values, proving the utility of Hydranet with targeted regularization for achieving double robustness (which was demonstrated in Section 3.2).
Errors of the Different Algorithms w.r.t. Dataset Size.
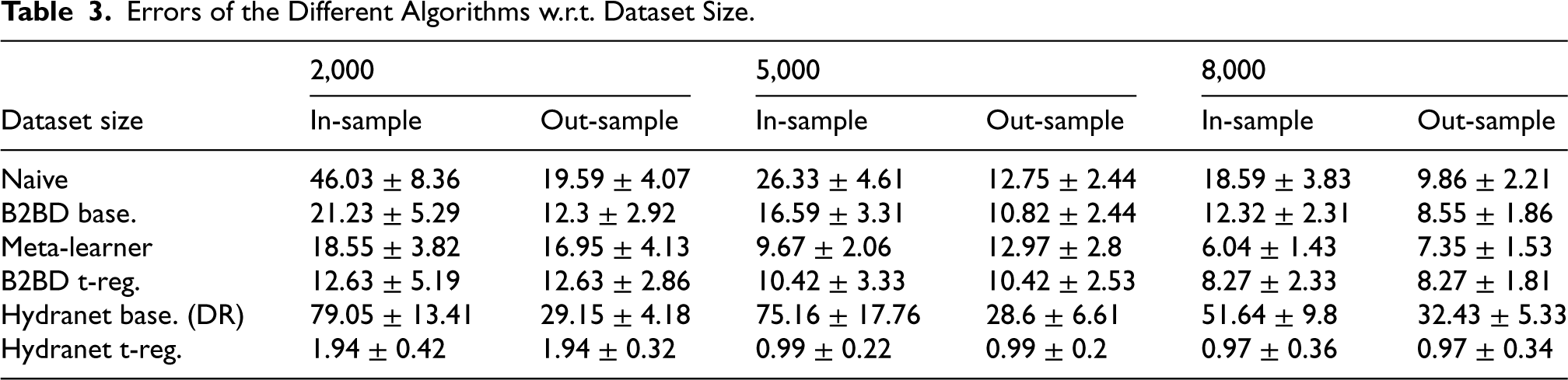
Table 4 shows the error of the different algorithms with the IHDP dataset. Similarly as with synthetic data, Hydranet (both baseline and targeted regularization) outperforms the comparators. The targeted regularization algorithm has a slightly smaller error than the baseline algorithm. These results prove the efficacy of Hydranet with semisynthetic data, showing its potential suitability for real-world scenarios.
Performance With IHDP Dataset.
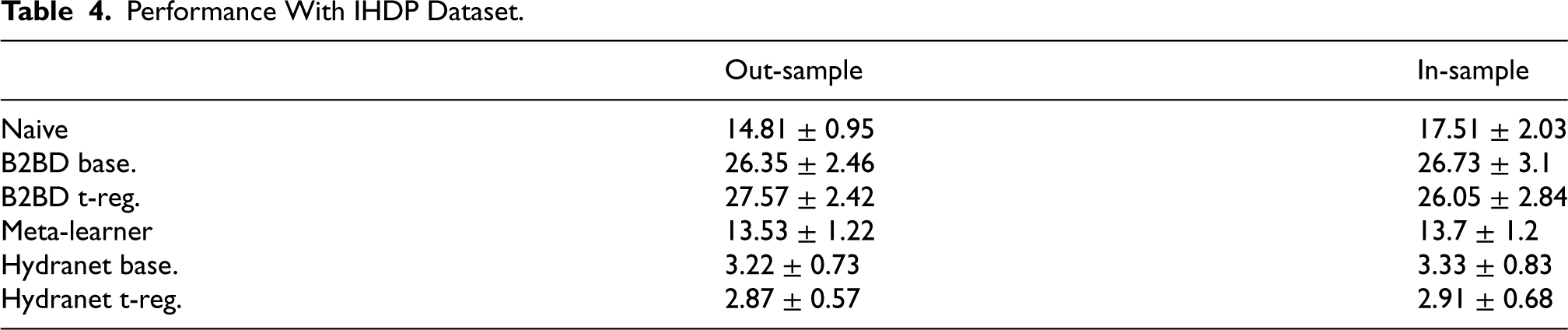
Performance With IHDP Dataset.
In this work, a top-performing, neural network-based algorithm for ATE estimation has been generalized from a binary treatment setting to a five-valued treatment setting. Synthetic and semi-synthetic DGPs for algorithmic benchmarking purposes in multivalued settings have been developed and implemented, and comparator algorithms have been designed for evaluating the performance of Hydranet. It is shown that Hydranet performs well under different bias sizes and degrees of positivity, and both theoretical and empirical evidence for the motivation of developing targeted regularization-equipped Hydranet is provided: the data efficiency of the algorithm is shown in the varying data set size scenario and when double robustness is attempted through a naive approach such as the plug-in A-IPTW estimator. In addition, the good performance of the algorithm with semi-synthetic data is also demonstrated, with the IHDP dataset. This suggests its potential value for real-world datasets. Note also that the property of double robustness means twice as many chances of avoiding model misspecification (with respect to a simple estimator), which can be especially relevant in real-world scenarios where assumptions such as the “no hidden confounder” can be harder to make.
The direct generalizability of neural network-based algorithms for ATE estimation from binary settings to
The main limitations of this work are twofold: on the one hand, only a five-valued treatment scenario has been tested. It is a line of future work to adapt the algorithm and perform experiments for
Supplemental Material
sj-pdf-1-eai-10.1177_30504554251385053 - Supplemental material for Hydranet: A Neural Network for the Estimation of Multi-valued Treatment Effects
Supplemental material, sj-pdf-1-eai-10.1177_30504554251385053 for Hydranet: A Neural Network for the Estimation of Multi-valued Treatment Effects by Borja Velasco-Regulez and Jesus Cerquides in The European Journal on Artificial Intelligence
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Doctorat Industrial funded by Generalitat de Catalunya (DI-2020-18) and by project CI-SUSTAIN funded by the Spanish Ministry of Science and Innovation (PID2019-104156GB-I00). Borja Velasco-Regúlez was a PhD Student of the doctoral program in Computer Science at the Universitat Autonoma de Barcelona.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.