
Abstract
Word sense disambiguation (WSD) remains a critical challenge in natural language processing (NLP), requiring precise identification of context-dependent word meanings. This article proposes a novel global optimization framework for WSD by reformulating it as a combinatorial optimization problem. We introduce a discrete variant of the rat swarm optimizer (RSO), a metaheuristic inspired by rat foraging behavior, to efficiently select optimal sense combinations across sentences. Unlike local disambiguation methods, our approach leverages phrase-level embeddings and WordNet gloss definitions within a unified semantic fitness function, enabling robust global sense selection. Experiments on SensEval and SemEval benchmarks demonstrate state-of-the-art performance, achieving accuracy improvements of 76.32% (SensEval2), 71.80% (SensEval3), 58.30% (SemEval2007), 77.17% (SemEval2013), and 74.40% (SemEval2015) surpassing previous methods. The effectiveness of the model shows its benefits for downstream NLP tasks such as machine translation, information retrieval, and document indexing. Future work will focus on hyperparameter optimization and multilingual adaptation to enhance scalability for low-resource languages.
Keywords
Introduction
Word sense disambiguation (WSD) is one of the open problems in computational linguistics. It attempts to determine the intended meaning of a word according to its context (Ransing & Gulati, 2022). WSD typically involves two major processes: identifying ambiguous words and contextually labeling every word by its correct meaning with high precision. The word
It is crucial for real-world natural language processing (NLP) applications, which impacts accuracy and user experience. Consider machine translation (Nguyen et al., 2018), where
WSD approaches can be categorized into two main types: knowledge-based methods that utilize external resources and machine learning-based methods, which include techniques such as artificial neural networks and swarm intelligence algorithms (Bevilacqua et al., 2021).
Despite significant advancements in WSD research, various existing methods, such as supervised, unsupervised, and knowledge-based, still encounter considerable limitations. Supervised WSD techniques are generally accurate but rely heavily on large annotated datasets, which are both resource-intensive and specific to individual languages, thus limiting their scalability. On the other hand, unsupervised methods address this dependency but often result in lower precision and face challenges with ambiguous clustering, particularly in complex linguistic contexts. Knowledge-based methods, which depend on lexical databases like WordNet, may struggle to adapt to domain-specific or under-resourced scenarios where such resources are incomplete (Ransing & Gulati, 2022).
Word embeddings, distributed representations of words as real-valued vectors, capture semantic and syntactic relationships from unannotated corpora, proving invaluable in various NLP applications like word similarity and machine translation (Pham & Le, 2018). Recent advances in WSD have also incorporated word embeddings, leveraging their ability to provide context-aware representations. Swarm optimization algorithms, which are inspired by natural social behaviors (Esmin et al., 2015; Monga et al., 2022), provide efficient solutions to complex optimization problems by balancing exploration and exploitation strategies (Gad, 2022; Yang & Karamanoglu, 2020). Although these algorithms have been successful in various domains (Hussien et al., 2020), their application in WSD, especially alongside modern NLP techniques, has not been thoroughly explored.
This paper introduces DRSO-WSD, a novel variant of discrete rat swarm optimization (RSO) (Dhiman et al., 2021) aimed at addressing the WSD challenge. Unlike traditional WSD methods that rely heavily on extensive labeled data or predefined lexical resources, our approach determines the semantic similarity between the context of an ambiguous word and its candidate senses using two embedding strategies: Doc2Vec (Lau & Baldwin, 2016), which captures the overall semantics of a document, and BERT (Devlin et al., 2018), which offers contextualized word-level representations. These similarity scores serve as fitness values in the DRSO algorithm, which iteratively searches for the optimal sense assignment by balancing exploration and exploitation.
We demonstrate the effectiveness of DRSO-WSD through comprehensive evaluations on the SensEval2 (Edmonds & Cotton, 2001), SensEval3 (Mihalcea et al., 2004), SemEval2007 (Navigli et al., 2007), SemEval2013 (Navigli et al., 2013), and SemEval2015 (Moro & Navigli, 2015) benchmarks, comparing our results against state-of-the-art methods.
The following research questions guide this study: RQ1: Can integrating Doc2Vec and BERT embeddings with a swarm-based optimizer improve WSD accuracy over traditional methods? RQ2: How effective is a discrete form of the rat swarm optimization algorithm in navigating the WSD search space? RQ3: Does the proposed approach generalize well across standard WSD benchmarks?
We hypothesize that combining semantic similarity measures from modern embedding models with a discrete swarm optimization strategy will outperform existing WSD methods in accuracy and robustness across diverse benchmark datasets. The DRSO-WSD method shows strong potential for real-world NLP applications by improving WSD. Machine translation improves translation quality by selecting the correct word sense based on context. Information retrieval allows for more relevant document retrieval, boosting precision and user satisfaction. The method also applies in question answering, sentiment analysis, and text summarization, highlighting its versatility for different linguistic contexts and multilingual applications. The rest of the article is structured as follows: Section 2 addresses related work in WSD. Section 3 introduces our proposed hybrid method. Section 4 presents and analyzes the experimental results. Finally, Section 5 concludes the study and suggests directions for future research.
Related Works
This section focuses on previous works on two main tasks: the WSD approach, which uses machine learning techniques or knowledge-based methods for tagging the corpora explicitly, and the word embedding approach, which uses linguistic resources, such as WordNet, to represent meanings. Many researchers have addressed the WSD studies, including supervised, semi-supervised, and unsupervised approaches. Supervised methods use sense-annotated datasets to identify the appropriate meanings of the words. Training and testing are the most critical phases in supervised approaches. The training phase requires annotated data to create classifiers based on machine learning algorithms. During the evaluation stage, approaches attempt to determine the appropriate senses based on context. In the literature, there are many supervised methods available. Probability methods use the Bayes theorem to predict the meanings of ambiguous words. Several authors in different languages have adopted this model, like Wang and Hirst (2014) and Walia et al. (2018). The decision list technique is a supervised method of classifying test instances using discriminative rules. The training sets extract a feature set, generating type rules (feature value, sense, and score). The recognition of rules based on their descending score determines the decision list. Similarity-based methods disambiguate the words by comparing the features of raw sample data with those of trained data and then selecting the most similar pattern. The results of supervised methods are always better than those of other approaches (Ransing & Gulati, 2022). While supervised models have their strengths, they also face limitations. They rely on extensive training data for each ambiguous word, necessitating manual sense label annotation. Unfortunately, manual sense annotation is impractical for large-scale projects due to the task’s difficulty, expense, and time-consuming nature. As a result, supervised models often need help with disambiguation, and the lack of high-quality training data hinders their performance (Bevilacqua et al., 2021). Unsupervised methods for WSD acquire knowledge from unannotated data by assuming similarity in word clusters based on the idea that ambiguous words share similar contexts (Bevilacqua et al., 2021). For this reason, they use some contextual similarity metrics. The main task of unsupervised methods is to identify sense classes to avoid knowledge acquisition bottlenecks caused by limited manually annotated linguistic resources (Ransing & Gulati, 2022). Recently, swarm intelligence techniques have successfully solved unsupervised WSD, such as the work of Farahani et al. (2020). Bakhouche et al. (2015) applied the ant colony algorithm to solve the WSD problem, relying on gloss overlap similarity to maximize the semantic relatedness between words in sentences. Vij and Jain used the genetic algorithm (Vij et al., 2020) to attain the same objective. Several works have used the semantic similarity techniques adopted by Zhang et al. (2008) in the maximization task of the genetic algorithm. To address this problem, Alsaeedan et al. (2017) present a hybrid approach using ant colony optimization and genetic algorithms. The authors used an untagged corpus to identify semantic classes of ambiguous words. Bhatia et al. (2022) used the dynamic configuration window function to perform Hindi WSD using a genetic algorithm. The comparison results show that this approach outperforms several other WSD methods. Nodehi and Charkari (2022) created the hybrid meta-heuristic algorithm. They combine the meta-heuristic method with the neural surrogate function to help researchers find the best meaning in a given situation. Researchers used a neural network as an objective function. Rajini and Vasuki (2021) employed techniques, such as the Bees’ algorithm, the Optimization Firefly, and the Cuckoo algorithm, to label samples and numerous words within the corpus. These methods were evaluated using SemEval 2016 task 11. According to the experiment results, optimizing fireflies performs better than any other algorithm. Ajeena Beegom and Chinmayan (2020) proposed another approach for solving WSD problems involving combinatorial optimization. In terms of performance, the proposed algorithm outperforms others due to its powerful features. Using a combinatorial optimization approach, Abdelaali et al. (2022) disambiguated the ambiguous words in specific contexts. They achieved this goal by implementing the second version of Crow search optimization. Using specific benchmark datasets, they compared the proposed method to other methods. The results demonstrate that this approach performs well. The swarm-based optimization algorithms attain high precision in WSD in many languages (Abualigah et al., 2021). They proposed a discrete version of RSO, a metaheuristic, for the WSD problem because it effectively solves various optimization problems (Dhiman et al., 2021) and yields superior results. However, sense embedding is an alternative to traditional word vector models, such as word2vec (Pennington et al., 2014) and GloVe (Mikolov et al., 2013), which represent monosemous words well but fail when it comes to ambiguous words. Sense embeddings represent each sense of polysemous words with a separate vector. A sense inventory can be induced from unlabeled data (Iacobacci & Navigli, 2019) or linked to a particular inventory (Iacobacci et al., 2015). LSTMEmbed uses pre-trained embeddings to learn BabelNet-linked sense embeddings (Navigli & Ponzetto, 2012). Despite primary testing in English, this approach could apply to other BabelNet languages. A GlossBERT model (Huang et al., 2019) implements a system WSD that improves significantly by leveraging gloss information. According to Wang et al. (2019), the sentence-pair classification technique is helpful in this model. The system uses context and gloss as inputs. The system concatenates and categorizes context-gloss pairs using a specific token. Batanović and Nikolić (2017) used word embeddings from a large unlabeled corpus as classification features. They looked at how lemmatization and stemming methods affected the performance of sentiment analysis classifiers trained on the Serbian Movie Review Dataset for sentiment analysis. Batanović et al. (2018) present a novel supervised bag-of-words model for semantic textual similarity (STS) tasks. They’re integrating part-of-speech and term frequency weightings. The authors introduce a new STS dataset for evaluation: the Serbian Semantic Textual Similarity News Corpus (STS.news.sr). This corpus comprises 1192 news-based sentence pairs annotated with fine-grained similarity scores comparable to existing English and other primary language datasets.
Proposed Approach Description
In this section, we present our approach in further detail. It includes two main parts. The first part explains how to use pre-trained word embedding models to represent target words’ contexts and sense definitions. The second part introduces the DRSO algorithm and demonstrates its application to WSD. Figure 1 illustrates an overview of the proposed approach.
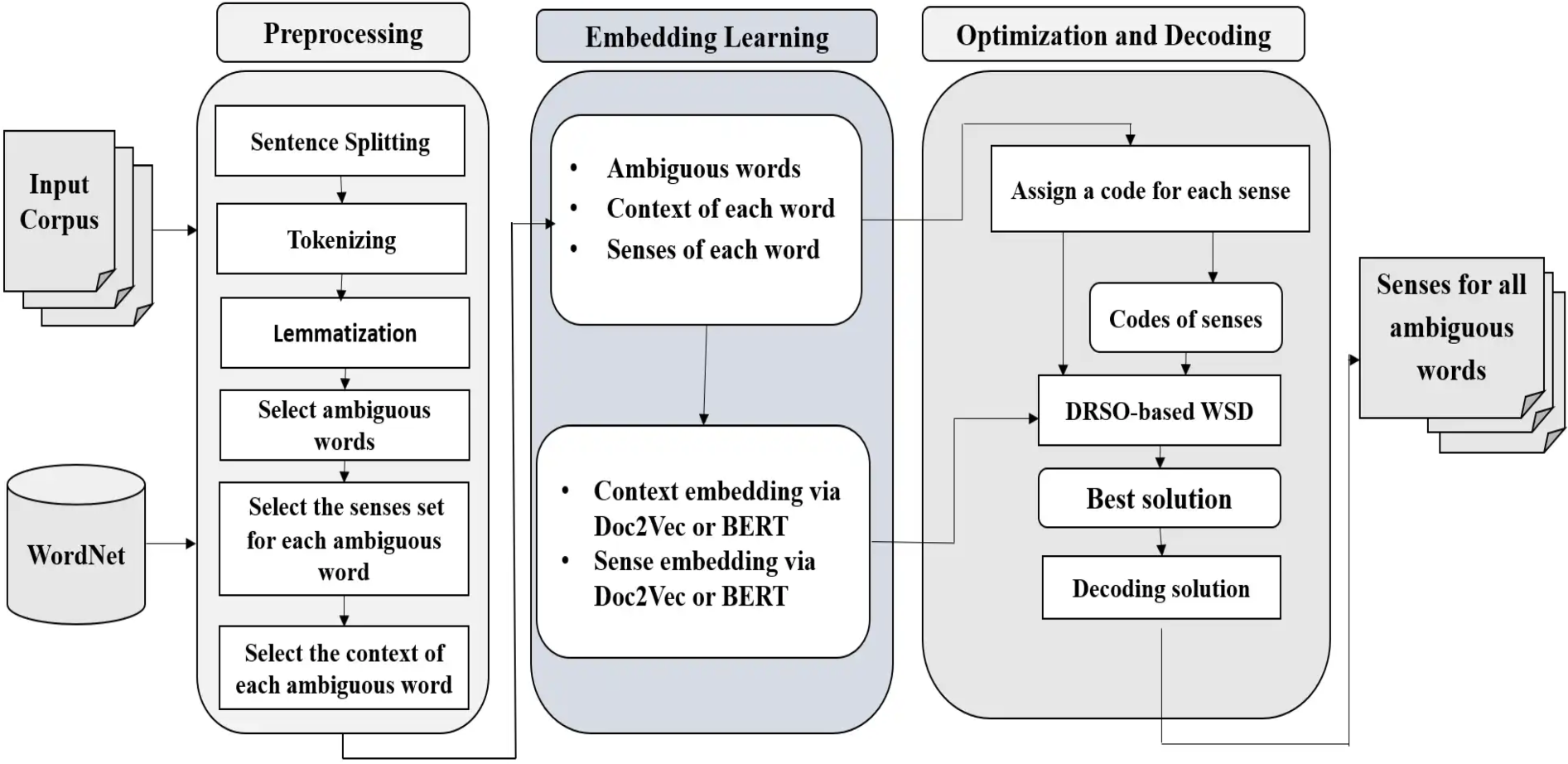
An overview of the proposed DRSO-WSD approach.
The experimental methodology is based on swarm intelligence and distributional semantics. It utilizes the RSO algorithm to navigate complex search spaces in WSD, focusing on balancing exploration and exploitation to optimize sense assignments. The choice of RSO is theoretically motivated by its ability to efficiently search discrete solution spaces, aligning well to find the most semantically coherent global sense assignments. This theoretical foundation informs the experimental design and influences the selection and evaluation of the candidate sense. The fitness function is derived from distributional semantics, employing word embeddings such as Doc2Vec and BERT to compute the cosine similarity between ambiguous word contexts and their candidate senses. Doc2Vec captures document-level semantics, while BERT offers fine-grained contextualized representations, ensuring a nuanced understanding of the disambiguation context. The DRSO algorithm extends the RSO approach by incorporating discrete representation mechanisms and adaptive control, which enhance semantic coherence during sense assignment. DRSO was selected over alternative metaheuristics such as genetic algorithms (GA) and particle swarm optimization (PSO) due to its superior convergence behavior, robustness in high-dimensional spaces, and discrete solution modeling characteristics, particularly well suited for WSD tasks. This methodology exemplifies a multidisciplinary approach, integrating principles from optimization theory, computational linguistics, and deep learning. This integration enables a more robust and accurate disambiguation process that takes advantage of semantic understanding and efficient search strategies. The evaluation of the DRSO-WSD method is carried out using benchmark datasets, including SensEval2, SensEval3, SemEval2007, SemEval2013, and SemEval2015. Performance is assessed using standard evaluation metrics, including precision, recall, and F1-score.
Preprocessing
The proposed approach begins with a preprocessing phase that prepares the input corpus for disambiguation. The raw texts are first tokenized into individual words using the NLTK (Khemani & Adgaonkar, 2021) and TextBlob (Loria, 2018) libraries. Next, we remove punctuation, numerical tokens, and other non-alphabetic characters. All text is converted to lowercase to maintain consistency. Then stop-word removal is applied to eliminate commonly occurring but semantically weak terms (e.g., ‘‘the,’’ ‘‘and,’’ ‘‘is’’) that do not contribute meaningfully to sense disambiguation. In the case of multilingual or domain-specific corpora, a customized stop-word list was used to improve effectiveness. No stemming or lemmatization was applied, as we rely on contextual embeddings (e.g., BERT) that capture morphological and syntactic nuances directly from the full word form. This preprocessing pipeline ensures that the input to the disambiguation stage is clean and semantically informative, allowing the DRSO algorithm to operate effectively.
Distributed Representation of Context and Synset Gloss
In modern machine learning, a popular technique involves representing words or larger text units (sentences, paragraphs, or documents) as vectors. These vectors capture the text’s essential meaning and structure (semantics and syntax). Here, we use word embedding models to assess the representation of various word meanings and their surrounding context. Our approach uses existing word embedding models, such as Doc2Vec, for each sense in the definition provided by a resource like WordNet. Next, we will briefly explain the specific word embedding model we used to ensure understanding.
Document to Vector (Doc2Vec)
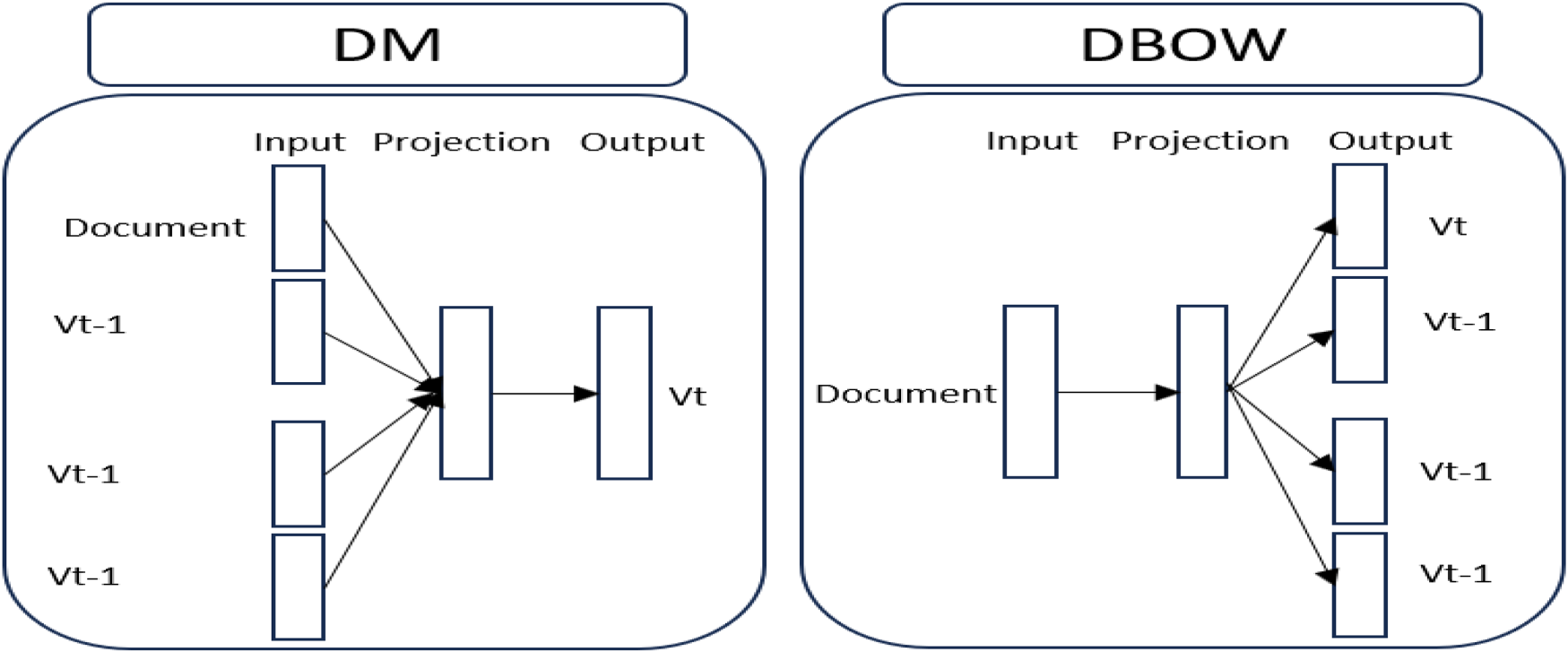
In 2014, Le and Mikolov introduced Doc2Vec, a popular method for learning text embeddings using simple neural networks. It focuses on projecting documents (sentences, paragraphs, or text) into a latent-dimensional space. Doc2Vec is an extension of Word2Vec and can be obtained using two neural network methods: paragraph embedding distributed memory and distributed bag-of-words. The PV-DM model, or ‘‘distributed memory’’ model, predicts a target word using surrounding words as context. On the other hand, the DBOW model, or ’distributed bag of words’, ignores context words and randomly selects words from the output. This approach may need to be more accurate, but it is useful in tasks where context is less relevant, such as language generation.
Bidirectional Encoder Representations From Transformers (BERT)
BERT is a language representation model that considers both the left and right contexts, achieving state-of-the-art results on NLP tasks without extensive architecture modifications. BERT generally offers strong context-based representation, pre-trained knowledge, fine-tuning capabilities, and competitive performance, making it compelling to address WSD challenges. BERT remains an excellent tool for WSD, but several alternatives offer specific advantages based on the task and the limited resources. Table 1 provides a comparative overview.
BERT vs. Alternative for WSD.
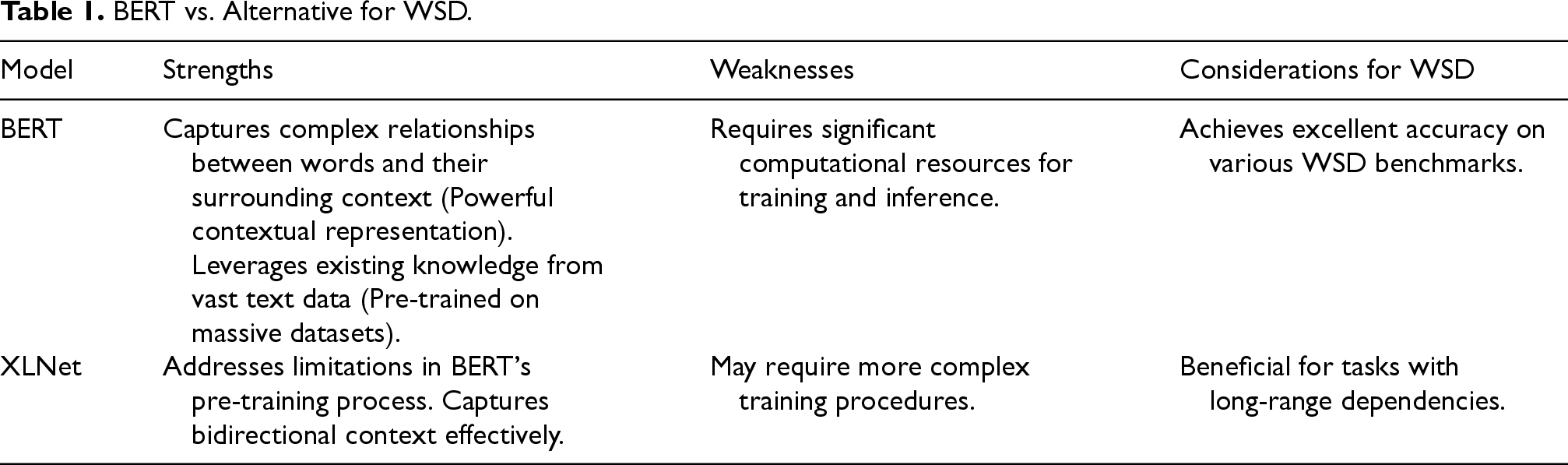
BERT vs. Alternative for WSD.
The proposed method is based on swarm intelligence and semantic similarity. It primarily consists of three key components:
These components work together to formulate WSD as an optimization problem, where the goal is to select the most coherent combination of word senses for a given context. The detailed mechanisms of the algorithm are explained in the following subsections.
Original RSO
The RSO algorithm is a new metaheuristic approach that helps solve global optimization problems. This algorithm takes its inspiration from the social intelligence of rats, known for their aggressive hunting behavior. In particular, rats follow specific behaviors when hunting prey, including chasing and fighting. The RSO algorithm mathematically models this behavior. Each possible solution is considered a rat’s position, and the population’s positions are randomly chosen in the solution space. Rats update their positions during iterations based on chasing and fighting principles. Chasing the prey: The social behavior of rats generally allows them to hunt in groups. They exploit the best rat’s position obtained to update their positions. It can be expressed mathematically, as in Eq. (1).
Fighting with prey: The fighting with prey behavior of the rats is mathematically modeled as in Eq. (3).
Step 1: Initialize the rats population Step 2: Initialize the parameters of RSO: A, C, and R. Step 3: Evaluate the fitness value of each rat’s position. Step 4: Check the best position of the rats. Step 5: Use Eq. (3) to update the rats’ positions. Step 6: Check if any particle exceeds the search space boundaries and adjust. Step 7: Update the



The RSO algorithm has yet to be proposed for solving optimization problems with discrete variables. Thus, this article proposes the implementation of DRSO as a discrete optimization algorithm based on RSO to solve WSD. The following section presents and describes an implementation of DRSO for WSD. The proposed discrete version of continuous RSO is designed to address the WSD problem. Thus, the new version of the RSO algorithm requires two modifications to the original version. The rat’s position is encoded, and the original position’s update formulas are modified to adjust them for discrete values.
Rat’s position encoding for WSD and initialization: In our proposed DRSO for WSD, the positions of the rat are represented using a discrete d-dimensional vector An overview of the document to vector (Doc2Vec). A sample of a rat’s position encoding. To initialize the rat’s population for the disambiguation of a text containing Discrete rat’s position updating: New discrete operations for discrete addition, subtraction, and multiplication ( Illustration of discrete addition operation. Illustration of discrete subtraction operation. Illustration of discrete multiplication operation. The The permutation of bits between Assuming Using the new discrete operators presented above, Eqs. (2) and (4) of the rat’s position updating in the original RSO are modified for DRSO and replaced by Eqs. (5) and (6), respectively.
The current position of the

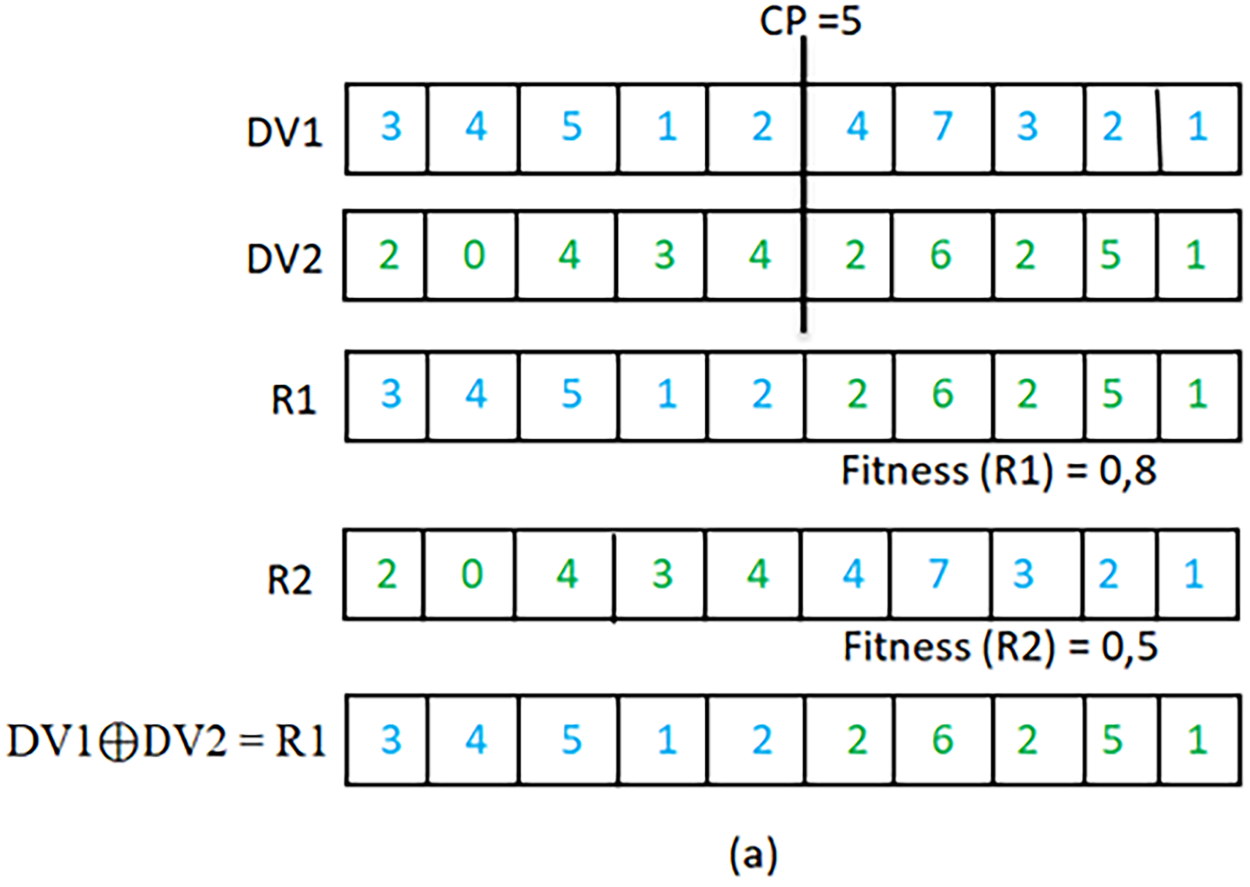
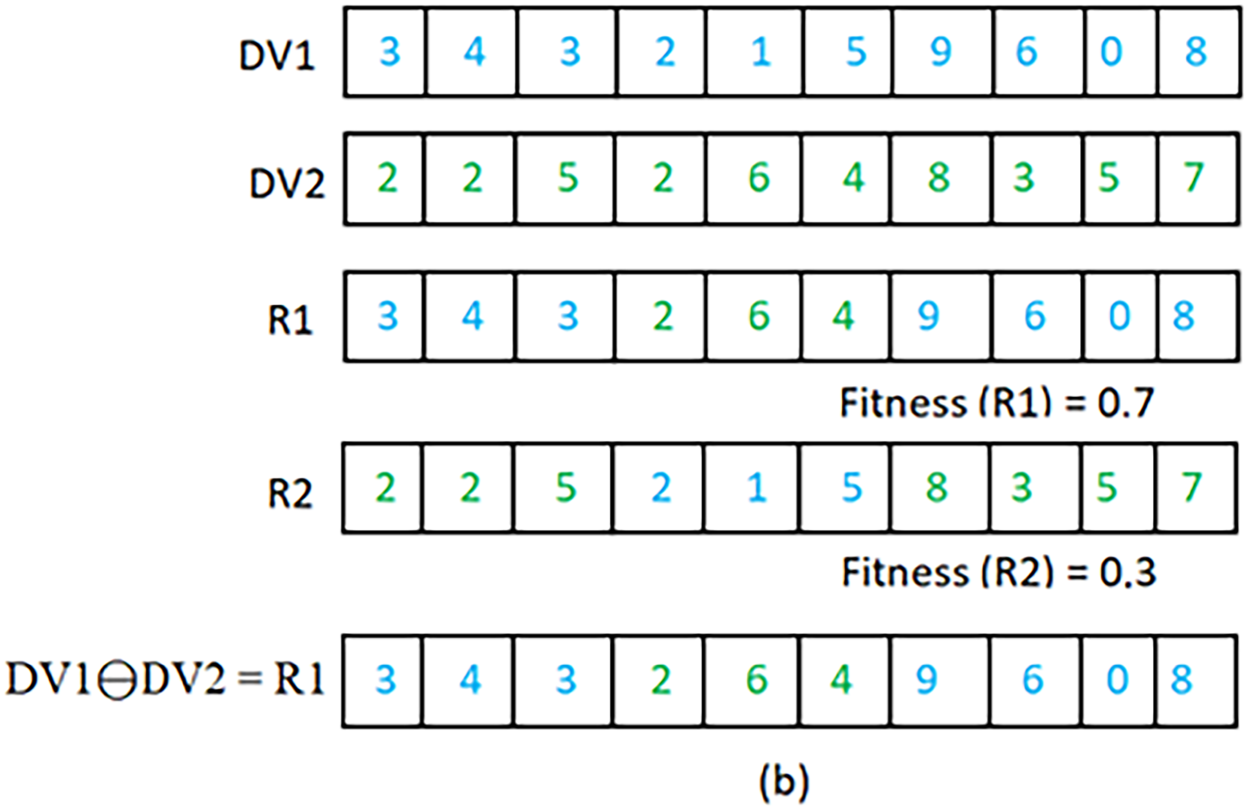
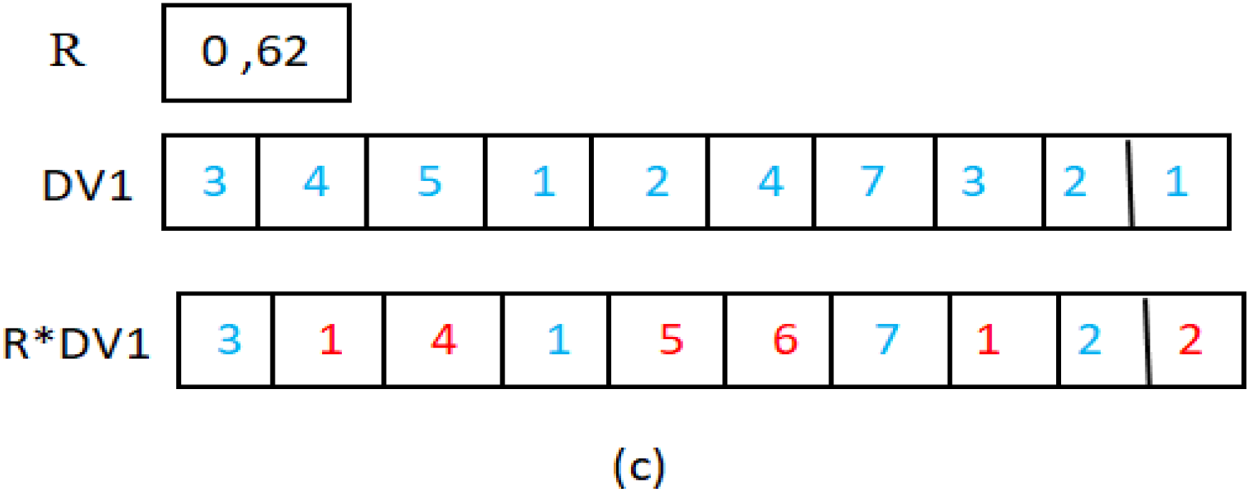



Since each rat’s position represents a solution to WSD problem, the rat’s position fitness indicates the quality of the selected senses corresponding to the rat’s position coding. In this paper, the semantic similarity between the context vector of the target word and the possible senses vector extracted from wordnet is used as a fitness function. The fitness function to be maximized is presented in Eq. (7).
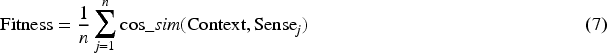
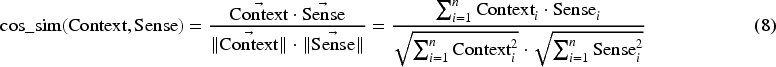
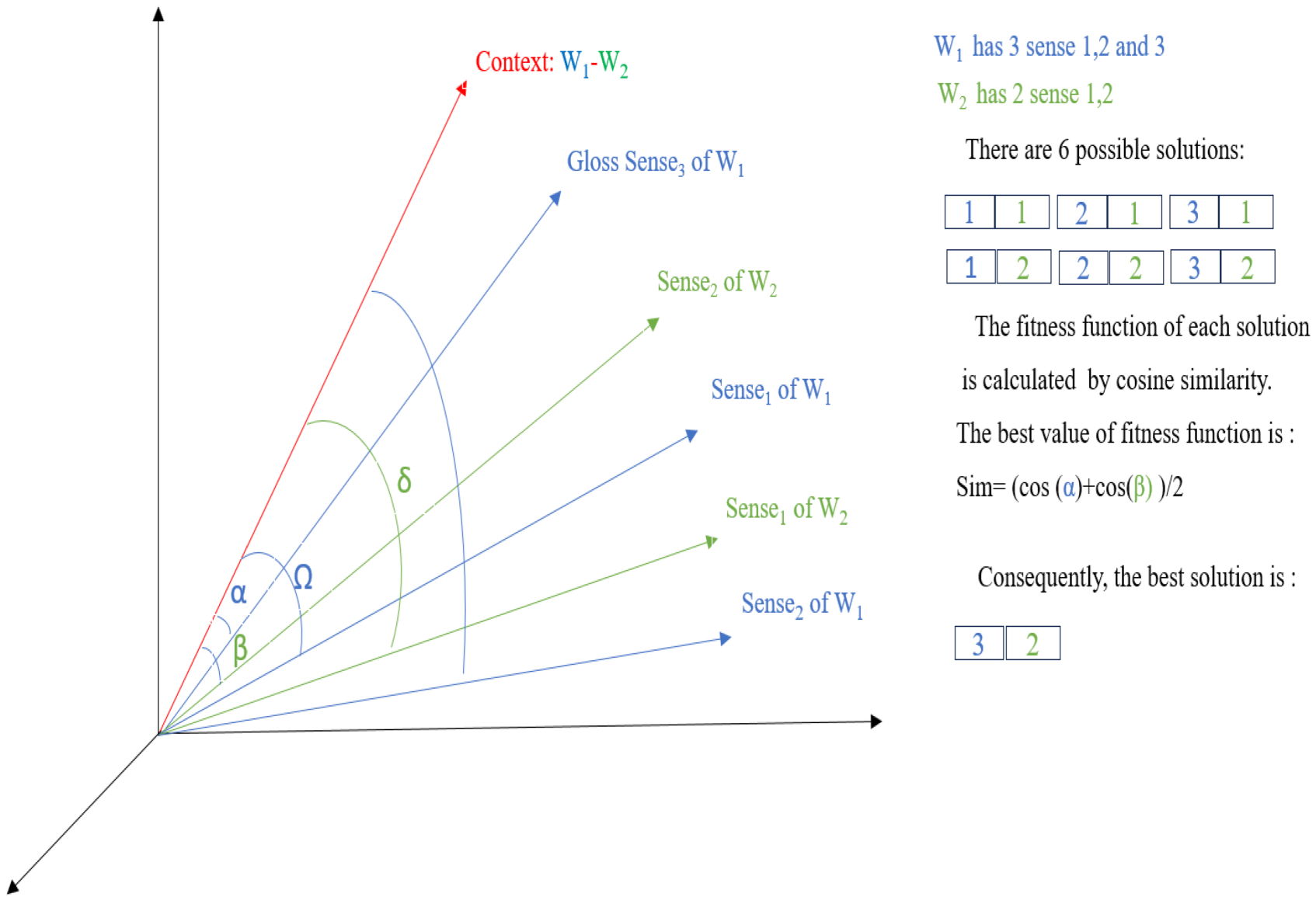
An illustrative example of our approach.
Algorithm 1 outlines our proposed approach, DRSO-WSD. It takes ambiguous word sets, context and synset vectors, population size, and number iterations as input and returns sense for each ambiguous word. The algorithm can be broadly divided into three main stages: Stage 1: The system generates an initial population of particles with random parameters. Stage 2: Update particles’ positions and algorithm parameters. Stage 3: Calculate the fitness function of all particles in a population to find the best solution to the problem.
The algorithm performs specific operations detailed in the pseudo-code within each stage.

Real-Time Applicability and Computational Analysis
We conducted a thorough analysis of its computational complexity to evaluate the practical applicability of the DRSO-WSD algorithm. We assessed its performance regarding runtime, scalability, and memory usage. The theoretical time complexity of DRSO-WSD is primarily influenced by the iterative nature of the RSO component and the semantic similarity computations involving Doc2Vec and BERT embeddings. In its discrete form, the RSO algorithm has a time complexity of
The semantic similarity calculations, which leverage pre-trained Doc2Vec and BERT models, contribute a complexity of
Empirical Evaluation
In this section, the performance of the proposed approach is evaluated with well-known benchmark corpora such as SemEval2007, SemEval2013, SemEval2015, SensEval2.0 and SensEval3.0 with famous evaluation criteria. In the next section, we will detail our experiments for evaluating whether multisense embeddings are effective for input descriptions and target terms.
Implementation Details
We perform all experiments on a computer with an Intel (R) Core (TM) i5-10600KF CPU, 16 GB of RAM, running Windows 11, and a 500-GB hard drive. The algorithm is implemented in Python 3.8 using the NLTK (natural language toolkit) package for analyzing text and obtaining word senses as synsets from its WordNet interface. We use genism to reproduce the results of the “Distributed Representation of Sentences and Documents,” relatedness score, and similarity measure.
Pre-trained Document Embedding Dataset
Table 2 details pre-trained word embedding (methods, tasks, training size, vector size, and window size) for the Doc2vec model to understand the document embedding models used in this approach.
Pretrained Document Embedding (doc2Vec).

Pretrained Document Embedding (doc2Vec).
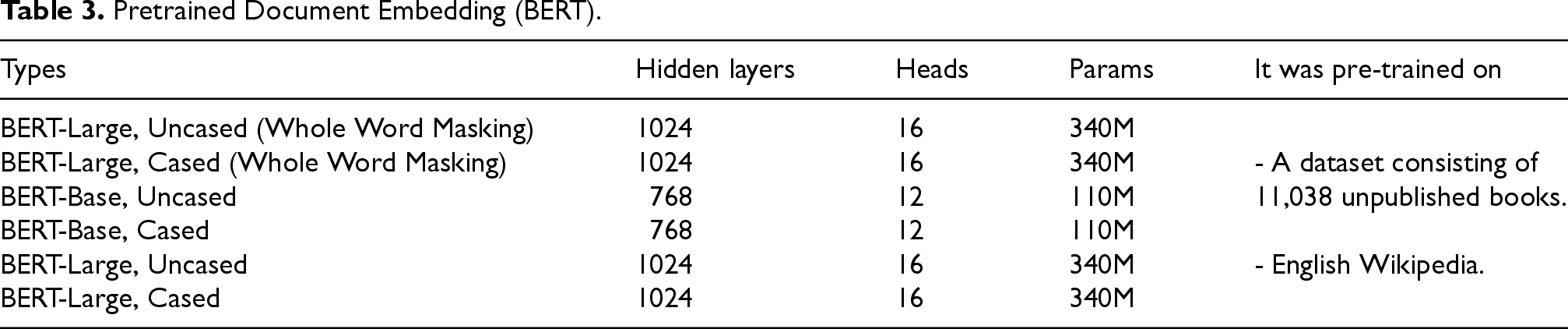
The pre-trained word embedding characteristics of BERT are presented in Table 3.
Pretrained Document Embedding (BERT).
The SemEval (Semantic Evaluation) international workshop series uses the SemEval corpus as a dataset to evaluate various natural language processing and computational linguistics tasks. In each edition of the workshop, the SemEval corpus refers specifically to the annotated data provided for the defined tasks. SemEval organizes multiple shared tasks or challenges annually, covering various NLP problems such as sentiment analysis, text classification, WSD, and more. Participants develop and evaluate their algorithms and models using the provided datasets, and the results are discussed and compared during the workshop. The SemEval corpus typically contains annotated text data related to the tasks of that year’s workshop, enabling researchers and participants to test and improve their algorithms on real-world language processing challenges. The structure and content of the SemEval corpus vary depending on the specific tasks and available data in each edition. In this paper, we evaluated our method using several benchmark corpora: Senseval2, SemEval3, SemEval2007, SemEval2013, and SemEval2015. These datasets consist of paragraphs from various domains such as computer science, reviews, and journalism. Table 4 presents the characteristics of each dataset. We aim to assign correct senses to over 2000 polysemous words from WordNet, with sense distinctions based on semantic closeness. Each task’s performance is evaluated according to its specific criteria.
Characteristics of SensEval Dataset.
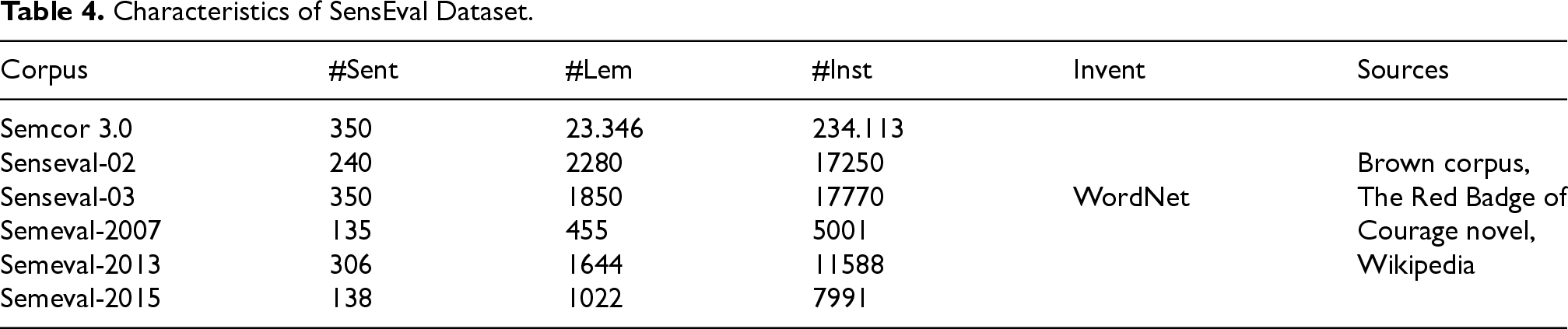
Characteristics of SensEval Dataset.
Evaluating the performance of WSD systems is crucial for assessing their effectiveness and identifying areas for improvement. To evaluate the effectiveness of this approach, we use a variety of metrics:
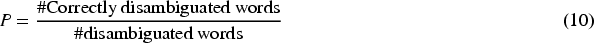
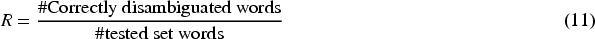

A convergence study is crucial for evaluating the effectiveness of the DRSO algorithm when applied to WSD tasks. This study examines how well DRSO approaches an optimal solution for WSD problems as the number of iterations and particles increase. Both fitness function convergence and accuracy convergence are important metrics to consider.
Impact of Population Size on Fitness Function Convergence
This metaheuristic algorithm explores the search space for optimization solutions in several iterations. Therefore, the convergence speed of metaheuristics is an important property. In this subsection, we analyze and present the convergence speed of the DRSO based on fitness values. We evaluated this approach using five corpora to study the convergence speed: SensE-val2, SensEval-3, SemEval 2007, SemEval 2013, and SemEval 2015. Figures 8- 12 plot the convergence curves. Convergence curves indicate that increasing the number of iterations increases DRSO’s exploration of search spaces to find appropriate solutions more quickly. Based on the different corpora tested, these figures illustrate the best fitness value of DRSO and the number of iterations required to arrive at the best solution. The DRSO algorithm demonstrated convergence to the best fitness in iterations for the SensEval and SemEval datasets (details in Table 5).
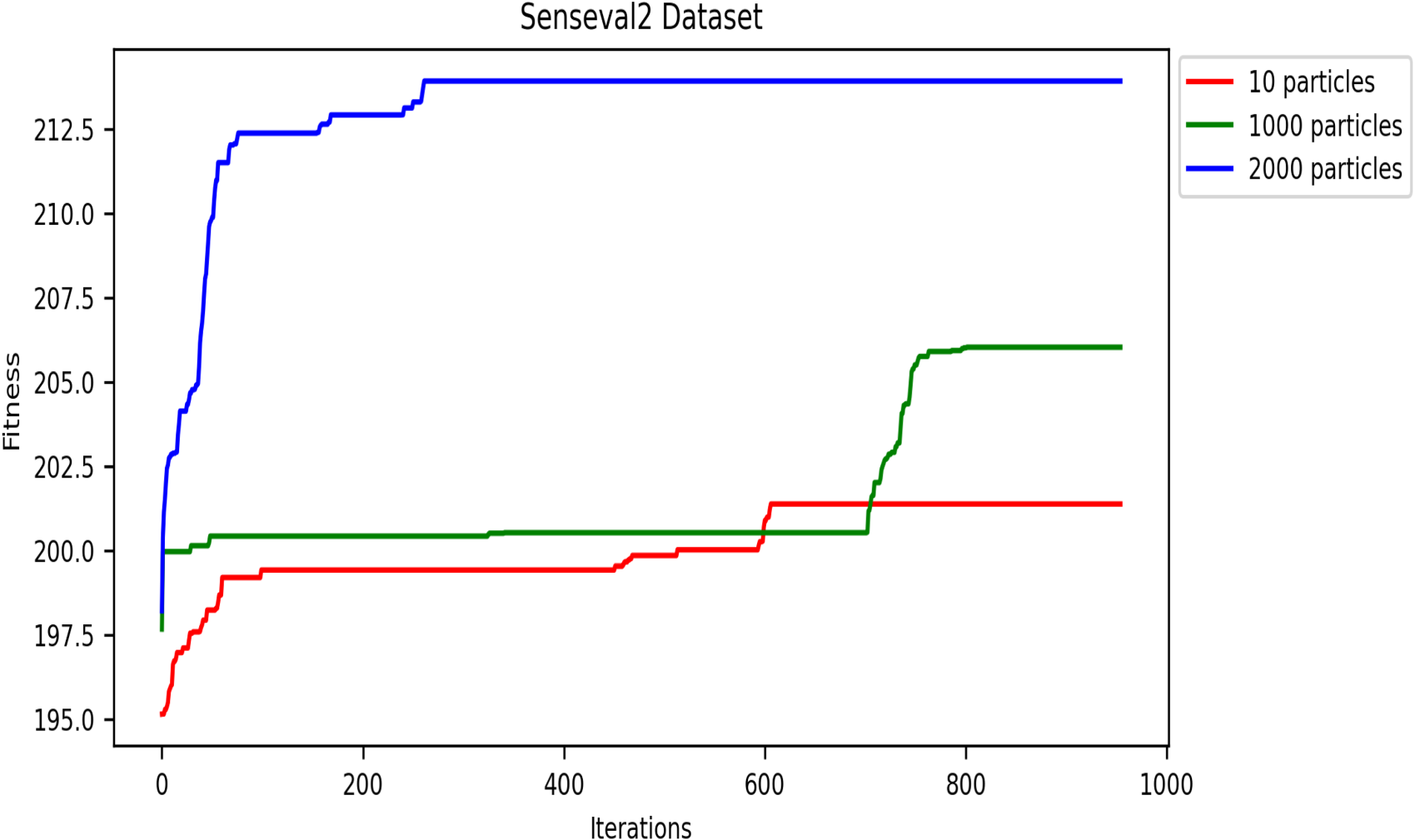
Convergence of fitness vs. iterations for different particle numbers on SensEval-2 dataset.
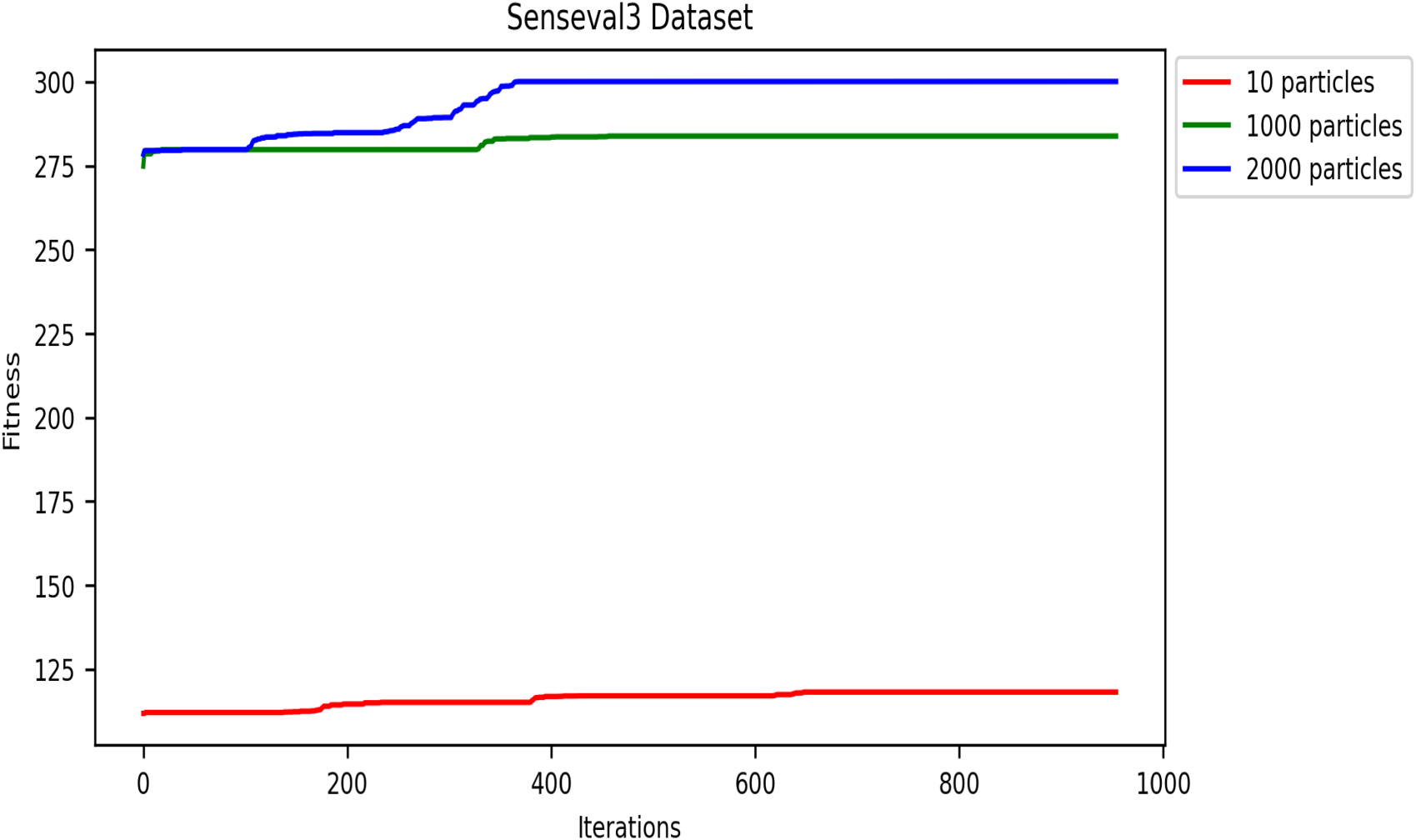
Convergence of fitness vs. iterations for different particle numbers on SensEval-3 dataset.
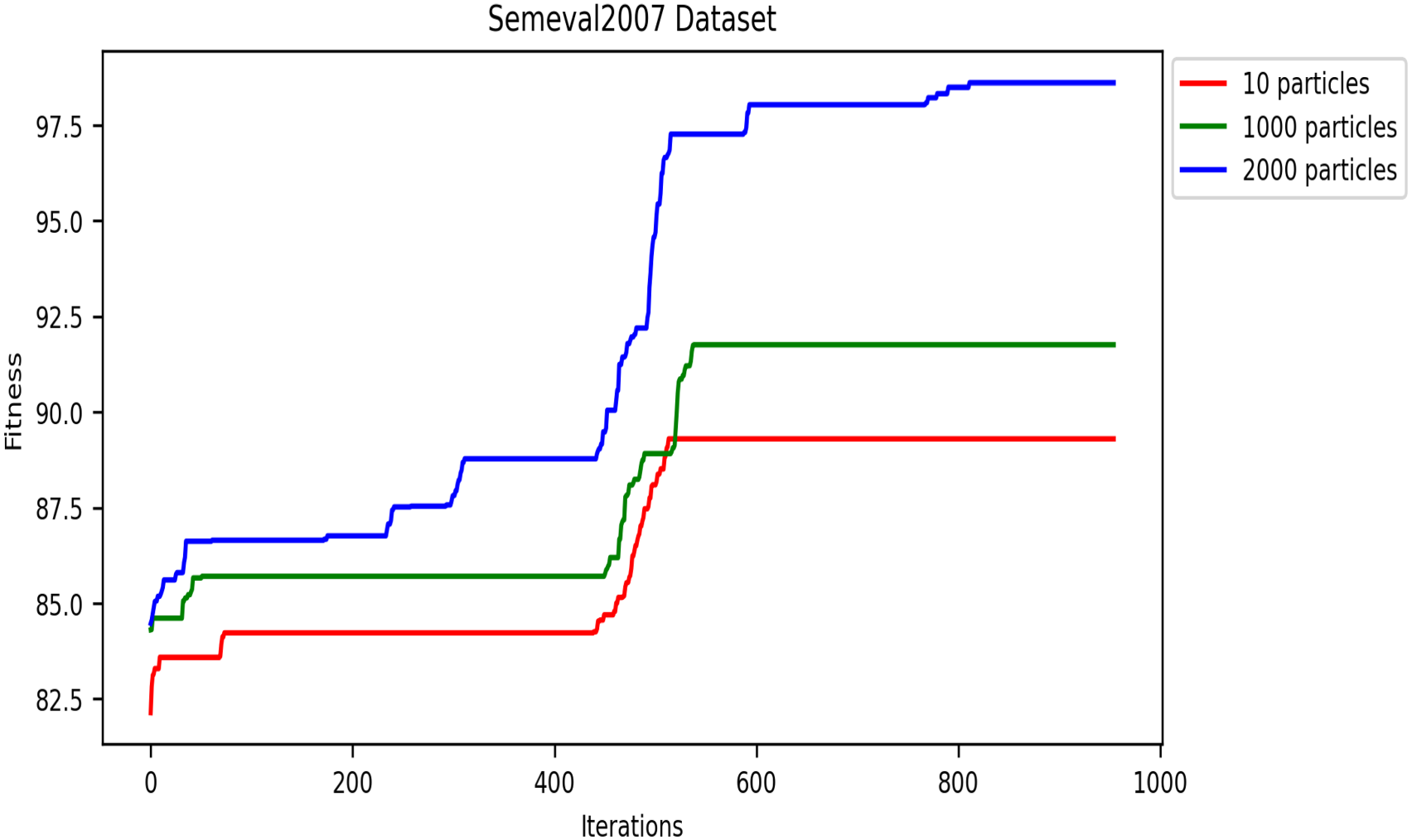
Convergence of fitness vs. iterations for different particle numbers on SemEval2007 dataset.
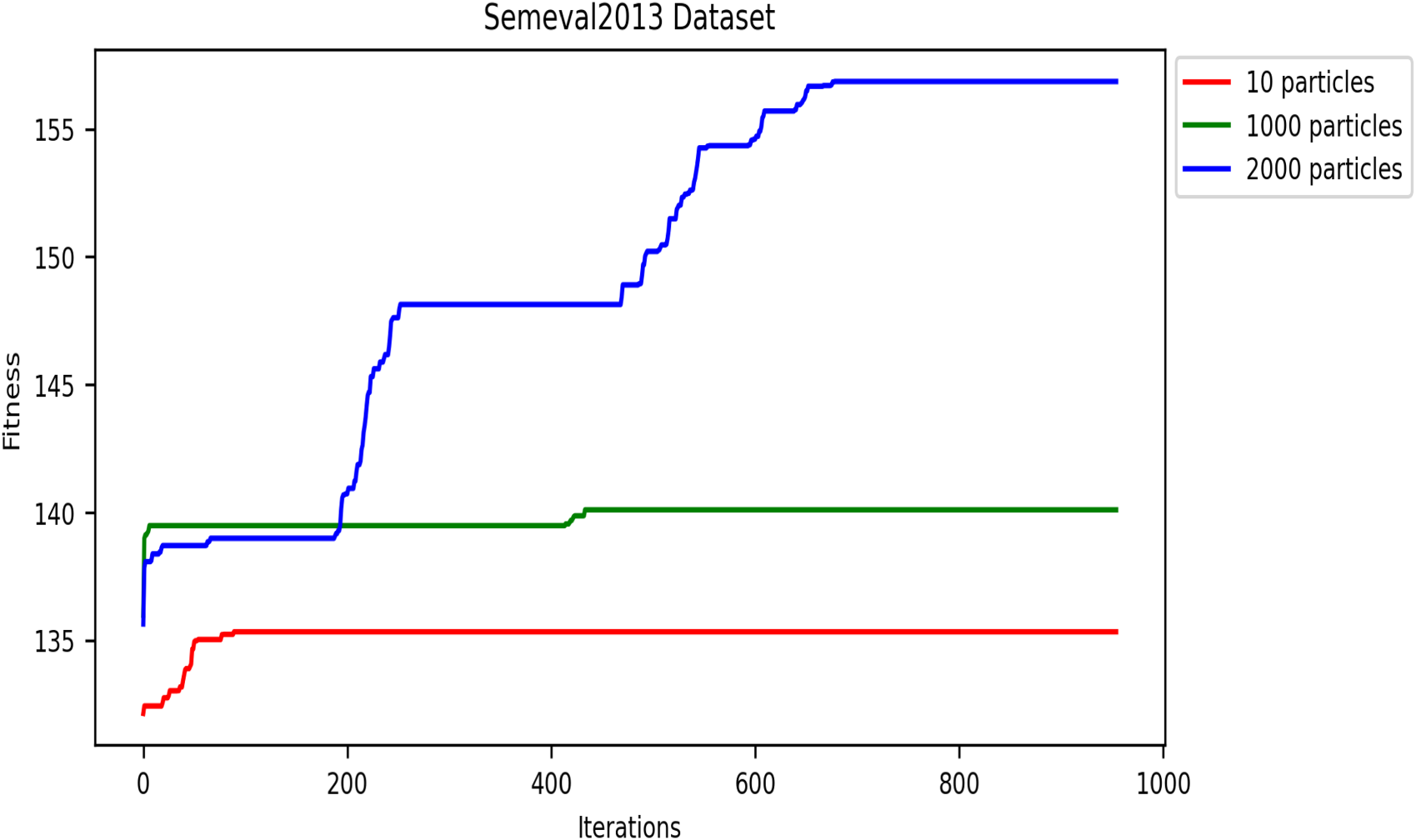
Convergence of fitness vs. iterations for different particle numbers on SemEval2013 dataset.
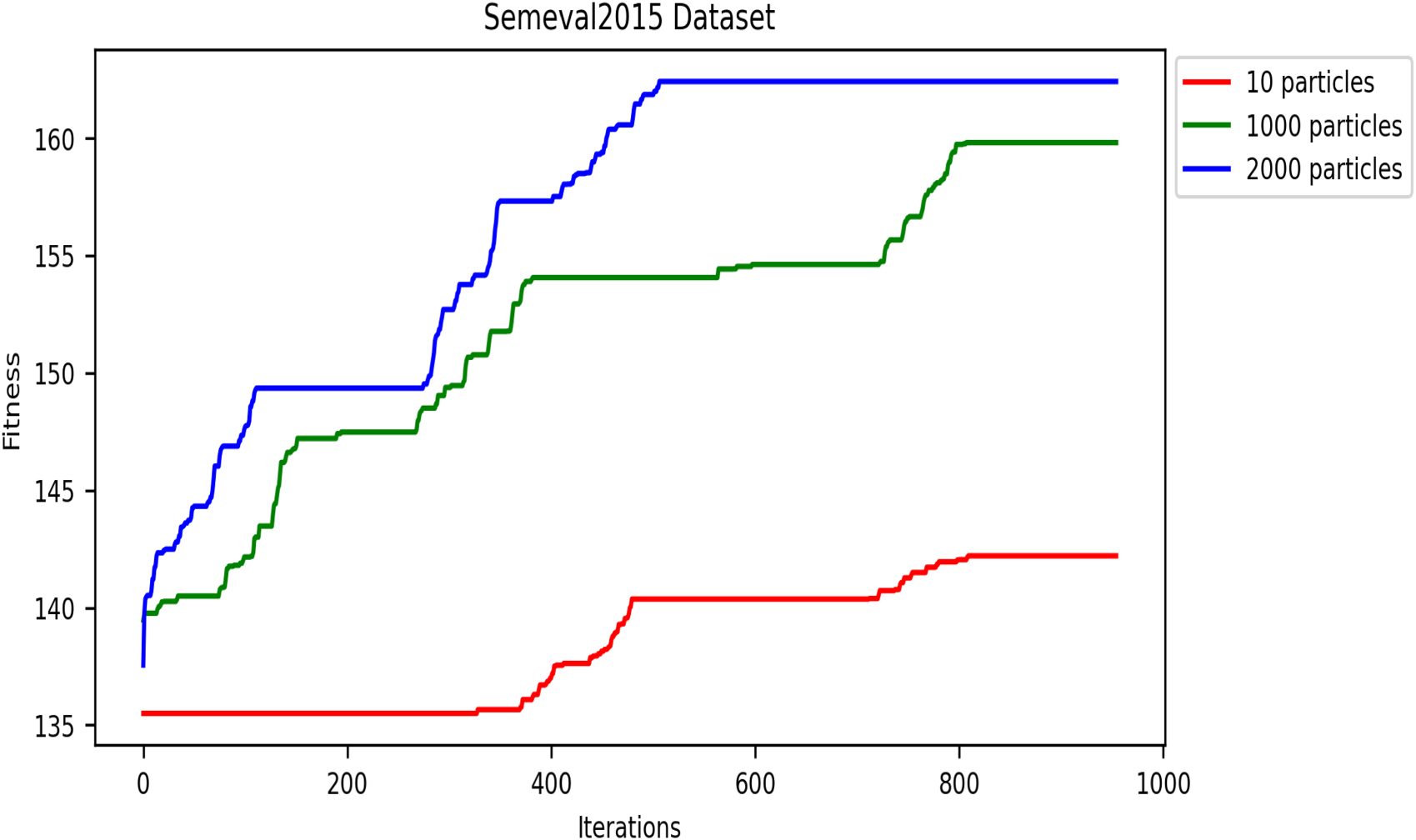
Convergence of fitness vs. iterations for different particle numbers on SemEval2015 dataset.
The Number of Iterations of the Best Fitness Values.

The number of iterations of the swarm-based approaches is one of the most critical hyperparameters. Generally, swarm algorithms usually perform better with more iterations up to a threshold, after which they remain stable. Like all swarm algorithms, DRSO is sensitive to the iteration setting. Thus, this section examines our approach’s performance by varying the accuracy metric over multiple iterations. We used population sizes of 10, 1,000, and 2,000 particles in this experiment to analyze the accuracy metric based on iterations, and we calculated the accuracy using Equation 8. Figures 13 to 17 present the accuracy values of all corpora. As shown in these figures, the proposed algorithm gets better and better until it reaches the highest accuracy value in iterations (details in Table 6).
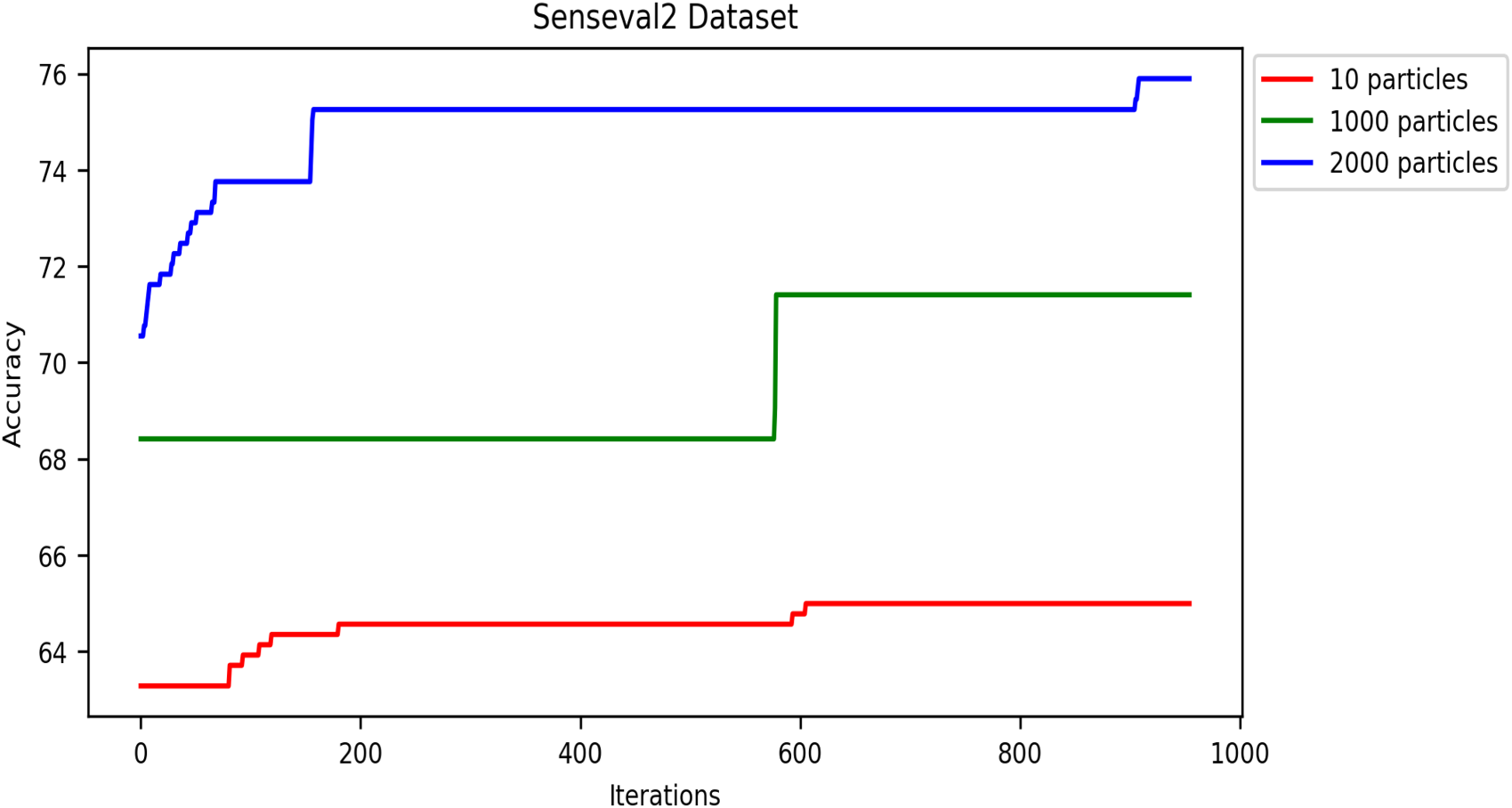
Effect of particle population number on accuracy convergence rate in the SensEval-2 dataset.
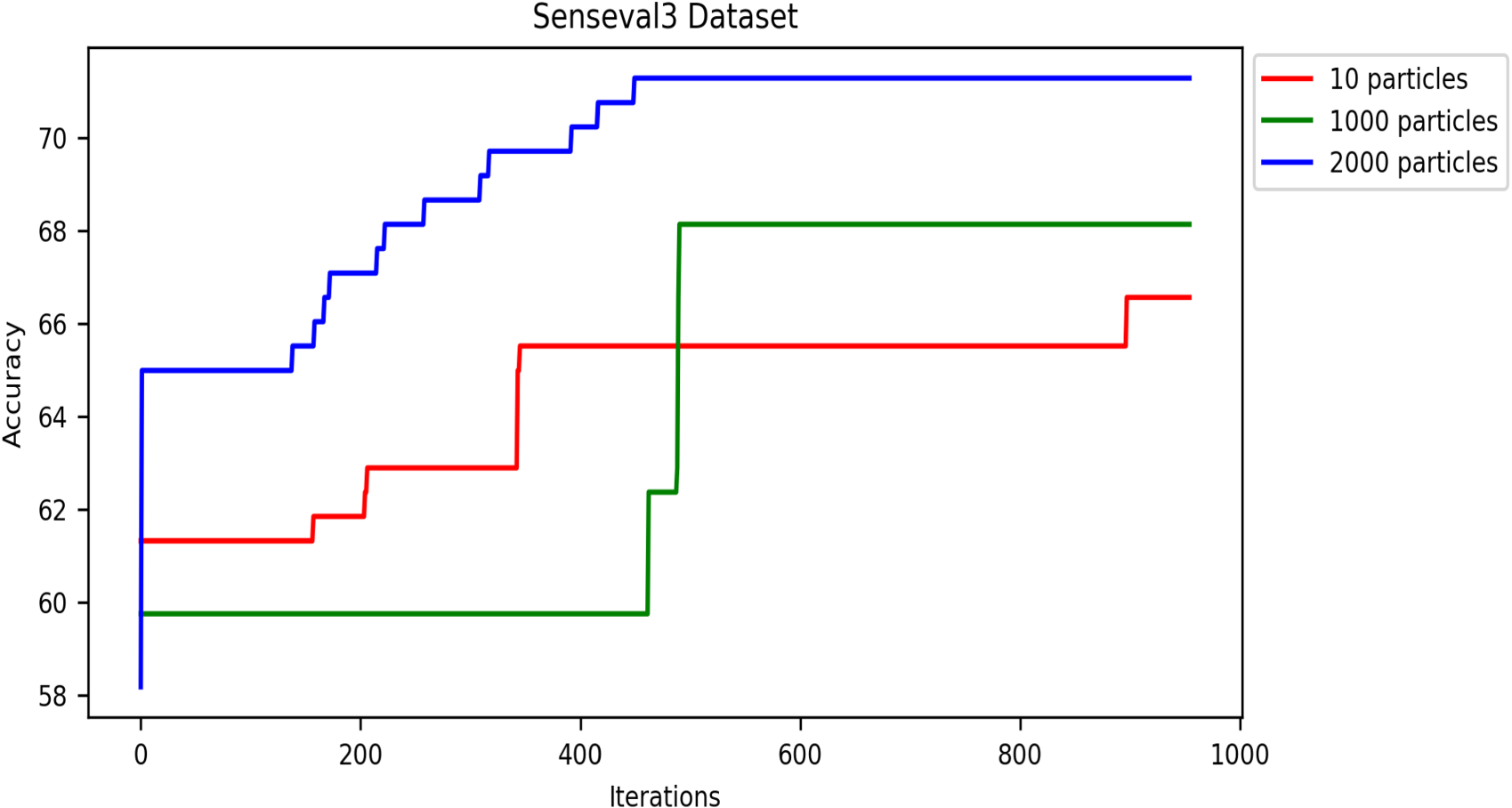
Effect of particle population number on accuracy convergence rate in the SensEval-3 dataset.
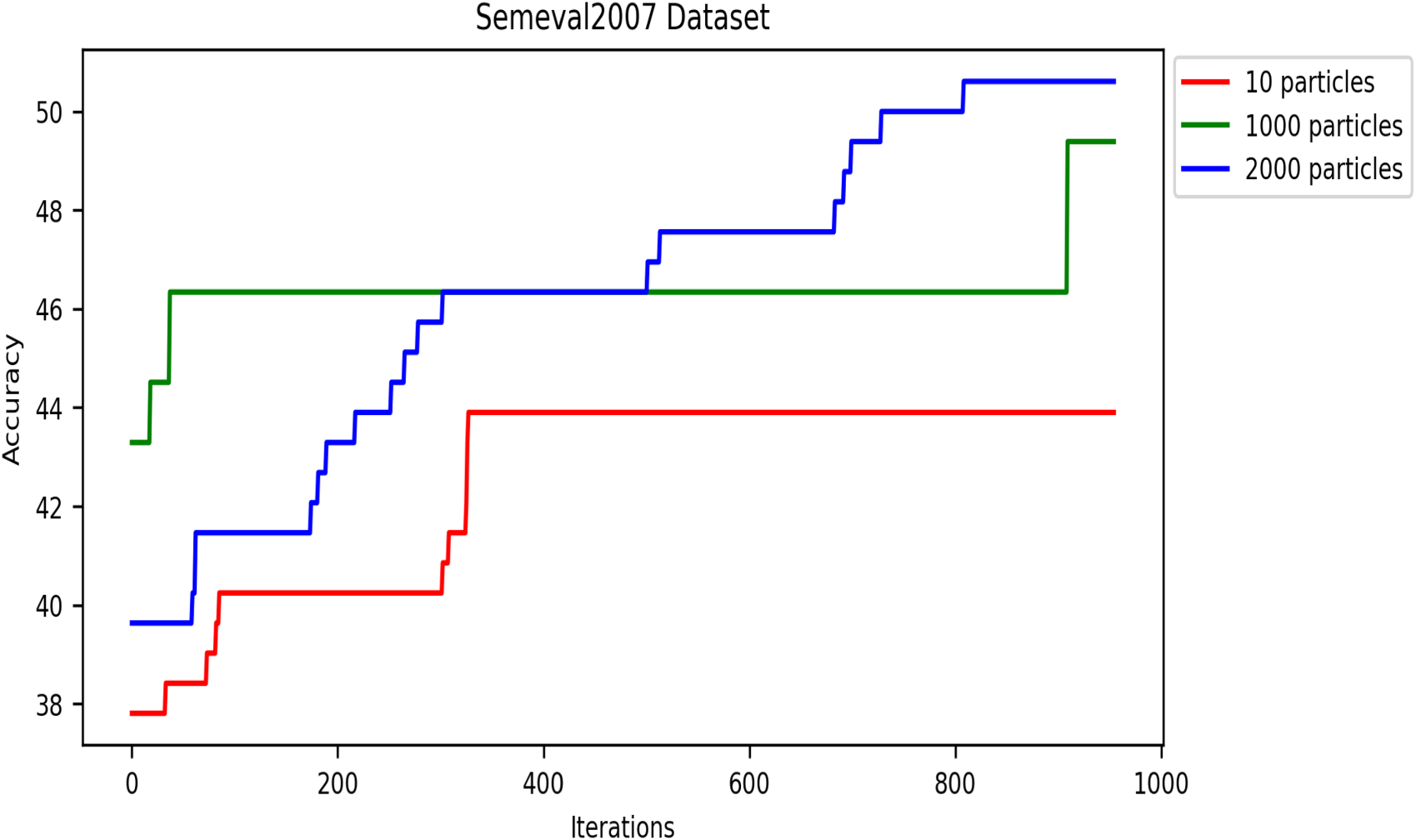
Effect of particle population number on accuracy convergence rate in the SemEval2007 dataset.
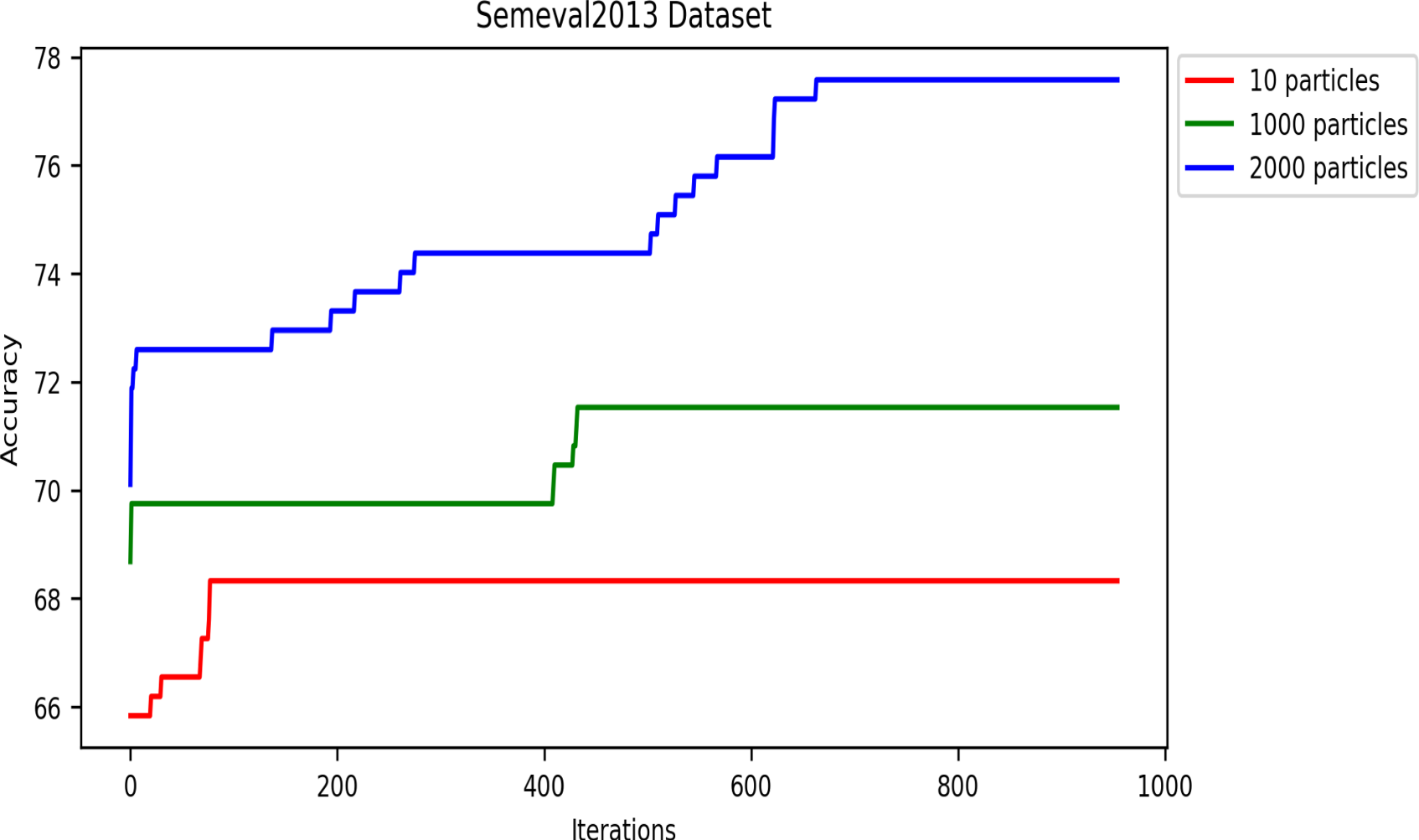
Effect of particle population number on accuracy convergence rate in the SemEval2013 dataset.
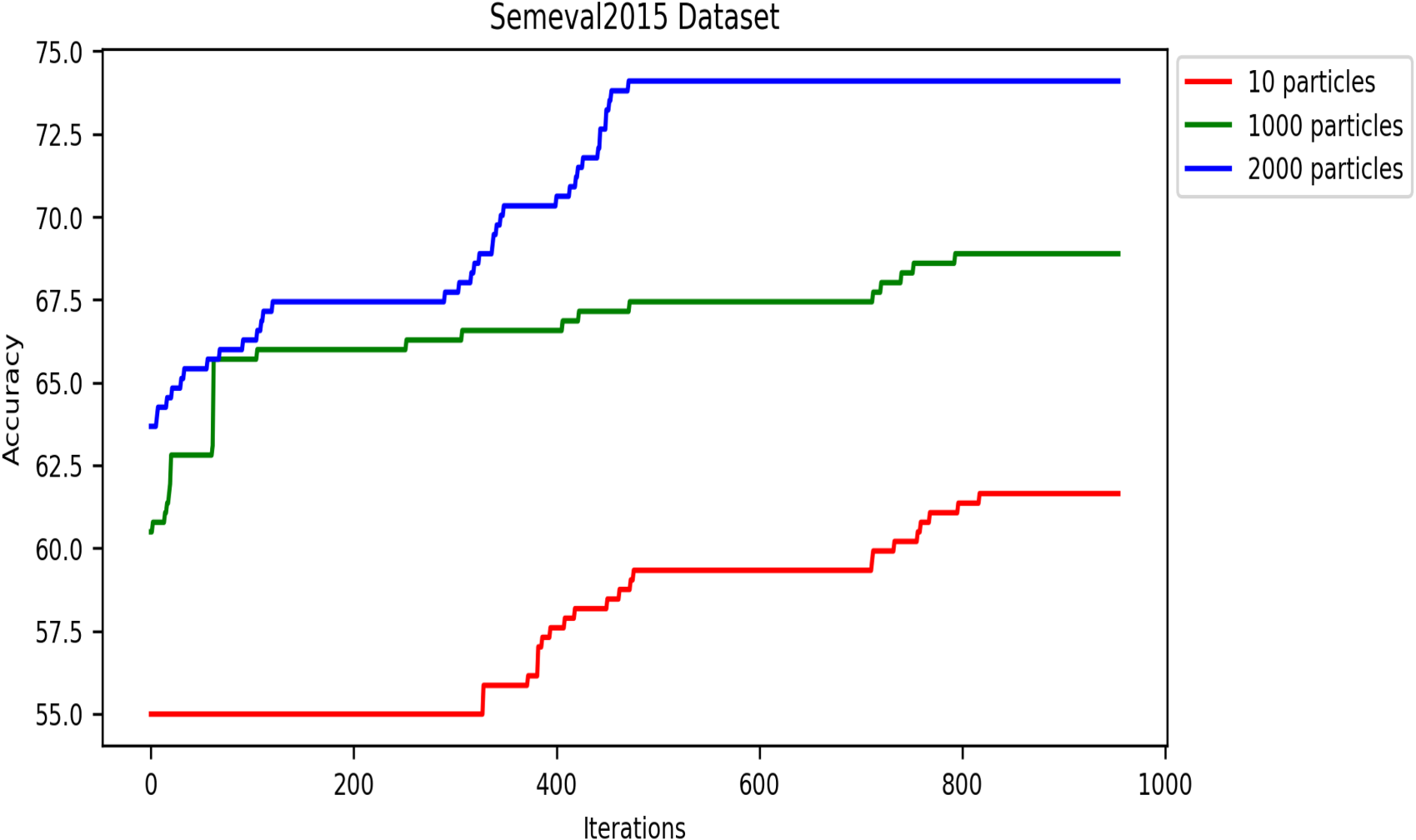
Effect of particle population number on accuracy convergence rate in the SemEval2015 dataset.
Best Accuracy by Population Size and Iterations.

In these experiments, we applied the DRSO to the WSD problem. We observed that using 2,000 particles yielded the best results compared to 10 and 1,000 particles. This suggests that a larger population size within the DRSO framework positively impacted the accuracy of the WSD system. There are two possible explanations for this trend:
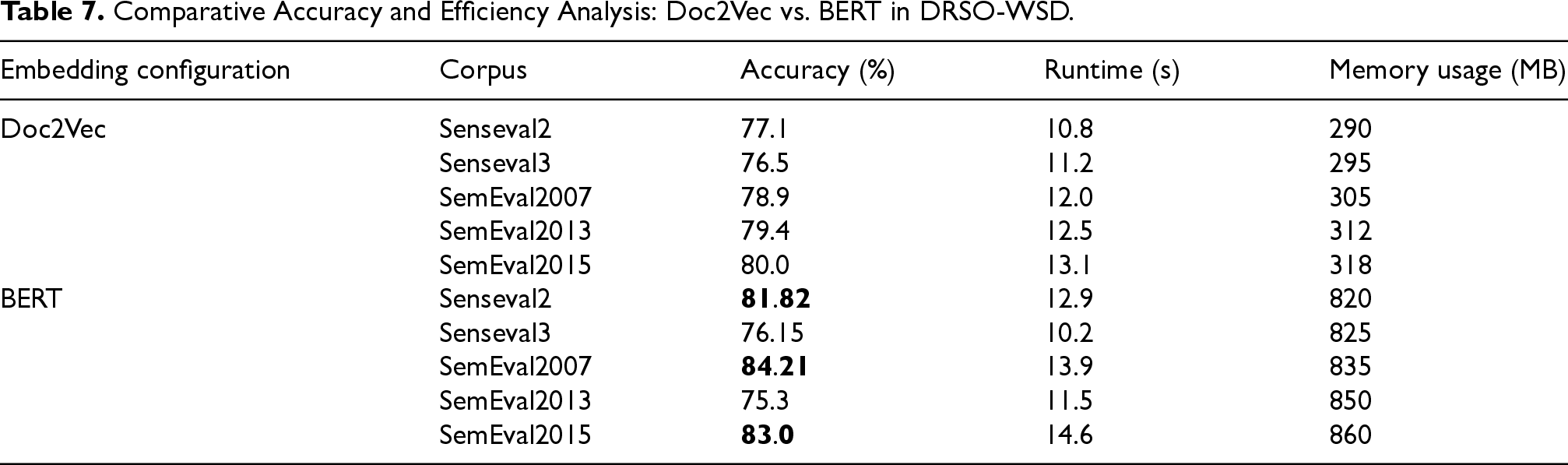
To evaluate the individual contributions of the embedding methods used within the DRSO-WSD fitness function, we conducted an ablation study comparing two configurations: one that utilized only Doc2Vec embeddings and another that used only BERT embeddings. The aim was to assess how each method impacts disambiguation accuracy and computational efficiency, including memory usage and runtime, thereby isolating the effects of the underlying semantic representation.
The evaluation was conducted across five benchmark corpora: SensEval2, SensEval3, SemEval2007, SemEval2013, and SemEval2015. To facilitate a practical comparison of runtime and memory usage, each configuration was executed on controlled subsets comprising a limited number of sentences (approximately 10–20) or around 100 ambiguous words from each dataset. This approach allowed us to estimate performance in a constrained and comparable environment.
The results presented in Table 7 indicate that BERT consistently outperforms Doc2Vec regarding accuracy across three corpora: SensEval2, SemEval2007, and SemEval2015. The accuracy improvements range from 2.5% to 5.3%. However, this increase in accuracy comes at the expense of significantly higher memory usage and longer runtimes. On average, BERT requires approximately 2.5 to 3 times more memory and takes roughly 1.5 times longer to process than Doc2Vec.
Comparative Accuracy and Efficiency Analysis: Doc2Vec vs. BERT in DRSO-WSD.
Comparative Accuracy and Efficiency Analysis: Doc2Vec vs. BERT in DRSO-WSD.
The higher resource consumption associated with the BERT-based configuration is primarily due to the large size of its pre-trained models and the deeper contextual representations it generates. This significantly affects both runtime and memory usage, especially when working with larger datasets. In contrast, Doc2Vec remains lightweight, with relatively low memory consumption and faster execution times, making it a better option for applications that prioritize rapid processing and minimal resource usage.
These findings highlight the trade-off between accuracy and computational cost. While BERT’s richer semantic understanding yields better performance, it is also computationally intensive, rendering it less suitable for environments with limited resources. Conversely, Doc2Vec, despite its lower accuracy rates, offers a more efficient alternative for scenarios where memory and speed are of more significant concern.
To test the optimization ability of the proposed approach, we evaluated it against six state-of-the-art methods, namely ADCSA-WSD (Abdelaali et al., 2022), TSP-ACO (Nguyen & Ock, 2013), HAS (Abed et al., 2015), SA-GA (Alsaeedan & Menai, 2015), H-PSO (Al-Saiagh et al., 2018), and GA (Gogoi et al., 2020). These methods utilize various swarm intelligence algorithms, including ant colony optimization, particle swarm optimization, and crow optimization. The reason for choosing these methods is their close correspondence with our approach. The methods of these approaches are explained in the related works section. The comparison has been made on five well-known corpora, including SemEval2007, SemEval2013, SemEval2015, SensEval2, and SenseEval3. We compare our technique with other approaches based on the scores of different evaluation metrics (precision, recall, and F-measure) and SensEval and SemEval datasets. Like other swarm optimization algorithms, DRSO-WSD relies on several hyperparameters. Table 8 lists the main ones used in our implementation. The algorithm consists of six parameters: three continuous parameters, A, C, and R, which serve as control parameters for balancing exploration and exploitation, and three integer parameters, which include population size, dimensions, and iterations. These parameters are configured when the algorithm is run multiple times on the training dataset.
DRSO-WSD Algorithm Parameters.

DRSO-WSD Algorithm Parameters.
We used the Friedman test to evaluate performance differences among the compared methods. This non-parametric test is ideal for analyzing related algorithms across multiple datasets without assuming data normality. Unlike the Kruskal–Wallis test, which applies to independent samples, the Friedman test accounts for our data’s related nature, as all methods are assessed on the same datasets. The results, shown in Table 9, reveal statistically significant performance differences across all three benchmark corpora.
Friedman Test Results Across Different Corpora.

Friedman Test Results Across Different Corpora.
The results of the Friedman test show statistically significant differences in the performance of the methods being compared across all three benchmark corpora. The p-values for each dataset are below the standard significance level of 0.05, prompting us to reject the null hypothesis of equal performance across methods. This finding validates the effectiveness of our evaluation methodology and supports the need for further post hoc analysis to identify the most effective method(s). Specifically, these results indicate that our proposed approach may outperform existing baselines, warranting a detailed pairwise comparison to highlight its specific advantages.
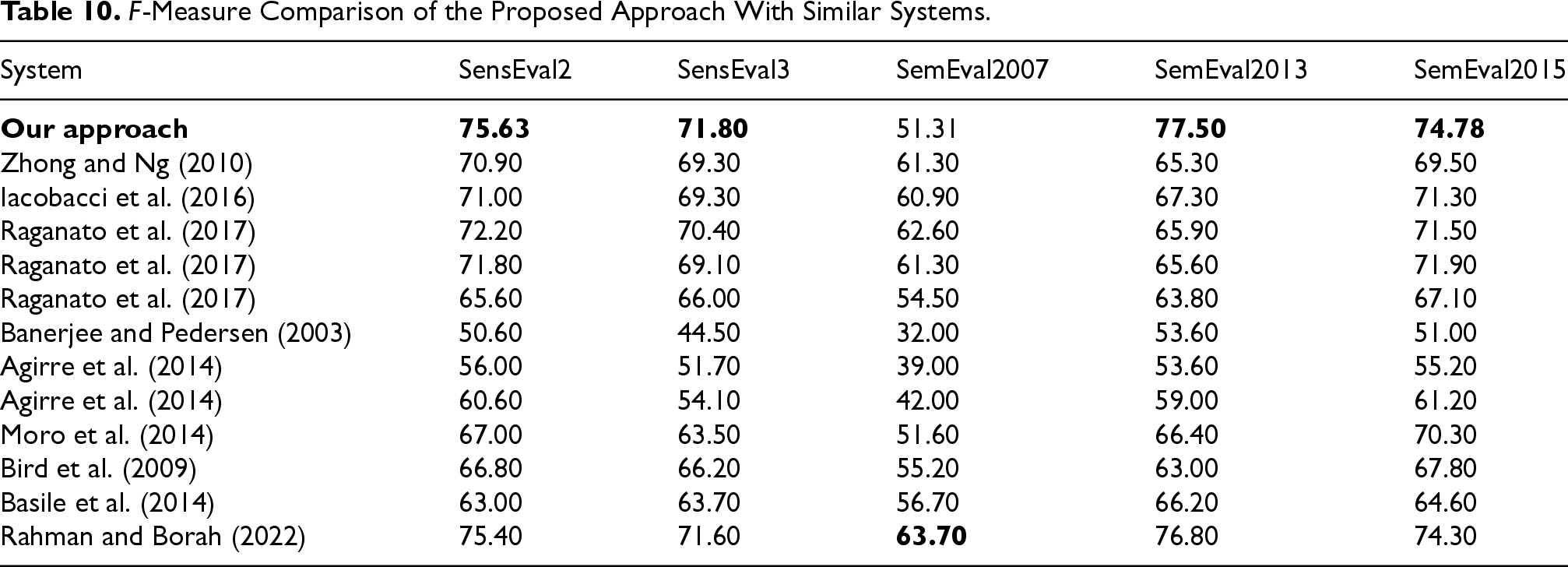
This study investigates the performance of the proposed DRSO-WSD model for WSD across various benchmark corpora, including SensEval2, SensEval3, SemEval2007, SemEval2013, and SemEval2015. WSD is a fundamental task in computational linguistics, significantly impacting the performance of various NLP applications. Figures 18, 19 and 20 illustrate a comparative evaluation of our method against several state-of-the-art approaches. Table 10 presents the corresponding F-measure values across all datasets. Notably, our approach consistently yields superior results compared to previous systems. For instance, on the SensEval2 dataset (Figure 18), DRSO-WSD achieves precision, recall, and F-measure scores of 76.32%, 66.66%, and 71.16%, respectively. This surpasses ADCSA-WSD, which only achieves 68.29% in F-measure. Our model’s F-measure value on this corpus is 75.63%, which is the highest among all compared approaches. Similarly, on SemEval2013 and SemEval2015 datasets, our method outperforms the approach of Rahman and Borah (2022) by 0.48% and 0.89%, respectively, demonstrating improved disambiguation capability. Even on challenging datasets like SemEval2007, although the scores are generally lower for all systems, DRSO-WSD maintains competitive performance. To assess the statistical significance of these improvements, we conducted the Friedman test on the F-measure values of the compared methods. The test yielded a p-value less than 0.05, indicating that the observed differences in performance are statistically significant and not due to chance. Beyond the numerical performance, a qualitative linguistic interpretation of the results provides deeper insights into the behavior of the DRSO-WSD approach. The algorithm demonstrates a strong ability to disambiguate polysemous words by effectively leveraging their surrounding context. For instance, in the SemEval2013 corpus, the system accurately distinguished between the noun sense of
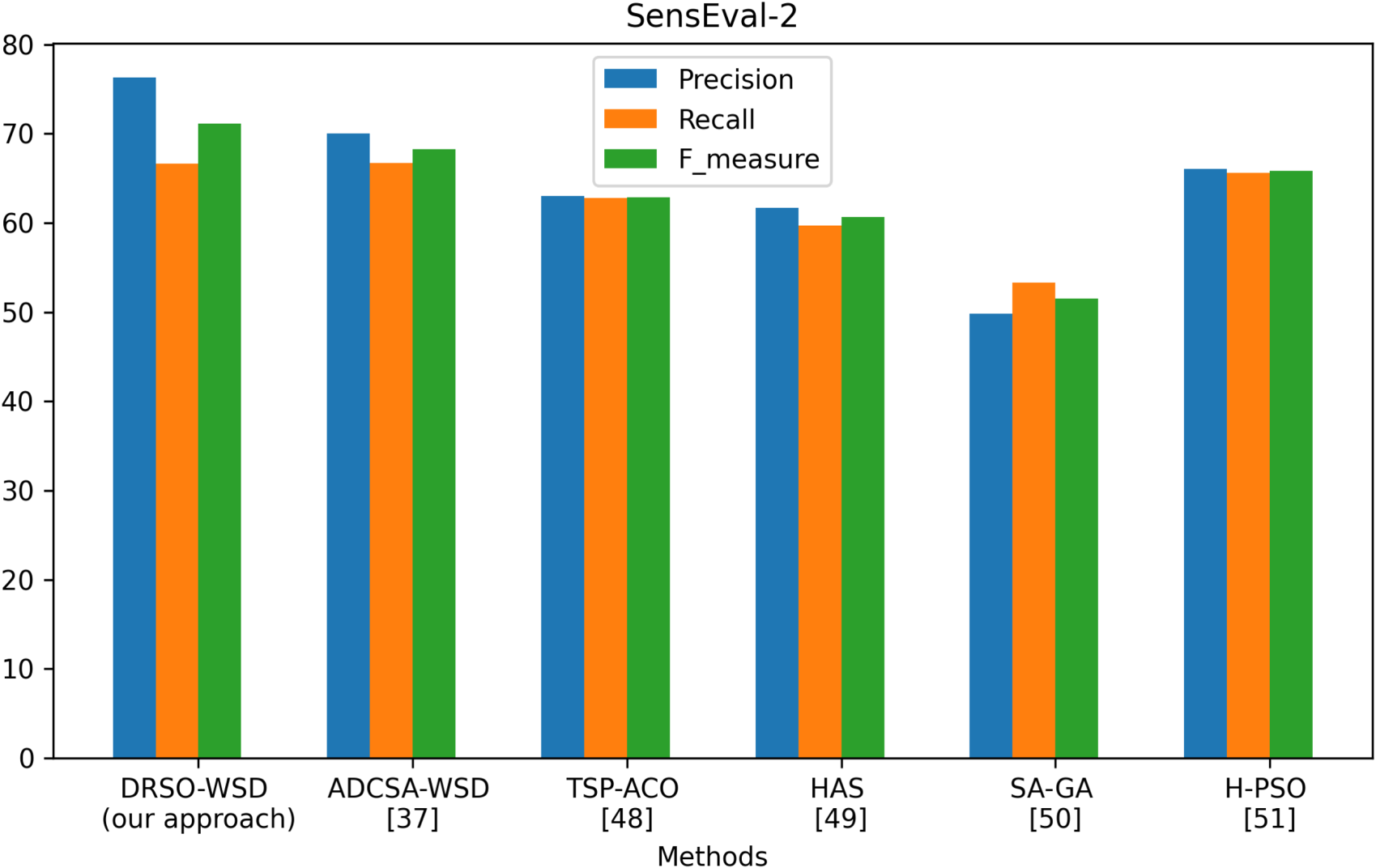
DRSO-WSD vs. other approaches on SensEval-2.
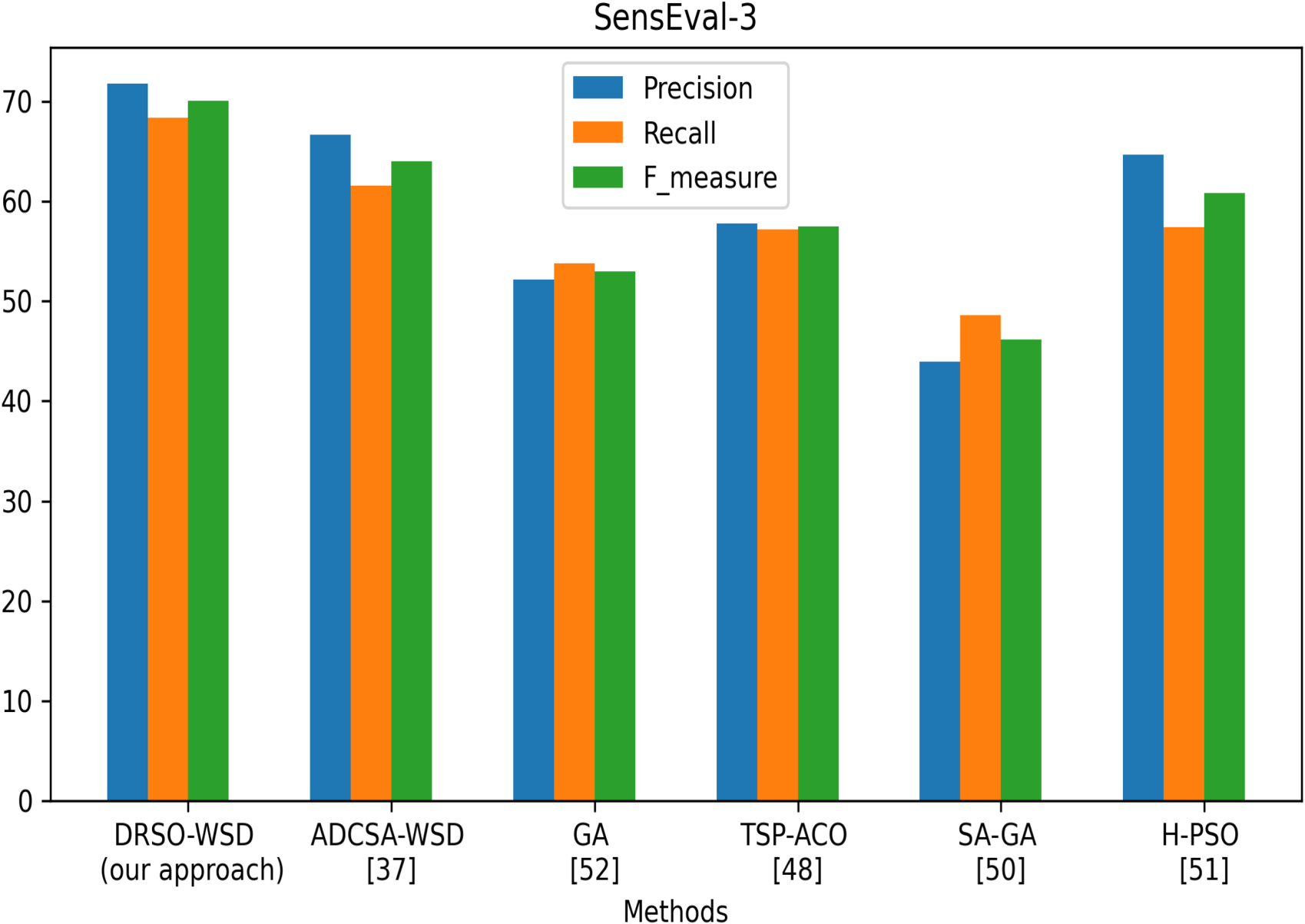
DRSO-WSD vs. other approaches on SensEval-3.
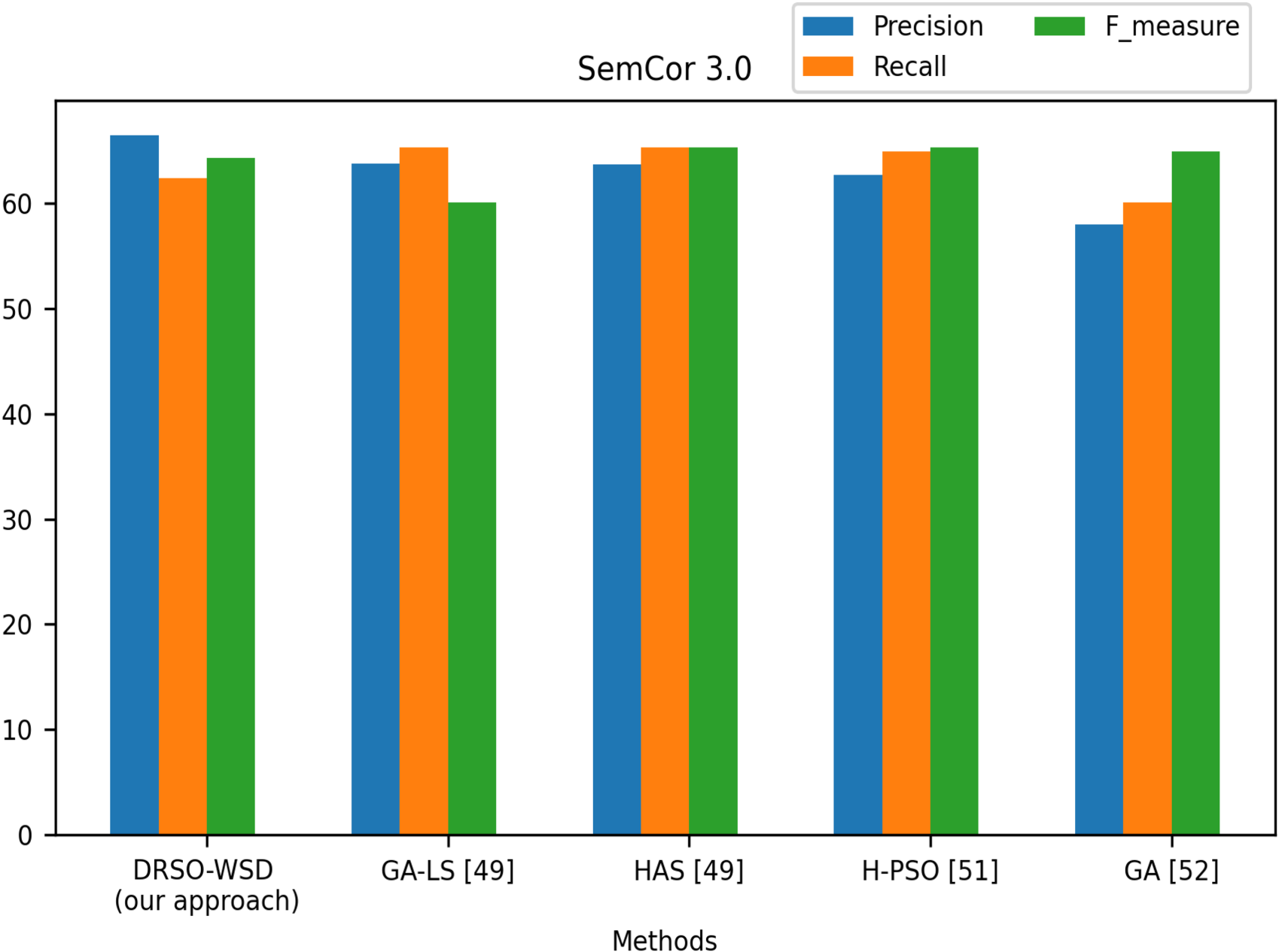
DRSO-WSD vs. other approaches on Semcor.
F-Measure Comparison of the Proposed Approach With Similar Systems.
The discrete reptile search optimization (DRSO) algorithm has primarily been evaluated on benchmark corpora such as SemEval and SensEval. However, it shows significant potential for use in real-world NLP applications. This section highlights four key use cases where accurate English WSD can greatly enhance the performance of downstream systems.
DRSO for Machine Translation (MT)
Machine translation systems often face challenges with English polysemy, particularly in ambiguous contexts. For example, the word
DRSO for Information Retrieval and Search Engines
Search engines frequently return irrelevant results when user queries contain ambiguous terms. For instance, a search query with the word
Integrating DRSO into query preprocessing enables systems to identify the intended meaning based on surrounding terms. In a simulated test using the TREC dataset, DRSO-enhanced retrieval systems achieved a 10. 2% improvement in precision, resulting in more relevant document rankings.
DRSO for Sentiment Analysis
Sentiment analysis tools in English can misclassify texts when ambiguous words carry conflicting sentiment polarities. For example, the term
DRSO for Conversational AI and Virtual Assistants
In interactive systems such as chatbots and virtual assistants, inaccurate sense resolution can lead to misunderstandings of user intent. For instance, when a user says,
Limitations and Potential Risks
While the DRSO-based approach shows significant promise in enhancing WSD, it is crucial to recognize its inherent limitations and potential risks, especially in high-stakes environments.
Firstly, although generally effective, the system’s dependence on contextual analysis may struggle when nuanced or domain-specific language is prevalent. For instance, legal and medical texts often contain intricate terminology and subtle semantic distinctions that present considerable challenges. In legal contexts, the word
Secondly, the performance of the DRSO model is closely tied to the quality and diversity of its training data. Although efforts were made to include a variety of corpora, gaps may still exist—particularly in specialized fields. This could lead to biases or inaccuracies when processing texts outside the model’s training scope.
Moreover, the real-time implementation of DRSO in critical applications raises concerns about computational efficiency. While the model has demonstrated promising results in controlled experiments, its performance in high-throughput environments, such as live translation or real-time medical diagnosis, warrants further investigation.
Finally, the ethical implications of deploying WSD systems in sensitive areas must not be overlooked. Incorrect disambiguation in legal or medical contexts can have serious consequences, such as contractual disputes, misdiagnosis, or inappropriate medical interventions. For instance, misinterpreting the word
To address these limitations and mitigate risks, future work should focus on several key areas:
Addressing these limitations is vital for the responsible and reliable deployment of DRSO-based WSD systems in real-world applications.
WSD plays a crucial role in identifying the correct meaning of ambiguous words within context. In this study, we proposed a two-step approach for WSD. First, we utilized word embeddings to represent the context and meanings of ambiguous words. Second, we employed a combinatorial optimization method, specifically a discrete variation of the RSO algorithm, to disambiguate the target words in context. Our proposed approach demonstrated superior performance, particularly in terms of accuracy, when tested on the SemEval and SensEval datasets. Compared to existing methods, our approach provides an effective and efficient solution as it does not depend on complex, resource-intensive techniques. Our experiments indicate that variations in disambiguation methods, such as the RSO algorithm, yield results comparable to more complicated approaches. These findings suggest that simpler, optimization-based methods can be as effective as those that rely on hard-to-build resources. However, further research is needed to overcome practical limitations, especially in retrieving domain-specific documents, which can be time-consuming, and in enhancing the marginal gains from semantic path exploration. While our framework is practical, there are several areas for improvement. We plan to enhance the model further by optimizing hyperparameters to boost performance and testing the approach on additional languages, particularly low-resource languages, to assess its cross-lingual applicability. Additionally, we aim to explore hybrid models that combine discrete optimization algorithms like RSO with neural networks to improve robustness and accuracy. In future work, we will concentrate on expanding the multilingual capabilities of our framework and extracting more comprehensive semantic relationships between senses. One promising direction is to integrate knowledge from broader knowledge graphs, such as BabelNet, to enhance sense representation and contextual relationships. This integration will not only improve disambiguation accuracy but also provide more robust solutions across various domains. Finally, the applications of our work extend beyond academic research. In industry, our framework could be applied to areas such as information retrieval, machine translation, and natural language understanding, where precise sense disambiguation is essential. Continued research in this area will contribute to the development of more efficient and scalable WSD systems that can be deployed in real-world applications.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.