
Abstract
Current fake news detection models do not adequately extract fine-grained image features and also ignore the important impact of shallow text features on the results. In addition, the fusion methods are too simple and do not take into account the different importance of various information sources on the final detection results. To address these limitations, we propose a named Dual-branch Hybrid Visual Networks and Hierarchical Adaptive Fusion Strategy Model (DVHAM). Specifically, we design a dual-branch hybrid network based on transformer and convolutional neural network architecture. This network not only considers the global features of the image but also fully incorporates the local details of the image. In addition, we incorporate the hierarchical information of text to construct a hierarchical adaptive dynamic fusion module. The module employs a paired multihead attention mechanism and an adaptive adjustment strategy based on a gating mechanism. This design enables the model to capture and utilize the complementarity and correlation between the semantic and visual information at different levels in the text model. Simultaneously, it adaptively fuses the modal interaction features containing different information for the final detection task. DVHAM achieves an accuracy of 91.5%, 92.4%, and 90.6% on the Weibo, TWITTER, and PHEME datasets, respectively. This proves the effectiveness of DVHAM in the field of fake news detection.
Introduction
With the rapid development of the Internet and social media, online media has become increasingly prominent as a channel for news acquisition. More and more people have begun to use social media to get information about all aspects of social life, from politics and the economy to celebrity gossip, which has brought a far-reaching impact on society. According to the latest statistics from the International Telecommunication Union, nearly 5.4 billion people worldwide, or about 67% of the world’s total population, are using the Internet by 2023, a 45% increase from 2018. This figure reflects the unprecedented ease of access to news, but it also poses the challenge of news authenticity. Compared with traditional media, social media allows individuals and organizations to publish content freely, and information generation and sharing have become free and flexible. However, while enjoying convenience, it has also lowered the threshold for posting information, which has led to the proliferation of fake news on social media, bringing negative impacts on society. Moreover, algorithmic recommendations and personalized screenings on social media made it easier for users to access information that agrees with their views, further exacerbating the distortion of the truth, and the proliferation of fake news, which seriously impedes the healthy development of social media and the Internet as a whole.
Compared with traditional newspaper media, social media platforms have become one of the main channels for news dissemination of their real-time and interactive features. In social media, news forms also exhibited a trend toward multimodality. According to the research statistics (Yang, 2016), 35.1% of the fake news adopts the form of text-image fusion, and 24.3% of the fake news combines the three modes of text, image, and video at the same time. Especially in the fields of public health and social events, false information is usually packaged and disseminated with rich multimedia content. This suggestion indicates that relying only on single-modal text features could no longer meet the demand for effective detection of multimodal fake news in social media. Therefore, how to effectively detect multimodal fake news spread by social media platforms to ensure the health of the cyberspace environment has become an important challenge in today’s society.
Fake news detection in the early days mainly relied on experts in the field to make factual judgments and verifications, which not only failed to guarantee timeliness and scalability, but also was a great waste of human resources. To solve the limitations of the early methods, researchers classified fake news by combining manually labeled features with traditional machine learning,(Noble, 2006; Rish et al., 2001; Safavian & Landgrebe, 1991) but did not achieve satisfactory detection results. With the continuous development and application of deep learning, researchers have started to utilize deep neural network methods to detect multimodal news content (Farhangian et al., 2023), and the methods represented by convolutional neural networks (CNNs; Yoo, 2015) and recurrent neural networks (RNNs; Sherstinsky, 2020) have been widely proposed. This approach typically employs pretrained models to separately extract text and image features from the news. These features are then combined or enhanced using a simple concatenation or an attention mechanism, respectively, to obtain the final classification features. With the advent of the transformer (Vaswani et al., 2017), many methods have begun to use the BERT model (Kenton & Toutanova, 2019) for text feature extraction, due to its powerful text semantic extraction capabilities. These methods typically use the output of the last encoding layer of the BERT model as the text feature representation. In addition, many methods also combine transformer-based visual models, such as vision-transformer (ViT; Dosovitskiy et al., 2020) and Swin-transformer (SwinT; Liu et al., 2021), to extract language and visual features, respectively. Although these methods have improved performance compared to traditional methods (Wu et al., 2023), there are still issues with insufficient utilization of text and visual features and difficulties in modeling fine-grained interactions between images and text. Considering the above issues, this paper identifies several challenges in feature extraction and feature fusion for multimodal fake news detection methods:
The current methods of feature extraction are not comprehensive enough to be used effectively for fusion (Dosovitskiy et al., 2020; Kenton & Toutanova, 2019; Vaswani et al., 2017). Specifically, for text feature extraction, a common detection method is to use the last layer of encoding of the BERT model as the text representation. However, this approach overlooks the nuanced information captured in the intermediate layers of the BERT model, resulting in the loss of some important shallow and local semantic information. For image content extraction, the general approach is to use traditional CNNs alone for modeling to extract the corresponding features. While CNNs excel at local feature extraction, their ability to obtain global features is limited, resulting in overly localized image feature extraction. Additionally, some methods rely solely on transformer-based networks to extract features. Transformer models are proficient in their global sensory field, but they perform poorly in extracting local features. Therefore, most of the models are unable to extract the image features adequately, which affects the multimodal fusion. Effective fusion of multimodal features is a major challenge in multimodal fake news detection tasks. Traditional fusion methods (Sherstinsky, 2020; Yoo, 2015), such as early fusion and late fusion, often fail to adequately capture the complex interactions across modalities. Some existing methods (Qian et al., 2021; Singhal et al., 2019) simply concatenate the extracted features, failing to deeply explore the intrinsic correlations and complementarities among multimodal features. Some methods employ fixed weights to fuse features from different modalities (Qian et al., 2021; Singhal et al., 2019; Zhou et al., 2020), potentially overlooking the fact that different information sources contribute differently to the final result. Consequently, the comprehensive extraction and effective utilization of multimodal features, as well as the effective modeling of multimodal fusion networks, have emerged as hot topics of research in this field. We propose a dual-branch hybrid network based on CNN and transformer for fine-grained image modeling. This network design allows for deep interaction and fusion between the local features of convolution operations and the global representations of the self-attention mechanism, thereby enhancing the learning of image feature representations. This method not only extracts key information from images but also captures subtle differences within the images to optimize subsequent fusion effects. We propose a hierarchical adaptive dynamic fusion module that uses a paired multi-head attention (MHA) mechanism and an adaptive adjustment strategy based on a gating mechanism. The hierarchical modal interaction approach enables the model to capture and exploit the complementarities and correlations between the different levels of semantic and visual information in the text model. The adaptive tuning strategy enables the model to dynamically adjust the importance of the multilevel fusion features for the final detection task based on the quality and reliability of each level of fusion. We propose a
To address the above problems, this study proposes a new detection model that combines a two-branch hybrid network and a hierarchical adaptive fusion strategy to improve the detection of multimodal fake news containing images and text. The main contributions of this paper are as follows:
Methods for fake news detection are closely related to the evolution of news forms. Therefore, this section introduces the unimodal-based methods and multimodal-based detection methods based on the process of news form transformation from unimodal to multimodal, respectively.
Unimodal Fake News Detection
In terms of text, traditional unimodal fake news detection methods based on text features mainly rely on hand-designed statistical features (Castillo et al., 2011; Potthast et al., 2017; Volkova et al., 2017). These methods can capture the surface features of text but are limited to deep semantic information. In recent years, deep learning-based methods have gained much attention in the field of fake news. These methods utilize techniques such as pretrained word vectors, CNNs, and long short-term memory networks to extract richer semantic information (Hochreiter & Schmidhuber, 1997; Mikolov et al., 2013). For example, Ma et al. (2015) proposed a fake news learning model based on a recursive neural network (RNN) represented by text features in time series. Chen et al. (2018) proposed an RNN-based fake news detection model, which can selectively learn the time-hidden representations of consecutive news text sequences and capture the contextual changes of related news content over time.
With the diversification of news formats, images have taken on a key role in news content. Consequently, methods that utilize visual features to detect fake news have rapidly increased. Researchers have begun to utilize visual features to detect false information (Jin et al., 2016; Wu et al., 2015). To address this problem, existing methods mainly focus on analyzing the accompanying image information and the type of image features. For example, Qi et al. (2019) proposed an image pattern capture model based on CNN. They used CNNs to extract the frequency domain patterns of images used RNNs for semantic detection of photo authenticity, and finally used an attention mechanism to fuse the image patterns with the frequency domain patterns. Due to the development of diverse forms of data, the unimodal approach to fake news detection has some limitations in real-world enablement applications.
Multimodal Fake News Detection
Multimodal fake news detection aims to detect the authenticity of news using multiple modal information such as text and images simultaneously. Early work is mainly based on the attention mechanism to learn and fuse multimodal features. For example, Jin et al. (2017) proposed an RNN based on the attention mechanism to fuse image, text, and background features. Kumari and Ekbal (2021) designed a framework to improve multimodal representation by maximizing the correlation between text and image features. In recent years, the application of pretrained language models has greatly contributed to the development of this field. For example, Tuan and Minh (2021) introduced BERT to learn textual features of posts; Wang et al. (2018) proposed EANN model to learn feature representation of text and image by event discriminator. Zhuang and Zhang (2022) used GloVe (Pennington et al., 2014) and VGG16 (Simonyan & Zisserman, 2014) to extract text and image features, respectively. Khattar et al. (2019) reconstruction task to help feature fusion. In addition, scholars also work on modeling the semantic hierarchy of text. Qian et al. (2021) designed the HMCAN, which can model the semantic hierarchical relationship. Li et al. (2021) further modeled the correspondence between image and text entities based on this, and proposed the Entity-oriented Multi-modal Alignment and Fusion network.
In general, multimodal fake news detection fuses text and visual information and can achieve better results than a single modality, but there are still some deficiencies yet to be solved. For example, the modeling in feature extraction is not deep enough, resulting in less comprehensive feature extraction. The fusion strategy of the model is too simple to make full use of the correlation between modalities, and even if the interactions between modalities are taken into account, most of the works only consider the interactions between the image features and the deep textual semantic features, ignoring the influence of the shallow features on the judgment of the authenticity of the information.
Method
Model Overview
In this paper, we propose a multimodal fake news detection model based on the visual feature extraction method of dual-branch hybrid network and hierarchical adaptive fusion strategy, and the overall structural framework of the model is shown in Figure 1. The model is mainly composed of the following four parts:
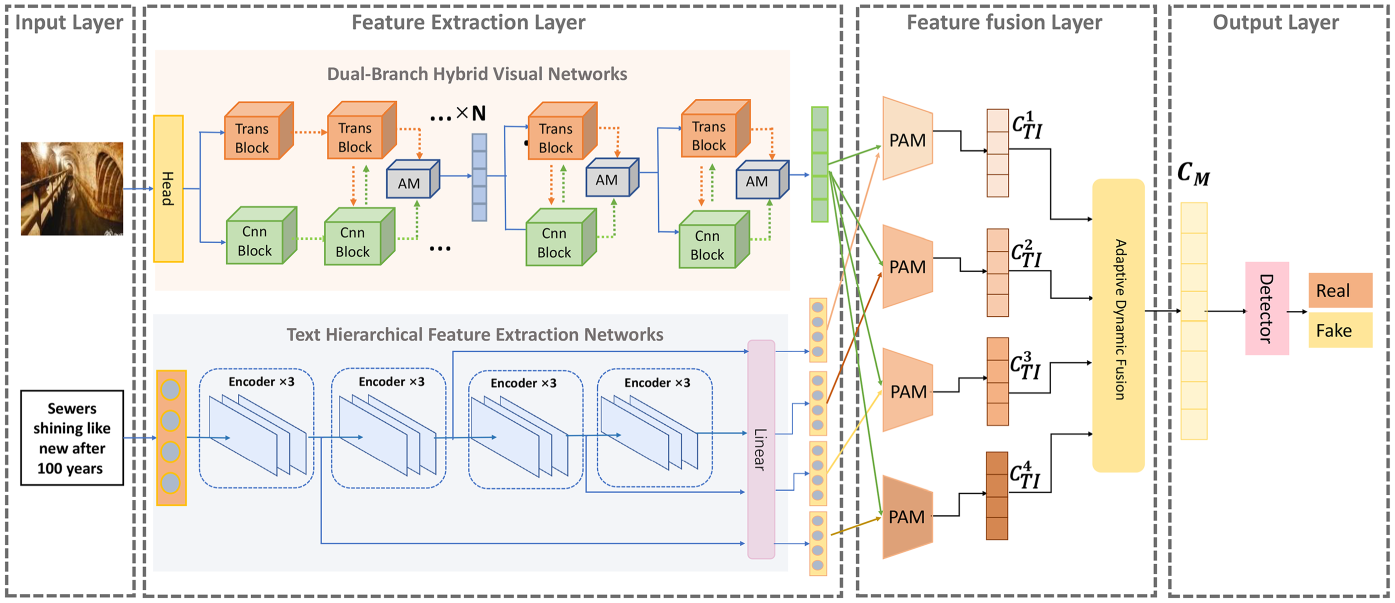
Overall Architecture of
For ease of reading, we provide a list of symbol definitions used as shown in Table 1.
Relevant Symbols and Definitions Used in This Document.
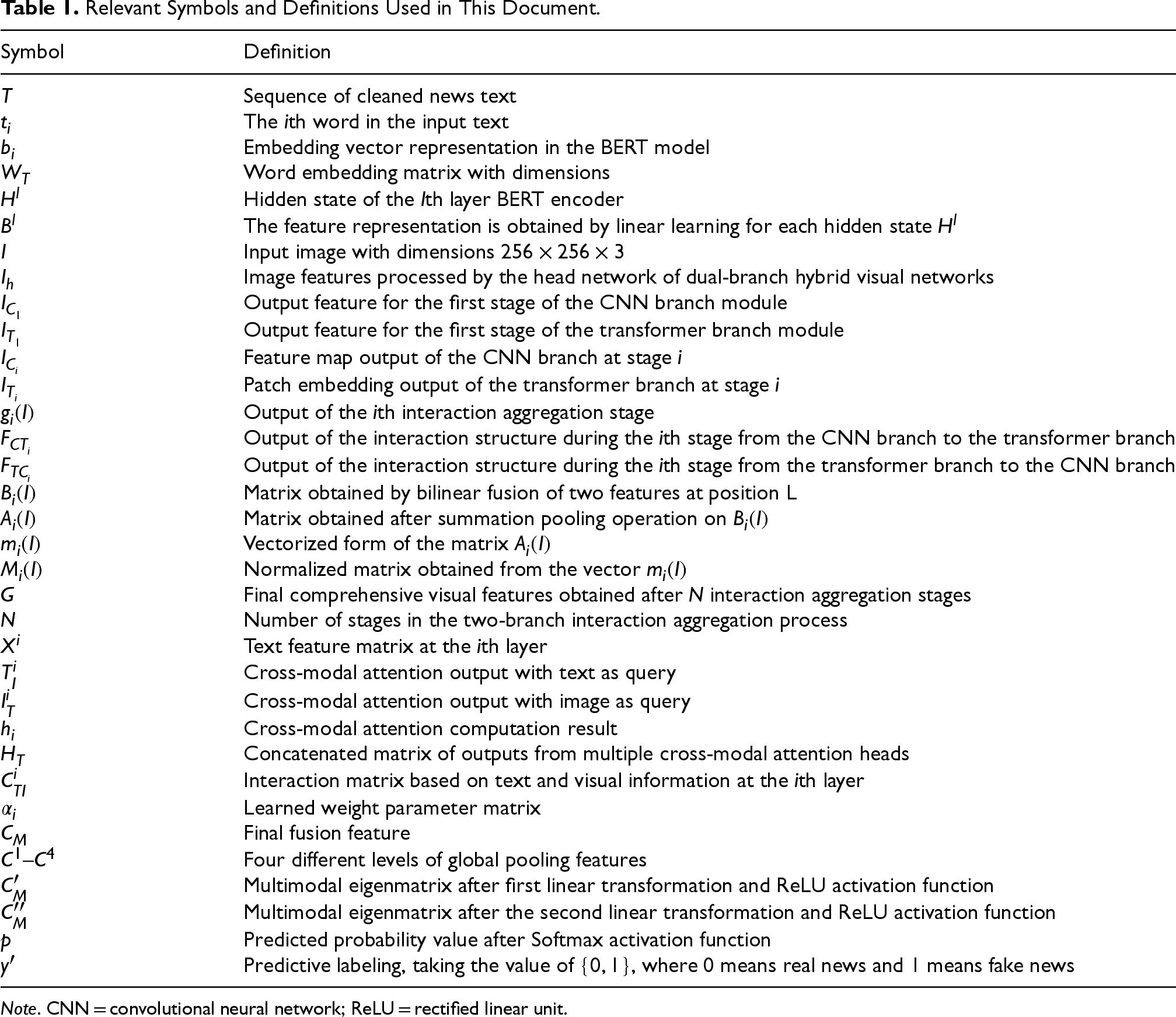
Note. CNN = convolutional neural network; ReLU = rectified linear unit.
The multimodal fake news detection task studied in this paper is modeled as a binary classification problem of determining whether the input news data is real news or fake news. The input data for the model is multimodal content containing both text and image information sources. The role of the input layer is mainly to preprocess the text and image content of the news data for model training. In the process of processing news text content, the first step is data cleaning, that is, removing irrelevant characters in the text. Then, the cleaned news text can be represented as 

In processing news image data, firstly, the input image
After a piece of news data has been preprocessed in the input layer, we feed the text and images into different feature extraction modules to realize the vectorized representation of the data. Therefore, the feature extraction layer of the model consists of two parts: hierarchical feature extraction of text and image feature extraction based on the dual-branch hybrid visual network.
Hierarchical Feature Extraction of Text
Text, as the main content of news, usually contains rich information, so text features become important clues for fake news detection. The quality of text feature extraction and whether it is adequately utilized have a significant impact on the final result of detection, so we use the BERT pretrained language model (Kenton & Toutanova, 2019) with excellent semantic extraction to extract text features. However, most of the methods use only the output of the last layer of the BERT model and ignore the hidden state of the middle layer, thus losing the complete hierarchical semantic information. To explore and capture complete text hierarchical semantic features to learn better multimodal news representations, we adopt a BERT pretrained model containing 12 layers of transformer encoders to extract text hierarchical semantic features. First, we input the text sequence 



As an important part of news, images contain feature information that is closely related to text information, thus playing an indispensable auxiliary role in the detection of fake news. For the current methods, most of them use pretrained visual models such as ResNet (He et al., 2016) and VGG (Simonyan & Zisserman, 2014) based on CNNs to extract features, but there is a lack of mining for the global features of the images. Some use Transformer-based visual models to acquire image features, but they are not as good as CNNs in focusing on the local salient features of the image. To better extract the rich and comprehensive features of an image, this paper designs a dual-branch hybrid network based on the architecture of Transformer and CNN to extract image features, and its detailed composition is shown in Figure 2.
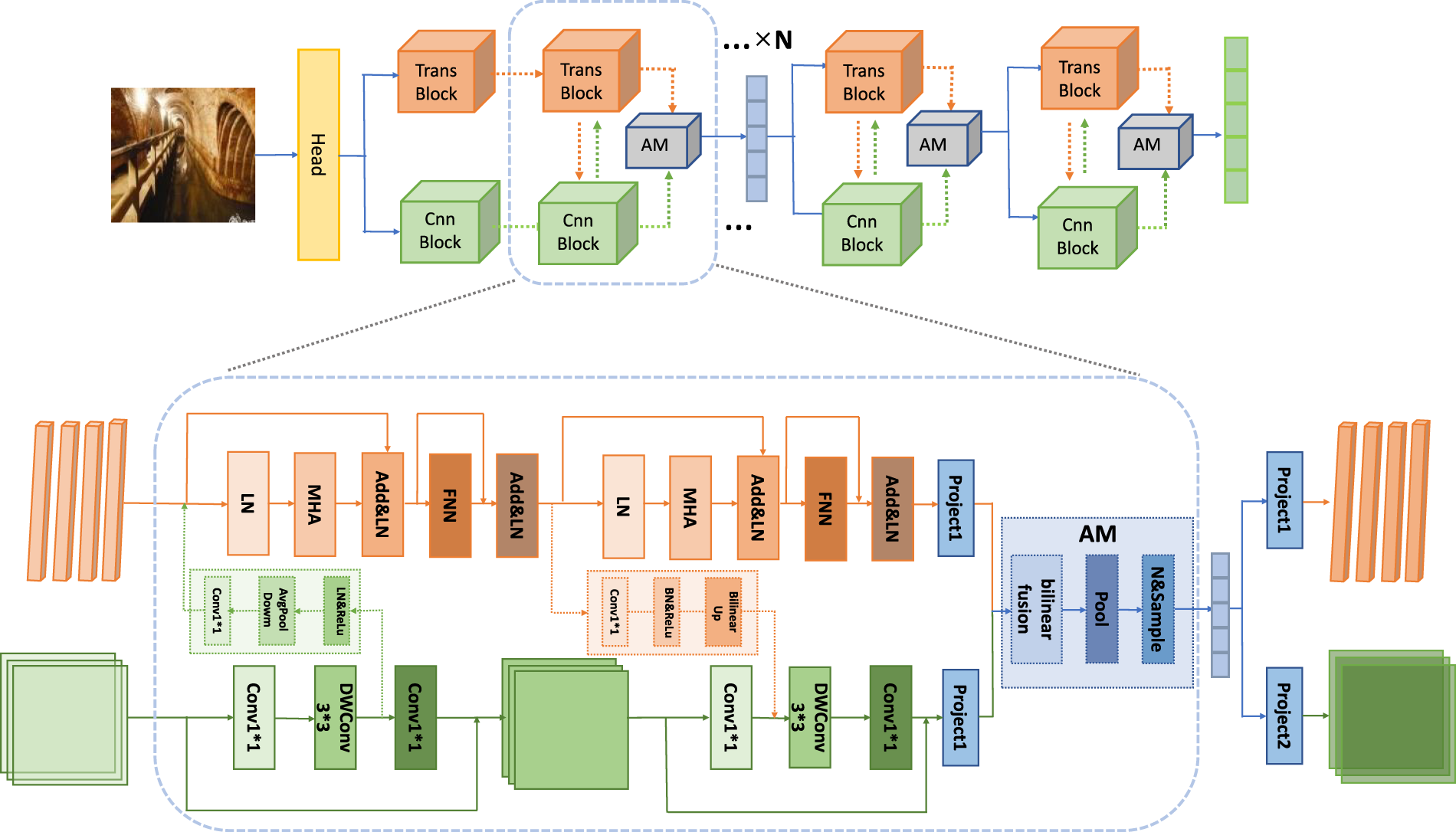
Dual-Branch Hybrid Visual Networks for Image Feature Extraction.
The dual-branch hybrid network is composed of a head module and 





The interaction structure comprises a down-sampling module and an up-sampling module. This is designed to address the misalignment issue when interacting between the feature maps of the CNN branch and the patch embeddings of the transformer branch. To input the feature maps from the CNN branch into the transformer branch, a 

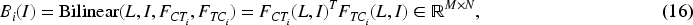
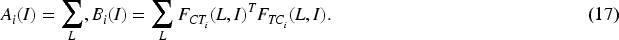

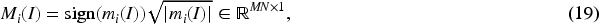

The primary objective of the feature fusion layer is to interact with the hierarchical text and image features outputted by the feature extraction layer, generating a fused feature vector for fake news detection. To address the issue in previous methods where multimodal features were simply concatenated, failing to capture the close connections between modalities at a fine-grained level, we designed a hierarchical adaptive dynamic fusion module. As shown in Figure 1, the module consists of four paired MHA mechanism (PAM) fusion modules and an adaptive dynamic fusion module. The detailed structure of the PAM fusion modules is shown in Figure 3, it can be observed that the proposed PAM module mainly consists of two cross-modal MHA layers (Vaswani et al., 2017) and feed-forward neural (FFN) networks. The inputs of the PAM module are feature vectors from two different modalities, and each of the outputs is an interaction feature after residual concatenation and normalization operations.
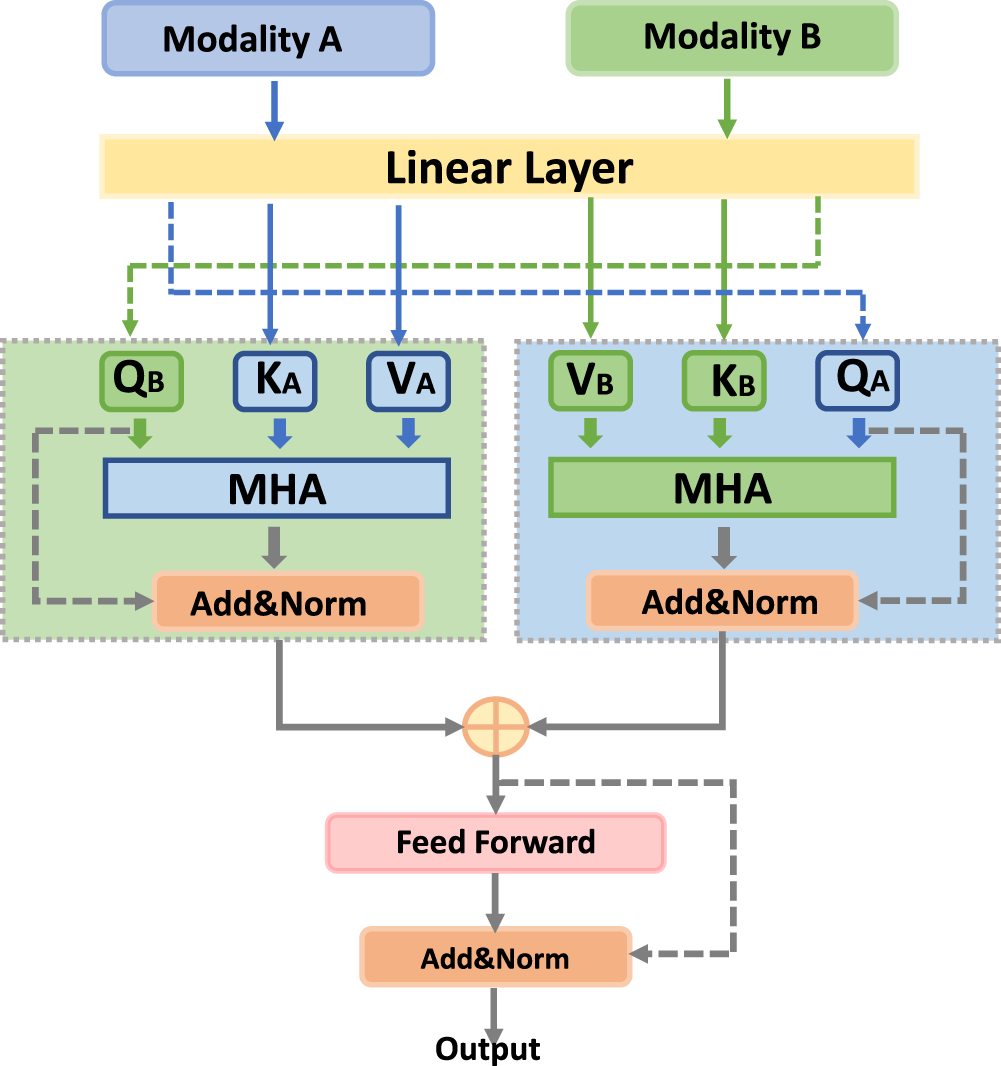
Paired Multi-Head Attention Mechanism (PAM).
To model multimodal information more effectively, we input four different levels of text features and image features together into four PAM fusion blocks for interaction, which allows the model to capture and exploit the complementarity and correlation between semantic and visual information at different levels of the text model. This enables the model to better understand and utilize the complex relationships between textual and visual information. The specific process is as follows: firstly, we regard a text feature matrix
For the PAM fusion block, the attention calculation process is shown in the following equation:
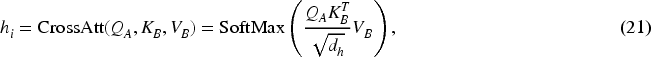






The effective integration of the four modal interaction vectors, each with varying degrees of importance, is a crucial aspect of the model detection task. Existing models often simply concatenate multimodal feature vectors or use average fixed weights to integrate features from different modalities. This approach overlooks the varying importance of different information sources to the final result, thereby introducing excessive noise. To address this issue, we propose an adaptive tuning structure that employs a gating mechanism, as illustrated in Figure 4. Specifically, our model assigns unique learnable parameters to four different fusion features and performs adaptive weighted concat operations to derive the final multimodal feature representation of a news article. The process unfolds as follows: initially, we apply global average pooling to the four output features, thereby compressing the global spatial information into a single-channel description. Subsequently, these four features are concatenated and processed through a gating mechanism, which comprises a fully connected layer, an ReLU layer, another fully connected layer, and a Sigmoid layer. This mechanism yields four weighting factors, denoted as 


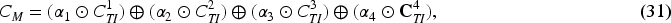
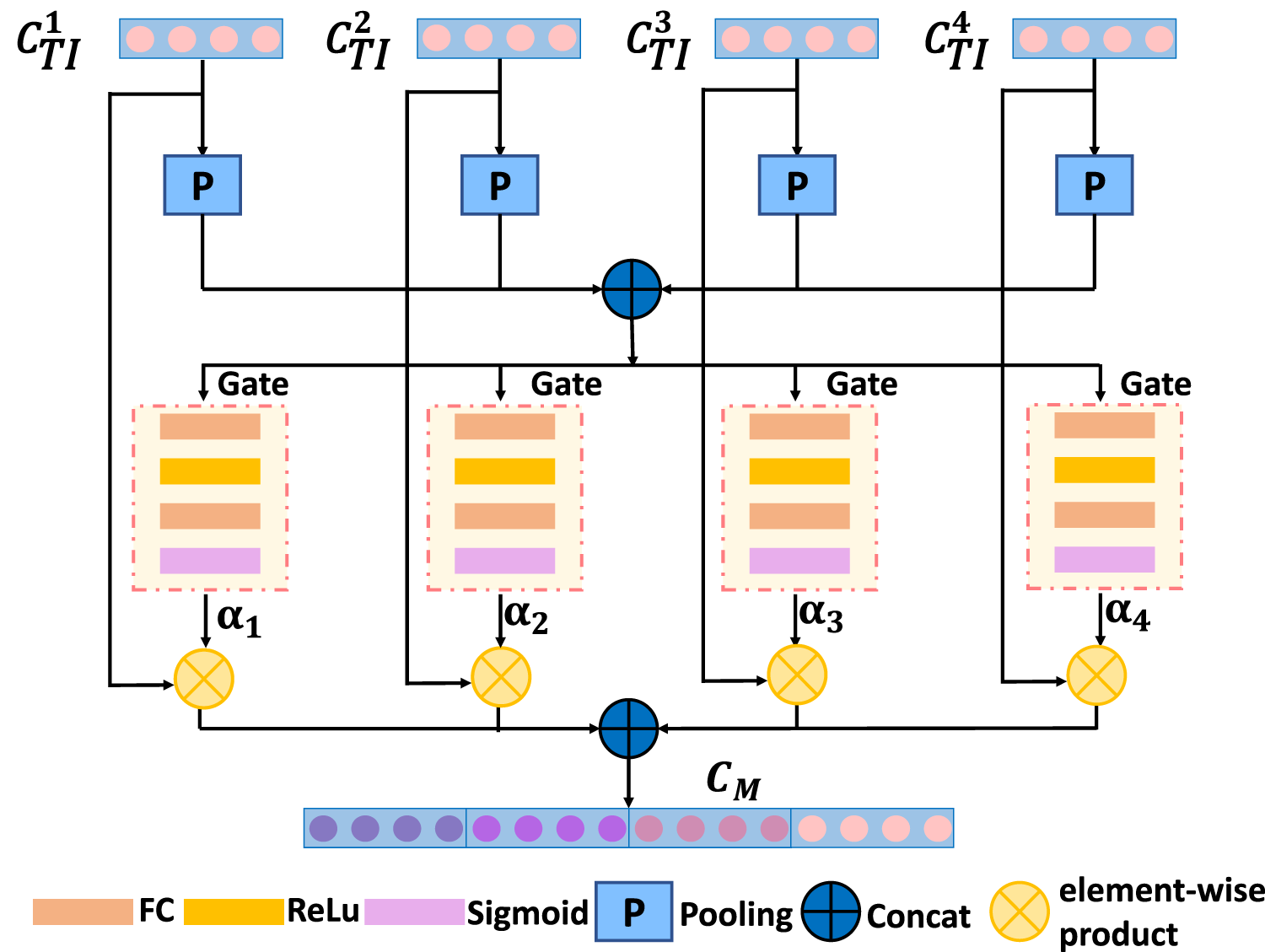
Adaptive Dynamic Fusion Module.
The output layer in the final part of DVHAM is the multimodal fake news detector. The role of this layer is to utilize the multimodal features obtained through the fusion layer to predict the authenticity of the news. This output layer is composed of two linear transformation layers, the ReLU activation function and a fully connected layer with the Softmax activation function. Its input is the multimodal feature 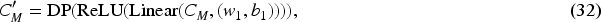



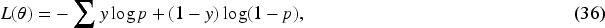
Datasets
In the research field of fake news detection, there are many publicly available real-world datasets available for use. However, to comprehensively and accurately evaluate the performance of DVHAM, we selected three multimodal datasets containing both image and textual information for experimental validation based on differences in language and collection objects, respectively: the WEIBO dataset (Jin et al., 2017), the TWITTER dataset (Boididou et al., 2014), and the PHEME dataset (Zubiaga et al., 2017). These three datasets enable us to test the generalization ability and validity of our model in diverse environments.
The WEIBO dataset was collected by (Jin et al., 2017), and originates from Sina Weibo, a prominent social platform in China. Consequently, the dataset is in Chinese and has been officially authenticated by China’s authoritative Xinhua News Agency. As depicted in Table 2, the dataset comprises 9,528 pairs of text and image matches corresponding to news articles, with an approximately even distribution of real and fake news. For the partitioning of the WEIBO dataset, we randomly allocated it into a training set, and validation set in an
Statistical Data for the WEIBO Dataset, TWITTER Dataset, and PHEME Dataset.

Statistical Data for the WEIBO Dataset, TWITTER Dataset, and PHEME Dataset.
The TWITTER dataset (Boididou et al., 2014) was collected on the multimedia social platform Twitter in the English language. Each tweet on this dataset contains text, visual information, and user information. To comply with our research objectives, we eliminated the user information from the dataset. This dataset comprises a development set and a testing set. The development set includes events associated with 17 rumors, whereas the test set includes events linked to an additional 35 rumors. As illustrated in Table 2, the dataset consists of 6,026 real news, 7,098 fake news, and 514 images, indicating a relatively small quantity of images. For this study, the development set serves as the training set, and the test set serves as the test set.
The PHEME dataset (Zubiaga et al., 2017) was collected by the authors on the Twitter platform for five different events in the English language. The original dataset comprises news text, corresponding images, and annotations. Given our objective of detecting fake news that includes both text and images, we retained only those data instances in the dataset that contain both text and images. The specifics of the data post-cleaning are presented in Table 2. The dataset includes matching pairs of text and images for 2018 news items. Compared to the WEIBO dataset, the distribution of news categories in the PHEME dataset is uneven, and the volume of data is relatively small. This presents a challenge for the validation of our model. For the partitioning of the PHEME dataset, we divided it into training and test sets at a ratio of
All the experiments in this paper were conducted under Ubuntu 20.04 and Python 3.8, utilizing the PyTorch deep learning framework for model construction and training. The GPU model used was the NVIDIA Tesla P100. The models used in our study are pretrained BERT models, bert-base-chinese and bert-base-uncased depending on the language of the datasets. The training process was configured with a batch size of 8 and was run for 200 epochs. To mitigate the risk of overfitting, a dropout rate of 0.6 was applied during training. The Adam optimizer was used with a learning rate of
The multimodal fake news detection studied in this paper is a binary classification problem. The experiments use four commonly used metrics of binary classification performance, namely accuracy, precision, recall, and F1 score, to evaluate the performance of DVHAM and baseline models. In this study, the time complexity can be expressed as
Baseline Model
To validate the performance of the proposed model in the multimodal fake news detection task, a series of comparison tests with the baseline models are conducted. These baseline models (Qian et al., 2021) are mainly categorized into two types: unimodal models and multimodal models.
Unimodal Baseline Models
Unimodal is a model that utilizes only a single information source such as text or image for fake news detection, and the unimodal model we selected is described in detail below:
Multimodal Baseline Model
Multimodal is a model that uses multiple sources of information such as text and images at the same time for fake news, and the multimodal baseline model we have chosen is described in detail below:
The data in Table 3 shows the comparison of the results of DVHAM and the baseline model on the three datasets. It can be observed that our proposed DVHAM outperforms the baseline model on all three datasets in several metrics. Specifically, DVHAM achieves accuracies of 0.915, 0.924, and 0.906 on these datasets, which are 1.2%, 6.9%, and 3.6% better than the latest benchmark model, MRAN, respectively. Notably, DVHAM outperforms all other models in terms of F1 scores for both real news classification and fake news classification on both the WEIBO and TWITTER datasets. This outcome demonstrates that our model has enhanced its performance comprehensively on both English and Chinese datasets. However, the F1 score of fake news on the PHEME dataset is not the best, and we analyze the reason for its small amount of data. Figure 5 shows the accuracy of all models and the comparison of F1 scores on fake news, we next analyze the data in detail from the following aspects:
From the level of traditional and deep learning methods, the SVM-TS model performs the worst in all aspects of the three datasets, indicating that the traditional manual extraction of features is not effective and cannot recognize fake news. Regarding unimodal and multimodal methods, the unimodal models (CNN, GRU, and TextGRU) in the baseline model significantly underperform in terms of accuracy and F1 scores. The DVHAM outperforms the best unimodal model, TextGRU, on the three datasets by 12.8%, 22.1%, and 7.8% in terms of accuracy, respectively. This suggests that employing multiple sources of information for fake news detection is superior to relying solely on text, and that visual information can play a significant supporting role. In terms of whether or not the fusion mechanism is used in the fusion process, the SpotFake model uses the BERT pretraining model to extract text features, which can achieve superior performance over the earlier multimodal models EANN and MVAE, which illustrates the power of the BERT model, but the SpotFake model is just a simple connection between image and textual features, which is worse than HMCAN and DVHAM, which used the attention mechanism for the fusion in terms of accuracy, and F1 scores, which demonstrates that the attention mechanism has a good effect in the modal fusion. DVHAM outperforms the individual baseline models in overall performance, illustrating the effectiveness of our designed pairwise MHA mechanism and adaptive fusion strategy.
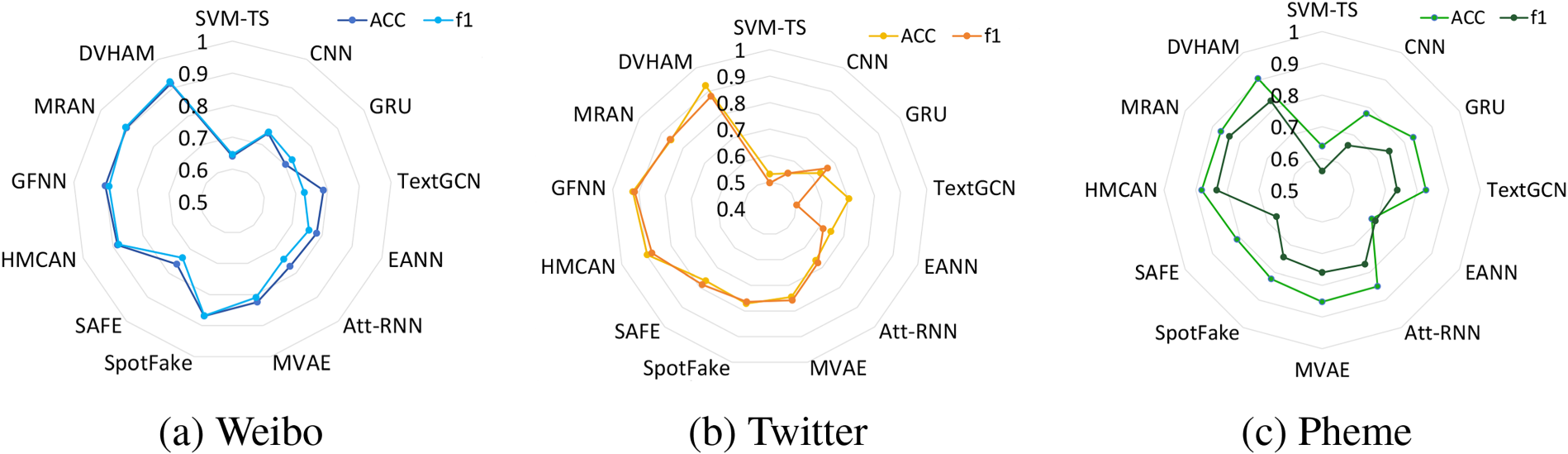
Comparison of Accuracy and F1 Scores for Fake News Detection Across Three Datasets: (a) WEIBO, (b) Twitter, and (c) PHEME.
The Comparison Results of
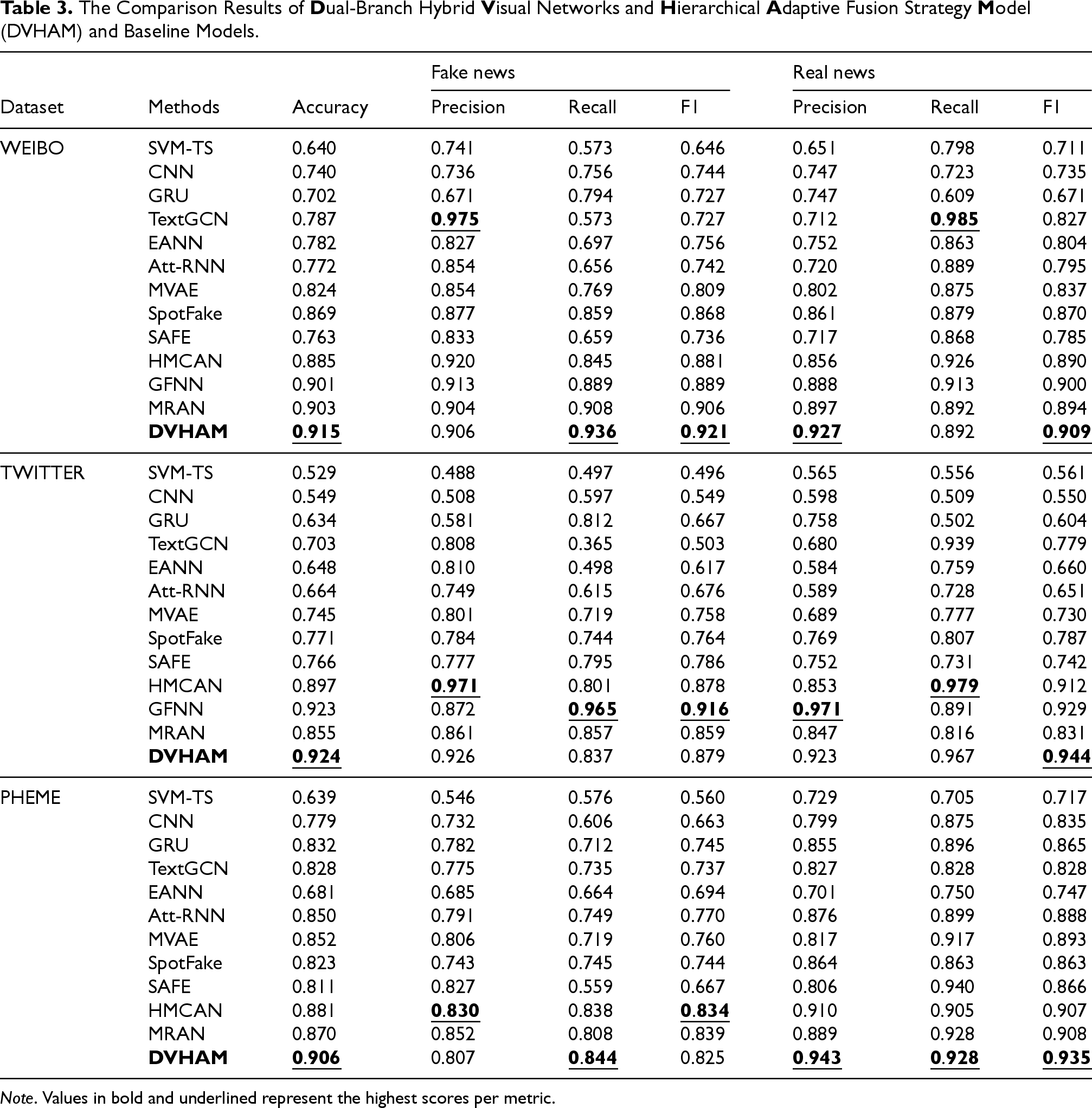
Note. Values in bold and underlined represent the highest scores per metric.
Given that DVHAM is constructed from multiple components, we aim to ascertain the impact of each component on the experimental outcomes. To this end, we have designed the following variants of DVHAM for analysis in ablation methods across each of the three datasets:
We compare DVHAM-T and DVHAM-I, which use only image features and text features for detection, respectively, and their accuracy and F1 scores are less effective than the other variant models. This indicates that the unimodal methods perform significantly lower than DVHAM, and DVHAM’s use of a combination of text and picture features is critical for improving model performance. For DVHAM-G and DVHAM-F, these two methods do not use adaptive dynamic fusion mechanisms and pairwise fusion with multiple attention mechanisms, respectively. The results are significantly lower than those of DVHAM, indicating that these two mechanisms play a significant role in DVHAM, especially the adaptive dynamic fusion mechanism, which dynamically adjusts the weights of the features according to different inputs to better capture the correlation between text and images. DVHAM-C, which deletes the hierarchical text features, compares with the final model, DVHAM, and its accuracy decreases by 0.6%, 7.6%, and 3.4% on the three datasets, respectively, which indicates that the shallow features of the model’s text also play a non-negligible role. Comparing DVHAM-R and DVHAM-V, which change the dual-branch hybrid visual network to a single-stream network, respectively, both the accuracy and F1 scores are drastically reduced compared to DVHAM, indicating that the dual-stream network we designed helps to improve the performance of the model because it is able to capture the features of the images from different perspectives, which provides richer information.
The experimental results are shown in Table 4. It can be seen that DVHAM has a better performance than any variant model, which indicates that our components play a non-negligible role in the final result. We analyze the ablation experiments in the following details:
The Comparison Results of
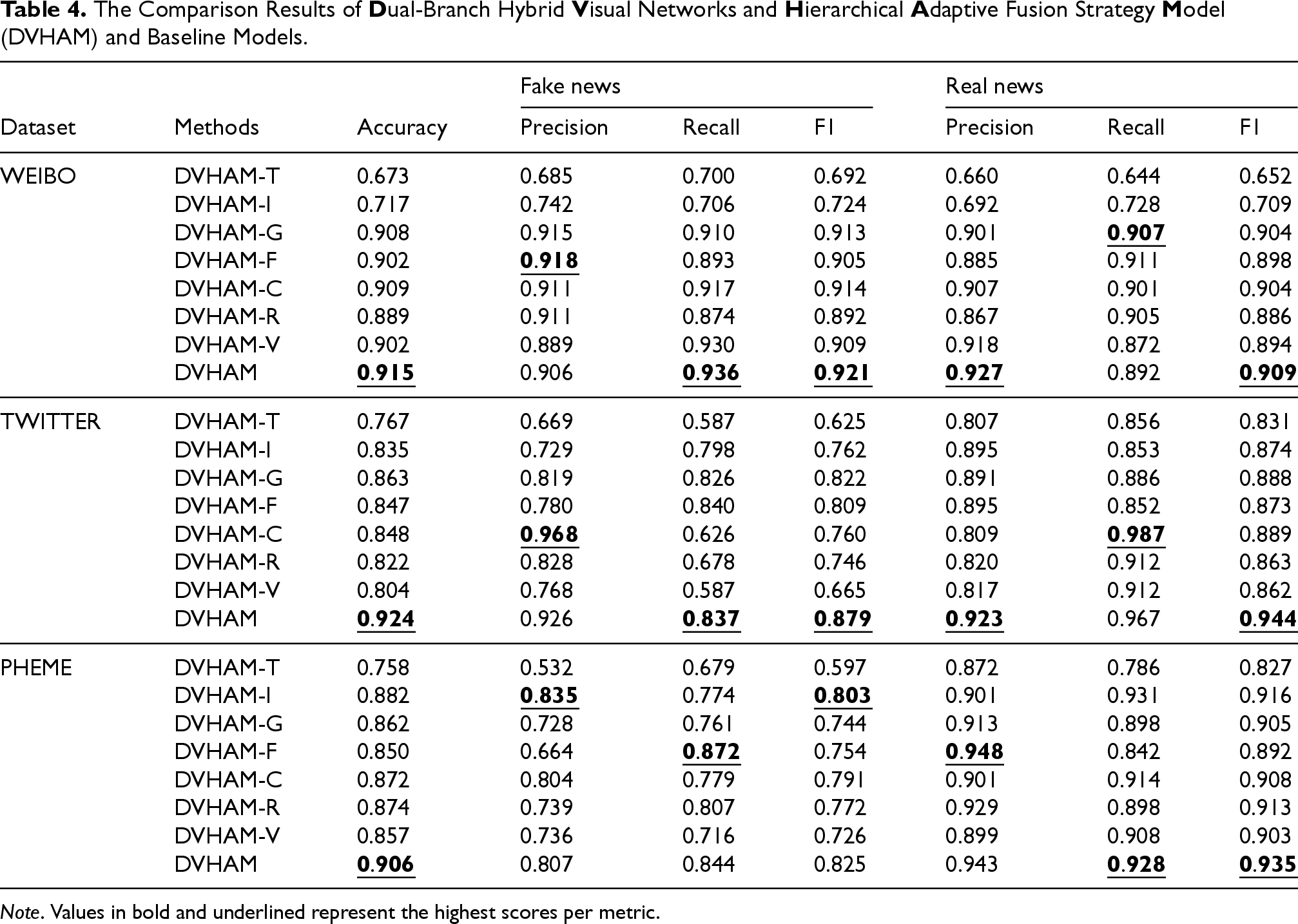
Note. Values in bold and underlined represent the highest scores per metric.
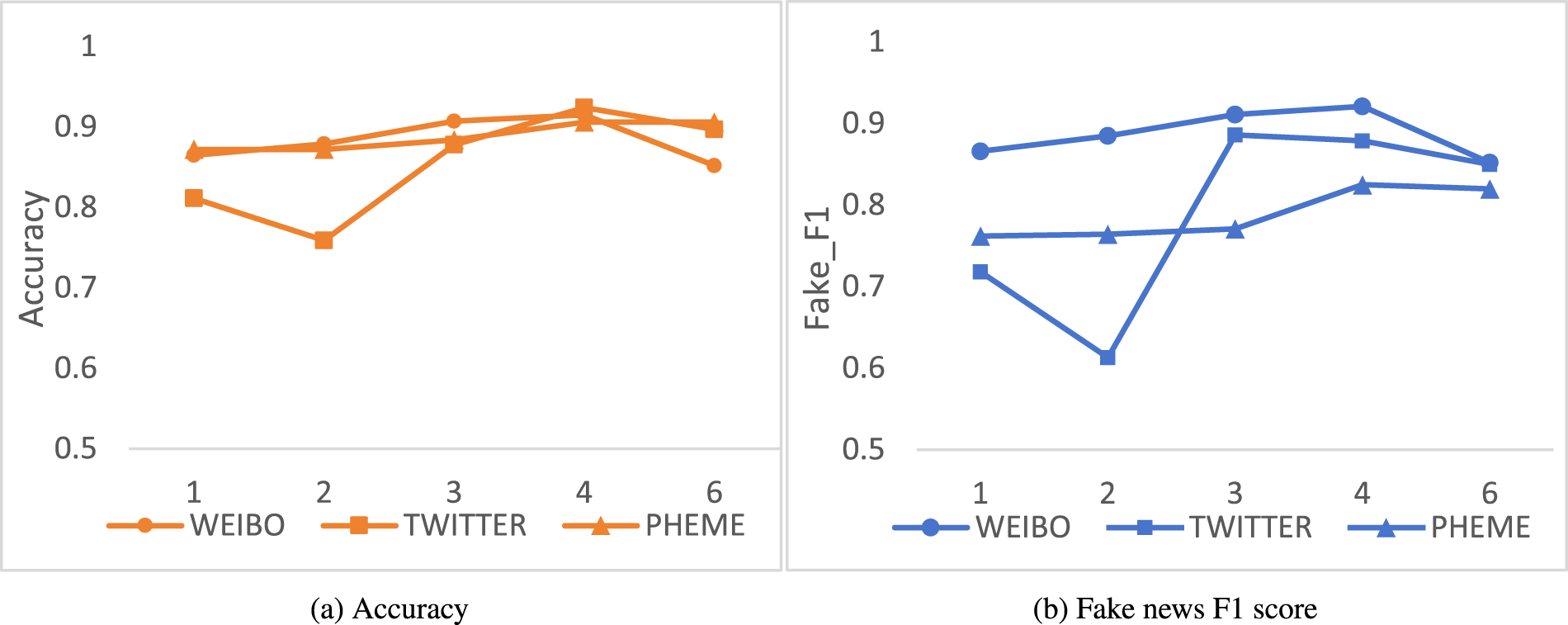
Effect of Parameter G on experimental results: (a) Accuracy and (b) Fake News F1 Score.
Overall, each component of DVHAM has an important impact on the model performance, and the combination of these components enables DVHAM to efficiently process multimodal information in text and images, which has improved the performance of the fake news detection task.
This section presents validation experiments conducted on three datasets, discussing the impact of key parameters within DVHAM on the experimental outcomes. Notably, the parameters exerting substantial influence on DVHAM are the number of text layers
Another critical parameter is the quantity of interaction aggregation modules
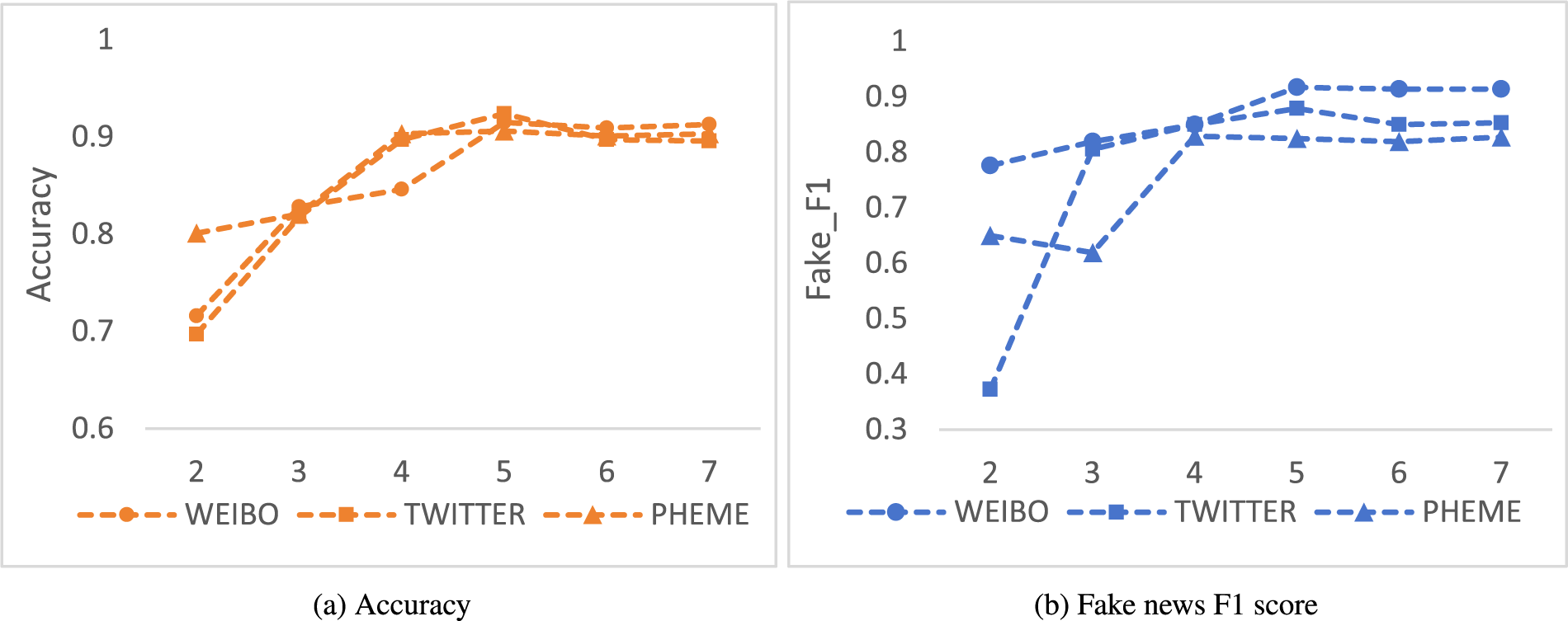
Effect of Parameter
In this paper, we address the social challenge posed by the spread of fake news, which significantly impacts cyberspace governance, by proposing a DVHAM. The DVHAM model introduces a dual-branch hybrid network architecture and a hierarchical adaptive dynamic fusion module. The dual-branch hybrid network, based on transformer and CNN architectures, not only considers the global features of the image, but also integrates the local details, addressing the limitations of existing models in image feature extraction. The model employs a paired MHA mechanism and an adaptive adjustment strategy based on a gating mechanism, which capture and utilize the complementarity and correlation between different levels of semantic and visual information within the text model, thus overcoming the limitations of current models in fusing multimodal information. Through comparative and ablation experiments on three datasets, DVHAM has demonstrated its effectiveness and feasibility in the domain of fake news detection.
Although DVHAM has demonstrated its effectiveness in extracting and fusing multimodal information for fake news detection, its robustness may be compromised in scenarios involving noisy data or adversarial attacks. For instance, in real-world settings where image data is significantly degraded, the dual-branch hybrid network’s ability to extract global and local features may encounter difficulties in distinguishing genuine features from noise. Similarly, text inputs embedded with adversarial perturbations can disrupt the paired MHA mechanism and the adaptive gating strategy, resulting in a suboptimal fusion of semantic and visual information. Future work on DVHAM should aim to improve its robustness by enhancing preprocessing with noise-reduction and augmentation techniques and adopting adversarial training methods to better handle corrupted data and resist attacks, ultimately evolving into a more resilient framework for diverse scenarios. However, DVHAM currently only considers the text and image information of news and has not yet covered information such as audio and the social context of news. Given the large amount of audio information, propagation paths, user characteristics, and data distribution in the current news, how to effectively utilize these multimodal information sources for fake news detection will be an important direction for our future research. We expect that through further research and exploration, we will be able to propose more comprehensive and effective fake news detection methods.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was supported by the National Natural Science Foundation of China (No. 61976085).
Declaration of Conflicting Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.