
Abstract
This paper aims to study human behavior recognition techniques in nighttime near-infrared surveillance videos and address the lack of lightweight behavior recognition networks in the field of nighttime near-infrared public monitoring. The goal is to develop a method suitable for lightweight edge processing devices. Due to the absence of a nighttime infrared video behavior recognition dataset, we have constructed a custom dataset for human behavior in near-infrared monitoring. This dataset involved 1630 video samples categorized into 10 classes. To overcome the challenge posed by large models and high device requirements, we propose a behavior recognition algorithm based on lightweight two-dimensional convolutional neural networks. This algorithm can adapt to low-quality near-infrared surveillance videos. Besides, it's able to focus on different temporal features and avoid interference from static background frames in long videos. The proposed method achieves an accuracy of 92.3% by using the self-built dataset captured by an active infrared camera and exhibits a processing speed of 35ms per video on the AGX Xavier device. Compared to popular lightweight algorithms like MoViNet-A0 and X3D-XS, this algorithm achieves higher accuracy and shorter processing time under similar model computational complexity.
Introduction
Human behavior recognition technology is an important task in computer vision, with significant demand and broad prospects in intelligent security, human–computer interaction, and autonomous driving. For example, the construction of “Safe Cities” relies on city alarm and surveillance systems, where manual review of nighttime public infrared surveillance video data is the primary method for security event analysis. However, this approach is associated with high costs, long processing times, and issues of inaccuracy or ambiguity in judgment. Therefore, implementing rapid online analysis of this video data through artificial intelligence techniques holds great significance. This approach enables the quick identification, tracking, and alerting of behaviors that pose a threat to public safety. However, nighttime infrared surveillance videos have a poor image quality and are subject to various interferences, making videos unsuitable for applying visible light analysis methods. Additionally, there need to be more available datasets for nighttime public near-infrared surveillance videos. In complex nighttime scenarios, human behavior constitutes only a tiny portion of the long video recorded by infrared surveillance devices, and blank background frames can affect recognition results. Besides, current deep learning models have high requirements for data and computational performance, making it a challenge to implement them in terminal applications.
Current research on infrared video behavior recognition mainly focuses on the thermal infrared video modality. For example, Hei et al. (2021) uses mapping methods to reduce input video data to a low-dimensional feature space and applies cosine similarity to weigh the features before using support vector machines for classification. Chen et al. (2021) designs a lightweight optical flow estimation network and applies attention mechanisms to fuse optical flow and thermal infrared modal features for video classification. These methods refer to visible light-related works and are specifically designed for thermal infrared videos, which lack color information and suffer from severe noise interference. However, due to the high cost of thermal infrared cameras and the lack of texture information in their images, thermal infrared cameras are mainly used in scenarios such as bank, military, and fire alarm systems. On the other hand, public surveillance infrared cameras mainly use active infrared cameras, which integrate RGB (Red, Green, Blue) visible light imaging and near-infrared imaging to achieve 24h imaging. And they are technically simple and cost-effective, allowing for wide application in indoor monitoring and public settings. However, the research field of thermal infrared videos benefits from publicly available datasets like Infer (Gao et al., 2015), which facilitate deep learning-based research. In contrast, the research field of near-infrared surveillance videos lacks relevant public datasets. Although the Nanyang Technological University (NTU) dataset (Liu et al., 2020) uses active infrared cameras for recording, it is primarily focused on indoor scenes. Compared to indoor settings, outdoor near-infrared surveillance videos require the construction of datasets that specifically address nighttime outdoor scenarios, as the infrared illuminator's lighting effect is significantly better than indoors. Therefore, constructing a nighttime near-infrared surveillance video dataset is one of the contributions of this paper.
According to the analysis above, current research on behavior analysis in nighttime surveillance videos primarily focuses on deep learning training using thermal infrared data. Whereas these models are large in scale and computationally complex, making them unsuitable for on-site deployment. In contrast, there have been some lightweight behavior recognition algorithms in the visible light domain. For instance, Abid Mehmood proposed a lightweight framework called LightAnomalyNet (Mehmood, 2021) for efficient anomaly detection. However, it requires complex preprocessing of input images, such as converting three consecutive frames of a video into a single 3-channel RGB image for feature extraction and inference. Although this approach enables the use of two-dimensional (2D) convolutional neural networks, the complex preprocessing stage cannot be integrated into the network, hindering low-latency real-time detection. Yuqi Huo et al. (2020) introduced a novel algorithm called Aligned Temporal Trilinear Pooling (ATTP), which integrates multiple modalities extracted from compressed videos, including RGB I-frames, motion vectors, and residuals. ATTP employs an explicit temporal fusion method to capture temporal context and combines models trained on feature alignment using knowledge distillation strategies and models trained on optical flow from uncompressed videos. Reference (Kondratyuk et al., 2021) proposed a computationally and memory-efficient video network for mobile devices. It uses neural architecture, which searches to generate efficient and diversified three-dimensional (3D) CNN architectures. Additionally, it introduces streaming buffering techniques to decouple memory and the duration of video segments, enabling 3D CNN to process arbitrarily long streaming video sequences with smaller memory footprint and simple integration techniques, further improving accuracy without sacrificing efficiency. Among these, the MoViNets-A0 network's parameters and computational complexity are similar to those in this study and will be compared in subsequent experiments. Evgeny Izutov provided a lightweight solution called LIGAR (Izutov, 2021), which employs a series of strategies to reduce model complexity and computational workload, including streamlined network structures, parameter reduction, and optimized model inference processes. Through these strategies, LIGAR achieves high behavior recognition accuracy while maintaining a tiny model size and a tiny computational complexity. Currently, lightweight behavior recognition algorithms yield lower results compared to regular convolutional neural network models and require more video preprocessing methods. Compared to end-to-end convolutional neural network approaches, lightweight behavior recognition algorithms increase model complexity and are not convenient for deployment. Yin et al. (2024) proposed a lightweight one-step behavior recognition method Dark-DSAR based on transformer. This method integrates domain transfer and classification tasks into one step, enhancing the functional consistency of the model on these two tasks, thereby reducing the computational complexity of Dark-DSAR. They also explored the matching relationship between the input video size and the model, and further optimized the inference efficiency by reducing the spatial resolution to remove redundant information in the video. Shi and Liu (2024) combined the pose estimation algorithm, CNN model and Vision Transformer to build an efficient human action recognition framework. The first step is to use the latest pose estimation algorithm to accurately extract human pose information from real RGB image frames. Then, the pretrained CNN model is used to extract features from the extracted pose information. Finally, the Vision Transformer model is applied to fuse and classify the extracted features. Currently, lightweight models (Shi & Liu, 2024; Yin et al., 2024) are moving toward lightweight Transformer models (Vaswani et al., 2017), which have achieved significant success as sequence modeling methods with self-attention mechanisms in natural language processing and image domains (Bertasius et al., 2021; Koot & Lu, 2021; Liu et al., 2022). However, reference (Koot & Lu, 2021) discusses the limitations of lightweight Transformer in video behavior recognition and demonstrates that composite models with enhanced convolutional backbones perform better than lightweight Transformer-based networks in lightweight action recognition. This is because models relying solely on attention mechanisms require more motion modeling capabilities, which are lacking in lightweight models implemented using Transformer. Therefore, this study does not compare the composite model with the Transformer model. Based on the advantages and disadvantages of the aforementioned lightweight models, this study plans to design a lightweight model applicable to nighttime near-infrared surveillance videos without using additional video processing methods but rather employing an end-to-end framework for ease of deployment.
Based on this, this article proposes a lightweight online human behavior recognition method for nighttime surveillance videos. The contributions of this study are as follows: (1) existing behavior recognition datasets, both domestically and internationally, mainly consist of videos captured in daytime scenes or thermal infrared videos. Therefore, to recognize common behavior in near-infrared video scenes, it is necessary to construct a nighttime infrared video dataset. This study uses a custom near-infrared human behavior dataset captured by an active infrared camera with our research group, which includes 1630 videos covering ten common human behaviors. (2) Current deep-learning methods for behavior recognition rely on large-scale models with high device requirements. In this study, instead of using voluminous 3D convolutional neural networks, a time modeling capability is designed based on a 2D convolutional neural network. The proposed network exhibits better motion information extraction capabilities with only 1/20th of the parameters of the latter. (3) The residual branch of the feature extraction network is redesigned to accommodate the characteristics of infrared surveillance videos. Motion attention mechanisms and spatiotemporal attention mechanisms are used to replace optical flow algorithms, providing motion information between adjacent frames. Simultaneously, self-attention mechanisms are applied to different temporal features, mitigating the interference caused by static background frames in long videos.
Related Work
With the development of deep learning technology, an increasing number of researchers are using deep learning for behavior recognition research. Currently, there are few behavior recognition methods based on infrared videos. Therefore, this paper mainly focuses on presenting works based on visible light. This chapter provides a comprehensive analysis of (1) lightweight video understanding networks, (2) motion information extraction algorithms, and (3) the impact of temporal features on behavior recognition.
Framework Based on TSN
The Temporal Segment Network (TSN) is a popular network architecture proposed by Limin Wang et al. (2016) for video action recognition tasks. The TSN network has a relatively simple structure and can be combined with various visual models such as 2D convolutional networks and 3D convolutional networks. The network segments the video and extracts single-frame video image features using a 2D convolutional neural network. It then fuses the features from different segments and performs classification. Compared to some optical flow-based methods, TSN has lower computational complexity. It also reduces the number of network parameters compared to 3D convolutional neural networks while lowering computational complexity. However, TSN performs poorly on videos with complex temporal relationships. For example, it achieves lower results on the Kinetics and Something V2 visible light datasets, with accuracies of 70.6% and 30%, respectively, which are significantly lower than the results of 3D convolutional neural networks. On the self-built dataset, the recognition accuracy is 69%, lower than that of other mainstream deep learning algorithms and lower than the results of traditional Improved Dense Trajectories (IDT) algorithms. This is because TSN only recognizes single-frame images or short-term optical flow images, and its modeling ability is limited for videos with complex content and longer durations. So, other methods are needed to assist with temporal modeling. Additionally, the TSN network uses ResNet50 as the feature extraction network, which has a high computational complexity and parameter count, making it unsuitable for deployment on edge devices. In 2018, Mark Sandler et al. proposed a lightweight convolutional neural network called MobileNetV2, which uses depthwise separable convolution to significantly reduce the computational complexity of the model. They also introduced an inverted residual structure to increase the feature dimension for feature extraction. MobileNetV2 achieves similar recognition accuracy as ResNet50 with only 1/20 of the parameters. Therefore, in this paper, MobileNetV2 is used as the backbone network instead of ResNet50.
To address the issue of temporal modeling in complex situations, this article introduces the Temporal Shift Module (TSM) into TSN. TSM is a module proposed by researchers from the Chinese University of Hong Kong in 2019 for video understanding tasks (Lin et al., 2019). TSM achieves temporal relationship modeling by shifting feature maps along the temporal dimension. It is a simple module with fewer parameters compared to 3D convolutional neural networks. However, directly introducing TSM does not yield satisfactory results in complex nighttime environments. On the one hand, the model's feature extraction capability is limited for near-infrared surveillance videos, which lack color information compared to visible light videos and often have blurry human body data. On the other hand, the lack of large-scale publicly available near-infrared surveillance datasets results in poor generalization of the network trained on small datasets. To address these issues, this paper introduces improvements to the network while using transfer learning methods with the TSM module. The schematic diagram of the TSM module is shown in Figure 1. Based on this model, this article further improves the model and makes the model more lightweight for near-infrared surveillance videos.
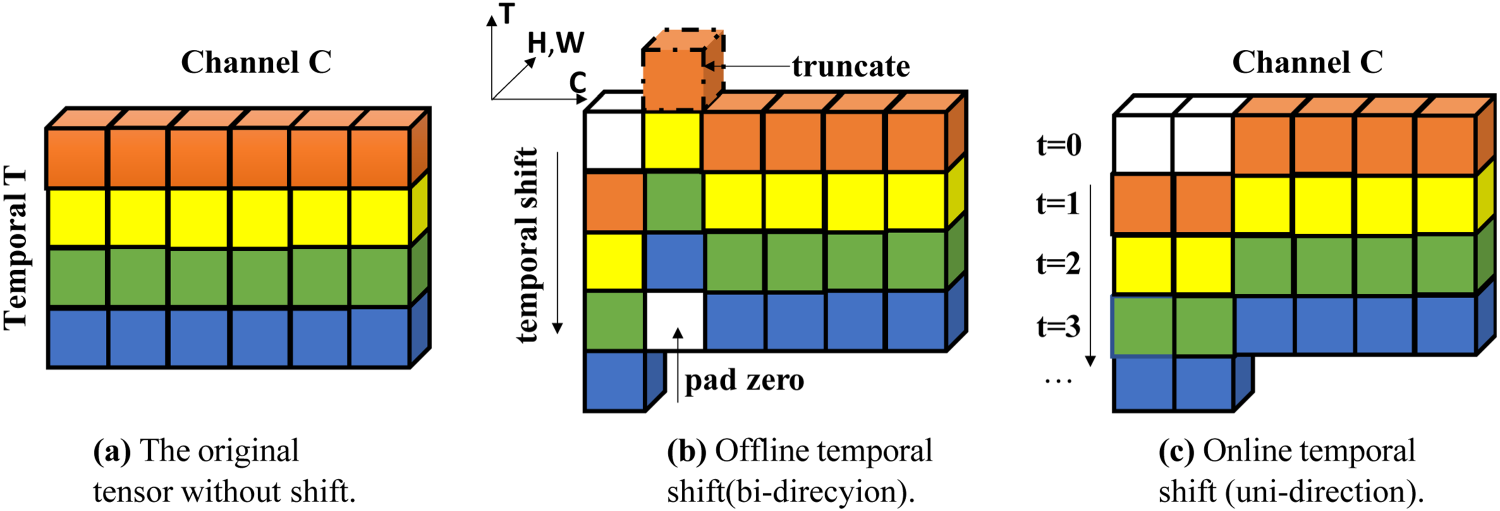
Temporal Shift Operation.
Due to the physical characteristics of near-infrared videos, the imaging quality of near-infrared videos is often poor, resulting in blurry human body data and other issues that affect motion information extraction. Therefore, existing methods usually adopt structures that incorporate multiple data streams to obtain richer features, such as visible light videos, optical flow, and difference image sequences. Previous algorithms that used convolutional neural networks (Tran et al., 2015) even had lower accuracy than traditional algorithms. This is because the IDT algorithm (Wang & Schmid, 2013) utilizes optical flow features to provide motion information instead of relying solely on RGB images for feature extraction. However, the decoupling of the optical flow feature extraction network and the recognition framework leads to the slow generation of optical flow and the large data volume of optical flow features, making it difficult to store and utilize. Recently, some works have introduced lightweight deep learning-based optical flow estimation algorithms (Chen et al., 2021; Ilg et al., 2017). Although these algorithms can be integrated into the model, they still significantly increase the parameter count of the model and have slow feature extraction speed.
Impact of Temporal Features on Action Recognition
Due to the long duration of videos recorded by infrared surveillance devices and the fact that human behavior only occupies a small portion of the videos, capturing and integrating useful feature information from different temporal segments is crucial for accurate and robust behavior representation in long video behavior recognition tasks. In the study (Wang et al., 2016), a temporal segment network was proposed to obtain video-level results by averaging the features from each temporal segment. However, due to the averaging fusion of each segment result, the feature information from static background frames without motion information in the video can interfere with behavior analysis and judgment. In another study (Sharir et al., 2021), the video data was decomposed into a series of temporal segments. For the temporal modeling part of the model, the authors used embedded vectors from the input frames and stacked them into a feature matrix as the input sequence. By applying “query,” “key,” and “value vectors” to this input sequence, temporal attention could be calculated to capture the temporal dependencies in the frame sequence. By applying temporal attention, the network could better utilize the high-level abstract features to capture temporal information.
Infrared Video Networks (InViNets)
This section introduces the algorithm model designed in this article, which is an improvement upon the framework of the TSN network (Wang et al., 2016). The entire algorithm consists of three parts: the preprocessing module, the backbone network, and the classification module. The following sections will provide detailed descriptions of each part of the model, and the specific algorithm framework is illustrated in Figure 2.
Step 1: Preprocessing Module:
The video is split into 224 × 224-sized images using FFmpeg. Then, the video is divided into T equally sized video segments, from which a random frame is sampled.
Step 2: Feature Extraction Module:
The T sampled frames from the previous step undergo convolutional operations, resulting in a feature
Overall Framework for Near-Infrared Behavior Recognition.
In the TSN network, the feature extraction network is based on ResNet50 (He et al., 2016). However, ResNet50 has a large computational complexity and parameter count, making it unsuitable for deployment on edge devices. To address this, model optimization is performed for mobile devices to reduce the model size and complexity, enabling efficient image processing on resource-constrained mobile devices. In this article, the MobileNet V2 model (Howard et al., 2018) is used, and the original residual blocks in the network are replaced with improved residual blocks proposed in the previous section. The improved feature extraction network is capable of capturing motion information from adjacent frames and has better temporal modeling capabilities. Next, the details of the improved residual blocks will be introduced.
TSM is a component in an effective video understanding framework that aims to improve the performance of convolutional neural networks (CNNs) when processing video data. The core idea of TSM is to introduce temporal displacement operations in the convolutional layers of the network, so that the network can capture the temporal information in the video sequence without increasing the computational cost and model parameters. The residual connection architecture of the TSM module is shown in Figure 3.
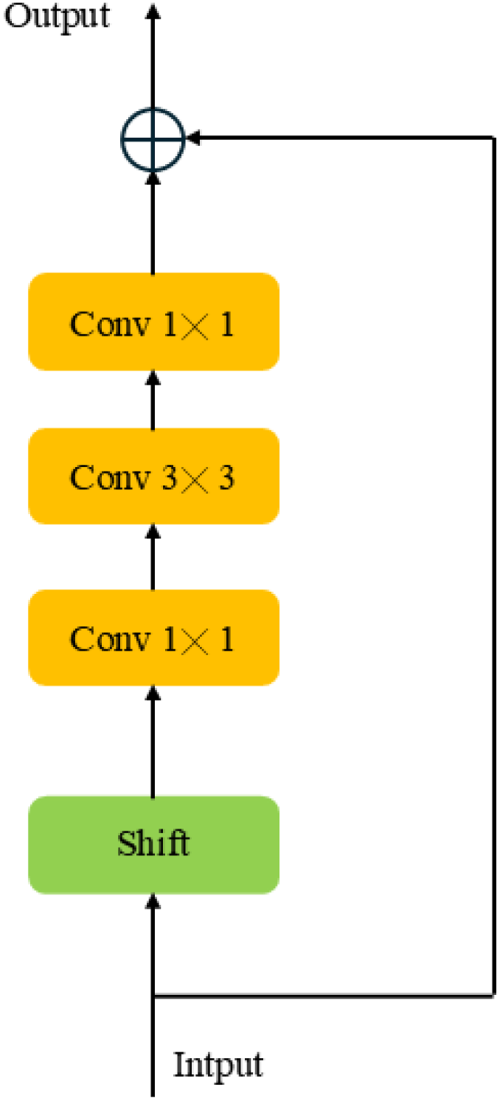
Residual Connection Structure for TSM.
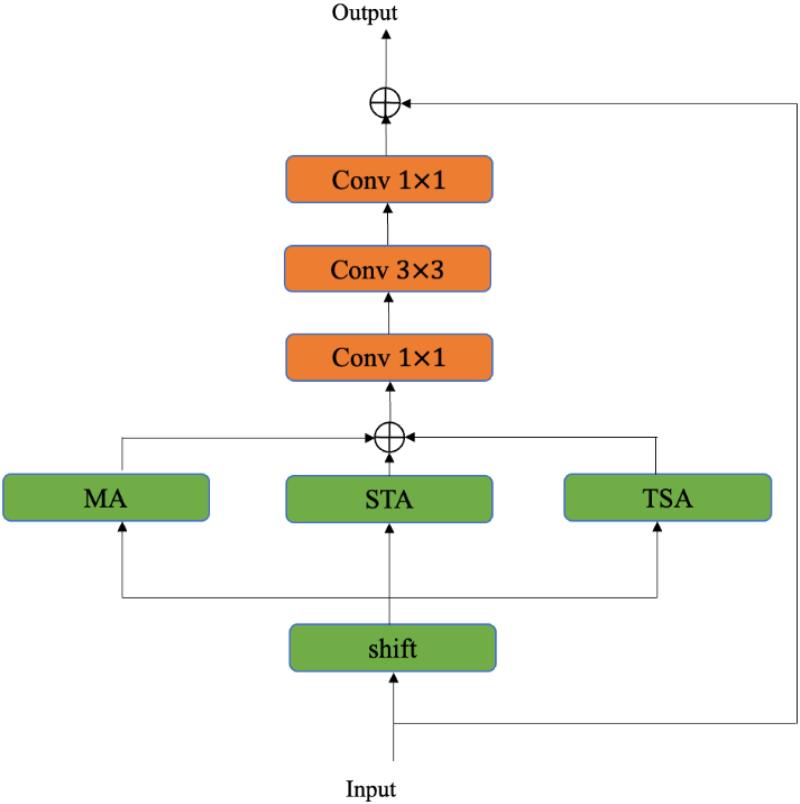
Residual Connection Structure for the Improved TSM.
Inspired by TSM algorithm (Lin et al., 2019), the improved module is embedded into a 2D neural network. More specifically, there are three excitations, including temporal attention, motion attention, and segment attention, embedded into the residual blocks in a parallel manner. Then every attention will be introduced in the following paragraphs, and the symbols used in this section are N (batch size), T (number of segments), C (number of channels), H (height), W (width), and r (channel reduction ratio). The structure of the improved residual blocks with attention modules is illustrated in Figure 4.
In Triangulation Estimation Algorithm (TEA) (Li et al., 2020), a motion attention mechanism is proposed to capture motion information in video sequences. By computing the differences between two frames, attention weights are obtained to simulate the effect of optical flow features. These motion attention weights are then fused with the original features to compensate for the recognition difficulties caused by the blurriness of infrared video frames. The input spatiotemporal features, denoted as X with a shape of
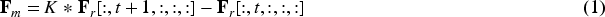
In this expression, K represents a

Afterwards, a 1 × 1 2D convolutional layer is used to expand the channel dimension of the motion features to the original channel dimension C. The sigmoid function is then applied to obtain the motion attention weights M. This can be expressed mathematically as follows:


If the above operations are directly applied to the features, it will affect the backbone network's learning of the original spatial information. Therefore, they are incorporated into the residual block. The Motion Attention (MA) structure designed is shown in Figure 5.
Motion Attention (MA) Structure.
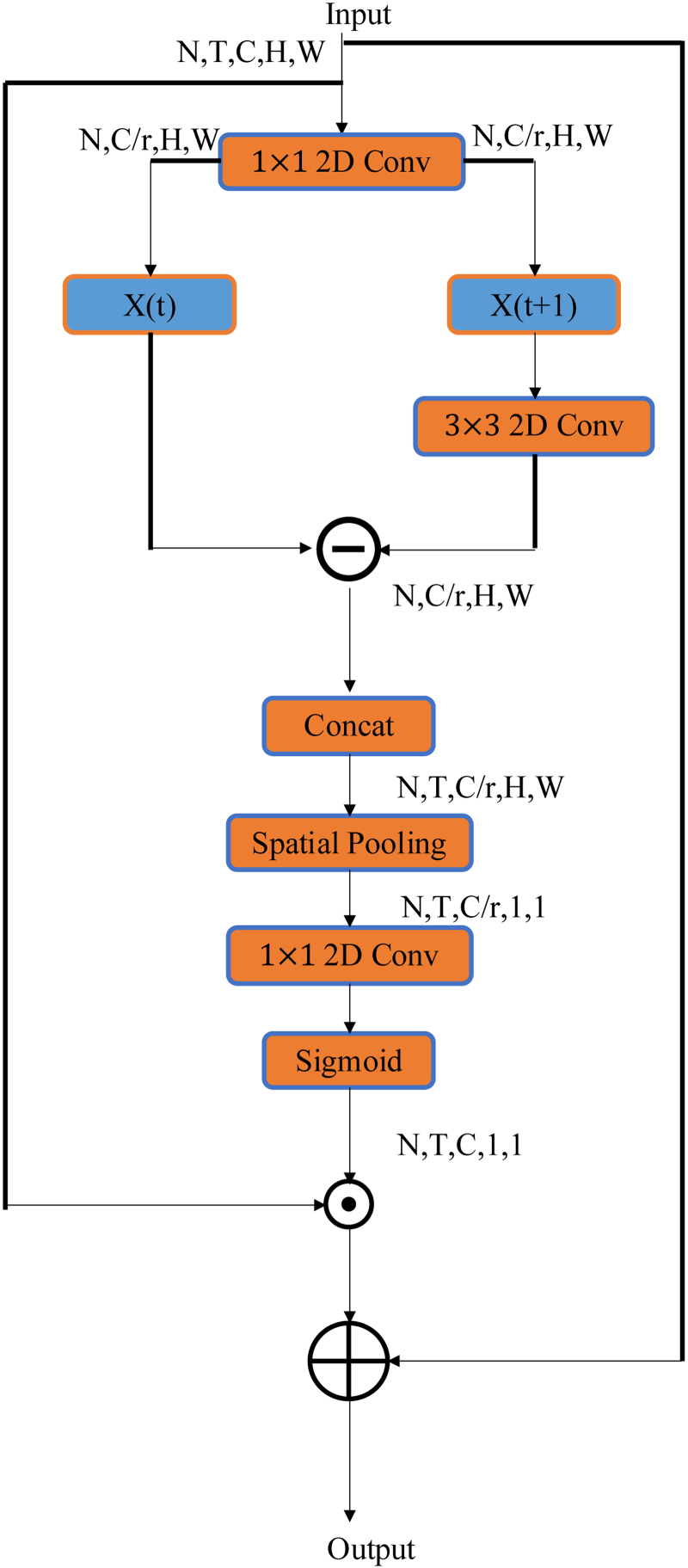
Spatiotemporal Attention (STA) Structure.
Although 2D neural networks are easy to train and have small model sizes, they can only learn spatial features and lack the ability to capture rich temporal information. Therefore, this article proposes to use spatiotemporal attention mechanism as a replacement for traditional 3D convolutional neural networks for spatiotemporal modeling. Previous works (Bertasius et al., 2021; Liu et al., 2022) typically used 3D convolutional neural networks to extract spatiotemporal features, but increasing the network dimensions significantly increases the model size and training difficulty. Therefore, this article proposes a spatiotemporal attention mechanism to replace the 3D convolutional neural network. The STA Structure designed is shown in Figure 6. The input features are represented as


The obtained attention weights are used to modulate the spatiotemporal features, and it can be expressed as follows:

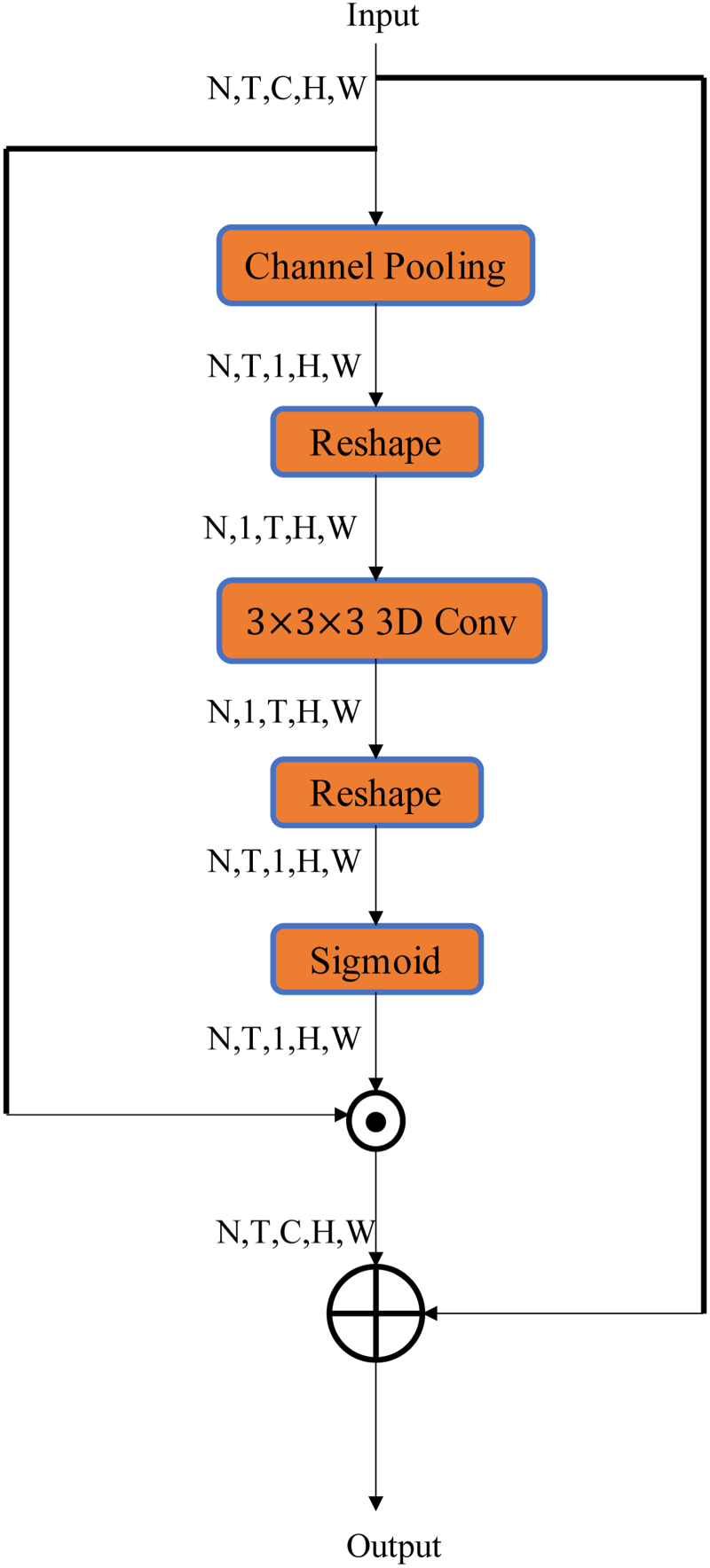
To focus on the impact of different time steps on the final action recognition, the time segment self-attention mechanism is introduced in the residual blocks of InViNet. The self-attention mechanism establishes relationships and weights allocation among different time steps, allowing the model to focus more on key time steps and features. The Temporal Segment Attention (TSA) Structure designed is shown in Figure 7. The input features are represented as

Temporal Segment Attention (TSA) Structure.
Next, the dot product is applied to Q and K to obtain the attention score matrix. Then, the softmax function is applied to the attention score matrix G along the last dimension to obtain the attention weight output:
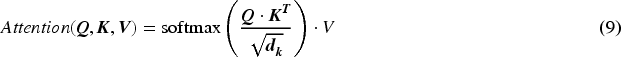
Here, the Softmax represents the softmax function. Then, the value V needs to be utilized dot product operation with the attention weight Attention, resulting in a weighted value tensor Z with the same shape:


Finally, the output features are reshaped back into a tensor of shape
In InViNet, the self-attention mechanism applied to the temporal step features plays two main roles:
Attention and integration of features within time segments: Through the self-attention mechanism, the network is able to automatically learn the relationships and importance of features within different time segments. This allows the network to focus more on the time segments that are crucial for the action recognition task and to integrate and weigh the features within these segments more accurately. This helps enhance the model's ability to capture and understand key action segments. Interaction and fusion of features: The self-attention mechanism enables the interaction and fusion of different features within the network. By computing attention weights between the features, the network can adjust the features’ representations based on their correlations and importance. The information exchange and collaboration, among different features, are facilitated by the new representations of the original features, allowing the network to utilize global contextual information better and improve the performance of action recognition tasks.
Step3:Action Classification Module:
The recognition and classification in this project are based on the framework of the 2D convolutional neural network TSN. Given an input video denoted as V, the video is divided into K video segments and every segment contains n frames. From these segments, a random frame is sampled, resulting in a total of K frames. These K frames are passed through the designed feature extraction network and fully connected layers, generating results for K time steps. The time-averaged pooling layer is used to obtain the average value of features along the time dimension. Finally, the entire temporal sequence information is compressed into a fixed-length vector, which is then input into a classifier or regressor for the final prediction.
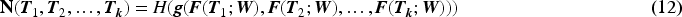
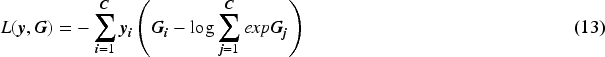
In the formulas, W represents the weights of the feature extraction network, and F represents the proposed feature extraction network in this project.

Algorithm Pseudocode.
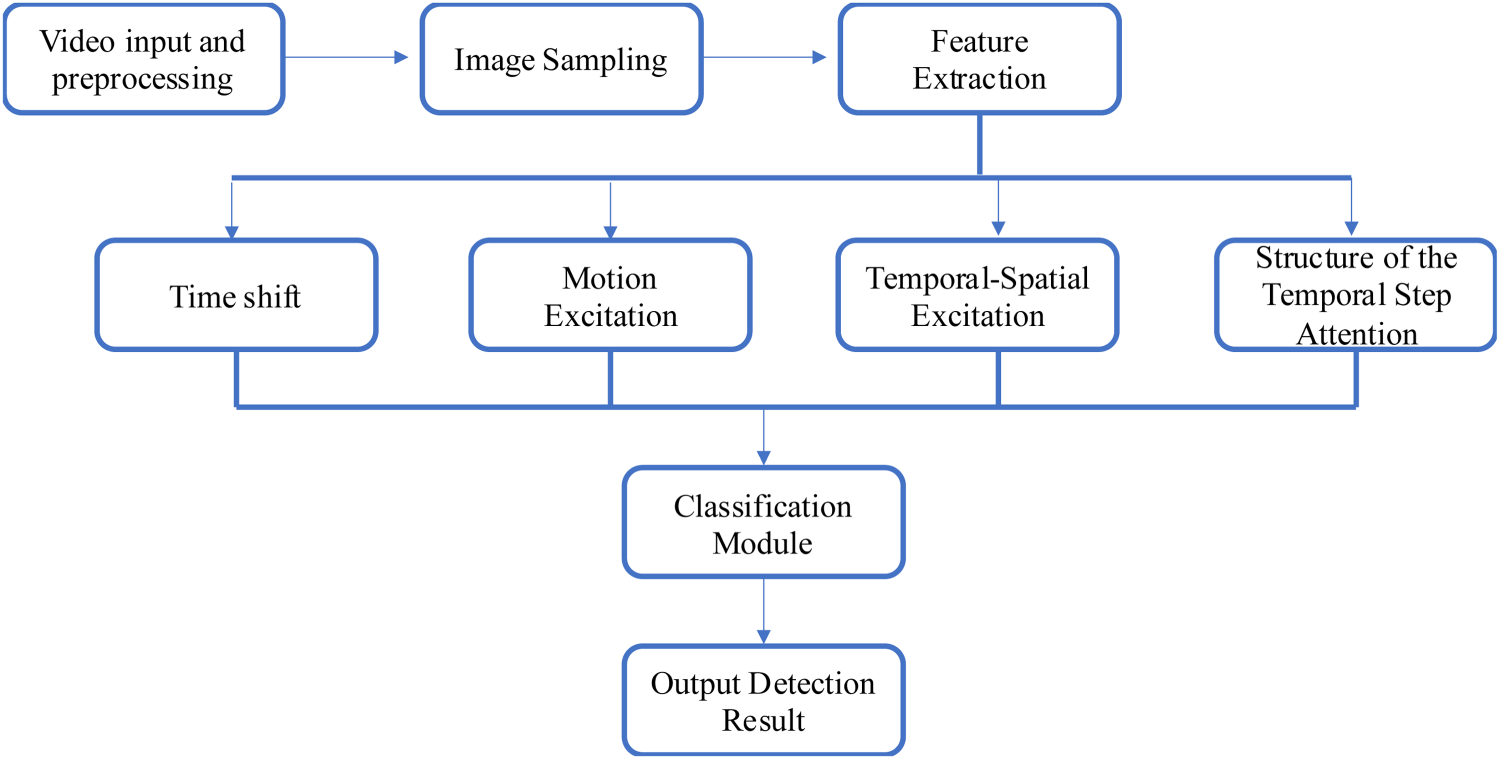
The Flowchart of the Algorithm in this Article is Shown Below.
Establishment of Near-Infrared Video Behavior Recognition Dataset
Although the research field of thermal infrared videos benefits from publicly available datasets like Infer, which facilitates the use of deep learning methods for related research, the research field of near-infrared surveillance videos lacks relevant public datasets. The NTU dataset (Liu et al., 2020) uses active infrared cameras for recording and it primarily focuses on indoor scenes. But, compared to outdoor scenarios, the infrared illuminator's lighting effect is significantly better than indoors. Therefore, in this article, we constructed a self-built dataset for near-infrared video behavior recognition, taking inspiration from the UCF-101 dataset (Soomro et al., 2012). The dataset construction process considered factors such as sample types and scene complexity, and so on. Additionally, considering that nighttime surveillance data has fixed cameras and backgrounds, and human behaviors remain the same for different individuals in different scenes, the dataset also incorporates scene transitions and diverse behavior categories. The dataset naming convention follows that of the UCF-101 dataset (Soomro et al., 2012). Shooting scene: the dataset was recorded in outdoor scenes, The lighting conditions at the shooting locations encompass both low-light environments with streetlight illumination and unlit environments, along with diverse weather scenarios such as overcast moonless conditions and clear nights with moonlight, specifically selected nighttime surveillance locations such as parking lots and garden pathways. Shooting time: the recordings took place during summer nights. Shooting samples: the dataset includes 16 actors of varying heights and body types. The videos were recorded using BATIANAN infrared surveillance cameras, with a selected resolution of 720p for high-definition quality. The picture of the surveillance camera is shown Figure 10.

Active Infrared Surveillance Camera.
As shown in Figure 11, the dataset consists of 10 behavior categories, including “Double Wave,” “Single Wave,” “Walk,” “Jump,” “Squat,” “Jogging,” “Push People,” “Shake Hands,” “Embrace,” and “Fight.” These categories encompass both single-person actions and interactions between two individuals. Each behavior category involves multiple individuals in the recordings. There are approximately 160 video samples for each behavior category, a total of 1630 video samples. The videos have a frame rate of 10 frames per second and a resolution of 480 × 248.

Nighttime Behavior Recognition Data Categories Image.
A comparative analysis of the behavior recognition dataset developed in this study versus existing benchmark datasets in both visible-light and thermal infrared modalities is systematically presented in Table 1.
Comparison of Common Datasets.

KTH Action dataset.
The experimental platform consists of a 15 vCPU Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60 GHz processor and an RTX 4090 GPU (24GB). The model training is performed on Ubuntu 20.04 system using the Pytorch framework with code written in Python. All videos are converted to 224 × 224 images using FFmpeg and then fed into the network for training. The self-built near-infrared human behavior dataset is split into a training set and a validation set in a 7:3 ratio. The network has a batch size of 16, and a total of 50 epochs are trained. The optimizer used is SGD, with a learning rate of 0.001 for the first ten epochs. Afterwards, the learning rate is decayed every ten epochs until it reaches 0.0001. Additionally, other relevant networks in the literature are also trained on this dataset.
Experimental Results
The offline behavior recognition experimental results are shown in Table 2. The proposed method in this article outperforms the traditional IDT algorithm that uses dense trajectories and other deep learning methods. In this article, transfer learning is employed by freezing all BatchNorm2D layers except for the first one. The model is initialized with pretrained weights from the 2D neural network on the ImageNet dataset and further fine-tuned on the Something-SomethingV2 dataset (Goyal et al., 2017) before being transferred to the self-built dataset. Tables 3 to 6 provide detailed explanations.
Comparison of Action Recognition Results on the Self-Built Dataset Using 8-Frame Images.
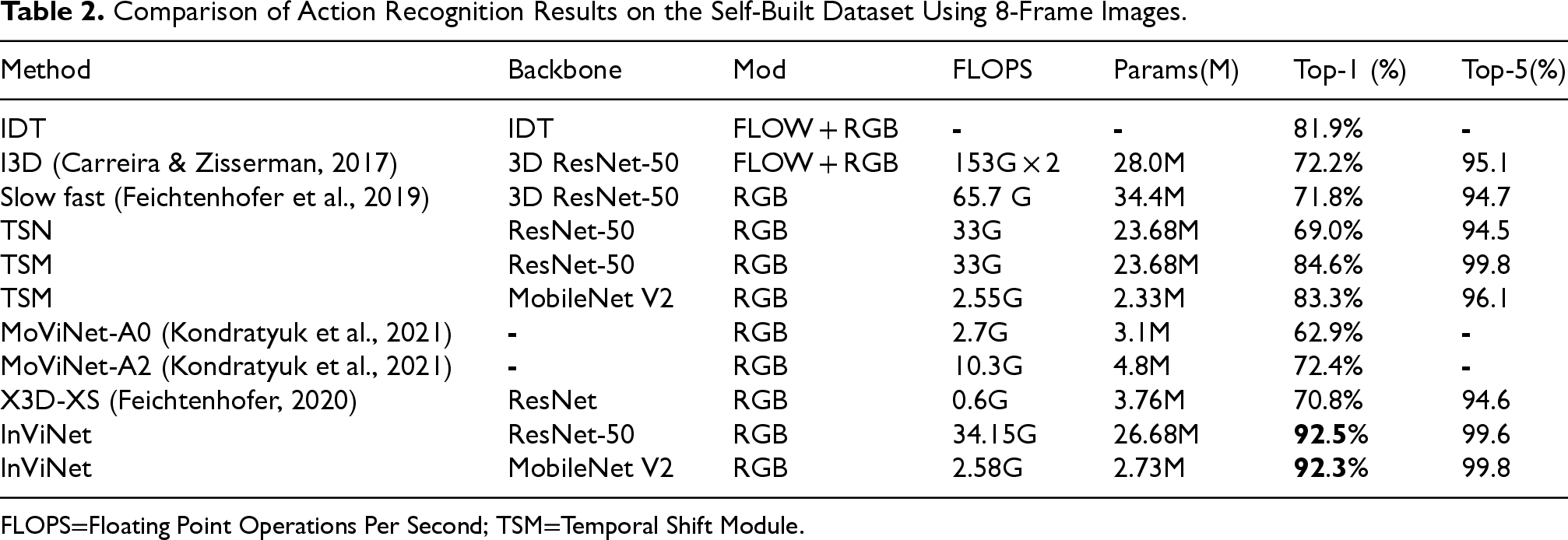
Comparison of Action Recognition Results on the Self-Built Dataset Using 8-Frame Images.
Floating Point Operations Per Second; TSM=Temporal Shift Module.
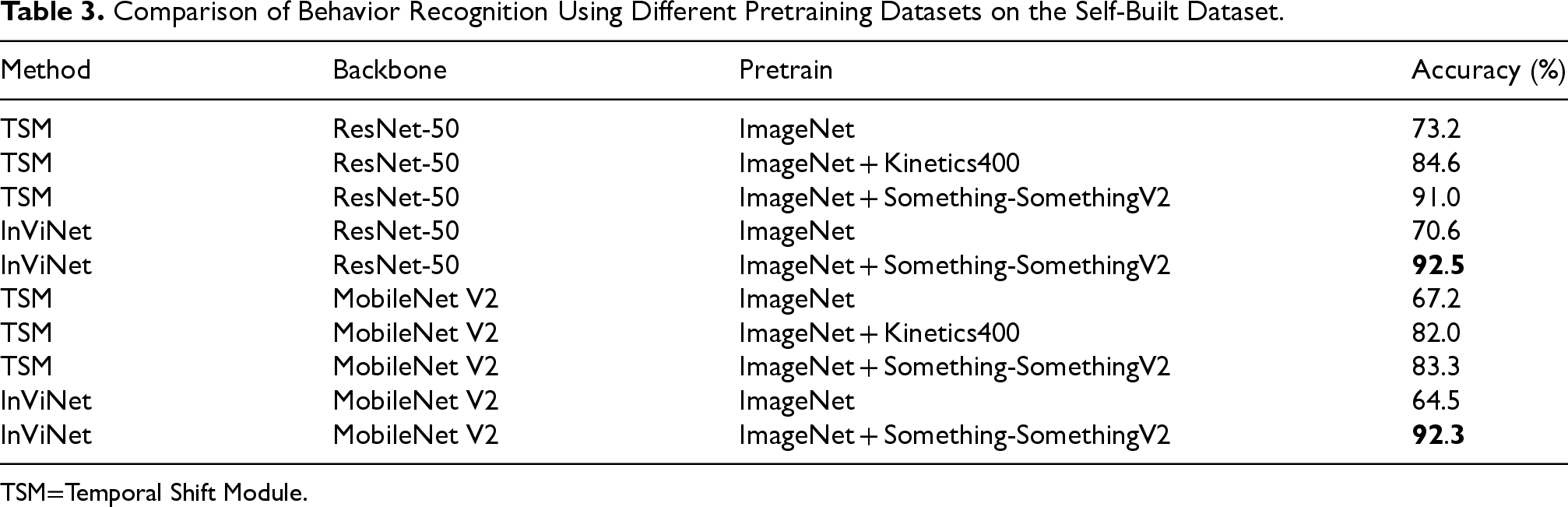
Comparison of Behavior Recognition Using Different Pretraining Datasets on the Self-Built Dataset.
Temporal Shift Module.
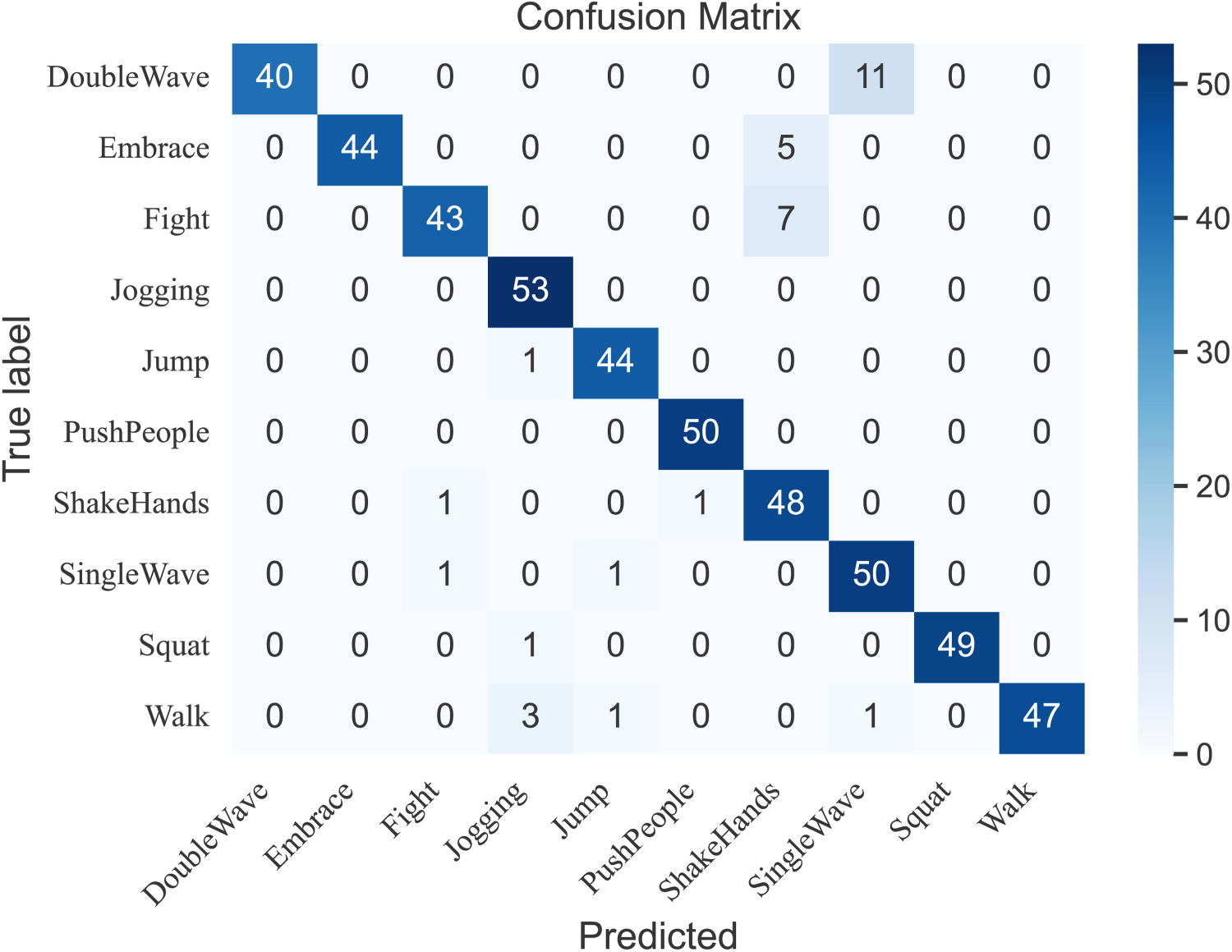
Confusion Matrix of the Test Results on the Self-Built Dataset.
By comparing InViNet with the TSM network, InViNet consistently outperforms the original TSM algorithm. It achieves a 1.5% to 8.53% improvement in accuracy with a small increase in computational complexity, making it more suitable for near-infrared videos. The impact of different backbone networks on recognition accuracy leads to the conclusion that InViNet-ResNet, pretrained on the Something-SomethingV2 dataset (Goyal et al., 2017), effectively captures motion information in videos and adapts well to near-infrared videos. However, it has a higher computational complexity and a larger parameter size, making it less suitable for edge devices. InViNet-MobileNet, on the other hand, only brings a slight increase in computational complexity (5.3%) but achieves an 8.35% improvement in accuracy. If InViNet-MobileNet is chosen, the computational complexity is only 7.3% compared to the ResNet model, with a negligible difference in accuracy (0.2%). This offers the advantage of potential deployment on embedded devices. As for lightweight networks like MoViNet-A0 (Kondratyuk et al., 2021) and X3D-XS (Feichtenhofer, 2020), they require more transfer learning or the support of pretrained models on smaller datasets. The number of frames input to these networks also limits their performance to some extent, as their results are not as good as the proposed network in this paper under the same number of frames inputted.
Figure 12 shows the confusion matrix, it can be observed that the accuracy is generally high for all action categories except for “Double Wave.” This is because “Double Wave” is easily confused with “Single Wave” due to their similar motion patterns. Moreover, in near-infrared videos, the blurriness of the images often leads to missing body parts, which affects the network's ability to extract features accurately.
As shown in Table 3. By comparing different pretraining datasets, it can be concluded that training solely on the ImageNet dataset does not yield results as good as training on both an image dataset and a video dataset. This is because the size of the self-built dataset is relatively small. Using transfer learning with frozen batch normalization (BN) layer parameters allows for the import of pretrained weights from a large-scale dataset, which improves learning efficiency, reduces training time and computational resources, and enhances model generalization and robustness. In the experiments, when the models were pretrained on the Something-Something V2 dataset and then fine-tuned on the self-built dataset, the results using ResNet-50 and MobileNet V2 as backbone networks were 92.5% and 92.3%, respectively, both higher than the results without transfer learning.
Furthermore, the choice of pretraining dataset affects the results after transfer learning. Something-Something V2 and the self-built dataset both emphasize temporal action information, while Kinetics400 focuses more on background and object information. Therefore, it is preferable to select a pretraining dataset that is stylistically similar to the training dataset.
Figure 13 verifies the impact of different input frame numbers on the accuracy of the model. This article counts the impact of the input frame number of 4 to 16 frames on the model accuracy. Based on the comprehensive data, it can be concluded that increasing the input frame number to a certain extent can significantly improve the accuracy of the model, but the accuracy improvement from 8 to 15 frames is gradually slowing down. Especially considering that the accuracy rate has reached 92.70% at 8 frames, this means that using 8 frames can achieve a relatively high accuracy rate at a lower computing cost. In practical applications, when using 8 frames of input, the model can balance operating efficiency and resource consumption, significantly reducing the demand for computing resources. This choice can not only adapt to real-time or resource-constrained scenarios, but also ensure a high accuracy rate.
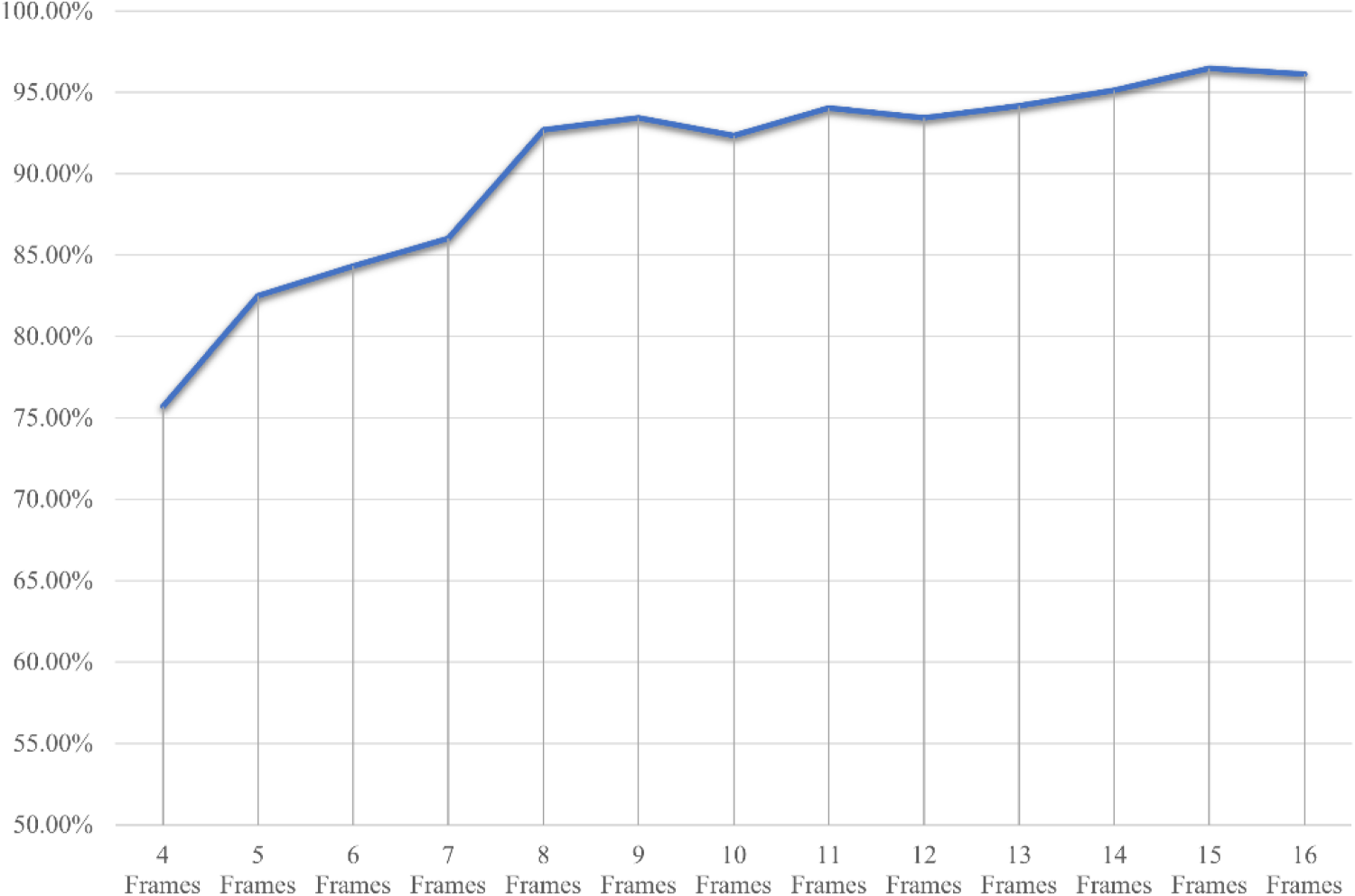
Model Accuracy Under Different Input Frame Numbers.
Results on the InfAR Dataset.

Dense Trajectories; HOF=Histogram of Oriented Flow; SCA=Selective Cross-stream Attention; TSM=Temporal Shift Module.
Based on the test results on the InfAR dataset, as shown in Table 4. It can be observed that there is a lack of publicly available infrared video datasets. The InfAR dataset from Chongqing University of Posts and Telecommunications is relatively mature, and therefore, the proposed network was also tested on this dataset and compared with previous methods. However, previous works based on the InfAR dataset did not utilize lightweight networks. In this article, TSM-MobileNet was adopted as a lightweight network for comparison. The proposed algorithm demonstrates better overall accuracy compared to TSM-MobileNet on this dataset. Although the SCA algorithm achieves higher accuracy on this dataset, it is not a lightweight network compared to the network proposed in this article. The proposed algorithm is more suitable for deployment on edge devices and has a shorter computation time. Furthermore, the performance of InViNet on both the thermal infrared dataset and the visible light dataset demonstrates its generalization ability.
The experimental comparison shown in Table 5. We evaluated the performance of different attentions, including MA, STA, and TSA. They were evaluated based on model size (Params), computational complexity (FLOPS), and accuracy (%).
As a baseline, the TSM-MobileNet model achieved 80.8% accuracy with 2.33 M parameters and 2.55G FLOPS. In addition, the module proposed in this article introduces three attentions, MA, STA, and TSA. When used individually, MA, STA, and TSA achieved accuracies of 89.6%, 88.5%, and 88.5%, respectively. InViNet, which incorporates the MA, STA, and TSA attention modules, outperformed the TSM-MobileNet model in the task of infrared video-based human behavior recognition. It achieved higher accuracy, demonstrating the effectiveness of these three modules in infrared video behavior recognition.
Results of Three Attention Mechanisms on the Self-Built Dataset.

Motion Attention; STA= Spatiotemporal Attention; TSA= Temporal Segment Attention; TSM=Temporal Shift Module.
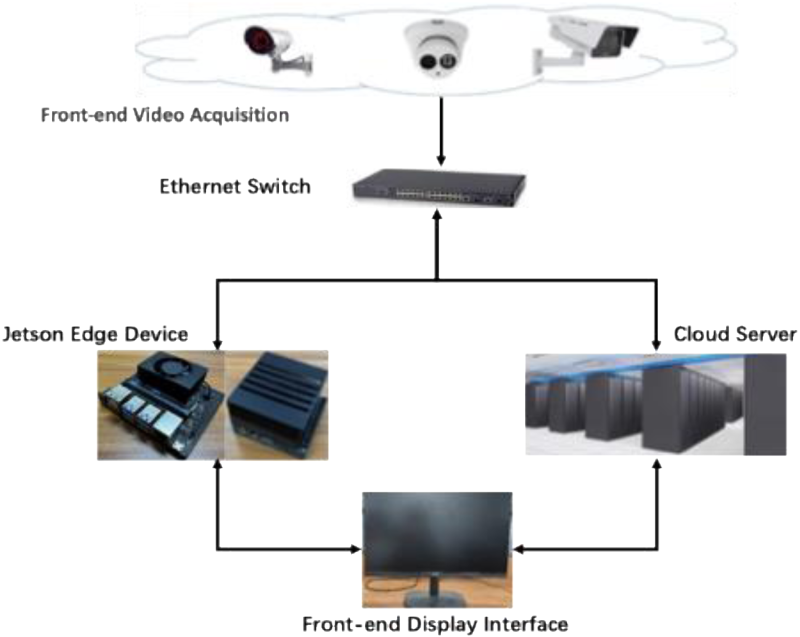
Theoretical Framework Diagram of Nighttime Behavior Detection System.
The edge device platforms used in the experiments were Jetson AGX Xavier and Jetson NX Xavier. Jetson AGX Xavier features eight custom ARMv8.2 CPU cores and 512 NVIDIA Volta GPU cores, with 16GB of high-speed memory. Jetson NX Xavier includes 384 CUDA cores, 48 Tensor Cores, a 6-core Carmel architecture @V8.2 64-bit CPU, and 2 NVDLA (NVIDIA Deep Learning Accelerator) engines. The implemented system consists of an active infrared surveillance camera, a router, edge devices, and a connected display system. The hardware diagram and testing setup are shown in Figures 14 and 15, respectively.

Multiclass Action Recognition Results.
Latency, Recognition Speed, and Accuracy of Near-Infrared Video Behavior Recognition on Edge Devices.
Temporal Shift Module.
The system follows the concept of edge computing. After the edge device receives video information, it processes the data and displays the detection results on a monitor. Simultaneously, the results are stored in a network server for easy retrieval and viewing by the users.
The Figure 15 shows a real surveillance video frame, while the Figure 15 shows the real-time interface of an online rapid behavior detection system. The system is configured with nine detection categories and confidence threshold values. In the interface, the behavior labels are displayed in English words, and the corresponding confidence scores are shown. When the confidence score exceeds the threshold, the detected behavior category is displayed to avoid interference. In the case of detecting dangerous behaviors (such as fighting or pushing), the text is displayed in red as a warning.
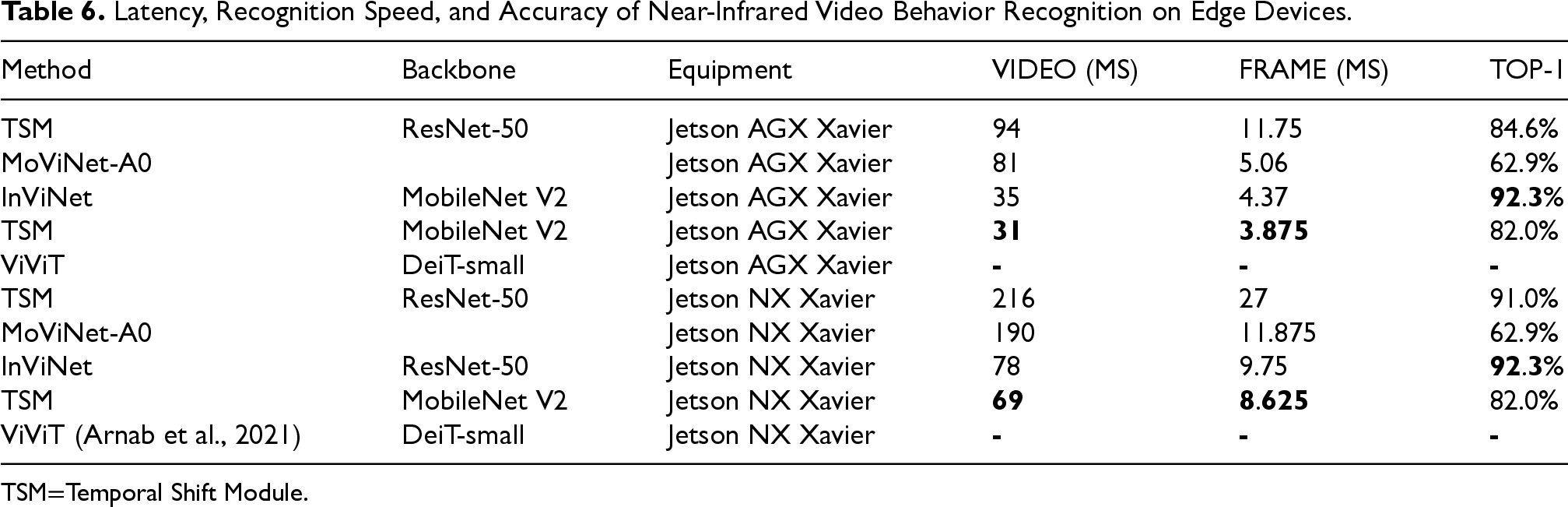
As shown in Table 6. The models of TSM, MoViNet-A0, and InViNet were tested on edge devices AGX Xavier and Jetson NX Xavier. The TSM model with MobileNet V2 as the backbone network achieved the fastest video inference results. However, the proposed algorithm in this paper achieved more than 10% higher accuracy at the cost of a slight increase in inference time. Among the three algorithms, the improved TSM network based on ResNet-50 had the highest latency but still remained operational. On the other hand, the model using Transformer was not suitable for these two edge devices, demonstrating that mainstream convolutional neural networks are more suitable for edge devices compared to Transformer-based models. Therefore, InViNet is the best choice for the aforementioned edge devices.
This study aims to explore human behavior recognition in nighttime environments and address the lack of in-depth research and widespread deployment in the field of public surveillance. The study has achieved certain results, including the construction of a self-built near-infrared human behavior dataset and the design of a lightweight behavior recognition algorithm based on 2D convolutional neural networks. Experimental results demonstrate that the proposed method achieves good performance in human behavior recognition tasks in nighttime environments. Compared to traditional methods, the proposed lightweight algorithm has advantages in model size and device requirements, making it suitable for practical applications. The introduction of motion attention and spatiotemporal attention effectively provides motion information, further improving the accuracy of behavior recognition. The application of the temporal segment self-attention mechanism fully considers the importance of features at different time steps in long videos, reducing the interference from static background frames and enhancing the robustness of behavior recognition. These research findings have significant application value in areas such as smart security, human–computer interaction, and autonomous driving and provide useful references for further advancing nighttime behavior recognition technology.
Footnotes
Funding
This work was supported in part by National Natural Science Foundation of China (grant no. 61902268), Sichuan Science and Technology Program (grant no, 20ZDYF0919, 21ZDYF4052,2020YFH0124, 2021YFSY0060).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.