
Abstract
Recent studies have shown that pillar-based detectors perform better in terms of both accuracy and speed, but these detectors perform poorly for detecting small objects such as pedestrians and cyclists. To solve this problem, we propose a highly efficient pillar-based model named MASNet, which mainly consists of a pillar mix attention (PMA) module, an attention-pooling operation, and a focal sparse network (FSN) module. The PMA module encodes the pillar features by fusion of the point-wise attention module and the channel-wise attention module. The attention-pooling operation aggregates the attention-encoded pillar features in a more comprehensive way to obtain the most expressive pillar features. In addition, the FSN module exploits the intrinsic sparsity of the data by introducing focal sparse convolution, which enriches the learned pillar features in the foreground without adding redundant pillars in other regions. On the KITTI three-dimensional (3D) Object Detection Benchmark, it achieves a 3D average precision of (77.81%, 60.30%, and 53.92%) in easy, moderate, and hard levels, which outperforms other pillar-based methods for the detection of cyclists. Additionally, our method is only 0.52% lower than the top-ranked method (pillar feature network (PIFENet)) on the KITTI Bird's Eye View pedestrian leaderboard, but our inference speed reaches 41 frames per second ahead of PIFENet by 57.69%.
Introduction
Three-dimensional (3D) object detection involves recognizing and localizing objects in a 3D scene, and its applications extend across various domains, including robot vision and autonomous driving (Guo et al., 2020). Utilizing point cloud data is more advantageous in handling localization challenges due to its ability to offer detailed geometric and positional information on the object surface. Consequently, light detection and ranging (LIDAR) has become the prevalent sensor in the realm of autonomous driving. In contrast to the two-dimensional (2D) image data captured by cameras, point cloud data are sparsely and irregularly distributed in continuous space, which pose challenges for accurate 3D object detection.
To handle these challenges and utilize the advantages of point cloud data, many methods based on point clouds have been proposed recently, which could be grouped into two categories: point-based (Chen et al., 2019; Huang et al., 2020; Qi et al., 2018a; Shi et al., 2019; Wang & Jia, 2019; Yang et al., 2020; Zhang et al., 2022) and voxel-based methods (Chen et al., 2020, 2023; Lang et al., 2019; Noh et al., 2021; Shi et al., 2020; Yan et al., 2018; Ye et al., 2020; Zhou et al., 2023; Zhou & Tuzel, 2018). Depending on the size of the voxel on the
Voxel-based methods typically take the classical “voxel feature encoder (VFE) layer-backbone-head” detection architecture. Voxel-based methods divide the input point cloud into regular 3D voxel grids or 2D pillars. For the pillar-based approaches, pillar features are extracted by the VFE layer after voxelization. Backbone is used to further encode the pillar features and perform multi-scale feature fusion. Then, the results are sent to the detection head. In addition, the pillar size also affects the detection performance of the network. A smaller pillar size can minimize the loss of fine-grained details and improve the detection accuracy, but it also generates higher-resolution feature maps and thus increases the computational cost. A larger pillar size leads to faster inference speed but worse detection performance, especially for small objects. Mask attention interaction and scale enhancement network (Zhang & Zhang, 2022) proposes a mask attention interaction and scale enhancement (SE) network to address the issue of detection accuracy for small objects. SE uses a content-aware reassembly of features block to generate an extra pyramid bottom level to boost small ship performance, a feature balance operation to improve scale feature description, and a global context block to refine features. The authors also propose a polarization fusion (PF) network with geometric feature embedding (PFGFE-Net) to address the issues of polarization insufficient utilization and traditional feature abandonment. PFGFE-Net (Zhang & Zhang, 2022) achieves the PF from the input data, feature-level, and decision-level. Moreover, geometric feature embedding (GFE) enriches expert experience. In addition, the author proposes a lightweight shipborne synthetic aperture radar (SAR) ship detector called Lite-YOLOv5 (Xu et al., 2022a) based on the You Only Look Once 5th edition (YOLOv5) algorithm to address the issue of huge computational complexity in complex models. The above work has played a profound role in the field of ship classification and inspection.
Larger voxels reduce the pillar features of small objects that can be learned by the network. Small objects such as pedestrians typically often located in complex backgrounds, which lead to false and missed detection. To address this limitation, TANet (Liu et al., 2020) proposes a triple attention module to enhance pillar feature extraction, but this approach only uses max pooling to select the most representative pillar features, suppressing a lot of effective information, which is important for the detection. To address the loss of fine-grained information during the point cloud encoding process, we present a more effective attention mechanism, the pillar mix attention (PMA) module. In addition, our research improves the pooling method of the VFE layer that enables to capture contextual information of all points and channels in a pillar. The PMA module is divided into two parts: channel-wise attention (CA) and point-wise attention (PA). Specifically, CA uses the non-local (Wang et al., 2018) operation to increase the receptive field and suppress unimportant information from each channel. Point attention aggregates point information within pillars through various pooling methods. Furthermore, we use attention pooling to extract the strongest pillar feature of each pillar.
To further strengthen the capability of pillar feature encoding, we adopt the 2D sparse network and introduce focal sparse convolution (Chen et al., 2022). For the sparsity of the point cloud, it allows the data to be extended at appropriate locations to achieve the filling of pillar features without destroying the sparsity of the data, which is very effective for small object detection. The idea of attention is introduced to predict the importance of the data at each pillar when processing the point cloud using sparse convolution, and the features predicted to be important are expanded into deformable output shapes, thereby separating the foreground and background in the scene. Importance is learned by an additional convolutional layer that dynamically depends on the input features. This module increases valuable information, thus compensating to some extent for the lack of data for small objects. Combining the aforementioned modules, we propose a novel 3D object detector: MASNet. The key contributions are as follows:
In point clouds, for smaller targets such as pedestrians, the effective points obtained by LiDAR on their bodies are few and may be more irregular and incomplete, making it difficult to accurately detect and identify. We propose a stackable PMA module, which enhances the pillar features extraction ability by integrating PA and CA. The PMA module can be stacked to obtain multi-level pillar feature attention, thus effectively improving the performance of small object detection. In the past, voxel-based methods typically used max pooling operations to reduce feature dimensions and aggregate point features. Max pooling selects the maximum value of each channel as the feature representation, but these maximum values cannot fully represent all features within the pillar and suppress a large amount of effective information. To further improve feature utilization, we present an attention-style pooling operation (attention pooling), which can effectively encode geometric information better and aggregate features based on importance. We propose a new sparse multi-scale-fusion module that powerfully encodes pillar features by focal sparse convolution and facilitates multi-level feature fusion of sparse features and dense features. The FSN module enhances the information exchange between features by generating dynamic outputs, achieving the fusion of sparse and dense features without incurring excessive computational costs, which is beneficial for further feature fusion learning. We evaluate the performance of our model on the KITTI (Geiger et al., 2012) benchmark. We further segment the training set into a training subset of 6,358 samples and a validation subset of 1,123 samples with a ratio of
Current 3D Object detection frameworks can be broadly categorized into point-based and voxel-based methods.
Point-Based Methods
PointNet (Qi et al., 2017) consists of two main modules: a feature extraction network and a global feature pooling network. The feature extraction network consists of MLP to extract local features at each point. The global feature pooling network aggregates the features of all points into a global feature vector through a max pooling operation. Unlike PointNet, PointNet++ (Qi et al., 2017) employs a hierarchical architecture that gradually focuses on local features by operating layer by layer. This hierarchical design allows PointNet++ to better capture local structures and relationships in point cloud data. Influenced by Fast Region-based-CNN (Girshick, 2015), Shi et al. (2019) proposed a network named PointRCNN, which is a two-stage network. PointRCNN utilizes PointNet++ to distinguish foreground and background points and then generate a small number of high-quality initial detection frames in the first stage, while the second stage involves refining and fine-tuning the initial detection frames. To further improve the inference speed of the network, Yang et al. (2020) proposed a pioneering one-stage target detection network for 3D object detection, which greatly improves the detection efficiency and improves the sampling strategy in PointNet. Since previous point cloud down-sampling methods are task-independent, Zhang et al. (2022) proposed the single-stage detector based on instance-aware (IA-SSD) network that adopts a task-oriented down-sampling method. IA-SSD greatly increases the proportion of foreground points while down-sampling results generate more reliable bounding boxes (BBoxes). Although point-based methods do not require preprocessing such as voxelization, these methods still suffer from expensive computational/memory costs that cannot meet the real-time requirements.
Voxel-Based Methods
Unlike point-based methods, voxel-based methods typically transform unstructured point clouds into structured 3D voxels or 2D pillars.
Pillar-based methods are a technique in 3D object detection that converts point cloud data into a cylindrical representation and processes it using 2D convolutional networks to improve computational efficiency and reduce resource consumption.
The core idea of pillar-based methods is to map point cloud data in 3D space to a 2D columnar structure, where each column represents a vertical voxel and contains information about all point cloud data within that voxel. The advantage of this method is that it can utilize mature 2D CNNs for feature extraction while avoiding the high computational complexity of 3D convolution. In addition, as autonomous vehicles are typically equipped with sensors such as LiDAR, the point cloud data generated by these sensors is naturally suitable for columnar representation as they typically scan along the direction of the vehicle’s travel.
Recent advancements in pillar-based methods have focused on enhancing the feature learning capabilities of the network to improve detection accuracy. One notable development is the introduction of the PillarNet architecture, which employs a powerful encoder network for effective pillar feature learning, a neck network for spatial-semantic feature fusion, and a detection head for box regression, classification, and intersection-over-union (IoU) prediction. PillarNet is designed to be flexible with respect to pillar size and compatible with classical 2D CNN backbones such as VGGNet and ResNet. It also incorporates an orientation-decoupled IoU regression loss and an IoU-aware prediction branch to further refine the detection performance.
Zhou and Tuzel (2018) proposed VoxelNet to extract voxel features by using a 3D CNN network and project the voxel features into a 2D pseudo-image on the bird’s eye view (BEV) plane. Furthermore, building a region proposal network for further filtering and classification of the candidate BBoxes. SECOND (Yan et al., 2018) introduced the submanifold sparse convolution (Graham et al., 2018) to replace the ordinary 3D convolution, efficiently improving network inference efficiency. Based on SECOND, Lang et al. (2019) firstly convert the point cloud into a 2D pillar, in which no more voxel height is set in the
Attention Mechanism
In recent years, the attention mechanism has proved to be effective in various computer vision applications such as image segmentation, classification, and object detection. Meanwhile, it has been widely welcomed due to its lightweight, small computational cost, especially in the detection of small objects. It makes the network pay more attention to important information and ignore irrelevant background in the scene.
Using group-wise feature enhancement-and-fusion network, Xu et al. (2022b) proposed a hybrid pooling channel attention for channel modeling to balance the contribution of each polarization feature. In addition, its main contributions include: rich dual-polarization features, enriched feature library, suppression of clutter interference, and ease of feature extraction; GFE is used to enhance each polarized semantic feature to highlight each polarized feature region; group feature fusion combines multi-scale polarization features to achieve group information exchange of polarization features.
Shadow-background-noise 3D spatial decomposition (SBN-3D-SD; Xu et al., 2022c) points out the sparse, low-rank, and Gaussian properties of the shadow, background, and noise in Video-SAR data and takes advantage of sparse, low-rank, Gaussian properties of shadows, backgrounds, and noises to enhance shadows. Alternating direction method of multipliers is used to solve SBN-3D-SD. Shadows are separated from backgrounds and noises. Besides, this is the first attempt in the Video-SAR moving target detection-tracking community.
SENet (Hu et al., 2018) uses a global average pooling operation and fully connected (FC) layer to compute CA in the squeeze and excitation block for image-related tasks. However, SENet ignores spatial attention, which plays a crucial role in determining “where.” To address this problem, using a convolutional block attention module, Woo et al. (2018) sequentially generate attention maps along channel dimensions and spatial dimensions, which performs better than other methods that only use one kind of attention mechanism. In recent years, some approaches have tried to use the attention mechanism at the network based on the point cloud. Qiu et al. (2021) used experiments to verify that the introduction of a 2D or 3D attention module into current 3D object detection frameworks can improve detection performance. TANet (Liu et al., 2020) combines CA, PA, and voxel-wise attention, which enhances the critical information of the object, suppresses the unstable points, and improves the robustness of the network. In order to retain important information while generalizing to various pedestrian representations, the network needs to use more comprehensive attention mechanisms when learning pillar features. Le et al. (2022) proposed pillar feature network (PIFENet) and designed a pillar aware attention module to adaptively focus on the important pillar features.
Method
In this section, we detail the structure of the MASNet, which is an advanced one-stage end-to-end model for 3D object detection. As illustrated in Figure 1, it consists of three main stages (a) the PMA module; (b) the attention pooling; (c) the FSN module.
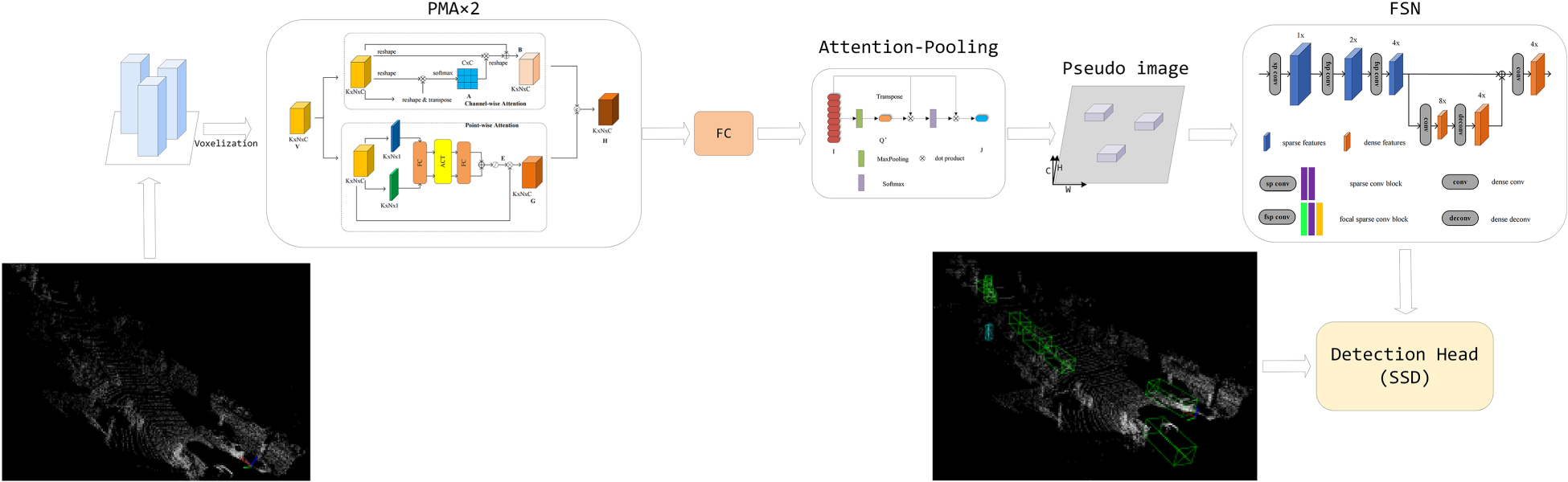
The structure of MASNet. Firstly, the input point clouds are transformed into 2D pillars. Pillar features are extracted via a stackable PMA module, and then an attention-pooling operation is used to aggregate information about each pillar and form a pseudo-image. Finally, the FSN module is employed to fuse the multi-scale feature maps and the result serves as input for generating 3D bounding boxes.Note. 2D = two-dimensional; PMA = pillar mix attention; FSN = focal sparse network; 3D = three-dimensional.
We take point cloud data as input that are defined as
PMA Module
In the point cloud, pedestrians are smaller in size, which makes the LIDAR scan fewer valid points on the pedestrians. Furthermore, the shape of pedestrians may be more irregular in 3D space which leads to incomplete representations in the point cloud and therefore difficult to accurately detect and recognize. In order to improve the network’s detection accuracy on small objects, we introduce a PMA module, which is expected to increase the expressive capability of pillar features for small objects by adopting a more comprehensive attention mechanism. The PMA module consists of two parts: PA and CA, which aggregate information at the feature-map level in parallel, the structural model of the PMA is shown in the following Figure 2. Compared with other attention mechanisms, we will simultaneously use two channels to obtain the features that they are more interested in, and ultimately aggregate the information. The CA captures remote dependencies by aggregating remote information to enhance global capabilities. And PA is used to obtain independent point features in the data through a series of pooling operations.
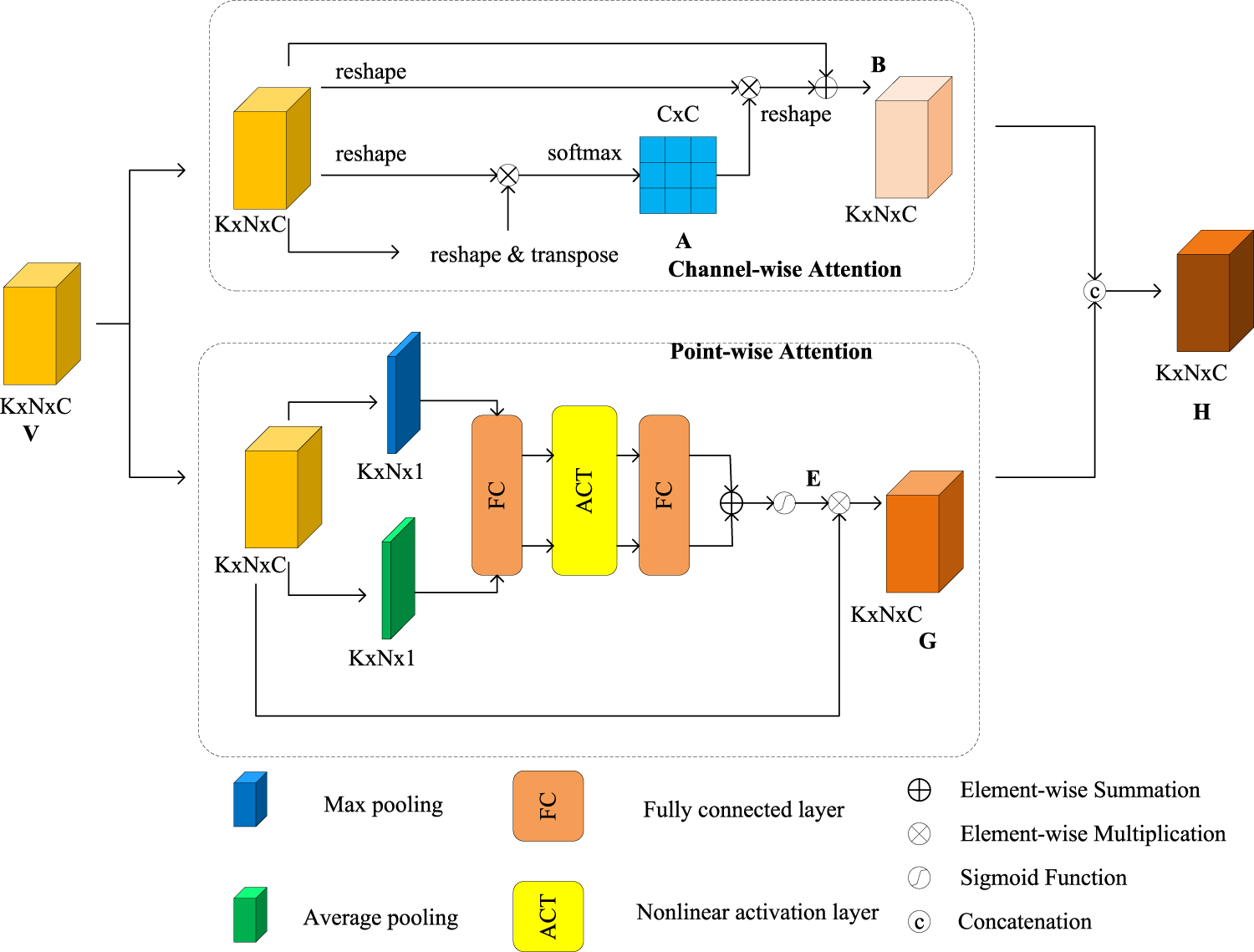
The architecture of pillar mix attention (PMA) module.
Every channel map of high-level features can be viewed as a class-specific response, where different semantic responses are interrelated. To capture long-range dependencies and aggregate remote contextual information adaptively, we design a CA module as shown in the channel-wise attention (CA) section of Figure 2. We introduce non-local operations to establish associations between channel features to explore global contextual information and thus obtain a sufficient receptive field. Given a pillar set


Consider a pillar set
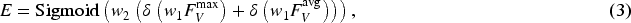

The final output
PMA modules are stacked to utilize multiple levels of feature attention, with the first PMA acting directly on the original pillar feature and the output of the first PMA module serves as input for the second PMA module. Finally, we obtain a high-dimensional representation of the features
Attention Pooling
Attention mechanism is an important concept in deep learning that mimics the function of human visual attention, allowing models to focus on the most important parts of input data. This mechanism has been widely applied in various fields such as natural language processing, computer vision, and audio processing, and has achieved significant performance improvements in various tasks.
The current research status indicates that the study of attention mechanisms is very active, with new models and variants constantly being proposed. For example, the self-attention mechanism in the transformer model is an important breakthrough that improves computational efficiency through parallel processing and achieves excellent performance in tasks such as machine translation and text classification. In addition, multi-head attention allows the model to learn information in parallel in different representation subspaces, further enhancing the model’s expressive power.
In addition to the standard attention mechanism, there are many variants and extensions, such as hard attention and soft attention, which introduce different probability distributions in the model to guide the focus of information. In addition, there are applications of attention-based models in unsupervised or semi-supervised learning tasks, which may utilize unlabeled data to learn useful feature representations.
Previous voxel-based methods usually adopt a simplified version of PointNet to extract the features of the pillar. PointNet uses a max pooling operation to reduce the dimension of the feature maps and aggregate point features in the pillar. This operation selects the maximum value of each channel as the encoded representation. However, these maximum values cannot represent the rich feature representation of all points within pillars and suppress the amount of effective information. To comprehensively utilize all the information in the pillars and extract the most representative pillar features, we propose an attention-style pooling operation: attention-pooling, as shown in Figure 3.
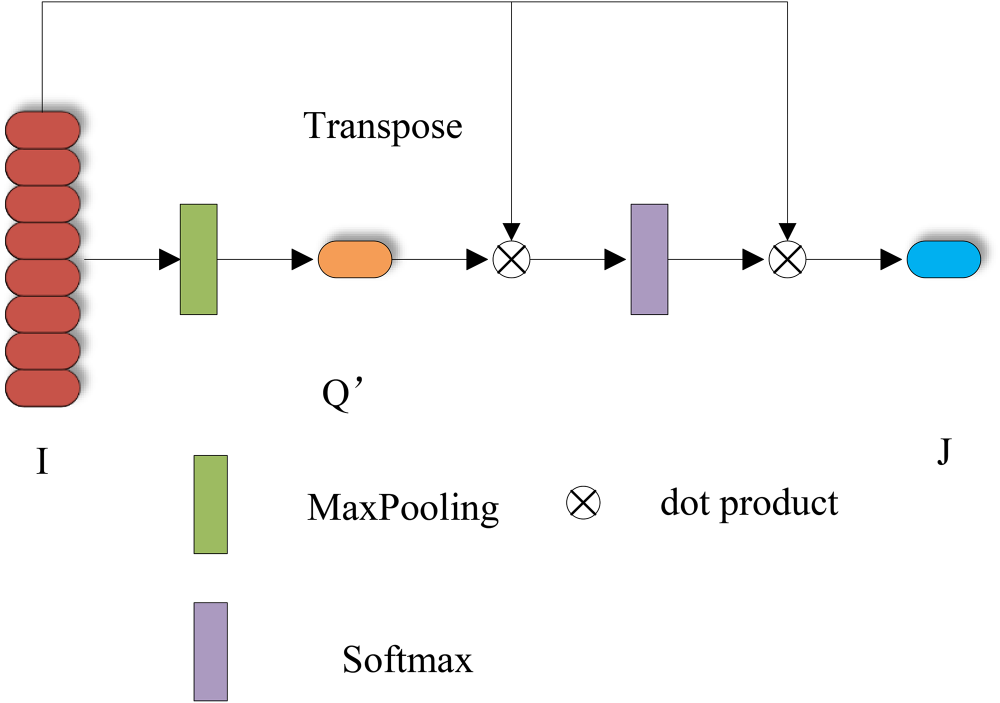
The framework of attention pooling.
For each non-empty pillar feature


The result of attention-pooling is regarded as an input to the backbone. The experiment proves that the operation is simple but helpful for the detection and localization of the pedestrian.
Similar to PillarNet (Shi et al., 2022), we use the 2D sparse encoder network for effective pillar feature encoding. Within the 2D sparse encoder network, focal sparse convolution is introduced to facilitate the network in extracting deep sparse pillar features from the projected sparse 2D pillar features, which enhances the network’s 3D sensing capability. We propose an FSN module, as shown in Figure 4.
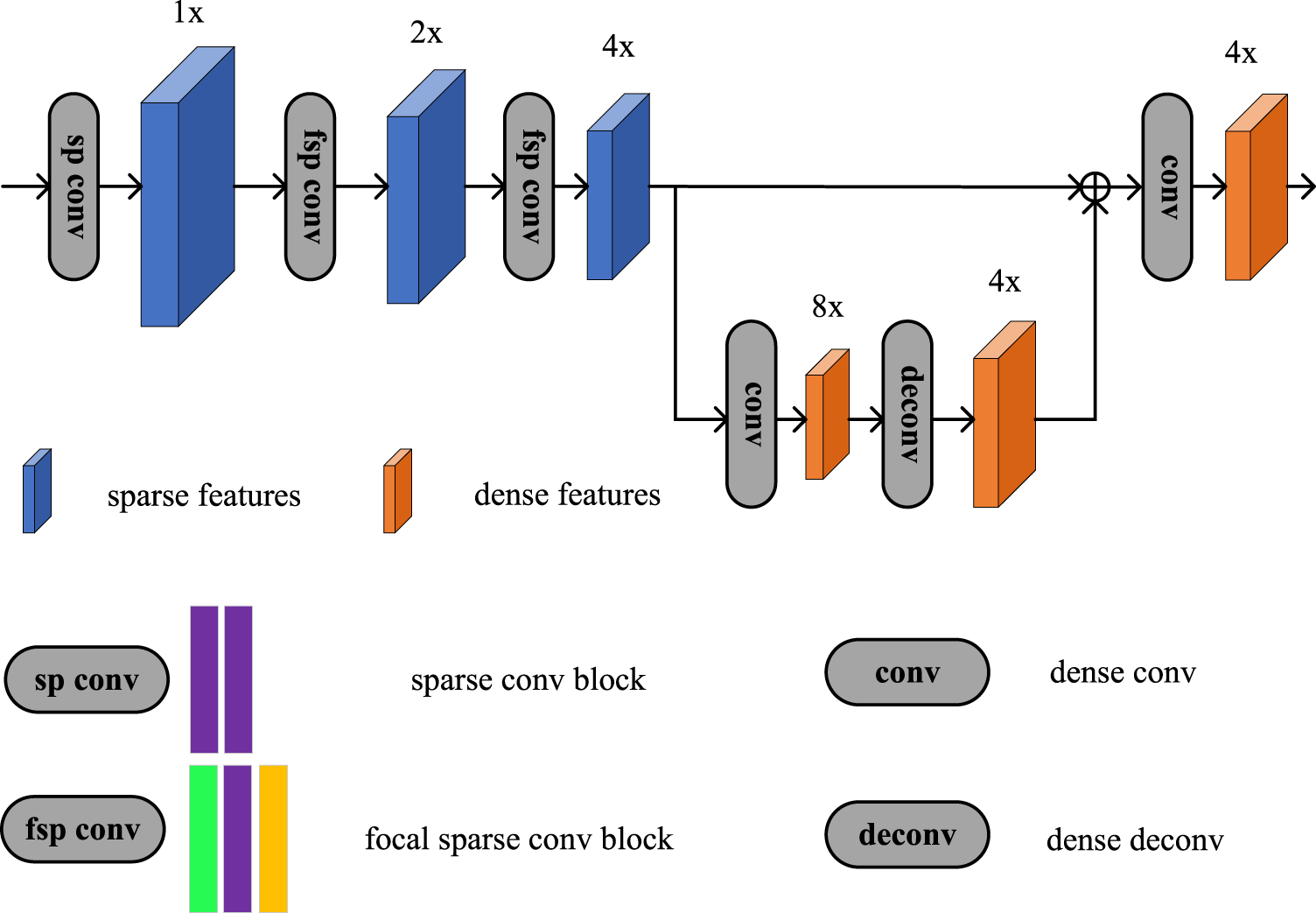
The framework of the focal sparse network (FSN) module. The green box represents the regular sparse convolution layer, the purple boxes represent the submanifold sparse convolution layer, and the gold box represents the focal sparse convolution layer.
We construct a 2D sparse encoder network by using the focal sparse convolution (Chen et al., 2022). The entire computational process can be divided into three steps: (a) calculate the importance map, (b) obtain the location of the important inputs, and (c) generate the dynamic output. The framework of focal sparse convolution is shown in Figure 5.
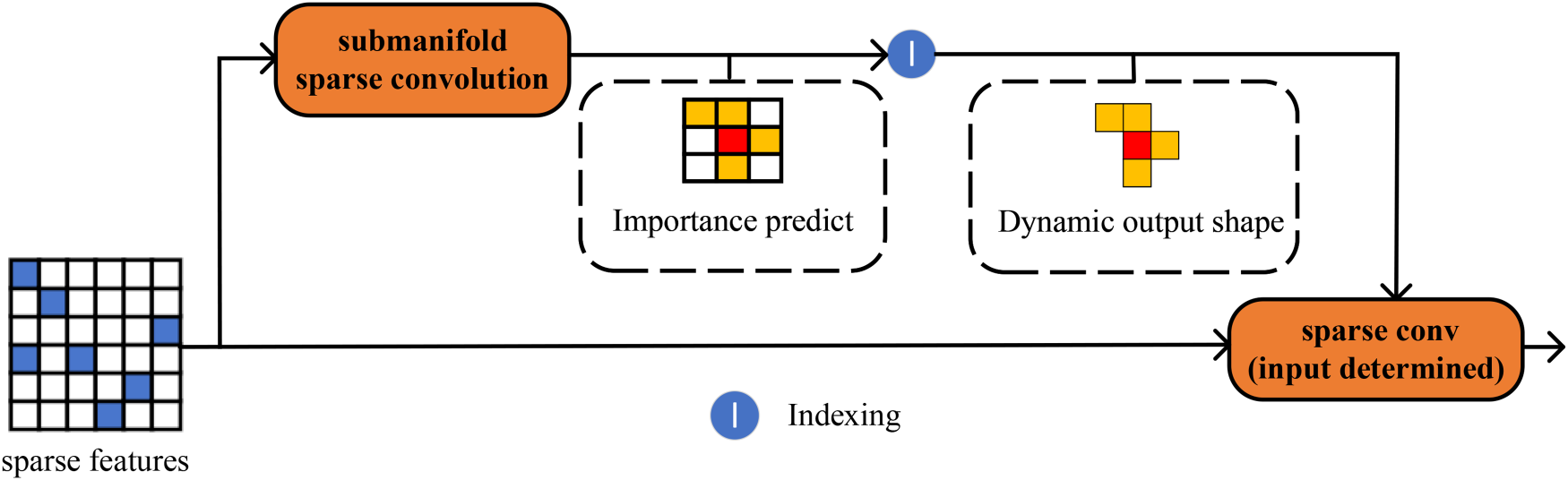
Framework of focal sparse convolution. An additional branch predicts an importance map for each input sparse feature, which determines the output feature positions.
To obtain the importance map, firstly, we use submanifold sparse convolution to process the pseudo-image and the channel of output is determined by

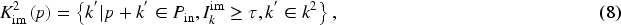

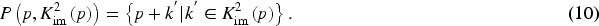
In contrast to regular sparse convolution, focal sparse convolution more effectively preserves data sparsity and significantly reduces computational load. Moreover, when compared to submanifold sparse convolution, focal sparse convolution generates a dynamical output shape based on input positions, thereby facilitating information exchange between disconnected features. Additionally, utilizing the focal loss function to supervise the prediction of important maps during training and multiplying the important maps with output features to encode sparse features, enables the inflation of output shapes at appropriate locations and enriches the learnable features of the object. This approach proves particularly advantageous for small object detection.
The entire backbone comprises four stages, Stages 1 to 3 can be characterized by a series of blocks (
Loss Function
Similar to SECOND, focal loss (Lin et al., 2017) and L1 loss are used for BBox classification and regression, respectively (Le et al., 2022). We use the loss function in PointPillar. The PointPillars algorithm divides the point cloud into individual pillars from a top-down perspective, effectively discarding height information and retaining only the
The residual of localization regression between truth and anchor is defined as follows:
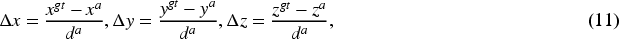
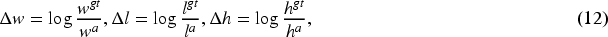

Smooth L1 loss function was used for training:

A Softmax loss is introduced to learn the direction of objects in order to avoid direction discrimination errors. The loss is recorded as

The overall loss function is as follows:
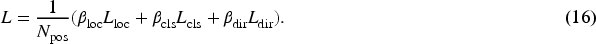
Setup and Implementation
All the experiments are conducted on the KITTI object detection benchmark dataset, which consists of 7,481 training samples and 7,518 test samples. It contains three test classes: Car, Cyclist, and Pedestrian. Each class contains three levels: easy, moderate, and hard, which depend on the size of the object with respect to the level of occlusion and truncation. Due to the ground truth of the test set being unavailable in the official dataset, we further segment the training set into a training subset of 6,358 samples and a validation subset of 1,123 samples with a ratio of
Implementation Details
For the data enhancement part, in order to enrich the training data, we put the point clouds contained in the ground truth 3D BBoxes of other frames and their BBoxes into the blank positions in the frame to be trained. For training data, we first adopt a data augmentation strategy, we put the point clouds contained in the ground truth 3D BBoxes of other frames and their BBoxes into the blank positions in the frame to be trained. Then we utilize the method of minimum point filtering to select the points in each BBox. The points in the ground truth 3D BBoxes are transformed along the
We use the PyTorch deep learning framework to build our algorithm model based on the model structure diagram in the previous section. We set the batch size to 2 and trained the model for 80 epochs. We use the adaptive moment estimation (Adam) optimizer for end-to-end model training during the training process and set the initial learning rate to 0.003. We use the cosine annealing learning strategy with a weight of 0.01 to attenuate the learning rate.
In all our experiments, the number of points within each pillar is set to
All the experiments are conducted on the KITTI object detection benchmark dataset, which consists of 7,481 training samples and 7,518 test samples. It contains three test classes: Car, Cyclist, and Pedestrian. Each class contains three levels: easy, moderate, and hard, which depend on the size of the object with respect to the level of occlusion and truncation. Due to the ground truth of the test set being unavailable in the official dataset, we further segment the training set into a training subset of 6,358 samples and a validation subset of 1,123 samples with a ratio of
The performance indicators of object detection are key factors in evaluating the effectiveness of a model on specific tasks. In the field of autonomous driving, 3D object detection is particularly important as it directly relates to the vehicle’s understanding and responsiveness to the surrounding environment. Here are some main performance indicators:
Precision: Refers to the proportion of samples that are truly positive among all the samples predicted as positive by the model. The calculation formula is TP/(TP + FP), where TP is the true positive case and FP is the false-positive case. Recall: Refers to the proportion of samples that are correctly predicted as positive by the model among all samples that are actually positive. The calculation formula is TP/(TP + FN), where FN is a false negative example. F1 score: The harmonic mean of precision and recall, which is a performance metric that comprehensively considers both precision and recall. The calculation formula is AP: In object detection, AP measures the model’s performance in each category. It calculates the AP at different recall levels. mAP: mAP measures the goodness or badness across all types, usually taking the average of all categories’ APs.
In this article, we use AP and mAP as performance metrics.
As shown in Table 1, we compare our model with the state-of-the-art models on the KITTI test set for three types of objects: cars, pedestrians, and cyclists on the 3D detection benchmark of the KITTI test server. The proposed method achieves the best detection performance for the cyclist category of all pillar-based methods on three difficulty levels, leading the second-best SMS-Net and TANet methods by over 2.46%, 0.07%, 0.55% and 2.11%, 0.86%, 1.39% in easy, moderate, and hard difficulty levels, respectively. In particular, for the pedestrian category, our model outperforms all other methods on the easy and hard difficulty level. Furthermore, MASNet achieves the second-ranked performance in pedestrians on the medium difficulty level and is only inferior to the PIFENet. In the case of car detection, we compare our model with sparse-to-dense (STD) and graph neural network for 3D object detection in a point cloud (Point-GNN), although there is little difference in performance in the easy level of difficulty, our method performs relatively poorly in moderate and hard difficulty levels, lagging behind 3.82%, 5.43%, and 3.58%, 2.63%, respectively. But the inference speed of STD is only 12.5 FPS) and Point-GNN even only 1.6 FPS, which cannot guarantee real-time performance. Our proposed method achieves an inference speed of 41 FPS which is ahead of most of the one-stage methods.
Performance Comparison of 3D Detection on KITTI Test Set. We Report Results for Point-Based (Point), Voxel-Based Methods Using 3D Voxel Representations (Voxel-3D), and Pillar-Based (Voxel-PI) Methods.
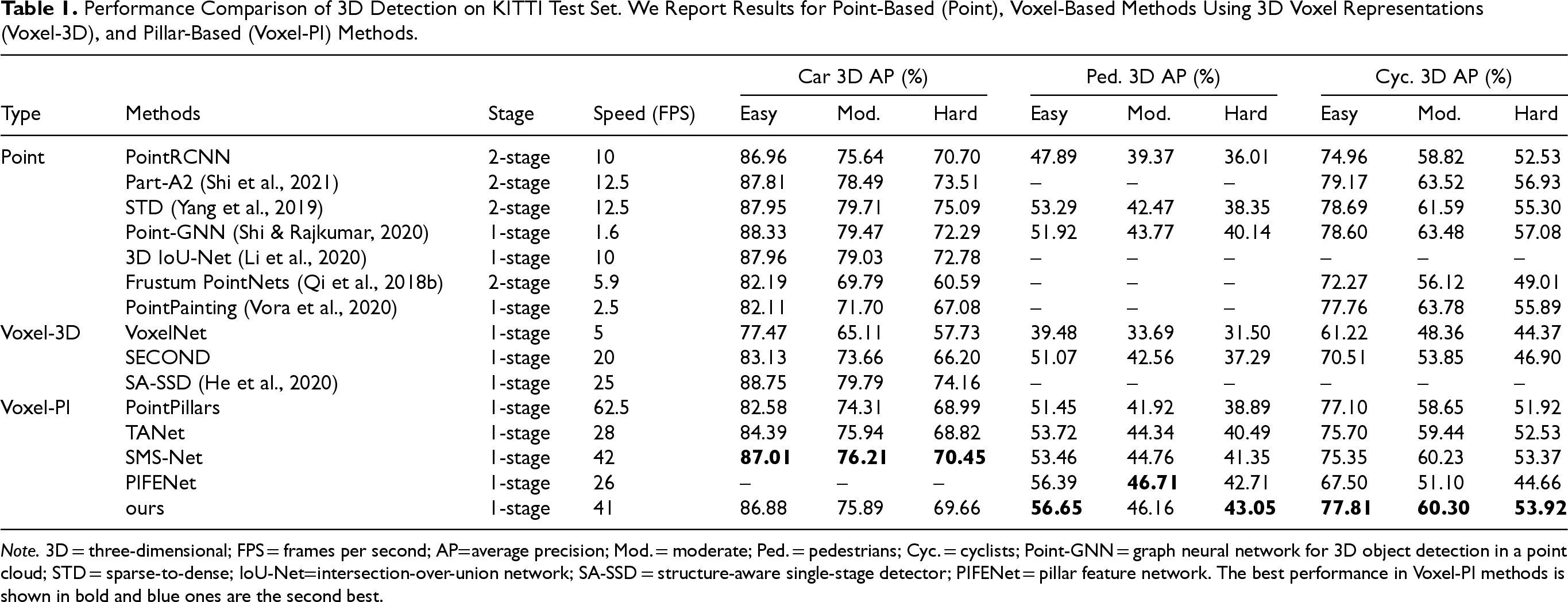
Performance Comparison of 3D Detection on KITTI Test Set. We Report Results for Point-Based (Point), Voxel-Based Methods Using 3D Voxel Representations (Voxel-3D), and Pillar-Based (Voxel-PI) Methods.
Note. 3D = three-dimensional; FPS = frames per second; AP=average precision; Mod. = moderate; Ped. = pedestrians; Cyc. = cyclists; Point-GNN = graph neural network for 3D object detection in a point cloud; STD = sparse-to-dense; IoU-Net=intersection-over-union network; SA-SSD = structure-aware single-stage detector; PIFENet = pillar feature network. The best performance in Voxel-PI methods is shown in bold and blue ones are the second best.
We present in Table 2 the performance of our method in BEV detection. In pedestrian detection, MASNet attains a BEV mAP of 53.38%, which exceeds all methods except PIFENet. Besides, in terms of speed of inference, our approach surpasses PIFENet by 57.69%. This suggests that our method provides a reference for balancing speed and accuracy. These significant improvements demonstrate that our network can enhance the expressiveness of pillars, better utilize the sparsity of the point cloud data, and allow the sparse and dense information to fully communicate thus producing more discriminative features, which are beneficial for small object detection.
Performance Comparison of Bird’s-Eye Views on KITTI Test Dataset for Pedestrian Class. Results in Bold Denote the Best of all of the Methods, and the Second-Ranked Performance is Shown in Blue.
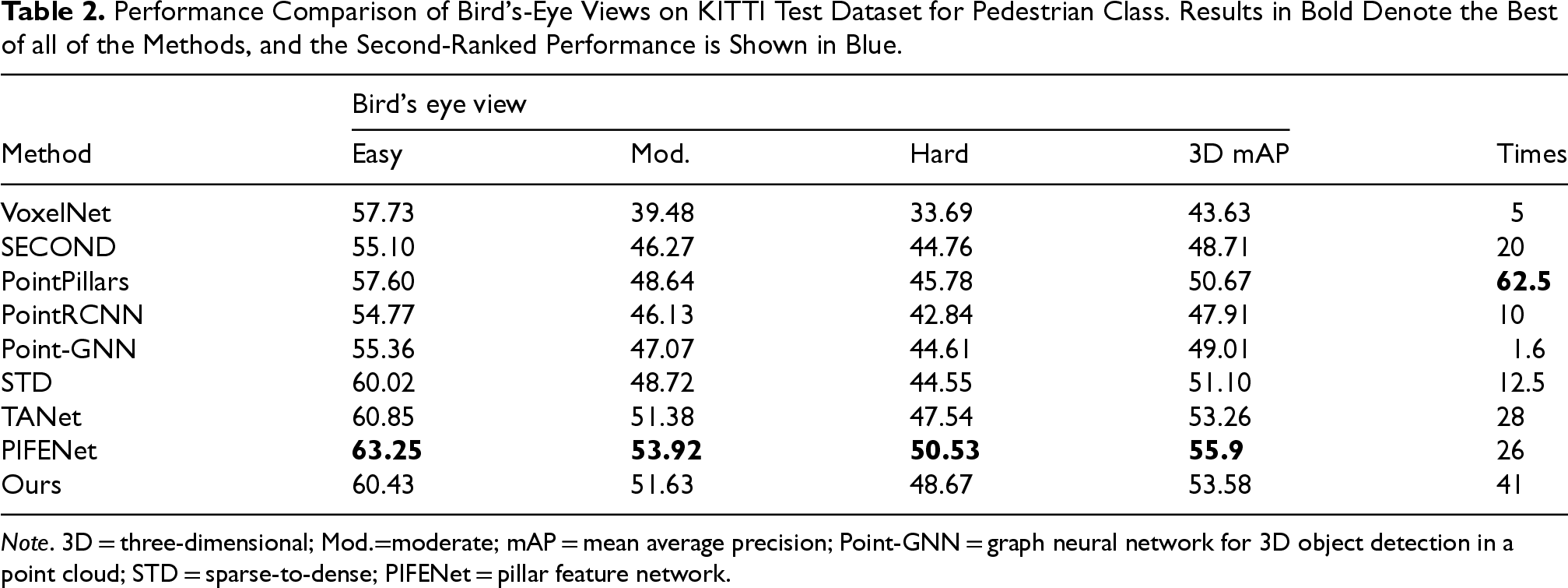
Note. 3D = three-dimensional; Mod.=moderate; mAP = mean average precision; Point-GNN = graph neural network for 3D object detection in a point cloud; STD = sparse-to-dense; PIFENet = pillar feature network.
Several qualitative results for 3D detection on KITTI are shown in Figure 6. From Figure 6, we notice that PointPillars has serious false detection problems, especially for small objects. Because pedestrians are smaller in size than cars, the effective points scanned by LiDAR are fewer. Then pedestrians are often in various backgrounds, such as poles, trees, and other objects are often mixed with pedestrians, resulting in PointPillars providing a false-positive target for pedestrians. Our method solves the above problem to some extent, which proves the accuracy and robustness of our model.
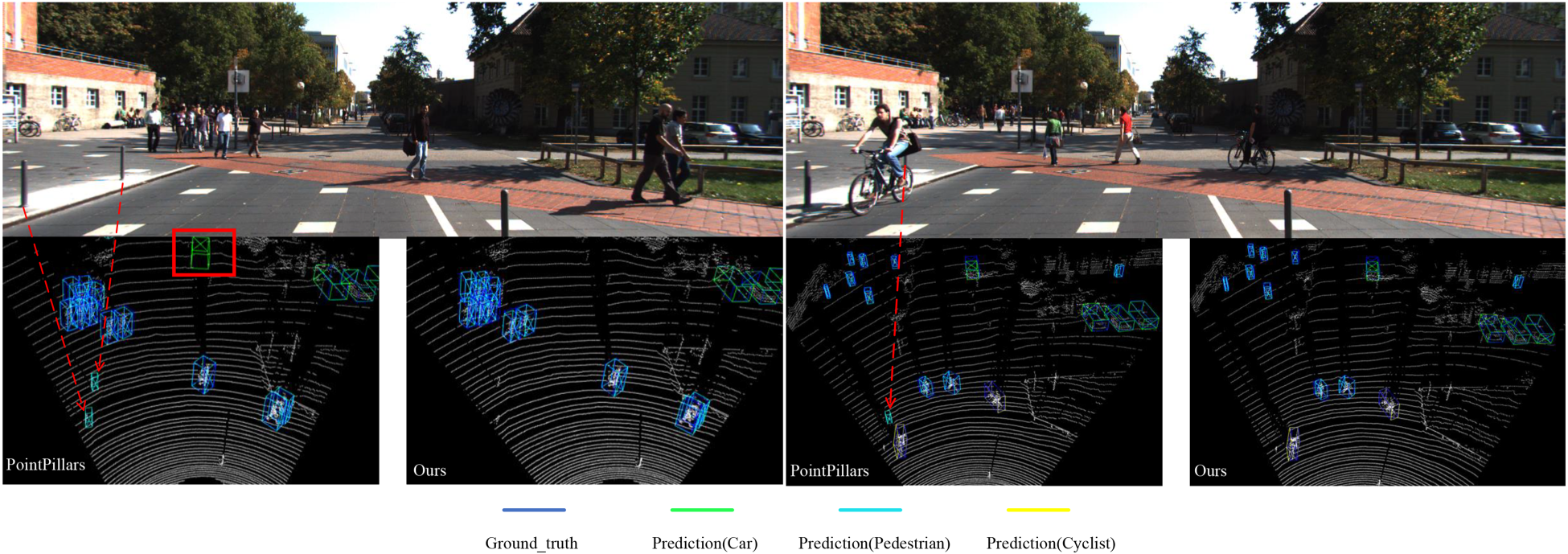
Qualitative results for pedestrian detection on KITTI validation set. The two-dimensional (2D) scene (top), object detection result for PointPillars (bottom left), and object detection result for our method (bottom right). The ground-truth boxes are dark blue, and the predicted boxes are other color.
In the process of model construction and training, some of the model hyperparameters and training optimizer parameters we use are selected based on excellent parameters. We did not discuss it extensively, but these parameters will also have an impact on the performance of the model. Therefore, we should consider using intelligent optimization algorithms to optimize and search for these hyperparameters in order to obtain the best performance.
The experimental results show that our algorithm model can generate high-quality 3D BBoxes for all target categories, especially for pedestrian and bicycle object lists, but it does not perform as well as the other two categories in detecting car categories, which may be due to issues with our model structure. In addition, our experiments were conducted on the same dataset, and the generalization ability of the model will be one of the challenges in the future.
We adopted sparse convolution operation in the FSN module of this article, which can directly perform convolution operation on active data points while ignoring blank or irrelevant data areas. Compared to regular convolutions, this can significantly reduce computational complexity and improve processing speed, as regular convolutions require operations on the entire data region, including a large number of zero or blank areas. Sparse convolution, due to its design, may have fewer parameters as it only processes the active parts of the data. However, ordinary convolutions may have more parameters due to the need to process the entire data area. Reducing the number of parameters can reduce the complexity of the model and help prevent overfitting. In addition, sparse convolution can reduce memory usage as it only stores and processes information from active data points. In terms of model structure, sparse convolutional networks can run strictly on submanifolds, which means they can maintain the sparsity of data without expanding the entire data area. This design can make sparse convolutional networks more efficient in processing sparse data.
3D object detection plays a crucial role in the field of autonomous driving, providing vehicles with precise spatial understanding of their surrounding environment. This technology can identify and locate objects from various sensor data, including their 3D information such as position, size, and shape. These pieces of information are crucial for tasks such as navigation, obstacle avoidance, path planning, and motion prediction in autonomous vehicles. And the experimental results of our algorithm show its superior performance in pedestrian and bicycle categories, especially for detecting small target objects. Therefore, our research will further improve the performance of recognition and localization problems in autonomous driving processes.
The challenges faced by 3D object detection in the field of autonomous driving, such as occlusion, constantly changing lighting conditions, and complex traffic scenes, are currently a hot research topic. To solve the occlusion problem, we consider using Repulse Loss to optimize the prediction box so that it is not only close to the target, but also far away from other objects, reducing the impact of occlusion. The variation of lighting has a significant impact on the accuracy of object detection algorithms. To address this challenge, researchers have tried various methods. We consider using data augmentation techniques to simulate different lighting conditions to create diverse datasets and improve the robustness of the model through training. In complex traffic scenarios, object detection models need to handle highly dynamic and complex environments. They can use multi-scale feature fusion for multi-scale feature prediction, as well as establish connections between objects and context using relational networks.
In the field of autonomous driving, performance metrics for 3D object detection are crucial for evaluating the effectiveness of models. These indicators not only measure the accuracy of the model, but also reflect its inference speed, model complexity, and resource requirements in practical applications, which are key factors in balancing performance and computational cost. Fast and accurate object detection is essential in autonomous driving. The model must process and respond to sensor data in a very short amount of time in order to make real-time decisions. Therefore, inference speed is a key performance indicator that directly affects the real-time performance of the system. The complexity of a model is usually directly proportional to its performance. More complex models may provide higher detection accuracy, but at the same time require more computational resources, which may lead to a decrease in inference speed. The auto drive system usually needs to run on limited hardware resources, which requires that the 3D object detection model should not only maintain high accuracy, but also control its resource consumption.
In this section, we analyze the effect of each component in MASNet through ablation experiments on the KITTI validation dataset. We use PointPillars as the Baseline. Our Baseline achieves a 3D mAP of 78.33%, 61.40%, and 66.11% for car, pedestrian, and cyclist detection, respectively.
PMA Modules Analysis
We evaluate the contribution of the PMA module by adding the CA module and the PA module to the baseline in different ways. As shown in Table 3, using the PA module and the CA module alone can improve the detection performance of the network, but the improvement is relatively limited. We also provide some variants of PA and CA: PMA, CA–PA, and PA–CA. PMA represents the concatenation of the outputs of PA and CA along the channel dimension. PA–CA stands for PA cascading with CA, CA–PA is opposite to PA–CA. For CA–PA and PA–CA, further performance improvement can be achieved. This shows the importance of reasonably using the channel-wise and the point-wise information. It is clear that PMA achieves a significant 2.03% mAP increase which is the best performance in the combination of two attention mechanisms, which verifies the superiority of PMA better.
Ablation Experiments on Effects of Proposed PMA Module. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
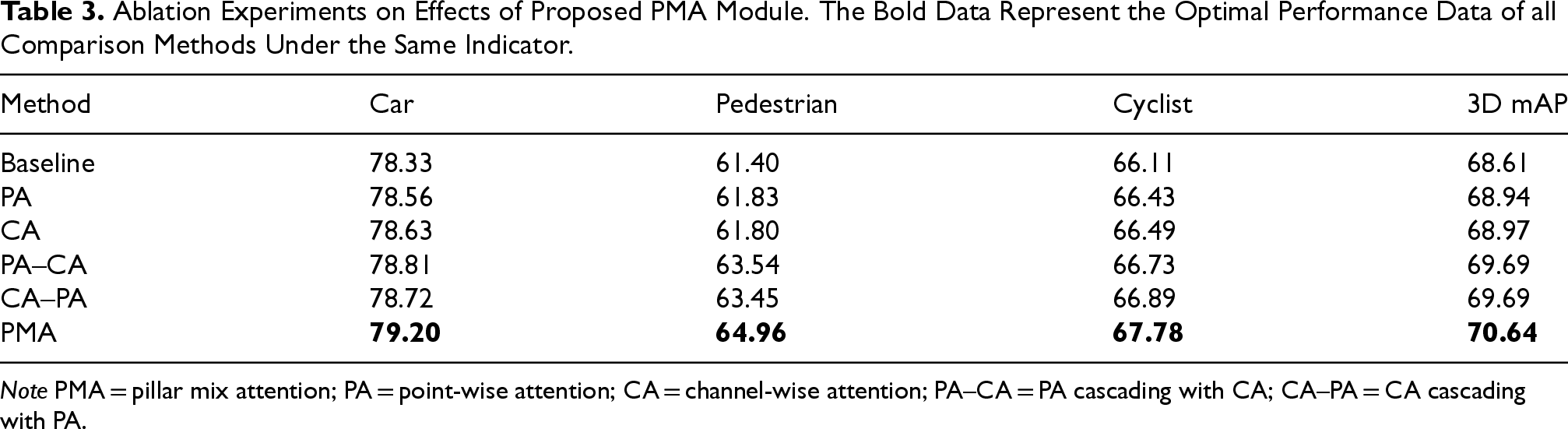
Ablation Experiments on Effects of Proposed PMA Module. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
Note PMA = pillar mix attention; PA = point-wise attention; CA = channel-wise attention; PA–CA = PA cascading with CA; CA–PA = CA cascading with PA.
Table 4 shows the role of attention-pooling. To reduce the computation load, we only replace max pooling in the simple PointNet structure of PointPillars. Different pooling methods are used for experiments in the two cases: with and without the PMA module. As shown in Table 4, compared to max pooling (Max.), using average pooling (Avg.) under unchanged conditions does not significantly enhance performance. Using attention pooling (Att.) alone, yielding a 3D mAP of 69.06%, only 0.45% higher than the baseline model. However, with the introduction of the PMA module, performance is elevated to 71.64%. Especially in pedestrian category detection, there is an additional 0.89% improvement in 3D mAP. This proves the PMA module and attention pooling mutually enhance each other. The results of the experiments also indirectly prove that the use of max pooling to aggregate the information of the pillar is flawed. This also provides a proof that our attention pooling can fully exploit the global information in the pillar and generate high-quality feature pseudo-image, which improves the detection accuracy and proves the effectiveness of the method.
Ablation Experiments on Effects of Proposed Attention Pooling Operation. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
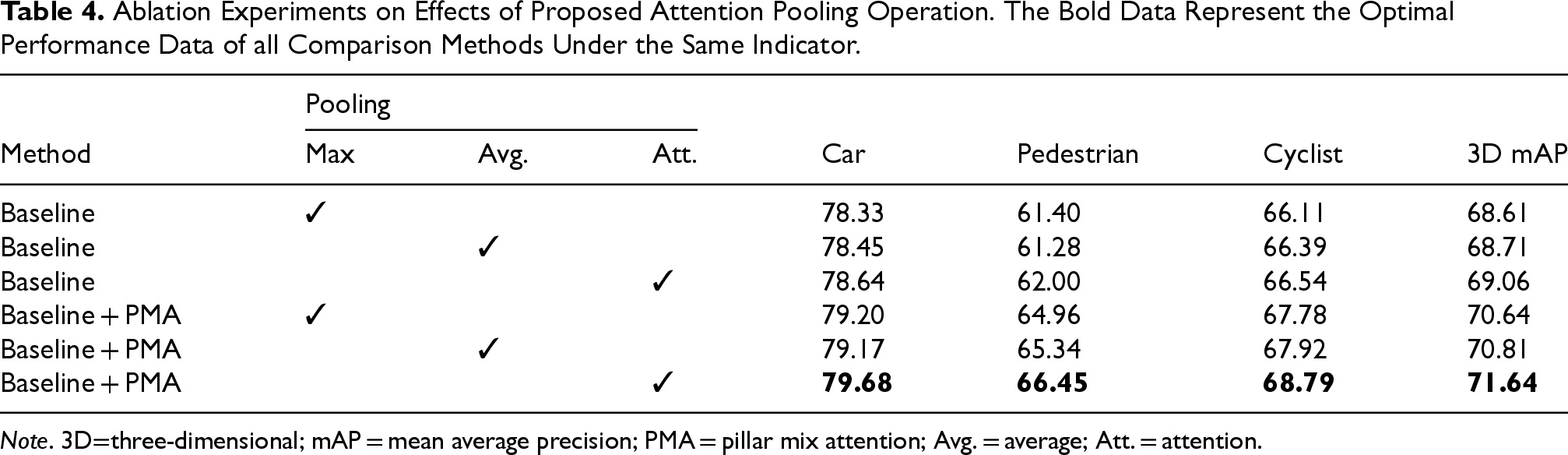
Ablation Experiments on Effects of Proposed Attention Pooling Operation. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
Note. 3D=three-dimensional; mAP = mean average precision; PMA = pillar mix attention; Avg. = average; Att. = attention.
We further validate the effectiveness of the FSN module, and the experimental results are shown in Table 5. In the FSN module, we introduce a sparse convolutional network and focal sparse convolution to obtain a greater number of learnable features as well as stronger sparse pillar feature encoding capability, while we utilize a simple network to implement the fusion of sparse features with dense features. As shown in Table 5, compared with the baseline model, the performance is boosted to 70.08% by introducing the FSN module, and the 3D mAPs for car, pedestrian, and cyclist show improvements of 2.27%, 3.06%, and 1.33%, respectively. It can be noticed that we get a compelling performance improvement after using PMA, attention pooling, and FSN simultaneously, proving that they are all indispensable parts of the network.
Ablation Experiments on Effects of Proposed FSN Module. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
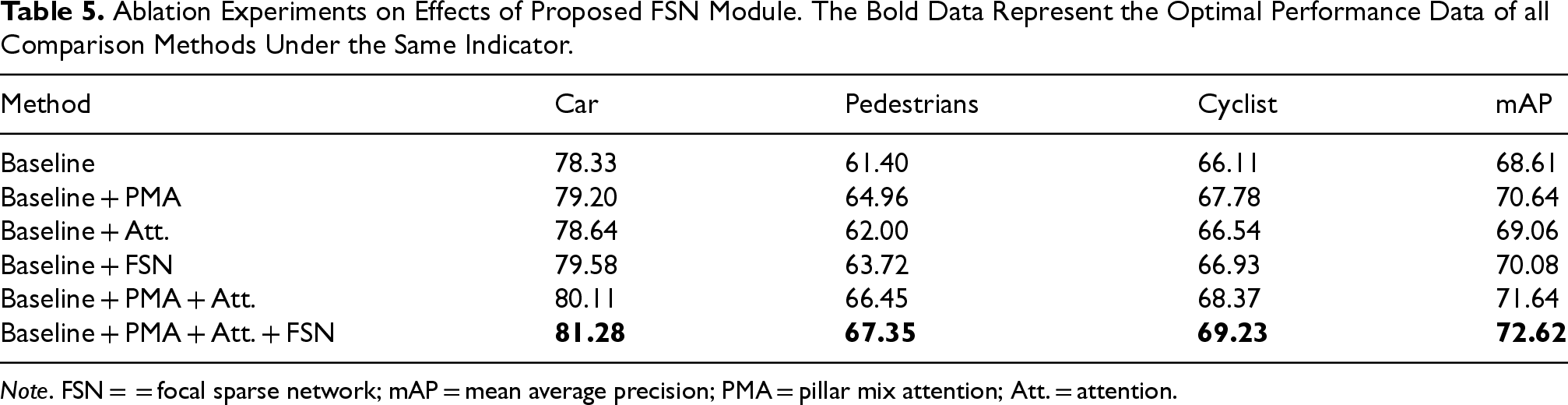
Ablation Experiments on Effects of Proposed FSN Module. The Bold Data Represent the Optimal Performance Data of all Comparison Methods Under the Same Indicator.
Note. FSN = = focal sparse network; mAP = mean average precision; PMA = pillar mix attention; Att. = attention.
In this paper, we propose a novel one-stage MASNet for 3D object detection. The PMA module, the attention pooling method, and the FSN module are the core components of the MASNet.
We propose a stackable PMA module, which enhances the pillar features extraction ability by integrating PA and CA. The PMA module can also be stacked to obtain multi-level columnar feature attention, further improving the performance of small object detection. The PMA module combines CA and PA to better extract pillar features. To further improve feature utilization, We present an attention-style pooling operation (attention pooling), which can effectively encode geometric information better and aggregate features based on importance. Attention pooling makes full use of the information of all points in the pillar to reduce the loss of fine-grained information. We propose a new sparse multi-scale-fusion module that powerfully encodes pillar features by focal sparse convolution and facilitates multi-level feature fusion of sparse features and dense features. The FSN module enhances the information exchange between disconnected features by generating dynamic outputs and achieves the fusion of sparse and dense features without incurring too much computational cost. In the process of model construction and training, some of the model hyperparameters and training optimizer parameters we use are selected based on excellent parameters. Therefore, we should consider using intelligent optimization algorithms to optimize and search for these hyperparameters in order to obtain the best performance. And our experiment was only conducted on one dataset, so we are considering extending the model to other commonly used datasets, such as nuScenes and Waymo Open. These datasets provide rich scene and annotation information for training and testing models to characterize our model’s generalization ability. The experiments show that our method can generate high-quality 3D BBoxes for all categories, especially for objects in the pedestrian and cyclist categories, but the car category does not show a consistent improvement in detection. In the future, we hope to use a multi-modal fusion approach to further improve the detection performance by introducing red–blue–green images to provide a priori information and then fusing the features of both modalities.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.