
Abstract
In order to solve the problem of accuracy decline caused by feature redundancy, this paper designs a federated learning strategy that combines composite meta-consistency loss and multi-head attention. Firstly, this paper decorrelates the features based on the dual theory of constraints to eliminate redundant information, and improves the stability of the model through gradient-based regularization. Composite meta-consistency loss is constructed based on these two optimization methods. Experiments show that compared with the latest algorithms, the maximum accuracy of CIFAR-10 and Oxford-Pets in this paper is improved by 0.82% and 2.19%, respectively. After that, this paper introduces multi-head attention into the framework of federated learning. After capturing richer context information in the process of feature extraction, the combination of inner-layer update and outer-layer update of the meta-learning method enables the federated learning framework to effectively cope with the data distribution of different clients and finally accelerate the convergence speed. Compared with other algorithms, the average accuracy of the first 40 rounds in the MINIST, CIFAR-10 and CIFAR-100 data sets is higher. In CIFAR-10, SVHN, Oxford-Pets, taking Robust-HDP as the benchmark, the speedup ratio reaches 1.5, 1.42, and 1.34, respectively, which is faster than other algorithms.
Introduction
In recent years, machine learning technology has been widely applied to people’s daily life and all walks of life, and has had a profound impact on social development. Machine learning relies heavily on model training supported by massive data. However, with the continuous improvement of people’s awareness of data security and privacy protection, the willingness of data owners to share sensitive data has gradually decreased, and various governments have successively promulgated relevant regulations on privacy data protection, such as the General Data Protection Regulation of the European Union (Goddard, 2017). To address this data silo problem, Google proposed the concept of federated learning (FL). FL is a special distributed machine learning framework that aims to build a global model based on distributed clients (Konen et al., 2016; Mcmahan et al., 2016; Yu et al., 2020). The emergence of FL can effectively solve the problem of data silos, so that different institutions and individuals can legally share dispersed data and train high-quality models together, which provides theoretical support for the progress of science and technology.
In FL, the design and application of the loss function directly affect the training effect and final performance of the model. Cross-entropy loss function is widely used in federated classification learning tasks, but there are some shortcomings in its application: (a) poor processing of non-independently and identically distributed (non-IID) data may lead to deviation of global model; (b) lack of consistency constraints on the feature space, the correlation of the feature space is too strong, and there is redundant information; (c) because the data volume of different clients is different, and cross-entropy is sensitive to label noise and false labels, it is easy to overfit local data. These problems cause that there is still room for optimization in the accuracy and speed of training in FL. Several methods have been proposed to optimize the FL loss function. Wang et al. (2018) analyzed the convergence boundary of distributed gradient descent to minimize the FL loss function. Wei et al. (2020) and Chen et al. (2021) have proposed theoretical convergence bounds and expected convergence rate optimization of FL algorithms, respectively, with the aim of improving convergence performance and minimizing loss functions. Ghosh et al. (2020) proposed an iterative federated clustering algorithm to analyze the convergence rate of strongly convex smooth loss functions. Dinh et al. (2021) and Li et al. (2021b) proposed FEDL model and Fed LSGAN framework, respectively, to improve training stability and generation quality. Zhang et al. (2021) and Shlezinger et al. (2021) further optimized the loss minimization of FL through a three-tier collaborative FL architecture and a universal vector quantization approach. Wang et al. (2020) designed the ratio loss function to reduce the problem of data imbalance. Li et al. (2021a) and Dong et al. (2022) optimize the loss function minimization problem through blockchain-assisted learning and SphereFed framework, respectively. The composite meta-consistency loss (CMCL) constructed in this paper can adjust and reduce feature redundancy and constrain the correlation of feature space, reduce the influence of noise to improve the utilization rate of effective information, and enable the model to focus more on extracting and utilizing important and distinguishing features. Ultimately, it improves classification or prediction accuracy and provides model robustness.
In addition, reducing the communication overhead by optimizing the FL framework is another important direction of FL research. In FL, communication cost is an important consideration. Frequent data exchange may significantly increase network overhead and latency. Accelerating the convergence speed of FL can reduce the overall bandwidth requirement of the system and improve the efficiency and scalability of FL. Several studies have been conducted to improve the performance of FL. Li et al. (2023) proposed a method to realize universality and personalization of FL by using equiangular tight frame classifiers. Lee et al. (2021) preserve the global view of non-true classes through federated not-true distillation algorithm. Oh et al. (2021) proposed FedBABU algorithm to update the model body during training and fine-tune the head during evaluation. The SCAFFOLD algorithm proposed by Karimireddy et al. (2019) corrects client drift. Jhunjhunwala et al. (2023) developed a FedExP mechanism to accelerate POCS. Kim et al. (2024) improved the alignment of local models and the aggregation of global models by using FedDr+ algorithm.
In theory, meta-learning can take advantage of the way of performing inner updates on each client and then summarizing these updates for outer updates, so that the model can quickly adapt to new tasks with a small amount of training data and fewer communication rounds, and through the multi-head attention mechanism, the model can integrate global information from other clients during local updates. This effective use of global information reduces the dependence of the model on frequent communication and speeds up the convergence of the global model. Several studies have explored advancements in fault diagnosis and meta-learning (Feng et al., 2021; Tao et al., 2022; Yang et al., 2022b), such as Tao Hongfeng who designed a fault diagnosis method combining parameter optimization and feature measurement. In terms of the combination of FL and meta-learning, some studies focus on improving model performance and convergence. Khodak et al. (2019) developed a framework to enhance meta-testing, while Liu et al. (2021b) and Yue et al. (2022) proposed a NUFM algorithm to accelerate convergence and achieve distributed interference recognition. Wang et al. (2022) used the PrivRec model for personalized FL (PFL). Some emphasize fine-tuning models and ways to improve communication efficiency. Xiong et al. (2022) and Yang et al. (2022a) used model-agnostic meta-learning (MAML) and G-FML frameworks to realize FL personalization, and Liu et al. (2021a) introduced communication efficient PFA+ algorithm to realize FL. Noble et al. (2021) explore the convergence of convex and non-convex joint learning algorithms using differential privacy. Malekmohammadi et al. (2024) proposed a Robust-HDP model to reduce model update noise and improve the stability and accuracy of FL systems.
The existing FL methods, such as FedAvg, DPFedAvg, and Robust-HDP in Table 1, while making progress in improving model accuracy and handling data heterogeneity, often overlook the constraints between the feature spaces of different tasks. This leads to imbalanced feature representations during the learning of multiple tasks. Such imbalanced representations prevent the model from effectively sharing information between tasks, thereby reducing its generalization ability. Additionally, these methods fail to handle redundant data effectively, with some redundant data being processed repeatedly across tasks, increasing the risk of overfitting to specific tasks and affecting the model’s stability. Especially in cases where there is significant heterogeneity in data distribution, existing FL methods typically assume that data is independently and identically distributed (IID), but in practice, client data is often non-IID. Non-IID data refer to scenarios where the data distributions on different clients are not the same, either due to differences in data types, class distributions, or the way data are collected. This inconsistency in data distribution introduces challenges, such as slower convergence, reduced model stability, and increased risks of overfitting, as the model struggles to generalize across clients with different data characteristics.
Comparison of FL Methods and Their Contributions.
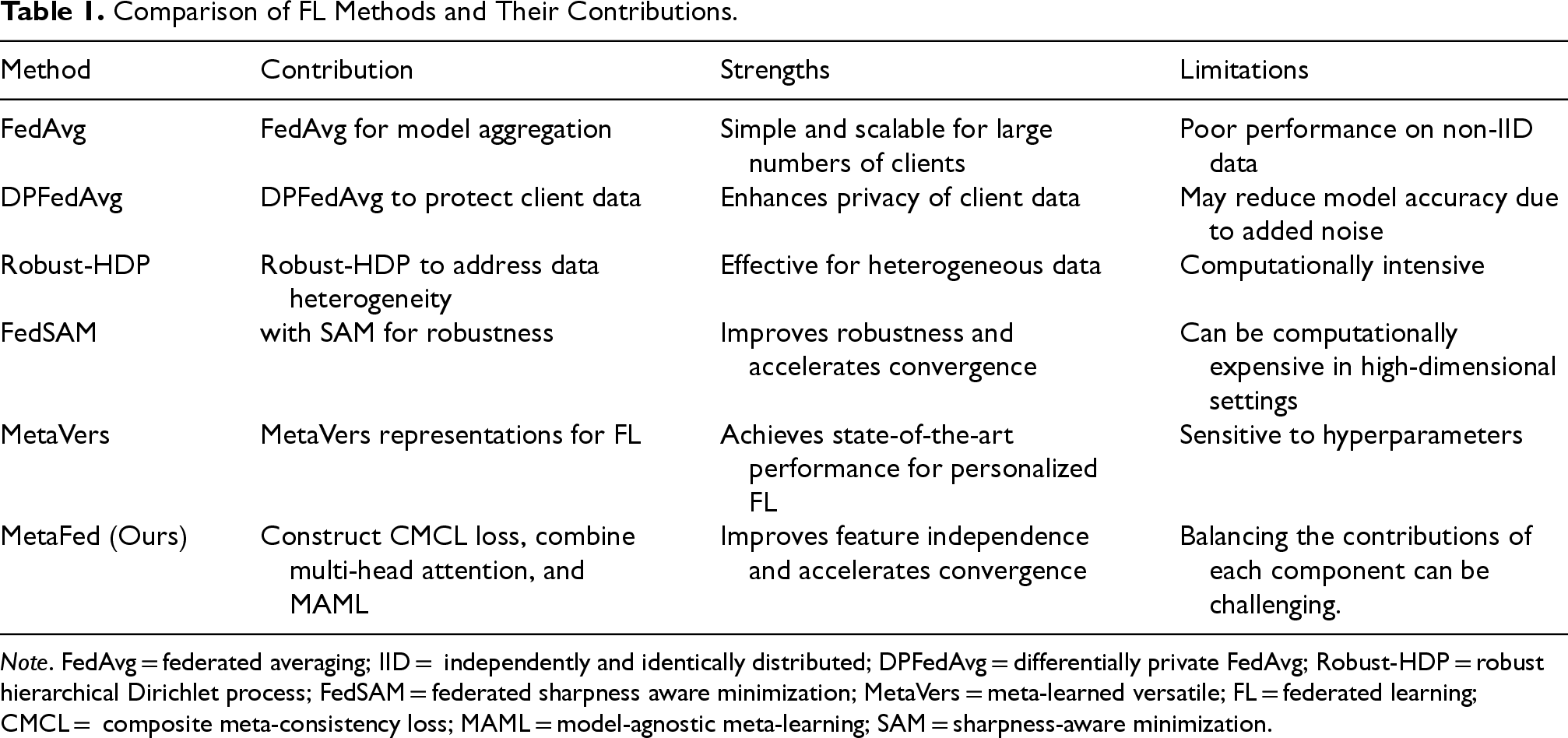
Comparison of FL Methods and Their Contributions.
Note. FedAvg = federated averaging; IID = independently and identically distributed; DPFedAvg = differentially private FedAvg; Robust-HDP = robust hierarchical Dirichlet process; FedSAM = federated sharpness aware minimization; MetaVers = meta-learned versatile; FL = federated learning; CMCL = composite meta-consistency loss; MAML = model-agnostic meta-learning; SAM = sharpness-aware minimization.
To address these issues, this paper proposes a new CMCL loss function, which introduces a constraint-based decorrelation technique to improve the independence between features and avoid unnecessary noise. This innovation allows the model to focus on independent feature dimensions during training, enhancing feature representation balance and stability while avoiding overfitting to specific task data. Additionally, this paper introduces a multi-head attention mechanism, which helps the model capture richer context information during feature extraction, effectively addressing the challenges posed by non-IID data and improving the model’s adaptability to client data heterogeneity. Building on this, the paper also integrates the MAML method, accelerating the convergence speed of FL through inner and outer-layer updates, further improving the model’s generalization ability. Through these innovations, the proposed optimized framework not only significantly enhances the accuracy of FL but also accelerates the convergence process, addressing the limitations of existing methods in non-IID data environments.
The key contributions of this paper are as follows:
A new CMCL loss function is proposed, which improves the independence between features through decorrelation techniques, reducing interference from redundant information, and enhancing the model’s stability and generalization ability. In this paper, a new FL framework is designed for the first time by combining multi-head attention mechanism and model-agnostic meta-learning, which together improve the expressiveness and adaptability of the model, achieve faster convergence and better handle the data distribution between different clients. A series of experiments, such as contrast experiment, robustness experiment, hyperparameter sensitivity experiment, etc. jointly verify the effectiveness of the MetaFed method, providing a powerful solution for scalable, efficient, and robust FL.
Vertical FL
Vertical FL is a type of FL, FL is a distributed machine learning approach designed to protect data privacy and security while enabling collaborative learning across multiple devices or organizations. While traditional machine learning methods typically require data to be centralized on a central server for training, FL allows the model to be trained locally on the data-hosting device and only model updates are uploaded, not the raw data.
A situation where different data holders have different characteristics of the data, and the data samples may overlap or not overlap, applies to vertical FL. The scenario of two data owners (i.e., companies A and B) is taken as an example to introduce the system structure of vertical FL (Mcmahan et al., 2016). The FL system architecture in Figure 1 consists of three parts that extend to the case of multiple data owners.
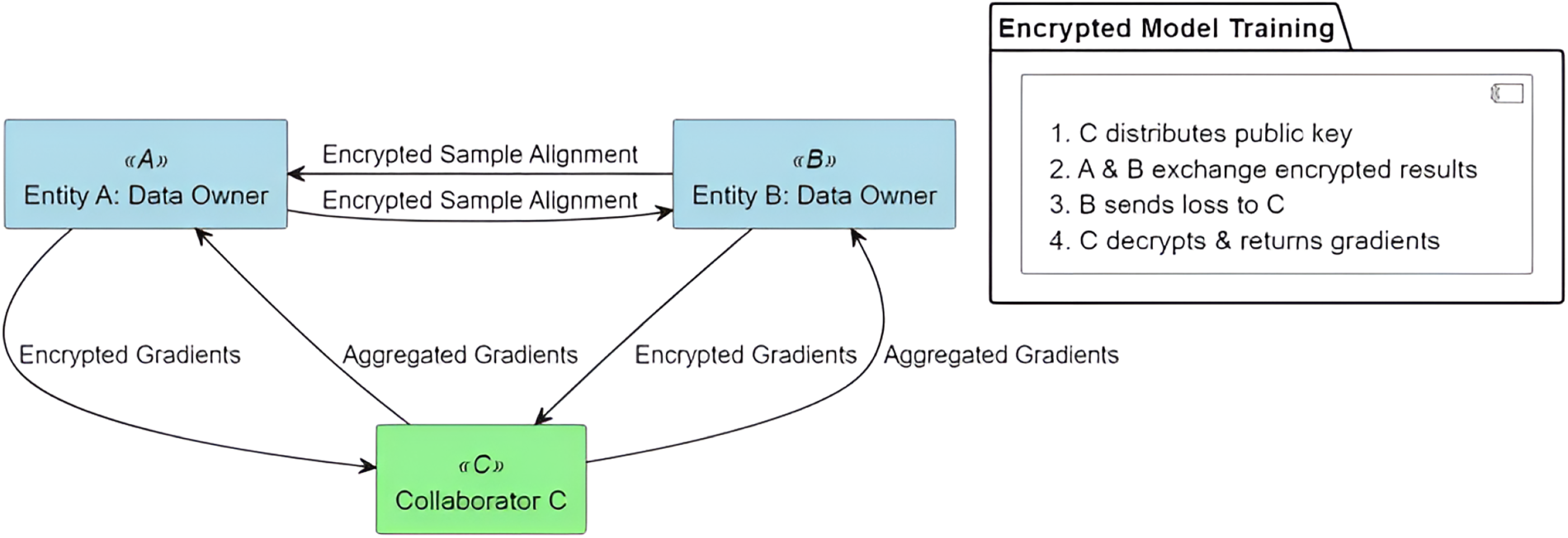
Vertical federated learning system architecture.
Duality theory in constrained optimization is a mathematical theory widely used to solve optimization problems, especially constrained optimization problems. The basic idea of the theory is to transform the original problem into a dual problem and solve the original problem indirectly by solving the dual problem. In many cases, solving the dual problem is simpler or more efficient than solving the original problem directly, especially in complex scenarios such as nonlinear optimization and convex optimization.
Liu et al. (2022) explore the application of Lagrange duality discovery in energy systems and transparent computing. Robey et al. (2021) use non-convex duality theory and semi-infinite optimization to analyze and improve robust learning, especially adversarial training. Ji and Lejeune (2021) use duality theory to solve challenges in robust learning and random constrained optimization.
In constrained optimization problems, the original problem is usually expressed in the following form.
Under the conditions of
The duality problem is generally coinstructed by introducing Lagrange multipliers 
The goal of this dual problem is to find the dual variable
This paper applies duality theory to constrained optimization problems with data-driven uncertainties and complex constraints, where new formulas using Lagrange multipliers are introduced to solve specific challenges in non-IID data distribution and robust learning, with a focus on improving optimization accuracy and stability by enhancing duality formulas. This contribution extends the application of traditional duality theory to more complex real-world optimization problems involving multiple types of uncertainty.
Gradient-based regularization is a regularization technique that measures the difference between task gradient and global gradient to adjust the updating direction of the model and enhance the stability of the model:
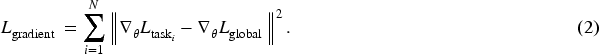
In equation (2),
Meta-learning focuses on making the model learn to learn, that is, learn to learn, make the model acquire the ability to adjust hyperparameters and focus on optimizing the learning algorithm itself. The core idea is to enable machine learning systems to quickly adapt to new tasks or environments by learning how to learn. Meta-learning is widely used in many fields.
Jeon et al. (2024) use meta-variational dropout to personalize FL models in non-IID data settings, improving classification accuracy. Alsulaimawi (2024) introduced meta-FL, a framework that improves global model performance by leveraging optimization-based meta-aggregators to achieve superior accuracy, scalability, and efficiency. Wang et al. (2023) introduced a memory-based stochastic algorithm for MAML to ensure convergence and vanishing errors, making it suitable for continuous learning and cross-device FL scenarios. Lim et al. (2024) introduced MetVers, a meta-learning-based approach for PFL that is achieving state-of-the-art performance on PFL benchmarks. Lan et al. (2023) enhance the convergence of meta-learning by using historical local adaptation models to limit the inner ring direction and overcome local adaptation instability caused by non-convex loss functions and random sampling updates.
Figure 2 shows the brief flow of meta-learning. In the specific training process of meta-learning, the MAML method optimizes the generalization ability of the model through inner-layer updating and outer-layer updating. The specific formula is as follows:


The Multi-head attention mechanism is a variant of the attention mechanism commonly used in deep learning models, especially for processing multiple information sources or learning multiple representations. It computes multiple attention weights in parallel and focuses attention on inputs from different angles to enhance the expressibility of the model when dealing with complex relationships and multi-modal data.
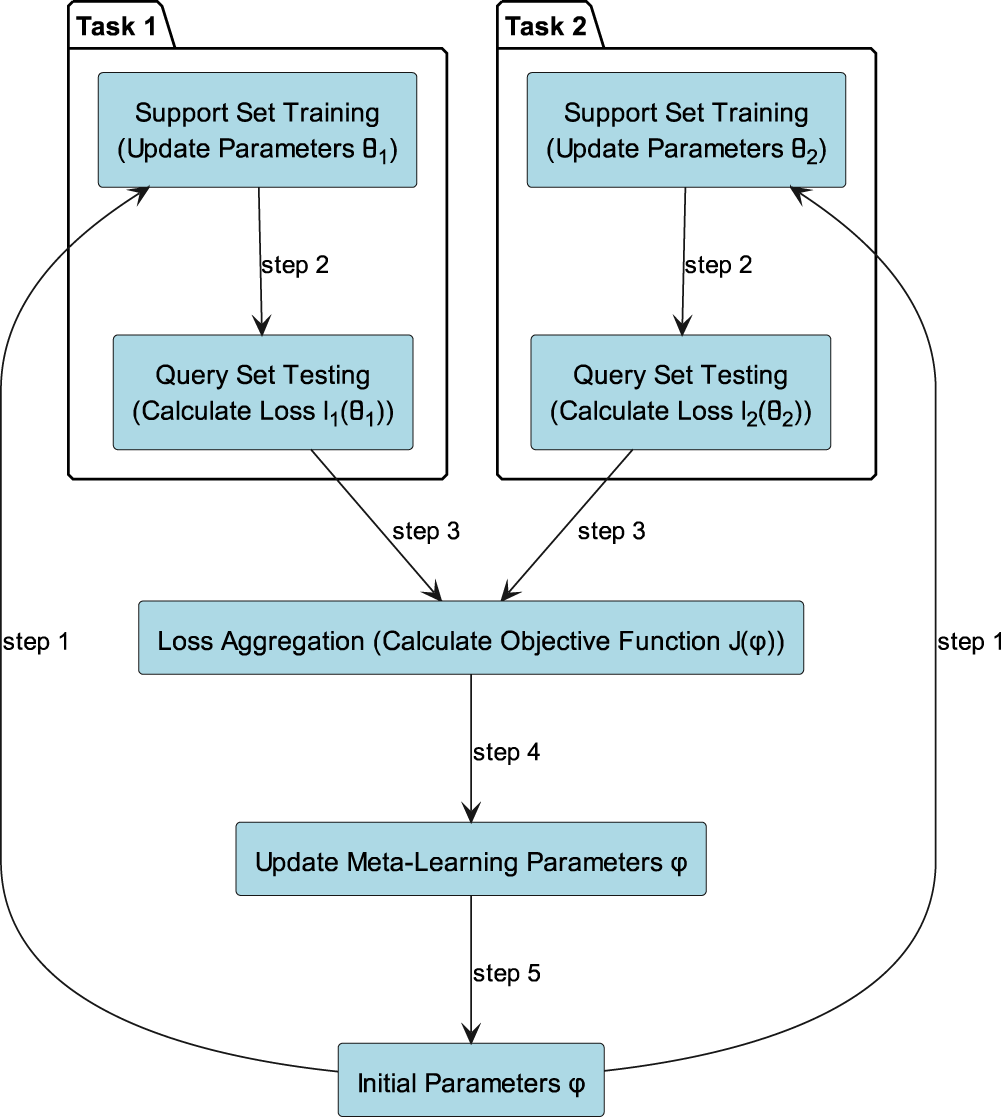
Meta-learning process framework.
The multi-head attention mechanism is widely used in current FL (Chen et al., 2024; Choudhry et al., 2024; Wang et al., 2024). Li et al. (2024) proposed residual attention for FL (RAFL), which uses multiple attention mechanisms to enrich personalized feature information. Jiang et al. (2023) have improved the personalization of local models while aggregating them into new global models. Wu and Kwon (2023) recommended a system to introduce the multi-focus mechanism in the personalized federated knowledge distillation model.
Figure 3 shows multi-head attention using a fully connected layer to implement learnable linear transformations:
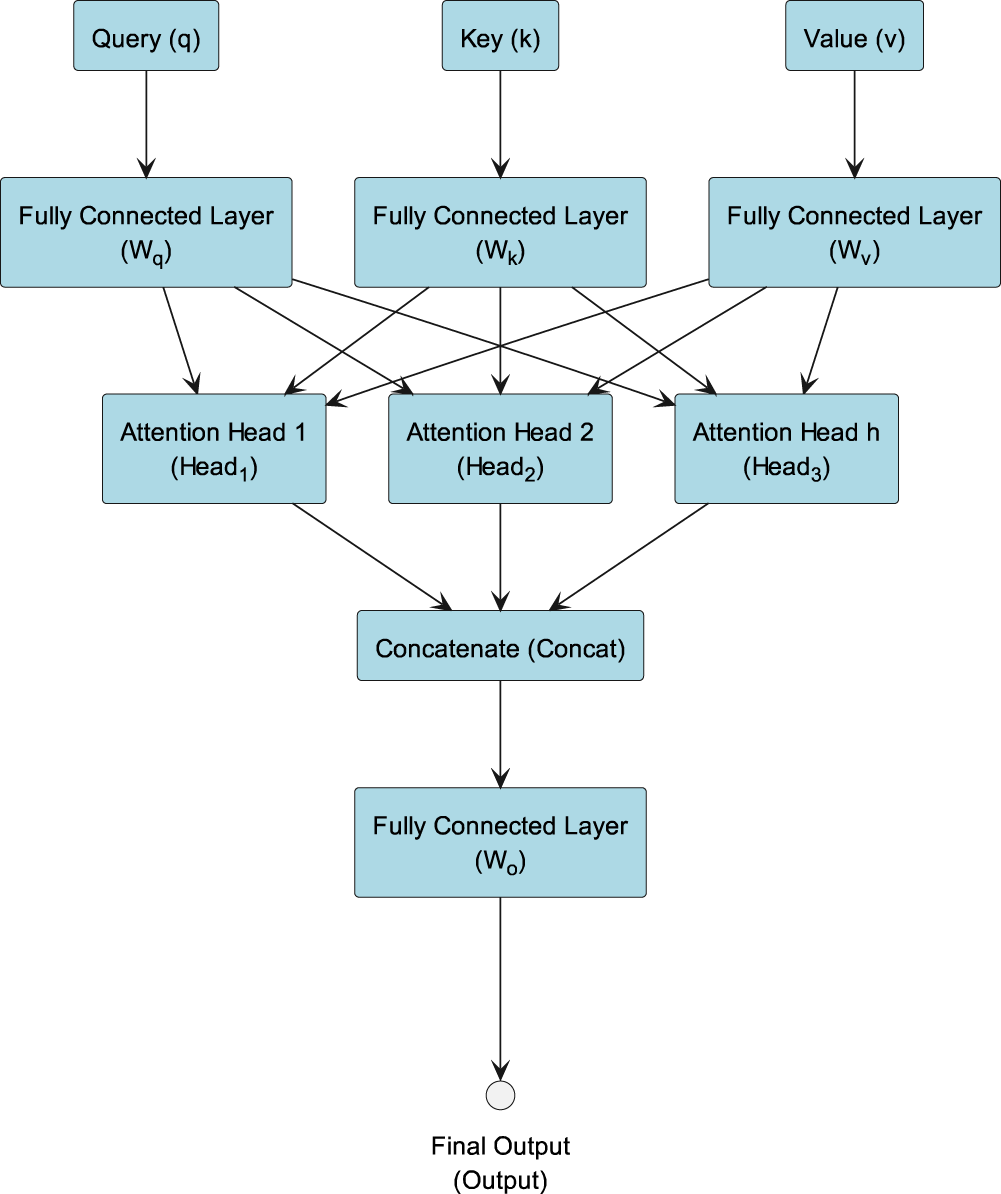
Multi-head attention flowchart.
As shown in Figure 3, given query 

Then the operation of concatenating the outputs of multiple attention heads is shown in equation (7):
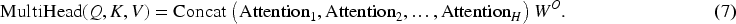
While earlier methods use multi-head attention to improve personalization by enhancing local feature extraction (as in RAFL, Li et al., 2024, and other PFL models), this paper goes further by addressing the feature space constraint between different tasks, which leads to unbalanced feature representations and redundant data processing. By introducing the CMCL loss function, this paper enhances feature independence and stability and combines it with multi-head attention to capture richer context information during feature extraction. This novel approach not only refines the model’s expressiveness but also integrates the MAML framework, allowing FL to effectively adapt to data heterogeneity and accelerate convergence, thus offering a more comprehensive solution that improves both accuracy and training efficiency.
Feature redundancy makes it possible for the model to learn the same information multiple times, while ignoring useful features in the data that really contribute to the task, which not only reduces the learning efficiency of the model, but also may lead to overfitting. Yi et al. (2024) proposed an FL framework FedPE that combines adaptive pruning extension, error compensation strategy, and fair aggregation. Zhou et al. (2024) proposed a new PFL framework combining adaptive pruning of edge data to solve non-IID data. Yan et al. (2024a, 2024b) introduced cluster-contrastive federated clustering and CCFC++, which is a method that combines representation learning with federated clustering to improve clustering performance.
In order to reduce the feature redundancy and the correlation between features, this paper constructs an optimization problem using the dual theory to find the optimal feature transformation matrix, which realizes the removal of the correlation between features and reduces the influence of redundant information. In addition, this paper also improves the stability of model training through gradient-based regularization. Finally, the CMCL algorithm is constructed by integrating feature decorrelation and gradient-based regularization into cross-entropy loss, in order to obtain better results in FL training.
CMCL Algorithm
Feature decorrelation is an important part of this CMCL, and then the design process of this scheme is mainly explained. Huang et al. (2024) introduced salience-guided feature declination (SGFD) for vision-based reinforcement learning, which uses random Fourier functions and significance maps to eliminate feature correlations to achieve generalization. Wen et al. (2024) proposed a Fourier feature decorrelation-based sample focus method for locating dense crowds. Fourier transform and cross-covariance operators are used to decouple feature correlation and improve the model’s focus on relevant target features. In this paper, the feature correlation is mainly based on duality theory.
The Construction of the Duality Problem for Feature Decorrelation
In this paper, we hope to reduce the redundancy among features by means of feature decorrelation, so as to improve the generalization ability of the model. According to the duality theory of constraints, the problem can be formulated as an optimization problem with the goal of finding a transformation matrix
The optimization problem is specifically defined as follows: under the condition of
Then, according to duality theory, we construct the Lagrangian duality problem. By introducing the Lagrange multiplier 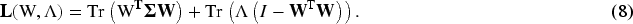
By taking the derivative of
In the above article, we have established the goal of finding the transformation matrix
Calculate the covariance matrix of the data In neural network training, we first need to calculate the covariance matrix Eigenvalue decomposition Eigenvalues and eigenvectors are obtained through the eigenvalue decomposition of covariance matrix Select the principal component In this step, we need to select the eigenvectors Data transformation By selecting the eigenvector matrix




By decorrelating features at the local level using the described process, each client can generate a more meaningful representation of its local data distribution. When these representations are aggregated, the global model benefits from more personalized and generalizable features, improving convergence speed and model robustness. Moreover, by reducing redundant feature information and focusing on the most relevant features, the communication overhead in FL is reduced. Since only the transformed, decoupled features need to be transmitted rather than raw, high-dimensional data, the communication efficiency is significantly improved, particularly in federated scenarios with limited bandwidth or high communication cost.
Figures 4 and 5 show the thermal maps of feature correlation of CIFAR-10, CIFAR-100, and MINISTdata sets before and after feature decorrelation, in which red represents positive correlation, blue represents negative correlation, and white represents no correlation. The diagonal line is the correlation between itself and itself, so 1 is shown as red. As shown in Figures 4 and 5, the heat maps of the three data sets changed from red and blue to white, indicating that the degree of correlation between the features of the three data sets decreased significantly.
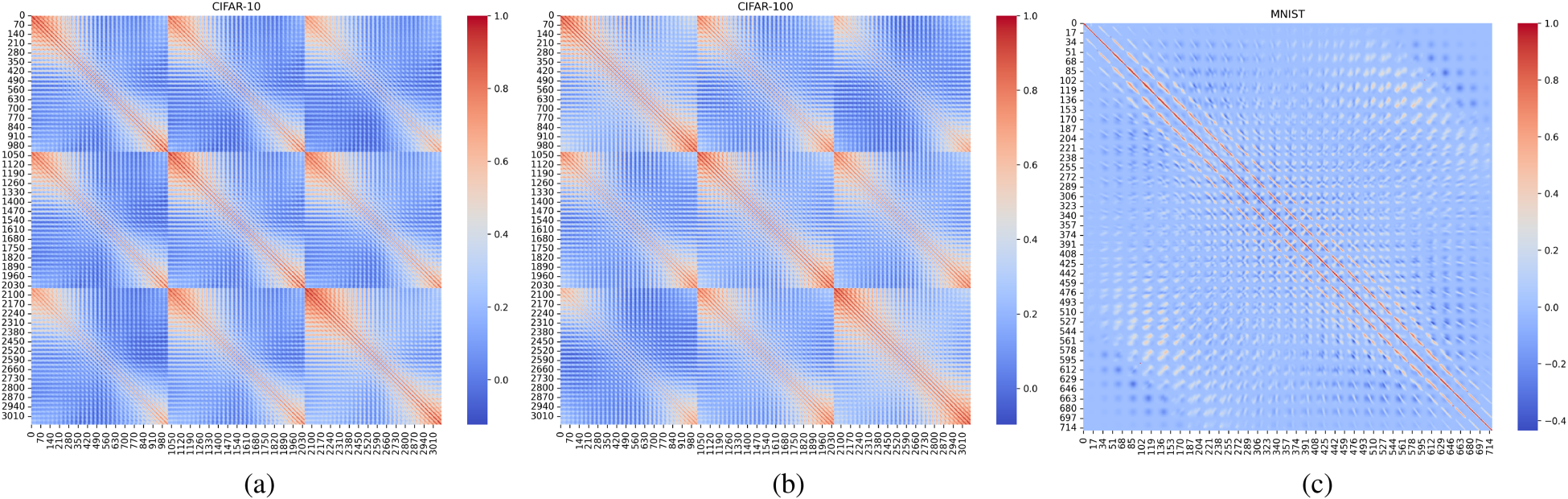
Thermal maps of feature correlation before feature decorrelation.
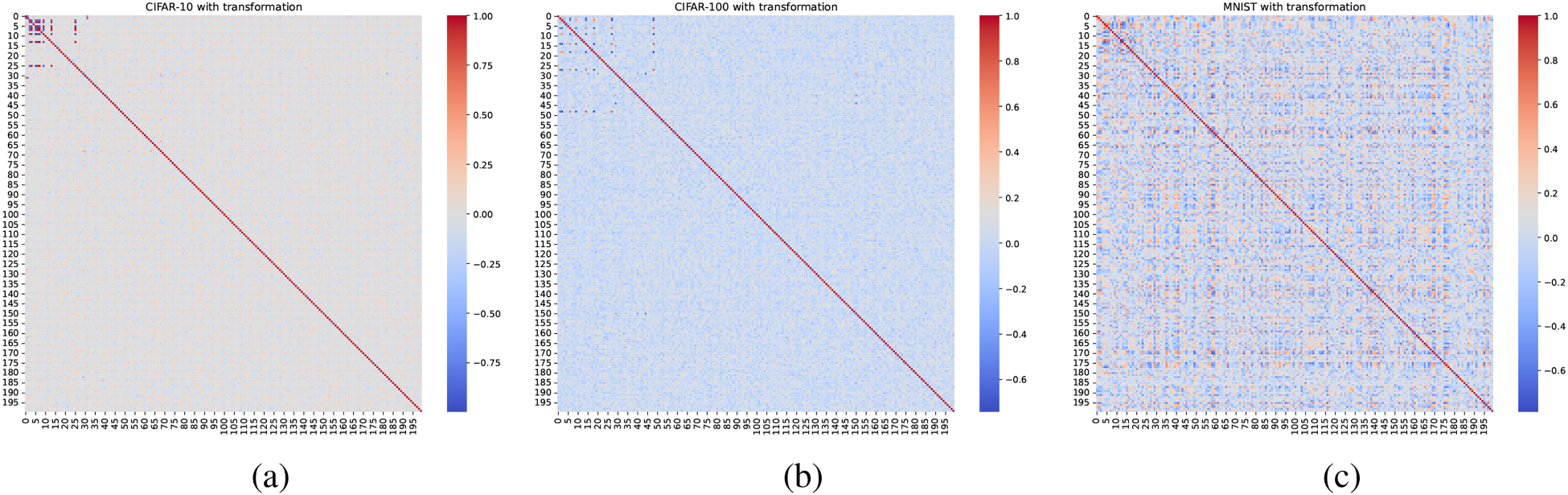
Feature correlation heat maps after feature decorrelation.
In machine learning, if the correlation between adjacent features is high, it may mean that those features have duplication in information. By analyzing the mean correlation of adjacent features, redundant features can be identified to help reduce feature dimensions and improve model efficiency and performance. Table 2 shows the mean value correlation changes of adjacent features in the three data sets before and after feature decorrelation. It can be seen from Table 2 that the feature decorrelation scheme constructed by the duality theory in this paper is effective.
Mean Correlation of Adjacent Features.

In this paper, we hope to optimize both the predictive ability and feature decorrelation of the model. Therefore, the final loss function should combine three objectives:
Basic task loss (cross-entropy loss). Remove the correlation regularization term and reduce the feature redundancy by minimizing the trace of the covariance matrix. Measure the difference between task gradient and global gradient, adjust the updating direction of the model, and enhance the stability of the model.
Therefore, the final CMCL is as equations (13)
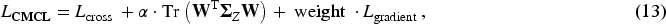
In this section, we present the experimental results of CMCL in FL (hereinafter referred to as FedCMCL) in this paper, including the ablation experiment comparison, and the interaction with FedAvg (Goddard, 2017), FedDr+ (Kim et al., 2024), FedSAM (Li et al., 2025), and MetaVers (Lim et al., 2024).
Experimental Setup Data Set and Model
To simulate a real FL scenario involving multiple data sets, we tested six datasets, CIFAR-10, CIFAR-100, MINIST, SVHN, Fashion MINIST, and Oxford-Pets.
Ablation Experiment
Figure 6 shows the change in accuracy of the training model using the cross-entropy loss function and FedCMCL on three datasets (CIFAR-10, CIFAR-100, and MNIST), respectively. The horizontal axis of each chart represents the number of rounds trained, and the vertical axis represents the accuracy of the model. Each chart consists of two lines:
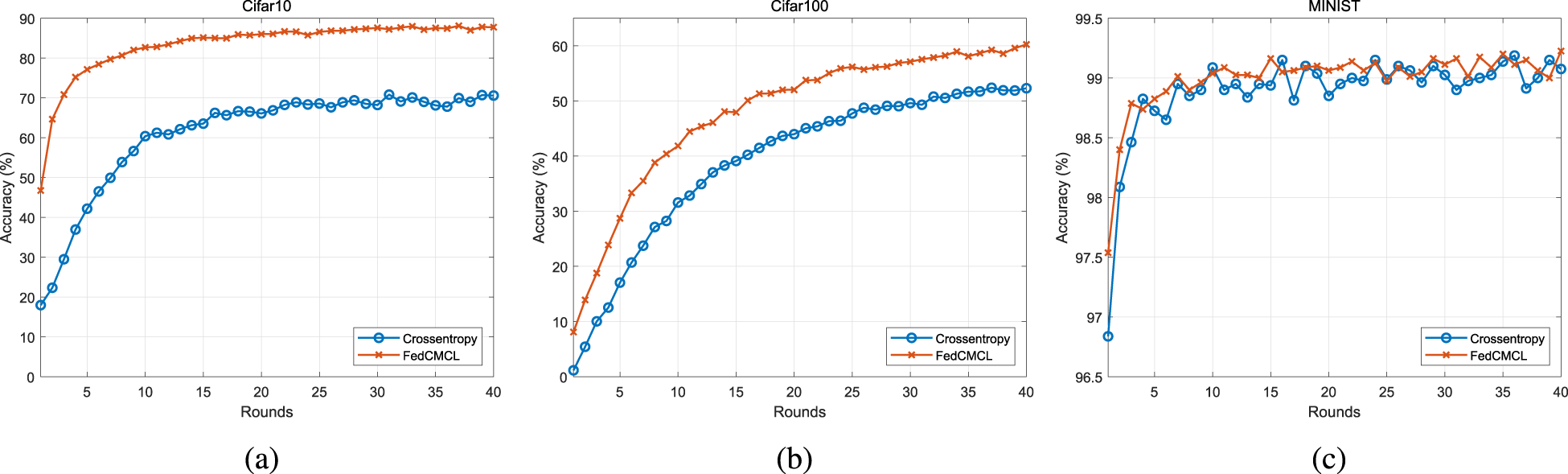
Cross-entropy loss function and composite meta-consistency loss (CMCL) accuracy on different data sets.
As shown in Figure 6, the blue broken line represents the accuracy of the model trained using the cross-entropy loss function, and the orange broken line represents the accuracy of the model trained using FedCMCL. Figure 6(a) and 6(b) shows that the orange line rises significantly more than the blue line, indicating that FedCMCL has faster accuracy improvement during training. In Figure 6(c), although the accuracy of the orange polyline is higher in the early stage, the gap with the blue polyline narrows subsequently. In general, FedCMCL shows significant advantages on different data sets. Thanks to the feature decorrelation in FedCMCL, the features learned by the model can be more focused on the dimensions that are independent and helpful for decision-making, avoiding the interference of redundant information and improving accuracy. As shown in Table 3, FedCMCL outperforms cross-entropy in the first round accuracy on CIFAR-10, CIFAR-100, and MNIST data sets. At the same time, FedCMCL uses a gradient-based regularization method to further enhance the robustness of the model and ensure that the performance is steadily improved during training. The combination of these factors enables FedCMCL to quickly adapt to task changes on multiple datasets and show better performance than the traditional cross-entropy loss function in the final stage, which is further proved by the accuracy of the 40th round in Table 3.
Comparison of Composite Meta-Consistency Loss in Federated Learning (FedCMCL and Cross-Entropy Accuracy in Round 1 and Round 40.

As shown in Table 4, this histogram shows the difference between FedCMCL and FedAvg (Goddard, 2017), FedDr+ (Kim et al., 2024), FedSAM (Li et al., 2025), and MetaVers (Lim et al., 2024).
Results of Different Algorithms on Different Data Sets.
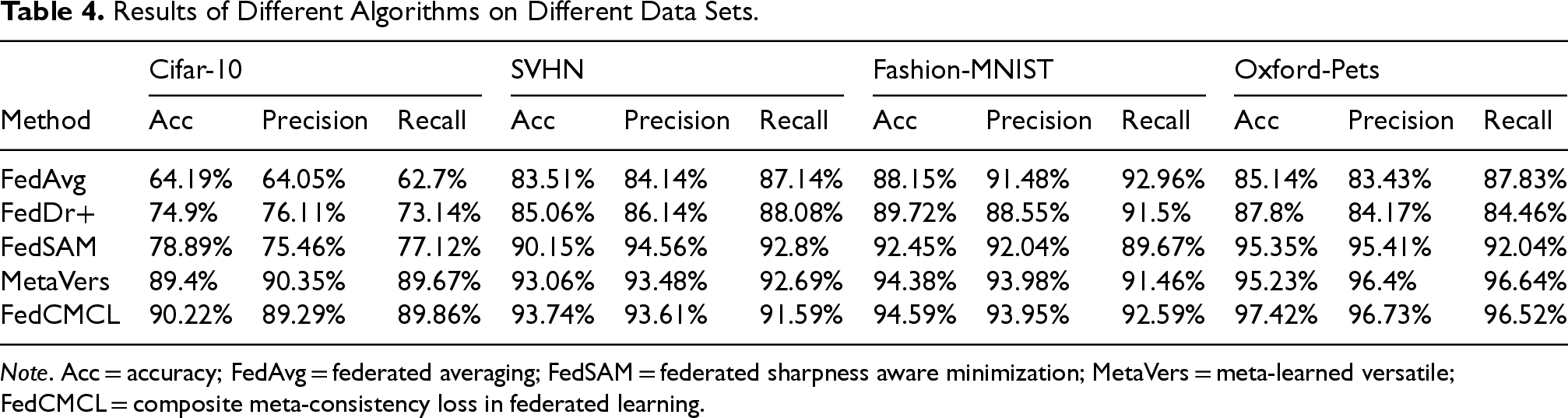
Results of Different Algorithms on Different Data Sets.
Note. Acc = accuracy; FedAvg = federated averaging; FedSAM = federated sharpness aware minimization; MetaVers = meta-learned versatile; FedCMCL = composite meta-consistency loss in federated learning.
In Table 4, the accuracy, precision, and recall values for each algorithm on four different datasets (CIFAR-10, SVHN, Fashion-MNIST, and Oxford-Pets) are presented. FedCMCL significantly outperforms other algorithms in most aspects, demonstrating its strong capabilities in FL. Specifically, on the CIFAR-10 data set, FedCMCL achieves the highest accuracy, outperforming the second-place algorithm by a notable margin. However, in terms of precision, MetaVers slightly outperforms FedCMCL, this is due to MetaVers employing a more refined feature representation learning mechanism, which enhances class separability, leading to higher precision. On the SVHN data set, FedCMCL also shows its superiority with the highest accuracy, outperforming other methods. However, in terms of precision and recall, FedSAM achieves better results compared to FedCMCL. This is attributed to FedSAM’s sharpness-aware minimization (SAM) strategy, which helps the model converge to flatter minima, thereby reducing overfitting to specific classes and improving precision and recall. On Fashion-MNIST, FedCMCL continues to lead with the highest accuracy, surpassing other methods. However, in terms of precision and recall, MetaVers slightly outperforms FedCMCL. This is because Fashion-MNIST has relatively simple visual patterns, and MetaVers, which employs advanced contrastive learning techniques, can better distinguish fine-grained class differences, leading to improved precision and recall. Moreover, on Oxford-Pets, FedCMCL achieves the highest accuracy, well ahead of other baseline algorithms. However, for recall, MetaVers marginally surpasses FedCMCL. This stems from MetaVers’s ability to retain more fine-grained feature details, which aids in identifying more difficult-to-classify instances, leading to a higher recall.
Overall, the results across all data sets demonstrate that FedCMCL is the most consistently strong-performing algorithm, achieving the highest accuracy in all four data sets while maintaining competitive precision and recall. Its superior accuracy highlights its effectiveness in handling diverse data distributions, making it a robust choice for FL. Although some precision and recall values are slightly lower than those of other methods, FedCMCL maintains a balanced performance across all metrics, reinforcing its reliability and adaptability.
In the above, this paper solves the accuracy problem of FL through CMCL. However, in order to speed up the convergence of FL to reduce the overall bandwidth requirements and latency, and further improve the efficiency and scalability of FL, based on the above research, this paper designs a meta-FL framework while using CMCL to improve the accuracy of FL. It can better solve the problem of communication overhead of FL.
Design of a Meta-FL Framework With Multi-Head Attention
Through the multi-head attention mechanism, the model can fuse global information from other clients during local updates, so as to adapt to the heterogeneous data distribution of different clients more quickly. This effective use of global information reduces the dependence of the model on frequent communication and speeds up the convergence of the global model. Then, we combine the MAML inner-layer update and outer-layer update, by performing the inner-layer update on each client and summarizing these updates for the outer-layer update, so that the model can quickly adapt to new tasks with a small amount of training data and fewer communication rounds. This mechanism allows each client model to approach the global optimal solution in a short time, thus reducing the overall training time.
The structural design of the multi-head attention-based meta-FL framework constructed in this paper (hereinafter referred to as MetaFed), as shown in Figure 7.
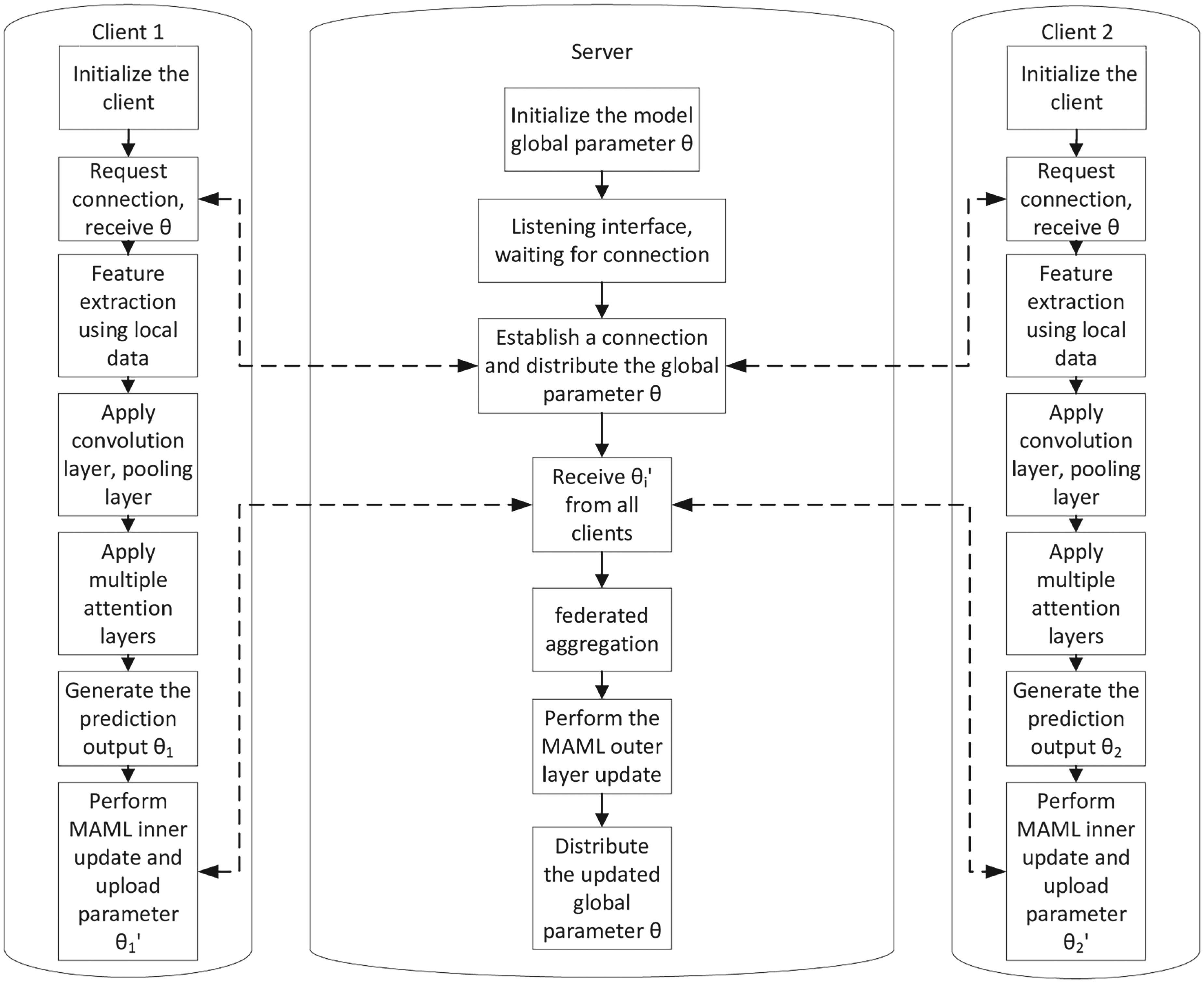
Algorithmic flow of meta-federated learning based on multi-head attention.
This algorithm describes the process of meta-FL based on a multi-head attention mechanism. The entire process is divided into two parts: client-side and server-side, where model updates occur locally and globally. The primary inputs to the MetaFed framework include the local client data and the global model parameters. Each client initializes its model using its local data. The global model parameters
First, the server initializes the global model parameters
Once the predicted output is generated, each client performs an inner-layer update using the MAML method, yielding updated model parameters
After receiving the updated parameters
The computational requirements of the MetaFed framework mainly include the processes involved in feature decorrelation, model updates, and attention mechanism computations. The CMCL process requires calculating the covariance matrix, performing feature decorrelation, and selecting the principal components, which may have a different time complexity depending on the number of clients and the scale of dataset (e.g., the feature decorrelation time of CIFAR-10, CIFAR-100, MINIST, SVHN, and Oxford-Pets in this paper requires 5.7281 s, 6.3243 s, 2.1977 s, 9.3658 s, and 6.4839 s, respectively). The multi-head attention mechanism also adds computational complexity, as it performs attention layer computations to fuse information across clients during local updates, ultimately speeding up model convergence and improving generalization. The setting of different hyperparameters will affect the computing requirements of the multi-head attention.
In this section, we present the experimental results of MetaFed. In this paper, we use three datasets, SVHN, Oxfoxd-Pets, and MINIST, and compare them with RHDP (Malekmohammadi et al., 2024), PFA, WeiAvg (Liu et al., 2021a), FedAvg (Goddard, 2017), FedDr+ (Kim et al., 2024), FedSAM (Li et al., 2025), and MetaVers (Lim et al., 2024) in terms of average accuracy.
Comparative Experiment
The average accuracy can reflect the overall performance of different algorithms in the training process, and help to evaluate the stability and effect of the model. A higher average accuracy rate means that the model can maintain good classification performance in multiple rounds. The experimental results in Figure 8 cover the three data sets MNIST, CIFAR-10, and CIFAR-100, and show the average accuracy of different algorithms in the case of guaranteed convergence in the first 40 rounds.
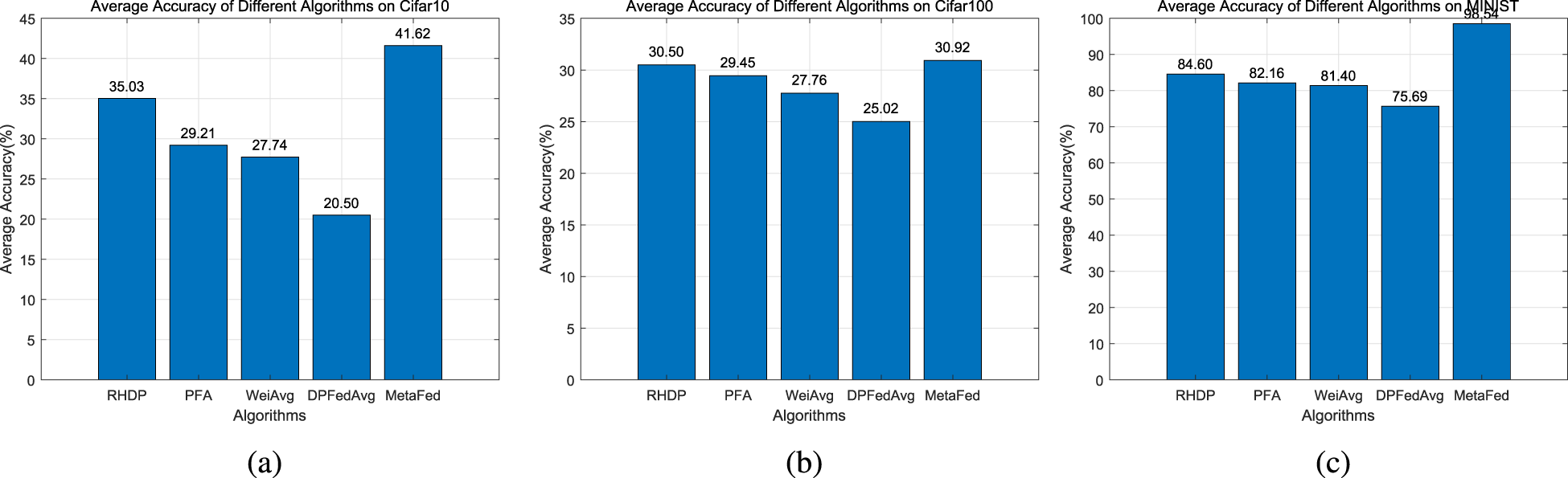
Comparison of average accuracy of MetaFed with other algorithms on different data sets.
As shown in Figure 8, the performance of the MetaFed framework on different datasets highlights its advantages in convergence speed and accuracy. On the MNIST data set, MetaFed achieves an average accuracy of 98.54%, which is much higher than RHDP’s 84.6% and PFA’s 82.16%, indicating that it effectively integrates global information through the multi-head attention mechanism and quickly adapts to simple data sets. In the CIFAR-10 data set, MetaFed also performs well, achieving an accuracy of 41.62%, which is higher than that of RHDP (35.03%) and PFA (29.21%), which verifies its ability to combine the MAML method to improve adaptation to new tasks. However, in the more complex CIFAR-100 data set, MetaFed’s performance weakens somewhat, with only 30.92%, slightly higher than RHDP’s 30.6%, but better than Baseline’s 25.02%. This result shows that while MetaFed performs well on simple and moderately complex data sets, its advantage diminishes when dealing with more complex data sets.
Table 5 presents the performance of different methods on various data sets, including CIFAR-10, SVHN, and Oxford-Pets, respectively. MetaFed consistently outperforms the other algorithms in terms of both accuracy and convergence speed. On the CIFAR-10 data set, MetaFed achieves the highest accuracy of 90.75%, surpassing MetaVers (89.40%) and Robust-HDP (86.71%). Notably, MetaFed achieves a significant speedup ratio of 1.5, outperforming DPFedAvg (1.35) and Robust-HDP (1). Similarly, on the SVHN data set, MetaFed achieves 94.28% accuracy and a speedup ratio of 1.42, demonstrating better performance than FedSAM (90.15%) and MetaVers (93.04%). In terms of training efficiency, MetaFed requires 4872.96 s on SVHN, which is lower than Robust-HDP (6901.72 s) and DPFedAvg (5412.04 s), confirming its efficiency in reducing both time and computational overhead. Additionally, MetaFed achieves the highest accuracy on the Oxford-Pets data set (96.18%) with a speedup ratio of 1.34, outperforming FedSAM (95.35%) and MetaVers (95.23%). These results demonstrate that MetaFed not only achieves high accuracy but also significantly reduces training time compared to other FL methods, offering a compelling tradeoff between performance and efficiency. The integration of CMCL with multi-head attention in MetaFed contributes to its fast convergence and robust performance, making it a superior choice for FL tasks across different data sets.
Performance of Different Methods on Various Data Sets.
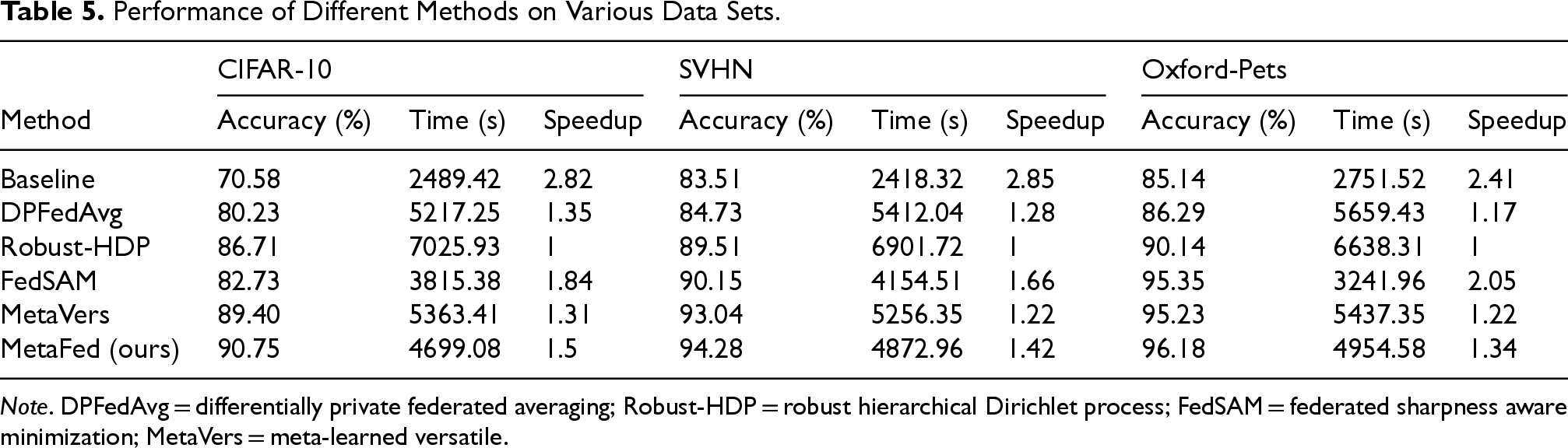
Note. DPFedAvg = differentially private federated averaging; Robust-HDP = robust hierarchical Dirichlet process; FedSAM = federated sharpness aware minimization; MetaVers = meta-learned versatile.
The results in Figure 9 show that while increasing the number of clients generally results in a slight drop in accuracy and slower convergence, the performance drop for the proposed approach is small. Specifically, the 100-client model had an accuracy of about 79% to 80% at round 60, while 50 clients reached 81% and 20 clients showed slightly higher accuracy and faster convergence. Despite the increase in the number of clients, the performance decline is relatively small, indicating that the proposed method combines meta-joint learning and multi-head attention, and maintains good accuracy and convergence even in the presence of more clients, demonstrating its robustness and scalability.
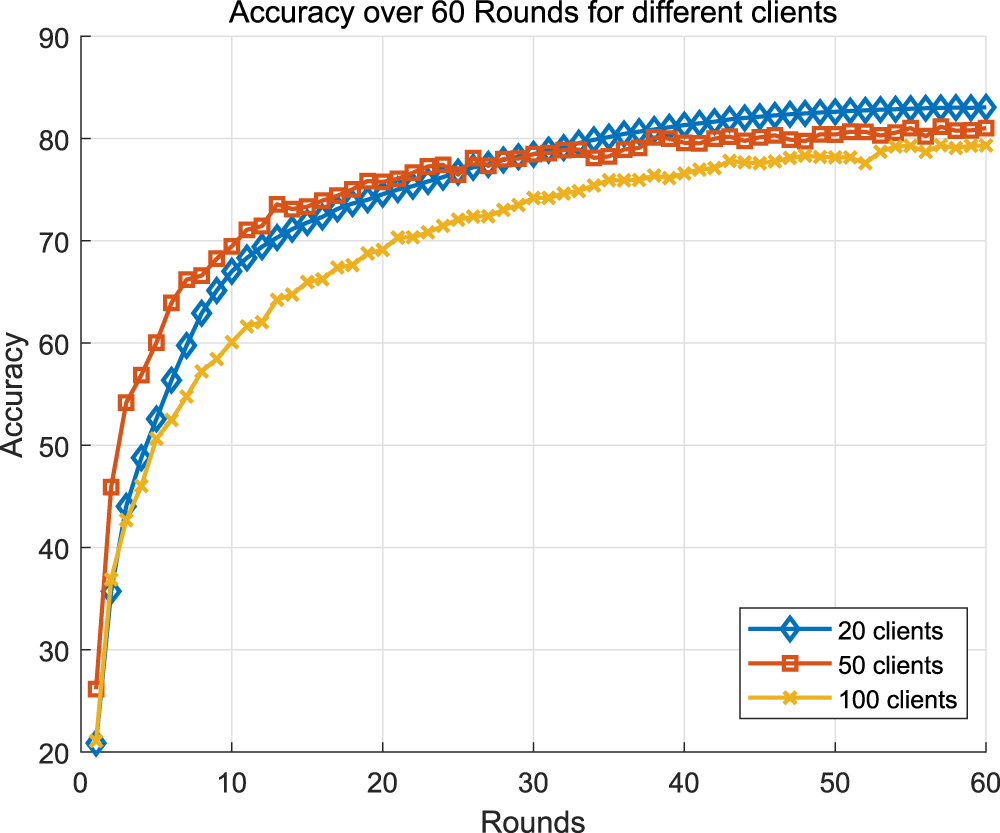
Trend of results for different number of clients.
The robustness experiment results in Table 6 show that MetaFed consistently outperforms other methods in handling both label and input noise on the CIFAR-10 data set. While FedAvg experiences the greatest accuracy decline under both types of noise, with a drop from 63.38% to 60.15% for label noise and 63.38% to 54.56% for input noise, MetaFed maintains the highest post-noise accuracy, dropping from 89.34% to 86.83% under label noise and from 89.34% to 86.28% under input noise. MetaFed also achieves faster convergence with fewer rounds (80 for label noise and 85 for input noise) compared to other methods, making it more efficient. Overall, MetaFed demonstrates superior robustness to noisy data, maintaining both high accuracy and reduced training time, outperforming other algorithms such as FedDr+, FedSAM, and MetaVers.
Corresponding Results of Different Methods in CIFAR-10 for the Noisy Case.
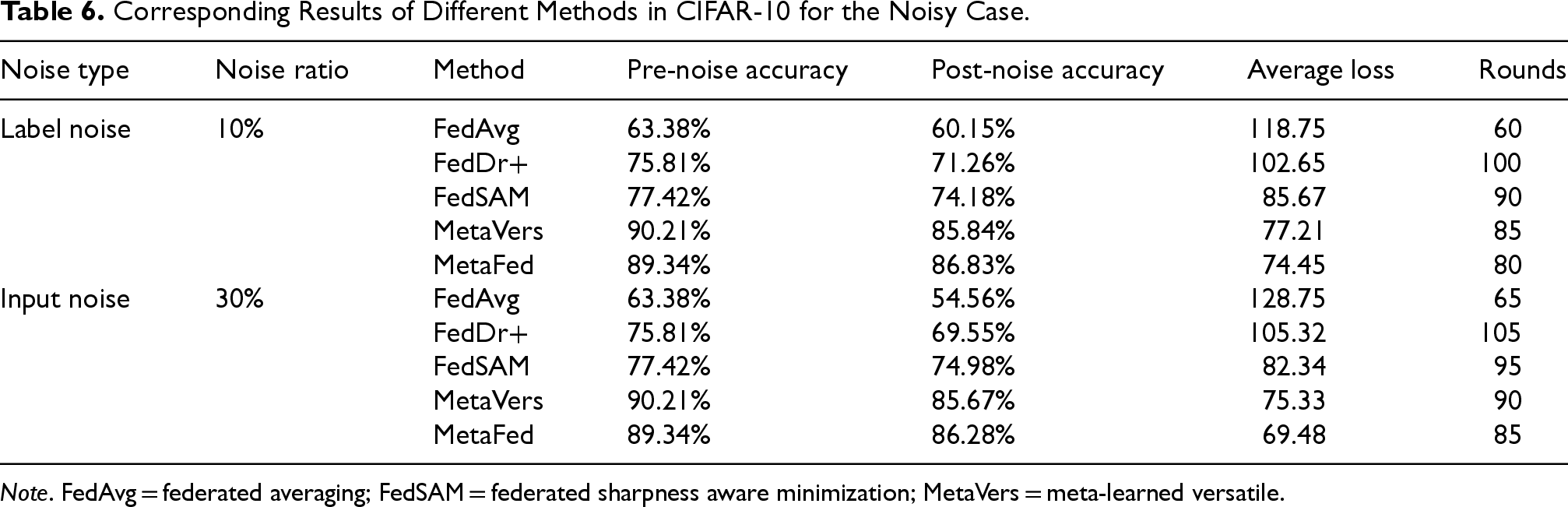
Corresponding Results of Different Methods in CIFAR-10 for the Noisy Case.
Note. FedAvg = federated averaging; FedSAM = federated sharpness aware minimization; MetaVers = meta-learned versatile.
The hyperparameter sensitivity results of multi-head attention in Table 7 indicate that increasing the number of heads and hidden layer dimensions typically improves the performance of the model in terms of accuracy, precision, and recall. Experiment 9 achieved the highest performance with 16 heads, 512-dimensional hidden layers, and a learning rate of 0.0005, particularly in terms of accuracy (89.56%), precision (90.34%), and recall (86.78%). A smaller learning rate (0.0005) often performs better in certain configurations, especially when the hidden layer is large and attention is focused. Overall, the best configuration to achieve optimal performance is to combine more heads, larger hidden layers, and lower learning rates.
In this paper, we address the accuracy problem in FL by introducing the CMCL technique, which reduces redundancy and improves feature independence. This enhances the model’s ability to focus on learning the most relevant features, thereby improving the generalization ability and accuracy of the FL model. However, to further improve the efficiency and scalability of FL, we design a meta-FL framework (MetaFed) that combines CMCL with MAML and a multi-head attention mechanism. The multi-head attention mechanism enables the model to efficiently fuse global information from other clients during local updates, allowing it to adapt to the heterogeneous data distribution across clients more effectively. This reduces the model’s reliance on frequent communication, speeding up the convergence of the global model and reducing both communication overhead and latency. Furthermore, by integrating MAML, we perform inner-layer updates on each client, followed by outer-layer updates, which allows the model to adapt to new tasks with a minimal amount of training data and fewer communication rounds. This accelerates convergence and enables each client model to approach the global optimal solution quickly, thus reducing the overall training time. The MetaFed framework, combining the power of CMCL, MAML, and multi-head attention, not only improves the accuracy and robustness of FL but also ensures better communication efficiency and scalability across diverse clients, making it a highly efficient solution for large-scale FL tasks.
Cross-Validation of Hyperparameter Sensitivity for Multi-Head Attention.
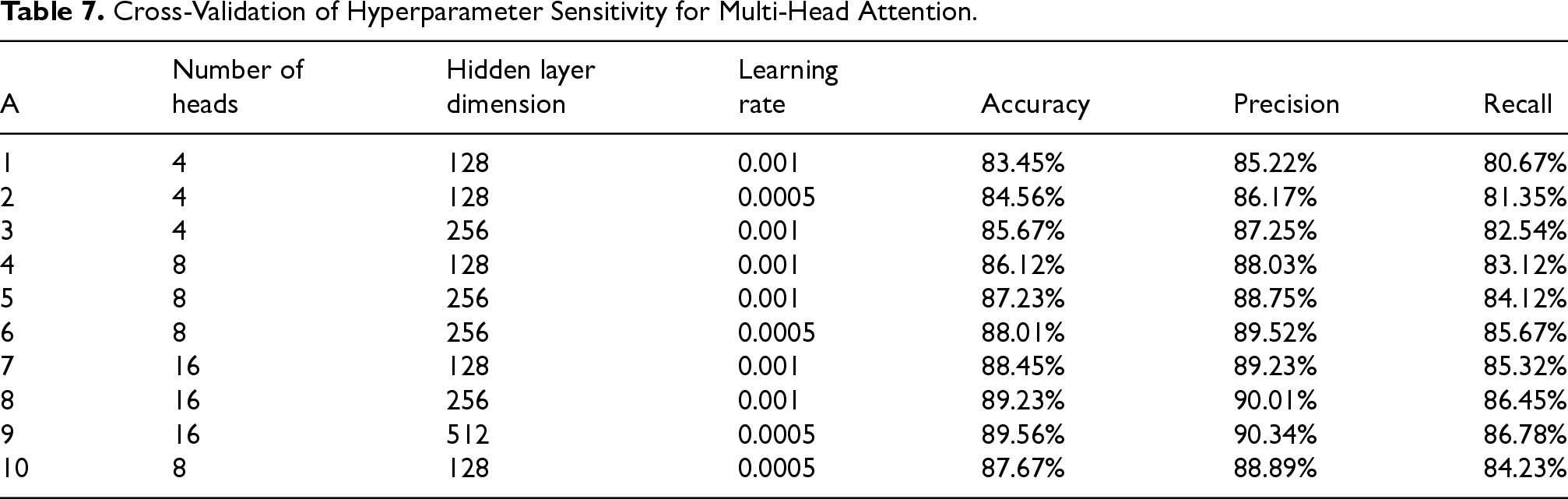
Cross-Validation of Hyperparameter Sensitivity for Multi-Head Attention.
In this paper, in order to improve the accuracy of FL, a new loss function: the CMCL function is proposed to encourage the model to maintain a consistent performance across different tasks. In order to further optimize the model’s effectiveness, entropy penalty and gradient-based regularization are used to prevent model overfitting, enhance the generalization ability and stability of the model, and ultimately improve the accuracy of FL. Through the experimental results on six data sets, CIFAR-10, CIFAR-100, MINIST, SVHN, Fashion MINIST, and Oxford-Pets, this paper verifies the effectiveness of CMCL. After that, in order to reduce the communication overhead of FL, in the further research of this paper, this paper introduces multi-head attention into the framework of FL, which improves the expressive ability of the model by capturing richer contextual information during feature extraction, and combines the MAML, with the inner-layer updating and outer-layer updating, the FL framework can quickly adapt to new tasks and accelerate the convergence speed. The experimental results show that on Oxford-Pets and CIFAR-10 data sets, the models combining the multi-head attention mechanism and the MAML method outperform the traditional methods in terms of convergence speed, which further validates the effectiveness of the method in this paper.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Natural Science Foundation of China(No. 61972334).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.